canner / vulcan-sql Goto Github PK
View Code? Open in Web Editor NEWData API Framework for AI Agents and Data Apps
Home Page: https://vulcansql.com
License: Apache License 2.0
Data API Framework for AI Agents and Data Apps
Home Page: https://vulcansql.com
License: Apache License 2.0
We've defined lots of interfaces for nunjucks here, but it was not exported, so extension developer won't able to use it.

Re-export Nunjucks with correct interfaces or publish the declaration files.
We can generate different queries depending on the user attribute, so it is easy to mask some columns manually like below:
SELECT
{% if context.user.attr.group == 'admin' %}
id
{% else %}
CONCAT(SUBSTR(id, 0, 4), 'xxxxxx')
{% endif %} as id,
age
FROM users;But manually masking each column might be annoying and unpredictable, we should provide "masking" tag with some masking functions.
Inspired by MSSQL DDM, we can add a built-in tag masking with syntax:
{% masking <column-name> <masking-function> %}
We can implement the most commonly used masking function partial first.
For example, assuming that we have a user table:
| id | name |
|---|---|
| AB1234567CD | Ivan |
| EF2345678GH | Freda |
SELECT
{% masking id partial(2, 'xxxxxxx', 2) %} as id,
name
FROM user;We'll get the result below:
| id | name |
|---|---|
| ABxxxxxxxCD | Ivan |
| EFxxxxxxxGH | Freda |
dev
When we add parameters in templates but not in schemas, the document doesn't get these parameters.
It should get these parameters with default validators.
{{ context.params.id }} but not in schema definitions.Most data analysts haven't installed NodeJS in their environment, we can provide some alternative solutions for them.
Package our CLI and NPM to a Docker image, then we can use docker run -it vulcan/cli <some-command> directly, e.g. docker run -it -v ${PWD}:/usr/app -p 3000:3000 run -it vulcan/cli init.
Users can use an alias the avoid duplicated commands
alias vulcan="docker run -it -v ${PWD}:/usr/app -p 3000:3000 run -it vulcan/cli"
vulcan initOur project name is confused with other projects.
Rename the repository from vulcan to vulcan-sql. Github will automatically redirect the URLs to the new one. Following services might be impacted:
In order to enhance our query performance after users send the API request to run our data endpoint to get the result from the data source. We need to provide a Caching (pre-loading) Layer with the duckDB to enhance query performance.
Define the cache layer in YAML by cache field, and define each cacheTableName and its config. For example we define an sql select * from order query the result from data source pg and keep to duckDB by order table name.
Otherwise, the refreshTime and refreshExpression means when should we need to refresh the query and keep the new result in the cache table in duckDB. The index is a duckDB indexes feature to index like the original database and make query efficient.
# API schema YAML
cache:
# "order" table keep in duckDB
- cacheTableName: "order"
sql: "select * from order",
# optional
profile: pg
# optional
refreshTime:
every: "5m"
# optional
refreshExpression:
expression: "MAX(created_at)"
every: "5m"
# optional
indexes:
'idx_a': 'col_a'
'idx_b': 'col_b'
# "product" table keep in duckDB
- cacheTableName: "product"
sql: "select * from product",
# used data source
profiles: pgHere is our SQL file, which makes our query send to duckDB to get results. In the scop of {% cache %} ... {% endcache %} , when we send the query to duckDB, we will search the each table keep in duckDB or not, so if your YAML not defined the same cache table name, it will make the query failed.
-- The "cache" scope means the SQL statement will send the query to duckDB cache data source
{% cache %}
select * from order
where type = {{ context.params.type }}
and where exists (
select * from product where price >= {{ context.params.price }}
and order.product_id = product.id
)
{% endcache %}The #157 not contains in the epic, we will arrange to develop it in the future.
We need a production build that only includes necessary context, e.g. artifacts, production dependency, serve package ...etc.
Provide package command to do production builds, and use --output flag to indicate the output type. We can implement node and docker output first:
vulcan package --output nodenode ./dist/index.jsvulcan package --output node && docker build ./distdocker run <imagedev
The server always returns data in JSON format even if we send the requests env with .csv. e.g. http://localhost:3000/api/artist/1/works.csv
It should returns csv format.
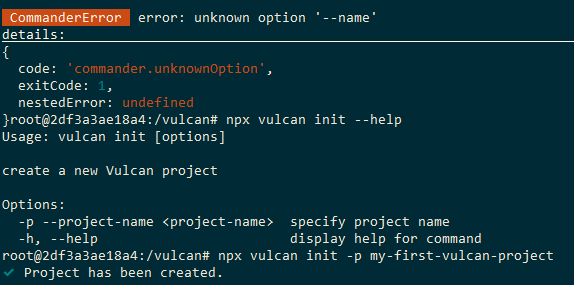
follow document, this command must vulcan init --name <project-name>, but actually need use vulcan init -p <project-name>.
