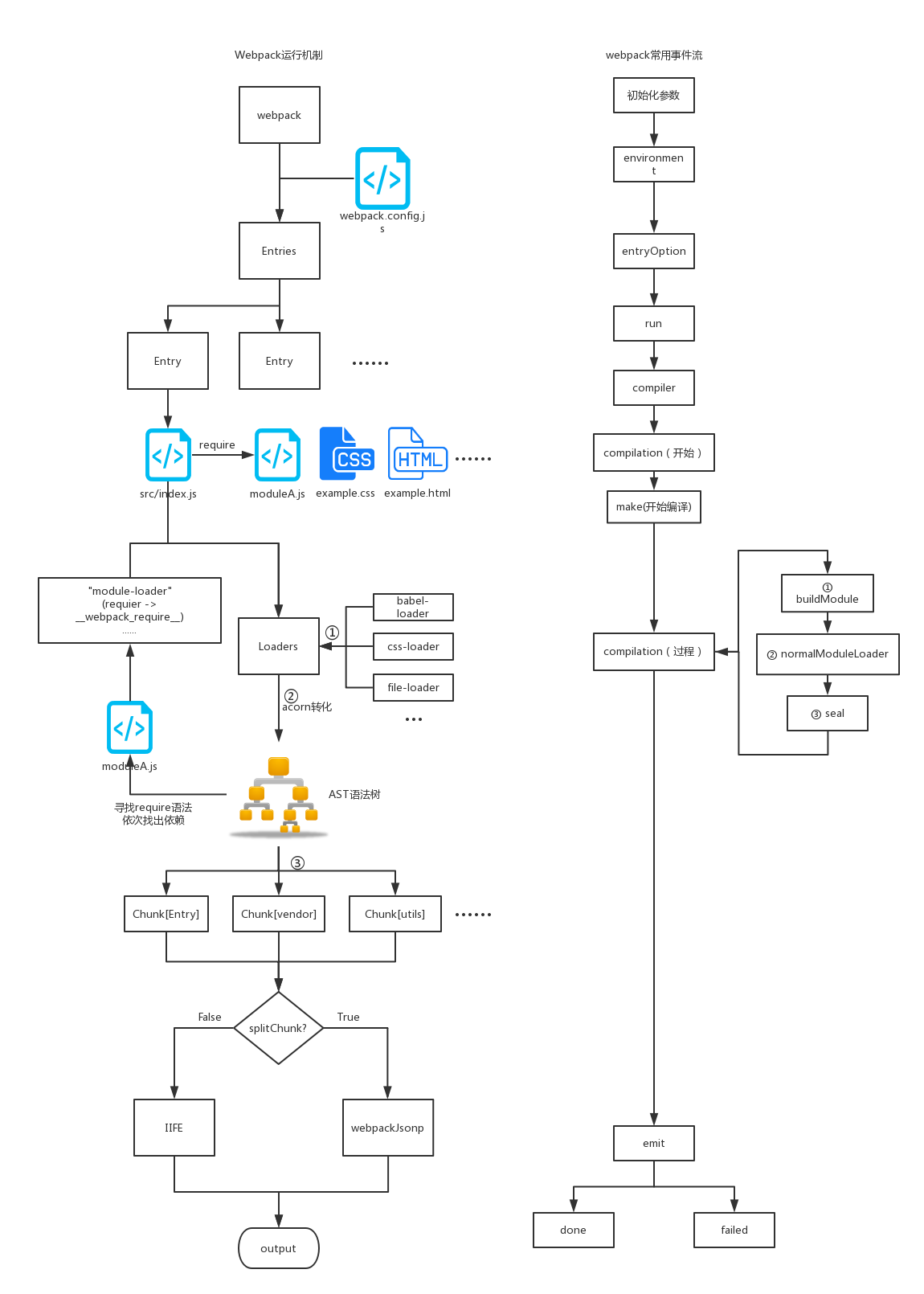
异常处理,"try..catch" [译]
原文地址
不管你多么的精通编程,有时我们的脚本总还是会有一些错误。可能是因为我们的编写出错,或是与预期不同的用户输入,或是错误的的服务端返回或者是其他总总不同的原因。
通常,一段代码会在出错的时候“死掉”(停止执行)并在控制台将异常打印出来。
但是有一种更为合理的语法结构 try..catch,它会在捕捉到异常的同时不会使得代码停止执行而是可以做一些更为合理的操作。
"try..catch" 语法
try..catch 结构由两部分组成:try 和 catch:
try {
// 代码...
