YouTube на русскоязычную аудиторию
На видеохостингах основная нагрузка приходится на просмотр видео, поэтому необходимо посчитать сколько часов видео российские пользователи смотрят в YouTube.
По данным Google в день на YouTube просматривается более одного миллиарда видео. Эти просмотры генерируются глоабальной аудиторией — MAU более двух миллиардов человек(исходя из пресс-релиза Google). Таким образом один человек в месяц смотрит в среднем 15 видео на youtube.
По данным YouTube на 2018 год в России YouTube используют примерно 70 миллионов человек. Средний показатель просмотров видео в месяц от одного пользователя — 5 часов. Каждую минуту в систему загружаются 100 часов видео. Большая часть трафика приходится на смартфоны.
Следовательно в месяц в России на YouTube приходится 5 * 70 000 000 = 350 000 000 часов просмотра видео в месяц. Соответсвенно в день на YouTube смотрят 350 000 000 / 30 ≈ 12 000 000 часов видео.
Если взять, что в минуту на Youtube загружают 100 часов видео, то получим, что в день загружают примерно 100 * 60 * 24 = 144 000 часов видео. В месяц соответсвенно этот показатель будет равен 144 000 * 30 = 4 320 000 часов видео.
- MAU примерно равен 70 млн пользователей
- DAU примерно равен 10 млн (источник: Mediascope)
- Колличество часов просотра видео в месяц: 350 000 000
- Колличество часов просмотра видео в день: 12 000 000
- Колличество часов видео загружаемых на платформу в месяц: 4 320 000
- Колличество часов видео загружаемых на платформу в день: 144 000
При посещении главной страницы пользователь делает примерно 3 запроса в API и загружает порядка 50 статических файлов. При переходе на страницу просмотра видео пользователь отсылает примерно 14 запросов в API и загружает примерно 60 статических файлов.
Заходя на сайт пользователь выбирает видео из списка, после чего переходит на страницу просмотра. По статистике решение о том, чтобы продолжить просмотр пользователь принимает за 10 секунд, поэтому первые 10 секунд каждого видео являются самым просматриваемым местом.
Допустим, что пользователь досматривает до конца каждое третье видео, которое начинает смотреть. Тогда в среднем, перед тем, как начать просмотр видео, пользователь посещает 4 страницы: главную и 3 перехода между разными видео.
Таким образом перед началом просмотра видео средний пользователь генерирует
- 3 + 14 * 3 = 45 запросов к API
- 50 + 60 * 3 = 230 загрузок статических файлов
- 10 * 3 = 30 секунд просмотра видео
Чтобы рассчитать колличество часов видео отдаваемых в секунду возьмем колличество часов просмтра в день и разделим на колличество секунд:

Для рассчета RPS умножаем колличество запросов на число пользователей в день и делим на колличество секунд в сутках.
Получим для запросов к API:

Получим для запросов на статику:

Значение нагрузки для каждой категории контета:
- Видео: 140 часов в секунду
- API: 5300 RPS
- Статика: 27000 RPS
Модели проекта:
-
Пользователь
-
Видео
-
Лайк
-
Комментарий
-
Рекомендация
База данных намеренно денормализована так, чтобы в моделе видео храниться пользователь, который его загрузил, комментарий хранит модель пользователя, который его написал, рекомендация хранит в себе информацию о всех рекомендованных видео. Лайк же, например, хранит исключительно id объектов, а не их полные модели.
В схеме базы данных не учтены всевозможные статистические данные для подбора релеватных видео для пользователя.

Для хранения сессий будем использовать in-memory Redis. Благодаря тому, что Redis является in-memory базой данных, то доступ к определенной записи будет практически равен доступу к оперативной памяти. Помимо свой быстроты Redis поддерживает неблокирующую master-slave репликацию из коробки.
Основная часть всех запросов приходится на получение рекомендаций(с главной страницы и на странице с видео), поэтому подобные данные лучше хранить в нерелеационной in-memory базе данных, чтобы не увеличивать колличество разных технологий в проекте, то оптимальным решением будет также использовать Redis. Ключем будет uuid пользователя, а в значении будут лежать объекты всех рекомендованных видео.
Так как основное время, проведенное на сайте, пользователи смотрят видео, то к хранению видео необходимо отнестись с наибольшей внимательностью.
Разделим видео на несколько категорий по популярности:
- Меньше 1 000 просмотров
- Меньше 100 000 просмотров
- Больше 100 000 просмотров
Если видео является среднем по числу просмотров(больше 1000, меньше 100 000), то для таких видео можно кэшировать на более быстрый SSD исключительно первые 15 секунд(самая просматриваемая часть).
Если же на видео больше 100 000 просмотров, то такие видео можно хранить целиком в кэше на более быстрых SSD.