When some uncatched errors are thrown from downstream of Vulcan server, e.g. data source, Vulcan sometimes crashes and exits.
We should catch all errors and keep the server listening.
PostgreSQL data source throws uncached errors when databases disconnected, this issue will be fixed in the future
.
Version:
cli version: 0.2.1
core version: 0.2.1
build version: 0.2.1
serve version: 0.2.1
VulcanSQL tried to parameterize the variables without values, e.g.
{% set someArr = [] %}
{{ someArr.push(1) }}
select {{ someArr[0] }} as a;Generated query:
$1 --- This should be removed
select $1 as a;We should ignore the variables without values:
select $1 as a;We can use expressions instead of variables to mitigate this issue.
{% set someArr = [] %}
{% set temp = someArr.push(1) %}
select {{ someArr[0] }} as a;dev
Vulcan server throws format errors when the URL is not found.
Error: Url ending format not matched in "formats" options
It should do nothing with URLs that are not found.
Snowflake is one of the most commonly used warehouses, we should add driver support.
Provide Snowflake driver as an individual extension.
We only support executing queries and preparing statements now, so the driver can ignore the builder commands (ExecuteOptions.operations)
We need to restart the server manually after updating SQL or schemas now, it'll be better if Vulcan can watch these files and reload services automatically.
Provide a flag --watch, -w for start command, which lets the server watch SQL and schemas changes, and restart or reload the server when needed.
With the increase of users and version updates, the current documentation is no longer sufficient to meet the user's needs and requires an update.
The set-sampler section does not mention that incomplete parameter settings can cause the server to fail during the startup phase, for example, if we would like to check data from context.req.xxx like below:
-- We use the req in sql file
select
*,
{{ context.req.method }} as "req-method",
{{ context.req.url }} as "req-url"
from "artists" where
ConstituentID = {{ context.params.id }}
and
{{ context.req.method }} = 'GET'
# API Schema
urlPath: /artist/:id
request:
- fieldName: id
fieldIn: path
description: constituent id
validators:
- required
sample:
req:
method: GET
url: 'localhost:3000'
parameters:
id: '1'
profile: duck
profile: duck
Then we should also set the req in the sample.
Otherwise the install-vulcansql-cli section has different instructions for Windows users, etc.
We need to load data source connection information to execute queries, e.g. host, port, dbname, dbuser, dbpassword ... for Postgres.
Users can set profiles property in their project config file (vulcan.yaml), it contains all the profiles' paths, in order of priority, from top to bottom.
profiles:
- some/path/to/profiles.yaml
- another/path/to/profiles.yamlTwo default paths will append at the end automatically: profiles.yaml and ~/.vulcan/profiles.yaml. For example:
profiles:
- some/path/to/profiles.yaml
- another/path/to/profiles.yamlWe'll try to find profiles from some/path/to/profiles.yaml first, then another/path/to/profiles.yaml, profiles.yaml, and ~/.vulcan/profiles.yaml
Profiles are duplicated by their names.
This is an example of a profile file:
- name: pg-admin # required. the name of this profile
type: pg # required. which driver we should use
connection: # required. connection info, which depends on drivers
host: example.com
username: vulcan
password: xxxx
- name: duck
type: duck
connection:
path: ./path/to/dbWe'll need to set which profile we want to use at endpoints' schemas:
urlPath: /users
profile: pg-adminPostgres is one of the most commonly used warehouses, we should add driver support.
Provide Postgres driver as an individual extension.
We only support executing queries and preparing statements now, so the driver can ignore the builder commands (ExecuteOptions.operations)
The components: TagRunner, TagBuilder, FIlterRunner, and FilterBuilder are designed for low-level operations, that is, accessing the compiler's parser directly. It's difficult for most users, we should wrap this API and provide more delightful components.
Wrap parser API with high-level components.
Examples:
import { createTagExtension, FunctionalTag } from '@vulcan-sql/core';
const MaskTag: FunctionalTag = async ({ sql, args }) => {
return `CONCAT(SUBSTR(${sql}, 0, ${args['len'] + 1}), 'xxxx')`;
};
export default createTagExtension('mask', MaskTag);select
{% mask len=5 %} DisplayName {% endmask %} as name
from "artists"
limit 10We need clear documentation on our official website before the first release.
