很高兴你能关注我,我从 17 年开始写博客至今,已完成了深入系列、专题系列、underscore 系列、ES6 系列、TypeScript 系列、博客搭建系列等 6 个系列上百篇文章,做一个持续原创,输出干货的博主。
mqyqingfeng / blog Goto Github PK
View Code? Open in Web Editor NEW冴羽写博客的地方,预计写四个系列:JavaScript深入系列、JavaScript专题系列、ES6系列、React系列。
冴羽写博客的地方,预计写四个系列:JavaScript深入系列、JavaScript专题系列、ES6系列、React系列。
很高兴你能关注我,我从 17 年开始写博客至今,已完成了深入系列、专题系列、underscore 系列、ES6 系列、TypeScript 系列、博客搭建系列等 6 个系列上百篇文章,做一个持续原创,输出干货的博主。










































































































































































































在上篇《JavaScript专题之类型判断(上)》中,我们抄袭 jQuery 写了一个 type 函数,可以检测出常见的数据类型,然而在开发中还有更加复杂的判断,比如 plainObject、空对象、Window 对象等,这一篇就让我们接着抄袭 jQuery 去看一下这些类型的判断。
plainObject 来自于 jQuery,可以翻译成纯粹的对象,所谓"纯粹的对象",就是该对象是通过 "{}" 或 "new Object" 创建的,该对象含有零个或者多个键值对。
之所以要判断是不是 plainObject,是为了跟其他的 JavaScript对象如 null,数组,宿主对象(documents)等作区分,因为这些用 typeof 都会返回object。
jQuery提供了 isPlainObject 方法进行判断,先让我们看看使用的效果:
function Person(name) {
this.name = name;
}
console.log($.isPlainObject({})) // true
console.log($.isPlainObject(new Object)) // true
console.log($.isPlainObject(Object.create(null))); // true
console.log($.isPlainObject(Object.assign({a: 1}, {b: 2}))); // true
console.log($.isPlainObject(new Person('yayu'))); // false
console.log($.isPlainObject(Object.create({}))); // false由此我们可以看到,除了 {} 和 new Object 创建的之外,jQuery 认为一个没有原型的对象也是一个纯粹的对象。
实际上随着 jQuery 版本的提升,isPlainObject 的实现也在变化,我们今天讲的是 3.0 版本下的 isPlainObject,我们直接看源码:
// 上节中写 type 函数时,用来存放 toString 映射结果的对象
var class2type = {};
// 相当于 Object.prototype.toString
var toString = class2type.toString;
// 相当于 Object.prototype.hasOwnProperty
var hasOwn = class2type.hasOwnProperty;
function isPlainObject(obj) {
var proto, Ctor;
// 排除掉明显不是obj的以及一些宿主对象如Window
if (!obj || toString.call(obj) !== "[object Object]") {
return false;
}
/**
* getPrototypeOf es5 方法,获取 obj 的原型
* 以 new Object 创建的对象为例的话
* obj.__proto__ === Object.prototype
*/
proto = Object.getPrototypeOf(obj);
// 没有原型的对象是纯粹的,Object.create(null) 就在这里返回 true
if (!proto) {
return true;
}
/**
* 以下判断通过 new Object 方式创建的对象
* 判断 proto 是否有 constructor 属性,如果有就让 Ctor 的值为 proto.constructor
* 如果是 Object 函数创建的对象,Ctor 在这里就等于 Object 构造函数
*/
Ctor = hasOwn.call(proto, "constructor") && proto.constructor;
// 在这里判断 Ctor 构造函数是不是 Object 构造函数,用于区分自定义构造函数和 Object 构造函数
return typeof Ctor === "function" && hasOwn.toString.call(Ctor) === hasOwn.toString.call(Object);
}注意:我们判断 Ctor 构造函数是不是 Object 构造函数,用的是 hasOwn.toString.call(Ctor),这个方法可不是 Object.prototype.toString,不信我们在函数里加上下面这两句话:
console.log(hasOwn.toString.call(Ctor)); // function Object() { [native code] }
console.log(Object.prototype.toString.call(Ctor)); // [object Function]发现返回的值并不一样,这是因为 hasOwn.toString 调用的其实是 Function.prototype.toString,毕竟 hasOwnProperty 可是一个函数!
而且 Function 对象覆盖了从 Object 继承来的 Object.prototype.toString 方法。函数的 toString 方法会返回一个表示函数源代码的字符串。具体来说,包括 function关键字,形参列表,大括号,以及函数体中的内容。
jQuery提供了 isEmptyObject 方法来判断是否是空对象,代码简单,我们直接看源码:
function isEmptyObject( obj ) {
var name;
for ( name in obj ) {
return false;
}
return true;
}其实所谓的 isEmptyObject 就是判断是否有属性,for 循环一旦执行,就说明有属性,有属性就会返回 false。
但是根据这个源码我们可以看出isEmptyObject实际上判断的并不仅仅是空对象。
举个栗子:
console.log(isEmptyObject({})); // true
console.log(isEmptyObject([])); // true
console.log(isEmptyObject(null)); // true
console.log(isEmptyObject(undefined)); // true
console.log(isEmptyObject(1)); // true
console.log(isEmptyObject('')); // true
console.log(isEmptyObject(true)); // true以上都会返回 true。
但是既然 jQuery 是这样写,可能是因为考虑到实际开发中 isEmptyObject 用来判断 {} 和 {a: 1} 是足够的吧。如果真的是只判断 {},完全可以结合上篇写的 type 函数筛选掉不适合的情况。
Window 对象作为客户端 JavaScript 的全局对象,它有一个 window 属性指向自身,这点在《JavaScript深入之变量对象》中讲到过。我们可以利用这个特性判断是否是 Window 对象。
function isWindow( obj ) {
return obj != null && obj === obj.window;
}isArrayLike,看名字可能会让我们觉得这是判断类数组对象的,其实不仅仅是这样,jQuery 实现的 isArrayLike,数组和类数组都会返回 true。
因为源码比较简单,我们直接看源码:
function isArrayLike(obj) {
// obj 必须有 length属性
var length = !!obj && "length" in obj && obj.length;
var typeRes = type(obj);
// 排除掉函数和 Window 对象
if (typeRes === "function" || isWindow(obj)) {
return false;
}
return typeRes === "array" || length === 0 ||
typeof length === "number" && length > 0 && (length - 1) in obj;
}重点分析 return 这一行,使用了或语句,只要一个为 true,结果就返回 true。
所以如果 isArrayLike 返回true,至少要满足三个条件之一:
第一个就不说了,看第二个,为什么长度为 0 就可以直接判断为 true 呢?
那我们写个对象:
var obj = {a: 1, b: 2, length: 0}isArrayLike 函数就会返回 true,那这个合理吗?
回答合不合理之前,我们先看一个例子:
function a(){
console.log(isArrayLike(arguments))
}
a();如果我们去掉length === 0 这个判断,就会打印 false,然而我们都知道 arguments 是一个类数组对象,这里是应该返回 true 的。
所以是不是为了放过空的 arguments 时也放过了一些存在争议的对象呢?
第三个条件:length 是数字,并且 length > 0 且最后一个元素存在。
为什么仅仅要求最后一个元素存在呢?
让我们先想下数组是不是可以这样写:
var arr = [,,3]当我们写一个对应的类数组对象就是:
var arrLike = {
2: 3,
length: 3
}也就是说当我们在数组中用逗号直接跳过的时候,我们认为该元素是不存在的,类数组对象中也就不用写这个元素,但是最后一个元素是一定要写的,要不然 length 的长度就不会是最后一个元素的 key 值加 1。比如数组可以这样写
var arr = [1,,];
console.log(arr.length) // 2但是类数组对象就只能写成:
var arrLike = {
0: 1,
length: 1
}所以符合条件的类数组对象是一定存在最后一个元素的!
这就是满足 isArrayLike 的三个条件,其实除了 jQuery 之外,很多库都有对 isArrayLike 的实现,比如 underscore:
var MAX_ARRAY_INDEX = Math.pow(2, 53) - 1;
var isArrayLike = function(collection) {
var length = getLength(collection);
return typeof length == 'number' && length >= 0 && length <= MAX_ARRAY_INDEX;
};isElement 判断是不是 DOM 元素。
isElement = function(obj) {
return !!(obj && obj.nodeType === 1);
};这一篇我们介绍了 jQuery 的 isPlainObject、isEmptyObject、isWindow、isArrayLike、以及 underscore 的 isElement 实现。我们可以看到,即使是 jQuery 这样优秀的库,一些方法的实现也并不是非常完美和严密的,但是最后为什么这么做,其实也是一种权衡,权衡所失与所得,正如玉伯在《从 JavaScript 数组去重谈性能优化》中讲到:
所有这些点,都必须脚踏实地在具体应用场景下去分析、去选择,要让场景说话。
JavaScript专题系列目录地址:https://github.com/mqyqingfeng/Blog。
JavaScript专题系列预计写二十篇左右,主要研究日常开发中一些功能点的实现,比如防抖、节流、去重、类型判断、拷贝、最值、扁平、柯里、递归、乱序、排序等,特点是研(chao)究(xi) underscore 和 jQuery 的实现方式。
如果有错误或者不严谨的地方,请务必给予指正,十分感谢。如果喜欢或者有所启发,欢迎 star,对作者也是一种鼓励。
数组去重方法老生常谈,既然是常谈,我也来谈谈。
也许我们首先想到的是使用 indexOf 来循环判断一遍,但在这个方法之前,让我们先看看最原始的方法:
var array = [1, 1, '1', '1'];
function unique(array) {
// res用来存储结果
var res = [];
for (var i = 0, arrayLen = array.length; i < arrayLen; i++) {
for (var j = 0, resLen = res.length; j < resLen; j++ ) {
if (array[i] === res[j]) {
break;
}
}
// 如果array[i]是唯一的,那么执行完循环,j等于resLen
if (j === resLen) {
res.push(array[i])
}
}
return res;
}
console.log(unique(array)); // [1, "1"]在这个方法中,我们使用循环嵌套,最外层循环 array,里面循环 res,如果 array[i] 的值跟 res[j] 的值相等,就跳出循环,如果都不等于,说明元素是唯一的,这时候 j 的值就会等于 res 的长度,根据这个特点进行判断,将值添加进 res。
看起来很简单吧,之所以要讲一讲这个方法,是因为——————兼容性好!
我们可以用 indexOf 简化内层的循环:
var array = [1, 1, '1'];
function unique(array) {
var res = [];
for (var i = 0, len = array.length; i < len; i++) {
var current = array[i];
if (res.indexOf(current) === -1) {
res.push(current)
}
}
return res;
}
console.log(unique(array));试想我们先将要去重的数组使用 sort 方法排序后,相同的值就会被排在一起,然后我们就可以只判断当前元素与上一个元素是否相同,相同就说明重复,不相同就添加进 res,让我们写个 demo:
var array = [1, 1, '1'];
function unique(array) {
var res = [];
var sortedArray = array.concat().sort();
var seen;
for (var i = 0, len = sortedArray.length; i < len; i++) {
// 如果是第一个元素或者相邻的元素不相同
if (!i || seen !== sortedArray[i]) {
res.push(sortedArray[i])
}
seen = sortedArray[i];
}
return res;
}
console.log(unique(array));如果我们对一个已经排好序的数组去重,这种方法效率肯定高于使用 indexOf。
知道了这两种方法后,我们可以去尝试写一个名为 unique 的工具函数,我们根据一个参数 isSorted 判断传入的数组是否是已排序的,如果为 true,我们就判断相邻元素是否相同,如果为 false,我们就使用 indexOf 进行判断
var array1 = [1, 2, '1', 2, 1];
var array2 = [1, 1, '1', 2, 2];
// 第一版
function unique(array, isSorted) {
var res = [];
var seen = [];
for (var i = 0, len = array.length; i < len; i++) {
var value = array[i];
if (isSorted) {
if (!i || seen !== value) {
res.push(value)
}
seen = value;
}
else if (res.indexOf(value) === -1) {
res.push(value);
}
}
return res;
}
console.log(unique(array1)); // [1, 2, "1"]
console.log(unique(array2, true)); // [1, "1", 2]尽管 unqique 已经可以试下去重功能,但是为了让这个 API 更加强大,我们来考虑一个需求:
新需求:字母的大小写视为一致,比如'a'和'A',保留一个就可以了!
虽然我们可以先处理数组中的所有数据,比如将所有的字母转成小写,然后再传入unique函数,但是有没有方法可以省掉处理数组的这一遍循环,直接就在去重的循环中做呢?让我们去完成这个需求:
var array3 = [1, 1, 'a', 'A', 2, 2];
// 第二版
// iteratee 英文释义:迭代 重复
function unique(array, isSorted, iteratee) {
var res = [];
var seen = [];
for (var i = 0, len = array.length; i < len; i++) {
var value = array[i];
var computed = iteratee ? iteratee(value, i, array) : value;
if (isSorted) {
if (!i || seen !== computed) {
res.push(value)
}
seen = computed;
}
else if (iteratee) {
if (seen.indexOf(computed) === -1) {
seen.push(computed);
res.push(value);
}
}
else if (res.indexOf(value) === -1) {
res.push(value);
}
}
return res;
}
console.log(unique(array3, false, function(item){
return typeof item == 'string' ? item.toLowerCase() : item
})); // [1, "a", 2]在这一版也是最后一版的实现中,函数传递三个参数:
array:表示要去重的数组,必填
isSorted:表示函数传入的数组是否已排过序,如果为 true,将会采用更快的方法进行去重
iteratee:传入一个函数,可以对每个元素进行重新的计算,然后根据处理的结果进行去重
至此,我们已经仿照着 underscore 的思路写了一个 unique 函数,具体可以查看 Github。
ES5 提供了 filter 方法,我们可以用来简化外层循环:
比如使用 indexOf 的方法:
var array = [1, 2, 1, 1, '1'];
function unique(array) {
var res = array.filter(function(item, index, array){
return array.indexOf(item) === index;
})
return res;
}
console.log(unique(array));排序去重的方法:
var array = [1, 2, 1, 1, '1'];
function unique(array) {
return array.concat().sort().filter(function(item, index, array){
return !index || item !== array[index - 1]
})
}
console.log(unique(array));去重的方法众多,尽管我们已经跟着 underscore 写了一个 unqiue API,但是让我们看看其他的方法拓展下视野:
这种方法是利用一个空的 Object 对象,我们把数组的值存成 Object 的 key 值,比如 Object[value1] = true,在判断另一个值的时候,如果 Object[value2]存在的话,就说明该值是重复的。示例代码如下:
var array = [1, 2, 1, 1, '1'];
function unique(array) {
var obj = {};
return array.filter(function(item, index, array){
return obj.hasOwnProperty(item) ? false : (obj[item] = true)
})
}
console.log(unique(array)); // [1, 2]我们可以发现,是有问题的,因为 1 和 '1' 是不同的,但是这种方法会判断为同一个值,这是因为对象的键值只能是字符串,所以我们可以使用 typeof item + item 拼成字符串作为 key 值来避免这个问题:
var array = [1, 2, 1, 1, '1'];
function unique(array) {
var obj = {};
return array.filter(function(item, index, array){
return obj.hasOwnProperty(typeof item + item) ? false : (obj[typeof item + item] = true)
})
}
console.log(unique(array)); // [1, 2, "1"]然而,即便如此,我们依然无法正确区分出两个对象,比如 {value: 1} 和 {value: 2},因为 typeof item + item 的结果都会是 object[object Object],不过我们可以使用 JSON.stringify 将对象序列化:
var array = [{value: 1}, {value: 1}, {value: 2}];
function unique(array) {
var obj = {};
return array.filter(function(item, index, array){
console.log(typeof item + JSON.stringify(item))
return obj.hasOwnProperty(typeof item + JSON.stringify(item)) ? false : (obj[typeof item + JSON.stringify(item)] = true)
})
}
console.log(unique(array)); // [{value: 1}, {value: 2}]看似已经万无一失,但考虑到 JSON.stringify 任何一个正则表达式的结果都是 {},所以这个方法并不适用于处理正则表达式去重。(引用勘误 )
console.log(JSON.stringify(/a/)); // {}
console.log(JSON.stringify(/b/)); // {}随着 ES6 的到来,去重的方法又有了进展,比如我们可以使用 Set 和 Map 数据结构,以 Set 为例,ES6 提供了新的数据结构 Set。它类似于数组,但是成员的值都是唯一的,没有重复的值。
是不是感觉就像是为去重而准备的?让我们来写一版:
var array = [1, 2, 1, 1, '1'];
function unique(array) {
return Array.from(new Set(array));
}
console.log(unique(array)); // [1, 2, "1"]甚至可以再简化下:
function unique(array) {
return [...new Set(array)];
}还可以再简化下:
var unique = (a) => [...new Set(a)]此外,如果用 Map 的话:
function unique (arr) {
const seen = new Map()
return arr.filter((a) => !seen.has(a) && seen.set(a, 1))
}我们可以看到,去重方法从原始的 14 行代码到 ES6 的 1 行代码,其实也说明了 JavaScript 这门语言在不停的进步,相信以后的开发也会越来越高效。
去重的方法就到此结束了,然而要去重的元素类型可能是多种多样,除了例子中简单的 1 和 '1' 之外,其实还有 null、undefined、NaN、对象等,那么对于这些元素,之前的这些方法的去重结果又是怎样呢?
在此之前,先让我们先看几个例子:
var str1 = '1';
var str2 = new String('1');
console.log(str1 == str2); // true
console.log(str1 === str2); // false
console.log(null == null); // true
console.log(null === null); // true
console.log(undefined == undefined); // true
console.log(undefined === undefined); // true
console.log(NaN == NaN); // false
console.log(NaN === NaN); // false
console.log(/a/ == /a/); // false
console.log(/a/ === /a/); // false
console.log({} == {}); // false
console.log({} === {}); // false那么,对于这样一个数组
var array = [1, 1, '1', '1', null, null, undefined, undefined, new String('1'), new String('1'), /a/, /a/, NaN, NaN];以上各种方法去重的结果到底是什么样的呢?
我特地整理了一个列表,我们重点关注下对象和 NaN 的去重情况:
| 方法 | 结果 | 说明 |
|---|---|---|
| for循环 | [1, "1", null, undefined, String, String, /a/, /a/, NaN, NaN] | 对象和 NaN 不去重 |
| indexOf | [1, "1", null, undefined, String, String, /a/, /a/, NaN, NaN] | 对象和 NaN 不去重 |
| sort | [/a/, /a/, "1", 1, String, 1, String, NaN, NaN, null, undefined] | 对象和 NaN 不去重 数字 1 也不去重 |
| filter + indexOf | [1, "1", null, undefined, String, String, /a/, /a/] | 对象不去重 NaN 会被忽略掉 |
| filter + sort | [/a/, /a/, "1", 1, String, 1, String, NaN, NaN, null, undefined] | 对象和 NaN 不去重 数字 1 不去重 |
| 优化后的键值对方法 | [1, "1", null, undefined, String, /a/, NaN] | 全部去重 |
| Set | [1, "1", null, undefined, String, String, /a/, /a/, NaN] | 对象不去重 NaN 去重 |
这里再次声明一下,键值对方法不能去重正则表达式。
想了解为什么会出现以上的结果,看两个 demo 便能明白:
// demo1
var arr = [1, 2, NaN];
arr.indexOf(NaN); // -1indexOf 底层还是使用 === 进行判断,因为 NaN === NaN的结果为 false,所以使用 indexOf 查找不到 NaN 元素
// demo2
function unique(array) {
return Array.from(new Set(array));
}
console.log(unique([NaN, NaN])) // [NaN]Set 认为尽管 NaN === NaN 为 false,但是这两个元素是重复的。
虽然去重的结果有所不同,但更重要的是让我们知道在合适的场景要选择合适的方法。
JavaScript专题系列目录地址:https://github.com/mqyqingfeng/Blog。
JavaScript专题系列预计写二十篇左右,主要研究日常开发中一些功能点的实现,比如防抖、节流、去重、类型判断、拷贝、最值、扁平、柯里、递归、乱序、排序等,特点是研(chao)究(xi) underscore 和 jQuery 的实现方式。
如果有错误或者不严谨的地方,请务必给予指正,十分感谢。如果喜欢或者有所启发,欢迎 star,对作者也是一种鼓励。
一句话介绍 bind:
bind() 方法会创建一个新函数。当这个新函数被调用时,bind() 的第一个参数将作为它运行时的 this,之后的一序列参数将会在传递的实参前传入作为它的参数。(来自于 MDN )
由此我们可以首先得出 bind 函数的两个特点:
从第一个特点开始,我们举个例子:
var foo = {
value: 1
};
function bar() {
console.log(this.value);
}
// 返回了一个函数
var bindFoo = bar.bind(foo);
bindFoo(); // 1关于指定 this 的指向,我们可以使用 call 或者 apply 实现,关于 call 和 apply 的模拟实现,可以查看《JavaScript深入之call和apply的模拟实现》。我们来写第一版的代码:
// 第一版
Function.prototype.bind2 = function (context) {
var self = this;
return function () {
return self.apply(context);
}
}此外,之所以 return self.apply(context),是考虑到绑定函数可能是有返回值的,依然是这个例子:
var foo = {
value: 1
};
function bar() {
return this.value;
}
var bindFoo = bar.bind(foo);
console.log(bindFoo()); // 1接下来看第二点,可以传入参数。这个就有点让人费解了,我在 bind 的时候,是否可以传参呢?我在执行 bind 返回的函数的时候,可不可以传参呢?让我们看个例子:
var foo = {
value: 1
};
function bar(name, age) {
console.log(this.value);
console.log(name);
console.log(age);
}
var bindFoo = bar.bind(foo, 'daisy');
bindFoo('18');
// 1
// daisy
// 18函数需要传 name 和 age 两个参数,竟然还可以在 bind 的时候,只传一个 name,在执行返回的函数的时候,再传另一个参数 age!
这可咋办?不急,我们用 arguments 进行处理:
// 第二版
Function.prototype.bind2 = function (context) {
var self = this;
// 获取bind2函数从第二个参数到最后一个参数
var args = Array.prototype.slice.call(arguments, 1);
return function () {
// 这个时候的arguments是指bind返回的函数传入的参数
var bindArgs = Array.prototype.slice.call(arguments);
return self.apply(context, args.concat(bindArgs));
}
}完成了这两点,最难的部分到啦!因为 bind 还有一个特点,就是
一个绑定函数也能使用new操作符创建对象:这种行为就像把原函数当成构造器。提供的 this 值被忽略,同时调用时的参数被提供给模拟函数。
也就是说当 bind 返回的函数作为构造函数的时候,bind 时指定的 this 值会失效,但传入的参数依然生效。举个例子:
var value = 2;
var foo = {
value: 1
};
function bar(name, age) {
this.habit = 'shopping';
console.log(this.value);
console.log(name);
console.log(age);
}
bar.prototype.friend = 'kevin';
var bindFoo = bar.bind(foo, 'daisy');
var obj = new bindFoo('18');
// undefined
// daisy
// 18
console.log(obj.habit);
console.log(obj.friend);
// shopping
// kevin注意:尽管在全局和 foo 中都声明了 value 值,最后依然返回了 undefind,说明绑定的 this 失效了,如果大家了解 new 的模拟实现,就会知道这个时候的 this 已经指向了 obj。
(哈哈,我这是为我的下一篇文章《JavaScript深入系列之new的模拟实现》打广告)。
所以我们可以通过修改返回的函数的原型来实现,让我们写一下:
// 第三版
Function.prototype.bind2 = function (context) {
var self = this;
var args = Array.prototype.slice.call(arguments, 1);
var fBound = function () {
var bindArgs = Array.prototype.slice.call(arguments);
// 当作为构造函数时,this 指向实例,此时结果为 true,将绑定函数的 this 指向该实例,可以让实例获得来自绑定函数的值
// 以上面的是 demo 为例,如果改成 `this instanceof fBound ? null : context`,实例只是一个空对象,将 null 改成 this ,实例会具有 habit 属性
// 当作为普通函数时,this 指向 window,此时结果为 false,将绑定函数的 this 指向 context
return self.apply(this instanceof fBound ? this : context, args.concat(bindArgs));
}
// 修改返回函数的 prototype 为绑定函数的 prototype,实例就可以继承绑定函数的原型中的值
fBound.prototype = this.prototype;
return fBound;
}如果对原型链稍有困惑,可以查看《JavaScript深入之从原型到原型链》。
但是在这个写法中,我们直接将 fBound.prototype = this.prototype,我们直接修改 fBound.prototype 的时候,也会直接修改绑定函数的 prototype。这个时候,我们可以通过一个空函数来进行中转:
// 第四版
Function.prototype.bind2 = function (context) {
var self = this;
var args = Array.prototype.slice.call(arguments, 1);
var fNOP = function () {};
var fBound = function () {
var bindArgs = Array.prototype.slice.call(arguments);
return self.apply(this instanceof fNOP ? this : context, args.concat(bindArgs));
}
fNOP.prototype = this.prototype;
fBound.prototype = new fNOP();
return fBound;
}到此为止,大的问题都已经解决,给自己一个赞!o( ̄▽ ̄)d
接下来处理些小问题:
1.apply 这段代码跟 MDN 上的稍有不同
在 MDN 中文版讲 bind 的模拟实现时,apply 这里的代码是:
self.apply(this instanceof self ? this : context || this, args.concat(bindArgs))多了一个关于 context 是否存在的判断,然而这个是错误的!
举个例子:
var value = 2;
var foo = {
value: 1,
bar: bar.bind(null)
};
function bar() {
console.log(this.value);
}
foo.bar() // 2以上代码正常情况下会打印 2,如果换成了 context || this,这段代码就会打印 1!
所以这里不应该进行 context 的判断,大家查看 MDN 同样内容的英文版,就不存在这个判断!
(2018年3月27日更新,中文版已经改了😀)
2.调用 bind 的不是函数咋办?
不行,我们要报错!
if (typeof this !== "function") {
throw new Error("Function.prototype.bind - what is trying to be bound is not callable");
}3.我要在线上用
那别忘了做个兼容:
Function.prototype.bind = Function.prototype.bind || function () {
……
};当然最好是用 es5-shim 啦。
所以最最后的代码就是:
Function.prototype.bind2 = function (context) {
if (typeof this !== "function") {
throw new Error("Function.prototype.bind - what is trying to be bound is not callable");
}
var self = this;
var args = Array.prototype.slice.call(arguments, 1);
var fNOP = function () {};
var fBound = function () {
var bindArgs = Array.prototype.slice.call(arguments);
return self.apply(this instanceof fNOP ? this : context, args.concat(bindArgs));
}
fNOP.prototype = this.prototype;
fBound.prototype = new fNOP();
return fBound;
}《JavaScript深入之call和apply的模拟实现》
JavaScript深入系列目录地址:https://github.com/mqyqingfeng/Blog。
JavaScript深入系列预计写十五篇左右,旨在帮大家捋顺JavaScript底层知识,重点讲解如原型、作用域、执行上下文、变量对象、this、闭包、按值传递、call、apply、bind、new、继承等难点概念。
如果有错误或者不严谨的地方,请务必给予指正,十分感谢。如果喜欢或者有所启发,欢迎star,对作者也是一种鼓励。
作用域是指程序源代码中定义变量的区域。
作用域规定了如何查找变量,也就是确定当前执行代码对变量的访问权限。
JavaScript 采用词法作用域(lexical scoping),也就是静态作用域。
因为 JavaScript 采用的是词法作用域,函数的作用域在函数定义的时候就决定了。
而与词法作用域相对的是动态作用域,函数的作用域是在函数调用的时候才决定的。
让我们认真看个例子就能明白之间的区别:
var value = 1;
function foo() {
console.log(value);
}
function bar() {
var value = 2;
foo();
}
bar();
// 结果是 ???假设JavaScript采用静态作用域,让我们分析下执行过程:
执行 foo 函数,先从 foo 函数内部查找是否有局部变量 value,如果没有,就根据书写的位置,查找上面一层的代码,也就是 value 等于 1,所以结果会打印 1。
假设JavaScript采用动态作用域,让我们分析下执行过程:
执行 foo 函数,依然是从 foo 函数内部查找是否有局部变量 value。如果没有,就从调用函数的作用域,也就是 bar 函数内部查找 value 变量,所以结果会打印 2。
前面我们已经说了,JavaScript采用的是静态作用域,所以这个例子的结果是 1。
也许你会好奇什么语言是动态作用域?
bash 就是动态作用域,不信的话,把下面的脚本存成例如 scope.bash,然后进入相应的目录,用命令行执行 bash ./scope.bash,看看打印的值是多少。
value=1
function foo () {
echo $value;
}
function bar () {
local value=2;
foo;
}
bar这个文件也可以在 Github 博客仓库中找到。
最后,让我们看一个《JavaScript权威指南》中的例子:
var scope = "global scope";
function checkscope(){
var scope = "local scope";
function f(){
return scope;
}
return f();
}
checkscope();var scope = "global scope";
function checkscope(){
var scope = "local scope";
function f(){
return scope;
}
return f;
}
checkscope()();猜猜两段代码各自的执行结果是多少?
