chris1610 / pbpython Goto Github PK
View Code? Open in Web Editor NEWCode, Notebooks and Examples from Practical Business Python
Home Page: https://pbpython.com
License: BSD 3-Clause "New" or "Revised" License
Code, Notebooks and Examples from Practical Business Python
Home Page: https://pbpython.com
License: BSD 3-Clause "New" or "Revised" License









































































































































































































@chris1610
First, Thanks for the good example of MonteCarlo Simulation.
I'm trying to implement MonteCarlo for risk analysis. This is my simple data

On this data i've two types of asset value and also each asset value has high and low values. I'm trying to get risk value of each given percentage. Can you pls help me out how to fit two values in your code ?
and do you have discord account ?
The file Traffic_20170306-20170519.xlsx does not seem to exist
We have a few sort() hard stops in Python 3.5. Thus:
In [13]:
#df = df.sort('date') # AKH fails
df = df.sort_values(by='date') # AKH this works
In [26]
# df[(df['sku'].str.contains('B1-531')) & (df['quantity']>40)].sort(columns=['quantity','name'],ascending=[0,1]) # AKH fails
df[(df['sku'].str.contains('B1-531')) & (df['quantity']>40)].sort_values(by=['quantity','name'],ascending=[0,1]) # AKH works
Could also replace ix In [29]:
# df.drop_duplicates(subset=["account number","name"]).ix[:,[0,1]] # AKH
df.drop_duplicates(subset=["account number","name"]).loc[:,["account number","name"]] # AKH
I'm getting this error when I try to convert a file, or even view the man page of the md_to_email script. Dependencies installed. Is this code compatible with python3?
*****-MacBook-Pro:md_to_email ******$ python email_gen.py issue2.md File "email_gen.py", line 45 out_file = Path.cwd() / f'{in_doc.stem}_email.html' ^ SyntaxError: invalid syntax
Thanks for the nice examples. Could you use:
I think this fixes the problem of missing values. Is it correct way of handling missing values ?
def wavg(group, avg_name, weight_name):
import numpy as np
group=group[np.isfinite(group[avg_name])] # ignores missing values
d = group[avg_name]
w = group[weight_name]
try:
return (d * w).sum() / w.sum()
except ZeroDivisionError:
return d.mean()
hey @chris1610, great article and notebook on mortgage / ammortization. I noticed that you rounded the np.pmt which sometimes throws off the number of payments. for example I was doing a 3.875% interest, 30 year, 427500 principal and I got 361 periods instead of 360. removing the rounding fixed the error.
in addition, it would be cool if you added support for PMI, property tax, and home insurance to show the total out of pocket expense in another column
thanks!
update: in addition to removing the rounding, I found i also had to add: while round(end_balance, 5) > 0:
For me this gives the unfortunate ImportError: cannot import name 'SignedJwtAssertionCredentials' as explained at https://stackoverflow.com/questions/14063124/importerror-cannot-import-name-signedjwtassertioncredentials
However the proposed solution on SO i.e.pip install oauth2client==1.5.2
just gives me a later error:
FileNotFoundError: [Errno 2] No such file or directory: 'Pbpython-key.json'
I'm not yet competent enough to take this forward.
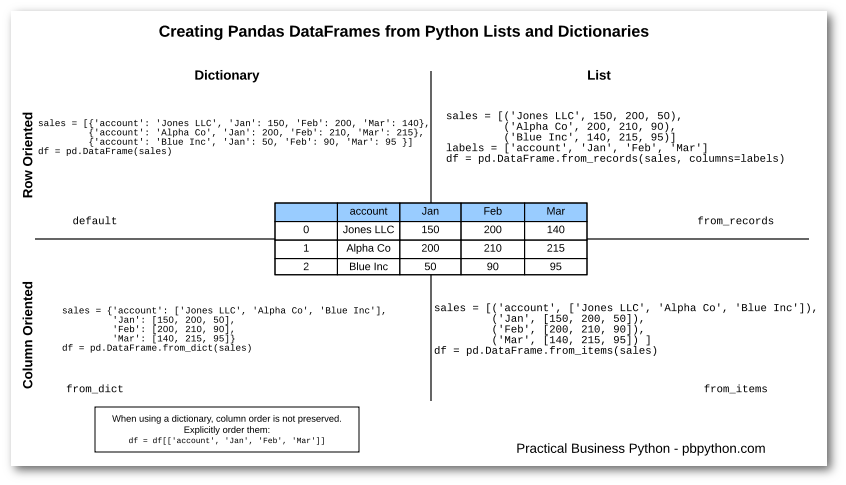
The figure https://pbpython.com/images/pandas-dataframe-shadow.png, being in use on https://pbpython.com/pandas-list-dict.html, has a mistake in the upper right corner.
