copyes / articles Goto Github PK
View Code? Open in Web Editor NEWmy learning articles
my learning articles




















听很多人说起过移动端的click事件存在300ms的延迟,然后很多都是用touchstart来代替click事件,但是touchstart事件也会有自己的缺点,就是用户在滑动的过程中,可能触发相关元素的touchstart,所以很难受,但是这个问题还是有解决方法的。下面就是我了解的,然后通过查源码理解了下。
《300ms tap delay, gone away》
大意是说因为移动端要判断是否是双击,所以单击之后不能够立刻触发click,要等300ms,直到确认不是双击了才触发click。
有兴趣的也可以去看看click/touch的触发顺序。
Zepto有一个自定义事件tap,它是一个没有延迟的click事件。
自定义事件:
;['swipe', 'swipeLeft', 'swipeRight', 'swipeUp', 'swipeDown',
'doubleTap', 'tap', 'singleTap', 'longTap'].forEach(function(eventName){
$.fn[eventName] = function(callback){ return this.on(eventName, callback) }
})判定用户是点击还是在上下滑:
Zepto是用的位移偏差,即记录下touchstart的时候的初始位移,然后用touchend的时候的位移减掉初始位移的偏差,如果这个差值在30以内,则认为用户是点击,大于30则认为是滑动。
部分源码截取:
// normal tap
else if ('last' in touch)
// don't fire tap when delta position changed by more than 30 pixels,
// for instance when moving to a point and back to origin
if (deltaX < 30 && deltaY < 30) {
//...
}fastclick是在touchend之后生成一个click事件,并立即触发这个click,再取消原本的click事件。这个合成click是用MouseEvents代替,以下是源码截取:
clickEvent = document.createEvent('MouseEvents');
clickEvent.initMouseEvent(this.determineEventType(targetElement), true, true, window, 1, touch.screenX, touch.screenY, touch.clientX, touch.clientY, false, false, false, false, 0, null);
clickEvent.forwardedTouchEvent = true;
targetElement.dispatchEvent(clickEvent);// needsClick 主要是判断当前目标元素是不是自带点击属性的元素。
FastClick.prototype.needsClick = function(target) {
switch (target.nodeName.toLowerCase()) {
// Don't send a synthetic click to disabled inputs (issue #62)
case 'button':
case 'select':
case 'textarea':
if (target.disabled) {
return true;
}
break;
case 'input':
// File inputs need real clicks on iOS 6 due to a browser bug (issue #68)
if ((deviceIsIOS && target.type === 'file') || target.disabled) {
return true;
}
break;
case 'label':
case 'iframe': // iOS8 homescreen apps can prevent events bubbling into frames
case 'video':
return true;
}
return (/\bneedsclick\b/).test(target.className);
};
//...
if (!this.needsClick(targetElement)) {
event.preventDefault();
this.sendClick(targetElement, event);
}
return false;判定用户是点击还是在上下滑:
fastclick是用的时间偏差,分别记录touchstart和touchend的时间戳,如果它们的时间差大于700毫秒,则认为是滑动操作,否则是点击操作。
部分源码截取:
this.tapTimeout = options.tapTimeout || 700;
//...
if ((event.timeStamp - this.trackingClickStart) > this.tapTimeout) {
return true;
}在chrome自己页面的代码中实现tap是根据时间差来判断是否出发了tap,部分源码如下:
/**
* The time, in milliseconds, that a touch must be held to be considered
* 'long'.
* @type {number}
* @private
*/
TouchHandler.TIME_FOR_LONG_PRESS_ = 500;上面定义了长时间按压long press的时间阈值为500ms,在touchstart后开启了一个定时器:
this.longPressTimeout_ = window.setTimeout(
this.onLongPress_.bind(this), TouchHandler.TIME_FOR_LONG_PRESS_);
onLongPress_: function() {
this.disableTap_ = true;
}如果时间超过了阈值500ms,就给一个long press的标志disableTap_,并设置为true。
在后面touchend里面就会因为disableTap_而不触发tap:
if (!this.disableTap_)
this.dispatchEvent_(TouchHandler.EventType.TAP, touch);相对于其他的库的tap实现方式,chrome要复杂的多。
如何基于webpack做持久化缓存目前感觉是一直没有一个非常好的方案来实践。网上的文章非常多,但是真的有用的非常少,并没有一些真正深入研究和总结的文章。现在依托于于早教宝线上项目和自己的实践,有了一个完整的方案。
1、webpack的hash的两种计算方式
想要做持久化缓存那么就要依赖 webpack 自身提供的两个 hash :hash和chunkhash。
接着就来看看这两个值之间的具体含义和差别吧:
hash: webpack在每一次构建的时候都会产生一个compilation对象,这个hash值就是根据compilation内所有的内容计算而来的值。
chunkhash:这个值是根据每个chunk的内容而计算出来的值。
所以单纯根据上面的描述来说,chunkhash是用来做持久化缓存最有效的。
2、hash和chunkhash的测试
| entry | 入口文件 | 入口依赖 |
|---|---|---|
| pageA | a.js | a.less->a.css, common.js->common.css |
| pageB | b.js | b.less->b.css, common.js->common.css |
const path = require('path')
const ExtractTextPlugin = require('extract-text-webpack-plugin')
module.exports = {
entry: {
pageA: './src/a.js',
pageB: './src/b.js'
},
output: {
filename: '[name]-[hash].js',
path: path.resolve(__dirname, 'dist')
},
module: {
rules: [
{
test: /\.css$/,
use: ExtractTextPlugin.extract({
fallback: 'style-loader',
use: ['css-loader?minimize']
})
}
]
},
plugins: [new ExtractTextPlugin('[name]-[hash].css')]
}构建结果
Hash: 80c922b349f516e79fb5
Version: webpack 3.8.1
Time: 1014ms
Asset Size Chunks Chunk Names
pageB-80c922b349f516e79fb5.js 2.86 kB 0 [emitted] pageB
pageA-80c922b349f516e79fb5.js 2.84 kB 1 [emitted] pageA
pageA-80c922b349f516e79fb5.css 21 bytes 1 [emitted] pageA
pageB-80c922b349f516e79fb5.css 21 bytes 0 [emitted] pageB结论
可以发现所有文件的hash全部都是一样的,但是你多构建几次产生的hash都是不一样的。原因在于我们使用了 ExtractTextPlugin,ExtractTextPlugin 本身涉及到异步的抽取流程,所以在生成 assets 资源时存在了不确定性(先后顺序),而 updateHash 则对其敏感,所以就出现了如上所说的 hash 异动的情况。另外所有 assets 资源的 hash 值保持一致,这对于所有资源的持久化缓存来说并没有深远的意义。
const path = require('path')
const ExtractTextPlugin = require('extract-text-webpack-plugin')
module.exports = {
entry: {
pageA: './src/a.js',
pageB: './src/b.js'
},
output: {
filename: '[name]-[chunkhash].js',
path: path.resolve(__dirname, 'dist')
},
module: {
rules: [
{
test: /\.css$/,
use: ExtractTextPlugin.extract({
fallback: 'style-loader',
use: ['css-loader?minimize']
})
}
]
},
plugins: [new ExtractTextPlugin('[name]-[chunkhash].css')]
}构建结果
Hash: 810904f973cc0cf41992
Version: webpack 3.8.1
Time: 1038ms
Asset Size Chunks Chunk Names
pageB-e9ed5150262ba39827d4.js 2.86 kB 0 [emitted] pageB
pageA-3a2e5ef3d4506fce8d93.js 2.84 kB 1 [emitted] pageA
pageA-3a2e5ef3d4506fce8d93.css 21 bytes 1 [emitted] pageA
pageB-e9ed5150262ba39827d4.css 21 bytes 0 [emitted] pageB结论
此时可以发现,运行多少次,hash 的变动没有了,每个 entry 拥有了自己独一的 hash 值,细心的你或许会发现此时样式资源的 hash 值和 入口脚本保持了一致,这似乎并不符合我们的想法,冥冥之中告诉我们发生了某些坏事情。
3、探索css文件的hash和入口文件hash之间的关系
在上面的构建结果中,我们发现css的hash值和入口文件的hash值是一样的,这里我们容易产生疑问,是不是这两个文件之间一定会有联系呢?呆着疑问去修改下b.css文件中的内容,产生构建结果:
Hash: 3d95035f096f3ca08761
Version: webpack 3.8.1
Time: 1028ms
Asset Size Chunks Chunk Names
pageB-e9ed5150262ba39827d4.js 2.86 kB 0 [emitted] pageB
pageA-3a2e5ef3d4506fce8d93.js 2.84 kB 1 [emitted] pageA
pageA-3a2e5ef3d4506fce8d93.css 21 bytes 1 [emitted] pageA
pageB-e9ed5150262ba39827d4.css 41 bytes 0 [emitted] pageB纳尼???改动css文件内容,为什么css文件的hash没有改变呢?不科学啊,入口文件的hash也没有改变。仔细想了一下 webpack 是将所有的内容都认为是js文件的一部分。在构建的过程中使用 ExtractTextPlugin 将样式抽离出entry chunk 了,而此时的 entry chunk 本身并没有发生改变,改变的是已经被抽离出去的css部分。而chunkunhash 却是根据 chunk 计算出来的,所以不变更应该是正常的。但是这个又不符合我们想要做的持久化缓存的要求,因为又变动就应该改变hash才是。
开心的是 ExtractTextPlugin 插件为我们提供了一个contenthash来变化:
plugins: [new ExtractTextPlugin('[name]-[contenthash].css')]修改b.css前后两次构建结果:
Hash: 3d95035f096f3ca08761
Version: webpack 3.8.1
Time: 1091ms
Asset Size Chunks Chunk Names
pageB-e9ed5150262ba39827d4.js 2.86 kB 0 [emitted] pageB
pageA-3a2e5ef3d4506fce8d93.js 2.84 kB 1 [emitted] pageA
pageA-9783744431577cdcfea658734b7db20f.css 21 bytes 1 [emitted] pageA
pageB-2d03aa12ae45c64dedd7f66bb88dd3db.css 41 bytes 0 [emitted] pageBHash: 7a96bcf1ef668a49c9d8
Version: webpack 3.8.1
Time: 1193ms
Asset Size Chunks Chunk Names
pageB-e9ed5150262ba39827d4.js 2.86 kB 0 [emitted] pageB
pageA-3a2e5ef3d4506fce8d93.js 2.84 kB 1 [emitted] pageA
pageA-9783744431577cdcfea658734b7db20f.css 21 bytes 1 [emitted] pageA
pageB-7e05e00e24f795b674df5701f6a38bd9.css 42 bytes 0 [emitted] pageB对比发现修改了样式文件后只有样式文件的hash发生了改变,符合我们想要的预期。
4、module id的不可控和修正
经过上面的测试,我们理所当然的认为我完成了持久化缓存的hash稳定。然后我们不小心删除了a.js中的a.less文件,然后前后两次构建:
Hash: 88ab71080c53db9d9f70
Version: webpack 3.8.1
Time: 1279ms
Asset Size Chunks Chunk Names
pageB-a2d1e1d73336f17e2dc4.js 3.82 kB 0 [emitted] pageB
pageA-96c9f5afea30e7e09628.js 3.8 kB 1 [emitted] pageA
pageA-d7ac82de795ddf50c9df43291d77b4c8.css 92 bytes 1 [emitted] pageA
pageB-56185455ea60f01155a65497e9bf6c85.css 108 bytes 0 [emitted] pageBHash: 172153ea2b39c2046a92
Version: webpack 3.8.1
Time: 1260ms
Asset Size Chunks Chunk Names
pageB-884da67fe2322246ab28.js 3.81 kB 0 [emitted] pageB
pageA-4c0dfb634722c556ffa0.js 3.68 kB 1 [emitted] pageA
pageA-35be2c21107ce4016c324daaa1dd5e28.css 49 bytes 1 [emitted] pageA
pageB-56185455ea60f01155a65497e9bf6c85.css 108 bytes 0 [emitted] pageB奇怪的事产生了,我移除了a.less文件后发现pageB入口文件的hash都改变了。如果只有pageA相关的文件hash变了我还可以理解。但是????为什么都变了???不行我得看看为什么都变了。

通过上面的diff发现我们移除了a.less后整体的id发生了改变了。那么这个地方的id我们可以推测是代表的是具体的引用的模块。
接着我们在看看前后两次构建模块的信息:
[3] ./src/a.js 284 bytes {1} [built]
[4] ./src/a.less 41 bytes {1} [built]
[5] ./src/b.js 284 bytes {0} [built]
[6] ./src/b.less 41 bytes {0} [built][3] ./src/a.js 264 bytes {1} [built]
[4] ./src/b.js 284 bytes {0} [built]
[5] ./src/b.less 41 bytes {0} [built]通过对比发现前面的序号在构建出来的pageB中有隐藏pageA相关的信息,这对于我们来做持久化缓存来说是非常不便的。我们期待的是pageB中只包含和自身相关的信息,不包含其他与自身无关的信息。
5、module id的变化
排除与己不相关的module id或者内容
会用webpack的人大概都之都一个特性:Code Splitting,本质上是对 chunk 进行拆分再组合的过程。具体要怎么做呢?
The answer is CommonsChunkPlugin,在plugin中添加:
plugins: [
new ExtractTextPlugin('[name]-[contenthash].css'),
new webpack.optimize.CommonsChunkPlugin({
name: 'runtime'
})
]接下来在看看移除pageA中的a.less的前后变化:
Hash: 697b36118920d991364a
Version: webpack 3.8.1
Time: 1488ms
Asset Size Chunks Chunk Names
pageB-9b2eb6768499c911a728.js 491 bytes 0 [emitted] pageB
pageA-c342383ca09604e8e7b8.js 495 bytes 1 [emitted] pageA
runtime-b6ec3c0d350aef6cbf3e.js 6.8 kB 2 [emitted] runtime
pageA-b812cf5b72744af29181f642fe4dbf38.css 43 bytes 1 [emitted] pageA
pageB-af8f1e92fd031bd1d1d8db5390b5d0d5.css 59 bytes 0 [emitted] pageB
runtime-35be2c21107ce4016c324daaa1dd5e28.css 49 bytes 2 [emitted] runtimeHash: 7ddaf109d5aa67c43ce2
Version: webpack 3.8.1
Time: 1793ms
Asset Size Chunks Chunk Names
pageB-613cc5a6a90adfb635f4.js 491 bytes 0 [emitted] pageB
pageA-0b72f85fda69a9442076.js 375 bytes 1 [emitted] pageA
runtime-a41b8b8bfe7ec70fd058.js 6.79 kB 2 [emitted] runtime
pageB-af8f1e92fd031bd1d1d8db5390b5d0d5.css 59 bytes 0 [emitted] pageB
runtime-35be2c21107ce4016c324daaa1dd5e28.css 49 bytes 2 [emitted] runtime接着在看看两次构建中pageB的对比:

经过对比我们发现在pageB中只包含的是自身相关的内容。所以使用CommonsChunkPlugin达到了我们的期望。而抽离出去的代码就是webpack的运行时代码。运行时代码也存储着webpack对module和chunk相关的信息。另外我们发现pageA和pageB的文件大小也发生了变化。导致这个变化的原因是CommonsChunkPlugin会默认的把entry chunk都包含的module抽取到我们取名为runtime的normal chunk中去。
假如我们在开发中每个页面都会用到一些工具库,例如lodash这类的。由于CommonsChunkPlugin的默认行为会抽取公共部分,可能lodash并没有发生改变,但是被抽离在运行时代码中的时候,每次都是会去请求新的。这不能达到我们要求的最小更新原则。所以我们要人工去干预一些代码。
plugins: [
new ExtractTextPlugin('[name]-[contenthash].css'),
new webpack.optimize.CommonsChunkPlugin({
name: 'vendor',
minChunks: Infinity
}),
new webpack.optimize.CommonsChunkPlugin({
name: 'runtime'
})在次对边前后两次构建的日志:
Hash: a703a57c828ec32b24e1
Version: webpack 3.8.1
Time: 1493ms
Asset Size Chunks Chunk Names
vendor-f11f58b8150930590a10.js 541 kB 0 [emitted] [big] vendor
pageB-7d065cd319176f44c605.js 938 bytes 1 [emitted] pageB
pageA-2b7e3707314e7ec4d770.js 910 bytes 2 [emitted] pageA
runtime-e68dec8bcad8a5870f0c.js 5.88 kB 3 [emitted] runtime
pageA-d7ac82de795ddf50c9df43291d77b4c8.css 92 bytes 2 [emitted] pageA
pageB-56185455ea60f01155a65497e9bf6c85.css 108 bytes 1 [emitted] pageBHash: 26fc9ad18554b28cd8e1
Version: webpack 3.8.1
Time: 1806ms
Asset Size Chunks Chunk Names
vendor-d9bad56677b04b803651.js 541 kB 0 [emitted] [big] vendor
pageB-a55dadfbf25a45856d6a.js 929 bytes 1 [emitted] pageB
pageA-7cbd77a502262ddcdd19.js 790 bytes 2 [emitted] pageA
runtime-fa8eba6e81ed41f50d6f.js 5.88 kB 3 [emitted] runtime
pageA-35be2c21107ce4016c324daaa1dd5e28.css 49 bytes 2 [emitted] pageA
pageB-56185455ea60f01155a65497e9bf6c85.css 108 bytes 1 [emitted] pageB到此为止我们解决了:排除与己不相关的module id或者内容问题。
稳定module id,尽可能的保持module id保持不变
一个module id是一个模块的唯一标示,并且该标示会出现在对应的entry chunk构建后的代码中。看个pageB的构建后代码的例子:
__webpack_require__(7)
const sum = __webpack_require__(0)
const _ = __webpack_require__(3)根据前面的实验,模块的增加或者减少都会引起module id的改变,所以为了不引起module id的改变,那么我们只能找一个东西来代替module id作为标示。我们在构建的过程中就将寻找出来替代标示来替换module id。
所以上面的叙述可以转换成两个步骤来行动。
6、稳定 module id 的相关操作
找到替代module id的方式
我们在日常的开发中,经常引用模块,都是通过地址来引用的。从这里我们可以得到启发,我们能不能够把module id全部替换成路径呢?再一个我们了解到在webpack resolve module阶段我们肯定是可以拿到资源路径的。在开始我们担心平台的路径差异性。幸运的是webpack 的源码其中在 ContextModule#74 和 ContextModule#35 中 webpack 对 module 的路径做了差异性修复。也就是说我们可以放心的通过module的libIdent来获取模块的路径了。
在整个webpack的执行过程中涉及到module id有三个钩子:
before-module-ids -> optimize-module-ids -> after-optimize-module-ids
所以我们只要在before-module-ids中做出修改就好了。
编写插件:
'use strict'
class moduleIDsByFilePath {
constructor(options) {}
apply(compiler) {
compiler.plugin('compilation', compilation => {
compilation.plugin("before-module-ids", (modules) => {
modules.forEach((module) => {
if(module.id === null && module.libIdent) {
module.id = module.libIdent({
context: this.options.context || compiler.options.context
})
}
})
})
})
}
}
module.exports = moduleIDsByFilePath上面的其实已经被webpack抽成一个插件了:
NamedModulesPlugin所以只需要在插件那一部分里面添加上
new webpack.NamedModulesPlugin()接下来对比下两次构建前后文件的变化:
Hash: e5bc78237ca9a3ad31f8
Version: webpack 3.8.1
Time: 1508ms
Asset Size Chunks Chunk Names
vendor-ebd9bfc583f45a344630.js 541 kB 0 [emitted] [big] vendor
pageB-432105effc229524c683.js 1.09 kB 1 [emitted] pageB
pageA-158bf2a923c98ab49be2.js 1.09 kB 2 [emitted] pageA
runtime-9ca4cebe90e444e723b9.js 5.88 kB 3 [emitted] runtime
pageA-d7ac82de795ddf50c9df43291d77b4c8.css 92 bytes 2 [emitted] pageA
pageB-56185455ea60f01155a65497e9bf6c85.css 108 bytes 1 [emitted] pageBHash: 7dce5d9dc88f619522fe
Version: webpack 3.8.1
Time: 1422ms
Asset Size Chunks Chunk Names
vendor-ebd9bfc583f45a344630.js 541 kB 0 [emitted] [big] vendor
pageB-432105effc229524c683.js 1.09 kB 1 [emitted] pageB
pageA-dae883ddaeff861761da.js 940 bytes 2 [emitted] pageA
runtime-c874a0c304fa03493296.js 5.88 kB 3 [emitted] runtime
pageA-35be2c21107ce4016c324daaa1dd5e28.css 49 bytes 2 [emitted] pageA
pageB-56185455ea60f01155a65497e9bf6c85.css 108 bytes 1 [emitted] pageB哇,我们对比发现只有相关改动的文件和运行时代码发生了改变,vendor和pageB相关都没有发生改变。美滋滋~~
这下我们达到了我们的目的,我们可以去看看我们构建后的代码了:
__webpack_require__("./src/b.less")
const sum = __webpack_require__("./src/common.js")
const _ = __webpack_require__("./node_modules/lodash/lodash.js")真的是变成了路径,成功~~。但是新的问题貌似又来了,和之前的文件对比发现我们的文件普遍比之前的变大了。好吧,是我们换成文件路径的时候造成的。这个时候我们能不能用hash来代替文件路径呢?答案是可以,官方也有插件可以供我们使用:
new webpack.HashedModuleIdsPlugin()官方说 NamedModulesPlugin 适合在开发环境,而在生产环境下请使用 HashedModuleIdsPlugin。
这样我们就达成了使用hash来代替原来的module id使之稳定。而且构建后的代码也不会变化太大。
本以为可以到此为止了。但是细心的人会发现runtime文件每次编译都发生了变化。是什么导致呢的?来看看吧:

我们观察发现,在我们的entry chunk数量没有发生变化的时候,改变一个entry chunk的内容导致runtime内容发生变化的只有chunk id这个时候问题就又来了。根据上面稳定module id的操作一样,数值型的chunk id不稳定性太大,我们要换,方式和上面一样。
7、稳定chunk id的相关操作
找到稳定chunk id的方式
因为我们知道webpack在打包的时候入口是具有唯一性的,那么很简单我们能不能够用入口对应的name呢?所以这里就比较简单了我们就用我们的entry name来替换chunk id。
找到改变chunk id的时机
根据经验module 有上面的过程那么 chunk我觉得也是有的。
before-chunk-ids -> optimize-chunk-ids -> after-optimize-chunk-ids
所以编写插件:
'use strict'
class chunkIDsByFilePath {
constructor(options) {}
apply(compiler) {
compiler.plugin('compilation', compilation => {
compilation.plugin('before-chunk-ids', chunks => {
chunks.forEach(chunk => {
chunk.id = chunk.name
})
})
})
}
}
module.exports = chunkIDsByFilePath不巧的是官方也有这个插件所以不用我们写。
NamedChunksPlugin构建后的代码里面我们可以看到了:
/******/ script.src = __webpack_require__.p + "" + chunkId + "-" + {"vendor":"ed00d7222262ac99e510","pageA":"b5b4e2893bce99fd5c57","pageB":"34be879b3374ac9b2072"}[chunkId] + ".js";原来的chunk id现在全部变成了entry name了,变更的风险又小了一点了。美滋滋~~
我们换成名字后那么问题又和上面module id换成name 又一样的问题,文件会变大。这个时候还是想到和上面的方式一样用hash来处理。这个时候就真的要编写插件了。安利一波我们自己写的
webpack-hashed-chunk-id-plugin。
到此持久化缓存中遇到的核心难题都已经处理完了。
测试项目地址
webpack-test
如果你想要快速搭建一个项目,欢迎使用这边的项目架构哦。
webpack-project-seed已经有线上项目用的用这个在跑了哦。顺便star一个吧。
感谢:@pigcan
之前已经把数据的单向绑定简单的实现了,能够直接将实例中data中的对应属性绑定到对应的视图中名字一样的属性。但是这个也只是一个简单的数据绑定。那么我们能不能够在input框里面输入的时候自动去更新视图里面对应绑定的属性呢?
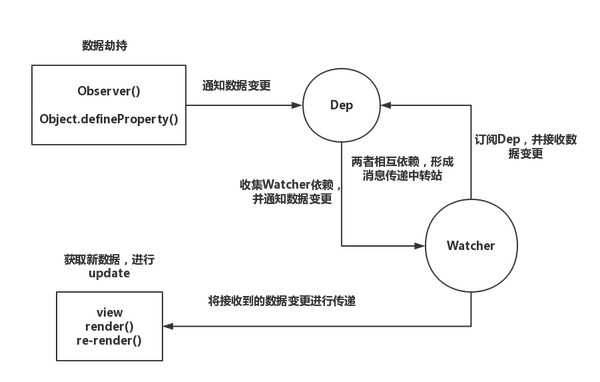
答案是肯定,先看一张图:
这张图是网上找的一个双向绑定的基本流程图。
首先我们要有一个方法来监听属性的变化。这个方法去递归便利监听每一个属性。在前面的文章中(1)、(2)中有提到如何去监听属性的变化。对应本文的代码是如下:
const observer = (data, vm) => {
// 遍历劫持data下面的所有的属性
Object.keys(data).forEach((key) => {
defineReactive(vm, key, data[key]);
});
}
// 属性劫持封装
const defineReactive = (vm, key, val) => {
// 新建通知者
var dep = new Dep();
// 利用setter 和 getter 访问器来对属性的值监听
Object.defineProperty(vm, key, {
get: () => {
console.log('被访问了');
if(Dep.target){
console.log(val);
dep.addSub(Dep.target);
}
return val;
},
set: (newVal) => {
console.log('被设置了');
if(val === newVal){
return;
}
val = newVal;
// 新的值要赋值给原来实例中data对应的属性
vm.data[key] = val;
// 通知订阅者,我们有数据改变了。
dep.notify();
}
});
}
以上代码大概就是对属性监听的视线,但是里面有使用到Dep(); 这个Dep()又是什么呢?
暂时我们就叫它通知者吧,他的作用是什么呢?简单点来说就是为了通知订阅了data中的属性的地方,我们属性的值发生了改变了。你要做好接下来的操作哦。
通知者的代码实现:
function Dep(){
// 搜集所有订阅了某个属性的订阅者
this.subs = [];
}
Dep.prototype = {
// 添加有用到属性的节点进图观察者队列中
addSub(watcher){
this.subs.push(watcher);
},
// 通知所有的观察者,使相应的数据节点去更新view层的值,model => view;
notify(){
this.subs.forEach((watcher) => {
// 每个观察者对应的更新操作。
watcher.update();
});
}
}
有了一个类似于通知中心的地方后我们在来看看放在通知中心中的那些订阅者watcher是什么。
代码如下:
// 订阅者(为每个节点的数据建立watcher 队列,每次接受更改数据需求哈后,利用数据劫持执行对应的节点的数据更新操作)
function Watcher(vm, node, name){
// 类似一个全局变量吧,用来临时保存下watcher
Dep.target = this;
this.vm = vm;
// 订阅的节点
this.node = node;
// 节点订阅的属性
this.name = name;
this.update();
// 为保证只有一个全局watcher,添加到队列后,清空全局watcher
Dep.target = null;
}
Watcher.prototype = {
// 在通知中心里面遍历的观察者的方法;
update(){
this.get();
if(this.node.nodeName === 'INPUT'){
this.node.value = this.value;
}else{
this.node.nodeValue = this.value;
}
},
// 订阅者拿到最新的属性值,是属性劫持getter拿到的值
get(){
this.value = this.vm[this.name];
}
}
观察车就是做了上面的那些事,但是这些观察者是在哪里被new 出来的呢?接下来看下面的关键步骤:
// 初始化绑定数据
const compile = (node, vm) => {
console.log(node);
// node为元素节点的时候
if(node.nodeType === 1){
// 获取处元素节点上所有属性主要是为了获得v-model
var attrs = node.attributes;
for(let i = 0; i < attrs.length; ++i){
if(attrs[i].nodeName === 'v-model'){
var name = attrs[i].nodeValue;
// 对input绑定了一个keyup事件,没次输入的操作都把新值赋值给对应的属性,
// 因为之前是把这些属性劫持了,所有有新值改变的时候都会触发通知者的notify方法
if(node.nodeName === 'INPUT'){
node.addEventListener('keyup', (e) => {
vm[name] = e.target.value;
console.log(vm[name]);
console.log(vm);
});
}
node.value = vm[name];
node.removeAttribute(attrs[i].nodeName);
}
}
}
// 文本节点
if(node.nodeType === 3){
console.log(node.nodeValue);
let reg = /\{\{(.*)\}\}/;
if(reg.test(node.nodeValue)){
// 这个就是为了去除表达式两边的空格
var name = RegExp.$1.trim();
//node.nodeValue = vm.data[name];
// 这个地方就是添加的订阅者,就是所有的文本节点中订阅了相关data的属性的地方
new Watcher(vm, node, name);
}
}
}
上面就是关键的一步啦。一些其它的代码就没写上来了。完成了了这些操作后就可以实现双向绑定了。
详细代码请看
因为按耐不住学习的心,搞了一个服务器,然后自己玩玩(真实目的是为了玩ssr)所以我要记录下我一步一步似爪牙,似魔鬼的步伐。持续更新。http://120.24.83.35:3000/
1、首先你得有个服务器
这个时候云卖服务器的地方就多了。我还是买的阿里云(第二次买了),机智的我找了在校生搞了个学生优惠,简直不要太好9.9一个月。
2、node环境安装
好吧,买服务器的时候没有选择带有镜像的,只有一个操作系统CentOS,所以这一切都要从头开始。我选择的是编译安装node(我没有用最新版的)。所以这个环境安装的步骤是:
(1)下载node安装包(去掉s貌似会快点,下载速度反正难受)
wget https://nodejs.org/dist/v6.9.5/node-v6.9.5-linux-x64.tar.xz
(2)解压文件
tar xvf node-v6.9.5-linux-x64.tar.xz
(3)解压完毕的话可以直接创建软链了(但是node-v6.9.5-linux-x64这个目录你喜欢嘛?我是不喜欢的,于是看下面)
mkdir -p /opt/node/
mv /root/node-v6.9.5-linux-x64/* /opt/node/
rm -f /usr/local/bin/node
rm -f /usr/local/bin/npm
ln -s /opt/node/bin/node /usr/local/bin/node
ln -s /opt/node/bin/npm /usr/local/bin/npm
(4)到这里我们就可以查看node,npm的版本了。
node -v
npm -v
3、git,nvm配置安装
4、nginx反向代理
希望自己在不断的学习过程中总结自己学习到的东西和问题
1.对象字面量解析报语法错误
{a:"a"}.a // 报Uncaught SyntaxError: Unexpected token .
({a:"a"}).a 或者 ({a: "a"}.a) // a
原因是js解析器认为上面以{ 开始是块语句的开始。所以才会报错。
2 、parseInt在解析多位数小数的时候结果不一样
parseInt(0.000008);
0
parseInt(0.0000008);
8
原因是因为parseInt(arg)的时候先是执行的是arg.toString();也就是说的小数点后面7位及以上的时候就会
采用科学计数法来显示(8e-7).toString();也就是说成了8所以上面浏览器的结果就是上面
3、获取闭包函数内部的对象数据(一道面试题)
let o = (function(){
var person = {
name: 'Copyes',
age: 24,
};
return {
run: function(k) {
return person[k];
},
}
}());
Object.defineProperty(Object.prototype, 'self',
{
get: function() {
return this;
},
configurable: true
});
o.run('self'); // 输出 person4、请说出下列情况中console的this,为什么是这样的?
function nsm() {console.log(this);}
nsm(); // Window{top: xxxx}
nsm.call(null/undefined); // Window{top: xxxx}
nsm.call(1); // Number {[[PrimitiveValue]]: 1}
function sm() {'use strict'; console.log(this);}
sm(); // undefined
sm.call(null); // null
sm.call(undefined); // undefined
sm.call(1); // 1非严格模式下,this默认指向全局对象,call/apply显式指定this参数时也会强制转换参数为对象(如果不是对象)。其中,null/undefined被替换为全局对象,基础类型被转换为包装对象。
严格模式下,this默认为undefined,且call/apply显式指定this参数时也不会有强制转换。
5、全局环境中变量提升。
if (!("a" in window)) {
var a = 1;
}
console.log(a);在浏览器环境中,全局变量都是window的一个属性,即
var a = 1 等价于 window.a = 1。in操作符用来判断某个属性属于某个对象,可以是对象的直接属性,也可以是通过prototype继承的属性。
6、数组展开
[1,2,[2,3,[4,5]]] ---> [1,2,2,3,4,5]
function flatArr(arr){
function isArray(arr){
return Object.prototype.toString.call(arr).slice(8, -1).toLowerCase() === 'array';
}
if(!isArray(arr) || !arr.length){
return [];
}else{
return Array.prototype.concat.apply([], arr.map(function(val){
return isArray(val) ? flatArr(val) : val;
}));
}
}
flatArr([1,2,[2,3,[4,5]]])关于组内读书会的一些总结,和自己查阅资料的一些纪录
一、浏览器为ajax做了什么
1、 标准浏览器通过 XMLHttpRequest 对象实现了ajax的功能. 只需要通过一行语句便可创建一个用于发送ajax请求的对象.
2、 IE浏览器通过 XMLHttpRequest 或者 ActiveXObject 对象同样实现了ajax的功能.
3、 IE的套路太深导致它的浏览器获取XMLHttpRequest对象的方式有很多种看这个地址去了解吧看看微软的。还有各个版本的ie的MSXML
4、 封装一个简单的全平台兼容的XMLHttpRequest对象

二、ajax与浏览器相关线程的关系
1、浏览器一般情况下的常驻线程主要有四个:GUI渲染线程、javascript引擎线程、浏览器事件触发线程、http请求线程。
2、通常, 线程间交互以事件的方式发生, 通过事件回调的方式进行通知. 而事件回调, 又是以先进先出的方式添加到任务队列 的末尾 , 等到js引擎空闲时, 任务队列 中排队的任务将会依次被执行. 这些事件回调包括 setTimeout, setInterval, click, ajax异步请求等回调.
3、浏览器中, js引擎线程会循环从 任务队列 中读取事件并且执行, 这种运行机制称作 Event Loop (事件循环).
4、对于一个ajax请求, js引擎首先生成 XMLHttpRequest 实例对象, open过后再调用send方法. 至此, 所有的语句都是同步执行. 但从send方法内部开始, 浏览器为将要发生的网络请求创建了新的http请求线程, 这个线程独立于js引擎线程, 于是网络请求异步被发送出去了. 另一方面, js引擎并不会等待 ajax 发起的http请求收到结果, 而是直接顺序往下执行.当ajax请求被服务器响应并且收到response后, 浏览器事件触发线程捕获到了ajax的回调事件 onreadystatechange (当然也可能触发onload, 或者 onerror等等) . 该回调事件并没有被立即执行, 而是被添加到 任务队列 的末尾. 直到js引擎空闲了, 任务队列 的任务才被捞出来, 按照添加顺序, 挨个执行, 当然也包括刚刚append到队列末尾的 onreadystatechange 事件.在 onreadystatechange 事件内部, 有可能对dom进行操作. 此时浏览器便会挂起js引擎线程, 转而执行GUI渲染线程, 进行UI重绘(repaint)或者回流(reflow). 当js引擎重新执行时, GUI渲染线程又会被挂起, GUI更新将被保存起来, 等到js引擎空闲时立即被执行.以上整个ajax请求过程中, 有涉及到浏览器的4种线程. 其中除了 GUI渲染线程 和 js引擎线程 是互斥的. 其他线程相互之间, 都是可以并行执行的. 通过这样的一种方式, ajax并没有破坏js的单线程机制.
三、ajax与setTimeout排队问题
通常, ajax 和 setTimeout 的事件回调都被同等的对待, 按照顺序自动的被添加到 任务队列 的末尾, 等待js引擎空闲时执行. 但请注意, 并非xhr的所有回调执行都滞后于setTImeout的回调.
四、XMLHttpRequest属性解读
在ajax中,XMLHttpRequest对象时做出了巨大的贡献的。那么这个作出贡献的对象包含了什么属性呢?来一起看下。
那么这些属性和方法是不是都是挂在这个对象上的呢?可能大家会觉得是都挂在这个上面的。我们还是实际点,来看看到底是挂在哪里的吧?直接上验证的代码吧:
上面这个代码就说明本身XMLHttpRequest对象上是没有挂任何属性和方法的。所有的我们平时用到的属性和方法都是来自于XMLHttpRequest的原型。然后我们去追根朔源,看看源头是来自哪里的(好吧我就不展示代码了毕竟截图太长了我就直接说了吧):
xhr ——> XMLHttpRequest.prototype ——> XMLHttpRequestEventTarget.prototype ——> EventTarget.prototype ——> Object.prototype
由这个原型链可以看出,xhr会具有Object等原型的方法哦。其实你可以去浏览器里面试试 xhr.toString()。
之前在和组内同事分享ajax的时候,有提到过GUI渲染引擎相关的操作,这个时候貌似就勾起了我对CSS渲染的理解,其实我自己理解的也不是特别的深,但是通过去翻看一些经典的文章,也加深了自己对浏览器渲染页面的一点理解吧。于是乎就有了这样一篇相关的东西。
一、关于浏览器的渲染步骤
标签中的每一行文字都会被视为一个单独的渲染节点。渲染树的一个节点也称为frame-结构体,或者盒子-box(与CSS盒子类似)。每个渲染节点都具有CSS盒子的属性,如width、height、border、margin等。
举个例子:
<html>
<head>
<meta name="viewport" content="width=device-width,initial-scale=1">
<link href="style.css" rel="stylesheet">
<title>browser rendering</title>
</head>
<body>
<p>Hello <span>web performance</span> students!</p>
<div><img src="awesome-photo.jpg"></div>
</body>
</html>body { font-size: 16px }
p { font-weight: bold }
span { color: red }
p span { display: none }
img { float: right }上面的代码的构建过程就是下面的图(借用别人的图和代码,原文链接在最后面哦):

