justadudewhohacks / face-api.js Goto Github PK
View Code? Open in Web Editor NEWJavaScript API for face detection and face recognition in the browser and nodejs with tensorflow.js
License: MIT License
JavaScript API for face detection and face recognition in the browser and nodejs with tensorflow.js
License: MIT License



























































































































































































































Hi,
I was locating faces with SSD Mobile Net (faceapi.locateFaces) because with other nets (MTCNN, Tiny Yolo v2) the result was unstable. Now I updated the library from 0.11.0 to 0.12.0 version and same code produces different results. At 0.11.0 version faceapi.locateFaces was stable but with 0.12.0 version is unstable (like MTCNN, Tiny Yolo v2 at 0.11.0).
Greetings and thanks for the repository.
Would it be possible to list the browsers which support this package? For example can this work server-side on node or is it primarily client side focused?
It might be worth it to also investigate in yolo v2 or v3 as an alternative face detector. From the looks I would tend to yolo v2, as it is more leaned towards achieving high fps. Furthermore, there seem to be some already trained models for face detection with yolo v2 out there, which would make it easier to get started.
Is it possible to use allFaces function with MTCNN?
Hi @justadudewhohacks
I was trying the api on a Mobile browser, but is not working 😟
I tried it on a Android 8.0, Chrome, and I was using React.js
If you want to try it too, here is the repo:
https://github.com/BonnieMilian/face-api-webcam-react
When I call the function computeFaceDescriptor with an image which the different between width and height is 1 pixel, it will cause an error "Shapes can not be <= 0. Found 0 at dim 1" at this line:
face-api.js/src/padToSquare.ts
Line 35 in cc63d78
The value of paddingAmount is 0 so it cannot be concat.
npm-debug.log
I cloned the repository, and run the example as the tutorial. but got error, I'm on Windows 10.
Allow batch input for face recognition net.
The Current Implementation does not support loading of models from sources other than the current domain.
This could be a useful feature as it could allow for loading of models from cdns or directly from a cloud object storage instance.
I have implemented the required change here, let me know if this is desired feature and I can create a PR.
P.S.
Thanks for the excellent library.
I am trying to understand how face-api matches names to faces. Most of it seems to occur at the function getBestMatch
function getBestMatch(descriptorsByClass, queryDescriptor) {
function computeMeanDistance(descriptorsOfClass) {
return faceapi.round(
descriptorsOfClass
.map(d => faceapi.euclideanDistance(d, queryDescriptor))
.reduce((d1, d2) => d1 + d2, 0)
/ (descriptorsOfClass.length || 1)
)
}
return descriptorsByClass
.map(
({ descriptors, className }) => ({
distance: computeMeanDistance(descriptors),
className
})
)
.reduce((best, curr) => best.distance < curr.distance ? best : curr)
}
However when I look at other functions in the common.js file. It looks like values for comparison are calculated by loading each character into the model and using those values. (If that is correct, I feel like those values for the main characters could be saved in a json object file) Can someone explain the process for making these matches. I am fairly sure non of this data is actually saved in the models.
My minimalist demo of just bounding boxes is here and an attempt to match characters is here (Crashes on the array.reduce calculation since one of my arrays is empty)
As my demos are just single page webpages just right click to view the source.
P.S. helps to have the console open as it gives some idea of the process.
Note: my bounding boxes are working on my windows and ubuntu laptops, but strangely are too high on my windows10 desktop.
Hi firstly i want to thank you for this amazing API that help me a lot for my project !!
