bisohns / search-engine-parser Goto Github PK
View Code? Open in Web Editor NEWLightweight package to query popular search engines and scrape for result titles, links and descriptions
Home Page: https://search-engine-parser.readthedocs.io
Lightweight package to query popular search engines and scrape for result titles, links and descriptions
Home Page: https://search-engine-parser.readthedocs.io
![allcontributors[bot] avatar](https://avatars.githubusercontent.com/in/23186?v=4 "allcontributors[bot]")




![dependabot[bot] avatar](https://avatars.githubusercontent.com/in/29110?v=4 "dependabot[bot]")


























































































































This markdown should contain steps in contributing by raising issues, fixing bugs, creating new engines ( issue #12) and so on
The search engine fails after making search queries between 100 to 120.
It shows the following error message: "Google engine failure", because of unusual traffic.
This can be avoided by adding proxies I guess.
I have tried to make changes in the base file and google engine file through "Requests proxies" and "SOCKS5" but it didn't work.
@deven96 suggested me to do it through aiohttp requests but there is no success.
Apply some piece of code through which we can add some paid proxies so Google Engine will not flag it unusual traffic or something.
Stack overflow engine parsed and returned like regular search engine results
I am trying to scrape some Bing search results and I get the above error.
from search_engine_parser.core.engines.bing import Search as BingSearch
import pprint
search_args = ('example', 1)
bsearch = BingSearch()
bresults = bsearch.search(*search_args)
print(bresults["descriptions"][1])
I'm using Jupyter notebook. Thanks.
Describe the bug
Package doesn't install at all.
To Reproduce
Steps to reproduce the behaviour:
Trying to install search-engine-parser>=0.4.2 using pip3 (requirements.txt)
Expected behaviour
The package should install.
Screenshots
If applicable, add screenshots to help explain your problem.
Desktop (please complete the following information):
Additional context
Here's the error log.
Collecting search-engine-parser>=0.4.2 (from -r requirements.txt (line 33))
Downloading https://files.pythonhosted.org/packages/ec/56/29a3e6e098674ffef9a12c360275e90146a96bde626f277d329248aafe76/search-engine-parser-0.5.0.tar.gz
ERROR: Command errored out with exit status 1:
command: /usr/bin/python3.7 -c 'import sys, setuptools, tokenize; sys.argv[0] = '"'"'/tmp/pip-install-shzymtgy/search-engine-parser/setup.py'"'"'; __file__='"'"'/tmp/pip-install-shzymtgy/search-engine-parser/setup.py'"'"';f=getattr(tokenize, '"'"'open'"'"', open)(__file__);code=f.read().replace('"'"'\r\n'"'"', '"'"'\n'"'"');f.close();exec(compile(code, __file__, '"'"'exec'"'"'))' egg_info --egg-base pip-egg-info
cwd: /tmp/pip-install-shzymtgy/search-engine-parser/
Complete output (5 lines):
Traceback (most recent call last):
File "<string>", line 1, in <module>
File "/tmp/pip-install-shzymtgy/search-engine-parser/setup.py", line 5, in <module>
from _version import VERSION
ModuleNotFoundError: No module named '_version'
----------------------------------------
Describe the bug
A clear and concise description of what the bug is.
To Reproduce
Steps to reproduce the behavior:
Expected behavior
A clear and concise description of what you expected to happen.
Screenshots
If applicable, add screenshots to help explain your problem.
Desktop (please complete the following information):
Additional context
Add any other context about the problem here.
Post deploy and pre deploy tests for the console entry point on pipeline.
