Comments (21)
 lmcinnes
commented on April 28, 2024
8
lmcinnes
commented on April 28, 2024
8
Yes, if you check the 0.4dev branch you'll find an implementation. It isn't the fastest, but it should work.
from umap.
lmcinnes
commented on April 28, 2024
5
Thanks for highlighting this. It is good to see people exercising this code. I'll have to dig in and find out what is going on here. I can't promise a quick resolution, but it is definitely important to get this working.
from umap.
 danilsson
commented on April 28, 2024
4
danilsson
commented on April 28, 2024
4
Hi!
I would be interested in giving this a look. I would like to try to use this for anomaly detection using the standard transform -> inverse transform reconstruction error.
from umap.
lmcinnes
commented on April 28, 2024
1
Thanks @danielnilssonjj . Email me at [email protected] and I can try to sketch the process for you.
from umap.
 ahsanMah
commented on April 28, 2024
1
ahsanMah
commented on April 28, 2024
1
Hey guys! I seem to be getting an error when I try to run the inverse_transform on data where the sample size is less than the number of dimensions. Is this expected behavior?
Really appreciate all the great work btw! :)
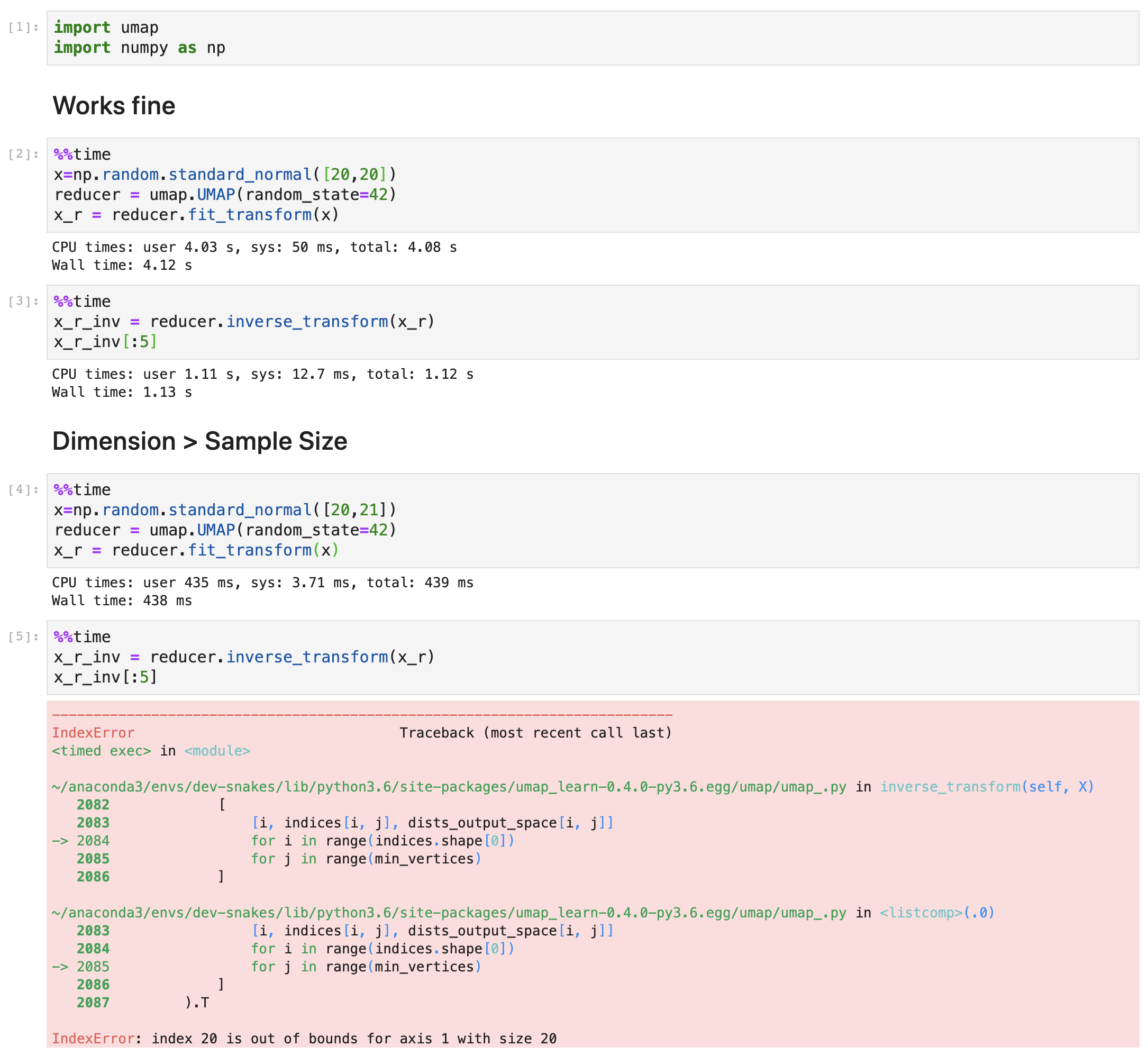
from umap.
