For this project I wanted to tackle Reinforcement learning and AI. The questions I wanted to answer are:
-
Can an agent learn new domains from a tablua rasa state?
-
Can an agent apply their knowledge to new domains both similar and different?
-
How does scale affect learning in an agent?
-
Can I make an AI that plays better than humans without doing any feature engineering or AI design?
To answer the first question I researched Alpha Zero from DeepMind. I created a working replica of there original methodology. Using state of the art techniques in reinforcement learning, I created a model that learns how to play any perfect knowledge game better than humans in a fraction of the time it would take to create this AI by hand. I first trained it on Tic Tac Toe, TTT, as I do not have the computational power to train an agent on chess! The agent took 5 hours to train running on my personal gtx 1080 graphics card.
I achieved super human level of play in Connect 4 after only 16 hours of training! The data it trains on is all self generated. The only coding I needed to do was to create the model, define the types and number of players, and to create a game environment. Everything else was done for me by the model. All of it’s behaviour, it’s strategy, it’s knowledge, and it's intelligence was created by the model.
It learned how to play the game using a Monte Carlo Tree Search, MCTS, which learns from experience. It also used an Actor Critic model with a residual CNN as the Critic and a MCTS powered ConvResNet as the Actor.
This is what the error for the model over time looked like.
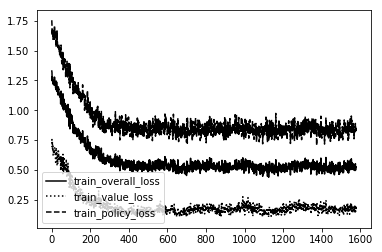
As you can see it reduces quickly then levels out. This is a fairly stable result. Doing the same for Connect 4, and MetaSquares I am sure that the agent learned generalities and strategy for each game and quickly surpased human level performance.
Each generation of the model makes large steps forward. After only 3 generations of TTT models the agent mastered the game and played perfectly no matter what the opponent does. I call this a 'Solved Model' because TTT and C4 are 'Solved' games meaning that humans have mathematically came up with a solution to the game to where if both players played perfectly it would create the same result every time. TTT's solved state is a draw. C4's solved state is player 1 winning. So I knew the model achieved complete success when they followed the perfect game almost every time.
The data that is needed for this is very small and very much unlike normal machine learning. ALL data is self-generated and there is NO prior knowledge needed for AI to learn from the games they are in. They learn like humans and adjust to each new environment they are in; given they have sufficient resources. This lets us train every new agent in a way that is unique to the game they live in. You could also transfer over knowledge from similar games to have the agent learn from a starting position. This will create a strange but useful AI where not all of its tendencies and knowledge come from the world it lives in. So it's a little unpredictable.
To answer the second question I created a system that let me do tournaments with each game and I numbered the various classes of each game with numbers 1xxx-9xxx. You can then compete each model against each other depending on which game is currently loaded as 'game.py'.
The outcomes are what you would expect. The better models with a larger scale win more at lower generations then smaller scale models and all models basically compete equally when you get to the models that reached a 'solved' state for each class.
It is more interesting when you compete the models on new domains. When both models are on different domains the models act more randomly then confidentally. When one model is on its own domain and the other is new, the experienced model will try to predict the moves of their opponent but fails as the new model acts a little randomly. This can lead to the newer model winning some games as its moves are just so out there that the experienced model doesn't know how to handle them.
Overall high scale models that are on their own domain will be better then generalized models from another domain. Although lower scale models will lose to high scale models from a different domain.
To answer the third question I adjusted the training variables to make a larger scale of learning and computation that the model can do every update.
Its training variables are:
Memory Size - The amount of data the model can hold in its system at any point in time.
Episodes - The number of training games played before an update to the model.
MCTS Sims - The amount of Sims or Q-depth of the tree search.
Epsilon - The % of time the agent will select random moves during a training session.
Alpha - The discount factor of the agent.
Batch Size - This is the batch size for the learning update. Standard supervised learning.
Learning Rate - Same as above. Learning Rate for update.
Momentum - Same as above. Momentum for Learning Rate update.
Training Loops - The amount of times the model is updated during update.
Scoring Threshold - The % of games needed to win to create a new generation.
Eval Episodes - The number of games in the learning tournament.
Tau - The number of turns a model will play randomly before the MCTS turns on.
Adjusting these will lead to wildly new results during training. You can also adjust these during tournament play to affect each model's performance.
I focused on MCTS Sims, Memory Size, and Episodes as these affect how large and complex the model is the most. Making the Q-depth larger makes training time increase almost exponentailly. It also effects how complex the model is the most. Memory Size is the second most important factor in strength of a model as it decides how much the model can know at any given time. Episodes is how much 'data' or the number of games played in each training block is sent to update the model. Having a large number of games without an update creates a very data rich update but can also make it an unstable update as there is so much updated that the model may be too different from its past.
I created 4 types of TTT and C4 models: Dumb - Q-depth of 2, low memory, and HIGH episodes 100 or more. Semi-Dumb - Q-depth of 10, very high memory, 20 episodes. Standard - Q-depth of 50, high memory, 30 episodes. Smart - Q-depth of 1000, medium memory, 10 episodes.
Using the standard as the benchmark I compared each model in a tournament on their own domains. In C4 the dumb model couldn't even create a stable model. Each dumb generation was the same as the past but since the model acted randomly sometimes that would determine if a new generation was created as one player would win past the threshold more than the other. The semi dumb model did actually create a stable model but was generally weaker under all circumstances then the smart and standard versions.
