



我的另外一个作品: https://github.com/chyroc/lark ,基于代码生成的 Lark/飞书 Go SDK,欢迎 star 。

__ __ _ _ ____
\ \ / /__ ___| |__ __ _| |_/ ___| ___ __ _ ___ _ _
\ \ /\ / / _ \/ __| '_ \ / _` | __\___ \ / _ \ / _` |/ _ \| | | |
\ V V / __/ (__| | | | (_| | |_ ___) | (_) | (_| | (_) | |_| |
\_/\_/ \___|\___|_| |_|\__,_|\__|____/ \___/ \__, |\___/ \__,_|
|___/
基于搜狗微信搜索的微信公众号爬虫接口,可以扩展成基于搜狗搜索的爬虫
如果有问题,请提issue
-
QQ群(只需加一个)
- 一群 132955136(已满)
- 二群 819084985
-
微信群
甲鱼说,咖啡是灵魂的饮料,买点咖啡
支付宝扫码大家一起领红包:

或者直接转账:


Q:没有得到原始文章url / 提示链接已经过期?
A:微信屏蔽此接口,请在临时链接有效期内保存文章内容。
Q:获取文章只能10篇?
A:是的,仅显示最近10条群发。
Q:使用的是python 2 还是 3?
A:都支持,若出错,请报BUG。
pip install wechatsogou --upgrade
import wechatsogou
# 可配置参数
# 直连
ws_api = wechatsogou.WechatSogouAPI()
# 验证码输入错误的重试次数,默认为1
ws_api = wechatsogou.WechatSogouAPI(captcha_break_time=3)
# 所有requests库的参数都能在这用
# 如 配置代理,代理列表中至少需包含1个 HTTPS 协议的代理, 并确保代理可用
ws_api = wechatsogou.WechatSogouAPI(proxies={
"http": "127.0.0.1:8888",
"https": "127.0.0.1:8888",
})
# 如 设置超时
ws_api = wechatsogou.WechatSogouAPI(timeout=0.1)
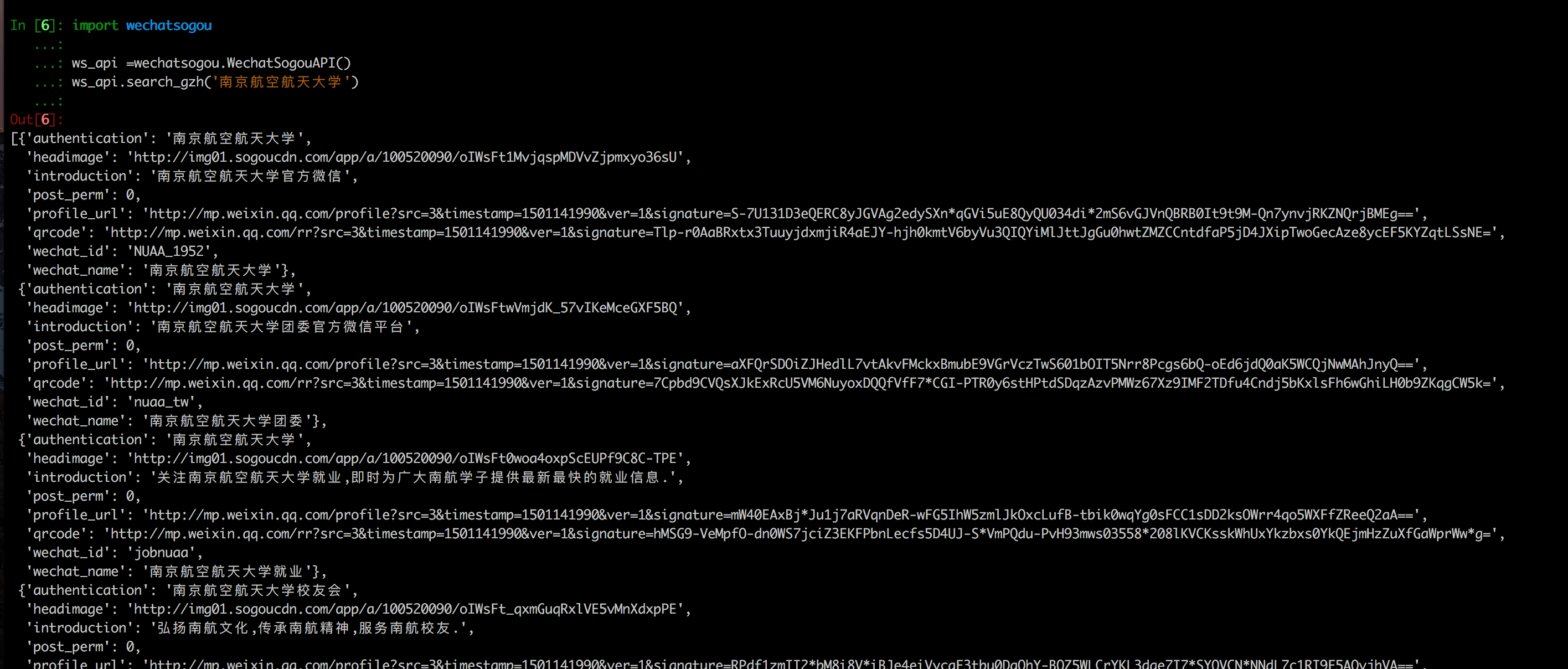
- 使用
In [5]: import wechatsogou
...:
...: ws_api =wechatsogou.WechatSogouAPI()
