-
CNN의 깊이에 중점을 둠. 이를 위해 다른 파라미터들을 고정하고 3x3 필터로 합성곱층을 추가해 모델의 깊이를 획기적으로 늘렸다.
=> sota 달성 및 다양한 데이터셋에 적용가능한 성능 좋은 모델
- 훈련셋의 각 픽셀에서 평균 RGB값을 뺀 전처리를 한 224x224x3 RGB 이미지 사용
- 전처리된 이미지들은 3x3크기의 필터가 있는 합성곱층을 지난다. 스트라이드는 1 / 비선형성을 위해 1x1 필터도 적용함
- 공간해상도… 이미지의 공간적 정보를 보존하기 위해 = 이미지 크기 유지를 위해 3x3 합성곱층에 대해 1픽셀에 패딩 적용
- 풀링은 맥스풀링으로 2x2필터에 스트라이드2
- 합성곱층을 거치고 나서 노드 4096개의 완전연결층 2개 거치고 마지막 출력층에는 클래스 개수인 1000개에 소프트맥스 사용
- 활성화 함수로는 ReLU사용
- 여기에선 LRN (Local Response Normalisation) 안씀 ← 성능 향상도 없고 자원 소모만 늘어남.
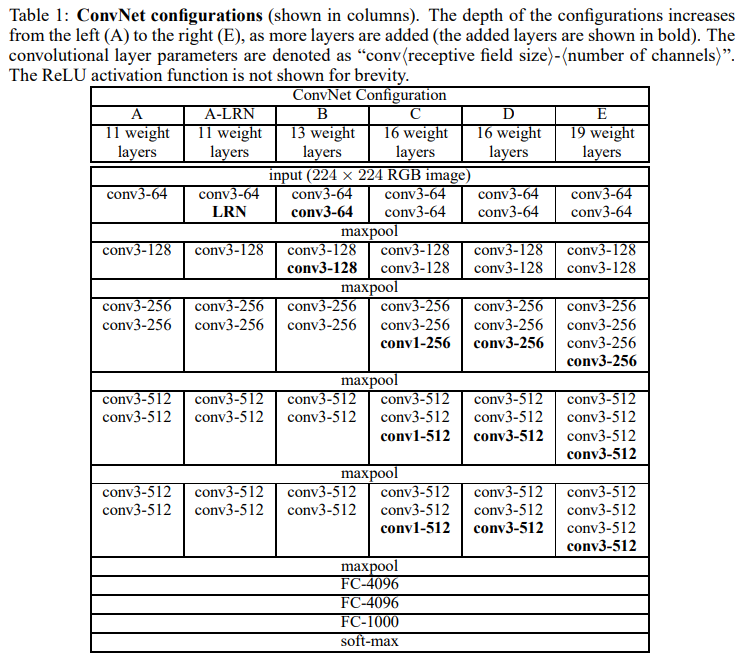

-
VGGNet을 여러 케이스로 나누어 나타낸 구조도. 이거 하나만 보고 구현이 가능할 정도로 VGG를 잘 나타낸 구조도이다.
-
풀링을 거친다음엔 채널을 2배로 증가시켜 64에서 512까지 늘림
-
이전의 알렉스넷 처럼 다른 모델들이 11x11 크기 필터에 스트라이드 4 합성곱층을 쓰거나 7x7 필터에 스트라이드 2 합성곱층을 쓴것과 달리 VGGNet은 모든 층에서 3x3 필터만 사용한다.
-
왜 작은 필터사이즈가 더 좋은가??
-
비선형성의 증가. 층을 더 깊게 쌓으면 그만큼 활성화 함수를 더 많이 거치게 되면서 비선형성을 증가시킬 수 있고, 따라서 비선형적인 문제를 해결하는데 더 좋은 효과를 얻을 수 있다
-
파라미터의 개수가 더 적으므로 연산 효율이 더 좋음.
