
关于订阅
喜欢请点右上角 `star`。订阅的话,请 `watch` 按钮。
转载注意事项
除注明外,所有文章均采用Creative Commons BY-NC-ND 4.0(自由转载-保持署名-非商用-禁止演绎)协议发布。
前端博客,关注基础知识和性能优化。
License: MIT License
关于订阅
喜欢请点右上角 `star`。订阅的话,请 `watch` 按钮。
转载注意事项
除注明外,所有文章均采用Creative Commons BY-NC-ND 4.0(自由转载-保持署名-非商用-禁止演绎)协议发布。

![dependabot[bot] avatar](https://avatars.githubusercontent.com/in/29110?v=4 "dependabot[bot]")








































































































































































































GraphQL is a query language for your API, and a server-side runtime for executing queries by using a type system you define for your data. GraphQL isn't tied to any specific database or storage engine and is instead backed by your existing code and data.
GraphQL 是一种 API 查询语言,同时也是基于 自定义类型系统 执行查询的一个服务端运行时(runtime) 。GraphQL 本身不绑定任何数据库或存储引擎,而是可以在现有代码和数据上提供支持。
介绍概念后,一般应该紧跟介绍 GraphQL 的特性,跟前辈 Restful API 的比较等等。不过我觉得对初学者来说(包括我),这样的先后顺序并不友好,特别是对 GraphQL 这样全新的技术,以 demo 来快速了解怎么用,有个大概印象会更好。
所以下面紧接 GraphQL 的应用。
所有示例基于 GraphQL 的 node.js 实现(graphql-js),请确保已安装以下依赖:
node>=6npm install graphql,GraphQL 的 JS 实现,提供了两个重要能力:创建 type schema 和 对对应的 schema 执行查询。npm install express express-graphql,创建 GraphQL HTTP server。GraphQL 查询本质是客户端发送字符串到服务端,服务端解析后返回 JSON 给客户端。下面我们尝试构建最基本的 查询。
const { graphql, buildSchema } = require('graphql')
// 使用 GraphQL 的 schema 语言构造一个 schema
const schema = buildSchema(`
type Query {
hello: String
}
`)
// root 为每个 API endpoint 提供 resolver 函数
const root = {
hello() {
return `Hello world!`
}
}
// query
const query = `{ hello }`
graphql(schema, query).then(response => {
console.log('No root:', response)
// No root: { data: { hello: null } }
})
graphql(schema, query, root).then(response => {
console.log('With root:', response)
// With root: { data: { hello: 'Hello world!' } }
})这个例子中没有引入客服端和服务端的区分,只是展示了怎么创建 Schema ,query 怎么被处理。下面一个例子结合 express 构建一个正常的 GraphQL 服务。
服务端使用 express 和 express-graphql 搭建 GraphQL 服务。
const express = require('express')
const graphqlHTTP = require('express-graphql')
const { buildSchema } = require('graphql')
// 创建 schema,需要注意到:
// 1. 感叹号 ! 代表 not-null
// 2. rollDice 接受参数
const schema = buildSchema(`
type Query {
quoteOfTheDay: String
random: Float!
rollThreeDice: [Int]
rollDice(numDice: Int!, numSides: Int): [Int]
}
`)
// The root provides a resolver function for each API endpoint
const root = {
quoteOfTheDay: () => {
return Math.random() < 0.5 ? 'Take it easy' : 'Salvation lies within'
},
random: () => {
return Math.random()
},
rollThreeDice: () => {
return [1, 2, 3].map(_ => 1 + Math.floor(Math.random() * 6))
},
rollDice: ({ numDice, numSides }) => {
const output = []
for (let i = 0; i < numDice; i++) {
output.push(1 + Math.floor(Math.random() * (numSides || 6)))
}
return output
}
}
const app = express()
app.use('/graphql', graphqlHTTP({
schema: schema,
rootValue: root,
graphiql: true
}))
app.listen(4000)
console.log('Running a GraphQL API server at localhost:4000/graphql')客户端代码:
const fetch = require('node-fetch')
fetch('http://localhost:4000/graphql', {
method: 'POST',
headers: {
'Content-Type': 'application/json',
'Accept': 'application/json'
},
body: JSON.stringify({
query: `{
random,
quoteOfTheDay,
rollThreeDice,
rollDice(numDice: 9, numSides: 6)
}`
})
}).then(res => {
return res.json()
}).then(data => {
console.log(data)
/**
*
{ data:
{ random: 0.3099461279459266,
quoteOfTheDay: 'Salvation lies within',
rollThreeDice: [ 3, 1, 2 ],
rollDice: [ 2, 6, 4, 1, 1, 5, 2, 1, 1 ] } }
*/
})上面代码中我们展示了怎集成 express-graphql,前端怎么向后台发起查询等等。需要注意到
基本类型有:String, Int, Float, Boolean, ID 5种,我们试验了 String|Float|Int 等 3 种。其中 ID 对应 JavaScript 中的 Symbol。
默认情况下,指定基本类型时返回 null 是合法的。但如果在后面加上感叹号则表示不允许为空,比如这里的 Float!。
给基本类型加上方括号则表示为数组,如 [Int]。
此外,查询时可以使用参数,参数用圆括号包裹,如 rollDice(numDice: 3, numSides: 6)。
当然,有时候我们可能不希望把参数直接写死,那么可以这样传参:
body: JSON.stringify({
query: `query RollDice($dice: Int!, $sides: Int) {
rollDice(numDice: $dice, numSides: $sides)
}`,
variables: { dice: 9, sides: 6 }
})咳咳 转为拼音是错的
什么是AMD(不是做显卡的:joy:)?如果不熟的话,require.js总应该比较熟。
AMD是_Asynchronous Module Definition_的缩写,字面上即异步模块定义。require.js是模块加载器,实现了AMD的规范。
本文想说的就是怎么实现一个类似require.js的加载器。但在这之前,我们应该了解下JS模块化的历史。
https://github.com/Huxpro/js-module-7day
这个Slides讲的比我好的多,所以想了解前端模块化的前世今生的可以去看看。这里简单总结下:
为什么需要模块化?
前端模块历史?
但模块化还需要解决加载问题:
define包裹,在打包时解决模块化;请相信,题目着重简单,没有撒谎,这篇博文的所有算法相关的内容都是简单的。
作为一个早把《数据结构》还给老师的非专业选手,博主也正在努力学习算法。这篇文章以题目为组织形式,算是一个学习笔记吧。
从原博客迁移过来(有更改),并将保持更新。
关于JavaScript,工作和学习过程中遇到过许多问题,也解答过许多别人的问题。这篇文章记录了一些有价值的问题。
问题:{a:1}.a报错,错误Uncaught SyntaxError: Unexpected token .。
解决:
({a:1}.a) // 或({a:1}).a原因:
An object literal is a list of zero or more pairs of property names and associated values of an object, enclosed in curly braces ({}). You should not use an object literal at the beginning of a statement. This will lead to an error or not behave as you expect, because the { will be interpreted as the beginning of a block.
简单说,就是声明对象字面值时,语句开头不应该用{,因为js解释器会认为这是语句块(block)的开始。
同理,类似问题{ name: "mc", id: 1 }会报错Uncaught SyntaxError: Unexpected token :也是这个道理。({ name: "mc", id: 1 })即可正确解析。但稍注意下,{name: "mc"}是不会报错的,它等同于name: "mc",并返回一个字符串"mc"。
问题:123.toFixed(2)报错,错误Uncaught SyntaxError: Unexpected token ILLEGAL
解决:
(123).toFixed(2) // >> "123.00"
// 以下两种都可以,但完全不推荐
123..toFixed(2)
123 .toFixed(2)原因:
很简单,js解释器会把数字后的.当做小数点而不是点操作符。
问题:尝试解释下连等赋值的过程。下面的代码为什么是这样的输出?
var a = {n: 1};
var b = a;
a.x = a = {n: 2};
console.log(a.x);// --> undefined
console.log(b.x);// --> {n:2}原因:
我们可以先尝试交换下连等赋值顺序(a = a.x = {n: 2};),可以发现输出不变,即顺序不影响结果。
那么现在来解释对象连等赋值的问题:按照es5规范,题中连等赋值等价于
a.x = (a = {n: 2});,按优先获取左引用(lref),然后获取右引用(rref)的顺序,a.x和a中的a都指向了{n: 1}。至此,至关重要或者说最迷惑的一步明确。(a = {n: 2})执行完成后,变量a指向{n: 2},并返回{n: 2};接着执行a.x = {n: 2},这里的a就是b(指向{n: 1}),所以b.x就指向了{n: 2}。
搜索此题答案时,颜海镜的一篇博客关于此题也有讲述,不过没有讲清楚(或许是我没有领会 :P)。
esprima 提供解析 JS 到 AST 的功能,我们可以借此看一下这段代码在引擎眼里到底是什么。(其实 node 从 8 开始开始支持编译 JS 到 AST 了 (V8 ignition interpreter),不过 node 好像没有提供接口给我们使用)。
下面是我拿到的上面代码的 AST:
{
"type": "Program",
"body": [
{
"type": "VariableDeclaration",
"declarations": [
{
"type": "VariableDeclarator",
"id": {
"type": "Identifier",
"name": "a"
},
"init": {
"type": "ObjectExpression",
"properties": [
{
"type": "Property",
"key": {
"type": "Identifier",
"name": "n"
},
"computed": false,
"value": {
"type": "Literal",
"value": 1,
"raw": "1"
},
"kind": "init",
"method": false,
"shorthand": false
}
]
}
}
],
"kind": "var"
},
{
"type": "VariableDeclaration",
"declarations": [
{
"type": "VariableDeclarator",
"id": {
"type": "Identifier",
"name": "b"
},
"init": {
"type": "Identifier",
"name": "a"
}
}
],
"kind": "var"
},
{
"type": "ExpressionStatement",
"expression": {
"type": "AssignmentExpression",
"operator": "=",
"left": {
"type": "MemberExpression",
"computed": false,
"object": {
"type": "Identifier",
"name": "a"
},
"property": {
"type": "Identifier",
"name": "x"
}
},
"right": {
"type": "AssignmentExpression",
"operator": "=",
"left": {
"type": "Identifier",
"name": "a"
},
"right": {
"type": "ObjectExpression",
"properties": [
{
"type": "Property",
"key": {
"type": "Identifier",
"name": "n"
},
"computed": false,
"value": {
"type": "Literal",
"value": 2,
"raw": "2"
},
"kind": "init",
"method": false,
"shorthand": false
}
]
}
}
}
}
],
"sourceType": "script"
}可以清晰地得到,代码等价于:a.x = (a = {n: 2});。然后核心的知识点是:引用解析发生在实际赋值之前 。
问题: 下面的代码返回什么,为什么?
var x = 20;
var temp = {
x: 40,
foo: function() {
var x = 10;
return this.x;
}
};
(temp.foo, temp.foo)(); // 20,而不是40原因:
The comma operator evaluates each of its operands (from left to right) and returns the value of the last operand.