...: ws_api.get_gzh_info('南航青年志愿者')
...:
Out[5]:
{
'authentication': '南京航空航天大学',
'headimage': 'http://img01.sogoucdn.com/app/a/100520090/oIWsFt1tmWoG6vO6BcsS7St61bRE',
'introduction': '南航大志愿活动的领跑者,为你提供校内外的志愿资源和精彩消息.',
'post_perm': 26,
'view_perm': 1000,
'profile_url': 'http://mp.weixin.qq.com/profile?src=3×tamp=1501140102&ver=1&signature=OpcTZp20TUdKHjSqWh7m73RWBIzwYwINpib2ZktBkLG8NyHamTvK2jtzl7mf-VdpE246zXAq18GNm*S*bq4klw==',
'qrcode': 'http://mp.weixin.qq.com/rr?src=3×tamp=1501140102&ver=1&signature=-DnFampQflbiOadckRJaTaDRzGSNfisIfECELSo-lN-GeEOH8-XTtM*ASdavl0xuavw-bmAEQXOa1T39*EIsjzxz30LjyBNkjmgbT6bGnZM=',
'wechat_id': 'nanhangqinggong',
'wechat_name': '南航青年志愿者'
}
- 返回数据结构
{
'profile_url': '', # 最近10条群发页链接
'headimage': '', # 头像
'wechat_name': '', # 名称
'wechat_id': '', # 微信id
'post_perm': int, # 最近一月群发数
'view_perm': int, # 最近一月阅读量
'qrcode': '', # 二维码
'introduction': '', # 简介
'authentication': '' # 认证
}
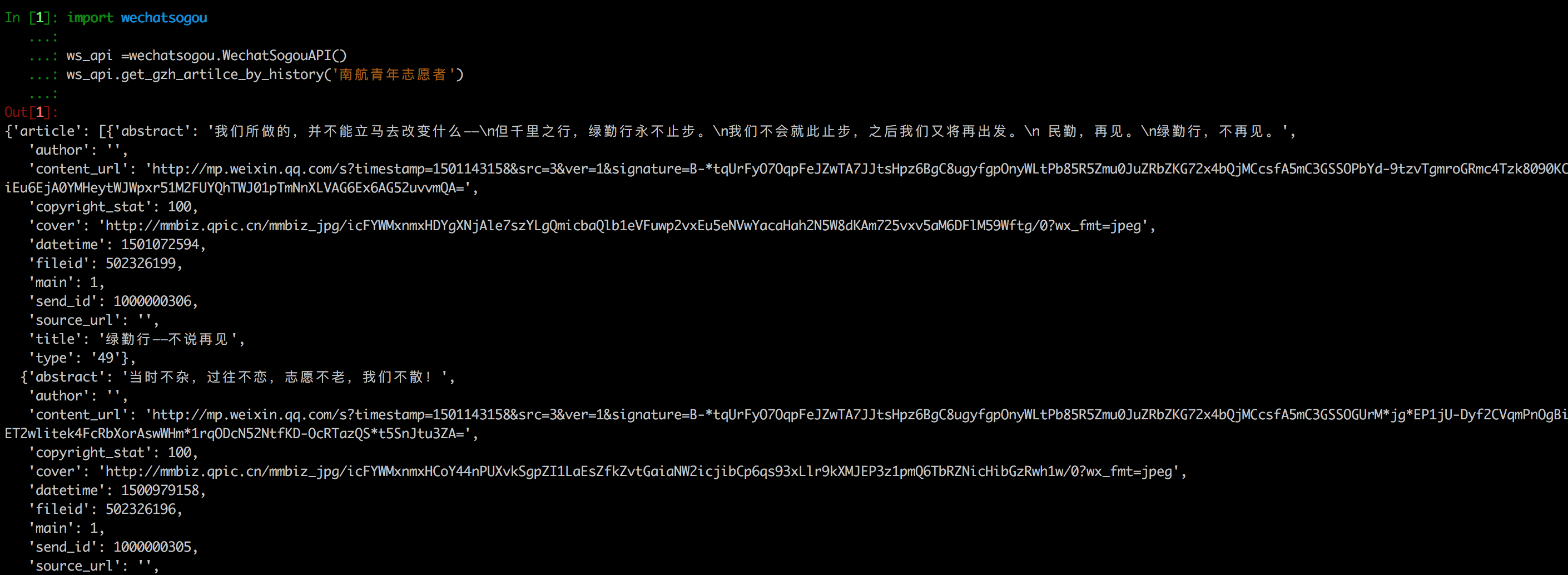
- 使用
In [6]: import wechatsogou
...:
...: ws_api =wechatsogou.WechatSogouAPI()
...: ws_api.search_gzh('南京航空航天大学')
...:
Out[6]:
[
{
'authentication': '南京航空航天大学',