这里直接告诉大家结果,两段代码都会打印:local scope。
原因也很简单,因为JavaScript采用的是词法作用域,函数的作用域基于函数创建的位置。
而引用《JavaScript权威指南》的回答就是:
JavaScript 函数的执行用到了作用域链,这个作用域链是在函数定义的时候创建的。嵌套的函数 f() 定义在这个作用域链里,其中的变量 scope 一定是局部变量,不管何时何地执行函数 f(),这种绑定在执行 f() 时依然有效。
但是在这里真正想让大家思考的是:
虽然两段代码执行的结果一样,但是两段代码究竟有哪些不同呢?
如果要回答这个问题,就要牵涉到很多的内容,词法作用域只是其中的一小部分,让我们期待下一篇文章————《JavaScript深入之执行上下文栈》。
JavaScript深入系列目录地址:https://github.com/mqyqingfeng/Blog。
JavaScript深入系列预计写十五篇左右,旨在帮大家捋顺JavaScript底层知识,重点讲解如原型、作用域、执行上下文、变量对象、this、闭包、按值传递、call、apply、bind、new、继承等难点概念。
如果有错误或者不严谨的地方,请务必给予指正,十分感谢。如果喜欢或者有所启发,欢迎star,对作者也是一种鼓励。
在《JavaScript深入之执行上下文栈》中讲到,当 JavaScript 代码执行一段可执行代码(executable code)时,会创建对应的执行上下文(execution context)。
对于每个执行上下文,都有三个重要属性:
然后分别在《JavaScript深入之变量对象》、《JavaScript深入之作用域链》、《JavaScript深入之从ECMAScript规范解读this》中讲解了这三个属性。
阅读本文前,如果对以上的概念不是很清楚,希望先阅读这些文章。
因为,这一篇,我们会结合着所有内容,讲讲执行上下文的具体处理过程。
在《JavaScript深入之词法作用域和动态作用域》中,提出这样一道思考题:
var scope = "global scope";
function checkscope(){
var scope = "local scope";
function f(){
return scope;
}
return f();
}
checkscope();var scope = "global scope";
function checkscope(){
var scope = "local scope";
function f(){
return scope;
}
return f;
}
checkscope()();两段代码都会打印'local scope'。虽然两段代码执行的结果一样,但是两段代码究竟有哪些不同呢?
紧接着就在下一篇《JavaScript深入之执行上下文栈》中,讲到了两者的区别在于执行上下文栈的变化不一样,然而,如果是这样笼统的回答,依然显得不够详细,本篇就会详细的解析执行上下文栈和执行上下文的具体变化过程。
我们分析第一段代码:
var scope = "global scope";
function checkscope(){
var scope = "local scope";
function f(){
return scope;
}
return f();
}
checkscope();执行过程如下:
1.执行全局代码,创建全局执行上下文,全局上下文被压入执行上下文栈
ECStack = [
globalContext
];2.全局上下文初始化
globalContext = {
VO: [global],
Scope: [globalContext.VO],
this: globalContext.VO
}2.初始化的同时,checkscope 函数被创建,保存作用域链到函数的内部属性[[scope]]
checkscope.[[scope]] = [
globalContext.VO
];3.执行 checkscope 函数,创建 checkscope 函数执行上下文,checkscope 函数执行上下文被压入执行上下文栈
ECStack = [
checkscopeContext,
globalContext
];4.checkscope 函数执行上下文初始化:
同时 f 函数被创建,保存作用域链到 f 函数的内部属性[[scope]]
checkscopeContext = {
AO: {
arguments: {
length: 0
},
scope: undefined,
f: reference to function f(){}
},
Scope: [AO, globalContext.VO],
this: undefined
}5.执行 f 函数,创建 f 函数执行上下文,f 函数执行上下文被压入执行上下文栈
ECStack = [
fContext,
checkscopeContext,
globalContext
];6.f 函数执行上下文初始化, 以下跟第 4 步相同:
fContext = {
AO: {
arguments: {
length: 0
}
},
Scope: [AO, checkscopeContext.AO, globalContext.VO],
this: undefined
}7.f 函数执行,沿着作用域链查找 scope 值,返回 scope 值
8.f 函数执行完毕,f 函数上下文从执行上下文栈中弹出
ECStack = [
checkscopeContext,
globalContext
];9.checkscope 函数执行完毕,checkscope 执行上下文从执行上下文栈中弹出
ECStack = [
globalContext
];第二段代码就留给大家去尝试模拟它的执行过程。
var scope = "global scope";
function checkscope(){
var scope = "local scope";
function f(){
return scope;
}
return f;
}
checkscope()();不过,在下一篇《JavaScript深入之闭包》中也会提及这段代码的执行过程。
《JavaScript深入之从ECMAScript规范解读this》
本文写的太好,给了我很多启发。感激不尽!
JavaScript深入系列目录地址:https://github.com/mqyqingfeng/Blog。
JavaScript深入系列预计写十五篇左右,旨在帮大家捋顺JavaScript底层知识,重点讲解如原型、作用域、执行上下文、变量对象、this、闭包、按值传递、call、apply、bind、new、继承等难点概念。
如果有错误或者不严谨的地方,请务必给予指正,十分感谢。如果喜欢或者有所启发,欢迎star,对作者也是一种鼓励。
取出数组中的最大值或者最小值是开发中常见的需求,但你能想出几种方法来实现这个需求呢?
JavaScript 提供了 Math.max 函数返回一组数中的最大值,用法是:
Math.max([value1[,value2, ...]])值得注意的是:
-Infinity (注意是负无穷大)而我们需要分析的是:
1.如果任一参数不能被转换为数值,这就意味着如果参数可以被转换成数字,就是可以进行比较的,比如:
Math.max(true, 0) // 1
Math.max(true, '2', null) // 2
Math.max(1, undefined) // NaN
Math.max(1, {}) // NaN2.如果没有参数,则结果为 -Infinity,对应的,Math.min 函数,如果没有参数,则结果为 Infinity,所以:
var min = Math.min();
var max = Math.max();
console.log(min > max);了解了 Math.max 方法,我们以求数组最大值的为例,思考有哪些方法可以实现这个需求。
最最原始的方法,莫过于循环遍历一遍:
var arr = [6, 4, 1, 8, 2, 11, 23];
var result = arr[0];
for (var i = 1; i < arr.length; i++) {
result = Math.max(result, arr[i]);
}
console.log(result);既然是通过遍历数组求出一个最终值,那么我们就可以使用 reduce 方法:
var arr = [6, 4, 1, 8, 2, 11, 23];
function max(prev, next) {
return Math.max(prev, next);
}
console.log(arr.reduce(max));如果我们先对数组进行一次排序,那么最大值就是最后一个值:
var arr = [6, 4, 1, 8, 2, 11, 23];
arr.sort(function(a,b){return a - b;});
console.log(arr[arr.length - 1])Math.max 支持传多个参数来进行比较,那么我们如何将一个数组转换成参数传进 Math.max 函数呢?eval 便是一种
var arr = [6, 4, 1, 8, 2, 11, 23];
var max = eval("Math.max(" + arr + ")");
console.log(max)使用 apply 是另一种。
var arr = [6, 4, 1, 8, 2, 11, 23];
console.log(Math.max.apply(null, arr))使用 ES6 的扩展运算符:
var arr = [6, 4, 1, 8, 2, 11, 23];
console.log(Math.max(...arr))有更多的方法欢迎留言哈~
JavaScript专题系列目录地址:https://github.com/mqyqingfeng/Blog。
JavaScript专题系列预计写二十篇左右,主要研究日常开发中一些功能点的实现,比如防抖、节流、去重、类型判断、拷贝、最值、扁平、柯里、递归、乱序、排序等,特点是研(chao)究(xi) underscore 和 jQuery 的实现方式。
如果有错误或者不严谨的地方,请务必给予指正,十分感谢。如果喜欢或者有所启发,欢迎 star,对作者也是一种鼓励。
jQuery 的 extend 是 jQuery 中应用非常多的一个函数,今天我们一边看 jQuery 的 extend 的特性,一边实现一个 extend!
先来看看 extend 的功能,引用 jQuery 官网:
Merge the contents of two or more objects together into the first object.
翻译过来就是,合并两个或者更多的对象的内容到第一个对象中。
让我们看看 extend 的用法:
jQuery.extend( target [, object1 ] [, objectN ] )第一个参数 target,表示要拓展的目标,我们就称它为目标对象吧。
后面的参数,都传入对象,内容都会复制到目标对象中,我们就称它们为待复制对象吧。
举个例子:
var obj1 = {
a: 1,
b: { b1: 1, b2: 2 }
};
var obj2 = {
b: { b1: 3, b3: 4 },
c: 3
};
var obj3 = {
d: 4
}
console.log($.extend(obj1, obj2, obj3));
// {
// a: 1,
// b: { b1: 3, b3: 4 },
// c: 3,
// d: 4
// }当两个对象出现相同字段的时候,后者会覆盖前者,而不会进行深层次的覆盖。
结合着上篇写得 《JavaScript专题之深浅拷贝》,我们尝试着自己写一个 extend 函数:
// 第一版
function extend() {
var name, options, copy;
var length = arguments.length;
var i = 1;
var target = arguments[0];
for (; i < length; i++) {
options = arguments[i];
if (options != null) {
for (name in options) {
copy = options[name];
if (copy !== undefined){
target[name] = copy;
}
}
}
}
return target;
};那如何进行深层次的复制呢?jQuery v1.1.4 加入了一个新的用法:
jQuery.extend( [deep], target, object1 [, objectN ] )也就是说,函数的第一个参数可以传一个布尔值,如果为 true,我们就会进行深拷贝,false 依然当做浅拷贝,这个时候,target 就往后移动到第二个参数。
还是举这个例子:
var obj1 = {
a: 1,
b: { b1: 1, b2: 2 }
};
var obj2 = {
b: { b1: 3, b3: 4 },
c: 3
};
var obj3 = {
d: 4
}
console.log($.extend(true, obj1, obj2, obj3));
// {
// a: 1,
// b: { b1: 3, b2: 2, b3: 4 },
// c: 3,
// d: 4
// }因为采用了深拷贝,会遍历到更深的层次进行添加和覆盖。
我们来实现深拷贝的功能,值得注意的是:
// 第二版
function extend() {
// 默认不进行深拷贝
var deep = false;
var name, options, src, copy;
var length = arguments.length;
// 记录要复制的对象的下标
var i = 1;
// 第一个参数不传布尔值的情况下,target默认是第一个参数
var target = arguments[0] || {};
// 如果第一个参数是布尔值,第二个参数是才是target
if (typeof target == 'boolean') {
deep = target;
target = arguments[i] || {};
i++;
}
// 如果target不是对象,我们是无法进行复制的,所以设为{}
if (typeof target !== 'object') {
target = {}
}
// 循环遍历要复制的对象们
for (; i < length; i++) {
// 获取当前对象
options = arguments[i];
// 要求不能为空 避免extend(a,,b)这种情况
if (options != null) {
for (name in options) {
// 目标属性值
src = target[name];
// 要复制的对象的属性值
copy = options[name];
if (deep && copy && typeof copy == 'object') {
// 递归调用
target[name] = extend(deep, src, copy);
}
else if (copy !== undefined){
target[name] = copy;
}
}
}
}
return target;
};在实现上,核心的部分还是跟上篇实现的深浅拷贝函数一致,如果要复制的对象的属性值是一个对象,就递归调用 extend。不过 extend 的实现中,多了很多细节上的判断,比如第一个参数是否是布尔值,target 是否是一个对象,不传参数时的默认值等。
接下来,我们看几个 jQuery 的 extend 使用效果:
在我们的实现中,typeof target 必须等于 object,我们才会在这个 target 基础上进行拓展,然而我们用 typeof 判断一个函数时,会返回function,也就是说,我们无法在一个函数上进行拓展!
什么,我们还能在一个函数上进行拓展!!
当然啦,毕竟函数也是一种对象嘛,让我们看个例子:
function a() {}
a.target = 'b';
console.log(a.target); // b实际上,在 underscore 的实现中,underscore 的各种方法便是挂在了函数上!
所以在这里我们还要判断是不是函数,这时候我们便可以使用《JavaScript专题之类型判断(上)》中写得 isFunction 函数
我们这样修改:
if (typeof target !== "object" && !isFunction(target)) {
target = {};
}其实我们实现的方法有个小 bug ,不信我们写个 demo:
var obj1 = {
a: 1,
b: {
c: 2
}
}
var obj2 = {
b: {
c: [5],
}
}
var d = extend(true, obj1, obj2)
console.log(d);我们预期会返回这样一个对象:
{
a: 1,
b: {
c: [5]
}
}然而返回了这样一个对象:
{
a: 1,
b: {
c: {
0: 5
}
}
}让我们细细分析为什么会导致这种情况:
首先我们在函数的开始写一个 console 函数比如:console.log(1),然后以上面这个 demo 为例,执行一下,我们会发现 1 打印了三次,这就是说 extend 函数执行了三遍,让我们捋一捋这三遍传入的参数:
第一遍执行到递归调用时:
var src = { c: 2 };
var copy = { c: [5]};
target[name] = extend(true, src, copy);第二遍执行到递归调用时:
var src = 2;
var copy = [5];
target[name] = extend(true, src, copy);第三遍进行最终的赋值,因为 src 是一个基本类型,我们默认使用一个空对象作为目标值,所以最终的结果就变成了对象的属性!
为了解决这个问题,我们需要对目标属性值和待复制对象的属性值进行判断:
判断目标属性值跟要复制的对象的属性值类型是否一致:
如果待复制对象属性值类型为数组,目标属性值类型不为数组的话,目标属性值就设为 []
如果待复制对象属性值类型为对象,目标属性值类型不为对象的话,目标属性值就设为 {}
结合着《JavaScript专题之类型判断(下)》中的 isPlainObject 函数,我们可以对类型进行更细致的划分:
var clone, copyIsArray;
...
if (deep && copy && (isPlainObject(copy) ||
(copyIsArray = Array.isArray(copy)))) {
if (copyIsArray) {
copyIsArray = false;
clone = src && Array.isArray(src) ? src : [];
} else {
clone = src && isPlainObject(src) ? src : {};
}
target[name] = extend(deep, clone, copy);
} else if (copy !== undefined) {
target[name] = copy;
}实际上,我们还可能遇到一个循环引用的问题,举个例子:
var a = {name : b};
var b = {name : a}
var c = extend(a, b);
console.log(c);我们会得到一个可以无限展开的对象,类似于这样:
为了避免这个问题,我们需要判断要复制的对象属性是否等于 target,如果等于,我们就跳过:
...
src = target[name];
copy = options[name];
if (target === copy) {
continue;
}
...如果加上这句,结果就会是:
{name: undefined}// isPlainObject 函数来自于 [JavaScript专题之类型判断(下) ](https://github.com/mqyqingfeng/Blog/issues/30)
var class2type = {};
var toString = class2type.toString;
var hasOwn = class2type.hasOwnProperty;
function isPlainObject(obj) {
var proto, Ctor;
if (!obj || toString.call(obj) !== "[object Object]") {
return false;
}
proto = Object.getPrototypeOf(obj);
if (!proto) {
return true;
}
Ctor = hasOwn.call(proto, "constructor") && proto.constructor;
return typeof Ctor === "function" && hasOwn.toString.call(Ctor) === hasOwn.toString.call(Object);
}
function extend() {
// 默认不进行深拷贝
var deep = false;
var name, options, src, copy, clone, copyIsArray;
var length = arguments.length;
// 记录要复制的对象的下标
var i = 1;
// 第一个参数不传布尔值的情况下,target 默认是第一个参数
var target = arguments[0] || {};
// 如果第一个参数是布尔值,第二个参数是 target
if (typeof target == 'boolean') {
deep = target;
target = arguments[i] || {};
i++;
}
// 如果target不是对象,我们是无法进行复制的,所以设为 {}
if (typeof target !== "object" && !isFunction(target)) {
target = {};
}
// 循环遍历要复制的对象们
for (; i < length; i++) {
// 获取当前对象
options = arguments[i];
// 要求不能为空 避免 extend(a,,b) 这种情况
if (options != null) {
for (name in options) {
// 目标属性值
src = target[name];
// 要复制的对象的属性值
copy = options[name];
// 解决循环引用
if (target === copy) {
continue;
}
// 要递归的对象必须是 plainObject 或者数组
if (deep && copy && (isPlainObject(copy) ||
(copyIsArray = Array.isArray(copy)))) {
// 要复制的对象属性值类型需要与目标属性值相同
if (copyIsArray) {
copyIsArray = false;
clone = src && Array.isArray(src) ? src : [];
} else {
clone = src && isPlainObject(src) ? src : {};
}
target[name] = extend(deep, clone, copy);
} else if (copy !== undefined) {
target[name] = copy;
}
}
}
}
return target;
};如果觉得看明白了上面的代码,想想下面两个 demo 的结果:
var a = extend(true, [4, 5, 6, 7, 8, 9], [1, 2, 3]);
console.log(a) // ???var obj1 = {
value: {
3: 1
}
}
var obj2 = {
value: [5, 6, 7],
}
var b = extend(true, obj1, obj2) // ???
var c = extend(true, obj2, obj1) // ???JavaScript专题系列目录地址:https://github.com/mqyqingfeng/Blog。
JavaScript专题系列预计写二十篇左右,主要研究日常开发中一些功能点的实现,比如防抖、节流、去重、类型判断、拷贝、最值、扁平、柯里、递归、乱序、排序等,特点是研(chao)究(xi) underscore 和 jQuery 的实现方式。
如果有错误或者不严谨的地方,请务必给予指正,十分感谢。如果喜欢或者有所启发,欢迎 star,对作者也是一种鼓励。
一句话介绍 call:
call() 方法在使用一个指定的 this 值和若干个指定的参数值的前提下调用某个函数或方法。
举个例子:
var foo = {
value: 1
};
function bar() {
console.log(this.value);
}
bar.call(foo); // 1注意两点:
那么我们该怎么模拟实现这两个效果呢?
试想当调用 call 的时候,把 foo 对象改造成如下:
var foo = {
value: 1,
bar: function() {
console.log(this.value)
}
};
foo.bar(); // 1这个时候 this 就指向了 foo,是不是很简单呢?
但是这样却给 foo 对象本身添加了一个属性,这可不行呐!
不过也不用担心,我们用 delete 再删除它不就好了~
所以我们模拟的步骤可以分为:
以上个例子为例,就是:
// 第一步
foo.fn = bar
// 第二步
foo.fn()
// 第三步
delete foo.fnfn 是对象的属性名,反正最后也要删除它,所以起成什么都无所谓。
根据这个思路,我们可以尝试着去写第一版的 call2 函数:
// 第一版
Function.prototype.call2 = function(context) {
// 首先要获取调用call的函数,用this可以获取
context.fn = this;
context.fn();
delete context.fn;
}
// 测试一下
var foo = {
value: 1
};
function bar() {
console.log(this.value);
}
bar.call2(foo); // 1正好可以打印 1 哎!是不是很开心!(~ ̄▽ ̄)~
最一开始也讲了,call 函数还能给定参数执行函数。举个例子:
var foo = {
value: 1
};
function bar(name, age) {
console.log(name)
console.log(age)
console.log(this.value);
}
bar.call(foo, 'kevin', 18);
// kevin
// 18
// 1注意:传入的参数并不确定,这可咋办?
不急,我们可以从 Arguments 对象中取值,取出第二个到最后一个参数,然后放到一个数组里。
比如这样:
// 以上个例子为例,此时的arguments为:
// arguments = {
// 0: foo,
// 1: 'kevin',
// 2: 18,
// length: 3
// }
// 因为arguments是类数组对象,所以可以用for循环
var args = [];
for(var i = 1, len = arguments.length; i < len; i++) {
args.push('arguments[' + i + ']');
}
// 执行后 args为 ["arguments[1]", "arguments[2]", "arguments[3]"]不定长的参数问题解决了,我们接着要把这个参数数组放到要执行的函数的参数里面去。
// 将数组里的元素作为多个参数放进函数的形参里
context.fn(args.join(','))
// (O_o)??
// 这个方法肯定是不行的啦!!!也许有人想到用 ES6 的方法,不过 call 是 ES3 的方法,我们为了模拟实现一个 ES3 的方法,要用到ES6的方法,好像……,嗯,也可以啦。但是我们这次用 eval 方法拼成一个函数,类似于这样:
eval('context.fn(' + args +')')这里 args 会自动调用 Array.toString() 这个方法。
所以我们的第二版克服了两个大问题,代码如下:
// 第二版
Function.prototype.call2 = function(context) {
context.fn = this;
var args = [];
for(var i = 1, len = arguments.length; i < len; i++) {
args.push('arguments[' + i + ']');
}
eval('context.fn(' + args +')');
delete context.fn;
}
// 测试一下
var foo = {
value: 1
};
function bar(name, age) {
console.log(name)
console.log(age)
console.log(this.value);
}
bar.call2(foo, 'kevin', 18);
// kevin
// 18
// 1(๑•̀ㅂ•́)و✧
模拟代码已经完成 80%,还有两个小点要注意:
1.this 参数可以传 null,当为 null 的时候,视为指向 window
举个例子:
var value = 1;
function bar() {
console.log(this.value);
}
bar.call(null); // 1虽然这个例子本身不使用 call,结果依然一样。
2.函数是可以有返回值的!
举个例子:
var obj = {
value: 1
}
function bar(name, age) {
return {
value: this.value,
name: name,
age: age
}
}
console.log(bar.call(obj, 'kevin', 18));
// Object {
// value: 1,
// name: 'kevin',
// age: 18
// }不过都很好解决,让我们直接看第三版也就是最后一版的代码:
// 第三版
Function.prototype.call2 = function (context) {
var context = context || window;
context.fn = this;
var args = [];
for(var i = 1, len = arguments.length; i < len; i++) {
args.push('arguments[' + i + ']');
}
var result = eval('context.fn(' + args +')');
delete context.fn
return result;
}
// 测试一下
var value = 2;
var obj = {
value: 1
}
function bar(name, age) {
console.log(this.value);
return {
value: this.value,
name: name,
age: age
}
}
bar.call2(null); // 2
console.log(bar.call2(obj, 'kevin', 18));
// 1
// Object {
// value: 1,
// name: 'kevin',
// age: 18
// }到此,我们完成了 call 的模拟实现,给自己一个赞 b( ̄▽ ̄)d
apply 的实现跟 call 类似,在这里直接给代码,代码来自于知乎 @郑航的实现:
Function.prototype.apply = function (context, arr) {
var context = Object(context) || window;
context.fn = this;
var result;
if (!arr) {
result = context.fn();
}
else {
var args = [];
for (var i = 0, len = arr.length; i < len; i++) {
args.push('arr[' + i + ']');
}
result = eval('context.fn(' + args + ')')
}
delete context.fn
return result;
}知乎问题 不能使用call、apply、bind,如何用 js 实现 call 或者 apply 的功能?
JavaScript深入系列目录地址:https://github.com/mqyqingfeng/Blog。
JavaScript深入系列预计写十五篇左右,旨在帮大家捋顺JavaScript底层知识,重点讲解如原型、作用域、执行上下文、变量对象、this、闭包、按值传递、call、apply、bind、new、继承等难点概念。
如果有错误或者不严谨的地方,请务必给予指正,十分感谢。如果喜欢或者有所启发,欢迎star,对作者也是一种鼓励。
在《JavaScript专题之跟着underscore学防抖》中,我们了解了为什么要限制事件的频繁触发,以及如何做限制:
今天重点讲讲节流的实现。
节流的原理很简单:
如果你持续触发事件,每隔一段时间,只执行一次事件。
根据首次是否执行以及结束后是否执行,效果有所不同,实现的方式也有所不同。
我们用 leading 代表首次是否执行,trailing 代表结束后是否再执行一次。
关于节流的实现,有两种主流的实现方式,一种是使用时间戳,一种是设置定时器。
让我们来看第一种方法:使用时间戳,当触发事件的时候,我们取出当前的时间戳,然后减去之前的时间戳(最一开始值设为 0 ),如果大于设置的时间周期,就执行函数,然后更新时间戳为当前的时间戳,如果小于,就不执行。
看了这个表述,是不是感觉已经可以写出代码了…… 让我们来写第一版的代码:
// 第一版
function throttle(func, wait) {
var context, args;
var previous = 0;
return function() {
var now = +new Date();
context = this;
args = arguments;
if (now - previous > wait) {
func.apply(context, args);
previous = now;
}
}
}例子依然是用讲 debounce 中的例子,如果你要使用:
container.onmousemove = throttle(getUserAction, 1000);效果演示如下:
我们可以看到:当鼠标移入的时候,事件立刻执行,每过 1s 会执行一次,如果在 4.2s 停止触发,以后不会再执行事件。
接下来,我们讲讲第二种实现方式,使用定时器。
当触发事件的时候,我们设置一个定时器,再触发事件的时候,如果定时器存在,就不执行,直到定时器执行,然后执行函数,清空定时器,这样就可以设置下个定时器。
// 第二版
function throttle(func, wait) {
var timeout;
var previous = 0;
return function() {
context = this;
args = arguments;
if (!timeout) {
timeout = setTimeout(function(){
timeout = null;
func.apply(context, args)
}, wait)
}
}
}为了让效果更加明显,我们设置 wait 的时间为 3s,效果演示如下:
我们可以看到:当鼠标移入的时候,事件不会立刻执行,晃了 3s 后终于执行了一次,此后每 3s 执行一次,当数字显示为 3 的时候,立刻移出鼠标,相当于大约 9.2s 的时候停止触发,但是依然会在第 12s 的时候执行一次事件。
所以比较两个方法:
那我们想要一个什么样的呢?
有人就说了:我想要一个有头有尾的!就是鼠标移入能立刻执行,停止触发的时候还能再执行一次!
所以我们综合两者的优势,然后双剑合璧,写一版代码:
// 第三版
function throttle(func, wait) {
var timeout, context, args, result;
var previous = 0;
var later = function() {
previous = +new Date();
timeout = null;
func.apply(context, args)
};
var throttled = function() {
var now = +new Date();
//下次触发 func 剩余的时间
var remaining = wait - (now - previous);
context = this;
args = arguments;
// 如果没有剩余的时间了或者你改了系统时间
if (remaining <= 0 || remaining > wait) {
if (timeout) {
clearTimeout(timeout);
timeout = null;
}
previous = now;
func.apply(context, args);
} else if (!timeout) {
timeout = setTimeout(later, remaining);
}
};
return throttled;
}效果演示如下:
我们可以看到:鼠标移入,事件立刻执行,晃了 3s,事件再一次执行,当数字变成 3 的时候,也就是 6s 后,我们立刻移出鼠标,停止触发事件,9s 的时候,依然会再执行一次事件。
但是我有时也希望无头有尾,或者有头无尾,这个咋办?
