Comments (18)
 shivammalviya712
commented on June 9, 2024
1
shivammalviya712
commented on June 9, 2024
1
"""All the files are integrated here."""
from settings import Settings
from model import model, load_model, train_model
from scipy.io import wavfile
from pydub import AudioSegment
from pydub.playback import play
import numpy as np
import matplotlib.pyplot as plt
def spectrogram(sound, fs):
"""It generates the spectrogram
of the sound given.
# Arguments
sound: ndarray
The recorded sound.
fs: Integer
Sampling rate
# Returns
x: ndarray
The spectrogram of the sound.
"""
plt.subplot(2, 1, 1)
nfft = 200
noverlap = 120
nchannels = sound.ndim
if nchannels == 1:
x, freqs, bins, im = plt.specgram(
x=sound, NFFT=nfft, Fs=fs, noverlap=noverlap)
elif nchannels == 2:
x, freqs, bins, im = plt.specgram(
x=sound[:, 0], NFFT=nfft, Fs=fs, noverlap=noverlap)
else:
print('The audio has more than 2 channels')
return x
def play_chime(y):
"""It checks if wake word is
predicted or not. If the wake
word is present then it produces
a chime sound.
# Arguments
y: ndarray
Prediction of our model for
Realtime.x as the input.
"""
threshold = 0.7
counter = 75
chime = AudioSegment.from_wav(
'./dataset/activate/chime/chime.wav')
for i in range(y.shape[1]):
if y[0, i, 0] > threshold and counter >= 75:
play(chime)
counter = 0
counter += 1
print('Everything is successfully imported')
settings = Settings()
print('Settings is done')
model = load_model()
# Path to the file you want to load
filepath = './dataset/activate/train/train0.wav'
# Load the file in the form of ndarray
fs, audio = wavfile.read(filepath)
# audio (ndarray): Its spectrogram(x) is calculated here
x = spectrogram(audio, fs)
# Dimension of x is (101, 5511)
# Model accepts input of shape (1, 5511, 101)
x = np.expand_dims(x.T, axis = 0)
y = model.predict(x)
# Play chime sound if trigger word is present
play_chime(y)
# Plotting x (spectrogram) and y
plt.subplot(2, 1, 2)
plt.plot(y[0, :, 0]) # Since, y has a shape (1, 1375, 1)
plt.show()
print('Done')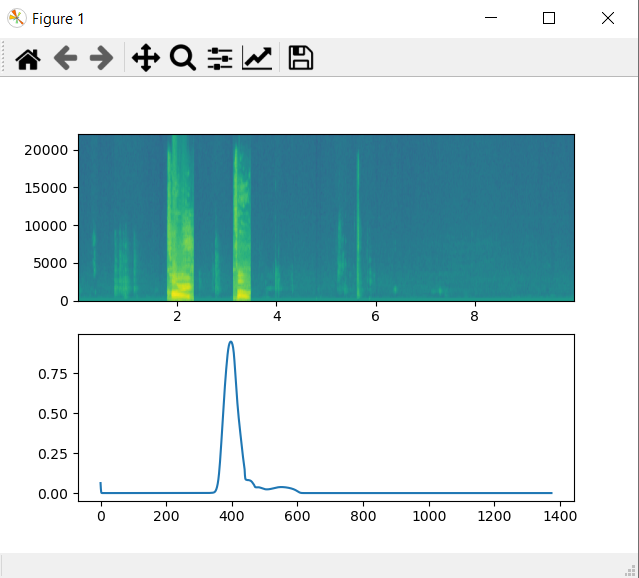
from trigger-word-detection.
 dimanshu
commented on June 9, 2024
1
dimanshu
commented on June 9, 2024
1
thank you so much @shivammalviya712 just one last thing
what should be properties of loaded file ,
sample rate =44100 and what else ?
from trigger-word-detection.
shivammalviya712
commented on June 9, 2024
1
Audio length should be 10 sec.
If you want to do for smaller length then you may try padding. And if you want to do it for larger length then try trimming.
from trigger-word-detection.
dimanshu
commented on June 9, 2024
1
okay then i have to check first the length of the audio if it is less then 10 sec then padding else trimming to make it 10 sec
from trigger-word-detection.
shivammalviya712
commented on June 9, 2024
1
You can input larger files in chunks, for example; if file length is 15-sec then first run the code for 0-10 sec and then for 5-15sec. At last, combine the two outputs. This way you can check for trigger word in the whole length, which can't be done in case of trimming.
from trigger-word-detection.
shivammalviya712
commented on June 9, 2024
Do you want to the predictions from the model?
I didn't understand your question, can you please elaborate.
from trigger-word-detection.
shivammalviya712
commented on June 9, 2024
load .mp3 or .wav file?
If you want to put the audio files in the positives folder then it should be in the .wav format.