'headimage': 'http://img01.sogoucdn.com/app/a/100520090/oIWsFt1MvjqspMDVvZjpmxyo36sU',
'introduction': '南京航空航天大学官方微信',
'post_perm': 0,
'view_perm': 0,
'profile_url': 'http://mp.weixin.qq.com/profile?src=3×tamp=1501141990&ver=1&signature=S-7U131D3eQERC8yJGVAg2edySXn*qGVi5uE8QyQU034di*2mS6vGJVnQBRB0It9t9M-Qn7ynvjRKZNQrjBMEg==',
'qrcode': 'http://mp.weixin.qq.com/rr?src=3×tamp=1501141990&ver=1&signature=Tlp-r0AaBRxtx3TuuyjdxmjiR4aEJY-hjh0kmtV6byVu3QIQYiMlJttJgGu0hwtZMZCCntdfaP5jD4JXipTwoGecAze8ycEF5KYZqtLSsNE=',
'wechat_id': 'NUAA_1952',
'wechat_name': '南京航空航天大学'
},
{
'authentication': '南京航空航天大学',
'headimage': 'http://img01.sogoucdn.com/app/a/100520090/oIWsFtwVmjdK_57vIKeMceGXF5BQ',
'introduction': '南京航空航天大学团委官方微信平台',
'post_perm': 0,
'view_perm': 0,
'profile_url': 'http://mp.weixin.qq.com/profile?src=3×tamp=1501141990&ver=1&signature=aXFQrSDOiZJHedlL7vtAkvFMckxBmubE9VGrVczTwS601bOIT5Nrr8Pcgs6bQ-oEd6jdQ0aK5WCQjNwMAhJnyQ==',
'qrcode': 'http://mp.weixin.qq.com/rr?src=3×tamp=1501141990&ver=1&signature=7Cpbd9CVQsXJkExRcU5VM6NuyoxDQQfVfF7*CGI-PTR0y6stHPtdSDqzAzvPMWz67Xz9IMF2TDfu4Cndj5bKxlsFh6wGhiLH0b9ZKqgCW5k=',
'wechat_id': 'nuaa_tw',
'wechat_name': '南京航空航天大学团委'
},
...