那我们设置个 options 作为第三个参数,然后根据传的值判断到底哪种效果,我们约定:
leading:false 表示禁用第一次执行
trailing: false 表示禁用停止触发的回调
我们来改一下代码:
// 第四版
function throttle(func, wait, options) {
var timeout, context, args, result;
var previous = 0;
if (!options) options = {};
var later = function() {
previous = options.leading === false ? 0 : new Date().getTime();
timeout = null;
func.apply(context, args);
if (!timeout) context = args = null;
};
var throttled = function() {
var now = new Date().getTime();
if (!previous && options.leading === false) previous = now;
var remaining = wait - (now - previous);
context = this;
args = arguments;
if (remaining <= 0 || remaining > wait) {
if (timeout) {
clearTimeout(timeout);
timeout = null;
}
previous = now;
func.apply(context, args);
if (!timeout) context = args = null;
} else if (!timeout && options.trailing !== false) {
timeout = setTimeout(later, remaining);
}
};
return throttled;
}在 debounce 的实现中,我们加了一个 cancel 方法,throttle 我们也加个 cancel 方法:
// 第五版 非完整代码,完整代码请查看最后的演示代码链接
...
throttled.cancel = function() {
clearTimeout(timeout);
previous = 0;
timeout = null;
}
...我们要注意 underscore 的实现中有这样一个问题:
那就是 leading:false 和 trailing: false 不能同时设置。
如果同时设置的话,比如当你将鼠标移出的时候,因为 trailing 设置为 false,停止触发的时候不会设置定时器,所以只要再过了设置的时间,再移入的话,就会立刻执行,就违反了 leading: false,bug 就出来了,所以,这个 throttle 只有三种用法:
container.onmousemove = throttle(getUserAction, 1000);
container.onmousemove = throttle(getUserAction, 1000, {
leading: false
});
container.onmousemove = throttle(getUserAction, 1000, {
trailing: false
});至此我们已经完整实现了一个 underscore 中的 throttle 函数,恭喜,撒花!
相关的代码可以在 Github 博客仓库 中找到
JavaScript专题系列目录地址:https://github.com/mqyqingfeng/Blog。
JavaScript专题系列预计写二十篇左右,主要研究日常开发中一些功能点的实现,比如防抖、节流、去重、类型判断、拷贝、最值、扁平、柯里、递归、乱序、排序等,特点是研(chao)究(xi) underscore 和 jQuery 的实现方式。
如果有错误或者不严谨的地方,请务必给予指正,十分感谢。如果喜欢或者有所启发,欢迎 star,对作者也是一种鼓励。
函数记忆是指将上次的计算结果缓存起来,当下次调用时,如果遇到相同的参数,就直接返回缓存中的数据。
举个例子:
function add(a, b) {
return a + b;
}
// 假设 memoize 可以实现函数记忆
var memoizedAdd = memoize(add);
memoizedAdd(1, 2) // 3
memoizedAdd(1, 2) // 相同的参数,第二次调用时,从缓存中取出数据,而非重新计算一次实现这样一个 memoize 函数很简单,原理上只用把参数和对应的结果数据存到一个对象中,调用时,判断参数对应的数据是否存在,存在就返回对应的结果数据。
我们来写一版:
// 第一版 (来自《JavaScript权威指南》)
function memoize(f) {
var cache = {};
return function(){
var key = arguments.length + Array.prototype.join.call(arguments, ",");
if (key in cache) {
return cache[key]
}
else {
return cache[key] = f.apply(this, arguments)
}
}
}我们来测试一下:
var add = function(a, b, c) {
return a + b + c
}
var memoizedAdd = memoize(add)
console.time('use memoize')
for(var i = 0; i < 100000; i++) {
memoizedAdd(1, 2, 3)
}
console.timeEnd('use memoize')
console.time('not use memoize')
for(var i = 0; i < 100000; i++) {
add(1, 2, 3)
}
console.timeEnd('not use memoize')在 Chrome 中,使用 memoize 大约耗时 60ms,如果我们不使用函数记忆,大约耗时 1.3 ms 左右。
什么,我们使用了看似高大上的函数记忆,结果却更加耗时,这个例子近乎有 60 倍呢!
所以,函数记忆也并不是万能的,你看这个简单的场景,其实并不适合用函数记忆。
需要注意的是,函数记忆只是一种编程技巧,本质上是牺牲算法的空间复杂度以换取更优的时间复杂度,在客户端 JavaScript 中代码的执行时间复杂度往往成为瓶颈,因此在大多数场景下,这种牺牲空间换取时间的做法以提升程序执行效率的做法是非常可取的。
因为第一版使用了 join 方法,我们很容易想到当参数是对象的时候,就会自动调用 toString 方法转换成 [Object object],再拼接字符串作为 key 值。我们写个 demo 验证一下这个问题:
var propValue = function(obj){
return obj.value
}
var memoizedAdd = memoize(propValue)
console.log(memoizedAdd({value: 1})) // 1
console.log(memoizedAdd({value: 2})) // 1两者都返回了 1,显然是有问题的,所以我们看看 underscore 的 memoize 函数是如何实现的:
// 第二版 (来自 underscore 的实现)
var memoize = function(func, hasher) {
var memoize = function(key) {
var cache = memoize.cache;
var address = '' + (hasher ? hasher.apply(this, arguments) : key);
if (!cache[address]) {
cache[address] = func.apply(this, arguments);
}
return cache[address];
};
memoize.cache = {};
return memoize;
};从这个实现可以看出,underscore 默认使用 function 的第一个参数作为 key,所以如果直接使用
var add = function(a, b, c) {
return a + b + c
}
var memoizedAdd = memoize(add)
memoizedAdd(1, 2, 3) // 6
memoizedAdd(1, 2, 4) // 6肯定是有问题的,如果要支持多参数,我们就需要传入 hasher 函数,自定义存储的 key 值。所以我们考虑使用 JSON.stringify:
var memoizedAdd = memoize(add, function(){
var args = Array.prototype.slice.call(arguments)
return JSON.stringify(args)
})
console.log(memoizedAdd(1, 2, 3)) // 6
console.log(memoizedAdd(1, 2, 4)) // 7如果使用 JSON.stringify,参数是对象的问题也可以得到解决,因为存储的是对象序列化后的字符串。
我们以斐波那契数列为例:
var count = 0;
var fibonacci = function(n){
count++;
return n < 2? n : fibonacci(n-1) + fibonacci(n-2);
};
for (var i = 0; i <= 10; i++){
fibonacci(i)
}
console.log(count) // 453我们会发现最后的 count 数为 453,也就是说 fibonacci 函数被调用了 453 次!也许你会想,我只是循环到了 10,为什么就被调用了这么多次,所以我们来具体分析下:
当执行 fib(0) 时,调用 1 次
当执行 fib(1) 时,调用 1 次
当执行 fib(2) 时,相当于 fib(1) + fib(0) 加上 fib(2) 本身这一次,共 1 + 1 + 1 = 3 次
当执行 fib(3) 时,相当于 fib(2) + fib(1) 加上 fib(3) 本身这一次,共 3 + 1 + 1 = 5 次
当执行 fib(4) 时,相当于 fib(3) + fib(2) 加上 fib(4) 本身这一次,共 5 + 3 + 1 = 9 次
当执行 fib(5) 时,相当于 fib(4) + fib(3) 加上 fib(5) 本身这一次,共 9 + 5 + 1 = 15 次
当执行 fib(6) 时,相当于 fib(5) + fib(4) 加上 fib(6) 本身这一次,共 15 + 9 + 1 = 25 次
当执行 fib(7) 时,相当于 fib(6) + fib(5) 加上 fib(7) 本身这一次,共 25 + 15 + 1 = 41 次
当执行 fib(8) 时,相当于 fib(7) + fib(6) 加上 fib(8) 本身这一次,共 41 + 25 + 1 = 67 次
当执行 fib(9) 时,相当于 fib(8) + fib(7) 加上 fib(9) 本身这一次,共 67 + 41 + 1 = 109 次
当执行 fib(10) 时,相当于 fib(9) + fib(8) 加上 fib(10) 本身这一次,共 109 + 67 + 1 = 177 次所以执行的总次数为:177 + 109 + 67 + 41 + 25 + 15 + 9 + 5 + 3 + 1 + 1 = 453 次!
如果我们使用函数记忆呢?
var count = 0;
var fibonacci = function(n) {
count++;
return n < 2 ? n : fibonacci(n - 1) + fibonacci(n - 2);
};
fibonacci = memoize(fibonacci)
for (var i = 0; i <= 10; i++) {
fibonacci(i)
}
console.log(count) // 12我们会发现最后的总次数为 12 次,因为使用了函数记忆,调用次数从 453 次降低为了 12 次!
兴奋的同时不要忘记思考:为什么会是 12 次呢?
从 0 到 10 的结果各储存一遍,应该是 11 次呐?咦,那多出来的一次是从哪里来的?
所以我们还需要认真看下我们的写法,在我们的写法中,其实我们用生成的 fibonacci 函数覆盖了原本了 fibonacci 函数,当我们执行 fibonacci(0) 时,执行一次函数,cache 为 {0: 0},但是当我们执行 fibonacci(2) 的时候,执行 fibonacci(1) + fibonacci(0),因为 fibonacci(0) 的值为 0,!cache[address] 的结果为 true,又会执行一次 fibonacci 函数。原来,多出来的那一次是在这里!
也许你会觉得在日常开发中又用不到 fibonacci,这个例子感觉实用价值不高呐,其实,这个例子是用来表明一种使用的场景,也就是如果需要大量重复的计算,或者大量计算又依赖于之前的结果,便可以考虑使用函数记忆。而这种场景,当你遇到的时候,你就会知道的。
JavaScript专题系列目录地址:https://github.com/mqyqingfeng/Blog。
JavaScript专题系列预计写二十篇左右,主要研究日常开发中一些功能点的实现,比如防抖、节流、去重、类型判断、拷贝、最值、扁平、柯里、递归、乱序、排序等,特点是研(chao)究(xi) underscore 和 jQuery 的实现方式。
如果有错误或者不严谨的地方,请务必给予指正,十分感谢。如果喜欢或者有所启发,欢迎 star,对作者也是一种鼓励。
sixsixsix
在前端开发中会遇到一些频繁的事件触发,比如:
为此,我们举个示例代码来了解事件如何频繁的触发:
我们写个 index.html 文件:
<!DOCTYPE html>
<html lang="zh-cmn-Hans">
<head>
<meta charset="utf-8">
<meta http-equiv="x-ua-compatible" content="IE=edge, chrome=1">
<title>debounce</title>
<style>
#container{
width: 100%; height: 200px; line-height: 200px; text-align: center; color: #fff; background-color: #444; font-size: 30px;
}
</style>
</head>
<body>
<div id="container"></div>
<script src="debounce.js"></script>
</body>
</html>debounce.js 文件的代码如下:
var count = 1;
var container = document.getElementById('container');
function getUserAction() {
container.innerHTML = count++;
};
container.onmousemove = getUserAction;我们来看看效果:
从左边滑到右边就触发了 165 次 getUserAction 函数!
因为这个例子很简单,所以浏览器完全反应的过来,可是如果是复杂的回调函数或是 ajax 请求呢?假设 1 秒触发了 60 次,每个回调就必须在 1000 / 60 = 16.67ms 内完成,否则就会有卡顿出现。
为了解决这个问题,一般有两种解决方案:
今天重点讲讲防抖的实现。
防抖的原理就是:你尽管触发事件,但是我一定在事件触发 n 秒后才执行,如果你在一个事件触发的 n 秒内又触发了这个事件,那我就以新的事件的时间为准,n 秒后才执行,总之,就是要等你触发完事件 n 秒内不再触发事件,我才执行,真是任性呐!
根据这段表述,我们可以写第一版的代码:
// 第一版
function debounce(func, wait) {
var timeout;
return function () {
clearTimeout(timeout)
timeout = setTimeout(func, wait);
}
}如果我们要使用它,以最一开始的例子为例:
container.onmousemove = debounce(getUserAction, 1000);现在随你怎么移动,反正你移动完 1000ms 内不再触发,我才执行事件。看看使用效果:
顿时就从 165 次降低成了 1 次!
棒棒哒,我们接着完善它。
如果我们在 getUserAction 函数中 console.log(this),在不使用 debounce 函数的时候,this 的值为:
<div id="container"></div>但是如果使用我们的 debounce 函数,this 就会指向 Window 对象!
所以我们需要将 this 指向正确的对象。
我们修改下代码:
// 第二版
function debounce(func, wait) {
var timeout;
return function () {
var context = this;
clearTimeout(timeout)
timeout = setTimeout(function(){
func.apply(context)
}, wait);
}
}现在 this 已经可以正确指向了。让我们看下个问题:
JavaScript 在事件处理函数中会提供事件对象 event,我们修改下 getUserAction 函数:
function getUserAction(e) {
console.log(e);
container.innerHTML = count++;
};如果我们不使用 debouce 函数,这里会打印 MouseEvent 对象,如图所示:
但是在我们实现的 debounce 函数中,却只会打印 undefined!
所以我们再修改一下代码:
// 第三版
function debounce(func, wait) {
var timeout;
return function () {
var context = this;
var args = arguments;
clearTimeout(timeout)
timeout = setTimeout(function(){
func.apply(context, args)
}, wait);
}
}到此为止,我们修复了两个小问题:
这个时候,代码已经很是完善了,但是为了让这个函数更加完善,我们接下来思考一个新的需求。
这个需求就是:
我不希望非要等到事件停止触发后才执行,我希望立刻执行函数,然后等到停止触发 n 秒后,才可以重新触发执行。
想想这个需求也是很有道理的嘛,那我们加个 immediate 参数判断是否是立刻执行。
// 第四版
function debounce(func, wait, immediate) {
var timeout;
return function () {
var context = this;
var args = arguments;
if (timeout) clearTimeout(timeout);
if (immediate) {
// 如果已经执行过,不再执行
var callNow = !timeout;
timeout = setTimeout(function(){
timeout = null;
}, wait)
if (callNow) func.apply(context, args)
}
else {
timeout = setTimeout(function(){
func.apply(context, args)
}, wait);
}
}
}再来看看使用效果:
此时注意一点,就是 getUserAction 函数可能是有返回值的,所以我们也要返回函数的执行结果,但是当 immediate 为 false 的时候,因为使用了 setTimeout ,我们将 func.apply(context, args) 的返回值赋给变量,最后再 return 的时候,值将会一直是 undefined,所以我们只在 immediate 为 true 的时候返回函数的执行结果。
// 第五版
function debounce(func, wait, immediate) {
var timeout, result;
return function () {
var context = this;
var args = arguments;
if (timeout) clearTimeout(timeout);
if (immediate) {
// 如果已经执行过,不再执行
var callNow = !timeout;
timeout = setTimeout(function(){
timeout = null;
}, wait)
if (callNow) result = func.apply(context, args)
}
else {
timeout = setTimeout(function(){
func.apply(context, args)
}, wait);
}
return result;
}
}最后我们再思考一个小需求,我希望能取消 debounce 函数,比如说我 debounce 的时间间隔是 10 秒钟,immediate 为 true,这样的话,我只有等 10 秒后才能重新触发事件,现在我希望有一个按钮,点击后,取消防抖,这样我再去触发,就可以又立刻执行啦,是不是很开心?
为了这个需求,我们写最后一版的代码:
// 第六版
function debounce(func, wait, immediate) {
var timeout, result;
var debounced = function () {
var context = this;
var args = arguments;
if (timeout) clearTimeout(timeout);
if (immediate) {
// 如果已经执行过,不再执行
var callNow = !timeout;
timeout = setTimeout(function(){
timeout = null;
}, wait)
if (callNow) result = func.apply(context, args)
}
else {
timeout = setTimeout(function(){
func.apply(context, args)
}, wait);
}
return result;
};
debounced.cancel = function() {
clearTimeout(timeout);
timeout = null;
};
return debounced;
}那么该如何使用这个 cancel 函数呢?依然是以上面的 demo 为例:
var count = 1;
var container = document.getElementById('container');
function getUserAction(e) {
container.innerHTML = count++;
};
var setUseAction = debounce(getUserAction, 10000, true);
container.onmousemove = setUseAction;
document.getElementById("button").addEventListener('click', function(){
setUseAction.cancel();
})演示效果如下:
至此我们已经完整实现了一个 underscore 中的 debounce 函数,恭喜,撒花!
相关的代码可以在 Github 博客仓库 中找到
JavaScript专题系列目录地址:https://github.com/mqyqingfeng/Blog。
JavaScript专题系列预计写二十篇左右,主要研究日常开发中一些功能点的实现,比如防抖、节流、去重、类型判断、拷贝、最值、扁平、柯里、递归、乱序、排序等,特点是研(chao)究(xi) underscore 和 jQuery 的实现方式。
如果有错误或者不严谨的地方,请务必给予指正,十分感谢。如果喜欢或者有所启发,欢迎 star,对作者也是一种鼓励。
Hi there
I hope guys translate english
如果要问到 JavaScript 代码执行顺序的话,想必写过 JavaScript 的开发者都会有个直观的印象,那就是顺序执行,毕竟:
var foo = function () {
console.log('foo1');
}
foo(); // foo1
var foo = function () {
console.log('foo2');
}
foo(); // foo2然而去看这段代码:
function foo() {
console.log('foo1');
}
foo(); // foo2
function foo() {
console.log('foo2');
}
foo(); // foo2打印的结果却是两个 foo2。
刷过面试题的都知道这是因为 JavaScript 引擎并非一行一行地分析和执行程序,而是一段一段地分析执行。当执行一段代码的时候,会进行一个“准备工作”,比如第一个例子中的变量提升,和第二个例子中的函数提升。
但是本文真正想让大家思考的是:这个“一段一段”中的“段”究竟是怎么划分的呢?
到底JavaScript引擎遇到一段怎样的代码时才会做“准备工作”呢?
这就要说到 JavaScript 的可执行代码(executable code)的类型有哪些了?
其实很简单,就三种,全局代码、函数代码、eval代码。
举个例子,当执行到一个函数的时候,就会进行准备工作,这里的“准备工作”,让我们用个更专业一点的说法,就叫做"执行上下文(execution context)"。
接下来问题来了,我们写的函数多了去了,如何管理创建的那么多执行上下文呢?
所以 JavaScript 引擎创建了执行上下文栈(Execution context stack,ECS)来管理执行上下文
为了模拟执行上下文栈的行为,让我们定义执行上下文栈是一个数组:
ECStack = [];试想当 JavaScript 开始要解释执行代码的时候,最先遇到的就是全局代码,所以初始化的时候首先就会向执行上下文栈压入一个全局执行上下文,我们用 globalContext 表示它,并且只有当整个应用程序结束的时候,ECStack 才会被清空,所以程序结束之前, ECStack 最底部永远有个 globalContext:
ECStack = [
globalContext
];现在 JavaScript 遇到下面的这段代码了:
function fun3() {
console.log('fun3')
}
function fun2() {
fun3();
}
function fun1() {
fun2();
}
fun1();当执行一个函数的时候,就会创建一个执行上下文,并且压入执行上下文栈,当函数执行完毕的时候,就会将函数的执行上下文从栈中弹出。知道了这样的工作原理,让我们来看看如何处理上面这段代码:
// 伪代码
// fun1()
ECStack.push(<fun1> functionContext);
// fun1中竟然调用了fun2,还要创建fun2的执行上下文
ECStack.push(<fun2> functionContext);
// 擦,fun2还调用了fun3!
ECStack.push(<fun3> functionContext);
// fun3执行完毕
ECStack.pop();
// fun2执行完毕
ECStack.pop();
// fun1执行完毕
ECStack.pop();
// javascript接着执行下面的代码,但是ECStack底层永远有个globalContext好啦,现在我们已经了解了执行上下文栈是如何处理执行上下文的,所以让我们看看上篇文章《JavaScript深入之词法作用域和动态作用域》最后的问题:
var scope = "global scope";
function checkscope(){
var scope = "local scope";
function f(){
return scope;
}
return f();
}
checkscope();var scope = "global scope";
function checkscope(){
var scope = "local scope";
function f(){
return scope;
}
return f;
}
checkscope()();两段代码执行的结果一样,但是两段代码究竟有哪些不同呢?
答案就是执行上下文栈的变化不一样。
让我们模拟第一段代码:
ECStack.push(<checkscope> functionContext);
ECStack.push(<f> functionContext);
ECStack.pop();
ECStack.pop();让我们模拟第二段代码:
ECStack.push(<checkscope> functionContext);
ECStack.pop();
ECStack.push(<f> functionContext);
ECStack.pop();是不是有些不同呢?
当然了,这样概括的回答执行上下文栈的变化不同,是不是依然有一种意犹未尽的感觉呢,为了更详细讲解两个函数执行上的区别,我们需要探究一下执行上下文到底包含了哪些内容,所以欢迎阅读下一篇《JavaScript深入之变量对象》。
JavaScript深入系列目录地址:https://github.com/mqyqingfeng/Blog。
JavaScript深入系列预计写十五篇左右,旨在帮大家捋顺JavaScript底层知识,重点讲解如原型、作用域、执行上下文、变量对象、this、闭包、按值传递、call、apply、bind、new、继承等难点概念。
如果有错误或者不严谨的地方,请务必给予指正,十分感谢。如果喜欢或者有所启发,欢迎star,对作者也是一种鼓励。
ary.proto.constructor === Array.prototype.constructor === Array
返回false
JavaScript 深入系列共计 15 篇已经正式完结,这是一个旨在帮助大家,其实也是帮助自己捋顺 JavaScript 底层知识的系列。重点讲解了如原型、作用域、执行上下文、变量对象、this、闭包、按值传递、call、apply、bind、new、继承等 JS 语言中的比较难懂的概念。
JavaScript 深入系列自 4 月 6 日发布第一篇文章,到 5 月 12 日发布最后一篇,感谢各位朋友的收藏、点赞,鼓励、指正。
顺便宣传一下该博客的 Github 仓库:https://github.com/mqyqingfeng/Blog,欢迎 star,鼓励一下作者。
而此篇,作为深入系列的总结篇,除了汇总各篇文章,作为目录篇之外,还希望跟大家聊聊,我为什么要写这个系列?
讲一个对我学技术的态度很有影响的一件事情。
曾经团队邀请过 Nodejs 领域一个非常著名的大神来分享,这里便不说是谁了。当知道是他后,简直是粉丝的心情。但是课讲得确实一般,也许是第一次讲,准备不是很充足吧,以至于我都觉得我能讲得比他好,但是有两次,让我觉得这是真正的大神。一次就是,当有同事问到今年有什么流行的前端框架吗?这些框架有怎样的适用场景?该如何抉择?我以为大神一定会回答当时正火的 React、以及小鲜肉 Vue 之类,然后老生常谈的比较一番,但是他回答道:“I dont't care!因为这些并不重要,真正重要的是底层,当你了解了底层,你就能很轻松的明白这些框架的原理,当你明白了原理,这些框架又有什么意思呢?”
虽然这段话因为过去太久,已经不记得确切的表述,但是给了我非常深刻的印象,自己一路学习过来,新的东西不停的冒出,但是学的再多感觉自己也只是学了一堆 API,如果仅仅是为了解决工作上的问题,或许已经足够,但是内心经常还会冒出一种不安定感,这种不安定感或许来自于对 JavaScript 未知部分的恐惧,或许来自于解决问题却不明所以的尴尬,或许来自于屡次学习语言难点却不得门道的失败……代码写的越久,这种感觉就越是鲜明。
当然了,大家也不要过分解读底层,各种计算机语言追究到底层都是编译原理之类,如果是有这方面的兴趣,固然可以,但是如果本质上还是为了解决上层问题,倒不必一定要深究到这个层面。用 JavaScript 了解这门语言本身的使用和原理,用 jQuery 看看 jQuery 的源码实现,用 React 技术栈,写写 React、Redux 简单的模拟实现,诸如此类,都是对底层的一种追求。
这样讲的话,底层这个词,更像是一个方向,一种学习的态度吧。
为了更加深入的了解 JavaScript 这门语言,我将之前记录的一些要学习的关键词作为课题进行研究,后来研究的差不多了,才决定动笔写下这个系列。尽管这个系列很多地方上依然不够所谓的“深入”,但就跟学习这些内容之前的我相比,已然多了份安定感,解决一些问题时也多了份得心应手,也希望大家能从这个系列中有所收获。
然而即便已经写了 15 篇,也只是漫长路途的开始,在我 Github 博客仓库的描述中有写到,我预计写 4 个系列,JavaScript 深入系列,JavaScript 专题系列,ES6 系列,React 系列,其实从“深入系列”到“专题系列”再到“ React 系列”,就是原来写着上层的我决定从语言层面开始一步一步走回上层的记录,而现在,我也只是迈出了第一步。
在发布完最后一篇后,我花了一周时间,根据大家的评论和留言,并且参照阮一峰老师的《中文技术文档的写作规范》对所有的文章进行了一次修订。
说起来,改的最多的就是给英文单词两边加个空格……
此外,大家有疑问或指正或鼓励或感谢,尽管留言回复哈 []~( ̄▽ ̄)~* 。
在我研究一些课题的时候,有时感觉自己深受启发,颇有醍醐灌顶的感觉,我也希望这个系列的读者能感受到跟作者当初学习这些内容时的一样兴奋的感觉,所以强烈推荐以下三篇:
JavaScript 底层知识哪有这么一点呐!在不断学习的过程中,还会冒出一些新的课题适合划分到深入系列,如果是这样的话,就会偶尔发布一篇,当然了,如果冒出太多的话,不保证再来一个深入系列第二季。
一周之内,会发布新的系列即 JavaScript 专题系列,这个系列主要研究日常开发中一些功能点的实现,比如防抖、节流、去重、拷贝、最值、扁平、柯里、递归、乱序、排序等,特点是抄袭 underscore 和 jQuery 的实现方式,而这次预计写二十篇左右。
感谢大家的阅读和支持,我是冴羽,JavaScript 专题系列再见啦![]~( ̄▽ ̄)~**
如题,请问一下什么时候写个异步教程,从定时器到async
在上篇《JavaScript深入之执行上下文栈》中讲到,当 JavaScript 代码执行一段可执行代码(executable code)时,会创建对应的执行上下文(execution context)。
对于每个执行上下文,都有三个重要属性:
今天重点讲讲创建变量对象的过程。
变量对象是与执行上下文相关的数据作用域,存储了在上下文中定义的变量和函数声明。
因为不同执行上下文下的变量对象稍有不同,所以我们来聊聊全局上下文下的变量对象和函数上下文下的变量对象。
我们先了解一个概念,叫全局对象。在 W3School 中也有介绍:
全局对象是预定义的对象,作为 JavaScript 的全局函数和全局属性的占位符。通过使用全局对象,可以访问所有其他所有预定义的对象、函数和属性。
在顶层 JavaScript 代码中,可以用关键字 this 引用全局对象。因为全局对象是作用域链的头,这意味着所有非限定性的变量和函数名都会作为该对象的属性来查询。
例如,当JavaScript 代码引用 parseInt() 函数时,它引用的是全局对象的 parseInt 属性。全局对象是作用域链的头,还意味着在顶层 JavaScript 代码中声明的所有变量都将成为全局对象的属性。
如果看的不是很懂的话,容我再来介绍下全局对象:
1.可以通过 this 引用,在客户端 JavaScript 中,全局对象就是 Window 对象。
console.log(this);2.全局对象是由 Object 构造函数实例化的一个对象。
console.log(this instanceof Object);3.预定义了一堆,嗯,一大堆函数和属性。
// 都能生效
console.log(Math.random());
console.log(this.Math.random());4.作为全局变量的宿主。
var a = 1;
console.log(this.a);5.客户端 JavaScript 中,全局对象有 window 属性指向自身。
var a = 1;
console.log(window.a);
this.window.b = 2;
console.log(this.b);花了一个大篇幅介绍全局对象,其实就想说:
全局上下文中的变量对象就是全局对象呐!
