Hello from npx amio
amio / amio.github.com Goto Github PK
View Code? Open in Web Editor NEWAmio on Github
Home Page: https://amio.github.io/
Amio on Github
Home Page: https://amio.github.io/








http://www.dwmkerr.com/the-death-of-microservice-madness-in-2018/
其实是一篇”如何理性使用微服务“
In choosing computer languages, there are classes of program which range from the plainly descriptive (such as Dublin Core metadata, or the content of most databases, or HTML) though logical languages of limited power (such as access control lists, or conneg content negotiation) which include limited propositional logic, though declarative languages which verge on the Turing Complete (Postscript is, but PDF isn't, I am told) through those which are in fact Turing Complete though one is led not to use them that way (XSLT, SQL) to those which are unashamedly procedural (Java, C).
The choice of language is a common design choice. The low power end of the scale is typically simpler to design, implement and use, but the high power end of the scale has all the attraction of being an open-ended hook into which anything can be placed: a door to uses bounded only by the imagination of the programmer.
Computer Science in the 1960s to 80s spent a lot of effort making languages which were as powerful as possible. Nowadays we have to appreciate the reasons for picking not the most powerful solution but the least powerful. The reason for this is that the less powerful the language, the more you can do with the data stored in that language. If you write it in a simple declarative from, anyone can write a program to analyze it in many ways. The Semantic Web is an attempt, largely, to map large quantities of existing data onto a common language so that the data can be analyzed in ways never dreamed of by its creators. If, for example, a web page with weather data has RDF describing that data, a user can retrieve it as a table, perhaps average it, plot it, deduce things from it in combination with other information. At the other end of the scale is the weather information portrayed by the cunning Java applet. While this might allow a very cool user interface, it cannot be analyzed at all. The search engine finding the page will have no idea of what the data is or what it is about. This the only way to find out what a Java applet means is to set it running in front of a person.
I hope that is a good enough explanation of this principle. There are millions of examples of the choice. I chose HTML not to be a programming language because I wanted different programs to do different things with it: present it differently, extract tables of contents, index it, and so on.
一劳永逸地设置下文件夹所有权即可:
sudo chown -R `whoami` /usr/local/lib/node_modules ~/.npmhttps://www.youtube.com/watch?v=rNQR1HqfEl0
观点很有意思:对照人体,一个系统想要生生不息,它需要能够轻松进行新陈代谢,微服务化就是实现手段。小的服务小的项目不会生命周期很长,它们很快建好很快更新或者抛弃,然而它们的交替更迭,组合在一起达成平衡,最终实现整个系统长久的生命力。
另一个凶猛的小标题是:Unit tests, are a design smell. 不过要这么蔑视单元测试,得先有强力的监控报警和灰度发布系统,任何发布都从一小撮线上流量开始走起,Real Tests。
无它,就是很喜欢这份 JD,值得学习下。
Full Time / San Francisco (Remote)
GitHub is looking for an experienced manager to help grow and lead a team of engineers focused on Atom: the world's most hackable text editor. This person will lead the development team, guide technical decisions, and contribute code to the project.
This role is not about dictating or managing a team member’s work directly, but rather guiding and serving to ensure the happiness and productivity of the team. The primary goal of this job is to enable every team member to do the best work of their lives.
This person will work closely with the Director of Client Apps, the VP of Engineering, and the community of over a million active Atom users.
Examples of successful backgrounds and skills:
WHO WE ARE
GitHub is the best place to share code with friends, co-workers, classmates, and complete strangers. Over ten million people use GitHub to build amazing things together. With the collaborative features of GitHub.com, our desktop and mobile apps, and GitHub Enterprise, it has never been easier for individuals and teams to write better code, faster.
We have a lot of exciting things to do, and we’re looking for the right people to grow with us!
WHY YOU SHOULD JOIN
Working at GitHub is, to put it simply, a special slice of the universe. We're committed to transparency, collaboration, experimentation, and always staying classy.
Because of this unique perspective, we've established one of the most flexible and well designed physical workspaces around that encourages you to work as you work best. Right now, over 60% of our employees are based outside of our San Francisco (SOMA) headquarters and work according to how they get their best stuff done.
Ensuring that GitHubbers are healthy, motivated, focused and creative is how GitHub stays awesome. Part of this is ensuring that our benefits* are out of this world.
In a nutshell, we've built and are growing a place where we truly love working, and we think you will too.
GitHub is made up of people with many different backgrounds and lifestyles, and we like it that way. We invite applications from people of all stripes. We don't discriminate against employees or applicants based on gender identity or expression, sexual orientation, race, religion, age, national origin, citizenship, pregnancy status, veteran status, or any other differences that people imagine to discriminate against one another. Also, if you have a disability, please let us know if there's anything we can do to make the interview process better for you; we're happy to accommodate.
*Please note that benefits vary by country, if you have any questions don't hesitate to ask your recruiter!
Handlbars
数据双向绑定太美妙了。数据和表现永远一致,一处修改,到处生效。用过 Handlbars 之后再也不想回到 Backbone + Underscore 那种手动更新界面的时代。
Controller 和 Model
Emberjs 提出了个有趣的概念,Model 负责跟服务器完全同步的数据(例如论坛帖子正文),Controller 作为 Model 的封装/代理,为 Template 提供界面表现的数据(例如是否展开全文,或者日历控件默认填写的当天日期)。虽然有人质疑这样的 Controller 还叫 Controller 么,但是我喜欢这个想法。Model 非常干净。
另一个方便之处是 Computed Properties,设置了依赖之后,可以完全当做静态属性一样使用(当然得是在 Handlbars 模板中),虽然它是动态更新的。在实际应用场景中能节约相当多的零碎代码。
Ember.Data
正在开发中、功能计划非常完善的数据访问库。甚至提供了客户端的对象关系映射(ORM)。整个就是一个库,虽然它基本上应该算是Ember.js的子集,但是7000行代码的体量和功能规划都和使它如同一个库一样复杂。
昨晚我试着写了一个backbone的demo 感觉就三个字:反人类 —— @寒冬winter
哈哈,那你写emberjs的时候肯定觉得反宇宙。—— @青山老妖_黄冠
文档
先前听说 Emberjs 的文档问题,但是没想到这么严重,刚看到新版文档的时候还觉得这么漂亮,看各种特性觉得太厉害了。但是等到实际开工的时候发现竟然无法串联出来一个能运行的App。文档中讲述了 Ember.js 的各种闪光点,但是却不是一本全面完整的参考书。至于那个 API 栏目,更是没什么参考价值,完全看不出配置 Router 的时候除了 model 和 setController 之外还能配置点什么(根据对整个文档的归纳,目前已知这两个):
App.PostsRoute = Ember.Route.extend({
model: function() {
return App.Post.find();
}
});
就在我写本文的一周前,Ember.js 的合作者之一 Tom Dale 刚刚在博客上发表了一篇“MAKING EMBER.JS EASIER”,作为对 Hacker News 上八天前的热门话题 “GETTING STARTED WITH EMBER.JS IS EASY.” - no it isn’t 的官方答复。两位作者已经充分认识到 Ember.js 起步之难,也在努力纠正这个问题——对此我很欣慰也很看好未来。但是现在?它的文档太糟糕了。
关于 Ember.js 入门困难的讨论非常多,比如这里,还有这里,以及 HackerNews上的一大堆讨论。一部分是因为文档缺失,一部分是因为缺少示例应用,相比 Backbone 来说,Ember.js 社区里可供拿来参考的实际应用太少——几乎是个恶性循环。
API
大概是作者极端推崇 Rails,所以在客户端也极力维持和服务器端 Rails 一致的API哲学,最近的 Router API 是刚刚改的,以前的 Router 要这么声明:
App.Router.map(function(match) {
match("/").to("home");
match("/users/:user_id").to("user");
});现在是这样的:
App.Router.map(function() {
this.route("home", { path: "/" });
this.resource('post', { path: '/post/:post_id' });
});啊哦……又多出来一个 resource?好累,感觉不会再爱了。文档中说:“NOTE: You should use this.resource for URLs that represent a noun, and this.route for URLs that represent adjectives or verbs modifying those nouns.” Why? 以前用一个 match 搞定不是好好的么。
神奇路由
"When your application starts, the router is responsible for displaying templates, loading data, and otherwise setting up application state." Router 是不是做的事情有点多了?
