18888628835 / blog Goto Github PK
View Code? Open in Web Editor NEW我的心得笔记,文档已迁移至👇🏻👇🏻👇🏻 。website:https://qiuyanxi.com/
我的心得笔记,文档已迁移至👇🏻👇🏻👇🏻 。website:https://qiuyanxi.com/

![github-actions[bot] avatar](https://avatars.githubusercontent.com/in/15368?v=4 "github-actions[bot]")











































































































当JS执行到一段可执行代码时(全局代码、函数代码、eval)就会创建执行上下文,执行上下文内有三个重要属性:
不同执行上下文中的变量对象是不同的,下面介绍一下全局变量对象和函数变量对象。
MDN的解释:
一个全局对象是一个永远存在于 global scope 的 object。window 对象是浏览器中的全局对象。
任何全局变量或者全局函数都可以通过 window 的属性来访问。
在顶层 JavaScript 代码中,可以用关键字 this 引用全局对象。
举例
console.log(this) //window
var a=1 //挂到window上的属性
window.a //1在顶层作用域(全局上下文)上的变量对象就是全局对象
在函数上下文中,我们用活动对象(activation object, AO)来表示变量对象
活动对象和变量对象其实是一个东西,只是变量对象是规范上的或者说是引擎实现上的,不可在 JavaScript 环境中访问,只有到当进入一个执行上下文中,这个执行上下文的变量对象才会被激活,所以才叫 activation object ,而只有被激活的变量对象,他上面的各种属性才能被访问。
活动对象是在进入函数上下文时刻被创建的,它通过函数的 arguments 属性初始化。arguments 属性值是 Arguments 对象。
执行上下文的代码会分成两个阶段进行处理:分析和执行,我们也可以叫做:
1、进入执行上下文
2、代码执行
当进入执行上下文阶段,这时候还没有执行代码
变量对象包括
1、函数的所有形参(如果是函数上下文)
2、函数声明
3、变量声明
举个例子
function foo(a) {
var b = 2;
function c() {}
var d = function() {};
b = 3;
}
foo(1)在调用函数foo并进入函数执行上下文后,这时候的 AO 是:
AO = {
arguments: {
0: 1,
length: 1
},
a: 1,
b: undefined,
c: reference to function c(){},
d: undefined
}在代码执行阶段,会顺序执行代码,根据代码,修改变量对象的值
还是上面的例子,当代码执行完后,这时候的 AO 是:
AO = {
arguments: {
0: 1,
length: 1
},
a: 1,
b: 3,
c: reference to function c(){},
d: reference to FunctionExpression "d"
}到这里变量对象的创建过程就介绍完了,让我们简洁的总结我们上述所说:
全局上下文的变量对象初始化是全局对象
函数上下文的变量对象初始化只包括 Arguments 对象
在进入执行上下文时会给变量对象添加形参、函数声明、变量声明等初始的属性值
在代码执行阶段,会再次修改变量对象的属性值
第一题
function foo() {
console.log(a);
a = 1;
}
foo(); // ???
function bar() {
a = 1;
console.log(a);
}
bar(); // ???第一个foo函数会报错:Uncaught ReferenceError: a is not defined
第二个bar函数会打印:1
原因是第一个函数进入执行上下文后,没有var声明,此时它的上下文是这样的
AO = {
arguments: {
length: 0
},
}当函数执行时,找不到a声明,所以就会报错
第二个函数进入执行上下文时,依然没有a的声明,但是函数里的代码执行时,能够从全局作用域里找到a,所以就打出1
第二题
console.log(foo);//???
function foo(){
console.log("foo");
}
var foo = 1;
console.log(foo);//???第一个log会打印出函数体,而不是undefined,可见var声明提升被函数声明提升取代了
第二个log会打印出1
原因是会优先处理函数声明,再处理变量声明。如果变量名称跟已经声明的形参或函数相同,则变量声明不会干扰已经存在的这类属性,我们结合过程来分析:
在进入执行上下文时,此时变量对象是这样的
{
foo:undefined
}代码执行时是这样的,优先处理函数声明,此时变量对象变成:
{
foo:reference to function foo(){}
}
当执行到第二个log时,foo又被另外赋值了,此时变量对象变成:
{
foo:1
}
第三题
var foo = 1;
console.log(foo);//??
function foo(){
console.log("foo");
};打印的结果为:1
我们来分析一下其执行过程,在进入上下文时,变量对象变成
{
foo:undefined
}在执行代码时,变量对象先变成函数再变成1
{
foo:reference to function foo(){}
}
// foo=1
{
foo:1
}
console.log(foo) // 所以结果就是1函数 memory(函数记忆)可以理解为当执行某个函数时,先把它的返回值记下来,当下次函数执行,如果传递的参数相同时,则直接返回记忆的返回值,而不是重新执行一遍函数。
function add(a,b){
return a+b
}
// 假设 memorize 可以实现让传入的函数记忆
const memorizedAdd = memorize(add);
console.log(memorizedAdd(1, 2))//第一次时返回3,并将结果记下来
console.log(memorizedAdd(1, 2)) //第二次时不进行 a+b 操作,而是直接将第一次的结果3记下来要实现这样的memorize函数非常简单,还是熟悉的配方,使用闭包。
function memorize(func) {
let cache = {}
return function(...rest) {
let key = rest.join('-')
if (cache[key]) {
console.log('第二次执行到缓存')
return cache[key]
} else {
console.log('第一次执行,做缓存处理')
cache[key] = func(...rest)
return cache[key]
}
}
}我们来检查一下
console.log(memorizedAdd(1, 2))
//"第一次执行,做缓存处理"
//3
console.log(memorizedAdd(1, 2))
//"第二次执行到缓存"
//3
函数memory更多的是一种编程技巧,其实概念非常简单,适用场景在于如果你需要进行大量的重复计算,那么可以采取函数memory的方式来缓存数据。
这里有一道关于 memory 函数的面试题
const memo = (fn) => {
请补全
}
const x2 = memo((x) => {
console.log('执行了一次')
return x * 2
})
// 第一次调用 x2(1)
console.log(x2(1)) // 打印出执行了,并且返回2
// 第二次调用 x2(1)
console.log(x2(1)) // 不打印执行,并且返回上次的结果2
// 第三次调用 x2(1)
console.log(x2(1)) // 不打印执行,并且返回上次的结果2思路整理:
1、看调用方式,可以得出memo调用后返回一个函数
2、采用闭包的形式来做记录即可,返回记录的结果即可
const memo = (fn) => {
//请补全
const cache = {}
return function(...rest) {
const key = rest
if (cache[key]) {
return cache[key]
} else {
return cache[key] = fn(...rest)
}
}
}结束~
enjoy!
如下代码
{
let a=10;
var b=20
}
a //Uncaught ReferenceError: a is not defined
b //20当被块级作用域包围时,可以看到let声明使得块级作用域外部无法访问a这个变量,但是var声明的b却不会有这样的问题。
说明var不受块级作用域的影响,而let声明只在块级作用域中有效。
这就使得在循环时,let比var更有优势,因为不会出现变量外泄问题。
for(let i=0;i<5;i++){
...
}
console.log(i) //Uncaught ReferenceError: i is not defined
for(var i=0;i<5;i++){
...
}
console.log(i) //5当for循环配合var声明时,由于不受块级作用域影响,全局只有一个作用域,i变量所在的作用域就是全局作用域,这就使得i变量会外泄。
当for循环配合let声明时,则会创建独立的块级作用域,与全局作用域不同,所以我们在外层无法获取到内部的i变量。
上面说到let声明配合循环会生成独立的作用域,下面有个更好的例子
for(var i=0;i<6;i++){
setTimeout(()=>{
console.log(i)
},0)
}
//6 6 6 6 6 6这个例子在《你不知道的JavaScript》中有提及,被我写到博客上多次。
由于这个循环只有一个全局作用域,所以当循环结束,异步代码执行时,只能获取到全局作用域上的i,这时候i已经变成了6,所以打出来就是6个6。
例子换成let就不一样了
for(let i=0;i<6;i++){
setTimeout(()=>{
console.log(i)
},0)
}
//0 1 2 3 4 5 这是由于每次循环都会生成一个作用域,当前循环中的i就存在于这个作用域中,所以实际上会生成6个不同的作用域,那么当异步代码执行时,会从对应的作用域读取i,所以结果就是0 1 2 3 4 5。
再来看一个例子:
var a = [];
for (var i = 0; i < 10; i++) {
a[i] = function () {
console.log(i);
};
}
a[6](); // 10由于只有一个作用域,所以i也只有一个。循环结束,i变成了10。
数组中的函数执行后console.log(i)中的i始终指向全局作用域下的i。所以最后的输出是10。
如果变成let声明,则会产生多个作用域,每个作用域下的i都是独立的,都是新生成的变量,当进行访问时,会访问函数生成时的那个作用域里的i,结果则是我们希望的。
var a = [];
for (let i = 0; i < 10; i++) {
a[i] = function () {
console.log(i);
};
}
a[6](); // 6有一点需要注意的是,for循环会生成一个父级作用域,它还有一个子级作用域。
for (let i = 0; i < 3; i++) {
let i = 'abc';
console.log(i);
}
// abc
// abc
// abc我们知道大括号{}会生成一个作用域,上面的例子中的let i=abc就是在大括号中生成的,它跟for循环作用域下产生的i又不同,它是在循环体内产生的单独的子作用域。
由于原来的js编译设计机制问题,导致var声明会被提升到代码顶部,所以我们在声明变量之前也可以访问变量。
console.log(a)//undefined
var a=1个中原理可以看这篇博客【你不知道的JavaScript】作用域是什么?
不过es6纠正了这个逻辑,使用let就不存在变量提升问题
console.log(a)//Uncaught ReferenceError: a is not defined
let a=10一定要先声明后访问,因为先访问时,变量a是不存在的,所以报了一个查找不到的错误。
只要块级作用域内存在let命令,那么就会牢牢地被绑定在这个区域,不受外部影响。
var a=123
function fn(){
console.log(a) //Uncaught ReferenceError: Cannot access 'a' before initialization
let a=888
}上面代码中,虽然全局作用域下有个a,但是引擎已经预先知道内部有个let声明的a了,所以不会往外部获取全局下的a,而是先把函数作用域内的a锁死。
ES6明确规定,如果区块中存在let和const命令,这个区块对这些命令声明的变量,从一开始就形成了封闭作用域。凡是在声明之前就使用这些变量,就会报错。
在代码块内,使用let命令声明变量之前,该变量都是不可用的。这在语法上,称为“暂时性死区”(temporal dead zone,简称 TDZ)。
暂时性死区的本质就是,只要一进入当前作用域,所要使用的变量就已经存在了,但是不可获取,只有等到声明变量的那一行代码出现,才可以获取和使用该变量。
有兴趣的同学还可以看看我写的这一篇JS薛定谔的变量提升
在同一作用域下,let不允许声明两次同名的变量。
{
let a=0
let a=0
}
//Uncaught SyntaxError: Identifier 'a' has already been declared不过var是可以的,新变量会覆盖老变量。
var a=0
var a=1
a //1因此,不能在函数内部重新声明参数。
function func(arg) {
let arg;
}
func() // 报错
function func(arg) {
{
let arg;
}
}
func() // 不报错顶层对象,在浏览器环境指的是window对象,在 Node 指的是global对象。ES5 之中,顶层对象的属性与全局变量是等价的。
全局下let声明跟var声明所在的作用域并不算同一层,var所在的全局作用域会指向window对象,所以我们可以通过window来访问var声明的全局变量,但是let却不能通过window对象访问。
var a=10
window.a //10
let b=99
window.b //undefined这是因为es6新设计了全局变量,纠正了原来全局变量会与window顶层对象挂钩的设计问题。
const声明跟let声明一模一样,唯一的区别就是const声明是一个常量,一旦定义,不能改变。
所以不能只声明不赋值
const a //Uncaught SyntaxError: Missing initializer in const declaration赋值后,值不可改变。
const a=10
a=100 //Uncaught TypeError: Assignment to constant variable.如果赋值给一个复杂对象,那么变量的值就是一个引用地址,只要不改变这个引用地址,还是可以修改复杂对象内部的属性的。
const a={name:'qiu'}
a.name='qiuyanxi'
a //{name:"qiuyanxi"}
a={name:"qiuyanxi"}//报错简单来说,它们是基于promises的语法糖,使异步代码更易于编写和阅读。通过使用它们,异步代码看起来更像是老式同步代码,因此它们非常值得学习。
async function hello() { return "Hello" };
hello();
//Promise {<fulfilled>: "Hello"}上面的代码增加async关键字后,这个函数会返回promise。这是异步的基础,可以说,现在的异步JS就是使用promise。
箭头函数写法
let hello=async ()=>{return 'hello'}现在我们可以使用.then方法啦
hello().then((mes)=>{console.log(mes)})await只在异步函数里面才起作用,它的主动作用是会暂停代码在该行上,直到promise完成,然后返回结果值,await后面应该放promise对象
我们可以造一个实际的例子
const p=new Promise((resolve,reject)=>{
setTimeout(resolve,3000,'doing')
})
const r=new Promise((resolve,reject)=>{
setTimeout(resolve,0,p)
})
const o=r.then((mes)=>{
return mes+'=>done'
})
o.then((mes)=>{console.log(mes)}).catch((error)=>{console.log(error)})
//doing => done上面代码中,r会拿到p的结果,然后链式调用下去。
我们可以使用async+await进行封装
function promise(ms, mes) {
return new Promise((resolve, reject) => {
setTimeout(resolve, ms, mes);
});
}
async function fn() {
const p = await promise(3000, "doing");
console.log(p); // doing
const r = await promise(0, p);
console.log(r); //doing
const o = await (r + "=>done");
console.log(o); //doing =>done
}
fn();可以看到上面的异步代码就跟同步代码的写法一样。
async和await要同时使用才会有异步的效果,单单使用async依然是同步代码,只是返回promise对象
在使用async/await关键字的时候,错误处理是关键,一般我们会这么写来捕捉错误
function ajax(){
return Promise.reject(1)
}
async function fn(){
try{
const result=await ajax()
console.log(result)
}catch(error){
console.log(error)
}
}
fn() 下面我们可以使用更好的方法
function ajax(){
return Promise.reject(1)
}
function ErrorHandler(error){
throw Error(error)
}
async function fn(){
const result=await ajax().then(null,(error)=>{ErrorHandler(error)})
console.log('result',result)
}
fn()这里要注意的就是ErrorHandler时不要用return,以免把结果返回给result,使用throw Error就可以抛出一个错误。那么后续的代码就不会执行了
function async2(){
console.log('async2')
}
async function fn(){
console.log('fn')
await async2() //同步的
console.log('我是异步?')
}
fn()
console.log('end')
//fn
//async2
//end
//我是异步?最后的console.log('我是什么步?')是后于await关键字的,说明它是异步的,如果我们想执行同步代码,最好都放在await的上面,因为有时候await会带给我们疑惑,会误以为没有写await关键字的代码是同步的。
也许你会怀疑是否第一行log也是异步的,下面这个代码可以告诉你答案,并非写了async关键字就代表这是异步函数。
let a=0
async function fn(){
console.log(a)
await Promise.resolve(333).then((r)=>{console.log(r)})
console.log('我是什么步?')
}
fn()
console.log(++a)
//结果
/*
0
1
333
"我是什么步?"
*/await天生是串行的,所谓串行,就是按照顺序执行。
function async2(delay){
return new Promise((resolve)=>{
setTimeout(()=>{
console.log('执行')
resolve()
},delay)
})
}
async function fn(){
await async2(5000)
await async2(2000)
await async2(1000)
}
fn()由于async跟setTimeout同时用没有效果,所以我使用上面的代码做实验,log台五秒钟后会分别打印,这说明默认就是按照顺序执行await的
如果想要并行,就可以使用Promise.all或者forEach方法
function fn(){
await Promise.all([async2(5000),async2(2000),async2(1000)])
}function async2(delay){
return new Promise((resolve)=>{
setTimeout(()=>{
console.log('执行')
resolve()
},delay)
})
}
function fn3(ms){
return function fn(){
async2(ms)
}
}
[fn3(5000),fn3(2000),fn3(1000)].forEach(async (v)=>{
await v()
})fetch就是使用promise版本的XMLHttpRequest
fetch('products.json').then(function(response) {
return response.json();
}).then(function(json) {
console.log(json)
}).catch(function(err) {
console.log('Fetch problem: ' + err.message);
});上面的代码的意思是通过fetch申请一个json数据,然后得到数据后将其json化,再打印出来。
转化成async和await方法
const promise=()=>{
try{
const j=await fetch('products.json')
const result=await j.json()
console.log(result)
}catch(error){
console.log(error)
}
}
promise()我们有一个名为 f 的“普通”函数。你会怎样调用 async 函数 wait() 并在 f 中使用其结果?
async function wait() {
await new Promise(resolve => setTimeout(resolve, 1000));
return 10;
}
function f() {
// ……这里你应该怎么写?
// 我们需要调用 async wait() 并等待以拿到结果 10
// 记住,我们不能使用 "await"
}其实解决方法很简单,由于 await 会返回一个 promise,所以直接在后面写 then 方法就可以拿到结果
function f() {
wait().then(result => alert(result));
}http缓存指的是: 当客户端向服务器请求资源时,会先抵达浏览器缓存,如果浏览器有“要请求资源”的副本,就可以直接从浏览器缓存中提取而不是从原始服务器中提取这个资源。
常见的http缓存只能缓存get请求响应的资源,http缓存都是从第二次请求开始的。第一次请求资源时,服务器返回资源,并在respone header头中回传资源的缓存参数;第二次请求时,浏览器判断这些请求参数,命中强缓存就直接200,否则就把请求参数加到request header头中传给服务器,看是否命中对比缓存,命中则返回304,否则服务器会返回新的资源。
缓存(cache)是优化系统性能的利器,由于链路长,网络延迟不可控,通过 HTTP 获取网络资源的成本比较高,所以,浏览器采用了缓存机制,将拿到的数据缓存起来,下次再请求的时候尽可能复用,这样的好处也很明显:响应速度快、节省网络带宽。
根据是否需要重新向服务器发起请求来分类,可分为强制缓存,对比缓存(又称协商缓存).
强缓存如果生效,那么不再和服务器发生交互.
对比缓存不管生不生效,都需要跟服务器发生交互.
也就是说强缓存可以不发请求,而对比缓存都得发请求.
跟强缓存相关的 API 有 Expires 和 Cache-Control 等,跟对比缓存相关的有 Etag 等,两种缓存可以同时存在,但是优先级是强缓存更高.
整个浏览器的缓存是这样的:

强缓存跟缓存数据的时间有效性有关,当浏览器没有缓存数据的时候,会发送第一次请求给服务器,服务器会在响应头中附带相关的缓存规则,响应头中有关的字段就是 Expires/Cache-Control.
服务器标记资源的有效时间的头字段是Cache-Control,常用的属性是max-age=xx,意思是最大持续时间多少秒。这个属性在 Cookie 那一节也有类似,只是头字段不一样。
Cookie 的 max-age 是在浏览器收到 Cookie 的时间开始算的,而 Cache-Control的 max-age 则是在服务器发送响应头字段开始计算的。

上面的例子就是设置了多少秒的缓存时间,这种方式比 Expires 靠谱得多.
还有其他的属性例如:

Expires 中会表明具体的到期时间,在时间内都可以进行缓存.但是这里会有一个 BUG,因为本地时间跟服务器时间不一定相同,而且本地时间可以修改,比如说我的本地时间往前调整了两年,那么浏览器的强缓存就会一直延续两年,所以这种方式已不太准确。
服务器发送了缓存指令,浏览器就会把缓存数据给保存到本地,等到需要用的时候,就会读取本地缓存中的服务器资源,提高网络效率。
不止浏览器可以发 Cache-Control 头,浏览器也可以发,这说明请求-应答双方都可以用Cache-Control 字段进行缓存控制。
当我们点击刷新按钮的时候,浏览器会在请求头里面加Cache-Control:max-age=0,表示的意思是我要最新的资源。这时候不会读取浏览器的缓存,而是向服务器发送请求。
下图是我在chrome浏览器中点击刷新时发送出去的请求头,自动带上了 Cache-Control:no-cache,跟 max-age效果是一样的。

浏览器的缓存什么时候生效呢?当我们点击前进、后退按钮的时候,会看到 from disk cache 的字样,这就触发了浏览器的缓存。
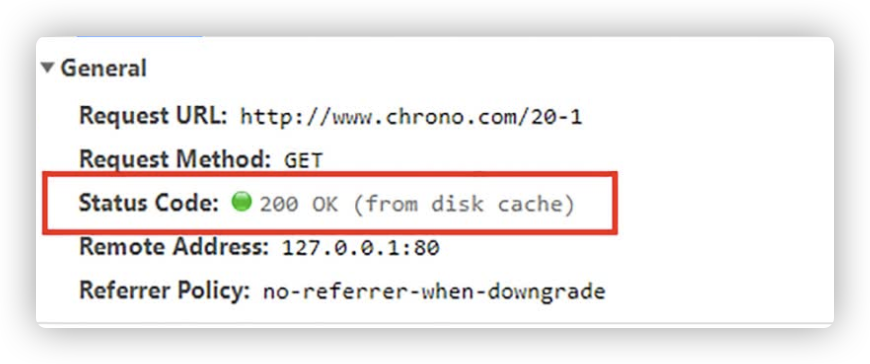
因为前进、后退等操作,浏览器只会添加最基本的请求头,不会增加Cache-Control之类的字段,所以会触发本地缓存。
使用 Cache-Control 做缓存控制只能刷新数据,不能很好地利用缓存数据,所以这里又有一个协商缓存的概念,也叫条件请求。
协商缓存做的就是 发给服务器做一下资源对比,看看是不是需要用到缓存的数据.这里的资源对比需要一个标识,这个标识也是第一次请求时服务器返回给浏览器保存在浏览器缓存库中的。
它的做法是利用两个连续的请求来组成验证动作,它是这样运作的:
第一步:先发一个 HEAD 请求,获取资源的修改时间或者其他元信息,然后与缓存数据比较,如果没有改就使用缓存数据,如果改了就走第二步。
第二步:发送 GET 请求,获取最新的版本。
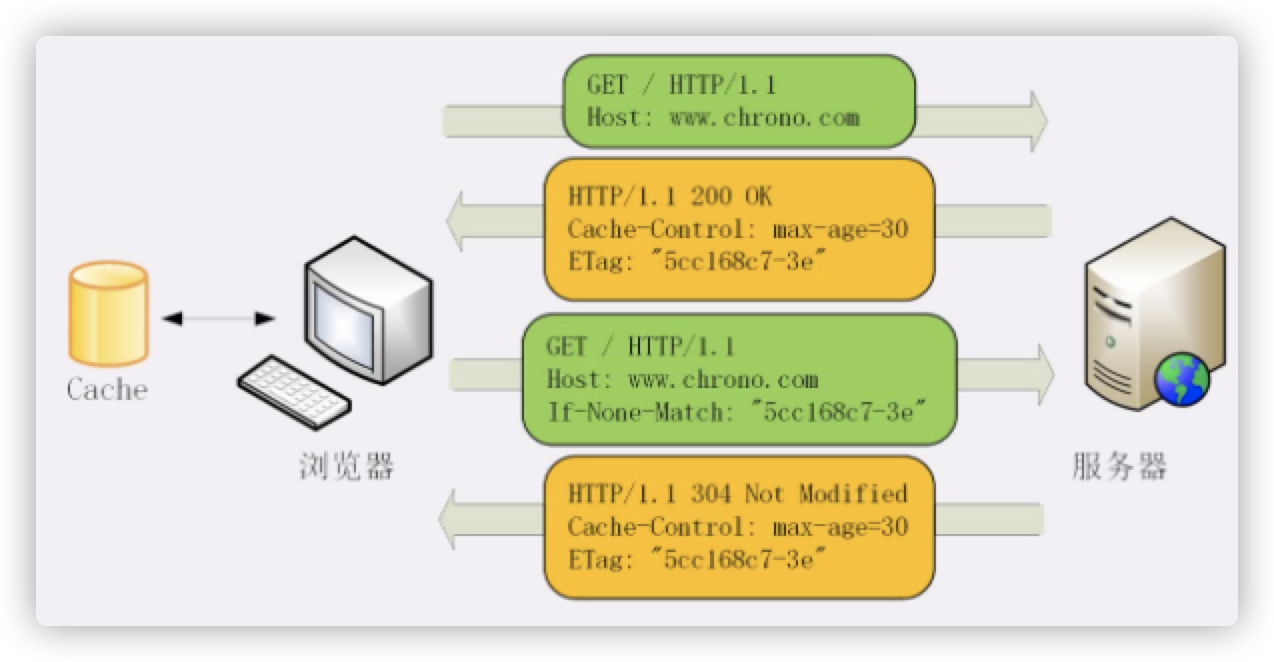
为此 HTTP 协议还定义了 If 开头的条件请求字段。服务器第一次响应时需要提供 Last-Modified 和 ETag,然后第二次请求时就可以带上缓存里的原值,验证资源是否是最新的。
如果资源没有变,服务器就回应一个304 Not Modified 的状态码,表示缓存依然有效,浏览器就可以更新一下有效期,然后使用缓存。由于服务器只返回响应头,不需要返回响应主体,所以数据量大大降低.
Last-modified 的意思是文件的最后修改时间。
修改时间需要用到两个字段 Last-Modified / If-Modified-Since
Last-Modified 是第一次请求时服务器发送给浏览器的响应头字段,上面记录服务器资源的最后修改时间.
If-Modified-Since 是浏览器第二次请求时发送的头字段,服务器通过这个头字段来对比一下自己的最后修改时间.
当服务器第一次发送 Last-modified 给浏览器时,浏览器就把资源缓存下来,然后下次请求时在HEAD请求的头部带上 if-Modified-Since:第一次的 Last-modified 的值给服务器,服务器经过对比,告诉浏览器我这里的文件都是那段时间以前的,于是浏览器就使用缓存加载资源。
如果时间一样,说明资源没有修改过,则响应 304 状态码,告诉浏览器用缓存数据.
如果时间不一样,说明资源有动过,那么就响应 200 状态码,并把报文主体也发过去。
但Last-Modified有一个问题:
比如说一个文件定期更新,即使文件内容没有变,Last-Modified会认为已经变化了,传给浏览器就会浪费带宽。为了解决这个问题,还有一种 ETag的方式。
ETag主要用来解决修改时间无法准确区分文件变化的问题,使用 ETag可以精确识别资源的变动情况,让浏览器可以有效利用缓存。
ETag 是资源唯一标识,是由服务器决定规则的标识,当第一次访问时,服务器就会在响应头中带着这个标识,这个标识长这样:

ETag 对应的常用条件请求字段是 If-None-Match。当再次访问服务器时,浏览器会在请求头中发送 If-None-Match 这个字段并附上之前的 Etag 标识,如果服务器发现有这个标识就会跟自己的唯一标识做对比.
如果一样,说明资源没改过,响应 304 状态码,告诉浏览器用缓存数据
如果不一样,说明资源改动过,响应 200 并且发最新的资源主体过去.
缓存是优化系统性能的重要手段,HTTP 传输时每个环节都可以使用到缓存。
HTTP 缓存就类似于浏览器跟服务器中间的一个缓存数据库,至于用不用这个缓存库就需要服务器来指定。
浏览器收到数据就会存入缓存,如果没过期就可以直接使用,过期就要去服务器验证是否依然可用
服务器可以指定两种方式:强制缓存和对比缓存.强制缓存比对比缓存优先级高
强制缓存不会发请求给服务器,它就是设定一个时间,这个时间可以分为 Expires 和 Cache-Control。
Expires 就是定一个具体的时间节点,但是有 bug,会因为服务器时间跟本地时间不同而有误差.
而 Cache-Control 常用的是 max-age,表示资源有效期,就是指定多少秒内用强制缓存.当强制缓存成功后返回 200.
对比缓存就是发送一段请求给服务器,请求信息可以有两种:修改时间和唯一标识.
两种都是需要跟服务器的信息进行对比,对比成功就返回 304,告诉浏览器用缓存数据,对比失败就返回 200,然后把用户需要请求的数据作为资源主体发回去.
验证资源的时间是否失效需要使用条件请求,常用if-Modified-Since和 If-None-Match,如果返回304就可以使用缓存里面的资源
验证资源是否被修改涉及到两个条件,ETag和Last-Modified,需要服务器预先在响应报文中设置,搭配条件请求使用
浏览器也可以发送 Cache-Control,比如刷新操作,就会发送 max-age=0来刷新数据
浏览器缓存的一个中心**就是:没有请求的请求,才是最快的请求
在JS中,所有的拷贝API都是浅拷贝,比如数组的拷贝,我们一般使用Array.prototype.slice来拷贝一个数组,但是对于嵌套数组,就会只拷贝其中的引用。
const arr=[[1,2,3],[4,5,6]]
const arr2=arr.slice()
arr2[0].push(666)
console.log(arr) //[[1, 2, 3, 666], [4, 5, 6]]上面的arr2是拷贝后的数组,arr2改变了同样会影响到arr的值,所以这就不是深拷贝。
官方解释是这样的
将一个对象从内存中完整的拷贝一份出来,从堆内存中开辟一个新的区域存放新对象,且修改新对象不会影响原对象
我所理解的深拷贝,就是当我克隆一个东西出来之后,跟原来的完全不相交。
在工作中,我们一般都会使用序列化进行深拷贝,就是采用JSON.stringify和JSON.parse来进行深拷贝
const obj={
name:'yanxi',
props:{name:'qiu'}
}
const obj2=JSON.parse(JSON.stringify(obj))
obj2.props.name='11111'
obj
//{name: "yanxi", props: {name: "qiu"}}这种方式非常简单,但JSON的局限性较大。
局限性如下:
1、不支持函数,会自动忽略
2、不支持undefined,JSON天然不支持
3、不支持环状引用(即引用自身)会报错
4、不支持Date,会转成字符串
5、不支持symbol,JSON天然不支持
我们可以看到JSON.parse(JSON.stringify())虽然能够深拷贝一个对象,但是存在很大的局限性,对于复杂的对象就不适用了。因此,我们需要采用另外的方式来实现深拷贝,也就是通过递归的方式手动实现深拷贝。
JS中存在七种类型:number、string、boolean、symbol、null、undefined、object
其中除了object属于引用类型,其余都是简单数据类型,所以我们主要要对object的数据类型进行分辨,其余的简单数据类型都只要直接返回即可。
知道了深拷贝的概念,有了深拷贝的思路
下面我们从0开始,手撸一个深拷贝
简单数据是不可变的
let a=1
let b=a
b=2
a //1上面的代码只是改变了b的指向,并不影响原来的数据a。
那么我们就可以直接实现对于简单数据类型的深拷贝函数
function deepClone(target){
return target
}深拷贝中最重要的是解决 object 类型深拷贝的思路,基于这个复杂数据类型,我们需要对Javascript 中的各种对象(数组对象,函数对象等)进行深拷贝的实现。
function cloneDeep(target) {
let result
if (typeof target === 'object') {
result = {}
for (let key in target) {
result[key] = cloneDeep(target[key])
}
return result
}
return target
}上面的代码通过对类型的检测,如果发现传入的是一个 object 对象,那么就循环它的属性,并且通过递归的方式一一将 object 对象的属性打到新创建的空白对象中,并将其返回。
在对数组类型进行检测的时候,我们不能用 typeof 进行检测,因为会返回 object,这里我们需要使用的Object.prototype.toString.call(Array)或者instanceof关键字,为了方便,这里就使用 instanceof 关键字
function cloneDeep(target) {
let result
if (typeof target === 'object') {
if (target instanceof Array) {
result = []
for (let key of target) {
result.push(cloneDeep(key))
}
} else {
result = {}
for (let key in target) {
result[key] = cloneDeep(target[key])
}
}
return result
}
return target
}函数需要怎么深拷贝呢?我们知道函数中的参数传递都是值传递,虽然目标函数会改变引用地址,但是函数已经把值作为参数传递进去了,所以我们直接返回调用函数的结果就可以了。
let fn=function (){return 123}
cloneDeep(fn) / /值传递
fn=function (){return 456} // 这里的函数改变了引用地址
cloneDeep(fn)() //需要做到返回123下面是实现代码,为了维持代码的结构,让简单数据类型和复杂数据类型做分离,我使用 instanceof 检测 target 类型,当检测函数时才使用 typeof 关键字
function cloneDeep(target) {
let result
if (target instanceof Object) {
if (target instanceof Array) {
result = []
for (let key of target) {
result.push(cloneDeep(key))
}
} else if (typeof target === 'function') {
result = function(...rest) {
return target(...rest)
}
} else {
result = {}
for (let key in target) {
result[key] = cloneDeep(target[key])
}
}
return result
}
return target
}还有更多的数据对象如果想要实现深拷贝,只要新增类型判断即可,这里就不再扩展了。
结束~
enjoy!
当我们在 Web browser(网页浏览器)的地址栏输入 URL 时,Web 浏览器会根据URL从指定的Web服务器端获取文件资源(resource),从而显示出 Web 信息。
像这种通过请求获取到服务端资源的Web 浏览器,都可以称之为客户端(client)。Web 使用超文本传输协议(HyperText Transfer Protocol)作为规范,完成从客户端到服务端的一系列运作流程。超文本传输协议缩写就是 HTTP 协议,本质上来说,这是一种规则的约定,Web 通过这个约定进行通信。
下面我们来通过 HTTP 诞生的背景来了解为什么会制定 HTTP 协议,以便于我们更好地理解 HTTP。
20 世纪 60 年代,美国国防部高等研究计划署(ARPA)建立了 ARPA 网,它有四个分布在各地的节点,被认为是如今互联网的“始祖”。
然后在 70 年代,基于对 ARPA 网的实践和思考,研究人员发明出了著名的 TCP/IP 协议。由于具有良好的分层结构和稳定的性能,TCP/IP 协议迅速战胜其他竞争对手流行起来。
1989 年,一位名叫蒂姆·伯纳斯 - 李(Tim Berners-Lee)的博士发表了一篇论文,提出了在互联网上构建超链接文档系统的构想。
最初设想的基本理念是:借助多文档之间相互关联形成的超文本(HyperText),连成可相互参阅的WWW(World WideWeb,万维网)。
现在已确立了三项关键技术。
基于这个**,李博士把这个系统称为“万维网”(World Wide Web),也就是现在的 Web。在这一年,HTTP 诞生了。
由于当时互联网世界受到内存、cpu 计算能力、网速等多重影响,在 HTTP 涉及初始时,结构简单,它也采用纯文本形式。这时候只允许 GET 请求,通过这个动作从服务器获取 HTML 文档,并且请求一次后马上关闭连接。
虽然它很简单,但是作为一个原型,很成功完成了历史使命,验证了 web 的可行性,为后来的拓展打下基础。
1993年,实际上第一个可以图文混合的浏览器 Mosaic 诞生,随后1995年服务器软件 Apache 诞生,简化了 HTTP 服务器的搭建工作。
同时期,计算器多媒体类似于 JPEG 和MP3的诞生促进了 HTTP 的发展。这时候进入1.0时代,这个版本从形式上跟目前的 HTTP 差别非常小。比如:
1995 年,网景的 Netscape Navigator 和微软的 Internet Explorer 开始了著名的“浏览器大战”,这一大战极大推动了 Web 的发展。
1999年,HTTP/1.1发布 RFC文档,此后这份文档延续了十余年。相较于1.0,它变更了以下内容:
由于1.1版本存在连接慢、无法跟上迅猛发展的互联网等问题,Google 公司为了解决这个问题,在自家流行的 Chrome 浏览器上应用了自家的服务器,并且推出新的 SPDY 协议。这时候互联网标准化组织以此为基础最终发布了2.0版本。
HTTP2.0充分考虑到目前的宽带、安全性、移动互联网等情况,补充了1.1版本的性能短板:
不过2.0版本直到今天还不够普及。
谷歌公司再次发布更加优化版本的 QUIC 协议,在自己的 Chrome 浏览器中试验,以庞大用户量和数据为支撑,持续推动 QUIC 协议的发展。
2018年,国际化标准组织以此为标准发布了HTTP3.0版本。有可能我们会直接跳过2.0采用3.0的标准。
在《你不知道的Javascript》中,有一道题
for(var i=0; i < 6; i++) {
setTimeout(function(){
console.log(i);
},0);
}答案是6个6。
这道题粗略的解释是i属于全局作用域,在异步定时器里,也引用的是相同作用域中的i,当定时器启动时,i已经变成了6,所以打印出来的结果并不是我们预期的0、1、2、3、4、5。
那么有没有更加专业(zhuangbility)一点的说法呢?有的,我们可以从执行上下文和闭包的角度来解题。
今天我们来深入说一说其中的原理
首先我们需要知道闭包究竟是什么东西。
MDN中对于闭包的解释是这样的:
一个函数和对其周围状态(lexical environment,词法环境)的引用捆绑在一起(或者说函数被引用包围),这样的组合就是闭包(closure)。也就是说,闭包让你可以在一个内层函数中访问到其外层函数的作用域。
这么专业的解释肯定看不懂啦,我们来看看它给的例子:
function init() {
var name = "Mozilla"; // name 是一个被 init 创建的局部变量
function displayName() { // displayName() 是内部函数,一个闭包
alert(name); // 使用了父函数中声明的变量
}
displayName();
}
init();以上代码非常简单,它的大概意思就是displayName函数里并没有name这个变量,它引用了外层作用域中的name,那么displayName就是一个闭包
所以我们用大白话定义一下:闭包 = 函数 + 访问外层作用域的变量。
要明白执行上下文与闭包的关系,首先我们需要写一下上面例子中的执行上下文过程:
1、创建全局上下文,压栈
ECStack=[globalContext]2、全局上下文初始化完成
globalContext={
VO:{ //全局变量对象中有个init函数变量声明
init:referance to function init
},
Scope:[globalContext.VO],
this:globalContext.VO
}同时init函数内部有个[[scope]]属性保存了globalContext.VO
3、调用函数,创建函数上下文后压栈
ECStack=[globalContext,initContext]4、进入上下文,此时函数并没执行,初始化函数上下文,将[[scope]]内部属性复制给函数上下文中的Scope属性,并将当前上下文中的AO(活动变量对象)放到最前面
initContext={
AO:{
arguments:{
length:0
},
name:undefined,
displayName:referance to function displayName
},
Scope:[AO,globalContext.VO],
this:undefined
}5、函数代码执行,变量对象完成赋值
initContext={
AO:{
arguments:{
length:0
},
name:Mozilla,
displayName:referance to function displayName
},
Scope:[AO,globalContext.VO],
this:undefined
}6、遇到displayName代码,此时内部生成[[scope]]属性保存外层作用域层级链
displayName.[[scope]]=[initContext.AO,globalContext.VO]7、开始调用displayName函数,创建函数上下文,压栈
ECStack=[globalContext,initContext,displayNameContext]8、进入函数上下文,初始化displayNameContext,把活动对象压入作用域链中
displayNameContext={
AO:{
arguments:{
length:0
},
}
Scope:[AO,initContext.AO,globalContext.VO]
}9、函数执行,完成变量对象赋值,然后找到外层的name,打印
10、开始弹栈
// 先弹displayName的上下文
ECStack=[globalContext,initContext]
// 再弹init的上下文
ECStack=[globalContext]以上就是执行上下文的过程,而displayName之所以能够访问到外层作用域中的name,就是因为displayName中的Scope属性,里面保存了initContext和全局上下文中的变量对象。
displayName.Scope=[AO,initContext.AO,globalContext.VO]有了这个属性,即使initContext被弹出执行栈了,displayName同样可以获取到它的变量对象。
这就是闭包的底层逻辑。同时也是闭包和执行上下文的关系
现在我们来重新审视一下最开始的代码
for(var i=0; i < 6; i++) {
setTimeout(function(){
console.log(i);
},0);
}当执行function函数时,此时的执行上下文有什么呢?全局上下文变量对象中有一个i
globalContext.VO={
i:6
}我们可以修改一下代码使它变成我们想要的0、1、2、3、4、5
1、第一种改法
for(var i=0; i < 6; i++) {
setTimeout(function(i){
console.log(i);
},0,i);
}使用这种方法,会让setTimeout函数传i给function,此时匿名函数第一次执行时它的上下文中是这样的
functionContext={
AO:{
arguments:{
0:0, // 实参中的 i
length:1
},
i:0,
}
...
}函数调用时,i已经被定时器当成参数传递给匿名函数了。第一次匿名函数执行时i为0。
2、第二种改法
for (var i = 0; i < 6; i++) {
(function (i) {
setTimeout(() => {
console.log(i);
}, 0);
})(i);
}类似第一种改法,只是此时i保存在外层立即执行函数的变量对象里面
外层匿名函数Context = {
AO: {
arguments: {
0: 0,
length: 1
},
i: 0
}
}内层匿名函数的Scope属性为[AO,外层匿名函数Context.AO,globalContext.VO]
3、第三种改法
for(let i=0; i < 6; i++) {
setTimeout(function(){
console.log(i);
},0);
}使用let声明不会将i挂在全局变量对象下(跟var声明不是同一个)。此时开辟了不同的变量对象。
定时器参数函数Context={
AO:{
length:0
},
Scope:[AO,无名氏作用域变量对象,globalContext.VO]
}于是定时器参数函数function顺着Scope属性找到对应的i
选择排序可以用额外空间,也可以原地排序,这种排序行为的时间复杂度是 O(n²)
额外空间选择排序算法思路:
用循环不断将最小的取出来,排列到额外空间上
const array: number[] = [1, 3, 2, 7, 55, 9, 2, 44, 9, 2, 44, 33, 96, 101];
function selectionSort(args: number[]) {
let len = args.length;
let newArray: number[] = [];
for (let i = 0; i < len; i++) {
let min = Math.min(...args);
newArray.push(min);
let index = args.indexOf(min);
args.splice(index, 1);
}
return newArray;
}这种方式的空间复杂度是 O(n),因为开辟了新的空间newArray。
时间复杂度是 O(n²),原因是 Math.min方法跟 for 循环是一样的,整个函数相当于进行了两次 for 循环。
下面用双指针来实现原地排序,不用 Math.min 方法了
核心思路:
利用两个指针,当指针i停时,另一个指针j找最小的数。
如果能够找到,就跟当前i 所在位置的数互换。
function selectionSort2(args) {
for (let i = 0; i < args.length; i++) {
//先取第一个数的 index,当它是数组中最小的数的索引
let minIndex = i;
//需要用来记找到的更小的数的 index
//由于是互换机制,每次都会从前到后排列数字。所以只需要每次从 i 的位置开始找就行了
for (let j = i; j < args.length; j++) {
if (args[j] < args[minIndex]) {
minIndex = j;
}
}
//互换一下
[args[i], args[minIndex]] = [args[minIndex], args[i]];
}
return args;
}队列的结构跟栈相反,队列是先进先出的数据结构。
队列基本操作有两种:入队和出队。从队列的后端位置添加实体,称为入队;从队列的前端位置移除实体,称为出队。
对应的 API 为 Array.prototype.push 和Array.prototype.shift方法。
当出队列时,即调用 shift 方法时,由于所有后排的数据都要往前推一格,所以出队列时的时间复杂度为 O(n)。
下图为队列中元素先进先出 FIFO (first in, first out)的示意

请你仅使用两个队列实现一个后入先出(LIFO)的栈,并支持普通队列的全部四种操作(push、top、pop 和 empty)。
实现 MyStack 类:
void push(int x) 将元素 x 压入栈顶。
int pop() 移除并返回栈顶元素。
int top() 返回栈顶元素。
boolean empty() 如果栈是空的,返回 true ;否则,返回 false 。
注意:
你只能使用队列的基本操作 —— 也就是 push to back、peek/pop from front、size 和 is empty 这些操作。
你所使用的语言也许不支持队列。 你可以使用 list (列表)或者 deque(双端队列)来模拟一个队列 , 只要是标准的队列操作即可。
示例:
输入:
["MyStack", "push", "push", "top", "pop", "empty"]
[[], [1], [2], [], [], []]
输出:
[null, null, null, 2, 2, false]
解释:
MyStack myStack = new MyStack();
myStack.push(1);
myStack.push(2);
myStack.top(); // 返回 2
myStack.pop(); // 返回 2
myStack.empty(); // 返回 False
提示:
1 <= x <= 9
最多调用100 次 push、pop、top 和 empty
每次调用 pop 和 top 都保证栈不为空
答案
var MyStack = function() {
this.queue=[]
this._queue=[]
};
MyStack.prototype.push = function(x) {
//直接 push 即可
this.queue.push(x)
};
MyStack.prototype.pop = function() {
//把主队列的元素除了最后一个外都shift出来 push 进副队列
while(this.queue.length>1){
this._queue.push(this.queue.shift())
}
//剩下的 这个就是要返回的 pop 的元素
const num=this.queue.shift()
// 记下 pop 出去的元素后记得把副队列的元素 push 回主队列
while(this._queue.length){
this.queue.push(this._queue.shift());
}
return num
};
MyStack.prototype.top = function() {
//队列的顶就是队列的最后一个元素
return this.queue[this.queue.length-1]
};
MyStack.prototype.empty = function() {
//没啥好说的
return this.queue.length===0
};浏览器是 HTTP 中的请求方,而协议的另一方就是应答方==>服务器,Web Server
Web服务器有两个层面的含义:硬件和软件。
硬件指的就是物理形式或者云形式的机器,在多数情况下它不一定是服务器,而是利用反向代理、负载均衡等多种技术组成的集群。
软件就是提供 Web 服务的应用程序,通常运行在硬件含义的服务器上,它利用硬件能力响应海量的 HTTP 请求,处理各种网页、图片等文件,或者转发请求等等。
目前世界上最流行两类 Web 服务器,分别是老牌的 Apache 服务器(特点:功能完善,学习门槛低)和后起之秀 Nginx(特点:高性能、高稳定性)。
CDN 全称是内容分发网络Content Delivery Network,它是浏览器和服务器之间的内容架设,它应用了 HTTP 协议中的缓存和代理技术,能够代理源站响应客户端的请求。
它有什么好处呢?
它可以缓存源站数据,让浏览器不用再千里迢迢到达源站服务器,而是在半路直接获取响应。如果 cdn 的调度算法优秀,那么就可以找到距离用户跟进的节点,大幅度缩短响应时间。
浏览器是一种用户代理,代替我们访问互联网。
但是这个代理也可以是机器人,这些机器人就称为爬虫。本质上是一种可以自动访问 Web 资源的应用程序。
爬虫是怎么来的呢?绝大多数都是由搜索引擎放出来的,它能够抓取网页并存入庞大的数据库中,再建立关键字索引,这样我们才可以在搜索引擎中搜索到互联网的各个页面。
爬虫也有一些不好的地方,比如导致敏感信息泄露。所以,现在也出现了一种反爬虫技术,通过各个手段来限制爬虫。
Web Service 和 Web Server的名字很像,但是确实完全不同的东西。
它是基于 Web(HTTP)的服务架构技术,既可以运行在内网,也可以在适当保护后运行在外网。
因为采用了 HTTP 协议传输数据,所以在 Web Service 架构里服务器和客户端可以采用不同的操作系统或编程语言开发。例如服务器端用 Linux+Java,客户端用 Windows+C#,具有跨平台跨语言的优点。
互联网上绝大部分资源都使用 HTTP 协议传输,浏览器是 HTTP 协议里的请求方,即 User Agent; 服务器是 HTTP 协议里的应答方,常用的有 Apache 和 Nginx;
CDN 位于浏览器和服务器之间,主要起到缓存加速的作用;
爬虫是另一类 User Agent,是自动访问网络资源的程序;
Web Service 是一种服务架构技术,具有跨平台跨语言的特点。
TCP/IP 协议是目前网络世界“事实上”的标准通信协议,是一系列网络通信协议的统称,其中最核心的两个协议是TCP和IP。
它还有其他协议例如:UDP、ICMP、ARP 等等。他们共同组成一个复杂的协议栈。
这个协议有四层
IP 协议是Internet Protocol的缩写,它主要用来解决寻址和路由以及如何传送数据包的问题。
IP 系统用了 IP 地址这个概念来定位每一台计算机。对应电话系统,需要打电话必须要接入电话网,由通信公司分配一个号码,这个号码就相当于 IP 地址。
TCP 协议是Transmission Control Protocol的缩写,意思是“传输控制协议”,它位于 IP 协议之上,基于 IP 协议提供可靠的、字节流形式的通信,是 HTTP 协议得以实现的基础。
可靠指的是保证数据不流失,字节流则保证数据完整。
TCP/IP是可靠的、完整的协议
TCP/IP使用 IP 地址来标识计算机,由于计算机本身处理的就是数据,这样的地址对应计算机相当方便,但是却不利于人类记忆。
DNS 域名系统就可以解决这个问题。它用了一组有意义的名字来替代 ip 地址,并建立映射关系。比如:访问 www.baidu.com就是访问百度的 IP 地址14.215.177.38(不止这一个)
在 DNS 中,域名又称主机名,它被设计成一个非常有层次的结构。其中,最右边的比如.com,.cn等都是顶级域名
顶级域名下面是二级域名,它位于顶级域名的左侧。例如,在zh.wikipedia.org中,wikipedia是二级域名。w3.org中,w3也是二级域名。
二级域名下面是三级域名,它位于二级域名的左侧。例如,在zh.wikipedia.org中,zh是三级域名。
想要使用 TCP/IP 协议来通信仍然要使用 IP 地址,所以需要把域名做一个转换,“映射”到它的真实 IP,这就是所谓的“域名解析”。
DNS 和 IP 地址标记了互联网上的主机,但是主机上有大量文本、网页等,需要找哪一个呢?
这就出现了 URI,全称统一资源定位符标识符。使用它可以唯一地标记互联网上的资源。
URI 的另一个表现形式是 URL(统一资源定位符),就是我们俗称的网址。它是 URI 的子集,但是两者相差不大。
URI是怎样的呢?
http://nginx.org/en/download.html
上面的URI 由三个基本部分组成:
1.协议名:http
2.主机名:主机标记位置,可以是域名或 ip 地址。这里是nginx.org
3.路径,也就是资源在主机上的位置,用/分隔成多个目录。这里是/en/download.html
这是 HTTP 的安全版本,由于 HTTP 协议不够安全,所以在 TCP/IP协议之上,又架设一层 SSL/TLS 的协议,而 HTTPS 的意思就是运行在在 SSL/TLS 协议上的 HTTP。
全称为HTTP over SSL/TLS
SSL/TLS是负责加密通信的安全协议,也是可靠的传输协议
SSL/TLS一开始叫 SSL(Secure Socket Layer),后来改名叫 TLS(Transport Layer Security),由于历史原因很多人称之为 SSL/TLS。
它使用了许多密码学的研究成果,综合了对称加密、非对称加密、摘要算法、数字签名、数字证书等技术,能够在不安全的环境中为通信的双方创建出一个秘密的,安全的传输通道。
如果有网址的协议名是 https,则代表其启用了 HTTPS 协议。
代理(proxy)是 HTTP 协议中请求方和应答方中间的环境,作为中转站,可以转发请求,也可以转发响应。
以下列举代理的种类
匿名代理:完全“隐匿”了被代理的机器,外界看到的只是代理服务器;
透明代理:顾名思义,它在传输过程中是“透明开放”的,外界既知道代理,也知道客户端;
正向代理:靠近客户端,代表客户端向服务器发送请求;
反向代理:靠近服务器端,代表服务器响应客户端的请求;
CDN 实际上也是代理的一种,它替代服务器响应客户端的请求,通常扮演透明代理和反向代理的角色。
代理作为传输的中间层,可以做很多事情,例如:
负载均衡:把访问请求均匀分散到多台机器,实现访问集群化;
内容缓存:暂存上下行的数据,减轻后端的压力;
安全防护:隐匿 IP, 使用 WAF 等工具抵御网络攻击,保护被代理的机器;
数据处理:提供压缩、加密等额外的功能。
关于HTTP 代理还有一个特殊的代理协议(proxy protocol)。
TCP/IP是世界上最常用的协议,具有可靠、完整的特点。HTTP 运行在 TCP/IP 之上。
DNS 域名是 IP 地址的等价替代,需要用域名解析实现到 IP 地址的映射
URI 由协议、主机名、路径构成。
HTTPS 由 HTTP+SSL/TLS+TCP/IP 组成。
代理是 HTTP 传输的中转站,可以实现缓存加速、负载均衡等功能。
在 Request Header 中,有请求方法和请求的目标,目前 HTTP1.1一共有8种请求方法:
1.GET:获取资源,可以理解为读取或者下载数据
2.HEAD:获取资源的元信息
3.POST:提交数据,相当于写入数据
4.PUT:修改数据等
5.DELETE:删除 资源
6.CONNECT:建立特殊的连接隧道
7.OPTIONS:列出对资源实行的方法
8.TRACE:追踪请求-相应的传输路径
这些方法基本都是大写。
GET 是 HTTP 中最古老的请求方法,也是用得最多的方法。
它的语义是从服务器中获取资源,这个资源可以是静态的文本、页面、视频等等,一般来说,GET 请求如果有参数,那么它的参数需要增加查询字符串在 URI 中。
HEAD 跟 GET 请求方法类似,也是从服务器获取资源,但是服务器不会返回请求的实体数据,而是传回响应头,也就是资源的元信息。
HEAD 方法可以看成是 GET 方法的简化版或者说是轻量版。它可以用于不需要用到资源的场合,避免传输数据的浪费。
比如说,检查一个文件是否存在,就只要发 HEAD 请求就可以了。
这两个方法非常相似,都是指定向服务器发送数据,数据一般放到 body 里面。
例如,我们向服务器发送加入购物车请求,那么你喜欢的商品就会作为 body 中的数据发送给服务器。
PUT 也是一样,向服务器提交数据,但是从语义上来看,PUT 更像是 update,而 POST 更像是 create。
DELETE:方法指示服务器删除资源,因为这个动作危险性太大,所以通常服务器不会执行真正的删除操作,而是对资源做一个删除标记。
CONNECT是一个比较特殊的方法,要求服务器为客户端和另一台远程服务器建立一条特殊的连接隧道,这时 Web 服务器在中间充当了代理的角色。
OPTIONS方法要求服务器列出可对资源实行的操作方法,在响应头的 Allow 字段里返回。它的功能很有限,用处也不大,有的服务器(例如 Nginx)干脆就没有实现对它的支
持。
TRACE方法多用于对 HTTP 链路的测试或诊断,可以显示出请求 - 响应的传输路径。它的本意是好的,但存在漏洞,会泄漏网站的信息,所以 Web 服务器通常也是禁止使用。
在实际面试中,有两个重要的概念,安全和幂等。
所以安全,就是不会对服务器资源造成修改的风险,这里只有 GET 请求和 HEAD 请求是安全的,因为它们都是只读操作。
所谓幂等是一种数学概念,意思就是不管操作多少次,结果都是相同的。也就是幂次数结果相等。
很显然,GET 和 HEAD 是幂等的,而 POST 是不幂等的,原因是它的语义就代表着创建,既然创建了,当然会新增结果。PUT 比较特殊,虽然它也会修改数据,但是它的语义是修改而非新增或减少,不管做多少次,它都只更新一个资源,所以它也是幂等的。
我们可以认为这里的结果指的是数据的数量。多次 post 会增加数据量,而多次修改不会增加数据量,这就是幂等跟非幂等的通俗含义。
请求是客户端发出的,要求服务器执行的、对资源的一种操作。
请求只是指示,具体要怎么做,需要跟服务端协商。
常用的请求方法是 GET 和 POST。分别是获取数据和发送数据。
HEAD 是轻量级 GET,每次只获取元信息,也就是响应头。
PUT 基本上与POST 相同,多用于更新数据,PUT 是幂等的,POST 是非幂等的。
安全和幂等是描述请求方法的两个重要属性。
原生的HTML5通过<input type="file" >属性来上传文件,我们可以采用浏览器提供的 File API 对所选择的文件进行操控。
如果我们希望访问选择的文件,分为两步
<input type="file" id="input">const selectFile = document.getElementById('input')const selectFile = document.getElementById('input')
selectFile.addEventListener('change',()=>{
console.log(selectFile.files)
})通过 DOM 的 files属性,我们可以得知上传文件的相关信息,比如图中的文件名(name)和大小(size)
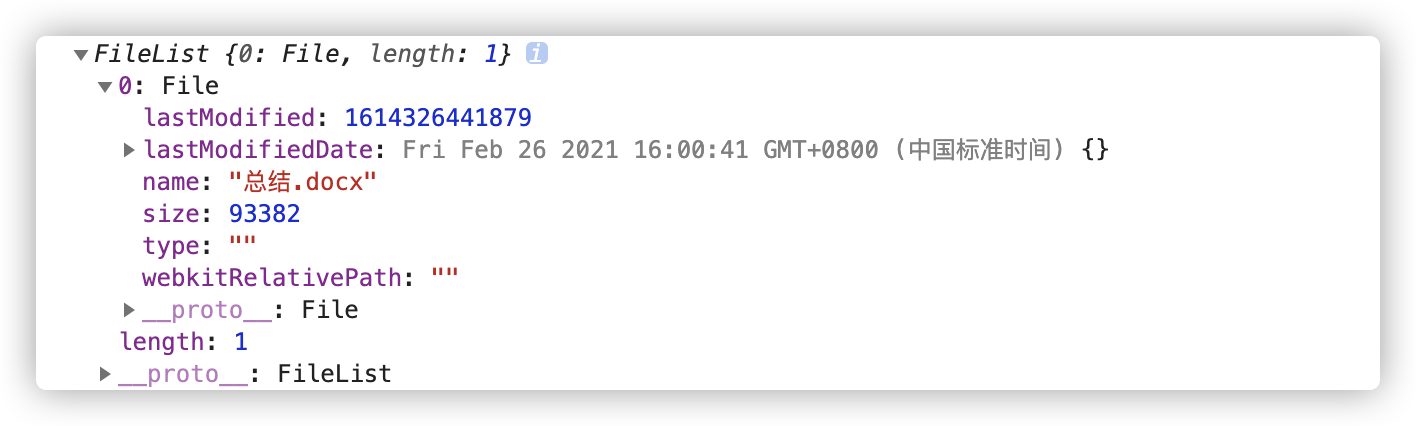
浏览器直接将上传文件存到 fileList 这个数据结构中,这个数据结构可以存很多个文件,如果想要存多个,那么就需要添加 html 属性multiple
<input type="file" multiple id="input">上传文件的控件实在很丑,我们有很多种方法改变它,这里就介绍最常用也是最简单的方式。
第一步,隐藏 input 控件
#input{
display:none;
}第二步,创建好看的点击区域,这里就用 button 控件吧
<button>上传</button>const selectFile = document.getElementById('input')
const button=document.querySelector('button') /
selectFile.addEventListener('change',()=>{
console.log(selectFile.files)
})
button.onclick=function (){
selectFile.click() // 调用 click函数点击
}现在只需要对 button 组件进行样式调整就行啦。
下面,我们需要做一个预览图片的小功能,还是使用上面的代码,不过这里添加一个新的预览区.
我们考虑使用FileReader对象让浏览器异步读取存储在用户计算机上的文件(或原始数据缓冲区)的内容。
<div>
<input type="file" multiple id="input">
</div>
<button>上传</button>
<img class='preview' />#input{
display:none;
}
.preview{
width:100px;
height:100px
}const selectFile = document.getElementById('input')
const button = document.querySelector('button')
const preview = document.querySelector('.preview')
selectFile.addEventListener('change', () => {
//循环读取 fileList 的file
for (let file of selectFile.files) {
const imageReg = /image\//g //正则表达式
// 检测 file 的 type 属性能否匹配到"image/"
if (!imageReg.test(file.type)) {
break
}
// 这里用到 FileReader API创建一个 Reader 读取器
let reader = new FileReader()
//当 reader 对某文件读取成功后的回调
reader.onload = function (e){
preview.src=e.target.result
}
//读取 DataURL后触发onload 回调
reader.readAsDataURL(file);
}
})
button.onclick = function() {
selectFile.click()
}上面代码中readAsDataURL 方法会读取指定的 Blob 或 File 对象。
读取操作完成的时候,readyState会变成已完成DONE,并触发 loadend (en-US) 事件,同时 result 属性将包含一个data:URL格式的字符串(base64编码)以表示所读取文件的内容。
我们把这个 base64编码放到创建好的 img 标签的 src 属性上,就可以完成图片的预览。
这个 API 跟readAsDataURL的效果差不多,不过它返回的不是base64编码,而是DOMString,我们可以理解为本地内存容器的URL地址。
只需要稍微修改一下代码就可以了
const selectFile = document.getElementById('input')
const button = document.querySelector('button')
const preview = document.querySelector('.preview')
selectFile.addEventListener('change', () => {
//循环读取 fileList 的file
for (let file of selectFile.files) {
const imageReg = /image\//g //正则表达式
// 检测 file 的 type 属性能否匹配到"image/"
if (!imageReg.test(file.type)) {
break
}
// 这里用到 createObjectURL API生成本地内存 url
preview.src = window.URL.createObjectURL(file)
preview.onload = function() {
//由于每次使用createObjectURL都会产生一个URL 对象。
//当你结束使用某个 URL 对象之后,应该通过调用这个方法来让浏览器知道不用在内存中继续保留对这个文件的引用了。
window.URL.revokeObjectURL(this.src)
}
}
})
button.onclick = function() {
selectFile.click()
}createObjectURL还可以用来生成 PDF 预览,我们可以采用 iframe 标签,让 pdf 展示在 iframe 上
<iframe id='viewer'></iframe>#viewer{
width:600px;
height:600px;
border:1px solid red;
}selectFile.addEventListener('change', () => {
//循环读取 fileList 的file
for (let file of selectFile.files) {
const obj_url=window.URL.createObjectURL(file)
// 这里用到 createObjectURL API生成本地内存 url
iframe.setAttribute('src', obj_url);
window.URL.revokeObjectURL(obj_url);
}
})先介绍这三种比较广泛的预览形式,后续如有需要,我再补充~
enjoy!
递归是一种解决问题的方法,它从解决问题的各个小部分开始,直到解决最初的大问题。
递归有两个条件:
下面用例子来分析采用递归方法来实现数组求和,假设数组为[1,2,3,4,5,6]。
我们首先分析一下数组求和的过程:
所以我们可以写出下面的代码
// 递归实现数组求和
//递归求和的重点:1.找到最小问题,2.调用自身
function sum(nums) {
function sum2(nums, len) {
if (len === nums.length) {
//这里就是基线条件
return 0;
}
return nums[len] + sum2(nums, len + 1); //调用自身
}
return sum2(nums, 0);
}我们在写递归时,比较难判别的是如何考量基线条件。
下面我们尝试来做一个更经典的递归问题-阶乘
我们来看看如何计算一个数的阶乘。数n的阶乘,定义为n!,表示从1到n的整数的乘积。
分析一下:
我们从n开始,一直到 1 才停止,分解一下就是n*(n-1)*(n-1-1)*...1
也就是说基线条件为 1,而且我们要不停调用自身。调用自身的行为就是不断乘以比自己小一位的数。
所以代码可以这样写
// 递归解决阶乘问题
function factorial(n) {
function factorial2(current) {
if (current === 1) {
return 1;
} else {
return current * factorial2(current - 1);
}
}
return factorial2(n);
}入门了递归的两个小案例,现在我们来了解一下调用栈问题。既然叫栈,那么说明这个数据结构是后进先出的。
调用栈是什么呢?我们可以理解为当进入一个函数内部时,底层会自动产生一个调用栈,把当前的函数的调用给push进去,当产生递归时,也就是进入一个函数后又进入一个函数时,会把当前函数的调用堆叠到调用栈中。这是因为每个调用都可能依赖前一个调用的结果。
我们把上面的函数复制到浏览器中,并且在factorial内打一个断点来检查一下就可以看到调用栈的处理过程。

