**Please note that this is not the repo for the MSG-GAN research paper. Please head over to the msg-stylegan-tf repository for the official code and trained models for the MSG-GAN paper.
MSG-GAN (Multi-Scale Gradients GAN): A Network architecture inspired from the ProGAN.
The architecture of this gan contains connections between the intermediate layers of the singular Generator and the Discriminator. The network is not trained by progressively growing the layers. All the layers get trained at the same time.
Implementation uses the PyTorch framework.

Please note that all the samples at various scales are generated by the network simultaneously.
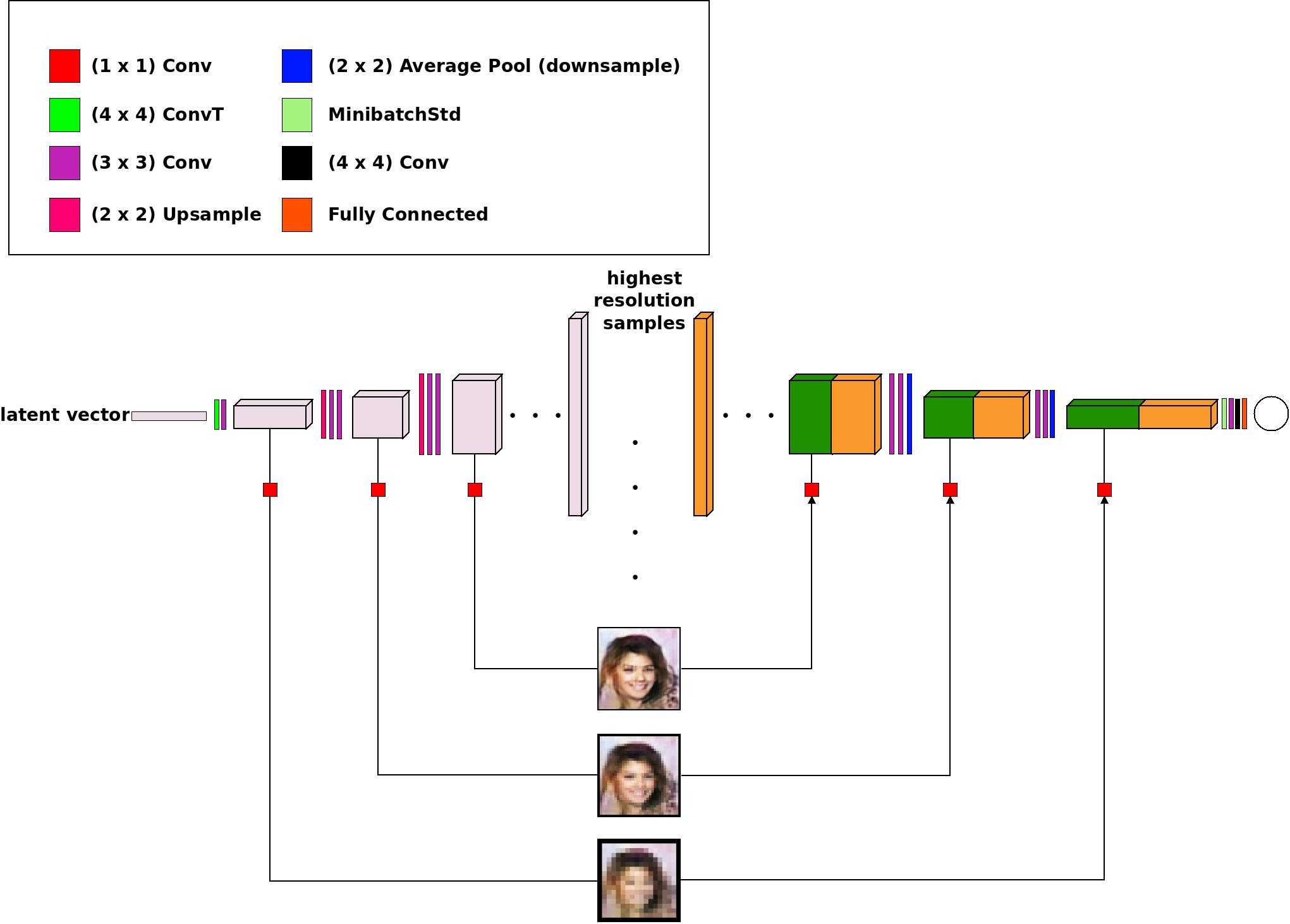
The above figure describes the architecture of the proposed Multi-Scale gradients GAN. As you can notice, from every intermediate layer of the Generator, a particular resolution image is extracted through (1 x 1) convolutions. These extracted images are in turn fed to the appropriate layers of the Discriminator. This allows for gradients to flow from the Discriminator to the Generator at multiple scales.