]
- 数据结构
list of dict, dict:
{
'profile_url': '', # 最近10条群发页链接
'headimage': '', # 头像
'wechat_name': '', # 名称
'wechat_id': '', # 微信id
'post_perm': int, # 最近一月群发数
'view_perm': int, # 最近一月阅读量
'qrcode': '', # 二维码
'introduction': '', # 介绍
'authentication': '' # 认证
}
- 使用
In [7]: import wechatsogou
...:
...: ws_api =wechatsogou.WechatSogouAPI()
...: ws_api.search_article('南京航空航天大学')
...:
Out[7]:
[
{
'article': {
'abstract': '【院校省份】江苏【报名时间】4月5日截止【考试时间】6月10日-11日南京航空航天大学2017年自主招生简章南京航空航天大学2017...',
'imgs': ['http://img01.sogoucdn.com/net/a/04/link?appid=100520033&url=http://mmbiz.qpic.cn/mmbiz_png/P07yicBRJfC71QB3lREx4J4x34QOibGaia5BkiaaiaiaibicWkTBULou9R08K6FaxlUA1RFBFWCmpO1Lepk7ZcXK45vguQ/0?wx_fmt=png'],
'time': 1490270644,
'title': '南京航空航天大学2017年自主招生简章',
'url': 'http://mp.weixin.qq.com/s?src=3×tamp=1501142580&ver=1&signature=hRMlQOLQpu4BNhBACavusZdmk**D65qHyz5LWDq1lPjVcm7*iiBS0l7Pq40h0fiCX*bZ8vSMLzAMDNzELYFKIQ7mND0-7cQi-N0BtfTBql*CQdsHun-GtaYEqRva6Ukwce3gZh46SXJzo90kyZ3dwVYl6*589bGDIzG6JTGfpxI='
},
'gzh': {
'headimage': 'http://wx.qlogo.cn/mmhead/Q3auHgzwzM5kiawibor6ABhnibMYnOADvqdcrl5XWiaFfM5mGYZ8cUica6A/0',
'isv': 0,
'profile_url': 'http://mp.weixin.qq.com/profile?src=3×tamp=1501142580&ver=1&signature=dVkDdcFr1suL1WHdCOJj7pwZhG9W*APi-j5kRtS09ccv-WID-zNs0ecDiiz1wwE7qbNSk5HBL*ffpyVXcF0fFQ==',
'wechat_name': '自主招生在线'
}
},
...
]
- 数据结构
list of dict, dict:
{
'article': {
'title': '', # 文章标题
'url': '', # 文章链接
'imgs': '', # 文章图片list
'abstract': '', # 文章摘要
'time': int # 文章推送时间 10位时间戳
},
'gzh': {
'profile_url': '', # 公众号最近10条群发页链接
'headimage': '', # 头像
'wechat_name': '', # 名称
'isv': int, # 是否加v 1 or 0
}
}
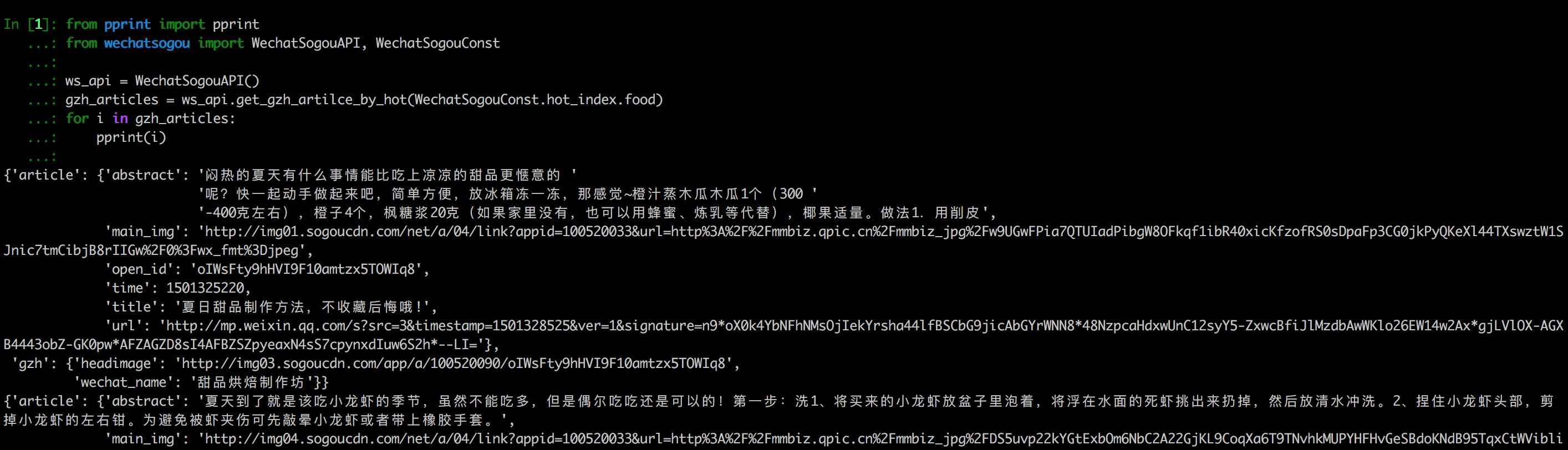
- 使用
In [1]: import wechatsogou
...:
...: ws_api =wechatsogou.WechatSogouAPI()
...: ws_api.get_gzh_article_by_history('南航青年志愿者')
...:
Out[1]:
{
'article': [
{
'abstract': '我们所做的,并不能立马去改变什么——\n但千里之行,绿勤行永不止步。\n我们不会就此止步,之后我们又将再出发。\n 民勤,再见。\n绿勤行,不再见。',
'author': '',
