![]()
This repository contains the MindMeld Conversational AI Platform.
The MindMeld Conversational AI platform is among the most advanced AI platforms for building production-quality conversational applications. It is a Python-based machine learning framework which encompasses all of the algorithms and utilities required for this purpose. Evolved over several years of building and deploying dozens of the most advanced conversational experiences achievable, MindMeld is optimized for building advanced conversational assistants which demonstrate deep understanding of a particular use case or domain while providing highly useful and versatile conversational experiences.
MindMeld is the only Conversational AI platform available today that provides tools and capabilities for every step in the workflow for a state-of-the-art conversational application. The architecture of MindMeld is illustrated below.
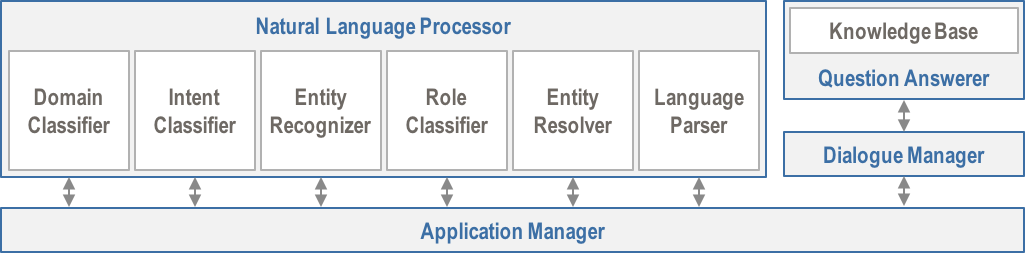
To summarize, the functionality available in MindMeld includes:
-
advanced Natural Language Processing, consisting of
- Domain Classification
- Intent Classification
- Entity Recognition
- Entity Role Labeling
- Entity Resolution
- Language Parsing
-
versatile dialogue management
-
custom knowledge base creation
-
advanced question answering
-
training data collection and management support
-
large-scale data analytics
MindMeld has been used for applications in dozens of different domains by some of the largest global organizations. Over the course of these production deployments, MindMeld has evolved to be ideally suited for building production-quality, large-vocabulary language understanding capabilities for any custom application domain. This has been achieved by following the architectural philosophy whose guiding principles are expressed in the table below.
| Concept | Description |
|---|---|
| Power and Versatility | Unlike GUI-based tools typically too rigid to accommodate the functionality required by many applications, MindMeld provides powerful command-line utilities with the flexibility to accommodate nearly any product requirements. |
| Algorithms and Data | In contrast to machine learning toolkits which offer algorithms but little data, MindMeld provides not only state-of-the-art algorithms, but also functionality which streamlines the collection and management of large sets of custom training data. |
| NLP plus QA and DM | While conversational AI platforms available today typically provide natural language processing (NLP) support, few assist with question answering (QA) or dialogue management (DM). MindMeld provides end-to-end functionality including advanced NLP, QA, and DM, all three of which are required for production applications today. |
| Knowledge-Driven Learning | Nearly all production conversational applications rely on a comprehensive knowledge base to enhance intelligence and utility. MindMeld is the only Conversational AI platform available today which supports custom knowledge base creation. This makes MindMeld ideally suited for applications which must demonstrate deep understanding of a large product catalog, content library, or FAQ database, for example. |
| You Own Your Data | Differently from cloud-based NLP services, which require that you forfeit your data, MindMeld was designed from the start to ensure that proprietary training data and models always remain within the control and ownership of your application. |
Assuming you have pip installed with Python 3.6 or Python 3.7 and Elasticsearch running in the background:
pip install mindmeld
mindmeld blueprint home_assistant
python -m home_assistant build
python -m home_assistant converse
For detailed installation instructions, see Getting Started. To start with pre-built sample applications, see MindMeld Blueprints.