lmcinnes
commented on April 28, 2024
1
You need the latest version, which is currently on in pre-release. That means it is not the default on PyPI, but can be accessed using the --pre flag. Thus you can do
pip install --pre umap-learn
to install that version.
from umap.
lmcinnes
commented on April 28, 2024
1
The current master branch has the problem resolved, but no release to PyPI has the fix yet. You can clone from github and install from that and it should work.
from umap.
 edebonneuil
commented on April 28, 2024
1
edebonneuil
commented on April 28, 2024
1
I continued along the idea of @paudom to use the inverse UMAP after UMAP in order to measure the reconstruction error, and to see to what "%var explained" this reconstruction error would correspond to if it were a PCA (https://stats.stackexchange.com/questions/184603/in-pca-what-is-the-connection-between-explained-variance-and-squared-error). This, to give an estimate of the extent to which one grasps "the whole picture" when looking at a 2D or 3D UMAP projection. For example, below 80% "var explained" one would need to be cautious when relying on a UMAP result.
As you indicate @lmcinnes, this reconstruction error embeds a margin due to the stochastic nature of the inverse UMAP. My question is: is there then a way to appreciate how to rectify the reconstruction error ? as a mean to appreciate how representative of the data a UMAP result is
PS: to partially answer, I investigated the behavior of the UMAP-inverseUMAP reconstruction error, starting with columns of uniform random numbers (a case of limited dimension reduction as there is no major pattern). It shed some light :
- as long as there are enough lines, eg 2000, the reconstruction error essentially depends on the number of initial columns in the data and the number of dimensions on which they are projected. Ok, intuitive.
- the reconstruction error with a UMAP3D is lower than with a UMAP2D, as expected (less dimension reduction). With more dimensions however, it is in-between instead of being further lower: at this stage, the programmed inverse UMAP appears to be not optimized for more than 3 dimensions (as the behavior unlikely comes from the UMAP program itself). Ok, no big deal but good to know for what follows
- in the very special case of no-dimension-reduction in 2D, the programmed inverse UMAP appears not to be optimized as this stage (or the UMAP, but unlikely): it leads to the same order of reconstruction error as starting with 3 columns instead of much less.. Ok, no big deal but good to know for what follows. Of note, the inverse UMAP3D does not have this inadequate behavior
- taking the above into account, for a low number of columns in the initial data, it seems adequate to offset the [mean-over-all-data, quadratic,] reconstruction error by approx -0.1 : it leads to a null reconstruction error in the no-dimension-reduction case, as one would have with a PCA. With these assumptions, with 2 to 4 columns in the initial data UMAP is more representative of complex (random) data than PCA. Intuitive, but nice to somewhat prove it. It also shows that a few random columns can be relatively well represented with one column less ("%var explained">80%) but not two : random data is hard to compress due to its lack of major pattern, OK, intuitive.
