A common need in many logistics scenarios is to estimate the distance and travel time between two or more points. Euclidean, Haversine, Manhattan and similar distance calculations may provide appropriate values in some scenarios, but in many others, the network of paths and roadways that must be traversed in order to travel between points must be taken into consideration.
The goal of Project OSRM is to make available software for the calculation of routes using map details provided by the OpenStreetMap Foundation. The OSRM Backend Server provides a simple to deploy solution capable of routing vehicles and foot traffic anywhere in the world.
The OSRM Backend Server deploys as a web service presenting a simple, fast REST API. Within many organizations, this server is deployed as a containerized service accessible to a wide range of internal applications. For analytics teams generating routes across large historical or simulated datasets, dedicated deployments are often necessary. To assist analysts with this need, we will demonstrate how the OSRM Backend Server may be deployed within a Databricks cluster and accessed as part of various data processing efforts.
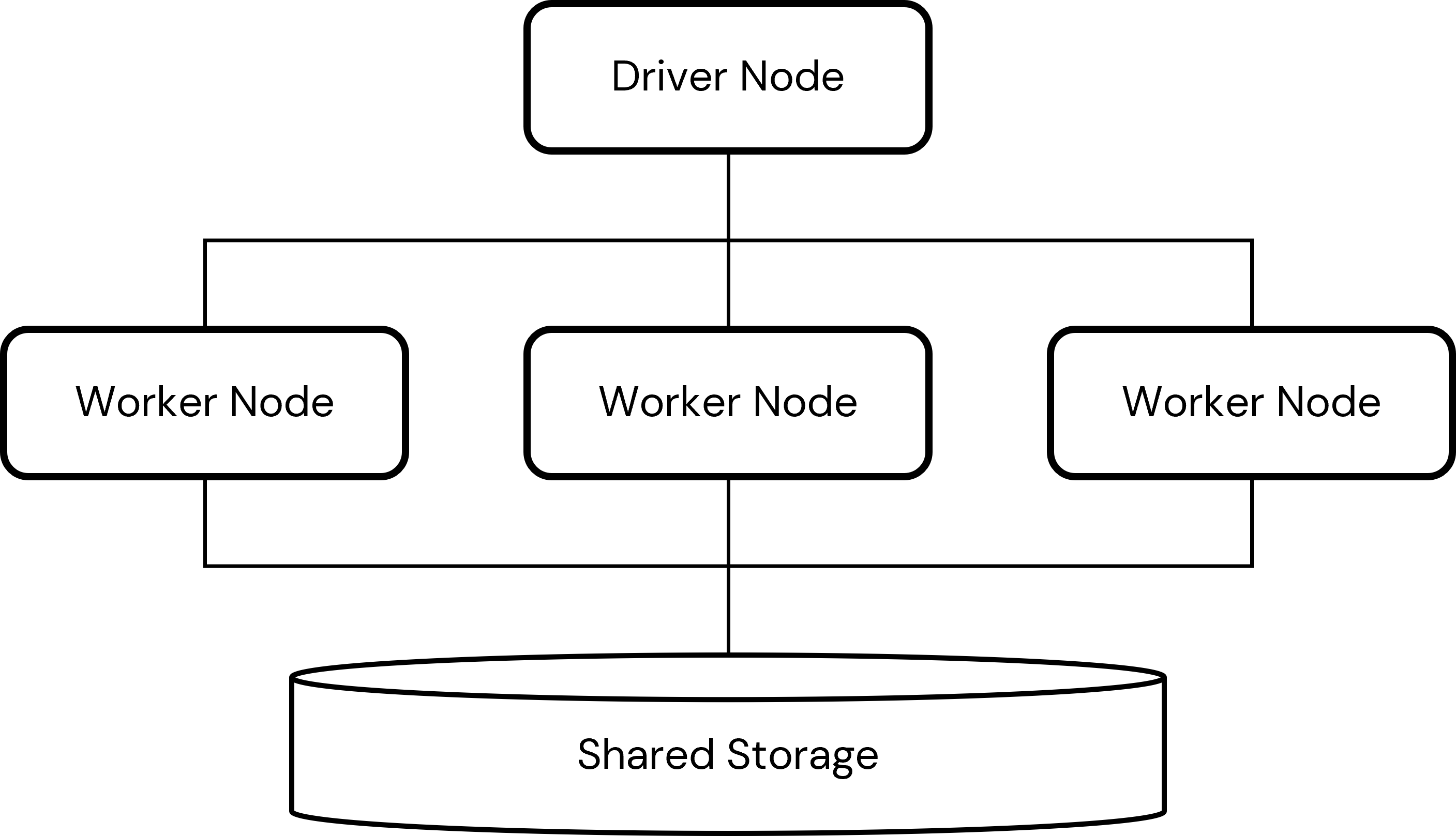
To better understand how the OSRM software will be deployed, it's important to have some knowledge of how a Databricks cluster works. A Databricks cluster consists of server computers working together to execute a shared data processing workload. Data loaded into a Spark dataframe is distributed across the resources of several computers known as the cluster's worker nodes. Another computer, the driver node, coordinates the processing of the data allocated to the worker nodes. All nodes have access to a shared storage location to which various datasets and other assets can be read or written. This is a highly simplistic representation of a Databricks cluster but one that's sufficient for explaining our approach.