파라미터 개수는 5x5 합성곱층 하나보단 3x3 합성곱층 두개가 더 적다. 3x3 두개가 5x5 하나보다 연산량, 가중치 개수가 더 적으므로 더 깊게 쌓을 수 있다 이렇게 7x7 필터대신 3x3 필터를 사용함으로써 파라미터의 개수를 줄이는 것은 일종의 규제를 하는 것으로도 간주할 수 있다 ⇒ ’This can be seen as imposing a regularisation on the 7x7 conv.filters'
아래 글이 해당 내용을 설명해줌

3 x 3 필터 2개 = 5 x 5 필터 1개
3 x 3 필터 3개 = 7 x 7 필터 1개
3 x 3 필터를 여러 개 사용해서 얻는 이점은?
⇒ decision function 성능이 더 향상되며, 파라미터 개수를 줄일 수 있다는 것. ⇒ 파라미터가 적다 = 연산량이 줄어든다 = 계산이 빨라진다모델이 C개의 채널을 가진다면 3x3 필터 3개 사용시 3 * ( 3² C² ) = 27C²
7x7 필터 1개 사용시 1 * ( 7² C² ) = 49C² 이다. 즉 3 * 3 필터 3개 사용시 parameter 개수를 81%가량 줄일수 있다.

++ 1x1 크기 필터도 사용. -> 원문 읽어보면 비선형성을 추가하기 위해 사용했다고 서술함. 입출력 채널을 동일하게 하고 1x1 필터를 사용함으로서 이미지의 크기는 그대로 유지하되 활성화 함수를 거치게 하여 추가적인 비선형성을 가지게 한다
레이어가 적을때, 그러니까 모델의 깊이가 얇으면(shallow) 근사가 잘 안됨. 비선형성 함수를 늘리면 더 고차원적인 함수를 더 잘 근사한다. => 따라서 비선형성의 증가는 문제 해결에 도움이 된다.
-
훈련과정은 이미지 크롭(sampling the input crops from multi-scale training image)을 제외하고는 알렉스넷과 동일하게 진행된다.
momentum이 있는 mini-batch gradient descent 사용
- batch size = 256
- momentum = 0.9
- weight decay = 0.0005 (L2) - 레이어? 옵티마이저??
- drop out = 0.5 (Dense층1,2에서 사용)
- epoch = 74
- learning rate = 0.01(0.1배씩 감소)
VGGNet이 알렉스넷보다 더 깊고 파라미터가 많으면서도 수렴하는데 더 적은 에폭이 걸린 이유로 논문의 저자는 두가지 추축을 언급함
-
implicit regularisation imposed by greater depth and smaller conv.
| “This can be seen as imposing a regularisation on the 7x7 conv”
=> 학습되는 파라미터 개수를 줄이는 것도 규제의 방법이다. (=dropout). 7x7 conv 하나 대신 3x3 conv 2개 쓰는 것이 파라미터 수가 더 적으므로 일종의 규제로 볼 수도 있다.
-
pre-initialisation of certain layers
Weights Initialisation, 모델의 가중치 초기화는 중요하다. 어떻게 초기화시키느냐에 따라 성능이 달라짐.
여기선 모델 A(랜덤 초기화를 쓰기에 충분히 얇은 모델)를 학습시키고 더 깊은 모델 학습시 맨 처음 합성곱층 4개, 맨 뒤의 완전연결층 3개를 모델 A로 학습된 레이어를 가져와서 사용한다
그 사이의 레이어들은 랜덤으로 초기화한다
-
S = the smallest side of an isotropically-rescaled training image
고정된 사이즈 224x224 이미지를 얻기 위해 rescaled된 이미지를 랜덤으로 크롭함.
추가적인 augmenation을 위해 크롭된 이미지를 랜덤으로 수평 뒤집기, 랜덤으로 RGB값 변경을 적용함
⇒ 순서대로 정리해보자면
- 이미지 rescale
- random crop
- random horizontal flip, random RGB colour shift
-
S는 가로세로비가 유지되며 스케일이 조정된 이미지의 가장 작은 면.
isotropically-rescaled training image에서 224x224 크기로 랜덤크롭한다
S = training scale, S값을 설정하는 두가지 방식이 있다
- single-scale training : S를 256, 384로 고정시켜 사용하는 방식. 먼저 S=256으로 학습시킨 후, S=256으로 사전학습된 웨이트로 초기화하여 S=384를 학습시킨다. 그리고 초기 학습률을 0.001로 줄여준다.