The sales list should be
[("Jones LLC", 150, 200, 140),
("Alpha Co", 200, 210, 215),
("Blue Inc", "140, 215, 95)]
I'm happy to recreate the figure if you tell me where I find it.
I changed the df.ix to df.loc
the function when we pass additional principal fails
I am using pandas 0.24.2
def amortization_table(interest_rate, years, payments_year, principal, addl_principal=0, start_date=date.today()):
""" Calculate the amortization schedule given the loan details
Args:
interest_rate: The annual interest rate for this loan
years: Number of years for the loan
payments_year: Number of payments in a year
principal: Amount borrowed
addl_principal (optional): Additional payments to be made each period. Assume 0 if nothing provided.
must be a value less then 0, the function will convert a positive value to
negative
start_date (optional): Start date. Will start on first of next month if none provided
Returns:
schedule: Amortization schedule as a pandas dataframe
summary: Pandas dataframe that summarizes the payoff information
"""
# Ensure the additional payments are negative
if addl_principal > 0:
addl_principal = -addl_principal
# Create an index of the payment dates
rng = pd.date_range(start_date, periods=years * payments_year, freq='MS')
rng.name = "Payment_Date"
# Build up the Amortization schedule as a DataFrame
df = pd.DataFrame(index=rng,columns=['Payment', 'Principal', 'Interest',
'Addl_Principal', 'Curr_Balance'], dtype='float')
# Add index by period (start at 1 not 0)
df.reset_index(inplace=True)
df.index += 1
df.index.name = "Period"
# Calculate the payment, principal and interests amounts using built in Numpy functions
per_payment = np.pmt(interest_rate/payments_year, years*payments_year, principal)
df["Payment"] = per_payment
df["Principal"] = np.ppmt(interest_rate/payments_year, df.index, years*payments_year, principal)
df["Interest"] = np.ipmt(interest_rate/payments_year, df.index, years*payments_year, principal)
# Round the values
df = df.round(2)
# Add in the additional principal payments
df["Addl_Principal"] = addl_principal
# Store the Cumulative Principal Payments and ensure it never gets larger than the original principal
df["Cumulative_Principal"] = (df["Principal"] + df["Addl_Principal"]).cumsum()
df["Cumulative_Principal"] = df["Cumulative_Principal"].clip(lower=-principal)
# Calculate the current balance for each period
df["Curr_Balance"] = principal + df["Cumulative_Principal"]
# Determine the last payment date
try:
last_payment = df.query("Curr_Balance <= 0")["Curr_Balance"].idxmax(axis=1, skipna=True)
except ValueError:
last_payment = df.last_valid_index()
last_payment_date = "{:%m-%d-%Y}".format(df.loc[last_payment, "Payment_Date"])
# Truncate the data frame if we have additional principal payments:
# Remove the extra payment periods
df = df.loc[0:last_payment].copy()
# Calculate the principal for the last row
df.loc[last_payment, "Principal"] = -(df.loc[last_payment-1, "Curr_Balance"])
# Calculate the total payment for the last row
df.loc[last_payment, "Payment"] = df.loc[last_payment, ["Principal", "Interest"]].sum()
# Zero out the additional principal
df.loc[last_payment, "Addl_Principal"] = 0
# Get the payment info into a DataFrame in column order
payment_info = (df[["Payment", "Principal", "Addl_Principal", "Interest"]]
.sum().to_frame().T)
# Format the Date DataFrame
payment_details = pd.DataFrame.from_dict(dict([('payoff_date', [last_payment_date]),
('Interest Rate', [interest_rate]),
('Number of years', [years])
]))
# Add a column showing how much we pay each period.
# Combine addl principal with principal for total payment
payment_details["Period_Payment"] = round(per_payment, 2) + addl_principal
payment_summary = pd.concat([payment_details, payment_info], axis=1)
return df, payment_summary
We have the method Path.name() to show the filename associated with a path, but there doesn't appear to a way to show the full file path without wrapping in a str() function, which is a little ugly.
Could something like Path.fullname() be included as a method?
data_file = "..\data\All Web Site Data Audience Overview.xlsx" should be
data_file = "..\data\All-Web-Site-Data-Audience-Overview.xlsx"
Separately m2.plot_components(forecast2); is taking an age to finish, even with a laptop beast.