If you have audio files in .mp3 or .mpeg format then there is code in the code folder (mpeg_to_wav) to convert those audio files from .mpeg or .mp3 to .wav format. So first .mp3 or .mpeg files will have to be converted into .wav format and then the model can be trained on it.
from trigger-word-detection.
dimanshu
commented on June 9, 2024
i have a file (wav file duration =15mins ) and i want to test this wav file .
i want to know there is trigger word in my wav file or not i don't want to go with real time.did you get my question ?
from trigger-word-detection.
dimanshu
commented on June 9, 2024
can i do this
import soundfile as sf
` def refresh_audio(self):
"""It adds spectrogram of new audio
to the x.
""" sf.read('existing_file.wav')
# self.new_audio = sd.rec(frames=int(self.Tnew * self.fs))
self.new_audio = sf.read('existing_file.wav')
sd.wait()
self.new_x = self.spectrogram(self.new_audio).T
self.x[0, :self.Tx-len(self.new_x)] = self.x[0, len(self.new_x):]
self.x[0, self.Tx-len(self.new_x):] = self.new_x
`
how to load a wav file in your model to test it
from trigger-word-detection.
shivammalviya712
commented on June 9, 2024
i have a file (wav file duration =15mins ) and i want to test this wav file .
i want to know there is trigger word in my wav file or not i don't want to go with real time.did you get my question ?
Yes, that can be done with some minor changes. As this model can take input for 10 sec, so your 15-sec input can be given as input to the model in parts. It just requires little modifications. And then the output from the model can be plotted to see whether the trigger word is there or not. Also, we can play a chime sound whenever the probability of the trigger word seems to be more than the threshold. It will be much easier if you don't want to do it in the real-time.
from trigger-word-detection.
dimanshu
commented on June 9, 2024
what are the changes ?
from trigger-word-detection.
shivammalviya712
commented on June 9, 2024
what are the changes ?
I will do it, and post it here.
from trigger-word-detection.
dimanshu
commented on June 9, 2024
thanks brother waiting for your reply
from trigger-word-detection.
shivammalviya712
commented on June 9, 2024
Replace the code in the main.py with the above code.
I have implemented it for a 10-sec file. I leave it on you to do it for 15 sec. Just give it a try. If any problem arises then send me that 15-sec file and I will implement for that.
from trigger-word-detection.
shivammalviya712
commented on June 9, 2024
Your welcome.
Sample rate should be 44100
And for above the code, the audio should be of length 10 sec.
from trigger-word-detection.
dimanshu
commented on June 9, 2024
i did change my sample rate to 44100 now i m testing with 4sec wav file having sample rate 44100.
but it is giving me error:-
File "sample.py", line 63, in
y = model.predict(x)
File "/home/dimanshu/venv/lib/python3.6/site-packages/keras/engine/training.py", line 1441, in predict
x, _, _ = self._standardize_user_data(x)
File "/home/dimanshu/venv/lib/python3.6/site-packages/keras/engine/training.py", line 579, in _standardize_user_data
exception_prefix='input')
File "/home/dimanshu/venv/lib/python3.6/site-packages/keras/engine/training_utils.py", line 145, in standardize_input_data
str(data_shape))
ValueError: Error when checking input: expected input_3 to have shape (5511, 101) but got array with shape (1503, 101)
from trigger-word-detection.
dimanshu
commented on June 9, 2024
so this model will run for 10sec audio right ? can i change it for 30 sec or 1min ?
from trigger-word-detection.
shivammalviya712
commented on June 9, 2024
Yes, you can do that.
For that following changes are required:
- Input shape of X_input in model architecture should be changed accordingly.
X_input = Input(shape = (settings.Tx, settings.n_freq))- The output of the convolution layer should be of the same length as of the final output you want. So settings.Ty should be changed along with the kernel_size and strides of the convolution layer.
X = Conv1D(filters=196, kernel_size=15, strides=4)(X_input)-
Data will have to be created again, as the length of the labels will be changed.
-
After all this, the model should be trained again from scratch. Alternatively, if kernel_size and strides, for the convolution, are the same and your trigger word is also 'activate' then you may use the parameters of the saved models.
from trigger-word-detection.
Related Issues (6)
Recommend Projects
-
 React
React
A declarative, efficient, and flexible JavaScript library for building user interfaces.
-
Vue.js
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
-
 Typescript
Typescript
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
-
TensorFlow
An Open Source Machine Learning Framework for Everyone
-
Django
The Web framework for perfectionists with deadlines.
-
 Laravel
Laravel
A PHP framework for web artisans
-
D3
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
-
Recommend Topics
-
javascript
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
-
web
Some thing interesting about web. New door for the world.
-
server
A server is a program made to process requests and deliver data to clients.
-
Machine learning
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
-
Visualization
Some thing interesting about visualization, use data art
-
Game
Some thing interesting about game, make everyone happy.
Recommend Org
-
Facebook
We are working to build community through open source technology. NB: members must have two-factor auth.
-
Microsoft
Open source projects and samples from Microsoft.
-
Google
Google ❤️ Open Source for everyone.
-
Alibaba
Alibaba Open Source for everyone
-
D3
Data-Driven Documents codes.
-
Tencent
China tencent open source team.
from trigger-word-detection.