- multi-scale training : S를 256~512 범위 내 랜덤값으로 사용하는 방식 이렇게 스케일을 다양하게 줌으로써 이미지 내 오브젝트가 다양한 사이즈가 되기 때문에 훈련에 유익하다 이런 data augmentation 방식을 scale jittering라고도 한다 = training set augmentation by scale jittering
=> 속도 때문에 multi-scale 모델들은 같은 구조의 S=384로 single-scale 모델의 가중치를 초기 가중치로 사용해 fine-tune으로 학습시켰다.
# 결과로 크롭,플립,RGB변형된 3장의 이미지를 출력
def single_scale_preprocessing(img, label):
scale=256
resized_img = tf.image.resize(img, [scale,scale])
cropped_img = tf.image.random_crop(resized_img, [224,224,3])
flipped_img = tf.image.random_flip_left_right(cropped_img,5)
shift_img = tf.image.random_hue(cropped_img, 0.5)
aug_img = [cropped_img, flipped_img, shift_img]
labels = [label, label, label]
aug_img = np.array(aug_img)/255
labels = np.array(labels)
return aug_img, labels
-
훈련뿐 아니라 테스트 시에도 rescaling을 한다. 훈련시 rescaling의 기준값을 S라 했다면 테스트시엔 Q라고 부른다. S와 Q는 같은 개념이고 훈련이냐 테스트냐만 구분하면 된다.
-
Single scale의 경우 하나의 사이즈로 고정하여 테스트 이미지들을 rescale함. S와 Q가 꼭 같을 필요는 x. 각각 S마다 다른 Q를 적용시 향상된 성능을 얻었다고함
-
Multi-scale의 경우 Test시 훈련에 사용되던 첫번째 Dense층을 7x7 합성곱층으로, 마지막 두 Dense층을 1x1 합성곱층으로 바꿈…. 왜? 이걸 통해서 whole(uncropped) 이미지에 적용시킬수 있다…? ????
⇒ 아아 원래 VGG에서 맨 마지막 층 3개는 Dense, FC layer로 되어있는데 [ 7x7 conv - 1x1 conv - 1x1 conv ] 인걸 보니 Flatten없이 7x7 conv에서 피쳐맵을 1x1로 압축하겠다는 얘기같은데 그럼 이미지 사이즈가 필터와 같은 크기인 7x7이 되게끔 해야할텐데 이게 whole(uncropped) 이미지에 적용이 가능한가…? shape를 어떻게 맞춘거지??
⇒ 224→112→56→28→14→7, 처음 224x224 크기의 이미지는 5번의 풀링을 거쳐 7x7 피쳐맵이 나온다. 여기에 같은 크기의 필터사이즈가 있는 합성곱층을 거치면 벡터와 같은 형태로 나온다 ( 1x1크기로 나와서 벡터는 아니겠지만). 근데 이게 적용되는 경우는 224x224 이미지가 들어온다는 전제하일 텐데.
-
신경망이 conv로만 구성되면 입력 이미지의 크기 제약이 없어진다라… => FCN의 개념을 생각하면 된다.
-
고정된 크기의 class score에 대한 벡터를 얻기 위해 결과물인 class score map은 spatially averaged(sum-pooled)되었다 + 좌우반전으로 테스트셋 이미지 증강도 함
-
합성곱층으로만 이루어진 모델이기때문에(=fully-convolutional network) 테스트시 multiple crops 할 필요가 없다. = 각 크롭을 위해 네트워크 재연산을 필요하기에 덜 효율적이기 때문
-
동시에 large set of crops를 사용하는것은 정확도 향상으로 이어질 수도 있다
-
dense evaluation, multi-crop evaluation, 둘을 섞어서 검증하는 등 여러 검증 방법에 대해 서술하고 있음
-
Multi-GPU training. 배치단위로 GPU에 들어가서 병렬적으로 처리되고 GPU 배치 기울기 계산후에 평균내어 전체 배치에 대한 기울기를 구한다
-
기울기 계산은 GPU들에 걸쳐 동시에 일어나므로 단일 GPU를 훈련시킬 때와 같은 결과가 나온다
⇒ 여러개의 GPU를 사용함으로써 계산에 걸리는 시간을 단축시킴. 단일 GPU 걸리는 시간에서 3.75배 더 빨라짐
- Dataset : ILSVRC-2012 dataset. 1000개의 클래스, 1.3M 훈련셋, 50K 검증셋, 100K 라벨 없는 테스트셋
- 평가 성능 지표는 top-1, top-5 error

-
테스트셋을 단일 이미지 크기로 검증함.