I'm not sure it will.
As instructed, all ipynb files run in sequence.
KeyError Traceback (most recent call last)
in
25 df = pd.read_csv(file, delimiter=";")
26 # Prepare the df befor merging (Drop obsolete, convert to datetime, filter to date, set index)
---> 27 df.drop(columns=obsolete_columns, inplace=True)
28 df["MESS_DATUM"] = pd.to_datetime(df["MESS_DATUM"], format="%Y%m%d%H")
29 df = df[df['MESS_DATUM']>= "2007-01-01"]
~\Anaconda3\envs\tide\lib\site-packages\pandas\core\frame.py in drop(self, labels, axis, index, columns, level, inplace, errors)
4306 weight 1.0 0.8
4307 """
-> 4308 return super().drop(
4309 labels=labels,
4310 axis=axis,
~\Anaconda3\envs\tide\lib\site-packages\pandas\core\generic.py in drop(self, labels, axis, index, columns, level, inplace, errors)
4151 for axis, labels in axes.items():
4152 if labels is not None:
-> 4153 obj = obj._drop_axis(labels, axis, level=level, errors=errors)
4154
4155 if inplace:
~\Anaconda3\envs\tide\lib\site-packages\pandas\core\generic.py in _drop_axis(self, labels, axis, level, errors)
4186 new_axis = axis.drop(labels, level=level, errors=errors)
4187 else:
-> 4188 new_axis = axis.drop(labels, errors=errors)
4189 result = self.reindex(**{axis_name: new_axis})
4190
~\Anaconda3\envs\tide\lib\site-packages\pandas\core\indexes\base.py in drop(self, labels, errors)
5589 if mask.any():
5590 if errors != "ignore":
-> 5591 raise KeyError(f"{labels[mask]} not found in axis")
5592 indexer = indexer[~mask]
5593 return self.delete(indexer)
KeyError: "['QN_9' 'RF_TU' 'eor'] not found in axis"
#SALES=pd.read_csv("../data/sample-sales-tax.csv", parse_dates='True') # AKH fails
SALES=pd.read_csv("../data/sample-sales-tax.csv", parse_dates=True) # AKH works
As a matter of style I would probably prefer the (excellent!) qgrid plugin to have been imported at the top. Caought it later though...
In the notebook Amortization-Corrected-Final.ipynb change the updated article link from the local http://localhost:8888/notebooks/amortization-model-revised.html to the web http://pbpython.com/amortization-model-revised.html
Hi Mr. Chris,
I recently learned the idea in your article Updated: Using Pandas To Create an Excel Diff , and I noticed that there was a function report_diff that did not take into account the case of empty lists. If there is no change, an error occurs. I think you should write like this.
def report_diff(x):
if any(x):
return x[0] if x[0] == x[1] else '{} ---> {}'.format(*x)
Thanks!
When grouping by month in the notebook below you use a pd.Grouper object:
pbpython/notebooks/pandas-styling.ipynb
Lines 733 to 735 in d170f44
..whereas the same could be accomplished by simply using the resample method:
monthly_sales = df.resample('MS', on='date')['ext price'].agg(['sum'])Whilst I think it's useful for power users to know they can construct Grouper objects themselves I think for less advanced users it's an internal implementation detail which they don't really need to know and which makes it seem more complicated than it needs to be
To rename a file, the correct function is f.rename(), with_name() only changes the name of the path object, not the real file.
Hi, I ran your function analyze_ppt(input, output) through a slide with set template that I was given.
I opened new file, set theme, saved and used as input for the function.
It finds the title page, which is under the theme name in power point. But it does not find the other slides that are for text and title only which are under another row in the new slides drop down menu in power point which are sub theme named MS_Template_External.
Is there anyway to get your code to recognize these other layouts inside the theme?
Code is located in code/script.py
and
data in directory as per your example But upon running I get
from flask import Flask
import pandas as pd
import numpy as np
import glob
all_data = pd.DataFrame()
for f in glob.glob("../data/sales*.xlsx"):
df = pd.read_excel(f)
all_data = all_data.append(df, ignore_index=True)
all_data.describe()
raise ValueError("Cannot describe a DataFrame without columns")
ValueError: Cannot describe a DataFrame without columns
Could anybody give me some help? Thanks more
Using Python 3.5...
In [19]
# all_data_st.sort(columns=["status"]).head() # AKH didn't run
all_data_st.sort_values(by=["status"]).head() # AKH runs
In [21]
# all_data_st.sort(columns=["status"]).head() # AKH didn't run
all_data_st.sort_values(by=["status"]).head() # AKH runs
In [25] we seem to have issues over the wrong magic numbers for columns, plus use of deprecated ix.