Tests for links, description, titles
Separate engine tests into their separate modules
Review entire package and ensure python 2 compatibility
Edit pipeline yml to test for python 2
when I search through Yahoo, Im getting links like below:
which is supposed to be:
https://finvestorplace.com/2019/04/microsoft-is-no-longer-a-dark-horse-in-race-for-jedi-contract-msft/
let me know if Im making any mistakes.
Describe the bug
Using 'google.it' as url parameter and not receiving italian localization response if I'm using it from a not italian IP address
To Reproduce
Steps to reproduce the behavior:
Expected behavior
Receive an italian response.
Additional context
There is a parameter to really present the desired localization and is "hl"
Suggestion
This url will present the language of you ip address.
https://www.google.com/search?q=ciao
This url with the hl parameter will present the results in italian.
https://www.google.com/search?q=ciao&hl=it
when used search_engine_parser in telethon userbot for telegram i get this error
raise NoResultsOrTrafficError(
search_engine_parser.core.exceptions.NoResultsOrTrafficError: The returned results could not be parsed. This might be due to site updates or server errors. Drop an issue at https://github.com/bisoncorps/search-engine-parser if this persists
Is your feature request related to a problem? Please describe.
i cant use the parser for searching google.de
Describe the solution you'd like
i want to be able to set a localization to use google.fr or google.de or whatever
Describe alternatives you've considered
Additional context
I would like to give it a localization to use it for other results...
regards
Results of searching on module and searching manually in any web browser are different. For instance, I want to search on google with filtering of wikipedia (e.g. keyword site:tr.wikipedia.org) and scrape first result. Generally, a first result is useless for me when tried to search on module. I am using following class and its "run" method:
from search_engine_parser.core.engines.google import Search as GoogleSearch