So:

I'm working on a prototype where I need to use tensorflow.js (load the models); there seems to be a conflict between the namespace with your version (assume you're just using core) and the official. I need access to, at least, loadModel which is not available in your module. I've tried importing both but only the first one assigns itself to the globally.
I download the source code and npm the example like the 'readme.md' said, but the result isn't right.
the detection draw on the canvas like the pic.
why this happen?

I have some questions, is it possible to use face-api in server side? for example: I need use it to process some image in db. If it is, possible, could it work correctly without environment config like on browser?
Use it like other package? And now, I can not setup it in server-side! :<
import faceApi from 'face-api'
// faceApi is undefinedThanks!
How can I use face-api.js in jquery - laravel blade?
Checked demo link as well as ran the local setup - why it hangs the browser in a blocking way for the time being it is detecting/recognizing face?
Currently I get some faces misaligned, the issue seems to be more with the ROI of the detector. Not completely sure in the end if its a detection or alignment model issue

With changing the detection ROI we can get good results

I'm looking how to get overall improvement up, maybe running mtcnn and SSD side by side. I'd rather do a bit slower detection then having users fix the ROI manualy
I'm using VueJS. How can I fix these errors?
Code (VueJS)
onPlay: async function(videoEl) {
if(videoEl.paused || videoEl.ended || !modelLoaded)
return false;
let minFaceSize = 200;
const { width, height } = faceapi.getMediaDimensions(videoEl);
const canvas = document.getElementById('inputVideo');
canvas.width = width;
canvas.height = height;
const mtcnnParams = {
minFaceSize
};
const fullFaceDescriptions = (faceapi.allFacesMtcnn(videoEl, mtcnnParams)).map(fd => fd.forSize(width, height));
fullFaceDescriptions.forEach(({ detection, landmarks, descriptor }) => {
faceapi.drawDetection('overlay', [detection], { withScore: false });
faceapi.drawLandmarks('overlay', landmarks.forSize(width, height), { lineWidth: 4, color: 'red' });
const bestMatch = getBestMatch(trainDescriptorsByClass, descriptor);
const text = `${bestMatch.distance < maxDistance ? bestMatch.className : 'unkown'} (${bestMatch.distance})`;
const { x, y, height: boxHeight } = detection.getBox();
faceapi.drawText(
canvas.getContext('2d'),
x,
y + boxHeight,
text,
Object.assign(faceapi.getDefaultDrawOptions(), { color: 'red', fontSize: 16 })
)
});
setTimeout(() => onPlay(videoEl), 150);
},
run: async function() {
await faceapi.loadMtcnnModel("/img/face-api/weights");
await faceapi.loadFaceRecognitionModel("/img/face-api/weights/");
trainDescriptorsByClass = initTrainDescriptorsByClass(faceapi.recognitionNet);
modelLoaded = true;
const videoEl = document.getElementById('inputVideo');
navigator.getUserMedia(
{ video: {} },
stream => videoEl.srcObject = stream,
err => console.error(err)
);
this.onPlay(videoEl);
}
Code (HTML)
<div style="position: relative" class="margin">
<video ref="inputVideo" onload="onPlay(this)" id="inputVideo" autoplay="true" muted></video>
<canvas id="overlay" />
</div>
Hi @justadudewhohacks ,
I'm getting the following after performing the below steps:
faceapi.loadModels('assets/models/') (this is successful)faceapi.allFaces(input, this.minConfidence).then(.. (where input is the id to a image element. This fails with below error).core.js:1449 ERROR Error: Uncaught (in promise): Error: Tensor is disposed.
Error: Tensor is disposed.