К такой схеме также подталкивает статистика, по которой 90 % видео на youtube набирают меньше 1000 просмотров и только 0.77% видео набирают больше 100 000 просмотров.
Необходимо также посчитать объем заюпросов на чтение видео, которые необходимо обрабатывать для средних по просмотрам и самых популярных видео.
Исходя из графика
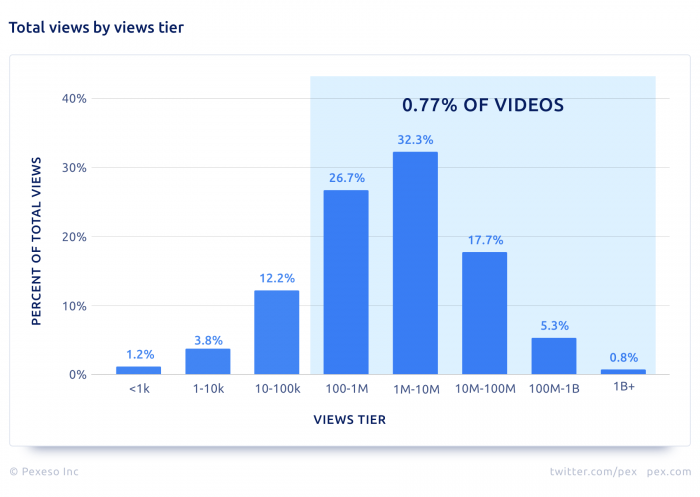
Можно понять, что на видео, где колличество просмотров около 100 000 приходится примерно 13 % всех просмотров
На самые популярные видео**(более 100 000 просмотров) приходится примерно 70 %** просмотров.
Посчитаем колличество часов просмотра в сутки каждой категории видео:
- Более 100 000 просмотров 12 000 000 - 30% = 8 400 000 часов просмотра в сутки
- Более 1 000, но менее 100 000 просмотров 12 000 000 - 71% = 3 480 000 часов просмотра в сутки
- Менее 1 000 просмотров 12 000 000 - 1% = 120 000 часов просмотра в сутки
Упростим и предположим, что все видео просматриваются в среднем разрешении: 720p, если верить подсчетам, приведенным на сайте google, то битрейт подобного видео может быть 1,500-4,000 Kbps, возьмем верхнюю оценку, тогда час подобного видео весит 1.8 GB.
Тогда посчитаем объем трафика видео по категориям:
- Более 100 000 просмотров: 8 400 000 часов * 1.8 Gb = 15 120 000 Gb = 16 Pb
- Более 1 000, но менее 100 000 просмотров 3 480 000 часов * 1.8 Gb = 6 264 000 Gb = 7 Pb
- Менее 1 000 просмотров 120 000 часов * 1.8 Gb = 216 000 Gb = 0.5 Pb
Суммарный объем трафика за сутки равен примерно 25 Pb, найдем объекм трафика в секунду:
25000 Tb / (24 * 60 * 60) = 290 Gb/sec
С учетом времени суток, пиоквая нагрузка может быть около 700 Gb/sec.
Для того, чтобы посчитать объем необходимой памяти также возьмем горизонт пять лет. Тогда посчитаем, какое колличество часов видео будет загружено за это время: 100(часов видео загружаемые в минуту) * 60 * 24 * 365 * 5 = 262 800 000 часов. Для хранения одного часа видео необходимо 1.8 Gb, следовательно все видео будут весить 262 800 000 * 1.8 Gb = 473 040 000 Gb = 474 Pb. Тк для надежности каждое видео будет хранится в двух экземплярах, то умножим это число на два, соотвественно получаем 474 Pb * 2 = 948 Pb.
В результате получаем, что для хранения видео, нам необходимо примерно 1000 Pb.
Система предполагает несколько уровней кэшеринования, для обычного хранения видео(HDD), куда доходят просмотры только непопулярных видео. А также более быстрая система из SSD накопителей, куда, в случае популярности видео копируется из более медленной системы хранения.
Данные, для которых необходима надежность и не нужен столь быстрый доступ(профили, комментарии, лайки) будем хранить в Postgresql. Для повышения доступности и надеждности сервиса будем использовать технологию шардирования и в разных шардах будем хранить информацию о разных сущностях проекта.
В качестве основного языка бекенда будет использоваться Golang, тк в нем удобный параллелизм, а также он прост в освоении командой разработки. Помимо этого под Go написано большое колличество сторонних моделей. И у языка есть сформировавшиеся сообщество. Если во время эксплаутации будут выявлены самые нагруженные части проекта, то они будут переписываться на более быстрые языки такие как, например, C++. Также бекенд будет иметь микросервисную архитектуру, все сервисы будут общаться по GRPC
На фронтенде будет стандартный стек технологий HTML, CSS, JS с использованием React. Этот набор технологий наиболее популярный на рынке, поэтому для него всегда можно найти разработчиков.