- however, offsetting the mean reconstruction error by -0.1 likely isn't enough when having UMAP digest more than 4 or 5 columns. It leads to the impression that UMAP is then much worse than PCA but it might simply correspond to badly correcting for the stochastic error of the inverse UMAP. I did not find a practical or theoretical basis to estimate how to rectify the reconstruction error with many dimensions. Views? Ideas?
from umap.
lmcinnes
commented on April 28, 2024
I have given the issue some thought, and have at least a theoretical back of the envelope sketch of how to do it. I don't have any immediate plans in code right now since there are a number of other items that currently have priority. If you would be interested in implementing it yourself please email me and I can try to outline what would be involved.
from umap.
 kaijfox
commented on April 28, 2024
kaijfox
commented on April 28, 2024
Wondering if there has been any progress on this @danielnilssonjj @lmcinnes ?
from umap.
 ncuxomun
commented on April 28, 2024
ncuxomun
commented on April 28, 2024
Thanks for highlighting this. It is good to see people exercising this code. I'll have to dig in and find out what is going on here. I can't promise a quick resolution, but it is definitely important to get this working.
Hi, I was wondering if the "inverse_transform" function is disabled.
I was going through the exercise but I can't complete due to the following error:
AttributeError: 'UMAP' object has no attribute 'inverse_transform'
from umap.
 paudom
commented on April 28, 2024
paudom
commented on April 28, 2024
Hi, I was wondering if the problem stated by @ahsanMah is solved. I'm trying to apply the "inverse_transform" but I'm encountering the same problem:
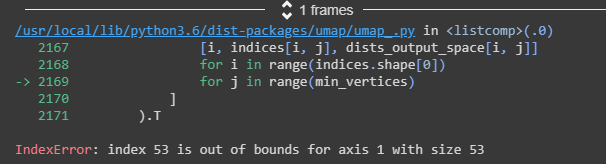
The data I'm working with has 53 samples of 7168 features (53,7168). Thanks to UMAP, I achieve
to project the data into 2D space. Now I want to create new samples on the 2D space back into the data space, so I'm creating an array of shape (# new samples, 2) but the error above appears when calling "inverse_transform". I think this is due to the same problem as @ahsanMah stated.
I'm using the version "umap-learn==0.4.0rc1".
Thanks in advance, I really appreciate all the work done!
from umap.
 vetrovav
commented on April 28, 2024
vetrovav
commented on April 28, 2024
Hi all,
It seems that I am experiencing the same issue as @ahsanMah and @paudom witn indexes. It would be so great to make it work for our research. Thanks so much in advance.
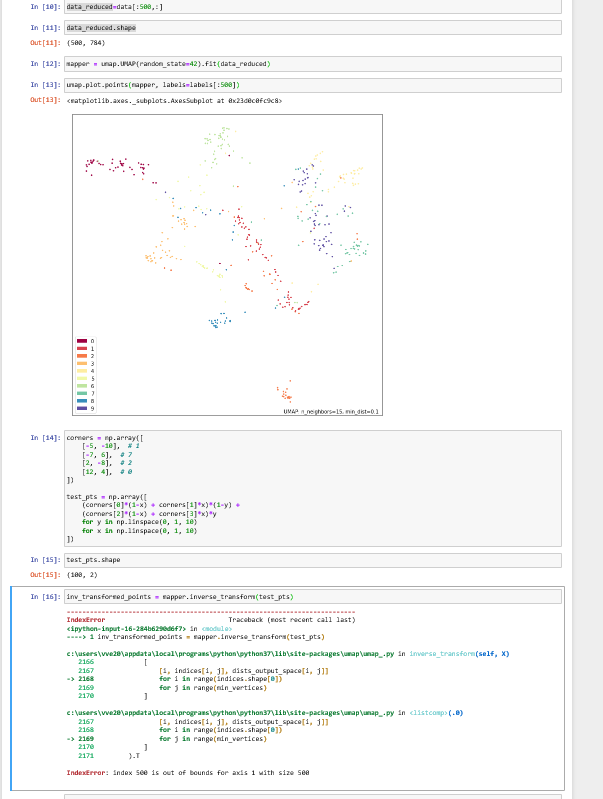
from umap.
paudom
commented on April 28, 2024
The current master branch has the problem resolved, but no release to PyPI has the fix yet. You can clone from github and install from that and it should work.
Hi, thanks for the quick response!
