allengkc / blog Goto Github PK
View Code? Open in Web Editor NEWPersonal Blog
Home Page: https://github.com/allenGKC/Blog
License: MIT License
Personal Blog
Home Page: https://github.com/allenGKC/Blog
License: MIT License





























之前团队中因为Node版本升级问题,项目整个瘫痪无法运行,搞得杰哥双休日折腾环境折腾了两天,老大遂提出以Docker的方式取代现有的环境。目前团队里Windows居多,还有部分Macbook,环境不统一也是个问题。昨日抱着试一试的想法,在自己的Macbook上搭建一个Docker的环境,谁知道这一搭,才发现其中存在无数的坑,所以写下这篇文章,分享给大家在安装docker的过程中需要注意的一些问题。
关于docker本身的一些介绍本文不做赘述,可以参考Docker — 从入门到实践,
网上对于安装Docker的文档已经很多,包括官网等,本文主要还是以Mac环境为主,Windows用户可以参考,主要介绍整个安装过程。对于Mac环境安装主要有两种方式,一种是安装Docker Toolbox,一种是安装Docker For Mac的Client,考虑到团队中有Mac和Windows两种环境,所以选择第一种方式。
目标:配置一个通用 Image,该Image可以在多种环境中使用,项目文件可以在容器中开发又可以在本机上用版本管理软件管理(如:git),预装开发过程中可能用到的包。
过程:
由于"墙"的问题,一开始没有注意这个问题,导致刚开始安装的时候非常慢,所以在吸取教训后,选择国内的一些站点来做镜像,国内可以选择的站点很多,这里我们选择阿里云镜像,里面有Mac和Windows两种版本的安装包,可以按需下载。BTW:没注册的小伙伴可以先注册一个阿里云的帐号,后面会用到。
Docker Toolbox 是 Docker 官方开发的 Docker 套装,里面有全套 Docker 环境,也有图形化工具 Kitematic,直接下载安装即可。
安装好Docker Toolbox后直接会发现电脑上多了下面三个东西:

此时你的VirtualBox是干净的,没有任何虚拟机,接下来,点击Kitematic,生成一个default的虚拟机,此时需要我们注册一个Docker Hub 账号,方便后面使用。
因为在下载镜像文件的时候不被墙,所以我们需要修改我们的配置,让我们在访问的时候,直接访问的是国内的站点。之前注册的阿里云的帐号后,请查看你的容器Hub服务控制台查看你的专属加速地址。
我的加速地址是:https://yvcphu9g.mirror.aliyuncs.com,也可以直接使用。
创建一台安装有Docker环境的Linux虚拟机,指定机器名称为default
docker-machine create -d virtualbox default
查看机器的环境配置,并配置到本地。然后通过Docker客户端访问Docker服务。
docker-machine env default
eval "$(docker-machine env default)"
docker info
配置Docker加速器
您可以使用如下的脚本将mirror的配置添加到docker daemon的启动参数中。
docker-machine ssh default "echo 'EXTRA_ARGS=\"--registry-mirror=https://yvcphu9g.mirror.aliyuncs.com\"' | sudo tee -a /var/lib/boot2docker/profile"
docker-machine restart default
此时你名为default的虚拟机对应mirror就已经配置完成。
打开Kitematic,在search框中输入ubuntu,这里我们下载最精简的ubuntu版本,对应下图第二排第一个,点击create,你会发现下载瞬间完成,如果是直接访问docker hub,不仅下载慢,而且还会因为网络问题无法访问,即使翻墙,下载速度依然不行,故之前配置的镜像此时发挥了作用。
下载完成后,在My images中我们看到了对应的刚刚下载好的ubuntu的镜像
点击create,就可以进入到管理页面,默认是开启,点击EXEC,就看到了熟悉的linux命令行模式
至此,ubuntu的镜像文件也安装完成
Ubuntu 装完系统第一件事是什么?没错,换源。
“源”其实就是网址,你在 Ubuntu 中用 apt-get install 安装软件的时候就是从“源”下载。Ubuntu 默认的源在国外,安装起来非常慢,所以要先换成国内的源。
国内有很多 Ubuntu 源,我用的是中科大源。
执行下面的命令进行换源操作:
sed -i 's/archive.ubuntu.com/mirrors.ustc.edu.cn/g' /etc/apt/sources.list
apt-get update
换源完毕,之后 apt-get 都会从中科大源下载软件。
前面说过,这个 Ubuntu Image 是超级精简版,很多不重要的工具都被删掉了,包括常用的 vim、curl、ipconfig、ping。除此之外,Linux 最常用的 TAB 补全路径也没有,所以下面先安装必要的编辑器和路径补全:
apt-get install vim bash-completion
这样就完成了基础配置,Ubuntu 可以正常用了
首先安装 npm:
apt-get install npm
然后安装 cnpm,之后所有 npm 操作都改成 cnpm,从淘宝源下载,速度会快很多。
npm install -g cnpm --registry=https://registry.npm.taobao.org
接着安装 n,TJ 大神的 NodeJS 版本管理工具,可以安装多个版本,一键切换。n 需要用到 curl,所以先安装 curl:
apt-get install curl
然后安装 n:
cnpm install -g n
最后使用 n 安装目前的稳定版 NodeJS:
n stable
这样就准备好了前端开发需要的基本工具,你可以根据你的项目需求安装对应的库。
终于到了最后一步,别忘了前面的提醒:如果不 commit,重启之后所有改动都会丢失!
所以先 commit。点击 Kitematic 左下角 “DOCKER CLI”,输入命令行执行:
docker ps
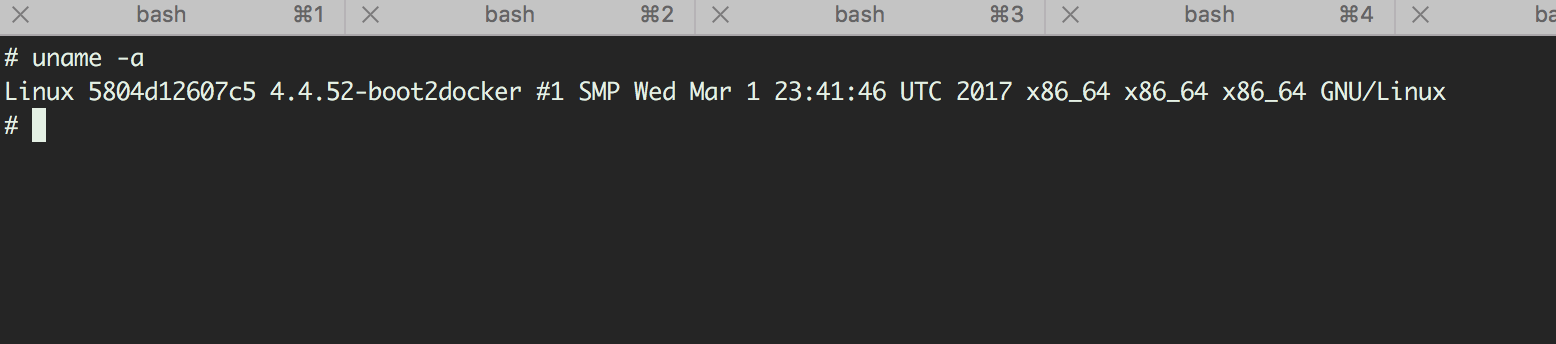
会看到下面这样的输出:

复制 Container ID,我这里是5804d12607c5,然后执行:
docker commit 5804d12607c5 username/imagename
username 换成你的 Docker Hub 用户名,imagename 换成你的镜像名称。我这里就是 cnyzgkc/ubuntu。
commit 之后就可以把当前 Container 导出 Image 了:
docker export 5804d12607c5 -o ubuntu
执行完后,在你的个人目录下(Mac 上是 /Users/你的用户名)可以找到 ubuntu 文件,这就是我们的最终目标:一个完成所有配置的 Image。至此,你的目标已经完成的差不多了,制作了一个配置好环境的Image,那么这个Image能不能给其他同事用呢?
我的初衷,也就是理想状态是这样的,对于新人来说,只需要按照如下步骤就可以配置完成:
docker run -t -i --privileged -p 137-139:137-139/tcp
-p 445:445/tcp -p 3000:3000/tcp -p 3123:3123/tcp
-p 8000:8000/tcp -p 8080:8080/tcp -d --name dev -v /web IMAGEID
/bin/bash
把其中的 IMAGEID 替换为上一步复制的内容
最后回到 Kitematic,应该可以看到左侧多了一个容器,此时环境已经搭建完毕
但是:理想总是丰满的,现实总是骨感的,在我正踌躇满志准备在windows上实践时,却发现有各种问题,首先是公司电脑的管理员权限,不会统一配置,再者在启动Docker的过程中出现了问题2,还是需要管理员权限,所以最后得出的结论是,如果你的windows不存在权限问题,ok,你按照我上述的过程后,可以直接放到windows机器上运行。但如果没有权限,囧~~
虽然本次的结果没有按照预期的方向走,最终没能成功,但在革命成功的路上总要走一些弯路,帮着团队扫清一些障碍也是好的,并且在这个安装docker的过程中,也学到了很多关于docker以及云服务的相关知识,踩了不少坑,分享给大家,以免后面的同学再做重复劳动。

最近项目结束,准备优化一下webpack,公司内部将打包工具单独抽出来作为npm包引入,既然要优化打包,必然涉及到要本地化调试npm包,下面介绍一下正确的✅调试姿势。
假设有一个已经编写好的本地node包test-npm-util包(github上的包同理)和一个测试该包的项目my-project在同一个文件夹下project下,有以下两种方式可以在my-project项目中测试本地的allen-npm-util包
|-- project
|-- my-project
| -- package.json
|-- test-npm-util
进入项目目录,按照相对路径找到test-npm-util包,npm install直接安装。
cd my-project
npm install ../test-npm-util
然后进入my-project中的node_modules文件夹检查是否安装成功,一般情况下只要路径正确,node包编写正确,都会安装成功,这样就可以在my-project中使用test-npm-util。
const xcxutil = require('xcxutil');
上面的方法的前提是node包和测试项目在同一个文件夹下,所以很方便的就找到路径,但很多情况是我们本地项目众多,分布在不同的文件夹下,所以找路径就很麻烦了,因此推荐使用npm link这种将node包连接到全局的方式,关于npm link的原理可以参考npm link官网。
cd test-npm-util
npm link
执行完会得到下面的输出:
/Users/allen/.nvm/versions/node/v10.0.0/lib/node_modules/test-npm-util -> /Users/allen/project/test-npm-util
意思是将project下的test-npm-util连接到全局的node_modules下,我们进入全局node_modules包下也可以查看到test-npm-util包
然后在my-project中也link一下该包即可测试使用
cd my-project
npm link test-npm-util
这样test-npm-util就被安装到my-project下啦,在test-npm-util下的修改也会同步到my-project下,就可以实现本地测试了。
如果想取消在全局的连接也非常的简单:
cd test-npm-util
npm unlink
以上就是npm包本地调试的方法,希望对你有帮助,感谢阅读。

改编自《成都》
让我掉下眼泪的 不止UI的要求
让我夜夜加班的 还有交互的愁
代码还要写多久 地铁还有没有
让我感到为难的 是产品的需求
时间总是很紧凑 会议还要开多久
旧的问题还没修 又来了新的需求
在每个上线的夜晚里 我从未忘记你
Bug 修不掉的 只有你
和我在代码的世界走一走
直到所有的Bug修掉了也不停留
既要完成业务要求 还要努力成为大牛
码农的路要走多久 何时才能走到尽头

前段时间做了个小活动的页面,页面很简单,很快也做完了,当然不知道那天脑子是不是抽了,一个浮动的元素让我很费解,其实之前做业务也遇到过浮动元素,当然清除浮动的方法有很多,什么overflow:hidden啊,clearfix啊都可以,但是突然我意识到,一直用这些属性,可是为什么设置了这些属性,它就能清除浮动呢?带着这个疑问,我决定搞清楚这个里面的门道。
关于overflow,MDN的定义是:
常见的overflow的value:
// Content is not clipped
overflow: visible;
// Content is clipped, with no scrollbars
overflow: hidden;
// Content is clipped, with scrollbars
overflow: scroll;
// Let the browser decide
overflow: auto;
// Global values
overflow: inherit;
overflow: initial;
overflow: unset;
关于overflow的常见的属性,Chris Coyier在css-tricks上写过一篇比较简单通俗的文章《The CSS Overflow Property》可以看看,这里不做详述。
当我在看overflow时,看到了通过overflow:hidden属性可以清除浮动,这不是大家都知道的嘛~但是突然一个名词映入我的眼帘:block formatting context,乍一看怎么这么不顺眼,再细看,原来就是BFC啊,以前面试不是被问过么,但是当时只知道记住是什么,具体原理好像也不理解,我就在想这overflow和BFC有啥关系啊,既然如此,那咱就好好来看看这BFC到底是什么鬼。
关于BFC,依旧看一下MDN的定义:
然后我就懵逼了,这是什么?说了半天我也没明白,好吧,还是来看看W3C的定义吧:
看完这个定义后,相信大家还是稍微有点了解了BFC是个什么东西了吧?大概能猜到这个BFC是和float。overflow这些属性相关的,也就是说和我之前说的浮动元素肯定是有关联的,好,顺着这个方向,我们继续研究BFC相关内容。
MDN中解释满足下列情况便会创建BFC:
- the root element or something that contains it
高清无码翻译来了:
- 根元素或其它包含它的元素
只要符合上述其中一种情况,一个BFC就可以被很简单的创建,下面我们简单地建立一个BFC:
<div class="container">
Some Content here
</div>
通过给上述class为container添加符合BFC要求的任何一个属性,都可以让该div成为一个BFC,如overflow: scroll,overflow: hidden,display: flex,float: left等等。
但是,有些属性可能会存在一些问题:
display:table:可能在响应方面会产生一些问题overflow:scroll:可能会显示不必要的滚动条float:left:将会把元素置于容器的左边,其他元素环绕着它overflow:hidden:将会剪切掉溢出的元素根据实际情况,可以选择不同的方式去建立所需要的BFC。
可能会有人有疑问了,BFC中设置了这些特殊的属性会不会对里面的正常流布局以及对齐方式产生影响,下面我们就这个问题,简单讨论一下。
W3C官方的解释如下:
In a block formatting context, each box’s left outer edge touches the left edge of the containing block (for right-to-left formatting, right edges touch). This is true even in the presence of floats (although a box’s line boxes may shrink due to the floats), unless the box establishes a new block formatting context (in which case the box itself may become narrower due to the floats).
在BFC中,每个盒子的左外边框紧挨着包含块的左边框(从右到左的格式,则为紧挨右边框)。即使存在浮动也是这样的(尽管一个盒子的边框会由于浮动而收缩),除非这个盒子的内部创建了一个新的BFC浮动,盒子本身将会变得更窄)