在函数上下文中,我们用活动对象(activation object, AO)来表示变量对象。
活动对象和变量对象其实是一个东西,只是变量对象是规范上的或者说是引擎实现上的,不可在 JavaScript 环境中访问,只有到当进入一个执行上下文中,这个执行上下文的变量对象才会被激活,所以才叫 activation object 呐,而只有被激活的变量对象,也就是活动对象上的各种属性才能被访问。
活动对象是在进入函数上下文时刻被创建的,它通过函数的 arguments 属性初始化。arguments 属性值是 Arguments 对象。
执行上下文的代码会分成两个阶段进行处理:分析和执行,我们也可以叫做:
当进入执行上下文时,这时候还没有执行代码,
变量对象会包括:
函数的所有形参 (如果是函数上下文)
函数声明
变量声明
举个例子:
function foo(a) {
var b = 2;
function c() {}
var d = function() {};
b = 3;
}
foo(1);在进入执行上下文后,这时候的 AO 是:
AO = {
arguments: {
0: 1,
length: 1
},
a: 1,
b: undefined,
c: reference to function c(){},
d: undefined
}在代码执行阶段,会顺序执行代码,根据代码,修改变量对象的值
还是上面的例子,当代码执行完后,这时候的 AO 是:
AO = {
arguments: {
0: 1,
length: 1
},
a: 1,
b: 3,
c: reference to function c(){},
d: reference to FunctionExpression "d"
}到这里变量对象的创建过程就介绍完了,让我们简洁的总结我们上述所说:
全局上下文的变量对象初始化是全局对象
函数上下文的变量对象初始化只包括 Arguments 对象
在进入执行上下文时会给变量对象添加形参、函数声明、变量声明等初始的属性值
在代码执行阶段,会再次修改变量对象的属性值
最后让我们看几个例子:
1.第一题
function foo() {
console.log(a);
a = 1;
}
foo(); // ???
function bar() {
a = 1;
console.log(a);
}
bar(); // ???第一段会报错:Uncaught ReferenceError: a is not defined。
第二段会打印:1。
这是因为函数中的 "a" 并没有通过 var 关键字声明,所有不会被存放在 AO 中。
第一段执行 console 的时候, AO 的值是:
AO = {
arguments: {
length: 0
}
}没有 a 的值,然后就会到全局去找,全局也没有,所以会报错。
当第二段执行 console 的时候,全局对象已经被赋予了 a 属性,这时候就可以从全局找到 a 的值,所以会打印 1。
2.第二题
console.log(foo);
function foo(){
console.log("foo");
}
var foo = 1;会打印函数,而不是 undefined 。
这是因为在进入执行上下文时,首先会处理函数声明,其次会处理变量声明,如果变量名称跟已经声明的形式参数或函数相同,则变量声明不会干扰已经存在的这类属性。
JavaScript深入系列目录地址:https://github.com/mqyqingfeng/Blog。
JavaScript深入系列预计写十五篇左右,旨在帮大家捋顺JavaScript底层知识,重点讲解如原型、作用域、执行上下文、变量对象、this、闭包、按值传递、call、apply、bind、new、继承等难点概念。
如果有错误或者不严谨的地方,请务必给予指正,十分感谢。如果喜欢或者有所启发,欢迎star,对作者也是一种鼓励。
RT
在《JavaScript深入之执行上下文栈》中讲到,当JavaScript代码执行一段可执行代码(executable code)时,会创建对应的执行上下文(execution context)。
对于每个执行上下文,都有三个重要属性
今天重点讲讲 this,然而不好讲。
……
因为我们要从 ECMASciript5 规范开始讲起。
先奉上 ECMAScript 5.1 规范地址:
英文版:http://es5.github.io/#x15.1
中文版:http://yanhaijing.com/es5/#115
让我们开始了解规范吧!
首先是第 8 章 Types:
Types are further subclassified into ECMAScript language types and specification types.
An ECMAScript language type corresponds to values that are directly manipulated by an ECMAScript programmer using the ECMAScript language. The ECMAScript language types are Undefined, Null, Boolean, String, Number, and Object.
A specification type corresponds to meta-values that are used within algorithms to describe the semantics of ECMAScript language constructs and ECMAScript language types. The specification types are Reference, List, Completion, Property Descriptor, Property Identifier, Lexical Environment, and Environment Record.
我们简单的翻译一下:
ECMAScript 的类型分为语言类型和规范类型。
ECMAScript 语言类型是开发者直接使用 ECMAScript 可以操作的。其实就是我们常说的Undefined, Null, Boolean, String, Number, 和 Object。
而规范类型相当于 meta-values,是用来用算法描述 ECMAScript 语言结构和 ECMAScript 语言类型的。规范类型包括:Reference, List, Completion, Property Descriptor, Property Identifier, Lexical Environment, 和 Environment Record。
没懂?没关系,我们只要知道在 ECMAScript 规范中还有一种只存在于规范中的类型,它们的作用是用来描述语言底层行为逻辑。
今天我们要讲的重点是便是其中的 Reference 类型。它与 this 的指向有着密切的关联。
那什么又是 Reference ?
让我们看 8.7 章 The Reference Specification Type:
The Reference type is used to explain the behaviour of such operators as delete, typeof, and the assignment operators.
所以 Reference 类型就是用来解释诸如 delete、typeof 以及赋值等操作行为的。
抄袭尤雨溪大大的话,就是:
这里的 Reference 是一个 Specification Type,也就是 “只存在于规范里的抽象类型”。它们是为了更好地描述语言的底层行为逻辑才存在的,但并不存在于实际的 js 代码中。
再看接下来的这段具体介绍 Reference 的内容:
A Reference is a resolved name binding.
A Reference consists of three components, the base value, the referenced name and the Boolean valued strict reference flag.
The base value is either undefined, an Object, a Boolean, a String, a Number, or an environment record (10.2.1).
A base value of undefined indicates that the reference could not be resolved to a binding. The referenced name is a String.
这段讲述了 Reference 的构成,由三个组成部分,分别是:
可是这些到底是什么呢?
我们简单的理解的话:
base value 就是属性所在的对象或者就是 EnvironmentRecord,它的值只可能是 undefined, an Object, a Boolean, a String, a Number, or an environment record 其中的一种。
referenced name 就是属性的名称。
举个例子:
var foo = 1;
// 对应的Reference是:
var fooReference = {
base: EnvironmentRecord,
name: 'foo',
strict: false
};再举个例子:
var foo = {
bar: function () {
return this;
}
};
foo.bar(); // foo
// bar对应的Reference是:
var BarReference = {
base: foo,
propertyName: 'bar',
strict: false
};而且规范中还提供了获取 Reference 组成部分的方法,比如 GetBase 和 IsPropertyReference。
这两个方法很简单,简单看一看:
1.GetBase
GetBase(V). Returns the base value component of the reference V.
返回 reference 的 base value。
2.IsPropertyReference
IsPropertyReference(V). Returns true if either the base value is an object or HasPrimitiveBase(V) is true; otherwise returns false.
简单的理解:如果 base value 是一个对象,就返回true。
除此之外,紧接着在 8.7.1 章规范中就讲了一个用于从 Reference 类型获取对应值的方法: GetValue。
简单模拟 GetValue 的使用:
var foo = 1;
var fooReference = {
base: EnvironmentRecord,
name: 'foo',
strict: false
};
GetValue(fooReference) // 1;GetValue 返回对象属性真正的值,但是要注意:
调用 GetValue,返回的将是具体的值,而不再是一个 Reference
这个很重要,这个很重要,这个很重要。
关于 Reference 讲了那么多,为什么要讲 Reference 呢?到底 Reference 跟本文的主题 this 有哪些关联呢?如果你能耐心看完之前的内容,以下开始进入高能阶段:
看规范 11.2.3 Function Calls:
这里讲了当函数调用的时候,如何确定 this 的取值。
只看第一步、第六步、第七步:
1.Let ref be the result of evaluating MemberExpression.
6.If Type(ref) is Reference, then
a.If IsPropertyReference(ref) is true, then
i.Let thisValue be GetBase(ref).
b.Else, the base of ref is an Environment Record
i.Let thisValue be the result of calling the ImplicitThisValue concrete method of GetBase(ref).7.Else, Type(ref) is not Reference.
a. Let thisValue be undefined.
让我们描述一下:
1.计算 MemberExpression 的结果赋值给 ref
2.判断 ref 是不是一个 Reference 类型
2.1 如果 ref 是 Reference,并且 IsPropertyReference(ref) 是 true, 那么 this 的值为 GetBase(ref)
2.2 如果 ref 是 Reference,并且 base value 值是 Environment Record, 那么this的值为 ImplicitThisValue(ref)
2.3 如果 ref 不是 Reference,那么 this 的值为 undefined
让我们一步一步看:
什么是 MemberExpression?看规范 11.2 Left-Hand-Side Expressions:
MemberExpression :
举个例子:
function foo() {
console.log(this)
}
foo(); // MemberExpression 是 foo
function foo() {
return function() {
console.log(this)
}
}
foo()(); // MemberExpression 是 foo()
var foo = {
bar: function () {
return this;
}
}
foo.bar(); // MemberExpression 是 foo.bar所以简单理解 MemberExpression 其实就是()左边的部分。
2.判断 ref 是不是一个 Reference 类型。
关键就在于看规范是如何处理各种 MemberExpression,返回的结果是不是一个Reference类型。
举最后一个例子:
var value = 1;
var foo = {
value: 2,
bar: function () {
return this.value;
}
}
//示例1
console.log(foo.bar());
//示例2
console.log((foo.bar)());
//示例3
console.log((foo.bar = foo.bar)());
//示例4
console.log((false || foo.bar)());
//示例5
console.log((foo.bar, foo.bar)());在示例 1 中,MemberExpression 计算的结果是 foo.bar,那么 foo.bar 是不是一个 Reference 呢?
查看规范 11.2.1 Property Accessors,这里展示了一个计算的过程,什么都不管了,就看最后一步:
Return a value of type Reference whose base value is baseValue and whose referenced name is propertyNameString, and whose strict mode flag is strict.
我们得知该表达式返回了一个 Reference 类型!
根据之前的内容,我们知道该值为:
var Reference = {
base: foo,
name: 'bar',
strict: false
};接下来按照 2.1 的判断流程走:
2.1 如果 ref 是 Reference,并且 IsPropertyReference(ref) 是 true, 那么 this 的值为 GetBase(ref)
该值是 Reference 类型,那么 IsPropertyReference(ref) 的结果是多少呢?
前面我们已经铺垫了 IsPropertyReference 方法,如果 base value 是一个对象,结果返回 true。
base value 为 foo,是一个对象,所以 IsPropertyReference(ref) 结果为 true。
这个时候我们就可以确定 this 的值了:
this = GetBase(ref),GetBase 也已经铺垫了,获得 base value 值,这个例子中就是foo,所以 this 的值就是 foo ,示例1的结果就是 2!
唉呀妈呀,为了证明 this 指向foo,真是累死我了!但是知道了原理,剩下的就更快了。
看示例2:
console.log((foo.bar)());foo.bar 被 () 包住,查看规范 11.1.6 The Grouping Operator
直接看结果部分:
Return the result of evaluating Expression. This may be of type Reference.
NOTE This algorithm does not apply GetValue to the result of evaluating Expression.
实际上 () 并没有对 MemberExpression 进行计算,所以其实跟示例 1 的结果是一样的。
看示例3,有赋值操作符,查看规范 11.13.1 Simple Assignment ( = ):
计算的第三步:
3.Let rval be GetValue(rref).
因为使用了 GetValue,所以返回的值不是 Reference 类型,
按照之前讲的判断逻辑:
2.3 如果 ref 不是Reference,那么 this 的值为 undefined
this 为 undefined,非严格模式下,this 的值为 undefined 的时候,其值会被隐式转换为全局对象。
看示例4,逻辑与算法,查看规范 11.11 Binary Logical Operators:
计算第二步:
2.Let lval be GetValue(lref).
因为使用了 GetValue,所以返回的不是 Reference 类型,this 为 undefined
看示例5,逗号操作符,查看规范11.14 Comma Operator ( , )
计算第二步:
2.Call GetValue(lref).
因为使用了 GetValue,所以返回的不是 Reference 类型,this 为 undefined
所以最后一个例子的结果是:
var value = 1;
var foo = {
value: 2,
bar: function () {
return this.value;
}
}
//示例1
console.log(foo.bar()); // 2
//示例2
console.log((foo.bar)()); // 2
//示例3
console.log((foo.bar = foo.bar)()); // 1
//示例4
console.log((false || foo.bar)()); // 1
//示例5
console.log((foo.bar, foo.bar)()); // 1注意:以上是在非严格模式下的结果,严格模式下因为 this 返回 undefined,所以示例 3 会报错。
最最后,忘记了一个最最普通的情况:
function foo() {
console.log(this)
}
foo(); MemberExpression 是 foo,解析标识符,查看规范 10.3.1 Identifier Resolution,会返回一个 Reference 类型的值:
var fooReference = {
base: EnvironmentRecord,
name: 'foo',
strict: false
};接下来进行判断:
2.1 如果 ref 是 Reference,并且 IsPropertyReference(ref) 是 true, 那么 this 的值为 GetBase(ref)
因为 base value 是 EnvironmentRecord,并不是一个 Object 类型,还记得前面讲过的 base value 的取值可能吗? 只可能是 undefined, an Object, a Boolean, a String, a Number, 和 an environment record 中的一种。
IsPropertyReference(ref) 的结果为 false,进入下个判断:
2.2 如果 ref 是 Reference,并且 base value 值是 Environment Record, 那么this的值为 ImplicitThisValue(ref)
base value 正是 Environment Record,所以会调用 ImplicitThisValue(ref)
查看规范 10.2.1.1.6,ImplicitThisValue 方法的介绍:该函数始终返回 undefined。
所以最后 this 的值就是 undefined。
尽管我们可以简单的理解 this 为调用函数的对象,如果是这样的话,如何解释下面这个例子呢?
var value = 1;
var foo = {
value: 2,
bar: function () {
return this.value;
}
}
console.log((false || foo.bar)()); // 1此外,又如何确定调用函数的对象是谁呢?在写文章之初,我就面临着这些问题,最后还是放弃从多个情形下给大家讲解 this 指向的思路,而是追根溯源的从 ECMASciript 规范讲解 this 的指向,尽管从这个角度写起来和读起来都比较吃力,但是一旦多读几遍,明白原理,绝对会给你一个全新的视角看待 this 。而你也就能明白,尽管 foo() 和 (foo.bar = foo.bar)() 最后结果都指向了 undefined,但是两者从规范的角度上却有着本质的区别。
此篇讲解执行上下文的 this,即便不是很理解此篇的内容,依然不影响大家了解执行上下文这个主题下其他的内容。所以,依然可以安心的看下一篇文章。
JavaScript深入系列目录地址:https://github.com/mqyqingfeng/Blog。
JavaScript深入系列预计写十五篇左右,旨在帮大家捋顺JavaScript底层知识,重点讲解如原型、作用域、执行上下文、变量对象、this、闭包、按值传递、call、apply、bind、new、继承等难点概念。
如果有错误或者不严谨的地方,请务必给予指正,十分感谢。如果喜欢或者有所启发,欢迎star,对作者也是一种鼓励。
维基百科中对柯里化 (Currying) 的定义为:
In mathematics and computer science, currying is the technique of translating the evaluation of a function that takes multiple arguments (or a tuple of arguments) into evaluating a sequence of functions, each with a single argument.
翻译成中文:
在数学和计算机科学中,柯里化是一种将使用多个参数的一个函数转换成一系列使用一个参数的函数的技术。
举个例子:
function add(a, b) {
return a + b;
}
// 执行 add 函数,一次传入两个参数即可
add(1, 2) // 3
// 假设有一个 curry 函数可以做到柯里化
var addCurry = curry(add);
addCurry(1)(2) // 3我们会讲到如何写出这个 curry 函数,并且会将这个 curry 函数写的很强大,但是在编写之前,我们需要知道柯里化到底有什么用?
举个例子:
// 示意而已
function ajax(type, url, data) {
var xhr = new XMLHttpRequest();
xhr.open(type, url, true);
xhr.send(data);
}
// 虽然 ajax 这个函数非常通用,但在重复调用的时候参数冗余
ajax('POST', 'www.test.com', "name=kevin")
ajax('POST', 'www.test2.com', "name=kevin")
ajax('POST', 'www.test3.com', "name=kevin")
// 利用 curry
var ajaxCurry = curry(ajax);
// 以 POST 类型请求数据
var post = ajaxCurry('POST');
post('www.test.com', "name=kevin");
// 以 POST 类型请求来自于 www.test.com 的数据
var postFromTest = post('www.test.com');
postFromTest("name=kevin");想想 jQuery 虽然有
curry 的这种用途可以理解为:参数复用。本质上是降低通用性,提高适用性。
可是即便如此,是不是依然感觉没什么用呢?
如果我们仅仅是把参数一个一个传进去,意义可能不大,但是如果我们是把柯里化后的函数传给其他函数比如 map 呢?
举个例子:
比如我们有这样一段数据:
var person = [{name: 'kevin'}, {name: 'daisy'}]如果我们要获取所有的 name 值,我们可以这样做:
var name = person.map(function (item) {
return item.name;
})不过如果我们有 curry 函数:
var prop = curry(function (key, obj) {
return obj[key]
});
var name = person.map(prop('name'))我们为了获取 name 属性还要再编写一个 prop 函数,是不是又麻烦了些?
但是要注意,prop 函数编写一次后,以后可以多次使用,实际上代码从原本的三行精简成了一行,而且你看代码是不是更加易懂了?
person.map(prop('name')) 就好像直白的告诉你:person 对象遍历(map)获取(prop) name 属性。
是不是感觉有点意思了呢?
未来我们会接触到更多有关柯里化的应用,不过那是未来的事情了,现在我们该编写这个 curry 函数了。
一个经常会看到的 curry 函数的实现为:
// 第一版
var curry = function (fn) {
var args = [].slice.call(arguments, 1);
return function() {
var newArgs = args.concat([].slice.call(arguments));
return fn.apply(this, newArgs);
};
};我们可以这样使用:
function add(a, b) {
return a + b;
}
var addCurry = curry(add, 1, 2);
addCurry() // 3
//或者
var addCurry = curry(add, 1);
addCurry(2) // 3
//或者
var addCurry = curry(add);
addCurry(1, 2) // 3已经有柯里化的感觉了,但是还没有达到要求,不过我们可以把这个函数用作辅助函数,帮助我们写真正的 curry 函数。
// 第二版
function sub_curry(fn) {
var args = [].slice.call(arguments, 1);
return function() {
return fn.apply(this, args.concat([].slice.call(arguments)));
};
}
function curry(fn, length) {
length = length || fn.length;
var slice = Array.prototype.slice;
return function() {
if (arguments.length < length) {
var combined = [fn].concat(slice.call(arguments));
return curry(sub_curry.apply(this, combined), length - arguments.length);
} else {
return fn.apply(this, arguments);
}
};
}我们验证下这个函数:
var fn = curry(function(a, b, c) {
return [a, b, c];
});
fn("a", "b", "c") // ["a", "b", "c"]
fn("a", "b")("c") // ["a", "b", "c"]
fn("a")("b")("c") // ["a", "b", "c"]
fn("a")("b", "c") // ["a", "b", "c"]效果已经达到我们的预期,然而这个 curry 函数的实现好难理解呐……
为了让大家更好的理解这个 curry 函数,我给大家写个极简版的代码:
function sub_curry(fn){
return function(){
return fn()
}
}
function curry(fn, length){
length = length || 4;
return function(){
if (length > 1) {
return curry(sub_curry(fn), --length)
}
else {
return fn()
}
}
}
var fn0 = function(){
console.log(1)
}
var fn1 = curry(fn0)
fn1()()()() // 1大家先从理解这个 curry 函数开始。
当执行 fn1() 时,函数返回:
curry(sub_curry(fn0))
// 相当于
curry(function(){
return fn0()
})当执行 fn1()() 时,函数返回:
curry(sub_curry(function(){
return fn0()
}))
// 相当于
curry(function(){
return (function(){
return fn0()
})()
})
// 相当于
curry(function(){
return fn0()
})当执行 fn1()()() 时,函数返回:
// 跟 fn1()() 的分析过程一样
curry(function(){
return fn0()
})当执行 fn1()()()() 时,因为此时 length > 2 为 false,所以执行 fn():
fn()
// 相当于
(function(){
return fn0()
})()
// 相当于
fn0()
// 执行 fn0 函数,打印 1再回到真正的 curry 函数,我们以下面的例子为例:
var fn0 = function(a, b, c, d) {
return [a, b, c, d];
}
var fn1 = curry(fn0);
fn1("a", "b")("c")("d")当执行 fn1("a", "b") 时:
fn1("a", "b")
// 相当于
curry(fn0)("a", "b")
// 相当于
curry(sub_curry(fn0, "a", "b"))
// 相当于
// 注意 ... 只是一个示意,表示该函数执行时传入的参数会作为 fn0 后面的参数传入
curry(function(...){
return fn0("a", "b", ...)
})当执行 fn1("a", "b")("c") 时,函数返回:
curry(sub_curry(function(...){
return fn0("a", "b", ...)
}), "c")
// 相当于
curry(function(...){
return (function(...) {return fn0("a", "b", ...)})("c")
})
// 相当于
curry(function(...){
return fn0("a", "b", "c", ...)
})当执行 fn1("a", "b")("c")("d") 时,此时 arguments.length < length 为 false ,执行 fn(arguments),相当于:
(function(...){
return fn0("a", "b", "c", ...)
})("d")
// 相当于
fn0("a", "b", "c", "d")函数执行结束。
所以,其实整段代码又很好理解:
sub_curry 的作用就是用函数包裹原函数,然后给原函数传入之前的参数,当执行 fn0(...)(...) 的时候,执行包裹函数,返回原函数,然后再调用 sub_curry 再包裹原函数,然后将新的参数混合旧的参数再传入原函数,直到函数参数的数目达到要求为止。
如果要明白 curry 函数的运行原理,大家还是要动手写一遍,尝试着分析执行步骤。
当然了,如果你觉得还是无法理解,你可以选择下面这种实现方式,可以实现同样的效果:
function curry(fn, args) {
var length = fn.length;
args = args || [];
return function() {
var _args = args.slice(0),
arg, i;
for (i = 0; i < arguments.length; i++) {
arg = arguments[i];
_args.push(arg);
}
if (_args.length < length) {
return curry.call(this, fn, _args);
}
else {
return fn.apply(this, _args);
}
}
}
var fn = curry(function(a, b, c) {
console.log([a, b, c]);
});
fn("a", "b", "c") // ["a", "b", "c"]
fn("a", "b")("c") // ["a", "b", "c"]
fn("a")("b")("c") // ["a", "b", "c"]
fn("a")("b", "c") // ["a", "b", "c"]或许大家觉得这种方式更好理解,又能实现一样的效果,为什么不直接就讲这种呢?
因为想给大家介绍各种实现的方法嘛,不能因为难以理解就不给大家介绍呐~
curry 函数写到这里其实已经很完善了,但是注意这个函数的传参顺序必须是从左到右,根据形参的顺序依次传入,如果我不想根据这个顺序传呢?
我们可以创建一个占位符,比如这样:
var fn = curry(function(a, b, c) {
console.log([a, b, c]);
});
fn("a", _, "c")("b") // ["a", "b", "c"]我们直接看第三版的代码:
// 第三版
function curry(fn, args, holes) {
length = fn.length;
args = args || [];
holes = holes || [];
return function() {
var _args = args.slice(0),
_holes = holes.slice(0),
argsLen = args.length,
holesLen = holes.length,
arg, i, index = 0;
for (i = 0; i < arguments.length; i++) {
arg = arguments[i];
// 处理类似 fn(1, _, _, 4)(_, 3) 这种情况,index 需要指向 holes 正确的下标
if (arg === _ && holesLen) {
index++
if (index > holesLen) {
_args.push(arg);
_holes.push(argsLen - 1 + index - holesLen)
}
}
// 处理类似 fn(1)(_) 这种情况
else if (arg === _) {
_args.push(arg);
_holes.push(argsLen + i);
}
// 处理类似 fn(_, 2)(1) 这种情况
else if (holesLen) {
// fn(_, 2)(_, 3)
if (index >= holesLen) {
_args.push(arg);
}
// fn(_, 2)(1) 用参数 1 替换占位符
else {
_args.splice(_holes[index], 1, arg);
_holes.splice(index, 1)
}
}
else {
_args.push(arg);
}
}
if (_holes.length || _args.length < length) {
return curry.call(this, fn, _args, _holes);
}
else {
return fn.apply(this, _args);
}
}
}
var _ = {};
var fn = curry(function(a, b, c, d, e) {
console.log([a, b, c, d, e]);
});
// 验证 输出全部都是 [1, 2, 3, 4, 5]
fn(1, 2, 3, 4, 5);
fn(_, 2, 3, 4, 5)(1);
fn(1, _, 3, 4, 5)(2);
fn(1, _, 3)(_, 4)(2)(5);
fn(1, _, _, 4)(_, 3)(2)(5);
fn(_, 2)(_, _, 4)(1)(3)(5)至此,我们已经实现了一个强大的 curry 函数,可是这个 curry 函数符合柯里化的定义吗?柯里化可是将一个多参数的函数转换成多个单参数的函数,但是现在我们不仅可以传入一个参数,还可以一次传入两个参数,甚至更多参数……这看起来更像一个柯里化 (curry) 和偏函数 (partial application) 的综合应用,可是什么又是偏函数呢?下篇文章会讲到。
JavaScript专题系列目录地址:https://github.com/mqyqingfeng/Blog。
JavaScript专题系列预计写二十篇左右,主要研究日常开发中一些功能点的实现,比如防抖、节流、去重、类型判断、拷贝、最值、扁平、柯里、递归、乱序、排序等,特点是研(chao)究(xi) underscore 和 jQuery 的实现方式。
如果有错误或者不严谨的地方,请务必给予指正,十分感谢。如果喜欢或者有所启发,欢迎 star,对作者也是一种鼓励。
请问,执行上下文是不是意思:开始执行一段代码?
请教博主,其实有一点不是很明白,就是文中说“构造函数的prototype指向实例的原型”,可是构造函数的prototype不是本身是一个值为对象的属性吗?我之前只是知道,实例的_protote_属性会指向构造函数的原型的prototype,实例在查找属性或者方法时,如果找不到的话,就会通过_protote_到它的构造函数的prototype对象上去找,所有的实例共享它的构造函数上的prototype的属性和方法。但是如果照博主的说法,构造函数的prototype指向实例的原型,那如果实例有很多,它到底指向的是哪一个实例的原型呢,不同实例的属性和方法如何做到共享。但是如果按照我这种说法,文中的案例:

实例化之后改变了Person 的prototype后,实例一其实是可以访问到getName这个方法的,所以这就有了矛盾,可能我的理解有误,但是博主这里讲的我也不是很懂,望不吝赐教!