} catch (err) {
// 异常处理
}它按照以下步骤执行:
- 首先,执行
try {...} 里面的代码。
- 如果执行过程中没有异常,那么忽略
catch(err) 里面的代码,try 里面的代码执行完之后跳出该代码块。
- 如果执行过程中发生异常,控制流就到了
catch(err) 的开头。变量 err(可以取其他任何的名称)是一个包含了异常信息的对象。
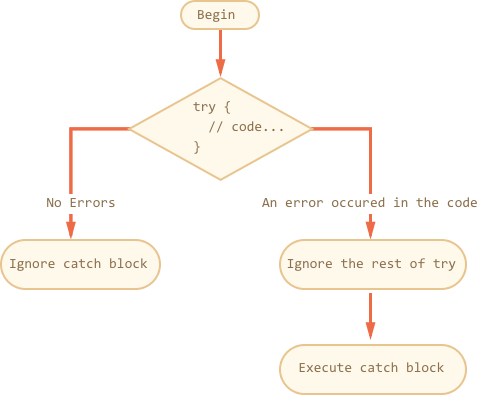
所以,发生在 try {…} 代码块的异常不会使代码停止执行:我们可以在 catch 里面处理异常。
让我们来看更多的例子。
````warn header="try..catch only works for runtime errors"
要使得 `try..catch` 能工作,代码必须是可执行的,换句话说,它必须是有效的 JavaScript 代码。
如果代码包含语法错误,那么 try..catch 不能正常工作,例如含有未闭合的花括号:
try {
{{{{{{{{{{{{
} catch(e) {
alert("The engine can't understand this code, it's invalid");
}JavaScript 引擎读取然后执行代码。发生在读取代码阶段的异常被称为 "parse-time" 异常,它们不会被 try..catch 覆盖到(包括那之间的代码)。这是因为引擎读不懂这段代码。
所以,try..catch 只能处理有效代码之中的异常。这类异常被称为 "runtime errors",有时候也称为 "exceptions"。
````warn header="`try..catch` works synchronously"
如果一个异常是发生在计划中将要执行的代码中,例如在 `setTimeout` 中,那么 `try..catch` 不能捕捉到:
```js run
try {
setTimeout(function() {
noSuchVariable; // 代码在这里停止执行
}, 1000);
} catch (e) {
alert( "won't work" );
}
```
因为 `try..catch` 包裹了计划要执行的 `setTimeout` 函数。但是函数本身要稍后才能执行,这时引擎已经离开了 `try..catch` 结构。
要捕捉到计划中将要执行的函数中的异常,那么 `try..catch` 必须在这个函数之中:
```js run
setTimeout(function() {
try {
noSuchVariable; // try..catch 处理异常!
} catch (e) {
alert( "error is caught here!" );
}
}, 1000);
```
Error 对象
当一个异常发生之后,JavaScript 生成一个包含异常细节的对象。这个对象会作为一个参数传递给 catch:
try {
// ...
} catch(err) { // <-- “异常对象”,可以用其他参数名代替 err
// ...
}对于所有内置的异常,catch 代码块捕捉到的相应的异常的对象都有两个属性:
name
: 异常名称,对于一个未定义的变量,名称是 "ReferenceError"
message
: 异常详情的文字描述。
还有很多非标准的属性在绝大多数环境中可用。其中使用最广泛并且被广泛支持的是:
stack
: 当前的调用栈:用于调试的,一个包含引发异常的嵌套调用序列的字符串。
例如:
try {
*!*
lalala; // 异常,变量未定义!
*/!*
} catch(err) {
alert(err.name); // ReferenceError
alert(err.message); // lalala 未定义
alert(err.stack); // ReferenceError: lalala 在... 中未定义
// 可以完整的显示一个异常
// 可以转化成 "name: message" 形式的字符串
alert(err); // ReferenceError: lalala 未定义
}使用 "try..catch"
让我们一起探究一下真实使用场景中 try..catch 的使用。
正如我们所知,JavaScript 支持 JSON.parse(str) 方法来解析 JSON 编码的值。
通常,它被用来解析从网络,从服务器或是从其他来源收到的数据。
我们收到数据后,像下面这样调用 JSON.parse:
let json = '{"name":"John", "age": 30}'; // 来自服务器的数据
*!*
let user = JSON.parse(json); // 将文本表示转化成 JS 对象
*/!*
// 现在 user 是一个解析自 json 字符串的有自己属性的对象
alert( user.name ); // John
alert( user.age ); // 30你可以在 info:json 这章找到更多的关于 JSON 的详细信息。
如果 json 格式错误,JSON.parse 就会报错,代码就会停止执行。
得到报错之后我们就应该满意了吗?当然不!