class SearchOnline():
def __init__(self):
self.target_url = ""
def run(self, keyword):
search_args = ((keyword + ' site:tr.wikipedia.org'), 1)
gsearch = GoogleSearch()
gresults = gsearch.search(*search_args, url="google.com.tr")
self.target_url = gresults["links"][0]
return self.target_url
Here you can find following scenario:
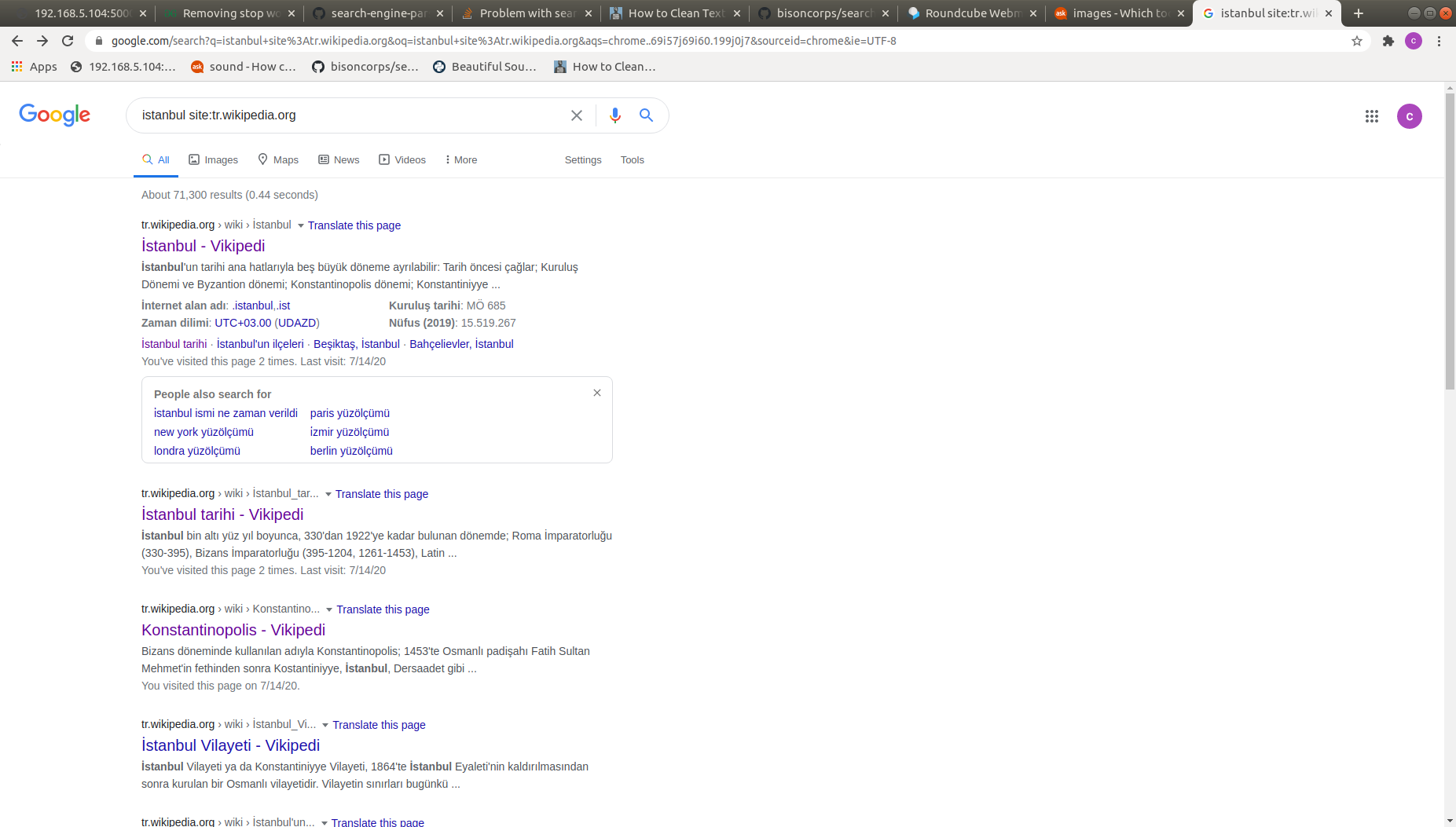
('istanbul site:tr.wikipedia.org', 1) -> These are my searching args in code
---- These are results (I take 0th url) ----
['https://tr.wikipedia.org/wiki/Portal:%C4%B0stanbul', 'https://tr.wikipedia.org/wiki/%C4%B0stanbul_Vilayeti', 'https://tr.wikipedia.org/wiki/%C4%B0stanbul%27daki_meydanlar_listesi', 'https://tr.wikipedia.org/wiki/%C4%B0stanbul_tarihi', 'https://tr.wikipedia.org/wiki/Kategori:%C4%B0stanbul%27un_b%C3%B6lgeleri', 'https://tr.wikipedia.org/wiki/%C4%B0stanbul%27un_il%C3%A7eleri', 'https://tr.wikipedia.org/wiki/%C4%B0stanbul%27un_idari_yap%C4%B1lanmas%C4%B1', 'https://tr.wikipedia.org/wiki/Konstantinopolis', 'https://tr.wikipedia.org/wiki/Kategori:%C4%B0stanbul', 'https://tr.wikipedia.org/wiki/Be%C5%9Fikta%C5%9F,_%C4%B0stanbul']
---- This is result of manual searching (It is not even in results array of module) ----
https://tr.wikipedia.org/wiki/%C4%B0stanbul
Here is screenshot of manual searching results.
Desktop:
Describe the bug
I receive the error The authenticity of host 'github.com (140.82.121.3)' can't be established. when cloning the repo by running git clone [email protected]:bisoncorps/search-engine-parser.git
To Reproduce
Steps to reproduce the behavior:
git clone [email protected]:bisoncorps/search-engine-parser.gitExpected behavior
The repo is cloned successfully.
Desktop (please complete the following information):
Additional context
full error:
Cloning into 'search-engine-parser'...
The authenticity of host 'github.com (140.82.121.3)' can't be established.
RSA key fingerprint is SHA256:nThbg6kXUpJWGl7E1IGOCspRomTxdCARLviKw6E5SY8.
Are you sure you want to continue connecting (yes/no/[fingerprint])?
