we will dive deeper into the experimental setup, highlighting the key steps involved in training and evaluating the YOLOv8s and YOLOv8m models on the Argoversehd dataset. We will discuss the training process, including data preparation, model configuration of YOLOv8 in the context of object detection on the Argoversehd dataset.1
The Argoverse dataset, which forms the basis of our object detection experiment using YOLOv8 models, consists of a total of 66,954 images. The dataset is divided into three subsets: training, validation, and testing, with 39,384, 12,507, and 15,063 images, respectively. The training and validation subsets contain annotations in the COCO format, while the testing subset lacks ground truth annotations. In the absence of annotations, we will utilize the trained YOLOv8 models to predict and detect objects within the test images.
The Argoverse dataset encompasses eight classes of objects, namely: "person," "bicycle," "car," "motorcycle," "bus," "truck," "traffic_light," and "stop_sign." These classes represent common objects typically found in agricultural contexts.
To prepare the dataset for YOLOv8, a specific directory structure is required.
root_data
├── train
│ ├── images
│ │ ├── image1.jpg
│ │ ├── image2.jpg
│ │ └── ...
│ └── labels
│ ├── image1.txt
│ ├── image2.txt
│ └── ...
├── val
│ ├── images
│ │ ├── image1.jpg
│ │ ├── image2.jpg
│ │ └── ...
│ └── labels
│ ├── image1.txt
│ ├── image2.txt
│ └── ...
└── test
└── images
├── image1.jpg
├── image2.jpg
└── ...To meet the YOLO format requirements, the annotations need to be converted from the COCO format to the YOLO format. Each linein the labels text file represents a single object annotation with its corresponding class ID, normalized coordinates, and dimensions.
class_id x_center y_center width height class_id x_center y_center width height class_id x_center y_center width height ...
Here is a sneak peek of the code used to convert the annotations to the YOLO format:
def convert_annotations_to_yolo_format(data, file_names, output_path):
def get_img(filename):
for img in data['images']:
if img['file_name'] == filename:
return img
def get_img_ann(image_id):
img_ann = []
isFound = False
for ann in data['annotations']:
if ann['image_id'] == image_id:
img_ann.append(ann)
isFound = True
if isFound:
return img_ann
else:
return None
count = 0
for filename in file_names:
# Extracting image
img = get_img(filename)
img_id = img['id']
img_w = img['width']
img_h = img['height']
# Get Annotations for this image
img_ann = get_img_ann(img_id)
fname = filename.split(".")[0]
if img_ann:
# Opening file for the current image
file_object = open(f"{output_path}/{fname}.txt", "a")
if img_ann is not None:
for ann in img_ann:
current_category = ann['category_id'] # As YOLO format labels start from 0
current_bbox = ann['bbox']
x = current_bbox[0]
y = current_bbox[1]
w = current_bbox[2]
h = current_bbox[3]
# Finding midpoints
x_centre = (x + (x+w))/2
y_centre = (y + (y+h))/2
# Normalization
x_centre = x_centre / img_w
y_centre = y_centre / img_h
w = w / img_w
h = h / img_h
# Limiting up to a fixed number of decimal places
x_centre = format(x_centre, '.6f')
y_centre = format(y_centre, '.6f')
w = format(w, '.6f')
h = format(h, '.6f')
# Writing the current object
file_object.write(f"{current_category} {x_centre} {y_centre} {w} {h}\n")
file_object.close()
count += 1After the conversion, the labels are saved as individual text files in the "labels" folder, corresponding to each image.
With the dataset now prepared in the YOLOv8 format, we can proceed to train and evaluate the YOLOv8s and YOLOv8m models on the Argoverse dataset.
In this section, we will explore the architecture of YOLOv8 and focus on one of its notable features: anchor-free detection. YOLOv8 is an evolution of the YOLO (You Only Look Once) family of models, designed for efficient and accurate object detection.
One significant update in YOLOv8 is its transition to anchor-free detection. Traditional object detection models often rely on predefined anchor boxes of different scales and aspect ratios to detect objects at various sizes. However, YOLOv8 takes a different approach by predicting the center of an object directly, rather than the offset from predefined anchor boxes.
This anchor-free approach brings several advantages. Firstly, it simplifies the model architecture by removing the need for anchor boxes and associated calculations. This leads to a more streamlined and efficient network. Additionally, anchor-free detection allows for better localization accuracy, as the model directly predicts the object center with high precision.