A range of possible ways forward, with the last one bypassing the issue altogether:
# all_data_st.drop_duplicates(subset=["account number","name"]).ix[:,[0,1,7]].groupby(["status"])["name"].count()
# all_data_st.drop_duplicates(subset=["account number","name"]).groupby(["status"])["name"].count() # AKH lazy, but no magic numbers!
# all_data_st.drop_duplicates(subset=["account number","name"]).ix[:,[0,11,15]].groupby(["status"])["name"].count() # AKH updated magic numbers
# all_data_st.drop_duplicates(subset=["account number","name"]).ix[:,[0,"name","status"]].groupby(["status"])["name"].count() # AKH non-lazy, no magic numbers, but still deprecated
# AKH Following solution grabs the relevant columns up front - avoiding magic numbers and use of ix (or even loc).
all_data_st[["account number","name","status"]].drop_duplicates(subset=["account number","name"]).groupby(["status"])["name"].count() # non-lazy, no magic numbers
A number of notebooks require modules which are not part of the Anaconda distribution. Generally that's fine; the error message is easily understood and you can just pip install required_module.
It seems that fbprophet is a little more challenging. The notes I've saved in the top of Forecasting-with-prophet.ipynb and Pymntos-Demo.ipynb run:
# watch fbprophet installation:
# pip install fbprophet => fails late on
# conda install -c conda-forge fbprophet => worked
Perhaps you could consider adding a similar note?
Using:
Pycharm 2018.2.4
Python 3.6
Just want to copy and run the code, but this is what I get:
Traceback (most recent call last):
File "C:/Users/Fabian/PycharmProjects/Thesis/stacked_bar_app.py", line 8, in
"https://github.com/chris1610/pbpython/blob/master/data/salesfunnel.xlsx?raw=True"
File "C:\Users\Fabian\AppData\Local\Programs\Python\Python36-32\lib\site-packages\pandas\util_decorators.py", line 118, in wrapper
return func(*args, **kwargs)
File "C:\Users\Fabian\AppData\Local\Programs\Python\Python36-32\lib\site-packages\pandas\io\excel.py", line 230, in read_excel
io = ExcelFile(io, engine=engine)
File "C:\Users\Fabian\AppData\Local\Programs\Python\Python36-32\lib\site-packages\pandas\io\excel.py", line 292, in init
self.book = xlrd.open_workbook(file_contents=data)
File "C:\Users\Fabian\AppData\Local\Programs\Python\Python36-32\lib\site-packages\xlrd_init_.py", line 141, in open_workbook
ragged_rows=ragged_rows,
File "C:\Users\Fabian\AppData\Local\Programs\Python\Python36-32\lib\site-packages\xlrd\xlsx.py", line 808, in open_workbook_2007_xml
x12book.process_stream(zflo, 'Workbook')
File "C:\Users\Fabian\AppData\Local\Programs\Python\Python36-32\lib\site-packages\xlrd\xlsx.py", line 265, in process_stream
meth(self, elem)
File "C:\Users\Fabian\AppData\Local\Programs\Python\Python36-32\lib\site-packages\xlrd\xlsx.py", line 392, in do_sheet
sheet = Sheet(bk, position=None, name=name, number=sheetx)
File "C:\Users\Fabian\AppData\Local\Programs\Python\Python36-32\lib\site-packages\xlrd\sheet.py", line 326, in init
self.extract_formulas = book.extract_formulas
AttributeError: 'Book' object has no attribute 'extract_formulas'
Does anyone can help?
Thanks!
This issue is about the website, not the Python code. I didn't find a better way to report it, so I've put it here.
In the RSS feed the very first (the oldest) entry leads to Introduction to the site page, which resolves to 403 Access Denied.
So either something went wrong and this page now has a different URL on the website, or you removed it intentionally but forgot to also remove it from the RSS feed. A minor issue really, just wanted to let you know.
Also it might be a good idea not to put the entire articles content to RSS feed (instead it could be just the couple of paragraphs). Although, if you intended it like this, that is fine of course.
I'm looking at the code you have and see it might be adapted, but I'm not sure how easy that will be done. :)
When taking out a Certificate of Deposit the term can be specified in years or months, but also the date when it is taken out may be any day of the month when that happens. At the end of the term you may have a partial payment of interest.
What I need is basically a generator that will give elements that allow partial fractions for the months (starting and finish) along with those full months in between. I think I can get this figured out eventually... :)
Thanks for what you have posted so far!
Show an example of using this library - https://github.com/Bergvca/string_grouper
https://bergvca.github.io/2017/10/14/super-fast-string-matching.html
See the notes in the comments.
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.
{kind=link}