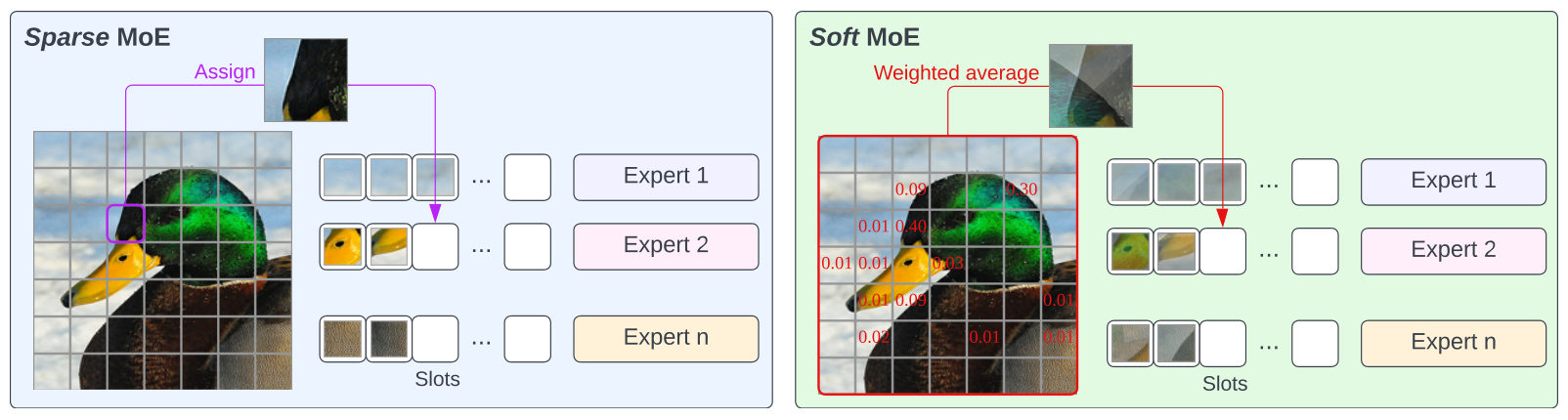
Lol, I had fun with this code. But it wasn't all that suited to my use without the position embedding interpolation and some registers. So I added them. See if you feel like you want to include them into your code:
import math
from functools import partial
from typing import Callable
import torch
import torch.jit
import torch.nn as nn
import torch.utils.checkpoint
from timm.layers import Mlp, PatchDropout, trunc_normal_
from timm.models._manipulate import checkpoint_seq, named_apply
from timm.models.vision_transformer import (Block, _load_weights,
get_init_weights_vit,
init_weights_vit_timm)
from soft_moe.soft_moe import SoftMoELayerWrapper
class PatchEmbed(nn.Module):
# converts image into patch embeddings based on total number of non-overlapping crops.
# For each image containing n patches, there should be n embedding vectors per image, so a n x embedding_vector matrix.
def __init__(self,img_size,patch_size,in_channels=3, embed_dim=256):
super().__init__()
self.img_size = img_size
self.patch_size = patch_size
self.in_channels = in_channels
self.n_patches = (img_size // patch_size)**2
self.project = nn.Conv2d(
in_channels =in_channels,
out_channels = embed_dim,
kernel_size = patch_size,
stride = patch_size,
)
def forward(self,x):
# x has input a tensor of shape B, C, H, W (batch, channel, height, width)
x = self.project(x) # Batch X Embedding Dim X sqrt(N_patches) X sqrt(N_patches)
x = x.flatten(2) # Batch X Embedding Dim X N_patches
x = x.transpose(1,2) # Batch X N_patches X Embedding Dim
return x
class SoftMoEVisionTransformer(nn.Module):
"""Vision Transformer with Soft Mixture of Experts MLP layers.
From the paper "From Sparse to Soft Mixtures of Experts"
https://arxiv.org/pdf/2308.00951.pdf
Code modified from:
https://github.com/huggingface/pytorch-image-models/blob/main/timm/models/vision_transformer.py
"""
def __init__(
self,
num_experts: int = 128,
slots_per_expert: int = 1,
moe_layer_index: int | list[int] = 6,
img_size: int | tuple[int, int] = 224,
patch_size: int | tuple[int, int] = 16,
in_chans: int = 3,
global_pool: str = "token",
embed_dim: int = 768,
depth: int = 12,
num_heads: int = 12,
mlp_ratio: float = 4.0,
qkv_bias: bool = True,
qk_norm: bool = False,
init_values: float | None = None,
class_token: bool = True,
no_embed_class: bool = False,
pre_norm: bool = False,
fc_norm: bool | None = None,
drop_rate: float = 0.0,
pos_drop_rate: float = 0.0,
patch_drop_rate: float = 0.0,
proj_drop_rate: float = 0.0,
attn_drop_rate: float = 0.0,
drop_path_rate: float = 0.0,
weight_init: str = "",
embed_layer: Callable = PatchEmbed,
norm_layer: Callable | None = None,
act_layer: Callable | None = None,
block_fn: Callable = Block,
mlp_layer: Callable = Mlp,
):
"""
Args:
num_experts (int): Number of experts in MoE layers.