看下面这段代码,来自 Emberjs 的第一作者 Yehuda Katz 在 todoMVC 上提交的 Emberjs 例程:
Todos.TodosActiveRoute = Ember.Route.extend({
setupController: function () {
var todos = Todos.Todo.filter(function (todo) {
if (!todo.get('isCompleted')) {
return true;
}
});
this.controllerFor('todos').set('filteredTodos', todos);
}
});这个 Router 里对 Controller 进行了配置,而这个配置过程是获取一份数据(todos)然后分配给 Controller。Router 很忙。
Ember-data
Ember.js 的重度依赖组件,比 Handlebars 还要依赖,可是它还未开发完成,甚至都不提供一个方便加载的文件,而需要你自己下载项目进行编译。Ember Data 是一个极具野心的客户端数据模型,甚至像数据库一样可以定义一对多、多对多的关系,可是 它的主页 上说,“API直到1.0之前都尚未稳定,Emberjs 网站上的文档基于r11版的(实际上文档中的示例已经写着 revision:12 了)”。鉴于整个 Emberjs 文档的数据部分都基于 Ember Data,这是个不可逾越的坎儿。
Ember.js 对 Data 的依赖就像 Handlbars,你可以替换为任何其他同类库,但是这也意味着你失去了一大堆它所提供的便利,你需要添加很多代码以完成工作,By Yourself。
Data 部分的文档没有关于异步加载数据的介绍,对于任何一个单页应用来说这都应该是基础设施。最后延伸阅读的章节里有个“Manage Asynchrony”(BTW,这篇是参考大家的反馈而增加的文章,仍是一个讲述 Ember 闪光点的文章,却没有融入整个 Guide),第一次出现了实例化:var post = App.Post.create();,原来 Emberjs App 不只是声明类就完事儿了啊……等等,我说到了“实例化”?
对象的实例化
文档中的示例全都是声明各种类(如 App.SongController = Ember.ObjectController.extend({});),看起来只要把类实现了就可以让 Ember.js App 运转起来,但是实例化在哪里?是EmberJS在幕后完成的么?如果我想调用某个 Controller 实例的方法(比如在日历控件里选择了日期之后,去设置另外一个 Controller 里的值),要怎么去做?
Ember.js 提供了一大堆魔法,涵盖了“构建超级 Web 应用所需的一切”,从功能和体积上都傲视群雄,但是计划太有野心而目前仍属早期。文档也远远不够,近3W行的代码很难从阅读源码上快速理解它的设计哪怕只是一个局部。
非常 Rails Way 的设计思路,为 Rails 提供项目模板,当然也可以用于其它服务器,不过就需要自行编写适配代码了。
https://www.christianheilmann.com/2016/07/27/why-chakracore-matters/
核心观点在最后两段:
This angers a few people in the Node world. They worry that with several VMs, the “browser hell” of “supporting all kind of environment” will come to Node. Yes, it will mean having to support more engines. But it is also an opportunity to understand that by using standardised code, ratified by the TC39, your solutions will be much sturdier. Relying on specialist functionality of one engine always means that you are dependent on it not changing. And we are already seeing far too many Node based solutions that can’t upgrade to the latest version as breaking changes would mean a complete re-write.
ChakraCore matters the same way browsers that dared to support web standards mattered. It is a choice showing that to be future proof, Node developers need to be ready to allow their solutions to run on various VMs. I’m looking forward to seeing how this plays out. It took the web a few years to understand the value of standards and choice. Much rhetoric was thrown around on either side. I hope that with the great opportunity that Node is to innovate and use ECMAScript for everything we will get there faster and with less dogmatic messaging.
A generator for icon font repo.
看看这个功能你喜不喜欢:当你开始调试代码,项目基于一个你完全不熟悉的库(而且还比较大型,像 jQuery / Angular / Ember 等等)——
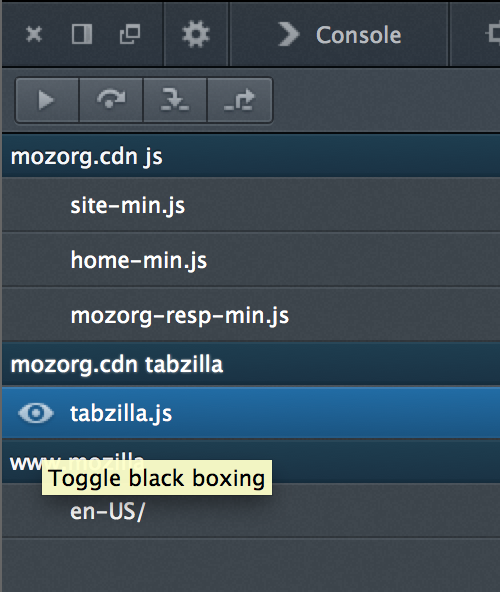
是不是很赞?再也不用因为追踪一个外部问题而深陷到数千行(哦,如果只有一行的话那就更糟了)的外部代码中无法自拔,在数不清的嵌套里焦头烂额。现在 Firefox 和 Chrome 都支持了类似的黑盒功能(Firefox 称为黑盒,Chrome 还没有特定名字)。
chrome://flags/ 里开启 Enable Developer Tools experiments. (记得重启Chrome)

再进一步,文本框内可以填写正则表达式哟 😄
比 Chrome 简单多了,在源码列表里点击源文件左侧的眼睛图标即可切换黑盒模式。
进阶技巧:在 Firefox 的控制台(Shift+F2)里可以批量设置。
dbg blackbox --glob *-min.js
http://www.divshot.com/blog/tips-and-tricks/ignoring-library-code-while-debugging-in-chrome/
https://hacks.mozilla.org/2013/08/new-features-of-firefox-developer-tools-episode-25/
https://code.google.com/p/chromium/issues/detail?id=267592
http://spy-js.com/why.html
https://news.ycombinator.com/item?id=12843590
避开 remote-friendly 的团队,去找 remote-first 的公司:
If you're one of few people in the company working remotely (or worse: one of few in your team), you get cut off really easily. Remote practices won't be up to scratch (because most people aren't using them), meetings will happen in person and dialing you in will be a chore, and things won't work as well. You'll hear about major events by email that everybody knew about last week from office chatter. This isn't to say it'll be a disaster, but it'll be less effective, and less fun.
Companies where everybody works remote by default meanwhile are a different ballgame. Everybody understands how remote interactions should work, and that's what gets used to get everything done. People are good at using the tools and processes required to pull this off well, and the company will be better at managing solutions to the downsides of remote work (by flying everybody into a summit to see each other in person every 6 months, for example, or covering coworking space costs). You're no longer the great developer they want despite you working remotely - you're now one of many people, all working remotely, and all working together on the same playing field.