当第一次进入factorial函数时,此时还没有调用factorial2函数,左边的 call stack 上只显示一个函数,然后当我们点击step into next function 按钮时,就可以看到调用栈内又多了一个函数,说明此时已经压栈了。

如果一直点下去,随着 current 的逐步减少,可以看到 call stack一直在增加函数,直到 current 等于1之后,开始弹栈,call stack 内的函数逐渐从顶部开始弹出。
可以用下图表示执行栈的步骤

每个调用栈不可能无限扩展,在浏览器中,调用栈也有大小限制,如果超过了这个数量,那么就会出现栈过大的提示。
斐波那契数列是另一个可以用递归解决的问题。它是一个由0、1、1、2、3、5、8、13、21、34等数组成的序列。从第二个1开始(也就是第二位),每一个数都是前一位和前两位的总和。
已知当 n 为1或者0时都返回 n 自身,所以这就是自身的基线点。那么我们可以写出一个输入n 得出n 位是多少数值的函数
function fibonacci(n) {
if (n === 0 || n === 1) {
return n;
}
return fibonacci(n - 1) + fibonacci(n - 2);
}所谓记忆化函数,就是在函数内部增加一个闭包来进行缓存。当我们调用fibonacci(5)时,可以画一张这样的图来查看执行过程。

可以看到fibonacci(3)被调用两次了,这就可以用到缓存来记录下这个结果。
function memorizeFibonacci(n) {
let cache = [0, 1];
function fibonacci(n) {
if (n === 1 || n === 0) {
return n;
}
if (cache[n]) {
return cache[n];
}
let result = fibonacci(n - 1) + fibonacci(n - 2);
cache[n] = result;
return result;
}
return fibonacci(n);
}使用缓存可以有效减少重复的计算,优化计算效率。
这里有一道 leecode 题目,就可以使用缓存以避免计算时间过长而导致做题失败。
剑指 Offer 10- I. 斐波那契数列
当JavaScript代码执行一段可执行代码(executable code)时,会创建对应的执行上下文(execution context)。
每个执行上下文包含三个重要属性
当查找变量时,首先从当前上下文中的变量对象查找,如果没有就会往上查找父级作用域中的变量对象,最后的终点是访问最外层上下文中的变量对象,如果没有就报错。这样由多个执行上下文的变量对象构成的链表就叫做作用域链。
当执行一段全局代码时,就会生成一个执行上下文,里面会包含全局变量对象
var a=123
globalContext.VO={
a:123
}当书写一段函数代码时,就会创建一个词法作用域,这个作用域是函数内部的属性,我们用[[scope]]表示,它里面保存父变量对象,所以[[scope]]就是一条层级链。
function fn(){
}
/*
fn.[[scope]]=[
globalContext.VO
]
*/当函数调用,就意味着函数被激活了,此时创建函数上下文,创建活动对象,然后将活动对象(AO)推到作用域链的前端。
我们用scope来表示此时的作用域
fnContext={
Scope:[AO,fn.[[scope]]]
}我们来分析以下代码函数上下文中的变量对象和作用域的创建过程
var scope = "global scope";
function checkscope(){
var scope2 = 'local scope';
return scope2;
}
checkscope();1、全局上下文创建,生成全局变量对象VO,checkscope函数创建,生成内部属性[[scope]],并且把父变量对象放进去。
checkscope.[[scope]]=[
globalContext.VO
]2、函数调用了,创建函数上下文并压入执行栈
ECStack=[globalContext,checkscopeContext]3、函数调用的分析阶段,做准备工作,第一步:复制函数[[scope]]属性创建作用域链
checkscopeContext={
Scope:checkscope.[[scope]]
}4、第二步:创建活动对象,初始化活动对象,加入形参、函数声明、变量声明
checkscopeContext = {
AO: {
arguments: {
length: 0
},
scope2: undefined
},
Scope: checkscope.[[scope]],
}5、第三步:将活动对象压入 checkscope 作用域链顶端
checkscopeContext = {
AO: {
arguments: {
length: 0
},
scope2: undefined
},
Scope: [AO, [[Scope]]]
}6、准备工作做完,开始执行函数,随着函数的执行,修改 AO 的属性值
checkscopeContext = {
AO: {
arguments: {
length: 0
},
scope2: 'local scope'
},
Scope: [AO, [[Scope]]]
}7.查找到 scope2 的值,返回后函数执行完毕,函数上下文从执行上下文栈中弹出
ECStack = [
globalContext
];HTTP 是无状态的,也就是没有记忆能力,好在 HTTP 可以扩展,有了扩展,也就有了记忆能力,这里要说到Cookie 技术
Cookie相当于服务器给浏览器的小纸条,上面写了只有服务器才可以理解的数据,需要客户端把这个信息发送给服务器,当服务器看到这张小纸条,就能认出发送请求的客户端是谁。
Cookie 传输时需要用到两个HTTP 头部字段:响应头Set-Cookie 和 请求头Cookie。
1.当用户第一次访问服务器的时候,服务器肯定不知道它的身份,于是服务器首先要创建一个 key=value 格式的身份标识数据,这就需要用到 Set-Cookie,然后通过这个响应头部字段,将键值对的数据发送给浏览器。
HTTP/1.0 200 OK
Content-type: text/html
Set-Cookie: theme=light
Set-Cookie: sessionToken=abc123; Expires=Wed, 09 Jun 2020 10:18:14 GMT
...2.当浏览器收到响应报文后,发现响应报文中有 Set-Cookie 的字段,就将其保存下来,下次请求时自动将这个值放进 Cookie 头字段中发送给服务器。
GET /spec.html HTTP/1.1
Host: www.example.org
Cookie: theme=light; sessionToken=abc123
…3.当服务器看到请求字段中含有 Cookie 字段时,就会认出这是之前来过的浏览器,识别出身份后,可以提供个性化服务。
之前我们说过,大多数 HTTP 头字段是不可以重复的,但是 Set-Cookie 除外,它可以一次性设置多个。这样就可以存储多个 key=value 格式的数据,浏览器发送时,只用一个 Cookie 字段,但是会用;隔开。
由于 Cookie 是浏览器保存的,所以换了浏览器还得重新走一遍 Cookie 的流程。
Cookie是服务器委托浏览器存储在客户端的一些数据,而这些数据会识别用户的关键信息,所以就需要在 key=value以外再加上一些其他属性来保护。
Cookie 的生命周期俗称为有效期,这里可以用到两个属性:Max-Age 和 Expires。
Max-Age 是相对时间,翻译过来是最大存在时间,它的单位是秒,也就是服务器收到 Cookie 并返回后,浏览器收到响应报文的时间再加上Max-Age 时间就是 Cookie 的有效时间。
Expires 是绝对时间,翻译就是过期时限,可以理解为截止日期。
它俩的写法是这样的
Set-Cookie:Max-Age=100;Expires=Fri,07-Jun-19 08:19:00 GMT;意思是过期时间100秒,截止时间2019年6月7日8点19分,星期五。
两者可以同时存在,浏览器优先选择 Max-Age
作用域就是让浏览器不要随便发 Cookie,要发给特定的服务器和 URI。
Set-Cookie:Domain=www.baidu.com;path=/;这个设置就比较简单,浏览器在带 Cookie 的时候,会去比较域名Domain和路径path 部分。如果不满足条件,就不会在请求头中发送Cookie。
使用这两个属性可以分别在不同的路径发送不同的Cookie,比如/index和/users路径分别发不同的Cookie,不过一般为了省事,会在 path 部分用一个/表示根目录下都发Cookie。
在 JavaScript 中,有一个读取 Cookie 的方法document.cookie,这可能造成安全隐患,造成 XSS 攻击(跨站脚本攻击)。
这时候可以使用 HttpOnly属性告诉浏览器,不允许使用 Javascript 访问。
还有一个属性,可以防止XSRF 攻击(跨站请求伪造),它就是SameSite=Strict,它可以严格规定Cookie 不能随着跳转链接跨站发送,SameSite=Lax则宽松一点,允许 GET/HEAD 发送 Cookie,但禁止POST发送。
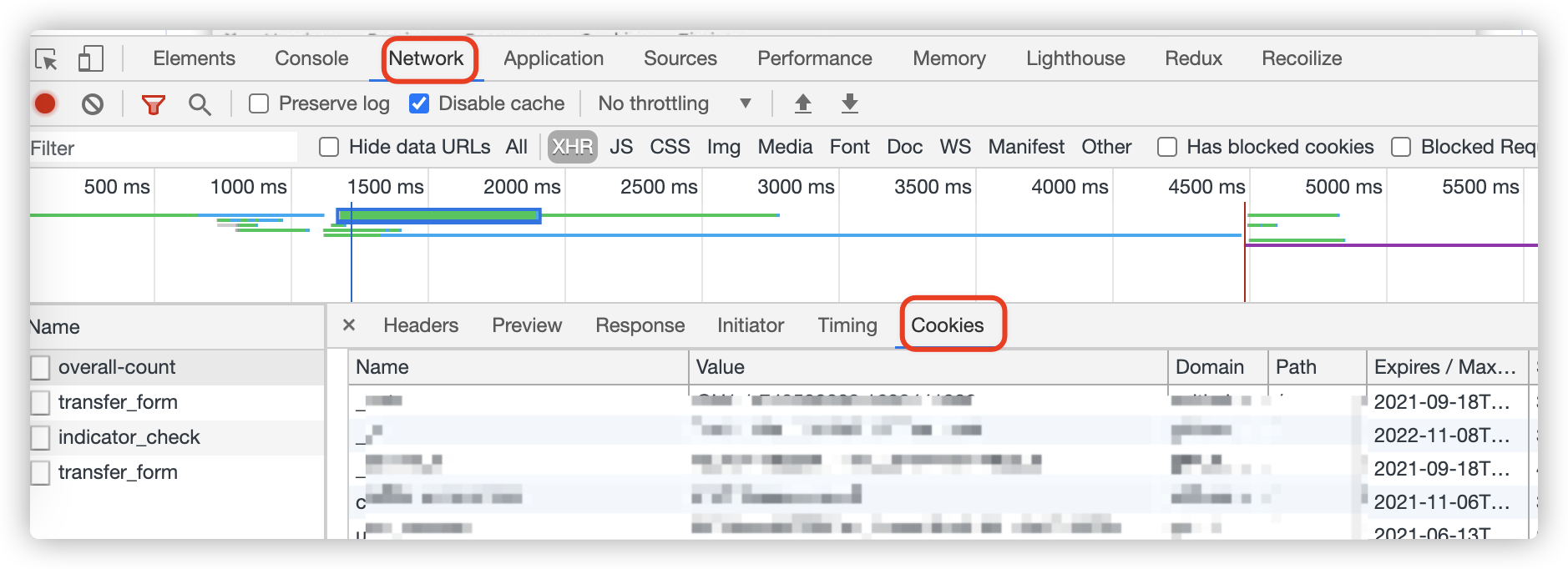
Cookie本身不是加密的,在浏览器中可以查看得到。
通过浏览器 Network-Cookies 和 Application都可以看到 Cookie。Application 则可以看到全站所有 Cookie。
Cookie的基本作用是身份识别,保存用户的登录信息,实现会话事务。
比如,你用账号和密码登录某电商,登录成功后网站服务器就会发给浏览器一个 Cookie,内容大概是“name=yourid”,这样就成功地把身份标签贴在了你身上。
之后你在网站里随便访问哪件商品的页面,浏览器都会自动把Cookie 发给服务器,所以服务器总会知道你的身份,一方面免去了重复登录的麻烦,另一方面也能够自动记录你的浏览记录和购物下单(在后台数据库或者也用 Cookie),实现了“状态保持”。
Cookie 的另一个常见用途是广告跟踪。
你上网的时候肯定看过很多的广告图片,这些图片背后都是广告商网站(例如 Google),
它会“偷偷地”给你贴上 Cookie 小纸条,这样你上其他的网站,别的广告就能用 Cookie读出你的身份,然后做行为分析,再推给你广告。
Cookie 是服务器委托浏览器存储的一些数据,让服务器有了
“记忆能力”;
响应报文使用 Set-Cookie 字段发送“key=value”形式的 Cookie 值;
请求报文里用 Cookie 字段发送多个 Cookie 值;
为了保护 Cookie,还要给它设置有效期、作用域等属性,常用的有 Max-Age、Expires、Domain、HttpOnly 等;
Cookie 最基本的用途是身份识别,实现有状态的会话事务。
在实现 new 关键字之前我们需要了解 new 到底做了什么工作?
我们从一段简单的代码入手来看
function fn(name){
this.name=name
}
fn.prototype.say=function (){
alert(this.name)
}
const boy=new fn('qiuyanxi')这段代码非常简单,它定义了一个构造函数,然后给了这个构造函数的原型一个名叫 say 的函数。
毫无疑问,当我调用 boy.say的时候会打印qiuyanxi,那么我们推断 new 做了什么?
qiuyanxi。为了证明我们的猜想,我们从打印台查看一下boy 这个对象