这篇文章讲解创建对象的各种方式,以及优缺点。
但是注意:
这篇文章更像是笔记,因为《JavaScript高级程序设计》写得真是太好了!
function createPerson(name) {
var o = new Object();
o.name = name;
o.getName = function () {
console.log(this.name);
};
return o;
}
var person1 = createPerson('kevin');缺点:对象无法识别,因为所有的实例都指向一个原型
function Person(name) {
this.name = name;
this.getName = function () {
console.log(this.name);
};
}
var person1 = new Person('kevin');优点:实例可以识别为一个特定的类型
缺点:每次创建实例时,每个方法都要被创建一次
function Person(name) {
this.name = name;
this.getName = getName;
}
function getName() {
console.log(this.name);
}
var person1 = new Person('kevin');优点:解决了每个方法都要被重新创建的问题
缺点:这叫啥封装……
function Person(name) {
}
Person.prototype.name = 'keivn';
Person.prototype.getName = function () {
console.log(this.name);
};
var person1 = new Person();优点:方法不会重新创建
缺点:1. 所有的属性和方法都共享 2. 不能初始化参数
function Person(name) {
}
Person.prototype = {
name: 'kevin',
getName: function () {
console.log(this.name);
}
};
var person1 = new Person();优点:封装性好了一点
缺点:重写了原型,丢失了constructor属性
function Person(name) {
}
Person.prototype = {
constructor: Person,
name: 'kevin',
getName: function () {
console.log(this.name);
}
};
var person1 = new Person();优点:实例可以通过constructor属性找到所属构造函数
缺点:原型模式该有的缺点还是有
构造函数模式与原型模式双剑合璧。
function Person(name) {
this.name = name;
}
Person.prototype = {
constructor: Person,
getName: function () {
console.log(this.name);
}
};
var person1 = new Person();优点:该共享的共享,该私有的私有,使用最广泛的方式
缺点:有的人就是希望全部都写在一起,即更好的封装性
function Person(name) {
this.name = name;
if (typeof this.getName != "function") {
Person.prototype.getName = function () {
console.log(this.name);
}
}
}
var person1 = new Person();注意:使用动态原型模式时,不能用对象字面量重写原型
解释下为什么:
function Person(name) {
this.name = name;
if (typeof this.getName != "function") {
Person.prototype = {
constructor: Person,
getName: function () {
console.log(this.name);
}
}
}
}
var person1 = new Person('kevin');
var person2 = new Person('daisy');
// 报错 并没有该方法
person1.getName();
// 注释掉上面的代码,这句是可以执行的。
person2.getName();为了解释这个问题,假设开始执行var person1 = new Person('kevin')。
如果对 new 和 apply 的底层执行过程不是很熟悉,可以阅读底部相关链接中的文章。
我们回顾下 new 的实现步骤:
注意这个时候,回顾下 apply 的实现步骤,会执行 obj.Person 方法,这个时候就会执行 if 语句里的内容,注意构造函数的 prototype 属性指向了实例的原型,使用字面量方式直接覆盖 Person.prototype,并不会更改实例的原型的值,person1 依然是指向了以前的原型,而不是 Person.prototype。而之前的原型是没有 getName 方法的,所以就报错了!
如果你就是想用字面量方式写代码,可以尝试下这种:
function Person(name) {
this.name = name;
if (typeof this.getName != "function") {
Person.prototype = {
constructor: Person,
getName: function () {
console.log(this.name);
}
}
return new Person(name);
}
}
var person1 = new Person('kevin');
var person2 = new Person('daisy');
person1.getName(); // kevin
person2.getName(); // daisyfunction Person(name) {
var o = new Object();
o.name = name;
o.getName = function () {
console.log(this.name);
};
return o;
}
var person1 = new Person('kevin');
console.log(person1 instanceof Person) // false
console.log(person1 instanceof Object) // true寄生构造函数模式,我个人认为应该这样读:
寄生-构造函数-模式,也就是说寄生在构造函数的一种方法。
也就是说打着构造函数的幌子挂羊头卖狗肉,你看创建的实例使用 instanceof 都无法指向构造函数!
这样方法可以在特殊情况下使用。比如我们想创建一个具有额外方法的特殊数组,但是又不想直接修改Array构造函数,我们可以这样写:
function SpecialArray() {
var values = new Array();
for (var i = 0, len = arguments.length; i < len; i++) {
values.push(arguments[i]);
}
values.toPipedString = function () {
return this.join("|");
};
return values;
}
var colors = new SpecialArray('red', 'blue', 'green');
var colors2 = SpecialArray('red2', 'blue2', 'green2');
console.log(colors);
console.log(colors.toPipedString()); // red|blue|green
console.log(colors2);
console.log(colors2.toPipedString()); // red2|blue2|green2你会发现,其实所谓的寄生构造函数模式就是比工厂模式在创建对象的时候,多使用了一个new,实际上两者的结果是一样的。
但是作者可能是希望能像使用普通 Array 一样使用 SpecialArray,虽然把 SpecialArray 当成函数也一样能用,但是这并不是作者的本意,也变得不优雅。
在可以使用其他模式的情况下,不要使用这种模式。
但是值得一提的是,上面例子中的循环:
for (var i = 0, len = arguments.length; i < len; i++) {
values.push(arguments[i]);
}可以替换成:
values.push.apply(values, arguments);function person(name){
var o = new Object();
o.sayName = function(){
console.log(name);
};
return o;
}
var person1 = person('kevin');
person1.sayName(); // kevin
person1.name = "daisy";
person1.sayName(); // kevin
console.log(person1.name); // daisy所谓稳妥对象,指的是没有公共属性,而且其方法也不引用 this 的对象。
与寄生构造函数模式有两点不同:
稳妥对象最适合在一些安全的环境中。
稳妥构造函数模式也跟工厂模式一样,无法识别对象所属类型。
《JavaScript深入之call和apply的模拟实现》
JavaScript深入系列目录地址:https://github.com/mqyqingfeng/Blog。
JavaScript深入系列预计写十五篇左右,旨在帮大家捋顺JavaScript底层知识,重点讲解如原型、作用域、执行上下文、变量对象、this、闭包、按值传递、call、apply、bind、new、继承等难点概念。
如果有错误或者不严谨的地方,请务必给予指正,十分感谢。如果喜欢或者有所启发,欢迎star,对作者也是一种鼓励。
我们先使用构造函数创建一个对象:
function Person() {
}
var person = new Person();
person.name = 'Kevin';
console.log(person.name) // Kevin在这个例子中,Person 就是一个构造函数,我们使用 new 创建了一个实例对象 person。
很简单吧,接下来进入正题:
每个函数都有一个 prototype 属性,就是我们经常在各种例子中看到的那个 prototype ,比如:
function Person() {
}
// 虽然写在注释里,但是你要注意:
// prototype是函数才会有的属性
Person.prototype.name = 'Kevin';
var person1 = new Person();
var person2 = new Person();
console.log(person1.name) // Kevin
console.log(person2.name) // Kevin那这个函数的 prototype 属性到底指向的是什么呢?是这个函数的原型吗?
其实,函数的 prototype 属性指向了一个对象,这个对象正是调用该构造函数而创建的实例的原型,也就是这个例子中的 person1 和 person2 的原型。
那什么是原型呢?你可以这样理解:每一个JavaScript对象(null除外)在创建的时候就会与之关联另一个对象,这个对象就是我们所说的原型,每一个对象都会从原型"继承"属性。
让我们用一张图表示构造函数和实例原型之间的关系:
在这张图中我们用 Object.prototype 表示实例原型。
那么我们该怎么表示实例与实例原型,也就是 person 和 Person.prototype 之间的关系呢,这时候我们就要讲到第二个属性:
这是每一个JavaScript对象(除了 null )都具有的一个属性,叫__proto__,这个属性会指向该对象的原型。
为了证明这一点,我们可以在火狐或者谷歌中输入:
function Person() {
}
var person = new Person();
console.log(person.__proto__ === Person.prototype); // true于是我们更新下关系图:
既然实例对象和构造函数都可以指向原型,那么原型是否有属性指向构造函数或者实例呢?
指向实例倒是没有,因为一个构造函数可以生成多个实例,但是原型指向构造函数倒是有的,这就要讲到第三个属性:constructor,每个原型都有一个 constructor 属性指向关联的构造函数。
为了验证这一点,我们可以尝试:
function Person() {
}
console.log(Person === Person.prototype.constructor); // true所以再更新下关系图:
综上我们已经得出:
function Person() {
}
var person = new Person();
console.log(person.__proto__ == Person.prototype) // true
console.log(Person.prototype.constructor == Person) // true
// 顺便学习一个ES5的方法,可以获得对象的原型
console.log(Object.getPrototypeOf(person) === Person.prototype) // true了解了构造函数、实例原型、和实例之间的关系,接下来我们讲讲实例和原型的关系:
当读取实例的属性时,如果找不到,就会查找与对象关联的原型中的属性,如果还查不到,就去找原型的原型,一直找到最顶层为止。
举个例子:
function Person() {
}
Person.prototype.name = 'Kevin';
var person = new Person();
person.name = 'Daisy';
console.log(person.name) // Daisy
delete person.name;
console.log(person.name) // Kevin在这个例子中,我们给实例对象 person 添加了 name 属性,当我们打印 person.name 的时候,结果自然为 Daisy。
但是当我们删除了 person 的 name 属性时,读取 person.name,从 person 对象中找不到 name 属性就会从 person 的原型也就是 person.__proto__ ,也就是 Person.prototype中查找,幸运的是我们找到了 name 属性,结果为 Kevin。
但是万一还没有找到呢?原型的原型又是什么呢?
在前面,我们已经讲了原型也是一个对象,既然是对象,我们就可以用最原始的方式创建它,那就是:
var obj = new Object();
obj.name = 'Kevin'
console.log(obj.name) // Kevin其实原型对象就是通过 Object 构造函数生成的,结合之前所讲,实例的 __proto__ 指向构造函数的 prototype ,所以我们再更新下关系图:
那 Object.prototype 的原型呢?
null,我们可以打印:
console.log(Object.prototype.__proto__ === null) // true然而 null 究竟代表了什么呢?
引用阮一峰老师的 《undefined与null的区别》 就是:
null 表示“没有对象”,即该处不应该有值。
所以 Object.prototype.__proto__ 的值为 null 跟 Object.prototype 没有原型,其实表达了一个意思。
所以查找属性的时候查到 Object.prototype 就可以停止查找了。
最后一张关系图也可以更新为:
顺便还要说一下,图中由相互关联的原型组成的链状结构就是原型链,也就是蓝色的这条线。
最后,补充三点大家可能不会注意的地方:
首先是 constructor 属性,我们看个例子:
function Person() {
}
var person = new Person();
console.log(person.constructor === Person); // true当获取 person.constructor 时,其实 person 中并没有 constructor 属性,当不能读取到constructor 属性时,会从 person 的原型也就是 Person.prototype 中读取,正好原型中有该属性,所以:
person.constructor === Person.prototype.constructor其次是 __proto__ ,绝大部分浏览器都支持这个非标准的方法访问原型,然而它并不存在于 Person.prototype 中,实际上,它是来自于 Object.prototype ,与其说是一个属性,不如说是一个 getter/setter,当使用 obj.__proto__ 时,可以理解成返回了 Object.getPrototypeOf(obj)。
最后是关于继承,前面我们讲到“每一个对象都会从原型‘继承’属性”,实际上,继承是一个十分具有迷惑性的说法,引用《你不知道的JavaScript》中的话,就是:
继承意味着复制操作,然而 JavaScript 默认并不会复制对象的属性,相反,JavaScript 只是在两个对象之间创建一个关联,这样,一个对象就可以通过委托访问另一个对象的属性和函数,所以与其叫继承,委托的说法反而更准确些。
JavaScript深入系列目录地址:https://github.com/mqyqingfeng/Blog。
JavaScript深入系列预计写十五篇左右,旨在帮大家捋顺JavaScript底层知识,重点讲解如原型、作用域、执行上下文、变量对象、this、闭包、按值传递、call、apply、bind、new、继承等难点概念。
如果有错误或者不严谨的地方,请务必给予指正,十分感谢。如果喜欢或者有所启发,欢迎star,对作者也是一种鼓励。
在开发中,我们经常会遇到在数组中查找指定元素的需求,可能大家觉得这个需求过于简单,然而如何优雅的去实现一个 findIndex 和 findLastIndex、indexOf 和 lastIndexOf 方法却是很少人去思考的。本文就带着大家一起参考着 underscore 去实现这些方法。
在实现前,先看看 ES6 的 findIndex 方法,让大家了解 findIndex 的使用方法。
ES6 对数组新增了 findIndex 方法,它会返回数组中满足提供的函数的第一个元素的索引,否则返回 -1。
举个例子:
function isBigEnough(element) {
return element >= 15;
}
[12, 5, 8, 130, 44].findIndex(isBigEnough); // 3findIndex 会找出第一个大于 15 的元素的下标,所以最后返回 3。
是不是很简单,其实,我们自己去实现一个 findIndex 也很简单。
思路自然很明了,遍历一遍,返回符合要求的值的下标即可。
function findIndex(array, predicate, context) {
for (var i = 0; i < array.length; i++) {
if (predicate.call(context, array[i], i, array)) return i;
}
return -1;
}
console.log(findIndex([1, 2, 3, 4], function(item, i, array){
if (item == 3) return true;
})) // 2findIndex 是正序查找,但正如 indexOf 还有一个对应的 lastIndexOf 方法,我们也想写一个倒序查找的 findLastIndex 函数。实现自然也很简单,只要修改下循环即可。
function findLastIndex(array, predicate, context) {
var length = array.length;
for (var i = length - 1; i >= 0; i--) {
if (predicate.call(context, array[i], i, array)) return i;
}
return -1;
}
console.log(findLastIndex([1, 2, 3, 4], function(item, index, array){
if (item == 1) return true;
})) // 0然而问题在于,findIndex 和 findLastIndex 其实有很多重复的部分,如何精简冗余的内容呢?这便是我们要学习的地方,日后面试问到此类问题,也是加分的选项。
underscore 的思路就是利用传参的不同,返回不同的函数。这个自然是简单,但是如何根据参数的不同,在同一个循环中,实现正序和倒序遍历呢?
让我们直接模仿 underscore 的实现:
function createIndexFinder(dir) {
return function(array, predicate, context) {
var length = array.length;
var index = dir > 0 ? 0 : length - 1;
for (; index >= 0 && index < length; index += dir) {
if (predicate.call(context, array[index], index, array)) return index;
}
return -1;
}
}
var findIndex = createIndexFinder(1);
var findLastIndex = createIndexFinder(-1);findIndex 和 findLastIndex 的需求算是结束了,但是又来了一个新需求:在一个排好序的数组中找到 value 对应的位置,保证插入数组后,依然保持有序的状态。
假设该函数命名为 sortedIndex,效果为:
sortedIndex([10, 20, 30], 25); // 2也就是说如果,注意是如果,25 按照此下标插入数组后,数组变成 [10, 20, 25, 30],数组依然是有序的状态。
那么这个又该如何实现呢?
既然是有序的数组,那我们就不需要遍历,大可以使用二分查找法,确定值的位置。让我们尝试着去写一版:
// 第一版
function sortedIndex(array, obj) {
var low = 0, high = array.length;
while (low < high) {
var mid = Math.floor((low + high) / 2);
if (array[mid] < obj) low = mid + 1;
else high = mid;
}
return high;
};
console.log(sortedIndex([10, 20, 30, 40, 50], 35)) // 3现在的方法虽然能用,但通用性不够,比如我们希望能处理这样的情况:
// stooges 配角 比如 三个臭皮匠 The Three Stooges
var stooges = [{name: 'stooge1', age: 10}, {name: 'stooge2', age: 30}];
var result = sortedIndex(stooges, {name: 'stooge3', age: 20}, function(stooge){
return stooge.age
});
console.log(result) // 1所以我们还需要再加上一个参数 iteratee 函数对数组的每一个元素进行处理,一般这个时候,还会涉及到 this 指向的问题,所以我们再传一个 context 来让我们可以指定 this,那么这样一个函数又该如何写呢?
// 第二版
function cb(func, context) {
if (context === void 0) return func;
return function() {
return func.apply(context, arguments);
};
}
function sortedIndex(array, obj, iteratee, context) {
iteratee = cb(iteratee, context)
var low = 0, high = array.length;
while (low < high) {
var mid = Math.floor((low + high) / 2);
if (iteratee(array[mid]) < iteratee(obj)) low = mid + 1;
else high = mid;
}
return high;
};sortedIndex 也完成了,现在我们尝试着去写一个 indexOf 和 lastIndexOf 函数,学习 findIndex 和 FindLastIndex 的方式,我们写一版:
// 第一版
function createIndexOfFinder(dir) {
return function(array, item){
var length = array.length;
var index = dir > 0 ? 0 : length - 1;
for (; index >= 0 && index < length; index += dir) {
if (array[index] === item) return index;
}
return -1;
}
}
var indexOf = createIndexOfFinder(1);
var lastIndexOf = createIndexOfFinder(-1);
var result = indexOf([1, 2, 3, 4, 5], 2);
console.log(result) // 1但是即使是数组的 indexOf 方法也可以多传递一个参数 fromIndex,从 MDN 中看到 fromIndex 的讲究可有点多:
设定开始查找的位置。如果该索引值大于或等于数组长度,意味着不会在数组里查找,返回 -1。如果参数中提供的索引值是一个负值,则将其作为数组末尾的一个抵消,即 -1 表示从最后一个元素开始查找,-2 表示从倒数第二个元素开始查找 ,以此类推。 注意:如果参数中提供的索引值是一个负值,仍然从前向后查询数组。如果抵消后的索引值仍小于 0,则整个数组都将会被查询。其默认值为 0。
再看看 lastIndexOf 的 fromIndex:
从此位置开始逆向查找。默认为数组的长度减 1,即整个数组都被查找。如果该值大于或等于数组的长度,则整个数组会被查找。如果为负值,将其视为从数组末尾向前的偏移。即使该值为负,数组仍然会被从后向前查找。如果该值为负时,其绝对值大于数组长度,则方法返回 -1,即数组不会被查找。
按照这么多的规则,我们尝试着去写第二版:
// 第二版
function createIndexOfFinder(dir) {
return function(array, item, idx){
var length = array.length;
var i = 0;
if (typeof idx == "number") {
if (dir > 0) {
i = idx >= 0 ? idx : Math.max(length + idx, 0);
}
else {
length = idx >= 0 ? Math.min(idx + 1, length) : idx + length + 1;
}
}
for (idx = dir > 0 ? i : length - 1; idx >= 0 && idx < length; idx += dir) {
if (array[idx] === item) return idx;
}
return -1;
}
}
var indexOf = createIndexOfFinder(1);
var lastIndexOf = createIndexOfFinder(-1);到此为止,已经很接近原生的 indexOf 函数了,但是 underscore 在此基础上还做了两点优化。
第一个优化是支持查找 NaN。
因为 NaN 不全等于 NaN,所以原生的 indexOf 并不能找出 NaN 的下标。
[1, NaN].indexOf(NaN) // -1那么我们该如何实现这个功能呢?
就是从数组中找到符合条件的值的下标嘛,不就是我们最一开始写的 findIndex 吗?
我们来写一下:
// 第三版
function createIndexOfFinder(dir, predicate) {
return function(array, item, idx){
if () { ... }
// 判断元素是否是 NaN
if (item !== item) {
// 在截取好的数组中查找第一个满足isNaN函数的元素的下标
idx = predicate(array.slice(i, length), isNaN)
return idx >= 0 ? idx + i: -1;
}
for () { ... }
}
}
var indexOf = createIndexOfFinder(1, findIndex);
var lastIndexOf = createIndexOfFinder(-1, findLastIndex);第二个优化是支持对有序的数组进行更快的二分查找。
如果 indexOf 第三个参数不传开始搜索的下标值,而是一个布尔值 true,就认为数组是一个排好序的数组,这时候,就会采用更快的二分法进行查找,这个时候,可以利用我们写的 sortedIndex 函数。
在这里直接给最终的源码:
// 第四版
function createIndexOfFinder(dir, predicate, sortedIndex) {
return function(array, item, idx){
var length = array.length;
var i = 0;
if (typeof idx == "number") {
if (dir > 0) {
i = idx >= 0 ? idx : Math.max(length + idx, 0);
}
else {
length = idx >= 0 ? Math.min(idx + 1, length) : idx + length + 1;
}
}
else if (sortedIndex && idx && length) {
idx = sortedIndex(array, item);
// 如果该插入的位置的值正好等于元素的值,说明是第一个符合要求的值
return array[idx] === item ? idx : -1;
}
// 判断是否是 NaN
if (item !== item) {
idx = predicate(array.slice(i, length), isNaN)
return idx >= 0 ? idx + i: -1;
}
for (idx = dir > 0 ? i : length - 1; idx >= 0 && idx < length; idx += dir) {
if (array[idx] === item) return idx;
}
return -1;
}
}
var indexOf = createIndexOfFinder(1, findIndex, sortedIndex);
var lastIndexOf = createIndexOfFinder(-1, findLastIndex);值得注意的是:在 underscore 的实现中,只有 indexOf 是支持有序数组使用二分查找,lastIndexOf 并不支持。
我们需要写一个函数,输入 'kevin',返回 'HELLO, KEVIN'。
var toUpperCase = function(x) { return x.toUpperCase(); };
var hello = function(x) { return 'HELLO, ' + x; };
var greet = function(x){
return hello(toUpperCase(x));
};
greet('kevin');还好我们只有两个步骤,首先小写转大写,然后拼接字符串。如果有更多的操作,greet 函数里就需要更多的嵌套,类似于 fn3(fn2(fn1(fn0(x))))。
试想我们写个 compose 函数:
var compose = function(f,g) {
return function(x) {
return f(g(x));
};
};greet 函数就可以被优化为:
var greet = compose(hello, toUpperCase);
greet('kevin');利用 compose 将两个函数组合成一个函数,让代码从右向左运行,而不是由内而外运行,可读性大大提升。这便是函数组合。
但是现在的 compose 函数也只是能支持两个参数,如果有更多的步骤呢?我们岂不是要这样做:
compose(d, compose(c, compose(b, a)))为什么我们不写一个帅气的 compose 函数支持传入多个函数呢?这样就变成了:
compose(d, c, b, a)我们直接抄袭 underscore 的 compose 函数的实现:
function compose() {
var args = arguments;
var start = args.length - 1;
return function() {
var i = start;
var result = args[start].apply(this, arguments);
while (i--) result = args[i].call(this, result);
return result;
};
};现在的 compose 函数已经可以支持多个函数了,然而有了这个又有什么用呢?
在此之前,我们先了解一个概念叫做 pointfree。
pointfree 指的是函数无须提及将要操作的数据是什么样的。依然是以最初的需求为例:
// 需求:输入 'kevin',返回 'HELLO, KEVIN'。
// 非 pointfree,因为提到了数据:name
var greet = function(name) {
return ('hello ' + name).toUpperCase();
}
// pointfree
// 先定义基本运算,这些可以封装起来复用
var toUpperCase = function(x) { return x.toUpperCase(); };
var hello = function(x) { return 'HELLO, ' + x; };
var greet = compose(hello, toUpperCase);
greet('kevin');我们再举个稍微复杂一点的例子,为了方便书写,我们需要借助在《JavaScript专题之函数柯里化》中写到的 curry 函数:
// 需求:输入 'kevin daisy kelly',返回 'K.D.K'
// 非 pointfree,因为提到了数据:name
var initials = function (name) {
return name.split(' ').map(compose(toUpperCase, head)).join('. ');
};
// pointfree
// 先定义基本运算
var split = curry(function(separator, str) { return str.split(separator) })
var head = function(str) { return str.slice(0, 1) }
var toUpperCase = function(str) { return str.toUpperCase() }
var join = curry(function(separator, arr) { return arr.join(separator) })
var map = curry(function(fn, arr) { return arr.map(fn) })
var initials = compose(join('.'), map(compose(toUpperCase, head)), split(' '));
initials("kevin daisy kelly");从这个例子中我们可以看到,利用柯里化(curry)和函数组合 (compose) 非常有助于实现 pointfree。
也许你会想,这种写法好麻烦呐,我们还需要定义那么多的基础函数……可是如果有工具库已经帮你写好了呢?比如 ramda.js:
// 使用 ramda.js
var initials = R.compose(R.join('.'), R.map(R.compose(R.toUpper, R.head)), R.split(' '));而且你也会发现:
Pointfree 的本质就是使用一些通用的函数,组合出各种复杂运算。上层运算不要直接操作数据,而是通过底层函数去处理。即不使用所要处理的值,只合成运算过程。
那么使用 pointfree 模式究竟有什么好处呢?