如果这样做,当拿到的数据出错,用户就不会知道(除非他们打开开发者控制台)。代码执行失败却没有提示信息会导致糟糕的用户体验。
让我们来用 try..catch 来处理这个错误:
let json = "{ bad json }";
try {
*!*
let user = JSON.parse(json); // <-- 当这里抛出异常...
*/!*
alert( user.name ); // 不工作
} catch (e) {
*!*
// ...跳到这里继续执行
alert( "Our apologies, the data has errors, we'll try to request it one more time." );
alert( e.name );
alert( e.message );
*/!*
}我们用 catch 代码块来展示信息,但是我们可以做的更多:发送一个新的网络请求,给用户提供另外的选择,把异常信息发送给记录日志的工具,... 。所有这些都比让代码直接停止执行好的多。
抛出自定义的异常
如果这个 json 数据语法正确,但是少了我们需要的 name 属性呢?
像这样:
let json = '{ "age": 30 }'; // 不完整的数据
try {
let user = JSON.parse(json); // <-- 不抛出异常
*!*
alert( user.name ); // 没有 name!
*/!*
} catch (e) {
alert( "doesn't execute" );
}这里 JSON.parse 正常执行,但是缺少 name 属性对我们来说确实是个异常。
为了统一的异常处理,我们会使用 throw 运算符。
"Throw" 运算符
throw 运算符生成异常对象。
语法如下:
技术上讲,我们可以使用任何东西来作为一个异常对象。甚至可以是基础类型,比如数字或者字符串。但是更好的方式是用对象,尤其是有 name 和 message 属性的对象(某种程度上和内置的异常有可比性)。
JavaScript 有很多标准异常的内置的构造器:Error、 SyntaxError、ReferenceError、TypeError 和其他的。我们也可以用他们来创建异常对象。
他们的语法是:
let error = new Error(message);
// 或者
let error = new SyntaxError(message);
let error = new ReferenceError(message);
// ...
对于内置的异常对象(不是对于其他的对象,而是对于异常对象),name 属性刚好是构造器的名字。message 则来自于参数。
例如:
let error = new Error("Things happen o_O");
alert(error.name); // Error
alert(error.message); // Things happen o_O让我们来看看 JSON.parse 会生成什么样的错误:
try {
JSON.parse("{ bad json o_O }");
} catch(e) {
*!*
alert(e.name); // SyntaxError
*/!*
alert(e.message); // Unexpected token o in JSON at position 0
}如我们所见, 那是一个 SyntaxError。
假定用户必须有一个 name 属性,在我们看来,该属性的缺失也可以看作语法问题。
所以,让我们抛出这个异常。
let json = '{ "age": 30 }'; // 不完整的数据
try {
let user = JSON.parse(json); // <-- 没有异常
if (!user.name) {
*!*
抛出 new SyntaxError("Incomplete data: no name"); // (*)
*/!*
}
alert( user.name );
} catch(e) {
alert( "JSON Error: " + e.message ); // JSON Error: Incomplete data: no name
}在 (*) 标记的这一行,throw 操作符生成了包含着我们所给的 message 的 SyntaxError,就如同 JavaScript 自己生成的一样。try 里面的代码执行停止,控制权转交到 catch 代码块。
现在 catch 代码块成为了处理包括 JSON.parse 在内和其他所有异常的地方。
再次抛出异常
上面的例子中,我们用 try..catch 处理没有被正确返回的数据,但是也有可能在 try {...} 代码块内发生另一个预料之外的异常,例如变量未定义或者其他不是返回的数据不正确的异常。
例如:
let json = '{ "age": 30 }'; // 不完整的数据
try {
user = JSON.parse(json); // <-- 忘了在 user 前加 "let"
// ...