To generate routing information at scale, we'll deploy the OSRM Backend Server on each of the worker nodes in the cluster. This will take place through a cluster init script which will be run on each node of the cluster as that node is provisioned. Through this script, a local instance of the OSRM Backend Server will be deployed on each worker. These instances of the OSRM software will allow us to generate routes locally when processing data in a Spark dataframe:
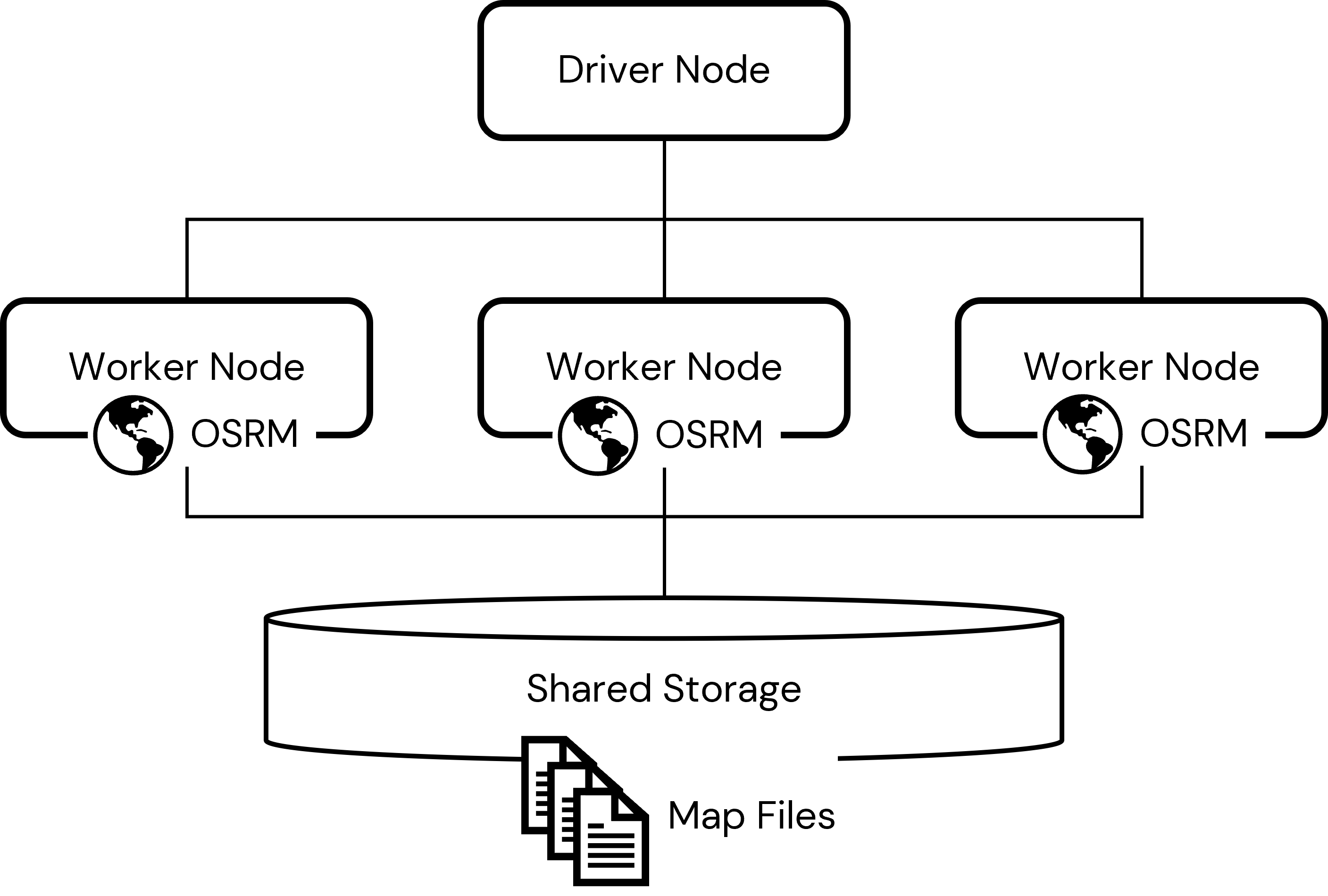
Each instance of the OSRM Backend Server will require access to map data. This data will be housed in the shared storage so that each worker node can easily access it from a shared, consistent location. This data must be downloaded and pre-processed before the OSRM software can make use of it. In order to prepare this data for use (and to compile the OSRM Backend Server software itself), we will make use of a lightweight cluster with no worker nodes, i.e. a single node cluster. We will place the processed map data (and the compiled software) in a shared storage location accessible to any cluster within our Databricks workspace.
