Comments (21)
 lmcinnes
commented on April 28, 2024
4
lmcinnes
commented on April 28, 2024
4
Thanks, I have a clearer understanding now. The catch compared to PCA is that UMAP in general is stochastic -- refitting to the same data repeatedly will give different results (just like t-SNE). I believe it is more stable than t-SNE, but it will be different thus:
from sklearn import datasets
import umap
import numpy as np
iris = datasets.load_iris()
X = iris.data
y = iris.target
embedding1 = umap.UMAP().fit_transform(X)
embedding2 = umap.UMAP().fit_transform(X)
np.testing.assert_array_almost_equal(embedding1, embedding2, decimal=14)
will return raise an error. This is ultimately baked into the algorithm, and can be remedied by setting a fixed seed, but that is just a matter of making the randomness consistent rather than eliminating the random component.
The current transform function operates the same way, since it is using the same fundamental UMAP building blocks to perform the transformation (it isn't a deterministic parameterised function) -- repeated application to the same (new or otherwise) data will produce a slightly different result each time. This could possibly be remedied by fixing random seeds, and I will certainly look into making that a possibility. My goal so far has been to provide a method that would allow one to fit against some data (say the MNIST train set) and then perform a transformation on new data (say the MNIST test set) and have it work reasonably efficiently and embed the new data with respect to the prior learned embedding. This much I believe works, and I've tested it on MNIST, Fashion-MNIST and a few other datasets and it seems to place new data well.
I will have to look into setting seeds for the transform so that one can fix it, however, to get more consistent results.
from umap.
lmcinnes
commented on April 28, 2024
3
No, you haven't missed anything. Right now UMAP is transductive -- it creates a single transform of all the data at once and you would need to redo the embedding for the combined old and new data. This is similar to, say, t-SNE.
On the other hand I am currently working on implementing a transform function that would do this. It's still experimental, and so isn't in the mainline codebase yet. Right now I am working on the necessary refactoring to make it easy to implement what I have sketched-out/hacked-together in some notebooks. Eventually it will appear in the 0.3dev branch.
You can also look at issue #40 which discusses some of these topics. An alternative approach is to train a neural network to learn the non-linear transformation as a parameterised function and then use the NN to transform new points. I am not much of neural network person, but other have apparently had some success with those approaches.
from umap.
lmcinnes
commented on April 28, 2024
2
You are welcome to try it. It is still in somewhat experimental state (and will be even when 0.3 comes out). That is to say, the basic theory is all there, and the implementation should work, but it hasn't been well tested against a wide range of datasets and problems yet, and there may be some fine tuning to be done in both theory an implementation in the future. I would certainly welcome your experiments and comments if you are willing to take the trouble to try it out.
from umap.
lmcinnes
commented on April 28, 2024
2
So the first part is expected to be true in that, for example, using PCA fit + transform will give a different result than fitting on the whole dataset -- that's sort of how this has to work if one expects to keep the initial results fixed; calling transform is essentially trying to embed the data twice in this case. The stochastic nature of things is what makes it "unstable".
The second issue is because the transform itself is stochastic just like the fit. In general results should be close, but I believe one would have to fix a seed to fix the transform, and I don't believe the sklearn API allows for that (a seed on a transform operation). I would welcome suggestions on what the right approach is under such circumstances.
from umap.
lmcinnes
commented on April 28, 2024
2
Fit for PCA learns a deterministic transform function, but the principal eigenvectors for the data that was fit may be different from the data you wish to transform (or the combination of the fit and new data).
The catch with UMAP is that the fitting is stochastic rather than deterministic, and as a result having a similar transform function results in it also being stochastic.
from umap.
lmcinnes
commented on April 28, 2024
2
I believe we may be talking at cross purposes here, which is probably my fault. My understanding was that the goal for a transform function was to be able to something like the following:
from sklearn import datasets
from sklearn.decomposition import PCA
import numpy as np
iris = datasets.load_iris()
X = iris.data
y = iris.target
# Quick and dirty split, but imagine a test/train split
data_to_fit = X[:100]
data_to_transform = X[100:]
pca = PCA(n_components=2)
pca_model = pca1.fit(data_to_fit)
fit_embedding = pca.components_
new_embedding = pca_model.transform(data_to_transform)
If you simply want the embedding produced by the initial fit you can access it as the embedding_ attribute of the model, just like the t-SNE model in sklearn. Am I understanding correctly that this is what you want?
Edit: Just to be clear -- thank you for being patient with me and clarifying the issue; it is greatly appreciated, and I'm sorry if I am slow to understand.
from umap.
lmcinnes
commented on April 28, 2024
2
I don't have an explicit timeline. The core code refactoring and new features are done, but I really want to have a much more comprehensive test suite and get some documentation in place. Hopefully some time in late June or early July.