这儿还有个 Ultimate guide to remote work:
https://zapier.com/learn/the-ultimate-guide-to-remote-working/
原文:http://www.html5rocks.com/en/tutorials/es6/promises/
作者:Jake Archibald
翻译:Amio
女士们先生们,请准备好迎接 Web 开发历史上一个重大时刻……
[鼓声响起]
_JavaScript 有了原生的 Promise!_
[漫天的烟花绽放,人群沸腾了]
这时候你大概是这三种人之一:
JavaScript 是单线程的,这意味着任何两句代码都不能同时运行,它们得一个接一个来。在浏览器中,JavaScript 和其他任务共享一个线程,不同的浏览器略有差异,但大体上这些和 JavaScript 共享线程的任务包括重绘、更新样式、用户交互等,所有这些任务操作都会阻塞其他任务。
作为人类,你是多线程的。你可以用多个手指同时敲键盘,也可以一边开车一遍电话。唯一的全局阻塞函数是打喷嚏,打喷嚏期间所有其他事务都会暂停。很烦人对么?尤其是当你开着车打着电话的时候。我们都不喜欢这样打喷嚏的代码。
你应该会用事件加回调的办法来处理这类情况:
var img1 = document.querySelector('.img-1');
img1.addEventListener('load', function() {
// woo yey image loaded
});
img1.addEventListener('error', function() {
// argh everything's broken
});这样就不打喷嚏了。我们添加几个监听函数,请求图片,然后 JavaScript 就停止运行了,直到触发某个监听函数。
上面的例子中唯一的问题是,事件有可能在我们绑定监听器之前就已经发生,所以我们先要检查图片的complete属性:
var img1 = document.querySelector('.img-1');
function loaded() {
// woo yey image loaded
}
if (img1.complete) {
loaded();
}
else {
img1.addEventListener('load', loaded);
}
img1.addEventListener('error', function() {
// argh everything's broken
});这样还不够,如果在添加监听函数之前图片加载发生错误,我们的监听函数还是白费,不幸的是 DOM 也没有为这个需求提供解决办法。而且,这还只是处理一张图片的情况,如果有一堆图片要处理那就更麻烦了。
事件机制最适合处理同一个对象上反复发生的事情—— keyup、touchstart 等等。你不需要考虑当绑定监听器之前所发生的事情,当碰到异步请求成功/失败的时候,你想要的通常是这样:
img1.callThisIfLoadedOrWhenLoaded(function() {
// loaded
}).orIfFailedCallThis(function() {
// failed
});
// and…
whenAllTheseHaveLoaded([img1, img2]).callThis(function() {
// all loaded
}).orIfSomeFailedCallThis(function() {
// one or more failed
});这就是 Promise。如果 HTML 图片元素有一个 ready() 方法的话,我们就可以这样:
img1.ready().then(function() {
// loaded
}, function() {
// failed
});
// and…
Promise.all([img1.ready(), img2.ready()]).then(function() {
// all loaded
}, function() {
// one or more failed
});基本上 Promise 还是有点像事件回调的,除了:
这些特性非常适合处理异步操作的成功/失败情景,你无需再担心事件发生的时间点,而只需对其做出响应。
Domenic Denicola 审阅了本文初稿,给我在术语方面打了个“F”,关了禁闭并且责令我打印 States and Fates 一百遍,还写了一封家长信给我父母。即便如此,我还是对术语有些迷糊,不过基本上应该是这样:
一个 Promise 的状态可以是:
确认(fulfilled)- 成功了
否定(rejected)- 失败了
等待(pending)- 还没有确认或者否定,进行中
结束(settled)- 已经确认或者否定了
规范里还使用“thenable”来描述一个对象是否是“类 Promise”(拥有名为“then”的方法)的。这个术语使我想起来前英格兰足球经理 Terry Venables 所以我尽量少用它。
其实已经有一些第三方库实现了 Promise:
上面这些库和 JavaScript 原生 Promise 都遵守一个通用的、标准化的规范:Promises/A+,jQuery 有个类似的方法叫 Deferreds,但不兼容 Promises/A+ 规范,于是会有点小问题,使用需谨慎。jQuery 还有一个Promise 类型,但只是 Deferreds 的缩减版,所以也有同样问题。
尽管 Promise 的各路实现遵循同一规范,它们的 API 还是各不相同。JavaScript Promise 的 API 比较接近 RSVP.js,如下创建 Promise:
var promise = new Promise(function(resolve, reject) {
// do a thing, possibly async, then…
if (/* everything turned out fine */) {
resolve("Stuff worked!");
}
else {
reject(Error("It broke"));
}
});Promise 的构造器接受一个函数作为参数,它会传递给这个回调函数两个变量 resolve 和 reject。在回调函数中做一些异步操作,成功之后调用 resolve,否则调用 reject。
调用 reject 的时候传递给它一个 Error 对象只是个惯例并非必须,这和经典 JavaScript 中的 throw 一样。传递 Error 对象的好处是它包含了调用堆栈,在调试的时候会有点用处。
现在来看看如何使用 Promise:
promise.then(function(result) {
console.log(result); // "Stuff worked!"
}, function(err) {
console.log(err); // Error: "It broke"
});then 接受两个参数,成功的时候调用一个,失败的时候调用另一个,两个都是可选的,所以你可以只处理成功的情况或者失败的情况。
JavaScript Promise 最初以“Futures”的名称归为 DOM 规范,后来改名为“Promises”,最终纳入 JavaScript 规范。将其加入 JavaScript 而非 DOM 的好处是方便在非浏览器环境中使用,如Node.js(他们会不会在核心API中使用就是另一回事了)。
目前的浏览器已经(部分)实现了 Promise。
用 Chrome 的话,就像个 Chroman 一样装上 Canary 版,默认即启用了 Promise 支持。如果是 Firefox 拥趸,安装最新的 nightly build 也一样。
不过这两个浏览器的实现都还不够完整彻底,你可以在 bugzilla 上跟踪 Firefox 的最新进展或者到 Chromium Dashboard 查看 Chrome 的实现情况。
要在这两个浏览器上达到兼容标准 Promise,或者在其他浏览器以及 Node.js 中使用 Promise,可以看看这个 polyfill(gzip 之后 2K)
JavaScript Promise 的 API 会把任何包含有 then 方法的对象当作“类 Promise”(或者用术语来说就是 thenable。叹气)的对象,这些对象经过 Promise.cast() 处理之后就和原生的 JavaScript Promise 实例没有任何区别了。所以如果你使用的库返回一个 Q Promise,那没问题,无缝融入新的 JavaScript Promise。
尽管,如前所述,jQuery 的 Deferred 对象有点……没什么用,不过幸好还可以转换成标准 Promise,你最好一拿到对象就马上加以转换:
var jsPromise = Promise.cast($.ajax('/whatever.json'));这里 jQuery 的 $.ajax 返回一个 Deferred 对象,含有 then 方法,因此 Promise.cast 可以将其转换为 JavaScript Promise。不过有时候 Deferred 对象会给它的回调函数传递多个参数,例如:
var jqDeferred = $.ajax('/whatever.json');
jqDeferred.then(function(response, statusText, xhrObj) {
// ...
}, function(xhrObj, textStatus, err) {
// ...
});除了第一个参数,其他都会被 JavaScript Promise 忽略掉:
jsPromise.then(function(response) {
// ...
}, function(xhrObj) {
// ...