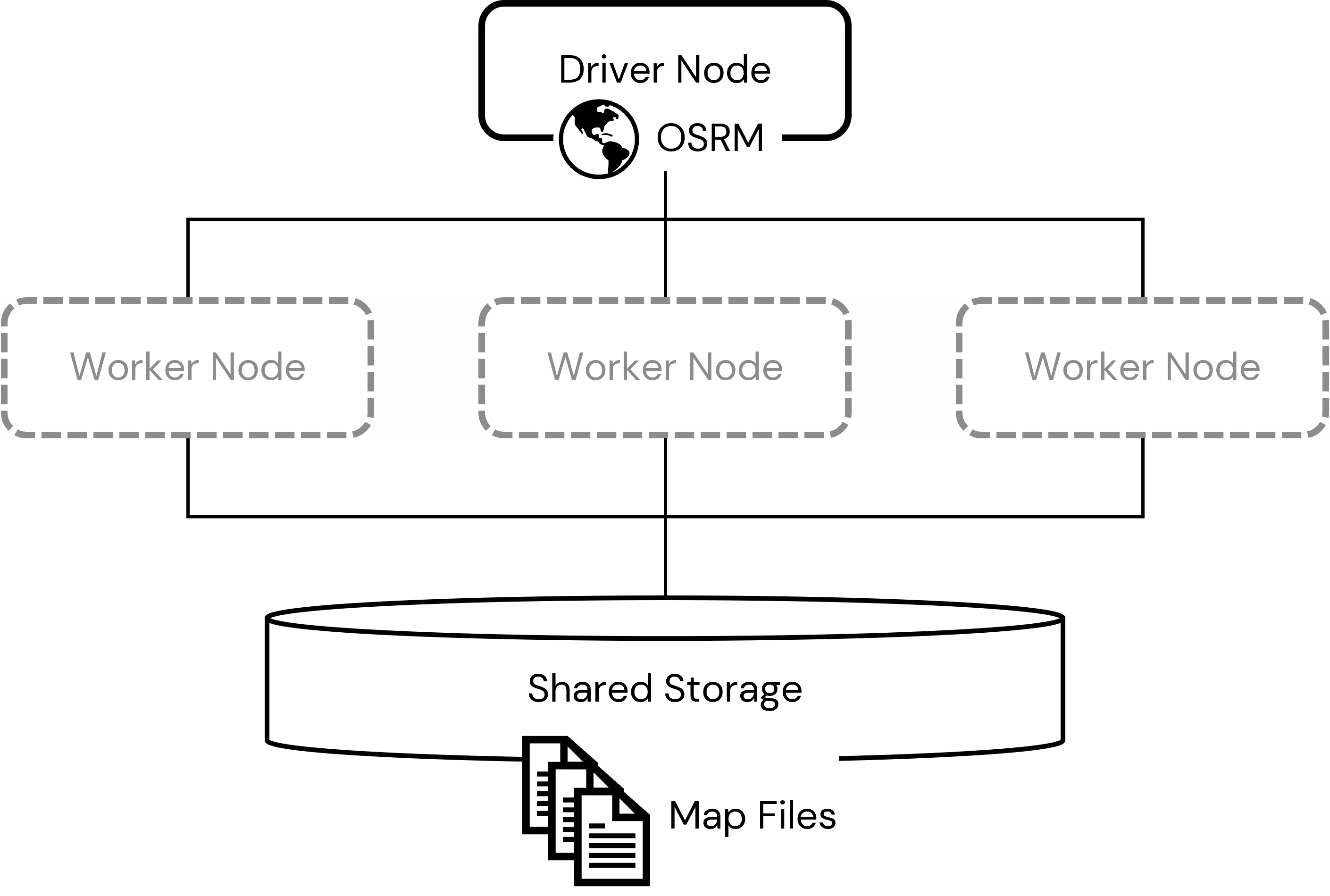
As you plan your cluster deployment topology, it's important to keep in mind that the OSRM software loads the somewhat large map file assets into memory. This speeds route resolution but requires each computer hosting an instance of the OSRM software to have available quite a bit of RAM. If there is not sufficient memory, the OSRM software will often shutdown without a clear error message. It is important that you pay careful attention to steps in the pre-processing steps that if successful will indicate the amount of RAM consumed by the map files and be sure to adjust the size of the worker nodes in your routing cluster deployment accordingly.
To run this accelerator, clone this repo into a Databricks workspace. Attach the RUNME notebook to any cluster running a DBR 11.0 or later runtime, and execute the notebook via Run-All. A multi-step-job describing the accelerator pipeline will be created, and the link will be provided. Execute the multi-step-job to see how the pipeline runs.
The job configuration is written in the RUNME notebook in json format. The cost associated with running the accelerator is the user's responsibility.

