coleygroup / graph2smiles Goto Github PK
View Code? Open in Web Editor NEWLicense: MIT License
License: MIT License









































The model throws the error "RuntimeError: CUDA error: device-side assertion fired" (graph2seq_series_rel.py
,line 125, in forward, memory_lengths=memory_lengths) when I run reaction prediction, not when I run retrosynthesis.
I have been training the model for USPTO-480K for forward-reaction prediction and observing a somewhat slow training process. Since the training time was not mentioned in the paper and in the repository, I wanted to verify if this is a problem due to my system settings or is the same with your implementation.
For each 100 steps it takes around 100 seconds for model to train. I have a single NVIDIA A40 GPU with torch==1.13.1 and CUDA 11.6 and GPU utilization is always around %50. This is why I felt the need to open this issue because I think this is different from what #4 mentioned. Comparing to Molecular Transformer (MT), this is 5 times slower approximately.
Lastly, thanks for contributing open-source AI and sharing your content in detail with others.
Hi
I want to know how you clean and token data for USPTO_50k, USPTO_full, USPTO_480k, USPTO_STEREO
Since they are different from the origin data.
The given pretrained models (USPTO_480k_dgat.pt and USPTO_480k_dgcn.pt) in scripts/dowload_checkpoints.py have unexpected options for arguments like --data_name=MIT_mixed. The paths in the pretrained model are all wrong in my opinion because instead of paths that includes "USPTO_480k", it looks for paths that holds "MIT_mixed" during inference (in predict.sh).
As a natural result, I get the following:
Loading vocab from ./preprocessed/MIT_mixed_g2s_series_rel_smiles_smiles/vocab_smiles.txt
Traceback (most recent call last):
File "/nfsdata/home/ismail.aslan/PycharmProjects/ncs-benchmarks/models/2Graph2SMILES/predict.py", line 169, in <module>
main(args)
File "/nfsdata/home/ismail.aslan/PycharmProjects/ncs-benchmarks/models/2Graph2SMILES/predict.py", line 61, in main
vocab = load_vocab(pretrain_args.vocab_file)
File "/nfsdata/home/ismail.aslan/PycharmProjects/ncs-benchmarks/models/2Graph2SMILES/utils/data_utils.py", line 782, in load_vocab
with open(vocab_file, "r") as f:
FileNotFoundError: [Errno 2] No such file or directory: './preprocessed/MIT_mixed_g2s_series_rel_smiles_smiles/vocab_smiles.txt'
But in my opinion, the inference should have looked into './preprocessed/USPTO_480k_g2s_series_rel_smiles_smiles/vocab_smiles.txt'. Even when I correct this by reading the pretrained model args and rewriting those, it has another problem with the expected output shape which makes me think there is something weird.
On the other hand, when I train a model on USPTO_480k and use a checkpoint from the last step during inference (predict.sh), it works without any problem. That makes me think that there is a problem with the pretrained model arguments. Is there any chance you updated the model files recently?
The funny thing is that I was able to reproduce the same results 1-2 weeks ago. Any opinion about this issue is appreciated.