at t.throwIfDisposed (face-api.min.js:1)
at t.asType (face-api.min.js:1)
at t.toFloat (face-api.min.js:1)
at face-api.min.js:1
at Array.map ()
at face-api.min.js:1
at t.tidy (face-api.min.js:1)
at rc (face-api.min.js:1)
at face-api.min.js:1
at t.tidy (face-api.min.js:1)
at t.throwIfDisposed (face-api.min.js:1)
at t.asType (face-api.min.js:1)
at t.toFloat (face-api.min.js:1)
at face-api.min.js:1
at Array.map ()
at face-api.min.js:1
at t.tidy (face-api.min.js:1)
at rc (face-api.min.js:1)
at face-api.min.js:1
at t.tidy (face-api.min.js:1)
at c (polyfills.js:3)
at c (polyfills.js:3)
at polyfills.js:3
at t.invokeTask (polyfills.js:3)
at Object.onInvokeTask (core.js:4751)
at t.invokeTask (polyfills.js:3)
at r.runTask (polyfills.js:3)
at o (polyfills.js:3)
at e.invokeTask (polyfills.js:3)
at i.isUsingGlobalCallback.invoke (polyfills.js:3)
Did I forget to do sth? Sorry, not familiar with how tensors work so maybe its a stupid question.
Thanks
There is a known bug with tensorflow.js on Safari that keeps it from performing accurately (on mobile and Desktop). The good news is it was just recently fixed tensorflow/tfjs-core#978 The changes are merged into master but not released as a new version yet.
Here's what the difference looks like in practice. Chrome:

Safari:

I am trying to use the detected faces from face-api.js for the recognition of face-recognition.js but they don't use the same dimensions.
Face-api faces can be for example: 67x94 px
Face-recognition always expects a face of: 150x150 px
Is it possible to scale up the detection box (in face-api) to 150x150 px and how? Or should I take another approach?
The readme and repo don't mention license info.
Hello,
At first, the library and your tutorial are amazing. I am currently implementing a real time face recognition from webcam with nodeJS and face-api and there was an error comes up. It happens few minutes after the streaming appeared or sometimes right after the webcam stream appeared. While it's working, it detect and recognize face quite good, but it would stop detecting and recognizing after some times (the webcam stream still works).
Below is the error message taken from console window from Chrome 68 after it stop detecting or recognizing.
Uncaught (in promise) Error: Error in slice4D: begin[1] + size[1] (519) would overflow input.shape[1] (480) tf-core.esm.js:17
at assert (tf-core.esm.js:17)
at assertParamsValid (tf-core.esm.js:17)
at e.slice (tf-core.esm.js:17)
at tf-core.esm.js:17
at e.tidy (tf-core.esm.js:17)
at n.value (tf-core.esm.js:17)
at extractFaceTensors.ts:43
at Array.map ()
at extractFaceTensors.ts:42
at e.tidy (tf-core.esm.js:17)
Then I tried to run your examples directly and same thing keeps happening.
(519)
number here changed each time error appeared, it seemed to depends on the duration of time it can run.
Whenever I reload the page, it repeats the error after some another duration of time.
Am I doing wrong somewhere? (noob in JS)
Thank you.
Hey Vincent,
Can you enlighten me on how you converted the weights provided in https://github.com/yeephycho/tensorflow-face-detection to tfjs. I tried this but hit unsupported ops issue.
tensorflowjs_converter --input_format=tf_frozen_model --output_node_names='concat,concat_1' frozen_inference_graph_face.pb output
Unsupported Ops in the model
Where, TopKV2, Assert, NonMaxSuppression
Hi, Getting this error on loading the models.
I would love any advice in the right direction :)
I have detection running well and I don't need face recognition, but I'm looking for a way to determine if this is still the same person being detected as per previous frames, or is this now a completely different person.
Essentially I want to increase a variable every time a new person looks at the camera.
Following #75, I have succeeded in downloading the models.
But for some reason when on my android device using faceapi.locateFaces returns an empty array.
Though it works flawlessly on my browser.
Any pointers on what I should check ?
I noticed that the weight files are missing since the model weights have been quantized,
Does this mean that we now should use the shards if we want to load the weights as a Float32Arrays?
How would the following code then work?
// using fetch
const res = await fetch('/models/face_detection_model.weights')
const weights = new Float32Array(await res.arrayBuffer())
net.load(weights)
// using axios
const res = await axios.get('/models/face_detection_model.weights', { responseType: 'arraybuffer' })
const weights = new Float32Array(res.data)
net.load(weights)
Hi, we've been messing around with face-api and especially MTCNN face detection and 5 face landmarks detection. I think you guys did a great job on the lib overall 😄
However we were trying to get it work faster and more precisely. So far we've been able to get 7fps on a webcam stream.