For the discrimination process, appropriately downsampled versions of the real images are fed to corresponding layers of the discriminator as shown in the diagram.
The problem of occurence of random gradients for GANs at the higher resolutions is tackled by layerwise training in the ProGAN paper. I present another solution for it. I have run the following experiment that preliminarily validates the proposed approach.

Above figure explains how the Meaningful Gradients penetrate the Generator from Bottoms-up. Initially, only the lower resolution gradients are menaingful and thus start generating good images at those resolutions, but eventually, all the scales synchronize and start producing images. This results in a stabler training for the higher resolution.
I ran the experiment on a skimmed version of the architecture as described in the
ProGAN paper. Following table summarize the details of the Networks:
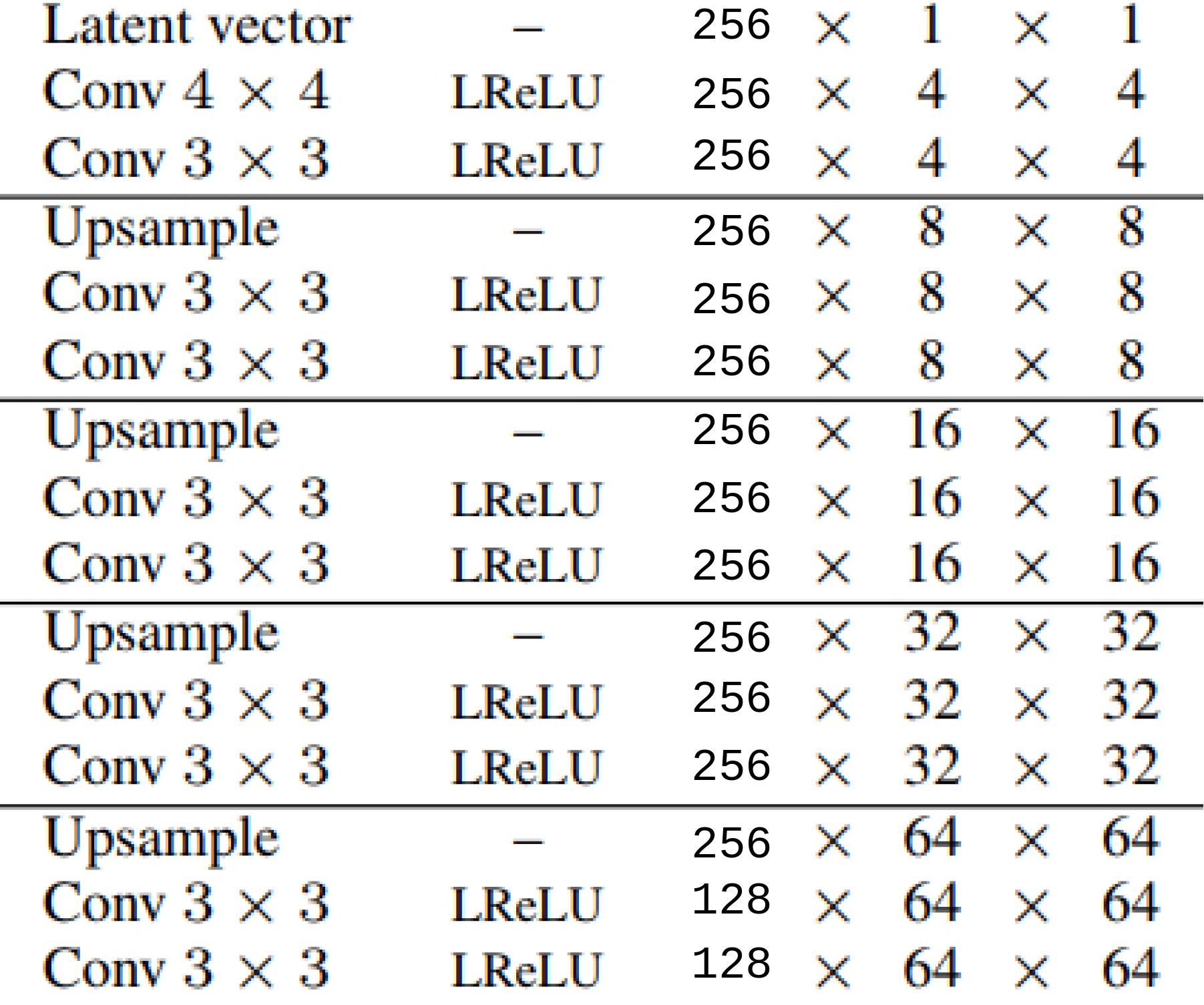
For extracting images after every 3 layer block at that resolution, I used 1 x 1 convolutions. Similar operation is performed for feeding the images to discriminator intermediate layers.