简单来说,在上图中我们可以看到,所有属于同一个BFC的盒子都左对齐(左至右的格式),他们的左外边框紧贴着包含块的左边框。在最后一个盒子里我们可以看到尽管那里有一个浮动元素(棕色)在它的左边,另一个元素(绿色)仍然紧贴着包含块的左边框。关于为什么会发生这种情况的原理将会在下面进行讨论。
谈了很多,终于回归到主题了,一开始我们的出发点就是为了研究为什么一个小小的属性就能清除浮动,下面我们来看看BFC与浮动的关系。
在我们日常开发的时候经常会碰到这种情况,一个容器里有浮动元素,但容器元素没有高度,它的浮动元素将会脱离页面的常规流。我们通常使用清除浮动来解决这个问题,最受欢迎的方法是使用一个clearfix的伪类元素。但我们同样可以通过定义一个BFC来达到这个目的。

举个栗子:
<div class="container">
<div>Sibling</div>
<div>Sibling</div>
</div>
对应CSS
.container {
background-color: green;
}
.container div {
float: left;
background-color: lightgreen;
margin: 10px;
}
以上例子中,父容器的高度为0,它将无法包含已经浮动的子元素。为了解决这个问题,我们通过添加overflow: hidden,在容器中创建一个新的BFC。经过修改过的CSS为:
.container {
overflow: hidden; /* creates block formatting context */
background-color: green;
}
.container div {
float: left;
background-color: lightgreen;
margin: 10px;
}
这样一个BFC块就成功将浮动元素包裹在里面了,在这个BFC中,这些元素将会回到页面的常规文档流。
见:https://codepen.io/SitePoint/pen/eNyxZB/
本文主要从浮动这一普通现象一步步发散,探寻了BFC的原理,以及通过BFC来清除浮动的原理,当然BFC还有更多有用的特性,欢迎大家补充和更新。

无意中看到一篇讲JavaScript中super关键字不错的文章,对文章进行翻译,仅供学习。
注:本人翻译水平有限,如果有错误,欢迎指正。
原文地址:What is super() in JavaScript?
原文作者:Bailey Jones
译文作者:Allen Gong
当你看到一些JavaScript代码在调用super()时,其中到底发生了什么?在子类中,你通过使用super()来调用父类的构造函数,调用super.<methodName>来访问父类的方法。这篇文章假设你至少对构造函数,子类父类这些概念有了基本的认识,如果你没有的话,你可能需要先阅读一下Mozilla的适合初学者的JavaScript面向对象文章。
Super不是JavaScript所特有的——很多编程语言,包括Java和Python,都有super()的关键字,它可以提供对父类的引用。与Java和Python不用,JavaScript不是以class模型构建的,取而代之的它是沿用JavaScript的原型继承模型的方式去实现与class模型相一致的行为特征。
让我们多了解一点并且看一些例子。
首先,以下对classes的定义,引用自Mozilla的官方文档:
ECMAScript 2015 中引入的 JavaScript 类实质上是 JavaScript 现有的基于原型的继承的语法糖。类语法不会为JavaScript引入新的面向对象的继承模型。
下面是一个简单的子类继承父类的例子用来说明上面的引用的具体含义:
我的例子中有两个类:fish和trout。所有的fish都拥有habitat和length的信息,所有这些属性属于fish的类。Trout有一个variety的属性,它通过继承fish在最上面获得了这两个属性,下面是fish和trout的构造函数:
class fish {
constructor(habitat, length) {
this.habitat = habitat
this.length = length
}
}
class trout extends fish {
constructor(habitat, length, variety) {
super(habitat, length)
this.variety = variety
}
}
fish类的构造函数定义了habitat和length,trout的构造函数定义了variety。我必须在trout的构造函数中调用super(),否则我在尝试设置this.variety的时候会得到一个引用错误。那是因为我在trout类的第一行,我通过extentds关键字告诉JavaScript trout是fish的子类。那代表着trout的this上下文包含了fish类中定义的属性和方法,也包含trout自己定义的任何属性和方法。调用super()主要是为了让JavaScript知道fish是什么以便于它可以为trout创建this的上下文,包含所有在fish中定义的东西,也包含我们在trout中定义的。fish类不需要super()因为他的"父类"是JavaScript中的Object类。Fish已经是原型链中的顶端了,所有调用super()并不是非常必要——fish的this上下文只需要包含Object类,这一点JavaScript已经知道了。
对于fish和trout,在这条原型链上,所有的属性都是可访问的。从头开始,原型链从Object->fish->trout
我在trout的构造函数中调用super(habitat, length)(引用fish类),使得trout的this立刻拥有所有三个属性的访问权限。在trout的构造函数外面也有其他的方法可以获取同样的效果。为了避免引用错误,我必须调用super(),但是我不一定非要和fish的构造函数期望的一样的结构去调用它。那是因为我不需要通过使用super()来给fish创建的字段赋值——我只需要保证这些字段存在于trout的this上下文中即可。这是一个JavaScript与真正意义类模型的编程语言,如Java,最大的区别。下面的代码实现了fish类,但在这些语言中就会报错了:
class trout extends fish {
constructor(habitat, length, variety) {
super()
this.habitat = habitat
this.length = length
this.variety = variety
}
}
这种可供选择的trout的构造函数使我们更难分辨哪些属性属于fish和哪些属性属于trout,但是根据前面的例子获得的结果是一样的。唯一的区别在于调用没有参数的super()会创建一个this上下文,但是没有给habitat和length赋值。如果你在第三行调用console.log(this),它会打印出{habitat: undefined, length: undefined}。第四行和第五行赋值。
我也可以在trout构造函数外调用super(),目的是为了引用父类中的方法。这里我定义了一个renderProperties的方法,用来展示所有我传给HTML元素的class的属性。super()在这个时候就非常有用了因为我想我的trout类可以实现一个类似的方法但只要增加一点点东西——它在更新他的HTML之前赋值了一个类的名称。我可以通过调用super.renderProperties()复用fish类中的相关的类的方法。
class fish {
renderProperties(element) {
element.innerHTML = JSON.stringify(this)
}
}
class trout extends fish {
renderPropertiesWithSuper(element) {
element.className="green"
super.renderProperties(element);
}
函数名字的选择非常重要。我在trout类中的调用的方法的名字叫renderPropertiesWithSuper(),因为我还可以调用trout.renderProperties(),这个方法原来是在fish类中定义的。如果我将函数的名字定成renderProperties,那也是正确的。但是,但我再也无法通过trout的实例直接同时访问这两个函数——调用trout.renderProperties只会调用trout中定义的函数。这不是一个非常必要且有用的实现方式——一个函数覆盖父类函数的名字这样调用super,这是一个有争议的方式——但是这也论证了JavaScript允许你的class的灵活性。
不使用super()或者extends关键字实现这个例子,是完全有可能的,并且对于之前的例子是很有帮助的,只是不是那么方便。这就是Mozilla说的所谓"语法糖"的意思。事实上,如果我把之前的代码插入到类似Babel的转换器中,去保证旧的版本的我的类的代码和旧版JavaScript的代码兼容运行,这会产生类似下面的代码的东西。代码是相似的,但是你会发现没有extends和super(),我必须讲fish和trout定义成函数并且直接访问他们的原型对象。同样我也必须在15,16和17行做一些额外的操作用来让trout成为fish的子类,并且保证在trout的构造函数中被传入正确的this上下文。如果你对此感兴趣想深入了解到底原理是怎样的,Eric Green在博客中使用了很多例子来如何构建一个class。
在JavaScript中类是共享功能的一种强大的方式。举个例子,在React中的类组件中,是非常依赖类的。但是,如果你已经在其他面向对象编程语言中使用过类,你会发现JavaScript的行为还是有些让人惊讶。学习原型继承有时候会帮助理解JavaScript是如何与类协作的。

