Comments (26)
 rafaelvalle
commented on June 4, 2024
3
rafaelvalle
commented on June 4, 2024
3
As we describe it in the paper, we first train Flowtron with one step of flow and then add the second step of flow. We also start with a pre-trained text embedding. In your case you could use your Tacotron 2 text encoder.
from flowtron.
rafaelvalle
commented on June 4, 2024
3
Assuming your dataset is non-english.
If you have a Tacotron 2 trained on your data, use it to warm-start your Flowtron and follow steps 2 and 3.
If you don't, you can start directly from step 2.
from flowtron.
rafaelvalle
commented on June 4, 2024
2
It's probably because the token vocabulary is different.
Try warm-starting with the text and token embeddings from our pre-trained LJS Flowtron model.
from flowtron.
 taalua
commented on June 4, 2024
2
taalua
commented on June 4, 2024
2
Hi, @rafaelvalle
Would you consider to release the scripts to train model from scratch instead of warmstarting from pre-trained model? Thanks
from flowtron.
 machineko
commented on June 4, 2024
2
machineko
commented on June 4, 2024
2
@rafaelvalle pre-trained models without speaker embedding on my own dataset. (~2/3h per speaker 6 speakers)
from flowtron.
rafaelvalle
commented on June 4, 2024
1
With the current config:
- Set train_config.warmstart_checkpoint_path to provide a path for a pre-trained model providing token and text embeddings.
- Set train_config.include_layers to provide the name of the layers to be included from your pre-trained model. For example, if you're warm-starting from our Tacotron 2 pre-trained model without speaker embeddings, you would set this to ["encoder", "embedding"]
- We find it easier to progressively add steps of Flow, similar to Progressive Growing of GANs. Hence, we first train a Flowtron with model_config.n_flows=k=1 until it learns to attend.
- Train a model with k+1 steps of flow by warmstarting from the model with k steps of flow. Provide its path and set train_config.include_layers to None.
from flowtron.
rafaelvalle
commented on June 4, 2024
1
@CookiePPP Early stop in WaveGlow is not just for helping with gradient propagation but also to add information at multiple time scales.
In Flowtron, when training multiple steps of flow at the same time we hit an optimization issue that prevents the model from learning to attend to the text at any step of flow. We circumvent this optimization issue by progressively training each step of flow.
from flowtron.
rafaelvalle
commented on June 4, 2024
Training from scratch or using the pre-trained model?
from flowtron.
 BlazJurisic
commented on June 4, 2024
BlazJurisic
commented on June 4, 2024
From scratch
from flowtron.
 daun-io
commented on June 4, 2024
daun-io
commented on June 4, 2024
Oh I've forgot to use pre-trained text embedding at my first trial for training from scratch. Thanks :)
from flowtron.
taalua
commented on June 4, 2024
Could you please give example how to train Flowtron from scratch (i.e., with one step of flow, then add the second step of flow)?
How to input the pre-trained text embedding when training from scratch?
from flowtron.
 CookiePPP
commented on June 4, 2024
CookiePPP
commented on June 4, 2024
@rafaelvalle
(offtopic) Would a similar trick work for extending WaveGlow as an alternative to using early outputs?
from flowtron.
taalua
commented on June 4, 2024
@rafaelvalle Thanks.
I tried warm-starting from Tacotron 2 pre-trained model without speaker embeddings and got this error:
line 315, in forward
curr_x = x[b_ind:b_ind+1, :, :in_lens[b_ind]].clone()
RuntimeError: CUDA error: device-side assert triggered
config:
... 'checkpoint_path': '', 'ignore_layers': [], 'include_layers': ['encoder', 'embedding'], 'warmstart_checkpoint_path': 'models/tacotron2_statedict.pt', 'with_tensorboard': True, 'fp16_run': True}, 'data_config': {'training_files': 'filelists/ljs_audiopaths_text_sid_train_filelist.txt', 'validation_files': 'filelists/ljs_audiopaths_text_sid_val_filelist.txt', ...
from flowtron.
taalua
commented on June 4, 2024
@rafaelvalle Thanks.
any suggestions for training from scratch without using pre-trained Flowtron models?
from flowtron.
rafaelvalle
commented on June 4, 2024
Initialize the weights of the token embedding and text embedding (Encoder) to similar mean and standard deviation to our pre-trained model.
