一个基于cnn+adjacent feature结构、使用tensorflow实现的情感分析模型。基于卷积神经网络(CNN)的方法在情感分类任务中已经取得了不错的效果,此类模型使用词向量作为网络的输入,但是在卷积过程中每个词向量只能表征单个单词,并不蕴含上下文信息,这不利于信息传递的连续性,并且卷积操作在局部范围内可能会打乱词向量的序列性。本项目中提出的临近特征(Adjacent Feature)很好的解决了这个问题,该机制可同时考虑到前后词语的语义,并一同代入下一轮卷积计算中。
在卷积过程中,对于某个词语





假设输入层句子





其中






其中,运算符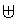
,向量



目录TF_WORD2VEC_CNN_C2是2分类模型,TF_WORD2VEC_CNN_C3是3分类模型,其中均包含get_corpus_info.py(获取预料基本信息)、data_helper.py(数据预处理)、cnn_model.py(模型结构)、train_dev_test.py(训练、验证、测试)文件,以TF_WORD2VEC_CNN_C3中该文件为例,可配置参数在train_dev_test.py文件顶部:
## 配置说明
# Data path and parameter
# 负面语料文件路径
tf.flags.DEFINE_string("positive_data_file", "./data/1.txt", "Data source for the positive data.")
# 中性语料文件路径
tf.flags.DEFINE_string("neutral_data_file", "./data/0.txt", "Data source for the neutral data.")
# 正面语料文件路径
tf.flags.DEFINE_string("negtive_data_file", "./data/-1.txt", "Data source for the negative data.")
# 使用word2vec训练的词向量路径
tf.flags.DEFINE_string("w2vModelPath", "/home/lvchao/vectors/vectors_300.bin", "the model of word2vec")
# 语料中最大的句子长度
tf.flags.DEFINE_integer("sequence_length", 102, "the max of words in a sentence")
# Model Hyperparameters
# 临近特征附加策略,可选NC、LC、RC、LRC,默认NC
tf.flags.DEFINE_string("cxt_type", "NC", "Adjacent feature strategy (default: NC)")
# 词向量长度,默认300
tf.flags.DEFINE_integer("embedding_dim", 300, "Dimensionality of character embedding (default: 300)")
# 使用3种过滤器以及尺寸
tf.flags.DEFINE_string("filter_sizes", "3,4,5", "Comma-separated filter sizes (default: '3,4,5')")
# 过滤器数量
tf.flags.DEFINE_integer("num_filters", 128, "Number of filters per filter size (default: 128)")
# dropout比例
tf.flags.DEFINE_float("dropout_keep_prob", 0.5, "Dropout keep probability (default: 0.5)")
# L2正则参数
tf.flags.DEFINE_float("l2_reg_lambda", 1.0, "L2 regularizaion lambda (default: 1.0)")
# Training parameters
# 批处理大小
tf.flags.DEFINE_integer("batch_size", 64, "Batch Size (default: 64)")
# 训练多少轮epoch
tf.flags.DEFINE_integer("num_epochs", 200, "Number of training epochs (default: 200)")
# Misc Parameters
# 如果指定的GPU设备不存在,允许TF自动分配设备
tf.flags.DEFINE_boolean("allow_soft_placement", True, "Allow device soft device placement")
# 是否打印设备分配日志
tf.flags.DEFINE_boolean("log_device_placement", False, "Log placement of ops on devices")
## 运行程序
# 配置好以上默认参数后,即可开始训练、测试,运行train_dev_test.py文件时亦可从控制台重新指定各个参数,比如指定临近特征附加策略为'不附加',此时模型结构实际是基本CNN模型
python train_dev_test.py --cxt_type="NC"
模型对比实验在COAE2014上的查准率、召回率、F1值、准确率:
| 模型 | 负面 | 正面 | 准确率 | ||||
| 查准率 | 召回率 | F1值 | 查准率 | 召回率 | F1值 | ||
| CNN | 87.30% | 82.72% | 84.94% | 85.75% | 89.63% | 87.65% | 86.43% |
| LAF-CNN | 87.38% | 85.49% | 86.43% | 87.73% | 89.36% | 88.54% | 87.57% |
| RAF-CNN | 88.20% | 83.02% | 85.53% | 86.08% | 90.43% | 88.20% | 87.00% |
| LRAF-CNN | 90.97% | 85.98% | 88.40% | 88.21% | 92.47% | 90.29% | 89.43% |
模型对比实验在COAE2015上的查准率、召回率、F1值、准确率:
| 模型 | 负面 | 中性 | 正面 | 准确率 | ||||||
| 查准率 | 召回率 | F1值 | 查准率 | 召回率 | F1值 | 查准率 | 召回率 | F1值 | ||
| CNN | 83.02% | 80.13% | 81.55% | 56.00% | 23.46% | 33.07% | 85.64% | 94.32% | 89.77% | 83.78% |
| LAF-CNN | 80.19% | 88.67% | 84.22% | 55.91% | 30.95% | 39.85% | 90.83% | 91.29% | 91.06% | 85.41% |
| RAF-CNN | 76.29% | 88.70% | 82.03% | 64.00% | 9.82% | 17.02% | 89.71% | 92.75% | 91.20% | 84.87% |
| LRAF-CNN | 84.52% | 83.72% | 84.12% | 50.00% | 21.23% | 29.81% | 87.80% | 94.23% | 90.90% | 85.61% |
本项目中的词向量vectors_300.bin是基于1000W条微博数据训练而成,因此词向量的泛华能力有限,为了覆盖更多的词汇,建议去收集更多领域的语料,然后自己使用word2vec重新训练词向量(当然,这其中还需要经过数据清洗、分词等步骤)。另外,模型的训练语料和测试语料均不足(COAE2014包含4000条、COAE2015包含133201条),无法测试出模型的对于其他特定领域语料的测试效果如何,建议开发者自行测试。
如果有什么问题、建议、BUG都可以在这个Issue和我讨论
或者也可以在gitter上交流:

当然也您可以加入新建的QQ群与我讨论:568079625