之前做了个在线的分享平台,但是使用的过程有些繁琐,故想起使用shell脚本将整个过程进行自动化,因为是第一次写shell脚本,所以在做的过程中遇到了一些问题,并且这些问题只是在MacOS下才有,shell脚本原生的Linux环境并没有这么多问题,如果有同学在Mac下写shell脚本遇到了和我同样的问题,可以参考一下。
问题描述:sed编辑命令:sed -i 's/a/b/g' test.txt
报错:sed: 1: "test.txt": undefined label 'est.txt'
解决方案:sed -i '' 's/a/b/g' test.txt 在-i后面加上一对''
原因:-i参数是强制替换原有文件,但是mac强制要求备份,否则报错,这个在Mac上系统会有问题,否则-i参数无法使用,请注意。
问题描述:sed追加命令:sed -i '' "/a/a\xxx" test.txt匹配到a字符后追加xxx内容
报错:sed: 1: "/a/a\xxx": extra characters after \ at the end of a command
解决方案:在追加内容前换行,且要用双斜杠\
sed -i '' "/a/a\\
xxx \\
" test.txt
备注:/i操作同理

一直对webpack的打包流程很感兴趣,但是无奈官网文档实在太多,搜出来的大部分文章要么偏理论要么纯粹讲过程不讲原理,最近终于找到一篇入门文章,文章对于初学者讲的很清晰,但是由于是英文的,而且我没有找到这篇文章对应的中文翻译版,所以本文主要是对那篇文章进行翻译,介绍一下webpack2的入门知识。
注:本人翻译水平有限,如果有错误,欢迎指正。
原文地址:A Beginner’s Guide to Webpack 2 and Module Bundling
原文作者:Mark Brown
译文作者:Allen Gong
Webpack是一个模块打包机
Webpack已然成为当前web开发最重要的工具之一。首先它是一个Javascript的打包工具,但同时他也能打包包括HTML,CSS,甚至是图片等形式的资源。它能更好的控制你正在编写的App的HTTP请求,并且允许你去使用更多的资源(如Jade,Sass以及ES6)。Webpack同时允许你更容易的从npm获取安装包。
这篇文章主要面向那些对于webpack完全陌生的同学,内容将包括初始安装和配置,模块,模块加载器,插件,代码拆分以及模块热替换(HMR,hot module replacement)。如果你觉得入门视频比较有用的话,我推荐Glen Maddern的Webpack初体验作为开始学习的起点,会让你理解为什么webpack如此特殊。
为了更加后续的阅读,请确保先安装了Node.js,安装可以参考Node.js安装教程。你也在Github上下载到对应的Demo。
让我们用npm和webpack新建一个项目吧:
mkdir webpack-demo
cd webpack-demo
npm init -y
npm install webpack@beta --save-dev
mkdir src
touch index.html src/app.js webpack.config.js
编辑以下文件:
<!-- index.html -->
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="utf-8">
<title>Hello webpack</title>
</head>
<body>
<div id="root"></div>
<script src="dist/bundle.js"></script>
</body>
</html>
// src/app.js
const root = document.querySelector('#root')
root.innerHTML = `<p>Hello webpack.</p>`
// webpack.config.js
const webpack = require('webpack')
const path = require('path')
const config = {
context: path.resolve(__dirname, 'src'),
entry: './app.js',
output: {
path: path.resolve(__dirname, 'dist'),
filename: 'bundle.js'
},
module: {
rules: [{
test: /\.js$/,
include: path.resolve(__dirname, 'src'),
use: [{
loader: 'babel-loader',
options: {
presets: [
['es2015', { modules: false }]
]
}
}]
}]
}
}
module.exports = config
以上的设置只是通用配置,它会指导你的webpack将我们的入口文件src/app.js编译输入为/dist/bundle.js,并且所有的.js文件都将通过Babel从ES2015转换为ES5。
为了让这个项目能运行起来,我们需要安装三个安装包,babel-core,webpack的加载器babel-loader以及预处理模块babel-preset-es2015,这些模块都是为了支持Javascript的编写。{ modules: false }可以确保使用Tree Shaking去去除掉不必要的模块,同时会降低文件大小。
npm install babel-core babel-loader babel-preset-es2015 --save-dev
最后使用下面代码更新package.json:
"scripts": {
"start": "webpack --watch",
"build": "webpack -p"
},
运行npm start将会以观察模式启动webpack,在这种模式下,会持续监听我们src文件夹下的.js文件。控制台的输出结果显示了生成的打包后的文件,我们应该持续关注生成的文件的大小和数量。

现在你可以在浏览器中访问index.html,将会看到“Hello webpack.”
open index.html
打开dist/bundle.js看看webpack到底做了什么事,在文件的顶部是bootstrapping模块的代码,在它下面是我们自己的模块。你可能目前还没有什么感觉webpack好处,但是你现在可以编写ES6代码并且webpack将会把各个模块打成生产所需要的包,这样所有浏览器都能访问。
使用Ctrl + C停止webpack的服务,运行npm run build,编译成生成环境所需要的包。
注意:包的大小从2.61 kB降到了585 bytes
重新看看dist/bundle.js,你会发现代码变得一团糟,UglifyJS对打包后的代码进行了压缩,运行起来是没有差别的,但同时字符数是相当少的。
对于外部模块,webpack有多种方式去引入,其中比较重要的两种是:
import方法require()方法我们可以通过安装lodash来测试上述方式,并且导入到app.js中。
npm install lodash --save
// src/app.js
import {groupBy} from 'lodash/collection'
const people = [{
manager: 'Jen',
name: 'Bob'
}, {
manager: 'Jen',
name: 'Sue'
}, {
manager: 'Bob',
name: 'Shirley'
}, {
manager: 'Bob',
name: 'Terrence'
}]
const managerGroups = groupBy(people, 'manager')
const root = document.querySelector('#root')
root.innerHTML = `<pre>${JSON.stringify(managerGroups, null, 2)}</pre>`
运行npm start重启webpack并刷新index.html,你会在页面上看到一个按照manager分好组人名的数组。
接下来让我们把这个数组部分单独放在people.js这个模块里。
// src/people.js
const people = [{
manager: 'Jen',
name: 'Bob'
}, {
manager: 'Jen',
name: 'Sue'
}, {
manager: 'Bob',
name: 'Shirley'
}, {
manager: 'Bob',
name: 'Terrence'
}]
export default people
我们可以以相对路径的方式将模块导入到app.js
// src/app.js
import {groupBy} from 'lodash/collection'
import people from './people'
const managerGroups = groupBy(people, 'manager')
const root = document.querySelector('#root')
root.innerHTML = `<pre>${JSON.stringify(managerGroups, null, 2)}</pre>`
注意:导入像'lodash/collection这种不使用相对路径的,是那些通过npm安装的,从/node_modules中引入,你自定义的模块则需要像'./people'相对路径的方式引入,通过这种方式可以对两种模块进行区分。
我们已经介绍了babel-loader,它是众多loader中的一种,能够告诉webpack当遇到不同的文件时如何处理。比较好的方式是将loader进行串联,加载到一个加载器中,我们通过从Javascript中引入Sass包来看看loader是如何进行工作的。
这个转换器包括了三个单独的加载器和node-sass库:
npm install css-loader style-loader sass-loader node-sass --save-dev
在配置文件中为.scss引入新的规则:
// webpack.config.js
rules: [{
test: /\.scss$/,
use: [
'style-loader',
'css-loader',
'sass-loader'
]
}, {
// ...
}]
注意:不管什么时候你改变了webpack.config.js中的加载规则,你都需要通过Ctrl + C然后npm start的方式重启webpack。
loader以倒序的方式运行:
sass-loader转换Sass成CSScss-loader将CSS解析Javascript并解决依赖包问题style-loader将CSS导出成<tag>便签放在document下你可以将上述过程想象成函数的调用关系,一个函数运行的结果作为另一个函数的输入:
styleLoader(cssLoader(sassLoader('source')))
接下来让我们增加一个Sass源文件:
/* src/style.scss */
$bluegrey: #2B3A42;
pre {
padding: 20px;
background: $bluegrey;
color: #dedede;
text-shadow: 0 1px 1px rgba(#000, .5);
}
现在你可以在你的app.js中直接引入Sass文件:
// src/app.js
import './style.scss'
// ...
刷新index.html你会看到样式发生了变化。
我们刚刚把Sass作为一个模块引入到我们的入口文件中。
打开dist/bundle.js,搜索pre {。事实上,Sass已经被编译成一段CSS的字符串,并以模块的形式存在。当我们在我们的Javascript文件中导入这个模块时,style-loader就会将其编译输出成内嵌的<style>标签。
我知道你在想什么?为什么要这么做?
关于这个问题,我在这个话题中不想说太多,但下面几个原因值得思考一下:
最后一个关于loader的例子是关于处理图片的url-loader。
在标准HTML文档中,图片通过<img>标签或者background-image属性获得。但是通过webpack,一些小图片可以以字符串的形式存储在Javascript中。通过这种方式,你可以在预加载的时候就获取到图片,从而不需要单独的请求去请求图片。
npm install file-loader url-loader --save-dev
在配置文件中增加一条图片的规则:
// webpack.config.js
rules: [{
test: /\.(png|jpg)$/,
use: [{
loader: 'url-loader',
options: { limit: 10000 } // Convert images < 10k to base64 strings
}]
}, {
// ...
}]
通过Ctrl + C和npm start重启服务。
通过下面的命令下载一个测试图片:
curl https://raw.githubusercontent.com/sitepoint-editors/webpack-demo/master/src/code.png --output src/code.png
现在可以在app.js中加载图片资源:
// src/app.js
import codeURL from './code.png'
const img = document.createElement('img')
img.src = codeURL
img.style.backgroundColor = "#2B3A42"
img.style.padding = "20px"
img.width = 32
document.body.appendChild(img)
// ...
这样页面中多了一个img,它的src属性包含了图片自身的data URI。
<img src="data:image/png;base64,iVBO..." style="background: #2B3A42; padding: 20px" width="32">
同时,因为css-loader的缘故,通过url()属性引入的图片,也通过url-loader转换成行内元素。
/* src/style.scss */
pre {
background: $bluegrey url('code.png') no-repeat center center / 32px 32px;
}
编译后变成:
pre {
background: #2b3a42 url("data:image/png;base64,iVBO...") no-repeat scroll center center / 32px 32px;
}
现在你可以webpack是如何帮助你对将你项目中一系列的依赖资源进行打包处理的,下面这张图是webpack官网主页上的。