Describe the bug
There are few issues in documentation (mostly due to copy/pasting errors), I guess, which must be removed
To Reproduce
Go to documentation for StackOverflow, it says it is a parser for AOL and describes GitHub
Additional note
I will be opening a PR to fix the bug in StackOverflow module, but in the summary parts of docs, there are ugly \t\n characters. Also, in many cases, the params are not linted nicely (fine here but not here)
Maybe you guys can create a list of subtasks on this issue, and they can be ticked off as and when these docs related issues are solved?
Describe the bug
The library fails to parse Google search results, probably because of changes by Google.
To Reproduce
Steps to reproduce the behaviour:
pip install search-engine-parser)search.py)python3 search.py)Expected behaviour
It should show the search results, as formatted by the snippet.
Screenshots
N/A
Desktop (please complete the following information):
Additional context
Here's the error log to help with debugging.
[avinash@rustbucket ~]$ python search.py
https://www.google.com/search?num=10&start=1&q=preaching+to+the+choir&client=ubuntu True
Traceback (most recent call last):
File "/home/avinash/PPRPLNRMX/lib/python3.8/site-packages/search_engine_parser/core/base.py", line 239, in get_results
search_results = self.parse_result(results, **kwargs)
File "/home/avinash/PPRPLNRMX/lib/python3.8/site-packages/search_engine_parser/core/base.py", line 151, in parse_result
rdict = self.parse_single_result(each, **kwargs)
File "/home/avinash/PPRPLNRMX/lib/python3.8/site-packages/search_engine_parser/core/engines/google.py", line 49, in parse_single_result
h3_tag = r_elem.find('h3')
AttributeError: 'NoneType' object has no attribute 'find'
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "search.py", line 11, in <module>
gresults = gsearch.search(*search_args)
File "/home/avinash/PPRPLNRMX/lib/python3.8/site-packages/search_engine_parser/core/base.py", line 266, in search
return self.get_results(soup, **kwargs)
File "/home/avinash/PPRPLNRMX/lib/python3.8/site-packages/search_engine_parser/core/base.py", line 242, in get_results
raise NoResultsOrTrafficError(
search_engine_parser.core.exceptions.NoResultsOrTrafficError: The returned results could not be parsed. This might be due to site updates or server errors. Drop an issue at https://github.com/bisoncorps/search-engine-parser if this persists
The Wikipedia engine is not as straight forward as the search engines with the related links having a different length from the titles and descriptions. Other nuances should be looked at to ensure smooth parsing
Apply techniques to prevent search engine scraper from being flagged as suspicious activity. Randomly cycle through browser headers for scraping
Query edx for results, cli option to download using edx-dl
I think the list of user agents is too small (USER_AGENT_LIST).
In other projects, I use (successfully) this library: fake-user agent. Up to date simple useragent faker with real world database.
In utils.py, get_rand_user_agent() maybe like this :
from fake_useragent import UserAgent
def get_rand_user_agent():
ua = UserAgent()
# Return random UA via real world browser usage statistic
return ua.random
Youtube Engine should be capable of scraping and returning links, titles and descriptions to the individual videos with option of downloading the videos (when using the CLI)
It would be good too support baidu news searching. Example query: https://www.baidu.com/s?rtt=1&bsst=1&cl=2&tn=news&rsv_dl=ns_pc&word=python
Consider switching to pycurl to return html. Implement #1 on pycurl if completed
Query coursera with added cli option to download using coursera-dl
Describe the bug
After doing a search once, the next searches always return the same result of the first one, both when the same or different search engine is used.
To Reproduce
Steps to reproduce the behavior:
Code samples
from search_engine_parser import GoogleSearch
google_search = GoogleSearch()
res_apple = google_search.search('apple', 1)
print(res_apple[0])
res_orange = google_search.search('orange', 1)
print(res_orange[0])
from search_engine_parser.core.engines.yahoo import Search as YahooSearch
from search_engine_parser.core.engines.google import Search as GoogleSearch2
yahoo_search = YahooSearch()
google_search_2 = GoogleSearch2()
res_banana = google_search_2.search('banana', 1)
print(res_banana[0])
res_apricot = yahoo_search.search('apricot', 1)
print(res_apricot[0])
Expected behavior
The search results should be different.