});……还好这通常就是你想要的了,至少你能够用这个办法实现想要的。另外还要注意,jQuery 也没有遵循给否定回调函数传递 Error 对象的惯例。
OK,现在我们来写点实际的代码。假设我们想要:
……这个过程中如果发生什么错误了要通知用户,并且把加载指示停掉,不然它就会不停转下去,令人眼晕,或者搞坏界面什么的。
当然了,你不会用 JavaScript 去这么繁琐地显示一篇文章,直接输出 HTML 要快得多,不过这个流程是非常典型的 API 请求模式:获取多个数据,当它们全部完成之后再做一些事情。
首先搞定从网络加载数据的步骤:
只要能保持向后兼容,现有 API 都会更新以支持 Promise,XMLHttpRequest 是重点考虑对象之一。不过现在我们先来写个 GET 请求:
function get(url) {
// Return a new promise.
return new Promise(function(resolve, reject) {
// Do the usual XHR stuff
var req = new XMLHttpRequest();
req.open('GET', url);
req.onload = function() {
// This is called even on 404 etc
// so check the status
if (req.status == 200) {
// Resolve the promise with the response text
resolve(req.response);
}
else {
// Otherwise reject with the status text
// which will hopefully be a meaningful error
reject(Error(req.statusText));
}
};
// Handle network errors
req.onerror = function() {
reject(Error("Network Error"));
};
// Make the request
req.send();
});
}然后调用它:
get('story.json').then(function(response) {
console.log("Success!", response);
}, function(error) {
console.error("Failed!", error);
});点击这里查看代码运行页面,打开控制台查看输出结果。现在我们可以直接发起 HTTP 请求而不需要手敲 XMLHttpRequest,这样感觉好多了,能少看一次这个狂驼峰命名的 XMLHttpRequest 我就多快乐一点。
“then”的故事还没完,你可以把这些“then”串联起来修改结果或者添加进行更多异步操作。
你可以对结果做些修改然后返回一个新值:
var promise = new Promise(function(resolve, reject) {
resolve(1);
});
promise.then(function(val) {
console.log(val); // 1
return val + 2;
}).then(function(val) {
console.log(val); // 3
});回到前面的代码:
get('story.json').then(function(response) {
console.log("Success!", response);
});收到的响应是一个纯文本的 JSON,我们可以修改 get 函数,设置 responseType 要求服务器以 JSON 格式提供响应,不过还是用 Promise 的方式来搞定吧:
get('story.json').then(function(response) {
return JSON.parse(response);
}).then(function(response) {
console.log("Yey JSON!", response);
});既然 JSON.parse 只接收一个参数,并返回转换后的结果,我们还可以再精简一点:
get('story.json').then(JSON.parse).then(function(response) {
console.log("Yey JSON!", response);
});点击这里查看代码运行页面,打开控制台查看输出结果。事实上,我们可以把 getJSON 函数写得超级简单:
function getJSON(url) {
return get(url).then(JSON.parse);
}getJSON 会返回一个获取 JSON 并加以解析的 Promise。
你也可以把 then 串联起来依次执行异步操作。
当你从 then 的回调函数返回的时候,这里有点小魔法。如果你返回一个值,它就会被传给下一个 then 的回调;而如果你返回一个“类 Promise”的对象,则下一个 then 就会等待这个 Promise 明确结束(成功/失败)才会执行。例如:
getJSON('story.json').then(function(story) {
return getJSON(story.chapterUrls[0]);
}).then(function(chapter1) {
console.log("Got chapter 1!", chapter1);
});这里我们发起一个对 story.json 的异步请求,返回给我们更多 URL,然后我们会请求其中的第一个。Promise 开始首次显现出相较事件回调的优越性了。你甚至可以写一个抓取章节内容的独立函数:
var storyPromise;
function getChapter(i) {
storyPromise = storyPromise || getJSON('story.json');
return storyPromise.then(function(story) {
return getJSON(story.chapterUrls[i]);
})
}
// and using it is simple:
getChapter(0).then(function(chapter) {
console.log(chapter);
return getChapter(1);
}).then(function(chapter) {
console.log(chapter);
});我们一开始并不加载 story.json,直到第一次 getChapter,而以后每次 getChapter 的时候都可以重用已经加载完成的 story Promise,所以 story.json 只需要请求一次。Promise 好棒!
前面已经看到,“then”接受两个参数,一个处理成功,一个处理失败(或者说确认和否定,按 Promise 术语):
get('story.json').then(function(response) {
console.log("Success!", response);
}, function(error) {
console.log("Failed!", error);
});你还可以使用 catch:
get('story.json').then(function(response) {
console.log("Success!", response);
}).catch(function(error) {
console.log("Failed!", error);
});这里的 catch 并无任何特殊之处,只是 then(undefined, func) 的语法糖衣,更直观一点而已。注意上面两段代码的行为不仅相同,后者相当于:
get('story.json').then(function(response) {
console.log("Success!", response);
}).then(undefined, function(error) {
console.log("Failed!", error);
});差异不大,但意义非凡。Promise 被否定之后会跳转到之后第一个配置了否定回调的 then(或 catch,一样的)。对于 then(func1, func2) 来说,必会调用 func1 或 func2 之一,但绝不会两个都调用。而 then(func1).catch(func2) 这样,如果 func1 返回否定的话 func2 也会被调用,因为他们是链式调用中独立的两个步骤。看下面这段代码:
asyncThing1().then(function() {
return asyncThing2();
}).then(function() {
return asyncThing3();
}).catch(function(err) {
return asyncRecovery1();
}).then(function() {
return asyncThing4();
}, function(err) {
return asyncRecovery2();
}).catch(function(err) {
console.log("Don't worry about it");
}).then(function() {
console.log("All done!");
});这段流程非常像 JavaScript 的 try/catch 组合,try 代码块中发生的错误会径直跳转到 catch 代码块。这是上面那段代码的流程图(我最爱流程图了):
绿线是确认的 Promise 流程,红线是否定的。
Promise 的否定回调可以由 Promise.reject() 触发,也可以由构造器回调中抛出的错误触发:
var jsonPromise = new Promise(function(resolve, reject) {
// JSON.parse throws an error if you feed it some
// invalid JSON, so this implicitly rejects:
resolve(JSON.parse("This ain't JSON"));
});
jsonPromise.then(function(data) {
// This never happens:
console.log("It worked!", data);
}).catch(function(err) {
// Instead, this happens:
console.log("It failed!", err);
});这意味着你可以把所有 Promise 相关操作都放在它的构造函数回调中进行,这样发生任何错误都能捕捉到并且触发 Promise 否定。
“then”回调中抛出的错误也一样:
get('/').then(JSON.parse).then(function() {
// This never happens, '/' is an HTML page, not JSON
// so JSON.parse throws
console.log("It worked!", data);
}).catch(function(err) {
// Instead, this happens:
console.log("It failed!", err);
});回到我们的故事和章节,我们用 catch 来捕捉错误并显示给用户:
getJSON('story.json').then(function(story) {
return getJSON(story.chapterUrls[0]);
}).then(function(chapter1) {
addHtmlToPage(chapter1.html);
}).catch(function() {
addTextToPage("Failed to show chapter");
}).then(function() {
document.querySelector('.spinner').style.display = 'none';
});如果请求 story.chapterUrls[0] 失败(http 500 或者用户掉线什么的)了,它会跳过之后所有针对成功的回调,包括 getJSON 中将响应解析为 JSON 的回调,和这里把第一张内容添加到页面里的回调。JavaScript 的执行会进入 catch 回调。结果就是前面任何章节请求出错,页面上都会显示“Failed to show chapter”。
和 JavaScript 的 catch 一样,捕捉到错误之后,接下来的代码会继续执行,按计划把加载指示器给停掉。上面的代码就是下面这段的非阻塞异步版:
try {
var story = getJSONSync('story.json');
var chapter1 = getJSONSync(story.chapterUrls[0]);
addHtmlToPage(chapter1.html);
}
catch (e) {
addTextToPage("Failed to show chapter");
}
document.querySelector('.spinner').style.display = 'none';如果只是要捕捉异常做记录输出,不打算在用户界面上对错误进行反馈的话,只要抛出 Error 就行了,这一步可以放在 getJSON 中:
function getJSON(url) {
return get(url).then(JSON.parse).catch(function(err) {
console.log("getJSON failed for", url, err);
throw err;
});
}现在我们已经搞定第一章了,接下来搞定全部章节。
异步的思维方式并不符合直觉,如果你觉得起步困难,那就试试先写个同步的方法,就像这个:
try {
var story = getJSONSync('story.json');
addHtmlToPage(story.heading);
story.chapterUrls.forEach(function(chapterUrl) {
var chapter = getJSONSync(chapterUrl);
addHtmlToPage(chapter.html);
});
addTextToPage("All done");
}
catch (err) {
addTextToPage("Argh, broken: " + err.message);
}
document.querySelector('.spinner').style.display = 'none';它执行起来完全正常!(查看示例)不过它是同步的,在加载内容时会卡住整个浏览器。要让它异步工作的话,我们用 then 把它们一个接一个串起来:
getJSON('story.json').then(function(story) {
addHtmlToPage(story.heading);
// TODO: for each url in story.chapterUrls, fetch & display
}).then(function() {
// And we're all done!