虽然Javascript是入口文件,但是webpack还是倾向于你的其他类型的资源像HTML, CSS, and SVG能有自己的依赖,把它们作为构建包的一部分。
我们已经看过了webpack其中一个构建插件的例子,使用UglifyJsPlugin的npm run build脚本可以调用webpack -p,它的作用是与webpack搭配压缩生成后的包。
当loader在单个文件上操作相应变换时,插件可以在各个大型代码块上交叉运行。
commons-chunk-plugin是另一个核心插件,搭配webpack用来创建在多个入口文件中使用的拥有公共代码的单文件模块。到目前为止,我们使用的都是单一入口和单一出口文件。但是很多real-world scenarios中更好的方法是使用多文件入口和多文件出口。
如果你在你的应用中有两个完全独立的领域但是却拥有共同的模块,举个例子,app.js是面向用户的,admin.js是面向管理员的,你就可以为他们单独创建不同的入口文件,就像下面这样:
// webpack.config.js
const webpack = require('webpack')
const path = require('path')
const extractCommons = new webpack.optimize.CommonsChunkPlugin({
name: 'commons',
filename: 'commons.js'
})
const config = {
context: path.resolve(__dirname, 'src'),
entry: {
app: './app.js',
admin: './admin.js'
},
output: {
path: path.resolve(__dirname, 'dist'),
filename: '[name].bundle.js'
},
module: {
// ...
},
plugins: [
extractCommons
]
}
module.exports = config
注意对于结果文件,现在包含了名字,这样我们区分出两个不同的结果文件对应不同的入口文件:app.bundle.js和admin.bundle.js。
commonschunk插件生成了第三个文件commons.js,他包含了我们入口文件的公共模块。
// src/app.js
import './style.scss'
import {groupBy} from 'lodash/collection'
import people from './people'
const managerGroups = groupBy(people, 'manager')
const root = document.querySelector('#root')
root.innerHTML = `<pre>${JSON.stringify(managerGroups, null, 2)}</pre>`
// src/admin.js
import people from './people'
const root = document.querySelector('#root')
root.innerHTML = `<p>There are ${people.length} people.</p>`
这些入口文件将会产生下列文件:
lodash/collection模块people模块我们可以在两个入口文件中都引入公共模块:
<!-- index.html -->
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="utf-8">
<title>Hello webpack</title>
</head>
<body>
<div id="root"></div>
<script src="dist/commons.js"></script>
<script src="dist/app.bundle.js"></script>
</body>
</html>
<!-- admin.html -->
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="utf-8">
<title>Hello webpack</title>
</head>
<body>
<div id="root"></div>
<script src="dist/commons.js"></script>
<script src="dist/admin.bundle.js"></script>
</body>
</html>
试试在浏览器中重新加载index.html和admin.html,看看自动生成的公共模块部分。
另一个受欢迎的插件是extract-text-webpack-plugin,它的用途是抽取模块到对应的结果文件中。
下面我们在配置文件中修改.scss的规则编译成对应的Sass文件,加载CSS,接着把他们抽取到各自的CSS包中,这样就可以把它们从Javascript包中移除。
npm install [email protected] --save-dev
// webpack.config.js
const ExtractTextPlugin = require('extract-text-webpack-plugin')
const extractCSS = new ExtractTextPlugin('[name].bundle.css')
const config = {
// ...
module: {
rules: [{
test: /\.scss$/,
loader: extractCSS.extract(['css-loader','sass-loader'])
}, {
// ...
}]
},
plugins: [
extractCSS,
// ...
]
}
重启webpack你会看到一个新的打包后的文件app.bundle.css,你可以照例直接引用它。
<!-- index.html -->
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="utf-8">
<title>Hello webpack</title>
<link rel="stylesheet" href="dist/app.bundle.css">
</head>
<body>
<div id="root"></div>
<script src="dist/commons.js"></script>
<script src="dist/app.bundle.js"></script>
</body>
</html>
刷新页面,确认CSS已经被编译过了,并从app.bundle.js移到了app.bundle.css,成功了!
我们已经看了几种代码拆分的方法:
拆分包还有其他方法:System.import和require.ensure。通过在这些函数中包含代码段,你可以创建一个在运行时按需加载的模块。这个从根本上提高了性能,因为在启动过程中不需要把所有东西都发送到客户端。System.import将模块名作为参数,并返回一个Promise对象。require.ensure获取依赖关系的列表,回调函数以及可选的模块名。
如果应用程序的某一部分具有很大的依赖关系,则应用程序的其余部分就不需要了,最好的方式就是拆分到各个模块中去。我们通过新建一个需要依赖d3的模块dashboard.js来证明这点。
npm install d3 --save
// src/dashboard.js
import * as d3 from 'd3'
console.log('Loaded!', d3)
export const draw = () => {
console.log('Draw!')
}
在app.js的顶部引入dashboard.js:
// ...
const routes = {
dashboard: () => {
System.import('./dashboard').then((dashboard) => {
dashboard.draw()
}).catch((err) => {
console.log("Chunk loading failed")
})
}
}
// demo async loading with a timeout
setTimeout(routes.dashboard, 1000)
因为我们加载了异步模块,我们需要在配置文件中增加output.publicPath属性,因此webpack知道去哪里获取。
// webpack.config.js
const config = {
// ...
output: {
path: path.resolve(__dirname, 'dist'),
publicPath: '/dist/',
filename: '[name].bundle.js'
},
// ...
}
运行npm build操作,你会看到一个新的神秘的打包文件0.bundle.js。