from flowtron.
 ajinkyakulkarni14
commented on June 4, 2024
ajinkyakulkarni14
commented on June 4, 2024
Thank you for above information to train from the scratch. I want to train Flowtron on French multispeaker speech synthesis corpus. @rafaelvalle Do I need to follow any more additional steps than mentioned previously ? (I have dataloaders, dataset implemented for French speech synthesis data for Mellotron).
from flowtron.
rafaelvalle
commented on June 4, 2024
If you properly trained Mellotron on your data, I suggest warmstarting from your pre-trained Mellotron model, specially re-using your token, text and speaker embeddings.
from flowtron.
 markovka17
commented on June 4, 2024
markovka17
commented on June 4, 2024
Hi, @rafaelvalle!
I would like to train the Flowtron on LJS from "scratch". As you advised above, I started with one step of flow and use text and token embeddings from your pre-trained LJS Flowtron model.
How many epochs does it take to train a model? At least for the attention to be a diagonal, not a flat line.
from flowtron.
rafaelvalle
commented on June 4, 2024
@marka17 on a DGX with 8 V100s it takes about 12 hours for it to learn attention.
from flowtron.
rafaelvalle
commented on June 4, 2024
We're working on changes that makes training from scratch quicker and more efficient.
from flowtron.
markovka17
commented on June 4, 2024
@marka17 on a DGX with 8 V100s it takes about 12 hours for it to learn attention.
I tried to train the model on 8 V100 and 4 V100 and didn't get the expected result :(
