A lightweight tool to gather current and historic Google analytics codes for OSINT investigations.
·
Report Bug
·
Request Feature
Table of Contents
Wayback Google Analytics is a lightweight tool that gathers current and historic Google analytics data (UA, GA and GTM codes) from a collection of website urls.
Read Bellingcat's article about using this tool to uncover disinformation networks online here.
Google Analytics codes are a useful data point when examining relationships between websites. If two seemingly disparate websites share the same UA, GA or GTM code then there is a good chance that they are managed by the same individual or group. This useful breadcrumb has been used by researchers and journalists in OSINT investigations regularly over the last decade, but a recent change in how Google handles its analytics codes threatens to limit its effectiveness. Google began phasing out UA codes as part of its Google Analytics 4 upgrade in July 2023, making it significantly more challenging to use this breadcrumb during investigations.
Luckily, the Internet Archive's Wayback Machine contains useful snapshots of websites containing their historic GA IDs. While you could feasibly check each snapshot manually, this tool automates that process with the Wayback Machines CDX API to simplify and speed up the process. Enter a list of urls and a time frame (along with extra, optional parameters) to collect current and historic GA, UA and GTM codes and return them in a format you choose (json, txt, xlsx or csv).
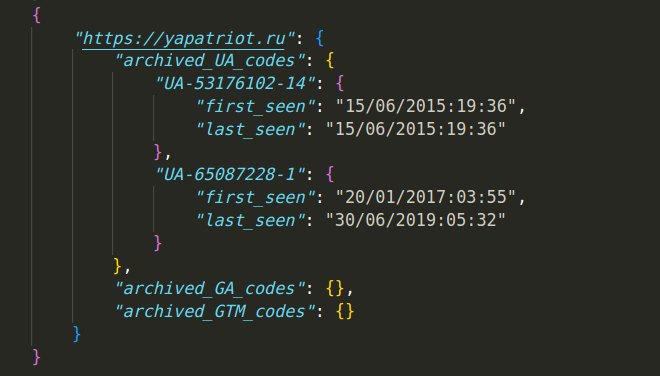
The raw json output for each provided url looks something like this:
"someurl.com": {
"current_UA_code": "UA-12345678-1",
"current_GA_code": "G-1234567890",
"current_GTM_code": "GTM-12345678",
"archived_UA_codes": {
"UA-12345678-1": {
"first_seen": "01/01/2019(12:30)",
"last_seen": "03/10/2020(00:00)",
},
},
"archived_GA_codes": {
"G-1234567890": {
"first_seen": "01/01/2019(12:30)",
"last_seen": "01/01/2019(12:30)",
}
},
"archived_GTM_codes": {
"GTM-12345678": {
"first_seen": "01/01/2019(12:30)",
"last_seen": "01/01/2019(12:30)",
},
},
}-
For more info about analytics codes and what the GA-4 rollout means for OSINT: https://digitalinvestigations.substack.com/p/what-the-rollout-of-google-analytics
-
For an example investigation usings analytics codes: https://www.bellingcat.com/resources/how-tos/2015/07/23/unveiling-hidden-connections-with-google-analytics-ids/
Additional libraries/tools: BeautifulSoup4, Asyncio, Aiohttp
Install from pypi (with pip)

The easiest way to to install Wayback Google Analytics is from the command line with pip.
- Open a terminal window and navigate to your chosen directory.
- Create a virtual environment and activate it (optional, but recommended; if you use Poetry or pipenv those package managers do it for you)
python3 -m venv venv source venv/bin/activate - Install the project with pip
pip install wayback-google-analytics - Get a high-level overview
wayback-google-analytics -h
You can also clone and download the repo from github and use the tool locally.
-
Clone repo:
git clone [email protected]:bellingcat/wayback-google-analytics.git -
Navigate to root, create a venv and install requirements.txt:
cd wayback-google-analytics python -m venv venv source venv/bin/activate pip install -r requirements.txt -
Get a high-level overview:
python -m wayback_google_analytics.main -h
-
Enter a list of urls manually through the command line using
--urls(-u) or from a given file using--input_file(-i). -
Specify your output format (.csv, .txt, .xlsx or .csv) using
--output(-o). -
Add any of the following options:
Options list (run wayback-google-analytics -h to see in terminal):
options:
-h, --help show this help message and exit
-i INPUT_FILE, --input_file INPUT_FILE
Enter a file path to a list of urls in a readable file type
(e.g. .txt, .csv, .md)
-u URLS [URLS ...], --urls URLS [URLS ...]
Enter a list of urls separated by spaces to get their UA/GA
codes (e.g. --urls https://www.google.com
https://www.facebook.com)
-o {csv,txt,json,xlsx}, --output {csv,txt,json,xlsx}
Enter an output type to write results to file. Defaults to
json.
-s START_DATE, --start_date START_DATE
Start date for time range (dd/mm/YYYY:HH:MM) Defaults to
01/10/2012:00:00, when UA codes were adopted.
-e END_DATE, --end_date END_DATE
End date for time range (dd/mm/YYYY:HH:MM). Defaults to None.
-f {yearly,monthly,daily,hourly}, --frequency {yearly,monthly,daily,hourly}
Can limit snapshots to remove duplicates (1 per hr, day, month,
etc). Defaults to None.
-l LIMIT, --limit LIMIT
Limits number of snapshots returned. Defaults to -100 (most
recent 100 snapshots).