即逗号操作符会从左到右计算它的操作数,返回最后一个操作数的值。所以(temp.foo, temp.foo)();等价于var fun = temp.foo; fun();,fun调用时this指向window,所以返回20。
问题: parseInt传入数字时为什么有以下输出?
parseInt(0.000008) // >> 0
parseInt(0.0000008) // >> 8原因:
parseInt(arg)时会调用arg.toString()。
(0.000008).toString() // "0.000008"
(0.0000008).toString() // "8e-7"var o = (function() {
var person = {
name: 'Vincent',
age: 24,
};
return {
run: function(k) {
return person[k];
},
}
}());在不改变上面的代码情况下, 怎么得到原有的 person 对象?
解决:
Object.defineProperty(Object.prototype, 'self',
{
get: function() {
return this;
},
configurable: true
});
o.run('self'); // 输出 person但如果加上person.__proto__ = null,目前还没找到解决方法。
You Don't Know JS: Types & Grammar
很多开发者认为动态语言没有类型。但ES5规范定义:
此规范内的算法在处理每个值时都有一个关联的类型。可能的值类型都定义在这个条款中。类型可以进一步分为 ECMAScript 语言类型和规范类型。
ECMAScript 语言类型和使用ECMAScript语言的程序员处理的值相符。ECMAScript语言类型有:Undefined, Null, Boolean, String, Number, 和 Object。
内置类型有:null,undefined,boolean,number,string,object,symbol(ES6新加)。
除了object都是基础类型(primitives)。
typeof操作符检查给定操作数的类型。类型是undefined,boolean,number,string,object,symbol,function七种中的一个。
为什么没有null?
typeof null; // 'object',这是个浏览器的bug,null不是对象。
为什么有function?
typeof function a(){ /* .. */ } === "function"; // true,function是JS内置的顶级类型之一,也是对象(的子类型),可以调用的对象。
在JS中,变量(variables)没有类型——值有类型。变量可以在任何时候有任何值。
换一种方法理解JS类型:JS没有强制类型,引擎不要求变量总是存储与初始化时相同类型的值。
undefined vs "undeclared"当前没有值的变量,其实是当前值为undefined。两者区别是:
undefined的变量在当前可访问作用域里已经声明了,只是当前没有值;typeof undeclared对未声明的变量执行typeof得到"undefined",这可能会造成一点混淆。但这是安全的检测未声明变量的方法。
var declared;
typeof declared; // "undefined"
typeof undeclared; // "undefined"
if(undeclared){} // Uncaught ReferenceError: undeclared is not defined数组就是数值索引的任何类型值的集合。
数组不需要你提前定义长度。delete会删除对应位置的值,但即使你delete了所有值,数组的长度不会变化。这样的数组是稀疏数组("sparse" array),即留下或创建了空槽。
注意,稀疏数组看起来是索引对应的值为undefined,但这和显示设置arr[index] = undefined不同。
数组是数值索引的,但同时它是对象,所以可以有字符串键值对。一般,你设置字符串属性时,不会影响length,但如果这个key可以转换成十进制数字时,会假设你想使用数值索引:
var a = [ ];
a['key'] = 'value';
a.length; // 0
a['13'] = 42;
a.length; // 14, a: [undefined × 13, 42]类数组可以通过Array.prototype.slice.call或Array.from(ES6)来转换成数组。
Array.prototype.slice.call({length: 2}) // [undefined × 2]认为字符串就是字符数组的想法很常见。但不管字符串的底层实现是否使用数组,字符串与数组有很多不同,相似只是表面的。
尽管字符串和数组有indexOf,length等等相似属性,但注意:JS字符串是不可变的(immutable),而数组是可变的。
更进一步,字符串的不可变性:没有一个字符串方法可以就地改变字符串的内容,相反,这些方法都创建并返回一个新字符串。而数组的许多方法可以改变数组本身的内容。
JS只有一个数值类型:number。这个类型包括"整数"和小数。"整数"之所以有引号是因为JS并不像其它语言有真的整数。
所以,在JS中,"整数"就是没有小数部分的数字:42.0和42一样是"整数"。
像大多数现代语言,包括实际上所有脚本语言,JS的number基于IEEE 754标准,常称为"浮点数"。JS尤其使用了标准的双精度(double precision)格式(64位二进制)。
JS中数字通常用十进制表示:
var b = 42.3;
b = 0.42;
b = .42; // 十进制开始部分如果是0可以省略
b = 42.0;
b = 42. ;// 十进制结束部分如果是0可以省略
b = 42.300; b; // 42.3 尾部多余的0通常被移除
b = 42.0; b; // 42很大或很小的数字一般以指数形式输出,等同于toExponential()方法的输出:
var a = 5E10;
a; // 50000000000
a.toExponential(); // "5e+10"
var b = a * a;
b; // 2.5e+21
var c = 1 / a;
c; // 2e-11toFixed(..)可以指定小数部分的输出位数(0-20)。toPrecision(..)指定显示数字时有效数字的个数(1-21)。
var a = 42.59;
a.toFixed( 0 ); // "43"
a.toFixed( 1 ); // "42.6"
a.toFixed( 2 ); // "42.59"
a.toFixed( 3 ); // "42.590"
a.toPrecision( 1 ); // "4e+1"
a.toPrecision( 2 ); // "43"
a.toPrecision( 3 ); // "42.6"
a.toPrecision( 4 ); // "42.59"
a.toPrecision( 5 ); // "42.590"注意数字的**.**点操作符。因为点是有效的数字字符,所以它首先被解释为数字的一部分,而不是属性访问。
// invalid syntax:
42.toFixed( 3 ); // SyntaxError
// these are all valid:
(42).toFixed( 3 ); // "42.000"
0.42.toFixed( 3 ); // "0.420"
42..toFixed( 3 ); // "42.000"
42 .toFixed(3); // "42.000"数字可以以指数形式定义,如1e3。可以16进制定义,0xf3。可以8进制定义,0363。
注意,ES6+ strict模式下,8进制的0363不在允许。但ES6允许两种新形式:0o363-8进制,0b11110011-2进制。
使用二进制浮点数(使用IEEE 754的所有语言)的最著名副作用是:
0.1 + 0.2 === 0.3; // false简单说,0.1和0.2的二进制浮点表示都不是精确的,所以相加后不是0.3,接近(不等于)0.30000000000000004。
所以,比较数字时,应该有个宽容值。ES6中这个宽容值被预定义了:Number.EPSILON。
由于数字的表示方法,整数肯定有个安全范围,并且肯定小于Number.MAX_VALUE。整数的最大安全值是2^53 - 1,即9007199254740991,最小安全值是-9007199254740991,分别被定义在Number.MAX_SAFE_INTEGER和Number.MIN_SAFE_INTEGER。
我们通常会遇到数据库的64位ID值,由于64位数字无法被JS数字表示,所以必须用字符串表示。
Number.isInteger(..)测试是否是整数。Number.isSafeInteger(..)测试是否安全的整数。
安全的整数可以到53位(二进制),但很多数字操作(如二进制操作符)只支持32位,所以整数的安全范围可能更小。
a | 0可以把数字强制转换为32位有符号整数,因为|二进制操作符只对32位整数有效。
注意:NaN和Infinity当然不是安全的整数,但二进制操作符要工作的话首先会把它们转换成+0。Infinity | 0 // => 0。
undefined类型的值有且只有undefined一个。null类型的值有且只有null一个。
undefined和null通常被用来当作可互换的空值或非值。可以这么区分:
null是空值(empty value);undefined是无值(missing value)。null有值但不做任何事;undefined还没有值。非严格模式下,可以向全局的undefined赋值。严格与非严格模式下,都可以定义叫undefined的变量。但这么做是会被打的。
function foo() {
undefined = 2; // really bad idea!
}
foo();
function bar() {
"use strict";
var undefined = 2;
console.log( undefined ); // 2
}
bar();void操作符void操作符可以生成undefined值,void 42;//undefined。
NaN--Not a number。NaN是一个哨兵值,表示数字范围内的一种错误情况。
NaN不等于任何值,包括自己。一般用isNaN来测试是否是NaN,但:
window.isNaN(2 / "foo"); // true
window.isNaN("foo"); // true -- ouch!1 /0; // Infinity
-1 / 0; // -Infinity (1 / -0)
Infinity / Infinity; // NaN (Infinity / -Infinity)如果一个操作如加法产生太大而难以表示的数字,IEEE 754舍入到最近值("round-to-nearest")的模式指定值。
var a = Number.MAX_VALUE; // 1.7976931348623157e+308
a + a; // Infinity
a + Math.pow( 2, 970 ); // Infinity Number.MAX_VALUE + Math.pow( 2, 970 )与Infinity更近
a + Math.pow( 2, 969 ); // 1.7976931348623157e+308 Number.MAX_VALUE + Math.pow( 2, 969 )与Number.MAX_VALUE更近JS中有0和-0。除了-0的显示写法,-0一般从特殊算数运算中得来,如0 / -3或0 * -3。加减运算不会产生-0。
最近浏览器控制台才输出(揭示)-0,但字符串化-0只会得到0,根据规范。
var a = 0 / -3;
// (some browser) consoles at least get it right
a; // -0
// but the spec insists on lying to you!
a.toString(); // "0"
a + ""; // "0"
String( a ); // "0"
// strangely, even JSON gets in on the deception
JSON.stringify( a ); // "0"有趣的是,相反操作(从字符串到数字)不会说谎:
+"-0"; // -0
Number( "-0" ); // -0
JSON.parse( "-0" ); // -0比较操作也说谎,即0等于-0。
常用的原生对象有:String(),Number(),Boolean(),Array(),Object(),Function(),RegExp(),Date(),Error(),Symbol()。
可以看出,这些原生对象其实是内置函数。
typeof结果为object的值额外有个[[Class]]属性来标记(可看做内部分类)。这个属性无法直接访问,可通过Object.prototype.toString(..)获取。
而对基础类型的值来说:
Object.prototype.toString.call( null ); // "[object Null]"
Object.prototype.toString.call( undefined ); // "[object Undefined]"
Object.prototype.toString.call( "abc" ); // "[object String]"
Object.prototype.toString.call( 42 ); // "[object Number]"
Object.prototype.toString.call( true ); // "[object Boolean]"对null和undefined来说,尽管没有Null()和Undefined(),但内部[[Class]]的值暴露了"Null"和"Undefined"。
对其它基础类型来说,输出的是它对应包装对象的[[Class]]。
基础类型没有属性或方法,但JS自动包装基础类型的值,但你尝试访问属性或方法时。
特意手动创建包装对象来访问属性方法是不必要的,看起来JS不用去包装了,但浏览器很久以前就对这些常见情况优化了,手动创建反而会拖慢程序。
!new Boolean( false ); // false
typeof new String('a'); // object 注意,String前需要new
Object('a') instanceof String; // true 注意,Object前的new可以省略使用valueOf()来获取包装对象对应的基础类型值。
new String( "abc" ).valueOf() // "abc"另外拆箱可以隐式发生,如new String( "abc" ) + ''。这个(类型转换)会在第四章讲。
对于array,object,function,和正则来说,更常用的是它们的字面值形式。
就像上面看到的其它原生对象,这些构造函数形式一般要避免,因为构造函数可能带来陷阱。
Array可以不加new。Array(1,2,3)返回[1, 2, 3]。Array的参数是一个数字时,当成数组长度。此时会创建稀疏数组。map陷阱。var a = new Array( 3 ); // [undefined × 3]
var b = [ undefined, undefined, undefined ]; // [undefined, undefined, undefined]
var c = [];
c.length = 3; // [undefined × 3]a、c是稀疏数组,它们一些情况下和b表现一致,然后其它情况和b不一样。
a.join( "-" ); // "--"
b.join( "-" ); // "--"
a.map(function(v,i){ return i; }); // [ undefined x 3 ]
b.map(function(v,i){ return i; }); // [ 0, 1, 2 ]怎么显式创建填充undefined的数组(非手动)?Array.apply( null, { length: 3 } )。apply会把第二个参数当作(类)数组,这就是魔法所在。
Object(..)/Function(..)/RegExp(..)构造函数都是可选的,也最好不用。
Function(..)有时很有用,比如你想动态定义采数和函数体。但不要把Function(..)当做eval的替代。
Date(..)和Error(..)很有用,因为没有对应的字面值形式。
Symbol可以用作属性名。但一般你无法访问或看到symbol的真实值。
ES6预定义了一些symbol,如Symbol.create和Symbol.iterator。
内置原生对象构造函数都有自己的.prototype对象。这些.prototype对象包含原生对象独特的行为。
Function.prototype是空函数。
RegExp.prototype是空正则(不匹配任何字符串)。
Array.prototype是空数组。
这些都是很好的默认值。
看到过下面这样一道题:
(function test() {
setTimeout(function() {console.log(4)}, 0);
new Promise(function executor(resolve) {
console.log(1);
for( var i=0 ; i<10000 ; i++ ) {
i == 9999 && resolve();
}
console.log(2);
}).then(function() {
console.log(5);
});
console.log(3);
})()为什么输出结果是1,2,3,5,4而非1,2,3,4,5?