The architecture for the discriminator is also the same (reverse mirror), with the distinction that half of the channels come from the (1 x 1 convolution) transformed downsampled real images and half from conventional top-to-bottom path.
All the 3 x 3 convolution weights have a forward hook that applies
spectral normalization on them. Apart from that, in the discriminator
for the 4 x 4 layer, there is a MinibatchStd layer for improving
sample diversity. No other stablization techniques are applied.
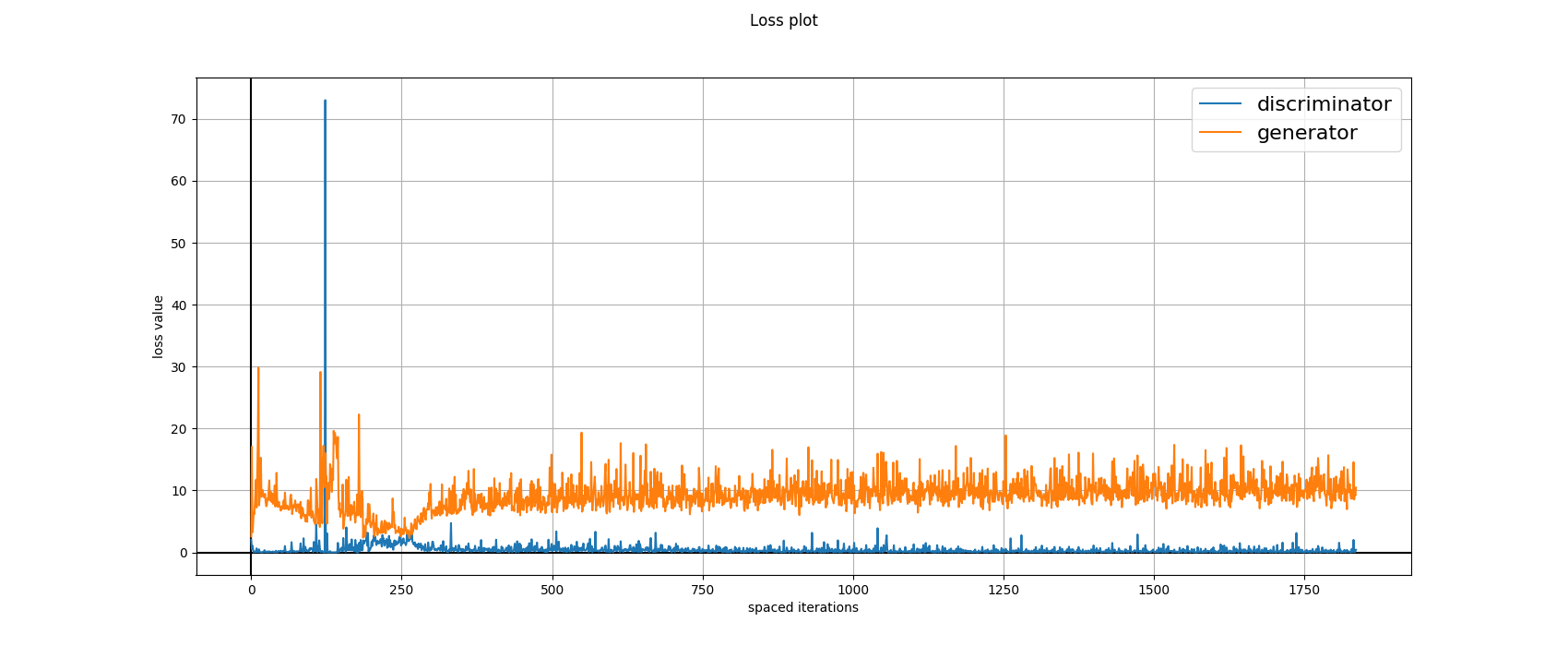