-sc, --skip_current Add this flag to skip current UA/GA codes when getting archived
codes.
Examples:
To get current codes for two websites and archived codes between Oct 1, 2012 and Oct 25, 2012:
wayback-google-analytics --urls https://someurl.com https://otherurl.org --output json --start_date 01/10/2012 --end_date 25/10/2012 --frequency hourly
To get current codes for a list of websites (from a file) from January 1, 2012 to the present day, checking for snapshots monthly and returning it as an excel spreadsheet:
wayback-google-analytics --input_file path/to/file.txt --output xlsx --start_date 01/01/2012
To check a single website for its current codes plus codes from the last 2,000 archive.org snapshots:
wayback-google-analytics --urls https://someurl.com --limit -2000
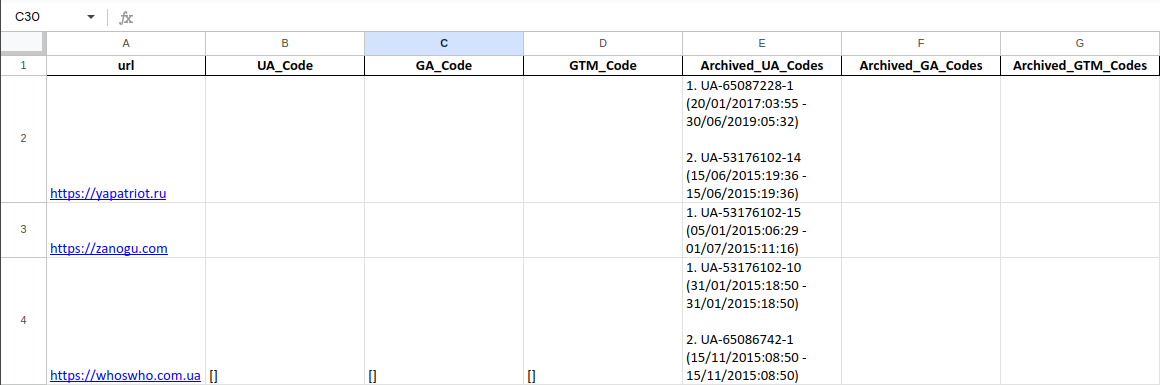
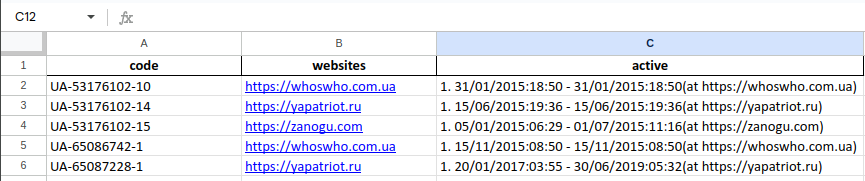
Wayback Google Analytics allows you to export your findings to either .csv or .xlsx spreadsheets. When choosing to save your findings as a spreadsheet, the tool generates two databases: one where each url is the primary index and another where each identified code is the primary index. In an .xlsx file this is one spreadsheet with two sheets, while the .csv option generates one file sorted by codes and another sorted by websites. All output files can be found in /output, which is created in the directory from which the code is executed.
Let's say we're looking into data from 4 websites from 2015 until present and we want to save what we find in an excel spreadsheet. Our start command looks something like this:
wayback-google-analytics -u https://yapatriot.ru https://zanogu.com https://whoswho.com.ua https://adamants.ru -s 01/01/2015 -f yearly -o xlsx
The result is a single .xlsx file with two sheets.
Ordered by website:
Ordered by code:
We recommend that you limit your list of urls to ~10 and your max snapshot limit to <500 during queries. While Wayback Google Analytics doesn't have any hardcoded limitations in regards to how many urls or snapshots you can request, large queries can cause 443 errors (rate limiting). Being rate limited can result in a temporary 5-10 minute ban from web.archive.org and the CDX api.
The app currently uses asyncio.Semaphore() along with delays between requests, but large queries or operations that take a long time can still result in a 443. Use your judgment and break large queries into smaller, more manageable pieces if you find yourself getting rate limited.
Please feel free to open an issue should you encounter any bugs or have suggestions for new features or improvements. You can also reach out to me directly with suggestions or thoughts.
- Run tests with
python -m unittest discover - Check coverage with
coverage run -m unittest
Wayback Google Analytics uses Poetry, a Python dependency management and packaging tool. A GitHub workflow automates the tests on PRs and to main (see our workflow here), be sure to update the semantic version number in pyproject.toml when opening a PR.
If you have push access, follow these steps to trigger the GitHub workflow that will build and release a new version to PyPI :
- Change the version number in pyproject.toml
- Create a new tag for that version
git tag "vX.0.0" - Push the tag
git push --tags
Distributed under the MIT License. See LICENSE.txt for more information.
You can contact me through email or social media.
- email: jclarksummit at gmail dot com
- Twitter/X: @JustinClarkJO
- Linkedin: Justin Clark
Project Link: https://github.com/bellingcat/wayback-google-analytics
- Bellingcat for hosting this project
- Miguel Ramalho for constant support, thoughtful code reviews and suggesting the original idea for this project








































































