I trained both models for ~12 hours with n_flows=1 and with pretrained embeddings and text encoder.
Also, a convergence of train/valid loss with 4 V100 is better. Below is the loss of validation:
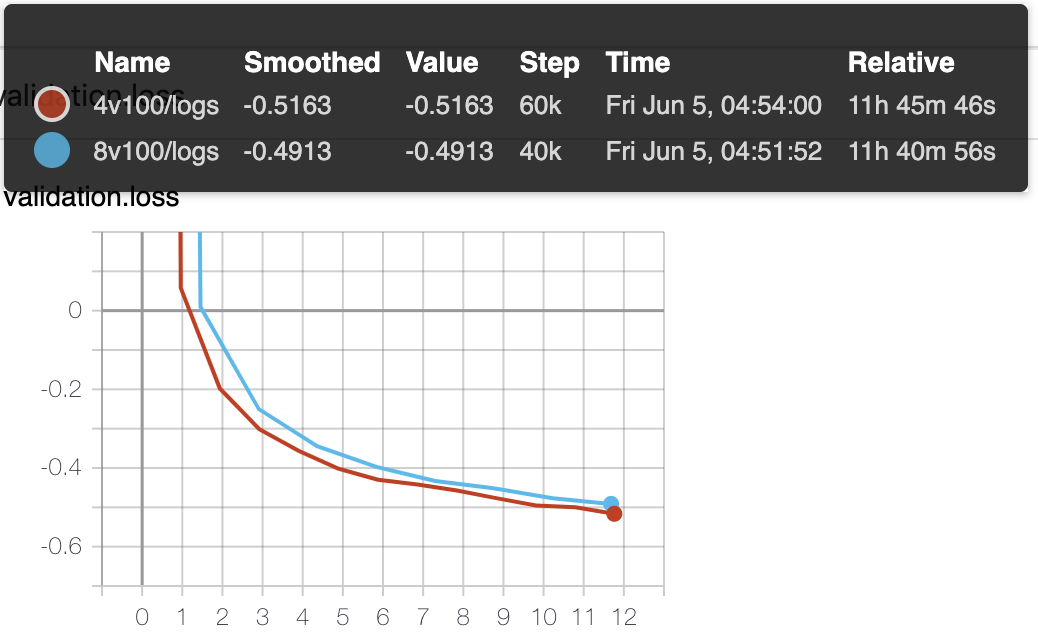
And attention is a flat line:
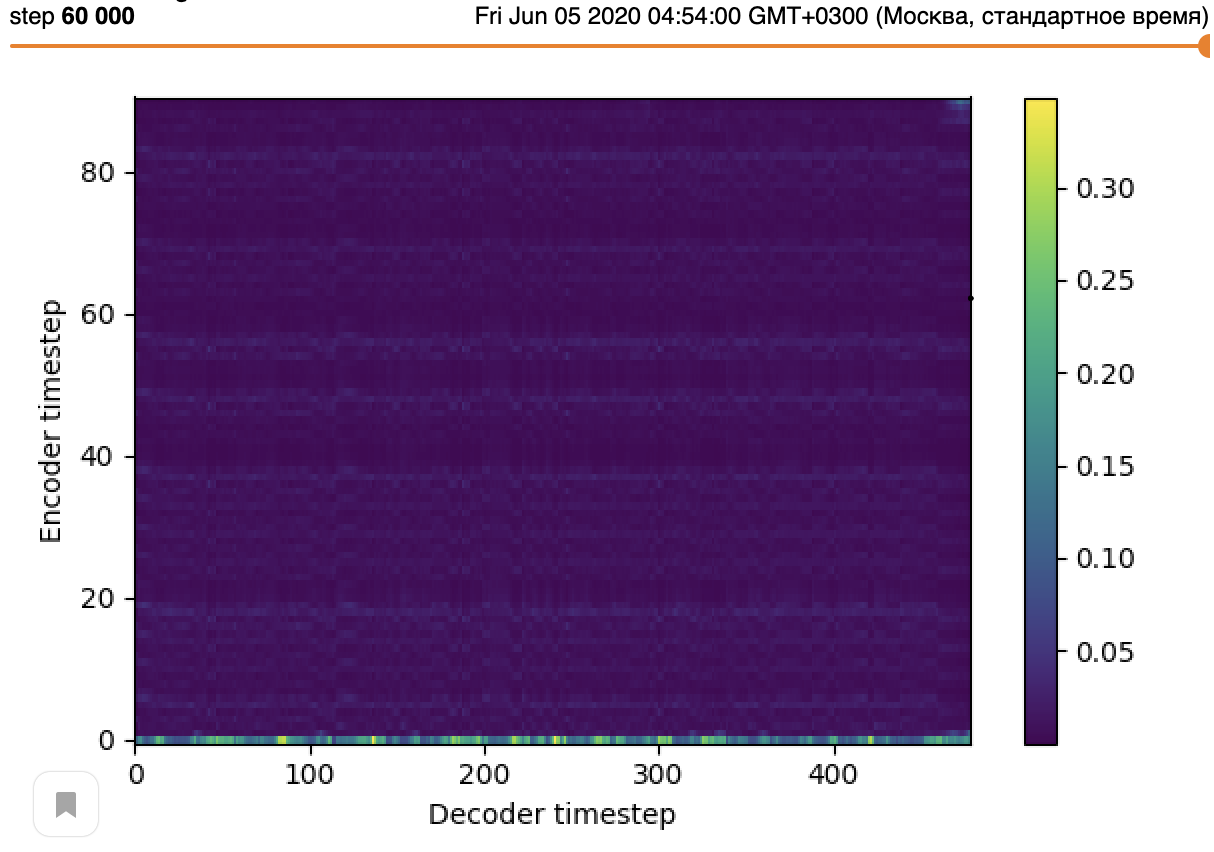
So, what could be wrong?
from flowtron.
machineko
commented on June 4, 2024
@marka17 Try lower learning rate I've had similar looking results on my dataset using 2e-4 (this model seems to be VERY depend on the LR in 9e-5 attention looks good in 2e-4 it was flat line)
from flowtron.
rafaelvalle
commented on June 4, 2024
@machineko did you train from scratch or did you use the pre-trained text and token embedding?
from flowtron.
rafaelvalle
commented on June 4, 2024
Closing due to inactivity. Please re-open if needed.
from flowtron.
 zjFFFFFF
commented on June 4, 2024
zjFFFFFF
commented on June 4, 2024
With the current config:
- Set train_config.warmstart_checkpoint_path to provide a path for a pre-trained model providing token and text embeddings.
- Set train_config.include_layers to provide the name of the layers to be included from your pre-trained model. For example, if you're warm-starting from our Tacotron 2 pre-trained model without speaker embeddings, you would set this to ["encoder", "embedding"]
- We find it easier to progressively add steps of Flow, similar to Progressive Growing of GANs. Hence, we first train a Flowtron with model_config.n_flows=k=1 until it learns to attend.