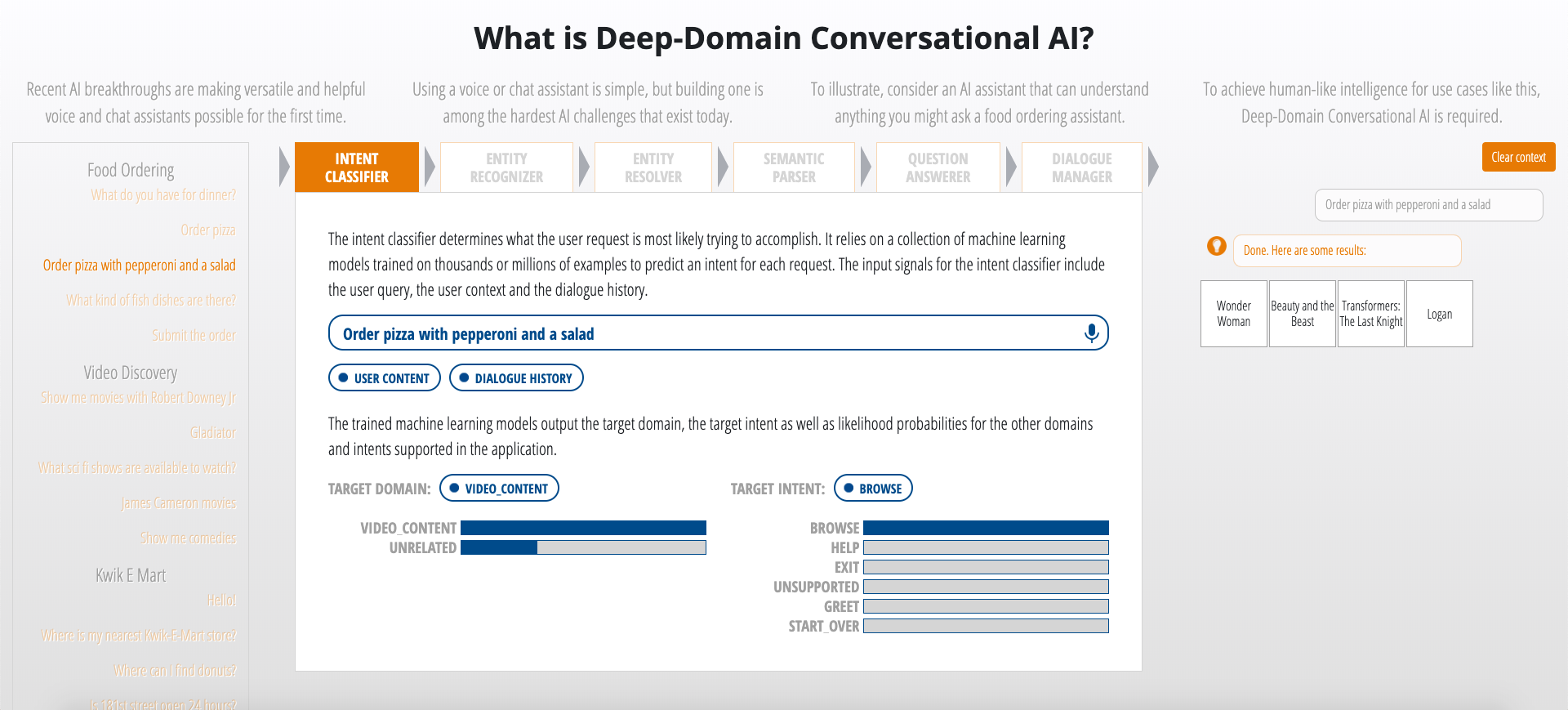
You can use our sample web-based chat client interface to interact with any MindMeld application. This web UI also serves as a debugging tool to step through the various stages of query processing by the MindMeld pipeline.
git clone [email protected]:cisco/mindmeld.git
cd mindmeld/mindmeld-ui
npm install
npm start
For detailed installation instructions, see Getting Started for UI.
Note: this web client only works on Chrome browser.
We are very happy to receive your contributions. We maintain a list of open issues on our GitHub project.
You can also create your own issue and link it to your code in a pull request, which we will promptly review.
To setup local development for MindMeld, first you will need to fork the MindMeld repository from GitHub and follow instructions on Getting Started page to setup the virtual environment.
git clone [email protected]:[username]/mindmeld.git
cd mindmeld
virtualenv -p python3 .
source bin/activate
To develop MindMeld, you need Python 3.6 or Python 3.7. To install and manage different versions of Python, you can checkout pyenv which also works with virtualenv.
Now we can install MindMeld and its dependencies:
pip install -e .
pip install -r dev-requirements.txt
pip install -r test-requirements.txt
Make sure that the numerical parser and Elasticsearch are running in the background. Finally we are ready to run MindMeld static style checks and unit tests.
./lintme
cd tests
pytest .
After making changes and all tests are passing locally, commit the code to your fork and issue a PR against the cisco/mindmeld repo.
You can view the documentation for the latest stable release on mindmeld.com/docs and the documentation for the latest master branch version on our Github Page.
You can contribute to the documentation under the source directory.
To generate the documentation, please follow these steps:
pip install -r docs-requirements.txt
make apidoc
Please cite this paper if you use MindMeld in your work:
Raghuvanshi, A., Carroll, L. and Raghunathan, K., 2018, November. Developing Production-Level Conversational Interfaces with Shallow Semantic Parsing. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing: System Demonstrations (pp. 157-162)
@inproceedings{raghuvanshi2018developing,
title={Developing Production-Level Conversational Interfaces with Shallow Semantic Parsing},
author={Raghuvanshi, Arushi and Carroll, Lucien and Raghunathan, Karthik},
booktitle={Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing:
System Demonstrations},
pages={157--162},
year={2018}
}
Visit the MindMeld website.
Please contact us at [email protected].







![dependabot[bot] avatar](https://avatars.githubusercontent.com/in/29110?v=4 "dependabot[bot]")





















































































































































