aaazc / svm_blog Goto Github PK
View Code? Open in Web Editor NEW学习支持向量机时的心得,及其python实现
学习支持向量机时的心得,及其python实现
《机器学习实战》终究只是一本实践型的书籍,它更多地是为了带着读者去了解算法的使用,而减少了理论部分的比重。就如第六章:支持向量机,它里面最关键的分类器求解优化问题只有不到两页。支持向量机的知识本来就晦涩难懂,这下更难看懂了,但是这本书仍然是一本很好的入门教材,我相信还有很多的同学在使用这本优秀的教材,所以我以这本教材为基础进行解析。
网上很多关于SVM的文章写的都很好,其中我觉得写的最好的一篇是July所著的《支持向量机通俗导论(理解SVM的三层境界)》,公式的推导都很全面,有理有据。但是我是一个数学差生,所以我觉得这篇文章对于我来说还是太过”硬核”,而且我认为既然要学会一个算法首先就是要理解嘛,说的通俗点就是把理论上的东西转化成自己的话。所以我想写一篇适合我这种数学水平的学生能够很容易理解的文章,当然我不会少了数学公式的推导,因为这个是核心,但是我会用更通俗的方式来解读它。
其实这是一篇学习笔记,纯属个人理解,如果有问题欢迎大家不吝指正,谢谢!
教材上这部分讲的实在是太难弄懂了。(没看过的同学可以看一下下面的内容)



在有一篇文章里看到一个非常生动的例子:
在很久很久以前,一个大侠的爱人被魔鬼抓走了,大侠要救她,但是魔鬼却跟他玩了一个游戏,题目是这样的:桌子上有一把米和一把石头,我现在给你一根棍子,我要你拿这跟棍子把这两种东西分开。
于是大侠这么分:
看起来好像还不错?但是这时候魔鬼故意刁难他,又多放了很多东西在桌子上,这时候似乎有东西站错了阵营?
于是大侠又放了一次棍子
现在不管魔鬼再在桌子上放多少,这根棍子也能起到一个很好的分界效果:
这时候魔鬼急了,他重新把大米和石头摆成这样,让后给大侠一张纸,让他把它们分开:
大侠一看感觉不对劲,好家伙你这魔鬼不讲武德,生气的猛拍桌面,这时候像大米这种稍微轻一点的就被拍的很高,而石头就跟低一些,这时候大侠眼疾手快把这张纸摆在它们之间,完成了条件。
像魔鬼出的第一道题那样的,用一根直线就能把两类物品分开的情况,被称作线性可分。但是现实生活中很少有数据是线性可分的,因此我们需要将其引入更高的维度去,用一张纸将其分开,而这张分割的纸或棍子被称作超平面或分隔超平面,而且我们希望我们找到的超平面是稳定的,无论数据再怎么放,也很难发生错误,这就是支持向量机的来源。如果我们能找到离超平面最近的点,并求出它们之间的距离,是不是就说明这两类数据之间隔的很开了,也就是数据隔得越开越不容易出错嘛。支持向量机解决的就是找最大间隔的问题。
而支持向量是指那些离超平面很近的点,支持向量到超平面的距离被称作间隔。而使用向量这个概念是因为向量是矢量,在更高维的情况下,既有方向又有大小的数据是更利于我们去处理的。
在继续讨论SVM之前,我们需要先解决一下书上将两个类别的标签设置为1和-1的由来。
这就不得不从线性分类的起源Logistic回归说起:
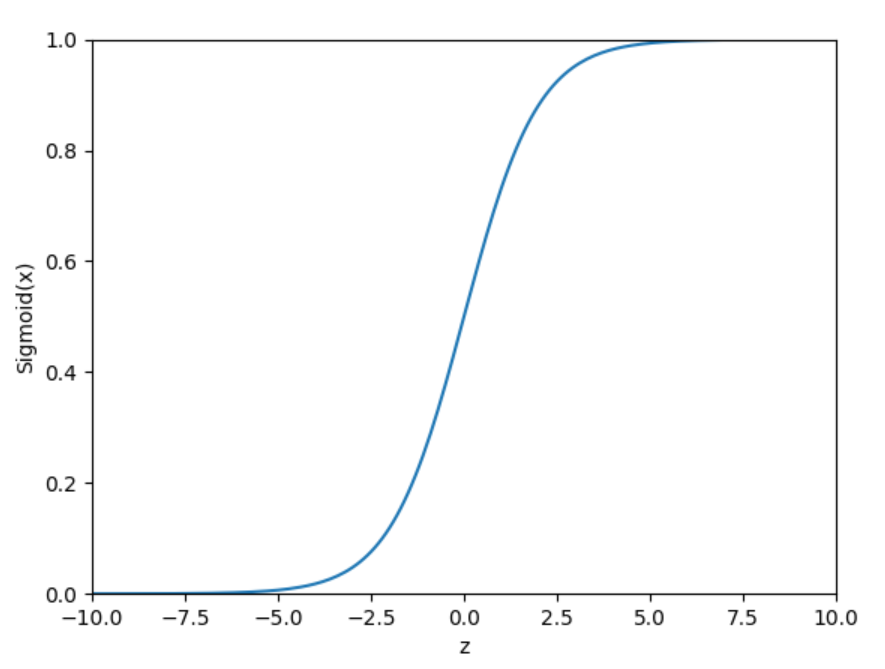