比较难回答,但我们可以首先说一说可以从输出结果反推出的结论:
Promise.then是异步执行的,而创建Promise实例(executor)是同步执行的。setTimeout的异步和Promise.then的异步看起来 “不太一样” ——至少是不在同一个队列中。在解答问题前,我们必须先去了解相关的知识。(这部分相当枯燥,想看结论的同学可以跳到最后即可。)
Promise/A+规范要想找到原因,最自然的做法就是去看规范。我们首先去看看Promise的规范。
摘录promise.then相关的部分如下:
promise.then(onFulfilled, onRejected)
2.2.4 onFulfilled or onRejected must not be called until the execution context stack contains only platform code. [3.1].
Here “platform code” means engine, environment, and promise implementation code. In practice, this requirement ensures that onFulfilled and onRejected execute asynchronously, after the event loop turn in which then is called, and with a fresh stack. This can be implemented with either a “macro-task” mechanism such as setTimeout or setImmediate, or with a “micro-task” mechanism such as MutationObserver or process.nextTick. Since the promise implementation is considered platform code, it may itself contain a task-scheduling queue or “trampoline” in which the handlers are called.
规范要求,onFulfilled必须在 执行上下文栈(execution context stack) 只包含 平台代码(platform code) 后才能执行。平台代码指 引擎,环境,Promise实现代码。实践上来说,这个要求保证了onFulfilled的异步执行(以全新的栈),在then被调用的这个事件循环之后。
规范的实现可以通过 macro-task 机制,比如setTimeout和 setImmediate,或者 micro-task 机制,比如MutationObserver或者process.nextTick。因为promise的实现被认为是平台代码,所以可以自己包涵一个task-scheduling队列或者trampoline。
通过对规范的翻译和解读,我们可以确定的是promise.then是异步的,但它的实现又是平台相关的。要继续解答我们的疑问,必须理解下面几个概念:
Event Loop规范HTML5规范里有Event loops这一章节(读起来比较晦涩,只关注相关部分即可)。
Events task,Parsing task, Callbacks task, Using a resource task, Reacting to DOM manipulation task等。每个task都有自己相关的document,比如一个task在某个element的上下文中进入队列,那么它的document就是这个element的document。
每个task定义时都有一个task source,从同一个task source来的task必须放到同一个task queue,从不同源来的则被添加到不同队列。
每个(task source对应的)task queue都保证自己队列的先进先出的执行顺序,但event loop的每个turn,是由浏览器决定从哪个task source挑选task。这允许浏览器为不同的task source设置不同的优先级,比如为用户交互设置更高优先级来使用户感觉流畅。
Jobs and Job Queues规范本来应该接着上面Event Loop的话题继续深入,讲macro-task和micro-task,但先不急,我们跳到ES2015规范,看看Jobs and Job Queues这一新增的概念,它有点类似于上面提到的task queue。
一个Job Queue是一个先进先出的队列。一个ECMAScript实现必须至少包含以下两个Job Queue:
| Name | Purpose |
|---|---|
| ScriptJobs | Jobs that validate and evaluate ECMAScript Script and Module source text. See clauses 10 and 15. |
| PromiseJobs | Jobs that are responses to the settlement of a Promise (see 25.4). |
单个Job Queue中的PendingJob总是按序(先进先出)执行,但多个Job Queue可能会交错执行。
跟随PromiseJobs到25.4章节,可以看到PerformPromiseThen ( promise, onFulfilled, onRejected, resultCapability ):
这里我们看到,promise.then的执行其实是向PromiseJobs添加Job。
好了,现在可以让我们真正来深入task(macro-task)和micro-task。
认真说,规范并没有包括macro-task 和 micro-task这部分概念的描述,但阅读一些大神的博文以及从规范相关概念推测,以下所提到的在我看来,是合理的解释。但是请看文章的同学辩证和批判地看。
首先,micro-task在ES2015规范中称为Job。 其次,macro-task代指task。
哇,所以我们可以结合前面的规范,来讲一讲Event Loop(事件循环)是怎么来处理task和microtask的了。
mutation observer callbacks和promise callbacks。定位到开头的题目,流程如下:
setTimeout的callback被添加到tasks queue中;1; promise resolved;输出 2;promise.then的callback被添加到microtasks queue中;3;5;4。不知不觉,从事前端 4 年多了,距离本篇的前作 JavaScript问题集锦 也有 2 年多了 —— 青葱岁月啊。
又忽然想起“我变秃了,也变强了!”的梗,正好程序员工作久了,容易变秃... 当然我没有秃,所以说 😂
收起半夜突然来的感概,正式解释下文章题目和目的:
本文还是会以 JS 的一个个知识点为粒度来讲,这算是对之前那篇的继承。这个秋天,静极思动,面了BA以及其它一些公司,和面试官的尬聊中,有些觉得很懂的东西并没有解释的很好,这里也提醒下自己和大家:学无止境。
IIFE (Immediately Invoked Function Expression) 即立即调用/执行函数表达式。我们常看到(包括某些库中):
(function() {})()上面的即 IIFE 的一种写法,匿名函数会立即执行。下面是一些等价写法:
(function() {}())
!function() {}()
~function() {}()是不是觉得很熟悉,然后觉得没什么要注意的?那下面问个问题:
function(){}()它是 IIFE 吗?为什么?Console 中输入会发生什么?单独拎出来这样问是不是有些发懵?
上面的代码运行的话会报错,并且更进一步,单独执行 function(){} 也会报错:

下面首先简要解释下原因:
JS 应用是由(无语法错误的) statements 组成的。
当我们单独输入:function (){}时,解释器其实期待的是合法的 statement,即一个函数声明。但很抱歉,函数声明必须有 name,所以这里报错了。
同理,function (){}() 是一样的错误原因,因为当解释器首先看到关键字 function 时,它就认为要接收一个函数声明了,但我们并没有满足这个规则。
下面的图可以帮助理解:

接下来我们更深入一点,来全面了解下 JS 中的 Statements 和 Expression。
An expression is any valid unit of code that resolves to a value.
对 expression ,一句话:任意合法的产生值的代码单元都是表达式。所以:
5this a = 5func()(function () {})等等都是表达式。更详细的可参考 https://developer.mozilla.org/en-US/docs/Web/JavaScript/Guide/Expressions_and_Operators。
对于 statement,我们可以直接看规范 http://es5.github.io/#x12,可以看到 statement 有
等等。其中,我们重点要讲一讲 ExpressionStatement (表达式语句) ,这是我们这个问题的由来。
ExpressionStatement :
[lookahead ∉ {{, function}] Expression ;
表达式语句的定义如上,用中文解释下就是 合法的 expression 加上 ;(即 expression;)就是表达式语句了。但是,
{ 开头的不是,因为会和 BlockStatement 产生歧义function 开头的不是,因为会和 FunctionDeclaration 产生歧义所以你看,一切写在规范里了。
结合规范,我们就知道开头如果是 function,那么一律按函数定义来解析,不合法就报错;而我们可以通过 () 括号/group操作符来避免。
同样{a:1}.a 报错就是因为开头是{被当作 BlockStatement 解释了,想当作对象那加括号吧:({a:1}).a。
有天刷掘金,看到这样一篇文章利用Android源码,轻松实现汉字转拼音功能,非常感兴趣,花了两个多小时,阅读了博客和代码,算是弄懂了原理。然后就想,是不是可以从Java移植到JavaScript。
本篇博客记录的就是阅读和折腾的过程,顺便提醒自己,借助现代浏览器的能力(API),几百行代码可以轻松搞定汉字转拼音。
2017/05/12 更新:
依据本篇博客编写的汉字转拼音库 tiny-pinyin 已上线,越300行代码左右,可轻松阅读。Online demo 地址 https://creeperyang.github.io/pinyin/,可放心体验。

首先应该说,汉字转拼音是个强需求,比如联系人按拼音字母排序/筛选;比如目的地(典型如机票购买)
按拼音首字母分类等等。但是这个需求的解决方案,但好像没听过什么巧妙的实现(特别是浏览器端),大概都需要一个庞大的字典。
具体到JavaScript,查查github和npm,比较优秀的处理汉字转拼音的库有pinyin和
pinyinjs,可以看到,两者都自带了庞大的字典。
这些字典动辄几十上百KB(有的甚至几MB),想在浏览器端使用还是需要一些勇气的。所以当我们碰到汉字转拼音的需求,也不怪我们第一反应就是拒绝需求(或者服务端实现)。
现在,如果我告诉你可以浏览器端 300 行代码实现汉字转拼音,是不是不可置信?
再次强调这篇博客——利用Android源码,轻松实现汉字转拼音功能。
今天和大家分享一个从Android系统源代码提取出来的汉字转成拼音实现方案,只要一个类,560多行代码就可以让你轻松实现汉字转成拼音的功能,且无需其他任何第三方依赖。
是不是打破了你的思维定势:难道有什么强大的算法可以抛弃字典?
第一遍看完博客,稍有些失望,并没有什么算法解析,只是介绍了从安卓代码发现的这几百行代码。第二遍时带着移植到JavaScript的想法阅读代码,算是弄懂了原理,于是开始了踩坑的移植之旅。
源码在Android Git Reposities,感兴趣的可以去看看。
首先直指核心:为什么有汉字转拼音必须有庞大字典的思维定势?
