This API is intended to help you fetch weather data from different data sources in an efficient and uniform way. By just supplying a list of locations and a time window you can get data for a specific source immediately.
This project can currently be found on the following location: https://github.com/alliander-opensource/Weather-Provider-API
For more information also check out this webinar:
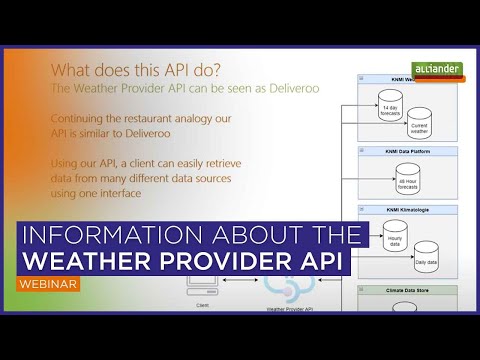
The project uses a number of data sources for the acquisition of weather data. Currently being supported by this API are the following weather data sources:
DATA SOURCE #1: KNMI Historical data per day / hour
Consists of the data from 35 weather stations for temperature, sun, cloud, air pressure, wind and precipitation.
A full description of available weather variables is available for the data per day: http://projects.knmi.nl/klimatologie/daggegevens/selectie.cgi
A full description for the data per hour consists only of a subset of the previous list: http://projects.knmi.nl/klimatologie/uurgegevens/selectie.cgi
DATA SOURCE #2: KNMI prediction data (14 day prediction, per block of 6 hours)
Prediction data for weather stations: De Bilt, Den Helder(De Kooy), Groningen(Eelde), Leeuwarden, Maastricht(Beek), Schiphol, Twente en Vlissingen
Available weather variables are temperature, wind, precipitation, cape for summer, and snow for winter.
An interactive graph can be found at:
https://www.knmi.nl/nederland-nu/weer/waarschuwingen-en-verwachtingen/weer-en-klimaatpluim
DATA SOURCE #3: KNMI prediction data (48 hour, per hour prediction)
Prediction data is updated every 6 hours (00, 06, 12 and 18 UTC+00) based on the HARMONIE AROME model of KNMI.
Geographical resolution is 0.037 grades west-east and 0.023 grades north-south.
A full description of available weather variables is available at: https://www.knmidata.nl/data-services/knmi-producten-overzicht/atmosfeer-modeldata/data-product-1
DATA SOURCE #4: KNMI current weather data()
Actuele waarnemingen
DATA SOURCE #5: CDS (Climate Data Store) hourly data from 1979 to present
ERA5 is the fifth generation ECMWF (European Centre for Medium Range Weather Forecast) atmospheric reanalysis of the global climate. ERA5 data released so far covers the period from 1979 to 2-3 months before the present. ERA5 provides worldwide data for temperature and pressure, wind (at 100 meter height), radiation and heat, clouds, evaporation and runoff, precipitation and rain, snow, soil, etc. The spatial resolution of the data set is approximately 80 km.
A full description of available weather variables is available at: https://cds.climate.copernicus.eu/cdsapp#!/dataset/reanalysis-era5-single-levels?tab=overview
NOTE: The Weather Provider Library and API currently only stores only a selection of the available variables in its archives.
- coords: nested 3-layer list representing a list of polygon. In case of points, they are treated as one-point polygon
- start: start time of output data, for prediction data this is not needed
- end: end time of output data, for prediction data this is not needed
- data_time: history or prediction data
- data_source: KNMI, Climate Data Store(CDS, not available yet), DarkSky (not available yet)
- data_timestep: day, hour, or day_part (6 hour)
- weather_factors: list of weather factors, default is all available weather factors
- output_unit: org (original), human_readable or SI (International System of Units), default is the original names and units in data sources.
For historical data from KNMI the value for weather_factors in input can be a list of desired variables in random order,
indicated by their acronyms separated by ':',
for example TG: TN: EV24.