slots_per_expert (int): Number of token slots per expert.
moe_layer_index (int or list[int]): Block depth indices where MoE layers are used.
Either an int which denotes where MoE layers are used from to the end, or a list
of ints denoting the specific blocks (both use 0-indexing).
img_size (int or tuple[int, int]): Input image size.
patch_size (int or tuple[int, int]): Patch size.
in_chans (int): Number of image input channels.
global_pool (str): Type of global pooling for the final sequence (default: 'token').
embed_dim (int): Transformer embedding dimension.
depth (int): Depth of the transformer.
num_heads (int): Number of attention heads.
mlp_ratio (float): Ratio of MLP hidden dim to embedding dim.
qkv_bias (bool): Enable bias for qkv projections if True.
qk_norm (bool): Enable normalization of query and key in self-attention.
init_values (float or None): Layer-scale init values (layer-scale enabled if not None).
class_token (bool): Use a class token.
no_embed_class (bool): Do not embed class tokens in the patch embedding.
pre_norm (bool): Apply normalization before self-attention in the transformer block.
fc_norm (bool or None): Pre-head norm after pool (instead of before).
If None, enabled when global_pool == 'avg'.
drop_rate (float): Head dropout rate.
pos_drop_rate (float): Position embedding dropout rate.
attn_drop_rate (float): Attention dropout rate.
drop_path_rate (float): Stochastic depth rate.
weight_init (str): Weight initialization scheme.
embed_layer (Callable): Patch embedding layer.
norm_layer (Callable or None): Normalization layer.
act_layer (Callable or None): MLP activation layer.
block_fn (Callable): Transformer block layer.
mlp_layer (Callable): MLP layer.
"""
super().__init__()
assert global_pool in ("", "avg", "token")
assert class_token or global_pool != "token"
use_fc_norm = global_pool == "avg" if fc_norm is None else fc_norm
norm_layer = norm_layer or partial(nn.LayerNorm, eps=1e-6)
act_layer = act_layer or nn.GELU
self.global_pool = global_pool
# num_features for consistency with other models
self.num_features = self.embed_dim = embed_dim
self.num_prefix_tokens = 1 if class_token else 0
self.no_embed_class = no_embed_class
self.grad_checkpointing = False
self.patch_embed = embed_layer(
img_size=img_size,
patch_size=patch_size,
in_channels=in_chans,
embed_dim=embed_dim,
)
self.patch_embed.project.bias = None
num_patches = (img_size//patch_size)**2
self.cls_token = (
nn.Parameter(torch.zeros(1, 1, embed_dim)) if class_token else None
)
self.numregisters = 4
self.registers = (
nn.Parameter(torch.zeros(1,4,embed_dim))
)
embed_len = (
num_patches if no_embed_class else num_patches + self.num_prefix_tokens
)
self.pos_embed = nn.Parameter(torch.randn(1, embed_len, embed_dim) * 0.02)
self.pos_drop = nn.Dropout(p=pos_drop_rate)
if patch_drop_rate > 0:
self.patch_drop = PatchDropout(
patch_drop_rate,
num_prefix_tokens=self.num_prefix_tokens,
)
else:
self.patch_drop = nn.Identity()
self.norm_pre = norm_layer(embed_dim) if pre_norm else nn.Identity()
# Wrap the mlp_layer in a soft-moe wrapper
self.num_experts = num_experts
self.slots_per_expert = slots_per_expert
moe_mlp_layer = partial(
SoftMoELayerWrapper,
layer=mlp_layer,
dim=embed_dim,
num_experts=self.num_experts,
slots_per_expert=self.slots_per_expert,
)
# Create a list where each index is the mlp layer class to
# use at that depth
self.moe_layer_index = moe_layer_index
if isinstance(moe_layer_index, list):
# Only the specified layers in moe_layer_index
assert len(moe_layer_index) > 0
assert all([0 <= l < depth for l in moe_layer_index])
mlp_layers_list = [
moe_mlp_layer if i in moe_layer_index else mlp_layer
for i in range(depth)
]
else:
if moe_layer_index < depth:
# All layers including and after moe_layer_index
mlp_layers_list = [
moe_mlp_layer if i >= moe_layer_index else mlp_layer
for i in range(depth)
]
else: # hack to make all layers mlp
mlp_layers_list = [
mlp_layer
for i in range(depth)
]
# stochastic depth decay rule
dpr = [x.item() for x in torch.linspace(0, drop_path_rate, depth)]
self.blocks = nn.Sequential(
*[
block_fn(
dim=embed_dim,
num_heads=num_heads,
mlp_ratio=mlp_ratio,
qkv_bias=qkv_bias,
qk_norm=qk_norm,
init_values=init_values,
proj_drop=proj_drop_rate,
attn_drop=attn_drop_rate,
drop_path=dpr[i],
norm_layer=norm_layer,
act_layer=act_layer,
mlp_layer=mlp_layers_list[i],
)
for i in range(depth)
]
)
self.norm = norm_layer(embed_dim) if not use_fc_norm else nn.Identity()
# Classifier Head
self.fc_norm = norm_layer(embed_dim) if use_fc_norm else nn.Identity()
if weight_init != "skip":
self.init_weights(weight_init)
def init_weights(self, mode=""):
assert mode in ("jax", "jax_nlhb", "moco", "")
trunc_normal_(self.pos_embed, std=0.02)
if self.cls_token is not None:
nn.init.normal_(self.cls_token, std=1e-6)
if self.registers is not None:
nn.init.normal_(self.registers, std=1e-6)
def _init_weights(self, m):
# this fn left here for compat with downstream users
init_weights_vit_timm(m)
@torch.jit.ignore()
def load_pretrained(self, checkpoint_path, prefix=""):
_load_weights(self, checkpoint_path, prefix)
@torch.jit.ignore
def no_weight_decay(self):
return {"pos_embed", "cls_token", "dist_token", "registers"}
@torch.jit.ignore
def group_matcher(self, coarse=False):
return dict(
stem=r"^cls_token|pos_embed|patch_embed", # stem and embed
blocks=[(r"^blocks\.(\d+)", None), (r"^norm", (99999,))],
)
@torch.jit.ignore
def set_grad_checkpointing(self, enable=True):
self.grad_checkpointing = enable
def pos_embedding_interp(self, x, h, w):
num_patches = x.shape[1] - 1 # because one is a class token
N = self.pos_embed.shape[1] - 1 # this is the shape the ViT expects
if num_patches == N: # won't include a check for the image being square
return self.pos_embed.shape[1] # because no interpolation needs to be done
# Now we need to do interpolation. So begin by separating class and position tokens
class_pos_embed = self.pos_embed[:,0]
patch_pos_embed = self.pos_embed[:,1:]
dim = x.shape[-1] # patch embedding dimensionality
w0 = w // self.patch_embed.patch_size
h0 = h // self.patch_embed.patch_size
w0, h0 = w0+0.1, h0+0.1 # preventing some division by zero (just in case)
# Perform the interpolation
patch_pos_embed = torch.nn.functional.interpolate(
patch_pos_embed.reshape(1, int(math.sqrt(N)), int(math.sqrt(N)), dim).permute(0, 3, 1, 2),
scale_factor=(w0 / math.sqrt(N), h0 / math.sqrt(N)),
mode='bicubic',
)
patch_pos_embed = patch_pos_embed.permute(0, 2, 3, 1).view(1, -1, dim)
return torch.cat((class_pos_embed.unsqueeze(0), patch_pos_embed), dim=1)
def _pos_embed(self, x):
# original timm, JAX, and deit vit impl
# pos_embed has entry for class token, concat then add
batches, _, W, H = x.shape # B, C, W, H
x = self.patch_embed(x)
x = torch.cat((self.cls_token.expand(batches, -1, -1), x), dim=1)
x = x + self.pos_embedding_interp(x,H,W) # I changed this else registers does not work
if self.registers is not None:
x = torch.cat(
(
x[:,0,:].unsqueeze(1),
self.registers.expand(x.shape[0],-1,-1),
x[:,1:],
),
dim = 1,
)
return self.pos_drop(x)
def forward_features(self, x):
x = self._pos_embed(x)
x = self.patch_drop(x)
x = self.norm_pre(x)
if self.grad_checkpointing and not torch.jit.is_scripting():
x = checkpoint_seq(self.blocks, x)
else:
x = self.blocks(x)
x = self.norm(x)
return x
def forward(self, x):
x = self.forward_features(x)
return x[:, 0] # you will only use the class token