推断正确,有一点值得我们注意,say 方法是在 boy.__poroto__上的,而这个属性有个constructor属性指向 fn,那么我们就知道这是 fn 函数的原型。
fn.prototype===boy.__proto__
// true知道了原理,那我们可以开始动手了
1.我们需要先定义一个构造函数
function create(name){
this.name=name
}
create.prototype.say=function (){
alert(this.name)
}2.创建一个 new 函数,接收构造函数为参数
function lineNew(func){
const x=Object.create(func.prototype) //创建一个空对象,原型连接到传入的构造函数身上
return x //返回一个对象
}3.既然内部需要有 name 属性,那我们就需要把 name 传进去,而且需要调用构造函数
function likeNew(func,...args){
const x=Object.create(func.prototype)
func.call(x,...args)
return x
}实验一下:
const boy=likeNew(create,'qiuyanxi')
看起来没问题。
虽然功能实现了,但是有些细节问题需要处理。
比如说箭头函数是没有 原型的,所以我们可以手动帮它创建一个。
比如说会不会有些人不传函数进去呀?所以我们需要做一点 Polyfill
优化代码
function likeNew(func,...args){
if(typeof func !=='function'){
throw new Error('first arg is not function')
}
let x={}
if(func.prototype){
x=Object.create(func.prototype)
}else{
x.__proto__={constructor:func} //手动创建一个原型接上
}
func.call(x,...args)
return x
}有时候面试题会问你构造函数返回一个对象,那么 new会怎么做。
我们直接实验出真知
function foo(name){
this.name=name;
return {age:18}
}
const boy=new foo('qiuyanxi')
boy // {age: 18}结论:如果构造函数返回了对象,那new就返回这个对象,否则就返回new自己创建的对象。
这一点MDN 也有介绍
当代码 new Foo(...) 执行时,会发生以下事情:
1.一个继承自 Foo.prototype 的新对象被创建。
2.使用指定的参数调用构造函数 Foo,并将 this 绑定到新创建的对象。new Foo 等同于 new Foo(),也就是没有指定参数列表,Foo 不带任何参数调用的情况。
3.由构造函数返回的对象就是 new 表达式的结果。如果构造函数没有显式返回一个对象,则使用步骤1创建的对象。(一般情况下,构造函数不返回值,但是用户可以选择主动返回对象,来覆盖正常的对象创建步骤)
那么我们继续改一下代码
function likeNew(func,...args){
if(typeof func !=='function'){
throw new Error('first arg is not function')
}
let x={}
if(func.prototype){
x=Object.create(func.prototype)
}else{
x.__proto__={constructor:func} //手动创建一个原型接上
}
return typeof func.call(x,...args)==='object'?func.call(x,...args):x
}一般面试不需要做 Polyfill,这里附上简单的几行代码
function _new(initFunc, ...rest) {
// let xx.__proto__ = initFunc.prototype
let cache = Object.create(initFunc.prototype);
let result = initFunc.call(cache, ...rest);
return typeof result === "object" ? result : cache;
}结束~
enjoy!
Set是ES6新产生的数据解构,它类似于数组,不一样的是它没有重复的值。
Set本身是构造函数,所以我们需要用new来生成一个Set数据解构
const set=new Set([1,2,3,4,5])
set //Set(5) {1, 2, 3, 4, 5}传递一个数组可以生成Set数据解构,实际上并非数组可以实现,具有iterable接口的数据都可以通过这种方式生成Set数据。
使用Set.prototype.add方法也可以生成Set数据解构
const s= new Set()
for(let v of [1,2,3,1,2,3]){
s.add(v)
}
// Set(3) {1, 2, 3}上面可以看到,Set并不会录重复值
iterable接口数组生成示例
function fn(){
return new Set(arguments)
}
fn(1,2,3,4,5,6)
// Set(6) {1, 2, 3, 4, 5, 6}
const set=new Set()
document.querySelectorAll('div').forEach(div=>{set.add(div)})const a=[1,2,1,2]
const b=[...new Set(a)]上面代码使用...展开运算符来展开Set数据解构,再用[]包起来就可以变成数组
或者也可以使用Array.from()转数组,取决于你的爱好
const a=[1,2,1,2]
const b=Array.from(new Set(a))字符串也可以去重
const a='123412'
const b=[...new Set(a)].join('')
b // '1,2,3,4'上面的代码用于字符串去重,因为字符串也具有iterable接口,可以当参数传递给Set构造函数
Set.prototype.constructor:默认为构造函数Set
Set.prototype.size:返回Set实例的成员总数,跟数组的length差不多
增:Set.prototype.add(value)
删:Set.prototype.delete(value)
查:Set.prototype.has(value)
清除:Set.prototype.clear()
Set.prototype.keys():返回键名的遍历器
Set.prototype.values():返回键值的遍历器
Set.prototype.entries():返回键值对的遍历器
Set.prototype.forEach():使用回调函数遍历每个成员
由于Set数据结构的键和值是一样的,所以keys和values方法返回的结果是一致的,我们可以通过entries论证键和值是一致的这个观点
let set= new Set(['qiu','yan','xi'])
set.forEach((value,key)=>{
console.log(`value:${value}=>key:${key}`)
})
//value:qiu=>key:qiu
//value:yan=>key:yan
//value:xi=>key:xi
for(let item of set.entries()){
console.log(item)
}
//['qiu','qiu']
//['yan','yan']
//['xi','xi']上面代码中,entries每次都会返回包含键值的数组。
由于Set拥有iterable接口,也可以使用for of循环。
let set= new Set(['qiu','yan','xi'])
for(let x of set){
console.log(x)
}
//qiu
//yan
//xi配合...运算符就可以实现变相实现set的map或者filter等方法
let set=new Set([1,2,3,4,5,6])
new Set([...set].map((value,key)=>{return value*2}))
//Set(6) {2, 4, 6, 8, 10, 12}
new Set([...set].filter((value)=>{
return value>3
}))
//Set(3) {4, 5, 6}javascript中,object对象是以键值对的形式存在的,但是其键全部都是字符串,当我们希望使用hash表的时候,ES6提供的Map比对象更适合,它打破了键值对中键为字符串的限制,提供以值值对的数据结构。
Map也是一个构造函数,我们可以采用传入一个二元数组的方式来生成数据结构,数组内的数组会形成值值对。
let map=new Map([['name','qiuyanxi'],['age',10]])
//Map(2) {"name" => "qiuyanxi", "age" => 10}Map键的位置也可以是对象,我们采用set方法来生成Map数据结构(添加成员)
let map=new Map().set({name:'qiuyanxi'},'男')
//Map(1) {{name:'qiuyanxi'} => "男"}实际上,在Map构造函数接收数组为参数时,实际上做的是以下操作
let array=[[name,'qiu'],[age,10]]
let map = new Map()
array.forEach(([key,value],index)=>{map.set(key,value)})
//Map(2) {"name" => "qiu", "age" => 10}上面的代码中[key,value]实际上就是将[name,'qiu']进行解构赋值,然后对map对象进行set方法添加对应的成员。
事实上,只要持有iterable接口,且每个成员都是双元素数组结构都可以成为Map构造函数的参数。
Map.prototype.size返回Map 结构的成员总数
Map.prototype.set(key, value)添加成员
Map.prototype.get(key)查成员
Map.prototype.delete(key)删除成员
Map.prototype.has(key)返回一个布尔值,表示某个键是否在当前 Map 对象之中。
Map.prototype.clear() 清除所有成员
const a = {'name':'qiu'}
const map = new Map()
map.set(a,'yanxi')
map.size //1
map.get(a) //'yanxi'
map.delete(a) //true
map.clear()
// Map(0) {}如果对同一个键多次赋值,则会覆盖原来的键
const map =new Map()
map.set(1,'123')
map.set(1,'456')
map.get(1) // '456'需要注意的是,当键为对象类型时,我们读取它或者想覆盖它最好是使用引用的方式,而不是直接书写
const map=new Map()
map.set({name:"qiu"},'123')
map.set({name:"qiu"},'456')
map.get({name:"qiu"}) //undefined
map//Map(2) {{name:'qiu'} => "123", {name:'qiu'} => "456"}上面的代码中,我使用map方法分别设置以{name:'qiu'}为对象的键名,但是实际上存在键名一致的情况,而并未出现值覆盖,并且get读取的时候读取出undefined,这是由于键的内存地址不同,Map不将其认同为一个键,所以我们要注意,在使用这种情况下,需要将键名转化为地址的引用
const map=new Map()
const n={name:"qiu"}
map.set(n,'123')
map.set(n,'456')
map.get(n) // '456'由上可知,其实Map的键是和地址绑定的,只要内存地址不同,就被认为是两个不同的键。
如果 Map 的键是一个简单类型的值(数字、字符串、布尔值),则只要两个值严格相等,Map 将其视为一个键,比如0和-0就是一个键,布尔值true和字符串true则是两个不同的键。另外,undefined和null也是两个不同的键。虽然NaN不严格相等于自身,但 Map 将其视为同一个键。
const map=new Map()
map.set(0,'123')
map.set(-0,'456')
map //Map(1) {0 => "456"}
map.set(true,123)
map.set('true',456)
map.set(null,666)
map.set(undefined,777)
map.set(NaN,888)
map.set(NaN,999)
map //Map(6) {0 => "456", true => 123, "true" => 456, null => 666, undefined => 777, NaN => 999}Map结构原生有以下方法遍历
Map.prototype.keys()返回键名的遍历器
Map.prototype.values()返回值的遍历器
Map.prototype.entries()返回所有成员的遍历器
Map.prototype.forEach()遍历所有成员
Map的遍历顺序就是插入顺序
const map=new Map([[1,'true'],[2,'false']])
for(let k of map.keys()){console.log(k)} // 1 2
for(let k of map.values()){console.log(k)} // 'true' 'false'
for(let k of map.entries()){console.log(k)} //[1, "true"][2, "false"]
map.forEach((value,key)=>{
console.log(value+':'+key)
}) // true:1 false:2使用扩展运算符能快速将Map转化为数组,同时由于Map没有Map方法,使用扩展运算符配合则可以使用filter方法或者map方法
const map=new Map([[1, 'one'],
[2, 'two'],
[3, 'three']])
const a=new Map([...map].filter(([key,value])=>{
return key>2
}))
a //Map(1) {3 => "three"}如果所有 Map 的键都是字符串,它可以无损地转为对象,如果是非字符串,则会转为字符串后再转化成对象
const map=new Map([[8, 'one'],
[9, 'two'],
[10, 'three']])
const obj={}
map.forEach((value,key)=>{
obj[key]=value
})
obj //{8: "one", 9: "two", 10: "three"}使用Object.entries()方法可以将对象转化成成员包含键名,键值的二元数组,然后再转化成Map
//接上面代码
let o =Object.entries(obj)
// [[8, 'one'],[9, 'two'],[10, 'three']]
let map =new Map(o)我们需要根据不同情况转成不同的JSON对象
当键名都是字符串时,可以转成对象JSON
const map=new Map()
map.set('qiu','yanxi')
map.set('height','180')
function mapToString(map){
const obj=Object.create(null)
map.forEach((value,key)=>{
obj[key]=value
})
return obj
}
const obj=mapToString(map)
JSON.stringify(obj) //"{"qiu":"yanxi","height":"180"}"当键名不单单是字符串时,可以转成数组JSON
const map=new Map()
map.set([1,2,3],'yanxi')
map.set(['height'],'180')
JSON.stringify([...map])
//"[[[1,2,3],"yanxi"],[["height"],"180"]]"JS的代码会按照顺序执行,例如
var foo = function () {
console.log('foo1');
}
foo(); // foo1
var foo = function () {
console.log('foo2');
}
foo(); // foo2如果把代码换成这样
function foo(){
console.log('foo1');
}
foo() //foo2
function foo(){
console.log('foo2')
}
foo() //foo2全部打印foo2了,原因在于第一个代码示例中,是变量提升,也就是foo提升了。而第二个代码示例属于函数提升,也就是第二个函数foo覆盖了第一个foo。这个题目也许很多面试题中都会有,在这里不过多讨论,使用这两个例子,只是为了说明,JS的代码在运行时,JS引擎会做一些准备工作。
那么JS引擎遇到怎样的代码才会做这样的准备工作呢?
这就要说到 JavaScript 的可执行代码(executable code)的类型有哪些了。
可执行代码有三种,分别是全局代码、函数代码、eval代码
eval现在在规范中已经不再使用,所以不在讨论之内。
比如说:当执行到一个函数的时候,就会进行准备工作,这里的“准备工作”,让我们用个更专业一点的说法,就叫做"执行上下文(execution context)"。
因为代码中函数很多,如何管理这么多的执行上下文呢?JavaScript 引擎创建了执行上下文栈(Execution context stack,ECS)来管理执行上下文。
既然叫栈,那么它的数据结构有点明朗了,它属于先进后出的数据结构,我们可以使用一个数组来模拟调用栈。
ECStack=[]当遇到全局代码时,执行上下文栈会压入一个全局上下文,我们使用globalContext来表示
ECStack.push(globalContext)只有当整个程序运行结束,执行上下文栈才会被清空,所以程序结束之前,在ECStack中始终有globalContext。
现在,JS引擎遇到函数代码了
function fun3() {
console.log('fun3')
}
function fun2() {
fun3();
}
function fun1() {
fun2();
}
fun1();ESCStack在fun1函数调用时会做以下事情
//每一个函数执行时都会创建一个执行上下文并被压入执行上下文栈中
//fun1执行了,创建一个context
// 压栈
ECStack.push(<fun1 context>) //发现内部还有`fun2`调用
ECStack.push(<fun2 context>) //发现内部还有`fun3`调用
ECStack.push(<fun3 context>) //发现内部还有log函数调用
ECStack.push(<log context>) //里面没了
打印fun3 //代码执行完了,该弹栈了
ECStack.pop(<log context>)
ECStack.pop(<fun3 context>)
ECStack.pop(<fun2 context>)
ECStack.pop(<fun1 context>)
此时ECStack还剩下[globalContext]
// 继续处理其他代码
// globalContext在程序结束前一直会存在下面我们来写一下以下代码的执行上下文栈
var scope = "global scope";
function checkscope(){
var scope = "local scope";
function f(){
return scope;
}
return f;
}
checkscope()();//遇到全局上下文
ECStack.push(globalContext) //此时的调用栈[globalContext]
//调用checkscope,进入checkscope的函数内
ECStack.push(<checkscope context>) //压栈
//内部没有函数调用,返回函数f
ECStack.pop(<checkscope context>) //弹栈
//返回的f被调用了
ECStack.push(<f context>) //压栈
ECStack.pop(<f context>) //弹栈当JS代码遇到可执行代码时,会创建相应的上下文,每个上下文中有三个重要的属性:
1、变量对象
2、作用域链
3、this
我们结合以下代码谈谈具体处理过程
第一题:
var scope = "global scope";
function checkscope(){
var scope = "local scope";
function f(){
return scope;
}
return f();
}
checkscope();1、执行全局代码,生成全局上下文,并且压入执行栈
ECStack=[
globalContext
]2、全局上下文初始化
globalContext={
VO=[global],
this:globalContext.VO,
Scope:[globalContext.VO]
}3、创建函数[[scope]]属性,并将全局变量对象存入其中
checkscope.[[scope]]={
globalContext.VO
}4、调用函数,创建函数上下文,压栈
ECStack=[
globalContext,
checkscopeContext
]5、此时函数还未执行,进入执行上下文
checkscopeContext = {
AO: {
arguments: {
length: 0
},
scope: undefined,
f: reference to function f(){}
},
Scope: [AO, globalContext.VO],
this: undefined
}6、f函数被创建生成[[scope]]属性,并保存作用域链条
f.[[scope]]=[
checkscopeContext.AO,
globalContext.VO
]7、f函数调用,生成f函数上下文,压栈
ECStack=[
globalContext,
checkscopeContext,
fContext
] 8、此时f函数还未执行,初始化执行上下文
fContext = {
AO: {
arguments: {
length: 0
},
},
Scope: [fContext.AO, checkscopeContext.AO, globalContext.VO],
this: undefined
}9、f 函数执行,沿着作用域链查找 scope 值,返回 scope 值
10、弹栈
// f函数弹栈
ECStack=[
globalContext,
checkscopeContext
]
// checkscope函数弹栈
ECStack=[
globalContext
]
……第二题
var scope = "global scope";
function checkscope(){
var scope = "local scope";
function f(){
return scope;
}
return f;
}
checkscope()();1、执行全局代码,创建全局上下文,压栈
ECStack=[
globalContext,
]2、初始化全局上下文
globalContext={
VO:[global],
Scope:[globalContext.VO]
this:globalContext.VO
}3、checkscope函数生成内部[[scope]]属性,并存入全局上下文变量对象
checkscope.[[scope]]=[
globalContext.VO
]4、调用checkscope函数,创建函数上下文,压栈
ECStack=[
globalContext,
checkscopeContext
]5、checkscope函数还未执行,上下文初始化
checkscopeContext = {
AO: {
arguments: {
length: 0
},
scope: undefined,
f: reference to function f(){}
},
Scope: [AO, globalContext.VO],
this: undefined
}6、checkscope函数执行阶段,赋值
checkscopeContext = {
AO: {
arguments: {
length: 0
},
scope: "local scope",
f: reference to function f(){}
},
Scope: [AO, globalContext.VO],
this: undefined
}7、遇到到f函数,内部[[scope]]属性产生,并放入父变量对象
f.[[scope]]=[checkscopeContext.AO,globalContext.VO]
8、返回函数f,此时checkscope函数执行完成,弹栈
ECStack=[
globalContext
]9、执行f函数,创建f函数上下文,压栈
ECStack=[
globalContext,
fContext
]10、初始化f函数的上下文
fContext={
AO:{
arguments:{
length:0
}
},
Scope:[AO,checkscopeContext.AO,globalContext.VO]
this:undefined
}11、checkscope函数执行阶段,赋值
12、找到scope变量,返回,此时f函数执行完毕,弹栈
ECStack=[
globalContext,
]在上面我们已经讲过 HTTP 传输数据时,有一个字段是 Accept-Encoding,它代表客户端支持的数据压缩的格式,这样服务器就可以选择其中一种,放到 Content-Encoding 中,再把原来的数据压缩后发送给浏览器。
如果压缩率有50%,那么原来100k 的数据就可以压缩成50k 大小,极大地提升传输效率。
这种压缩方式非常适合文本如(text/html)的压缩,不过并不适合传输图片、音频视频等数据,因为它们本身已经高度压缩了。
除了数据压缩之外,还可以把大文件整体变小,分解成很多个小块,这样就可以把小块分发给浏览器,浏览器收到后复原。
这种方式有个好处,每次只收发一小部分,网络不会被大文件长时间占用,可以节省带宽资源。
这种方法在 HTTP 中叫 chunked 分块传输,在响应报文里用头字段 Transfer-Encoding:chunked 来表示。意思是报文的 body 可以分成多次发送。
分块传输可以用于流式数据,例如数据库动态生成的表单页面,这种情况下 body 数据的长度是未知的,无法在头字段 Content-Length 里给出确切的长度,所以也只能用 chunked 方式分块发送。
“Transfer-Encoding: chunked”和“Content Length”这两个字段是互斥的,也就是说响应报文里这两个字段不能同时出现,一个响应报文的传输要么是长度已知,要么是长度未知(chunked)。
分块传输就是把大文件分成很多个小块,那么假设我希望获取大文件中特定的片段数据,显然没办法用分块传输做到。
HTTP 协议中,还有一种范围请求可(range requests)的概念,允许客户端在请求头里面使用专用字段来表示只获取文件的一部分。
在做范围请求前,需要 Web 服务器在响应头上使用字段 Accept-Ranges:bytes,明确告知客户端支持范围请求。不支持则可以不传这个字段或者设置为 none
请求头 Range 是 http 范围请求的专用字段,格式是 bytes=x-y,其中 x和 y 是以字节为单位的数据范围。
需要注意 x、y 表示的是偏移量,范围从0计算,比如前10个字节表示为0-9.
其中 x 和 y 是可以省略的,0-表示文档起点到终点,-1表示文档最后一个字节,-10表示从文档末尾倒数10个字节。
服务器收到 Range 字段后,需要做四件事
检查范围是否合法。不合法可以返回416编码。
范围正确,服务器需要根据 Range 头计算偏移量,读取文件的片段,返回206 Partial Content,表示 body 只是数据的一部分
服务器需要加上响应头 Content-Range,告诉片段的实际偏移量和资源的总大小,格式则是bytes x-y/length,和请求头的 Range 字段区别是没有=号且范围后多了总长度。
最后发送数据了
范围请求的常见应用是视频的拖拽进度和多段下载、断点续传等。
范围请求还支持一次获取多个片段数据,可以在 Range 中使用多个x-y。
这种情况需要一种特殊的 MIME 类型:multipart/byteranges,表示报文的 body 是由多段字节序列组成的,并且还要给一个参数 boundary=xxx给出段之间的分割标记。
压缩 HTML 等文件是传输大文件的基本方法
分块传输可以流式收发数据,节省内存和带宽。使用响应头 Transfer-Encoding:chunked
范围请求可以只获取部分数据。主要应用于断点续传和视频拖拽等。使用请求头字段 Range 和响应头字段 Content-Range。相关响应状态码416和206
也可以一次性请求多个范围,此时响应报文的Content-type 是multipart/byteranges,body 部分多个部分会用 boundary 字符串分隔。
JavaScript是没有类这个概念的,区别于其他传统的强类型语言,例如Java,JS的类(构造函数)在设计根本上就有本质的不同,Java的类是代码的拷贝,而JS则用了原型链继承而已,所谓的构造函数只不过就是个普通函数,(只是大家习惯在使用时大写,这事也就成了规范)。
ES6的class本质上是构造函数的语法糖,只是这个语法糖写得更像是Java,为了做区分,我将在这篇博客上专门对比class和es5构造函数的不同写法
通过构造函数,我们能更了解JS的原型链设计原理,下面是构造函数的基本用法
function Person(name,age){
this.name=name
this.age=age
}
const p=new Person('jack',23)class Person{
constructor(name,age){
this.name=name
this.age=age
}
}
const p=new Person('jack',23)Person.prototype={
constructor:Person,
fn1(){},
fn2(){}
}class Person{
constructor(name,age){
...
};
fn1(){};
fn2(){};
}function Person(name,age){
...
this.saiHi=function(){console.log(this.name)}
}class Person{
name='';
age='';
constructor(name,age){
...
};
fn1(){};//prototype上的
fn2(){};
sayHi=function(){console.log(this.name)} //自有的
}构造函数的静态属性指的是构造函数自己能访问
Person.prop1='staticProp1'
Person.prop2='staticProp2'class Person{
static prop1='staticProp1'
static prop2='staticProp2'
constructor(name,age){
...
};
fn1(){};//prototype上的
fn2(){};
sayHi=function(){console.log(this.name)} //自有的
}Person.staticFn=function (){}class Person{
...
static staticFn=function(){}
constructor(name,age){
...
};
...
}function Person(name,age){
let _selfName='123456' //构造函数私有属性,无法被外部直接访问
let _selfFn=()=>{return _selfName} //构造函数私有方法,无法被外部直接访问
this.saiHi=function(){console.log(_selfFn())} //实例的自有方法
}在变量名前加_,这种写法是开发者自己定义的,用来区分一下私有字段
class Person{
#selfName='123456'
#selfFn=()=>{return this.#selfName}
constructor(name,age){
...
};
sayHi=function(){console.log(this.#selfFn())}class写法采用#关键字符来定义,如果想访问,需要加上this
由于私有字段无法直接访问,只好通过sayHi方法来变相访问了。
function Person(name,age){
let _selfName='123456' //构造函数私有属性,无法被外部直接访问
let _selfFn=()=>{return _selfName} //构造函数私有方法,无法被外部直接访问
this.name=name //实例的自有属性
this.age=age
this.saiHi=function(){console.log(_selfFn())} //实例的自有方法
}
Person.prototype={ //实例的共有方法
constructor:Person,
fn1(){},
fn2(){}
}
Person.prop1='staticProp1' //构造函数的自有属性
Person.prop2='staticProp2'
Person.staticFn=function (){} //构造函数的自有方法
const p=new Person('jack',23)class Person{
name='';//这里也可以写实例的属性
age='';
static prop1='staticProp1'//构造函数的自有属性
static prop2='staticProp2'
#selfName='123456'//构造函数私有属性,无法被外部直接访问
#selfFn=()=>{return this.#selfName}//构造函数私有方法,无法被外部直接访问
constructor(name,age){
this.name=name//实例的自有属性
this.age=age//实例的自有属性
};
fn1(){};//实例的共有方法
fn2(){};//实例的共有方法
sayHi=function(){console.log(this.#selfFn())}//构造函数的自有方法
}
const p=new Person('jack',23)采用构造函数方法可以分成两步实现。
第一步是在子类的构造函数中,调用父类的构造函数。
function Super(name){
this.name=name
}
function Sub(name,age){
Super.call(this,name)
this.age=age
}上面代码中,Sub是子类的构造函数,this是子类的实例。在实例上调用父类的构造函数Super,就会让子类实例具有父类实例的属性。
第二步,是让子类的原型指向父类的原型,这样子类就可以继承父类原型。
Super.prototype.sayHi=function (){console.log('hi')}
Sub.prototype = Object.create(Super.prototype);
Sub.prototype.constructor = Sub;//这句可加可不加,建议加要注意不要直接Sub.prototype=Super.prototype,这样虽然也是有用的,但是就相当于两个构造函数共用一个原型,万一以后修改Sub或者Super其中一个的原型就会影响双方。
最好的方法就是使用Object.Create直接改造子构造函数的原型,让子构造函数的__proto__连接到父构造函数的原型上。
class Person{
name;
age;
constructor(name,age){
this.name=name
this.age=age
}
sayHi(){
console.log(this.name)
}
}
class Man extends Person{
constructor(name,age,prop){
super(name,age)//这里调用
this.prop=prop
}
}
const a=new Man('qiuyanxi',20,'帅')class的形式非常方便,目前子类已经能使用父类的方法了,而且无需再去关联子类和父类的原型链,extends关键字已经帮我们做好了工作
Man.prototype.__proto__===Person.prototype //true
Man.__proto__ ===Person //true //注意,这是class自动实现的class方法比ES5的方法多一种关系,ES5的方法并没有把子类的__proto__跟父类做关联,而class的写法则是自动做了关联。不过如果ES5想要实现的话也可以用Object.setPrototypeOf(Man,Person)关联
//传统ES5继承手动挡
//原来
Sub.__proto__ ===> Function.protoyype
Super.__proto__ ===> Function.protoyype
//使用Object.setPrototypeOf(Sub,Super)后
Sub.__proto__ ===>Super===>Super.__proto__===>Function.prototype
//使用Sub.prototype = Object.create(Super.prototype)后;
Sub.prototype.__proto__ ===> Super.prototypeclass的语法从未来来看,更多的新人朋友们可能会非常喜欢,这也非常符合学过JAVA的科班生,不过Js跟Java之间的差别还挺大的,还是建议能够在实践class的基础上,了解构造函数的工作原理,这能够帮助我们更好地理解Js这门不完美但是非常优秀的语言
https://wangdoc.com/javascript/oop/prototype.html
https://wangdoc.com/es6/class-extends.html
https://developer.mozilla.org/zh-CN/docs/Web/JavaScript/Reference/Classes
return代替 if``else嵌套式的代码非常丑陋,难以阅读,比如说
function fn(name,age){
if(name){
if(age){
console.log('有 name 有 age')
}else{
throw new Error('没有age')
}
}else{
throw new Error('没有name')
}
}提前 return 能够提高代码阅读性
function fn(name,age){
if(!name)throw new Error('没有 name')
if(!age)throw new Error('没有 age')
console.log('有 name 和 age')
}假设我现在需要一段代码判断属于哪种类型,一般来说会这样写
function fn(name){
if(typeof name==='string'||typeof name==='number'){
console.log('类型正确')
}else{
console.log('类型不正确')
}
}现在我可以这样修改
function fn(name){
var result=['string','number'].includes(typeof name)?'类型正确':'类型不正确'
console.log(result)
}是不是美观很多?
有时候函数没有传递参数,我们需要在代码中写这样的代码
const isBabyPet = (name, age) => {
if (!pet) pet = ‘cat’;
if (!age) age = 1;
if (age < 1) {
// Do something
}
};在函数体内写这样的代码非常冗余,所以我们可以使用函数默认值
const isBabyPet = (pet = ‘cat’, age = 1) => {
if (age < 1) {
console.log(‘baby’);
}
};如果给了您一些宠物,并要求检查所有宠物是否有四只脚怎么办?
比如:
const pets = [
{ name: ‘cat’, nLegs: 4 },
{ name: ‘snake’, nLegs: 0 },
{ name: ‘dog’, nLegs: 4 },
{ name: ‘bird’, nLegs: 2 }
];
const check = (pets) => {
for (let i = 0; i < pets.length; i++) {
if (pets[i].nLegs != 4) {
return false;
}
}
return true;
}
check(pets); // false我们会用到 for 去循环遍历这个数组,然后再用 if 来判断。
其实一条语句就可以简化:
let areAllFourLegs = pets.every(p => p.nLegs === 4);让我们稍微更改一下任务。 现在,我们将检查至少一只宠物是否有四只脚。 这时候我们可以使用 Array.some
let check = pets.some(p => p.nLegs === 4);在 React Reducer 中我们经常会这样写代码
const getBreeds = pet => {
switch (pet) {
case ‘dog’:
return [‘Husky’, ‘Poodle’, ‘Shiba’];
case ‘cat’:
return [‘Korat’, ‘Donskoy’];
case ‘bird’:
return [‘Parakeets’, ‘Canaries’];
default:
return [];
}
};
let dogBreeds = getBreeds(‘dog’); //[“Husky”, “Poodle”, “Shiba”]这里写了好多 case return,看到这样的代码,我们就要想,能不能优化它。
看看下面的表结构编程
const breeds = {
‘dog’: [‘Husky’, ‘Poodle’, ‘Shiba’],
‘cat’: [‘Korat’, ‘Donskoy’],
‘bird’: [‘Parakeets’, ‘Canaries’]
};
const getBreeds = pet => {
return breeds[pet] || [];
};
let dogBreeds = getBreeds(‘cat’); //[“Korat”, “Donskoy”]引入组件时,经常会写这样的代码:
import DropContainer from '@/components/DropContainer';
import DragControlItem from '@/components/DragControlItem';
import ButtonController from '@/components/ButtonController';
import DnDContainer from '@/components/DndContainer';
import Button from '@/components/Button';优化方法:
在 components 文件夹下建index 文件,统一导出:
export { default as Button } from './Button';
export { default as ButtonController } from './ButtonController';
export { default as DndContainer } from './DndContainer';
export { default as DragControlItem } from './DragControlItem';
export { default as DropContainer } from './DropContainer';然后在需要用的地方:
import { DropContainer, DragControlItem, ButtonController, DndContainer, Button } from '@/components';也可以这样
import * as components from '@/components';
const { DropContainer, DragControlItem, ButtonController, DndContainer, Button } = componentscall的作用就一句话:call 能够显式地绑定函数中的 this并调用函数。
参数
function.call(thisArg, arg1, arg2, ...)例子
function foo(){
console.log(this.age)
}
const obj={age:'18'}
foo() // undefined
foo.call(obj) // 18上面的例子中,call 显示地将 obj 绑定到 foo 函数中的 this 上,所以能够打印出 obj 的属性 age
了解原理后,我们直接开写
Function.prototype.likeCall=function (thisArg,...args){
thisArg.func=this //这里的 this 是 foo.call 中的 foo 函数,谁调用call,this 就是谁
const result=thisArg.func(...args)
delete thisArg.func //记得删除
return result
}有了 ES6的语法加持,我们很快就可以实现。
apply 跟 call 的唯一区别就是apply 第二个参数接收一个数组
参数
function.apply(thisArg, arrayArg)我们直接改写就行
Function.prototype.likeApply=function (thisArg,args){
thisArg.func=this //这里的 this 是 foo.apply 中的 foo 函数,谁调用apply,this 就是谁
const result=thisArg.func(...args)
delete thisArg.func //记得删除
return result
}bind() 方法创建一个新的函数,在 bind() 被调用时,这个新函数的 this 被指定为 bind() 的第一个参数,而其余参数将作为新函数的参数,供调用时使用。——MDN
示例
this.x = 9; // 在浏览器中,this 指向全局的 "window" 对象
var module = {
x: 81,
getX: function() { return this.x; }
};
module.getX(); // 81
var retrieveX = module.getX;
retrieveX();
// 返回 9 - 因为函数是在全局作用域中调用的
// 创建一个新函数,把 'this' 绑定到 module 对象
// 新手可能会将全局变量 x 与 module 的属性 x 混淆
var boundGetX = retrieveX.bind(module);
boundGetX(); // 81Function.prototype.likeBind=function (thisArg,...args1){
thisArg.func=this
return (...args2)=>{
thisArg.func(...args1,...args2)
delete thisArg.func
}
}这样基于柯里化的方式,不但可以在绑定bind调用时传递第二个参数,还可以在调用后加参数。
const boy={name:'qiuyanxi'}
function foo(args){
console.log(this.name)
console.log(args)
}
foo.likeBind(boy,'123')()
foo.likeBind(boy)('123')
// 'qiuyanxi'
// '123'
只是这个方法缺点也很显而易见,当没调用 bind方法返回的函数时,func 存在于传递的 thisArg 中。
Function.prototype.likeBind=function (asThis,...args){
const fn=this //这里是把取到调用bind的fn
return (...args1)=>{
return fn.likeCall(asThis,...args,...args1)
}
}Function.prototype.likeBind = function () {
var fn = this;
var args=Array.prototype.slice.likeCall(arguments)//由于 arguments 没有 Array 的原型,所以用这种方式调用 slice 方法
var asThis = args[0];//获取到要绑定的this
var args1 = args.slice(1);//获取到参数1
return function () {
var args2 = Array.prototype.slice.likeCall(arguments);//获取到参数2
return fn.likeApply(asThis, args1.concat(args2));
};
};
完成了~
enjoy!
数组(Array)是一种线性表数据结构。它用一组连续的内存空间,来存储一组具有相同类型的数据。
什么是线性表呢?线性表就是数据像一根线一样排列,它只有前和后的方向。
链表、队列、栈也是同样的线性表结构。
与线性表对立的概念叫非线性表,比如二叉树、图、堆等就是非线性表,因为它的数据之间并不单单只有前和后的关系。
在 JS 中,我们有时候可能不会定义具有相同类型的数据,不过数组的连续性在各语言中是相同的。由于有了连续性,所以我们可以对数组进行随机访问。
但同样也是因为数组是连续的,所以当我们要插入或者删除数组中元素时,效率是低下的。
试想一下如果要在数组的中间插入一个元素,那么就需要将插入位置后面的元素都后移。
假设现在我们定义一个数组a,数组a内都是 number 类型,长度为10。
计算机给这个数组一块内存空间,假设为1000-1039,那么内存的首块内存是从1000开始的。
base_address = 1000当我们需要随机访问一个数据时,计算机会根据我们传入的下标 i,动态计算出需要访问的数据的内存地址,然后再传给我们。
这个公式是这样的
target_address = base_address + i * data_size这个 data_size 就是数组中元素的内存大小。由于number 数据的字节为4个字节,所以就可以计算出最终要访问的地址。
数组适合查找,链表适合插入删除。
数组支持随机访问,根据下标进行随机访问的复杂度为 O(1)。
假设目前有个数组长度为 n,我们需要在它的第 k 个位置插入一个元素,为了将 k 位置腾出来,我们只能将从原来 k~n-1的位置上的元素给往后移一位。
当 k 为最后一个位置时,我们不需要移动任何,这时候时间复杂度为 O(1)。
如果 k 为第一个位置,那么就需要将 n 个元素都往后移一位,那么时间复杂度就是 O(n)。
如果 k 为其他位置,那么我们通过平均时间复杂度计算,就是(1+2+3+...+n)/n,最终时间复杂度依然为 O(n)。
当我们在一个无序的数组中,需要将某个数据插入到一个位置时,最简单、时间复杂度最低的一个办法就是将原先那个位置的数据放到最后,然后直接将新数据放到那个位置上。这时候时间复杂度为 O(1)。
举个例子,我有一个长度为5的数组array,里面的元素为 a,b,c,d,e
现在我需要将 x 元素放到第三个位置,步骤是这样的:
先将c 放到array[5],然后让元素 x 赋值给array[2]
利用这个技巧,时间复杂度就会降为 O(1)。
线性查找法是最简单的算法。什么是线性查找法呢?
在生活中假设我们需要从一沓试卷中找到自己的试卷该怎么做?一般我会这么做:
翻第一张:是吗?不是
翻第二张:是吗?不是
...
翻第五张:是吗?是的
结束。
这就是线性查找法,从前往后一直查找。这种算法跟数组 for 循环 + 索引查找元素一样的,所以我们可以写这样一段代码
//线性查找法
function LinearSearch<T>(data: Array<T>, target: T) {
for (let i = 0; i < data.length; i++) {
if (data[i] === target) return i;
}
return -1;
}
console.log(LinearSearch<number>([1, 2, 3, 4, 5], 6));//-1
console.log(LinearSearch<string>(["1", "2", "3", "4", "5"], "4"));//3上面的代码中,我们已经知道函数的循环体功能是确定是否目标
当第二轮 for 循环开始时,我们可以得知 data[0]并不是目标。
所以我们可以确认,每当循环开始时,有一个条件肯定是不变的:
data[0...i-1]没找到目标
比如,当 i 为1时,它的前提就是上一轮循环data[0]没有找到目标。
当 i 为2时,它的前提就是上一轮循环data[1]没有找到目标。
那么这个前提就是循环不变量。
循环体所维持的就是这个循环不变量。
循环不变量主要作用就是证明算法的正确性,因为这是一个前提条件,只有明白循环不变量到底是什么,才能帮助我们厘清目标,写出正确的代码。
可迭代(Iterable) 对象是数组的泛化。这个概念是说任何对象都可以被定制为可在 for..of 循环中使用的对象。
数组是可迭代的。但不仅仅是数组。很多其他内建对象也都是可迭代的。例如字符串也是可迭代的。
Iterator 就是针对那么多可迭代的数据结构中是一种统一的接口机制,只要部署了这个接口,就可以被依次遍历处理。
Iterator 的遍历过程是这样的:
{value:any,done:boolean}下面我们通过一个例子快速了解核心概念。
需要知道的是,对象默认是没有 Iterator 接口的,所以它不能被 for..of 循环。这里我们手动给它设置 Iterator 接口。
let range={
from:0,
to:5
}如果能让上面的range对象通过for..of循环打印出0、1、2、3、4、5。这就代表 iterator 接口部署成功了
1.首先我们要给它设置一个属性,这个属性只能通过Symbol.iterator访问,这个属性保存一个函数。
range[Symbol.iterator]=function(){}这个 Symbol.iterator是部署的开始,当 for..of 开始循环时,会调用Symbol.iterator函数
2.Symbol.iterator函数会返回一个对象,内部有一个 next 方法,并返回{value:xxx,done:boolean}这样的对象。
// 由for...of 调用range[Symbol.iterator]()并返回 Iterator 对象
range[Symbol.iterator]=function(){
// 返回一个iterator 对象
return {
first:0,
last:5,
next(){
//这里的 this 指向iterator 对象,由 for..of 每次循环时自动调用该对象的 next 方法
if(this.first<=this.last){
return {value:this.first++,done:false}
}else{
return {done:true}
}
}
}
}3.打印信息
for(let i of range){
alert(i)
}
会依次打出0-5的数,Iterator接口部署成功了。
如果需要部署 Iterator 接口,我们需要手动添加 Symbol.Iterator属性。
这个属性保存着一个函数,当 for..of 开始时,就会调用该函数,并返回Iterator 对象,此时指针初始化。
Iterator对象内部保存着一个 next 函数,for..of 的每次循环都会调用到Iterator对象中的next 函数,所以这时候的 this 指向 Iterator 对象。
next函数会返回{value:xx,done:boolean}的数据结构。 当 done 为 true 时,循环停止。
for..of循环每次都会取返回结果的value属性
数组跟字符串内置了 Iterator 接口,所以我们可以直接使用 for..of来循环,比如下面的字符串
for(let str of 'strings'){
console.log(str)
}
// s t r i n g s
下面我们直接获取它的Symbol.iterator属性,来看看到底发生了什么。
我们已经知道这个属性保存着一个函数,这个函数会返回 Iterator 对象,所以我们直接调用拿到这个对象。
let strings='strings'
let Iterator=strings[Symbol.iterator]()这个对象内部会执行 next 方法,返回{value:xx,done:boolean}对象
Iterator.next()
//{value: "s", done: false}现在我们得出一个结论:可迭代对象就是内部部署了 Iterator接口的对象,这个部署 Iterator 接口的标志是内部有 [Symbol.iterator]属性。
我们可以通过浏览器打印出来看一下,比如例子中的strings 的原型上就有[Symbol.iterator]属性,它是一个函数。
我们直接调用这个方法,然后看看内部到底是个啥
可以看到返回的StringIterator 的原型上有个 next 方法。
可迭代对象的概念就是实现[Symbol.iterator]方法的对象
伪数组和数组一样,本质上是个对象,但是数组有数组原型(Array.prototype),而伪数组没有数组原型。
通过上面的截图我们知道[Symbol.iterator]会部署在原型上,比如数组原型、字符串原型里就有部署这个属性。
对象以及其原型是没有部署 Iterator 接口的。伪数组既然没有数组的原型,那就不一定有 Iterator 接口。
比如下面是一个伪数组
let arrayLike = { // 有索引和 length 属性 => 类数组对象
0: "Hello",
1: "World",
length: 2
};它的原型直接连接到 Object.prototype 上,所以它没有数组的共用方法。比如 push,pop 等等。
如果希望实现,那可以采用Array.from。
Array.from(arrayLike)
这样这个伪数组就具备 Iterator 接口了。
有没有一种伪数组虽然没有数组的原型,但是却默认部署 Iterator 接口的呢?
有的,任何可以被扩展运算符变成数组的伪数组都有Iterator接口。
比如arguments虽然没有数组的原型,但是却具有 [Symbol.iterator] 接口
也许你会认为扩展运算符能把所有伪数组变成数组,不过这只对了一半。
扩展运算符只能把已经具备 Iterator 接口的数据变成数组。不信我们看
结论就是只要你部署了Iterator 接口,才能用扩展运算符转化为数组。可不要弄反顺序噢。
Iterator 是一个接口,具备 Iterator 接口的特点是内部有[Symbol.iterator]属性。这个属性保存着一个会返回 Iterator 对象的函数。
Iterator对象内部具备 next 方法,会返回键名为 done 和 value 的对象。
for..of 遍历器为部署了 Iterator 接口的数据结构而生,当使用 for..of 遍历时,会首先调用[Symbol.iterator] 方法,生成Iterator对象,每次循环都会调用这个对象内部的 next 方法。
有一些伪数组没有部署Iterator 接口,所以不能被扩展运算符转化为数组。这时候需要采用 Array.from方法。
Symbol.iterator 方法会被 for..of 自动调用,但我们也可以直接调用它。
内置的可迭代对象例如字符串和数组,都实现了 Symbol.iterator。
在 TCP/IP的协议栈中,传输数据基本上都是 Header+body 的格式,在传输过程中加上各自的头,它们并不关心 body 的数据是什么,只要把数据发送出去就可以了。
HTTP 并不是这样的,它是应用层的协议,数据到达之后的工作只完成了一半,它还必须告诉上层应用这是什么数据。
假设 HTTP 没有告知数据类型的功能,服务器把数据发送给浏览器,那么浏览器该怎么办?
它可以靠猜测,很多数据都是有固定格式的,所以通过代码检查数据的前几个字节也许就可以知道这是个 gif 或者是 mp3文件,但这样做无疑是低效的。
在 HTTP 诞生之前就已经有了针对这种问题的解决方法,这就是应用于电子邮件系统的 MIME(多用途互联网邮件扩展),他可以让电子邮件发送除了 ASCII 码外的数据。
HTTP 借鉴了一部分,用来标记 body 的数据类型,这就是我们经常听到的 MIME type
MIME 把数据分成八类,每个大类下继续分成子类,形式是 type/subtype的字符串,这刚好可以纳入 HTTP 头字段中。
常用类别:
text:即文本格式的可读数据,我们常见的就是 text/html,表示超文本文档。此外还有text/plain 和 text/css。
image:图像文件,常见 image/gif、image/jpeg、image/png 等。
audio/video:音频和视频数据,例如 audio/mpeg、video/mp4等。
application:数据格式不固定,由上层应用程序解释。常见的有 application/json、application/JavaScript、application/pdf 等。如果实现不知道数据是什么,就会是 application/octet-stream,即不透明的二进制数据。
在 HTTP 传输时,为了节约带宽,有时候还会压缩数据,为了不让浏览器继续猜,还需要一个 Encoding type,告诉数据是用什么编码格式,这样对方才能够正确解压缩,还原出原始的数据。
比起 MIME type ,Encoding type 就少很多,常用的就只有三种:
1.gzip:GNU zip 压缩格式,也是互联网流行的压缩格式。
2.deflate:zlib(deflate)压缩格式,流行程度仅次于 gzip
3.br:专门为 HTTP 优化的新压缩算法。
有了 Encoding type 和 MIME type,服务器和浏览器都可以知道body 数据的类型,那么能不能有一种字段,让双方互相协商,传递对方想要的数据呢?
有的。HTTP 定义了两个 Accept 请求头字段和两个 Content 实体头字段,用于客户端和服务器进行“内容协商”。
其中 Accept(接收)是浏览器告诉服务器希望接收什么样的数据,Content(内容)是服务器告诉浏览器传递过来的数据类型。
请求的头字段
POST /api/base/facade/file/file?action=upload HTTP/1.1
Accept: */*
Accept-Encoding: gzip, deflate, br
响应的头字段
HTTP/1.1 200 OK
content-type: application/json;charset=UTF-8
Content-Encoding: gzip
Accept字段标明客户端能够理解的MIME type,上面*/*的意思是都可以理解。多个格式之间使用,分割。
Accept:text/html,application/json
Content-Type字段标明服务器给明的实体数据的类型。这样可以方便浏览器根据数据类型做出处理,比如是 text/html 就可以将它渲染出来。
Accept-Encoding和Content-Encoding分别是浏览器支持的解压缩格式和服务器的实际的压缩格式。
这个过程可以用收发快递来类比,比如我寄出去一个快递告诉我朋友我希望拿到 xxx 类型的东西(Accept),不过这东西我知道我朋友肯定会打包寄给我,所以我告诉他我支持用什么方式来拆包装(Accept-Encoding),我朋友收到后就返回给我某种类型(Content-Type),然后告诉我用指定的方式去拆包装(Content-Encoding)。
MIME type 和 Encoding type 解决了计算机理解 body 数据的问题,那么如何解决各国语言的问题呢?
HTTP 引入了语言类型与字符集。
所谓语言类型就是我们使用的汉语、英语、日语等,而语言可能也还有下属的地方语言,所以也是采用 type-subtype的形式,唯一的区别是语言类型用-做分割。
例如:en 表示任意的英语,en-US 则表示美式英语,en-GB 表示英式英语,我们用的 zh-CN 则是汉语。
字符集是为什么而诞生呢?在计算机早期出现了很多语言环境下的字符集,比如英语下的 ASCII 码,汉语下的 GBK 等,为了做到字符的统一,Unicode 诞生了,后来随着互联网的普及,作为 Unicode的实现之一--utf-8大幅度流行,目前 utf-8也成为互联网上的标准字符集。
HTTP 同样支持语言类型的 Accept 和 Content 实体头字段。
浏览器用的头字段为 Accept-Language,允许用,分割。
Accept-Language:zh-CN,zh,en上面的头字段意思是给我zh-CN 的汉语文字,没有的话就给我随便什么汉语,实在不行就给我英文吧。
字符集在请求短则使用 Accept-Charset。
Accept-Charset:utf-8,gbk
服务器使用的头字段为Content-Language,也就是服务器告诉浏览器我传的什么文字类型。
Content-Language:zh-CN
在服务器返回的字符集则是放在 Content-Type字段的后面,用‘charset=xxx’来表示。
Content-Type:text/html;charset=utf-8
现在的浏览器由于功能太强大,一般来说不会发送 Accept-Charset,因为它支持多种字符集,而服务器也不会发送 Content-Language,而是直接告诉浏览器用什么 charset 就行了。
数据类型表示实体数据的内容是什么,使用 MIME type,相关的头部字段为 Accept 和 Content-Type
数据编码表示实体数据的压缩方式,相关的字段为 Accept-Encoding 和 Content-Encoding
语言类型表示实体数据的语言,相关的字段是 Accept-Language 和 Content-Language
字符集是实体数据的编码方式,相关的字段是 Accept-Charset 和 Content-Type
请求方法是通过指令的方式向服务器发送指示来指导服务器完成某个动作,常用的就是获取资源,那么怎么区分资源呢?
答案是用的是 URI 获取,也就是统一资源标识符。由于它经常出现在浏览器的地址栏,所以俗称为网址。
严格来说,URI 并不完全等同于网址,它包含 URl和 URN 两个部分,在 HTTP 中用的是 URL---统一资源定位符,由于 URL 实在太普及,所以经常把 URI 跟 URL 划上等号。
URI 非常重要,要搞懂 HTTP,就必须搞懂 URI。
URI 本质上是一个字符串,这个字符串的作用是唯一地标记资源的位置或者名字,它不仅可以标记万维网的资源,也可以标记邮件系统、本地文件系统等任意资源,而资源既可以是静态文本、页面数据,也可以是Java 提供的动态服务。
URI 常用形式由 scheme、host:post、path 和 query 四个部分组成。
URI 的第一个组成部分叫 scheme,也叫协议名,它表示应该使用哪种协议来访问资源。
最常见的是 HTTP 协议,另外还有经过安全加密的 HTTPS 协议等等。
在浏览器中,如果浏览器看到地址栏上有 scheme,就会调用相应的下层 API来处理 URI。
在 scheme 的后面,固定有三个字符:‘://’,它把 scheme 和后面的部分分离开。
在“://”之后,是被称为“authority”的部分,表示资源所在的主机名,通常的形式是“host:port”,即主机名加端口号。
主机可以是 IP 地址或者域名,必须要有,否则浏览器会找不到服务器。端口号有时候可以忽略,浏览器会自动根据 scheme 使用默认的端口号,常见的有 HTTP 默认端口号80,HTTPS 默认端口号是443。
有了 authority,后面的 path 部分标记着资源在哪个path 下,有了 scheme、主机名、端口号和 path,那么服务区就可以访问资源了。
URI 里面的 path 采用了类似文件系统的目录路径,早期的 UNIX 系统的文件目录就是采用/做分割的。
path部分必须以/开始。
下面分析几个实例
http://nginx.org
http://www.chrono.com:8080/11-1
https://tools.ietf.org/html/rfc7230
file:///D:/http_study/www/
第一个 URI 比较简单,协议是 http,主机名是 nginx.org,端口号是默认的80.路径被忽略了,默认为/。也就是根目录的意思。
第二个 URI 有完整的路径和端口号。
第三个 URI 则是 HTTPS 协议,端口号为默认的443,路径为/html/rfc7230
第四个 URI 则是 file 协议,表示本地文件,后面三个斜杠的含义是
://表示分割协议和 authority的部分,剩下的/表示的是路径开头,也就是根目录下的 D 盘的/http_study/www/路径。由于 file 是 URI 的特例,它允许忽略主机名,默认为localhost。
在浏览器上看到的 URI 和服务器上看到的是不一样的,例如我的掘金主页,打开F12开发者工具,点击 view source 后可以看到这样的原始请求头
服务器看到的 URI是/v1/list,对应我请求时的路径,这是因为协议名和主机名都已经出现在请求行和 Host 字段中,所以服务器只需要取删除了协议名和主机名的 URI 即可。
使用协议名+主机名+路径的方式已经可以精确定位到网络上的资源了,但我们还想附加一些额外的修饰参数来做特定的场景,比如想要获取商品列表,根据某种规则来做分页和排序,查询参数就用上派场了。
URI 后面还有一个 query 部分,它采用?开始,表示附加的要求。
查询参数 query 有一套自己的格式,往往是多个 key=value 的字符串,这个键值对不是用 Javascript 的:连接,而是用&做连接的,浏览器和客户端都按照这个格式把长串的查询参数解析成可以理解的数据结构。
https://www.youtube.com/watch?v=FUN5rfoqLLA&t=116s
上面网址中的?v=FUN5rfoqLLA&t=116s就是查询参数 query。
在 URI 中只能使用 ASCII编码,如果要用到英语之外的语言,比如汉语、日语等,还有某些特殊的 URI 会在 path、query 上出现“@&?”这些字符,而这些字符在 URI 上有特殊用途,要如何区分呢?
这就要说到 URI 的编码规则了,URI引入了编码机制,对除了 ASCII编码外的字符集或者特殊字符做了特殊操作,俗称转义。
URI 的转义规则有点简单粗暴,直接把非 ASCII 码或者特殊字符转化成十六进制字节值,再在前面加上%。
比如银河会被转义成%E9%93%B6%E6%B2%B3”
encodeURI('银河')
//"%E9%93%B6%E6%B2%B3"
decodeURI('%E9%93%B6%E6%B2%B3')
//"银河"
encodeURIComponent('你好')
//"%E4%BD%A0%E5%A5%BD"
decodeURIComponent("%E4%BD%A0%E5%A5%BD")
//"你好"上面两个JavaScript函数可以对 URI进行编码和解码。
fragment 是片段标识符,也就是速成的锚点。浏览器获取资源后根据这个锚点来直接跳转到它指示的位置,不过这个片段标识符只对浏览器有用,因为它不会像查询参数一样发送给服务器处理。
https://github.com/sudheerj/reactjs-interview-questions#table-of-contents
这里的#table-of-contents就是锚点。
URI 是用来唯一标记服务器上资源的字符串,通常也叫 URL。
URI 通常由 scheme、host:post、path 和 query 四个部分组成。
URI 会对@&?这些有特定用法的特殊字符以及汉字等非 ASCII 码的字符进行编码转义。
响应报文由响应头和响应体数据组成,响应头由状态行和头部字段组成。
以下是状态行的结构
在状态行中,协议号版本跟 原因短语(Reason)的作用不是很大,最重要的是状态码。它是一个十进制的数字,以代码的形式表示服务器的处理结果。它的意义在于表达 HTTP 数据处理的状态,客户端可以根据代码适时转换处理状态。
目前 RFC 标准规定状态码为3位数,按照100-599的范围一共分为五类,类别以百分号为标识:
1xx:提示信息,表示目前是协议处理的中间状态,需要后续操作
2xx:成功,报文已经收到并被正确处理
3xx:重定向,资源位置发生变化,需要客户端重新发送请求
4xx:客户端错误,请求报文有误,服务器没办法处理
5xx:服务器错误,服务器在处理请求时内部发生错误
在HTTP中,正确地理解并应用这些状态码不是客户端或者服务器单方的责任,是双方共同的责任。
客户端作为请求的发起方,获取响应报文后,需要通过状态码知道请求是否被正确处理,是否要再次发送请求,如果出错了原因是什么。
服务端作为请求的接收方,也要很好地运用状态码,在处理请求时,选择最恰当的状态码回复客户端,告知客户端处理的结果,指示客户端下一步行动,特别是出错时,尽量不要简单回复400、500这样含糊不清的状态码。
目前 RFC 有41个状态码,但是状态码的定义是开放的,允许自动扩展,下面是常用状态码的介绍。
1xx类状态码属于提示信息,是协议处理的中间状态,实际运用非常少,偶尔我们会遇到‘101 Switching Protocols’,它的意思是要求客户端在 HTTP 协议的基础上使用其他协议继续通信。
2xx 表示服务器成功收到并处理了客户端的请求。
200 OK:表示一切正常,服务器返回了处理结果。
204 No Content:表示状态成功,但是响应没有 body 数据。
3xx 类状态码表示客户端请求的资源发生变动,客户端必须用新的 URI 重新发送请求获取资源,也就是说的重定向。
301 Moved Permanently:永久重定向,意思是此次请求的资源已经不存在了,需要改用新的 URI 访问。
302 Found:临时重定向,意思是请求的资源还在,但是暂时需要另一个 URI 访问。
301和302都会在响应头后使用字段 Location 指明需要跳转的 URI,最终效果类似,但是语义差别很大。
比如 HTTP 升级成 HTTPS,原来的 HTTP 不打算继续用了,这时候就需要用永久重定向301跳转。
有时候服务器升级,暂时服务不可用,这时候可以配置成302临时重定向,浏览器看到302就知道是暂时的情况,不会做缓存优化,第二天还会访问原来的地址。
4xx 类状态码表示客户端发送的请求报文有误,服务器无法处理,它就是真正的错误码含义了。
400 Bad Request:通用错误码,表示请求有误,但是哪里有误没有明确说,只是笼统的错误,一般来说最好使用其他更有明确含义的状态码
403 Forvidden:表示不是客户端请求出错,而是服务器禁止访问资源,有可能是请求没有权限,或者没有登录等等原因。
404 Not Found:表示需要的资源服务器上没找到,只是现在这个状态码被服务端滥用了,只要服务器“不高兴”就直接返回404。
414 Request-URI Too Long:请求的 URL 过长。
5xx 类状态码表示客户端请求正确,但服务器处理时内部发生错误,无法返回响应数据,是服务器的错误码。
500 Internal Server Error:通用错误码,表示服务器有问题,不过是什么问题就不明说了。实际上这样的处理对于服务器是好事,因为它能够防止黑客的窥探或者分析。
501 Not Implemented:表示客户端请求的功能现在还不支持,敬请期待。
502 Bad Geteway:通常是服务器作为网关或者代理时返回的错误码,表示服务器自身正常,访问后端服务器时发生了错误。
503 Service Unavailable:表示服务器很忙,暂时无法响应服务。503是临时的状态,很可能过一段时间就不忙了,所以503响应报文中通常还会有 Retry-After 的字段,表示过多久再来试试可能就好了。
状态行在响应报文中表示服务器对请求的处理结果
状态码后的原因短语是简单的文字描述,可自定义
状态码是十进制的三位数,从100-599分为五类
1xx:不常用,表示还需要后续操作
2xx:请求并处理成功,常用200、204
3xx:请求重定向,常用301、302、304
4xx:客户端错误,常用400、403、404、414
5xx:服务器错误,常用500、501、502、503
| 分类 | 分类描述 |
|---|---|
| 1** | 信息,服务器收到请求,需要请求者继续执行操作 |
| 2** | 成功,操作被成功接收并处理 |
| 3** | 重定向,需要进一步的操作以完成请求 |
| 4** | 客户端错误,请求包含语法错误或无法完成请求 |
| 5** | 服务器错误,服务器在处理请求的过程中发生了错误 |
临时重定向和永久重定向的区别:
比如你的网站从 HTTP 升级到了 HTTPS 了,以前的站点再也不用了,应当返回 301,这个时候浏览器默认会做缓存优化,在第二次访问的时候自动访问重定向的那个地址。
而如果只是暂时不可用,那么直接返回 302 即可,和 301 不同的是,浏览器并不会做缓存优化。
作用域就是程序源代码中定义变量的区域,JS中按照作用域的范围可分为全局作用域跟局部作用域(块级作用域、函数作用域)
作用域主要用来规定JS引擎查找变量的访问权限。
作用域的类型有两种,动态作用域和词法作用域,词法作用域也称静态作用域。JS的作用域属于词法作用域
词法作用域说通俗一点就是在写代码的时候就已经确定了作用域范围。
var value = 1;
function foo() {
console.log(value);
}
function bar() {
var value = 2;
foo();
}
bar();上面的代码会打印出1,也就是说,在foo这个函数定义的时候,value这个变量就已经确定了是全局作用域下的value。
我们分析一下它的执行过程:
1、bar执行,作用域记录里面有个value变量,值为2。
2、foo执行,进入foo函数内
3、foo内部打印value变量,此时查找value变量
4、value不存在于foo函数内部,此时查找foo定义时词法作用域下的环境,查找上一层作用域,最后发现全局下有个value变量
5、打印value,结果为1。
以上属于JS词法作用域的执行过程,我们拿它和动态作用域做一个对比.
依然是上面的代码,如果打印出value的值为2,那就是动态作用域。很多语言诸如Java就是动态作用域。说白了动态作用域会按照当前的运行环境动态选择作用域范围,这样查找的变量就会发生动态变化。
动态作用域取决于函数的调用环境,如果是动态作用域的语言,那么上面代码的执行过程是这样的:
1、bar执行,作用域记录里面有个value变量,值为2。
2、foo执行,进入foo函数内
3、foo内部打印value变量,此时查找value变量
4、value不存在于foo函数内部,此时查找foo运行时的环境,发现调用foo时的作用域是bar函数,内部有个value变量
5、打印value,结果为2。
我个人觉得动态作用域更符合人类的思维。不过JS的设计也减轻阅读代码的难度。
var scope = "global scope";
function checkscope(){
var scope = "local scope";
function f(){
return scope;
}
return f();
}
checkscope(); //打印出什么var scope = "global scope";
function checkscope(){
var scope = "local scope";
function f(){
return scope;
}
return f;
}
checkscope()(); //打印出什么
var a=checkscope()
a() //打印出什么上面的代码分别执行打印的结果是什么?
上面的答案全部都是local scope
原因很简单,只需要记住JS是词法作用域,所有变量在函数定义的时候就已经跟着作用域确定好了,所以不管是处于怎样的运行环境,始终会牢牢绑定函数checkscope内部的scope变量。
小贴士:JS的作用域是静态的,那么有什么是动态的呢?答案是
this,所谓动态,就是根据运行环境变化而变化。this就是能代表变量跟随运行环境变化的关键字。
以前,为变量赋值,只能直接指定值。
let a = 1;
let b = 2;
let c = 3;现在可以这样
let [a, b, c] = [1, 2, 3];
a //1
b //2
c //3还支持嵌套解构
let [foo, [[bar], baz]] = [1, [[2], 3]];留空也是可以的
let [ , , third] = ["foo", "bar", "baz"];
third // "baz"配合rest运算符,也可以解构
let [head, ...tail] = [1, 2, 3, 4];
head // 1
tail // [2, 3, 4]不成功则为undefined
let [foo] = [];
let [bar, foo] = [1];
foo //undefined还支持不完全解构
let [x, y] = [1, 2, 3];
x // 1
y // 2唯一的限制就是需要等号右边为部署了iterator接口的数据结构,准确来说就是可以遍历的数据结构。
// 报错
let [foo] = 1;
let [foo] = false;
let [foo] = NaN;
let [foo] = undefined;
let [foo] = null;
let [foo] = {};由于等号右边的属性都不具备iterator接口,所以上面的解构赋值都会报错。
作为对比,这里放一个set数据结构,由于其具备iterator接口,所以可以采用数组的形式解构赋值
let [x, y, z] = new Set(['a', 'b', 'c']);
x // "a"对象也可以解构赋值,换一下括号就行。
跟数组解构不同的是,数组解构非常在意顺序,而对象解构则在意的是属性名是否相同。
let { foo, bar } = { foo: 'aaa', bar: 'bbb' };
foo //'aaa'
bar //'bbb'上面是从对应的对象中取到对应的属性。
变量名和属性名必须是相同的才可以成功。
let props={ foo: 'aaa', bar: 'bbb' }
let foo =props.foo
let bar =props.bar
//简化为
let {foo,bar}=props如果解构失败,同样也是undefined
let { baz } = { foo: 'aaa', bar: 'bbb' };
baz // undefined那么如果我一定要属性名和变量名不一样怎么办?
可以这样写。
let { foo:baz } = { foo: 'aaa', bar: 'bbb' };
baz // 'aaa'这实际上也说明其实对象的赋值是这样的
let { foo:foo } = { foo: 'aaa', bar: 'bbb' };只不过当对象的属性名和其属性值对应的变量名相同时,可以简写成这样
let {foo:foo}
//等于
let {foo}真正被赋值的是后者,而不是前者。
所以对象的解构赋值的内部机制是先找到同名属性,然后赋值给对应的变量。
let { foo: baz } = { foo: 'aaa', bar: 'bbb' };
baz // "aaa"
foo // error: foo is not defined上面代码中,foo只是匹配模式,需要找到对应的属性名,而真正赋予的是baz这个变量名。
嵌套数据结构也可以被解构
const node = {
loc: {
start: {
line: 1,
column: 5
}
}
};
let { loc, loc: { start }, loc: { start: { line }} } = node;
line // 1
loc // Object {start: Object}
start // Object {line: 1, column: 5}我们一定要知道的是,属性名只是匹配模式,真正要赋值的是属性值。
所以上面代码中,第一次匹配时,会匹配{loc:loc},所以loc变量是 Object {start: Object}
第二次赋值loc内的start属性对应的start变量,所以start变量是Object {line: 1, column: 5}
第三次赋值同理。
对象的解构赋值可以取到原型链上的属性
let a={age:111}
let b=Object.create(a)//把b的__proto__链接到a上
b //{}
let { age }=b
age //111
const obj1 = {};
const obj2 = { foo: 'bar' };
Object.setPrototypeOf(obj1, obj2);//把obj1的__proto__链接到obj2上
const { foo } = obj1;
foo // "bar"解构赋值支持默认值形式
// 数组解构赋值
let [foo = true] = [];
foo // true
let [x, y = 'b'] = ['a']; // x='a', y='b'
let [x, y = 'b'] = ['a', undefined]; // x='a', y='b'es6内部使用===运算符,判断位置上是否有值,所以只要一个数组成员为undefined,那么默认值就生效。
默认值可以引用其他变量,但是前提是该变量已经声明
let [x = 1, y = x] = [1, 2]; // x=1; y=2
let [x = y, y = 1] = []; // ReferenceError: y is not defined最后发生错误是因为x拿y做声明时,y还没有声明。
//对象的解构赋值
var {x = 3} = {};
x // 3
var {x, y = 5} = {x: 1};
x // 1
y // 5同样的,如果对象的属性值严格等于undefined,也会让默认值生效。
var {x = 3} = {x: undefined};
x // 3
var {x = 3} = {x: null};
x // null如果需要将一个已经声明的变量用于解构赋值,需要加上圆括号。
let x;
{x}={x:1}// SyntaxError: syntax error
({x}={x:1})
x //1由于字符串也有 iterator接口,所以可以用于解构赋值
const [a, b, c, d, e] = 'hello';
a // "h"
b // "e"
c // "l"
d // "l"
e // "o"字符串身上的 length 属性也可以被解构出来
let {length : len} = 'hello';
len // 5当等号右边是数值和布尔值时,会被转为对象。
let {toString: s} = 123;
s === Number.prototype.toString // true
let {toString: s} = true;
s === Boolean.prototype.toString // true解构赋值的规则是,只要等号右边不是对象或者数组,那么就先转化为对象。由于 undefined 和 null 没办法这样做,所以不能对它们进行解构赋值
函数参数可以用来解构,这是非常常见的用法。
function add([x, y]){
return x + y;
}
add([1, 2]); // 3同理,也可以使用默认值
function move({x = 0, y = 0} = {}) {
return [x, y];
}
move({x: 3, y: 8}); // [3, 8]
move({x: 3}); // [3, 0]
move({}); // [0, 0]
move(); // [0, 0]let x = 1;
let y = 2;
[x, y] = [y, x];这种方法不但简洁而且易懂。
函数如果需要返回多个值,就可以将其放到数组或者对象中,然后使用解构赋值的形式取出。比如 React 的 hooks ,我们一般是这样写的
const [state,setState]=useState('')这就是因为 useState 返回了一个数组,我们用解构赋值来取值。
解构赋值可以很直观地取出函数的参数
// 参数是一组有次序的值
function f([x, y, z]) { ... }
f([1, 2, 3]);
// 参数是一组无次序的值
function f({x, y, z}) { ... }
f({z: 3, y: 2, x: 1});let jsonData = {
id: 42,
status: "OK",
data: [867, 5309]
};
let { id, status, data: number } = jsonData;
console.log(id, status, number);function fn({a=1,b=2}){
console.log(a)
}
fn({b:3})const map = new Map();
map.set('first', 'hello');
map.set('second', 'world');
for (let [key, value] of map) {
console.log(key + " is " + value);
}
// first is hello
// second is worldconst { SourceMapConsumer, SourceNode } = require("source-map");我大概围绕以下总体流程来撰写这篇博客
其中还会参杂一些可能会被问到的点,比如为什么需要三次握手,为什么需要四次挥手等常考问题。
下面详细讲讲每个阶段吧。
由于计算机更擅长处理数字,但是让人去记忆ip地址会非常困难,为了解决这种问题,于是就设置了一套域名对应 ip 地址的机制.
那么DNS 解析就是通过你输入的域名找到对应的ip 地址,例如操作系统默认 localhost就会被转化成127.0.0.1被计算机读取.
url是外国人发明的,在一开始设计的时候, url 就只被允许使用字母+数字+一些特殊符号(例如下划线和句号等等)并形成标准.但是随着日本人,**人,泰国人开始上网,明显大家语言不通,假设一个**人在输入 url 时需要中文字怎么办?这就需要用到编码规则.
下面是我根据阮一峰的博客总结的url 中包含中文编码规则:
1.网址路径的编码,用的是utf-8编码。
2.查询字符串是中文的情况下会采用GB2312发送.
3.GET和POST方法的编码,用的是网页的HTML源码编码
<meta http-equiv="Content-Type" content="text/html;charset=xxxx">如果上面这一行最后的charset是UTF-8,则URL就以UTF-8编码;如果是GB2312,URL就以GB2312编码。
4.Ajax调用的URL包含汉字也就是说由Javascript生成HTTP请求各浏览器不同处理
DNS缓存记录hosts文件看看里面有没有DNS缓存DNS服务器进行递归查询下面这张图很好解释递归查询和迭代查询是什么
简单来说递归查询就是老板,只要吩咐下去(发送一次请求),然后就等着本地 DNS 域名服务器给结果.
迭代查询就是项目经理,问老板要资源(这里的老板是根DNS服务器),老板给一个联系方式,让你去找产品经理(顶级域名服务器),产品又给一个地址,我干不了,你去找开发吧(下面的各级域名服务器),反正就是给地址,需要你自己去问.
浏览器通过向DNS 服务器发送域名,然后由 DNS 服务器解析域名(找到对应的服务器 IP 地址并返回),最后由浏览器跟对应的服务器建立 tcp 连接
TCP 会进行三次握手以同步客户端和服务端的序列号和确认号.
TCP 三次握手的过程如下:
客户端发送一个带 SYN=1,Seq=X 的数据包到服务器端口(第一次握手,由浏览器发起,告诉服务器我要发送请求了)
服务器发回一个带 SYN=1, ACK=X+1, Seq=Y 的响应包以示传达确认信息(第二次握手,由服务器发起,告诉浏览器我准备接受了,你赶紧发送吧)
客户端再回传一个带 ACK=Y+1, Seq=Z 的数据包,代表“握手结束”(第三次握手,由浏览器发送,告诉服务器,我马上就发了,准备接受吧)
TCP 是可靠通信协议,必须保证接收方收到的数据是完整,有序,无差错的.
为了实现可靠传输,通信双方需要判断自己已经发送的数据包是否都被接收方收到, 如果没收到, 就需要重发。 为了实现这个需求, 很自然地就会引出序号(sequence number) 和 确认号(acknowledgement number) 的使用。发送方和接收方始终需要同步( SYNchronize )序号。
需要注意的是, 序号并不是从 0 开始的, 而是由发送方随机选择的初始序列号 ( Initial Sequence Number, ISN )开始。由于 TCP 是一个双向通信协议, 通信双方都有能力发送信息,并接收响应。因此,通信双方都需要随机产生一个初始的序列号,并且把这个起始值告诉对方。
于是整个过程就变成了这样:
结论:
TCP连接是两个端点之间的事,由于TCP连接是可靠连接,所以不管是建立连接还是关闭连接,需要两个端点都要发送请求和收到确认
上面的图中,我们可以看到浏览器发出的 SYN 会变成 ACK(ack number 变成上一个seq number+1),这是因为 ACK的作用是向对方表示,我期待收到的下一个序号。如果你向对方回复了 ack = 31, 代表着你已经收到了序号截止到30的数据,期待的下一个数据起点是31。
TCP 三次握手结束后,开始发送 HTTP 请求报文。
请求报文由请求行(request line)、请求头(header)、请求体三个部分组成,如下图所示:
get 请求没有请求体.它大概长这样
name=tom&password=1234&realName=tomson然后发送请求时会经历 HTTP缓存处理
http缓存指的是: 当客户端向服务器请求资源时,会先抵达浏览器缓存,如果浏览器有“要请求资源”的副本,就可以直接从浏览器缓存中提取而不是从原始服务器中提取这个资源。
常见的http缓存只能缓存get请求响应的资源,http缓存都是从第二次请求开始的。第一次请求资源时,服务器返回资源,并在respone header头中回传资源的缓存参数;第二次请求时,浏览器判断这些请求参数,命中强缓存就直接200,否则就把请求参数加到request header头中传给服务器,看是否命中对比缓存,命中则返回304,否则服务器会返回新的资源。
根据是否需要重新向服务器发起请求来分类,可分为(强制缓存,对比缓存).
强缓存如果生效,那么不再和服务器发生交互.
对比缓存不管生不生效,都需要跟服务器发生交互.
也就是说强缓存可以不发请求,而对比缓存都得发请求.
跟强缓存相关的 API 有 Expires 和 Cache-Control等,跟对比缓存相关的有 Etag等,两种缓存可以同时存在,但是优先级是强缓存更高.
强缓存跟缓存数据的时间有效性有关,当浏览器没有缓存数据的时候,会发送第一次请求给服务器,服务器会在响应头中附带相关的缓存规则,响应头中有关的字段就是Expires/Cache-Control.
Expires中会表明具体的到期时间,在时间内都可以进行缓存.但是这里会有一个 BUG,因为本地时间跟服务器时间不一定相同,而且本地时间可以修改,比如说我的本地时间往前调整了两年,那么浏览器的强缓存就会一直延续两年,所以这种方式已经过时不用了
Cache-Control可以设置缓存的时间,比如它有个属性为 max-age,可以设置缓存在多少秒之后失效
上面的例子就是设置了多少秒的缓存时间,这种方式比Expires靠谱得多.
对比缓存的意思就是发给服务器做一下资源对比,看看是不是需要缓存数据.
这里的资源对比需要一个标识,这个标识也是第一次请求时服务器返回给浏览器保存在浏览器缓存库中的,那么对比缓存就会发送带这个标识的请求给服务器看看是不是一样的,如果一样的话那就用缓存数据好了.判断成功后会返回304状态码.
对比成功时,由于服务器只返回响应头,不需要返回响应主体,所以数据量大大降低.
这里就需要提到缓存标识,缓存标识一共分两种:修改时间和资源唯一标识Etag
修改时间需要用到两个字段Last-Modified / If-Modified-Since
Last-Modified是第一次请求时服务器发送给浏览器的响应头字段,上面记录服务器资源的最后修改时间.
If-Modified-Since是浏览器第二次请求时发送的响应头字段,服务器通过这个响应头字段来对比一下自己的最后修改时间.
如果时间一样,说明资源没有修改过,则响应304状态码,告诉浏览器用缓存数据.
如果时间不一样,说明资源有动过,那么就响应200状态码,并把报文主体也发过去.
这个是由服务器决定规则的标识,当第一次访问时,服务器就会在响应头中带着这个标识,这个标识长这样
当再次访问服务器时,浏览器会在请求头中发送If-None-Match这个字段并附上之前的 Etag 标识,如果服务器发现有这个标识就会跟自己的唯一标识做对比.
如果一样,说明资源没改过,响应304状态码,告诉浏览器用缓存数据
如果不一样,说明资源改动过,响应200并且发最新的资源主体过去.
HTTP 缓存就类似于浏览器跟服务器中间的一个缓存数据库,至于用不用这个缓存库就需要服务器来指定.
服务器有两种方式:强制缓存和对比缓存.强制缓存比对比缓存优先级高
强制缓存不会发请求给服务器,它就是设定一个时间,这个时间可以分为 Expires 和 Cache-Control,Expires就是定一个具体的时间节点,但是有 bug,会因为服务器时间跟本地时间不同而有误差.而Cache-Control就是指定多少秒内用强制缓存.当强制缓存成功后返回200.
对比缓存就是发送一段请求给服务器,请求信息可以有两种:修改时间和唯一标识.
两种都是需要跟服务器的信息进行对比,对比成功就返回304,告诉浏览器用缓存数据,对比失败就返回200,然后把用户需要请求的数据作为资源主体发回去.
不管怎么用,服务器总算返回数据了,这里主要讲一下响应报文
响应报文由响应行(request line)、响应头部(header)、响应主体三个部分组成
(1) 响应行包含:协议版本,状态码,状态码描述
状态码规则如下:
(2) 响应头部包含响应报文的附加信息,由 名/值 对组成
(3) 响应主体包含回车符、换行符和响应返回数据,并不是所有响应报文都有响应数据
浏览器解析渲染页面分为一下六个步骤:
1、构建html树 (dom)
2、构建css树(cssom)
3、将两棵树合并成一棵树 (render tree)
4、Layout布局(文档流、盒模型、计算大小、位置)【主要动html或有关的css】
5、paint绘制(绘制颜色、阴影等)【主要动css】
6、compsite合并 根据层叠关系展示画面
这又引出另外一个回流跟重绘的问题
回流就是触发布局阶段,重绘就是触发绘制阶段.
通过上面的阶段,我们可以得知layout阶段在 paint 阶段之前, 所以得出一句话结论:
回流必将引起重绘,重绘不一定会引起回流。
当Render Tree中部分或全部元素的尺寸、结构、或某些属性发生改变时,浏览器重新渲染部分或全部文档的过程称为回流。
会导致回流的操作:
当页面中元素样式的改变并不影响它在文档流中的位置时(例如:color、background-color、visibility等),浏览器会将新样式赋予给元素并重新绘制它,这个过程称为重绘。
当数据传送完毕,需要断开 tcp 连接,此时发起 tcp 四次挥手。
TCP连接是双向传输的对等的模式,就是说双方都可以同时向对方发送或接收数据。当有一方要关闭连接时,会发送指令告知对方,我要关闭连接了。这时对方会回一个ACK,此时一个方向的连接关闭。
但是另一个方向仍然可以继续传输数据,等到发送完了所有的数据后,会发送一个FIN段来关闭此方向上的连接。接收方发送ACK确认关闭连接。注意,接收到FIN报文的一方只能回复一个ACK, 它是无法马上返回对方一个FIN报文段的。
这就是需要四次挥手的原因。
URL 的编码方式被浏览器搞出了很多种,为了保证客户端只用一种编码方法向服务器发出请求,这里就需要用到这两个函数来进行 JavaScript手动编码,
两者的不同之处在于encodeURI()更着眼于整个URL 的编码,而encodeURIComponent()适合给参数编码,就范围而言encodeURIComponent更宽广.
文章写到这里就算讲完了,上面的答案可能不全,但我尽量把我所学到的都归纳上来了。
如果还需要补充,后续我会再来更新这篇博客。
最后的最后
非常感谢你花费时间来阅读我的博客,下期再见!
google-Render-tree Construction, Layout, and Paint
本文的源码可通过这里查看
链表(Linked List)可以存储有序的元素集合, 但是不同于数组,链表中的元素在内存中并不是连续放置的。每个元素由一个存储元素本身的节点和一个指向下一个元素的引用(也称指针或链接)组成。下面是图片解释:

链表的一个好处是,在添加或者删除元素的时候,不需要移动其他元素,这一点数组就做不到。
链表的操作需要用到指针,访问数组时,可以随机访问其中一个元素(通过索引),而链表的访问元素需要从起点(表头)开始迭代链表直到找到所需的元素。
链表的增删改查可以抽象成现实中的火车,当我们需要往里面增加一列车厢时,需要断开两节车厢之间的连接,然后把车厢放进去,重新接上就可以了。
下面我们手动实现链表的 class类,在实现这个类前,我们需要先实现一个能够创建节点的类。
class CreateNode {
element;
next;
constructor(element) {
this.element = element;
this.next = null;
}
}然后开始搭建链表的类函数,以下是一个骨架
class LinkedList {
count = 0; //链表的元素数量
head: any = null; //保存第一个元素的引用
constructor() {}
}要往尾部添加元素,这里有两种场景:
第一种是链表中没有元素,那么我们创建的就是头元素。
第二种是链表中有头元素,那么我们需要遍历到链表的最后一个元素,然后在它的尾部添加一个元素。如何判断尾部呢?链表的最后一个元素的 next 属性指向的是 undefined或者 null(这里我们用 null)。我们通过这个就可以判断其为尾元素。
那么我们就可以实现 push 函数
//链表最后元素添加新元素
push(element) {
let node = new CreateNode(element);
let current; //当前引用的指针
if (!this.head) {
this.head = node;
} else {
current = this.head;
while (current.next) {
current = current.next;
}
current.next = node;
}
this.count += 1;
}首先我们根据传入的元素创建一个新的 node 节点,然后进行判断:
如果当前不存在 head,那么创建的 node 节点就变成 head。
如果当前存在 head,那么需要遍历得到最后一个元素,把创建的节点连接到最后一个元素的 next 上。
如何遍历呢?方法是创建一个指针current,首先指向 head 节点, 如果 head 节点的 next 不为 null,那么就不是最后一个元素,我们让这个指针再指向下一个元素(当前指针所在元素的 next)即可。
链表的索引跟数组是一致,都是从0开始,head 位置指向的就是第0个位置。
const LinkedList ={
count: 2,
head: {
element: 0,
next: { element: 1, next: null }
}
}上面的链表中的 element 的值跟索引是一致的。
下面我们实现一个 removeAt 方法,通过传入索引(index)来移除在该位置的元素。
//从链表的指定索引移除一个元素。
removeAt(index) {
//空链表或者传入位置大于等于链表的节点数量或者小于0,都直接不操作
if (this.head === null || index >= this.count || index < 0) {
return null;
}
//如果index 是0,则将head 引用直接改为其next
if (index === 0) {
this.head = this.head.next;
} else {
let current = this.head;
let previous; //记录要删除元素位置的上一个元素
for (let i = 0; i < index; i++) {
previous = current;
current = current.next;
}
previous.next = current.next; //上一个元素的 next 连接到下一个元素的 next,current 就没了
this.count -= 1;
}
}区别于数组的随机访问,链表的随机访问需要用循环遍历到指定位置,所以它的时间复杂度为 O(n),下面实现一个函数能够访问到指定 index 的链表元素。
//返回链表中特定位置的元素,如果不存在,返回 undefined
getElementAt(index) {
if (index >= this.count || index < 0) {
return undefined;
}
let current = this.head;
for (let i = 0; i < index; i++) {
current = current.next;
}
return current;
}下面,我们需要能够在任意位置插入元素:
//链表的特定位置插入一个新元素
insert(index, element) {
//首先,我们需要验证 index 是否在范围内,即小于 等于节点数,大于等于0。
if (index <= this.count && index >= 0) {
let node = new CreateNode(element);
//我们还需要考虑head节点,当 index 为0时,头节点就要指向新传入的元素,新元素的 next 需要指向原来 head 节点。
if (index === 0) {
node.next = this.head;
this.head = node;
} else {
//考虑完头节点,就可以使用写好的`getElementAt`方法将分别获取指定位置的上一个元素节点,以及指定位置的当前元素节点,让上一个元素节点的 next 指向 新创建的 node,新创建的 node节点的 next 指向当前元素节点就完成了插入操作。
let previous = this.getElementAt(index - 1);
let current = previous.next;
previous.next = node;
node.next = current;
}
this.count += 1;
return true;
}
return false;
}头节点插入操作