注意webpack为了保持诚实,通过凸现[big]的包来让你保持关注。
这个0.bundle.js将会通过JSONP的请求按需加载,所以从文件目录中获取将不在有效,我们需要启动一个服务来获取文件。
python -m SimpleHTTPServer 8001
打开浏览器,输入http://localhost:8001/
加载一秒钟后,你会获得一个GET请求,我们动态生成了/dist/0.bundle.js文件,在控制台上打印除了"Loaded!",成功!
当文件改变时,实时地重新加载能提高开发者的开发效率。只要安装它,并且以webpack-dev-server的形式启动,就可以体验啦。
npm install [email protected] --save-dev
修改package.json中的start脚本:
"start": "webpack-dev-server --inline",
重新运行npm start,在浏览器中打开http://localhost:8080
试着去改变src目录中任何文件,如改变people.js中的任意一个名字,或者style.scss中的任意样式,去看看它如何实时改变。
如果你对实时重新加载印象深刻,那么hot module replacement(HMR)一定会让你吃惊不已。
现在是2017年了,你在工作中已经可以在单页面应用中使用全局状态了。在开发过程中,你可能会对组件进行许多小的修改,并且希望能在浏览器中看到修改后生成的结果,这样可以实时去更改。但是通过刷新页面或者实时热更新并不能改变全局的状态,你就必须重头开始。但是HMR永远地改变了这一问题。
最后对package.json中的start脚本做修改:
"start": "webpack-dev-server --inline --hot",
在app.js中告诉webpack去接受这个模块以及对应依赖的热更新。
if (module.hot) {
module.hot.accept()
}
// ...
注意:webpack-dev-server --hot设置了 module.hot为true,但只是在开发过程中。当以生产模式打包时,module.hot被设成了false,这样这些包就被从结果中抽离了。
在webpack.config.js中增加一个NamedModulesPlugin插件,去改善控制台的记录功能。
plugins: [
new webpack.NamedModulesPlugin(),
// ...
]
最后我们在页面中增加一个<input>元素,我们可以在里面增加一些文字,用来确保我们更改自己模块时页面不会刷新。
<body>
<input />
<div id="root"></div>
...
运行npm start重启服务,观察热更新如何工作吧。
为了实验,在input框中输入“HMR Rules”,接着改变一个people.js中的名字,你会发现页面在不刷新也能做出修改,而忽略input的状态。
这只是一个简单的例子,但是希望你能看到其广泛的用途。在诸如React的开发模式中,你可能有很多"哑巴"组件是与他们的状态分离开的,通过热更新,这些组件将不会失去状态,也能实时更新,因此你将获得及时的反馈。
修改style.scss文件中<pre>元素的背景颜色,你发现他并没有被HMR替换。
pre {
background: red;
}
事实证明当你使用style-loader时,CSS的热更新将会免费为你提供而不需要你做任何特殊处理。我们只需要断开CSS模块与最终抽取的包之间的链接,这个包是无法被替换的。
如果我们将Sass规则恢复到原始状态,并从插件列表中删除extractCSS,那么您也可以看到Sass的热重新加载。
{
test: /\.scss$/,
loader: ['style-loader', 'css-loader','sass-loader']
}
使用像webpack这样的模块打包工具的主要好处之一是,您可以通过控制资源的构建方式以及在客户端上的获取方式,从而帮助你提高性能。多年以来,它被认为是最佳实践,通过连接文件减少客户端请求。现在还是有效,但是HTTP2在单一请求中发送多文件,因此连接文件的方式不不再是"银弹"。你的应用程序实际上可以从多个小文件单独缓存,但客户端可以获取单个更改的模块,而不必再次获取大部分相同内容的整个包。
Webpack的创始人Tobias Koppers的撰写了一篇内容丰富的帖子,解释了为什么打包仍然很重要,即使在HTTP/2时代。
想了解更多请参考webpack & HTTP/2
我真心希望你已经发现这个介绍webpack 2的文章对你有帮助,并能够开始很好使用它。围绕webpack的配置,加载程序和插件可能需要一些时间,但是了解这个工具的工作原理后会对你有很大帮助。
文档仍在进行更新中,但如果您想将现有的Webpack1项目移到Webpack2,则可以参考Migrating from v1 to v2。
webpack是否是你打包的选择,从评论中你就可以知晓。
本文由Scott Molinari,Joan Yin和Joyce Echessa进行了同行评审。 感谢SitePoint的同行评议人员,使SitePoint内容成为最棒的内容!
本文翻译自A Beginner’s Guide to Webpack 2 and Module Bundling
翻译者:Allen Gong

一直以来,我主要的业务线都是活动相关,因此活动页做的相对比较多,大家都知道活动页的特点是以图为主,按钮文字为辅,由于都是在移动端H5页面,而我经常碰到的问题就是整个页面都是图片,几乎没有文字,因此如何将图片压缩到最小,提升页面速度,节省带宽是至关重要的。带着这个疑问,无意中搜到一篇关于图片压缩的文章,其中提到之前没有接触过的一种图片格式——webP。这让我提起了兴趣,该文章讲到这是google提出的一种新的图片格式,能大幅度降低图片的大小,抱着试一试的态度,我决定研究一下这个神秘的webP究竟为何方神圣。
webP(发音weppy),根据维基百科的结果,是一种同时提供了有损压缩与无损压缩(可逆压缩)的图片文件格式,派生自视频编码格式VP8,被认为是WebM多媒体格式的姊妹项目,是由Google在购买On2 Technologies后发展出来,以BSD授权条款发布。根据Google较早的测试,WebP的无损压缩比网络上找到的PNG档少了45%的文件大小,即使这些PNG档在使用pngcrush和PNGOUT处理过,WebP还是可以减少28%的文件大小。
以上是官方对webP的介绍,详情可以参考webP官方主页。但这样的介绍未免枯燥乏味,根据我自己的理解,简单概括webP:一个体积小,但是还不损失精度的图片文件格式,和它的兄弟png,jpg相比,体积小很多哦~并且还能支持无损压缩和有损压缩,在这样的情况下,还能保持原先高精度,实乃绝佳的图片压缩解决方案。
So, why shall we use it?
通过以上对webP的简单介绍,我们发现了原来除了jpg,png还有一个如此有优势叫webP的小婊砸,那我们为什么要使用webP?