We have to install Vulcan CLI and download the required dependencies if we want to try Vulcan, it might be a barry that prevents new users to try Vulcan.
Provide an online environment like Codesandbox that uses in-memory databases, as a playground for new users.
In #150, In order to enhance our query performance after users send the API request to run our data endpoint to get the result from the data source. We need to provide a Caching (pre-loading) Layer with the duckDB to enhance query performance.
Define the tag scope of {% cache %} ... {% endcache %} to parse the scope of {% cache %} ... {% endcache %} tag and send the SQL to duckDB.
-- The "cache" scope means the SQL statement will send the query to duckDB cache data source
{% cache %}
select * from order
where type = {{ context.params.type }}
and where exists (
select * from product where price >= {{ context.params.price }}
and order.product_id = product.id
)
{% endcache %}In the build time, define a CacheTagBuilder to parse {% cache %} … {% endcache %} to the AST tree, set the cache metadata name cache.vulcan.com to make schema parser #151 to work, then keep to the artifact.

follow document, this command must vulcan start --watch.
We haven't had any guide for developing extensions.
Add a new document series for Vulcan developers:
(TBD, feel free to edit the content below)
We haven't had a proper way to set log levels and control what components to show (e.g. file path, function name ...etc.)
Provide a global flag for CLI --verbose, -v. Set the log level to silly or debug and show file paths and function names, otherwise set the log level to info and hide file paths and function names.
Support gzip compression to compress the data result ( e.g: JSON, CSV ).
Support three parameters - always, enable, disable for setting compression gzip in each API schema to control compression by Accept-Encoding or ending word of API URL
# schema.yaml
gzip: enableenable mode ( control by request )The enable means do the Gzip compression feature according to you pass Accept-Encoding: gzip in the header, or indicating the .gz in the URL ending or not, like below:
/xxxx.json.gz ,/xxxx.json.gz ,/xxxx.csv.gzThe priority is detecting the URL ending word .gz first, then detecting the HTTP header Accept-Encoding: gzip second, below is samples:
Accept-Encoding: gzip, but you add the .gz on the URL ending word, then we will do the Gzip compression.Accept-Encoding: gzip, but you do not add the .gz on the URL ending word, then we will do the Gzip compression too.always modeThe always means always do the Gzip compression, whether you specify the URL ending word or give it by HTTP header Accept-Encoding: gzip.
disable modeThe disable means never do the Gzip compression feature, so even if you pass .gz in the URL ending word or Accept-Encoding: gzip in the header, it still does not do the compression.
We've implemented offset-based pagination #104, but our API response didn't give extra information about it, e.g. total count.
We can wrap our result to "results" property, and add extra information about pagination like below:
{
"_links": {
"next": "/api/users?limit=20&offset=20",
},
"offset": 0
"limit": 20,
"results": [
// Data gose here
],
"total_count": 100,
}Version:
cli version: 0.3.0
core version: 0.3.0
build version: 0.3.0
serve version: 0.3.0
Snowflake driver prints logs with console:
2022-10-28 03:26:55.957 INFO [CLI] Starting server...
2022-10-28 03:26:56.166 DEBUG [SERVE] Initializing data source: mock
2022-10-28 03:26:56.166 DEBUG [SERVE] Data source mock initialized
2022-10-28 03:26:56.167 DEBUG [SERVE] Initializing data source: snowflake
2022-10-28 03:26:56.169 DEBUG [CORE] Initializing profile: snow using snowflake driver
Unable to connect: Incorrect username or password was specified.
Unable to connect: Incorrect username or password was specified.
Unable to connect: Incorrect username or password was specified
It should print logs through our logger (tslog).
Snowflake driver used winston as their logger and not allow us to modify it.
https://github.com/snowflakedb/snowflake-connector-nodejs/blob/master/lib/snowflake.js#L23
We found some issues with PostgreSQL and DuckDB drivers, we should fix them.
We should have issue / PR templates for the community.
BigQuery is one of the most commonly used warehouses, we should add driver support.
Provide BigQuery driver as an individual extension.
We only support executing queries and preparing statements now, so the driver can ignore the builder commands (ExecuteOptions.operations)
In #150, In order to enhance our query performance after users send the API request to run our data endpoint to get the result from the data source. We need to provide a Caching (pre-loading) Layer with the duckDB to enhance query performance.
In the part, only focus on parsing the YAML by the above cache format.