The transform method just lets you add new points to an existing embedding. For MNIST, for example, I can add the 10000 test digits to a model trained on the 60000 train digits in around 20 seconds. That's not stunningly fast, but it should be respectable.
The supervised dimension reduction let's you use labels to inform your embedding. This means, for example, that you could embed fashion-MNIST and have each clothing item cluster separately while still maintaining the internal structure of the clusters and the relative positioning among clusters (to some extent). See the example embedding below:
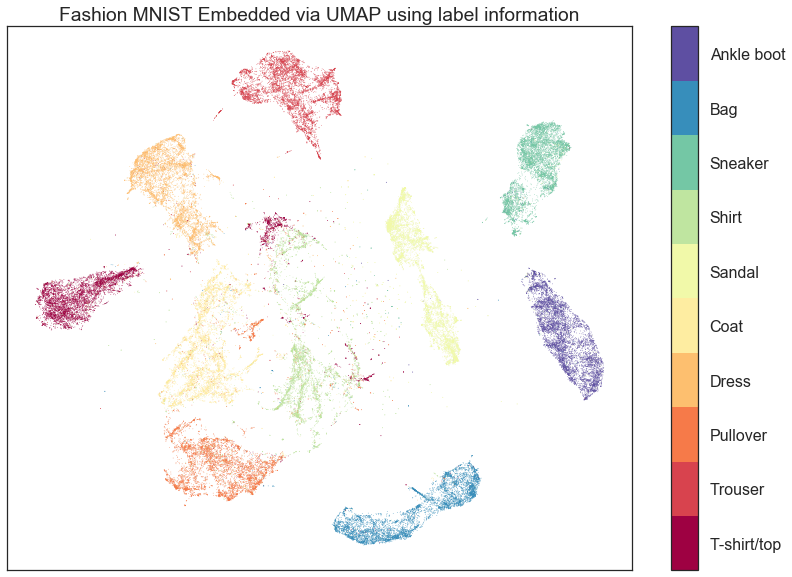
from umap.
 alexander-rakhlin
commented on April 28, 2024
1
alexander-rakhlin
commented on April 28, 2024
1
What I noticed so far is that embedding of the same data via fit + transform produces different result than fit_transform. In the following data is 1207x768 array, and embedding != embedding2, not even close. Furthermore, consecutive calls model.transform(data) give different results every time.
model = umap.UMAP(n_neighbors=15, min_dist=1e-7, random_state=0, metric="euclidean").fit(data)
embedding = model.transform(data)
embedding2 = umap.UMAP(n_neighbors=15, min_dist=1e-7, random_state=0, metric="euclidean").fit_transform(data)
from umap.
alexander-rakhlin
commented on April 28, 2024
1
My ultimate goal is, just like the goal of topic starter, embedding of new data via previously learned transformation. Deterministic if possible. That is what you have shown.
Transformation of the same data was to confirm that PCA is deterministic. And yes, embedding_ attribute would be useful too, I overlooked it. Thank you.
from umap.
alexander-rakhlin
commented on April 28, 2024
1
@lmcinnes thank you for your work and response. I can confirm that transform produces reasonably consistent results. For instance, 1) I fit my data set using UMAP to 2D, then cluster and label it with DBSCAN to obtain ~22 classes. I use this labeling as ground truth. 2) Then I split data to train/test in proportion 9/1 and refit train, label it with DBSCAN (+ establish correspondence of this new labeling with ground truth using majority matching; this correspondence isn't exact of course). 3) Then I transform test set with model obtained on 2) and label it via KNN against fitted train clusters. Main result is accuracy of train and test labeling against "ground truth" obtained on 1) is very similar and quite high - 85-95%
from umap.
lmcinnes
commented on April 28, 2024
1
The 0.3dev branch is largely stable and should be good enough for general use at this point, with the obvious caveat that it is still in development and there may be a few quirks hiding that may result in something breaking unexpectedly in less standard use cases. The transform function should now be consistent in the transformation (via a fixed transform seed which you can pick on instantiation if you wish). I've been testing it lately in combination with the supervised dimension reduction for metric learning and it seems to be performing pretty decently in that case.
from umap.
 LavoriniV
commented on April 28, 2024
LavoriniV
commented on April 28, 2024
Thank you, I did not saw that discussion. I'll give a try!
from umap.
alexander-rakhlin
commented on April 28, 2024
@lmcinnes thank you for your work.
I suppose transform has been already implemented in 0.3dev branch. Can we try it?
from umap.
alexander-rakhlin
commented on April 28, 2024
Why does not fit learn deterministic transformation?