To visualize the YOLOv8 architecture and its anchor-free detection, we can refer to a detailed diagram created by GitHub user RangeKing (shown below). The diagram provides a comprehensive overview of the network's structure and the flow of information through different layers.

YOLOv8 Architecture, visualisation made by GitHub user Special thanks to RangeKing
By adopting anchor-free detection, YOLOv8 enhances object detection performance. In the following sections, we will evaluate the model's performance on the Argoversehd dataset and compare the results with the original dataset, highlighting the effectiveness of YOLOv8 for object detection tasks.
To train YOLOv8 on the Argoverse dataset, we need to create a data.yaml file and install the necessary dependencies. Here's a step-by-step guide to training YOLOv8 on the Argoverse dataset:
- Create the
data.yamlFile: Before training, we need to create adata.yamlfile to specify the dataset's configuration. The structure of thedata.yamlfile is as follows:
path: /your/root/path
train: root/train/images/
val: root/val/images/
nc: number_of_classes
names: [class1, class2, ..., classN]Ensure that you replace /your/root/path with the actual root path of your dataset, root/train/images/ with the path to the training images folder, root/val/images/ with the path to the validation images folder, number_of_classes with the total number of classes in your dataset, and [class1, class2, ..., classN] with a list of the class names in string format.
- Install Dependencies: Install the required dependencies by running the following command:
!pip install ultralytics- Import YOLO and Load the Model: Import the
YOLOclass from theultralyticspackage and load the YOLOv8 model using the desired.ptfile:
from ultralytics import YOLO
model = YOLO('yolov8s.pt')The YOLO class from ultralytics automatically downloads the required YOLOv8 models, such as yolov8s or yolov8m, based on the specified .pt file.
- Start Training: Begin the training process by calling the
trainmethod on themodelobject with appropriate arguments. Here's an example configuration:
output = model.train(
data='Argoverse.yaml',
imgsz=512,
epochs=10,
batch=8,
save=True,
name='yolov8m_custom',
val=True,
project='yolov8m_custom_Argoverse',
save_period=2
)In this example, we specify the data parameter as 'Argoverse.yaml' to use the created data.yaml file. Adjust the other parameters such as imgsz (image size), epochs (number of training epochs), batch (batch size), save (whether to save checkpoints), name (name for the trained model), val (whether to evaluate on the validation set), project (project name for logging), and save_period (number of epochs between saving checkpoints) according to your requirements.
- Monitor Training Progress: During training, the YOLO model will provide updates on the training loss, bounding box loss, mean Average Precision (mAP), etc.
For more detailed information and additional training options, refer to the YOLOv5 Train Mode Documentation provided by Ultralytics.
After training the YOLOv8 model on the Argoverse dataset, it's time to evaluate its performance on the test data. In this section, we will test the best trained YOLOv8s and YOLOv8m models on the test dataset.
Firstly, the test data for Argoverse consists of individual images. To provide a more comprehensive evaluation, I converted 2000 frames of the test data into a video at 24 frames per second (fps). This video allows for a sequential analysis of the model's object detection capabilities. Also predicted on whole test data.
Here's an example configaration :
model.predict('Yolov8/test_video.mp4', save=True, conf=0.5) # You Can also add path to your imagesBelow are the videos showcasing the testing results of the YOLOv8s and YOLOv8m models on the test data:
TEST Video for YOLOv8