pointfree 模式能够帮助我们减少不必要的命名,让代码保持简洁和通用,更符合语义,更容易复用,测试也变得轻而易举。
这个例子来自于 Favoring Curry:
假设我们从服务器获取这样的数据:
var data = {
result: "SUCCESS",
tasks: [
{id: 104, complete: false, priority: "high",
dueDate: "2013-11-29", username: "Scott",
title: "Do something", created: "9/22/2013"},
{id: 105, complete: false, priority: "medium",
dueDate: "2013-11-22", username: "Lena",
title: "Do something else", created: "9/22/2013"},
{id: 107, complete: true, priority: "high",
dueDate: "2013-11-22", username: "Mike",
title: "Fix the foo", created: "9/22/2013"},
{id: 108, complete: false, priority: "low",
dueDate: "2013-11-15", username: "Punam",
title: "Adjust the bar", created: "9/25/2013"},
{id: 110, complete: false, priority: "medium",
dueDate: "2013-11-15", username: "Scott",
title: "Rename everything", created: "10/2/2013"},
{id: 112, complete: true, priority: "high",
dueDate: "2013-11-27", username: "Lena",
title: "Alter all quuxes", created: "10/5/2013"}
]
};我们需要写一个名为 getIncompleteTaskSummaries 的函数,接收一个 username 作为参数,从服务器获取数据,然后筛选出这个用户的未完成的任务的 ids、priorities、titles、和 dueDate 数据,并且按照日期升序排序。
以 Scott 为例,最终筛选出的数据为:
[
{id: 110, title: "Rename everything",
dueDate: "2013-11-15", priority: "medium"},
{id: 104, title: "Do something",
dueDate: "2013-11-29", priority: "high"}
]普通的方式为:
// 第一版 过程式编程
var fetchData = function() {
// 模拟
return Promise.resolve(data)
};
var getIncompleteTaskSummaries = function(membername) {
return fetchData()
.then(function(data) {
return data.tasks;
})
.then(function(tasks) {
return tasks.filter(function(task) {
return task.username == membername
})
})
.then(function(tasks) {
return tasks.filter(function(task) {
return !task.complete
})
})
.then(function(tasks) {
return tasks.map(function(task) {
return {
id: task.id,
dueDate: task.dueDate,
title: task.title,
priority: task.priority
}
})
})
.then(function(tasks) {
return tasks.sort(function(first, second) {
var a = first.dueDate,
b = second.dueDate;
return a < b ? -1 : a > b ? 1 : 0;
});
})
.then(function(task) {
console.log(task)
})
};
getIncompleteTaskSummaries('Scott')如果使用 pointfree 模式:
// 第二版 pointfree 改写
var fetchData = function() {
return Promise.resolve(data)
};
// 编写基本函数
var prop = curry(function(name, obj) {
return obj[name];
});
var propEq = curry(function(name, val, obj) {
return obj[name] === val;
});
var filter = curry(function(fn, arr) {
return arr.filter(fn)
});
var map = curry(function(fn, arr) {
return arr.map(fn)
});
var pick = curry(function(args, obj){
var result = {};
for (var i = 0; i < args.length; i++) {
result[args[i]] = obj[args[i]]
}
return result;
});
var sortBy = curry(function(fn, arr) {
return arr.sort(function(a, b){
var a = fn(a),
b = fn(b);
return a < b ? -1 : a > b ? 1 : 0;
})
});
var getIncompleteTaskSummaries = function(membername) {
return fetchData()
.then(prop('tasks'))
.then(filter(propEq('username', membername)))
.then(filter(propEq('complete', false)))
.then(map(pick(['id', 'dueDate', 'title', 'priority'])))
.then(sortBy(prop('dueDate')))
.then(console.log)
};
getIncompleteTaskSummaries('Scott')如果直接使用 ramda.js,你可以省去编写基本函数:
// 第三版 使用 ramda.js
var fetchData = function() {
return Promise.resolve(data)
};
var getIncompleteTaskSummaries = function(membername) {
return fetchData()
.then(R.prop('tasks'))
.then(R.filter(R.propEq('username', membername)))
.then(R.filter(R.propEq('complete', false)))
.then(R.map(R.pick(['id', 'dueDate', 'title', 'priority'])))
.then(R.sortBy(R.prop('dueDate')))
.then(console.log)
};
getIncompleteTaskSummaries('Scott')当然了,利用 compose,你也可以这样写:
// 第四版 使用 compose
var fetchData = function() {
return Promise.resolve(data)
};
var getIncompleteTaskSummaries = function(membername) {
return fetchData()
.then(R.compose(
console.log,
R.sortBy(R.prop('dueDate')),
R.map(R.pick(['id', 'dueDate', 'title', 'priority'])
),
R.filter(R.propEq('complete', false)),
R.filter(R.propEq('username', membername)),
R.prop('tasks'),
))
};
getIncompleteTaskSummaries('Scott')compose 是从右到左依此执行,当然你也可以写一个从左到右的版本,但是从右向左执行更加能够反映数学上的含义。
ramda.js 提供了一个 R.pipe 函数,可以做的从左到右,以上可以改写为:
// 第五版 使用 R.pipe
var getIncompleteTaskSummaries = function(membername) {
return fetchData()
.then(R.pipe(
R.prop('tasks'),
R.filter(R.propEq('username', membername)),
R.filter(R.propEq('complete', false)),
R.map(R.pick(['id', 'dueDate', 'title', 'priority'])
R.sortBy(R.prop('dueDate')),
console.log,
))
};JavaScript专题系列目录地址:https://github.com/mqyqingfeng/Blog。
JavaScript专题系列预计写二十篇左右,主要研究日常开发中一些功能点的实现,比如防抖、节流、去重、类型判断、拷贝、最值、扁平、柯里、递归、乱序、排序等,特点是研(chao)究(xi) underscore 和 jQuery 的实现方式。
如果有错误或者不严谨的地方,请务必给予指正,十分感谢。如果喜欢或者有所启发,欢迎 star,对作者也是一种鼓励。
我们现在需要写一个 foo 函数,这个函数返回首次调用时的 Date 对象,注意是首次。
var t;
function foo() {
if (t) return t;
t = new Date()
return t;
}问题有两个,一是污染了全局变量,二是每次调用 foo 的时候都需要进行一次判断。
我们很容易想到用闭包避免污染全局变量。
var foo = (function() {
var t;
return function() {
if (t) return t;
t = new Date();
return t;
}
})();然而还是没有解决调用时都必须进行一次判断的问题。
函数也是一种对象,利用这个特性,我们也可以解决这个问题。
function foo() {
if (foo.t) return foo.t;
foo.t = new Date();
return foo.t;
}依旧没有解决调用时都必须进行一次判断的问题。
不错,惰性函数就是解决每次都要进行判断的这个问题,解决原理很简单,重写函数。
var foo = function() {
var t = new Date();
foo = function() {
return t;
};
return foo();
};DOM 事件添加中,为了兼容现代浏览器和 IE 浏览器,我们需要对浏览器环境进行一次判断:
// 简化写法
function addEvent (type, el, fn) {
if (window.addEventListener) {
el.addEventListener(type, fn, false);
}
else if(window.attachEvent){
el.attachEvent('on' + type, fn);
}
}问题在于我们每当使用一次 addEvent 时都会进行一次判断。
利用惰性函数,我们可以这样做:
function addEvent (type, el, fn) {
if (window.addEventListener) {
addEvent = function (type, el, fn) {
el.addEventListener(type, fn, false);
}
}
else if(window.attachEvent){
addEvent = function (type, el, fn) {
el.attachEvent('on' + type, fn);
}
}
}当然我们也可以使用闭包的形式:
var addEvent = (function(){
if (window.addEventListener) {
return function (type, el, fn) {
el.addEventListener(type, fn, false);
}
}
else if(window.attachEvent){
return function (type, el, fn) {
el.attachEvent('on' + type, fn);
}
}
})();当我们每次都需要进行条件判断,其实只需要判断一次,接下来的使用方式都不会发生改变的时候,想想是否可以考虑使用惰性函数。
Lazy Function Definition Pattern
JavaScript专题系列目录地址:https://github.com/mqyqingfeng/Blog。
JavaScript专题系列预计写二十篇左右,主要研究日常开发中一些功能点的实现,比如防抖、节流、去重、类型判断、拷贝、最值、扁平、柯里、递归、乱序、排序等,特点是研(chao)究(xi) underscore 和 jQuery 的实现方式。
如果有错误或者不严谨的地方,请务必给予指正,十分感谢。如果喜欢或者有所启发,欢迎 star,对作者也是一种鼓励。
在《JavaScript高级程序设计》第三版 4.1.3,讲到传递参数:
ECMAScript中所有函数的参数都是按值传递的。
什么是按值传递呢?
也就是说,把函数外部的值复制给函数内部的参数,就和把值从一个变量复制到另一个变量一样。
举个简单的例子:
var value = 1;
function foo(v) {
v = 2;
console.log(v); //2
}
foo(value);
console.log(value) // 1很好理解,当传递 value 到函数 foo 中,相当于拷贝了一份 value,假设拷贝的这份叫 _value,函数中修改的都是 _value 的值,而不会影响原来的 value 值。
拷贝虽然很好理解,但是当值是一个复杂的数据结构的时候,拷贝就会产生性能上的问题。
所以还有另一种传递方式叫做按引用传递。
所谓按引用传递,就是传递对象的引用,函数内部对参数的任何改变都会影响该对象的值,因为两者引用的是同一个对象。
举个例子:
var obj = {
value: 1
};
function foo(o) {
o.value = 2;
console.log(o.value); //2
}
foo(obj);
console.log(obj.value) // 2哎,不对啊,连我们的红宝书都说了 ECMAScript 中所有函数的参数都是按值传递的,这怎么能按"引用传递"成功呢?
而这究竟是不是引用传递呢?
不急,让我们再看个例子:
var obj = {
value: 1
};
function foo(o) {
o = 2;
console.log(o); //2
}
foo(obj);
console.log(obj.value) // 1如果 JavaScript 采用的是引用传递,外层的值也会被修改呐,这怎么又没被改呢?所以真的不是引用传递吗?
这就要讲到其实还有第三种传递方式,叫按共享传递。
而共享传递是指,在传递对象的时候,传递对象的引用的副本。
注意: 按引用传递是传递对象的引用,而按共享传递是传递对象的引用的副本!
所以修改 o.value,可以通过引用找到原值,但是直接修改 o,并不会修改原值。所以第二个和第三个例子其实都是按共享传递。
最后,你可以这样理解:
参数如果是基本类型是按值传递,如果是引用类型按共享传递。
但是因为拷贝副本也是一种值的拷贝,所以在高程中也直接认为是按值传递了。
所以,高程,谁叫你是红宝书嘞!
JavaScript深入系列目录地址:https://github.com/mqyqingfeng/Blog。
JavaScript深入系列预计写十五篇左右,旨在帮大家捋顺JavaScript底层知识,重点讲解如原型、作用域、执行上下文、变量对象、this、闭包、按值传递、call、apply、bind、new、继承等难点概念。
如果有错误或者不严谨的地方,请务必给予指正,十分感谢。如果喜欢或者有所启发,欢迎star,对作者也是一种鼓励。
本文讲解JavaScript各种继承方式和优缺点。
但是注意:
这篇文章更像是笔记,哎,再让我感叹一句:《JavaScript高级程序设计》写得真是太好了!
function Parent () {
this.name = 'kevin';
}
Parent.prototype.getName = function () {
console.log(this.name);
}
function Child () {
}
Child.prototype = new Parent();
var child1 = new Child();
console.log(child1.getName()) // kevin问题:
1.引用类型的属性被所有实例共享,举个例子:
function Parent () {
this.names = ['kevin', 'daisy'];
}
function Child () {
}
Child.prototype = new Parent();
var child1 = new Child();
child1.names.push('yayu');
console.log(child1.names); // ["kevin", "daisy", "yayu"]
var child2 = new Child();
console.log(child2.names); // ["kevin", "daisy", "yayu"]2.在创建 Child 的实例时,不能向Parent传参
function Parent () {
this.names = ['kevin', 'daisy'];
}
function Child () {
Parent.call(this);
}
var child1 = new Child();
child1.names.push('yayu');
console.log(child1.names); // ["kevin", "daisy", "yayu"]
var child2 = new Child();
console.log(child2.names); // ["kevin", "daisy"]优点:
1.避免了引用类型的属性被所有实例共享
2.可以在 Child 中向 Parent 传参
举个例子:
function Parent (name) {
this.name = name;
}
function Child (name) {
Parent.call(this, name);
}
var child1 = new Child('kevin');
console.log(child1.name); // kevin
var child2 = new Child('daisy');
console.log(child2.name); // daisy缺点:
方法都在构造函数中定义,每次创建实例都会创建一遍方法。
原型链继承和经典继承双剑合璧。
function Parent (name) {
this.name = name;
this.colors = ['red', 'blue', 'green'];
}
Parent.prototype.getName = function () {
console.log(this.name)
}
function Child (name, age) {
Parent.call(this, name);
this.age = age;
}
Child.prototype = new Parent();
Child.prototype.constructor = Child;
var child1 = new Child('kevin', '18');
child1.colors.push('black');
console.log(child1.name); // kevin
console.log(child1.age); // 18
console.log(child1.colors); // ["red", "blue", "green", "black"]
var child2 = new Child('daisy', '20');
console.log(child2.name); // daisy
console.log(child2.age); // 20
console.log(child2.colors); // ["red", "blue", "green"]优点:融合原型链继承和构造函数的优点,是 JavaScript 中最常用的继承模式。
function createObj(o) {
function F(){}
F.prototype = o;
return new F();
}就是 ES5 Object.create 的模拟实现,将传入的对象作为创建的对象的原型。
缺点:
包含引用类型的属性值始终都会共享相应的值,这点跟原型链继承一样。
var person = {
name: 'kevin',
friends: ['daisy', 'kelly']
}
var person1 = createObj(person);
var person2 = createObj(person);
person1.name = 'person1';
console.log(person2.name); // kevin
person1.friends.push('taylor');
console.log(person2.friends); // ["daisy", "kelly", "taylor"]注意:修改person1.name的值,person2.name的值并未发生改变,并不是因为person1和person2有独立的 name 值,而是因为person1.name = 'person1',给person1添加了 name 值,并非修改了原型上的 name 值。
创建一个仅用于封装继承过程的函数,该函数在内部以某种形式来做增强对象,最后返回对象。
function createObj (o) {
var clone = Object.create(o);
clone.sayName = function () {
console.log('hi');
}
return clone;
}缺点:跟借用构造函数模式一样,每次创建对象都会创建一遍方法。
为了方便大家阅读,在这里重复一下组合继承的代码:
function Parent (name) {
this.name = name;
this.colors = ['red', 'blue', 'green'];
}
Parent.prototype.getName = function () {
console.log(this.name)
}
function Child (name, age) {
Parent.call(this, name);
this.age = age;
}
Child.prototype = new Parent();
var child1 = new Child('kevin', '18');
console.log(child1)组合继承最大的缺点是会调用两次父构造函数。
一次是设置子类型实例的原型的时候:
Child.prototype = new Parent();一次在创建子类型实例的时候:
var child1 = new Child('kevin', '18');回想下 new 的模拟实现,其实在这句中,我们会执行:
Parent.call(this, name);在这里,我们又会调用了一次 Parent 构造函数。
所以,在这个例子中,如果我们打印 child1 对象,我们会发现 Child.prototype 和 child1 都有一个属性为colors,属性值为['red', 'blue', 'green']。
那么我们该如何精益求精,避免这一次重复调用呢?
如果我们不使用 Child.prototype = new Parent() ,而是间接的让 Child.prototype 访问到 Parent.prototype 呢?
看看如何实现:
function Parent (name) {
this.name = name;
this.colors = ['red', 'blue', 'green'];
}
Parent.prototype.getName = function () {
console.log(this.name)
}
function Child (name, age) {
Parent.call(this, name);
this.age = age;
}
// 关键的三步
var F = function () {};
F.prototype = Parent.prototype;
Child.prototype = new F();
var child1 = new Child('kevin', '18');
console.log(child1);最后我们封装一下这个继承方法:
function object(o) {
function F() {}
F.prototype = o;
return new F();
}
function prototype(child, parent) {
var prototype = object(parent.prototype);
prototype.constructor = child;
child.prototype = prototype;
}
// 当我们使用的时候:
prototype(Child, Parent);引用《JavaScript高级程序设计》中对寄生组合式继承的夸赞就是:
这种方式的高效率体现它只调用了一次 Parent 构造函数,并且因此避免了在 Parent.prototype 上面创建不必要的、多余的属性。与此同时,原型链还能保持不变;因此,还能够正常使用 instanceof 和 isPrototypeOf。开发人员普遍认为寄生组合式继承是引用类型最理想的继承范式。
《JavaScript深入之call和apply的模拟实现》
JavaScript深入系列目录地址:https://github.com/mqyqingfeng/Blog。
JavaScript深入系列预计写十五篇左右,旨在帮大家捋顺JavaScript底层知识,重点讲解如原型、作用域、执行上下文、变量对象、this、闭包、按值传递、call、apply、bind、new、继承等难点概念。
如果有错误或者不严谨的地方,请务必给予指正,十分感谢。如果喜欢或者有所启发,欢迎star,对作者也是一种鼓励。
数组的扁平化,就是将一个嵌套多层的数组 array (嵌套可以是任何层数)转换为只有一层的数组。
举个例子,假设有个名为 flatten 的函数可以做到数组扁平化,效果就会如下:
var arr = [1, [2, [3, 4]]];
console.log(flatten(arr)) // [1, 2, 3, 4]知道了效果是什么样的了,我们可以去尝试着写这个 flatten 函数了
我们最一开始能想到的莫过于循环数组元素,如果还是一个数组,就递归调用该方法:
// 方法 1
var arr = [1, [2, [3, 4]]];
function flatten(arr) {
var result = [];
for (var i = 0, len = arr.length; i < len; i++) {
if (Array.isArray(arr[i])) {
result = result.concat(flatten(arr[i]))
}
else {
result.push(arr[i])
}
}
return result;
}
console.log(flatten(arr))如果数组的元素都是数字,那么我们可以考虑使用 toString 方法,因为:
[1, [2, [3, 4]]].toString() // "1,2,3,4"调用 toString 方法,返回了一个逗号分隔的扁平的字符串,这时候我们再 split,然后转成数字不就可以实现扁平化了吗?
// 方法2
var arr = [1, [2, [3, 4]]];
function flatten(arr) {
return arr.toString().split(',').map(function(item){
return +item
})
}
console.log(flatten(arr))然而这种方法使用的场景却非常有限,如果数组是 [1, '1', 2, '2'] 的话,这种方法就会产生错误的结果。
既然是对数组进行处理,最终返回一个值,我们就可以考虑使用 reduce 来简化代码:
// 方法3
var arr = [1, [2, [3, 4]]];
function flatten(arr) {
return arr.reduce(function(prev, next){
return prev.concat(Array.isArray(next) ? flatten(next) : next)
}, [])
}
console.log(flatten(arr))ES6 增加了扩展运算符,用于取出参数对象的所有可遍历属性,拷贝到当前对象之中:
var arr = [1, [2, [3, 4]]];
console.log([].concat(...arr)); // [1, 2, [3, 4]]我们用这种方法只可以扁平一层,但是顺着这个方法一直思考,我们可以写出这样的方法:
// 方法4
var arr = [1, [2, [3, 4]]];
function flatten(arr) {
while (arr.some(item => Array.isArray(item))) {
arr = [].concat(...arr);
}
return arr;
}
console.log(flatten(arr))那么如何写一个抽象的扁平函数,来方便我们的开发呢,所有又到了我们抄袭 underscore 的时候了~
在这里直接给出源码和注释,但是要注意,这里的 flatten 函数并不是最终的 _.flatten,为了方便多个 API 进行调用,这里对扁平进行了更多的配置。
/**
* 数组扁平化
* @param {Array} input 要处理的数组
* @param {boolean} shallow 是否只扁平一层
* @param {boolean} strict 是否严格处理元素,下面有解释
* @param {Array} output 这是为了方便递归而传递的参数
* 源码地址:https://github.com/jashkenas/underscore/blob/master/underscore.js#L528
*/
function flatten(input, shallow, strict, output) {
// 递归使用的时候会用到output
output = output || [];
var idx = output.length;
for (var i = 0, len = input.length; i < len; i++) {
var value = input[i];
// 如果是数组,就进行处理
if (Array.isArray(value)) {
// 如果是只扁平一层,遍历该数组,依此填入 output
if (shallow) {
var j = 0, length = value.length;
while (j < length) output[idx++] = value[j++];
}
// 如果是全部扁平就递归,传入已经处理的 output,递归中接着处理 output
else {
flatten(value, shallow, strict, output);
idx = output.length;
}
}
// 不是数组,根据 strict 的值判断是跳过不处理还是放入 output
else if (!strict){
output[idx++] = value;
}
}
return output;
}解释下 strict,在代码里我们可以看出,当遍历数组元素时,如果元素不是数组,就会对 strict 取反的结果进行判断,如果设置 strict 为 true,就会跳过不进行任何处理,这意味着可以过滤非数组的元素,举个例子:
var arr = [1, 2, [3, 4]];
console.log(flatten(arr, true, true)); // [3, 4]那么设置 strict 到底有什么用呢?不急,我们先看下 shallow 和 strct 各种值对应的结果:
我们看看 underscore 中哪些方法调用了 flatten 这个基本函数:
首先就是 _.flatten:
_.flatten = function(array, shallow) {
return flatten(array, shallow, false);
};在正常的扁平中,我们并不需要去掉非数组元素。
接下来是 _.union:
该函数传入多个数组,然后返回传入的数组的并集,
举个例子:
_.union([1, 2, 3], [101, 2, 1, 10], [2, 1]);
=> [1, 2, 3, 101, 10]如果传入的参数并不是数组,就会将该参数跳过:
_.union([1, 2, 3], [101, 2, 1, 10], 4, 5);
=> [1, 2, 3, 101, 10]为了实现这个效果,我们可以将传入的所有数组扁平化,然后去重,因为只能传入数组,这时候我们直接设置 strict 为 true,就可以跳过传入的非数组的元素。
// 关于 unique 可以查看《JavaScript专题之数组去重》[](https://github.com/mqyqingfeng/Blog/issues/27)
function unique(array) {
return Array.from(new Set(array));
}
_.union = function() {
return unique(flatten(arguments, true, true));
}是不是感觉折腾 strict 有点用处了,我们再看一个 _.difference:
语法为:
_.difference(array, *others)
效果是取出来自 array 数组,并且不存在于多个 other 数组的元素。跟 _.union 一样,都会排除掉不是数组的元素。
举个例子:
_.difference([1, 2, 3, 4, 5], [5, 2, 10], [4], 3);
=> [1, 3]实现方法也很简单,扁平 others 的数组,筛选出 array 中不在扁平化数组中的值:
function difference(array, ...rest) {
rest = flatten(rest, true, true);
return array.filter(function(item){
return rest.indexOf(item) === -1;
})
}注意,以上实现的细节并不是完全按照 underscore,具体细节的实现感兴趣可以查看源码。
JavaScript专题系列目录地址:https://github.com/mqyqingfeng/Blog。
JavaScript专题系列预计写二十篇左右,主要研究日常开发中一些功能点的实现,比如防抖、节流、去重、类型判断、拷贝、最值、扁平、柯里、递归、乱序、排序等,特点是研(chao)究(xi) underscore 和 jQuery 的实现方式。
如果有错误或者不严谨的地方,请务必给予指正,十分感谢。如果喜欢或者有所启发,欢迎 star,对作者也是一种鼓励。
jQuery 的 each 方法,作为一个通用遍历方法,可用于遍历对象和数组。
语法为:
jQuery.each(object, [callback])回调函数拥有两个参数:第一个为对象的成员或数组的索引,第二个为对应变量或内容。
// 遍历数组
$.each( [0,1,2], function(i, n){
console.log( "Item #" + i + ": " + n );
});
// Item #0: 0
// Item #1: 1
// Item #2: 2// 遍历对象
$.each({ name: "John", lang: "JS" }, function(i, n) {
console.log("Name: " + i + ", Value: " + n);
});
// Name: name, Value: John
// Name: lang, Value: JS尽管 ES5 提供了 forEach 方法,但是 forEach 没有办法中止或者跳出 forEach 循环,除了抛出一个异常。但是对于 jQuery 的 each 函数,如果需要退出 each 循环可使回调函数返回 false,其它返回值将被忽略。
$.each( [0, 1, 2, 3, 4, 5], function(i, n){
if (i > 2) return false;
console.log( "Item #" + i + ": " + n );
});
// Item #0: 0
// Item #1: 1
// Item #2: 2那么我们该怎么实现这样一个 each 方法呢?
首先,我们肯定要根据参数的类型进行判断,如果是数组,就调用 for 循环,如果是对象,就使用 for in 循环,有一个例外是类数组对象,对于类数组对象,我们依然可以使用 for 循环。
更多关于类数组对象的知识,我们可以查看《JavaScript专题之类数组对象与arguments》
那么又该如何判断类数组对象和数组呢?实际上,我们在《JavaScript专题之类型判断(下)》就讲过jQuery 数组和类数组对象判断函数 isArrayLike 的实现。
所以,我们可以轻松写出第一版:
// 第一版
function each(obj, callback) {
var length, i = 0;
if ( isArrayLike(obj) ) {
length = obj.length;
for ( ; i < length; i++ ) {
callback(i, obj[i])
}
} else {
for ( i in obj ) {
callback(i, obj[i])
}
}
return obj;
}现在已经可以遍历对象和数组了,但是依然有一个效果没有实现,就是中止循环,按照 jQuery each 的实现,当回调函数返回 false 的时候,我们就中止循环。这个实现起来也很简单:
我们只用把:
callback(i, obj[i])替换成:
if (callback(i, obj[i]) === false) {
break;
}轻松实现中止循环的功能。
我们在实际的开发中,我们有时会在 callback 函数中用到 this,先举个不怎么恰当的例子:
// 我们给每个人添加一个 age 属性,age 的值为 18 + index
var person = [
{name: 'kevin'},
{name: 'daisy'}
]
$.each(person, function(index, item){
this.age = 18 + index;
})
console.log(person)这个时候,我们就希望 this 能指向当前遍历的元素,然后给每个元素添加 age 属性。
指定 this,我们可以使用 call 或者 apply,其实也很简单:
我们把:
if (callback(i, obj[i]) === false) {
break;
}替换成:
if (callback.call(obj[i], i, obj[i]) === false) {
break;
}关于 this,我们再举个常用的例子:
$.each($("p"), function(){
$(this).hover(function(){ ... });
})虽然我们经常会这样写:
$("p").each(function(){
$(this).hover(function(){ ... });
})但是因为
回到第一种写法上,就是因为将 this 指向了当前 DOM 元素,我们才能使用 $(this)将当前 DOM 元素包装成 jQuery 对象,优雅的使用 hover 方法。
所以最终的 each 源码为:
function each(obj, callback) {
var length, i = 0;
if (isArrayLike(obj)) {
length = obj.length;
for (; i < length; i++) {
if (callback.call(obj[i], i, obj[i]) === false) {
break;
}
}
} else {
for (i in obj) {
if (callback.call(obj[i], i, obj[i]) === false) {
break;
}
}
}
return obj;
}我们在性能上比较下 for 循环和 each 函数:
var arr = Array.from({length: 1000000}, (v, i) => i);
console.time('for')
var i = 0;
for (; i < arr.length; i++) {
i += arr[i];
}
console.timeEnd('for')
console.time('each')
var j = 0;
$.each(arr, function(index, item){
j += item;
})
console.timeEnd('each')这里显示一次运算的结果:

从上图可以看出,for 循环的性能是明显好于 each 函数的,each 函数本质上也是用的 for 循环,到底是慢在了哪里呢?
我们再看一个例子:
function each(obj, callback) {
var i = 0;
var length = obj.length
for (; i < length; i++) {
value = callback(i, obj[i]);
}
}
function eachWithCall(obj, callback) {
var i = 0;
var length = obj.length
for (; i < length; i++) {
value = callback.call(obj[i], i, obj[i]);
}
}
var arr = Array.from({length: 1000000}, (v, i) => i);
console.time('each')
var i = 0;
each(arr, function(index, item){
i += item;
})
console.timeEnd('each')
console.time('eachWithCall')
var j = 0;
eachWithCall(arr, function(index, item){
j += item;
})
console.timeEnd('eachWithCall')这里显示一次运算的结果:
each 函数和 eachWithCall 函数唯一的区别就是 eachWithCall 调用了 call,从结果我们可以推测出,call 会导致性能损失,但也正是 call 的存在,我们才能将 this 指向循环中当前的元素。
有舍有得吧。
JavaScript专题系列目录地址:https://github.com/mqyqingfeng/Blog。
JavaScript专题系列预计写二十篇左右,主要研究日常开发中一些功能点的实现,比如防抖、节流、去重、类型判断、拷贝、最值、扁平、柯里、递归、乱序、排序等,特点是研(chao)究(xi) underscore 和 jQuery 的实现方式。
如果有错误或者不严谨的地方,请务必给予指正,十分感谢。如果喜欢或者有所启发,欢迎 star,对作者也是一种鼓励。
拷贝也是面试经典呐!
如果是数组,我们可以利用数组的一些方法比如:slice、concat 返回一个新数组的特性来实现拷贝。
比如:
var arr = ['old', 1, true, null, undefined];
var new_arr = arr.concat();
new_arr[0] = 'new';
console.log(arr) // ["old", 1, true, null, undefined]
console.log(new_arr) // ["new", 1, true, null, undefined]用 slice 可以这样做:
var new_arr = arr.slice();但是如果数组嵌套了对象或者数组的话,比如:
var arr = [{old: 'old'}, ['old']];
var new_arr = arr.concat();
arr[0].old = 'new';
arr[1][0] = 'new';
console.log(arr) // [{old: 'new'}, ['new']]
console.log(new_arr) // [{old: 'new'}, ['new']]我们会发现,无论是新数组还是旧数组都发生了变化,也就是说使用 concat 方法,克隆的并不彻底。
如果数组元素是基本类型,就会拷贝一份,互不影响,而如果是对象或者数组,就会只拷贝对象和数组的引用,这样我们无论在新旧数组进行了修改,两者都会发生变化。
我们把这种复制引用的拷贝方法称之为浅拷贝,与之对应的就是深拷贝,深拷贝就是指完全的拷贝一个对象,即使嵌套了对象,两者也相互分离,修改一个对象的属性,也不会影响另一个。
所以我们可以看出使用 concat 和 slice 是一种浅拷贝。
那如何深拷贝一个数组呢?这里介绍一个技巧,不仅适用于数组还适用于对象!那就是:
var arr = ['old', 1, true, ['old1', 'old2'], {old: 1}]
var new_arr = JSON.parse( JSON.stringify(arr) );
console.log(new_arr);是一个简单粗暴的好方法,就是有一个问题,不能拷贝函数,我们做个试验:
var arr = [function(){
console.log(a)
}, {
b: function(){
console.log(b)
}
}]
var new_arr = JSON.parse(JSON.stringify(arr));
console.log(new_arr);我们会发现 new_arr 变成了:
以上三个方法 concat、slice、JSON.stringify 都算是技巧类,可以根据实际项目情况选择使用,接下来我们思考下如何实现一个对象或者数组的浅拷贝。
想一想,好像很简单,遍历对象,然后把属性和属性值都放在一个新的对象不就好了~
嗯,就是这么简单,注意几个小点就可以了:
var shallowCopy = function(obj) {
// 只拷贝对象
if (typeof obj !== 'object') return;
// 根据obj的类型判断是新建一个数组还是对象
var newObj = obj instanceof Array ? [] : {};
// 遍历obj,并且判断是obj的属性才拷贝
for (var key in obj) {
if (obj.hasOwnProperty(key)) {
newObj[key] = obj[key];
}
}
return newObj;
}那如何实现一个深拷贝呢?说起来也好简单,我们在拷贝的时候判断一下属性值的类型,如果是对象,我们递归调用深拷贝函数不就好了~
var deepCopy = function(obj) {
if (typeof obj !== 'object') return;
var newObj = obj instanceof Array ? [] : {};
for (var key in obj) {
if (obj.hasOwnProperty(key)) {
newObj[key] = typeof obj[key] === 'object' ? deepCopy(obj[key]) : obj[key];
}
}
return newObj;
}尽管使用深拷贝会完全的克隆一个新对象,不会产生副作用,但是深拷贝因为使用递归,性能会不如浅拷贝,在开发中,还是要根据实际情况进行选择。
难道到这里就结束了?是的。然而本篇实际上是一个铺垫,我们真正要看的是 jquery 的 extend 函数的实现,下一篇,我们会讲一讲如何从零实现一个 jquery 的 extend 函数。
JavaScript专题系列目录地址:https://github.com/mqyqingfeng/Blog。
JavaScript专题系列预计写二十篇左右,主要研究日常开发中一些功能点的实现,比如防抖、节流、去重、类型判断、拷贝、最值、扁平、柯里、递归、乱序、排序等,特点是研(chao)究(xi) underscore 和 jQuery 的实现方式。
如果有错误或者不严谨的地方,请务必给予指正,十分感谢。如果喜欢或者有所启发,欢迎 star,对作者也是一种鼓励。
类型判断在 web 开发中有非常广泛的应用,简单的有判断数字还是字符串,进阶一点的有判断数组还是对象,再进阶一点的有判断日期、正则、错误类型,再再进阶一点还有比如判断 plainObject、空对象、Window 对象等等。
以上都会讲,今天是上半场。
我们最最常用的莫过于 typeof,注意,尽管我们会看到诸如:
console.log(typeof('yayu')) // string的写法,但是 typeof 可是一个正宗的运算符,就跟加减乘除一样!这就能解释为什么下面这种写法也是可行的:
console.log(typeof 'yayu') // string引用《JavaScript权威指南》中对 typeof 的介绍:
typeof 是一元操作符,放在其单个操作数的前面,操作数可以是任意类型。返回值为表示操作数类型的一个字符串。
那我们都知道,在 ES6 前,JavaScript 共六种数据类型,分别是:
Undefined、Null、Boolean、Number、String、Object
然而当我们使用 typeof 对这些数据类型的值进行操作的时候,返回的结果却不是一一对应,分别是:
undefined、object、boolean、number、string、object
注意以上都是小写的字符串。Null 和 Object 类型都返回了 object 字符串。
尽管不能一一对应,但是 typeof 却能检测出函数类型:
function a() {}
console.log(typeof a); // function所以 typeof 能检测出六种类型的值,但是,除此之外 Object 下还有很多细分的类型呐,如 Array、Function、Date、RegExp、Error 等。
如果用 typeof 去检测这些类型,举个例子:
var date = new Date();
var error = new Error();
console.log(typeof date); // object
console.log(typeof error); // object返回的都是 object 呐,这可怎么区分~ 所以有没有更好的方法呢?
