Created/maintained by Gerlof Langeveld [email protected]

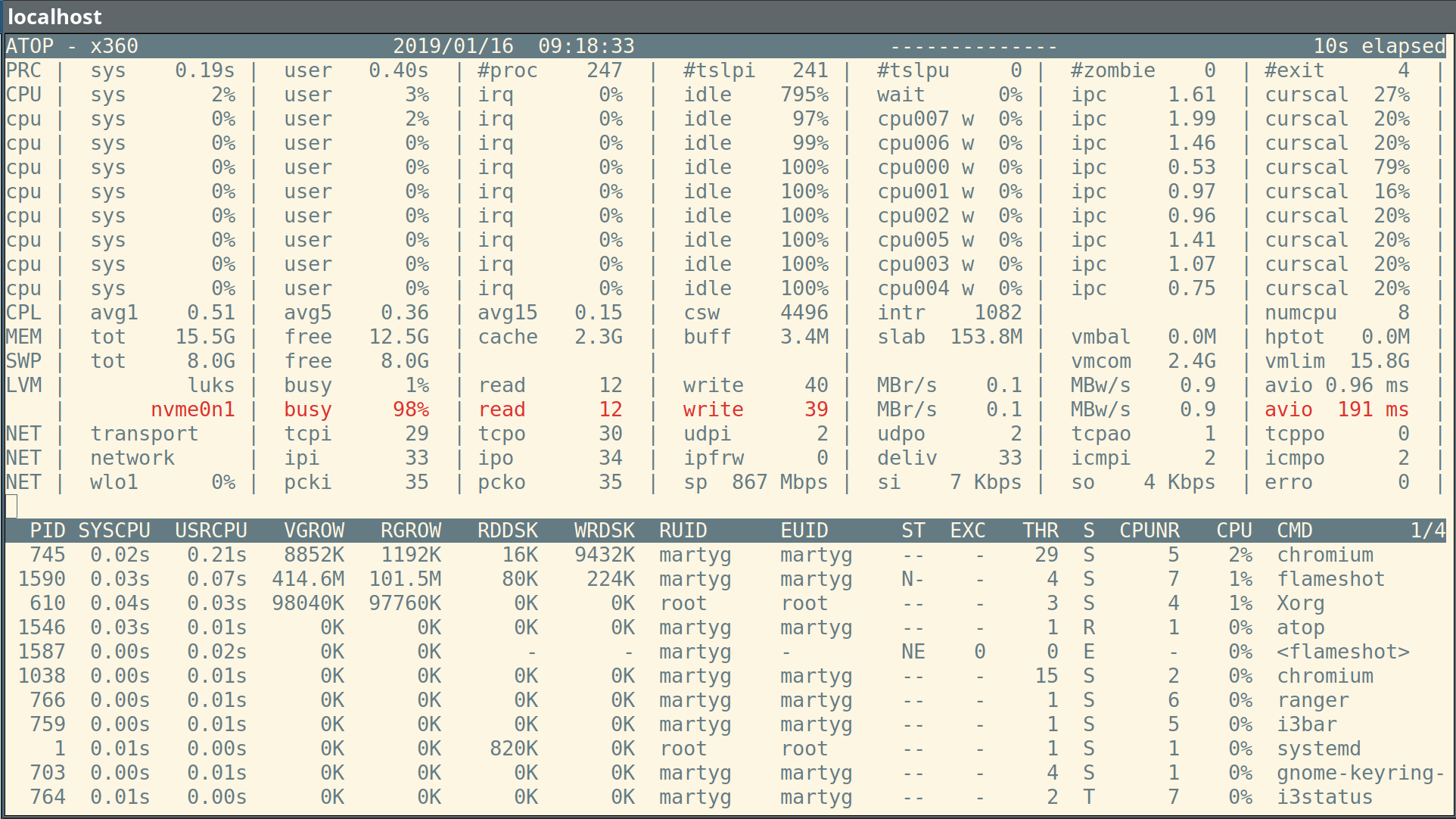
Atop is an ASCII full-screen performance monitor for Linux that is capable of reporting the activity of all processes (even if processes have finished during the interval), daily logging of system and process activity for long-term analysis, highlighting overloaded system resources by using colors, etcetera. At regular intervals, it shows system-level activity related to the CPU, memory, swap, disks (including LVM) and network layers, and for every process (and thread) it shows e.g. the CPU utilization, memory growth, disk utilization, priority, username, state, and exit code. In combination with the optional kernel module netatop, it even shows network activity per process/thread. In combination with the optional daemon atopgpud, it also shows GPU activity on system level and process level. Furthermore cgroup-level resource consumption can be shown, optionally with the processes contained by these cgroups.
The command atop has some major advantages compared to other performance monitoring tools:
-
Text mode for details and bar graph mode for global overview. In text mode details are shown about the utilization of system resources and the resource consumption by processes. In bar graph mode a (character-based) graphical overview is given about the utilization of the processors, disks, network interfaces and memory on system level.
-
Cgroups overview. In text mode the cgroups hierarchy can be shown with the utilization of CPU, memory and disk resources and the processes contained by these cgroups.
-
Resource consumption by all processes. It shows the resource consumption by all processes that were active during the interval, so also the resource consumption by those processes that have finished during the interval.
-
Utilization of all relevant resources. Obviously it shows system-level counters concerning utilization of cpu and memory/swap, however it also shows disk I/O and network utilization counters on system level.
-
Permanent logging of resource utilization. It is able to store raw counters in a file for long-term analysis on system level and process level. These raw counters are compressed at the moment of writing to minimize disk space usage. By default, the daily logfiles are preserved for 28 days. System activity reports can be generated from a logfile by using the atopsar command.
-
Highlight critical resources. It highlights resources that have (almost) reached a critical load by using colors for the system statistics.
-
Scalable window width. It is able to add or remove columns dynamically at the moment that you enlarge or shrink the width of your window.
-
Resource consumption by individual threads. It is able to show the resource consumption for each thread within a process.
-
Watch activity only. By default, it only shows system resources and processes that were really active during the last interval, so output related to resources or processes that were completely passive during the interval is by default suppressed.
-
Watch deviations only. For the active system resources and processes, only the load during the last interval is shown (not the accumulated utilization since system boot or process startup).
-
Accumulated process activity per user. For each interval, it is able to accumulate the resource consumption for all processes per user.
-
Accumulated process activity per program. For each interval, it is able to accumulate the resource consumption for all processes with the same name.
-
Accumulated process activity per container. For each interval, it is able to accumulate the resource consumption for all processes within the same container.
-
Network activity per process. In combination with the optional kernel module netatop or the BPF module netatop-bpf, it shows process-level counters concerning the number of TCP and UDP packets transferred, and the consumed network bandwidth per process.
-
GPU activity on system level and per process. In combination with the optional daemon atopgpud, it shows system-level and process-level counters concerning the load and memory utilization per GPU.
- A BPF implementation to gather network statistics per process/thread (alternative for the 'netatop' kernel module)
- A Web interface for atop
- Graphical representation of system resource utilization