Desktop (please complete the following information):
Additional context
The bug doesn't happen in version 0.5.4.
Describe the bug
Hi when I tried to search for this sentence, it throws me a bug:
This event loop is already running
Code below:
from search_engine_parser import GoogleSearch,BingSearch,YahooSearch
query = "spider president ” president bill clinton filthy rich story financier jeffrey epstein years revelations arrest suicide"
gsearch = GoogleSearch()
args=(query,1)
try:
gr = gsearch.search(*args)
except Exception as e:
print(e)
Expected behavior
This event loop is already running
Screenshots
If applicable, add screenshots to help explain your problem.
Desktop (please complete the following information):
Additional context
Add any other context about the problem here.
Describe the bug
After installing the pysearch cli tool and try to use it, the tool reports error:
ImportError: cannot import name 'runner'
To Reproduce
Steps to reproduce the behavior:
mkvirtualenv search_engine_parser
pip install "search-engine-parser[cli]"
pysearch --helpTraceback (most recent call last):
File "/home/chrislin/.virtualenvs/search_engine_parser/bin/pysearch", line 5, in <module>
from search_engine_parser.core.cli import runner
ImportError: cannot import name 'runner'Expected behavior
Show help message from pysearch
Screenshots

Desktop (please complete the following information):
Additional context
Cause:
The runner function was removed.
Solution:
Either add back runner in search_engine_parser.core.cli or change the entry_points in setup.py
Related pull request:
#108
Describe the bug
Cannot search YouTube via the pysearch CLI tool.
To Reproduce
Steps to reproduce the behavior:
pysearch --e youtube search --q "NoCopyrightSounds"Engine < youtube > does not existExpected behavior
Since NCS is very popular over at YouTube, it should have returned something.
Screenshots
If applicable, add screenshots to help explain your problem.
Desktop (please complete the following information):
Additional context
The same goes for the other search engines like, Ask, AOL, Baidu.
In Google's search string parameters, there is num=xx parameter
This parameter determines the number of results to show per page. Use in combination with the page parameter to implement pagination.
The maximum number of results Google return per request is 100 for all search_type values aside from places, where the limit is 20 per request (a Google-imposed limitation).
These must be a numeric value, and can be anything up to 100. Doesn't work with fractions. I've tried.
It seems that this parameter (and others?) is not processed when creating the Google search url.
from search_engine_parser.core.engines.google import Search as GoogleSearch
gsearch = GoogleSearch()
gresults = gsearch.search(query='search-engine-parser', page=1, cache=True, num=100)
A solution could be that:
import pprint
from search_engine_parser.core.engines.google import Search as GoogleSearch
class MyGoogleSearch(GoogleSearch):
def __init__(self):
super().__init__()
def get_params(self, query=None, offset=None, page=None, **kwargs):
# Default parameters
params = {
"start": (page-1) * 10,
"q": query,
"gbv": 1
}
# Additional parameters
for key, value in kwargs.items():
params[key] = value
return params
gsearch = MyGoogleSearch()
gresults = gsearch.search(query='search-engine-parser', page=1, cache=True, num=100)
for index, result in enumerate(gresults):
print(f"-------------{index}------------")
pprint.pprint(result)
Search Github api for repositories and tags
Yes i'm trying to add date range as shown here i need your help gys :

Dear Search engine parser team,
From the Windows 10 command line, I successfully used pip to install search-engine-parser and search-engine-parser[cli]. However, when trying to clone this repository, git clone [email protected]:bisoncorps/search-engine-parser.git, I receive the following for search-engine-parser 0.6:
Cloning into 'search-engine-parser'...
The authenticity of host 'github.com (140.82.118.3)' can't be established.
RSA key fingerprint is SHA256:nThbg6kXUpJWGl7E1IGOCspRomTxdCARLviKw6E5SY8.