因为汉字的排布和拼音并没有什么关联,比如在汉字区间\u4E00-\u9FFF,前一个可能是ha,后一个可能就是ze,没有办法从汉字的unicode关联到拼音,所以只能有一个庞大的字典记录每个汉字(或常用汉字)的拼音。
但是,假设我们可以把所有汉字按拼音排序,比如按'A', 'AI', 'AN', 'ANG', 'AO', 'BA',...,'ZUI', 'ZUN', 'ZUO'排序,那么,我们只需要记住每个相同拼音的汉字队列的第一个汉字就好了。那么,所需要的字典就会很小(覆盖所有拼音即可,拼音数量本身不多)。
现在,难点就是把汉字按拼音排序了。很幸运,ICU/本地化相关的API提供了这个排序API(如果没有方便的排序/比较方法,那么本篇文章可能就不会出现了)。
所以,这就是为什么 300 行可以实现汉字转拼音:
Intl.Collator API:Intl.Collator内部实现了本土化相关的字符串排序。我们通过Intl.Collator.prototype.compare可以把所有汉字 基本 按照拼音来排序。说到这里,可能仍然有没说清楚的地方,所以直接上一段代码:
/**
* 说明:19968-40959,即所有汉字(4e00-9fff)的charCode
*
* 输出结果(即排序)如下:
*
* [{
* "hanzi": "阿", // 拼音 a
* "unicode": "\u963f",
* "index": 0
* },
* {
* "hanzi": "锕", // 拼音 a
* "unicode": "\u9515",
* "index": 1
* },
* ...
* {
* "hanzi": "鿿",
* "unicode": "\u9fff",
* "index": 20991
* }]
*
*/
const fs = require('fs')
const FIRST_PINYIN_UNIHAN = 19968
const LAST_PINYIN_UNIHAN = 40959
function listAllHanziInOrder() {
const arr = []
for(let i = FIRST_PINYIN_UNIHAN; i <= LAST_PINYIN_UNIHAN; i++) {
arr.push(String.fromCharCode(i))
}
const COLLATOR = new Intl.Collator(['zh-Hans-CN'])
arr.sort(COLLATOR.compare)
console.log(arr.length)
fs.writeFileSync(`${__dirname}/sortedHanzi.json`, JSON.stringify(
arr.map((v, i) => {
return {
hanzi: v,
unicode: `\\u${v.charCodeAt(0).toString(16)}`,
index: i
}
}),
null,
' '
))
console.log('done')
}
listAllHanziInOrder()有兴趣的同学可以执行node --icu-data-dir=node_modules/full-icu 上面的脚本.js看看,然后看看是不是得到了 基本 按照拼音排序的汉字表。
这里有几点要注意:
HanziToPinyin.java的表有不同,所以需要更新HanziToPinyin.java的表。(从Java转到JavaScript的最大的坑和工作量:更正边界表)const COLLATOR = new Intl.Collator(['zh-Hans-CN']),Intl.Collator(这里指定locale是**zh-Hans-CN)正是能把汉字按拼音排序的关键,它是按locale-specific顺序,排序字符串的Internationalization API。npm i full-icu,这个依赖会自动安装缺失的中文支持并提示如何指定ICU数据文件来执行脚本。ICUICU即International Components for Unicode,为应用提供Unicode和国际化支持。
ICU is a mature, widely used set of C/C++ and Java libraries providing Unicode and Globalization support for software applications. ICU is widely portable and gives applications the same results on all platforms and between C/C++ and Java software.
并且 ICU 提供了本地化字符串比较服务(Unicode Collation Algorithm + 本地特定的比较规则):
Collation: Compare strings according to the conventions and standards of a particular language, region or country. ICU's collation is based on the Unicode Collation Algorithm plus locale-specific comparison rules from the Common Locale Data Repository, a comprehensive source for this type of data.
想更深入了解的可以看http://site.icu-project.org/。但我们只需要知道node/chrome等等都是通过ICU来支持国际化,包括我们用到的根据本地惯例和规则去排序字符。
在现代浏览器上,一般ICU内置了对用户本地语言的支持,我们直接使用即可。
但对node.js来说,通常情况下,ICU只包含了一个子集(通常是英语),所以我们需要自行添加对中文的支持。一般来说,可以通过npm install full-icu安装full-icu来安装缺失的中文支持。(参见上面node --icu-data-dir=node_modules/full-icu)。
对full-icu,更多信息可查看full-icu-npm,以及一个讨论nodejs/node#3460。
同时,node ICU的跟多信息可查看https://github.com/nodejs/node/wiki/Intl。
Intl API上一小节应该基本讲清楚了国际化/本地化相关的知识,这里再补充一下内置API的使用。
Intl.Collator.supportedLocalesOf(array|string)返回包含支持(不用回退到默认locale)的locales的数组,参数可以是数组或字符串,为想要测试的locales(即BCP 47 language tag)。


通过Intl.Collator.prototype.compare,我们可以按语言指定的顺序来排序字符串。而中文中,这个排序恰好绝大多数都是按拼音的顺序来的,'A', 'AI', 'AN', 'ANG', 'AO', 'BA', 'BAI', 'BAN', 'BANG', 'BAO', 'BEI', 'BEN', 'BENG', 'BI', 'BIAN', 'BIAO', 'BIE', 'BIN', 'BING', 'BO', 'BU', 'CA', 'CAI', 'CAN', ...,这正是我们上面提到的汉字转拼音的关键。
使用与安卓代码相同的边界表,测试默认的常用汉字(6000+),得到结果如下:

显然,这个边界表是有问题的,需要更正。
我们可看到,大部分的汉字被转成了qing,可见,qing这个拼音对应的汉字有问题。
'\u72c5'/'狅',加上前后各一个字,['\u4eb2', '\u72c5', '\u828e']/["亲", "狅", "芎"]。'\u72c5'/'狅'可以读qing,但现在多读kuang,这应该就是错误的原因了。qing的第一个汉字是'\u9751'/'靑'。
整个更新过程即如上所属:不断测试,找出错误的边界汉字并更正。
tiny-pinyin 提交历史 可看到大量的字典修正,顺便帮常用汉字拼音字典(用于测试)更正了不少拼音,花了大约有一天工作时间,算是辛苦。
此外,可看到 Node.js 上 7.x/6.x 都测试通过了,但 5.x/4.x 部分汉字转换后的拼音存在问题。这可以通过为特定版本 Node.js 更正字典来解决。
最后,希望大家理解了本篇提到的汉字转拼音的原理,也欢迎大家为 tiny-pinyin 提问题。
今天遇到并讨论了一个CSS相关的问题,很有意思,并更正了我的某些错误概念。想以问答的形式记录下,发现只有 JavaScript问题集锦,于是干脆就新开了一个issue,以后所有的HTML与CSS相关问题都记录在这里。
此段为 朴灵 《深入浅出 Node.js》 阅读笔记。
在 V8 中,所有 JavaScript 的对象都是通过 堆来分配 的。
当我们在代码中声明变量并赋值时,所使用对象的内存就分配在堆中。如果已申请的堆空闲内存不够分配新的对象,将继续申请堆内存,直到堆大小超过V8的限制。
那为什么 V8 要限制堆大小?
V8 的垃圾回收策略主要基于 分代式垃圾回收 机制。因为实际应用中,对象的生存周期长短不一,不同的算法只针对特定情况有最好效果,所以现代垃圾回收算法中,按对象存活时间将内存的垃圾回收进行不同的分代,然后分别运用不同算法。
V8 主要将内存分为 新生代 和 老生代 两代。新生代中的对象为存活时间较短的对象,老生代中的对象为存活时间较长或常驻内存的对象。
新生代的对象主要通过 Scavenge 算法进行垃圾回收。而 Scavenge 的具体实现中,采用 Cheney 算法—— 一种采用复制方式实现的垃圾回收算法:
Scavenge 的缺点是只能使用堆内存的一半,但由于只复制存活对象,并且由于生命周期短的场景中存活对象只占少部分,所以它在时间效率上不错。
当一个对象经过多次复制依然存活时,它会被认为是生命周期较长的对象,会被移动到老生代中,采用新的算法进行管理。对象从新生代移动到老生代称为晋升。
不同于单纯的 Scavenge 过程,在分代式垃圾回收的前提下,From 空间的存活对象复制到 To 空间前需要进行检查:即是否可以晋升。
晋升的两个条件:
对于老生代,由于存活对象占比高,采用 Scavenge 会有两个问题:
所以老生代采用 Mark-Sweep 和 Mark-Compact 相结合的方式进行垃圾回收。
Mark-Sweep,即标记清除 ,分为标记和清除两个阶段。
相比 Scavenge ,Mark-Sweep 不存在浪费空间的行为,只清理死亡对象。
当 Mark-Sweep 最大的问题是在 进行一次标记清除回收后,内存空间会存在不连续的状态 。这种内存碎片会对后续的内存分配造成问题,因为很可能出现需要分配一个大对象的情况,这时所有的碎片空间都无法完成此次分配,就会提前触发垃圾回收,而这次垃圾回收是不必要的。
Mark-Compact 可以解决内存碎片的问题,Mark-Compact 是 标记整理 ,在 Mark-Sweep 基础上演变而来。它们的差别在于在标记后,在整理的过程中,将活着的对象向一端移动,移动完成后,直接清理掉边界外的内存。
为避免出现 JavaScript 应用逻辑与垃圾回收器看到的不一致的情况,以上 3 种垃圾回收算法都需要将应用逻辑暂停,执行回收后再运行——即全停顿(stop-the-world)。
为了降低全堆垃圾回收带来的停顿时间,V8 从标记阶段入手,将全量标记改为增量标记,垃圾回收与应用逻辑交替执行,直到标记阶段完成。
接手的项目是维护了很久的老项目,一个传统网站,后端是PHP,前端以PHP模板+jQuery为核心。项目后端代码文件结构还算清晰:
application
├── config
├── controllers
├── errors
├── helpers
├── models
├── service
├── third_party
└── views
└── page
├── index
├── user
└── weixin前端部分:
front
├── output
├── page
│ ├── index
│ ├── user
│ └── weixin
├── static
│ ├── index
│ │ └── img
│ ├── user
│ ├── util
│ └── weixin
└── widget
├── footer
│ └── img
├── header
│ └── img
├── layer
├── notice
│ └── img
└── pager目录树省略了部分,但已经可以看出来,各个文件夹按部就班,就是传统的PHP项目。
项目开发测试流程:前端模板部分编译到后端views文件夹;前端其它部分直接编译上传到CDN,同时输出一个静态资源表(json文件:本地路径到CDN路径的映射),这个JSON被fis利用来替换模板中的资源路径。
整体来说,对前端而言,这是一个以PHP模板为核心的传统网站项目,而其中的一些问题应该也是许多还在维护老代码同学碰到的共性问题,本文更多作为一个讨论贴,讨论怎么重构这样一类项目,改善开发体验,提高开发效率。
有句玩笑话叫“重构一时爽,....”,后面就不接了。实践中,尤其对业务线的前端同学,重构整个项目风险很大,可能也没有足够时间来设计规划和执行整个重构。
但是,要不要重构,其实是个权衡利弊的过程,当弊端真的很大时,下定决心重构是一条可选的路。
对我接手的项目而言:
首先项目以PHP模板为核心(可以理解为组织前端代码的核心/入口),JS/HTML/CSS散落不同文件夹,前后端耦合,开发体验极差。
当项目很简单时,后端模板的开发方式其实没什么可吐槽。但当项目足够复杂时,前后端耦合,相互依赖,甚至前端无法本地预览/测试功能(依赖公司内部PHP框架),那就简直是前端的噩梦。
同时,虽然看起来是遵循所谓结构、表现和行为分离的原则,JS/HTML/CSS放置在各自独立的文件夹,但当你添加一个功能时,需要查找和修改(不止)3处地方,开发体验真的不是很好。而组件化,模块化才是正确的道路(资源内聚/内敛更利于维护)。
前端以jQuery为主的技术栈。jQuery不是问题,但在大型项目里,数据驱动,专注数据(业务逻辑)是更好的方式。
DOM操作是必须的,但当你打开一个js文件,一大堆的$dom.on('xxx', handler),你肯定是崩溃的。尤其后面维护的同学要理清里面的逻辑不是那么容易的。
同时项目中全局对象滥用,或者说依赖不清晰现象严重。一个JS中突然出现的全局变量你可能根本不知道它是怎么出现的,因为JS都是通过script标签引入的,你不知道哪个JS突然暴露了全局变量。