addTextToPage("All done");
}).catch(function(err) {
// Catch any error that happened along the way
addTextToPage("Argh, broken: " + err.message);
}).then(function() {
// Always hide the spinner
document.querySelector('.spinner').style.display = 'none';
});那么我们如何遍历章节的 URL 并且依次请求?这样是不行的:
story.chapterUrls.forEach(function(chapterUrl) {
// Fetch chapter
getJSON(chapterUrl).then(function(chapter) {
// and add it to the page
addHtmlToPage(chapter.html);
});
});forEach 没有对异步操作的支持,所以我们的故事章节会按照它们加载完成的顺序显示,基本上《低俗小说》就是这么写出来的。我们不写低俗小说,所以得修正它:
我们要把章节 URL 数组转换成 Promise 的序列,还是用 then:
// Start off with a promise that always resolves
var sequence = Promise.resolve();
// Loop through our chapter urls
story.chapterUrls.forEach(function(chapterUrl) {
// Add these actions to the end of the sequence
sequence = sequence.then(function() {
return getJSON(chapterUrl);
}).then(function(chapter) {
addHtmlToPage(chapter.html);
});
});这是我们第一次用到 Promise.resolve,它会依据你传的任何值返回一个 Promise。如果你传给它一个类 Promise 对象(带有 then 方法),它会生成一个带有同样确认/否定回调的 Promise,基本上就是克隆。如果传给它任何别的值,如 Promise.resolve('Hello'),它会创建一个以这个值为完成结果的 Promise,如果不传任何值,则以 undefined 为完成结果。
还有一个对应的 Promise.reject(val),会创建以你传入的参数(或 undefined)为否定结果的 Promise。
我们可以用 array.reduce 精简一下上面的代码:
// Loop through our chapter urls
story.chapterUrls.reduce(function(sequence, chapterUrl) {
// Add these actions to the end of the sequence
return sequence.then(function() {
return getJSON(chapterUrl);
}).then(function(chapter) {
addHtmlToPage(chapter.html);
});
}, Promise.resolve());它和前面的例子功能一样,但是不需要显式声明 sequence 变量。reduce 回调会依次应用在每个数组元素上,第一轮里的“sequence”是 Promise.resolve(),之后的调用里“sequence”就是上次函数执行的的结果。array.reduce 非常适合用于把一组值归并处理为一个值,正是我们现在对 Promise 的用法。
汇总下上面的代码:
getJSON('story.json').then(function(story) {
addHtmlToPage(story.heading);
return story.chapterUrls.reduce(function(sequence, chapterUrl) {
// Once the last chapter's promise is done…
return sequence.then(function() {
// …fetch the next chapter
return getJSON(chapterUrl);
}).then(function(chapter) {
// and add it to the page
addHtmlToPage(chapter.html);
});
}, Promise.resolve());
}).then(function() {
// And we're all done!
addTextToPage("All done");
}).catch(function(err) {
// Catch any error that happened along the way
addTextToPage("Argh, broken: " + err.message);
}).then(function() {
// Always hide the spinner
document.querySelector('.spinner').style.display = 'none';
});运行示例看这里,前面的同步代码改造成了完全异步的版本。我们还可以更进一步,现在页面加载的效果是这样:
浏览器很擅长同时加载多个文件,我们这种一个接一个下载章节的方法非常不效率。我们希望同时下载所有章节,全部完成后一次搞定,正好就有这么个 API:
Promise.all(arrayOfPromises).then(function(arrayOfResults) {
//...
});Promise.all 接受一个 Promise 数组为参数,创建一个当所有 Promise 都完成之后就完成的 Promise,它的完成结果是一个数组,包含了所有先前传入的那些 Promise 的完成结果,顺序和将它们传入的数组顺序一致。
getJSON('story.json').then(function(story) {
addHtmlToPage(story.heading);
// Take an array of promises and wait on them all
return Promise.all(
// Map our array of chapter urls to
// an array of chapter json promises
story.chapterUrls.map(getJSON)
);
}).then(function(chapters) {
// Now we have the chapters jsons in order! Loop through…
chapters.forEach(function(chapter) {
// …and add to the page
addHtmlToPage(chapter.html);
});
addTextToPage("All done");
}).catch(function(err) {
// catch any error that happened so far
addTextToPage("Argh, broken: " + err.message);
}).then(function() {
document.querySelector('.spinner').style.display = 'none';
});根据连接状况,改进的代码会比顺序加载方式提速数秒,甚至代码行数也更少。章节加载完成的顺序不确定,但它们显示在页面上的顺序准确无误。
然而这样还是有提高空间。当第一章内容加载完毕我们可以立即填进页面,这样用户可以在其他加载任务尚未完成之前就开始阅读;当第三章到达的时候我们不动声色,第二章也到达之后我们再把第二章和第三章内容填入页面,以此类推。
为了达到这样的效果,我们同时请求所有的章节内容,然后创建一个序列依次将其填入页面:
getJSON('story.json').then(function(story) {
addHtmlToPage(story.heading);
// Map our array of chapter urls to
// an array of chapter json promises.
// This makes sure they all download parallel.
return story.chapterUrls.map(getJSON)
.reduce(function(sequence, chapterPromise) {
// Use reduce to chain the promises together,
// adding content to the page for each chapter
return sequence.then(function() {
// Wait for everything in the sequence so far,
// then wait for this chapter to arrive.
return chapterPromise;
}).then(function(chapter) {
addHtmlToPage(chapter.html);
});
}, Promise.resolve());
}).then(function() {
addTextToPage("All done");
}).catch(function(err) {
// catch any error that happened along the way
addTextToPage("Argh, broken: " + err.message);
}).then(function() {
document.querySelector('.spinner').style.display = 'none';
});哈哈(查看示例),鱼与熊掌兼得!加载所有内容的时间未变,但用户可以更早看到第一章。
这个小例子中各部分章节加载差不多同时完成,逐章显示的策略在章节内容很多的时候优势将会更加显著。
上面的代码如果用 Node.js 风格的回调或者事件机制实现的话代码量大约要翻一倍,更重要的是可读性也不如此例。然而,Promise 的厉害不止于此,和其他 ES6 的新功能结合起来还能更加高效……
接下来的内容涉及到一大堆 ES6 的新特性,不过对于现在应用 Promise 来说并非必须,把它当作接下来的第二部豪华续集的预告片来看就好了。
ES6 还给我们带来了 Generator,允许函数在特定地方像 return 一样退出,但是稍后又能恢复到这个位置和状态上继续执行。
function *addGenerator() {
var i = 0;
while (true) {
i += yield i;
}
}注意函数名前的星号,这表示该函数是一个 Generator。关键字 yield 标记了暂停/继续的位置,使用方法像这样:
var adder = addGenerator();
adder.next().value; // 0
adder.next(5).value; // 5
adder.next(5).value; // 10
adder.next(5).value; // 15
adder.next(50).value; // 65这对 Promise 有什么用呢?你可以用这种暂停/继续的机制写出来和同步代码看上去差不多(理解起来也一样简单)的代码。下面是一个辅助函数(helper function),我们在 yield 位置等待 Promise 完成:
function spawn(generatorFunc) {
function continuer(verb, arg) {
var result;
try {
result = generator[verb](arg);
} catch (err) {
return Promise.reject(err);
}
if (result.done) {
return result.value;
} else {
return Promise.cast(result.value).then(onFulfilled, onRejected);
}
}
var generator = generatorFunc();
var onFulfilled = continuer.bind(continuer, "next");
var onRejected = continuer.bind(continuer, "throw");
return onFulfilled();
}这段代码原样拷贝自 Q,只是改成 JavaScript Promise 的 API。把我们前面的最终方案和 ES6 最新特性结合在一起之后:
spawn(function *() {
try {
// 'yield' effectively does an async wait,
// returning the result of the promise
let story = yield getJSON('story.json');
addHtmlToPage(story.heading);
// Map our array of chapter urls to
// an array of chapter json promises.