这里列举一个简单的测试:对比 PNG 原图、PNG 无损压缩、PNG 转 WebP(无损)、PNG 转 WebP(有损)的压缩效果。更多测试查看这里(请用 Chrome 浏览器打开)
关于几种图片格式的特点可以参见《web前端图片极限优化策略》,里面对于各个图片格式的优势与劣势介绍的较为详细,这里就不一一列举了。
由上面的介绍,我们可以得出几个结论:
- PNG 转 WebP 的压缩率要高于 PNG 原图压缩率,同样支持有损与无损压缩
根据Google的测试,目前WebP与JPG相比较,编码速度慢10倍,解码速度慢1.5倍。
在编码方面,一般来说,我们可以在图片上传时生成一份WebP图片或者在第一次访问JPG图片时生成WebP图片,对用户体验的影响基本忽略不计,主要问题在于1.5倍的解码速度是否会影响用户体验。
下面通过同样质量的WebP与JPG图片加载的速度进行测试 。测试的JPG和WebP图片大小如下:

测试数据折线图如下:

从折线图可以看到,WebP虽然会增加额外的解码时间,但由于减少了文件体积,缩短了加载的时间,页面的渲染速度加快了。同时,随着图片数量的增多,WebP页面加载的速度相对JPG页面增快了。所以,使用WebP基本没有技术阻碍,还能带来性能提升以及带宽节省。
看到这里大家肯定有疑问了,既然这种图片格式这么好,那么现在普及型如何?有没有公司在用呢?兼容性如何?下面就一一为大家解答这些疑惑。
有没有公司在使用webP呢?答案是 YES!2010 年 WebP 发布,在 Google 的明星产品如 Youtube、Gmail、Google Play 中都可以看到 WebP 的身影,而 Chrome 网上商店甚至已完全使用了 WebP。国外公司如 Facebook、ebay 和国内公司如腾讯、淘宝、美团等也早已尝鲜。Youtube上有介绍关于webP的视频,感兴趣的朋友可以看看。

根据can I use中对webP兼容性最新的搜索结果,国内至少有50%的用户可以使用webP这种图片格式。

可以发现除了chrome浏览器和还有基于 Chromium 内核的浏览器,其他浏览器和IOS平台支持性还是一般。
使用webP,首先需要区别的是在什么场景下使用:
1.在线转换工具:
官方介绍可以使用命令行工具cwebp,生成webP文件。
在Mac下,可以使用homebrew安装webp工具:
brew install webp
Linux采用源码包来安装(CentOS下):
yum install -y gcc make autoconf automake libtool libjpeg-devel libpng-devel# 安装编译器以及依赖包
wget https://storage.googleapis.com/downloads.webmproject.org/releases/webp/libwebp-0.5.0.tar.gz
tar -zxvf libwebp-0.5.0.tar.gz
cd libwebp-0.5.0
./configure
make
make install
运行cwebp -h,成功显示帮助信息就表示安装好了。

安装完命令行工具后,就可以使用cwebp将JPG或PNG图片转换成WebP格式。
cwebp [-preset <...>] [options] in_file [-o out_file]
options参数列表中包含质量参数q,q为0~100之间的数字,比较典型的质量值大约为80。
更多细节详见使用文档
4.浏览器:
由于webP在浏览器中的兼容性的问题,在浏览器端使用webP,首先需要检测浏览器是否支持webP的格式。
JavaScript检测是否支持WebP代码如下:(出自Google官方文档)
// check_webp_feature:
// 'feature' can be one of 'lossy', 'lossless', 'alpha' or 'animation'.
// 'callback(feature, result)' will be passed back the detection result (in an asynchronous way!)
function check_webp_feature(feature, callback) {
var kTestImages = {
lossy: "UklGRiIAAABXRUJQVlA4IBYAAAAwAQCdASoBAAEADsD+JaQAA3AAAAAA",
lossless: "UklGRhoAAABXRUJQVlA4TA0AAAAvAAAAEAcQERGIiP4HAA==",
alpha: "UklGRkoAAABXRUJQVlA4WAoAAAAQAAAAAAAAAAAAQUxQSAwAAAARBxAR/Q9ERP8DAABWUDggGAAAABQBAJ0BKgEAAQAAAP4AAA3AAP7mtQAAAA==",
animation: "UklGRlIAAABXRUJQVlA4WAoAAAASAAAAAAAAAAAAQU5JTQYAAAD/////AABBTk1GJgAAAAAAAAAAAAAAAAAAAGQAAABWUDhMDQAAAC8AAAAQBxAREYiI/gcA"
};
var img = new Image();
img.onload = function () {
var result = (img.width > 0) && (img.height > 0);
callback(feature, result);
};
img.onerror = function () {
callback(feature, false);
};
img.src = "data:image/webp;base64," + kTestImages[feature];
}
在浏览器向服务器发起请求时,对于支持WebP图片的浏览器,会在请求头Accept中带上image/webp的信息,服务器便能识别到浏览器是否支持WebP,在服务器中处理图片。
最直接和简单的方法是直接在支持webP的浏览器中直接使用webP,具体方法可以参见JEREMY WAGNER在Using WebP Images中的使用方法。
但是除了这个方法,还有其他方式使用webP吗?当然有!
Matt Shull 在他的《WebP Images & Performance》中使用了四种方法:
结论:根据实验结果,可以发现使用Picturefill的方法相对最优。
本文主要介绍了webP的相关知识,由于篇幅的原因,对webP的介绍不全,欢迎大家补充。总的来说,webP作为Google推荐的图片格式,在支持的浏览器中表现的还是优于jpg和png的,因此鼓励大家在部分场景下可以使用webP,不仅可以压缩图片的大小,还可以节省带宽。
最近写项目的时候,需要将webpack打包后的静态文件压缩发送给后端传到服务器上,由于每次打包压缩比较机械,所以想到写个shell脚本来自动化。
但是在写shell脚本时遇到一个问题:需要判断目录下是否存在.zip文件?
刚开始我查资料,使用了if [ -f *.zip ],用-f和通配符来判断是否有.zip的文件存在,然而运行结果一直报错“unexpected operator”,因此在-f下,后面是不能使用通配符的。
后来,我又想了一个办法,if [ -n “‘ls *.zip'” ],这句话的意思是,如果ls命令执行后有得到内容,则是真,其中-n表示后面的内容不是空值时为真。这句话是可以用,可以判断文件存在在目录下,但是,这是出现了个问题,如果目录下没有.zip的文件,就会报错“No such file or directory”,于是我放弃了这个方法。
最后一个看了一个博客里方法,使用 if ls *.c >/dev/null 2>&1;then,这是一个重定向的方法,ls所有以.zip为后缀的文件,如果不存在,将标准错误重定向到标准输出,这里2>&1 的意思就是将标准错误也输出到标准输出当中。重定向中 0-标准输出,1-标准输出,2-标准错误,而No such file or directory是一个标准错误。
值得注意的是:这个if后面没有中括号!并且2>&1的“>”是没有空格的!