二、reflow和repaint的简介
三、重绘和回流产生的情况小总结
1.增加,删除,更新DOM节点
2.移动节点和给对应的节点加上动画
3.通过display:none来控制隐藏和显示会触发回流和重绘操作。而visibility:none来隐藏的话只会触发重绘,因为该操作不回导致结构的改变。
4.给节点动态增加和调整样式。
5.用户自己手动改变窗口的大小,改变字体,滚动窗口等。
举个例子(该代码是别人的,自己懒得写了,链接在最后):
var bstyle = document.body.style; // 缓存
bstyle.padding = "20px"; // 触发重绘和回流
bstyle.border = "10px solid red"; // 再次触发重绘和回流
bstyle.color = "blue"; // 只触发重绘,因为几何结构没有改变
bstyle.backgroundColor = "#fad"; // 同上
bstyle.fontSize = "2em"; // 再再次触发重绘和回流
// 新增DOM节点,再再再次触发重绘和回流
document.body.appendChild(document.createTextNode('dude!'));四、聪明的浏览器
现在的浏览器都是比较厉害的。像上面的操作浏览器是不会一遇到改变就触发回流或者重绘的,往往他们会把这些操作加在一个队列里面。最后执行这些操作时以块方式执行的,这些又叫做异步回流或者增量异步回流。但是还是有些操作不会做像上面说的那种优化,还是会立即执行。比如执行改变窗口大小的resize的时候或者改变页面默认字体的时候。
肯定还有一些操作是不会遵守异步回流这个操作的:
offsetTop,offsetLeft,offsetWidth,offsetheight
scrollTop/Left/Width/Height
clientTop/Left/Width/Height
getComputedStyle(),或者IE下的currentStyle因为,如果我们的程序需要这些值,那么浏览器需要返回最新的值,而这样一样会flush出去一些样式的改变,从而造成频繁的reflow/repaint。
所以在一条语句中既对dom设操作又对dom取值操作时非常耗性能的。比如:
el.style.left = el.offsetLeft + 10 + "px";五、怎么减少回流和重绘(参考别人的例子)
1.不要一条一条地修改DOM的样式。与其这样,还不如预先定义好css的class,然后修改DOM的className
// bad
var left = 10,
top = 10;
el.style.left = left + "px";
el.style.top = top + "px";
// Good
el.className += " theclassname";
// Good
el.style.cssText += "; left: " + left + "px; top: " + top + "px;";2."离线"处理多个DOM操作。“离线”的意思是将需要进行的DOM操作脱离DOM树,比如:
(1)通过documentFragment集中处理临时操作;
(2)将需要更新的节点克隆,在克隆节点上进行更新操作,然后把原始节点替换为克隆节点;
(3)先通过设置display:none将节点隐藏(此时出发一次回流和重绘),然后对隐藏的节点进行100个操作(这些操作都会单独触发回流和重绘),完毕后将节点的display改回原值(此时再次触发一次回流和重绘)。通过这种方法,将100次回流和重绘缩减为2次,大大减少了消耗
3.不要过多进行重复的样式计算操作。如果你需要重复利用一个静态样式值,可以只计算一次,用一个局部变量储存,然后利用这个局部变量进行相关操作。
//糟糕的做法
for(big; loop; here) {
el.style.left = el.offsetLeft + 10 + "px";
el.style.top = el.offsetTop + 10 + "px";
}
//优化后的代码
var left = el.offsetLeft,
top = el.offsetTop
esty = el.style;
for(big; loop; here) {
left += 10;
top += 10;
esty.left = left + "px";
esty.top = top + "px";
}4.尽可能的修改层级比较低的DOM。当然,改变层级比较底的DOM有可能会造成大面积的reflow,但是也可能影响范围很小。
5.为动画的HTML元件使用fixed或absoult的position,那么修改他们的CSS是不会reflow的。
6.千万不要使用table布局。因为可能很小的一个小改动会造成整个table的重新布局。(这一点,基本现在很少涉及到了,很少用table布局了)
六、参考资料
http://www.phpied.com/rendering-repaint-reflowrelayout-restyle/
浏览器渲染那些事
浏览器的渲染原理简介
浏览器渲染神文
通过一个简单的例子来看看 koa2 的源码
示例
原生 http 请求方式
const http = require('http')
const server = http.createServer((req, res) => {
res.statusCode = 200
res.setHeader('Content-Type', 'text/plain')
res.end('Hello World\n')
})
server.listen(3000)koa2 使用方式
const Koa = require('koa')
const app = new Koa()
app.use(ctx => {
ctx.body = 'Hello Koa'
})
app.listen(3000)1、构造函数
application.js
这个文件里面主要是在做new 一个koa实例的初始化工作,以及收集中间件等操作。关键操作就是下面这几步。
this.middleware = [] // 用于存储中间件的数组
this.context = Object.create(context) // 创建上下文
this.request = Object.create(request) // 创建request
this.response = Object.create(response) // 创建response2、注册中间件
use(fn) {
if (typeof fn !== 'function') throw new TypeError('middleware must be a function!');
if (isGeneratorFunction(fn)) {
deprecate('Support for generators will be removed in v3. ' +
'See the documentation for examples of how to convert old middleware ' +
'https://github.com/koajs/koa/blob/master/docs/migration.md');
fn = convert(fn);
}
debug('use %s', fn._name || fn.name || '-');
this.middleware.push(fn);
return this;
}初始化构造函数完成后,如果我们有很多中间件的话,那么这个时候就是调用 use 来注册中间件了。上面就是注册中间件的方法。这个方法里面主要就是判断,传进来的是不是一个函数,如果是一个迭代器函数,那么会调用 convert 方法,将迭代器函数转化成为普通的函数,当然还会提示你不要用迭代器了。最后就是将传进来的函数存在构造函数里面声明的 middleware 数组中。
3、调用 listen 方法
listen(...args) {
debug('listen');
const server = http.createServer(this.callback());
return server.listen(...args);
}在构造函数里面初始化完成后,按照我们的使用方式就是注册中间件,然后在最后的时候调用 listen 方法。这个方法很简单,就是以向原生 http.createServer 传入一个函数的形式来创建自身的一个实例。listen 方法就做了这么简单的一个事。
4、在看 this.callback()
看到这里我们就明白我们实际上最关心的就是这个 this.callback 函数。其实这个也是 koa2 的核心所在。
callback() {
const fn = compose(this.middleware);
// 这里是调用Emitter类里面的方法
if (!this.listeners('error').length) this.on('error', this.onerror);
// 包装函数,将ctx和中间件和并函数传给内部
const handleRequest = (req, res) => {
// 基于req和req封装出我们使用的ctx对象。
const ctx = this.createContext(req, res);
return this.handleRequest(ctx, fn);
};
return handleRequest;
}this.callback 执行的结果是一个函数,这个函数的主要作用就是根据 req 获取请求信息,然后向 res 中写入返回内容。具体做法就是在一开始的时候合并中间件返回一个函数。然后基于 res 和 req 封装出我们平时使用的 ctx 对象。接着就是调用 koa 自己的 handleRequest 方法,将合并好的中间件函数和刚生成的 ctx 对象传入。
5、创建 ctx---createContext
前面已经说过了 ctx 这个对象就是基于 res 和 res 封装来的,接下来就看看是怎么封装的。
createContext(req, res) {
const context = Object.create(this.context);
const request = context.request = Object.create(this.request);
const response = context.response = Object.create(this.response);
context.app = request.app = response.app = this;
context.req = request.req = response.req = req;
context.res = request.res = response.res = res;
request.ctx = response.ctx = context;
request.response = response;
response.request = request;
context.originalUrl = request.originalUrl = req.url;
context.cookies = new Cookies(req, res, {
keys: this.keys,
secure: request.secure
});
request.ip = request.ips[0] || req.socket.remoteAddress || '';
context.accept = request.accept = accepts(req);
context.state = {};
return context;
}上面的主要操作就是创建了三个对象 context,request,response
6、关于 handleRequest 函数
上面我们知道传进 handleRequest 方法的参数就是经过封装的 ctx 和合并后的中间件函数。并且将他们的原型指定为我们 app 中对应的对象,然后将原生的 req 和 res 赋值给相应的属性,就完成了。
handleRequest(ctx, fnMiddleware) {
const res = ctx.res;
res.statusCode = 404;
const onerror = err => ctx.onerror(err);
// response 辅助函数
const handleResponse = () => respond(ctx);
// onFinished 是确保一个流在关闭、完成和报错时都会执行相应的回调函数
onFinished(res, onerror);
return fnMiddleware(ctx).then(handleResponse).catch(onerror);
}这里做的主要是将封装的 ctx 传给合并后的中间件函数 fnMiddleware,中间件函数返回的是一个 promise。resolve 的话就调用 handleResponse,reject 的话就调用 onerror。handleResponse 里面主要做的操作就是通过 ctx 中的信息向 res 中写入信息。
7、respond 的分析
respond 方法就是一个辅助方法,主要作用就是根据 ctx 中的相关信息向 res 中写入信息。
function respond(ctx) {
// allow bypassing koa
if (false === ctx.respond) return
const res = ctx.res
if (!ctx.writable) return
let body = ctx.body
const code = ctx.status
// ignore body
if (statuses.empty[code]) {
// strip headers
ctx.body = null
return res.end()
}
if ('HEAD' == ctx.method) {
if (!res.headersSent && isJSON(body)) {
ctx.length = Buffer.byteLength(JSON.stringify(body))
}
return res.end()
}
// status body
if (null == body) {
body = ctx.message || String(code)
if (!res.headersSent) {
ctx.type = 'text'
ctx.length = Buffer.byteLength(body)
}
return res.end(body)
}
// responses
if (Buffer.isBuffer(body)) return res.end(body)
if ('string' == typeof body) return res.end(body)
if (body instanceof Stream) return body.pipe(res)
// body: json
body = JSON.stringify(body)
if (!res.headersSent) {
ctx.length = Buffer.byteLength(body)
}
res.end(body)
}前面说了比较重要的是这个installModules方法了。但是这方法到底干了什么呢?
所以直接看下面的源码分析就好了。基本每一行代码都注释了。里面还是有很多老版本的设计和新版本的设计是不一样的。最后我会说出哪些地方有差别。
// 这个方法有五个参数,store就是表示当前实例本身,
// rootState表示的就是根state,说的通俗点就是我们总的状态树
// path表示当前模块嵌套的路径
// module表示当前安装的模块
// hot表示动态改变module或者在热更新的时候设置为true
function installModule (store, rootState, path, module, hot) {
// 通过path数组的长度判断是不是根
const isRoot = !path.length
// 假如是单独有模块的状态维护的话,那么对应单独的模块应该有自己的命名空间,防止起冲突
// 这里会有示例代码的 方法源码请看module/module-collection.js
const namespace = store._modules.getNamespace(path)
// 这个就是注册命名空间对应的模块的相印的vuex代码
// register in namespace map
if (namespace) {
store._modulesNamespaceMap[namespace] = module
}
// 这里主要是用来在不是根状态或者热更新的时候,设置一个级联的状态。感觉这样说有点不好理解
// 看了下面的几段代码,这个getNestedState方法很好理解了,就是根据 path 查找 state 上的嵌套 state。
// 在这里就是传入 rootState 和 path,计算出当前模块的父模块的 state,
// 由于模块的 path 是根据模块的名称 concat 连接的,所以 path 的最后一个元素就是当前模块的模块名
// set state
if (!isRoot && !hot) {
// 先看看这个方法
const parentState = getNestedState(rootState, path.slice(0, -1))
const moduleName = path[path.length - 1]
// 把当前module的state添加到根状态上去,
// _withcommit方法是用来干嘛的呢?
// 因为vuex中对所有的state的修改都会用_withCommit来包装下。保证在修改state的时候
// this._committing的值都是始终为true.所以假如我们在观测state的时候这个值不为true的话
// 那么观测的这个state就是有问题的。
store._withCommit(() => {
Vue.set(parentState, moduleName, module.state)
})
}
// 当前module的上下文
const local = module.context = makeLocalContext(store, namespace, path)
// 下面这连着三段代码都还是比较好理解的。因为我们暂且可以理解为有module状态的概念,
// 假如我们的vuex程序只有一棵主状态树,没有其他的module状态树的时候,下面的东西我们只去执行一次就好了如果还有其他模块的,那么会递归调用,就在下面。
// 这个感觉就是vuex的优雅的地方了,引入的module的**。可以单个module维护自己的一套。不用所有的都写在主状态树上
// 这下面三个就是把主状态相关的mutations, actions, getters进行注册
module.forEachMutation((mutation, key) => {
const namespacedType = namespace + key
registerMutation(store, namespacedType, mutation, local)
})
module.forEachAction((action, key) => {
const namespacedType = namespace + key
registerAction(store, namespacedType, action, local)
})
module.forEachGetter((getter, key) => {
const namespacedType = namespace + key
registerGetter(store, namespacedType, getter, local)
})
// 这下面主要就是为了把module状体树相关mutations, actions, getters进行注册
module.forEachChild((child, key) => {
installModule(store, rootState, path.concat(key), child, hot)
})
}上面有额外用到的方法我这个也把代码贴出来,注释都在上面调用该方法的地方。
1.获取命名空间的:
getNamespace (path) {
let module = this.root
return path.reduce((namespace, key) => {
module = module.getChild(key)
return namespace + (module.namespaced ? key + '/' : '')
}, '')
}
2.计算出当前模块的父模块的 state
getNamespace (path) {
let module = this.root
return path.reduce((namespace, key) => {
module = module.getChild(key)
return namespace + (module.namespaced ? key + '/' : '')
}, '')
}
3.committing包装函数
_withCommit (fn) {
const committing = this._committing
this._committing = true
fn()
this._committing = committing
}
1.主状态相关的mutations, actions, getters注册和模块注册的代码形势不一样
2.新版本有了模块的命名空间的概念。上面第二行代码
1.registerAction分析
// 这个函数是对state上的actions的初始化。action是可以异步去修改state的,这里说是异步修改并不是直接
// 在action中就修改了state,而是还是要通过mutation去修改。state。在vuex中mutation是修改state的唯一途径
// 结下来就具体去看看这个方法中做了什么事情。
function registerAction (store, type, handler, local) {
// 首先事通过type获得对应action的对象数组
const entry = store._actions[type] || (store._actions[type] = [])
// 这里是把对应action的包装函数push进这个对象数组中去,这个函数接受两个参数,一个叫载荷俗称就是方法的参数,另一个
// 就是回调了。这个函数在执行的时候会去调用action的回调函数。这个地方的local就算是对应module的上下文对象吧
// 然后就把对应的上下文对象中的dispatch,commit,getters,state以及根状态和根getter传进去。
entry.push(function wrappedActionHandler (payload, cb) {
let res = handler({
dispatch: local.dispatch,
commit: local.commit,
getters: local.getters,
state: local.state,
rootGetters: store.getters,
rootState: store.state
}, payload, cb)
// 接着就是对这个函数的返回值res进行判断,是不是一个promise对象。isPromise函数的封装请看util.js文件中的。
if (!isPromise(res)) {
res = Promise.resolve(res)
}
// 这个就是工具的判断了。只有当vuex devtool开启的时候我们才能捕获异常
if (store._devtoolHook) {
return res.catch(err => {
store._devtoolHook.emit('vuex:error', err)
throw err
})
} else {
return res
}
})
}示例代码来自官方购物车demo:
const actions = {
checkout ({ commit, state }, products) {
const savedCartItems = [...state.added]
commit(types.CHECKOUT_REQUEST)
shop.buyProducts(
products,
() => commit(types.CHECKOUT_SUCCESS),
() => commit(types.CHECKOUT_FAILURE, { savedCartItems })
)
}
}这个例子就是说我们在当前这个module中注册了checkout这个action。这个commit就是store的API,而这个state就是当前module中的state。可以看到这个代码中我们可以通过同步的方式commit到对应的mutation去。当然也可以是异步提交。
我们要知道是什么时候调用了这个action呢?想必你应该知道vue的dispatch吧?不知道?去看看文档吧。
就是通过在组件里面触发dispatch来通知这个action执行的。
vuex源码里面有dispatch的实现,最后可以看看。
2.registerMutation分析
先看最新的源码分析
// 这个函数是对state上的mutations的初始化。这个方法就简单多了。
// store为当前 Store 实例,type为 mutation 的 key,handler 为 mutation 执行的回调函数,path 为当前模块的路径。
// mutation 的作用就是同步修改当前模块的 state ,
// 函数首先通过 type 拿到对应的 mutation 对象数组, 然后把一个 mutation 的包装函数 push 到这个数组中,
// 这个函数接收一个参数 payload,这个就是我们在定义 mutation 的时候接收的额外参数。
// 这个函数执行的时候会调用 mutation 的回调函数,将当前模块的 state,和 playload 一起作为回调函数的参数
function registerMutation (store, type, handler, local) {
const entry = store._mutations[type] || (store._mutations[type] = [])
entry.push(function wrappedMutationHandler (payload) {
handler(local.state, payload)
})
}官方的实例分析:
const mutations = {
[types.CHECKOUT_REQUEST] (state) {
// clear cart
state.added = []
state.checkoutStatus = null
},
[types.CHECKOUT_SUCCESS] (state) {
state.checkoutStatus = 'successful'
},
[types.CHECKOUT_FAILURE] (state, { savedCartItems }) {
// rollback to the cart saved before sending the request
state.added = savedCartItems
state.checkoutStatus = 'failed'
}
}这里定义了几个mutations,通过registerMutation方法把各个mutation注册了,然后mutation是接受两个参数的一个当前模块的state,一个是额外的参数(非必需)。这个时候我们就又要知道mutation是怎么被调用的了,其实在上面的action分析中可以看到是在对应的action中调用了commit,提交对应的mutation。
那么问题又来了commit函数哪里来的,又是怎么运作的?
3.registerGetter分析
直接上源码:
// 还是老套路,这个函数是对stroe上的getters的初始化,接受的是四个参数,store就是实例本身,type为对应的getter的key
// local是当前module的上下文。至于rawGetter的话,我没有找到在哪里定义了这个方法,但是大概猜是执行对应getter的回调函数,
// 把当前module的state,当前的所有getters,根状态,根getters都穿进去当参数。
//
function registerGetter (store, type, rawGetter, local) {
if (store._wrappedGetters[type]) {
console.error(`[vuex] duplicate getter key: ${type}`)
return
}
store._wrappedGetters[type] = function wrappedGetter (store) {
return rawGetter(
local.state, // local state
local.getters, // local getters
store.state, // root state
store.getters // root getters
)
}
}接着就是官方的实例
const state = {
added: [],
checkoutStatus: null
}
// getters
const getters = {
checkoutStatus: state => state.checkoutStatus
}看getter的回调,就是可以访问当前模块里面的state,看来上面我的猜想是正确的。
套路就是,这个就是直接把checkoutStatus这个getter放在store._wrappedGetters[checkoutStatus],回调的参数就是当前模块的state。因为是放在了store上,所以直接使用this.$store.getters.checkoutStatus就能访问了。但是怎么把getter绑定到this.$store上的呢?接下来就要看下面的这个方法了。累~~~~
4.resetStoreVM分析
// 四个重要的方法中最后一个,套路就是参数是store实例,状态树,还有热更新的标志
//
function resetStoreVM (store, state, hot) {
const oldVm = store._vm
// 在store上挂载对外的getter空对象
// bind store public getters
store.getters = {}
// 获取store上的私有的getters对象数组
const wrappedGetters = store._wrappedGetters
// 定义一个计算属性的对象。
const computed = {}
// 这个地方的主要作用是用计算属性的方式存储getter实现方式。
forEachValue(wrappedGetters, (fn, key) => {
// use computed to leverage its lazy-caching mechanism
computed[key] = () => fn(store)
// 用 ES5 的 Object.defineProperty 方法为 store.getters 定义了 get 方法,
// 也就是当我们在组件中调用this.$store.getters.xxxgetters 这个方法的时候,会访问 store._vm[xxxgetters]
Object.defineProperty(store.getters, key, {
get: () => store._vm[key],
enumerable: true // for local getters
})
})
// use a Vue instance to store the state tree
// suppress warnings just in case the user has added
// some funky global mixins
// 首先先拿全局 Vue.config.silent 的配置,然后临时把这个配置设成 true,
// 接着实例化一个 Vue 的实例,把 store 的状态树 state 作为 data 传入,
// 当我们在组件中访问 this.$store.getters.xxxgetters 的时候,
// 就相当于访问 store._vm[xxxgetters],也就是在访问 computed[xxxgetters],
// 这样就访问到了 xxxgetters 对应的回调函数了
const silent = Vue.config.silent
Vue.config.silent = true
store._vm = new Vue({
data: {
$$state: state
},
// 把 computed 对象作为 _vm 的 computed 属性,这样就完成了 getters 的注册
computed
})
Vue.config.silent = silent
// enable strict mode for new vm
// 判断是不是开启严格模式
if (store.strict) {
// 这里的严格模式不是传统意义上的严格模式
enableStrictMode(store)
}
// 由于这个函数每次都会创建新的 Vue 实例并赋值到 store._vm 上,那么旧的 _vm 对象的状态设置为 null,
// 并调用 $destroy 方法销毁这个旧的 _vm 对象
if (oldVm) {
if (hot) {
// dispatch changes in all subscribed watchers
// to force getter re-evaluation for hot reloading.
store._withCommit(() => {
oldVm._data.$$state = null
})
}
Vue.nextTick(() => oldVm.$destroy())
}
}没有示例了。这个就要靠自己的理解了。
在此已经将四个重要的方法分析了。但是里面的commit和dispatch没有去分析,我觉得嘛还是应该你们自己去找源码看看了,然后再理解下它们做了什么事。另外这四个方法我事看的最新的vuex的代码,和以前的老代码实现的方式有些不一样,但是总体方向上是一样的。可以去找以前的源码看看。到此对Store类的分析几本结束,接下来就是最后的对外暴露的API方法了。
发布-订阅模式又称为观察者模式,它定义的是一种一对多的依赖关系,当一个状态发生改变的时候,所有以来这个状态的对象都会得到通知。
上面事发布-订阅模式的一个比较正式的解释,可能这个解释不大好理解。所以我们通过实际生活中的例子来理解。
比如看中了一套房子,等到去了售楼处的说以后才被告知房子已经售罄了。但是售楼小姐告知,将来会有尾盘推出。具体什么时候推出,目前没人知道。
但是买家又不想频繁的跑,于是就把自己的电话号码登记在售楼处,在登记的花名册上有很多类似的买家。售楼小姐答应买家,新的房源一出来就一一通知买家。
所以上面就是一个发布订阅模式的简单例子。购房者(订阅者)订阅房源信息,售楼处(发布者)发布新房源消息给购房者(订阅者),购房者(订阅者)接收到消息后作出相应的反应。
1、售楼处的例子
一步步实现发布订阅模式:
let salesOffices = {} // 售楼处
salesOffices.books = [] // 缓存列表,存放订阅者的回调函数。
// 增加订阅者
salesOffices.listen = function(fn) {
this.books.push(fn) // 订阅的消息添加近缓存列表里面
}
salesOffices.trigger = function() {
// 发布消息
for (let i = 0, fn; (fn = salesOffices.books[i++]); ) {
fn.apply(this, arguments) // arguments 是发布消息的时候带上的参数
}
}
salesOffices.listen(function(price, squareMeter) {
// 购买者a
console.log(`价格是:${price}`)
console.log(`面积大小:${squareMeter}`)
})
salesOffices.listen(function(price, squareMeter) {
// 购买者b
console.log(`价格是:${price}`)
console.log(`面积大小:${squareMeter}`)
})
salesOffices.trigger(2000000, 88)
salesOffices.trigger(3000000, 128)上面实现了一个最简单的发布订阅模式。肯定还有很多问题的,例如订阅者只订阅了某一个消息,但是上面会把所有消息发给每一个订阅者。所以还得通过其他的方式让订阅者只订阅自己感兴趣的消息。
2、vue 对发布订阅模式的使用
我们都知道 Vue 有个最显著的特性,便是侵入性不是很强的响应式系统。这个特性就是对发布订阅模式非常好的应用。我们接下来就来看看这个特性是怎么应用的。
vue 的数据初始化:
var v = new Vue({
data() {
return {
a: 'hello'
}
}
})这个初始化的代码的背后包含着发布订阅模式的**,接下来看看官网的一个图
接下来就是网友的一个图:@xuqiang521
从上图可以看到,数据劫持的核心方法就是使用Object.defineProperty把属性转化成getter/setter。(因为这个是 ES5 中的方法,所以这也是 Vue 不支持 ie8 及以下浏览器的原因之一。)在数据传递变更的时候,会进入到我们封装的Dep和Watcher中进行处理。
数据不紧紧是基本类型的数据,也有可能是对象或者数组。基本类型的数据和对象的处理起来比较简单。
walk(obj) {
const keys = Object.keys(obj)
for (let i = 0; i < keys.length; ++i) {
defineReactive(obj, keys[i], obj[keys[i]])
}
}核心的劫持相关函数以及属性的订阅和发布
/**
* Define a reactive property on an Object.
*/
export function defineReactive(
obj: Object,
key: string,
val: any,
customSetter?: Function
) {
/*在闭包中定义一个dep对象*/
const dep = new Dep()
const property = Object.getOwnPropertyDescriptor(obj, key)
if (property && property.configurable === false) {
return
}
/*如果之前该对象已经预设了getter以及setter函数则将其取出来,新定义的getter/setter中会将其执行,保证不会覆盖之前已经定义的getter/setter。*/
// cater for pre-defined getter/setters
const getter = property && property.get
const setter = property && property.set
/*对象的子对象递归进行observe并返回子节点的Observer对象*/
let childOb = observe(val)
Object.defineProperty(obj, key, {
enumerable: true,
configurable: true,
get: function reactiveGetter() {
/*如果原本对象拥有getter方法则执行*/
const value = getter ? getter.call(obj) : val
if (Dep.target) {
/*进行依赖收集*/
dep.depend()
if (childOb) {
/*子对象进行依赖收集,其实就是将同一个watcher观察者实例放进了两个depend中,一个是正在本身闭包中的depend,另一个是子元素的depend*/
childOb.dep.depend()
}
if (Array.isArray(value)) {
/*是数组则需要对每一个成员都进行依赖收集,如果数组的成员还是数组,则递归。*/
dependArray(value)
}
}
return value
},
set: function reactiveSetter(newVal) {
/*通过getter方法获取当前值,与新值进行比较,一致则不需要执行下面的操作*/
const value = getter ? getter.call(obj) : val
/* eslint-disable no-self-compare */
if (newVal === value || (newVal !== newVal && value !== value)) {
return
}
/* eslint-enable no-self-compare */
if (process.env.NODE_ENV !== 'production' && customSetter) {
customSetter()
}
if (setter) {
/*如果原本对象拥有setter方法则执行setter*/
setter.call(obj, newVal)
} else {
val = newVal
}
/*新的值需要重新进行observe,保证数据响应式*/
childOb = observe(newVal)
/*dep对象通知所有的观察者*/
dep.notify()
}
})
}最开始在初始化的时候是对 data 里面的数据就开始劫持监听了。初始化的时候就调用了observe方法
/**
* Attempt to create an observer instance for a value,
* returns the new observer if successfully observed,
* or the existing observer if the value already has one.
*/
/*
尝试创建一个Observer实例(__ob__),如果成功创建Observer实例则返回新的Observer实例,如果已有Observer实例则返回现有的Observer实例。
*/
export function observe(value: any, asRootData: ?boolean): Observer | void {
/*判断是否是一个对象*/
if (!isObject(value)) {
return
}
let ob: Observer | void
/*这里用__ob__这个属性来判断是否已经有Observer实例,如果没有Observer实例则会新建一个Observer实例并赋值给__ob__这个属性,如果已有Observer实例则直接返回该Observer实例*/
if (hasOwn(value, '__ob__') && value.__ob__ instanceof Observer) {
ob = value.__ob__
} else if (
/*这里的判断是为了确保value是单纯的对象,而不是函数或者是Regexp等情况。*/
observerState.shouldConvert &&
!isServerRendering() &&
(Array.isArray(value) || isPlainObject(value)) &&
Object.isExtensible(value) &&
!value._isVue
) {
ob = new Observer(value)
}
if (asRootData && ob) {
/*如果是根数据则计数,后面Observer中的observe的asRootData非true*/
ob.vmCount++
}
return ob
}上面的数据observe之后返回的就是一个 Observer 的实例
ob = new Observer(value)
return ob在第一步数据劫持的时候,数据的获取或者修改的时候,都会做出对应的操作。这些操作的目的很简单,就是“通知”到“中转站”。这个“中转站”主要就是对数据的变更起通知作用以及存放依赖这些数据的“地方”。
这个"中转站"就是由"Dep"和“Watcher” 类构成的。每个被劫持的数据都会产生一个这样的“中转站”
Dep,全名 Dependency,从名字我们也能大概看出 Dep 类是用来做依赖收集的,但是也有通知对应的订阅者的作用 �,让它执行自己的操作,具体怎么收集呢?
/**
* A dep is an observable that can have multiple
* directives subscribing to it.
*/
export default class Dep {
static target: ?Watcher
id: number
subs: Array<Watcher>
constructor() {
this.id = uid++
this.subs = []
}
/*添加一个观察者对象*/
addSub(sub: Watcher) {
this.subs.push(sub)
}
/*移除一个观察者对象*/
removeSub(sub: Watcher) {
remove(this.subs, sub)
}
/*依赖收集,当存在Dep.target的时候添加观察者对象*/
depend() {
if (Dep.target) {
Dep.target.addDep(this)
}
}
/*通知所有订阅者*/
notify() {
// stabilize the subscriber list first
const subs = this.subs.slice()
for (let i = 0, l = subs.length; i < l; i++) {
subs[i].update()
}
}
}
// the current target watcher being evaluated.
// this is globally unique because there could be only one
// watcher being evaluated at any time.
Dep.target = null
/*依赖收集完需要将Dep.target设为null,防止后面重复添加依赖。*/
const targetStack = []
export function pushTarget(_target: Watcher) {
if (Dep.target) targetStack.push(Dep.target)
// 改变目标指向
Dep.target = _target
}
export function popTarget() {
// 删除当前目标,重算指向
Dep.target = targetStack.pop()
}代码很简短,但它做的事情却很重要
Watcher 就是订阅者(观察者)。� 主要的作用就是就是订阅 Dep(每个属性都会有一个 dep),当 Dep 发出消息传递(notify)的时候,所以订阅着 Dep 的 Watchers 会进行自己的 update 操作。
export default class Watcher {
vm: Component
expression: string
cb: Function
id: number
deep: boolean
user: boolean
lazy: boolean
sync: boolean
dirty: boolean
active: boolean
deps: Array<Dep>
newDeps: Array<Dep>
depIds: ISet
newDepIds: ISet
getter: Function
value: any
constructor(
vm: Component,
expOrFn: string | Function,
cb: Function,
options?: Object
) {
this.vm = vm
/*_watchers存放订阅者实例*/
vm._watchers.push(this)
// options
if (options) {
this.deep = !!options.deep
this.user = !!options.user
this.lazy = !!options.lazy
this.sync = !!options.sync
} else {
this.deep = this.user = this.lazy = this.sync = false
}
this.cb = cb
this.id = ++uid // uid for batching
this.active = true
this.dirty = this.lazy // for lazy watchers
this.deps = []
this.newDeps = []
this.depIds = new Set()
this.newDepIds = new Set()
this.expression =
process.env.NODE_ENV !== 'production' ? expOrFn.toString() : ''
// parse expression for getter
/*把表达式expOrFn解析成getter*/
if (typeof expOrFn === 'function') {
this.getter = expOrFn
} else {
this.getter = parsePath(expOrFn)
if (!this.getter) {
this.getter = function() {}
process.env.NODE_ENV !== 'production' &&
warn(
`Failed watching path: "${expOrFn}" ` +
'Watcher only accepts simple dot-delimited paths. ' +
'For full control, use a function instead.',
vm
)
}
}
this.value = this.lazy ? undefined : this.get()
}
/**
* Evaluate the getter, and re-collect dependencies.
*/
/*获得getter的值并且重新进行依赖收集*/
get() {
/*将自身watcher观察者实例设置给Dep.target,用以依赖收集。*/
pushTarget(this)
let value
const vm = this.vm
/*
执行了getter操作,看似执行了渲染操作,其实是执行了依赖收集。
在将Dep.target设置为自生观察者实例以后,执行getter操作。
譬如说现在的的data中可能有a、b、c三个数据,getter渲染需要依赖a跟c,
那么在执行getter的时候就会触发a跟c两个数据的getter函数,
在getter函数中即可判断Dep.target是否存在然后完成依赖收集,
将该观察者对象放入闭包中的Dep的subs中去。
*/
if (this.user) {
try {
value = this.getter.call(vm, vm)
} catch (e) {
handleError(e, vm, `getter for watcher "${this.expression}"`)
}
} else {
value = this.getter.call(vm, vm)
}
// "touch" every property so they are all tracked as
// dependencies for deep watching
/*如果存在deep,则触发每个深层对象的依赖,追踪其变化*/
if (this.deep) {
/*递归每一个对象或者数组,触发它们的getter,使得对象或数组的每一个成员都被依赖收集,形成一个“深(deep)”依赖关系*/
traverse(value)
}
/*将观察者实例从target栈中取出并设置给Dep.target*/
popTarget()
this.cleanupDeps()
return value
}
/**
* Add a dependency to this directive.
*/
/*添加一个依赖关系到Deps集合中*/
addDep(dep: Dep) {
const id = dep.id
if (!this.newDepIds.has(id)) {
this.newDepIds.add(id)
this.newDeps.push(dep)
if (!this.depIds.has(id)) {
dep.addSub(this)
}
}
}
/**
* Clean up for dependency collection.
*/
/*清理依赖收集*/
cleanupDeps() {
/*移除所有观察者对象*/
let i = this.deps.length
while (i--) {
const dep = this.deps[i]
if (!this.newDepIds.has(dep.id)) {
dep.removeSub(this)
}
}
let tmp = this.depIds
this.depIds = this.newDepIds
this.newDepIds = tmp
this.newDepIds.clear()
tmp = this.deps
this.deps = this.newDeps
this.newDeps = tmp
this.newDeps.length = 0
}
/**
* Subscriber interface.
* Will be called when a dependency changes.
*/
/*
调度者接口,当依赖发生改变的时候进行回调。
*/
update() {
/* istanbul ignore else */
if (this.lazy) {
this.dirty = true
} else if (this.sync) {
/*同步则执行run直接渲染视图*/
this.run()
} else {
/*异步推送到观察者队列中,由调度者调用。*/
queueWatcher(this)
}
}
/**
* Scheduler job interface.
* Will be called by the scheduler.
*/
/*
调度者工作接口,将被调度者回调。
*/
run() {
if (this.active) {
const value = this.get()
if (
value !== this.value ||
// Deep watchers and watchers on Object/Arrays should fire even
// when the value is the same, because the value may
// have mutated.
/*
即便值相同,拥有Deep属性的观察者以及在对象/数组上的观察者应该被触发更新,因为它们的值可能发生改变。
*/
isObject(value) ||
this.deep
) {
// set new value
const oldValue = this.value
/*设置新的值*/
this.value = value
/*触发回调渲染视图*/
if (this.user) {
try {
this.cb.call(this.vm, value, oldValue)
} catch (e) {
handleError(e, this.vm, `callback for watcher "${this.expression}"`)
}
} else {
this.cb.call(this.vm, value, oldValue)
}
}
}
}
/**
* Evaluate the value of the watcher.
* This only gets called for lazy watchers.
*/
/*获取观察者的值*/
evaluate() {
this.value = this.get()
this.dirty = false
}
/**
* Depend on all deps collected by this watcher.
*/
/*收集该watcher的所有deps依赖*/
depend() {
let i = this.deps.length
while (i--) {
this.deps[i].depend()
}
}
/**
* Remove self from all dependencies' subscriber list.
*/
/*将自身从所有依赖收集订阅列表删除*/
teardown() {
if (this.active) {
// remove self from vm's watcher list
// this is a somewhat expensive operation so we skip it
// if the vm is being destroyed.
/*从vm实例的观察者列表中将自身移除,由于该操作比较耗费资源,所以如果vm实例正在被销毁则跳过该步骤。*/
if (!this.vm._isBeingDestroyed) {
remove(this.vm._watchers, this)
}
let i = this.deps.length
while (i--) {
this.deps[i].removeSub(this)
}
this.active = false
}
}
}通过上面对 vue 的响应系统的 � 学习,就可以了解到这个发布订阅模式就是这样的:
3、vue 中更多的应用
vue 中还有个组件之间的时间传递也是用到了发布订阅模式。
$emit 负责发布消息, $on � 负责消费消息(执行 cbs 里面的事件)
Vue.prototype.$on = function(
event: string | Array<string>,
fn: Function
): Component {
const vm: Component = this
if (Array.isArray(event)) {
for (let i = 0, l = event.length; i < l; i++) {
this.$on(event[i], fn)
}
} else {
;(vm._events[event] || (vm._events[event] = [])).push(fn)
}
return vm
}
Vue.prototype.$emit = function(event: string): Component {
const vm: Component = this
let cbs = vm._events[event]
if (cbs) {
cbs = cbs.length > 1 ? toArray(cbs) : cbs
const args = toArray(arguments, 1)
for (let i = 0, l = cbs.length; i < l; i++) {
cbs[i].apply(vm, args)
}
}
return vm
}本文通过对 vue 相关源码的学习,了解了发布订阅模式(观察者模式)的概念和应用。还了解了该模式的 � 一些优缺点:
《javascript 设计模式与开发实践》
一道经常被问的面试题:在浏览器地址栏里面输入url之后发生了什么,简单的说说~这就非常难受了。
1、DNS解析
DNS(Domain Name System,域名系统)即计算机域名系统,它由域名解析器和域名服务器组成。最初,由于ip长且难记,通过ip访问网站不方便。。所以后来通过发明了DNS服务器,这个时候我们访问网站输入网站域名,DNS服务器就解析我们的域名为ip。这样我们实际访问的就是对应的ip地址啦。
域的划分
首先我们要明白怎么区分域:
当我们输入www.beibei.com的时候。实际上就是访问了不同的域。.是域的命名空间,用来分割不同的域。在.com后面还有个域,只是因为是域名系统默认的,所以这里不用写,这个就是根域。
真实的域名应该是这样的
www.baidu.com.根域。根域记录了所有com(顶级域)和baidu(二级域)共同构成的顶级域名baidu.com,www(三级域)和baidu.com叫二级域名www.baidu.com。
解析过程
2、TCP连接
获得目标服务器的IP地址和端口号之后,客户端和服务器之间将建立一条TCP/IP连接。
TCP是面向连接的、无差错的、按序传输的。
第一次
第一次握手:建立连接时,客户端发送syn包(syn=j)到服务器,并进入SYN_SENT状态,等待服务器确认;SYN:同步序列编号(Synchronize Sequence Numbers)。
第二次
第二次握手:服务器收到syn包,必须确认客户的SYN(ack=j+1),同时自己也发送一个SYN包(syn=k),即SYN+ACK包,此时服务器进入SYN_RECV状态;
第三次
第三次握手:客户端收到服务器的SYN+ACK包,向服务器发送确认包ACK(ack=k+1),此包发送完毕,客户端和服务器进入ESTABLISHED(TCP连接成功)状态,完成三次握手。
3、HTTP请求
TCP/IP连接建立之后,浏览器会向服务器发送一条HTTP请求报文 -> 服务器向浏览器返回一条相应报文 -> 关闭连接
报文
报文可分为两类: 请求报文和相应报文,它们都由三部分组成
起始行
首部块
主体部分
是HTTP报文的负荷,也就是HTTP要传输的内容
连接方式
通常使用 少量并行+持久 的连接方式
HTTP/1.0 通过客户端设置请求首部 Connection: keep-alive
HTTP/1.1 默认持久连接,可以设置 Connection: close 关闭(默认持久连接并不代表连接会永远持续下去)
4、浏览器页面渲染
页面渲染
重排
发生条件:
重绘
发生条件:
大致过程是这么个过程,很多细节没有去深入研究。要针对每个点去深入研究的话这个篇幅是不够的。
占坑
上周封装了一个简单的手势库,但是是用ES6写的,所以可能不能直接拿来用这个时候就非擦尴尬了。那么有啥办法能把它搞成通用的呢?好吧,看来就只有把它编译下输出了。好吧用什么呢?本来想想这个简单的库用gulp来玩?又想了想,妹的,现在不是webpack大行其到么?而且恰好webpack对打包这种库有良好支持。(^_^)开心的飞起,然后就起飞啦。
先看看整体的目录结构吧。