中间或者尾部添加元素

给你一个链表的头节点 head 和一个整数 val ,请你删除链表中所有满足 Node.val == val 的节点,并返回 新的头节点 。
示例 1:

输入:head = [1,2,6,3,4,5,6], val = 6
输出:[1,2,3,4,5]
示例 2:
输入:head = [], val = 1
输出:[]
示例 3:
输入:head = [7,7,7,7], val = 7
输出:[]
提示:
列表中的节点数目在范围 [0, 104] 内
1 <= Node.val <= 50
0 <= val <= 50
题目解析:
如果要遍历链表,最好在链表的头部添加一个节点,这样可以有效减少边界条件,有助于帮助我们整理思路
/**
* Definition for singly-linked list.
* function ListNode(val, next) {
* this.val = (val===undefined ? 0 : val)
* this.next = (next===undefined ? null : next)
* }
*/
/**
* @param {ListNode} head
* @param {number} val
* @return {ListNode}
*/
var removeElements = function (head, val) {
let root = new ListNode(); //创建一个根节点
root.next = head; //根节点的后面是头节点
let previous = root; //指针 previous 指向 root 节点
let current = head; //指针 current 指向头节点
//当 current指针一直存在时遍历
while (current) {
// 如果当前遍历的节点的 val 等于 val,
if (current.val === val) {
// 刚开始时让保存着 root 节点的 previous 的 next 指向下一个
previous.next = current.next;
} else {
//如果判断不成立,那么previous 节点脱离 root 的引用,变成 current 节点
//当下次循环的时候,previous 就变成了current 节点的上一个节点
previous = current;
}
// current 指针随着遍历一直改变到下一个
current = current.next;
}
return root.next;
};删除链表元素很简单,当当前指针的 val 等于 val 时,就让上一个指针previous的 next 指向当前current指针的 next节点,切掉上层节点的连接就可以了。
如何获取 previous 指针呢?一个非常简单取巧的方法是新建一个虚拟的节点 root,连接到 head 节点上,然后让 previous 指针指向root 节点。这样每次遍历时,previous 总是在 current 之上。
这种方式很方便让我们获取 previous 指针,无需增加思维负担,思路简洁清晰。我们只需要有个印象,下次循环链表时,可以采取这样简单的方式。
反转链表是一个经典的链表题,最简单的思路是采用栈来实现反转,以下是题目
给你单链表的头节点 head ,请你反转链表,并返回反转后的链表。
示例 1:

输入:head = [1,2,3,4,5]
输出:[5,4,3,2,1]
示例 2:

输入:head = [1,2]
输出:[2,1]
使用栈实现:
/**
* Definition for singly-linked list.
* function ListNode(val, next) {
* this.val = (val===undefined ? 0 : val)
* this.next = (next===undefined ? null : next)
* }
*/
/**反转链表
* @param {ListNode} head
* @return {ListNode}
*/
var reverseList = function (head) {
let current = head;
let array = [];
let root = new ListNode();
let previous = root;
while (current) {
array.push(current);
current = current.next;
}
let len = array.length;
for (let i = 0; i < len; i++) {
previous.next = array.pop();
previous = previous.next;
}
previous.next = null; //最末尾时指针 pre.next 要手动指向 null,手动解除原来的引用关系
return root.next;
};使用栈实现非常简单清晰,很多反转的题目都可以用栈实现,这里就不多解释了。
使用双指针:
双指针解题思路:
定义两个指针:pre在后,cur在前,一次走一步,直到cur为null,即到链表尾部
每次让 cur 的 next 指向 pre ,完成一次局部反转
pre指向cur,cur指向cur的下一个节点,即前进一步
var reverseList = function (head) {
let root = null; //创建 root节点,由于链表的末尾元素是 null,这里就是 null
let current = head;
while (current) {
let nextTemp = current.next; //先记住 next 节点以免丢失
current.next = root; //current.next 指向 root
root = current; //root指针 往前走一位
current = nextTemp; //current 指针往前走一位
}
return root;
};图片懒加载是一直网页性能优化的方式,随着屏幕分辨率的飞速提升,人们对电脑上的视觉效果要求日益高涨。图片作为常见的网页内容,人们对它所呈现的效果需求自然水涨船高。越高分辨的图片意味着内存占用越大,一张图片以 M 为单位已经是屡见不鲜。
我们常用的淘宝首页,里面的商品图片不但内存占用大,而且数量非常多,如果一次性全部加载出来,对网速的要求高,而且对浏览器的性能开销非常巨大。如果这时候不做一些性能优化,那么浏览器很有可能因为加载图片而变得卡顿,非常影响用户体验。
常见的图片性能优化就是图片懒加载:根据用户的交互行为触发图片加载。
现在已经买入2021年了,这时候不提浏览器自动实现的懒加载方案无疑是落伍的。这种方式非常简单,只需要给 img 添加loading属性即可
<img src="" loading="lazy" alt="" /> //告诉浏览器懒加载图片
<img src="" loading="auto" alt="" /> //告诉浏览器懒加载还是立即加载你自己选
<img src="" loading="eager" alt="" /> //告诉浏览器立即加载这种方案最初是 chrome 实现的,为了方便开发者,提升浏览器的性能,谷歌公司在chrome浏览器内部实现根据图片尺寸、大小、用户交互行为等要素自动触发优化图片加载机制。目前很多浏览器已经采用这种方案,相信以后会成为流行。
截止目前为止的兼容性报告

我们有必要了解一下浏览器使用 loading 属性实现懒加载的触发机制。
根据大神张鑫旭这篇博客浏览器IMG图片原生懒加载loading=”lazy”实践指南,有兴趣直接点进去看测试过程,这里只放测试结论:
最后,总结下,原生懒加载的5个行为特性:
- Lazy loading加载数量与屏幕高度有关,高度越小加载数量越少,但并不是线性关系。
- Lazy loading加载数量与网速有关,网速越慢,加载数量越多,但并不是线性关系。
- Lazy loading加载没有缓冲,滚动即会触发新的图片资源加载。
- Lazy loading加载在窗口resize尺寸变化时候也会触发,例如屏幕高度从小变大的时候。
- Lazy loading加载也有可能会先加载后面的图片资源,例如页面加载时滚动高度很高的时候。
跟原生浏览器支持,这里的图片懒加载是当页面的图片进入到用户的可视范围之内再加载图片,逻辑是开发者构**到的。
构思过程如下:
1.img 标签不放 src 属性,而是放诸如data-src这样的自定义属性,把图片路径放在这个属性下。
2.当图片进入可视区域时,把 data-src 的图片路径拿出来放置到 src 属性上。
3.浏览器识别到 img 属性的 src 属性,触发重渲染,显示出图片。
需要解决的问题
我们如何知道图片进入可视区域了呢?一张图表示

可视区域的高度X:使用window.innerHeight属性获取
元素距离可视区域的top 高度:使用element.getBoundingClientRect()方法返回元素的大小及其相对于视口的位置,所以可以直接取。
接下来放代码:
<div>
<img data-src="./http.png" />
</div>
<div>
<img data-src="./http.png" />
</div>
<div>
<img data-src="./http.png" />
</div>
<div>
<img data-src="./http.png" />
</div>
<div>
<img data-src="./http.png" />
</div>
<div>
<img data-src="./http.png" />
</div>
<div>
<img data-src="./http.png" />
</div>
<div>
<img data-src="./http.png" />
</div>
<div>
<img data-src="./http.png" />
</div> #app div {
border: 1px solid red;
min-height: 200px;
}let images = document.querySelectorAll("img");
let viewHeight = window.innerHeight; //可视区域高度
let n = 0; //记录已触发渲染图片的数量
function loadLazy() {
for (let i = n; i < images.length; i++) {
//判断图片的top属性是否小于可视区域高度,是就说明要设置 src
if (images[i].getBoundingClientRect().top < viewHeight) {
images[i].src = images[i].getAttribute("data-src");
// 下次循环时,从最后设置 src的图片的下一张开始
n = i + 1;
} else {
break;
}
}
}
//当浏览器滚动时,最好用防抖函数,以免太过频繁触发 scroll 事件
function debounce(handler, delay) {
let timer = null;
return function (...args) {
let context = this;
clearTimeout(timer);
timer = setTimeout(() => {
handler.call(context, ...args);
clearTimeout(timer);
}, delay);
};
}
window.addEventListener("scroll", debounce(loadLazy, 500));效果

结束~
enjoy!
如果你需要处理复杂的字符串相关的功能,可以考虑使用正则表达式。
正则有两种作用,一种是查找字符,另外一种是替换字符
在学习正式的概念之前,我们通过一系列的案例来快速了解正则,然后再深入讲解一些正则的概念。
这里推荐正则练习网站:https://regexr.com/
通过这个网站可以跟着下面的案例快速学习正则的基础知识点。
正则的写法:
let reg=/.../
...就是你想匹配的内容,比如我希望在一连串的英文中匹配我的名字:qiuyanxi,怎么办呢?
RegExr was created by gskinner.com,
qiuyanxi and yanxi is proudly qiuyanxi hosted qiu yan xi by Media QiuYanxi Temple.
我就直接写/qiuyanxi/就可以正确匹配到。
这样只能访问到第一个,如果我希望访问到所有,也就是全局文字里的 qiuyanxi,这种匹配方式,我们称之为横向匹配模式,需要用到一个修饰符 g,表示全局匹配。它是这样写的/qiuyanxi/g
可以看到,上面的模式都是精准匹配字符,哪怕大写字母也是不行的,但是我还是希望能匹配到大写字符,则可以使用 i 修饰符,它是这样写的qiuyanxi/gi
现在我们转换一下文字
My name is QiuYanxi,my skill is 666.
My name is QiuYanxi,my skill is 66.
My name is QiuYanxi,my skill is 6.我希望能够匹配里面的数字,数字一般是0-9,如果你写成10-100,正则并不能帮你找10-100的数字,因为正则是挨个字符匹配的,它不认识数字大小。所以要记得正则里面的数字都是用0-9表示的。
也就是说我希望能够匹配到0-9其中的一个,这种匹配模式,我们称之为纵向匹配,可以用字符组[]进行匹配。它是这样写的
/[0-9]/g
注意看图中的红框,它的意思是匹配到了6个字符,也就是说,上面这种写法虽然可以匹配到数字,但是每个数字都拆开来匹配了。
我们并不想这样实现,所以我希望告诉正则,我想要匹配到的数量,那么就需要用到量词
量词使用{}表示,它是这样用的
这样我们就可以完整匹配到6,66,666三个数字了。
如果不想匹配到这三个数字呢,也是可以做到的,可以使用[^...]
在中括号中 ^ 可以表示为非的意思。
在使用字符组时,我们可以用[0-9A-Za-z]表示所有数字+大小写字母的任一字符,这里有简写形式
[0-9] 简写 \d
[0-9A-Za-z] 简写 \w
[^0-9] 简写 \D
[^0-9A-Za-z] 简写 \W
以下为常用字符集
| 简写 | 描述 |
|---|---|
| . | 除换行符外的所有字符 |
| \w | 匹配所有字母数字,等同于 [a-zA-Z0-9_] |
| \W | 匹配所有非字母数字,即符号,等同于: [^\w] |
| \d | 匹配数字: [0-9] |
| \D | 匹配非数字: [^\d] |
| \s | 匹配所有空格字符,等同于: [\t\n\f\r\p{Z}] |
| \S | 匹配所有非空格字符: [^\s] |
| \f | 匹配一个换页符 |
| \n | 匹配一个换行符 |
| \r | 匹配一个回车符 |
| \t | 匹配一个制表符 |
| \v | 匹配一个垂直制表符 |
| \p | 匹配 CR/LF(等同于 \r\n),用来匹配 DOS 行终止符 |
这里以.为例,我可以匹配除换行符外的所有字符。
那要是想要匹配点怎么办?这就跟 JS 一样,用到转义符了,正则的转义符是\
上面就是只匹配点符号。
下面字符中我希望能匹配到 My,应该如何做呢?
My name is QiuYanxi,My skill is 666.
My name is QiuYanxi,My skill is 66.
My name is QiuYanxi,My skill is 6.很简单,使用/My/g就可以匹配到,但是我只想匹配到第一个 My,需要怎样做呢?还是使用^这个元字符,它放在中括号里的意思表示非,不放在中括号里则表示开头。
它是这样写的
匹配成功了,这里看到另起一行没有匹配到。这是因为对于正则来说,换行符只不过是一个符号而已,我们需要让正则知道,我们希望它能匹配多行。这时候可以使用m 这个修饰符,它跟 g 一样都属于修饰符。
以下例子就是修饰符 m 的使用
所谓有头必然有尾,结尾则使用$这个元字符。
简写字符可以帮助我们将[0-9]用更简单的\d代替,那么量词呢?量词也有一些元字符可以帮助我们简写.
上面已经介绍了量词采用大括号表示,{最少位,最大位},例如
{0,1} 可以没有,最多1
{1,} 最少1,最多不限
{0,} 零个到无限个
使用元字符来替代就是
{0,1} ==> ?
{1,} ==> +
{0,} ==> *
例如,\d{1,}表示1个数字,无上限。可以用\d+表示
另外两个元字符是一样的使用方式。这里附上常用元字符表
| 元字符 | 描述 |
|---|---|
| . | 句号匹配任意单个字符除了换行符。 |
| [ ] | 字符种类。匹配方括号内的任意字符。 |
| [^ ] | 否定的字符种类。匹配除了方括号里的任意字符 |
| * | 匹配>=0个重复的在*号之前的字符。 |
| + | 匹配>=1个重复的+号前的字符。 |
| ? | 标记?之前的字符为可选. |
| {n,m} | 匹配num个大括号之前的字符或字符集 (n <= num <= m). |
| (xyz) | 字符集,匹配与 xyz 完全相等的字符串. |
| | | 或运算符,匹配符号前或后的字符. |
| \ | 转义字符,用于匹配一些保留的字符 [ ] ( ) { } . * + ? ^ $ \ | |
| ^ | 从开始行开始匹配. |
| $ | 从末端开始匹配. |
这里面比较重要的是中括号[]字符集、小括号()分组和管道符|。
中括号字符集已经基本了解了,在纵向匹配时使用,匹配其中之一的,比如[tT]就可以匹配 t 或者 T ,在里面没有顺序。

上面的例子还可以使用小括号()和管道符|写。
小括号()是分组,表示为整体。
管道符|表示或
比较难理解的可能是小括号分组(),它是一个分组,表示一个整体,在里面也严格定义顺序。
之所以说难理解是因为它一般需要配合$进行引用替换。
My name is QiuYanxi,QiuYanxi's skill is 666.
如何转化为 QiuYanxi => 666 ?
这里就需要先引用再替换。引用就是用小括号分组对应字符再使用$取得对应引用。就像下图
上面的例子先给需要的字符加上括号,然后用$+顺序号来引用。
如(QiuYanXi)被$1引用得到QiuYanXi
(\d+)被$2引用得到666
正则表达式是匹配模式,要么匹配字符,要么匹配位置。
横向模糊匹配的意思就是匹配1个或者多个数量的意思。
主要实现方法是使用量词,比如{m,n},表示 m-n 次
var regex = /ab{2,5}c/g;
var string = "abc abbc abbbc abbbbc abbbbbc abbbbbbc";
console.log( string.match(regex) );
//=> ["abbc", "abbbc", "abbbbc", "abbbbbc"]案例中的尾数 g是表示全局匹配模式,是一个修饰符。
即在目标字符串中按顺序找到满足匹配模式的所有子串,强调的是“所有”,而不只是“第一个”。g是单词global的首字母。
纵向模糊匹配的意思就是匹配的某一个字符可以是多种可能性,不一定非要这个。
实现的方法是使用字符组,譬如[abc],表示该字符是可以字符“a”、“b”、“c”中的任何一个。
var regex = /a[123]b/g;
var string = "a0b a1b a2b a3b a4b";
console.log( string.match(regex) ); 上面就是采用字符组,意思是中间的数可以是1或者2或者3。
横向模糊匹配用来匹配数量,纵向模糊匹配用来匹配多种可能性。
横向模糊匹配用量词,纵向模糊匹配用字符组
量词用通俗的话来说就是这个字符出现多少次。
{m,} 表示至少出现m次。
{m,n} 表示至少出现m次,最多出现n次
{m} 等价于{m,m},表示出现m次。
? 等价于{0,1},表示出现或者不出现。记忆方式:问号的意思表示,有吗?
+ 等价于{1,},表示出现至少一次。记忆方式:加号是追加的意思,得先有一个,然后才考虑追加。
* 等价于{0,},表示出现任意次,有可能不出现。记忆方式:看看天上的星星,可能一颗没有,可能零散有几颗,可能数也数不过来。
贪婪匹配就是我尽可能多的匹配
惰性匹配就是我尽可能少的匹配
var regex = /\d{2,5}/g;
var string = "123 1234 12345 123456";
console.log( string.match(regex) );
// => ["123", "1234", "12345", "12345"]这是一个贪婪匹配的例子,给我的我全都要。
上面的正则表示\d我需要数字,{2,5}表示我需要2-5个,有5个就要5个。
换成惰性匹配,就是给我2个,我就够了。
惰性匹配是这样写的
var regex = /\d{2,5}?/g;
var string = "123 1234 12345 123456";
console.log( string.match(regex) );
// => ["123", "1234", "12345", "12345"]通过在量词后面加个问号就能实现惰性匹配,因此所有惰性匹配情形如下:
{m,n}?
{m,}?
??
+?
*?
对惰性匹配的记忆方式是:量词后面加个问号,问一问你知足了吗,你很贪婪吗?
需要强调的是,虽叫字符组(字符类),但只是其中一个字符。例如[abc],表示匹配一个字符,它可以是“a”、“b”、“c”之一。
如果需要匹配的字符范围很多,写不完,可以用范围表示法。这里可以使用连字符-。
比如[123456abcdefGHIJKLM],可以写成[1-6a-fG-M]。
比如26个字母小写,可以写成[a-z]
因为连字符有特殊用途,那么要匹配“a”、“-”、“z”这三者中任意一个字符,该怎么做呢?不能写成[a-z],因为其表示小写字符中的任何一个字符。可以写成如下的方式:[-az]或[az-]或[a\-z]。即要么放在开头,要么放在结尾,要么转义。总之不会让引擎认为是范围表示法就行了。
比如字符可以是任何东西,但我们不需要“a”、“b”、“c”,就可以使用排除字符^,表示取反。
此时就是排除字符组(反义字符组)的概念。例如[^abc],表示是一个除"a"、"b"、"c"之外的任意一个字符。字符组的第一位放^(脱字符),表示求反的概念。
\d就是[0-9]。表示是一位数字。记忆方式:其英文是digit(数字)。
\D就是[^0-9]。表示除数字外的任意字符。
\w就是[0-9a-zA-Z_]。表示数字、大小写字母和下划线。记忆方式:w是word的简写,也称单词字符。
\W是[^0-9a-zA-Z_]。非单词字符。
\s是[ \t\v\n\r\f]。表示空白符,包括空格、水平制表符、垂直制表符、换行符、回车符、换页符。记忆方式:s是space character的首字母。
\S是[^ \t\v\n\r\f]。 非空白符。
.就是[^\n\r\u2028\u2029]。通配符,表示几乎任意字符。换行符、回车符、行分隔符和段分隔符除外。记忆方式:想想省略号...中的每个点,都可以理解成占位符,表示任何类似的东西。
如果要匹配任意字符怎么办?可以使用[\d\D]、[\w\W]、[\s\S]和[^]中任何的一个。
上面介绍的都是基于一个模式下的匹配,但是有时候我们需要多种模式,比如说我又想在 abc 中选一个,又想在 xyz 中选一个,就可以用多选模式,通过管道符|分割
var reg=/[abc]?|[xyz]?/g
var string='xyz abc '
var string2='abc xyz'
console.log(string.match(reg))
console.log(string2.match(reg))
// => ["x"]
// => ["a"]例如要匹配"good"和"nice"可以使用/good|nice/。测试如下:
var regex = /good|nice/g;
var string = "good idea, nice try.";
console.log( string.match(regex) );
// => ["good", "nice"]正则表达式最重要的是分析过程,其次是书写,比如要匹配以下字符
var string = "#ffbbad #Fc01DF #FFF #ffE abc";分析:
1.16进制字符范围在1-9,a-z,A—Z之间
2.前面有个#号
3.3-6位
范围就是第一个条件,使用字符组
数量就是第三个条件,使用量词
var reg=/#[0-9a-fA-F]{3,6}/g
var string = "#ffbbad #Fc01DF #FFF #ffE abc";
console.log(string.match(reg))
// => ["#ffbbad", "#Fc01DF", "#FFF", "#ffE"]23:59
12:59
24:00
分析:
1.第一位数字在0-2之间
2.第二位数字在0-9之间
3.第三位数字在0-5之间
4.第四位数字在0-9之间
5.如果第一位数字是2,那第二位数字在0-4之间
6.如果第一、二位数字是24,那么第三、四位只能是00
var reg=/(([0-1][0-9]|[2][0-3]):[0-5][0-9])|24:00/
console.log( reg.test("01:09") ); // true
console.log(reg.test("24:01")); // false
console.log(reg.test("00:60")); // false如果想忽略前面的0,可以这样写
var reg=/((^(0?[0-9]|1[0-9])|[2][0-3]):(0?|[0-5])[0-9])|24:00/
console.log(reg.test("21:19") ); // true
console.log(reg.test("24:01")); // false
console.log(reg.test("23:9")); // true比如yyyy-mm-dd格式为例。
要求匹配2017-06-10
分析:
需要匹配什么范围?
年:数字,在0-9之间[0-9]
月:数字,可能是在01-09,以及在10-12之间,可以用(0[1-9]|1[0-2])
日:数字,可能是01-09,以及10-29,最大31,可以用0[1-9]|[12][0-9]|3[0-1]
需要匹配几位?
年匹配4位,月匹配两位,日匹配两位
const reg=/[0-9]{4}-(0[1-9]|1[0-2])-0[1-9]|[12][0-9]|3[0-1]/
console.log(reg.test("2017-06-10") ); //true位置是相邻字符之间的位置。比如,下图中箭头所指的地方:
在正则中,一共有6个锚字符
^ $ \b \B (?=p) (?!p)
匹配开头和结尾用^和$
^(脱字符)匹配开头,在多行匹配中匹配行开头。
$(美元符号)匹配结尾,在多行匹配中匹配行结尾。
比如我们把字符串的开头和结尾用"#"替换(位置可以替换成字符的!):
var result = "hello".replace(/^|$/g, '#');
console.log(result);
// => "#hello#"多行匹配模式时,二者是行的概念,这个需要我们的注意:
var result = "I\nlove\njavascript".replace(/^|$/gm, '#');
console.log(result);
/*
#I#
#love#
#javascript#
*/\b是单词边界
\B是非单词边界
\b是单词边界,具体就是\w和\W之间的位置,也包括\w和^之间的位置,也包括\w和$之间的位置。
\w是[0-9a-zA-Z_]表示字母、数字、大写字母和下划线。
\W是除了字母、数字、大写字母和下划线,表示取反。
比如一个文件名是"[JS] Lesson_01.mp4"中的\b,如下:
var result = "[JS] Lesson_01.mp4".replace(/\b/g, '#');
console.log(result);
// => "[#JS#] #Lesson_01#.#mp4#"上面的正则要在单词边界上加入#。
什么是单词边界呢?首先JS就是跟\w 有关的单词,其次 Lesson_01和 mp4都属于\w。
那么\W是什么呢?就是[]、空格和.
那么我们来分析一下:
[跟J之间有一个单词边界S跟]之间有一个单词边界L之间有一个单词边界.之间有一个单词边界.跟m之间有一个单词边界#是因为4属于\w,跟$结尾之间有一个单词边界知道了\b的概念后,那么\B也就相对好理解了。
\B就是\b的反面的意思,非单词边界。例如在字符串中所有位置中,扣掉\b,剩下的都是\B的。
var result = "[JS] Lesson_01.mp4".replace(/\B/g, '#');
console.log(result);
// => "#[J#S]# L#e#s#s#o#n#_#0#1.m#p#4"(?=p)和(?!p)分别代表p模式前面的位置和非前面的位置。比如
var result = "hello".replace(/(?=l)/g, '#');
console.log(result);
// => "he#l#lo"上面的代码表示插入l 前面位置的字符为#
而(?!p)就是(?=p)的反面意思,比如:
var result = "hello".replace(/(?!l)/g, '#');
console.log(result);
// => "#h#ell#o#"可以把位置的特性理解为空字符。
比如"hello"字符串等价于如下的形式:
"hello" == "" + "h" + "" + "e" + "" + "l" + "" + "l" + "o" + "";也就是说字符之间的位置,可以写成多个。
把位置理解空字符,是对位置非常有效的理解方式。
比如把"12345678",变成"12,345,678"。
需要在三位数字前面加上逗号,所以就变成了
const reg=/(?=(\d{3})+$)/g
console.log('12345678'.replace(reg,','))
// "12,345,678"不过上面的字符如果换成123456789就会变成",123,456,789"
所以我们需要排除第一个位置,首位可以用^表示。
非首位可以用位置中的?!p模式,于是就变成了
const reg=/(?!^)(?=(\d{3})+$)/g
console.log('123456789'.replace(reg,','))
//"123,456,789"括号的作用,其实三言两语就能说明白,括号提供了分组,便于我们引用它。
引用某个分组,会有两种情形:在JavaScript里引用它,在正则表达式里引用它。
我们知道/a+/匹配连续出现的“a”,而要匹配连续出现的“ab”时,需要使用/(ab)+/。
其中括号是提供分组功能,使量词+作用于“ab”这个整体,测试如下:
var regex = /(ab)+/g;
var string = "ababa abbb ababab";
console.log( string.match(regex) );
// => ["abab", "ab", "ababab"]而在多选分支结构(p1|p2)中,此处括号的作用也是不言而喻的,提供了子表达式的所有可能。
比如,要匹配如下的字符串:
var regex = /^I love (JavaScript|Regular Expression)$/;
console.log( regex.test("I love JavaScript") );
console.log( regex.test("I love Regular Expression") );
// => true
// => true这是括号一个重要的作用,有了它,我们就可以进行数据提取,以及更强大的替换操作。
而要使用它带来的好处,必须配合使用实现环境的API。
以日期为例。假设格式是yyyy-mm-dd的,我们可以先写一个简单的正则:
var regex = /\d{4}-\d{2}-\d{2}/;然后再修改成括号版的:
var regex = /(\d{4})-(\d{2})-(\d{2})/;为什么要使用这个正则呢?
比如提取出年、月、日,可以这么做:
var regex = /(\d{4})-(\d{2})-(\d{2})/;
var string = "2017-06-12";
console.log( string.match(regex) );
// => ["2017-06-12", "2017", "06", "12", index: 0, input: "2017-06-12"]match返回的一个数组,第一个元素是整体匹配结果,然后是各个分组(括号里)匹配的内容,然后是匹配下标,最后是输入的文本。(注意:如果正则是否有修饰符g,match返回的数组格式是不一样的)。
另外也可以使用正则对象的exec方法:
var regex = /(\d{4})-(\d{2})-(\d{2})/;
var string = "2017-06-12";
console.log( regex.exec(string) );
// => ["2017-06-12", "2017", "06", "12", index: 0, input: "2017-06-12"]同时,也可以使用构造函数的全局属性$1至$9来获取:
var regex = /(\d{4})-(\d{2})-(\d{2})/;
var string = "2017-06-12";
regex.test(string); // 正则操作即可,例如
//regex.exec(string);
//string.match(regex);
console.log(RegExp.$1); // "2017"
console.log(RegExp.$2); // "06"
console.log(RegExp.$3); // "12"比如,想把yyyy-mm-dd格式,替换成mm/dd/yyyy怎么做?
var regex = /(\d{4})-(\d{2})-(\d{2})/;
var string = "2017-06-12";
var result = string.replace(regex, "$2/$3/$1");
console.log(result);
// => "06/12/2017"相当于
var regex = /(\d{4})-(\d{2})-(\d{2})/;
var string = "2017-06-12";
var result = string.replace(regex, function(){
return RegExp.$2 + "/" + RegExp.$3 + "/" + RegExp.$1;
});
console.log(result);
// => "06/12/2017"除了使用相应API来引用分组,也可以在正则本身里引用分组。但只能引用之前出现的分组,即反向引用。
还是以日期为例。
比如要写一个正则支持匹配如下三种格式:
2016-06-12
2016/06/12
2016.06.12
最先可能想到的正则是:
var regex = /\d{4}(-|\/|\.)\d{2}(-|\/|\.)\d{2}/;
var string1 = "2017-06-12";
var string2 = "2017/06/12";
var string3 = "2017.06.12";
var string4 = "2016-06/12";
console.log( regex.test(string1) ); // true
console.log( regex.test(string2) ); // true
console.log( regex.test(string3) ); // true
console.log( regex.test(string4) ); // true其中/和.需要转义。虽然匹配了要求的情况,但也匹配"2016-06/12"这样的数据。
假设我们想要求分割符前后一致怎么办?此时需要使用反向引用:
var regex = /\d{4}(-|\/|\.)\d{2}\1\d{2}/;
var string1 = "2017-06-12";
var string2 = "2017/06/12";
var string3 = "2017.06.12";
var string4 = "2016-06/12";
console.log( regex.test(string1) ); // true
console.log( regex.test(string2) ); // true
console.log( regex.test(string3) ); // true
console.log( regex.test(string4) ); // falsevar regex = /\d/;
var string = "abc123";
console.log( regex.test(string) );
// => true匹配上了,我们就可以进行一些操作,比如切分。
所谓“切分”,就是把目标字符串,切成一段一段的。在JS中使用的是split。
比如,目标字符串是"html,css,javascript",按逗号来切分:
var regex = /,/;
var string = "html,css,javascript";
console.log( string.split(regex) );
// => ["html", "css", "javascript"]可以使用split“切出”年月日:
var regex = /\D/;
console.log( "2017/06/26".split(regex) );
console.log( "2017.06.26".split(regex) );
console.log( "2017-06-26".split(regex) );
// => ["2017", "06", "26"]
// => ["2017", "06", "26"]
// => ["2017", "06", "26"]虽然整体匹配上了,但有时需要提取部分匹配的数据。
此时正则通常要使用分组引用(分组捕获)功能,还需要配合使用相关API。
这里,还是以日期为例,提取出年月日。注意下面正则中的括号:
var regex = /^(\d{4})\D(\d{2})\D(\d{2})$/;
var string = "2017-06-26";
console.log( string.match(regex) );
// =>["2017-06-26", "2017", "06", "26", index: 0, input: "2017-06-26"]找,往往不是目的,通常下一步是为了替换。在JS中,使用replace进行替换。
比如把日期格式,从yyyy-mm-dd替换成yyyy/mm/dd:
var string = "2017-06-26";
var today = new Date( string.replace(/-/g, "/") );
console.log( today );
// => Mon Jun 26 2017 00:00:00 GMT+0800 (**标准时间)HTTP 采用了请求-应答的模式,也就是都说起码会有两方互相协商,在前面的章节说过,我们的 HTTP 中间还可以夹杂各种代理,相当于中间商,这就是 HTTP 代理。
在这一层级链中,起点是浏览器,中间的角色被称为代理服务器,终点则是源服务器。
代理服务本身不产生任何数据内容,而只是作为中间位置转发上下游的请求和响应,也就是说,它既可以是信息的请求方,也可以是信息的响应方。
在简单的请求-应答模式下,为什么要加上一层代理,它有什么作用呢?
代理最基本的功能是负载均衡,所谓负载均衡,就是代理服务器掌握请求分发,将不同的请求流量尽可能地分散发送给不同的源服务器,尽量避免源服务器压力过大,提高整体资源利用率。
在做负载均衡的同时,中间的代理还可以做更多的功能:
代理服务器使用字段 Via标明代理的身份。
Via 是一个通用字段,在响应或者请求都可以使用。每当报文经过一个代理节点,代理服务器就会把自身的信息追加到字段的末尾。
如果通信链路中有很多个代理,就会在 Via 里形成一个链表,这样就可以知道报文究竟走过了多少个环节才到达目的地。