Below we recorded some gifs to visualize.


The questions I have regarding these are:
What do you think could help us improve the amount of recognitions per second (the thing I called fps before) ?
As you can see on the GIFs the recognitions are quite unstable even when the person is not moving, do you think there is some way that we could improve stability of the algorithm ?
Hope I made it clear 😉
Hi there! Great work on this plugin!
Has anybody managed to run this in a webworker?
I checked the Face Detection Video but it doesn't seem to work, there is an error message in the console panel, please see attached screenshot:
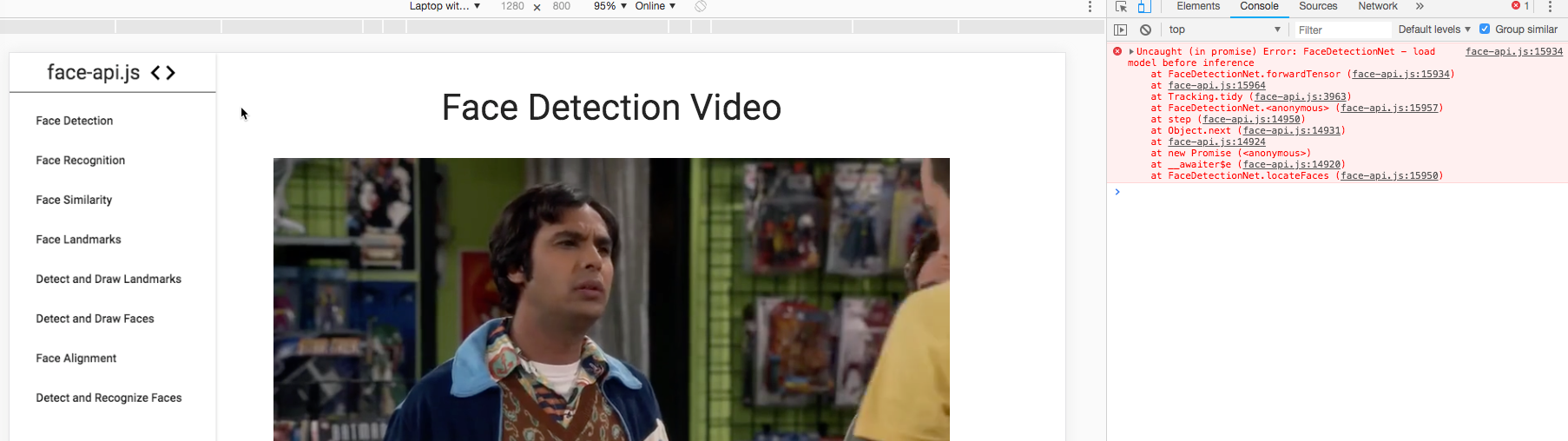
Thanks,
I was looking at the weight file sizes, they seem the same size like from original repos. Would be nice if the size could be reduced with quantization
I've tried the recent and last version of the face-api.js and get the same error with both.
Uncaught (in promise) TypeError: det.getBox is not a function
at face-api.js:1438
at Array.forEach ()
at Object.drawDetection (face-api.js:1437)
at getFace (facetest.php:41)
(anonymous) @ face-api.js:1438
drawDetection @ face-api.js:1437
getFace @ facetest.php:41
async function (async)
getFace @ facetest.php:23
(anonymous) @ facetest.php:20
j @ jquery-3.2.1.min.js:2
k @ jquery-3.2.1.min.js:2
setTimeout (async)
(anonymous) @ jquery-3.2.1.min.js:2
i @ jquery-3.2.1.min.js:2
fireWith @ jquery-3.2.1.min.js:2
fire @ jquery-3.2.1.min.js:2
i @ jquery-3.2.1.min.js:2
fireWith @ jquery-3.2.1.min.js:2
ready @ jquery-3.2.1.min.js:2
S @ jquery-3.2.1.min.js:3
Any help would be appreciated.

What I'm doing wrong? I just change the example to landmark model and it´s apparently not working correctly. I'm running it on Windows/Firefox and Windows/Chrome.