} catch(err) {
alert("JSON Error: " + err); // JSON Error: ReferenceError: user is not defined
// ( 实际上并没有 JSON Error)
}当然,一切皆有可能。程序员也是会犯错的。即使是一些开源的被数百万人用了几十年的项目 —— 一个严重的 bug 因为他引发的严重的黑客事件被发现(比如发生在 ssh 工具上的黑客事件)。
对我们来说,try..catch 是用来捕捉“数据错误”的异常,但是 catch 本身会捕捉到所有来自于 try 的异常。这里,我们遇到了预料之外的错误,但是仍然抛出了 "JSON Error" 的信息,这是不正确的,同时也会让我们的代码变得更难调试。
幸运的是,我们可以通过其他方式找出这个异常,例如通过它的 name 属性:
try {
user = { /*...*/ };
} catch(e) {
*!*
alert(e.name); // "ReferenceError" for accessing an undefined variable
*/!*
}规则很简单:
catch 应该只捕获已知的异常,而重新抛出其他的异常。
"rethrowing" 技术可以被更详细的理解为:
- 捕获全部异常。
- 在
catch(err) {...} 代码块,我们分析异常对象 err。
- 如果我们不知道如何处理它,那我们就做
throw err 操作。
在下面的代码中,为了达到只在 catch 代码块处理 SyntaxError 的目的,我们使用重新抛出的方法:
let json = '{ "age": 30 }'; // 不完整的数据
try {
let user = JSON.parse(json);
if (!user.name) {
throw new SyntaxError("Incomplete data: no name");
}
*!*
blabla(); // 预料之外的异常
*/!*
alert( user.name );
} catch(e) {
*!*
if (e.name == "SyntaxError") {
alert( "JSON Error: " + e.message );
} else {
throw e; // rethrow (*)
}
*/!*
}(*) 标记的这行从 catch 代码块抛出的异常,是独立于我们期望捕获的异常之外的,它也能被它外部的 try..catch 捕捉到(如果存在该代码块的话),如果不存在,那么代码会停止执行。
所以,catch 代码块只处理已知如何处理的异常,并且跳过其他的异常。
下面这段代码将演示,这种类型的异常如何被另外一层 try..catch 代码捕获。
function readData() {
let json = '{ "age": 30 }';
try {
// ...
*!*
blabla(); // 异常!
*/!*
} catch (e) {
// ...
if (e.name != 'SyntaxError') {
*!*
throw e; // 重新抛出(不知道如何处理它)
*/!*
}
}
}
try {
readData();
} catch (e) {
*!*
alert( "External catch got: " + e ); // 捕获到!
*/!*
}例子中的 readData 只能处理 SyntaxError,而外层的 try..catch 能够处理所有的异常。
try..catch..finally
然而,这并不是全部。
try..catch 还有另外的语法:finally
如果它有被使用,那么,所有条件下都会执行:
try 之后,如果没有异常。catch 之后,如果没有异常。
该扩展语法如下所示:
*!*try*/!* {
... 尝试执行的代码 ...
} *!*catch*/!*(e) {
... 异常处理 ...
} *!*finally*/!* {
... 最终会执行的代码 ...
}试试运行这段代码:
try {
alert( 'try' );
if (confirm('Make an error?')) BAD_CODE();
} catch (e) {
alert( 'catch' );
} finally {
alert( 'finally' );
}这段代码有两种执行方式:
- 如果对于 "Make an error?" 你的回答是 "Yes",那么执行
try -> catch -> finally。
- 如果你的回答是 "No",那么执行
try -> finally。
finally 的语法通常用在:我们在 try..catch 之前开始一个操作,不管在该代码块中执行的结果怎样,我们都想结束的时候执行某个操作。
比如,生成斐波那契数的函数 fib(n) 的执行时间,通常,我们在开始和结束的时候测量。但是,如果该函数在被调用的过程中发生异常,就如执行下面的代码就会返回负数或者非整数的异常。
任何情况下,finally 代码块就是一个很好的结束测量的地方。
这里,不管前面的代码正确执行,或者抛出异常,finally 都保证了正确的时间测量。
let num = +prompt("Enter a positive integer number?", 35)
let diff, result;
function fib(n) {
if (n < 0 || Math.trunc(n) != n) {
throw new Error("Must not be negative, and also an integer.");
}
return n <= 1 ? n : fib(n - 1) + fib(n - 2);
}
let start = Date.now();
try {
result = fib(num);
} catch (e) {
result = 0;
*!*
} finally {
diff = Date.now() - start;
}
*/!*
alert(result || "error occured");
alert( `execution took ${diff}ms` );你可以通过后面的不同的输入来检验上面代码的执行:先在 prompt 弹框中先输入 35 —— 它会正常执行,try 代码执行后执行 finally 里面的代码。然后再输入 -1,会立即捕获一个异常,执行时间将会是 0ms。两次的测量结果都是正确的。
换句话说,有两种方式退出这个函数的执行:return 或是 throw,finally 语法都能处理。
```smart header="Variables are local inside try..catch..finally"
请注意:上面代码中的 `result` 和 `diff` 变量,都需要在 `try..catch` 之前声明。
否则,如果用 let 在 {...} 代码块里声明,那么只能在该代码块访问到。
````smart header="`finally` and `return`"
`finally` 语法支持**任何**的结束 `try..catch` 执行的方式,包括明确的 `return`。
下面就是 `try` 代码块包含 `return` 的例子。在代码执行的控制权转移到外部代码之前,`finally` 代码块会被执行。
```js run
function func() {
try {
*!*
return 1;
*/!*
} catch (e) {
/* ... */
} finally {
*!*
alert( 'finally' );
*/!*
}
}
alert( func() ); // 先 alert "finally" 里面的内容,再执行这里
````smart header="`try..finally`"
`try..finally` 结构也很有用,当我们希望确保代码执行完成不想在这里处理异常时,我们会使用这种结构。
```js
function func() {
// 开始做需要被完成的操作(比如测量)
try {
// ...