Logistic回归是常用的二分类回归方法,在《机器学习实战》的第五章里有详细的说明,其实说白了就是,我们希望有一个函数它能够接收我们算出来的值,然后把它分成0或1类。最常见的这种函数就是sigmoid函数,它的计算公式和图像如下:
$$
\sigma(z) = \frac{1}{1+e^{-z}}
$$
通过观察图像,我们可以得到,当z=0时,$\sigma(z) = 0.5$,z越大,$\sigma(z)$就无限逼近于1、z越小,$\sigma(z)$无限逼近于0。大家可以想象一下这个图像在z的尺度很大的时候,是不是就很接近阶跃函数了,那我们就可以把这个函数作为一个分类器,当$\sigma(z)$>0.5的时候我就认为它时1类,反之为0类。
这个时候我们已经解决了分类器的问题,所以我们只需要把重心放在线性拟合上,也就是$z=w_0 + w_1x_1 + ...+w_nx_n$,所以上面的公式就可以转化为:
$$
\sigma({\sum_{i=0}^n w_ix_i} = \frac{1}{1 + e^{\sum_{i=0}^n w_ix_i}})
$$
这个就是我们所说的logistic回归。接下来我们将它于SVM联系起来:
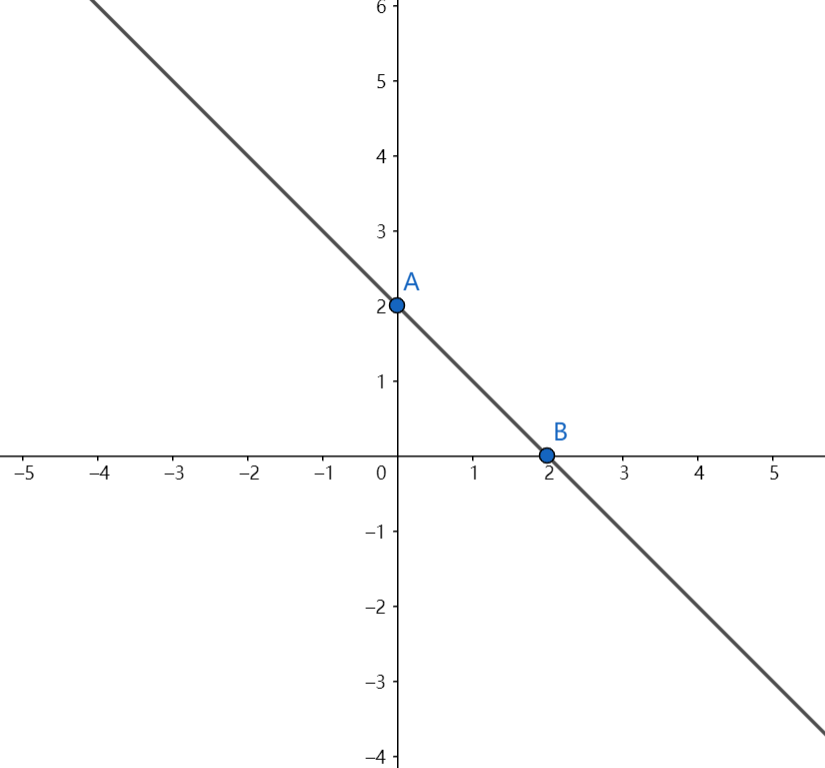
书中超平面的公式$w^Tx + b$,其实把它放在二维平面上是最容易理解的,w就是x和y前的参数,b就是截距。像下图中这条直线它的方程就是$-x + 2 = y$,把它移项得到:$x + y - 2 = 0$,b就是2,w就是[1, 1],x就是[x,y],其实就是这么个意思,为什么要用一个$w^T$来表示其实就是线性拟合问题中参数是会有很多个的,为了好看写成这个样子。
我们现在对sigmiod函数做一个改造,我们把标签y=0,改成y=-1,把z改成$w^Tx + b$,再代到函数里面,就得到了一个-1和1的映射关系:
$$
g(x) = \begin{cases}
1, z>=0\
-1, z<0
\end{cases}
$$
其实我们发现这个关系其实就只是把标签0改成了-1,其它的东西都没变。至于为什么不直接用0和1,我接下来会解释。
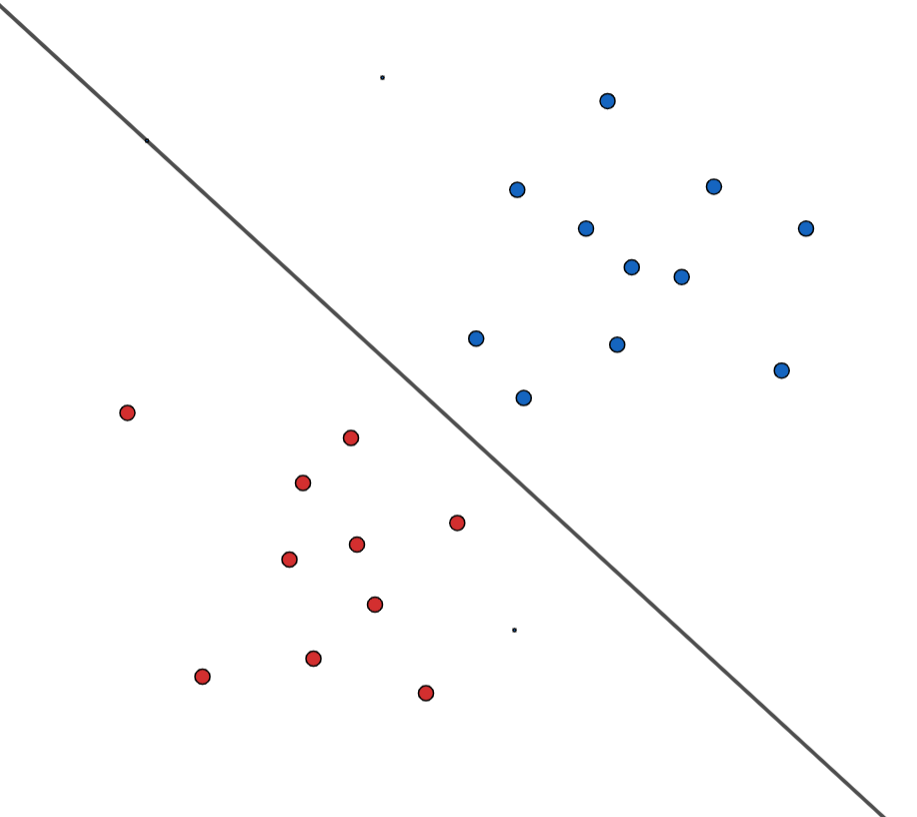
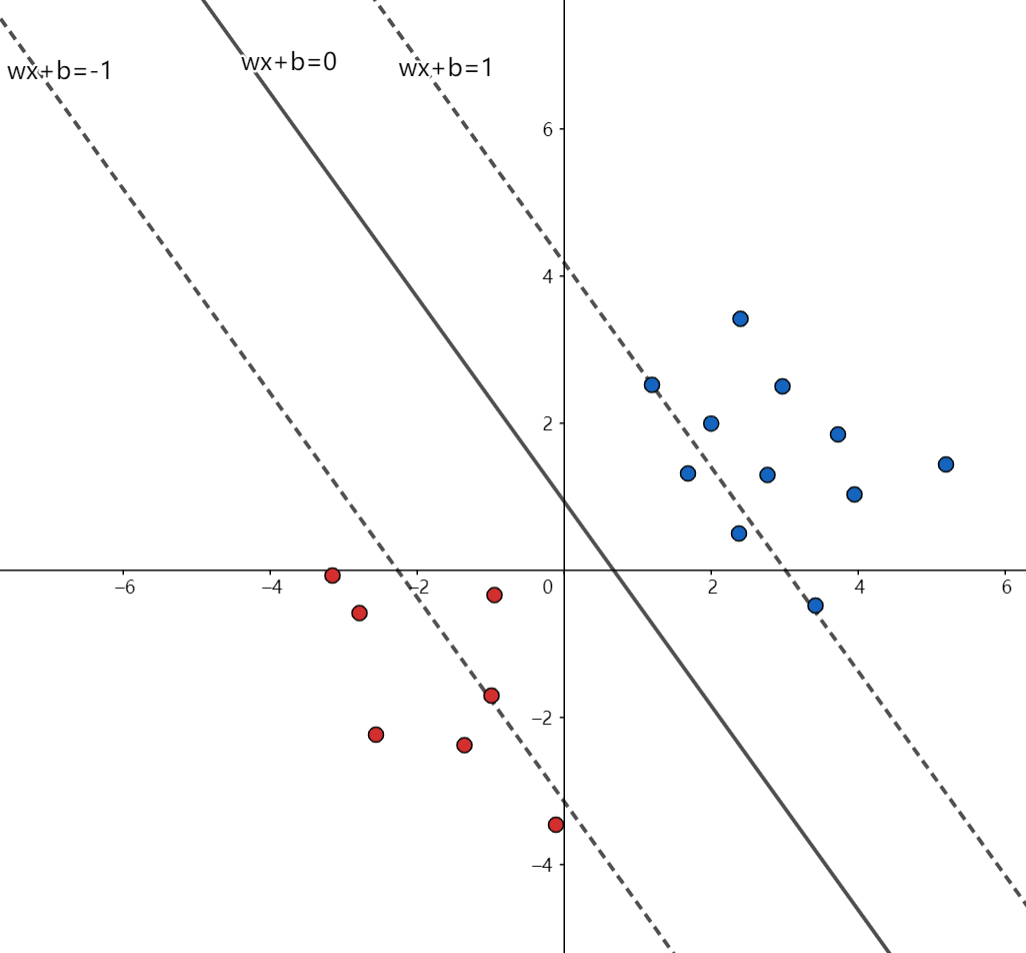
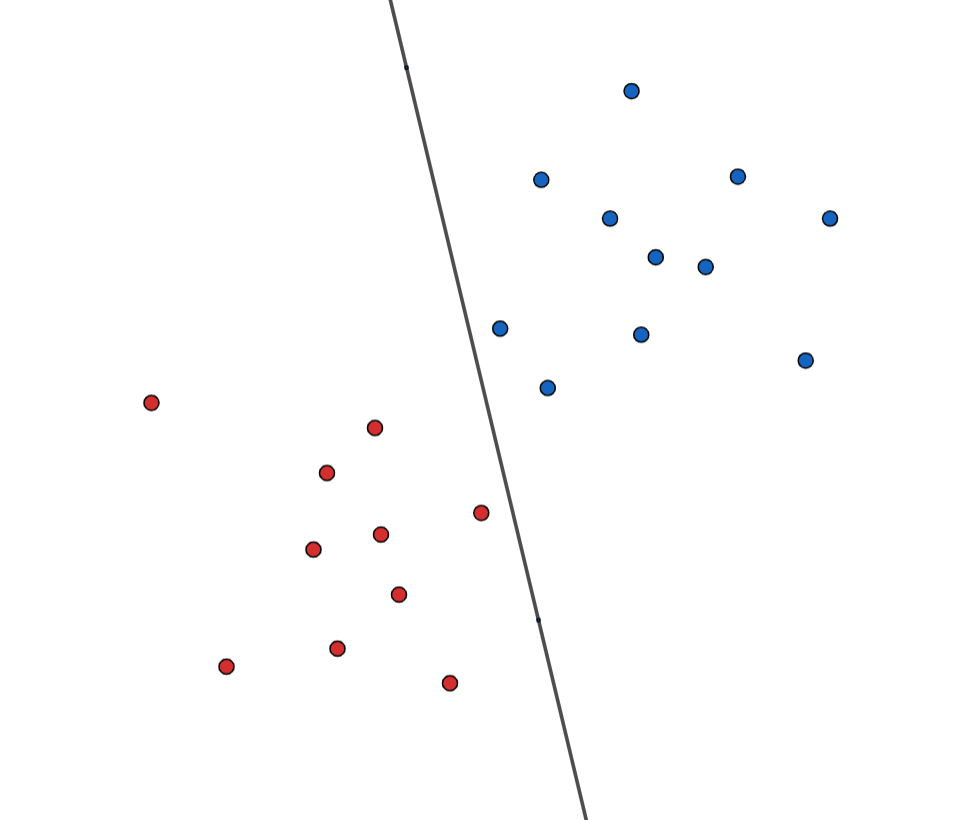
我们简单的举个例子,如下图所示,在二维平面上有两组数,一组用蓝色表示,一组用红色,设蓝色为1类,红色为-1类。不难看出它们线性可分,我们先随便找出一个超平面,那么在超平面以上的点就是1类,以下的就是-1类。
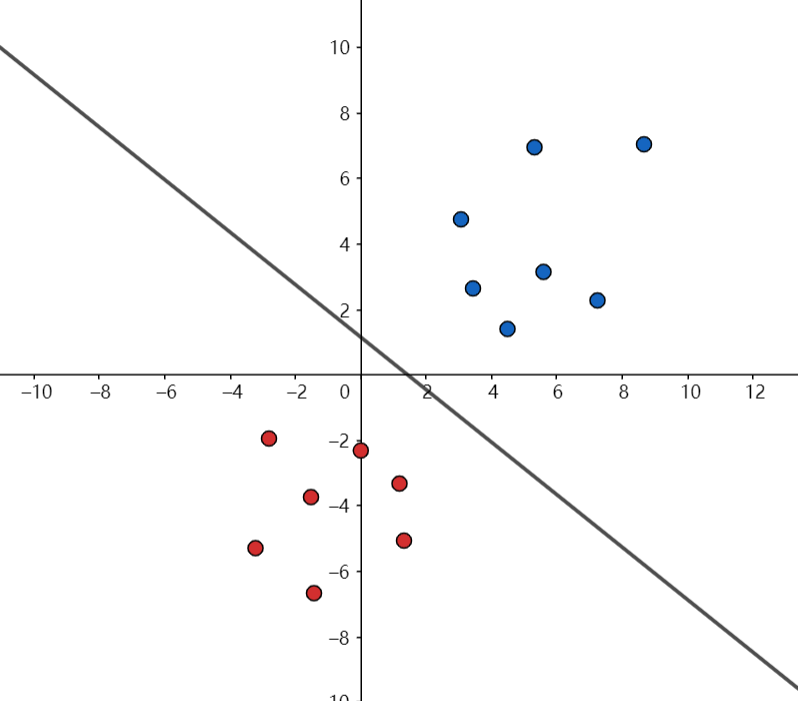
还记得SVM要解决什么问题吗?就是要在支持向量里面找一个离超平面最远的,进行直观的分析我们不妨平移这跟直线,这两根平行线最先碰到的点就是这跟超平面的支持向量,要求出它们之间的距离,首先想到的肯定是点到直线间的距离公式嘛,即:
$$
\frac{|Ax+By+C|}{\sqrt{A^2+B^2}}
$$
(说实话我们要用的就是这个公式,一开始我学习的时候,这一块我看的就很快,但是到了后面就看不懂了,因为SVM的推导含了很多的假设,所以这个地方是一个重点)