- Train a model with k+1 steps of flow by warmstarting from the model with k steps of flow. Provide its path and set train_config.include_layers to None.
Sorry, I am a beginner. I would like to ask:
Do you mean that if I want to use non-english dataset
- using Tacotron2 to get a pretrained model.(This model provides token and text embeddings)
2.Using the checkpoint(1) above to train flowtron with n_flow = 1
3.Using the checkpoint(2) above to train flowtron with n_flow = 2
I need to train three times.
from flowtron.
 letrongan
commented on June 4, 2024
letrongan
commented on June 4, 2024
With the current config:
- Set train_config.warmstart_checkpoint_path to provide a path for a pre-trained model providing token and text embeddings.
- Set train_config.include_layers to provide the name of the layers to be included from your pre-trained model. For example, if you're warm-starting from our Tacotron 2 pre-trained model without speaker embeddings, you would set this to ["encoder", "embedding"]
- We find it easier to progressively add steps of Flow, similar to Progressive Growing of GANs. Hence, we first train a Flowtron with model_config.n_flows=k=1 until it learns to attend.
- Train a model with k+1 steps of flow by warmstarting from the model with k steps of flow. Provide its path and set train_config.include_layers to None.
Sorry, I am a beginner. I would like to ask:
Do you mean that if I want to use non-english dataset
- using Tacotron2 to get a pretrained model.(This model provides token and text embeddings)
2.Using the checkpoint(1) above to train flowtron with n_flow = 1
3.Using the checkpoint(2) above to train flowtron with n_flow = 2
I need to train three times.
Sorry. I am a beginner, too. What is the checkpoint_1 and checkpoint 2 ?
I can understand your approach as follows:
Step 1: Train the tacotron2 model and use it as a starter for Flowtron
Step 2: Train the model with n_flows = 1. Warmstart model is tacotron2 model
Step 3: Train the model with n_flows = 2. Pretrain model is the model after step 2. Don't use warmstart model anymore
Please check and confirm according to my understanding
Thanks a lot
from flowtron.
Related Issues (20)
- Inference starting repeat itself. HOT 5
- List index out of range
- Request for clarification on some of the readme scripts. HOT 8
- Custom model resumed from pre-trained model has a stuttering problem.
- How would one keep the model loaded for immediate synthesis? HOT 17
- Inference on pre-trained model (flowtron_ljs) speaking nonsense. HOT 4
- Inference Demo "Hitting gate limit" HOT 2
- .
- inference speed on CPU
- Accelerated inference with TensorRT HOT 2
- Single word input leads to ValueError: Expected more than 1 spatial element when training, got input size torch.Size([1, 512, 1]) HOT 1
- Error on loading training model "_pickle.UnpicklingError: invalid load key, '<'"
- Custom trained model and dataset problem
- Index out of range for custom dataset.
- value error while training custom dataset
- TypeError: guvectorize() missing 1 required positional argument 'signature' HOT 1
- _pickle.UnpicklingError: invalid load key, '<'. in inference.py in colab HOT 3
- What's the filelist used to train LibriTTS2k pretrained embedding?
- Unable to train on custom data with multiple speakers HOT 6
- Which torch version to use?
Recommend Projects
-
 React
React
A declarative, efficient, and flexible JavaScript library for building user interfaces.
-
Vue.js
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
-
 Typescript
Typescript
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
-
TensorFlow
An Open Source Machine Learning Framework for Everyone
-
Django
The Web framework for perfectionists with deadlines.
-
 Laravel
Laravel
A PHP framework for web artisans
-
D3
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
-
Recommend Topics
-
javascript
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
-
web
Some thing interesting about web. New door for the world.
-
server
A server is a program made to process requests and deliver data to clients.
-
Machine learning
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
-
Visualization
Some thing interesting about visualization, use data art
-
Game
Some thing interesting about game, make everyone happy.
Recommend Org
-
Facebook
We are working to build community through open source technology. NB: members must have two-factor auth.
-
Microsoft
Open source projects and samples from Microsoft.
-
Google
Google ❤️ Open Source for everyone.
-
Alibaba
Alibaba Open Source for everyone
-
D3
Data-Driven Documents codes.
-
Tencent
China tencent open source team.
from flowtron.