I have downloaded the current master branch and installed UMAP manually as the readme suggests (installing the dependencies and then using setup.py), but the error keeps appearing. Is there something that I'm missing?
Thanks in advance!
from umap.
vetrovav
commented on April 28, 2024
I guess the issue which occurs when the number of dimensions in the input data is larger the number of samples is due to the fact that the min_vertices variable is the number of dimensions in the original data. However, the second dimension of indices array is the number of samples in the original data. Therefore, this error happens when min_vertices is larger than indices.shape(-1). Would be more than happy to help but I am not sure what is needed to fix it.
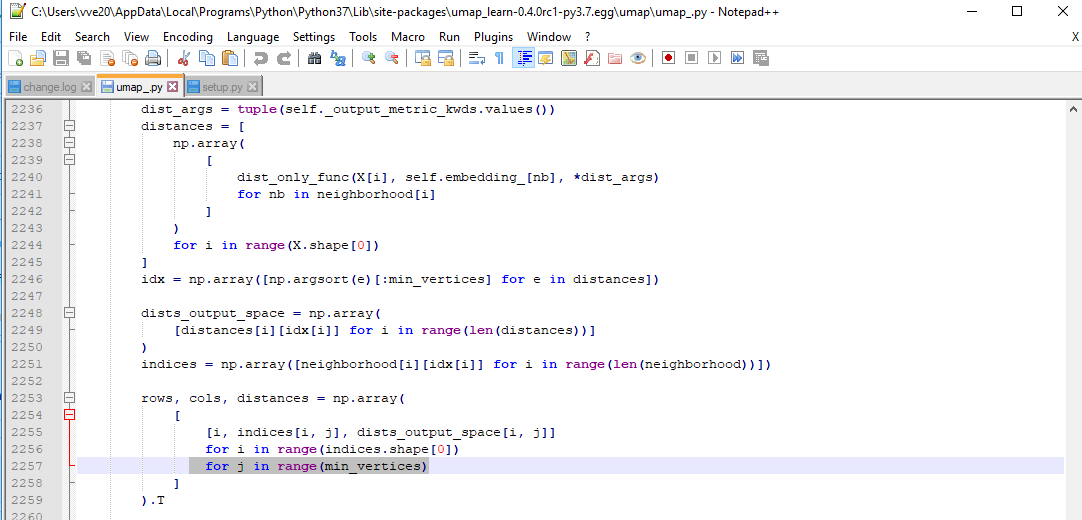
from umap.
lmcinnes
commented on April 28, 2024
Okay, I'll try to take a look and see if I can figure out the right fix here.
from umap.
lmcinnes
commented on April 28, 2024
I believe I have a potential fix. I haven't built a reproducer yet, so I can't test right now. If you would like to try with the current master and see if this resolves the issue I would appreciate it.
from umap.
paudom
commented on April 28, 2024
I believe I have a potential fix. I haven't built a reproducer yet, so I can't test right now. If you would like to try with the current master and see if this resolves the issue I would appreciate it.
Hi, trying the current master branch and installing it manually seems to work.
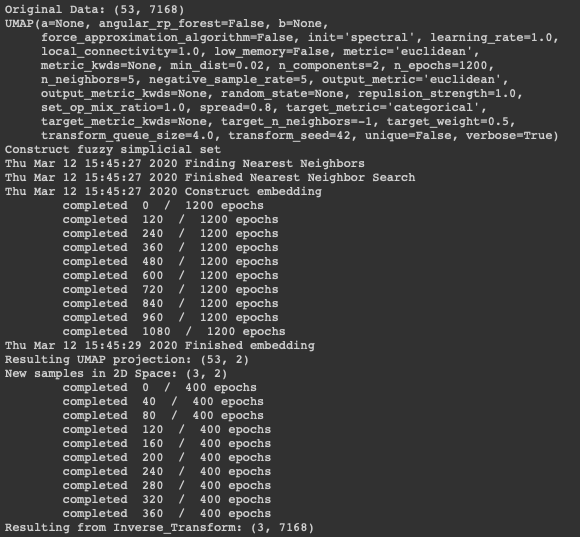
I have achieved to pass from data with shape (53,7168) to 2D space and then use 3 new samples in the 2D space back into the input space with the output shape of (3,7168).