YOLOv8s Predicted Video:
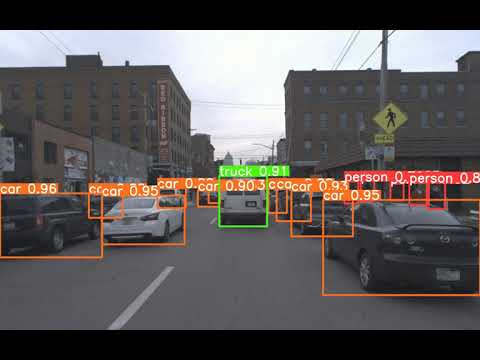
YOLOv8m Predicted Video:
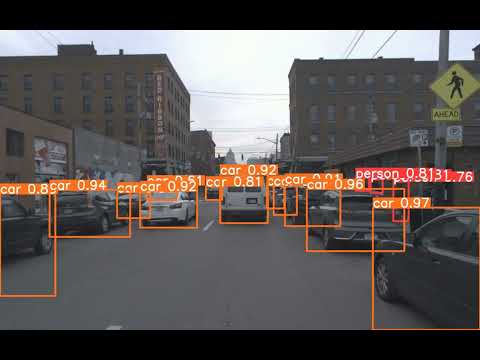
By visually examining the test videos, we can observe how the YOLOv8 models detect and classify objects in the Argoverse test dataset. The models' performance will be evident in their ability to accurately identify and localize objects of interest, such as people, bicycles, cars, motorcycles, buses, trucks, traffic lights, and stop signs.
The models will output bounding boxes around the detected objects, along with their corresponding class labels and confidence scores.
After testing the YOLOv8 models on the Argoversehd dataset and evaluating the results, it is important to conduct a thorough analysis to gain insights into the performance of the models. This analysis involves both visual inspection and the use of quantitative metrics to assess the models' effectiveness in object detection tasks.

Upon visually inspecting the test results, it becomes evident that the YOLOv8 models show promising performance in detecting and localizing objects. However, there are areas where the models exhibit limitations. For example, the models incorrectly identify certain objects as trucks and miss some instances of stop signs. These observations suggest that further improvements can be made by refining the training process and incorporating additional data.

The mean Average Precision (mAP) is a widely used metric for evaluating object detection models. The mAP measures the accuracy of object localization and classification. In the case of the YOLOv8 models trained on the Argoversehd dataset, the highest achieved mAP is 0.40, indicating good performance for certain instances. However, the average mAP typically falls within the range of 0.24 to 0.35. This implies that there is room for improvement in terms of the models' overall accuracy and precision.


A confusion matrix provides a detailed breakdown of the model's performance across different object classes. By analyzing the confusion matrix, we can identify specific areas where the YOLOv8 models excel and areas where they struggle. In the case of the Argoversehd dataset, the YOLO models face challenges in accurately detecting small objects and occasionally misclassifying certain objects. To address these limitations, it is advisable to consider strategies such as increasing the amount of training data and conducting further model optimization.

Based on the analysis of the test results, it is clear that there is room for improvement in the YOLOv8 models' performance on the Argoversehd dataset. By implementing different strategies and iteratively training and evaluating the YOLOv8 models, it is possible to improve their object detection accuracy and address the specific challenges observed during testing on the Argoversehd dataset.
Foot Note :
Footnotes
-
Beginner’s Work and Request for Understanding - Please note that this blog and the work presented herein are the efforts of a beginner in the field of image processing. While every attempt has been made to ensure accuracy and provide valuable insights, there may be certain limitations or areas for improvement. If any inconveniences or shortcomings are encountered, I kindly request your understanding and forgiveness. This blog serves as a starting point for exploring the fascinating world of Image processing and computer vision, and I am eager to learn and grow from this experience. Your feedback and suggestions are greatly appreciated as they will contribute to my growth as a learner and researcher. Thank you for your support and understanding. ↩