CSS的问题。CSS的重复和全局冲突比较多。
冗余/废弃却未清理的代码等等。
总的来说,这个项目就像是个黑盒,不论是添加功能还是维护,都是比较痛苦。
其实现有的React/Vue/Angular都没问题,但考虑到其他同学对框架的熟悉问题,学习曲线等等,最终选择了Vue.js。
题外话,React/Vue/Angular 三大框架互相学习进步,整体上没有大的短板了,选择哪个都可以。其中,React以JS为核心,JSX格外强大且不影响UI的声明式表达。Vue追求平衡中庸,追求符合规范,但是模板语法有时用得并不顺手(虽然可以借助工具用JSX来写)。
步子太大容易扯着蛋,本次重构的第一原则是逐步进行,最大化利用原有代码/工具等等,首先解除原有开发的最大痛点,以改善开发体验为主。
新页面用Vue实现,旧页面在迭代中逐渐改用Vue,新旧页面相互跳转;暂时不使用vue-router,保留后端路由。
暂时保留后端模板,但禁止使用include或者fis的inline指令,同时注入的数据集中在一处,通过js挂载到全局对象,尽量不使用php模板语法:
<!DOCTYPE html>
<html lang="zh-cn-hans">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<meta http-equiv="X-UA-Compatible" content="ie=edge">
<title>title</title>
---
css
---
<script>
window.DATA = {
// data here
}
</script>
</head>
<body>
<div id="app"></div>
---
script
---
</body>
</html>添加与front同级的目录vue-front,新代码都放在这里。这里的结构可以参考vue-cli给出的样例代码。开发时mock数据window.DATA即可(开发完全脱离PHP),编译时输出静态资源(JS/CSS),资源上传到CDN,输出map文件合并到application相应文件。同时,vue-front/pages文件夹里编写相应的后端模板,编译时直接拷贝到application/views。
首先产出重要公共组件:Header(Logo+头部主菜单+用户管理),Menu(左侧子菜单),Footer(版权/帮助/数据统计等),Container(内容容器,处理尺寸自适应等等)。
CSS/JS的问题。
[email protected]。数据处理的问题。
待补充/改正
对程序员来说,持续学习是很重要的。这里记录一些(未/待)读完的高质量文章/视频。
尽量敦促自己每周至少读完一篇。
| 时间 | 标题(含链接) | 描述 | 形式 | 时长 | 进度 |
|---|---|---|---|---|---|
| 2018/12/05 | A Quest to Guarantee Responsiveness: Scheduling On and Off the Main Thread (Chrome Dev Summit 2018) | 提高app的可响应性:通过scheduler以及worker | video | 35分钟 | ✅ |
| 2018/12/28 | 应对流量劫持,前端能做哪些工作? - 小爝的回答 - 知乎 | 流量劫持 1)监控:应用sri触发error,上报劫持内容 2)解决:脚本URL不加js后缀 |
article | 5分钟 | ✅ |
| 2018/12/31 | ES modules: A cartoon deep-dive | ES module入门 | article | 30分钟 | ✅ |
| 2019/01/15 | Things I Don’t Know as of 2018 | 大神也有不懂的地方,但是,在专注之余多了解一下其它领域没什么不好 | article | 3分钟 | ✅ |
| 2019/01/31 | Architecting your React application. The development and business perspective of what to be aware of | React应用开发的一些思考 | article | 8分钟 | ✅ |
| 2019/02/13 | Webpack 5.0 changelog | Webpack 5.0的新变化,可以先看起来了 | article | 15分钟 | |
| 2019/02/14 | Making Sense of React Hooks | Dan Abramov亲自解释了React Hooks的缘起、概念、简单使用和效果,对hooks还没概念的同学可以用十几分钟有个初步了解 | article | 18分钟 | ✅ |
| 2019/02/18 | 资源优先级 – 让浏览器助您一臂之力 | preload/preconnect/prefetch三者的用法 |
article | 5分钟 | ✅ |
| 2019/03/15 | JavaScript Performance Pitfalls in V8 | V8性能优化的两个tips 1)函数对应的字节码不要超过60KB(超过则放弃优化),最好分解为多个小函数 2)JS值的存储形式,及相关 Smi/HeapObject 等对应的优化 |
article | 30分钟 | ✅ |
| 2019/03/31 | Experimenting with the Streams API | 浏览器 stream API 了解下 | article | 8分钟 | ✅ |
| 2019/04/24 | Base64 encoding and decoding | JS实现base64编解码的几种方法(支持unicode) | article | 10分钟 | ✅ |
| 2019/07/15 | QuickJS Javascript Engine | 完整JS引擎的C实现(更小,只有利于嵌入使用的一些C文件,无其它依赖,相对V8性能差一点) | -- | -- | -- |
| 2019/08/01 | How do JavaScript’s global variables really work? | 介绍了JS的作用域链,尤其是 global environment 的机制(object record + declarative record ) |
article | 5分钟 | ✅ |
| 2019/09/23 | atomic design | atomic design 介绍,一种 UI设计体系 | article | 15分钟 | ✅ |
这个issue试图阐述JavaScript这门语言的3个难点:声明提升、作用域(链)和this。
首先推荐https://github.com/getify/You-Dont-Know-JS,这是一本非常棒的JavaScript书籍,几乎所有的JS知识点都包括并且详细解释了。看一遍相信必有大收获。
大部分编程语言都是先声明变量再使用,但在JS中,事情有些不一样:
console.log(a); // undefined
var a = 1;上面是合法的JS代码,正常输出undefined而不是报错Uncaught ReferenceError: a is not defined。为什么?就是因为声明提升(hoisting)。
参考:https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Statements/var
语法:
var varname1 [= value1 [, varname2 [, varname3 ... [, varnameN]]]];变量名可以是任意合法标识符;值可以是任意合法表达式。
重点:
var声明的变量的作用域就是当前执行上下文(execution context),即某个函数,或者全局作用域(声明在函数外)。声明变量和未声明变量的区别:
在es5 strict mode,赋值给未声明的变量将报错。
定义一个函数有两种方式:函数声明(function definition/declaration/statement)和函数表达式( function expression)。
语法:function name(arguments) {}
对参数而言,primitive parameter是传值,对象是传引用。
语法:var fun = function (arguments) {}
函数表达式中函数可以不需要名字,即匿名函数。
还可以用 Function构造函数来创建函数。
在函数内部引用函数本身有3种方式。比如var foo = function bar(){};
bar()arguments.callee()foo()1.1提到,var 声明的变量会在任意代码执行前处理,这意味着在任意地方声明变量都等同于在顶部声明——即声明提升。1.2特意强调了函数定义,因为声明提升中,需要综合考虑一般变量和函数。
在JavaScript中,一个变量名进入作用域的方式有 4 种:
this 和 arguments 两个变量名(global没有arguments);function foo() {};var foo,包括_函数表达式_。函数声明和变量声明总是会被移动(即hoist)到它们所在的作用域的顶部(这对你是透明的)。
而变量的解析顺序(优先级),与变量进入作用域的4种方式的顺序一致。
一个详细的例子:
function testOrder(arg) {
console.log(arg); // arg是形参,不会被重新定义
console.log(a); // 因为函数声明比变量声明优先级高,所以这里a是函数
var arg = 'hello'; // var arg;变量声明被忽略, arg = 'hello'被执行
var a = 10; // var a;被忽视; a = 10被执行,a变成number
function a() {
console.log('fun');
} // 被提升到作用域顶部
console.log(a); // 输出10
console.log(arg); // 输出hello
};
testOrder('hi');
/* 输出:
hi
function a() {
console.log('fun');
}
10
hello
*/就标题而言,这是七八篇里起得最满意的,高大上,即使外行人也会不明觉厉! 😂
不过不是开玩笑,本文的确打算从__proto__和prototype这两个容易混淆来理解JS的终极命题之一:对象与原型链。
__proto__和prototype__proto__引用《JavaScript权威指南》的一段描述:
Every JavaScript object has a second JavaScript object (or null ,
but this is rare) associated with it. This second object is known as a prototype, and the first object inherits properties from the prototype.
翻译出来就是每个JS对象一定对应一个原型对象,并从原型对象继承属性和方法。好啦,既然有这么一个原型对象,那么对象怎么和它对应的?
对象__proto__属性的值就是它所对应的原型对象:
var one = {x: 1};
var two = new Object();
one.__proto__ === Object.prototype // true
two.__proto__ === Object.prototype // true
one.toString === one.__proto__.toString // true上面的代码应该已经足够解释清楚__proto__了:grin:。好吧,显然还不够,或者说带来了新的问题:Object.prototype是什么?凭什么说one和two的原型就是Object.prototype?
prototype首先来说说prototype属性,不像每个对象都有__proto__属性来标识自己所继承的原型,只有函数才有prototype属性。
为什么只有函数才有prototype属性?ES规范就这么定的。
开玩笑了,其实函数在JS中真的很特殊,是所谓的_一等公民_。JS不像其它面向对象的语言,它没有类(class,ES6引进了这个关键字,但更多是语法糖)的概念。JS通过函数来模拟类。
当你创建函数时,JS会为这个函数自动添加prototype属性,值是空对象 值是一个有 constructor 属性的对象,不是空对象。而一旦你把这个函数当作构造函数(constructor)调用(即通过new关键字调用),那么JS就会帮你创建该构造函数的实例,实例继承构造函数prototype的所有属性和方法(实例通过设置自己的__proto__指向承构造函数的prototype来实现这种继承)。
虽然对不熟悉的人来说还有点绕,但JS正是通过__proto__和prototype的合作实现了原型链,以及对象的继承。
构造函数,通过prototype来存储要共享的属性和方法,也可以设置prototype指向现存的对象来继承该对象。
对象的__proto__指向自己构造函数的prototype。obj.__proto__.__proto__...的原型链由此产生,包括我们的操作符instanceof正是通过探测obj.__proto__.__proto__... === Constructor.prototype来验证obj是否是Constructor的实例。
回到开头的代码,two = new Object()中Object是构造函数,所以two.__proto__就是Object.prototype。至于one,ES规范定义对象字面量的原型就是Object.prototype。
我们知道JS是单继承的,Object.prototype是原型链的顶端,所有对象从它继承了包括toString等等方法和属性。
Object本身是构造函数,继承了Function.prototype;Function也是对象,继承了Object.prototype。这里就有一个_鸡和蛋_的问题:
Object instanceof Function // true
Function instanceof Object // true什么情况下会出现鸡和蛋的问题呢?就是声明一个包含所有集合的集合啊!好了,你们知道这是罗素悖论,但并不妨碍PL中这样设计。
那么具体到JS,ES规范是怎么说的?