其实这个公式的推导不是很难,但是在SVM为了让后续的操作更方便,带入了一个叫做函数距离的东西,所以我们先来看看函数距离是什么:
定义函数间隔(用表$\hat{y}$示)为:
$$
\hat{y} = y_i(w^Tx + b) = y_if(x)
$$
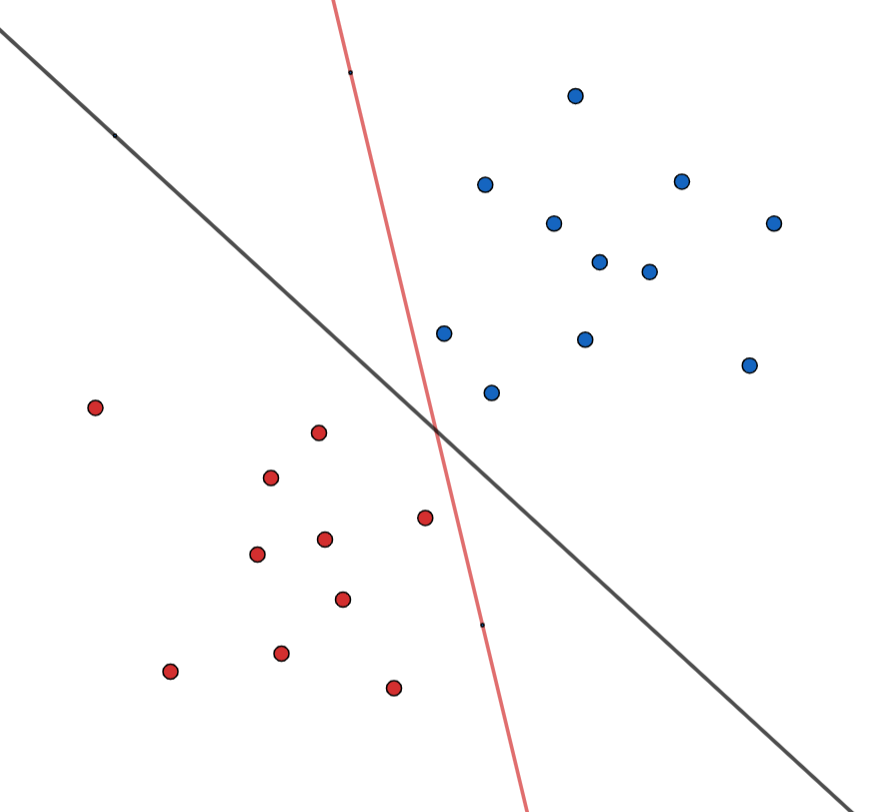
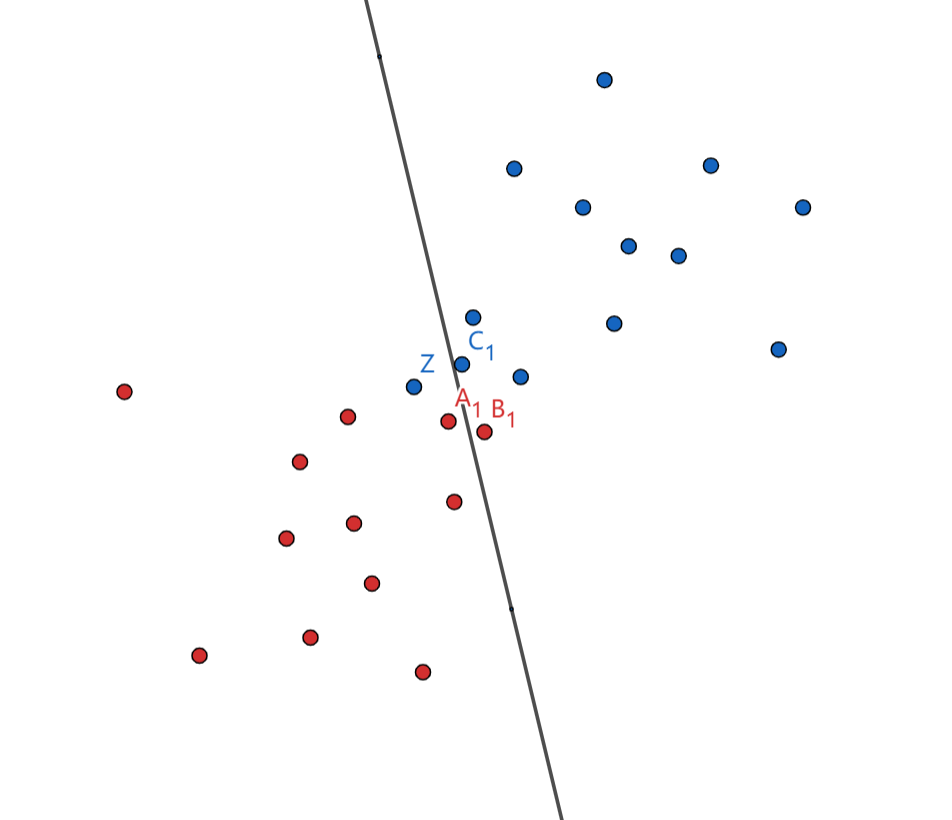
其中公式的$y_i$代表类别,而这个$f(x)$就是超平面的方程嘛,函数间隔就直观的理解成了类别乘以函数值,也就是下图红色的这一段:也就是说我们的超平面是黑色的这根实线,如果是在线上的点,带入方程$f(x)$应该是等于0的嘛,如果它不在线上,$f(x)$肯定是等于一个非0的数,现在我在它前面乘一个它的类别,就相当于给它加了一个绝对值。所以我们在计算的时候就不用管它是哪类的了,因为我们是要找到支持向量嘛,直接看距离不用管它在哪边的意思。所以这就是用-1和1的好处,这种定义不仅消除了符号的影响,还让函数值不受影响(因为乘1嘛)。
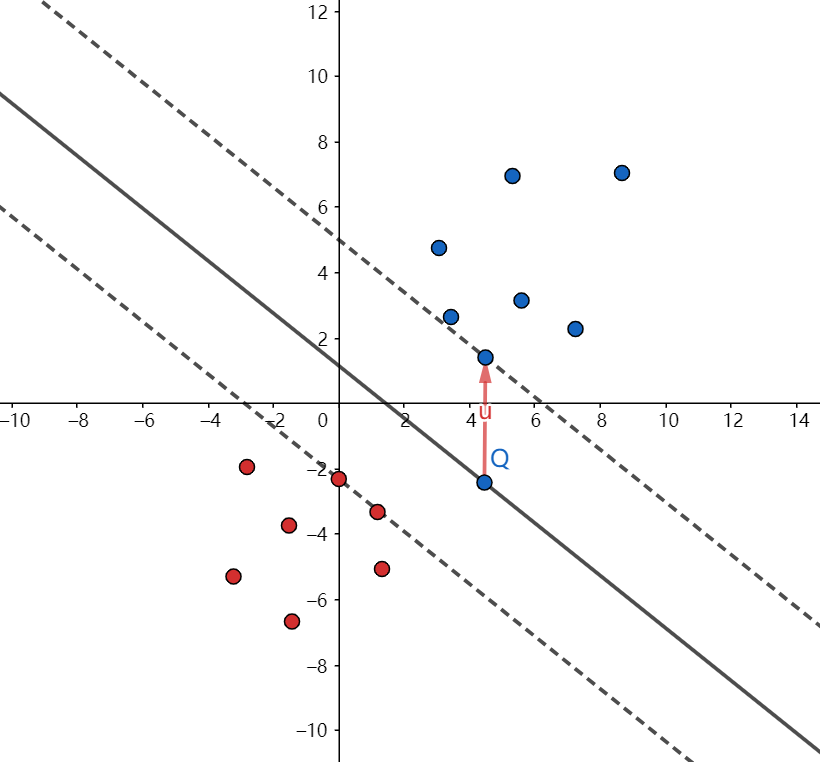
但是用来表示距离的话,用这个函数距离是不够的,大家可以想一个问题,当超平面方程的w和b分别扩大两倍,即$2w^Tx + 2b = 0$,对超平面是没有任何影响的,但是对函数距离就有影响了,它现在就扩大了四倍,显然是不对的。
所以这个时候就引入了几何间隔的概念:
假定有一个点x,它投影到超平面上是$x_0$,w是超平面的法向量,y是x到超平面的距离:
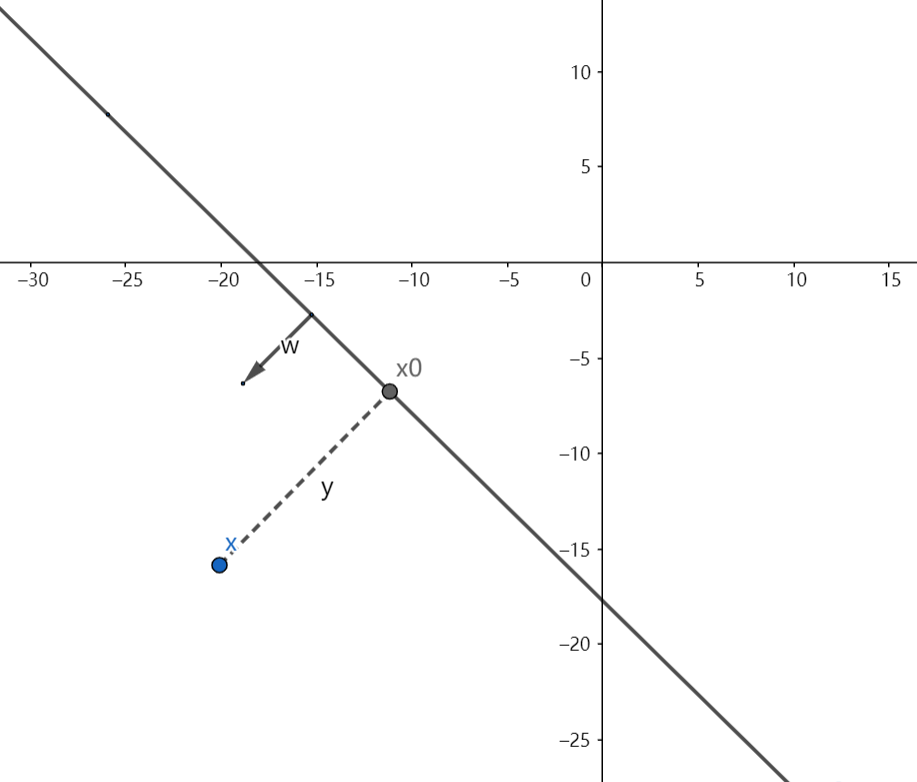
根据几何知识可以得到$x = x_0 + y\frac{w}{||w||}$
$$
y = \frac{w^Tx + b}{||w||}
$$
但是上面这个式子还有一点不足,就是它可能会为负数,距离肯定不能为负嘛,所以我们在它前面乘上类别,就相当于加了一个绝对值,于是得到了集合距离:
$$
\tilde{y} = \frac{y_i(w^Tx + b)}{||w||} = \frac{\hat{y}}{||w||}
$$
这个公式是不是很眼熟?,就是函数距离除以$||w||$,几何距离更为直观,所以接下来我们要求的就是这个几何距离。
这部分是教材缩水最严重的部分,上面的知识其实都很好理解,因为之前都学过,而最重要的部分教材用很简单的几句话就带过了,现在我们就结合上面的知识来讲解一下如何找到最大间隔。
再来回顾一下SVM要干什么?SVM就是要在支持向量里面找一个离超平面最远的。我们不管是在推导什么,到最后都是要回到这个问题上的!在上一节中我们说到用几何间隔求间隔,但是我们再仔细观察一下公式:
$$
\tilde{y} = \frac{y_i(w^Tx + b)}{||w||} = \frac{\hat{y}}{||w||}
$$
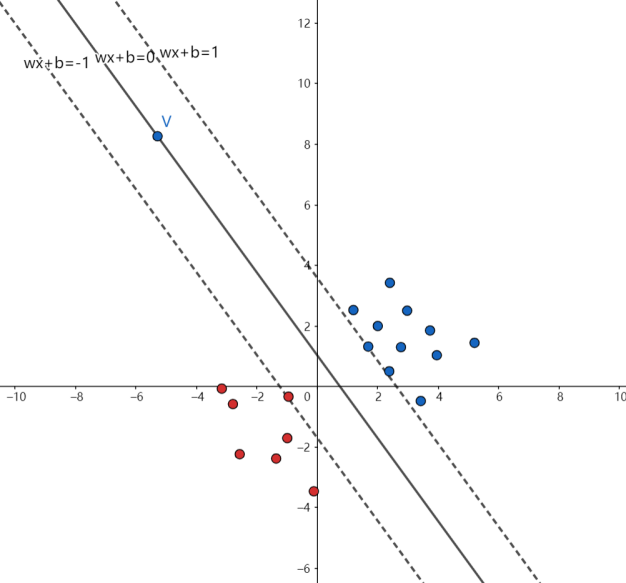
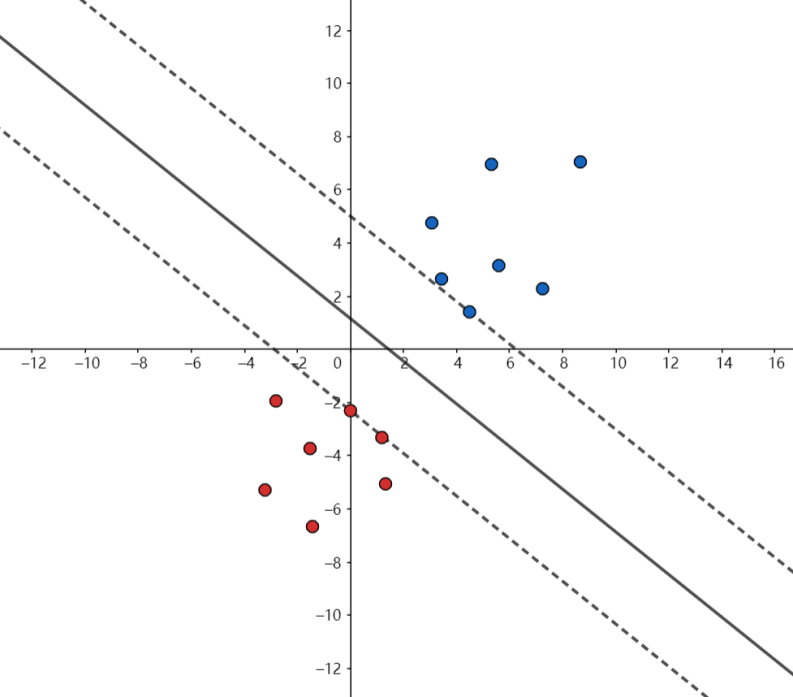
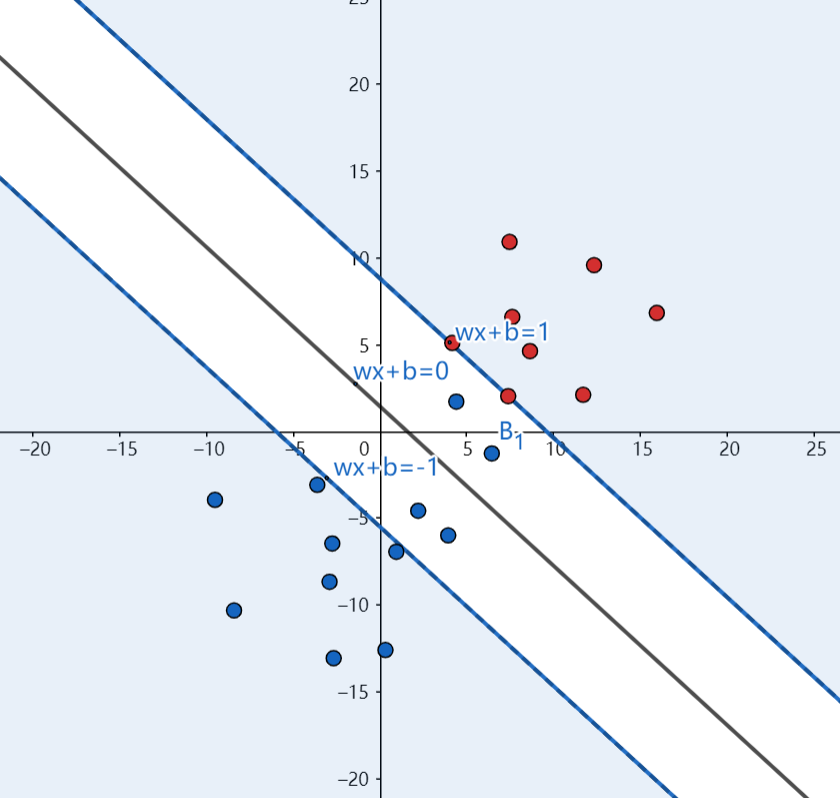