# API schema YAML
cache:
# "order" table keep in duckDB
- cacheTableName: "order"
sql: "select * from order",
# optional
profile: pg
# optional
refreshTime:
every: "5m"
# optional
refreshExpression:
expression: "MAX(created_at)"
every: "5m"
# optional
indexes:
'idx_a': 'col_a'
'idx_b': 'col_b'
# "product" table keep in duckDB
- cacheTableName: "product"
sql: "select * from product",If the refreshExpression and refreshTime are both setup, throw the error when the user type vulcan build.
Because we will solve the Caching (pre-loading) Layer with the duckDB by multiple issues, we need to define an interface to interact with the solution of other issues.
Here, make the APISchema like below, we add the cache!: Array<CacheLayerInfo>; in APISchema and define the CacheLayerInfo interface.
// packages/core/src/models/artifact.ts
export class CacheLayerInfo {
cacheTableName!: string;
sql!: string;
refreshTime?: Record<string, string>;
refreshExpression?: Record<string, string>;
// the used profile to query the data from data source
profile!: string;
// index key name -> index column
indexes?: Record<string, string>;
}
export class APISchema {
// graphql operation name
operationName!: string;
// restful url path
urlPath!: string;
// template, could be name or path
templateSource!: string;
@Type(() => RequestSchema)
request!: Array<RequestSchema>;
@Type(() => ErrorInfo)
errors!: Array<ErrorInfo>;
@Type(() => ResponseProperty)
response!: Array<ResponseProperty>;
description?: string;
// The pagination strategy that do paginate when querying
// If not set pagination, then API request not provide the field to do it
pagination?: PaginationSchema;
sample?: Sample;
profiles!: Array<string>;
cache!: Array<CacheLayerInfo>;
}Otherwise, when parsing the cache table name in YAML, please check whether the metadata which exists cache.vulcan.com key name or not:
cache setting in the schema.yaml or not, throw an error, because it means your SQL will use the cache feature, not YAML defined.RawAPISchema if metadata exists cache.vulcan.com key name.The files generated by CLI haven't been updated for the new design, we can't start the server with them.
Update these SQL files, schemas, and config.
Version:
OS: macOS
When not setting the formats field in reponse-format options of the vulcan.yaml, the API request will throw an internal error when API URL does not contain any format at the end of the URL.
It should get the default format.
formats field in the reponse-format options of the vulcan.yaml.# vulcan.yaml
response-format:
enabled: true
options:
default: jsonUse a browser to send HTTP GET requests which not has format in the end of the URL
e.g: http://localhost:3000/api/orders
Got the Internal Error and shows an error message in the terminal:
Error Response:
{
"message": "An internal error occurred",
"requestId": "d8d5d068-ef49-4e5b-bc1f-92d97a9308fb"
}Termal Shows Error:
TypeError Cannot read properties of undefined (reading 'formatToResponse')
cli version: 0.3.0
core version: 0.2.1
build version: 0.2.1
serve version: 0.2.1
The args property of TagRunnerOptions was constianted to be string, number, or boolean.
export declare type TagExtensionArgTypes = string | number | boolean;
export interface TagRunnerOptions {
context: nunjucks.Context;
args: TagExtensionArgTypes[];
contentArgs: TagExtensionContentArgGetter[];
metadata: NunjucksExecutionMetadata;
}But it can be object if inputs are keyword arguments.
{% tagname foo="bar" %}It should be allowed to be Record too.
I have been trying to connect VulcanSQL with BigQuery but receive an error 'Not found'.
Also, not getting any endpoints in /localhost/doc


The credentials file is working fine as I tested the connection with DBeaver.
Files: https://drive.google.com/drive/folders/1g1lyEG32x63hAzrIo2JK8vFAk5GpNC1U?usp=sharing
After #71, we have profiles for data sources, we want to do access control for them. For example, admin users can access pg-admin profile, but non-admin users can only access pg-no-admin profile.
We can implement a sample attribute-based access control (ABAC) for our profiles.
allow property to indicate what attributes users should have.admin can access this profile:
- name: 'pg-admin'
driver: 'pg'
connection: xx
allow:
- name: admingroup and its value should be admin:
- name: 'pg-admin'
driver: 'pg'
connection: xx
allow:
- attribute:
name: group
value: admin- name: 'pg-admin'
driver: 'pg'
connection: xx
allow:
- name: admin-*admin and has group attribute with value admin can access this profile.
- name: 'pg-admin'
driver: 'pg'
connection: xx
allow:
- name: admin
attribute:
name: group
value: admin admin, someoneelse, and those who have group attribute with value admin can access this profile.