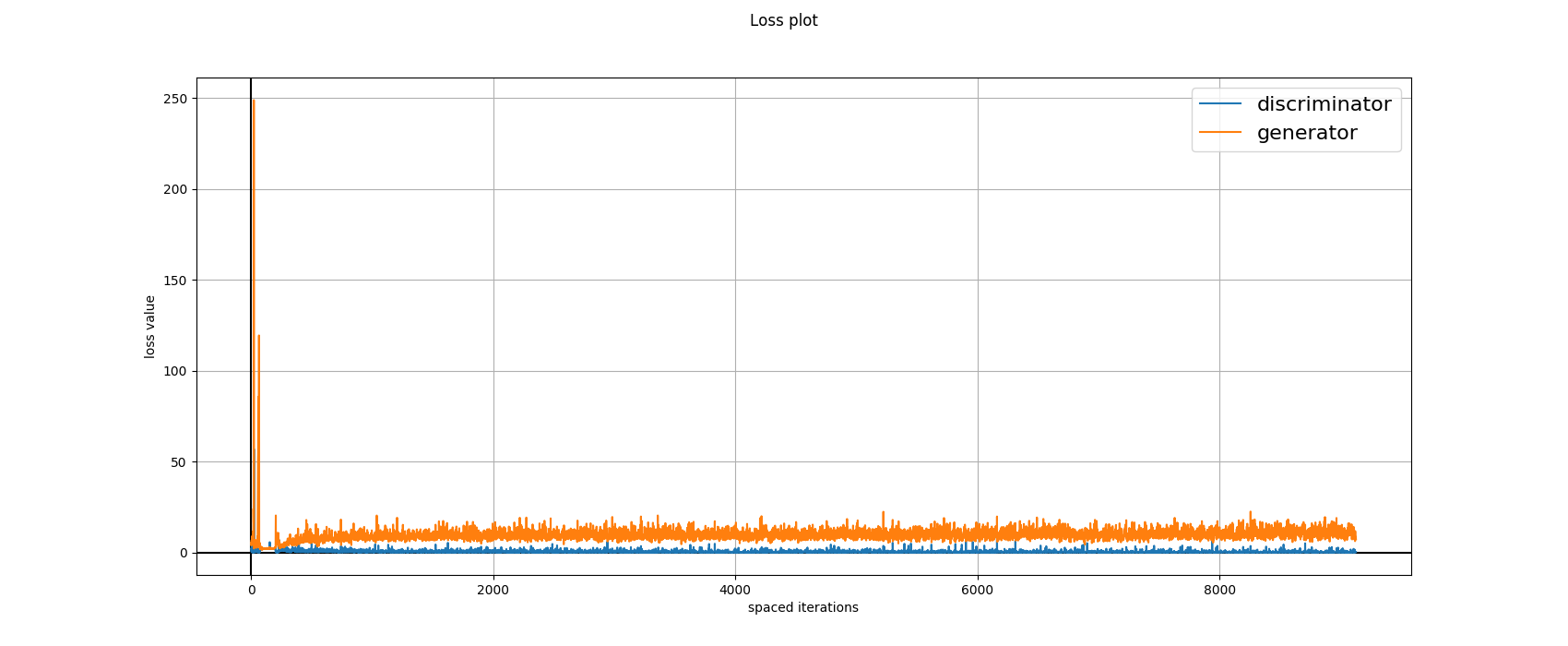
The above diagrams are the loss plots obtained during
training the Networks in an adversarial manner. The loss function used is
Relativistic Hinge-GAN. Apart from some initial aberrations, the training
has stayed smooth.
Please note to use value of learning_rate=0.0003 for both G and D for all experiments.
TTUR doesn't work with this architecture (from experience). And, you can find other better
learning rates, but the value 0.0003 always seems to work.
Running the training is actually very simple.