我们发现如果要求距离其实是非常麻烦的一件事,因为w和b我们不知道,合着我们分子分母都不知道,这样求解起来相当困难,所以我们不妨设分母为一个常数,这里很多书里都是设定分母=1,不为别的就因为1好算。这个时候几何间隔就变成了$\tilde{y} = \frac{1}{||w||}$,再求解间隔就变得容易多了,我想让几何间隔更大,那$||w||$就要更小,我们把上面的这个假设画出图来,就变成了这个样子:
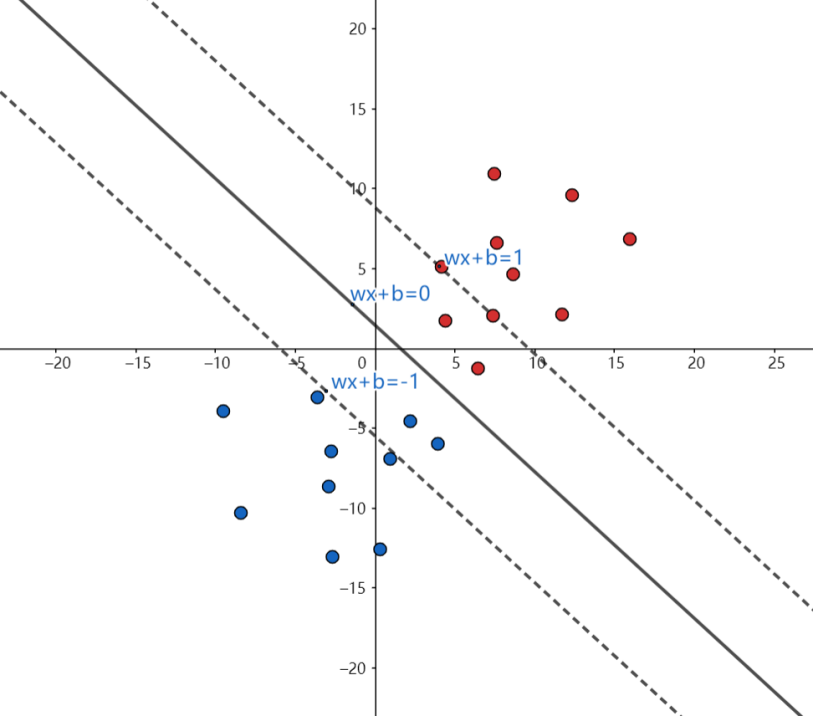
(其实困扰我比较久的也是这个图,因为一开始我一直在想它把函数距离规定成1,那么里面的点该怎么办呢?先不用在意这个疑问,这涉及到一个叫做 松弛变量 的东西,下面会讲)
假设之后就由原来的超平面变成了旁边的两条虚线嘛,它们到超平面的距离是$\frac{1}{||w||}$,所以整个区间的长度就是$\frac{1}{||w||}$,而这样一来,我们不仅将问题简化了,而且我们还把一些用不着的数据给分出来了,如上图所示在$wx + b = 1$、$wx + b = -1$上包括区间内的点就是支持向量,其它的点跟我们没有什么关系嘛我们又不要它,所以就设定了一个约束条件$y_i(w^Tx + b) >= 1$,也就是在这根直线上的点包括这跟直线以上的点都不是我们要的(为什么直线上的点我们也不要呢?因为这个直线不一定一开始就能找到支持向量,可能还有点在区间内)。所以我们求解的问题变成了这样,其中s.t.代表约束条件的意思:
$$
\tilde{y} = \frac{1}{||w||}\
s.t.\quad y_i(w^Tx + b) >= 1
$$
但是这跟公式还有不足的地方,就是这个$\frac{1}{||w||}$看的人很不顺眼,大家可以设想一下,给定一个方程让我们求解它的最值,我们第一时间就是想到对这个数求导嘛,这个分时看起来就让人很不舒服,所以我们将他转化一下,既然要求$\frac{1}{||w||}$的最大值,反过来就是求解$\frac{1}{2}||w||^2$的最小值嘛(这里大家可以求导看看,发现导数是w),引入平方是为了把它变成一个二元函数,那么求导得到的就是w本身了。
如果直观的去求解$\frac{1}{2}||w||^2$的最值,说实话,这本来是一件很容易的事,我直接对方程求导并且令它为0就可以了,但是现在这么求是不行的,因为我们上述这个方程被约束了,他要满足条件才能这么算。那么为了解决这种带约束条件求最值的问题,我们引入了拉格朗日乘子法,我直接引用别人的成果(因为写的很好):
首先来了解拉格朗日乘子法,那么为什么需要拉格朗日乘子法?记住,有拉格朗日乘子法的地方,必然是一个组合优化问题。那么带约束的优化问题很好说,就比如说下面这个:
$$
min\quad f=2x_1^2+3x_2^2+7x_3^2\
s.t.\quad 2x_1+x_2=1\
2x_2+3x_3=2
$$
这是一个带等式约束的优化问题,有目标值,有约束条件。那么想想假设没有约束条件这个问题是怎么求解的呢?是不是直接对各个x求导等于0,解x就可以了。但是x都为0不满足约束条件呀,那么问题就来了。这里在说一点的是,为什么上面说求导为0就可以呢?理论上多数问题是可以的,但是有的问题不可以。如果求导为0一定可以的话,那么f一定是个凸优化问题,什么是凸的呢?像下面这个图(凸其实只是一个简称,方向向上向下都可以):