Hello,
in the beginning, I would like to say that this library is beautiful, and I'm really impressed by how good it works. I mean how precise.
I have an issue with the speed of face and landmark detection. I feel that with this quality of precision it's hard to make it faster, but I'm really interested in slightly better speed of detecting.
I'm using this library with the stream from my camera, and I get very low results (sth around 1 FPS in face detection)
So Is there any known factor or something that I could change which will increase the speed of face detecting? I'm aware that the precision probably will decrease but I don't care much about this.
This is my code for detecting face landmarks using camera stream:
That's my code for drawing landmarks on camera stream
<html>
<head>
<script src="face-api.js"></script>
<script src="commons.js"></script>
<link rel="stylesheet" href="styles.css">
<link rel="stylesheet" href="https://cdnjs.cloudflare.com/ajax/libs/materialize/0.100.2/css/materialize.css">
<script type="text/javascript" src="https://code.jquery.com/jquery-2.1.1.min.js"></script>
<script src="https://cdnjs.cloudflare.com/ajax/libs/materialize/0.100.2/js/materialize.min.js"></script>
</head>
<body>
<video id="video" autoplay width="480" height="360"></video>
<canvas id="overlay" width="480" height="360"></canvas>
<script>
const video = document.getElementById('video');
const canvas = document.getElementById('overlay')
canvas.width = 480;
canvas.height = 360;
navigator.mediaDevices.getUserMedia({audio: true, video: true}).then(
stream => {
video.srcObject = stream;
video.play();
video.muted = true;
run()
}
).catch(e => console.warn(e));
const minConfidence = 0.6
const maxResults = 1
async function run() {
await faceapi.loadFaceLandmarkModel('/');
await faceapi.loadFaceDetectionModel('/');
requestAnimationFrame(processFrame)
}
async function processFrame() {
const detections = await faceapi.locateFaces(video, minConfidence, maxResults)
const faceTensors = await faceapi.extractFaceTensors(video, detections)
let landmarksByFace = await Promise.all(faceTensors.map(t => faceapi.detectLandmarks(t)))
faceTensors.forEach(t => t.dispose())
if(landmarksByFace.length > 0){
landmarksByFace = landmarksByFace.map((landmarks, i) => {
const box = detections[i].forSize(480, 360).getBox()
return landmarks.forSize(box.width, box.height).shift(box.x, box.y)
})
canvas.getContext('2d').clearRect(0, 0, canvas.width, canvas.height)
faceapi.drawLandmarks(canvas, landmarksByFace[0], {drawLines: true})
}
requestAnimationFrame(processFrame)
}
</script>
</body>
</html>
and this code is only for detecting face (1 FPS on chrome)
navigator.mediaDevices.getUserMedia({audio: true, video: true}).then(
stream => {
video.srcObject = stream;
video.play();
video.muted = true;
run()
}
).catch(e => console.warn(e));
const minConfidence = 0.6
const maxResults = 1
async function run() {
await faceapi.loadFaceLandmarkModel('/');
await faceapi.loadFaceDetectionModel('/');
requestAnimationFrame(processFrame)
}
async function processFrame() {
const detections = await faceapi.locateFaces(video, minConfidence, maxResults)
const detectionsForSize = detections.map(det => det.forSize(480, 360)
canvas.getContext('2d').clearRect(0, 0, canvas.width, canvas.height)
faceapi.drawDetection(canvas, detectionsForSize)
requestAnimationFrame(processFrame)
}
Allow smaller sizes of face image inputs then 150 x 150.
It would be great to port the dlib 5-point landmark detector to this framework.
https://github.com/davisking/dlib-models/blob/master/shape_predictor_5_face_landmarks.dat.bz2
Right now, to perform the entire recognition pipeline on a new photo, it requires:
Or around 73MB total, making it a bit unwieldy for most public-facing applications.
The dlib 5-point landmark net is only 5MB, and just as useful for alignment as the 68-point landmark net. This would bring the total from 73MB down to 49MB. In theory, it might be possible to use quantization too as described in #11 bringing the overall size closer to 12MB.