是的,当然有!这就是 Object.prototype.toString!
那 Object.protototype.toString 究竟是一个什么样的方法呢?
为了更加细致的讲解这个函数,让我先献上 ES5 规范地址:https://es5.github.io/#x15.2.4.2。
在第 15.2.4.2 节讲的就是 Object.prototype.toString(),为了不误导大家,我先奉上英文版:
When the toString method is called, the following steps are taken:
- If the this value is undefined, return "[object Undefined]".
- If the this value is null, return "[object Null]".
- Let O be the result of calling ToObject passing the this value as the argument.
- Let class be the value of the [[Class]] internal property of O.
- Return the String value that is the result of concatenating the three Strings "[object ", class, and "]".
凡是规范上加粗或者斜体的,在这里我也加粗或者斜体了,就是要让大家感受原汁原味的规范!
如果没有看懂,就不妨看看我理解的:
当 toString 方法被调用的时候,下面的步骤会被执行:
通过规范,我们至少知道了调用 Object.prototype.toString 会返回一个由 "[object " 和 class 和 "]" 组成的字符串,而 class 是要判断的对象的内部属性。
让我们写个 demo:
console.log(Object.prototype.toString.call(undefined)) // [object Undefined]
console.log(Object.prototype.toString.call(null)) // [object Null]
var date = new Date();
console.log(Object.prototype.toString.call(date)) // [object Date]由此我们可以看到这个 class 值就是识别对象类型的关键!
正是因为这种特性,我们可以用 Object.prototype.toString 方法识别出更多类型!
那到底能识别多少种类型呢?
至少 12 种!
你咋知道的?
我数的!
……
让我们看个 demo:
// 以下是11种:
var number = 1; // [object Number]
var string = '123'; // [object String]
var boolean = true; // [object Boolean]
var und = undefined; // [object Undefined]
var nul = null; // [object Null]
var obj = {a: 1} // [object Object]
var array = [1, 2, 3]; // [object Array]
var date = new Date(); // [object Date]
var error = new Error(); // [object Error]
var reg = /a/g; // [object RegExp]
var func = function a(){}; // [object Function]
function checkType() {
for (var i = 0; i < arguments.length; i++) {
console.log(Object.prototype.toString.call(arguments[i]))
}
}
checkType(number, string, boolean, und, nul, obj, array, date, error, reg, func)除了以上 11 种之外,还有:
console.log(Object.prototype.toString.call(Math)); // [object Math]
console.log(Object.prototype.toString.call(JSON)); // [object JSON]除了以上 13 种之外,还有:
function a() {
console.log(Object.prototype.toString.call(arguments)); // [object Arguments]
}
a();所以我们可以识别至少 14 种类型,当然我们也可以算出来,[[class]] 属性至少有 12 个。
既然有了 Object.prototype.toString 这个神器!那就让我们写个 type 函数帮助我们以后识别各种类型的值吧!
我的设想:
写一个 type 函数能检测各种类型的值,如果是基本类型,就使用 typeof,引用类型就使用 toString。此外鉴于 typeof 的结果是小写,我也希望所有的结果都是小写。
考虑到实际情况下并不会检测 Math 和 JSON,所以去掉这两个类型的检测。
我们来写一版代码:
// 第一版
var class2type = {};
// 生成class2type映射
"Boolean Number String Function Array Date RegExp Object Error Null Undefined".split(" ").map(function(item, index) {
class2type["[object " + item + "]"] = item.toLowerCase();
})
function type(obj) {
return typeof obj === "object" || typeof obj === "function" ?
class2type[Object.prototype.toString.call(obj)] || "object" :
typeof obj;
}嗯,看起来很完美的样子~~ 但是注意,在 IE6 中,null 和 undefined 会被 Object.prototype.toString 识别成 [object Object]!
我去,竟然还有这个兼容性!有什么简单的方法可以解决吗?那我们再改写一版,绝对让你惊艳!
// 第二版
var class2type = {};
// 生成class2type映射
"Boolean Number String Function Array Date RegExp Object Error".split(" ").map(function(item, index) {
class2type["[object " + item + "]"] = item.toLowerCase();
})
function type(obj) {
// 一箭双雕
if (obj == null) {
return obj + "";
}
return typeof obj === "object" || typeof obj === "function" ?
class2type[Object.prototype.toString.call(obj)] || "object" :
typeof obj;
}有了 type 函数后,我们可以对常用的判断直接封装,比如 isFunction:
function isFunction(obj) {
return type(obj) === "function";
}jQuery 判断数组类型,旧版本是通过判断 Array.isArray 方法是否存在,如果存在就使用该方法,不存在就使用 type 函数。
var isArray = Array.isArray || function( obj ) {
return type(obj) === "array";
}但是在 jQuery v3.0 中已经完全采用了 Array.isArray。
到此,类型判断的上篇就结束了,我们已经可以判断日期、正则、错误类型啦,但是还有更复杂的判断比如 plainObject、空对象、Window对象、类数组对象等,路漫漫其修远兮,吾将上下而求索。
哦, 对了,这个 type 函数抄的 jQuery,点击查看 type 源码。
JavaScript专题系列目录地址:https://github.com/mqyqingfeng/Blog。
JavaScript专题系列预计写二十篇左右,主要研究日常开发中一些功能点的实现,比如防抖、节流、去重、类型判断、拷贝、最值、扁平、柯里、递归、乱序、排序等,特点是研(chao)究(xi) underscore 和 jQuery 的实现方式。
如果有错误或者不严谨的地方,请务必给予指正,十分感谢。如果喜欢或者有所启发,欢迎 star,对作者也是一种鼓励。
程序调用自身的编程技巧称为递归(recursion)。
以阶乘为例:
function factorial(n) {
if (n == 1) return n;
return n * factorial(n - 1)
}
console.log(factorial(5)) // 5 * 4 * 3 * 2 * 1 = 120示意图(图片来自 wwww.penjee.com):
在《JavaScript专题之函数记忆》中讲到过的斐波那契数列也使用了递归:
function fibonacci(n){
return n < 2 ? n : fibonacci(n - 1) + fibonacci(n - 2);
}
console.log(fibonacci(5)) // 1 1 2 3 5从这两个例子中,我们可以看出:
构成递归需具备边界条件、递归前进段和递归返回段,当边界条件不满足时,递归前进,当边界条件满足时,递归返回。阶乘中的 n == 1 和 斐波那契数列中的 n < 2 都是边界条件。
总结一下递归的特点:
了解这些特点可以帮助我们更好的编写递归函数。
在《JavaScript深入之执行上下文栈》中,我们知道:
当执行一个函数的时候,就会创建一个执行上下文,并且压入执行上下文栈,当函数执行完毕的时候,就会将函数的执行上下文从栈中弹出。
试着对阶乘函数分析执行的过程,我们会发现,JavaScript 会不停的创建执行上下文压入执行上下文栈,对于内存而言,维护这么多的执行上下文也是一笔不小的开销呐!那么,我们该如何优化呢?
答案就是尾调用。
尾调用,是指函数内部的最后一个动作是函数调用。该调用的返回值,直接返回给函数。
举个例子:
// 尾调用
function f(x){
return g(x);
}然而
// 非尾调用
function f(x){
return g(x) + 1;
}并不是尾调用,因为 g(x) 的返回值还需要跟 1 进行计算后,f(x)才会返回值。
两者又有什么区别呢?答案就是执行上下文栈的变化不一样。
为了模拟执行上下文栈的行为,让我们定义执行上下文栈是一个数组:
ECStack = [];我们模拟下第一个尾调用函数执行时的执行上下文栈变化:
// 伪代码
ECStack.push(<f> functionContext);
ECStack.pop();
ECStack.push(<g> functionContext);
ECStack.pop();我们再来模拟一下第二个非尾调用函数执行时的执行上下文栈变化:
ECStack.push(<f> functionContext);
ECStack.push(<g> functionContext);
ECStack.pop();
ECStack.pop();也就说尾调用函数执行时,虽然也调用了一个函数,但是因为原来的的函数执行完毕,执行上下文会被弹出,执行上下文栈中相当于只多压入了一个执行上下文。然而非尾调用函数,就会创建多个执行上下文压入执行上下文栈。
函数调用自身,称为递归。如果尾调用自身,就称为尾递归。
所以我们只用把阶乘函数改造成一个尾递归形式,就可以避免创建那么多的执行上下文。但是我们该怎么做呢?
我们需要做的就是把所有用到的内部变量改写成函数的参数,以阶乘函数为例:
function factorial(n, res) {
if (n == 1) return res;
return factorial(n - 1, n * res)
}
console.log(factorial(4, 1)) // 24然而这个很奇怪呐……我们计算 4 的阶乘,结果函数要传入 4 和 1,我就不能只传入一个 4 吗?
这个时候就要用到我们在《JavaScript专题之偏函数》中编写的 partial 函数了:
var newFactorial = partial(factorial, _, 1)
newFactorial(4) // 24如果你看过 JavaScript 专题系列的文章,你会发现递归有着很多的应用。
作为专题系列的第十八篇,我们来盘点下之前的文章中都有哪些涉及到了递归:
function flatten(arr) {
return arr.reduce(function(prev, next){
return prev.concat(Array.isArray(next) ? flatten(next) : next)
}, [])
}var deepCopy = function(obj) {
if (typeof obj !== 'object') return;
var newObj = obj instanceof Array ? [] : {};
for (var key in obj) {
if (obj.hasOwnProperty(key)) {
newObj[key] = typeof obj[key] === 'object' ? deepCopy(obj[key]) : obj[key];
}
}
return newObj;
}3.JavaScript 专题之从零实现 jQuery 的 extend:
// 非完整版本,完整版本请点击查看具体的文章
function extend() {
...
// 循环遍历要复制的对象们
for (; i < length; i++) {
// 获取当前对象
options = arguments[i];
// 要求不能为空 避免extend(a,,b)这种情况
if (options != null) {
for (name in options) {
// 目标属性值
src = target[name];
// 要复制的对象的属性值
copy = options[name];
if (deep && copy && typeof copy == 'object') {
// 递归调用
target[name] = extend(deep, src, copy);
}
else if (copy !== undefined){
target[name] = copy;
}
}
}
}
...
};// 非完整版本,完整版本请点击查看具体的文章
// 属于间接调用
function eq(a, b, aStack, bStack) {
...
// 更复杂的对象使用 deepEq 函数进行深度比较
return deepEq(a, b, aStack, bStack);
};
function deepEq(a, b, aStack, bStack) {
...
// 数组判断
if (areArrays) {
length = a.length;
if (length !== b.length) return false;
while (length--) {
if (!eq(a[length], b[length], aStack, bStack)) return false;
}
}
// 对象判断
else {
var keys = Object.keys(a),
key;
length = keys.length;
if (Object.keys(b).length !== length) return false;
while (length--) {
key = keys[length];
if (!(b.hasOwnProperty(key) && eq(a[key], b[key], aStack, bStack))) return false;
}
}
}// 非完整版本,完整版本请点击查看具体的文章
function curry(fn, args) {
length = fn.length;
args = args || [];
return function() {
var _args = args.slice(0),
arg, i;
for (i = 0; i < arguments.length; i++) {
arg = arguments[i];
_args.push(arg);
}
if (_args.length < length) {
return curry.call(this, fn, _args);
}
else {
return fn.apply(this, _args);
}
}
}递归的内容远不止这些,比如还有汉诺塔、二叉树遍历等递归场景,本篇就不过多展开,真希望未来能写个算法系列。
JavaScript专题系列目录地址:https://github.com/mqyqingfeng/Blog。
JavaScript专题系列预计写二十篇左右,主要研究日常开发中一些功能点的实现,比如防抖、节流、去重、类型判断、拷贝、最值、扁平、柯里、递归、乱序、排序等,特点是研(chao)究(xi) underscore 和 jQuery 的实现方式。
如果有错误或者不严谨的地方,请务必给予指正,十分感谢。如果喜欢或者有所启发,欢迎 star,对作者也是一种鼓励。
MDN 对闭包的定义为:
闭包是指那些能够访问自由变量的函数。
那什么是自由变量呢?
自由变量是指在函数中使用的,但既不是函数参数也不是函数的局部变量的变量。
由此,我们可以看出闭包共有两部分组成:
闭包 = 函数 + 函数能够访问的自由变量
举个例子:
var a = 1;
function foo() {
console.log(a);
}
foo();foo 函数可以访问变量 a,但是 a 既不是 foo 函数的局部变量,也不是 foo 函数的参数,所以 a 就是自由变量。
那么,函数 foo + foo 函数访问的自由变量 a 不就是构成了一个闭包嘛……
还真是这样的!
所以在《JavaScript权威指南》中就讲到:从技术的角度讲,所有的JavaScript函数都是闭包。
咦,这怎么跟我们平时看到的讲到的闭包不一样呢!?
别着急,这是理论上的闭包,其实还有一个实践角度上的闭包,让我们看看汤姆大叔翻译的关于闭包的文章中的定义:
ECMAScript中,闭包指的是:
接下来就来讲讲实践上的闭包。
让我们先写个例子,例子依然是来自《JavaScript权威指南》,稍微做点改动:
var scope = "global scope";
function checkscope(){
var scope = "local scope";
function f(){
return scope;
}
return f;
}
var foo = checkscope();
foo();首先我们要分析一下这段代码中执行上下文栈和执行上下文的变化情况。
另一个与这段代码相似的例子,在《JavaScript深入之执行上下文》中有着非常详细的分析。如果看不懂以下的执行过程,建议先阅读这篇文章。
这里直接给出简要的执行过程:
了解到这个过程,我们应该思考一个问题,那就是:
当 f 函数执行的时候,checkscope 函数上下文已经被销毁了啊(即从执行上下文栈中被弹出),怎么还会读取到 checkscope 作用域下的 scope 值呢?
以上的代码,要是转换成 PHP,就会报错,因为在 PHP 中,f 函数只能读取到自己作用域和全局作用域里的值,所以读不到 checkscope 下的 scope 值。(这段我问的PHP同事……)
然而 JavaScript 却是可以的!
当我们了解了具体的执行过程后,我们知道 f 执行上下文维护了一个作用域链:
fContext = {
Scope: [AO, checkscopeContext.AO, globalContext.VO],
}对的,就是因为这个作用域链,f 函数依然可以读取到 checkscopeContext.AO 的值,说明当 f 函数引用了 checkscopeContext.AO 中的值的时候,即使 checkscopeContext 被销毁了,但是 JavaScript 依然会让 checkscopeContext.AO 活在内存中,f 函数依然可以通过 f 函数的作用域链找到它,正是因为 JavaScript 做到了这一点,从而实现了闭包这个概念。
所以,让我们再看一遍实践角度上闭包的定义:
在这里再补充一个《JavaScript权威指南》英文原版对闭包的定义:
This combination of a function object and a scope (a set of variable bindings) in which the function’s variables are resolved is called a closure in the computer science literature.
闭包在计算机科学中也只是一个普通的概念,大家不要去想得太复杂。
接下来,看这道刷题必刷,面试必考的闭包题:
var data = [];
for (var i = 0; i < 3; i++) {
data[i] = function () {
console.log(i);
};
}
data[0]();
data[1]();
data[2]();答案是都是 3,让我们分析一下原因:
当执行到 data[0] 函数之前,此时全局上下文的 VO 为:
globalContext = {
VO: {
data: [...],
i: 3
}
}当执行 data[0] 函数的时候,data[0] 函数的作用域链为:
data[0]Context = {
Scope: [AO, globalContext.VO]
}data[0]Context 的 AO 并没有 i 值,所以会从 globalContext.VO 中查找,i 为 3,所以打印的结果就是 3。
data[1] 和 data[2] 是一样的道理。
所以让我们改成闭包看看:
var data = [];
for (var i = 0; i < 3; i++) {
data[i] = (function (i) {
return function(){
console.log(i);
}
})(i);
}
data[0]();
data[1]();
data[2]();当执行到 data[0] 函数之前,此时全局上下文的 VO 为:
globalContext = {
VO: {
data: [...],
i: 3
}
}跟没改之前一模一样。
当执行 data[0] 函数的时候,data[0] 函数的作用域链发生了改变:
data[0]Context = {
Scope: [AO, 匿名函数Context.AO globalContext.VO]
}匿名函数执行上下文的AO为:
匿名函数Context = {
AO: {
arguments: {
0: 0,
length: 1
},
i: 0
}
}data[0]Context 的 AO 并没有 i 值,所以会沿着作用域链从匿名函数 Context.AO 中查找,这时候就会找 i 为 0,找到了就不会往 globalContext.VO 中查找了,即使 globalContext.VO 也有 i 的值(值为3),所以打印的结果就是0。
data[1] 和 data[2] 是一样的道理。
如果想了解执行上下文的具体变化,不妨循序渐进,阅读这六篇:
《JavaScript深入之从ECMAScript规范解读this》
JavaScript深入系列目录地址:https://github.com/mqyqingfeng/Blog。
JavaScript深入系列预计写十五篇左右,旨在帮大家捋顺JavaScript底层知识,重点讲解如原型、作用域、执行上下文、变量对象、this、闭包、按值传递、call、apply、bind、new、继承等难点概念。
如果有错误或者不严谨的地方,请务必给予指正,十分感谢。如果喜欢或者有所启发,欢迎star,对作者也是一种鼓励。
维基百科中对偏函数 (Partial application) 的定义为:
In computer science, partial application (or partial function application) refers to the process of fixing a number of arguments to a function, producing another function of smaller arity.
翻译成中文:
在计算机科学中,局部应用是指固定一个函数的一些参数,然后产生另一个更小元的函数。
什么是元?元是指函数参数的个数,比如一个带有两个参数的函数被称为二元函数。
举个简单的例子:
function add(a, b) {
return a + b;
}
// 执行 add 函数,一次传入两个参数即可
add(1, 2) // 3
// 假设有一个 partial 函数可以做到局部应用
var addOne = partial(add, 1);
addOne(2) // 3个人觉得翻译成“局部应用”或许更贴切些,以下全部使用“局部应用”。
如果看过上一篇文章《JavaScript专题之柯里化》,实际上你会发现这个例子和柯里化太像了,所以两者到底是有什么区别呢?
其实也很明显:
柯里化是将一个多参数函数转换成多个单参数函数,也就是将一个 n 元函数转换成 n 个一元函数。
局部应用则是固定一个函数的一个或者多个参数,也就是将一个 n 元函数转换成一个 n - x 元函数。
如果说两者有什么关系的话,引用 functional-programming-jargon 中的描述就是:
Curried functions are automatically partially applied.
我们今天的目的是模仿 underscore 写一个 partial 函数,比起 curry 函数,这个显然简单了很多。
也许你在想我们可以直接使用 bind 呐,举个例子:
function add(a, b) {
return a + b;
}
var addOne = add.bind(null, 1);
addOne(2) // 3然而使用 bind 我们还是改变了 this 指向,我们要写一个不改变 this 指向的方法。
根据之前的表述,我们可以尝试着写出第一版:
// 第一版
// 似曾相识的代码
function partial(fn) {
var args = [].slice.call(arguments, 1);
return function() {
var newArgs = args.concat([].slice.call(arguments));
return fn.apply(this, newArgs);
};
};我们来写个 demo 验证下 this 的指向:
function add(a, b) {
return a + b + this.value;
}
// var addOne = add.bind(null, 1);
var addOne = partial(add, 1);
var value = 1;
var obj = {
value: 2,
addOne: addOne
}
obj.addOne(2); // ???
// 使用 bind 时,结果为 4
// 使用 partial 时,结果为 5然而正如 curry 函数可以使用占位符一样,我们希望 partial 函数也可以实现这个功能,我们再来写第二版:
// 第二版
var _ = {};
function partial(fn) {
var args = [].slice.call(arguments, 1);
return function() {
var position = 0, len = args.length;
for(var i = 0; i < len; i++) {
args[i] = args[i] === _ ? arguments[position++] : args[i]
}
while(position < arguments.length) args.push(arguments[position++]);
return fn.apply(this, args);
};
};我们验证一下:
var subtract = function(a, b) { return b - a; };
subFrom20 = partial(subtract, _, 20);
subFrom20(5);值得注意的是:underscore 和 lodash 都提供了 partial 函数,但只有 lodash 提供了 curry 函数。
JavaScript专题系列目录地址:https://github.com/mqyqingfeng/Blog。
JavaScript专题系列预计写二十篇左右,主要研究日常开发中一些功能点的实现,比如防抖、节流、去重、类型判断、拷贝、最值、扁平、柯里、递归、乱序、排序等,特点是研(chao)究(xi) underscore 和 jQuery 的实现方式。
如果有错误或者不严谨的地方,请务必给予指正,十分感谢。如果喜欢或者有所启发,欢迎 star,对作者也是一种鼓励。
一句话介绍 new:
new 运算符创建一个用户定义的对象类型的实例或具有构造函数的内置对象类型之一
也许有点难懂,我们在模拟 new 之前,先看看 new 实现了哪些功能。
举个例子:
// Otaku 御宅族,简称宅
function Otaku (name, age) {
this.name = name;
this.age = age;
this.habit = 'Games';
}
// 因为缺乏锻炼的缘故,身体强度让人担忧
Otaku.prototype.strength = 60;
Otaku.prototype.sayYourName = function () {
console.log('I am ' + this.name);
}
var person = new Otaku('Kevin', '18');
console.log(person.name) // Kevin
console.log(person.habit) // Games
console.log(person.strength) // 60
person.sayYourName(); // I am Kevin从这个例子中,我们可以看到,实例 person 可以:
接下来,我们可以尝试着模拟一下了。
因为 new 是关键字,所以无法像 bind 函数一样直接覆盖,所以我们写一个函数,命名为 objectFactory,来模拟 new 的效果。用的时候是这样的:
function Otaku () {
……
}
// 使用 new
var person = new Otaku(……);
// 使用 objectFactory
var person = objectFactory(Otaku, ……)分析:
因为 new 的结果是一个新对象,所以在模拟实现的时候,我们也要建立一个新对象,假设这个对象叫 obj,因为 obj 会具有 Otaku 构造函数里的属性,想想经典继承的例子,我们可以使用 Otaku.apply(obj, arguments)来给 obj 添加新的属性。
在 JavaScript 深入系列第一篇中,我们便讲了原型与原型链,我们知道实例的 __proto__ 属性会指向构造函数的 prototype,也正是因为建立起这样的关系,实例可以访问原型上的属性。
现在,我们可以尝试着写第一版了:
// 第一版代码
function objectFactory() {
var obj = new Object(),
Constructor = [].shift.call(arguments);
obj.__proto__ = Constructor.prototype;
Constructor.apply(obj, arguments);
return obj;
};在这一版中,我们:
更多关于:
原型与原型链,可以看《JavaScript深入之从原型到原型链》
apply,可以看《JavaScript深入之call和apply的模拟实现》
经典继承,可以看《JavaScript深入之继承》
复制以下的代码,到浏览器中,我们可以做一下测试:
function Otaku (name, age) {
this.name = name;
this.age = age;
this.habit = 'Games';
}
Otaku.prototype.strength = 60;
Otaku.prototype.sayYourName = function () {
console.log('I am ' + this.name);
}
function objectFactory() {
var obj = new Object(),
Constructor = [].shift.call(arguments);
obj.__proto__ = Constructor.prototype;
Constructor.apply(obj, arguments);
return obj;
};
var person = objectFactory(Otaku, 'Kevin', '18')
console.log(person.name) // Kevin
console.log(person.habit) // Games
console.log(person.strength) // 60
person.sayYourName(); // I am Kevin[]~( ̄▽ ̄)~**
接下来我们再来看一种情况,假如构造函数有返回值,举个例子:
function Otaku (name, age) {
this.strength = 60;
this.age = age;
return {
name: name,
habit: 'Games'
}
}
var person = new Otaku('Kevin', '18');
console.log(person.name) // Kevin
console.log(person.habit) // Games
console.log(person.strength) // undefined
console.log(person.age) // undefined在这个例子中,构造函数返回了一个对象,在实例 person 中只能访问返回的对象中的属性。
而且还要注意一点,在这里我们是返回了一个对象,假如我们只是返回一个基本类型的值呢?
再举个例子:
function Otaku (name, age) {
this.strength = 60;
this.age = age;
return 'handsome boy';
}
var person = new Otaku('Kevin', '18');
console.log(person.name) // undefined
console.log(person.habit) // undefined
console.log(person.strength) // 60
console.log(person.age) // 18结果完全颠倒过来,这次尽管有返回值,但是相当于没有返回值进行处理。
所以我们还需要判断返回的值是不是一个对象,如果是一个对象,我们就返回这个对象,如果没有,我们该返回什么就返回什么。
再来看第二版的代码,也是最后一版的代码:
// 第二版的代码
function objectFactory() {
var obj = new Object(),
Constructor = [].shift.call(arguments);
obj.__proto__ = Constructor.prototype;
var ret = Constructor.apply(obj, arguments);
return typeof ret === 'object' ? ret : obj;
};《JavaScript深入之call和apply的模拟实现》
JavaScript深入系列目录地址:https://github.com/mqyqingfeng/Blog。
JavaScript深入系列预计写十五篇左右,旨在帮大家捋顺JavaScript底层知识,重点讲解如原型、作用域、执行上下文、变量对象、this、闭包、按值传递、call、apply、bind、new、继承等难点概念。
如果有错误或者不严谨的地方,请务必给予指正,十分感谢。如果喜欢或者有所启发,欢迎star,对作者也是一种鼓励。
虽然标题写的是如何判断两个对象相等,但本篇我们不仅仅判断两个对象相等,实际上,我们要做到的是如何判断两个参数相等,而这必然会涉及到多种类型的判断。
什么是相等?在《JavaScript专题之去重》中,我们认为只要 === 的结果为 true,两者就相等,然而今天我们重新定义相等:
我们认为:
不仅仅是这些长得一样的,还有
更复杂的我们会在接下来的内容中看到。
我们的目标是写一个 eq 函数用来判断两个参数是否相等,使用效果如下:
function eq(a, b) { ... }
var a = [1];
var b = [1];
console.log(eq(a, b)) // true在写这个看似很简单的函数之前,我们首先了解在一些简单的情况下是如何判断的?