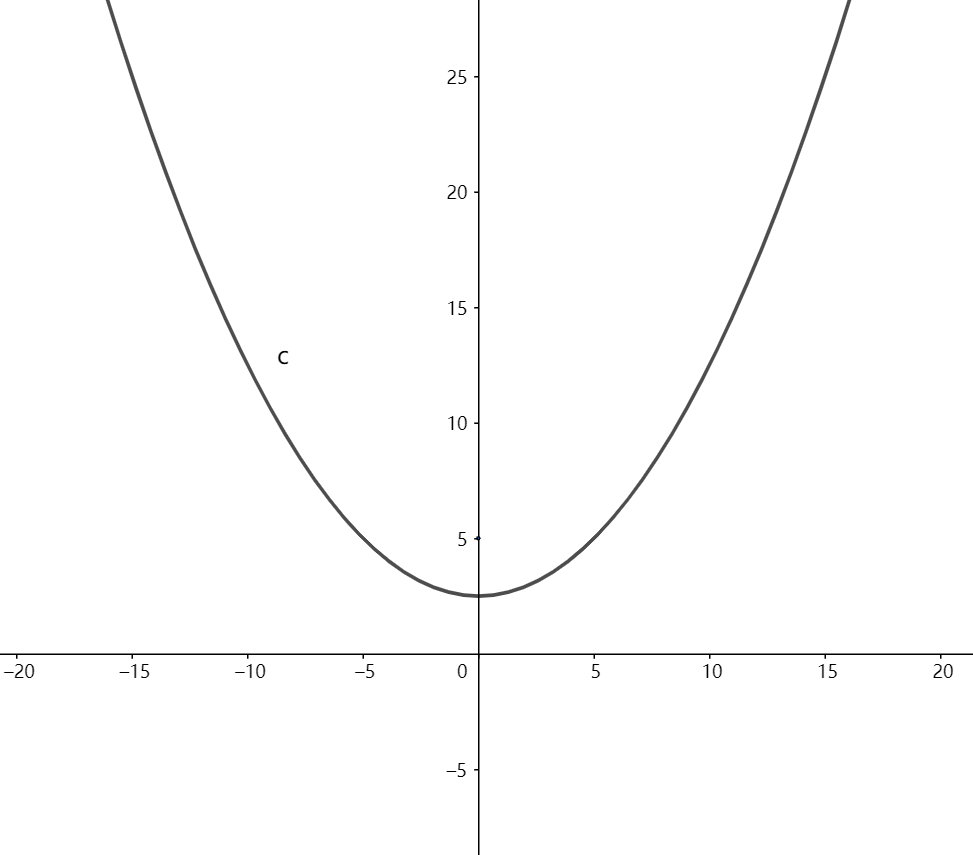
而对于这个凸优化,更准确的说就是:
满足$\frac{f(x_1)+f(x_2)}{2} >f(\frac{x_1+x_2}{2})\or\\frac{f(x_1)+f(x_2)}{2}<f(\frac{x_1+x_2}{2})$ ,就是凸函数。
那也就是说不是凸函数的函数就应该长这样(左边):
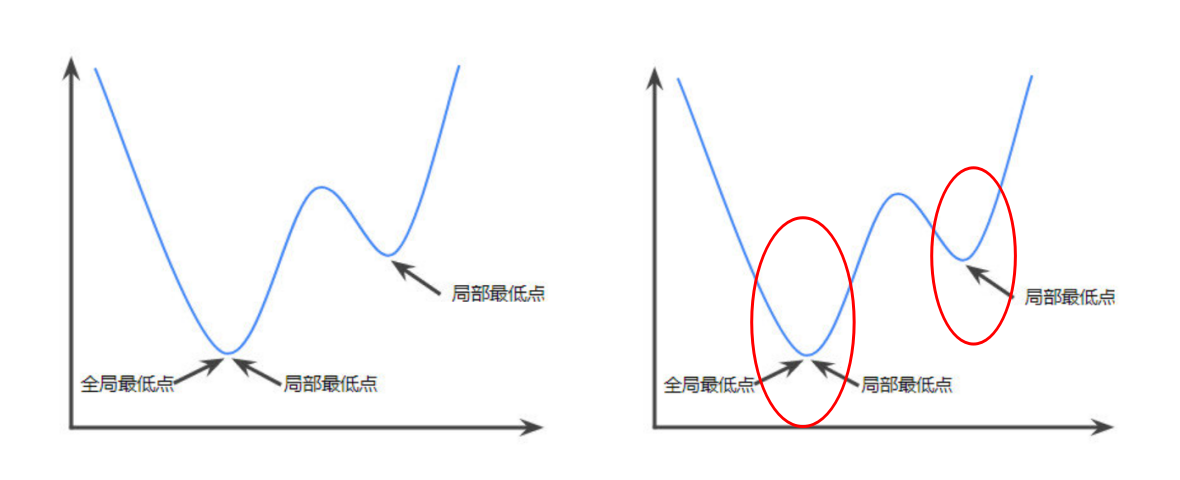
x一下满足条件二,一下满足条件一,它对应的区间也就不一样了嘛(右边),这个时候我们也不敢保证我们这一次求出来的一定是最优解。
回头再来看看有约束的问题,既然有了约束不能直接求导,那么如果把约束去掉不就可以了吗?怎么去掉呢?这才需要拉格朗日方法。既然是等式约束,那么我们把这个约束乘一个系数加到目标函数中去,这样就相当于既考虑了原目标函数,也考虑了约束条件,比如上面那个函数,加进去就变为:
$$
min\quad f=2x_1^2+3x_2^2+7x_3^2+\alpha_1(2x_1+x_2-1)+\alpha_2(2x_2+3x_3-2)
$$
这里可以看到与$\alpha_1$、$\alpha_2$相乘部分都等于0,所以$\alpha_1$、$\alpha_2$的取值为全体实数,现在这个优化目标函数就没有了约束了,所以接下来求解就只用求导等于0:
$$
\frac{\delta f}{\delta x_1}=4x_1+2\alpha_1=0 \Longrightarrow x_1 = -0.5\alpha_1\
\frac{\delta f}{\delta x_2}=6x_2+\alpha_1+2\alpha_2=0\Longrightarrow x_2=-\frac{\alpha_1+2\alpha_2}{6}\
\frac{\delta f}{\delta x_3}=14x_3+3\alpha_2=0 \Longrightarrow x_3 = -\frac{3\alpha_2}{14}
$$
再帮上面求出的结果带入到约束条件中去,可以求出结果$\alpha_1$=-0.39,$\alpha_2$=-1.63,那么把$\alpha$带入到原来的式子就得到x了。这个是求解等式约束条件的犯法,那么对于不等式约束法该怎么办呢?就要用到KKT条件。
(其实是要先把超平面的约束条件写进去再来证明它满足KKT条件才严谨,但是我觉得先把KKT看来,再反过来看问题会容易的多,因为能理解的话就能自己反证了)
我们继续讨论上面遗留下来的问题,其实约束条件就分为三种嘛,等式约束,大于号约束,小于号约束,我们为了方便就把大于号约束换成小于号约束了,所以就变成两类了。关于这个KKT条件,再举个例子:
$$
min\quad f=x_1^2-2x_1+1+x_2^2+4x_2+4\
s.t.\quad x_1+10x_2>10\
10x_1-10x_2<10
$$
按照上面的说法,我们把大于号问题转成小于号问题(为什么要换符号是因为为了统一操作,求解一个同方向的问题当然是要比求解不同方向的更容易吧),然后再按照拉格朗日乘子法的做法加上alpha,得到:
$$
L(x, \alpha)=f(x)+\alpha_1 g(x)+\alpha_2 g(x)\