1、开始webpack
webpack怎么安装自行去google,本来直接安装了webpack的话可以直接通过webpack的命令启动,但是,好吧我们用npm吧。本来想把mocha 测试搞进来的,但是哈哈哈,不是很熟悉,暂且算了。大概我们就使用npm run build 和 npm run dev 来分别构建压缩后的min版和本地开发版。
"dev": "webpack --progress --colors --watch --env dev",
"build": "webpack --env build",2、webpack.config.js配置文件
const webpack = require("webpack");
const UglifyJsPlugin = webpack.optimize.UglifyJsPlugin;
const path = require('path');
// node.js 命令行框架 yargs,获取里面的配置项信息
const env = require('yargs').argv.env;
// 你的lib的名字,可以考虑可配
let libraryName = 'Gesture';
// 插件列表和将要输出的文件名
let plugins = [], outputFile;
// 根据判断要构建什么样的版本
if(env === 'build'){
plugins.push(new UglifyJsPlugin({ minimize: true }));
outputFile = libraryName + '.min.js';
}else{
outputFile = libraryName + '.js';
}
// webpack配置
const config = {
devtool: 'source-map',
// 入口文件
entry: __dirname + '/src/index.js',
// 出口文件
output: {
path: __dirname + '/lib',
filename: outputFile,
//如果设置此选项,会将 bundle 导出为 library。output.library 是 library 的名称。
//如果你正在编写 library,并且需要将其发布为单独的文件,请使用此选项。
library: libraryName,
// library 的导出格式
libraryTarget: 'umd',
umdNamedDefine: true
},
// 指定了每个文件在处理过程中将被哪些模块处理,因为我们是es6写的,所以用babel,eslint也可以打开
module: {
rules: [
{
test: /(\.jsx|.\js)$/,
loader: 'babel-loader',
exclude: /node_modules/
},
// {
// test: /(\.jsx|.\js)$/,
// loader: 'eslint-loader',
// exclude: /node_modules/
// }
]
},
// 解析
resolve: {
modules: [path.resolve('./src')], // 告诉 webpack 解析模块时应该搜索的目录。
extensions: ['.json', '.js'] // 自动解析确定的扩展。默认值为:
},
plugins: plugins
};
module.exports = config;好了整个配置信息就这些,很简单的。
3、输出文件
我们执行了上面的代码后,根据你执行的命令生成对应的版本

生成的对应的代码就在lib下面啦。好了,你就可以直接拿去用了。
哈哈 ,我感觉好水啊。主要是因为我在配置里面很详细的注释。掌握只是才是最重要的。
看完了前面的,一直会发现有个问题困扰着,就是dispatch和commit的实现。这两个方法到底是怎么实现的呢?还有一些实现的细节是怎么回事呢?
1.commit方法解析:
2.dispatch方法解析:
// 该方法支持两个参数,type表示action的类型,payload表示额外的参数
dispatch (_type, _payload) {
// check object-style dispatch
const {
type,
payload
// this.$store.dispatch({ type: xxxx, param: xxxx })
} = unifyObjectStyle(_type, _payload)
// 直接找到对应type下的action对象数组,
const entry = this._actions[type]
if (!entry) {
console.error(`[vuex] unknown action type: ${type}`)
return
}
//
return entry.length > 1
? Promise.all(entry.map(handler => handler(payload)))
: entry[0](payload)
}

看这里this._actions里面每个action都是一个包装函数数组的。这里不是很好理解,为什么每个对应的key有可能有这么多个包装函数呢?
用了那么久的Promise。也仅仅是会用了。但是对于一些稍微深入一点的Promise的知识都脑子一片空白,简直是头皮发麻啊。这种状态肯定是不行的对吧,根据我的尿性,我还是会去了解下相关的知识。不出所料,妹的,这个还是挺复杂的啊。最后趁此机会去学习下,然后总结下。
1、Promise相关规范
Promise 规范有很多,如 Promise/A,Promise/B,Promise/D 以及 Promise/A 的升级版 Promise/A+。这么多规范,那么ES6最终采用的是什么规范呢?答案就是Promise/A+规范。下面就是规范的地址
我比较弱鸡,看的是中文翻译版规范。然后看完规范得出几个重要的结论:
2、为什么用Promise
在实际的使用当中,有非常多的应用场景我们不能立即知道应该如何继续往下执行。最重要也是最主要的一个场景就是ajax请求。通俗来说,由于网速的不同,可能你得到返回值的时间也是不同的,这个时候我们就需要等待,结果出来了之后才知道怎么样继续下去。再比如我们一个请求的参数会依赖于另一个请求的的返回值。假如这种相互之间的依赖多了呢?然后大家是不是就开始层层嵌套?callback-hell!!!
// callback-hell
asyncOperation(function(data){
// 处理 `data`
anotherAsync(function(data2){
// 处理 `data2`
yetAnotherAsync(function(){
// 完成
});
});
});3、Promise怎么玩
对于上面的例子,用Promise改写下,就这样了。
function promiseSomething(){
return new Promise(function(resolve, reject) {
asyncOperation(function(data){
if(data.success) {
resolve(data)
}else{
reject(data)
}
});
})
}
// 上面的代码
promiseSomething()
.then(function(data){
// 处理 `data`
return anotherAsync();
})
.then(function(data2){
// 处理 `data2`
return yetAnotherAsync();
})
.then(function(){
// 完成
})
.catch(function(err){
// 错误捕获
});上面相当于一个流程控制的用法还有另外的用法如下:
(1)Promise.all接收一个Promise对象组成的数组作为参数,当这个数组所有的Promise对象状态都变成resolved或者rejected的时候,它才会去调用then方法。
var url = 'xxxx';
var url1 = 'xxxx';
function getJSON(url){
// $.ajax
}
function renderAll() {
return Promise.all([getJSON(url), getJSON(url1)]);
}
renderAll().then(function(value) {
// 自己进行实际操作
console.log(value);
})(2)Promise.race都是以一个Promise对象组成的数组作为参数,不同的是,只要当数组中的其中一个Promsie状态变成resolved或者rejected时,就可以调用.then方法了。而传递给then方法的值也会有所不同。
var url = 'xxxx';
var url1 = 'xxxx';
function getJSON(url){
// $.ajax
}
function renderRace() {
return Promise.race([getJSON(url), getJSON(url1)]);
}
renderRace().then(function(value) {
// 自己进行实际操作
console.log(value);
})4、How to write a simple Promise?
待续
前面已经对vue的数据属性劫持监听有了一个基本的认识。
这只是一个达到了最基本的条件。接下来就是对这个最基本的条件运用起来,但是在运用这个之前还是要弄清楚数据绑定之前的原理,前期先用一个简单的单向数据绑定来了解一下解析模版和绑定的属性到输入框。
先来看下代码:
`
// 判断每个节点是不是有子节点,如果有那么就返回
const isChild = (node) => {
return !node.childNodes.length ? false : node;
}
// 用文档片段来劫持dom结构,进行dom解析完后重新渲染
const nodeToFrgment = (node, vm) => {
let frag = document.createDocumentFragment();
let child;
// 遍历所有的节点,并且解析所有的节点然后把对应的数据渲染上去。
while (child = node.firstChild){
// 解析下数据了
compile(child, vm);
// 子节点继续递归遍历
if(isChild(child)){
console.log(child);
nodeToFrgment(child, vm);
}
frag.appendChild(child);
}
node.appendChild(frag);
}
// 初始化绑定数据
const compile = (node, vm) => {
// node为元素节点的时候
if(node.nodeType === 1){
// 获取处元素节点上所有属性主要是为了获得v-model
var attr = node.attributes;
for(let i = 0; i < attr.length; ++i){
if(attr[i].nodeName === 'v-model'){
var name = attr[i].nodeValue;
node.value = vm.data[name];
node.removeAttribute(attr[i].nodeName);
}
}
}
// 文本节点
if(node.nodeType === 3){
let reg = /\{\{(.*)\}\}/;
if(reg.test(node.nodeValue)){
// 这个就是为了去除表达式两边的空格
var name = RegExp.$1.trim();
node.nodeValue = vm.data[name];
}
}
}
function Vue(options){
this.id = options.el;
this.data = options.data;
nodeToFrgment(document.getElementById(this.id), this);
}
let vm = new Vue({
el: 'app',
data: {
msg: '单向绑定的模式',
test: '测试键'
}
});
`
上面的代码只实现了数据绑定,并没有监听对象中属性变化去触发改变视图。接下来就是去想办法实现在视图里面去更改值的时候改变定义的值。
为什么要去了解函数节流和去抖呢?因为我想了解啊~搞事情~好了还是正经点吧,原因是是下面:
下面场景往往由于事件频繁被触发,因而频繁执行DOM操作、资源加载等重行为,导致UI停顿甚至浏览器崩溃。
1、简单的懒加载实现
我相信懒加载大家肯定是用了很多次了是吧?但是你有没有去了解下最基本的实现原理呢?虽然平时大家都在用,但是我估计和我一样,都没有去看代码。T^T,好吧那么我们就来简单了解下吧。
function lazyload(){
var oImgs = document.getElementsByTagName('img');
var len = oImgs.length;
var n = 0;
return function(){
var seeHeight = document.documentElement.clientHeight; // 可视区域的高度
var scrollHeight = document.documentElement.scrollTop || document.body.scrollTop // 滚动的距离
for(var i = n; i < len; i++){
if(oImgs[i].offsetTop < seeHeight + scrollHeight){
if(oImgs[i].getAttribute("data-src") !== ''){
oImgs[i].src = oImgs[i].getAttribute("data-src")
}
n = n + 1;
}
}
}
}解释下:就是我们先去获取所有的图片,然后判断每张图片是不是在可视区域里面,如果在可视区域里面的话,我们就把data-src中的值换到src中。注意我们用n来标记展示了多少张了。所以下次滚动的时候就从第n张开始了。我们一般是scroll的时候加载的对吧?诺~这个时候就正好对应了上面的为什么要节流那些了操作了。
2、简单的节流函数
好比一台自动的饮料机,按拿铁按钮,在出饮料的过程中,不管按多少这个按钮,都不会连续出饮料,中间按钮的响应会被忽略,必须要等这一杯的容量全部出完之后,再按拿铁按钮才会出下一杯。所以我们理解节流函数就是每隔一段时间执行一次函数。不用一动就执行,减少消耗。
function throttle(func, delay, time){
var timeout,
startTime = +Date.now();
return function(){
var context = this,
args = arguments,
curTime = +Date.now();
clearTimeout(timeout);
// 达到了最长触发时间
if(curTime - startTime >= time){
func.apply(context, args);
startTime = curTime;
}else{
// 没达到最长触发时间,重新设定定时器
timeout = setTimeout(function(){
func.apply(context, args);
}, delay);
}
}
}3、简单的去抖函数
去抖相比较节流函数要稍微简单一点,去抖是让函数延迟执行,而节流比去抖多了一个在一定时间内必须要执行一次
// debounce函数用来包裹我们的事件
function debounce(fn, delay) {
// 持久化一个定时器 timer
let timer = null;
// 闭包函数可以访问 timer
return function() {
// 通过 'this' 和 'arguments'
// 获得函数的作用域和参数
let context = this;
let args = arguments;
// 如果事件被触发,清除 timer 并重新开始计时
clearTimeout(timer);
timer = setTimeout(function() {
fn.apply(context, args);
}, delay);
}
}4、把节流函数用到懒加载中
这样就不会一滚动就触发懒加载了。
/**
* 简单的节流函数
* @param {[type]} fun 要执行的函数
* @param {[type]} delay 延迟
* @param {[type]} time 在time时间内必须执行一次
* @return {[type]}
*/
function throttle(func, delay, time){
var timeout,
startTime = +Date.now();
return function(){
var context = this,
args = arguments,
curTime = +Date.now();
clearTimeout(timeout);
// 达到了最长触发时间
if(curTime - startTime >= time){
func.apply(context, args);
startTime = curTime;
}else{
// 没达到最长触发时间,重新设定定时器
timeout = setTimeout(function(){
func.apply(context, args);
}, delay);
}
}
}
function lazyload(){
var oImgs = document.getElementsByTagName('img');
var len = oImgs.length;
var n = 0;
return function(){
var seeHeight = document.documentElement.clientHeight; // 可视区域的高度
var scrollHeight = document.documentElement.scrollTop || document.body.scrollTop // 滚动的距离
for(var i = n; i < len; i++){
if(oImgs[i].offsetTop < seeHeight + scrollHeight){
if(oImgs[i].getAttribute("data-src") !== ''){
oImgs[i].src = oImgs[i].getAttribute("data-src")
}
n = n + 1;
}
}
}
}
var lazyImages = lazyload();
lazyImages();
window.addEventListener('scroll', throttle(lazyImages, 500, 1000), false);又弄明白了一点点了。
新技术的探索和为了更好的解决单页应用的开发效率和代码的重复利用
1.组件分类,组件的职责
组件可以分为通用组件(可复用组件)和业务组件(一次性组件)。
(1)不使用vue-router的情况下:
约束好组件的职责,能让组件更好地解耦,知道什么功能是组件实现的,什么功能不需要实现。
(2)使用vue-router的情况下:
颗粒级组件不推荐在里面处理业务逻辑,只处理数据渲染。页面逻辑处理全部放在页面级组件。
例如:免费试用项目中的单个商品组件只做数据渲染,逻辑全部放在index.vue中
2.父子组件与兄弟组件之间通信
父子组件
在 Vue.js 中,父子组件的关系可以总结为 props down, events up 。父组件通过 props 向下传递数据给子组件,子组件通过 events 给父组件发送消息。看看它们是怎么工作的。
兄弟组件
因为部分公共组件会抽离成全局。就相当于这部分组件和页面级组件之间构成兄弟关系,那么兄弟组件之间在没有vuex的情况下通信的话建议使用桥梁bus。在根目录里面定义一个bus.js里面只用做如下处理(针对事件处理相关):
import Vue from 'vue'
var bus = new Vue()
export default bus其余地方import后。
使用bus.$emit('xxxx')发事件
在兄弟组件中使用bus.$on('xxxx')收事件。
3.全局组件在页面级组件中展示
依靠定义在app.vue里面的全局组件配置来进行管理。在路由即将离开之前关闭当前全局组件的显示配置。
// 全局组件的相关显示开关
comConfig: {
showTabFlag: true,
showBottomBtnFlag: false,
showSelectBarFlag: true,
showNotifyFlag: true
}
// 离开当前路由页面
beforeRouteLeave(to, from, next){
this.comConfig.showNotifyFlag = false
setTimeout(() => {
next()
})
},4.公共全局组件的样式
因为公共全局组件可能会被其他很多的地方引用,通过人肉维护相关的css module优点费劲,所以建议在公共全局组件中给样式加上scoped,避免业务组件对全局组件的样式污染。
5.组件命名空间
命名空间可以避免与浏览器自有标签和其他组件的冲突。特别是当项目引用外部 UI 组件或组件迁移到其他项目时,命名空间可以避免很多命名冲突的问题。
6.慎用keep-alive
因为keep-alive会讲组件实例初始化后就一直放在内存中,如果你当前的组件是有改变其它组件的状态的时候,这个时候就可能会出现状态管理混乱的问题。keep-alive配合vue-router做返回定位到上次浏览的位置的时候特别要注意。使用了keep-alive的组件有四个钩子。created, mounted, activated,deactivated。第一次加载组件的时候前面三个钩子依次被调用,离开当前组件的时候,最后一个钩子被调用,第二次进入的时候,是直接在内存中取的。不会执行第一第二个钩子,直接执行第三个钩子。离开当前组件的时候还是会执行最后一个 钩子。
这段时间一直在看vue的源码,源码非常多和杂,所以自己结合资料和理解理出了一个主线,然后根据主线去剥离其他的一些知识点,然后将各个知识点逐一学习。这里主要是分析的事件系统的实现。
在分析之前先了解下几个api的使用方式:
vm.$on(event, callback)
参数:
{string | Array<string>} event (数组只在 2.2.0+ 中支持){Function} callback用法:$on事件需要两个参数,一个是监听的当前实例上的事件名,一个是事件触发的回调函数,回调函数接受的是在事件出发的时候额外传递的参数。
例子:
vm.$on('test', function (msg) {
console.log(msg)
})
vm.$emit('test', 'hi')
// => "hi"vm.$once(event, callback)
$once事件整体上来说和$on事件的使用方式差不多,但是event只支持字符串也就是说只支持单个事件。并且该事件再触发一次后就移除了监听器。
vm.$once('testonce', function (msg) {
console.log(msg)
})vm.$off([event, callback])
参数:
{string | Array<string>} event(仅在 2.2.2+ 支持数组){Function} [callback] 用法:移除自定义事件监听器
例子:
vm.$off()
vm.$off('test')
vm.$off('test1', function (msg) {
console.log(msg)
})
vm.$off(['test1','test2'], function (msg) {
console.log(msg)
})vm.$emit(event, [..args])
参数:
{string} event 要触发的事件名[...args]可选用法:
触发当前实例上的事件。附加参数都会传给监听器回调。
例子
vm.$emit('test', '触发自定义事件')事件的初始化工作
我们在使用自定义事件的api的时候,肯定有个地方是需要来存我们的事件和回调的地方。在vue中大部分的初始化工作都是在core/instance/init.js的initMixin方法中。所以我们能够在initMixin看到initEvents方法。
// initEvents
export function initEvents (vm: Component) {
vm._events = Object.create(null)
vm._hasHookEvent = false
// init parent attached events
const listeners = vm.$options._parentListeners
if (listeners) {
updateComponentListeners(vm, listeners)
}
}上面的代码可以看到,在初始化Vue事件的时候,在vm实例上面挂载了一个_events的空对象。后面我们自己调用的自定义事件都存在里面。
因为vue本身在组件嵌套的时候就有子组件使用父组件的事件的时候。所以就可以通过updateComponentListeners方法把父组件事件监听器(比如click)传递给子组件。(这里不做过多讨论)
自定义事件的挂载方式
自定义事件的挂载是在eventsMixin方法中实现的。这里面将四个方法挂在Vue的原型上面。
Vue.prototype.$on
Vue.prototype.$once
Vue.prototype.$off
Vue.prototype.$emitVue.prototype.$on的实现
Vue.prototype.$on = function (event: string | Array<string>, fn: Function): Component {
const vm: Component = this
if (Array.isArray(event)) {
for (let i = 0, l = event.length; i < l; i++) {
this.$on(event[i], fn)
}
} else {
(vm._events[event] || (vm._events[event] = [])).push(fn)
// optimize hook:event cost by using a boolean flag marked at registration
// instead of a hash lookup
if (hookRE.test(event)) {
vm._hasHookEvent = true
}
}
return vm
}第一个参数就是自定义事件,因为可能是数组,所以判断如果是数组,那么就循环调用this.$on方法。
如果不是数组,那么就直接向最开始定义的_events对象集合里面添加自定义事件。
所以这个时候_events对象生成的格式大概就是下面:
vm._events={
'test':[fn,fn...],
'test1':[fn,fn...]
}Vue.prototype.$once 的实现
Vue.prototype.$once = function (event: string, fn: Function): Component {
const vm: Component = this
function on () {
vm.$off(event, on)
fn.apply(vm, arguments)
}
on.fn = fn
vm.$on(event, on)
return vm
}这里定义了一个on函数。接着把fn赋值给on.fn。最后在调用的是vm.$on。这里传入的就是事件名和前面定义的on函数。on函数在执行的时候会先移除_events中对应的事件,然后调用fn
所以分析下得到的是:
vm._events={
'oncetest':[
function on(){
vm.$off(event,on)
fn.apply(vm,arguments)
} ,
...
]
}Vue.prototype.$off的实现
Vue.prototype.$off = function (event?: string | Array<string>, fn?: Function): Component {
const vm: Component = this
// all
// 如果没有传任何参数的时候,直接清楚所有挂在_events对象上的所有事件。
if (!arguments.length) {
vm._events = Object.create(null)
return vm
}
// array of events
// 如果第一个参数是数组的话,那么就循环调用this.$off方法
if (Array.isArray(event)) {
for (let i = 0, l = event.length; i < l; i++) {
this.$off(event[i], fn)
}
return vm
}
// specific event
// 获取对应事件所有的回调可能是个数组
const cbs = vm._events[event]
// 没有相关的事件的时候直接返回vm实例
if (!cbs) {
return vm
}
// 如果只传入了事件名,那么清除该事件名下所有的事件。 也就是说 vm._events = {'test': null, ...}
if (!fn) {
vm._events[event] = null
return vm
}
// 如果传入的第二个参数为真,那么就去cbs里面遍历,在cbs中找到和fn相等的函数,然后通过splice删除该函数。
if (fn) {
// specific handler
let cb
let i = cbs.length
while (i--) {
cb = cbs[i]
if (cb === fn || cb.fn === fn) {
cbs.splice(i, 1)
break
}
}
}
return vm
}上面主要就是实现的下面三种情况:
如果没有提供参数,则移除所有的事件监听器;
如果只提供了事件,则移除该事件所有的监听器;
如果同时提供了事件与回调,则只移除这个回调的监听器。
Vue.prototype.$emit 的实现
Vue.prototype.$emit = function (event: string): Component {
const vm: Component = this
if (process.env.NODE_ENV !== 'production') {
const lowerCaseEvent = event.toLowerCase()
if (lowerCaseEvent !== event && vm._events[lowerCaseEvent]) {
tip(
`Event "${lowerCaseEvent}" is emitted in component ` +
`${formatComponentName(vm)} but the handler is registered for "${event}". ` +
`Note that HTML attributes are case-insensitive and you cannot use ` +
`v-on to listen to camelCase events when using in-DOM templates. ` +
`You should probably use "${hyphenate(event)}" instead of "${event}".`
)
}
}
// 匹配到事件列表,该列表是一个json。
let cbs = vm._events[event]
if (cbs) {
//将该json转化成为真正的数组
cbs = cbs.length > 1 ? toArray(cbs) : cbs
const args = toArray(arguments, 1)
// 循环遍历调用所有的自定义事件。
for (let i = 0, l = cbs.length; i < l; i++) {
try {
cbs[i].apply(vm, args)
} catch (e) {
handleError(e, vm, `event handler for "${event}"`)
}
}
}
return vm
}上面主要意思是:匹配到json中相关key值的value,这个value先转换成真正的数组,再循环遍历数组,传入给的参数执行数组中的每个函数
vue中的自定义事件主要目的是为了组件之间的通信。因为_events对象是挂在Vue实例上的。因此每个组件是都可以访问到vm._events的值的,也能够向其中push值的。
整个自定义事件系统呢就是在vm实例上挂载一个_events的对象,可以理解为一个json,其中json的key值就是自定义事件的名称,一个key值可能对应着多个自定义事件,因此json中每个key对应的value都是一个数组,每次执行事件监听都会向数组中push相关的函数,最终通过$emit函数传入的参数,匹配到json中相应的key,val值,从而使用给定的参数执行数组中的函数。
最后的_events对象:
vm._events={
'test1':[fn,fn,fn],
'test2':[fn],
'oncetest':[
function on(){
vm.$off(event,on)
fn.apply(vm,arguments)
},
...
],
...
}一直在说想要学习下怎么写爬虫,一直却没有认真对待这件事。终于有时间好好实践一下,写个爬虫玩玩了,在写之前还是要了解下写个爬虫需要了解的最简单的知识步骤。
在没有用其它复杂模块的情况下,只用最简单的模块来做的话,首先需要了解的是下面的几个模块。
1.cheerio模块
这个模块的主要作用就是在服务端提供一个像JQuery对dom操作的一样功能。另外Cheerio 工作在一个非常简单,一致的DOM模型之上。解析,操作,呈送都变得难以置信的高效。基础的端到端的基准测试显示Cheerio 大约比JSDOM快八倍(8x)。
主要用法:
var pageData = '要爬的网页';
var cheerio = require('cheerio');
var $ = cheerio.load(pageData);这样在拿到$的时候就可以直接像JQuery一样操作dom了API和JQuery基本一样。
提供下这个模块的文档。英文版,英语不好的看这里;
2.http模块
http模块是node的内置模块,require后就可以直接用了。不用去额外的install了。这个小爬虫只会用刀http模块里面的get方法。通过get方法去获取对应资源。在回调里面去处理获取到的资源。具体这个模块的其它的方法看这里,提供一个中文版的吧
爬虫的主要用法:
var req = http.get(href + search, function(res){}3.fs模块
fs模块是node内置的文件系统模块。在我们这个小爬虫里面的话,主要做的就是对文件的操作。具体其它的API的话可以去详细看文档。还是提供一篇文章吧
主要用法在后面具体有讲。
- 爬虫三步走“爬,改,存”
爬虫的套路基本就是这样吧。爬数据,改数据,存数据。先来看爬数据吧:
// 根据url和参数获取分页内容
function getHtml(href, search){
console.log("正在获取第"+ search + "页数据");
// 定义一个专门用来缓存爬来的数据,因为爬来的数据是一段一段的,这个时候把一段一段的数据合成一个整块的数据。
var pageData = '';
var req = http.get(href + search, function(res){
// 设置字符集
res.setEncoding('utf8');
// 接受数据流,然后合成一整块。
res.on('data', function(chunk){
pageData += chunk
});
// 当这个数据流接受完毕的时候我们就要进行手术刀般的操作了。
res.on('end', function(){
// cheerio的套路走起来
var $ = cheerio.load(pageData);
// 获取对应dom节点的数据,这里操作的是图片节点
var shtml = $(".joke-list-item .joke-main-content a img");
// 上面获取了所有的图片集合。这个时候就去拿每个图片对象的src属性上的链接,最后把所有的图片地址存起来。
for(var i = 0; i < shtml.length; ++i){
var src = shtml[i].attribs.src;
if(src.indexOf("http://image.haha.mx") > -1){
urls.push(src);
}
}
// 递归拿后面页数的。
if(search < pagemax){
getHtml(href, ++search);
} else {
console.log("图片链接获取完毕!");
sumConut = urls.length;
console.log("链接总数量:" + urls.length);
console.log(urls);
console.log("开始下载......");
// 拿完了就去下载图片了。
downloadImg(urls.shift());
}
});
});
}因为这个爬福利图片的小爬虫啊是纯拿图片并下载,并没有改数据的步骤,改数据的话可以去看我写的另外一个爬电影天堂的代码。
最后一步存数据。好吧,我们是为了直接把这些图片下载下来对吧。并没有做其他的一些数据拿取的操作。不存在对数据库的操作。只涉及文件的操作。好了,来看代码。
// 下载图片
function downloadImg(imgurl){
// 好吧这个只是为了处理对应图片的链接的。
var narr = imgurl.replace("http://image.haha.mx/","").split("/");
// 存在upload/topic1文件夹下的文件名。
var filename = "./upload/topic1/" + narr[0] + narr[1] + narr[2] + "_" + narr[4];
// 先判断当前文件是不是已经存在了,存在走else,自己看看else做了什么处理。
fs.exists(filename, function(b){
// 文件不存在的时候。
if(!b){
// 爬过来的图片是小图的哦,我们为了看福利图是不是要大的,要高清的?搞起来。大的!!!!清晰的!!!!0.0!!!
http.get(imgurl.replace("/small/","/big/"), function(res){
// 套路和上面拿网页资源一样一样的。
var imgData = "";
res.setEncoding("binary");
res.on("data", function(chunk){
imgData += chunk;
});
// 数据流拿完的时候坐处理了。
res.on("end", function(){
var savePath = "./upload/topic1/" + narr[0] + narr[1] + narr[2] + "_" + narr[4];
// 保存图片,以二进制的方式写进文件。
fs.writeFile(savePath, imgData, "binary", function(err){
if(err) {
console.log(err);
} else {
console.log(narr[0] + narr[1] + narr[2] + "_" + narr[4]);
if (urls.length > 0) {
// 递归调。
downloadImg(urls.shift());
downCount++;
}
}
});
})
});
}else{
// 统计重复的图片
console.log("该图片已经存在重复.");
reptCount++;
if (urls.length > 0) {
downloadImg(urls.shift());
}
}
});
if (urls.length <= 0) {
console.log("下载完毕");
console.log("重复图片:" + reptCount);
console.log("实际下载:" + downCount);
}
}好了套路就这样走完了,是不是还是比较简单的。这里只是讲怎么写一个爬虫,并没有讲一些原理的东西。我一想的原则就是原理要自己去看。先会用。完整代码可以看new文件目录下的。你自己找吧。😄😄😄
经常在自己的项目中会有用刀正则表达式的情况,一半情况下,我都是自己去网上搜,然后对着文档写。有时候实在写不出来的时候呢,就去找同事帮忙写一个正则表达式。从来没有认真的去系统的学习一下正则表达式。貌似这个东西是要必会的技能之一啊。入坑前端这么久了,还只会抄的地步,我是不是学了假前端了?有一丝丝尴尬。那么接下来就要开始系统的学习下正则表达式了。
一.基本语法
正则表达式的基本语法如下:
/正则表达式规则/修饰符(非必需)
// 例子:
/fanchao/g二.正则表达式的基本修饰符和字符讲解
1.修饰符g,i,m
g是执行全局匹配,没有g的时候就是匹配到第一个就结束
i是指对大小写不敏感的匹配,换句话说就是忽略大小写。
m是指执行多行匹配。
2.原义字符
\将下一个字符标记为一个特殊字符、或一个原义字符、或一个向后引用、或一个八进制转义符。例如,n”匹配字符“n”。“\n”匹配一个换行符。序列“\”匹配“\”而“(”则匹配“(”。
3.非打印字符

