Just a simple repo to collect high performance cuda kernel.
关于CUDA Reduce优化其实已经有很多经典的博客了,比如willzhang的这篇:
https://zhuanlan.zhihu.com/p/416959273
这里主要挑几个点讲下:
CUDA访问global memory是要让一个warp访问的尽可能连续,这里摘一下英伟达的PPT:

而对于实际访问,如果一个线程要访问多个元素,则需要跳blockDim.x*gridDim.x来访问

考虑到CUDA支持load128bit,我们也可以用向量化去访问,进一步提升带宽,减少指令数量,这部分在 packed_reduce.cu 里面也有体现:
using LoadType = PackType<float, 4>;
for(int32_t linear_index = global_idx * kVecSize; linear_index < elem_cnt; linear_index+=step*kVecSize){
const LoadType* x_load = reinterpret_cast<const LoadType*>(x + linear_index);
load_pack.storage = *x_load;
...他等价于:

注意的是,这里实际发生访存是转成float4类型指针后才取的值,并且此时是跨 blockDim.x * gridDim.x * 4 来取值,此时访存是连续的。
而如果是float指针,一个个取,取满4个,则实际发生访存的还是float指针,也就造成前面说的访存不连续,注意区别!

累加完Pack,再进入到下一个BlockReduce之前,我们需要对这个Pack先reduce,方法也很简单,就是一个展开的for循环:
template<typename T, int pack_size>
__device__ T PackReduce(Pack<T, pack_size> pack){
T res = 0.0;
#pragma unroll
for(int i = 0; i < pack_size; i++){
res += pack.elem[i];
}
return res;
}PS:我这里情况考虑的没那么复杂,但是涉及到累加这些操作的话,如果在fp16情况下,我更建议模板类型传入一个ComputeType,设置成fp32来做累加,避免溢出
willzhang博客其实是开辟了一片shared_memory来作为block中间存储,但其实我觉得blockreduce完全是够用了,在介绍BlockReduce之前,先介绍WarpReduce
CUDA执行单位还是warp,每32个线程构成一个warp。而CUDA自身也提供了一些线程束原语,我们可以借助他们来做warp级别的reduce
具体可参考NV官方的这篇博客:https://zhuanlan.zhihu.com/p/522714729
我们这里使用的是shfl_down_sync来做reduce,示意图如下:
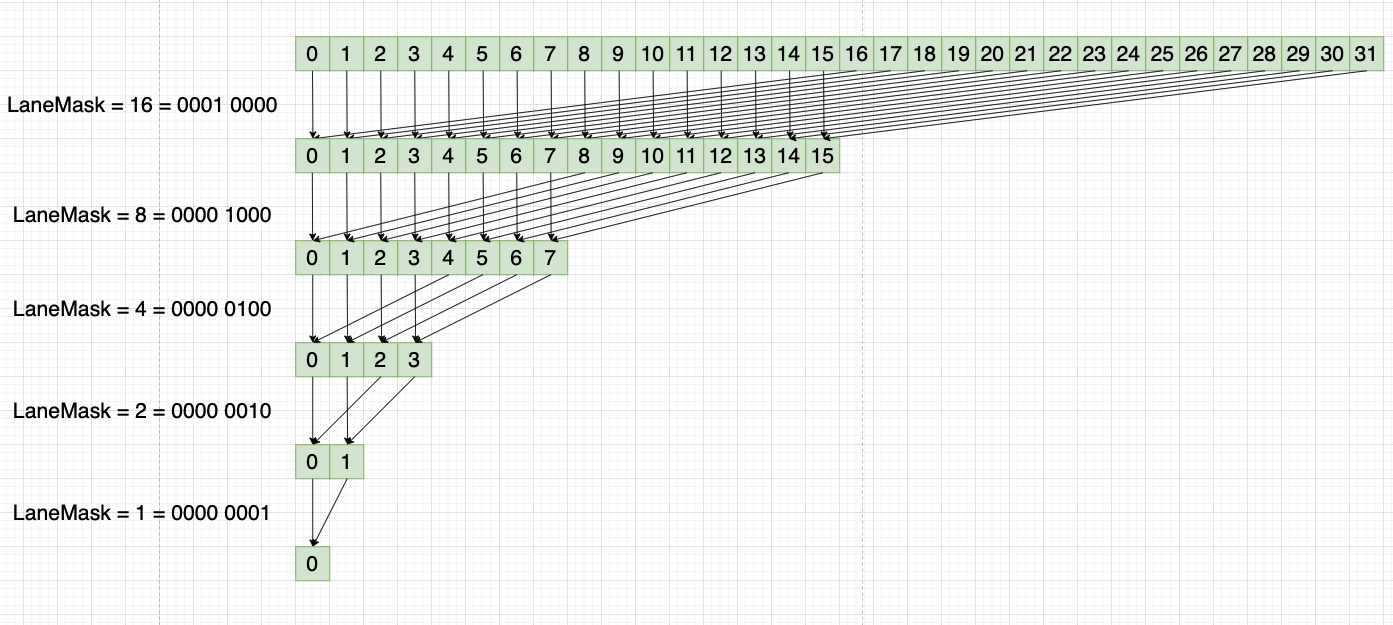
需要注意的是,最后只有线程0才是最终正确的reduce结果
这里参考的是Pytorch的BlockReduce实现
首先有个前提,BlockReduce借助warpreduce来做,因此blocksize必须是warp的整数倍
- 我们先让所有线程执行warpreduce
- 然后将每个线程束的reduce结果存储到shared memory中,注意这里是lane_id=0的线程去存储,因为前面我们提到了只有线程0上有正确的reduce结果
- 从shared memory把数据读取出来,最后再用一个warp对其做reduce,即可获得整个block的reduce结果
采取blockreduce后,每个block都有部分和,而如果要最终累加到一个标量里,那么其实有两种思路:
- 用atomicAdd累加,但是看李少侠的说法其实会有精度问题
global memory的atomicAdd和标准的浮点加法不等价,atomicAdd对denormalized float是round to zero的,理论上两者精度不一样
- 启动两次Kernel,第一次Kernel reduce得到block个部分和结果。然后再启动一个只有1个block的kernel,做最终的求和
合并访存
学习CUDA的人肯定会经常听到这个词,这篇就想简单谈下访存的几个点