The competetion between standard and smart is close though. Because each generation of the smart model took 20-26 hours to make I only made 10 versions of it. Compared to the 26 of the standard version or the 700 of the dumb version. Comparing versions 10 of the smart and 26 of the standard the matches are almost even. If you compare 10 of both it is very one-sided, smart wins every time.
This leads me to believe that scale has a huge effect on Reinforcement learning and the larger the scale of the model you can create the better the results will be.
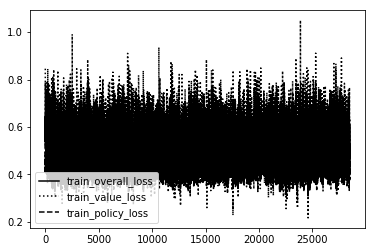
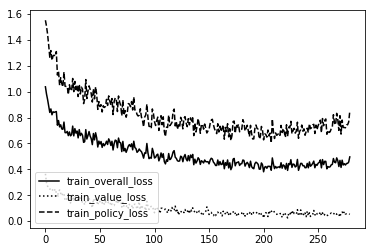
Here is the loss graph of each model in order from TTT dumb-Smart, C4 dumb-smart, and MS standard.
TTT Dumb
TTT Semi-Dumb
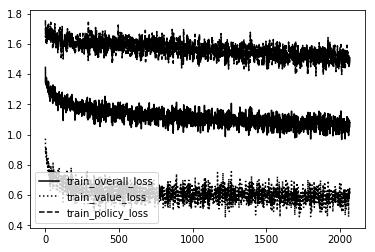
TTT Standard
TTT Smart
C4 Dumb
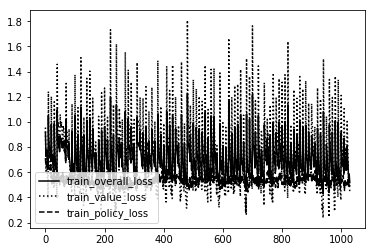
C4 Semi-Dumb
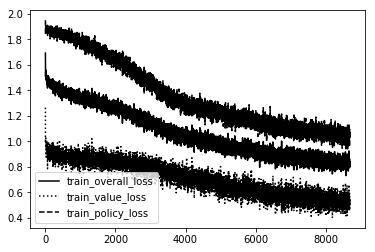
C4 Standard
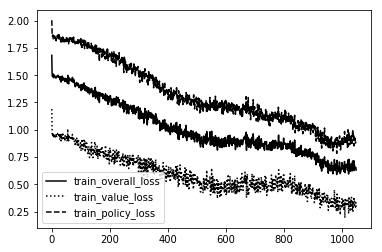
C4 Smart
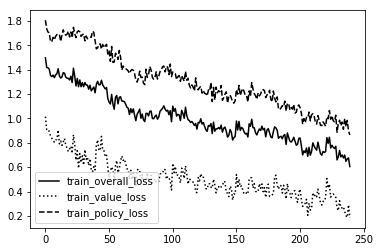
MS Standard
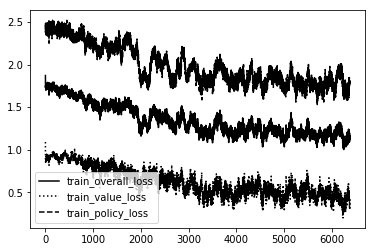
As you can see the Dumb ones are VERY unstable!!! So much so they couldn't even create a bad model. It was just random noise. The rest follow a pretty straightforward path. The more intelliegnt the model becomes the less updates it needs to create the same shape. We want a nice stable curve downward that will eventually level off and maybe only spike downward one or two more times if the creativity of the agent creates a 'boom' in knowledge not before discovered.
The answer to the last question was YES!!!
The future of this project would be to create more indepth game environments for the agent to learn on such as atarai games or MuJoCo simulations. I know that this agent could learn more advanced games from only observing the environment and using its controls.
I also could research how much of a difference there is between solved games and unsolved games. This technique could be used to solve any perfect knowledge game that we have that are not yet solved such as go and chess; Given enough time.
I am confident that we can use this approach on new AAA games to make lifelike AI that plays as good or better then humans for us to play against. Saving millions every year for major studios while also making it possible to increase the scale of indie games. Adding in real feeling AI will also make games feel more immersive in single player games and more challenging in Massive Multiplayer games. Imagine a game like titanfall with hundreds of unique and different AIs to play with or MMOs that give everyone supporters that act like real humans and come up with their own strategies to attack bosses and clear missions.
This could lead to a revolution in how we design and make games. It could impower game devs to be able to make new and interesting takes on AI that will make our gaming experience more unique to the worlds we play in. Imagine an AI recognizing patterns in fighting games and adjusting to them, or enemies truly seeing clues and suspicious things in stealth games to better search for the player. This will make AI feel like they are real and apart of the worlds that they live in.
This also has implications in non gaming ways. Agents that can learn from only having an environment and controls could learn to walk, ride a bike, trade stocks, cook, clean, put books away in a library, take care of animals, or even how to use chopsticks!!! All while having an innate understanding of ‘How?’ and ‘Why?’ they are doing what they are doing that they came up with themselves to understand their lives.
We could use this technology to better the lives of every human by creating ‘Games’ for AI to play and master that can help us do anything from everyday chores to solving global crisis such as global warming, poverty, food and water shortages. The reaches of AI and reinforcement learning are endless and it will lead us to a better future. I just hope that my work and ideas will help power that future in some way for the better.
If you want to contact me feel free to message me on linkedin or email me at [email protected]! I'm always up for suggestions on how to improve my models and code!