上图介绍了非打印字符的一些意义,感觉常用的就是\n,\r,\s,\S。所以想快速入门的话,就暂时掌握这几个值就好了。
来个简单的例子吧:

4.字符类[]和字符取反[^abc]
先看下例子吧,简单的手机号匹配和日期格式的匹配的正则表达式
/^1[3578][0-9]{9}$/
/^\d{4}[/-]\d{2}[/-]\d{2}$/上面的两个例子都是比较简单的,第一个是匹配以1开头的,接下来[3578]中任意一个。剩下的从[0-9]中任意取一个,取9次。第二个是以数字开始\d(ps:其实是等于[0-9])重复四次,接下来是[/-]这两个连接符任意一个都可以。接下来就是重复两次数字接着又是连接符,接着又是两次数字。其实就是形如:2017-03-18这种形式。这个只是简单的匹配并不是那么的严谨。
在看字符取反:还是先上例子吧:

看这个例子是不是一眼就明白我在说什么了是吧?哈哈哈。这个例子就是说匹配不在[a-z]中的。任意字符,然后把这些字符替换成🐶。厉害了。
5.范围类字符[-]
这个比较好理解,正则表达式支持一定范围规则比如 [a-z] [A-Z] [0-9] 可以连写[a-z0-9] 如果你只是想匹配-在 范围类最后加-即可。看例子:

看最后的那个时间的。多了一个-,意思就是说不光匹配[0-9]所有的数字还包括-。稳~~
6.预定义类

预定义类的作用大概就是为了写起来简单吧。比如我们准备匹配一个fan + 任意数字 + 任意字符 的字符串:这样写就好了。/fan\d./gi;
7.边界字符

^和$就是开头和结尾的意思。比如/^fan$/
另外两个的用法还是写个例子:
\b匹配单词和空格之间的位置

\B匹配不是单词和空格之间的位置。

8.量词

我们在写正则的时候往往会遇到要匹配几次的情况,如果次数少了可以重复写几次就好了,但是如果多了呢?就比如最上面的电话号码的正则。不用量词就要写九次[0-9]这样看起来就比较恼火了。更多例子
^[a-zA-Z0-9_]+$ //所有包含一个以上的字母、数字或下划线的字符串
^[0-9]+$ //所有的正整数
^\-?[0-9]+$ //所有的整数
^\-?[0-9]+\.?[0-9]*$ //所有的浮点数前面在实现双向数据绑定的时候,渲染模版的时候用的是比较笨的办法,就是当任何一个属性发生改变的时候,我都是直接遍历按所有的dom模版结构,然后把对应的{{xxx}}这些标记换成实际的值,并且利用fragment拼成统一的片段,最后把生成的统一的片段拿去替换掉以前的dom结构。不用多想,这个肯定是存在性能上的问题的。大概存在的猪腰问题:
(1)在修改任意被订阅的属性的时候,相关联的dom都会被重新渲染
(2)修改非dom相关的属性的时候,也会触发重新渲染dom。
好吧这篇文章经过了很久才在今天补上,主要最近为了去准备一个关于vuex的分享去了,并不是因为懒。今天参考了很多,再加上自己的理解,把这个双向绑定的第二版写完吧,但是还是不是最优的版本。
1、实现一个如下的双向绑定代码
<div id="app">
<form>
<input type="text" v-model="name.age.value" />
<input type="text" v-model="name.value" />
<button type="button" v-click="increment">increment</button>
<button type="button" v-click="alert">alert</button>
</form>
<p v-bind="name.age.value"></p>
<p v-bind="name.value"></p>
<p style="background-color: red; color: #fff;">{{name.value}}</p>
</div>window.onload=function(){
var app=new Fue({
el:"#app",
data:{
count:0,
name:{
value:'fanchao',
age:{
value: 18
}
}
},
methods:{
increment:function(){
this.name.age.value++;
},
alert:function(){
alert(this.name.value)
}
}
})
}好吧这个例子用的有毒,我们不管还是继续看看
- 入口new Fue()
我们假装封装一个Fue吧。先看代码
function Fue(options){
this._init(options);
}简单封装,所以不做其他的就来一个初始化方法吧。手动私有~~怪我咯。
看看我们的私有函数干了啥???
// 初始化函数,主要是为了把传进来的配置挂在实例上
Fue.prototype._init = function(options){
this.$options = options;
this.$el = document.querySelector(options.el);
this.$data = options.data;
this.$methods = options.methods;
// 对象深沉次属性的取值和修改,同时这两个方法可以直接this.fm.$data.$set(xxx)来搞
Object.prototype.$get = function(keyPath){
var getter = new Function('return this.' + keyPath);
return getter.call(this);
}
Object.prototype.$set = function(keyPath, val){
var setter = new Function('newVal', 'this.' + keyPath + ' = newVal')
setter.call(this,val);
}
// 用于存储与dom绑定的数据属性
// 就是用来保存使用了某个属性的所有的指令或者订阅的对象数组,卧槽是不是说的很难以理解?没事你可以自己看代码哈哈哈啊哈~~
this._binding = {};
// 劫持所有的属性
this._observer(this.$data);
// 解析模版将解析出来的指令和绑定的数据集合存在上面的binding对象中去。
this._compile(this.$el);
}初始化很简单,就是干了一些拿到options里面的值然后私有化的过程,然后调用了_observer和_compile把属性和指令等该劫持的劫持,该解析的解析。稳~~~
3._obverse方法
先看代码:
Fue.prototype._observer = function(obj, keyPath){
var OBJECT = 0, DATA = 1;
var value;
var keyPath = keyPath || '';
for(var key in obj){
if(obj.hasOwnProperty(key)){
this._binding[keyPath + key] = {
_directives: []
};
value = obj[key];
if(typeof value === 'object'){
this.convert(obj, key, value, keyPath + key, OBJECT);
this._observer(value, keyPath + key + '.');
}else{
this.convert(obj, key, value, keyPath + key, DATA);
}
}
}
}看到代码一眼就应该知道了啊,对吧?还是要说下。这个方法就是遍历data中的属性,给每个属性都定一个一个指令集的。并存在_binding中。目的很简单啊,就是为了后面有更新操作的时候,可以直接遍历指令集执行里面的update方法。这里面是更具data对应属性的值的类型来做了一个判断,如果是值本事还是对象的话就直接递归再来一发。如果不是就直接调用convert劫持属性了。接下来要看的是convert函数
4.convert方法
Fue.prototype.convert = function(obj, key, value, originPath, type){
console.log(value);
var binding = this._binding[originPath];
// 判断是不是当前属性的值是对象,不是对象直接就是值的话进去
if(type == 1){
Object.defineProperty(obj, key, {
get: function(){
console.log(`获取${value}`);
return value;
},
// 新值改变会触发对应的指令集合执行对应的更新,但是这里是直接遍历了整个集合
// 所以这个可能比较伤。
set: function(newVal){
console.log(`更新${newVal}`);
if(value !== newVal){
value = newVal;
// 这里就是遍历执行指令集合了。
binding._directives.forEach(function(item){
item.update();
});
}
}
});
}else{ // 如果是对象
var subObj = obj[key] || {};
Object.defineProperty(obj, key, {
get: function(){
console.log(`获取${value}`);
return value;
},
set: function(newVal){
console.log(`更新${newVal}`);
if(typeof newVal === 'object'){
for(var subKey in newVal){
subObj[subKey] = newVal[subKey];
}
}else{
subObj = newVal;
binding._directives.forEach(function(item){
item.update();
});
}
}
});
}
}上面的代码写的不好,根据代码整洁之道的指南的话,重复的操作应该封装下啊。但是算了,后面再改下。这个写法是别人的,直接拿过来的改了,没去多想。这里主要做的操作就是将对应属性的值拿到了劫持,当这个值被改变的时候,就遍历订阅这个值的集合。这个集合是一个对象数组,里面存的东西是当前dom节点对应的一些相关的值。可以先大概看下:

是不是没有骗你?老哥很稳的。
5.该来_compile了
上面我们已经处理好了对应属性的监听了。接下来就是看看对应属性和对应dom节点之间的关系了。
上代码:
// 解析模版
Fue.prototype._compile = function(rootElem){
var self = this;
var nodes = rootElem.children;
for(var i = 0; i < nodes.length; ++i){
var node = nodes[i];
// 当前元素有子节点的时候
if(node && node.children.length){
self._compile(node);
}
console.log(node);
// 绑定的点击事件指令
if(node.hasAttribute('v-click')){
node.addEventListener('click', (function(i){
var attrValue = nodes[i].getAttribute('v-click');
/*
* /\(.*\)/.exec("num('adf','sdf')");
* ["('adf','sdf')"]
*/
var args = /\(.*\)/.exec(attrValue);
if(args){
args = args[0];
var attrValue = attrValue.replace(args,'');
args = args.replace(/[\(\)\'\"]/,'').split(',');
}else{
args = [];
}
return function(){
self.$methods[attrValue].apply(self.$data, args);
}
})(i));
}
// 绑定的v-model,如果是input或者textarea标签
if(node.hasAttribute('v-model') && node.tagName == 'INPUT' || node.tagName == 'TEXTAREA'){
node.addEventListener('input', (function(key){
var attrValue = node.getAttribute('v-model');
self._binding[attrValue]._directives.push(new Directive(
"input",
node,
self,
attrValue,
'value'
));
return function(){
self.$data.$set(attrValue, nodes[key].value);
}
})(i));
}
// 手动绑定的方式。就是innerHTML操作
if(node.hasAttribute('v-bind')){
var attrValue = node.getAttribute('v-bind');
// 将innerHTML更新的指令加进去
self._binding[attrValue]._directives.push(new Directive(
'text',
node,
self,
attrValue,
'innerHTML'
));
}
// 直接绑定的值,有毒
if(/\{\{(.*)\}\}/.test(node.innerHTML)){
if(/\{\{(.*)\}\}/.test(node.innerHTML)){
// 这个就是为了去除表达式两边的空格
var attrValue = RegExp.$1.trim();
}
console.log(attrValue);
// 将innerHTML更新的指令加进去
self._binding[attrValue]._directives.push(new Directive(
'text',
node,
self,
attrValue,
'innerHTML'
));
}
}
}上面的代码就是处理了集中指令对应的操作。传进来的根结点就是挂载的el。遍历整个根结点的子节点。然后看子节点上面的attribute。判断是何种属性。然后再根据对应的属性来玩。显示v-click属性。假如有参数的话要处理有参数的情况。处理完了直接将我们在实例里面定义的函数绑定到该节点上。
同样,当时v-model绑定操作的时候,监听输入事件,每次有输入的时候就将新值更新到对应的绑定上。

_binding数组就是上面这个样子的。
后面就是手动绑定v-bind操作或者直接是{{xxx}}绑定属性操作了。这两个做的操作是一样的。可以考虑合并在一起,先这样写。
最后:

可以看到所有的属性都是有setter 和 getter函数的所以任何操作都是会被发现的。

binding数组是以属性的绝对路径为键的。方便确定唯一性。

循环遍历了所有的指令集,匹配的值才能找到对应的指令,这显然是效率很低的,最好是能够做到对象键值索引的那种,所以还能改。
理想状态下,我们在写业务的时候,往往很多公用的部分是被抽离的,同时还有很多公共的lib库等是可以被自己使用的。我们只需要加载这些就好了。在ES6之前,js是不支持类class的,所以也就没有模块module了。
1、require时代的模块
最开始的写法
当时的模块就是一些特定的函数的集合,这样单独放在一个文件里面,这样一个模块就算成了。
function a(){
//...
}
function b(){
//...
}一般情况下我们是引用这个模块文件,然后直接调用这些方法就好了。但是这就有个很大的问题了。就是“污染”了全局变量。并且也不能保证不会出现命名冲突的问题。模块之间的关系也是没法理清的。
对象包装的写法
为了简单解决上面的问题,一般情况下,我们都是用一个对象来简单包装下的。所有的模块成员都放在这个对象里面
var module = {
_count: 0,
a: function(){
//...
},
b: function(){
//...
}
}一般我们的使用方法也是特别简单的。
module.a();
module._count = 1;这样没有一个私有的属性,所有的东西都是暴露在外面,封装性不是特别好,难受。
立即执行函数IIFE
随着js越来越重要,我们也写的越来越多,这样就利用IIFE来达到不暴露私有成员的目的
var module = (function() {
var _count = 0;
var a = function(){
alert(_count);
};
var b = function(){
alert(_count + 1);
};
return {
a: a,
b: b
}
})()使用上面的当时定义模块,是没有办法在外面访问到_count变量的。
以上就是模块的基本写法。
2、时代在进步
在ES6之前,还没有一套正式的模块规范的,但是这没有架住js社区的活跃,通行着两种主要的模块规范:CommonJS 和 AMD规范。
CommonJS规范
由于种种原因当node.js被创造出来的时候,javascript模块化编程的概念也随之被提出来了。因为node是被用在服务端的,所以在服务端如果没有模块的话,是非常难受的。并且node编程中最重要的一个**就是模块。因为node的出现,所以也促使浏览器端出现类类如requirejs和seajs之类的工具包。
在CommonJS中,暴露模块是采用的module.export和exports;有一个全局的require()方法来加载模块,例如:
var math = require('math');
math.add(2,3); // 5正是因为CommonJS使用require,才有了后面AMD,CMD规范也采用require来引用模块的风格。
为什么会有上面的两种风格的诞生呢?
对于服务端来说,所有的模块都放在本地硬盘里,可以同步加载完成,等待的时间就是读取硬盘的时间。但是对于浏览器来说这就是一个大问题了。因为模块都在服务端,等待的时间取决于你的网速,如果网速慢的话,那么就会一直处于加载你的模块状态,页面不能做其他的操作了。因此浏览器不能采用这种加载模块的方式,就要采用的是“异步加载”了。这就诞生了AMD规范了。
AMD规范
AMD是Asynchronous Module Definition的缩写,意思就是”异步模块定义”。它采用异步方式加载模块,模块的加载不影响它后面语句的运行。所有依赖这个模块的语句,都定义在一个回调函数中,等到加载完成之后,这个回调函数才会运行。
定义一个:
// id:字符串,模块名称(可选)
// dependencies: 是我们要载入的依赖模块(可选),使用相对路径。,注意是数组格式
// factory: 工厂方法,返回一个模块函数
define(id,dependencies,factory);如果一个模块不依赖其他的模块那么:
define(function(){
var add = function(x, y){
return x + y;
};
return {
add: add
}
});如果这个模块是依赖其他模块的话,那么:
define(['lib'], function(lib){
function test(){
lib.do();
}
return {
test: test
}
});当用require加载这个模块的时候,会先把该模块的依赖加载完。
require([module], callback);
require(['math'], function (math) {
math.add(2, 3);
});math.add()与math模块加载不是同步的,浏览器不会发生假死。所以很显然,AMD比较适合浏览器环境。
CMD规范
CMD (Common Module Definition), 是seajs推崇的规范,CMD则是依赖就近,用的时候再require。写起来是这样的:
define(function(require, exports, module){
var math = require('math');
math.add(2,3);
});CMD和AMD一样,也是采用的特定的define()函数来定义,用require方式来引用模块
define(id,dependence,factory)
//id:字符串,模块名称(可选)
//dependencies: 是我们要载入的依赖模块(可选),使用相对路径。,注意是数组格式
//factory: 工厂方法,返回一个模块函数CMD和AMD规范的区别
这两个规范的最大的区别就是对模块的依赖的执行时机处理不同,而并不是两者的加载顺序不一样,两者都是采用的异步加载模块。
AMD依赖前置,js可以方便知道依赖模块是谁,立即加载;
而CMD就近依赖,需要使用把模块变为字符串解析一遍才知道依赖了那些模块,这也是很多人诟病CMD的一点,牺牲性能来带来开发的便利性,实际上解析模块用的时间短到可以忽略
前两天在做小程序的需求的时候用到bind的时候才想起自己对这三的东西的了解比较浅薄,这个时候用的时候就有点怕。时候还是要好好学习下,理解下怎么玩。
先说call 和 apply吧:
ECMAScript3给Function的原型定义了两个方法,他们是Function.prototype.call 和 Function.prototype.apply. 在实际开发中,特别是在一些函数式风格的代码编写中,call和apply方法尤为有用。
1、call和apply区别
其实他们的作用是一样的,只是传递的参数不一样而已。
apply: 接受2个参数,第一个参数指定了函数体内this对象的指向,第二个参数为数组或者一个类数组。apply传入的是一个参数数组,也就是将多个参数组合成为一个数组传入,而call则作为call的参数传入(从第二个参数开始)。
举个栗子:
let obj1 = {
name: "copyes",
getName: function(){
return this.name;
}
}
let obj2 = {
name: 'Fanchao'
}
console.log(obj1.getName()); // "copyes"
console.log(obj1.getName.call(obj2)); // "Fanchao"
console.log(obj1.getName.apply(obj2)); // "Fanchao"function showArgs(a, b, c){
console.log(a,b,c);
}
showArgs.call(this, 3,4,5);
showArgs.apply(this, [5,6,7]);2、常见的call 和 apply 用法
let arr1 = [12, 'foo', {name: 'fanchao'}, -1024];
let arr2 = ['copyes', '22', 1024];
Array.prototype.push.apply(arr1, arr2);
console.log(arr1);
// [ 12, 'foo', { name: 'fanchao' }, -1024, 'copyes', '22', 1024 ]let numbers = [5,665,32,773,77,3,996];
let maxNum = Math.max.apply(Math, numbers);
let maxNum2 = Math.min.call(Math, 5,665,32,773,77,3,996);
console.log(maxNum);
console.log(maxNum2);function isArray(obj){
return Object.prototype.toString.call(obj) === '[object Array]';
}
console.log(isArray(1));
console.log(isArray([1,2]));var domNodes = Array.prototype.slice.call(document.getElementsByTagName("*"));3、通过一个面试题去深入理解下apply 和 call
定义一个 log 方法,让它可以代理 console.log 方法:
// 常规做法
function log(msg){
console.log(msg);
}
log(12);
log(1,2)上面能够基本解决打印输出问题,但是下面多参数的时候就gg了。换个更好的方式吧。
function log(){
console.log.apply(console, arguments);
}
log(12);
log(1,2)接下来是要在每一条打印信息前面都要加上一个特定字符串'fanchao`s'又怎么说呢?
function log(){
let args = Array.prototype.slice.call(arguments);
args.unshift('(fanchao`s)');
console.log.apply(console, args);
}
log(12);
log(1,2)4、说完了call和apply,接下来说说bind
bind() 方法与 apply 和 call 很相似,也是可以改变函数体内 this 的指向。
MDN的解释是:bind()方法会创建一个新函数,称为绑定函数,当调用这个绑定函数时,绑定函数会以创建它时传入 bind()方法的第一个参数作为 this,传入 bind() 方法的第二个以及以后的参数加上绑定函数运行时本身的参数按照顺序作为原函数的参数来调用原函数。
看个栗子:
var func = function(){
console.log(this.x);
console.log(arguments);
}
func(); // undefined, {}
var obj = {
x: 2
}
var bar = func.bind(obj,1);
bar(); // 2 , {'0':1}一个有意思的事:
var bar = function() {
console.log(this.x);
}
var foo = {
x: 3
}
var sed = {
x: 4
}
var func = bar.bind(foo).bind(sed);
func(); //3
var fiv = {
x: 5
}
var func = bar.bind(foo).bind(sed).bind(fiv);
func(); //3在Javascript中,多次 bind() 是无效的。更深层次的原因, bind() 的实现,相当于使用函数在内部包了一个 call / apply ,第二次 bind() 相当于再包住第一次 bind() ,故第二次以后的 bind 是无法生效的。
5、这三个方法的异同点是什么呢?
还是先看个栗子:
var obj = {
x: 81,
};
var foo = {
getX: function() {
return this.x;
}
}
console.log(foo.getX.bind(obj)()); //81
console.log(foo.getX.call(obj)); //81
console.log(foo.getX.apply(obj)); //81看到bind后面对了一对括号。区别是,当你希望改变上下文环境之后并非立即执行,而是回调执行的时候,使用 bind() 方法。而 apply/call 则会立即执行函数。
apply 、 call 、bind 三者都是用来改变函数的this对象的指向的;
apply 、 call 、bind 三者第一个参数都是this要指向的对象,也就是想指定的上下文;
apply 、 call 、bind 三者都可以利用后续参数传参;
bind是返回对应函数,便于稍后调用;apply、call则是立即调用 。
一种软件架构风格,设计风格而不是标准,只是提供了一组设计原则和约束条件。它主要用于客户端和服务器交互类的软件。基于这个风格设计的软件可以更简洁,更有层次,更易于实现缓存等机制。使用的是标准的 HTTP 方法,比如 GET、PUT、POST 和 DELETE。
MVC 是一种使用 MVC(Model View Controller 模型-视图-控制器)设计创建 Web 应用程序的模式:
---server
---config 存放数据库连接配置文件
---dev
---prod
---index.js
---db 直接连接数据库操作
---db.js
---controllers 控制器
---xxxController.js
---models 直接操作数据库
---xxxModel.js
---routes 路由配置
---xxx.js
---schema 表结构
---table.js
---utils 工具库
---server.js 服务启动
1、 先说下web框koa
koa 是由 Express 原班人马打造的,致力于成为一个更小、更富有表现力、更健壮的 Web 框架。使用 koa 编写 web 应用,通过组合不同的 generator,可以免除重复繁琐的回调函数嵌套,并极大地提升错误处理的效率。koa 不在内核方法中绑定任何中间件,它仅仅提供了一个轻量优雅的函数库,使得编写 Web 应用变得得心应手。
koa2里面支持async和await,毕竟这个是取代koa1使用co配合generator的一种过度方式。
这里就讲下koa1来做吧。
2、起个服务
首先要做的是:
引入各种中间件
koa-bodyparse
koa-router
koa
编写node服务器脚本app.js
const Koa = require('koa')
const app = new Koa()
app.use( function* ( next ) {
//this.body = 'hello koa';
let start = new Date();
yield next;
let ms = new Date() - start;
console.log('%s %s - %s', this.method, this.url, ms);
})
app.listen(3000)
console.log('[demo] start-quick is starting at port 3000')3、路由的配置
上面就是启动了一个简单的web服务,我们平时调用接口的时候是http://api.xxx.com/api/xxxx/:page
引入路由中间件,并设置你要拦截的请求
const router = require('koa-router')();
const api = require('./routes/api.js');
router.use('/api', api.routes());这个时候所有的请求中带有/api的都被拦截,然后走这个对应的路由中间件,我们在这个对应的路由中间件中定义操作方法比如常见的增删改查这一套。
比如说你的请求的接口是:
http://api.xxx.com/api/list/:page
我们对应的api这个路由中间件里面就定义的有
router.get('/list/:page', getList);换句话说简单的理解,我们请求http://api.xxx.com/api/list/:page
会被映射到getList方法上,这个方法就定义在我们的控制器里面的。
4、控制器
按照以往我写后端的套路controller里面我制作一些校验啊之类的简单操作,不做复杂的逻辑处理之类的。然后对应的方法返回对应的值。
const xxxModel = require('xxxModel');
const getList = function *(){
let page = this.params.page;
let lists = yield xxxModel.getAllList();
}这个里面的model就是来自于表操作的数据实例。对应的控制器有对应的model。按照更好的架构设计,复杂的逻辑处理都应该单独拆个service层。真的model就是只拿最原始的数据实例,不做处理的。
5、model数据实例层
这里我没有做复杂的拆分。把一些逻辑处理也放在这里面的,这是不合适的。
本来这一层只用于获取原始数据的
const getAllList = function* (page){
const pageSize = 20;
const List = yield XXXX.findAll({
'where' : {
'del_flag': 0
},
'order': 'gmt_create DESC',
'limit' : pageSize,
'offset': pageSize * (page - 1)
});
return List;
}上面我用的是一个ORM(sequelize),操作数据库的,让不会写sql的也可以玩CURD。
6、连接数据库,倒入表结构
前面我已经把数据库连接操作放在了db.js里面了。所以这里直接引入就好了。
const db = require('../db/db.js');
// 导入表结构
const xxxTable = '../schema/xxx_table.js';
// 引入表实例
const xxxTableModel = db.database.import(xxxTable);这里我们就连接好对应的数据库,以及可以操作表啦。
之前我们先建好数据库里面的表,但是要手动把表结构写出来,这个就很伤了,可能并不会对不对。sequelize,使用这个东西很方便就可以自动根据数据库里面的表字断生成表结构,很爽。
下面是命令:
equelize-auto -o "./schema" -d beibei -t 表名 -h 域名 -u 用户名 -p 3306 -x 密码 -e mysql这个时候基本就大功告成了。但是~~你的数据库没有数据的话那还是只有gg。这个时候想要数据对不对,哈哈写个简单的爬虫吧~
这个只是一个node写接口的简单入门,没有涉及到很深,什么并发控制啊,鉴权啊,session啊那些东西,另外用node来做单元测试也是很舒服的
在前面的时候已经实现了对象的监听了。但是数组的改变还是没有被监听到。所以就参考下源码是怎么实现数组的监听。
据了解vue对数组的监听是包装了被监听的数组的方法。所以在触发这些被包装的方法的时候能够更新视图
但是对于vue的数组更新变化只能针对vue实例上的数据,并不需要被其他的数组的数据触发。所以到底要怎么去实现这个数组方法的包装呢?
`
// 数组原生的方法列表
const arrMethods = ['push','pop','shift','unshift','splice','sort','reverse'];
const arrayAugmentations = [];
arrMethods.forEach((method) => {
// 原生的数组方法
let originalMethod = Array.prototype[method];
// 将原生数组的一些基本方法定义在arrayAugmentations的属性上;注意直接是属性上,并不是什么原型的属性
arrayAugmentations[method] = function(){
console.log('我是被改变了的');
console.log('我自己定义的数组方法位置');
// 调用原生的数组方法,并且返回结果。
return originalMethod.apply(this, arguments);
};
});
let list = ['a','b','c'];
// 将我们要监听的数组的隐式原型指向上面定义的方法包装数组arrayAugmentations;
// 这个数组的属性就是我们自己定义的封装好的数组方法
list.__proto__ = arrayAugmentations;
// 调用我们封装的数组方法的
list.push('d'); // 我是被改变了的 4
// 正常输出的
let list2 = ['a','b','c'];
list2.push('d'); // 4
`
以上就是对一个数组的变化做出相应变化的简化代码。其实这个里面还涉及到很多其它的,为什么小尤要这么写呢?老司机有老司机的道理。但是还有其它的老司机也提出不同的方法。就是直接继承Array,继承后然后重写原来的方法。这里并没有去改变原来Array上面对应的原来的方法;
`
// class实现下
class FakeArray extends Array{
push(...args){
console.log('我被改变啦');
return super.push(...args);
}
}
var list3 = [1, 2, 3];
var arr = new FakeArray(...list3);
console.log(arr.length)
arr.push(4);
console.log(arr)
`
老司机就是老司机,这个就是其他人提出来的方法。当然这个是ES6中的;
因为JavaScript具有自动回收内存的机制,所以我们这些小前端是从来没有考虑过内存回收等东西。直接是忽略了这些,平时在学习的过程中也没有想到去了解下这块的东西。我感觉正是因为我对这块可能没有认识或者了解导致我很多东西学习的不够彻底。
1、堆与栈
JavaScript中并没有严格意义上区分栈内存与堆内存。因此我们可以粗浅的理解为JavaScript的所有数据都保存在堆内存中。但是在某些场景,我们仍然需要基于堆栈数据结构的思路进行处理,比如JavaScript的执行上下文。执行上下文在逻辑上实现了堆栈。因此理解堆栈数据结构的原理与特点任然十分重要。
在写 snabbdom 复刻版的时候,发现里面有个很有趣的东西,就是在做移动节点的这个操作的时候并不是真正的去把节点移动了,而是通过插入节点,然后再把新的节点删掉。这个做法让想起了一个求最小编辑距离的问题。再 virtual dom 的节点更新就可以抽象成为一个求最小编辑距离的问题。那么这个问题具体是怎么样的,它对应的解法有具体是怎么样的,接下来就来具体看看。
1、问题
给定 2 个字符串 a, b. 编辑距离是将 a 转换为 b 的最少操作次数,操作只允许如下 3 种:
插入一个字符,例如:xy -> xzy
删除一个字符,例如:xzy -> xy
替换一个字符,例如:xzy -> xwy
上面的求 a 转换为 b 的最少操作次数 就是所谓的最小编辑距离问题。
2、� 解法
递归的本质就是用分治的**将大的问题分成若干类似的小问题去解决。
假设字符串 a, 共 m 位,从 a[1] 到 a[m]
字符串 b, 共 m 位,从 b[1] 到 b[n]
d[m][n] 表示字符串 a[1]-a[m] 转换为 b[1]-b[n] 的编辑距离
看到上面的说法就可以转化成下面的递归规律:
1、当 a[m] === b[n]的时候
2、当 a[m] !== b[n]的时候,又可以分成下面三种情况了:
3、边界条件
代码实现:
function recursion(a, b, m, n) {
if (m === 0) {
return n
} else if (n === 0) {
return m
} else {
let d1 = recursion(a, b, m - 1, n) + 1
let d2 = recursion(a, b, m, n - 1) + 1
let d3 = recursion(a, b, m - 1, n - 1) + 1
return Math.min(d1, d2, d3)
}
}上面的递归的解法是从后面到前面的解法,比如我想知道 d[m][n],那么我可能就必须要知道 d[m-1][n-1],依次类推。那么动态规划就是从前到后面的解法。就是我先知道了若干字问题了,那么我根据这些子问题可以求到对应的原问题。举个 🌰:
我知道了 d[0][0] d[0][1] d[1][0] 那么我是可以求到 d[1][1]的:
然后可以依次求的 d[1][2]、d[1][3]、......�、d[2][1]、d[2][2]、......、� 一直到 d[m][n]为止
代码实现:
function dynamicDistance(a, b) {
let lenA = a.length
let lenB = b.length
let d = []
d[0] = []
for (let j = 0; j <= lenB; j++) {
d[0].push(j)
}
for (let i = 0; i <= lenA; i++) {
if (d[i]) {
d[i][0] = i
} else {
d[i] = []
d[i][0] = i
}
}
for (let i = 1; i <= lenA; i++) {
for (let j = 1; j <= lenB; j++) {
if (a[i - 1] === b[j - 1]) {
d[i][j] = d[i - 1][j - 1]
} else {
let m1 = d[i - 1][j] + 1
let m2 = d[i][j - 1] + 1
let m3 = d[i - 1][j - 1] + 1
d[i][j] = Math.min(m1, m2, m3)
}
}
}
return d[lenA][lenB]
}感谢:
1、编辑距离
2、最小编辑距离问题:递归与动态规划
3、动态规划求编辑距离
前面一篇文章里面主要是讲了vuex的入口文件和install方法干了什么。接下来就是我们在注册了vuex服务的后。我们会去new一个Store类的实例。来来来我们看看代码:
export default new Vuex.Store({
state,
actions,
mutations
})
既然调用了store这个类,那么我们就去看看这个类是干了啥吧。
先看构造函数:
constructor (options = {}) {
// 断言函数判断是不是已经执行了install函数
assert(Vue, `must call Vue.use(Vuex) before creating a store instance.`)
// 因为vuex是依赖Promise的,所以这个环境是判断是不是在全局环境中是不是有Promise.一般是用babel编译我们的es6的代码
assert(typeof Promise !== 'undefined', `vuex requires a Promise polyfill in this browser.`)
// 上面这个断言函数是在工具函数util.js里面的
// 结构options中的东西
const {
state = {}, // 获取传过来state中保存的状态,也就是传说中的根状态rootState;
plugins = [], // 插件! 不过为没有使用过
strict = false // 是不是开启严格模式。
} = options
// store internal state // 存储一些内部的属性
// 标志一个提交状态,作用是为了保证对vuex中的state修改只能是在mutation的回调函数中,而不能在其它的地方随便修改
this._committing = false
// 用来存储所有用户自己定义的actions
this._actions = Object.create(null)
// 用来存储所有用户自己定义的mutations
this._mutations = Object.create(null)
// 用来定义所有用户定义的getters
this._wrappedGetters = Object.create(null)
// 用来存储所有运行的modules
this._modules = new ModuleCollection(options)
// 用来保存所有模块的命名空间
this._modulesNamespaceMap = Object.create(null)
// 用来存储所有对mutations变化的订阅者
this._subscribers = []
// new一个vue的实例,其实这里主要是为了使用里面的$watch方法
this._watcherVM = new Vue()
// bind commit and dispatch to self
/*
* 这段代码的主要作用就是将store类的所有的dispatch和commit方法的上下文都
* 指向当前的store的实例,
*
*/
const store = this
const { dispatch, commit } = this
this.dispatch = function boundDispatch (type, payload) {
return dispatch.call(store, type, payload)
}
this.commit = function boundCommit (type, payload, options) {
return commit.call(store, type, payload, options)
}
// strict mode 是否开启严格模式
this.strict = strict
// init root module.
// this also recursively registers all sub-modules
// and collects all module getters inside this._wrappedGetters
// 大致意思就是把我们传进store类的options中的各种属性模块注册安装了。
installModule(this, state, [], this._modules.root)
// initialize the store vm, which is responsible for the reactivity
// (also registers _wrappedGetters as computed properties)
// 初始化store._vm 也是为了观测state和getter的变化,也是将所以的getter注册为计算属性
resetStoreVM(this, state)
// apply plugins 应用传入插件
plugins.concat(devtoolPlugin).forEach(plugin => plugin(this))
}上面就是构造函数干了什么,每个都注释出来了。其中有些是从老版本变化过来的,比如最上面的保存module的地方。总体上没有太大的改变。既然看了构造函数了,那么接下来的重点方法就知道是什么。
那就是installModule,我们要去看这个方法是怎么一步一步把我们传进去的属性给注册了的。
1、下面代码的实际执行过程是什么?
var name = 'fan'
var str = name.charAt(0)
console.log(str)var name = 'fan'
var temp = new String(name)
var str = temp.charAt(0)
temp = null
console.log(temp)2、使用原始值和原始封装类型是有区别的
var flag = new Boolean(false)
if(flag){
console.log(flag)
}因为flag是被解析成一个对象的,所以肯定是真的
3、函数是对象,函数有两种字面形式,第一种是函数声明,以function关键字开头后面跟函数名字。
function add(){
//...
}第二种形式是将函数作为一个值赋值给变量
var add = function(){
}函数声明会被提升到上下文顶部,可以先使用再定义
var result = add()
function add(){
//...
}而函数表达式仅能通过变量引用,因此是没有办法提升的。所以下面会报错
var result = add()
var add = function(){
//...
}4、函数的length属性表示该函数的期望参数个数,实现一个函数,求其接受任意数量的参数并返回他们的和
function sum(){
var result = 0,
i = 0,
l = arguments.length
while(i < l){
result += arguments[i]
i++
}
return result
}5、函数重载的理解,下面的函数输出什么?并解释下。
function sayHello(name){
console.log(name)
}
function sayHello(){
console.log('default msg')
}
sayHello('fan')解释:
var sayHello = new Function('name', 'console.log(name)')
var sayHello = new Function("console.log('default')")
sayHello('fan')可以利用参数的个数来模拟函数的重载
6、改变函数的this。
1、call()方法
function sayHi(context){
console.log(context + ':' + this.name)
}
var person1 = {
name: 'fanchao'
}
var person2 = {
name: '陈冠希'
}
var name = '小姐姐'
sayHi.call(this, 'global')
sayHi.call(person1, 'person1')
sayHi.call(person2, 'person2')这里是显示的指定this的值,并不是让javascript引擎去自动指定this
2、apply()方法
function sayHi(context){
console.log(context + ':' + this.name)
}
var person1 = {
name: 'fanchao'
}
var person2 = {
name: '陈冠希'
}
var name = '小姐姐'
sayHi.apply(this, ['global'])
sayHi.apply(person1, ['person1'])
sayHi.apply(person2, ['person2'])apply基本上和call的方式是一样的,就是接受的第二个参数不一样,是以数组的形式传入函数的,call是需要有多少就要以展开的方式传入参数例如:
xxxxFun.call(xxObj, param1,param2,...)3、bind()方法
bind方法是ECMAscript 5中的方法,和之前的call和apply有点不一样
function sayHi(context){
console.log(context + ':' + this.name)
}
var person1 = {
name: 'fanchao'
}
var person2 = {
name: '陈冠希'
}
//为person1创建一个方法sayHiPerson1
var sayHiPerson1 = sayHi.bind(person1)
sayHiPerson1('person1')
// 为person2创建一个方法sayHiPerson2
var sayHiPerson2 = sayHi.bind(person2,'person2')
sayHiPerson2()
// 因为this已经绑定给了person1,所以name还是person1的
person2.say = sayHiPerson1
person2.say('person2')sayHiPerson1方法没有绑定参数,所以自己还是要在调用的时候传参数
sayHiPerson2不仅绑定了this指向还绑定了第一个参数。参数的绑定类似call方法。
一个好的食用链接,给个star呗
7、理解对象相关
1、对象内部方法
在给一个对象定义属性的时候,会自动调用在对象上的一个叫[[Put]]的内部方法。该方法会在对象上创建一个新的节点来保存属性。当修改一个对象上已经存在的属性的时候,会调用对象上一个叫[[Set]]的内部方法。而在获取一个对象上的一个值的时候,会调用对象上一个叫[[Get]]的内部方法。当你手动的删除对象的某个属性的时候,delete操作符会自动调用对象内部的[[delete]]方法
2、对象的属性分为两种类型:数据属性和访问器属性
属性通用特征:
[[Enumerable]],[[Configurable]]数据属性独有特征:
[[Writable]]、[[Value]]访问器属性特征:
[[Get]],[[Set]]8、构造函数和原型对象
构造函数就是用new操作符调用的普通函数。可以随时定义自己的构造函数来创建多个具有同样属性的对象实例
function Person(){
this,name = 'fan'
}
let person1 = new Person()
let person2 = new Person()可以使用instanceof操作符或者访问constructor属性来查看是什么构造函数创建的
console.log(person1 instanceof Person) // true
console.log(person1.constructor) // Person每个函数都具有prototype属性。想要创建的实例共享一些属性和方法的时候,就可以在这上面定义共享的属性和方法。
原型对象被保存在实例的__proto__属性中。这个属性是一个引用。因为javascript的属性查找机制,对原型对象的修改都会出现在所有的对象实例中。访问一个对象的某个属性的时候都是从对象本身的属性里开始查找,然后沿着原型链查找。
9、继承相关
javascript内建的继承方法被称为原型对象链,又可以叫原型对象继承。
所有的对象,包括自己定义的对象都自动继承自Object(除了自己另有指定),确切点说就是所有的对象都继承自Object.prototype
var book = {
title: 'Javascript'
}
var prototype = Object.getPrototypeOf(book)
console.log(prototype === Object.prototype)1、修改
Object.prototype
所有的对象都是默认继承自Object.prototype的,所以改变Object.prototype会影响所有的对象。
Object.prototype.add = function(value){
return this + value
}
var book = {
title: ' javascript'
}
console.log(book.add(5)) // [object Object]5
console.log("title".add(5)) // "title5"
console.log(document.add(true)) // [object HTMLDocument]true
console.log(window.add(5)) // [object Window]5看到上面的例子就会发现问题的严重性了。
2、对象继承
用Object.create()做简单的继承
var person1 = {
name: 'Nicholas',
sayName: function(){
console.log(this.name)
}
}
var person2 = Object.create(person1, {
name: {
configurable: true,
enumerable: true,
value: 'fan',
writable: true
}
})
person1.sayName()
person2.sayName()
console.log(person1.hasOwnProperty('sayName'))
console.log(person2.hasOwnProperty('sayName'))
person1.isPrototypeOf(person2)
person2.__proto__ === person1
person1.__proto__ === Object.prototype
Object.prototype.__proto__ === null3、构造函数继承
javascript中的继承也是构造函数继承的基础
function YourConstructor(){
//...
}
YourConstructor.prototype = Object.create(Object.prototype, {
constructor: {
configurable: true,
enumerable: true,
value: YourConstructor,
writable: true
}
})几乎所有的函数都有prototype属性,它可以被修改和替换的。该prototype属性被自动设置为一个新的继承自Object.prototype的泛用对象。上面的示例所示。
4、构造函数窃取
为了正确继承自有属性,可以使用构造函数窃取。只需要用call和apply调用父类的构造函数,就可以在子类里完成各种初始化了。
function Rectangle(length, width){
this.length = length
this.width = width
}
Rectangle.prototype.getArea = function(){
return this.length * this.width
}
Rectangle.prototype.toString = function(){
return "[Rectangle] " + this.length + "x" + this.width
}
function Square(size){
Rectangle.call(this, size, size)
}
Square.prototype = Object.create(Rectangle.prototype,{
constructor:{
configurable: true,
enumerable: true,
value: Square,
writable: true
}
})
Square.prototype.toString = function(){
return "[Square] " + this.length + "x" + this.width
}
var square = new Square(6)
console.log(square.length)
console.log(square.width)
console.log(square.getArea())去年的时候和同事一起简单的了解了下hammer.js的源码,没有深入去读,但是源码里面手势检测却是让我了解了一番,原来是这样的啊。于是上周末的时候自己去用ES6写了一个简单的手势库。感觉还是有很多收获的。地址看这里->gesture.js特地来总结下。
1、tap检测
2、doubleTap检测
3、longPress检测
4、pinch检测
5、swipe检测
6、rotate检测
这个知识点是前两天看到的一篇博文。然后针对这个博文自己去实践和理解了一下。了解到两种不同的算法之间的区别。
- 基于帧的动画算法的理解
先上代码:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>基于帧的动画算法理解</title>
<style>
.div {
width: 30px;
height: 20px;
position: relative;
}
.green {
background-color: green;
}
.red {
background-color: red;
}
.blue {
background-color: blue;
}
</style>
</head>
<body>
<div class="title">60 fps:</div>
<div class="div green" id="div1"></div>
<div class="title">30 fps:</div>
<div class="div red" id="div2"></div>
<div class="title">10 fps:</div>
<div class="div blue" id="div3"></div>
</body>
<script>
function moveDiv(oDiv, fps){
var left = 0;
var param = 1;
function loop(){
updateDirection();
draw();
}
// 边界的转换
function updateDirection(){
left += param * 2;
if(left > 300){
left = 300;
param = -1;
}else if(left < 0){
left = 0;
param = 1;
}
}
function draw(){
oDiv.style.left = left + 'px';
}
setInterval(loop, 1000 / fps);
}
moveDiv(document.getElementById('div1'), 60);
moveDiv(document.getElementById('div2'), 30);
moveDiv(document.getElementById('div3'), 10);
</script>
</html>一个基本的知识:JavaScript中的定时器是不准确的。由于JavaScript运行时需要耗费时间,而JavaScript又是单线程的,所以如果一个定时器如果比较耗时的话,是会阻塞下一个定时器的执行。所以即使你设置了1000 / 60每秒60帧的帧率,在不同的浏览器平台的差异也会导致实际上你的没有60fps的帧率。
所以在上面的例子中我们假设在不同的平台上对应的fps分别是60, 30 ,10这样子。那么可以去执行下,结果就是三种情况又的看起来流畅,又的就是一顿一顿的,不忍直视。为什么会这样呢?
导致这种情况的原因很简单,因为我们计算和绘制每个div位置的时候是在每帧更新,每帧移动2px。在60fps的情况下,我们1秒钟会执行60帧,所以小块每秒钟会移动60 * 2 = 120px;如果是30fps,小块每秒就移动30 * 2 = 60px,以此类推10fps就是每秒移动20px。所以最后导致三个小块在单位时间里面移动的距离是不一样的。这种体验肯定不是很好的。
- 解决方法分析
虽然不同的浏览器平台上的运行差异可能会导致帧率的不一致,但是有一样东西是在任何平台上都一致的,那就是时间。所以我们可以改良我们的算法,不是以帧为基准来更新方块的位置,而是以时间为单位更新。也就是说,我们之前是px/frame,现在换成px/ms。
- 基于时间的动画算法的理解
基于时间的这个算法到底是怎么算呢?其实比较简单,我们就是算距离上一帧的时间差算出来就好了。然后根据过去的时间来更新小方块的位置。
看看代码:
function moveDivTimeBased(oDiv, fps){
var left = 0;
var param = 1;
var curTime = +new Date();
var preTime = +new Date();
function loop(){
var curTime = +new Date();
var dt = curTime - preTime;
preTime = curTime;
updateDirection(dt);
draw();
}
function updateDirection(dt){
left += param * (dt * 0.12);
if (left > 300) {
left = 300;
param = -1;
} else if (left < 0) {
left = 0;
param = 1;
}
}
function draw(){
oDiv.style.left = left + 'px';
}
setInterval(loop, 1000 / fps);
}
moveDivTimeBased(document.getElementById('div1'), 60);
moveDivTimeBased(document.getElementById('div2'), 30);
moveDivTimeBased(document.getElementById('div3'), 10);例如,上面的方块应该每秒钟移动120px,每毫秒移动120 / 1000 = 0.12像素(12px/ms)。如果上一帧方块的位置在left为10px的位置,到了这一帧的时候,假设相对于上一帧来说时间过去了200ms,那在时间上来说在这一帧方块应该移动200ms * 0.12px/ms = 240px。最终位置应该为10 + 240 = 250px。其实就是left = left + detalTime * speed;
上面的例子在运行的时候,会发现在运行到后面的时候10fps和30fps是追赶不上60fps的脚步的。会慢慢的落后于60fps。这就尴尬了,造成这个的原因就是在边界的时候会有损失。
假如我们现在方块的位置在left为290px的位置,这一帧传入的dt为100ms,那么我们left为290 + 100 * 0.12 = 302,但是302大于300,所以left会被设置为300。那么本来用来移动2px的时间就会白白被“抛弃”掉。dt越大,浪费得越多,所以30fps和10fps会比60fps越来越慢。
- 优化基于时间的动画算法
解决思路如下:不一次算整块的时间(dt)移动的距离,而是把dt分成固定的时间片,通过多次update固定的时间片来计算dt时间后应该到什么位置。
代码:
function moveDivTimeBased(oDiv, fps){
var left = 0;
var current = +new Date;
var previous = +new Date;
var dt = 1000 / 60;
var acc = 0;
var param = 1;
function loop() {
var current = +new Date;
var passed = current - previous;
previous = current;
acc += passed; // 累积过去的时间
while(acc >= dt) { // 当时间大于我们的固定的时间片的时候可以进行更新
update(dt); // 分片更新时间
acc -= dt;
}
draw();
}
function update (dt) {
left += param * (dt * 0.12);
if (left > 300) {
left = 300;
param = -1;
} else if (left < 0) {
left = 0;
param = 1;
}
}
function draw() {
oDiv.style.left = left + "px";
}
setInterval(loop, 1000 / fps);
}我们先确定一个固定更新的时间片,如固定为60fps时一帧的时间:1000 / 60 = 0.167ms。然后积累过去的时间,然后根据固定时间片分片进行更新。也就说,即使这一帧和上一帧相差过去了100ms,我也会把这100ms分成很多个0.167ms来执行update函数。这样做有两个好处:
1.固定的时间片足够小,更新的时候可以减少边缘损失的时间。
2.不同帧率,不管你是60,30,还是10fps,也是根据固定时间片来执行update函数,所以即使有损失,不同帧率之间的损失是一样的。那么我们三个方块就可以达到同步移动的效果的了!
看上面的代码,update和draw函数保持不变,而loop函数中,对过去的时间进行了累加,当时间超过固定的片就可以执行update。while循环可以保证更新直到把积累的时间都更新完。
对时间进行积累,然后分固定片更新。这种方式还有一个非常大的好处,如果你的帧率超过了60fps,如达到100fps或者200fps,这时候passed会小于0.167ms,时间就会被积累,积累大于0.167才会执行更新。碉堡的效果就是:不管你的帧率是高还是低,移动速度都可以和60fps情况下的速度同步。
在工作过程中,遇到很多布局的问题。有很多时候我们的布局方法各式各样的,但是自己发现对flexbox弹性盒子布局使用的比较少,用也就是简单的应用下基本的,对整体的理解不是很深,前两天在网上看文章的时候无意看到了一些与flexbox的相关的文章。在此前提之下,自己也想要对这个有个更好的理解,于是有了这一篇学习笔记。
- 属性:
display: flex