=x_1^2-2x_1+1+x_2^2+4x_2+4+\alpha_1 (10-x_1-10x_2)+\alpha_2 (10x_1-10x_2-10)
$$
那么KKT条件的定义是啥呢?就是一个关系式在完成了转变之后变成了:
$$
L(x,\alpha,\beta)=f(x)+\sum \alpha_i g_i(x_i)+\sum \beta_i h_i(x_i)
$$
其中g是不等式约束,h是等式约束,那么KKT就是指满足下列条件的函数的最优解:
$$
(1)L对各个x求导等于0\
(2)h(x)=0\
(3)\sum\alpha_i g_i(x_i)=0,\alpha>=0
$$
其实前两个都很好理解,都是和等式约束一样的,第三个我也不画图了,我直接用书上的公式来说明:
SVM的方程为:
$$
\tilde{y}=\frac{1}{||w||}\
s.t.\quad y_i(w^Tx+b)>=1
$$
KKT以后得到:
$$
L(w, b,\alpha)=\frac{1}{||w||}-\sum_{i=0}^{n}\alpha_i y_i(w^Tx_i+b-1)\quad 为了方便叙述下段记为1式
$$
现在对于第三个条件,我们可以这样理解:
在约束条件$y_i(w^Tx+b)>=1$以内的那些点,它都满足约束条件了,所以我们能直接求导了,换个说法就是在蓝色这片区域里面取出来的点本来就是在约束条件里面的,是不是相当于这个约束条件无效,那么alpha也就等于0了,我们就可以直接求最优解。反过来说,在约束外的点就是我们要求的,那么alpha就是非0的,也就是说我们要找一个最不满足约束条件的点,也就是alpha的最大值嘛。
所以根据上面的说法1式就可以写作:
$$
min\quad \theta(w)=min_{x,b}max_{\alpha_i>=0}L(w,b,\alpha)=p^*
$$
我们观察一下上面我们得到的式子:
$$
min\quad \theta(x)=min_{w,b}max_{\alpha_i>=0}L(w,b,\alpha)=p^*
$$
我们从左到右看嘛,很容易发现一个问题,解方程要先解里面这层,也就是说一开始我们就要去算关于不等式约束的解,然后再算w和b,但是这肯定是很难求的,那不如转换个**,先算没有约束条件的情况,再加上约束条件,再算一次,这也就是对偶律。也就是说我们上面的方程等价于:
$$
min\quad \theta(w)=max_{\alpha_i>=0}min_{w,b}L(w,b,\alpha)=d^*
$$
写的详细点就是
$$
max_{\alpha_i>=0}min_{x,b}(\frac{1}{2}||w||^2-\sum_{i=0}^n\alpha_1(y_i(x^Tx_i+b)))
$$
这个时候就方便多了嘛,而且这样转化也带来了一定的好处,我们求出了w,b然后再求alpha,也就是最后只有一个解就是alpha,它把我们的解减少到只有一个了,alpha就可以代表一切了,不知道大家还记不记得我们在上面提到的在约束条件以内的点alpha=0,那么这就好办咯,支持向量就是非0的alpha,上式求出的解也是alpha,怎么样,是不是很巧妙?