- name: 'pg-admin'
driver: 'pg'
connection: xx
allow:
- name: admin
- name: someoneelse
- attribute:
name: group
value: admin 403 error should be thrown.dev
Server only prints end square bracket when there is no data.
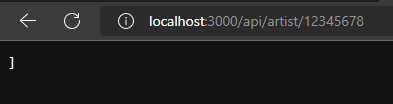
It should be [].
Provide new API style - GraphQL, the query language API for making users more choices.
Support GraphQL API type, you could activate it by appending the GRAPHQL in types of project config:
# vulcan.yaml
types:
- RESTFUL
- GRAPHQL

follow document, install command is npm install @vulcan-sql/cli, but it will install in local place.
But usage command is vulcan init, if modules install in local node_modules, command is npx vulcan init or write usage command in package.json.
And this project look like a sub-project control tool. Suggest install command modify to npm install -g @vulcan-sql/cli, it will make usage command right.

The route information like host, path ...etc. are useful while rendering SQL queries.
Pass host name and url path into built-in context.
For example: https://example.com/v1/users
{{ context.host }} -> example.com
{{ context.path }} -> /v1/users
or
{{ context.req.host }} ...
Catalog UI, which is our incoming feature, needs to preview the result of each endpoint, it needs a simple pagination implementation for doing so.
We can implement .limit() and .offset() of query builder. Query builder has the following operation:
export interface SQLClauseOperation {
// record select clause operations, null means select *
select: SelectClauseOperation | null;
// record where clause operations
where: Array<WhereClauseOperation>;
// record join clause operations => ok
join: Array<JoinClauseOperation>;
// record groupBy clause operations, array is column name
groupBy: GroupByClauseOperations;
// recode having clause operations
having: Array<HavingClauseOperation>;
// record orderBy operations
orderBy: Array<OrderByClauseOperation>;
// null means not set the value
limit: number | null;
// null means not set the value
offset: number | null;
}For a temporary solution, we can implement limit and offset only,
In DataSource:
public async execute({
statement: sql,
operations,
}: ExecuteOptions): Promise<DataResult> {
sql = `select * from (${sql}) as q limit ${limit} offset ${offset}` // Should handle sql injection
....It's a quick implementation for incoming features, it should be improved in the future.
DuckDB is an in-process OLAP database management system that can be used in experimental/demo environments.
Provide duckdb driver as an individual extension.
We only support executing queries and preparing statements now, so the driver can ignore the builder commands (ExecuteOptions.operations)
We haven't had a proper way to handle errors for restful API, that is, we'll always throw "500 internal server error" for any errors.
Catch these errors and set the proper HTTP status code. We can wrap our errors when they occurred and set the desired HTTP code there.
We've parameterized all the input data, but if the queries were generated by custom tags (Tag Extensions), we are not able to handle them.
Extension
createTagExtension('test', async ({ args, sql }) =>
`${args['arg']} ${sql}`
);Template
{% test arg=context.params.id %}
{{ context.params.id }}
{% endtest %}Result (with id = 'some injection')
some injection $1TBD
We'd parameterize the output of filters, so custom filters are not affected.
ClickHouse blazing fast analytics database
I would like to support easy analytics API creation with your great project
https://clickhouse.com/docs/en/integrations/language-clients/nodejs
We need to define our parameters in YAML file when we want to add validators or change parameter sources (path, query, or header). But it might be a hassle for data engineers to define parameters in another file.
Provide some syntax sugars in SQL:
Some possible solutions:
Functions
select * from user limit {{ context.params.limit.number({max: 10, min: 0}).required() }}Filters
select * from user limit {{ context.params.limit | number(max=10, min=0) | required }}We can add a prefix to validators toprevent collision.
select * from user limit {{ context.params.limit | validate.number(max=10, min=0) | validate.required }}Before every release, we need some published packages to do some manual tests, but we only publish our packages while releasing.
Build the updated packages (use nx affected) at 00:00 CST every day with pre-release tags in dev channel. e.g. @vulcan-sql/core:0.1.0-dev.20220907
We hosted our document on Vercel with a trial Pro plan, we need to get sponsorship from them to continue using their services.
Follow this requirement:
https://vercel.com/guides/can-vercel-sponsor-my-open-source-project
We need to ensure Canner policy allows us to do this. cc @wwwy3y3
Catalog server APIs might need some additional information about our endpoints that are not built into artifacts, e.g. request constraints. We should add the missing metadata.
We should provide a single executable file to serve Vulcan server, with no dependencies or docker env required,
Implement commands like vulcan build --output binary --platform x86 to built executable files.
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.