Thanks a lot for looking into it, I appreciate it! Keep the amazing work! :)
from umap.
lmcinnes
commented on April 28, 2024
Thanks -- hopefully others can also verify that it is working for them now.
…On Thu, Mar 12, 2020 at 11:50 AM paudom ***@***.***> wrote:
I believe I have a potential fix. I haven't built a reproducer yet, so I
can't test right now. If you would like to try with the current master and
see if this resolves the issue I would appreciate it.
Hi, trying the current master branch and installing it manually seems to
work.
[image: Captura de pantalla 2020-03-12 a las 16 45 44]
<https://user-images.githubusercontent.com/37597137/76539450-168b2d00-6481-11ea-9bb5-27105fd9f217.png>
I have achieved to pass from data with shape (53,7168) to 2D space and
then use 3 new samples in the 2D space back into the input space with the
output shape of (3,7168).
Thanks a lot for looking into it, I appreciate it! Keep the amazing work!
:)
—
You are receiving this because you were mentioned.
Reply to this email directly, view it on GitHub
<#44 (comment)>, or
unsubscribe
<https://github.com/notifications/unsubscribe-auth/AC3IUBL2HFSKCQ3O7A252CLRHEADFANCNFSM4ERGGMRA>
.
from umap.
paudom
commented on April 28, 2024
Hi @lmcinnes, I would like to know:
If a data point is projected using UMAP into 2D space and then use the inverse_transform on that same point, should it return the same original datapoint? Or I'm interpreting wrong how the inverse transform should work?
I'm trying to recover datapoints once UMAP has been applied and I haven't been able to do it.
Thanks in advance.

from umap.
lmcinnes
commented on April 28, 2024
The inverse transform, like the transform, is stochastic in nature. That means that in practice you can't be guaranteed to get the same point back. Ideally you will get a point very close to it.
from umap.
Related Issues (20)
- Setting a random state still leads to stochastic results
- Implementation of sciki-learn's get_feature_names_out() API is not correct
- Is 'n_training_epochs' working for parameteric UMAP?
- visualize video data
- How to combine UMAP models in new data?
- Edit instructions to make them compatible with zsh
- Empty API page on UMAP API Guide? HOT 1
- PCA diagnostic error HOT 2
- Speed inquries HOT 2
- UMAP crashes when torch also imported before first run HOT 2
- Unable to pickle trained UMAP instance
- Reducing Model Size for UMAP on Large Datasets HOT 2
- umap.UMAP accepts strings as n_neighbors and min_dist, causing later failures
- Optimal dimensions
- RunUMAP Failing HOT 1
- Semi-deterministic output even though randon_state is set
- TypeError: Dispatcher._rebuild() got an unexpected keyword argument 'impl_kind' HOT 1
- illegal hardware instruction python HOT 2
- Transform new input with composite model HOT 1
- Inquiry on Utilizing UMAP for Text Similarity and Clustering HOT 4
Recommend Projects
-
 React
React
A declarative, efficient, and flexible JavaScript library for building user interfaces.
-
Vue.js
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
-
 Typescript
Typescript
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
-
TensorFlow
An Open Source Machine Learning Framework for Everyone
-
Django
The Web framework for perfectionists with deadlines.
-
 Laravel
Laravel
A PHP framework for web artisans
-
D3
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
-
Recommend Topics
-
javascript
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
-
web
Some thing interesting about web. New door for the world.
-
server
A server is a program made to process requests and deliver data to clients.
-
Machine learning
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
-
Visualization
Some thing interesting about visualization, use data art
-
Game
Some thing interesting about game, make everyone happy.
Recommend Org
-
Facebook
We are working to build community through open source technology. NB: members must have two-factor auth.
-
Microsoft
Open source projects and samples from Microsoft.
-
Google
Google ❤️ Open Source for everyone.
-
Alibaba
Alibaba Open Source for everyone
-
D3
Data-Driven Documents codes.
-
Tencent
China tencent open source team.
from umap.