好久不写博客了,2018年的第一篇就给大家介绍一下大名鼎鼎的OpenCV吧~可能会有人奇怪,OpenCV.js是什么,别急,听我慢慢道来。
最近很火的人工智能,AI什么的,都映入了大家的眼帘,随着这些新型事物的出现,大家对于这块的关注度也随之提升,那么我们就跟随这AI的大潮,给大家介绍一下其中的一个分支——人脸识别。
首先介绍一下OpenCV是什么,很多人可能有所耳闻,我们看下维基百科对OpenCV的解释:
主要应用领域:
其中就有对于人脸识别这块的应用,那么我们今天主要介绍的就是这块内容。
OpenCV的官网上面有对于这个库详细的介绍以及用法,相信很多关注图形图像学的同学一定有所耳闻这个大名鼎鼎的库,而它大部分的接口都是基于C++的,后期也暴露了JAVA,Python等的接口,特别是Python,让很多对C++望而却步的同学有了机会去接触OpenCV,那问题来了,对于我们Javascript编程人员,能不能使用Javascript来调用OpenCV的库呢?当然可以,这就是我们要介绍给大家的OpenCV.js!
随着HTML5的兴起,在web端使用图像处理相关技术显得尤为重要,OpenCV.js为Javascript开发者与OpenCV之间搭建了桥梁。起初是由Intel公司发起的一项研究,后在2017年并入到OpenCV项目中。
Emscripten,一款LLVM-to-JavaScript的编译器,将C++的底层函数编译成可以直接在浏览器端运行的asm.js或者WebAssembly。而OpenCV.js是通过该Emscripten将OpenCV的函数编译进asm.js或WebAssembly中,并提供JS APIs给web应用使用。
OpenCV.js的目标:
1.安装Emscripten
安装这个的过程参考官网。
Tips1:如果在MacOS上安装需要提前安装好一些必须的工具,其中的cmake,不要使用官网上建议的下载方式,建议使用brew install cmake来安装最新版。
Tips2:本人在MacOS上按照上述安装过程的步骤安装完成了之后,出现了一些报错,其中有一个报错,发现是跟上述安装过程有出处:
报错:Mac linker error: dyld: Symbol not found: _futimens
解决方案:其中列举了很多解决方案,我亲测Fix bug with Emscripten's llvm-ar on OS X可以解决上述问题
2.获取OpenCV源码
git clone https://github.com/opencv/opencv.git<opencv_src_dir>/platforms/js/build_js.py <build_dir>cd opencv
python ./platforms/js/build_js.py build_js
Note:python和cmake要安装好,否则会报错。
--build_wasmpython ./platforms/js/build_js.py build_wasm --build_wasm其他安装版本请参考Build Open.js页面
目标:学会如何使用OpenCV.js,读取图像文件,并以canvas的形式展现出来。
在线Demo
1.新建一个简单的页面
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<title>Hello OpenCV.js</title>
</head>
<body>
<h2>Hello OpenCV.js</h2>
<div>
<div class="inputoutput">
<img id="imageSrc" alt="No Image" />
<div class="caption">imageSrc <input type="file" id="fileInput" name="file" /></div>
</div>
</div>
<script type="text/javascript">
let imgElement = document.getElementById("imageSrc")
let inputElement = document.getElementById("fileInput");
inputElement.addEventListener("change", (e) => {
imgElement.src = URL.createObjectURL(e.target.files[0]);
}, false);
</script>
</body>
</html>
Node:建议本地起一个local web server去运行上述文件
2.引入opencv.js,路径根据项目中的实际路径设置:
<script src="opencv.js" type="text/javascript"></script>
由于该文件比较大,建议使用异步加载的方式:
<script async src="opencv.js" onload="onOpenCvReady();" type="text/javascript"></script>
3.使用OpenCV.js
一但OpenCV.js加载完成,我们便可以通过使用cv对象来访问OpenCV对象以及它的函数
你可以通过cv.imread来创建cv.Mat
imgElement.onload = function() {
let mat = cv.imread(imgElement);
}
我们的本次的目标是将image文件读取并以canvas的形式显示,具体代码如下:
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<title>Hello OpenCV.js</title>
</head>
<body>
<h2>Hello OpenCV.js</h2>
<p id="status">OpenCV.js is loading...</p>
<div>
<div class="inputoutput">
<img id="imageSrc" alt="No Image" />
<div class="caption">imageSrc <input type="file" id="fileInput" name="file" /></div>
</div>
<div class="inputoutput">
<canvas id="canvasOutput" ></canvas>
<div class="caption">canvasOutput</div>
</div>
</div>
<script type="text/javascript">
let imgElement = document.getElementById('imageSrc');
let inputElement = document.getElementById('fileInput');
inputElement.addEventListener('change', (e) => {
imgElement.src = URL.createObjectURL(e.target.files[0]);
}, false);
imgElement.onload = function() {
let mat = cv.imread(imgElement);
cv.imshow('canvasOutput', mat);
mat.delete();
};
function onOpenCvReady() {
document.getElementById('status').innerHTML = 'OpenCV.js is ready.';
}
</script>
<script async src="opencv.js" onload="onOpenCvReady();" type="text/javascript"></script>
</body>
</html>
Note: 代码最后需要手动去delete方法去释放在Emscripten堆上的内存,更多请参考Emscripten的内存管理
OpenCV的优势在于可以对图像进行处理,所以在人脸识别这个方向,也当仁不让。
先贴一个在线Demo
其中对于摄像头获取视频信息,可以参考WebRTC,有一些在线Demo
,其中使用的getUserMedia方法在IOS端的兼容性不是非常好,只支持ios11以上,有兴趣的可以实际测试一下。
其实使用的Haar Feature-based Cascade,一种用于物体识别的数字图像的特征,本人才疏学浅,对于识别算法没有研究特别深入,有兴趣的同学可以研究一下,欢迎提意见。
更多OpenCV.js的Demo,请参考官网文档
个人觉得,API友好度还是一般,安装和使用都比较麻烦,给大家摸了个坑,还是不建议使用了。
Best face tracking and recognition related javascript libraries:
以上几个都是比较流行的人脸识别的js库,有兴趣的同学可以关注一下。
其实说是介绍人脸识别,但是本文对于人脸识别的算法,真的没有怎么介绍,实在惭愧,后面有机会还会再仔细研究一下,对于OpenCV.js给大家简单介绍一下,毕竟官网的介绍比较简单,其中也有坑,希望本文对于使用这个库的人有帮助,最后如果想使用JS去操作人脸识别,建议使用上面推荐的几个JS库,都封装的比较好。

近来闲来无事,翻翻之前收藏的一些网页,看到了《Javascript秘密花园》,这是很久之前面试前看到的,当时收藏了一下想着以后有时间看,但是一直没有时间去好好读一读,最近花了点时间仔细读了读,写下自己的一点感悟和心得。
本文包括了几块内容,涵盖了Javascript的一些常见的一些知识点,温故而知新。书中包括几大块:对象,函数,数组,类型,核心,其他。本书并没有对于一些常用的点进行罗列,而是列举了一些我们平时并不怎么会注意到的点,但又特别容易犯错,自己写了这么久代码,却对其知之甚少,实在惭愧,下面我自己对每一块内容记录一些自己觉得比较重要的点。
2..toString(); // 第二个点号可以正常解析
2 .toString(); // 注意点号前面的空格
(2).toString(); // 2先被计算
for(var i = 0; i < 10; i++) {
setTimeout(function() {
console.log(i);
}, 1000);
}
上面的代码不会输出数字 0 到 9,而是会输出数字 10 十次。
为了正确的获得循环序号,最好使用 匿名包装器(即自执行匿名函数):
for(var i = 0; i < 10; i++) {
(function(e) {
setTimeout(function() {
console.log(e);
}, 1000);
})(i);
}
function Foo() {
var obj = {};
obj.value = 'blub';
var private = 2;
obj.someMethod = function(value) {
this.value = value;
}
obj.getPrivate = function() {
return private;
}
return obj;
}
上面这种方式存在几个问题:1)会占用更多的内存,因为新创建的对象不能共享原型上的方法。2)为了实现继承,工厂方法需要从另外一个对象拷贝所有属性,或者把一个对象作为新创建对象的原型。3)放弃原型链仅仅是因为防止遗漏 new 带来的问题,这似乎和语言本身的**相违背。
7. 声明变量时绝对不要遗漏 var 关键字,不使用 var 声明变量将会导致隐式的全局变量产生。
8. 推荐使用匿名包装器(译者注:也就是自执行的匿名函数)来创建命名空间。这样不仅可以防止命名冲突, 而且有利于程序的模块化。
(function() {
// 函数创建一个命名空间
window.foo = function() {
// 对外公开的函数,创建了闭包
};
})(); // 立即执行此匿名函数
Value Class Type
-------------------------------------
"foo" String string
new String("foo") String object
1.2 Number number
new Number(1.2) Number object
true Boolean boolean
new Boolean(true) Boolean object
new Date() Date object
new Error() Error object
[1,2,3] Array object
new Array(1, 2, 3) Array object
new Function("") Function function
/abc/g RegExp object (function in Nitro/V8)
new RegExp("meow") RegExp object (function in Nitro/V8)
{} Object object
new Object() Object object
Object.prototype.toString.call([]) // "[object Array]"
Object.prototype.toString.call({}) // "[object Object]"
Object.prototype.toString.call(2) // "[object Number]"
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.