Function本身就是函数,
Function.__proto__是标准的内置对象Function.prototype。
Function.prototype.__proto__是标准的内置对象Object.prototype。
Update: 图片来自 mollypages.org
相信经过上面的详细阐述,这张图应该一目了然了。
Function.prototype和Function.__proto__都指向Function.prototype,这就是鸡和蛋的问题怎么出现的。Object.prototype.__proto__ === null,说明原型链到Object.prototype终止。伴随 React 兴起, Virtual DOM 也越来越火,各种各样的实现,各个 UI 库的引入等等。snabbdom 就是 Virtual DOM 的一个简洁实现。不过在解读 snabbdom 之前,首先谈一谈 Virtual DOM 。
在谈论 Virtual DOM 之前,必须要理解:什么是 DOM ?
DOM 即 Document Object Model,是一种 通过对象表示结构化文档的方式 。DOM 是跨平台的,也是语言无关的(比如 HTML 和 XML 都可以用它表示与操作)。浏览器处理 DOM 的实现细节,然后我们可以通过 JavaScript 和 CSS 来与它交互。
DOM 的主要问题是没有为创建动态 UI 而优化。
以前直接使用 DOM API 比较繁琐,然后有了 jQuery 等库来简化 DOM 操作;但这没有解决大量 DOM 操作的性能问题。大型页面/单页应用里动态创建/销毁 DOM 很频繁(尤其现在前端渲染的普遍),我们当然可以用各种 trick 来优化性能,但这太痛苦了。
而 Virtual DOM 就是解决问题的一种探索。
Virtual DOM 建立在 DOM 之上,是基于 DOM 的一层抽象,实际可理解为用更轻量的纯 JavaScript 对象(树)描述 DOM(树)。
操作 JavaScript 对象当然比操作 DOM 快,因为不用更新屏幕。我们可以随意改变 Virtual DOM ,然后找出改变再更新到 DOM 上。但要保证高效,需要解决以下问题:
带着这些问题,我们进入正题:以 snabbdom 为例,讲讲怎么实现一个 Virtual DOM 库。
snabbdom 的 ES6 改写代码可在 codes/snabbdom 浏览,有 id/className 处理等的小改动,但核心流程完全一致。
代码结构:
src
├── domApi.js # dom api,主要是各种 DOM 操作的包装,快速浏览即可。
├── export.js # export,决定暴露什么接口给调用者,可忽略。
├── h.js # `h()`帮助函数,很简单。
├── index.js # 核心代码,Virtual DOM 的 diff 实现,从 Virtual DOM 构建 DOM 等等。
├── modules # 各个模块,主要负责属性处理。
│ ├── class.js
│ ├── props.js
│ └── style.js
├── utils.js # util 函数。
└── vnode.js # vnode 定义和一些相关函数。snabbdom 是轻量的 Virtual DOM 实现,代码量少,模块化,结构清晰。这是我选择 snabbdom 作为源码阅读目标的主要原因。
snabbdom 主要的接口有:
h(type, data, children),返回 Virtual DOM 树。patch(oldVnode, newVnode),比较新旧 Virtual DOM 树并更新。从两个接口开始,下面我们深入讲解 snabbdom 的实现。
怎么实现 Virtual DOM ?我们首先要定义 Virtual DOM,或者具体点,定义一个 Virtual DOM 节点:vnode。
vnode.jsvnode 是对 DOM 节点的抽象,既然如此,我们很容易定义它的形式:
{
type, // String,DOM 节点的类型,如 'div'/'span'
data, // Object,包括 props,style等等 DOM 节点的各种属性
children // Array,子节点(子 vnode)
}对应源代码src/vnode.js:
const VNODE_TYPE = Symbol('virtual-node')
function vnode(type, key, data, children, text, elm) {
const element = {
__type: VNODE_TYPE,
type, key, data, children, text, elm
}
return element
}
function isVnode(vnode) {
return vnode && vnode.__type === VNODE_TYPE
}
function isSameVnode(oldVnode, vnode) {
return oldVnode.key === vnode.key && oldVnode.type === vnode.type
}代码几乎一眼就懂,有三点注意下:
构造 vnode 时内置了 __type,值为 symbol 。利用 symbol 的唯一性来校验 vnode。
vnode 的 children/text 二选一,不可共存。那为什么不把 text 视为 children 的一个元素 ?主要是方便处理,text 节点和其它类型的节点处理起来差异很大。
elm 用于保存 vnode 对应 DOM 节点。isSameVnode 检查两个 vnode 是否 相同。这里的相同是指后一个 vnode 是否由之前的 vnode 变换而来,要求 type 相同且 key 相同:
div 变到 p,那么 vnode 对应的 DOM 则必须整个替换掉了;h.js定义了 vnode 的格式,那么我们可以组合 vnode 得到一颗 Virtual DOM 树了。h 函数就是来帮我们生成虚拟 DOM 树的。
源代码src/h.js:
function h(type, config, ...children) {
const props = {}
// 省略用 config 填充 props 的过程
return vnode(
type,
key,
props,
flattenArray(children).map(c => {
return isPrimitive(c) ? vnode(undefined, undefined, undefined, undefined, c) : c
})
)
}如上,有一点可以注意:参数 children 既可以是 Array,也可以是 vnode,甚至是字符串。如果是字符串自动转换成 vnode(该 vnode 的 text 即该字符串)。
多数情况下,或者说要有更好的开发体验,我们应该支持 JSX 或类似的语法,然后通过 babel 插件转换成 h 的函数调用。鉴于本文主题是怎么实现 Virtual DOM,这里就不展开了。
index.js现在进入 snabbdom 的核心,来讲 Virtual DOM 必须实现的两个功能:
从简单的开始,先讲怎么从 vnode 生成 DOM:
function createElm(vnode, insertedVnodeQueue) {
let data = vnode.data
let i
// 省略 hook 调用
let children = vnode.children
let type = vnode.type
/// 根据 type 来分别生成 DOM
// 处理 comment
if (type === 'comment') {
if (vnode.text == null) {
vnode.text = ''
}
vnode.elm = api.createComment(vnode.text)
}
// 处理其它 type
else if (type) {
const elm = vnode.elm = data.ns
? api.createElementNS(data.ns, type)
: api.createElement(type)
// 调用 create hook
for (let i = 0; i < cbs.create.length; ++i) cbs.create[i](emptyNode, vnode)
// 分别处理 children 和 text。
// 这里隐含一个逻辑:vnode 的 children 和 text 不会/应该同时存在。
if (isArray(children)) {
// 递归 children,保证 vnode tree 中每个 vnode 都有自己对应的 dom;
// 即构建 vnode tree 对应的 dom tree。
children.forEach(ch => {
ch && api.appendChild(elm, createElm(ch, insertedVnodeQueue))
})
}
else if (isPrimitive(vnode.text)) {
api.appendChild(elm, api.createTextNode(vnode.text))
}
// 调用 create hook;为 insert hook 填充 insertedVnodeQueue。
i = vnode.data.hook
if (i) {
i.create && i.create(emptyNode, vnode)
i.insert && insertedVnodeQueue.push(vnode)
}
}
// 处理 text(text的 type 是空)
else {
vnode.elm = api.createTextNode(vnode.text)
}
return vnode.elm
}上面的代码并不复杂,也不应该复杂,因为 Virtual DOM 是对 DOM 的抽象,是描述,从 Virtual DOM 生成 DOM 本来就应该是直接简明的:根据 type 生成对应的 DOM,把 data 里定义的 各种属性设置到 DOM 上。
当然这里隐藏了一些复杂性,比如 style 处理,比如边缘情况处理等等。
接下来讲怎么 diff 两颗 Virtual DOM 树,并执行最小更新。
通常情况下,找到两棵任意的树之间最小修改的时间复杂度是 O(n^3),这不可接受。幸好,我们可以对 Virtual DOM 树有这样的假设:
如果 oldVnode 和 vnode 不同(如 type 从 div 变到 p,或者 key 改变),意味着整个 vnode 被替换(因为我们通常不会去跨层移动 vnode ),所以我们没有必要去比较 vnode 的 子 vnode(children) 了。基于这个假设,我们可以 按照层级分解 树,这大大简化了复杂度,大到接近 O(n) 的复杂度:

此外,对于 children (数组)的比较,因为同层是很可能有移动的,顺
序比较会无法最大化复用已有的 DOM。所以我们通过为每个 vnode 加上 key 来追踪这种顺序变动。

原理分析完,上代码:
function patchVnode(oldVnode, vnode, insertedVnodeQueue) {
// 因为 vnode 和 oldVnode 是相同的 vnode,所以我们可以复用 oldVnode.elm。
const elm = vnode.elm = oldVnode.elm
let oldCh = oldVnode.children
let ch = vnode.children
// 如果 oldVnode 和 vnode 是完全相同,说明无需更新,直接返回。
if (oldVnode === vnode) return
// 调用 update hook
if (vnode.data) {
for (i = 0; i < cbs.update.length; ++i) cbs.update[i](oldVnode, vnode)
}
// 如果 vnode.text 是 undefined
if (vnode.text === undefined) {
// 比较 old children 和 new children,并更新
if (oldCh && ch) {
if (oldCh !== ch) {
// 核心逻辑(最复杂的地方):怎么比较新旧 children 并更新,对应上面
// 的数组比较
updateChildren(elm, oldCh, ch, insertedVnodeQueue)
}
}
// 添加新 children
else if (ch) {
// 首先删除原来的 text
if (oldVnode.text) api.setTextContent(elm, '')
// 然后添加新 dom(对 ch 中每个 vnode 递归创建 dom 并插入到 elm)
addVnodes(elm, null, ch, 0, ch.length - 1, insertedVnodeQueue)
}
// 相反地,如果原来有 children 而现在没有,那么我们要删除 children。
else if (oldCh) {
removeVnodes(elm, oldCh, 0, oldCh.length - 1);
}
// 最后,如果 oldVnode 有 text,删除。
else if (oldVnode.text) {
api.setTextContent(elm, '');
}
}
// 否则 (vnode 有 text),只要 text 不等,更新 dom 的 text。
else if (oldVnode.text !== vnode.text) {
api.setTextContent(elm, vnode.text)
}
}
function updateChildren(parentElm, oldCh, newCh, insertedVnodeQueue) {
let oldStartIdx = 0, newStartIdx = 0
let oldEndIdx = oldCh.length - 1
let oldStartVnode = oldCh[0]
let oldEndVnode = oldCh[oldEndIdx]
let newEndIdx = newCh.length - 1
let newStartVnode = newCh[0]
let newEndVnode = newCh[newEndIdx]
let oldKeyToIdx
let idxInOld
let elmToMove
let before
// 遍历 oldCh 和 newCh 来比较和更新
while (oldStartIdx <= oldEndIdx && newStartIdx <= newEndIdx) {
// 1⃣️ 首先检查 4 种情况,保证 oldStart/oldEnd/newStart/newEnd
// 这 4 个 vnode 非空,左侧的 vnode 为空就右移下标,右侧的 vnode 为空就左移 下标。
if (oldStartVnode == null) {
oldStartVnode = oldCh[++oldStartIdx]
} else if (oldEndVnode == null) {
oldEndVnode = oldCh[--oldEndIdx]
} else if (newStartVnode == null) {
newStartVnode = newCh[++newStartIdx]
} else if (newEndVnode == null) {
newEndVnode = newCh[--newEndIdx]
}
/**
* 2⃣️ 然后 oldStartVnode/oldEndVnode/newStartVnode/newEndVnode 两两比较,
* 对有相同 vnode 的 4 种情况执行对应的 patch 逻辑。
* - 如果同 start 或同 end 的两个 vnode 是相同的(情况 1 和 2),
* 说明不用移动实际 dom,直接更新 dom 属性/children 即可;
* - 如果 start 和 end 两个 vnode 相同(情况 3 和 4),
* 那说明发生了 vnode 的移动,同理我们也要移动 dom。
*/
// 1. 如果 oldStartVnode 和 newStartVnode 相同(key相同),执行 patch
else if (isSameVnode(oldStartVnode, newStartVnode)) {
// 不需要移动 dom
patchVnode(oldStartVnode, newStartVnode, insertedVnodeQueue)
oldStartVnode = oldCh[++oldStartIdx]
newStartVnode = newCh[++newStartIdx]
}
// 2. 如果 oldEndVnode 和 newEndVnode 相同,执行 patch
else if (isSameVnode(oldEndVnode, newEndVnode)) {
// 不需要移动 dom
patchVnode(oldEndVnode, newEndVnode, insertedVnodeQueue)
oldEndVnode = oldCh[--oldEndIdx]
newEndVnode = newCh[--newEndIdx]
}
// 3. 如果 oldStartVnode 和 newEndVnode 相同,执行 patch
else if (isSameVnode(oldStartVnode, newEndVnode)) {
patchVnode(oldStartVnode, newEndVnode, insertedVnodeQueue)
// 把获得更新后的 (oldStartVnode/newEndVnode) 的 dom 右移,移动到
// oldEndVnode 对应的 dom 的右边。为什么这么右移?