В качестве основного протокла свзяи будет использоваться HTTPS. Но, в случае такой возможности, клиент будет переключаться на HTTP2, тк такой вид протокола является более актуальным и быстрым, особенно для медиафайлов.
Для обеспечения качества разработки будет использоваться GitLab CI с линтерами и юнит-тестами. На бекенде будут написаны end to end тесты, а на фронтенде основной функционал должен быть покрыть тестами на Selenium.
Раслкадка конфигов будет происходить с помощью puppet. А сам процесс довоза новых версий кода будет организован с помощью RPM-пакетов. Также в проекте будет использоваться Kubernetes.
Для хранения всех сессий пользователей(70 млн) согласно статье нам примерно потребуется: 70 000 000 * 220 = 15 400 000 000 байт = 16 GB. Так как мы будем использовать мастер-слейв репликацию, то умножим это число на три и получим 50 GB.
Тк ожидаемый RPS на походы в API равен примерно 5300, судя по статье, этого должно хватить.
По примерно такой же схеме посчитаем колличество необходимого места для хранения данных о пользователе, для этого нам потребуется примерно 70 000 000 * 350 = 24 500 000 000 байт = 25 гигабайт. Так как мы будем использовать мастер-слейв репликацию, то умножим это число на три и получим 75 GB.
Хранение рекомендаций предполагается в Redis, подобно сессиям, но только с информацией о том, какие видео стоит показать пользователю. Предполагается, что рекомендации в течение дня не обновляются. Для хранения id пользователя и вектора его интересов необходимо примерно 300 байт, тогда 70 000 000 * 300 = 21 000 000 000 байт = 21 гигабайт. Так как мы будем использовать мастер-слейв репликацию, то умножим это число на три и получим 65 GB.
Как упоминалось выше у нас будет два слоя хранения видео
В медленном слое будут хранится абсолютно все видео с использованием HDD памяти. В быстрый слой мы будем загружать только видео, пользующиеся популярностью в данный момент.
Мы будем исходить из того, что 99% всех видео для просмотра мы берем из SSD.
Так как наиболее просматриваемыми мы считаем 1% от всех видео, то для их хранения нам потребуется примерно 10 Pb, при среднем объеме диска в 4 tb, получим, что нам необходимо 2500 дисков SSD объема по 4tb.
Если в один сервер ставить по 20 дисков, то получим, что хранения данных в быстром слое нам потребуется примерно 125 серверов.
В пункте 5.3 было найдено, что нам необходима отдавать 290 GB в секунду. Поэтому сеть в быстром сервере должна уметь отдавать 290/30 = 10 Gb/s. Для надежности поставим две карты по GB/s.
Для хранения всех видео за 5 лет нам недобхимо 474 Pb(см. п. 3), тк мы будем использовать шардирование, где есть один мастер и два слейва, то нам необходимо будет примерно 1000 Pb памяти. То есть для хранения всех видео с учетом реплик нам будет необходимо 50000 HDD дисков объемом 20 терабайт.
Если в один сервер ставить по 90 дисков, то получим, что хранения данных в медленном слое нам потребуется примерно 660 серверов.
| Роль | CPU | RAM | SSD | HDD | Колличество |
|---|---|---|---|---|---|
| Сессии, Профиль, Рекомендации | 32 ядра | 126 Гб | 100 Гб | - | 3 |
| Быстрый слой хранения видео | 32 ядра | 256 Гб | 4 Тб * 20 | - | 125 |
| Медленный слой хранения видео | 32 ядра | 256 Гб | - | 20 Tб * 90 | 660 |
| Фронты | 64 ядра | 256 Гб | 4 Тб | - | 20 |
Для расположения такого колличества серверов можно воспользоваться услугами компании selectel, чьи дата-центры находятся в Москве и Санкт-Петербурге. Можно равномерно расположить сервера между этими ДЦ для увелечения стабильности, воспользовавшись услугой аренды серверной стойки.
Помимо Round Robin DNS балансировки между ДЦ с удалением неотвечающих ip с помощью скрипта. Внутри самих ДЦ трафик, не связанный с видео, балансируется с помощью балансировки L7 с использованием сети Nginx'ов. Тк он решает проблемы клиентов с медленным интернетом(60% трафика с телефонов). Помимо этого, тк весь трафик идет через https или http2, то в Nginx есть возможность быстро воспользоваться этим протоколом. А L7 балансировка позволяет хорошо обрабатывать запросы, связанные с мультиплексированием.
Что касается балансировки видео, то в ней load balancer(nginx), чтобы не создавать дополнительный трафик, будет перенаправлять клиента напрямую в ssd с необходимым видео, то есть будет использоваться механизм балансировки с редиректом.