'content_url': 'http://mp.weixin.qq.com/s?timestamp=1501143158&src=3&ver=1&signature=B-*tqUrFyO7OqpFeJZwTA7JJtsHpz6BgC8ugyfgpOnyWLtPb85R5Zmu0JuZRbZKG72x4bQjMCcsfA5mC3GSSOPbYd-9tzvTgmroGRmc4Tzk8090KCiEu6EjA0YMHeytWJWpxr51M2FUYQhTWJ01pTmNnXLVAG6Ex6AG52uvvmQA=',
'copyright_stat': 100,
'cover': 'http://mmbiz.qpic.cn/mmbiz_jpg/icFYWMxnmxHDYgXNjAle7szYLgQmicbaQlb1eVFuwp2vxEu5eNVwYacaHah2N5W8dKAm725vxv5aM6DFlM59Wftg/0?wx_fmt=jpeg',
'datetime': 1501072594,
'fileid': 502326199,
'main': 1,
'send_id': 1000000306,
'source_url': '',
'title': '绿勤行——不说再见',
'type': '49'
},
{
'abstract': '当时不杂,过往不恋,志愿不老,我们不散!',
'author': '',
'content_url': 'http://mp.weixin.qq.com/s?timestamp=1501143158&src=3&ver=1&signature=B-*tqUrFyO7OqpFeJZwTA7JJtsHpz6BgC8ugyfgpOnyWLtPb85R5Zmu0JuZRbZKG72x4bQjMCcsfA5mC3GSSOGUrM*jg*EP1jU-Dyf2CVqmPnOgBiET2wlitek4FcRbXorAswWHm*1rqODcN52NtfKD-OcRTazQS*t5SnJtu3ZA=',
'copyright_stat': 100,
'cover': 'http://mmbiz.qpic.cn/mmbiz_jpg/icFYWMxnmxHCoY44nPUXvkSgpZI1LaEsZfkZvtGaiaNW2icjibCp6qs93xLlr9kXMJEP3z1pmQ6TbRZNicHibGzRwh1w/0?wx_fmt=jpeg',
'datetime': 1500979158,
'fileid': 502326196,
'main': 1,
'send_id': 1000000305,
'source_url': '',
'title': '有始有终 | 2016-2017年度环境保护服务部工作总结',
'type': '49'
},
...
],
'gzh': {
'authentication': '南京航空航天大学',
'headimage': 'http://wx.qlogo.cn/mmhead/Q3auHgzwzM4xV5PgPjK5XoPaaQoxnWJAFicibMvPAnsoybawMBFxua1g/0',
'introduction': '南航大志愿活动的领跑者,为你提供校内外的志愿资源和精彩消息。',
'wechat_id': 'nanhangqinggong',
'wechat_name': '南航青年志愿者'
}
}
- 数据结构
{
'gzh': {
'wechat_name': '', # 名称
'wechat_id': '', # 微信id
'introduction': '', # 简介
'authentication': '', # 认证
'headimage': '' # 头像
},
'article': [
{
'send_id': int, # 群发id,注意不唯一,因为同一次群发多个消息,而群发id一致
'datetime': int, # 群发datatime 10位时间戳
'type': '', # 消息类型,均是49(在手机端历史消息页有其他类型,网页端最近10条消息页只有49),表示图文
'main': int, # 是否是一次群发的第一次消息 1 or 0
'title': '', # 文章标题
'abstract': '', # 摘要
'fileid': int, #
'content_url': '', # 文章链接
'source_url': '', # 阅读原文的链接
'cover': '', # 封面图
'author': '', # 作者
'copyright_stat': int, # 文章类型,例如:原创啊
},
...
