This repository is a PyTorch implementation for Deep Comprehensive Correlation Mining for Image Clustering (accepted to ICCV 2019) at https://arxiv.org/abs/1904.06925?context=cs.CV
by Jianlong Wu*, Keyu Long*, Fei Wang, Chen Qian, Cheng Li, Zhouchen Lin and Hongbin Zha.
If you find DCCM useful in your research, please consider citing:
@inproceedings{DCCM,
author={Wu, Jianlong and Long, Keyu and Wang, Fei and Qian, Chen and Li, Cheng and Lin, Zhouchen and Zha, Hongbin},
title={Deep Comprehensive Correlation Mining for Image Clustering},
booktitle={International Conference on Computer Vision},
year={2019},
}
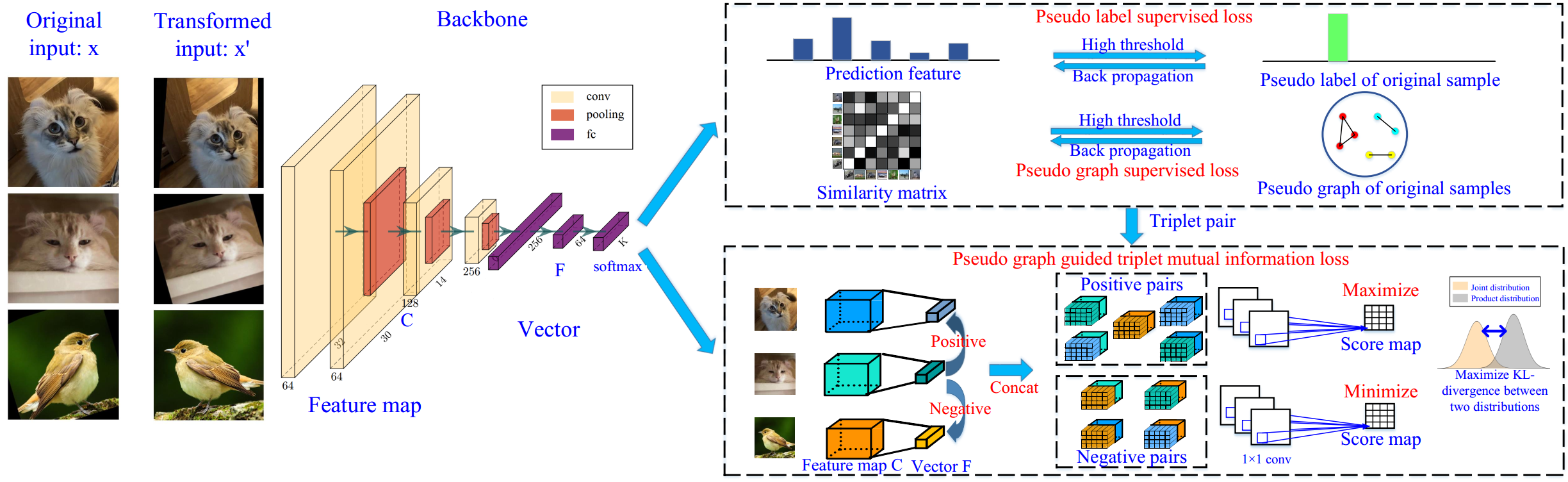 Figure 1. The pipeline of the proposed DCCM.
Figure 1. The pipeline of the proposed DCCM.
To train with CIFAR10/100 datasets, try:
$ python main.py --config cfgs/cifar10.yaml
$ python main.py --config cfgs/cifar100.yamlTo resume with a certain checkpoint , try:
$ python main.py --config cfgs/xx.yaml --resume xxx.ckptParameters and datapaths can be modified in the config files.
Note that we use meta-files (examples could be found in the folder 'meta') to load data.
- a Python installation version 3.6.5
- a Pytorch installation version 0.4.1
- a Keras installation version 2.0.2
- download the image dataset and stored according to the meta-files
Please note that all reported performance are tested under this environment.
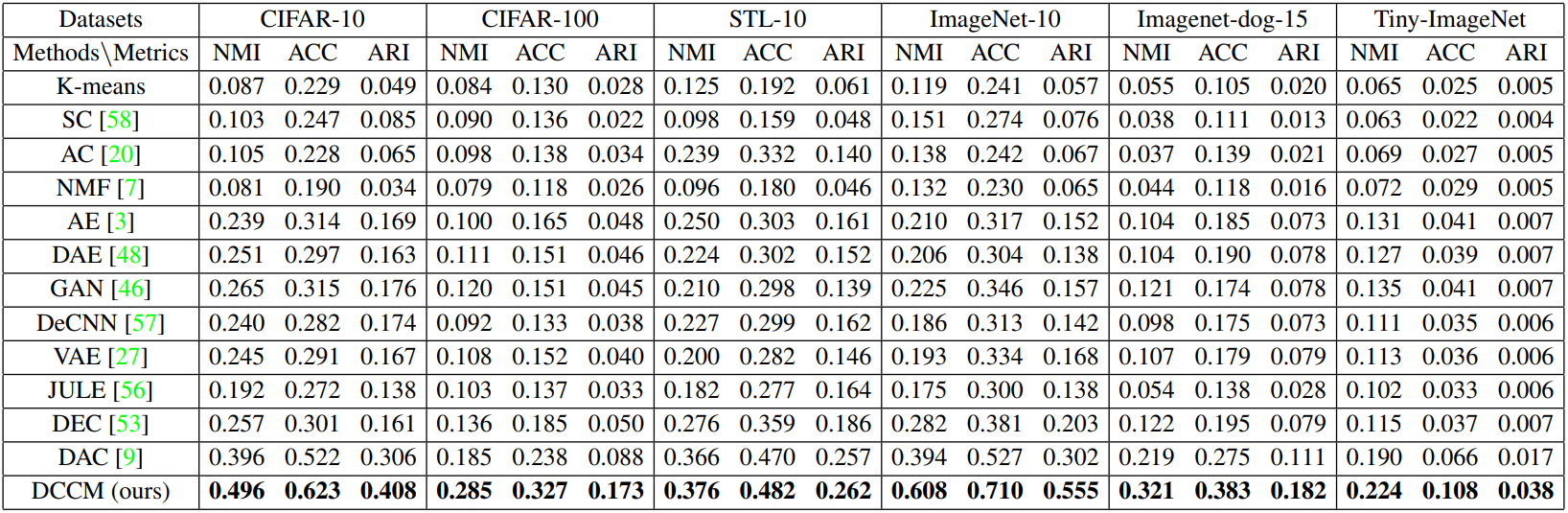
Table 1. Clustering performance of different methods on six challenging datasets.
- vector-1127/DAC: original implemention of DAC
- rdevon/DIM: original implementation of DIM
- 11-626/Deep-INFOMAX: PyTorch implementation of DIM
Our group at SenseTime Research is looking for algorithm researchers and engineers. Our research interests include object detection, tracking, classification, and segmentation, auto network search, network compression and quantization on mobile terminals, 3d gaze tracking, computer vision related SDK, and product platform development. Our group aims to pioneer the computer vision based IOT industry. We have a lot of NOI & ACM gold medal winners, and thousands of GPU Cards. Our team has win the world champions of MegaFace in face recognition and VOT challenge in object tracking, and has published many research papers in top conferences, such as CVPR, ICCV, ECCV, and NeurIPS. Please feel free to contact us with Wechat#: 18810636695 or Email: [email protected] if you are interested in our group.


















































