Just start the training by running the train.py script in the sourcecode/
directory. Refer to the following parameters for tweaking for your own use:
-h, --help show this help message and exit
--generator_file GENERATOR_FILE
pretrained weights file for generator
--discriminator_file DISCRIMINATOR_FILE
pretrained_weights file for discriminator
--images_dir IMAGES_DIR
path for the images directory
--sample_dir SAMPLE_DIR
path for the generated samples directory
--model_dir MODEL_DIR
path for saved models directory
--loss_function LOSS_FUNCTION
loss function to be used: 'hinge', 'relativistic-
hinge'
--depth DEPTH Depth of the GAN
--latent_size LATENT_SIZE
latent size for the generator
--batch_size BATCH_SIZE
batch_size for training
--start START starting epoch number
--num_epochs NUM_EPOCHS
number of epochs for training
--feedback_factor FEEDBACK_FACTOR
number of logs to generate per epoch
--num_samples NUM_SAMPLES
number of samples to generate for creating the grid
should be a square number preferably
--gen_dilation GEN_DILATION
amount of dilation for the generator
--dis_dilation DIS_DILATION
amount of dilation for the discriminator
--checkpoint_factor CHECKPOINT_FACTOR
save model per n epochs
--g_lr G_LR learning rate for generator
--d_lr D_LR learning rate for discriminator
--adam_beta1 ADAM_BETA1
value of beta_1 for adam optimizer
--adam_beta2 ADAM_BETA2
value of beta_2 for adam optimizer
--use_spectral_norm USE_SPECTRAL_NORM
Whether to use spectral normalization or not
--data_percentage DATA_PERCENTAGE
percentage of data to use
--num_workers NUM_WORKERS
number of parallel workers for reading files
For training a network as per the ProGAN CelebaHQ experiment, use the following arguments:
$ python train.py --depth=9 \
--latent_size=512 \
--images_dir=<path to CelebaHQ images> \
--sample_dir=samples/CelebaHQ_experiment \
--model_dir=models/CelebaHQ_experiment
Set the batch_size, feedback_factor and checkpoint_factor accordingly.
This experiment was carried out by me on a DGX-1 machine. The samples displayed in Figure 1. of this readme are the output of this experiment.
You can use the models pretrained for 3 epochs at [1024 x 1024] for your training. These are available at -> https://drive.google.com/drive/folders/119n0CoMDGq2K1dnnGpOA3gOf4RwFAGFs
Please refer to the models/Celeba/1/GAN_GEN_3.pth for the saved weights for
this model in PyTorch format.
medium blog -> https://medium.com/@animeshsk3/msg-gan-multi-scale-gradients-gan-ee2170f55d50
Training video -> https://www.youtube.com/watch?v=dx7ZHRcbFr8
Please feel free to open PRs here if
you train on other datasets using this architecture.
Best regards,
@akanimax :)
msg-gan-v1's People
Contributors



Stargazers




































































































Watchers









Forkers
esmaeilinia codeaudit kevinlemon dailyactie tony32769 skylion007 amirunpri2018 ianmcmill qing0991 459548764 maveriq zehaoy jdc08161063 imyzx2017 human2b annihi1ation sheex2018 manojtld haibao637 calm-6908 yxb-nku jorjiang zhongkey99 rushi-the-neural-arch promodelife yusaku-m tumble-weed bpranav11msg-gan-v1's Issues
about Paper <MSG-GAN>
Hi, I am reading your paper arxiv : 1903.06048v1 .
In your paper the github address is BMSG-GAN but I did not find it in your repos.
How to connect intermediate layer of generator to discriminator ??
about MSG-GAN paper
Hi, I look your paper and code of this repo.
This code is not implement :
- PixNorm,
- Equalized Learning Rate ,
- Exponential Moving Averaging of Generator Parameters
??? Is it true ?
Working with Gray scale images
Inorder to work with medical gray images, Pls let me know how the code has to be modified.
I find in_channels & out_channels in GAN.py. Is that to be modified? or in CustomLayers.py?
No Need to compute Generator Gradients when training Discriminator
Since Discriminator and Generator are trained separately, we don't need the gradients of the generator when training the discriminator.