图中有两个代理:proxy1 和 proxy2,客户端发送请求会经过这两个代理,依次添加就是 Via: proxy1, proxy2 ,等到服务器返回响应报文的时候就要反过来走,头字段就是 Via: proxy2, proxy1 。
Via 字段只解决了 客户端和源服务器判断是否存在代理的问题,还不能知道对方的真实信息。
但服务器的 IP 地址应该是保密的,关系到企业的内网安全,所以一般不会让客户端知道。不过反过来,通常服务器需要知道客户端的真实 IP 地址,方便做访问控制、用户画像、统计分析 。
可惜的是 HTTP 标准里并没有为此定义头字段 ,但已经出现了很多 事实上的标准 ,最常用的两个头字段是 X-Forwarded-For 和 X-Real-IP 。
字面意思是为 谁而转发 ,形式上和 Via 差不多,也是每经过一个代理节点就会在字段里追加一个信息,但 Via 追加的是代理主机名(或者域名),而 X-Forwarded-For 追加的是请求方的 IP 地址。所以,在字段里最左边的 IP 地址就客户端的地址。
是另一种获取客户端真实 IP 的手段,它的作用很简单,就是记录客户端 IP 地址,没有中间的代理信息。
如果客户端和源服务器之间只有一个代理,那么这两个字段的值就是相同的。
有了 X-Forwarded-For 等头字段,源服务器就可以拿到准确的客户端信息了。但对于代理服务器来说它并不是一个最佳的解决方案。
因为通过 X-Forwarded-For 操作代理信息 必须要解析 HTTP 报文头 ,这对于代理来说成本比较高,原本只需要简单地转发消息就好,而现在却必须要费力解析数据再修改数据,会降低代理的转发性能 。
另一个问题是 X-Forwarded-For 等头 必须要修改原始报文 ,而有些情况下是不允许甚至不可能的(比如使用 HTTPS 通信被加密 )。
所以就出现了一个专门的 代理协议 (The PROXY protocol) ,它由知名的代理软件 HAProxy 所定义,是一个 事实标准 ,被广泛采用(注意并不是 RFC)。
代理协议有 v1 和 v2 两个版本,v1 和 HTTP 差不多,也是明文,而 v2 是二进制格式。今天只介绍比较好理解的 v1,它在 HTTP 报文前增加了一行 ASCII 码文本,相当于又多了一个头。
这一行文本其实非常简单,开头必须是 PROXY 五个大写字母,然后是 TCP4 或者 TCP6 ,表示客户端的 IP 地址类型,再后面是请求方地址、应答方地址、请求方端口号、应答方端口号,最后用一个回车换行(\r\n)结束。
例如下面的这个例子,在 GET 请求行前多出了 PROXY 信息行,客户端的真实 IP 地址是 1.1.1.1 ,应答方地址是2.2.2.2,端口号是 55555。
PROXY TCP4 1.1.1.1 2.2.2.2 55555 80\r\n
GET / HTTP/1.1\r\n
Host: www.xxx.com\r\n
\r\n服务器看到这样的报文,只要解析第一行就可以拿到客户端地址,不需要再去理会后面的 HTTP 数据,省了很多事情。
不过代理协议并不支持 X-Forwarded-For 的链式地址形式,所以拿到客户端地址后再如何处理就需要代理服务器与后端自行约定。
TCP/UDP 的报文在传输的时候,都会加上头部数据,这个在上面我们已经讲过了。HTTP 协议也一样,会包装上一层数据,由于 HTTP 是超文本协议,那么实际上传输的很多东西并不需要经过解析,也可以肉眼看懂。
HTTP 请求报文和响应报文的结构基本相同,由三大部分组成
1.请求行(start line):描述请求或者响应的基本信息。
2.请求头(header):使用键值对的形式来表示表文
3.消息体(entity):实际传输的数据,有可能是纯文本,也可能是图片、视频等二进制数据。
其中请求行和请求头经常被合称请求头或者响应头。消息正文被称为“body”。
HTTP 协议规定报文必须有 header,但是可以没有 body,而且在 header 之后必须加一个空行。
在浏览器中他是这样的
这是一个请求报文:
它的第一行,是请求行,表示 GET 方式,基于 HTTP1.1版本
第二行是请求头,描述主机名、链接状态、接收方式等。
最后一行为空白行。后面没有 body
在发送 GET 请求的时候,允许没有 BODY。
虽然 HTTP 协议没有明确对 header 的大小做出限制,但是每个浏览器、Web 服务器都限制请求头以免太大可能影响运行效率。
请求行由三部分构成:
1.请求方法:是一个动词,如 GET/POST,表示对资源操作。
2.请求目标:通常是一个 URI,标记了请求方法要操作的资源。
3.版本号:表示采用的 HTTP 协议版本
这三个部分通常由空格分割,以换行CRLF结束。
在浏览器中是这样的
GET / HTTP/1.1 GET 就是请求方发。紧接着的/是目标的根目录,意思是我要访问默认资源。最后是 HTTP 版本。
状态行是在响应报文里面运行的,你也可以叫响应行,但是它也有个标准名字--状态行。意思是服务器响应的状态。
状态行分成三个部分:
1.版本号:表示报文使用的 HTTP 版本
2.状态码:一个三位数,用数字的形式表示处理的结果,比如200是成功,500是服务器错误。
3.原因:作为数字状态的补充,是更加详细的解释文字,比如帮助别人理解原因。
在浏览器中,它可能是这样的
HTTP/1.1 200 OK意思是基于 HTTP1.1版本的请求,状态码是200,一切 ok。
还有可能是这样的
HTTP/1.1 404 Not Found意思是404状态码,没有找到对应的资源。
请求行或状态行加上头部字段的集合就构成了 HTTP 完整的请求头或者响应头
请求头和响应头的结构是一样的,唯一的区别是起始行。
头部字段分为 key-value 的形式,之间使用:分割,最后以换行结束。比如“Host: 127.0.0.1”这一行里 key 就是“Host”,value就是“127.0.0.1”。
HTTP 字段非常灵活,不仅可以采用诸如 Host的标准字段,还可以使用任意的字段。所以扩展性非常强。
不过也需要注意一些细节:
字段名不区分大小写,例如“Host”也可以写成“host”,但首字母大写的可读性更好;
字段名里不允许出现空格,可以使用连字符“-”,但不能使用下划线“_”。例如,“test-name”是合法的字段名,而“test name”“test_name”是不正确的字段名;
字段名后面必须紧接着“:”,不能有空格,而“:”后的字段值前可以有多个空格;
字段的顺序是没有意义的,可以任意排列不影响语义;
字段原则上不能重复,除非这个字段本身的语义允许,例如 Set-Cookie。
HTTP 协议有非常多的头字段,可以实现各种功能,总体分为四大类:
1.通用字段:请求头或者响应头都可以出现。
2.请求字段:仅能够出现在请求头里,进一步说明请求信息或者额外条件。
3.响应字段:仅出现在响应头里,补充说明响应报文信息。
4.实体字段:也属于通用字段,描述 body 的额外信息。
下面来说几个常用字段
Host 字段:HTTP1.1中规定的必须出现的字段,表示告诉服务器这个请求应该让哪个主机处理。
User-Agent字段:请求字段,只在请求头中出现,表示发起请求的客户端。
Date 字段:通用字段,通常出现在响应头中,表示 HTTP 创建的时间。
Server 字段:响应字段,只出现在响应头中,它告诉客户端当前正则提供 Web 服务的软件名称和版本号。这个字段会把服务器的一部分信息暴露给外界,所以有可能引起黑客攻击,所以允许没有,或者给一段完全无关的描述信息。
在 github中,这个字段就没有告诉我们使用Apache 还是 Nginx。
HTTP 报文由起始行+头部+空行+实体组成,简单来说就是 header+body
HTTP 报文可以没有 body,但是必须有header 和空行。
请求头由请求行+头部字段组成,响应头由状态行+头部字段组成
请求行由请求方法、请求目标、版本号组成
状态行由状态码,附加信息,版本号组成
头部字段采用 key:value 形式,不拘束大小写,不存在顺序问题,还可以自定义字段,实现随意扩展的功能。
HTTP1.1中,必须出现 HOST 字段,它必须出现在请求头中,表示对方的主机名
Symbol 首先可以解决对象属性名重复的问题,由于对象的属性名是字符串,很容易出现重复,Symbol 会产生独一无二的类字符串的数据类型,所以不会产生冲突。
Symblol 需要如何创建呢?由于生成的是简单数据类型,不是一个对象,所以 ES6规定生成 Symbol 不能使用 new 关键字。我们可以这样生成
const s=Symbol()
console.log(typeof s)//"symbol"
const s=Symbol()
console.log(s)//Symbol()
const b=Symbol()
console.log(b)//Symbol()
s===b //false如果直接打印,会发现返回的都是 Symbol(),所以我们可以传入一个参数来添加描述 description。
const s=Symbol('s')
const b=Symbol('b')
undefined
s
//Symbol(s)
b
//Symbol(b)也可以传一个对象,当传入一个对象时,会自动在内部调用 toString 方法
const CustomToString={
toString(){
return 'abc'
}
}
const a=Symbol(CustomToString)
console.log(a)//Symbol(abc)由于传入的参数只是描述,所以即使描述是一样的,生成的 Symbol 值也是不相等的。
Symbol('abc')===Symbol('abc')
//false当我们需要区分 Symbol 时,可以通过传入的参数作为其描述来区分 Symbol,那么如果想获取其描述呢?
我们有两种方法:
let a=Symbol('a')
a.toString()
"Symbol(a)"let b=Symbol('b')
b.description
"b"Symbol 作为对象的属性名时保证不会出现同名属性,但是我们如果想要读取属性,不能直接用点来读取,而要使用中括号读取。
let a={}
let sym=Symbol()
a.sym='123'
a.sym //'123'
a[sym] //undefined这是因为当使用点的形式来读取对象的属性时,点后面的是字符串,所以实际上这是相等的
a['sym']===a.sym而 Symbol 属性被保存在 sym 这个变量名中,如果需要引用,只能这样写
a[sym]===a['sym'] //false
a[sym]='456'
a[sym] //'456'知道了 Symbol 的优点,那么究竟 Symbol 有什么用途?
当我们需要一个独一无二的东西且这个东西并不重要时可以使用,比如,当我从后端拿来数据,但是发现需要渲染到页面上的数据没有唯一的 key,这时候不一定需要 uuid,也可以自己给 key 生成一个 symbol 值。
还有一个用途是可以消除魔术字符串。
魔术字符串指的是,在代码之中多次出现、与代码形成强耦合的某一个具体的字符串或者数值。风格良好的代码,应该尽量消除魔术字符串,改由含义清晰的变量代替。
比如,当我使用 Redux 时,我可能会这样写
//页面1
dispatch({type:'add',payload})//页面2
dispatch({type:'add',payload})
...可以看到上面的add 就是魔术字符串。有可能很多个组件都会写这样的字符串,仔细看其实这个字符串也不是很重要,我们只是需要这个逻辑。
那么我可以这样写
//config
export const hashMap={
ADD:Symbol(),
REMOVE:Symbol(),
}//页面1
dispatch({type:hashMap.ADD,payload})//页面2
dispatch({type:hashMap.REMOVE,payload})
...Symbol 作为属性名,遍历对象的时候,该属性不会出现在for...in、for...of循环中,也不会被Object.keys()、Object.getOwnPropertyNames()、JSON.stringify()返回。
let a=Symbol()
obj[a]='123'
obj.b='456'
for(let i in obj){
console.log(i)
}
// '456'
目前关于 Symbol,实际应用的不是很多,就先介绍到这里,如果还有兴趣了解 Symbol 的 API,可以参见
Symbol
作为性能优化的手段,防抖和节流在前端界颇有名声,虽然网上的代码看起来封装得很复杂,但是经过一层层分解,可以知道这就是很基础的代码技巧,现在我来从最基础的代码模拟实现一遍防抖和节流。
防抖的概念就是使用清除定时器来对用户的操作进行限制,相当于一个cd条,如果打断了,就不执行(清除定时器)。
比如我现在要做一个button按钮,点击两秒钟后打出一句123,说干就干。
let btn=document.querySelector('button')
btn.addEventListener('click',()=>{
setTimeout(()=>{console.log(123)},1000)
})没有防抖前效果如下
简单做个防抖
let btn=document.querySelector('button')
let timer=null
btn.addEventListener('click',()=>{
clearTimeout(timer) //每点一次都清除上一次的timer,上一次的就不会执行
timer=setTimeout(()=>{console.log(123)},1000)
console.log(timer)
//这句代码是为了证明获取timer比console早
//只要执行了setTimeout就拿到timer了,不用执行参数函数console
})效果如下:
let btn=document.querySelector('button')
function debounce(callback, delay) {
let timer;
return function (...rest) {
clearTimeout(timer);
const context = this;
timer = setTimeout(() => {
callback.apply(context, rest);
clearTimeout(timer);
}, delay);
};
}
const handler=()=>{console.log(123)}
btn.addEventListener('click',debounce(handler,1000))优化代码思路:
逻辑是基于上面的简化版进行的函数封装,就是使用闭包,把timer包起来。
然后按照里面的内容拆开写debounce的参数,以上的参数是处理函数handler(就是console.log(123))和delay(时间),如果有更多的业务逻辑,就写更多的参数做封装就行了。
后来发现节流实际上就是不管用户点多少次,我只执行第一次。
它跟防抖的关系好比一个法师在施法,如果这个法师不断在施法,但是它的技能是可以被打断的,每打断一次都重新触发施法那就是防抖。
如果这个法师的技能不能被打断,不管你打了多少次,法师都能把刚开始的施法读条delay给做完,这就是节流。
没有节流的效果
思路:如何让上面的代码在我设置的时间范围内只跑一次呢?还是使用setTimeout实现,如果有一个开关,当开关是打开的时候,就跑代码。如果开关闭合,就不执行代码,跑代码过程中将闭合开关不就行了吗?
节流的效果
代码如下
let btn=document.querySelector('button')
const handler=()=>{console.log('初步节流')}
let toggle=true //设置一个开关
btn.addEventListener('click',()=>{
if(!toggle){//如果开关是关着的,就return
return null
}
toggle=false //此时函数正在执行,把开关闭合
setTimeout(()=>{
handler() //这里是处理业务逻辑了
toggle=true //处理完之后把开关打开
},1000)
})let btn=document.querySelector('button')
const handler=()=>{console.log('闭包封装')}
function throttle(){
let toggle=true //把toggle当做闭包
return function (){
if(!toggle){
return null
}
toggle=false
setTimeout(()=>{
toggle=true
handler()
},1000)
}
}
btn.addEventListener('click',throttle())let btn=document.querySelector('button')
const handler=()=>{console.log('封装函数')}
/*
参数:
handler: 执行函数
delay:时间
*/
function throttle(callback, delay) {
let timer;
let flag = false;
return function (...rest) {
if (flag) {
return;
}
flag = true;
const context = this;
timer = setTimeout(() => {
callback.apply(context, rest);
clearTimeout(timer);
flag = false;
}, delay);
};
}
btn.addEventListener('click',throttle(handler,2000))结束~
enjoy!
来看一个构造函数
var Person=function(){}
Person.prototype.name='qiuyanxi'
var p=new Person()
p.name==='qiuyanxi' //true
var p2=new Person()
p2.name==='qiuyanxi'在JS中,每一个构造函数在生成后都会有prototype属性,这个属性指向一个对象,此对象会给所有通过该函数生成的对象实例保存公共属性和方法。我们称这个对象为原型
不过prototype属性只会存在于函数中,实例对象是没有这个属性的,那么如何访问实例对象的原型?
每一个实例对象(包括构造函数自己其实也是Function的实例,除了null以外)都有_proto_属性。这个属性实际上就是指向原型的地址,通过这个属性,实例对象可以访问到原型身上的公共属性和方法。
var Person=function(){}
var p= new Person()
p._proto_===Person.prototype //true通过上面的代码,我们可以发现一个公式:实例对象身上的_proto_===其构造函数的prototype。
上面说到,构造函数自己也是Function的实例,那么Function身上的_proto_指向哪里?它指向Function.prototype。
每一个prototype身上都有constructor属性,这个属性指向构造函数本身。Function.prototype.constructor是Function
var Person=function(){}
Person.prototype.constructor===Person //true
Function.prototype.constructor===Function //true
Function.__proto__ ===Function.prototype //true由于constructor长在原型上面,所以实例对象是可以顺着身上的__proto__直接访问到它
var Person=function(){}
var p=new Person()
p.constructor === Person //true
p.__proto__===Pereson //true根据上面的结论,我们可以得出公式
_proto_属性,它指向其构造函数的prototypeFunction构造的,Function身上的_proto_属性指向Function.prototypeprototype身上都有constructor属性,指向构造函数每一个原型都有_proto_属性,它指向的是根原型,这个根原型刚好挂在Object()身上,取名为Object.prototype。它就是原型的原型。
var Person=function(){}
Person.prototype.__proto__ ===Object.prototype //true
Function.prototype.__proto__ ===Object.prototype //true根原型的__proto__最终指向null
Object.prototype.__proto__ ===null //trueFunction自己构造自己(所以Function.__proto__等于Function.prototype)否则推翻第一条Person.prototype.__proto__ 等于Object.prototype)Person.__proto__等于Function.prototype)上面公式其实只要死磕第一条、第二条,就可以不被原型绕晕�。
我们现在整理一下所有已知的点,画一张这样的图

原型链就是蓝色的线,当访问对象的属性时,会先找其身上的属性,如果没有,就会顺着__proto__往上查找,顶层原型Object.prototype的上面是null,意味着根原型再往上就没有东西了。
最后是关于继承,“每一个对象都会从原型‘继承’属性”,实际上,继承是一个十分具有迷惑性的说法,引用《你不知道的JavaScript》中的话,就是:
继承意味着复制操作,然而 JavaScript 默认并不会复制对象的属性,相反,JavaScript 只是在两个对象之间创建一个关联,这样,一个对象就可以通过委托访问另一个对象的属性和函数,所以与其叫继承,委托的说法反而更准确些。
函数柯里化就是把接受多个参数的函数变换成接受一个单一参数(最初函数的第一个参数)的函数,并且返回接受余下的参数而且返回结果的新函数
下面是一个例子:
function add(x,y){
return x+y
}
const curry=(fn)=>{
return (x)=>{
return (y)=>{
return fn(x,y)
}
}
}
curry(add)(1)(2)上面的curry函数接收一个多参数的函数add,并返回多个嵌套函数,每个嵌套函数的参数就是add的参数。
下面有一个面试题
需要将add(1,2,3,4,5,6) 柯里化为 curry(add)(1)(2)(3)(4)(5)(6)
思路整理
根据第一个示例,我们发现,参数跟return多少个函数有莫大的关系,所以我们可以得出,通过获取参数数量,来实现嵌套函数的目的。
//需要将`add(1,2,3,4,5,6)`
//柯里化为 `curry(add)(1)(2)(3)(4)(5)(6)`
function add(x, y) {
return x + y
}
let params = []
const curry = (fn) => {
return (x) => {
params.push(x)
if (params.length === fn.length) {
return fn(...params)
} else {
return curry(fn)
}
}
}
console.log(curry(add)(1)(2))上面的思路是当函数的参数跟外层的数组里面保存的参数是一样的时候,停止递归,然后执行 fn(...params),否则就一直递归循环。
下面是优化代码
const curry = (fn, params = []) => {
return function(x) {
const newParams = [...params, x]
if (newParams.length === fn.length) {
return fn(...newParams)
} else {
return curry(fn, newParams)
}
}
}结束~
enjoy!
TCP/IP 采用分而治之的**,将复杂的网络通信分成了四层
最下面的为第一层,往上递增。
第一层:链接层(link layer)
这一层主要负责在以太网、wifi 等这样的底层网络中发送原始数据包,工作在网卡这个层次,使用 MAC 地址来标记网络设备,所以也叫 MAC 层。
MAC 地址也称局域网地址,可以唯一标识一个网卡,也标识网卡所属的设备。
第二层:网络互连层(internet layer)
IP 协议就在这一层,因为 IP 协议定义了 IP 地址的概念,所以在链接层的基础上,用 IP 地址替代 MAC 地址,在由局域网、广域网等组成的虚拟网络中找设备时,把 IP 地址翻译成 MAC 地址就可以了。
第三层:传输层(transport layer)
这一层的职责是保证数据在两点之间可靠地传输,这一层是 TCP 所在层,同时还有一个 UDP 协议。
TCP 是可靠的、有状态的、有序的协议,必须在双方建立连接才可以发送数据,而且需要保证数据不丢失和重复。所以就诞生了那个经典的面试题:三次握手和四次挥手。
UDP 则比较简单,它没有状态也不需要事先建立连接就可以随意发送数据,但是并不保证数据一定能发送给对方。
TCP的数据是有先后顺序的,而 UDP 则是顺序发,乱序收。
第四层:应用层(application layer)
这一层就是 HTTP 协议所在的层,这里有各种面向应用的协议,除了 HTTP 外,还有负责远程终端协议的Telnet、SSH 加密等。
MAC 层传输单位是帧,IP 传输单位是包,TCP 传输单位是段,HTTP 传输单位是消息报文(message)。统称为数据包
OSI 全称“开放式系统互联通信参考模型”
在 TCP/IP协议诞生的年代,还有很多其他协议,这时候国际标准化组织就来了一个统一规范,于是设计了新的网络分层模型OSI。
国际标准化组织组织的简称是 ISO,倒过来念就是 OSI。
OSI 模型共七层,部分层次类似 TCP/IP,从下至上分别是
从特点来看,OSI 比 TCP/IP 更加完整,在补充了TCP/IP协议的细节内容后,还特地加上物理设备的层级。
由于OSI 在设计初期就参考了 TCP/IP 的分层结构,所以比较容易但不精确地表示两者的对应关系。以下图表示
由于 OSI 的七层模型分的太细,而 TCP/IP 实际应用时的会话管理、编码转换、压缩等和具体应用经常联系的很紧密,很难分开。所以就导致一个结果:
OSI 是标准协议,但是实际应用依然可以用TCP/IP协议,这样一比较,第五层会话层和第六层表示层就消失了。
现在我们已经知道了xx层的概念,那么我们就可以知道,四层指的是传输层,七层指的是应用层。
四层负载均衡指的是在传输层上,通过对 IP 地址、端口号等实现对后端服务器的负载均衡。
七层负载均衡指的是在应用层上,比如通过 HTTP 的 URL、主机名、资源类型等数据通过适当的策略转发给后端服务器。
当发送数据的时候:
1.首先HTTP 协议会对我们需要传输的内容进行包装---添加 HTTP专用附加连接。
这就好比我们需要发快递,那么需要拿个塑料袋自己包一下。
2.在经过 TCP 层时,TCP 层给数据再次打包,并加上 TCP 头
这就好比快递员拿到我们的快递,那么会压缩一下,继续包装。
3.按照上面的套路,分别给 TCP 数据加上 IP 头和 MAC 头
这就好比快递员把快递放进三轮车,最后放进大卡车。
当对方接收到数据的时候:
1.数据通往对方的 MAC 层和 IP 层,对方分别对数据进行拆包
快递员把快递卸下大卡车,装上三轮车通往对方家
2.去掉 TCP 头和 HTTP 头,获取到数据
对方拆掉快递包装和你的塑料袋,拿到里面的东西。
HTTP协议的传输过程就是这样通过协议栈逐层向上,每一层都添加上本层专用的数据,然后打包,最后发送出去。用一个成语形容就是层层包围
而接收数据刚好相反,从下往上穿过协议栈,每一层都去掉本层的专有头,最后拿到数据。用一个成语形容就是抽丝剥茧
可以用下图表示
TCP/IP 有四层,核心的是第二层 IP 和第三层 TCP,HTTP 在最上层。
OSI 有七层模型,其中数据链路层就是 TCP 的链接层,网络层就是 TCP 的网络互连层,传输层就是 TCP 的传输层,第七层应用层对应 TCP 的第四层。
OSI 的第一层TCP没有、第五层跟第六层都在 TCP 的应用层中,对比之下,这几层都消失了。
HTTP 利用 TCP/IP协议栈逐层打包,再逐层拆包实现数据传输。
一般来说,写应用程序的层为应用层,操作系统处理的是四层或者以下。
《JavaScript 高级程序设计第四版》关于垃圾回收,我个人认为关于标记清除写的是云里雾里的,直到我看到这篇文章,这里上英文版和中文版连接:
如果大家有兴趣可以读原文,我在这里用我的话描述一下并增加一些扩展内容。
如有错误,感谢指正。🌟🌟
首先我们需要先知道什么是垃圾。
生活常识里什么是垃圾呢?
现在以及未来都不再被需要的物体就是垃圾。程序里也是一样的道理。
文章说了一个名词,叫做可达性。
如果一个值可以通过引用或引用链从根访问任何其他值,则认为该值是可达的
也就是说你不再能够访问到它的数据,就是不可达的。
没有可达性的数据就可以被回收。
这个逻辑很简单暴力,你都访问不到它了,确实没有要它的必要啊。
毫无疑问,全局变量随时有可能被访问到,所以它是可达的,它不能是垃圾。
其次,正在执行的函数,比如说这样的
function fn(){
var b=2
console.log(b)
}
fn()当函数执行的时候,b的数据就会被生成,此时它是可达性的,不能被删除。
然而当函数执行完后,它不能再被访问到,此时它是不可达的,需要删除。
那么现在结论就是:
全局环境下的变量因为都具有可达性,所以都不是垃圾不能被回收。
局部环境下的变量因为不再具有可达性,所以都是垃圾可以被回收。
但凡事都可以被改变。
// user 具有对这个对象的引用
let user = {
name: "John"
};上面这段代码在内存中是这样的
这是一个在全局环境下的变量,很有可能别的代码会用到它,所以不能被回收。
但是,当 user 这个变量名引用变了
user = null那原来的{name:John}这个数据就访问不到它了,此时就可以被回收。
但是如果代码是这样的
let user = {
name: "John"
};
let admin = user
user = null此时{name:John}依然可以通过变量admin访问,它就不能被回收。
这里有一个更加复杂的对象
function marry(man, woman) {
woman.husband = man;
man.wife = woman;
return {
father: man,
mother: woman
}
}
let family = marry({
name: "John"
}, {
name: "Ann"
});此时内存图是这样的
如果此时执行这样的代码
delete family.father;
delete family.mother.husband;就会变成这样
此时 {name:John}不再可达,那么它就会被回收。
那么根据内存图,如果把family这个变量名引用到其他地方。
family = null;很显然,原先的数据不再可达,它就会被回收。
上面是垃圾回收的基本概念,非常符合现实逻辑。
下面是关于策略
定期执行以下“垃圾回收”步骤,一开始数据是这样的
1.垃圾收集器通过遍历找到所有的根,并“标记”(记住)它们。
2.如果还有引用的数据,说明是可达的。一直标记到最后一层引用。
3.此时发现有一个数据,从来没有被根(全局变量能访问到的)引用到,就把它回收掉。
当然遍历的同时,因为数据量很大,为了不影响 JS 代码运行,加快垃圾回收速度,就做了一些优化处理(包括但不限于)
JS代码先走,闲下来的时候再去收集垃圾这方面红宝书就写的比较清楚
另一种不常用的垃圾回收策略是引用计数(reference counting)。其思路是对每个值都记录它被引用的次数。
声明变量并给它赋一个引用值时,这个值的引用数为1。如果同一个值又被赋给另一个变量,那么引用数加1。类似地,如果保存对该值引用的变量被其他值给覆盖了,那么引用数减1。当一个值的引用数为0 时,就说明没办法再访问到这个值了,因此可以安全地收回其内存了。垃圾回收程序下次运行的时候就会释放引用数为0 的值的内存。
不过引用计数有非常大的问题:如果是互相引用,次数也会叠加
function fn(){
var a=1
var b=a
}
fn()此时变量a会被记成2次引用,即使函数执行完了,a也不会被当成垃圾回收。
注意到了吗,上面的例子没有讲到闭包,对于闭包我个人认为可以把它当成全局变量来看。
以下摘自阮一峰的博客
闭包可以用在许多地方。它的最大用处有两个,一个是前面提到的可以读取函数内部的变量,另一个就是让这些变量的值始终保持在内存中。
闭包的产生是因为一个函数被当前函数作用域外部的变量引用了,除非外部的变量被释放,否则闭包当然不会被回收。
下面是例子:
function f1(){
var n=999;
nAdd=function(){n+=1}
function f2(){
alert(n);
}
return f2;
}
var result=f1();//此时 result 相当于拿到了
result(); // 999
nAdd();
result(); // 1000上面的数据n虽然在函数中,但是依然会存于内存中。
如果nAdd跟result的引用没有被释放,那么数据n不会被垃圾回收。
以上就是我对于垃圾回收的简单分享。
如果您觉得对您有帮助,请顺手点个赞,谢谢!
完结撒花!🌸🌸🌸
栈这种数据结构在编程中非常常见,它是一种后进先出的数据结构,具有两种主要操作:
如果要用 Javascript 模拟,非常简单,调用 Array.prototype.pop()和 Array.prototype.push()即可
我们使用 WPS 或者 office时,经常会撤销,其实这种操作系统级的应用就是基于栈的后进先出原则。
在 Javascript 执行时,也在内部会生成调用栈,如果你经常使用递归,那你可能就会发现,递归就是栈的数据结构,每次在一个函数中执行另外一个函数,那么就会进入函数调用栈,当这个函数执行完之后,就会开始弹栈。
栈的 push 和 pop 操作的示意如下