我们已经很接近答案了,我们按照一开始的思路继续推导,现在整个方程已经化解成可以让我们直接求导=0就能得到最值的状态了,那我们试试看:
先是固定alpha,对w和b求偏导数:
$$
\frac{\delta L}{\delta w}=0\Longrightarrow w=\sum_{i=1}^n\alpha_i y_ix_i\
\frac{\delta L}{\delta b}=0\Longrightarrow 0=\sum_{i=1}^n\alpha_iy_i
$$
其实这个就是文章里这句代码的意思:
fXi = float(np.multiply(alphas, labelMat).T * (dataMatrix * dataMatrix[i, :].T)) + b 那么将上面的结果带入原式(打公式太麻烦了,我直接用july的推导过程了):
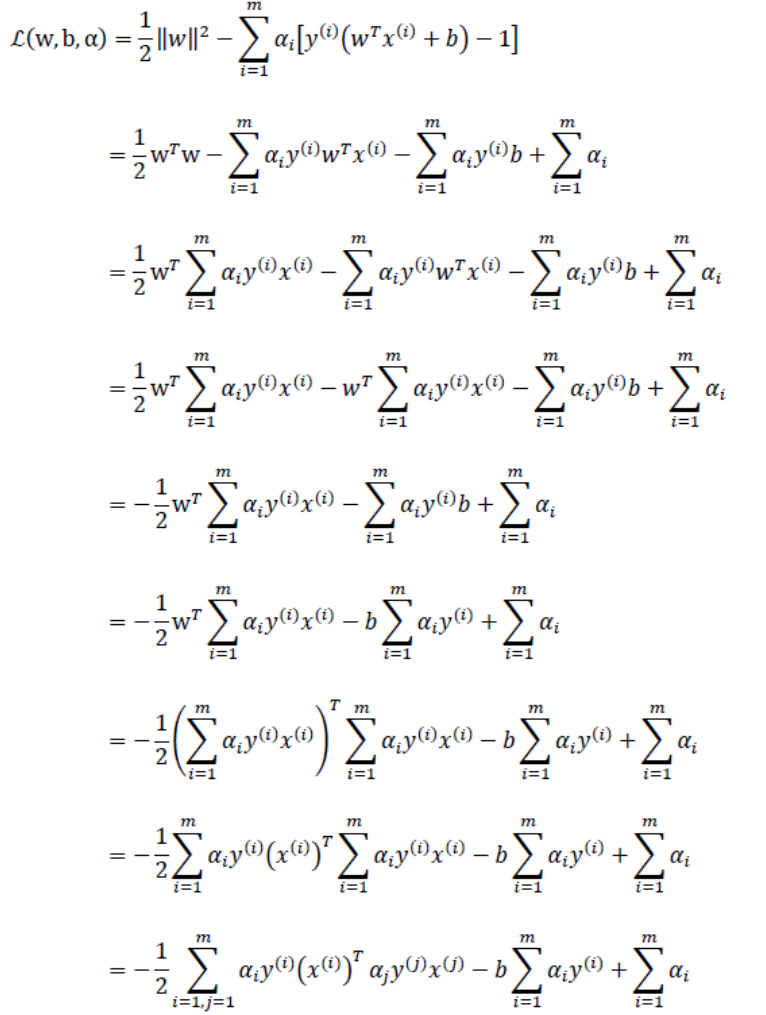
最后得到:
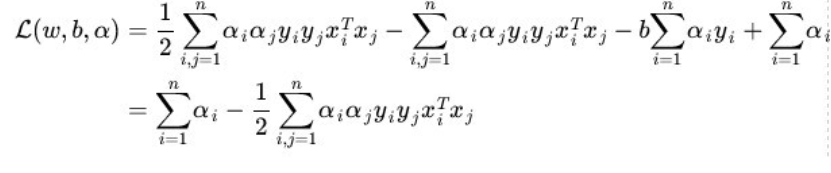
这部分的推导个人人为只要记住结果就行,因为推导过程其实是很复杂的,也没有必要,我们记住下面这个式子就可以。
$$
L(w,b,\alpha)=\sum_{i=1}^n\alpha_i-\frac{1}{2}\sum_{i,j=1}^n\alpha_i \alpha_j y_iy_j x_i^Tx_j
$$
上面推导出的东西在原来的公式上多出了一个i、j,其实就是说我们从向量中随便抽出两个来使用,用这两个向量来找出最大间隔。
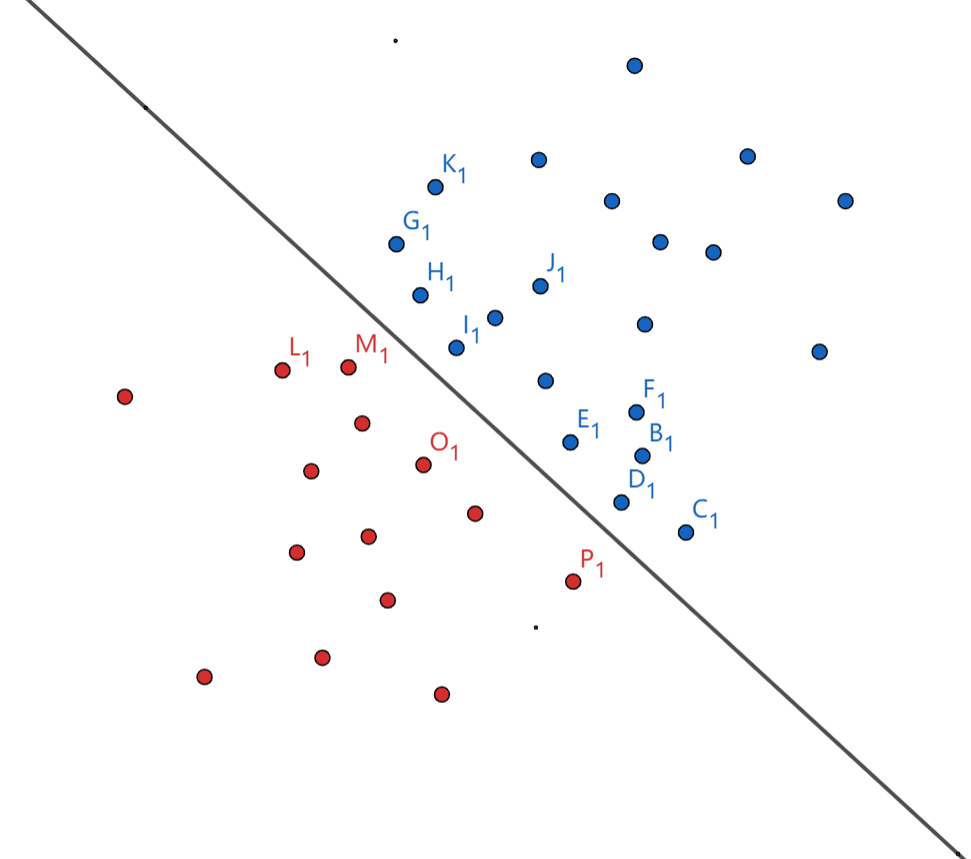
还记得我们遗留在上文中的一个问题吗?我们为了方便计算,所以将函数距离假设为1,但是我们发现假设为1以后有一些点在间隔内了,这该如何处理呢?例如下图,我们发现数据是线性可分的,那就好办了,我将函数距离假设为1以后确定了间隔的区间,那区间里面的点就是不满足约束的嘛,那我就拿着这两条虚线一直往里面动,越来越往里,范围越来越小,到最后范围内没点了这就是我们最后要得到的东西嘛。
也就是说只要数据是线性可分的,那我们一定是能得到一个超平面能将数据完美分开的。但是现实生活中这种数据很少,万一上面的数据出现了这种情况该怎么办:
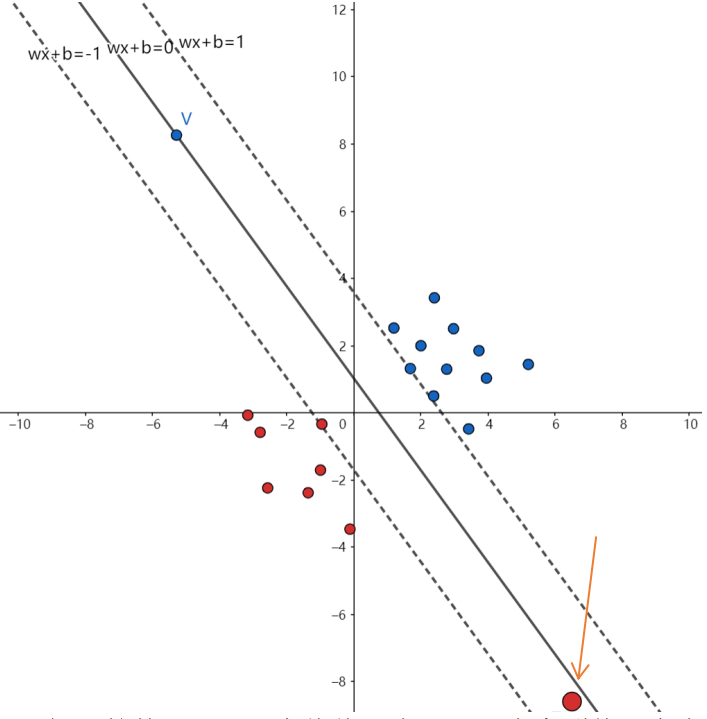
本来是一组很好的数据,但是它偏偏出来这么一个离群值(红色那个大点),本来我们的间隔可以很大的,但是就因为它这样一个数据导致间隔很小,甚至没有间隔。这个时候我们就需要引入一个叫做松弛变量的概念。
松弛变量,顾名思义就是对这个区间的要求放宽一点:
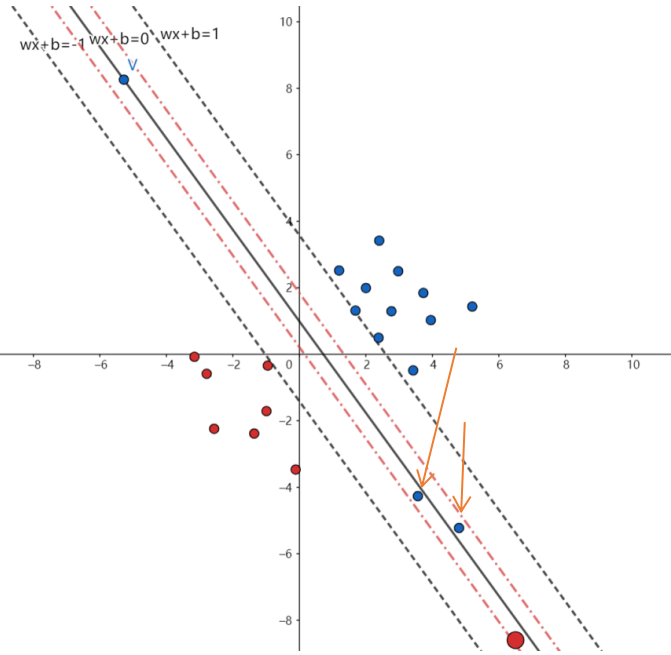
对比上下两个图,我在图像中又加了两根红色的虚线,这就是松弛变量,
设置这样一个东西也就是说,在松弛变量到超平面这个间隔内的数据我们也不用管它是哪个类别的,我们不要了,因为大家看看上面的这个数据的分布,那些奇奇怪怪的数据终究只是少数,我们样本这么大,少几个问题不大吧,那结合我们上面推导的知识,我们可以很容易推导出一个新的约束条件:
$$
0<\alpha<C\quad and\quad \sum_{i=1}^n\alpha_iy_i=0\
g(x)=\begin{cases}