上面四个div默认是display:block; div是块级元素,所以都会单独成行。
接下来我们给这四个div套上一个父盒子
.container {
display:flex;
}
四个div就变成了横向排列的了。这里其实是给div们加上了一个弹性上下文(flex context)
- 属性:
flex-deriction
先借用别人的一张图吧,就是这个“弹性方向”的理解:
坐标轴分为主轴和交叉轴:

这个属性一共有四个值:row row-reverse column column-reverse
见名知其意,依次是,横向顺序排列, 横向反转排列, 纵向顺序排列, 纵向反转排列


上面两张图是别人的,借用 https://medium.freecodecamp.com/an-animated-guide-to-flexbox-d280cf6afc35#.h4n9x6uv7
纵向排列的变化其实不能理解成把元素按照交叉轴排列了,而是要理解成元素按照主轴排列,然后把主轴的方向旋转了。
- 属性:
justify-content
这个属性有五个值,flex-start flex-end center space-between space-around,依次理解为:
在主轴左侧从左到右挨着排列, 在主轴右侧从左到右挨着排列, 在主轴中间从左到右排列, 延主轴两边无空隙中间等距从左向右排列 延主轴元素两侧等距空隙从左向右排列。好吧只观点以下是五个图的样子





justify-content 是沿着主轴工作的。 flex-direction 是改变的主轴方向的。
- 属性:
align-items
好吧这个属性也是有五个值:flex-start flex-end center stretch baseline
上面说了justify-content 是延主轴工作的,那么这个align-items则是按照交叉轴进行工作的。还是借用别人的图,谢谢了哦~

接着直接来看下效果图吧:
align-items: flex-start
交叉轴纵向顶部对齐

align-items: flex-end
交叉轴纵向底部对齐

align-items: center
交叉轴纵向正中间对齐

align-items: stretch
交叉轴纵向延父盒子高度拉伸
使用align-items: stretch 时每个 div 的 height 必须为 auto 否则 height 属性会覆盖 stretch 的效果

align-items: baseline
(有文字内容)交叉轴纵向延文字的基线对齐
使用align-items: baseline 时如果 div 内没有 p 标签或者 div 内没有文字或者子标签内没有文字将按照每个 div 的底部对齐


- 属性:
align-item
这个属性是设置某一个子元素的对齐方式的。它会覆盖掉应用在某一个子元素身上的align-items属性,因为子元素的height都是auto的,所以子元素会继承父元素的align-items属性。
例如我们给第二个div设置
.two {
align-self: center;
}效果就是下面:

夯实基础才是进步的根源,基础不牢地动山摇!!于是乎,结合《javascript高级程序设计》来点基础的学习和理解。本文主要会有两部分。rt!!
1、执行环境的理解
执行环境(或者执行上下文)(execution context 后面简称ec)定义了变量或者函数有权访问的其他数据,决定了他们各自的行为。如果不好理解的话,接着看后面。
全局执行环境是最外围的一个执行环境,在web浏览器中,全局执行环境被默认为是指window对象。因此所有的全局变量和函数都是作为window对象的属性和方法创建的。全局执行环境直到应用程序推出才会被销毁(例如关闭网页或者浏览器的时候)。
每个函数都有自己的执行环境。当执行流进入一个函数的时候,函数的环境就会被推入一个环境栈中,而在函数执行之后,栈将其环境弹出。把控制权返回给之前的执行环境了。
执行环境一般分为全局执行环境和函数执行环境。
这个时候应该上代码了(高程上的代码)
var color = 'blue';
function changeColor() {
var anotherColor = 'red';
function swapColors() {
var tempColor = anotherColor;
anotherColor = color;
color = tempColor;
}
swapColors();
}
changeColor();来看看流程吧:



总结
2、变量对象的理解
上面我们讲到了执行环境,环境中的变量和函数都是保存在什么地方的呢?
好了,不卖关子了。每个执行环境都有一个与该环境相关联的变量对象(variable object)。环境中定义的所有变量和函数都是保存在这个对象中的。虽然我们编写的代码没有办法直接访问这个对象,但是js解析器在处理数据的时候会使用它。
执行环境的生命周期:

变量对象的创建

上面就是变量对象的一个创建过程,这个过程的解释:
上面的代码解释:
function test(c, d) {
console.log(d);
console.log(a);
console.log(bar());
console.log(c);
var a = 1;
function bar() {
return 2;
}
}
test(3,4);
//创建过程 EC = execution context
testEC = {
// 变量对象
VO: {},
// 作用于链
scopeChain: {},
// 确定this指向
this: {}
}
// VO = Variable Object,即变量对象
VO = {
arguments: {
c: undefined,
d: undefined
}, //注:在浏览器的展示中,函数的参数可能并不是放在arguments对象中,这里为了方便理解,我做了这样的处理
bar: <bar reference> // 表示foo的地址引用
a: undefined
}
// 执行阶段
VO -> AO // Active Object
AO = {
arguments: {
c: 3,
d: 4
},
bar: <bar reference>,
a: 1
}
// 实际执行
function test(c, d) {
// arguments = { c : 3, d : 4 }; // 这样理解方便点,理解arguments对象
function foo() {
return 2;
}
var a;
console.log(a);
console.log(foo());
a = 1;
}
test(3, 4);就是在执行环境在创建阶段的时候所有的变量是不能被访问的,只有在执行阶段的时候才能被访问,因为此时的变量对象被转换成了活动对象。
// 执行阶段
VO -> AO // Active Object
AO = {
arguments: {...},
foo: <foo reference>,
a: 1
}说到底变量对象和活动对象本质上是一样的,只是处于执行环境的不同生命期。
最后全局环境的变量对象
windowEC = {
VO: window,
scopeChain: {},
this: window
}总结:
当一个web请求到达缓存的时候,并且本地有“已缓存”的副本,那么就可以直接从本地设备中获取这个文档,不必再去原始的服务器中请求该文档。
1、使用缓存的好处
2、应用缓存可能出现的情况
1. 命中的和未命中的缓存
可用的已有的副本为某些到达缓存的提供服务,这被称为命中缓存
其他一些到达缓存的请求,但是没有可用的缓存副本,被转发到原始服务器,这种称为未命中缓存
缓存在验证命中和缓存再验证未命中
如果我们一直使用缓存的话,假如有时我们的文档发生了改变,这时如何把服务器上的变更通知到客户端呢?
http使用了一些简单的机制,来保持已缓存的数据和服务器数据之间的一致性。
一般情况下是通过[新鲜度检测](也可以叫做是http再验证)对服务器上的文档进行再检测,从而查看服务器上的最新版本是不是和当前缓存的文档一致

http通过在请求的首部添加 If-Modified-Since字段,可以实现在验证的过程。再验证有如下三种结果:
304 Not Modified,表示服务器对象没有改变。200 OK响应,表示服务器文档已经改变,与缓存的副本不一样了,将重新从服务器获取文档404 Not Found,表示服务器上的该对象已经被删除了3、缓存机制图解
Cache-Control首部和Expires首部,HTTP让服务器向每个文档附加了一个”过期时间”,并将文档存入缓存当中。在文档过期之前,缓存可以任意频率使用这些副本,而无需与服务器联系(除非请求中有限制)。Last-Modified:< date >)和当前的标签是什么(Etag:< tag >)。If-Modified-Since和If-None-Match还记得上文提到的服务器响应中的Last-Modified首部和Etag首部吗?在发送”条件请求的时候”,请求首部中 If-Modified-Since的值即为上次在响应中收到的Last-Modified的值,而If-None-Match的值即为上次收到的响应中Etag的值。If-Modified-Since和If-Node-Match值取出,与服务器上的对应文档的请求头信息进行比较
304 Not Modified,并且在响应头上加入新的Cache-Control和Expire首部,用来更新缓存上的新鲜度
4、其他
Cache-Control
该首部可以设置的值:
max-age=XXXX(设置相对秒数,即还有XXXX秒文件变为”不新鲜”)
s-maxage=XXXX(仅适用于共有缓存)
no-store(禁止缓存对响应进行复制)
no-cache(响应可以存在缓存中,但是每次都要进行再验证)
Expires 和 Cache-Control
Expirese使用绝对日期,但由于许多服务器时钟都不同步,因此不建议使用
而Cache-Control则使用相对时间
If-Modified-Since 和 If-None-Match
当请求中同时存在If-Modified-Since 和 If-None-Match两种首部,则只有当两者条件都为真的时候,服务器才返回304 Not Modified
这个是一个简单的理解,有错误请指出
因为我是直接去小尤的github上下的代码,所以下到的都是最新版的,最新版的vuex都是支持namespace的,所以这几个暴露出去的辅助函数和以往的内部实现是有一些变化的。在上完源码后还要去官网看看怎么玩。
mapState分析
// 最新版本的vuex是支持命名空间的。所以这个API暴露出去的时候最新用法是:
export const mapState = normalizeNamespace((namespace, states) => {
const res = {}
normalizeMap(states).forEach(({ key, val }) => {
res[key] = function mappedState () {
let state = this.$store.state
let getters = this.$store.getters
// 有命名空间的话,去store实例上找,看看有没有这个实例的module.
if (namespace) {
const module = getModuleByNamespace(this.$store, 'mapState', namespace)
if (!module) {
return
}
// 是对应module的状态或者getter的话直接就赋值取出来了。
state = module.context.state
getters = module.context.getters
}
// 最后返回,一般是用在计算属性上的。
return typeof val === 'function'
? val.call(this, state, getters)
: state[val]
}
// mark vuex getter for devtools
res[key].vuex = true
})
return res
})
用法:如果是新版的话可以直接
computed: {
...mapState('some/nested/module', {
a: state => state.a,
b: state => state.b
})
},
老版本的话可以直接看官方的文档
自己去看了helper.js下面的代码后,发现这几个对外暴露的辅助函数,套路都是一样的啊。所以就那一个最难的出来分析了,其他的可以自己去看了。这几个辅助函数的用法的话的可以直接去官方文档看了。估计还会有两个番外篇之类的去分析下dispatch和commit等。
this一直是js中的重点,搞不清this的话,很快你就会出现乱调的情况。而且我们可能经常认为this是指向函数自身的,当然可能是处于字面理解。还有时候,我们会认为this会指向函数的作用域。在最开始我们先要明确一点就是this在任何情况下都不指向函数的词法作用域。
1、this的调用位置
首先要理解的是调用位置这个概念:调用位置就是函数在代码中被调用的位置(不是声明的位置)。
所以在这里我们要先学会分析函数的调用栈。看个例子:
function baz(){
}因为之前做了一个用了vue和vuex的简单记事本,做这个记事本的主要目的是为了体验vuex不是为了别的。然后发现vuex用来管理状态确实比较高效,虽然那个记事本程序代码量不是很大。但是我还是依然感觉到了vuex的厉害。所以的为了知其所以然,就只有去看看源码是怎么写的了。当然这个学习不光光是自己去看源码,还结合其他人的文章来理解的。因为vuex对外暴露了6个API。那么我们就对应这6个API来依依分析,看看它们到底做了什么。
先看看结构目录:

看到这个目录感觉非常的清爽啊,一眼就让我知道去找下index.js文件了。看到index.js文件面的代码非常简单,两个文件倒入,然后就是vuex对外暴露的几个API:
export default {
Store,
install,
version: '__VERSION__',
mapState,
mapMutations,
mapGetters,
mapActions
}
其中,Store类,就是vuex提供的一个状态存储相关的类,通常我们使用vuex就是通过这个store类创建的实例。例如我的本地记事本demo中的
export default new Vuex.Store({
state,
actions,
mutations
})
这个store类比较复杂,留着后面看。那就接下来看install这个API。先看代码:
export function install (_Vue) {
if (Vue) {
console.error(
'[vuex] already installed. Vue.use(Vuex) should be called only once.'
)
return
}
Vue = _Vue
applyMixin(Vue)
}
// auto install in dist mode
if (typeof window !== 'undefined' && window.Vue) {
install(window.Vue)
}
这里实现了一个install方法,这个方法是当我们全局引用vue的时候(俗话说的就是外链方式引用),也就是说window对象上已经有了vue的时候,这里会自动去执行install,并把vue实例传进去。但是我们如果是通过npm安装到项目中的时候,而且我们的代码是如下写的(看标星的):
import Vue from 'vue' ****
import App from './App'
import Vuex from 'vuex' *****
import store from './store/index'
Vue.use(Vuex); ****
的时候,当我们执行 Vue.use(Vuex) 这句代码的时候,实际上就是调用了 install 的方法并传入 Vue 的引用,在install方法里面我们看到使用vue作了一个判断,这个判断是保证vue只背安装可一次,还把参数_vue赋值给全局的vue,这样的目的是可以在其它的地方使用vue。,接下里就是applyMixin方法了。这个方法在mixin.js文件中实现的,先看下这个文件中的代码:
export default function (Vue) {
const version = Number(Vue.version.split('.')[0])
if (version >= 2) {
const usesInit = Vue.config._lifecycleHooks.indexOf('init') > -1
Vue.mixin(usesInit ? { init: vuexInit } : { beforeCreate: vuexInit })
} else {
// override init and inject vuex init procedure
// for 1.x backwards compatibility.
const _init = Vue.prototype._init
Vue.prototype._init = function (options = {}) {
options.init = options.init
? [vuexInit].concat(options.init)
: vuexInit
_init.call(this, options)
}
}
/**
* Vuex init hook, injected into each instances init hooks list.
*/
function vuexInit () {
const options = this.$options
// store injection
if (options.store) {
this.$store = options.store
} else if (options.parent && options.parent.$store) {
this.$store = options.parent.$store
}
}
}
这段代码的主要用途是用来在vue的生命周期中注入vuex的代码,这里作了vue的版本判断,在vue2.版本中是在beforeCreate钩子函数之前注入(PS: init: vuexInit 这个init貌似是1里面的钩子函数,这里何用?),在vue1中,为了做到向下兼容,重写了_init方法,当然重写的这段也是为了注入vuex的代码,当然注入的就是store类了。所以我们能够在vue的组件当中使用this.$strore.xxxx来访问到vuex中的各种状态和数据了。
第一步算是完成了,要弄清这里干了什么的话需要去知道很多其它的东西
你需要知道的有
这段时间,在工作中遇到了一个CDN导致的图片资源加载的错误,在排查问题的过程中,发现自己对CDN的了解非常的片面,仅仅停留在它能缓存静态资源,提升访问速度的了解中。所以觉得还是非常有必要深入去了解下。
CDN的全称是Content Delivery Network,即内容分发网络,是指一种通过互联网互相连接的电脑网络系统,利用最靠近每位用户的服务器,更快、更可靠地将音乐、图片、视频、应用程序及其他文件发送给用户,来提供高性能、可扩展性及低成本的网络内容传递给用户。————维基百科
最简单的CDN网络是由一台CDN服务器和多台缓存服务器构成。
主要工作过程为:
根本上的原因是访问速度,访问速度对互联网应用的用户体验,甚至说各种指标(DAU,PV,UV,营收...)都有巨大的影响,任何的互联网企业都渴望自己站点有更快的访问速度和更好的用户体验。而HTTP传输时延对web的访问速度的影响很大(HTTPS更耗时),在绝大多数情况下是起决定性作用的,这是由TCP/IP协议的一些特点决定的。
想要提高访问速度,最直接的做法就是多部署几个服务器在不同的地方,让当前访问用户更靠近服务器。但是多设置几个服务器又会有其他乱七八糟的问题(异地部署,访问一致性,服务管理,成本变高等等)。
这个时候就体现出CDN的作用了。CDN本身是一种公共服务,他本身有很多台位于不同地域、接入不同运营商的服务器,而所谓的使用CDN实质上就是让CDN作为网站的门面,用户访问到的是CDN服务器,而不是直接访问到网站。由于CDN内部对TCP的优化、对静态资源的缓存、预取,加上用户访问CDN时,会被智能地分配到最近的节点,降低大量延迟,让访问速度可以得到很大提升。
掌握CDN工作流程或者基本的原理这种知识,对于一个前端来说,在甩锅的时候更方便。当然最主要是为了解决工作中的问题。
维基百科、百度百科
这个是接着前面一篇文章的。这些文章主要是结合了 原文 Even more about how Flexbox works — explained in big, colorful, animated gifs 和自己的一些实践和理解写出来的。俗话说的好,站在巨人的肩膀上更快的成长。前一篇我们讲的属性是相对于容器的。这一篇主要讲的是关于容器里面的元素的相关。
- 属性flex-basis
这个属性的基本作用就是用来控制元素的基本尺寸。这个属性是依赖父盒子的flex-direction的值的。换句话说就是依赖主轴的排列方式。
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>flexbox理解2</title>
<style>
.container {
display: flex;
flex-direction: column;
width: 600px;
height: 600px;
background-color: #f2f2f2;
}
.box {
width: 100px;
height: 100px;
}
.box1 {
flex-basis: 140px;
background-color: red;
}
.box2 {
background-color: blue;
}
.box3 {
background-color: yellow;
}
.box4 {
background-color: green;
}
</style>
</head>
<body>
<div class="container">
<div class="box box1"></div>
<div class="box box2"></div>
<div class="box box3"></div>
<div class="box box4"></div>
</div>
</body>
</html>
另外的动图更直观

上图换句话说就是当主轴水平的时候 flex-basis是相当于覆盖了width。当主轴为竖直的时候flex-basis是相当于覆盖了height。
2.属性
flex-grow
这个属性比较难理解,但是有做好的动图理解起来还是比较方便的。 这里涉及两种计算规则,先看代码:
<style>
.container {
display: flex;
width: 800px;
height: 800px;
background-color: black;
}
.box {
flex-grow: 1;
margin-right: 10px;
width: 100px;
height: 100px;
}
.box1 {
background-color: red;
}
.box2 {
flex-grow: 3;
background-color: blue;
}
.box3 {
background-color: yellow;
}
.box4 {
background-color: green;
}
</style>1.当.box的宽度存在的时候,盒子二的宽度计算是(800 - 40 - 100 * 4)/ (1 + 3 + 1 + 1)* 3 + 100 = 280px;
2.当.box的宽度不存在的时候,盒子二的宽度计算是 (800 - 40 )/ (1 + 3 + 1 + 1)* 3 = 380
40是每个盒子的margin的总和;
由上面的计算规则可以明白flex-grow是指的是在容器内增长的宽度。有宽度增长的就是父盒子剩余的空间,没宽度就是按照父盒子的宽度来。
动图来了。其实动图还没有我的算术说明方便。哈哈哈啊

3.属性
flex-shrink
先看代码:
.container {
display: flex;
flex-direction: row;
width: 800px;
height: 800px;
background-color: black;
}
.box {
flex-shrink: 1;
margin-right: 10px;
width: 220px;
height: 100px;
}
.box1 {
background-color: red;
}
.box2 {
flex-shrink: 7;
background-color: blue;
}
.box3 {
background-color: yellow;
}
.box4 {
background-color: green;
}上面讲的flex-grow是增长,那么这个属性就是缩小。但是呢这个属性是会和父盒子的宽度有关系的。看上面例子:
父盒子是800的宽度。而子元素实际上加起来并加上margin宽度都已经超了120了。这个时候用了flex-shrink属性了那么就是缩小对吧。这个时候我们来看看要缩小多少
当父盒子宽度固定的时候,那么盒子二的宽度计算就是应该 220 -(220 * 4 + 40 - 800)/ (1+7+1+1)* 7 = 136
父盒子的宽度定没有定公式都是上面那样计算。


总结:flex-shrink 的作用是指定哪些元素缩小哪些不缩小。默认情况每个元素 flex-shrink: 1,意味着他们会随着父级容器的缩小而缩小。flex-shrink 也是相对值,按比例来计算的,若果一个元素 flex-shrink 的值为6,其他的为2,当容器空间压缩时,该元素会以 3x 的速度缩小。这里的 3x 指的是将缩小 3倍,而不是缩小为 1/3 的宽度。
4.属性:
flex
讲的最后一个属性。(三个值都存在的情况,一般情况可能只会用到其中的一个值。这里是说明三个值的情况)
flex 属性是把 flex-grow flex-shrink flex-basis 综合到了一起
默认值为 0 (flex-grow) 1 (flex-shrink) auto (flex-basis)
老规矩先上代码:
.container {
display: flex;
flex-direction: row;
width: 600px;
height: 600px;
background-color: black;
}
.box {
margin-right: 10px;
height: 100px;
}
.box1 {
flex: 1 2 300px;
background-color: red;
}
.box2 {
flex: 2 1 300px;
background-color: blue;
}这个时候这种写法是完全依据父盒子的宽度了,怎么说了?这里有两种情况。
1.当父盒子的宽度小于两个子元素的宽度加上边距的时候就相当于走的是flex-shrink
计算的话就是这样的:
盒子一:300 -(300 + 10 +300 + 10 - 600 )/ (2 + 1)* 2 = 286.67
盒子二: 300 -(300 +10 + 300 + 10 -600)/ ( 2 + 1)* 1 = 293.33
2.当父盒子的宽度大于两个子元素的宽度加上边距的时候就相当于走的是flex-grow
计算的话就是这样的:(假设父盒子的宽度变成了680)
盒子一: (680 - 300 -300 -10 -10)/ (1 + 2)* 1 + 300 = 320
盒子二: (680 - 300 -300 -10 -10)/ (1 + 2)* 2 + 300 = 340
看图:

所以看到了么?总结下:当 盒子一增长时他不会增长到 盒子二 的两倍;同样缩小时 盒子二也不会缩小为盒子一的一半因此这不是他们的大小比例为 1:2 或者 2:1 ,而是他们的收缩和增长速度
最近有点醉心 于node,但是一说到node就会想到如果没有Promise,generator,async等的话非常容易出现“回调地狱”。所以说我们在写node的过程中脑子里面可能时刻都要记住一些调用顺序之内的。而要想完美hold住node这些东西的话,必须要有一个扎实的基础知识储备。这个地方就出现了我想要深入了解的一个知识点--事件循环
事件循环从整体上来说就是我们要理解javascript运行的顺序。现在的前端已经不是简简单单以前的前端了,随着es6的推出,加入像promise这类用法。对于我们去理解事件循环机制就更加重要了。
理解事件循环机制的前提:
执行上下文、函数调用栈,数据结构--队列、Promise
先明确几个结论,后面会对这些结论一一做出解释
1.JavaScript代码的执行过程中,除了依靠函数调用栈来搞定函数的执行顺序外,还依靠任务队列(task queue)来搞定另外一些代码的执行。
2.可以有多个任务队列,但是事件循环只有一个(特指一个线程,现在web work涉及多线程,但是我并不了解)
3.setTimeout,Promise等称之为任务源,进入任务队列的是他们对应执行的任务。
4.任务队列又分为macro-task(宏任务)与micro-task(微任务),在最新标准中,它们被分别称为task与jobs。
5.macro-task大概包括:script(整体代码), setTimeout, setInterval, setImmediate, I/O, UI rendering。
6.micro-task大概包括: process.nextTick, Promise, Object.observe(已废弃), MutationObserver(html5新特性)
7.每一个任务的执行都是依赖函数调用栈来完成。
8.事件循环的顺序,决定了JavaScript代码的执行顺序。它从script(整体代码)开始第一次循环。之后全局上下文进入函数调用栈。直到调用栈清空(只剩全局),然后执行所有的micro-task。当所有可执行的micro-task执行完毕之后。循环再次从macro-task开始,找到其中一个任务队列执行完毕,然后再执行所有的micro-task,这样一直循环下去。
说了要根据代码理解,那么我们就用代码来说话,然后任务拆解的方式来说:
// 写这些demo的原因时想要依靠代码来一步一步理解
setTimeout(function(){
console.log('time1');
});
new Promise(function(resolve, reject){
console.log('Promise1');
for(var i = 0; i < 999; i++){
i == 999 && resolve();
}
console.log('Promise2');
}).then(function(){
console.log('then1');
});
console.log('globle1');1、事件循环是最先从宏任务开始的,也就是说第一个宏任务就是script整个代码块,每一个任务的执行顺序,都依靠函数调用栈来搞定,而当遇到任务源时,则会先分发任务到对应的队列中去。所以首先第一个进函数调用栈的是global。

2、接下来就是遇到第一个任务源setTimeout了,它是一个宏任务,然后该任务源就会将对应的宏任务分配到对饮的宏任务队列里面去。
setTimeout(function(){
console.log('time1');
});
3、第三步的时候就会遇到Promise,这就有点特殊了。Promise的构造函数的第一个参数实在new这个对象的时候执行的,并不是异步的,不会进去任何任务队列。只是会进入函数调用栈。但是这个执行完之后的.then()就会进入微任务Promise队列了。
Promise的构造函数执行的时候不会进入队列,所以是直接在函数调用栈里面执行了。for循环也不会进入任何任务队列里面。
最后的结果就是promise构造函数执行输出promise1,resolve()入栈执行完出栈,继续promise执行输出promise2,then进入微任务promise队列。

script任务接着往下执行就是最后输出global1了。到此整个script宏任务结束,接下来就是进入微任务了。
4、第一个宏任务执行完就执行所有可以执行的微任务了。上面代码的实例中微任务队列里面只有一个promise队列里面的then微任务。首先是从微任务队列里面把任务出队,然后任务进入函数调用栈里面执行。所以这个时候就输出的是then1.
5、一个宏任务和微任务为一轮,那么上面就算是已经结束完的一轮了。接下来就是又到宏任务了下一轮就开始了。这个时候我们发现宏任务队列中还有setTimeout任务源的任务。那么就可以开始执行了,还是先按照把任务放进函数调用栈中再执行。
最后,宏任务和微任务队列里面的任务都执行完毕了。没有东西可以在执行了,那么这个时候代码就执行结束了。上面的例子的结果就是:

上面的例子是比较简单的,那么假如有个比较难的,这个怎么说呢:
// demo02
console.log('golb1');
setTimeout(function() {
console.log('timeout1');
process.nextTick(function() {
console.log('timeout1_nextTick');
})
new Promise(function(resolve) {
console.log('timeout1_promise');
resolve();
}).then(function() {
console.log('timeout1_then')
})
})
setImmediate(function() {
console.log('immediate1');
process.nextTick(function() {
console.log('immediate1_nextTick');
})
new Promise(function(resolve) {
console.log('immediate1_promise');
resolve();
}).then(function() {
console.log('immediate1_then')
})
})
process.nextTick(function() {
console.log('glob1_nextTick');
})
new Promise(function(resolve) {
console.log('glob1_promise');
resolve();
}).then(function() {
console.log('glob1_then')
})
setTimeout(function() {
console.log('timeout2');
process.nextTick(function() {
console.log('timeout2_nextTick');
})
new Promise(function(resolve) {
console.log('timeout2_promise');
resolve();
}).then(function() {
console.log('timeout2_then')
})
})
process.nextTick(function() {
console.log('glob2_nextTick');
})
new Promise(function(resolve) {
console.log('glob2_promise');
resolve();
}).then(function() {
console.log('glob2_then')
})
setImmediate(function() {
console.log('immediate2');
process.nextTick(function() {
console.log('immediate2_nextTick');
})
new Promise(function(resolve) {
console.log('immediate2_promise');
resolve();
}).then(function() {
console.log('immediate2_then')
})
})过程自己去分析吧。贴个结果:

首先是画图工具
工具
这是著名神文
https://zhuanlan.zhihu.com/p/26229293
http://www.jianshu.com/p/a6d37c77e8db
http://www.jianshu.com/p/12b9f73c5a4f
ES6标准发布后,module成为了标准,该标准是采用export导出模块,以import方式引入模块,但是在我们的node模块中我们依然是使用CommonJs规范,使用require方式引入模块,使用module.exports到处模块
export语法用于导出函数,对象,指定文件(或模块)的原始置。
注意:在node中使用的是exports,非常容易混淆的。
export有哪些到处方式呢?我们这就来一起看看:
主要分为命名式导出和默认导出,命名式导出能够导出多个模块,默认导出则只能导出一个。
export { name, name1, name3 }
export { test as name, test2 as name2 }
export let a = 1,b = 2; //also var const
export const a,b,c
export default expression
export default function(){
//...
}
export default function name(){
//...
}
//也可以直接从其他的模块中导出
export * from ''
export { name, age,, money } from person
export { name as a, age as b } from person模块可以通过export前缀关键词声明导出对象,导出对象可以是多个。这些导出对象用名称进行区分,称之为命名式导出。
export { myFunction }; // 导出一个已定义的函数
export const foo = Math.sqrt(2); // 导出一个常量我们可以使用*和from关键字来表示模块的继承关系
export * from 'test'模块导出时,可以指定模块的导出成员。导出成员可以认为是类中的公有对象,而非导出成员可以认为是类中的私有对象:
var name = '小哥哥';
var money = 100000000;
export {name, money}; // 相当于导出
{name:name,money:money}我们还可以使用as关键词来对导出的模块进行重命名。
var name = '小哥哥';
var money = 100000000;
export {name as firstName, money};以下情况是错误的:
// 错误演示
export 1; // 绝对不可以
var a = 100;
export a;export在导出接口的时候,必须与模块内部的变量具有一一对应的关系。直接导出1没有任何意义,也不可能在import的时候有一个变量与之对应
export a虽然看上去成立,但是a的值是一个数字,根本无法完成解构,因此必须写成export {a}的形式。即使a被赋值为一个function,也是不允许的。
默认导出也被称做定义式导出。命名式导出可以导出多个值,但在在import引用时,也要使用相同的名称来引用相应的值。而默认导出每个导出只有一个单一值,这个输出可以是一个函数、类或其它类型的值,这样在模块import导入时也会很容易引用。
export default function() {}; // 可以导出一个函数
export default class(){}; // 也可以出一个类使用名称导出:
// module.js
export function cube(x){
return x * x * x
}
const test = Math.PI + 1
export {
test
}
// use.js
import { cube test } from 'module'
console.log(cube(2))
console.log(test)使用默认导出:
//module.js
export default function(x){
return x * x * x
}
// use.js
import cube from 'module'
console.log(cube(2));import语法声明用于从已导出的模块、脚本中导入函数、对象、指定文件(或模块)的原始值
import模块导入与export模块导出功能相对应,也存在两种模块导入方式:命名式导入(名称导入)和默认导入
import defaultMember from "module-name";
import * as name from "module-name";
import { member } from "module-name";
import { member as alias } from "module-name";
import { member1 , member2 } from "module-name";
import { member1 , member2 as alias2 , [...] } from "module-name";
import defaultMember, { member [ , [...] ] } from "module-name";
import defaultMember, * as name from "module-name";
import "module-name";花括号里面的变量与export后面的变量一一对应
import {myMember} from "my-module";
import {foo, bar} from "my-module";通过*符号,我们可以导入模块中的全部属性和方法。当导入模块全部导出内容时,就是将导出模块(’my-module.js’)所有的导出绑定内容,插入到当前模块(’myModule’)的作用域中:
import * as myModule from "my-module";导入模块对象时,也可以使用as对导入成员重命名,以方便在当前模块内使用:
import {reallyReallyLongModuleMemberName as shortName} from "my-module";导入多个成员时,同样可以使用别名:
import {reallyReallyLongModuleMemberName as shortName, anotherLongModuleName as short} from "my-module";导入一个模块,但不进行任何绑定:
import "my-module";在模块导出时,可能会存在默认导出。同样的,在导入时可以使用import指令导出这些默认值。
直接导出默认值:
import myDefault from "my-module";也可以在命名空间导入和名称导入中,同时使用默认导入:
import myDefault, * as myModule from "my-module"; // myModule 做为命名空间使用
或
import myDefault, {foo, bar} from "my-module"; // 指定成员导入// --file.js--
function getJSON(url, callback) {
let xhr = new XMLHttpRequest();
xhr.onload = function () {
callback(this.responseText)
};
xhr.open("GET", url, true);
xhr.send();
}
export function getUsefulContents(url, callback) {
getJSON(url, data => callback(JSON.parse(data)));
}
// --main.js--
import { getUsefulContents } from "file";
getUsefulContents("http://test.com", data => {
doSomethingUseful(data);
});#方法
1、为了学习后续的vue的底层实现,先要去了解怎么监听一个对象的变化。因为一个数据不可能只有对象,所以后面还要了解怎么监听一个数组的变化。
2、对对象监听的时候有两个难点:
(1)当属性变化的时候,怎么触发对应的回调呢?
(2)对象往往是一个 深层次的结构,对象的某个属性可能仍然是一个对象,这种情况怎么处理?
答:针对(1),因为ES5中有个Object.defineProperty方法。通过自定义setter和getter函数来达到监听属性被获取或者被设置的时候的回调;
针对(2)就使用递归吧。遇到是对象的时候那么就再深入去遍历;
#代码
`
let data = {
user: {
name: 'fanchao',
age: '24'
},
address: {
city: 'chengdu'
}
}
// 观察者模式
function Observer(data){
this.data = data;
this.walk(data);
}
let p = Observer.prototype;
// 遍历对象上的所有属性
p.walk = function(obj){
let val;
for(var key in obj){
// 这里用hasOwnProperty是因为要过滤非该对象的属性
if(obj.hasOwnProperty(key)){
val = obj[key];
if(typeof val === 'object'){
new Observer(val);
}else{
this.convert(key, val);
}
}
}
}
p.convert = function(key, val){
// 属性劫持
Object.defineProperty(this.data, key, {
enumerable: true,
configurable: true,
get: function(){
console.log('你访问了' + key);
return val;
},
set: function(newVal){
console.log('你设置了' + key);
console.log('新的' + key + '=' + newVal);
val = newVal;
}
});
}
let app = new Observer(data);`
#遗留问题
1、只处理了对象的监听,还有数组呢。
2、在新设置对象后,新设置的属性没有被监听,即新set的对象里面的属性不能调用getter和setter
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.