Are you sure you want to continue connecting (yes/no/[fingerprint])? yes
Warning: Permanently added 'github.com,140.82.118.3' (RSA) to the list of known hosts.
[email protected]: Permission denied (publickey).
fatal: Could not read from remote repository.
Please make sure you have the correct access rights
and the repository exists.
I have installed Python 3.8.3, by the way.
Thanks for your help.
Include options to empty cache
I used the package out of the box and found that there an error is raised when calling the search function. With a quick stackoverflow search, I fixed the error by using nest_asyncio; however, I was wondering if there is a way to fix this error without using nest asyncio since it seems like the developers of search_engine_parser intended on using asyncio (I am not incredibly familiar with asyncio).
Just for reference, I am using Jupyter Notebook and Python 3.8. Here is the code with and without the nest_asyncio code.

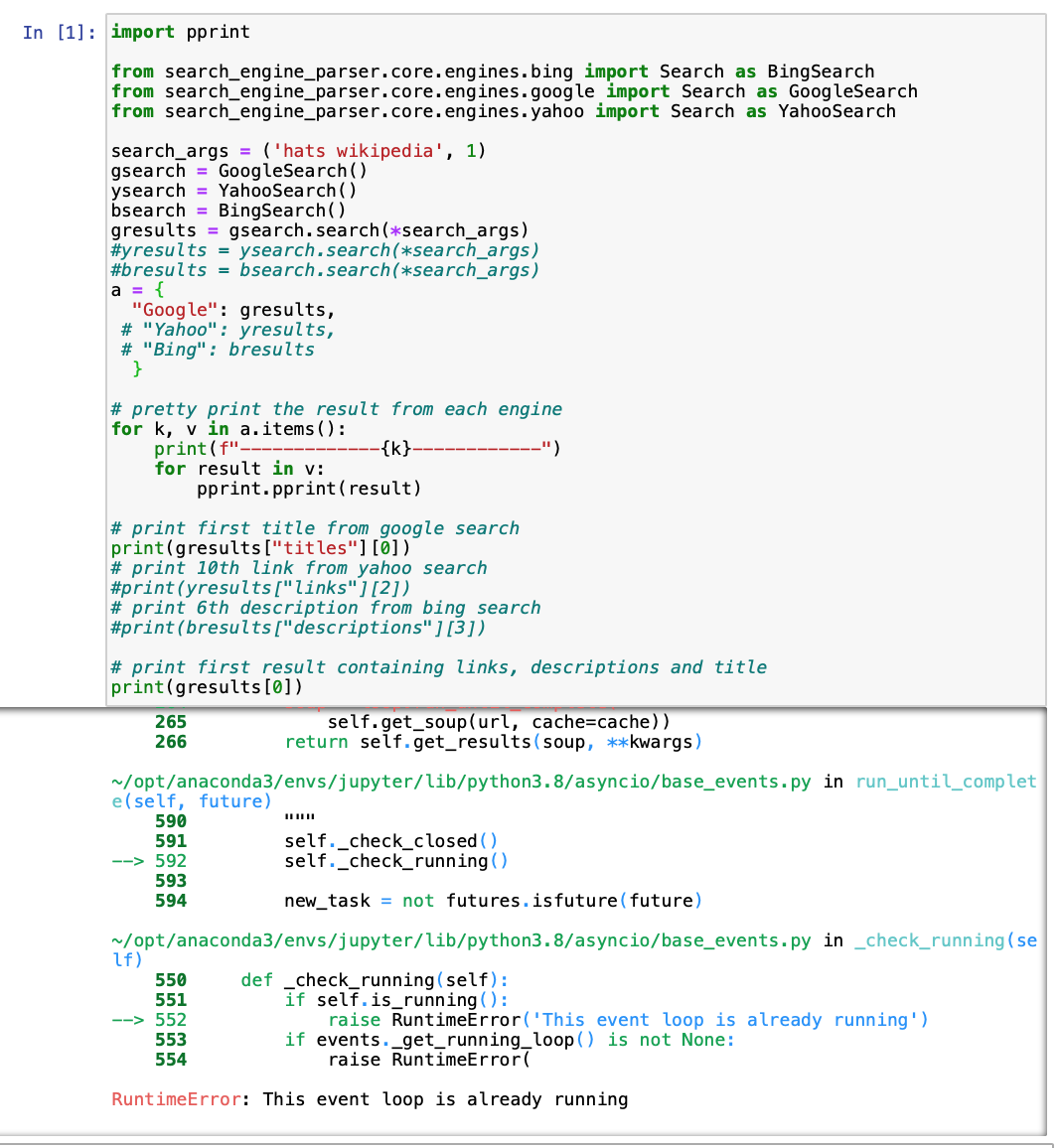

With other Search engines, we are able to add offsets for page numbers and number of results to return. DuckDuckGo however does not seem straight forward. We should look for the accurate way to make the requests to duckduckgo
Update the demo gif with the new API. GIF can be recorded using byzanz for reasonable size
https://pkgs.org/download/byzanz
Search function should accept further keyword arguments for special engines like Github (search users or select a language), StackOverflow(add search tags), e.t.c
Describe the bug
Could not search using pysearch CLI tool
To Reproduce
Steps to reproduce the behavior:
apt upgrade -yapt install pythonapt install clang libxslt libxml2 libxml2-utils and then use pip install search-engine-parser to install the package.pysearch --engine bing search --query "Preaching to the choir" --type descriptions from docs, to test.Expected behavior
As shown in the example gif in the README, it should return search results.
Screenshots
None.
Desktop (please complete the following information):
Additional context
Here's the traceback data which may help to solve the issue.