Here are some relevant issues:
https://github.com/junyanz/pytorch-CycleGAN-and-pix2pix/blob/d7e7ed851b3e5ac01167197011bf8204015a1ce7/models/cycle_gan_model.py#L140
pytorch/pytorch#5349
Fixing this will probably speed up training.
CUDA OOM During Training Due to self.create_grid().
For whatever reason, self.create_grid(self.gen(fixed_input), gen_img_files) seems to use a massive amount of GPU memory when training, so much so that I cannot train on 4TitanX with 1 image per GPU. There is probably some substantial optimization that can be done here to reduce the memory overhead. After removing it, I went from having out of memory errors to have 7GB freed on each GPU.
No FC layers?
ProGAN, and most GANs, use some fully-connected/dense layers in between the latent z vector and the first CNN/upscaling layers in the Generator. Most strikingly, StyleGAN uses no less than 8 FC layers as part of the 'style mapping' network which is then the input into its Generator.
The graph in the README implies that there's some FC layers (I think; the colors are so similar I can't tell where the FC layers are supposed to be), but they don't seem to be in the code? Looking at the CustomLayers.py's GenInitialBlock, it seems to be pure convolutions, and the printed model arch also seems to not have. Adding them is easy:
diff --git a/sourcecode/MSG_GAN/CustomLayers.py b/sourcecode/MSG_GAN/CustomLayers.py
index 381d9f8..bc91929 100644
--- a/sourcecode/MSG_GAN/CustomLayers.py
+++ b/sourcecode/MSG_GAN/CustomLayers.py
@@ -19,9 +19,13 @@ class GenInitialBlock(th.nn.Module):
:param in_channels: number of input channels to the block
"""
from torch.nn import LeakyReLU
- from torch.nn import Conv2d, ConvTranspose2d
+ from torch.nn import Conv2d, ConvTranspose2d, Linear
super().__init__()
+ # from torch.nn import LeakyReLU
+ self.fc1 = th.nn.Linear(in_channels, in_channels)
+ self.fc2 = th.nn.Linear(in_channels, in_channels)
+
self.conv_1 = ConvTranspose2d(in_channels, in_channels, (4, 4), bias=True)
self.conv_2 = Conv2d(in_channels, in_channels, (3, 3), padding=(1, 1), bias=True)
@@ -34,10 +38,14 @@ class GenInitialBlock(th.nn.Module):
:param x: input to the module
:return: y => output
"""
+ x = self.lrelu(self.fc1(x))
+ x = self.lrelu(self.fc2(x))
+
# convert the tensor shape:
y = x.view(*x.shape, 1, 1) # add two dummy dimensions for
# convolution operation
Seems to help training of some anime faces noticeably over the past few hours - although I also added self-attention layers to the D/G so not a clean comparison. Some overnight samples: https://imgur.com/a/CbnaWB0
Since most GANs do that, ProGAN does it and is the mentioned inspiration, and the graph seems to imply you intended to do it, maybe you want to add some fcs somewhere.
Specify format of CelebA-HQ
I was going to try to use some GPUs to get results for CelebA-HQ dataset in it's numpy format doesn't seem to work with this repo. What format do you expect CelebA-HQ to be in?
I want to just test the discriminator of this GAN using my abnormal images
Hi, @Skylion007 @Ianmcmill @akanimax
I trained successfully anomalyGAN with your MSG-GAN using my only normal images.
And now , I want to just test the discriminator of this GAN using my abnormal images...
How can I extract the discriminator from your MSG-GAN ?
Thanks in advance.
Best,
@bemoregt.
ask for a pretrained model 128*128
Hi, I am very interested in your work. Could you please provide the pretrained model on size 128*128?
Thank you very much.
Difference between this repo and BMSG-GAN
Hello,
It's really nice repo.
But could you please specify the difference betweent your another repo BMSG-GAN and this repo?
Seems this repo is somehow older. But what is the exactly update in BMSG-GAN?
thanks and best regards.
WGAN-GP loss with multiple images
Hi,
Thanks for creating this repository! I'm implementing the MSG-GAN method for my own project and I'm trying to use WGAN-GP loss, but I'm finding it difficult since there are multiple images. Could you point to the WGAN-GP loss implementation with multiple images in this repo so that I can use it for reference?
Thanks,
Tharun Mohandoss
Sizes of tensors must match except in dimension 0. Got 3 and 1 in dimension 1
I am not sure what is the important error.