]
}
- 使用
In [1]: from pprint import pprint
...: from wechatsogou import WechatSogouAPI, WechatSogouConst
...:
...: ws_api = WechatSogouAPI()
...: gzh_articles = ws_api.get_gzh_article_by_hot(WechatSogouConst.hot_index.food)
...: for i in gzh_articles:
...: pprint(i)
...:
{
'article': {
'abstract': '闷热的夏天有什么事情能比吃上凉凉的甜品更惬意的呢?快一起动手做起来吧,简单方便,放冰箱冻一冻,那感觉~橙汁蒸木瓜木瓜1个(300-400克左右),橙子4个,枫糖浆20克(如果家里没有,也可以用蜂蜜、炼乳等代替),椰果适量。做法1.用削皮',
'main_img': 'http://img01.sogoucdn.com/net/a/04/link?appid=100520033&url=http%3A%2F%2Fmmbiz.qpic.cn%2Fmmbiz_jpg%2Fw9UGwFPia7QTUIadPibgW8OFkqf1ibR40xicKfzofRS0sDpaFp3CG0jkPyQKeXl44TXswztW1SJnic7tmCibjB8rIIGw%2F0%3Fwx_fmt%3Djpeg',
'open_id': 'oIWsFty9hHVI9F10amtzx5TOWIq8',
'time': 1501325220,
'title': '夏日甜品制作方法,不收藏后悔哦!',
'url': 'http://mp.weixin.qq.com/s?src=3×tamp=1501328525&ver=1&signature=n9*oX0k4YbNFhNMsOjIekYrsha44lfBSCbG9jicAbGYrWNN8*48NzpcaHdxwUnC12syY5-ZxwcBfiJlMzdbAwWKlo26EW14w2Ax*gjLVlOX-AGXB4443obZ-GK0pw*AFZAGZD8sI4AFBZSZpyeaxN4sS7cpynxdIuw6S2h*--LI='
},
'gzh': {
'headimage': 'http://img03.sogoucdn.com/app/a/100520090/oIWsFty9hHVI9F10amtzx5TOWIq8',
'wechat_name': '甜品烘焙制作坊'
}
}
...
...
- 数据结构
{
'gzh': {
'headimage': str, # 公众号头像
'wechat_name': str, # 公众号名称
},
'article': {
'url': str, # 文章临时链接
'title': str, # 文章标题
'abstract': str, # 文章摘要
'time': int, # 推送时间,10位时间戳
'open_id': str, # open id
'main_img': str # 封面图片
}
}- 使用
In [1]: import wechatsogou
...:
...: ws_api =wechatsogou.WechatSogouAPI()
...: ws_api.get_sugg('高考')
...:
Out[1]:
['高考e通',
'高考专业培训',
'高考地理俱乐部',
'高考志愿填报咨讯',
'高考报考资讯',
'高考教育',
'高考早知道',
'高考服务志愿者',
'高考机构',
'高考福音']
- 数据结构
关键词列表
['a', 'b', ...]-
相似文章的公众号获取 - 主页热门公众号获取
- 文章详情页信息
-
所有类型的解析 - 验证码识别
- 接入爬虫框架
- 兼容py2



![dependabot[bot] avatar](https://avatars.githubusercontent.com/in/29110?v=4 "dependabot[bot]")

















































































































































































