// (1)oldStartVnode 和 newEndVnode 相同,显然是 vnode 右移了。
// (2)若 while 循环刚开始,那移到 oldEndVnode.elm 右边就是最右边,是合理的;
// (3)若循环不是刚开始,因为比较过程是两头向中间,那么两头的 dom 的位置已经是
// 合理的了,移动到 oldEndVnode.elm 右边是正确的位置;
// (4)记住,oldVnode 和 vnode 是相同的才 patch,且 oldVnode 自己对应的 dom
// 总是已经存在的,vnode 的 dom 是不存在的,直接复用 oldVnode 对应的 dom。
api.insertBefore(parentElm, oldStartVnode.elm, api.nextSibling(oldEndVnode.elm))
oldStartVnode = oldCh[++oldStartIdx]
newEndVnode = newCh[--newEndIdx]
}
// 4. 如果 oldEndVnode 和 newStartVnode 相同,执行 patch
else if (isSameVnode(oldEndVnode, newStartVnode)) {
patchVnode(oldEndVnode, newStartVnode, insertedVnodeQueue)
// 这里是左移更新后的 dom,原因参考上面的右移。
api.insertBefore(parentElm, oldEndVnode.elm, oldStartVnode.elm)
oldEndVnode = oldCh[--oldEndIdx]
newStartVnode = newCh[++newStartIdx]
}
// 3⃣️ 最后一种情况:4 个 vnode 都不相同,那么我们就要
// 1. 从 oldCh 数组建立 key --> index 的 map。
// 2. 只处理 newStartVnode (简化逻辑,有循环我们最终还是会处理到所有 vnode),
// 以它的 key 从上面的 map 里拿到 index;
// 3. 如果 index 存在,那么说明有对应的 old vnode,patch 就好了;
// 4. 如果 index 不存在,那么说明 newStartVnode 是全新的 vnode,直接
// 创建对应的 dom 并插入。
else {
// 如果 oldKeyToIdx 不存在,创建 old children 中 vnode 的 key 到 index 的
// 映射,方便我们之后通过 key 去拿下标。
if (oldKeyToIdx === undefined) {
oldKeyToIdx = createKeyToOldIdx(oldCh, oldStartIdx, oldEndIdx)
}
// 尝试通过 newStartVnode 的 key 去拿下标
idxInOld = oldKeyToIdx[newStartVnode.key]
// 下标不存在,说明 newStartVnode 是全新的 vnode。
if (idxInOld == null) {
// 那么为 newStartVnode 创建 dom 并插入到 oldStartVnode.elm 的前面。
api.insertBefore(parentElm, createElm(newStartVnode, insertedVnodeQueue), oldStartVnode.elm)
newStartVnode = newCh[++newStartIdx]
}
// 下标存在,说明 old children 中有相同 key 的 vnode,
else {
elmToMove = oldCh[idxInOld]
// 如果 type 不同,没办法,只能创建新 dom;
if (elmToMove.type !== newStartVnode.type) {
api.insertBefore(parentElm, createElm(newStartVnode, insertedVnodeQueue), oldStartVnode.elm)
}
// type 相同(且key相同),那么说明是相同的 vnode,执行 patch。
else {
patchVnode(elmToMove, newStartVnode, insertedVnodeQueue)
oldCh[idxInOld] = undefined
api.insertBefore(parentElm, elmToMove.elm, oldStartVnode.elm)
}
newStartVnode = newCh[++newStartIdx]
}
}
}
// 上面的循环结束后(循环条件有两个),处理可能的未处理到的 vnode。
// 如果是 new vnodes 里有未处理的(oldStartIdx > oldEndIdx
// 说明 old vnodes 先处理完毕)
if (oldStartIdx > oldEndIdx) {
before = newCh[newEndIdx+1] == null ? null : newCh[newEndIdx+1].elm
addVnodes(parentElm, before, newCh, newStartIdx, newEndIdx, insertedVnodeQueue)
}
// 相反,如果 old vnodes 有未处理的,删除 (为处理 vnodes 对应的) 多余的 dom。
else if (newStartIdx > newEndIdx) {
removeVnodes(parentElm, oldCh, oldStartIdx, oldEndIdx)
}
}到这里讲完了 snabbdom 的核心实现,可以发现,Virtual DOM 比我们想的会简单一点。
本篇限于篇幅,代码肯定不会贴全,想看完整代码的可以去官方或者我用 ES6 改写的仓库。
题外话,本篇作为 React学习笔记 系列的第二篇,可结合 #30 一起观看。
这是浏览器的工作原理:新式网络浏览器幕后揭秘(英文)/(中文)的阅读笔记。尽量精简原文章,方便回忆和复习相关概念。
十分推荐阅读原文(原文应该非常有名),这里只是自用的笔记和归纳~
浏览器的主要组件为:
渲染引擎负责渲染——即渲染HTML/XML文档或者图片(通过插件可以渲染PDF等等)。渲染引擎有
浏览器从网络层获取请求的文档内容,然后开始渲染流程:
注意,渲染过程是渐进式的。浏览器会尽早展示文档内容,即不会在所有HTML文档解析完成后才会去构建render tree,而是部分内容被解析和展示,并继续解析和展示剩下的。
对chrome而言,渲染的具体流程是
对firefox而言,
script 是同步的
web模型一直是同步的,即网页作者希望引擎遇到<script>标签时可以立即解析并执行——停止解析HTML,执行脚本(如果是外部脚本,先下载)。可以用defer属性指定脚本是异步的——不会停止文档解析,在文档解析完成后执行。
Speculative parsing(预解析)
当执行脚本时,其它线程会解析剩下的文档,找出里面的外部资源(script/style/img)来提前加载(可以并行加载)。这种解析只是去查找需要加载的外部资源,不会修改content tree。
所以我们可以看到多个外部资源并行下载。
样式
样式表有不同的模型。理论上,样式表不会更改 DOM tree,似乎没有必要等待样式表并停止文档解析。但有个问题,如果在文档解析阶段,脚本访问样式信息怎么办?Firefox会在脚本加载和解析阶段禁止所有的脚本;对于 WebKit 而言,仅当脚本尝试访问的样式属性可能受尚未加载的样式表影响时,它才会禁止该脚本。
这就是为什么推荐样式放在<head>里而脚本放在<body>底部。
构建 DOM tree的同时,浏览器还会构建另一个树:渲染树(render tree)。这是由可视化元素按照其显示顺序而组成的树,也是文档的可视化表示。它的作用是保证按照正确的顺序来绘制内容。
渲染树的每个节点(renderer)代表一个矩形区域——对应DOM元素的CSS Box。
renderer 和 DOM元素对应,但非一一对应。比如display:none的元素没有对应的renderer;比如select对应3个renderer(display area/drop down list box /button)。另外,根据css spec,一个inline元素只能包含一个block元素或者多个inline元素,如果不符规则,就会创建anonymous block renderer。
有些 renderers 与对应的 DOM 节点,在各自树中的位置不同。比如浮动定位和绝对定位的元素,它们在normal flow之外,放置在树的其它地方,并映射到真正的renderer,而放在原位的是placeholder renderer。
WebKit 使用一个标记来表示是否所有的顶级样式表(包括 @imports)均已加载完毕。如果在attaching(DOM+CSSOM --> Render tree)过程中样式尚未完全加载,则使用占位符,并在文档中进行标注,等样式表加载完毕后再重新计算。
renderer在创建完成并添加到render tree时,并不包含 位置和大小 信息。计算这些值的过程称为布局或重排(Layout/Reflow)。
HTML 采用基于流的布局模型,这意味着大多数情况下只要一次遍历就能计算出几何信息。处于流中靠后位置元素通常不会影响靠前位置元素的几何特征,因此布局可以按从左至右、从上至下的顺序遍历文档。
为避免对所有细小更改都进行整体布局,浏览器采用了一种“dirty 位”系统。如果renderer有更改,或者其自身及其children被标注为“dirty”——则需要进行布局。
有两种标记:“dirty”和“children are dirty”。“children are dirty”表示renderer自身没有变化,但它的children需要布局。
全局布局是指触发了整个render tree的布局,触发原因可能包括:
布局可以采用增量方式,也就是只对 dirty 的 renderer 进行布局(这样可能存在需要进行额外布局的弊端)。
当renderer为 dirty 时,触发增量布局(异步)。例如,当来自网络的额外内容添加到 DOM 树之后,新的renderer附加到了render tree中。
增量布局是异步执行的。
请求样式信息(如“offsetHeight”)的脚本可触发同步增量布局。
全局布局往往是同步执行的。
有时,当初始布局完成之后,如果一些属性(如滚动位置)发生变化,布局就会作为回调而触发。
布局过程通常如下:
父renderer确定自己的宽度。
父renderer依次处理子renderer,并且:
父renderer根据子renderer的累加高度以及边距和补白的高度来设置自身高度,此值也可供父renderer的父renderer使用。
将其 dirty 位设置为 false。
renderer宽度是根据容器块(container block)的宽度、renderer样式中的“width”属性以及边距和边框计算得出的。
如果renderer在布局过程中需要换行,会立即停止布局,并告知其父renderer需要换行。父renderer会创建额外的renderer,并对其调用布局。
在绘制阶段,会遍历render tree,并调用renderer的“paint”方法,将renderer的内容显示在屏幕上。绘制工作是使用用户界面基础组件(UI infrastructure component)完成的。
和布局一样,绘制也分为全局(绘制整个render tree)和增量两种。在增量绘制中,部分renderer发生了更改,但是不会影响整个树。更改后的renderer将其在屏幕上对应的矩形区域设为无效,这导致 OS 将其视为一块“dirty 区域”,并生成“paint”事件。OS 会很巧妙地将多个区域合并成一个。
CSS2 defines the order of the painting process. This is actually the order in which the elements are stacked in the stacking contexts. This order affects painting since the stacks are painted from back to front.
block renderer的堆栈顺序是:
在发生变化时,浏览器会尽可能做出最小的响应。比如元素的颜色改变后,只会对该元素进行重绘。元素的位置改变后,只会对该元素及其子元素(可能还有同级元素)进行布局和重绘。添加 DOM 节点后,会对该节点进行布局和重绘。
一些重大变化(例如增大“html”元素的字体)会导致缓存无效,使得整个render tree都会进行重新布局和绘制。
结合整个render tree构建和lauout,paint阶段,可以去思考怎么减少relayout/repaint。
渲染引擎是单线程的。几乎所有操作(除了网络操作)都是在单线程中进行的。在 Firefox 和 Safari 中,该线程就是浏览器的主线程。而在 Chrome 浏览器中,该线程是tab进程的主线程。
网络操作可由多个线程并行执行。并行连接数是有限的(通常为 2~6 个)。
The browser main thread is an event loop. It's an infinite loop that keeps the process alive. It waits for events (like layout and paint events) and processes them.