RuntimeError: invalid argument 0: Sizes of tensors must match except in dimension 0. Got 3 and 1 in dimension 1 at c:\new-builder_3\win-wheel\pytorch\aten\src\th\generic/THTensorMath.cpp:3616
or
RuntimeError: Couldn't open shared event: <torch_5308_2995310656_event>, error code: <2>
I converted the images to RGB with
mogrify -colorspace RGB *.jpg
but that didn't help.
Any hints?
Starting the training process ...
Epoch: 1
Elapsed [0:00:08.859118] batch: 1 d_loss: 2.000845 g_loss: 3.779521
Elapsed [0:00:10.685150] batch: 3 d_loss: 0.985300 g_loss: 4.276993
Elapsed [0:00:13.235160] batch: 6 d_loss: 1.903335 g_loss: 3.318109
Elapsed [0:00:15.852519] batch: 9 d_loss: 1.755461 g_loss: 3.607772
Traceback (most recent call last):
File "train.py", line 221, in <module>
main(parse_arguments())
File "train.py", line 215, in main
start=args.start
File "F:\portrait\MSG-GAN\sourcecode\MSG_GAN\GAN.py", line 423, in train
for (i, batch) in enumerate(data, 1):
File "C:\Users\castle\Envs\keras_tut\lib\site-packages\torch\utils\data\dataloader.py", line 336, in __next__
return self._process_next_batch(batch)
File "C:\Users\castle\Envs\keras_tut\lib\site-packages\torch\utils\data\dataloader.py", line 357, in _process_next_batch
raise batch.exc_type(batch.exc_msg)
RuntimeError: Traceback (most recent call last):
File "C:\Users\castle\Envs\keras_tut\lib\site-packages\torch\utils\data\dataloader.py", line 106, in _worker_loop
samples = collate_fn([dataset[i] for i in batch_indices])
File "C:\Users\castle\Envs\keras_tut\lib\site-packages\torch\utils\data\dataloader.py", line 164, in default_collate
return torch.stack(batch, 0, out=out)
RuntimeError: invalid argument 0: Sizes of tensors must match except in dimension 0. Got 3 and 1 in dimension 1 at c:\new-builder_3\win-wheel\pytorch\aten\src\th\generic/THTensorMath.cpp:3616
Exception ignored in: <bound method _DataLoaderIter.__del__ of <torch.utils.data.dataloader._DataLoaderIter object at 0x000002C3EC473978>>
Traceback (most recent call last):
File "C:\Users\castle\Envs\keras_tut\lib\site-packages\torch\utils\data\dataloader.py", line 399, in __del__
self._shutdown_workers()
File "C:\Users\castle\Envs\keras_tut\lib\site-packages\torch\utils\data\dataloader.py", line 378, in _shutdown_workers
self.worker_result_queue.get()
File "c:\users\castle\appdata\local\programs\python\python36\Lib\multiprocessing\queues.py", line 337, in get
return _ForkingPickler.loads(res)
File "C:\Users\castle\Envs\keras_tut\lib\site-packages\torch\multiprocessing\reductions.py", line 167, in rebuild_storage_filename
storage = cls._new_shared_filename(manager, handle, size)
RuntimeError: Couldn't open shared event: <torch_5308_2995310656_event>, error code: <2>
Recommend Projects
-
 React
React
A declarative, efficient, and flexible JavaScript library for building user interfaces.
-
Vue.js
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
-
 Typescript
Typescript
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
-
TensorFlow
An Open Source Machine Learning Framework for Everyone
-
Django
The Web framework for perfectionists with deadlines.
-
 Laravel
Laravel
A PHP framework for web artisans
-
D3
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
-
Recommend Topics
-
javascript
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
-
web
Some thing interesting about web. New door for the world.
-
server
A server is a program made to process requests and deliver data to clients.
-
Machine learning
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
-
Visualization
Some thing interesting about visualization, use data art
-
Game
Some thing interesting about game, make everyone happy.
Recommend Org
-
Facebook
We are working to build community through open source technology. NB: members must have two-factor auth.
-
Microsoft
Open source projects and samples from Microsoft.
-
Google
Google ❤️ Open Source for everyone.
-
Alibaba
Alibaba Open Source for everyone
-
D3
Data-Driven Documents codes.
-
Tencent
China tencent open source team.