Traceback (most recent call last):
File "/data/data/com.termux/files/usr/bin/pysearch", line 11, in <module>
load_entry_point('search-engine-parser==0.5.3.post3', 'console_scripts', 'pysearch')()
File "/data/data/com.termux/files/usr/lib/python3.7/site-packages/pkg_resources/__init__.py", line 489, in load_entry_point
return get_distribution(dist).load_entry_point(group, name)
File "/data/data/com.termux/files/usr/lib/python3.7/site-packages/pkg_resources/__init__.py", line 2793, in load_entry_point
return ep.load()
File "/data/data/com.termux/files/usr/lib/python3.7/site-packages/pkg_resources/__init__.py", line 2411, in load
return self.resolve()
File "/data/data/com.termux/files/usr/lib/python3.7/site-packages/pkg_resources/__init__.py", line 2417, in resolve
module = __import__(self.module_name, fromlist=['__name__'], level=0)
File "/data/data/com.termux/files/usr/lib/python3.7/site-packages/search_engine_parser/core/cli.py", line 7, in <module>
from blessed import Terminal
ModuleNotFoundError: No module named 'blessed'
Is your feature request related to a problem? Please describe.
No, it is a request for a new custom engine, namely MyAnimeList.
Why should it be added?
From Wikipedia, we have MyAnimeList, often abbreviated as MAL, is an anime and manga social networking and social cataloging application website. The site provides its users with a list-like system to organize and score anime and manga. It facilitates finding users who share similar tastes and provides a large database on anime and manga. The site claims to have 4.4 million anime and 775,000 manga entries. In 2015, the site received 120 million visitors a month. Right now, the traffic will be far more and there are projects like Jikan which are dedicated to this, so this project should definitely include MAL parsing.
Describe the solution you'd like
I don't see such option in the documentation:
-p PAGE, --page PAGE Page of the result to return details for (default: 1)
When I try to search on google, the program gives following error with some searching args. I could not specify all of them but I can give some examples of searching args.