In the PCA case, I don't see a reason why it can not be deterministic.
from umap.
alexander-rakhlin
commented on April 28, 2024
I mean, after PCA learned the principal eigenvectors from the training data, its transformation should not depend on new data to transform.
from umap.
lmcinnes
commented on April 28, 2024
My understanding, and perhaps I am wrong here, is that the transform function is supposed to take new data and project it into the space that was fit, so, for example, in PCA the transform function projects new previously unseen data onto the principal eigenvectors, generating an embedding for new data. My goal was to produce something similar for UMAP. If what you need is a transform function on the already fit data to return the previous fit then I can add a check to see if we match the original data and simply return the existing fit. Perhaps I am misunderstanding something here though?
from umap.
alexander-rakhlin
commented on April 28, 2024
My understanding is that the transform function does not change previously learned transformation, and transformation is deterministic function. I am not certain in regard to UMAP, but the PCA is:
from sklearn import datasets
from sklearn.decomposition import PCA
import numpy as np
iris = datasets.load_iris()
X = iris.data
y = iris.target
pca1 = PCA(n_components=2)
pca_model = pca1.fit(X)
X_r1 = pca_model.transform(X)
pca2 = PCA(n_components=2)
X_r2 = pca2.fit_transform(X)
np.testing.assert_array_almost_equal(X_r1, X_r2, decimal=14)
from umap.
 yueqiw
commented on April 28, 2024
yueqiw
commented on April 28, 2024
Hi, I'm wondering what's the status of the transform function? I found that umap gives me very intuitive embeddings and I'm hoping to be able to embed new data points onto existing embeddings.
I saw that there have been new commits in the 0.3dev branch, but I'm not sure if it's stable or whether I should wait for a while before using it? Thanks!
from umap.
yueqiw
commented on April 28, 2024
Thanks! I'll give it a try. Do you have a timeline on when the next stable version will be released?
in combination with the supervised dimension reduction for metric learning
Could you provide more details on this? And how does the transform function compare to the supervised dimension reduction in terms of performance? Thanks!
from umap.
yueqiw
commented on April 28, 2024
Thanks! If I understand correctly, standard UMAP embeddings of fashion-MNIST have clusters that are partially overlapping with each other (like the image on the homepage), but supervised dimension reduction separates the clusters much better. This is very interesting. Will this be part of the next release?
from umap.
lmcinnes
commented on April 28, 2024
Yes, that will be in the next release.
from umap.
Related Issues (20)
- Implementation of sciki-learn's get_feature_names_out() API is not correct
- Is 'n_training_epochs' working for parameteric UMAP?
- visualize video data
- How to combine UMAP models in new data?
- Edit instructions to make them compatible with zsh
- Empty API page on UMAP API Guide? HOT 1
- PCA diagnostic error HOT 2
- Speed inquries HOT 2
- UMAP crashes when torch also imported before first run HOT 2
- Unable to pickle trained UMAP instance
- Reducing Model Size for UMAP on Large Datasets HOT 2
- umap.UMAP accepts strings as n_neighbors and min_dist, causing later failures
- Optimal dimensions
- RunUMAP Failing HOT 1
- Semi-deterministic output even though randon_state is set
- TypeError: Dispatcher._rebuild() got an unexpected keyword argument 'impl_kind' HOT 1
- illegal hardware instruction python HOT 2
- Transform new input with composite model HOT 1
- Inquiry on Utilizing UMAP for Text Similarity and Clustering HOT 4
- No clear documentation of default parameter values HOT 1
Recommend Projects
-
 React
React
A declarative, efficient, and flexible JavaScript library for building user interfaces.
-
Vue.js
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
-
 Typescript
Typescript
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
-
TensorFlow
An Open Source Machine Learning Framework for Everyone
-
Django
The Web framework for perfectionists with deadlines.
-
 Laravel
Laravel
A PHP framework for web artisans
-
D3
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
-
Recommend Topics
-
javascript
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
-
web
Some thing interesting about web. New door for the world.
-
server
A server is a program made to process requests and deliver data to clients.
-
Machine learning
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
-
Visualization
Some thing interesting about visualization, use data art
-
Game
Some thing interesting about game, make everyone happy.
Recommend Org
-
Facebook
We are working to build community through open source technology. NB: members must have two-factor auth.
-
Microsoft
Open source projects and samples from Microsoft.
-
Google
Google ❤️ Open Source for everyone.
-
Alibaba
Alibaba Open Source for everyone
-
D3
Data-Driven Documents codes.
-
Tencent
China tencent open source team.
from umap.