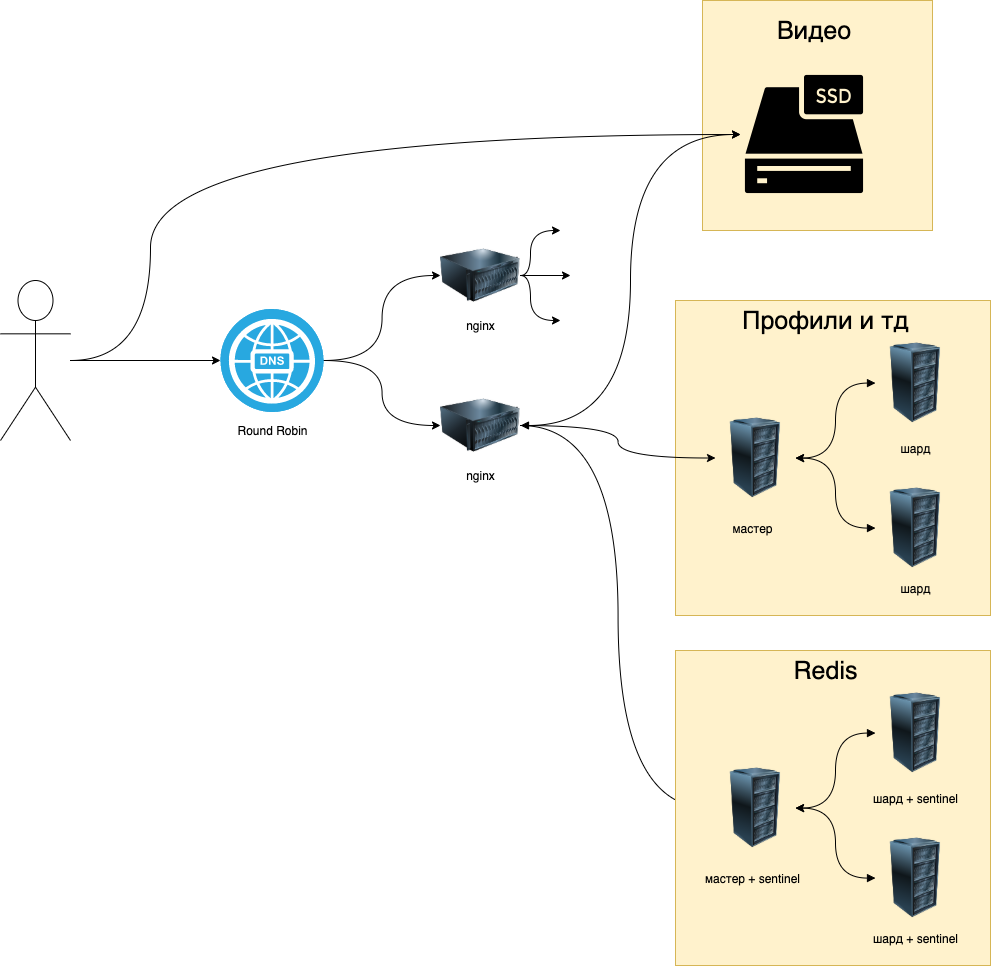
Внутри кластера микросервисы будут общаться с помощью envoy.
Разберем механизмы для обеспечения отказоустойчивости в основных местах проекта.
Как уже описывалось выше сессии и рекомендации будут храниться в Redis, у данной системы есть большое колличество возможностей из коробки для репликации, в данном проекте, предлагается к использованию Mater/Slave репликация, с двумя слейвами. Помимо этого имеет смысл использование стандартного механизма Redis — Sentinel Node для мониторинга и переключения нагрузки. Мастер и слейвы будут распологаться в разных датацентрах.
Так как в сервисе видео имеют ключевую ценность, то к их хранению нужно отнестись внимательно, но так как их объем является слишком большим, то много железа использовать тоже нельзя. Поэтому именно хранятся видео будут в двух экземплярах в разных дата-центрах, на случай внештатных ситуаций.
Отказоусточивость слоя кэша будет обеспечиваться за счет равномерного распределения в нескольких датацентрах.
Для подобной информации была выбрана PostresQL. Так как потенциально данных мы будем хранить не так много, а высокую доступность релиационных баз данных обеспичить не так просто. То можно воспользоваться облачными технологиями, например, решением от MCS, которые предлагают высокодоступный Postgresql с интграцией Patroni
В отличии от баз данных бекенд и фронты будут работать в k8s, что позволит обеспечить повышенную отказоустойчивость за счет равновномерного распределения вычислительных мощностей по разным дата-центрам.
Помимо всего прочего необходимо будет настроить монтироринг за основными показателями системы и создать дежурства, в том числе ночные и выходные дни. В мониторинге будут использоваться Prometheus и Grafana.