Hi,
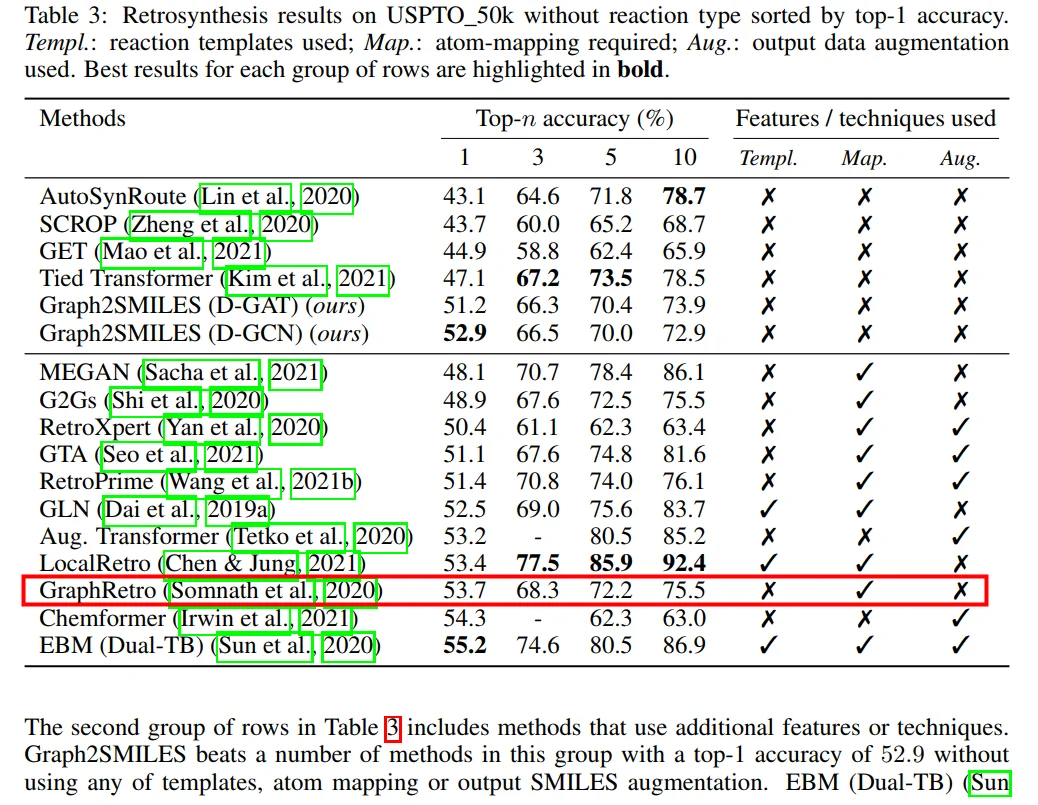
Would u plz explain why the performance of GraphRetro [1] in Table 3 of your paper is much lower than that of the original workshop paper [1]?
I further notice that one of the authors of Graph2SMILES is the author of GraphRetro.
[1] "Learning graph models for template-free retrosynthe". ICML Workshop, 2020
I am interested in your work. While I read the code, I found that during preprocessing, in the class get_graph_features_from_smi in data_utils.py.
The codes
# padding
for a_graph in a_graphs:
while len(a_graph) < 11: # OH MY GOODNESS... Fe can be bonded to 10...
a_graph.append(1e9)
for b_graph in b_graphs:
while len(b_graph) < 11: # OH MY GOODNESS... Fe can be bonded to 10...
b_graph.append(1e9)
I cannot understand why the atom and bond graphs needed to be padded to length 11. Could you tell me something about it?
Thanks a lot.
File "train.py", line 308, in
main(args)
File "train.py", line 127, in main
loss, acc = model(batch)
File "/root/anaconda3/envs/g2s/lib/python3.6/site-packages/torch/nn/modules/module.py", line 722, in _call_impl
result = self.forward(*input, **kwargs)
File "/Z70177/prog/wzp/g2s/models/graph2seq_series_rel.py", line 114, in forward
padded_memory_bank, memory_lengths = self.encode_and_reshape(reaction_batch)
File "/Z70177/prog/wzp/g2s/models/graph2seq_series_rel.py", line 106, in encode_and_reshape
reaction_batch.distances
File "/root/anaconda3/envs/g2s/lib/python3.6/site-packages/torch/nn/modules/module.py", line 722, in _call_impl
result = self.forward(*input, **kwargs)
File "/Z70177/prog/wzp/g2s/models/attention_xl.py", line 263, in forward
out = layer(out, mask, distances)
File "/root/anaconda3/envs/g2s/lib/python3.6/site-packages/torch/nn/modules/module.py", line 722, in _call_impl
result = self.forward(*input, **kwargs)
File "/Z70177/prog/wzp/g2s/models/attention_xl.py", line 202, in forward
context, _ = self.self_attn(input_norm, mask=mask, distances=distances)
File "/root/anaconda3/envs/g2s/lib/python3.6/site-packages/torch/nn/modules/module.py", line 722, in _call_impl
result = self.forward(*input, **kwargs)
File "/Z70177/prog/wzp/g2s/models/attention_xl.py", line 139, in forward
b_d = torch.matmul(query + v, rel_emb_t
RuntimeError: CUDA error: device-side assert triggered
Please help me solve it!
Hi,
I tried to train the model on ~230k reactions, but within 24hrs it reached only 1.3k steps. This seems a bit too few, therefore I wonder if I am missing some parameters or other detail. Also, how many steps you would suggest to train to get decent results?
Apart from this, the setup and scripts run pretty smoothly!
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.