} finally {
// 完成前面要做的事情,即使 try 里面执行失败
}
}
```
上面的代码中,由于没有 `catch`,`try` 代码块中的异常会跳出这块代码的执行。但是,在跳出之前 `finally` 里面的代码会被执行。
全局 catch
这个部分的内容并不是 JavaScript 核心的一部分。
设想一下,try..catch 之外出现了一个严重的异常,代码停止执行,可能是因为编程异常或者其他更严重的异常。
那么,有没办法来应对这种情况呢?我们希望记录这个异常,给用户一些提示信息(通常,用户是看不到提示信息的),或者做一些其他操作。
虽然没有这方面的规范,但是代码的执行环境一般会提供这种机制,因为这真的很有用。例如,Node.JS 有 process.on('uncaughtException') 。对于浏览器环境,我们可以绑定一个函数到 window.onerror,当遇到未知异常的时候,它就会执行。
语法如下:
window.onerror = function(message, url, line, col, error) {
// ...
};message
: 异常信息。
url
: 发生异常的代码的 URL。
line, col
: 错误发生的代码的行号和列号。
error
: 异常对象。
例如:
<script>
*!*
window.onerror = function(message, url, line, col, error) {
alert(`${message}\n At ${line}:${col} of ${url}`);
};
*/!*
function readData() {
badFunc(); // 哦,出问题了!
}
readData();
</script>window.onerror 的目的不是去处理整个代码的执行中的所有异常 —— 这几乎是不可能的,这只是为了给开发者提供异常信息。
也有针对这种情况提供异常日志的 web 服务,比如 https://errorception.com 或者 http://www.muscula.com。
它们会这样运行:
- 我们注册这个服务,拿到一段 JS 代码(或者代码的 URL),然后插入到页面中。
- 这段 JS 代码会有一个客户端的
window.onerror 函数。
- 发生异常时,它会发送一个异常相关的网络请求到服务提供方。
- 我们只要登录服务方提供方的网络接口就可以看到这些异常。
总结
try..catch 结构允许我们处理执行时的异常,它允许我们尝试执行代码,并且捕获执行过程中可能发生的异常。
语法如下:
try {
// 执行此处代码
} catch(err) {
// 如果发生异常,跳到这里
// err 是一个异常对象
} finally {
// 不管 try/catch 怎样都会执行
}可能会没有 catch 代码块,或者没有 finally 代码块。所以 try..catch 或者 try..finally 都是可用的。
异常对象包含下列属性:
message —— 我们能阅读的异常提示信息。name —— 异常名称(异常对象的构造函数的名称)。stack (没有标准) —— 异常发生时的调用栈。
我们也可以通过使用 throw 运算符来生成自定义的异常。技术上来讲,throw 的参数没有限制,但是通常它是一个继承自内置的 Error 类的异常对象。更对关于异常的扩展,请看下个章节。
重新抛出异常,是一种异常处理的基本模式:catch 代码块通常处理某种已知的特定类型的异常,所以它应该抛出其他未知类型的异常。
即使我们没有使用 try..catch,绝大多数执行环境允许我们设置全局的异常处理机制来捕获出现的异常。浏览器中,就是 window.onerror。
广而告之
本文发布于薄荷前端周刊,欢迎Watch & Star ★,转载请注明出处。
欢迎讨论,点个赞再走吧 。◕‿◕。 ~