// This makes sure they all download parallel.
let chapterPromises = story.chapterUrls.map(getJSON);
for (let chapterPromise of chapterPromises) {
// Wait for each chapter to be ready, then add it to the page
let chapter = yield chapterPromise;
addHtmlToPage(chapter.html);
}
addTextToPage("All done");
}
catch (err) {
// try/catch just works, rejected promises are thrown here
addTextToPage("Argh, broken: " + err.message);
}
document.querySelector('.spinner').style.display = 'none';
});功能完全一样,读起来要简单得多。这个例子目前可以在 Chrome Canary 中运行(查看示例),不过你得先到 about:flags 中开启 Enable experimental JavaScript 选项。
这里用到了一堆 ES6 的新语法:Promise、Generator、let、for-of。当我们把 yield 应用在一个 Promise 上,spawn 辅助函数会等待 Promise 完成,然后才返回最终的值。如果 Promise 给出否定结果,spawn 中的 yield 则会抛出一个异常,我们可以用 try/catch 捕捉到。这样写异步代码真是超级简单!
除非额外注明,最新版的 Chrome(Canary) 和 Firefox(nightly) 均支持下列所有方法。这个 Polyfill 则在所有浏览器内实现同样的接口。
Promise.cast(promise);
返回一个 Promise(当且仅当 promise.constructor == Promise)
备注:目前仅有 Chrome 实现
Promise.cast(obj);
创建一个以 obj 为成功结果的 Promise。
备注:目前仅有 Chrome 实现
Promise.resolve(thenable);
从 thenable 对象创建一个新的 Promise。一个 thenable(类 Promise)对象是一个带有“then”方法的对象。如果你传入一个原生的 JavaScript Promise 对象,则会创建一个新的 Promise。此方法涵盖了 Promise.cast 的特性,但是不如 Promise.cast 更简单高效。
Promise.resolve(obj);
创建一个以 obj 为确认结果的 Promise。这种情况下等同于 Promise.cast(obj)。
Promise.reject(obj);
创建一个以 obj 为否定结果的 Promise。为了一致性和调试便利(如堆栈追踪),obj 应该是一个 Error 实例对象。
Promise.all(array);
创建一个 Promise,当且仅当传入数组中的所有 Promise 都确认之后才确认,如果遇到数组中的任何一个 Promise 以否定结束,则抛出否定结果。每个数组元素都会首先经过 Promise.cast,所以数组可以包含类 Promise 对象或者其他对象。确认结果是一个数组,包含传入数组中每个 Promise 的确认结果(且保持顺序);否定结果是传入数组中第一个遇到的否定结果。
备注:目前仅有 Chrome 实现
Promise.race(array);
创建一个 Promise,当数组中的任意对象确认时将其结果作为确认结束,或者当数组中任意对象否定时将其结果作为否定结束。
备注:我不大确定这个接口是否有用,我更倾向于一个 Promise.all 的对立方法,仅当所有数组元素全部给出否定的时候才抛出否定结果
https://www.heavybit.com/library/podcasts/demuxed/ep-5-webtorrent-bringing-bittorrent-to-the-web/
WebTorrent,Videostream,和炸香蕉糖
有一些还不确定的想法,记下来讨论 @hax
就现实情况的感受是:
http://blog.professorbeekums.com/2016/12/beware-of-developers-who-do-negative.html
人们很容易高估提前一个月上线的好处,而低估了这之后擦一年屁股的成本。
https://alistapart.com/article/conducting-the-technical-interview
一场技术面试的内容远不止技术能力,此文讲的就是除开技术考察之外的其他内容。
https://dev.to/gonedark/when-to-make-a-git-commit
I make a commit when:
- I complete a unit of work.
- I have changes I may want to undo.
https://medium.com/friendship-dot-js/b89f63d21558
虽然我一直都知道有这种可能性但还是有点震惊居然这种事情如此常见如此随意,身边就一抓一大把。
于是我就做了这个 flaming-disk-usage
当我们开始着手实现 AngularJS 2.0 的时候,我们考虑应该告诉大家我们计划要做的内容和细节,这么做的原因以及设计思路,希望大家能帮助我们做出正确的选择。
AngularJS 2 是一个面向移动端的框架,它当然也适用于桌面环境,但是主要的挑战会在移动端所以我们决定先拿下这边。AngularJS 那些最具特色的功能一样也不会少,数据绑定、可扩展的HTML、对测试的天生支持。
所有 AngularJS 2 的设计文档都放在 Google Drive 上,本文则概述了我们的方向和设计思路,更具体的细节可以循着文中链接进一步了解。
注意:我们仍然处在早起的设计和原型阶段,文中的内容有可能在最终产品中有所不同甚至完全不存在。
我们按照这个世界将会变成的样子来设计 AngularJS,直白一点说就是面向现代浏览器,使用 ECMAScript 6。
现代浏览器是指那些公认特性完备以及保持更新的浏览器。面向这些浏览器意味着我们可以扔掉许多对 AngularJS 特性毫无帮助的 hack,无论开发或者应用都会变得更加简单。
这个浏览器清单里包括:Chrome,FireFox,Opera,Safari 和 IE11。在移动端的支持列表大致是 Chrome on Android,iOS 6+,Windows Phone 8+ 以及 Firefox mobile。有考虑在 Android 上支持更老一些的版本,但是暂定排除。
确实现在一些老浏览器的份额还不能忽视,不过我们支持的这些浏览器等到 AngularJS 2.0 发布的时候,应该已经占据绝大部分主流了,况且开发者们在新基础上构建 App 还要点时间呢。
AngularJS 2 的所有代码都是用 ES6 写的。目前的浏览器还不支持 ES6,所以我们用 Traceur compiler 来转换成 ES5 代码。我们也跟 Traceur 团队合作为其增加一些扩展支持,如备注和断言。
不用担心,尽管 AngularJS 会用 ES6 写就,如果你不想转换过来的话用 ES5 也完全没问题。Traceur 能够生成可读性优良的代码。更多细节参见此设计文档。
AngularJS 应用的核心就是 DOM 和 JS 对象的数据绑定,应用的速度也非常依赖于我们在背后采用的变化监测机制。我们深入讨论过在 Chrome M35 实现了 Object.observe() 之后如何改进变化监测,我们早晚会的!
不过,在经过庞杂的分析(详情参见文档)之后,我们也发现在原生的对象监测普及到所有浏览器之前,目前的变化监测在速度和内存效率上仍然有很大提升空间。
如果你还不知道怎么让 ls 变成彩色的话,试试这个:ls -G。
这些文本颜色的配置来自 Terminal 的设置项 ANSI Colors,不过默认的色彩太生硬了一点都不萌,我们来改掉它。例如想要用Linux颜色的话,把下面这行加入 .profile:
export LSCOLORS="ExGxBxDxCxEgEdxbxgxcxd"LSCOLORS 的值就是配置各种文件类型的不同颜色。每个字母表示一个颜色,它在字符串中的位置对应一种文件类型。每个颜色配置都是成对的:前景色和背景色。字母代表的颜色如下:
LSCOLORS 中字符位置的含义如下:
LSCOLORS 的系统默认值是exfxcxdxbxegedabagacad,表示文件目录使用蓝色前景色和默认背景色,符号链接使用紫色前景色和默认背景色,以此类推。
一篇 9 年前的老文,今天才发现
http://paulgraham.com/ramenprofitable.html
If you’re an early employee at a startup, one day you will wake up to find that what you worked on 24/7 for the last year is no longer the most important thing – you’re no longer the most important employee, and process, meetings, paperwork and managers and bosses have shown up. Most painfully, you’ll learn that your role in the company has to change.