给定一个只包括 '(',')','{','}','[',']' 的字符串 s ,判断字符串是否有效。
有效字符串需满足:
左括号必须用相同类型的右括号闭合。
左括号必须以正确的顺序闭合。
输入:s = "()"
输出:true
输入:s = "()[]{}"
输出:true
示例 3:
输入:s = "(]"
输出:false
输入:s = "([)]"
输出:false
输入:s = "{[]}"
输出:true
1 <= s.length <= 104
s 仅由括号 '()[]{}' 组成
这道题主要思路是采用栈(先进后出)的数据结构。
比如字符串是这样的({}),我们需要让{}先匹配,再匹配()。
我们可以用一个数组把遇到的左括号保存起来,每次匹配时,都从栈中拿出来,匹配遇到的右括号。由于是先进栈的后匹配,所以就可以用 push和 pop形成栈结构来解题
var isValid = function(s) {
//如果是奇数,肯定不会有互相匹配的括号
if(s.length%2!==0){
return false
}
const stack=[]
const map=new Map([[')','('],[']','['],['}','{']])
for(let i of s){
//遇到左括号放到栈里
if(['[','{','('].includes(i)){
stack.push(i)
}
if(map.get(i)){//看看有没有右括号
const left=map.get(i)//有右括号就去取对应的左括号
const item=stack.pop()//获取栈中的左括号
if(left!==item){//比对一下,不一样就肯定不匹配
return false
}
}
}
//还要看一下栈是不是被清空了,不然遇到’((‘这样的字符串不会返回 false
return stack.length===0?true:false
};请你仅使用两个栈实现先入先出队列。队列应当支持一般队列支持的所有操作(push、pop、peek、empty):
实现 MyQueue 类:
void push(int x) 将元素 x 推到队列的末尾
int pop() 从队列的开头移除并返回元素
int peek() 返回队列开头的元素
boolean empty() 如果队列为空,返回 true ;否则,返回 false
说明:
你只能使用标准的栈操作 —— 也就是只有 push to top, peek/pop from top, size, 和 is empty 操作是合法的。
你所使用的语言也许不支持栈。你可以使用 list 或者 deque(双端队列)来模拟一个栈,只要是标准的栈操作即可。
进阶:
你能否实现每个操作均摊时间复杂度为 O(1) 的队列?换句话说,执行 n 个操作的总时间复杂度为 O(n) ,即使其中一个操作可能花费较长时间。
示例:
输入:
["MyQueue", "push", "push", "peek", "pop", "empty"]
[[], [1], [2], [], [], []]
输出:
[null, null, null, 1, 1, false]
解释:
MyQueue myQueue = new MyQueue();
myQueue.push(1); // queue is: [1]
myQueue.push(2); // queue is: [1, 2] (leftmost is front of the queue)
myQueue.peek(); // return 1
myQueue.pop(); // return 1, queue is [2]
myQueue.empty(); // return false
提示:
1 <= x <= 9
最多调用 100 次 push、pop、peek 和 empty
假设所有操作都是有效的 (例如,一个空的队列不会调用 pop 或者 peek 操作)
答案
var MyQueue = function() {
this.stack=[]
this._stack=[]
};
MyQueue.prototype.push = function(x) {
this.stack.push(x)
};
MyQueue.prototype.pop = function() {
while(this.stack.length>1){
this._stack.push(this.stack.pop())
}
const last=this.stack.pop()
while(this._stack.length){
this.stack.push(this._stack.pop())
}
return last
};
MyQueue.prototype.peek = function() {
return this.stack[0]
};
MyQueue.prototype.empty = function() {
return this.stack.length===0
};基础的 HTTP 知识已经过完了,下面就基础内容对 HTTP 做一个特点总结
HTTP 是一个灵活可扩展的传输协议。
最初诞生时,HTTP 协议就本着开放的态度只规定了报文的基本格式,也就是请求行、空格、换行符、header+body 等,报文的各个组成部分并没有做严格规定,可以随开发者定制。
随着互联网的增长,HTTP 协议逐渐增加方法、版本号、状态码、头字段等。而 body 也不再局限于文本形式的 TXT 或者 HTML,增加了图片、音频视频等任意数据,也来源于其灵活可拓展的特点。
而 RFC 文档,更多的可以理解为对已有扩展的承认和标准化,实现了从实际中来,到实践中去的良性循环。
HTTP 协议是一个可靠的传输协议。
这是由于 HTTP 是基于TCP/IP 协议的,而 TCP 协议本身就是可靠的、完整的协议,所以 HTTP 继承了这个特性,能够实现在请求方和应答方进行可靠地传输。
它的具体做法跟 TCP/IP 差不多,都是对实际传输数据做一层包装,加上一个头,然后通过 TCP/IP 协议栈发送或者接收。
我们必须正确理解可靠的含义,可靠的传输意思是在正常的网络环境下,信息的收发必定成功。
HTTP 不能保证100%地传输能够从一方发送到另一方,可靠只是向使用者提供一个“承诺”,会在下层“尽量”保证数据的完整送达。
如果遇到非常恶劣的网络环境,比如连接环境差、网络繁忙等,也是有可能传输失败的。
HTTP 是应用层的协议。
在 TCP/IP 诞生后的十多年,出现了非常多的应用层协议,比如 负责远程登录的 SSH 协议,负责文件传输的 FTP 等等,但是他们都知关注于非常小的应用领域,在通用数据传输领域完全不能打。
HTTP 凭借可携带任意头字段和实体数据的报文结构,以及连接控制、缓存代理等特性,只要不太苛求性能,HTTP 几乎可以传递一切东西,满足各种需求,称得上万能协议。
HTTP 使用的是请求-应答的通信模式。
通俗来说,这个模式就是一发一收,有来有回,就像是函数调用,只要填写好头部字段,调用后就会收到答复。
请求-应答模式同时也明确了 HTTP 协议中双方的定位,永远是请求方先发送请求,是主动的,而应答方只能在收到请求后才能够回复,是被动的,如果没有请求就不会有动作。
在浏览器-服务器中往往浏览器是请求方,服务器是应答方。但如果服务器作为中间代理连接后端服务器,那么它就有可能同时扮演请求-应答的角色。
传统的C/S 系统架构是 Client/Server,也就是客户端/服务器,HTTP 协议的模式下请求方为客户端,应答方是服务器,这种应答模式非常契合传统架构。
随着互联网的发展,也出现了 B/S(Browser/Server)架构,用轻量级的浏览器作为客户端应用,实现客户端瘦身,而服务器则摒弃私有协议而采用通用的 HTTP 协议。
此外,请求-应答模式也完全符合 RPC(Remote Procedure Call) 的工作模式,可以把 HTTP请求封装成远程函数调用,导致了 WebService 等出现。
HTTP 协议是无状态的。
什么是无状态呢?状态其实就是客户端或者服务器保存的一些数据或者标志,记录通信过程中的变化信息。
作为对比,我们来看一下 TCP 协议,它就是一个有状态的协议,一开始它处于 CLOSED 状态,连接成功后是 ESTABLISHED 状态,断开连接是 FIN-WAIT 状态,最后又是 CLOSED 状态。
这些状态需要 TCP 内部有一些数据结构去维护。简单来说,就是一个标志量,标志着当前所处的状态。例如0代表 CLOSED,2是 ESTABLISHED 等等。
无状态可以形象地称为没有记忆能力,比如,浏览器发送了一个请求,并且附带上自己的身份令牌,比如 Token,服务器就会检查一下权限,然后发送数据回去。过了一会,浏览器再发送一个请求,由于服务器并不记录请求状态,所以也不知道是同一个浏览器请求的,依然要重新验证一下权限,这就是无状态。
在 HTTP 协议中,没有规定的任何状态,客户端和服务器永远都处于无知的状态。连接前两者并不知情,收发报文也是独立的,没有任何的联系,收发报文也不会对服务器或者浏览器造成影响,连接后也不会保存任何信息。
UDP 协议也是一种无状态的协议,但是UDP同时也是无连接的,顺序发包乱序收包,发送出去后就不管了。而 HTTP 则是有连接的,顺序发送,顺序收包,按照收发顺序管理报文。
不过由于 HTTP也是灵活可扩展的协议,虽然标准中没有规定状态,但是完全可以在协议的框架下打个补丁,增加这个特性。
HTTP 传输的实体数据可缓存可压缩,可分段获取、支持身份认证、国际化语言等等都是 HTTP 的特点。
HTTP 是灵活的可拓展的,可以添加任意头部字段实现各种功能
HTTP 是可靠的传输协议,基于 TCP/IP 尽量保证数据的完整送达
HTTP 是万能的应用层协议,比FTP、SSH 实现更多功能,可以传送任意数据
HTTP 使用了请求-应答模式,客户端主动发送请求,服务器被动回复请求
HTTP 本质上是无状态的,所谓无状态,通俗来讲就是没有记忆能力,协议不要求记录连接信息,每个请求之间、浏览器和服务器之间都是相互独立,毫无关联的。
我们现在已经知道 DNS 跟 IP 之间的关键,而 DNS 服务器将域名转化为 IP 地址的过程就叫域名解析。
目前全世界有几亿个站点,每天发生的 HTTP 流量更是天文数字,而这些请求大多数都是采用域名访问的,所以 DNS 成为了互联网重要的基础设施,必须要保证域名解析的准确、高效。
DNS 的核心系统是一个三层的树状、分布式服务,基本对应域名的结构:
1.根域名服务器(Root DNS Server):管理顶级域名服务器,返回“com”“net”“cn”等顶级域名服务器的 IP 地址
2.顶级域名服务器(Top-level DNS Server):管理各自域名下的权威域名服务器,比如com 顶级域名服务器可以返回 apple.com 域名服务器的 IP 地址;
3.权威域名服务器(Authoritative DNS Server):管理自己域名下主机的 IP 地址,比如apple.com 权威域名服务器可以返回 www.apple.com的 IP 地址
这里根域名服务器是关键,目前全世界共有 13 组根域名服务器,又有数百台的镜像,保证一定能够被访问到。
有了这个系统以后,任何一个域名都可以在这个树形结构里从顶至下进行查询,就好像是把域名从右到左顺序走了一遍,最终就获得了域名对应的 IP 地址。
例如,你要访问www.apple.com,就要进行下面的三次查询:
www.apple.com的地址。虽然核心的 DNS 系统遍布全球,服务能力很强也很稳定,但如果全世界的网民都往这个系统里挤,即使不挤瘫痪了,访问速度也会很慢
所以在核心 DNS 系统之外,还有两种手段用来减轻域名解析的压力,并且能够更快地获取结果,基本思路就是“缓存”。
首先,许多大公司、网络运行商都会建立自己的 DNS 服务器,作为用户 DNS 查询的代理,代替用户访问核心 DNS 系统。
这些“野生”服务器被称为“非权威域名服务器”,可以缓存之前的查询结果,如果已经有了记录,就无需再向根服务器发起查询,直接返回对应的 IP 地址。
其次,操作系统里也会对 DNS 解析结果做缓存,如果你之前访问过www.apple.com,那么下一次在浏览器里再输入这个网址的时候就不会再跑到DNS 那里去问了,直接在操作系统里就可以拿到 IP 地址。
另外,操作系统里还有一个特殊的“主机映射”文件,通常是一个可编辑的文本,在 Linux里是/etc/hosts,在 Windows 里是C:\WINDOWS\system32\drivers\etc\hosts,如果操作系统在缓存里找不到 DNS记录,就会找这个文件。
域名使用字符串来代替 IP 地址,方便用户记忆,本质上一个名字空间系统;
域名解析可以将域名转化成 IP 地址。DNS 就像是我们现实世界里的电话本、查号台,统管着互联网世界里的所有网站,是一个“超级大管家“。
全世界有13台重要的根域名服务器保存顶级域名的ip 地址,域名会从右往前查找 ip 地址,对应域名服务器就是根域名服务器==>顶级域名服务器(com查apple.com)==>权威域名服务器(apple.com查 www.apple.com)
DNS 是一个树状的分布式查询系统,但为了提高查询效率,外围有多级的缓存
常见的两种缓存方法分别是
插入排序的核心**是每次处理一个元素,如果当前元素比前面的小,就让当前元素插入到前面元素的前面。

如图,当 i 为1时,当前元素为4,此时跟前面的6做判断,如果比6小,那么就跟6互换位置。
当i为2时,与前面的6做对比。
此时我们还需要记录一下当前元素换到新的位置的下标,设为 j。
如果比6小,就跟6互换位置。

如果我们发现array[j]要比array[j-1]要小,那么就继续跟下标为 j-1 的元素换位置
如此重复根据新的下标 j 进行比较...
我们现在可以写一段伪代码
let array=[4,3,2,1]
for(let i=0;i<array.length;i++){
循环判断以下过程:
让 j=i 记录当前元素的下标
array[j]<array[j-1]?
是的话 array[i]与 array[i-1]互换一下位置
j=i-1 //更新下标
...
array[j]<array[j-1]?
是的话 array[j]和 array[j-1]换一下位置
重新设置当前元素换位置后的新下标 j=j-1
循环...
}实现代码
function insertionSort(array: Array<number>) {
for (let i = 0; i < array.length; i++) {
//记录当前元素的下标
//由于每次 j 自动-1,就相当于更新了元素的新下标
for (let j = i; j >= 0; j--) {
if (array[j] < array[j - 1]) {
//互换位置
[array[j], array[j - 1]] = [array[j - 1], array[j]];
} else {
//如果不符合要求,需要让内层循环停下
break;
}
}
}
return array;
}插入排序跟选择排序的逻辑差不多,循环不变量都是
[0-i)排好序,[i-n]没有排序
两者的差异是选择排序一开始就将整个数组的[0-i)排好顺序.
而插入排序并不是站着整个数组的基础上排序的。
插入排序的时间复杂度同样也是 O(n²)。
这里有个小例外,如果数组本身是有序的话,那么插入排序的时间复杂度是 O(n)
扩展运算符实际上就是...运算符,它可以将一个数组转为逗号分割的参数
以下是例子:
console.log(...[1,2,3]) // 1 2 3
console.log(1,...[2,3,4],5) //1 2 3 4 5
[...document.querySelectorAll('div')] //div div div
这个运算符主要用来做函数的调用
function fn(x,y){
return x + y
}
let arr =[1,2]
fn(...arr) //3
上面的代码中,将数组用扩展运算符处理后,数组就变成参数
扩展运算符可以跟正常的参数一起使用
function fn(a,b,c,d,e){
console.log(a,b,c,d,e)
}
let arr=[2,3,4]
fn(1,...arr,5) //1 2 3 4 5
注意:
只有函数调用时,才能放在圆括号中,否则会报错
(...[1,2,3]) //Uncaught SyntaxError: Unexpected token '...'
在es5时,如果我们想在把一个数组中的值当成函数中的参数,我们使用的是apply方法
function fn(x,y,z){console.log(x+y+z)}
fn.apply(null,[1,2,3]) //6
现在,有了扩展运算符,我们完全没必要这么做
function fn(x,y,z){console.log(x+y+z)}
fn(...[1,2,3]) //6
我们以前使用Math.min.apply来求数组中的最小数
Math.min.apply(null,[1,2,3,4,5,6]) //1
现在我们可以直接使用扩展运算符
Math.min(...[1,2,3,4,5,6]) //1
//等同于
Math.min(1,2,3,4,5,6)
当以前我们需要连接两个数组时,一般都使用concat或者使用Array.prototype.push.apply
let a=[1,2,3]
let b=[4,5,6]
a.concat(b) //[1,2,3,4,5,6]
Array.prototype.push.apply(a,b) //[1,2,3,4,5,6]
现在我们可以用扩展运算符来直接push,结果是一样的
a.push(...b)//[1,2,3,4,5,6]
在以前,由于数组是复杂数据结构,当我们直接给予赋值时,会把保存的地址赋值过去,所以我们不得不变通来复制
let a=[1,2,3]
let b= a //这种方法并不能克隆,只是传递地址
let c=a.slice() 使用slice克隆
let d=a.concat([]) //使用这个方法也可以克隆
有了扩展运算符,我们可以很方便进行克隆
let e=[...a] // [1,2,3]
e[0]=0 // e为[0,2,3]
a // [1,2,3] 不影响a
我们甚至也不需要用push或者concat来连接数组,直接用这个方法
let a=[1,2,3]
let b=[4,5,6]
let c=[...a,...b] //[1,2,3,4,5,6]
需要注意:js所有内置的方法都是浅拷贝,当数组内包含的是复杂数据类型时,对其进行修改会改变新的数组
let a=[{name:1}]
let b=[{age:2}]
let c=[...a,...b] //[{name:1},{age:2}]
a[0].name=2
c //[{name:"qiuyanxi"},{age:2}]
let [b,...c]=[1,2,3,4,5]
b // 1
c // [2,3,4,5]
let [...c,b]=[1,2,3,4,5]
b //Uncaught SyntaxError: Rest element must be last element
c //Uncaught SyntaxError: Rest element must be last element
上面代码中,使用结构赋值与扩展运算符相结合的形式来赋值数组,会发现,浏览器报错,要我们将扩展运算符的参数放在最后才有效
我们以前如果想要将字符串变成数组,我们会怎样做?
Array.from('hello') // ["h", "e", "l", "l", "o"]
扩展运算符可以做更多的事
[...'hello'] // ["h", "e", "l", "l", "o"]
我们还可以使用扩展运算符将伪数组变成真正的数组
function fn(){
return [...arguments]
}
fn(1,2,3) //[1,2,3]
例如 Map 数据解构和 Set 数据解构就可以用
//数组去重
let set=new Set([1,1,2,3])
[...set] //[1,2,3]对于没有部署iterator接口的数据解构,使用这个会报错
const obj = {a: 1, b: 2};
let arr = [...obj];
//Uncaught TypeError: obj is not iterable
at <anonymous>:2:15HTTP 的全称是超文本传输协议(HyperTextTransfer Protocol),从名字来看,这个协议可以拆成三个部分:
什么是协议呢?这个就跟平常生活中的协议:劳动协议、租房协议等是一个概念,HTTP 协议的本质也是类似于这样的协议。
我们从协议的字面意思入手,首先协是协同的意思,也就是说会有多方参与。其次,正是有了多方的协同,才需要一些基本的交流礼仪和行为约定,这就是议。
协议意味着多个参与者为了同样的目的而站着一起,为了保证协同工作,必须制定各方的责任、权利等行为约定。
那么自此,HTTP 的第一层含义出来了:
HTTP 是一个用在计算机世界里的协议。它使用计算机能够理解的语言确立了一种计算机之间交流通信的规范,以及相关的各种控制和错误处理方式。
HTTP 是一个用于传输的协议,传输(transfer)的意思就是把某个东西从 A 搬运到 B 点。它包含以下两个信息:
1.HTTP 是双向协议
HTTP 的传输起码需要保证有两个参与者,A 与 B。数据需要在 A 跟 B 之间双向流动。通常把先发起动作的 A 称之为请求方,后接收传输方称为响应方。
比如浏览器就经常是请求方,而响应方则是服务器,他们依靠 HTTP 协议进行通信,浏览器将数据请求发送给服务器,服务器返回一些格式的数据,最后浏览器拿到数据并进行渲染展示。
2.数据虽然是双向传输,但是允许有中转
原先的 A<==>B,变成了 A<==>中转站1<==>中转站2等<==>B,只要不影响 A 到 B 的传输,原理上传输过程中运行存在多个中间人。这样中间人同样也遵循HTTP 协议,但是他们可以做数据转发、安全认证、数据压缩等功能,优化传输过程。
由此,我们知道 HTTP 的第二层含义:
HTTP 是一个在计算机世界里专门用来在两点之间传输数据的约定和规范。
既然称文本(Text),就表示HTTP 传输的是一段完整的、有意义的数据,可以被浏览器、服务器等处理,并不是二进制包。
在早期,传输的文本只是普通的文字,但是现在,我们可以传输音频、图片、视频等多种数据流,所以超文本的意思就是超越普通文本,是多种数据的混合体文本,它还可以包括超链接,能够从一个超文本跳转到另外一个超文本,形成网状的结构关系。
HTML 就是超文本的一种,他本身只是纯文字的文件,但是他的标签可以定义图片、视频的连接,最后被浏览器所解释,形成含有多种视听信息的页面。
那么超文本的解释就是
文字、图片、音频、视频等超文本数据的集合
HTTP 是一个在计算机世界里专门用于两点之间传输视频、音频、图片、文字等超文本数据的通信约定和规范。
虽然HTTP 没有实体,但是依赖需要技术实现,它也是构建互联网的重要基础和技术
从广义上讲,数据结构就是指一组数据的存储结构.算法就是操作数据的方法.
比如,图书馆储存书籍,为了方便查找,图书管理员一般会将书籍分门别类进行存储.按照一定规律编号,这就是书籍这种数据的存储结构.
那么如何来查找一本书呢?我们可以一本一本查找,也可以根据书籍的某种规律(编号、类别)等方法查找。笼统来说,这些查找方法都是算法。
从狭义上讲,数据结构和算法比如队列、栈、堆、二分查找、动态规划等,这些都是前人智慧的结晶,我们可以直接拿来用。
数据结构和算法是相辅相成的。数据结构需要为算法服务,而算法需要作用在特定的数据结构之上。
比如:数据具有随机访问的特点,常用的二分查找算法需要用数组存储,但是如果选择了链表这种数据结构,二分查找就无法工作,因为链表不支持随机访问。
数据结构是静态的,它只是组织数据的一种方式。因为不在它的基础上操作、构建算法,孤立存在的数据结构是没用的。
学习数据结构和算法,首先需要掌握一个最重要的概念——复杂度分析。
这个概念几乎是数据结构和算法的半壁江山,是数据结构和算法学习的精髓。
数据结构和算法解决的是如何更省、更快地存储和处理数据的问题。因此,我们需要一个考量效率和资源消耗的方法,这就是复杂度分析。
很多时候,我们只需要把代码跑一遍,通过统计、监控就可以得到算法执行的时间和占用的内存大小。那为什么还需要做复杂度分析呢?这种分析方法能够比我实实在在跑一遍更加准确吗?
通过统计、监控的手段得出代码执行时间和占用内存大小有一个专业的名词,叫做事后统计法。但是这种统计方法具有非常大的局限性。
测试结果依赖测试环境
测试环境中的硬件设备的差异性会影响到测试结果,比如同一段代码在i3和i9之间处理,速度肯定是i9更快。你要怎样证明你写的代码比你同事的更快?放在同一台电脑上运行当然可以,但是可能换了一台电脑会得到截然相反的结果。
测试结果受数据规模影响大
同一个排序算法,在待排序数据的有序度不一样,排序的执行时间就会有很大差别。比如,数据已经是有序的,那么排序算法就不需要做任何操作,执行时间就会非常短。
此外,数据规模如果很小,可能无法真实反映算法性能。比如小规模的数据排序,插入排序可能比快速排序要快。
因此,我们需要一个不用具体的测试数据来测试,就可以粗略估计算法执行效率的方法。
算法的执行效率,可以粗略用执行时间来表示,如何在不运行代码的情况下,用肉眼得到一段代码的执行时间?
来看下面这段代码
function fn(n){
let sum=0;
let i=0
for(;i<n;i++){
sum= sum + i
}
return sum
}从cpu角度来看,这段代码每一行都执行类似的操作:读数据,运算,写数据。尽管每行代码对应的cpu执行个数、时间都不一样,但是,我们这里只是粗略估计,所以假设每行代码的执行时间都相同,为n_time。在这个基础上,我们可以得出总执行时间是多少?
当函数执行时,第二行、第三行代码为2个n_time时间。第四行、第五行则运行了n遍,为2n个n_time时间,计算下来总体的时间为 2*n_time+2n*n_time, 合并后则为
T(n)=(2n+2)*n_time
我们可以看出,代码的执行时间T(n)和每行代码执行次数n成正比。即n越大,T(n)越大。
按照这个思路,我们再来看一段代码
function fn(n){
let sum=0;
let i =0;
let j=0;
for(;i<=n;i++){
for(;j<=n;j++){
sum = sum + i +j
}
}
}依然假设这段代码每行的时间为n_time,那么第二、三、四行为3*n_time,第五行需要n*n_time时间,第六、七行则分别执行了n*n*n_time时间。所以T(n)时间为3*n_time+n*n_time+2*n²*n_time,简化后为
T(n)=(3+n+2n²)*n_time
通过两段代码,我们可以得到一个非常重要的规律
所有代码的执行时间T(n)与每行代码执行的次数n成正比
我们可以把这个规律总结成一个公式
其中T(n)表示代码执行的时间,n表示数据规模的大小,f(n)表示每行代码执行次数的总和。因为这是一个公式,所以用f(n)表示。公式中的O,表示代码执行时间T(n)与f(n)成正比
我们将第一个例子中的f(n)放入这个公式中,就变成了
T(n)=O(2n+2)
将第二个例子中的f(n)放入到公式中,就变成了
T(n)=O(3+n+2n²)
这就是大O时间复杂度表示法。大O时间复杂度表示法实际上并不是表示具体代码执行的时间,而是表示代码执行时间随数据规模增长的变化趋势,所以也称为时间复杂度。
当n很大时,比如n为1000000,那么诸如3+n+2n²中的3、n、2都可以忽略,因为并不会影响到增长趋势。我们只需要记录一个最大量级就可以了,于是最终的公式就变成:
第一个例子
T(n)=O(n)
第二个例子
T(n)=O(n²)
前面介绍了时间复杂度的演进过程和表示方法,那么我们如何分析一段代码的时间复杂度?有三个比较实用的方法。
由于大O法只表示一种数据变化的趋势,所以我们可以忽略掉公式中的常量、系数、低阶,只需要记录最大的量级即可。
所以我们在分析算法、代码的时间复杂度时只需要关注执行次数最多的那一段核心代码。这段核心代码执行次数的n的量级,就是整段要分析代码的时间复杂度。
以第一个例子为例:
function fn(n){
let sum=0;
let i=0
for(;i<n;i++){
sum= sum + i
}
return sum
}第二、三行代码就是常量,第四、五行的代码是循环执行最多的核心代码,应当记为2n次,2为系数,也可以忽略,因为系数是不变的,它并不影响增长趋势。所以最终得到O(n)
比如下面的三段代码:
function cal(n){
let sum_1=0;
let p1=0;
for(;p1<100;p1++){
sum_1 = sum_1 + p1
}
let sum_2=0;
let p2 =0;
for(;p2<n;p2++){
sum_2 += p2
}
let sum_3=0;
let p3 =0;
let p4 =0
for(;p3<n;p3++){
for(;p4<n;p4++){
sum_3 = sum_3 + p3 + p4
}
}
}上面的函数里面有三段不同的代码,我们在第一条规则的基础上忽略掉常量,只看代码段中执行最多的代码。
第一段代码的循环执行了100次,因为它已知且跟n无关,不管是10000次还是1000000次,它依然只是常量。时间复杂度所表现的是算法的执行效率和数据规模增长的变化趋势,当n无限大时,这个常量对数据规模的增长趋势并没有影响,所以我们直接忽略。
第二段代码执行了n次,记为O(n)
第三段代码执行了n²次,记为O(n²)
综合三段代码,我们取其中最大的量级,所以cal函数的时间复杂度为O(n²)。
举个例子
function cal(n){
let result=0
for(let i=0;i<n;i++){
result += fn(n)
}
}
function fn(n){
let r=0
for(let i=0;i<n;i++){
r += i
}
}单看第一个函数,我们可以得出复杂度为O(n),只是在第一个函数中,里面有一段fn(n)的执行代码,fn(n)的复杂度同样是O(n),最终我们得出复杂度为O(n²)
其中划线的部分称非多项式量级,当数据规模越来越大时,非多项式算法执行时间会急剧增加。
非划线部分为多项式量级。
O(1)是常量级时间复杂度的表示方法,比如说下面的代码
let i=0
let j=1
let k=i + j虽然有三行代码,但是其依然记作O(1)级代码。有个简单的记忆方式:只要算法中不存在循环、递归,那么即使代码行数过万,也只是O(1)级时间复杂度。
数阶的时间复杂度非常常见,但是非常难分析。比如下面这行代码
let i=1
while(i<n){
i=i*2
}我们可以看出第三行代码运算次数最多。只要i小于n,那么i会不断乘以2,直到大于n为止。
所以i的结果是
1 * 2=> 2 * 2=> 4 * 2=> 8 * 2=> 16 * 2=> ...x * 2 >= n
换算一下就可以表示为
所以,我们只要知道x是多少,那就知道代码执行了多少次。那么x怎么计算呢?就是x=log2(n)。意思是2为底数被n开方的结果为x。
得出这段代码的时间复杂度为O(log2(n))
不管底数是多少,由于底数可以互相转换,比如O(log3(n))等于log2(n)*log3(2)。
由于时间复杂度只是表示算法的执行效率和数据规模增长的变化趋势,所以我们可以把系数去除,最终我们得到代码
T(n)=O(logn)
那么现在O(nlogn)就很好理解了,只需要用一个循环把上面的代码再执行n遍,那么就是O(nlogn)的时间复杂度。
这种时间复杂度是由两个数据规模共同组成的。
看一段简单的代码
function fn(m,n){
let sum1=0
for(let i=0;i<m;i++){
sum1 += i
}
let sum2=0
for(let j=0;j<n;j++){
sum2 += j
}
}由于我们并不知道m跟n的数据规模,所以我们不能省略掉其中一个,只能加起来,所以最终的时间复杂度就是
T(m,n)=O(m+n)
时间复杂度表示算法效率(时间)与数据规模n增长趋势的关系,那么空间复杂度就是算法的存储空间与数据规模增长的趋势关系。
常见的空间复杂度就只有O(1)、O(n)、O(n²)三种。直接上代码
let a=1
let b=1
let c=a + b我们试着想象一下,这段代码开辟了多少跟数据规模n有关的内容?完全没有,所以这段代码的空间复杂度就是O(1)。
再来一段代码
let a=[]
for(let i=0;i<n;i++){
a[i] = i
}上面这段代码的循环中,只要n越大,那么数组a的存储空间就越多,所以这段代码的空间复杂度就是O(n)
时间复杂度表示算法执行效率和数据规模增长之间的关系。
空间复杂度表示算法存储空间和数据规模增长之间的关系。
我们用大O复杂度表示法来表示,同时我们忽略系数、常量、低阶的因素,最终我们常见的复杂度可以用以下表示
继续分析下面代码
function fn(array){
let i=0
let a=100
let c
for(,i<array.length,i++){
if(array[i]===a){
c=i
}
}
return c
}很简单,上面的代码的时间复杂度为O(n),n为array.length。
不过我们如果中途查到这个数字,那么后面就不用了再循环了,所以我们可以这样改进
function fn(array){
let i=0
let a=100
let c
for(,i<array.length,i++){
if(array[i]===a){
c=i
break;
}
}
return c
}
现在复杂度是多少?如果第一位就找到,那么复杂度就是O(1),如果不存在,那就是O(n),这说明在不同情况下,这段代码的复杂度不一样。
那么也就引进了最好时间复杂度、最坏时间复杂度和平均时间复杂度。
最好时间复杂度就是最快的,比如第一位就找到了,那自然是最好时间复杂度。
最坏时间复杂度就是最慢的,全部撸一遍,最后一个才找到,那自然是最坏时间复杂度。
但是上面的两种复杂度相对来说意义不大,因为概率小。所以我们需要平均时间复杂度这一说。
平均时间复杂度的计算方式是这样的:我们需要将遍历的所有元素之和加起来,然后除以所有情况,就可以得出平均时间复杂度。
以上面的代码为例,总共有 n+1种情况:0到n-1次为 n 种情况,另外一种情况是没有找到。
遍历元素之和是多少?假设第0个下标找到,就是遍历1个元素;第1个下标找到,就是遍历2个元素...第 n-1个下标(最后一个位置)找到,那么就是遍历 n 个元素,如果没有找到的情况,同样也要遍历 n 个元素。
所以我们可以得出公式为
平均复杂度=(1+2+3+...n+n)/n+1
其中(1+2+3+...n+n)可以变化为
得出公式为(3n+n²)/2
然后将目前的公式上下都乘以2
最终公式是这样的
由于系数、低阶等都不在考虑范围内,所以我们可以得出平均时间复杂度为 O(n)
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.