如果 a === b 的结果为 true, 那么 a 和 b 就是相等的吗?一般情况下,当然是这样的,但是有一个特殊的例子,就是 +0 和 -0。
JavaScript “处心积虑”的想抹平两者的差异:
// 表现1
console.log(+0 === -0); // true
// 表现2
(-0).toString() // '0'
(+0).toString() // '0'
// 表现3
-0 < +0 // false
+0 < -0 // false即便如此,两者依然是不同的:
1 / +0 // Infinity
1 / -0 // -Infinity
1 / +0 === 1 / -0 // false也许你会好奇为什么要有 +0 和 -0 呢?
这是因为 JavaScript 采用了IEEE_754 浮点数表示法(几乎所有现代编程语言所采用),这是一种二进制表示法,按照这个标准,最高位是符号位(0 代表正,1 代表负),剩下的用于表示大小。而对于零这个边界值 ,1000(-0) 和 0000(0)都是表示 0 ,这才有了正负零的区别。
也许你会好奇什么时候会产生 -0 呢?
Math.round(-0.1) // -0那么我们又该如何在 === 结果为 true 的时候,区别 0 和 -0 得出正确的结果呢?我们可以这样做:
function eq(a, b){
if (a === b) return a !== 0 || 1 / a === 1 / b;
return false;
}
console.log(eq(0, 0)) // true
console.log(eq(0, -0)) // false在本篇,我们认为 NaN 和 NaN 是相等的,那又该如何判断出 NaN 呢?
console.log(NaN === NaN); // false利用 NaN 不等于自身的特性,我们可以区别出 NaN,那么这个 eq 函数又该怎么写呢?
function eq(a, b) {
if (a !== a) return b !== b;
}
console.log(eq(NaN, NaN)); // true现在,我们已经可以去写 eq 函数的第一版了。
// eq 第一版
// 用来过滤掉简单的类型比较,复杂的对象使用 deepEq 函数进行处理
function eq(a, b) {
// === 结果为 true 的区别出 +0 和 -0
if (a === b) return a !== 0 || 1 / a === 1 / b;
// typeof null 的结果为 object ,这里做判断,是为了让有 null 的情况尽早退出函数
if (a == null || b == null) return false;
// 判断 NaN
if (a !== a) return b !== b;
// 判断参数 a 类型,如果是基本类型,在这里可以直接返回 false
var type = typeof a;
if (type !== 'function' && type !== 'object' && typeof b != 'object') return false;
// 更复杂的对象使用 deepEq 函数进行深度比较
return deepEq(a, b);
};也许你会好奇是不是少了一个 typeof b !== function?
试想如果我们添加上了这句,当 a 是基本类型,而 b 是函数的时候,就会进入 deepEq 函数,而去掉这一句,就会进入直接进入 false,实际上 基本类型和函数肯定是不会相等的,所以这样做代码又少,又可以让一种情况更早退出。
现在我们开始写 deepEq 函数,一个要处理的重大难题就是 'Curly' 和 new String('Curly') 如何判断成相等?
两者的类型都不一样呐!不信我们看 typeof 的操作结果:
console.log(typeof 'Curly'); // string
console.log(typeof new String('Curly')); // object可是我们在《JavaScript专题之类型判断上》中还学习过更多的方法判断类型,比如 Object.prototype.toString:
var toString = Object.prototype.toString;
toString.call('Curly'); // "[object String]"
toString.call(new String('Curly')); // "[object String]"神奇的是使用 toString 方法两者判断的结果却是一致的,可是就算知道了这一点,还是不知道如何判断字符串和字符串包装对象是相等的呢?
那我们利用隐式类型转换呢?
console.log('Curly' + '' === new String('Curly') + ''); // true看来我们已经有了思路:如果 a 和 b 的 Object.prototype.toString的结果一致,并且都是"[object String]",那我们就使用 '' + a === '' + b 进行判断。
可是不止有 String 对象呐,Boolean、Number、RegExp、Date呢?
跟 String 同样的思路,利用隐式类型转换。
Boolean
var a = true;
var b = new Boolean(true);
console.log(+a === +b) // trueDate
var a = new Date(2009, 9, 25);
var b = new Date(2009, 9, 25);
console.log(+a === +b) // trueRegExp
var a = /a/i;
var b = new RegExp(/a/i);
console.log('' + a === '' + b) // trueNumber
var a = 1;
var b = new Number(1);
console.log(+a === +b) // true嗯哼?你确定 Number 能这么简单的判断?
var a = Number(NaN);
var b = Number(NaN);
console.log(+a === +b); // false可是 a 和 b 应该被判断成 true 的呐~
那么我们就改成这样:
var a = Number(NaN);
var b = Number(NaN);
function eq() {
// 判断 Number(NaN) Object(NaN) 等情况
if (+a !== +a) return +b !== +b;
// 其他判断 ...
}
console.log(eq(a, b)); // true现在我们可以写一点 deepEq 函数了。
var toString = Object.prototype.toString;
function deepEq(a, b) {
var className = toString.call(a);
if (className !== toString.call(b)) return false;
switch (className) {
case '[object RegExp]':
case '[object String]':
return '' + a === '' + b;
case '[object Number]':
if (+a !== +a) return +b !== +b;
return +a === 0 ? 1 / +a === 1 / b : +a === +b;
case '[object Date]':
case '[object Boolean]':
return +a === +b;
}
// 其他判断
}我们看个例子:
function Person() {
this.name = name;
}
function Animal() {
this.name = name
}
var person = new Person('Kevin');
var animal = new Animal('Kevin');
eq(person, animal) // ???虽然 person 和 animal 都是 {name: 'Kevin'},但是 person 和 animal 属于不同构造函数的实例,为了做出区分,我们认为是不同的对象。
如果两个对象所属的构造函数对象不同,两个对象就一定不相等吗?
并不一定,我们再举个例子:
var attrs = Object.create(null);
attrs.name = "Bob";
eq(attrs, {name: "Bob"}); // ???尽管 attrs 没有原型,{name: "Bob"} 的构造函数是 Object,但是在实际应用中,只要他们有着相同的键值对,我们依然认为是相等。
从函数设计的角度来看,我们不应该让他们相等,但是从实践的角度,我们让他们相等,所以相等就是一件如此随意的事情吗?!对啊,我也在想:undersocre,你怎么能如此随意呢!!!
哎,吐槽完了,我们还是要接着写这个相等函数,我们可以先做个判断,对于不同构造函数下的实例直接返回 false。
function isFunction(obj) {
return toString.call(obj) === '[object Function]'
}
function deepEq(a, b) {
// 接着上面的内容
var areArrays = className === '[object Array]';
// 不是数组
if (!areArrays) {
// 过滤掉两个函数的情况
if (typeof a != 'object' || typeof b != 'object') return false;
var aCtor = a.constructor, bCtor = b.constructor;
// aCtor 和 bCtor 必须都存在并且都不是 Object 构造函数的情况下,aCtor 不等于 bCtor, 那这两个对象就真的不相等啦
if (aCtor !== bCtor && !(isFunction(aCtor) && aCtor instanceof aCtor && isFunction(bCtor) && bCtor instanceof bCtor) && ('constructor' in a && 'constructor' in b)) {
return false;
}
}
// 下面还有好多判断
}现在终于可以进入我们期待已久的数组和对象的判断,不过其实这个很简单,就是递归遍历一遍……
function deepEq(a, b) {
// 再接着上面的内容
if (areArrays) {
length = a.length;
if (length !== b.length) return false;
while (length--) {
if (!eq(a[length], b[length])) return false;
}
}
else {
var keys = Object.keys(a), key;
length = keys.length;
if (Object.keys(b).length !== length) return false;
while (length--) {
key = keys[length];
if (!(b.hasOwnProperty(key) && eq(a[key], b[key]))) return false;
}
}
return true;
}如果觉得这就结束了,简直是太天真,因为最难的部分才终于要开始,这个问题就是循环引用!
举个简单的例子:
a = {abc: null};
b = {abc: null};
a.abc = a;
b.abc = b;
eq(a, b)再复杂一点的,比如:
a = {foo: {b: {foo: {c: {foo: null}}}}};
b = {foo: {b: {foo: {c: {foo: null}}}}};
a.foo.b.foo.c.foo = a;
b.foo.b.foo.c.foo = b;
eq(a, b)为了给大家演示下循环引用,大家可以把下面这段已经精简过的代码复制到浏览器中尝试:
// demo
var a, b;
a = { foo: { b: { foo: { c: { foo: null } } } } };
b = { foo: { b: { foo: { c: { foo: null } } } } };
a.foo.b.foo.c.foo = a;
b.foo.b.foo.c.foo = b;
function eq(a, b, aStack, bStack) {
if (typeof a == 'number') {
return a === b;
}
return deepEq(a, b)
}
function deepEq(a, b) {
var keys = Object.keys(a);
var length = keys.length;
var key;
while (length--) {
key = keys[length]
// 这是为了让你看到代码其实一直在执行
console.log(a[key], b[key])
if (!eq(a[key], b[key])) return false;
}
return true;
}
eq(a, b)嗯,以上的代码是死循环。
那么,我们又该如何解决这个问题呢?underscore 的思路是 eq 的时候,多传递两个参数为 aStack 和 bStack,用来储存 a 和 b 递归比较过程中的 a 和 b 的值,咋说的这么绕口呢?
我们直接看个精简的例子:
var a, b;
a = { foo: { b: { foo: { c: { foo: null } } } } };
b = { foo: { b: { foo: { c: { foo: null } } } } };
a.foo.b.foo.c.foo = a;
b.foo.b.foo.c.foo = b;
function eq(a, b, aStack, bStack) {
if (typeof a == 'number') {
return a === b;
}
return deepEq(a, b, aStack, bStack)
}
function deepEq(a, b, aStack, bStack) {
aStack = aStack || [];
bStack = bStack || [];
var length = aStack.length;
while (length--) {
if (aStack[length] === a) {
return bStack[length] === b;
}
}
aStack.push(a);
bStack.push(b);
var keys = Object.keys(a);
var length = keys.length;
var key;
while (length--) {
key = keys[length]
console.log(a[key], b[key], aStack, bStack)
if (!eq(a[key], b[key], aStack, bStack)) return false;
}
// aStack.pop();
// bStack.pop();
return true;
}
console.log(eq(a, b))之所以注释掉 aStack.pop()和bStack.pop()这两句,是为了方便大家查看 aStack bStack的值。
最终的代码如下:
var toString = Object.prototype.toString;
function isFunction(obj) {
return toString.call(obj) === '[object Function]'
}
function eq(a, b, aStack, bStack) {
// === 结果为 true 的区别出 +0 和 -0
if (a === b) return a !== 0 || 1 / a === 1 / b;
// typeof null 的结果为 object ,这里做判断,是为了让有 null 的情况尽早退出函数
if (a == null || b == null) return false;
// 判断 NaN
if (a !== a) return b !== b;
// 判断参数 a 类型,如果是基本类型,在这里可以直接返回 false
var type = typeof a;
if (type !== 'function' && type !== 'object' && typeof b != 'object') return false;
// 更复杂的对象使用 deepEq 函数进行深度比较
return deepEq(a, b, aStack, bStack);
};
function deepEq(a, b, aStack, bStack) {
// a 和 b 的内部属性 [[class]] 相同时 返回 true
var className = toString.call(a);
if (className !== toString.call(b)) return false;
switch (className) {
case '[object RegExp]':
case '[object String]':
return '' + a === '' + b;
case '[object Number]':
if (+a !== +a) return +b !== +b;
return +a === 0 ? 1 / +a === 1 / b : +a === +b;
case '[object Date]':
case '[object Boolean]':
return +a === +b;
}
var areArrays = className === '[object Array]';
// 不是数组
if (!areArrays) {
// 过滤掉两个函数的情况
if (typeof a != 'object' || typeof b != 'object') return false;
var aCtor = a.constructor,
bCtor = b.constructor;
// aCtor 和 bCtor 必须都存在并且都不是 Object 构造函数的情况下,aCtor 不等于 bCtor, 那这两个对象就真的不相等啦
if (aCtor !== bCtor && !(isFunction(aCtor) && aCtor instanceof aCtor && isFunction(bCtor) && bCtor instanceof bCtor) && ('constructor' in a && 'constructor' in b)) {
return false;
}
}
aStack = aStack || [];
bStack = bStack || [];
var length = aStack.length;
// 检查是否有循环引用的部分
while (length--) {
if (aStack[length] === a) {
return bStack[length] === b;
}
}
aStack.push(a);
bStack.push(b);
// 数组判断
if (areArrays) {
length = a.length;
if (length !== b.length) return false;
while (length--) {
if (!eq(a[length], b[length], aStack, bStack)) return false;
}
}
// 对象判断
else {
var keys = Object.keys(a),
key;
length = keys.length;
if (Object.keys(b).length !== length) return false;
while (length--) {
key = keys[length];
if (!(b.hasOwnProperty(key) && eq(a[key], b[key], aStack, bStack))) return false;
}
}
aStack.pop();
bStack.pop();
return true;
}
console.log(eq(0, 0)) // true
console.log(eq(0, -0)) // false
console.log(eq(NaN, NaN)); // true
console.log(eq(Number(NaN), Number(NaN))); // true
console.log(eq('Curly', new String('Curly'))); // true
console.log(eq([1], [1])); // true
console.log(eq({ value: 1 }, { value: 1 })); // true
var a, b;
a = { foo: { b: { foo: { c: { foo: null } } } } };
b = { foo: { b: { foo: { c: { foo: null } } } } };
a.foo.b.foo.c.foo = a;
b.foo.b.foo.c.foo = b;
console.log(eq(a, b)) // true真让人感叹一句:eq 不愧是 underscore 中实现代码行数最多的函数了!
JavaScript专题系列目录地址:https://github.com/mqyqingfeng/Blog。
JavaScript专题系列预计写二十篇左右,主要研究日常开发中一些功能点的实现,比如防抖、节流、去重、类型判断、拷贝、最值、扁平、柯里、递归、乱序、排序等,特点是研(chao)究(xi) underscore 和 jQuery 的实现方式。
如果有错误或者不严谨的地方,请务必给予指正,十分感谢。如果喜欢或者有所启发,欢迎 star,对作者也是一种鼓励。
所谓的类数组对象:
拥有一个 length 属性和若干索引属性的对象
举个例子:
var array = ['name', 'age', 'sex'];
var arrayLike = {
0: 'name',
1: 'age',
2: 'sex',
length: 3
}即便如此,为什么叫做类数组对象呢?
那让我们从读写、获取长度、遍历三个方面看看这两个对象。
console.log(array[0]); // name
console.log(arrayLike[0]); // name
array[0] = 'new name';
arrayLike[0] = 'new name';console.log(array.length); // 3
console.log(arrayLike.length); // 3for(var i = 0, len = array.length; i < len; i++) {
……
}
for(var i = 0, len = arrayLike.length; i < len; i++) {
……
}是不是很像?
那类数组对象可以使用数组的方法吗?比如:
arrayLike.push('4');然而上述代码会报错: arrayLike.push is not a function
所以终归还是类数组呐……
如果类数组就是任性的想用数组的方法怎么办呢?
既然无法直接调用,我们可以用 Function.call 间接调用:
var arrayLike = {0: 'name', 1: 'age', 2: 'sex', length: 3 }
Array.prototype.join.call(arrayLike, '&'); // name&age&sex
Array.prototype.slice.call(arrayLike, 0); // ["name", "age", "sex"]
// slice可以做到类数组转数组
Array.prototype.map.call(arrayLike, function(item){
return item.toUpperCase();
});
// ["NAME", "AGE", "SEX"]在上面的例子中已经提到了一种类数组转数组的方法,再补充三个:
var arrayLike = {0: 'name', 1: 'age', 2: 'sex', length: 3 }
// 1. slice
Array.prototype.slice.call(arrayLike); // ["name", "age", "sex"]
// 2. splice
Array.prototype.splice.call(arrayLike, 0); // ["name", "age", "sex"]
// 3. ES6 Array.from
Array.from(arrayLike); // ["name", "age", "sex"]
// 4. apply
Array.prototype.concat.apply([], arrayLike)那么为什么会讲到类数组对象呢?以及类数组有什么应用吗?
要说到类数组对象,Arguments 对象就是一个类数组对象。在客户端 JavaScript 中,一些 DOM 方法(document.getElementsByTagName()等)也返回类数组对象。
接下来重点讲讲 Arguments 对象。
Arguments 对象只定义在函数体中,包括了函数的参数和其他属性。在函数体中,arguments 指代该函数的 Arguments 对象。
举个例子:
function foo(name, age, sex) {
console.log(arguments);
}
foo('name', 'age', 'sex')打印结果如下:
我们可以看到除了类数组的索引属性和length属性之外,还有一个callee属性,接下来我们一个一个介绍。
Arguments对象的length属性,表示实参的长度,举个例子:
function foo(b, c, d){
console.log("实参的长度为:" + arguments.length)
}
console.log("形参的长度为:" + foo.length)
foo(1)
// 形参的长度为:3
// 实参的长度为:1Arguments 对象的 callee 属性,通过它可以调用函数自身。
讲个闭包经典面试题使用 callee 的解决方法:
var data = [];
for (var i = 0; i < 3; i++) {
(data[i] = function () {
console.log(arguments.callee.i)
}).i = i;
}
data[0]();
data[1]();
data[2]();
// 0
// 1
// 2接下来讲讲 arguments 对象的几个注意要点:
function foo(name, age, sex, hobbit) {
console.log(name, arguments[0]); // name name
// 改变形参
name = 'new name';
console.log(name, arguments[0]); // new name new name
// 改变arguments
arguments[1] = 'new age';
console.log(age, arguments[1]); // new age new age
// 测试未传入的是否会绑定
console.log(sex); // undefined
sex = 'new sex';
console.log(sex, arguments[2]); // new sex undefined
arguments[3] = 'new hobbit';
console.log(hobbit, arguments[3]); // undefined new hobbit
}
foo('name', 'age')传入的参数,实参和 arguments 的值会共享,当没有传入时,实参与 arguments 值不会共享
除此之外,以上是在非严格模式下,如果是在严格模式下,实参和 arguments 是不会共享的。
将参数从一个函数传递到另一个函数
// 使用 apply 将 foo 的参数传递给 bar
function foo() {
bar.apply(this, arguments);
}
function bar(a, b, c) {
console.log(a, b, c);
}
foo(1, 2, 3)使用ES6的 ... 运算符,我们可以轻松转成数组。
function func(...arguments) {
console.log(arguments); // [1, 2, 3]
}
func(1, 2, 3);arguments的应用其实很多,在下个系列,也就是 JavaScript 专题系列中,我们会在 jQuery 的 extend 实现、函数柯里化、递归等场景看见 arguments 的身影。这篇文章就不具体展开了。
如果要总结这些场景的话,暂时能想到的包括:
欢迎留言回复。
JavaScript深入系列目录地址:https://github.com/mqyqingfeng/Blog。
JavaScript深入系列预计写十五篇左右,旨在帮大家捋顺JavaScript底层知识,重点讲解如原型、作用域、执行上下文、变量对象、this、闭包、按值传递、call、apply、bind、new、继承等难点概念。
如果有错误或者不严谨的地方,请务必给予指正,十分感谢。如果喜欢或者有所启发,欢迎star,对作者也是一种鼓励。
在《JavaScript深入之执行上下文栈》中讲到,当JavaScript代码执行一段可执行代码(executable code)时,会创建对应的执行上下文(execution context)。
对于每个执行上下文,都有三个重要属性:
今天重点讲讲作用域链。
在《JavaScript深入之变量对象》中讲到,当查找变量的时候,会先从当前上下文的变量对象中查找,如果没有找到,就会从父级(词法层面上的父级)执行上下文的变量对象中查找,一直找到全局上下文的变量对象,也就是全局对象。这样由多个执行上下文的变量对象构成的链表就叫做作用域链。
下面,让我们以一个函数的创建和激活两个时期来讲解作用域链是如何创建和变化的。
在《JavaScript深入之词法作用域和动态作用域》中讲到,函数的作用域在函数定义的时候就决定了。
这是因为函数有一个内部属性 [[scope]],当函数创建的时候,就会保存所有父变量对象到其中,你可以理解 [[scope]] 就是所有父变量对象的层级链,但是注意:[[scope]] 并不代表完整的作用域链!
举个例子:
function foo() {
function bar() {
...
}
}函数创建时,各自的[[scope]]为:
foo.[[scope]] = [
globalContext.VO
];
bar.[[scope]] = [
fooContext.AO,
globalContext.VO
];当函数激活时,进入函数上下文,创建 VO/AO 后,就会将活动对象添加到作用链的前端。
这时候执行上下文的作用域链,我们命名为 Scope:
Scope = [AO].concat([[Scope]]);至此,作用域链创建完毕。
以下面的例子为例,结合着之前讲的变量对象和执行上下文栈,我们来总结一下函数执行上下文中作用域链和变量对象的创建过程:
var scope = "global scope";
function checkscope(){
var scope2 = 'local scope';
return scope2;
}
checkscope();执行过程如下:
1.checkscope 函数被创建,保存作用域链到 内部属性[[scope]]
checkscope.[[scope]] = [
globalContext.VO
];2.执行 checkscope 函数,创建 checkscope 函数执行上下文,checkscope 函数执行上下文被压入执行上下文栈
ECStack = [
checkscopeContext,
globalContext
];3.checkscope 函数并不立刻执行,开始做准备工作,第一步:复制函数[[scope]]属性创建作用域链
checkscopeContext = {
Scope: checkscope.[[scope]],
}4.第二步:用 arguments 创建活动对象,随后初始化活动对象,加入形参、函数声明、变量声明
checkscopeContext = {
AO: {
arguments: {
length: 0
},
scope2: undefined
},
Scope: checkscope.[[scope]],
}5.第三步:将活动对象压入 checkscope 作用域链顶端
checkscopeContext = {
AO: {
arguments: {
length: 0
},
scope2: undefined
},
Scope: [AO, [[Scope]]]
}6.准备工作做完,开始执行函数,随着函数的执行,修改 AO 的属性值
checkscopeContext = {
AO: {
arguments: {
length: 0
},
scope2: 'local scope'
},
Scope: [AO, [[Scope]]]
}7.查找到 scope2 的值,返回后函数执行完毕,函数上下文从执行上下文栈中弹出
ECStack = [
globalContext
];《JavaScript深入之从ECMAScript规范解读this》
JavaScript深入系列目录地址:https://github.com/mqyqingfeng/Blog。
JavaScript深入系列预计写十五篇左右,旨在帮大家捋顺JavaScript底层知识,重点讲解如原型、作用域、执行上下文、变量对象、this、闭包、按值传递、call、apply、bind、new、继承等难点概念。
如果有错误或者不严谨的地方,请务必给予指正,十分感谢。如果喜欢或者有所启发,欢迎star,对作者也是一种鼓励。
Object.prototype.toString 出来就是 "[object Object]"
Object.prototype.toString.call() 为什么加上call() 后 就能获取不同的类型? 为什么?
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.








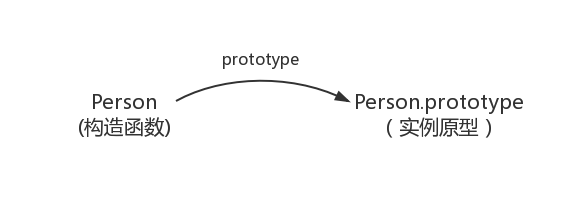
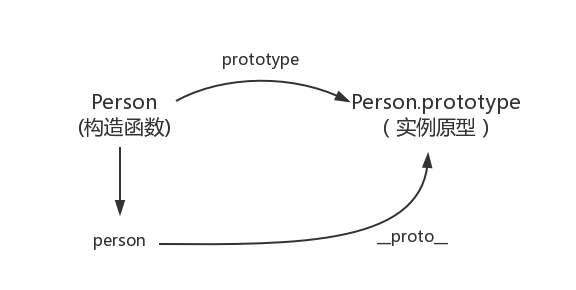
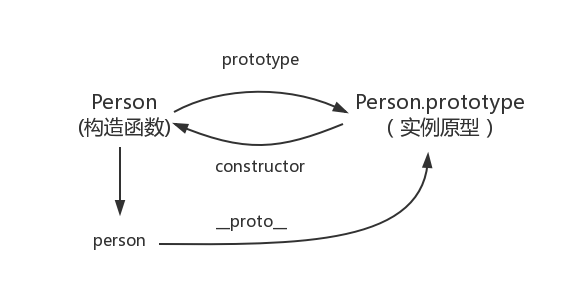
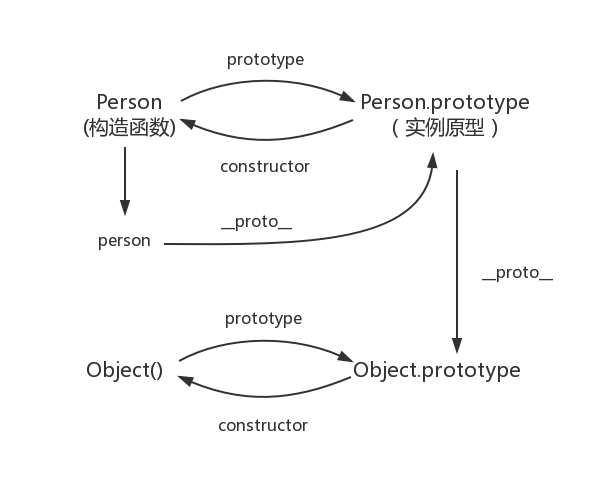
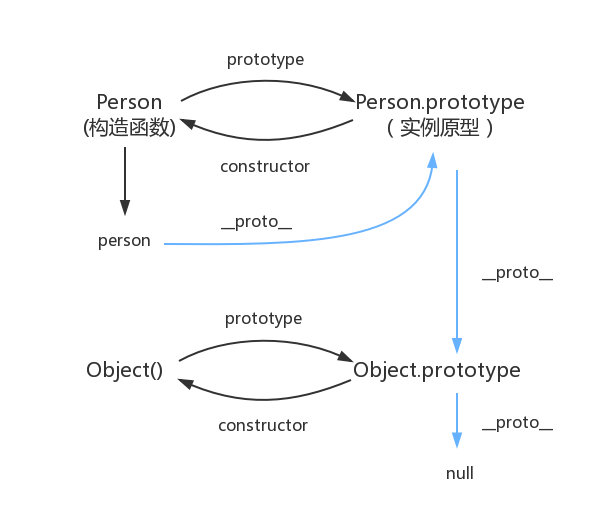



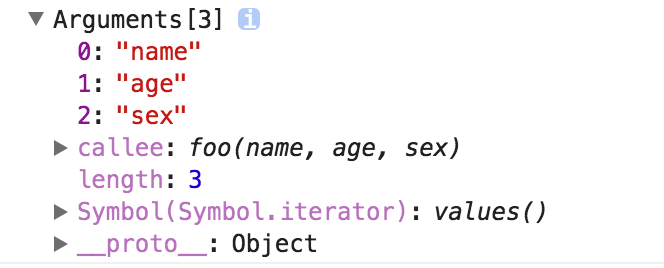
{kind=link}
{kind=link}