-
위에서 언급한 것처럼 LRN은 큰 효과가 없기에 B-E, 깊은 모델에선 사용하지 않는다
-
모델의 깊이가 증가할수록 에러가 감소하는 것을 확인함. 11층인 A모델부터 19층인 E모델까지.
-
C와 D모델의 차이는 이렇게 중간 합성곱층의 필터 사이즈가 다름. 하지만 같은 깊이에도 3x3 필터를 쓴 D모델이 성능이 더 좋았다
⇒ 모델 B와 모델 C를 비교했을때 1x1 합성곱층을 통해 비선형성을 추가해주는 것은 효과가 있지만 / 합성곱층을 통해 공간적 정보를 추출하는 것 또한 중요하다. 그런면에서 D가 C보다 더 좋음
= 1x1 필터를 사용하면 비선형성을 더 잘 표현할 수 있게 되지만 3x3 필터가 공간-위치 정보의 특징을 더 잘 추출하기 때문에 3x3 필터를 사용하는 것이 좋다
-
B의 형태에서 필터사이즈만 5x5로 바꿔서 만든 shallow net과 B를 비교, top-1 error에서 shallow net이 B보다 7% 더 높았다.
⇒ 둘의 성능 비교를 통해 깊은 모델에서 큰 필터보단 작은 필터가 더 좋은 성능을 냄을 확인함
-
훈련시 scale jittering(256~512 사이 랜덤 스케일 지정)은 고정된 스케일(S=256, S=384)보다 더 좋은 결과를 냈다
⇒ 일종의 노이즈 추가로 모델을 강건하게 만들어 과적합을 방지하고 성능을 향상시킨 것으로 보임

- 테스트셋으로 다양한 이미지 크기를 적용해 검증
- 학습시 scale jittering이 효과가 있었음을 확인, 테스트에도 효과가 있을지 확인해보려함
- 훈련셋과 테스트셋의 큰 스케일 차이는 성능을 떨어뜨릴 수 있다
- 고정된 S로 훈련된 모델은 테스트셋 스케일을 3가지로 지정한다, ( S-32, S, S+32 )
- 훈련시 S를 범위로 주어 훈련한 모델은 다음과 같이 지정한다. ( Smin, 0.5*(Smin + Smax), Smax )

- 여러개의 모델의 확률값들을 평균내어 앙상블.
- 모델 7개를 앙상블하거나 multi-scale 모델중 성능이 가장 좋은 2개를 앙상블하는 등 여러 모델 조합을 통해 앙상블함
- 모델의 레이어가 깊어질수록 발생하는 문제, 오버핏에 대해 간단하면서도 효과적인 방법을 사용하여 성능을 획기적으로 올린 VGGNet.
- 3x3 필터의 Conv, 더 깊은 레이어, 입력 이미지 사이즈에 대한 다양한 시도, 앙상블 등을 통한 sota 달성
- 알렉스넷과 함께 딥러닝의 초창기 모델로, 인공지능을 공부한다면 누구나 한번쯤은 들어보고 알만한 모델이다.
- 논문에서 제시한 방법들을 왜 사용했는지에 대해 살펴보면 좋은 인사이트들을 얻을 수 있다.
- 오래되고 간단한 모델이지만 딥러닝을 공부한다면 한번쯤은 꼭 공부하고 구현해보는 것이 도움이 될 것이다.