I’ve seen these transitions as an investor, board member and CEO. At times they are painful to watch and difficult to manage. Early in my career I lived it as an employee, and I handled it in the worst possible way.
Here’s what I wish I had known.
https://steveblank.com/2018/11/13/its-not-change-you-fear-its-loss/
原文:http://alistapart.com/blog/post/organize-that-sass
作者:Tim Smith
使用 SASS 最美妙的地方之一就是它的文件组织起来有多么方便。过去我们很少引入(import)CSS文件,那会造成更多的HTTP请求,现在使用 SASS 可以将样式表拆分为很多有意义的片段(partial)。什么是片段?SASS 官方文档解释得很清楚:
如果你有一些 SCSS 或者 Sass 文件,仅仅用于导入而不希望将其各自编译为 CSS 的话,可以在它们的文件名前加一个下划线。含有此标记的文件就不会被 SASS 编译为独立的 CSS。
用这种方式来组织SASS文件,你就可以创建一个相当于『索引目录』的global.scss。我这里有13个片段,包括 forms、icons、type、mixins、images 等等:
stylesheets/
_bits.scss
_forms.scss
_icons.scss
_images.scss
_mixins.scss
_type.scss
创建了这些文件之后,将其导入主样式表,我喜欢加点注释说明各个片段都有什么内容:
/*
VARIABLES
---------------
Setting up variables. Bringing in Colors and Spacing.
--------------- */
@import "bits";
/*
BASE STYLES
---------------
Setting up the base. Bringing in Type, Images, Forms, and Icons.
--------------- */
@import "type";
@import "images";
@import "forms";
@import "icons";刚开始用这种方式组织文件可能有点难以适应,但我能告诉你它为我节约了多少时间。以前在大型项目中找到要修改的代码位置比修改它花的时间还要多,现在呢,再也不用头疼那3000多行的CSS文件了,新的样式表简单、轻巧、精确,而最重要的是,它们的名字(文件名)都有意义了。
https://dev.to/adambsilver/the-problem-with-atomiccss
集中批斗 atomic CSS
https://infoq.cn/article/decisions-company-no-managers
我相信这样的公司里每个人都不但认同并且熟练地负担自己在这种文化下的责任,但他们假如离开这家公司加入另外一个拥有厚重管理层的传统企业中,他们并不会和其他人有什么不同,泯然众人矣。那么这样出色的组织到底是如何形成并存活成长?这不是参与其中的每个人共同贡献造就的,而是极大程度地依赖创始人/CEO的引领实现的。
看似砍掉了管理层,实现全员自治,能够摒弃很多繁冗管理消耗,公司也省了很多对管理成本的投入。然而选择这条路对创始人/CEO其实是非常高的管理挑战。
放权比用权要难得多。
He is higher in the scope chain than the window object.
他在作用域链中 window 对象的上层。
He once had a bug in his code, just to see how it would feel.
有天他写了个bug,体验下这是什么感觉。
Vars declare themselves for him.
每个 var 关键字都是用他声明的。
He knows every anonymous function by name.
他知道每个匿名函数的名字。
He doesn't call functions; they call him.
他不调用函数。函数都是请求他执行的。
He once coerced 0 to true.
他曾经强迫0为真。
He single-handedly stopped ECMAScript 4 from seeing the light of day.
他一手导演了 ECMAScript 4 的灭亡。
JSLint doesn't complain about anything in his code. Even the with statement.
JSLint 对他的代码一个字儿都不会指责。甚至包括 with 声明。
His client-side JavaScript runs on the server.
他写的客户端脚本其实是服务器跑给浏览器的。
His cat wrote a browser, named IE6.
他家的猫写了一个浏览器,名叫IE6。
推特上正在热火朝天地开展这个话题活动 themostinterestingjsmanintheworld
一起来吐槽吧,微博话题:世界上最神秘的JSer
发在 martinfowler.com 上的一片雄文,对 Serverless 架构做了系统的阐述,正反面都有考量,在 Hacker News 上也引起了热烈讨论。原文会按照 martinfowler 的 bliki 模式保持更新,本文也将尽量第一时间跟进增补。一点译注:为了方便交叉参考,“Serverless”、“BaaS” 等术语文中不做翻译。
原文:http://martinfowler.com/articles/serverless.html
作者:Mike Roberts
Serverless architectures refer to applications that significantly depend on third-party services (knows as Backend as a Service or "BaaS") or on custom code that's run in ephemeral containers (Function as a Service or "FaaS"), the best known vendor host of which currently is AWS Lambda. By using these ideas, and by moving much behavior to the front end, such architectures remove the need for the traditional 'always on' server system sitting behind an application. Depending on the circumstances, such systems can significantly reduce operational cost and complexity at a cost of vendor dependencies and (at the moment) immaturity of supporting services.
Severless 现在是软件架构圈中的热门话题,涌现出了数不清的相关书籍、开源框架、商业产品,甚至还有专注于这个话题的大会。什么是 Serverless?它有那些特性值得/不值得考量?通过持续更新的本文,我希望对这些问题做出解答。
开篇我们先来看看 Serverless 是什么,之后我会尽我所能中立地谈谈它的优势和缺点。
就像软件行业中的很多趋势一样,Serverless 的界限并不是特别清晰,尤其是它还涵盖了两个互相有重叠的概念:
我接下来要谈的主要是第二种情况,因为这个概念更新颖,也和我们传统考虑的技术架构大相径庭,并且也是目前最被热炒的 Serverless 概念。
不过这些概念实际上是相关、甚至有交叉的。Auth0 就是个好例子——他们最初是一个 BaaS 服务:“Authentication as a Service”,但是随着 Auth0 Webtask 的推出,他们也进入了 FaaS 的领域。
并且在很多情况下,开发一个 “BaaS” 应用尤其是富 Web 应用(相对于移动端 App),你肯定还是需要一些自定服务器端逻辑的,这种场景下 FaaS 函数会是不错的解决方案,尤其是当它作为扩展和你现有的 BaaS 服务整合在一起的时候,例如一些数据校验(防止身份伪造)的功能,或者需要大量计算的任务(图片、视频处理)。
我们来设想一个传统的三层 C/S 架构,例如一个常见的电子商务应用(我能说这是个在线宠物商店么?),假设它服务端用 Java,客户端用 HTML/JavaScript:
在这个架构下客户端通常没什么功能,系统中的大部分逻辑——身份验证、页面导航、搜索、交易——都在服务端实现。
把它改造成 Serverless 架构的话看起来会是这样:
这是张极度简化的图,但还是有相当多改变之处。请注意这并不是推荐架构迁移方式,我只是用这张图来展示 Serverless 中的一些概念:
再举一个后端数据处理服务的例子。假设你在做一个需要快速响应 UI 的用户中心应用,同时你又想捕捉记录所有的用户行为。设想一个在线广告系统,当用户点击了广告你需要立刻跳转到广告目标,同时你还需要记录这次点击以便向广告客户收费(这个例子并非虚构,我的一位前同事最近就在做这项重构)。
传统的架构会是这样:“广告服务器”同步响应用户的点击,同时发送一条消息给“点击处理应用”,异步地更新数据库(例如从客户的账户里扣款)。
在 Serverless 架构下会是这样:
这里两个架构的差异比我们上一个例子要小很多。我们把一个长期保持在内存中待命的任务替换为托管在第三方平台上以事件驱动的 FaaS 函数。注意这个第三方平台提供了消息代理和 FaaS 执行环境,这两个紧密相关的系统。
我们已经提到多次 FaaS 的概念,现在来挖掘下它究竟是什么含义。先来看看 Amazon 的 Lambda 产品简介:
通过 AWS Lambda,无需配置或管理服务器**(1)即可运行代码。您只需按消耗的计算时间付费 – 代码未运行时不产生费用。借助 Lambda,您几乎可以为任何类型的应用程序或后端服务(2)运行代码,而且全部无需管理。只需上传您的代码,Lambda 会处理运行(3)和扩展高可用性(4)代码所需的一切工作。您可以将您的代码设置为自动从其他 AWS 服务(5)触发,或者直接从任何 Web 或移动应用程序(6)**调用。
Every line of code written comes at a price: maintenance.