('fatih terim kimdir site:tr.wikipedia.org', 0)
('amerikanın yüz ölçümü ne kadardır site:tr.wikipedia.org', 0)
('almanyanın başkenti neresidir site:tr.wikipedia.org', 0)
Error:
Traceback (most recent call last):
File "/home/xavier/.local/lib/python3.6/site-packages/search_engine_parser/core/base.py", line 239, in get_results
search_results = self.parse_result(results, **kwargs)
File "/home/xavier/.local/lib/python3.6/site-packages/search_engine_parser/core/base.py", line 151, in parse_result
rdict = self.parse_single_result(each, **kwargs)
File "/home/xavier/.local/lib/python3.6/site-packages/search_engine_parser/core/engines/google.py", line 49, in parse_single_result
h3_tag = r_elem.find('h3')
AttributeError: 'NoneType' object has no attribute 'find'
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "get_request.py", line 106, in <module>
print(getrequest.run(keyword))
File "get_request.py", line 88, in run
url = SearchOnline().run(keyword)
File "/home/xavier/projects/Darvis_cpy/darvis/search/../../darvis/search/search_online.py", line 20, in run
gresults = self.gsearch.search(*search_args, url="https://google.com.tr")
File "/home/xavier/.local/lib/python3.6/site-packages/search_engine_parser/core/base.py", line 266, in search
return self.get_results(soup, **kwargs)
File "/home/xavier/.local/lib/python3.6/site-packages/search_engine_parser/core/base.py", line 243, in get_results
"The returned results could not be parsed. This might be due to site updates or "
search_engine_parser.core.exceptions.NoResultsOrTrafficError: The returned results could not be parsed. This might be due to site updates or server errors. Drop an issue at https://github.com/bisoncorps/search-engine-parser if this persists
Here is my searching class:
from search_engine_parser.core.engines.google import Search as GoogleSearch
class SearchOnline(metaclass = Singleton):
def __init__(self):
self.gsearch = GoogleSearch()
self.target_url = ""
def run(self, keyword):
search_args = ((keyword + ' site:tr.wikipedia.org'), 0)
print("search args:", search_args)
gresults = self.gsearch.search(*search_args, url="https://google.com.tr")
self.target_url = gresults["links"][0]
print("reached url:", self.target_url)
return self.target_url
Desktop:
OS: Ubuntu 18.04.4 LTS
Python Version: 3.6.9
Search-engine-parser version: 0.6.1
Describe the solution you'd like
Using async or multiple threads, searches should be executed. This is would be good for in-code implementations
Add extensive markdown guides in creating a new Engine by extending the base engine, coupled with the kind of tests to write and how to structure PRs for inclusion. search-engine-parser aims to be the largest combination of search engines
Is your feature request related to a problem? Please describe.
We can only find the search results for the search, not for images, news and other stuff. I've always wanted to scrape the latest news articles. But this method won't allow me to scrape them
Describe the solution you'd like
It would be better if we could add additional arguments with the query, like tbm=nws for news, tbm=isch for the image. Users would have more control and It could be done even if the repo is not updated.
Describe alternatives you've considered
These things could be added to the library directly by adding these to the codebase, but I think it would be more beneficial if the user could control the query and arguments
GOOGLE: "tbm=nws" for news, "tbm=isch" for images, "tbm=vid" for videos
BING: "FORM=HDRSC1" for search, "FORM=HDRSC2" for images, "FORM=HDRSC6" for news
Additional context
This was already implemented in commit : 056c1c3. The newer versions doesn't have that.
Is your feature request related to a problem? Please describe.
No, it is an optional enhancement
Describe the solution you'd like
Create an API for the search-engine-parser package and deploy it to a system like Heroku
Reason
Right now, the project has quite a few dependencies (which will only grow) and is kind of python-only (using it in a Spring-boot project is possible, but it's not easy), so why can't we create a minimalist flask app version of the library and deploy it to Heroku, so that people who build projects in other languages would also be able to integrate it, or use it directly from command line with curl or wget with something like curl -i https://searchengineparser.herokuapp.com/{path}? No hassle of setup either 😄
I am not saying this has to be an immediate target, but won't it be a nice enhancement/auxiliary feature? @deven96 , @MeNsaaH what do you think? 🤔
Note
If this is ever taken up, I would love to help with it. Not much changes would be required either (probably 😅 ), since the responses are in a nice, tidy JSON format already :)
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.