C\quad (\alpha>=C)\
0\quad (0<\alpha<C)\
1\quad (\alpha<=0)
\end{cases}
$$
这个关系的意思就是,对于alpha来说我们只要求找到的alpha在大于0、小于C的范围内即可,那其它地方的点就根据上面的约束来取嘛。
那我们现在结合SMO来看,SMO算法是随机取两个向量,然后看它们是不是能够被优化。什么是优化啊,就是取到的两个向量都是和我们要解决的问题有关的,认为还可以进一步的探究它们。那也就是说我们两个向量都要在(0,C)内才行了咯,那如果我们取的向量不是在这个范围内的该怎么办,那就让他等于边界嘛,例如上图中的,点取到黑虚线外面的那我就强行让他等于1嘛(alpha=0是上面解释过的),同理在红虚线外面的那就让他等于C嘛,这样就保证了,我每次抽取向量,抽到不需要的也不会影响我们假设的区间了。
现在我已经把最基础的部分讲解了,核函数部分待续。
《机器学习实战》Peter Harrington著
《人工智能数学基础》唐宇迪 著
支持向量机通俗导论(理解SVM的三层境界)
https://blog.csdn.net/v_JULY_v/article/details/7624837
深入解析python版SVM源码系列(三)——计算样本的预测类别
https://blog.csdn.net/bbbeoy/article/details/72598473
解密SVM系列(一):关于拉格朗日乘子法和KKT条件
https://blog.csdn.net/on2way/article/details/47729419
SVM基本**及入门学习(转载+自己解释为什么minL(w)变成minmaxL(a,w))
https://blog.csdn.net/appleyuchi/article/details/82503009
凸优化问题,凸二次规划问题QP,凸函数
https://blog.csdn.net/promisejia/article/details/81241201
SVM从原始问题到对偶问题的转换及原因
SVM为什么要将原问题转换为对偶问题?
https://blog.csdn.net/qq_40598006/article/details/114077093
支持向量机 数学推导 Part1
https://blog.csdn.net/qq_23869697/article/details/79242814
解密SVM系列(一):关于拉格朗日乘子法和KKT条件
https://blog.csdn.net/on2way/article/details/47729419
支持向量机松弛变量的理解
https://blog.csdn.net/ustbbsy/article/details/78873333
SVM松弛变量
https://blog.csdn.net/wusecaiyun/article/details/49659183
SVM最大间隔超平面学习笔记及对函数间隔设置为1的思考
https://blog.csdn.net/weixin_44027401/article/details/106464532
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.