Binary and multiclass sentiment detection using deep neural architectures (BLSTM and CNN) on Persian augmented texts
NB: DeepSentiPers is a modified version of our paper presented in the fifth conference of CL in Iran
https://arxiv.org/pdf/2004.05328.pdf
This paper focuses on how to extract opinions over each Persian sentence-level text. Deep learning models provided a new way to boost the quality of the output. However, these architectures need to feed on big annotated data as well as an accurate design. To best of our knowledge, we do not merely suffer from lack of well-annotated Persian sentiment corpus, but also a novel model to classify the Persian opinions in terms of both multiple and binary classification. So in this work, first we propose two novel deep learning architectures comprises of bidirectional LSTM and CNN. They are a part of a deep hierarchy designed precisely and also able to classify sentences in both cases. Second, we suggested three data augmentation techniques for the low-resources Persian sentiment corpus. Our comprehensive experiments on three baselines and two different neural word embedding methods show that our data augmentation methods and intended models successfully address the aims of the research.
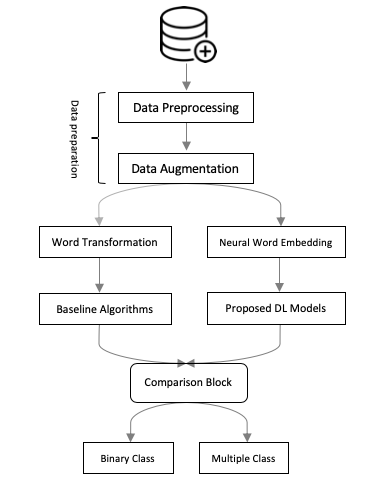
Overall the DeepSentiPers achieved the following results in the Persian sentiment analysis task. H/E, read the paper to find more about the results.
| Classification-Type | BLSTM F1-Score | Word-Embedding | Data-Augmentation |
|---|---|---|---|
| Binary | 91.98 | Keras | Translation |
| Multi-Class | 69.33 | FastText | Translation |
Please cite the arXiv paper if you use DeepSentiPers in your work:
@misc{sharami2020deepsentipers,
title={DeepSentiPers: Novel Deep Learning Models Trained Over Proposed Augmented Persian Sentiment Corpus},
author={Javad PourMostafa Roshan Sharami and Parsa Abbasi Sarabestani and Seyed Abolghasem Mirroshandel},
year={2020},
eprint={2004.05328},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
All the things you need to work on this project is an Ipython environment like the Google Colab or Jupyter and the dataset files.
The dataset is used in this project was collected from SentiPers corpus. It contains 7419 Persian sentences and their connected polarity. The original and augmented dataset files are accessible in the "Dataset" folder.
- Javad PourMostafa - GitHub, LinkedIn, ResearchGate, Website
- Parsa Abbasi - GitHub, LinkedIn, ResearchGate, Website
- Seyed Abolghasem Mirroshandel LinkedIn, ResearchGate, Website
See also the list of contributors who participated in this project.
We're glad to announce that the DeepSentiPers has been drafted in Persian as well. Find it at https://zenodo.org/record/3551273. Note that the intended version is slightly different from the English one.
Persian Title: ارائه یک سیستم تحلیل احساس در زبان فارسی با استفاده از مدل های یادگیری عمیق