I am having problems using this with corodva/ionic

Since you are using fetch to load the models and the models are on the file system, I am getting the above error. Also tried to use axios like in the readme but can't get it to work.
Any pointers on what I should be doing?
Could you explained about how to build a models please?
Hi I am trying to display the list of detected and aligned face images in a scroll div in html5. I am able to detect and append into the div dynamically however the size of the resultant face images are all different. At which function do I change the width and height so let's say they will all be 160x160.
const input = await faceapi.toNetInput(videoEl)
const locations = await faceapi.locateFaces(input, minConfidence)
//const resized_locations = locations.map(det => det.forSize(160, 160))
const faceImages = await faceapi.extractFaces(input.inputs[0], locations)
// detect landmarks and get the aligned face image bounding boxes
const alignedFaceBoxes = await Promise.all(faceImages.map(
async (faceCanvas, i) => {
const faceLandmarks = await faceapi.detectLandmarks(faceCanvas)
return faceLandmarks.align(locations[i])
}
))
const alignedFaceImages = await faceapi.extractFaces(input.inputs[0], alignedFaceBoxes)
// free memory for input tensors
input.dispose()
//$('#facesContainer').empty()
faceImages.forEach(async (faceCanvas, i) => {
$('#facesContainer').append(alignedFaceImages[i])
percentage = percentage + 5;
})
These are the script i used for detect and append. I tried resizing the faceCanvas, or looping through #faceContainer and resize them, or mapping the alignedFaceImages to 160x160 size but all to no avail. Any assistance is much appreciated. Thank you!
Euclidean distance never goes down below 0.4. What is the ideal number of picture of one person to train the model. Can we implement svm or multiclass classification here ?
My issue is i would like to use this code as an external package with my other tfjs models.
Currently you can only have one tensorflowjs script instance any other that gets loaded after the first one breaks.
Align faces returned from face detector properly before passing them to the face recognition net.
Hi thank you a lot for your efforts, but i need some helps in the face recognition : my goal is to compare two face images for that i compute the descriptor o each image and the euclidean Distance the same thing in the examples when i enter the same person and the same image it gives me 'match' but when i enter for example different photographs of the same person the result is 'no match' i really need to compare different photographs of the same person
When I give npm start, it shows below error
npm ERR! missing script: start
Hi,
First of all thank you for your work, it's excellent and very simple to use.
I have a small problem, when I use the face recognition, the api doesn't seem to work with external image sources. I would like to work with a data base and I'm receiving this error message :
"Failed to execute 'texImage2D' on 'WebGL2RenderingContext': Tainted canvases may not be loaded."
Do you know how can I overcome this problem ?
Apply score filtering and non max suppression to all input images in the post processing layer. Currently only the first image of the input batch is returned.
I ported it to node.js to compare faces, but the operation was slow when extracting 128-dimensional feature vectors. I replaced the latest @ tensorflow/ tfjs and used require('@tensorflow/tfjs-node'), but it is not accelerated, it is still very slow, each method call below will wait 5-20 seconds, but in the browser can be faster, what can I do to speed it up?
return tidy(function() {
var batchTensor = input.toBatchTensor(150, true);
var normalized = normalize(batchTensor);
var out = convDown(normalized, params.conv32_down);
out = maxPool(out, 3, 2, 'valid');
out = residual(out, params.conv32_1);
out = residual(out, params.conv32_2);
out = residual(out, params.conv32_3);
out = residualDown(out, params.conv64_down);
out = residual(out, params.conv64_1);
out = residual(out, params.conv64_2);
out = residual(out, params.conv64_3);
out = residualDown(out, params.conv128_down);
out = residual(out, params.conv128_1);
out = residual(out, params.conv128_2);
out = residualDown(out, params.conv256_down);
out = residual(out, params.conv256_1);
out = residual(out, params.conv256_2);
out = residualDown(out, params.conv256_down_out);
var globalAvg = out.mean([1, 2]);
var fullyConnected = matMul(globalAvg, params.fc);
return fullyConnected;
});
Beautiful work with the Face API 🙌😍
I was thinking... would it be possible to extend the API to extract sentiment from the detected faces or it'll be beyond the scope of the project?
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.