The following acronyms are defined to indicate groups of variables:
- WIND = DDVEC:FG:FHX:FHX:FX - wind
- TEMP = TG:TN:TX:T10N - temperature
- SUNR = SQ:SP:Q - sunshine duration and global radiation
- PRCP = DR:RH:EV24 - precipitation and evaporation
- PRES = PG:PGX - pressure at sea level
- VICL = VVN:VVX:NG - visibility and clouds
- MSTR = UG:UX:UN - humidity
- ALL - all variables (default)
The output data from the four data sources of KNMI may have different names and units for the same weather variable, which may not easy to use in analytics.
This API provides an option to chose a standard name/unit for the mostly used weather variables, see table below.
The value of output_unit in input can be set to:
org: to keep the originally used names and unitsSI: to convert the variable-names into SI/human readable name, and convert the units into SI unitshuman: to convert the variable-names into SI/human readable name, and convert the units into human-readable units.
| Hist day name | Hist day unit | Hist hour name | Hist hour unit | Forecast 14d name | Forecast 14d unit | Forecast 48h name | Forecast 48h unit | SI/Human readable name | SI unit | Human readable unit |
|---|---|---|---|---|---|---|---|---|---|---|
| FG | 0.1 m/s | FH | 0.1 m/s | wind_speed | km/uur | wind_speed | m/s | m/s | ||
| FHX | 0.1 m/s | FX | 0.1 m/s | wind_speed_max | m/s | m/s | ||||
| TG | 0.1 celsius | T | 0.1 celsius | temperature | celsius | 2T | K | temperature | K | celsius |
| Q | J/cm2 | Q | J/cm2 | GRAD | J m**-2 | global_radiation | J/m2 | J/m2 | ||
| RH | 0.1 mm | RH | 0.1 mm | precipitation | mm | precipitation | m | mm | ||
| PG | 0.1 hPa | P | 0.1 hPa | LSP | Pa | air_pressure | Pa | Pa | ||
| NG | [1,2…9] | N | [1,2…9] | cloud_cover | [1,2…9] | [1,2…9] | ||||
| UG | % | U | % | humidity | % | % |
The CDS data uses only SI units, and as such there is no distinction between org and si .
This package is supported from Python 3.8 or later. See '''requirements.txt''' for a list of dependencies. This package works under at least Linux and Windows environments. (Other Operating Systems not tested)
- Clone the repo
- Navigate to root
- Install the dependencies using conda/pip or both, depending on your environment
conda install --file requirements.txt
pip install -r requirements.txt
- Ready for use!
The full API can now be run by executing:
main.py
With the exception of ERA5 Single Levels and Harmonie Arome data, every data source can now be accessed
using either the created end points or the API docs interface at the running location.
(127.0.0.1:8080 when running locally)
Specific calls can now be run by executing the proper command. For examples, check out the \bin folder.
Install the wheel into your project environment and import the required classes. Usually this will be either a specific Weather Model or the Weather Controller.
Please read CONTRIBUTING.md for details on our code of conduct, and the process for submitting pull requests to us.
To contact the project owners directly please e-mail us at [email protected]
This project was initially created by:
- Tongyou Gu - Original API development
- Jeroen van de Logt - Functions in utilities
- Bas Niesink - Implementation weather REST API
- Raoul Linnenbank - Active API Development, Geo positioning, CDS ERA5, caching, remodeling, Harmonie Arome and optimisation
Currently, this project is governed in an open source fashion, this is documented in PROJECT_GOVERNANCE.
This project is licensed under the Mozilla Public License, version 2.0 - see LICENSE for details
This project includes third-party code, which is licensed under their own respective Open-Source licenses. SPDX-License-Identifier headers are used to show which license is applicable. The concerning license files can be found in the LICENSES directory.
Thanks to team Inzicht & Analytics and Strategie & Innovatie to make this project possible.
A big thanks as well to Alliander for being the main sponsor for this open source project.
And of course a big thanks to the guys of IT New Business & R&D to provide such an easy-to-use Python environment in the cloud.
![dependabot[bot] avatar](https://avatars.githubusercontent.com/in/29110?v=4 "dependabot[bot]")


