http://programmingisterrible.com/post/139222674273/write-code-that-is-easy-to-delete-not-easy-to
It’s not a web app. It’s an app you install from the web.
http://blog.forecast.io/its-not-a-web-app-its-an-app-you-install-from-the-web/
Forecast.io 的一些移动应用设计和开发经验,捡重点的说(排名不分先后)。
translate3d属性而非修改top和left的值。也要避免动画那些未经硬件加速的属性,像height之类。-webkit-overflow-scrolling: touch可以在iOS和Android 4.x 上创建允许滚动的div。用过一段时间之后 Terminal 启动速度变得超慢,打开窗口之后要10秒之后才能输入命令。
刚开始还以为因为用的 OSX Mavericks 开发者预览版,最后终于忍受不了跑去查了下,原来是 /private/var/log/asl/ 目录下的系统日志太多了,果断删除 = =
sudo rm -rf /private/var/log/asl/*https://medium.com/@kosamari/how-to-be-a-compiler-make-a-compiler-with-javascript-4a8a13d473b4
手把手教你明明白白看懂 compiler
可以结合这个看 https://astexplorer.net/
原文地址:http://peter.michaux.ca/articles/early-mixins-late-mixins
Javascript 中原型(Prototype)是主要的单继承方式,而从多个对象“继承”属性则要用到混元(Mixin)模式。实现混元有多种方式,本文比较了两种混元方法:Early Mixin 和 Late Mixin。
首先来看看 Late Binding。
var adam = {
greet: function() {
return "hello";
}
};
adam.greet(); // "hello"每次调用 adam 的 greet 方法的时候都会即时查找需要使用的函数,所以当我们重新定义了 greet 方法,之后的调用就会使用新的 greet,是为 Late Binding。
adam.greet = function(name) {
return "hello" + (name ? (", " + name) : "");
};
adam.greet("world"); // "hello, world";这使得我们可以方便扩展现有库的功能。
这两个特性加在一起会是什么样子?再来个例子,创建一个能自我介绍的对象 adam:
var adam = {
_name: "Adam";
greet: function() {
return "hello. I am " + this._name;
}
};貌似这个 Adam 挺合适做个基类的,我们可以基于它来创建更多的人:
function Person(name) {
this._name = name;
}
Person.prototype = adam;
var eve = new Person("Eve");
eve.greet(); // "hello. I am Eve"拜 Late Binding 和原型链所赐,任何对 adam 所做的修改都对 eve 有同样的效果:
adam.greet = function(name) {
return "hello" + (name ? (", " + name) : '') + ". I am " + this._name;
};
eve.greet("world"); // "hello, world. I am Eve"还有种重用代码的方法是创建一个专门用于混元(Mixin)的对象。通常的实现方法都是 Early Mixin 的。首先要有一个用于把一个对象上的所有方法绑定到另一个对象上去的混元函数:
function earlyMixin(sink, source) {
for (var property in source) {
sink[property] = source[property];
}
}这样就可以使用混元了。下面是一个叫做 speech.js 的函数库:
var speeches = {
greet: function() {
return "hello. I am " + this._name;
},
farewell: function() {
return "goodbye. I am " + this._name;
}
};这个库简洁优雅,测试完备,我们准备直接借鉴来用:
function Person(name) {
this._name = name;
}
earlyMixin(Person.prototype, speeches);
var adam = new Person('Adam');
adam.greet(); // "hello. I am Adam"如此这般,我们把 speeches 对象上的方法混元到了好多个其他对象上去(就像 Person.prototype 这样),然后我们准备修改下 speeches 的方法,希望所有跟 speeches 有关系的其他对象都能享受到新的改动(其实就是想做个 speech.js 的插件),像这样:
speeches.greet = function(name) {
return "hello" + (name ? (", " + name) : '') + ". I am " + this._name;
};郁闷的是这样不行了。因为 speeches 的老版 greet 方法已经被混元到 Person.prototype 对象上(当进行混元的时候)了,对 adam 调用 greet 方法结果照旧:
adam.greet("world"); // "hello. I am Adam"为了实现目标,我们需要在混元方法中加一层嵌套:
function lateMixin(sink, source) {
for (var property in source) {
(function(property) {
sink[property] = function() {
return source[property].apply(this, arguments);
}
}(property));
}
}这次不再直接把 source 上的方法赋给 sink,而是给 sink 生成一个同名方法,用来调用 source 上的对应方法。这就使得 sink 上的方法只有在调用的时候才去查找确定真正执行的函数——Late Mixin。
回到刚才的例子,现在我们可以如愿以偿了:
var speeches = {
greet: function() {
return "hello. I am " + this._name;
},
farewell: function() {
return "goodbye. I am " + this._name;
}
};
function Person(name) {
this._name = name;
}
lateMixin(Person.prototype, speeches);
var adam = new Person('Adam');
adam.greet(); // "hello. I am Adam"
speeches.greet = function(name) {
return "hello" + (name ? (", " + name) : '') + ". I am " + this._name;
};
adam.greet("world"); // "hello, world. I am Adam"当调用 adam.greet 的时候会使用最后一次对 greet 的定义,漂亮!Late mixin 使得 speech.js 这样的库能够在运行环境中进行各种实时扩展。
如果我们要_添加_方法到 speeches 上的话,是没法让已经混元过 speeches 的对象获得新方法的。解决方法有不少,ECMAScript Harmony 中的 proxy 应该会是我们未来的方案。
Lifecycle hooks allow us to handle the continuation of some rendering that originated on the server.
https://www.youtube.com/watch?v=wCfE-9bhY2Y
其实不是讲怎么写安全的 Code,是如何用 snyk 来保障你的 Node.js 项目安全。
几个例子很赞。
https://medium.freecodecamp.com/welcome-to-the-software-interview-ee673bc5ef6
把程序员面试中的各种吐槽了个遍,可以直接写进硅谷剧本了
https://paul.kinlan.me/slice-the-web/
SLICE 的概念很有意思:
https://hacks.mozilla.org/2017/02/a-cartoon-intro-to-webassembly/
https://hacks.mozilla.org/2017/02/a-crash-course-in-just-in-time-jit-compilers/
https://hacks.mozilla.org/2017/02/a-crash-course-in-assembly/
https://hacks.mozilla.org/2017/02/creating-and-working-with-webassembly-modules/
https://hacks.mozilla.org/2017/02/what-makes-webassembly-fast/
https://hacks.mozilla.org/2017/02/where-is-webassembly-now-and-whats-next/
https://medium.com/dev-channel/the-cost-of-javascript-84009f51e99e
我发现我常常会需要回头来参考这篇文章,最近一两年里前端性能优化的重要论述之一
在JS控制台执行函数太啰嗦了,hello()两个括号不胜其烦,要是能只写一句hello直接回车多酷!
Object.defineProperties(window, {
"hello": { get: function () { return confirm('Hello!') } },
});如果你正在为 Chrome DevTool 写 Snippets…… ;-D
修改此文件:
$ vim ~/.config/fish/config.fish
添加:
set -gx LANGUAGE en_US.utf8
set -gx LC_ALL en_US.utf8
set -gx LC_TYPE utf8
set -gx LANG en_US.utf8
如果不行的话,用 locale -a 看看本机有哪些可以用,挑一个用。
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.