CUDA在Global Memory上访问粒度是32B,而每32B组成一个sector,一个cacheline则对应4个sector,总共大小为128B
而CUDA执行指令的单位是线程束,当发生一次访存的时候,其实是该线程束的所有线程执行访存操作。每个线程访存粒度可以是1B,2B,4B,8B,16B。下图表示的是每个线程访问了4B,一共访问了128B,即4个sector

可以看到最大访问粒度是16B=128bit,其实对应的指令就是ldg128,这也是向量化的基础。比如float类型,则可以用向量化的方式,以float4的格式一次性读4个float,减少指令数量,提高带宽
即一个线程束内的每个线程之间访问的地址需要是连续的,如上图所示
而不合并访存则是每个线程之间访问的地址是不连续的。比如我一个线程束访问第0,32,64...1024这32个位置的float数据,那么一共访问了32*4B = 128B 的数据。但实际上,第0号线程为了访问第0个位置元素,则会启动一次内存事务,大小为32B。第1号线程访问第32个位置元素,由于该位置不在上一次内存事务覆盖的范围内,所以又要启动一次内存事务。
这样一共启动了32次内存事务,32x32B = 1024B,实际只访问了128B数据。带宽利用率则为 128 / 1024 = 12.5%

由于基础不牢固,以前犯过这个错误,自己纠结了半天后面才想通。
现在假设我们只有一个线程束(32个线程)要访问64个元素。
如果你不用向量化,每个线程跨gridDim.x * blockDim.x来循环读取

向量化的做法是每个线程用float2这个格式去访问,一次访问4B*2的数据,此时访存也是合并的。
错误的做法则是一个线程访问连续的两个float,这会导致访存不连续。
对应代码为:
__global__ void AccessKernel(float* in, float* out, int64_t elem_cnt){
const int32_t idx = threadIdx.x;
out[idx*2] = in[idx*2];
out[idx*2+1] = in[idx*2+1];
}下面简单解释一下
在thread0访问第0号元素的时候,就发生了内存事务了,前面提到过内存事务大小是32B,这里float类型对应4个float。

那么可以看到一次内存事务包含的元素,其实只有thread0, thread1用到了。也就是说有一半都浪费了。
我们计算下,一共64个float元素,只需要256B。而经过我们这么一浪费,实际上要花费512B的内存事务才能做到:

更多关于向量化的使用,我建议可以参考OneFlow的Elementwise模板,相关博客:https://zhuanlan.zhihu.com/p/447577193