这里可配合 #21 阅读,结合上面一小段,可展开讨论下。
在浏览器的具体实现里,浏览器内核(渲染进程)是多线程的。其中最重要的线程有(Blink 为例):
GUI线程,即本章所讲的渲染引擎线程,负责解析HTML/CSS,构建DOM tree和 render tree,布局和绘制等。
页面第一次展示,或者需要重绘(repaint)或由于某种操作引发回流(reflow)时,该线程运行。
JS线程,即JS引擎线程,负责解析JavaScript脚本,运行代码。JS引擎一直等待着任务队列中任务的到来,然后执行。
一个Tab页(渲染进程)中无论什么时候都只有一个JS线程在运行——JS是单线程的。
主线程,包括GUI+JS。所有的 JS 执行,HTML 解析和 DOM 构造,CSS 解析和计算得到 computed style,Layout,Paint(主要是决定 paint order,最终layer tree 和 paint order信息提交到 compositor 线程完成最终绘制) 等等。
其它线程,包括 worker 的,Blink 和 V8 创建的内部使用的线程(比如处理 webaudio、database)等等。
GUI线程和JS线程是互斥的(因为JavaScript可操纵DOM)。这就是为什么JS长时间运行会导致浏览器失去响应。 具体信息可参考 @starliiit 评论(和相关链接)。
JSON Web Tokens are an open, industry standard RFC 7519 method for representing claims securely between two parties.
JWT 是一个基于 JSON 的开放标准(RFC 7519),用于创建访问 token。
A JSON Web Token (JWT) is a JSON object that is defined in RFC 7519 as a safe way to represent a set of information between two parties. The token is composed of a header, a payload, and a signature.
简单来说,一个 JWT 就是一个字符串,形式如下:
header.payload.signature
如图所示,存在3个角色:authentication server (登录/授权服务器),user(用户),app server (应用服务器)。
可以看到,这是一套无状态的验证机制,不必在内存中保存用户状态。用户访问时自带 JWT,无需像传统应用使用 session,应用可以做到更多的解耦和扩展。同时,JWT 可以保存用户的数据,减少数据库访问。
JWT 的 header 部分包含怎么计算 signature 的信息。
{
"typ": "JWT", // 表明是 JWT
"alg": "HS256" // 代表生成 signature 所用的哈希算法,这里是 HMAC-SHA256
}JWT 的 payload 部分即 JWT 所带的数据。
比如我们这里存储了用户 ID:
{
"userId": "b08f86af-35da-48f2-8fab-cef3904660bd"
}你可以在 payload 里存储大量信息,但大量信息会降低性能,增加延迟。
把 header 和 payload 分别 base64 编码(两个对象已 JSON.stringify 转为字符串)后,通过 . 相加,然后用之前指定的哈希算法计算,即可得到 signature。
// signature algorithm
data = base64urlEncode( header ) + “.” + base64urlEncode( payload )
signature = Hash( data, secret );把 header,payload 和 signature 用 . 相连即最终的 JWT token。
header.payload.signature
// header 是 eyJ0eXAiOiJKV1QiLCJhbGciOiJIUzI1NiJ9
// payload 是 eyJ1c2VySWQiOiJiMDhmODZhZi0zNWRhLTQ4ZjItOGZhYi1jZWYzOTA0NjYwYmQifQ
// signature 是 -xN_h82PHVTCMA9vdoHrcZxH-x5mb11y1537t3rGzcM
// 最终 jwt token 是 eyJ0eXAiOiJKV1QiLCJhbGciOiJIUzI1NiJ9.eyJ1c2VySWQiOiJiMDhmODZhZi0zNWRhLTQ4ZjItOGZhYi1jZWYzOTA0NjYwYmQifQ.-xN_h82PHVTCMA9vdoHrcZxH-x5mb11y1537t3rGzcM通过前面 4 步生成了 jwt token,验证服务器把它发送给用户,用户带着它访问应用服务器,应用服务器怎么验证 JWT token ?
因为应用服务器知道验证服务器哈希计算 signature 的 secret key,所以应用服务器可以用这个 secret key 去重新计算 signature (用户发送过来的 token 里有 header 和 payload),并与用户发送过来的 token 中 signature 比较,最终验证是否合法。
因为 secret key 只有应用服务器和验证服务器知道,所以可以保证拥有这个 JWT token 的用户是验证服务器验证通过的用户。
JWT 并不比 cookie 更安全,所以最好配合使用 https。
原文:
参考:
一直觉得前端优化是个挺复杂的东西(可能是我比较菜 😂 ):
Babel 6生态现在写一个babel的简介好像已经不太必要了(太晚了😄 )。但大多数情况下,会配置babel来编译代码,不代表我们清楚babel的概念,而且Babel 6相关的多个babel-xx包还是容易让人混淆的。所以这里还是希望帮助理清整个Babel 6生态。
参考:
Babel 6的核心特性(相比5的巨大变化)我刚开始用babel的时候,版本是5,一个月后Babel 6发布——变化简直天翻地覆。
相比前一版本,Babel 6最大的变化是更模块化,各种内置库都被分散到独立的模块;其次,让所有插件可选,这意味着Babel默认不会编译ES2015代码,并且所有的transformer完全独立;同时,为了减少配置的复杂性,引入了preset;最后,提升了性能。
下面列出一些Babel 6的核心模块/变化:
babel package被弃用。
我们可以看[email protected]的源码,两个提示很明显:
babel-core。babel-cli。babel-core是babel的core compiler,主要用来对你的源码跑一系列变换(transform)。但默认情况下,不会应用任何变换——你必须自己安装和注册这些变换。
babel-cli是babel的command line,有babel/babel-external-helpers/babel-node3个命令。babel-doctor已被移除,见babel/babel#4678。
babel即用于编译代码。babel-external-helpers用于生成一段js代码(里面是一些helper函数)。这些helper如果被用到,一般被置于生成代码顶部(公用),所以生成的代码不会有内连这些helper好几遍。但是如果你有多个文件的话,你可能又要重复这些helper好几遍了。所以你可以生成这样一份代码,然后在每个文件中直接引入(node通过require,browser通过<script>)。详情见external-helpers。babel-node是方便开发的node二进制(非生产使用),内置了babel-polyfill,并用babel-register来编译被require的模块。babel-register,require hook,替换了node的require。
The require hook will bind itself to node's require and automatically compile files on the fly.
node_modules内的模块,则使用node的require。require,自动编译模块。Babel 6的plugins详情见https://babeljs.io/docs/plugins/。
这里不多说,只简单说两点:
plugins。babel-preset-es2015包括了完整的ES2015特性,引入它即可编译ES2015代码到ES5。babel-core仅仅聚焦于code transform,所以不是什么事都可以用babel来转换的。
比如,检索上面的plugins列表,你会发现没有一个plugin用来转换Promise;事实上,如果环境不支持Promise,你应该自己引入相应polyfill。
那么什么时候应该用tranform,什么时候该用polyfill呢?如果一个新特性你可以用ES5实现,那么,你应该用polyfill,比如Array.from。否则,你应该用transform,比如箭头函数。
babel-polyfill vs babel-runtime这可能是babel中最让人误解的一组概念:当你需要支持ES2015的所有特性时,究竟用babel-polyfill 还是 babel-runtime?
babel-polyfill 和 babel-runtime是达成同一种功能(模拟ES2015环境,包括global keywords,prototype methods,都基于core-js提供的一组polyfill和一个generator runtime)的两种方式:
babel-polyfill通过向全局对象和内置对象的prototype上添加方法来达成目的。这意味着你一旦引入babel-polyfill,像Map,Array.prototype.find这些就已经存在了——全局空间被污染。
babel-runtime不会污染全局空间和内置对象原型。事实上babel-runtime是一个模块,你可以把它作为依赖来达成ES2015的支持。
比如当前环境不支持Promise,你可以通过require(‘babel-runtime/core-js/promise’)来获取Promise。这很有用但不方便。幸运的是,babel-runtime并不是设计来直接使用的——它是和babel-plugin-transform-runtime一起使用的。babel-plugin-transform-runtime会自动重写你使用Promise的代码,转换为使用babel-runtime导出(export)的Promise-like对象。
注意: 所以plugin-transform-runtime一般用于开发(devDependencies),而runtime自身用于部署的代码(dependencies),两者配合来一起工作。
那么我们什么时候用babel-polyfill,什么时候用babel-runtime?
babel-polyfill会污染全局空间,并可能导致不同版本间的冲突,而babel-runtime不会。从这点看应该用babel-runtime。babel-runtime有个缺点,它不模拟实例方法,即内置对象原型上的方法,所以类似Array.prototype.find,你通过babel-runtime是无法使用的。require('babel-polyfill')),这会导致代码量很大。请按需引用最好。要理解Vue,从observer开使是一个不错的选择。因为从本质上来讲,除去生命周期函数,虚拟DOM,组件系统等以外,
Vue首先建立在数据监测之上,可以收集依赖,并在数据变化时自动通知到Vue的实例。
observer的相关代码在core/observer下,数据绑定的逻辑主要集中在dep/watcher/index/traverse4个文件中。
当有一个表达式,我们可以收集它的依赖,并在数据变化时,让依赖反过来去通知表达式这种变化。用一个例子来示意整个工作流程:
function expOrFn(vm) {
return vm.user
}很显然,expOrFn依赖vm.user,当user变化时,expOrFn应该自动重新执行。但,怎么知道这种依赖关系呢?
对数据vm来说,假设我们用getter来改写它的所有属性;那么当我们访问vm.user的时候,getter函数会执行,
所以,只要我们执行一次expOrFn,它的所有依赖就都知道了!bingo!
const vm = { user: 'creeper' }
defineGetter(vm)
let value = expOrFn(vm)一切看起来很简单。然后很自然地,我们加上setter来感知数据的更新。
当vm变化时,我们必须能够感知这种变化,否则收集依赖是完全没有意义的。
const vm = { user: 'creeper' }
defineGetterAndSetter(vm)
let value = expOrFn(vm)
// 然后我们更新数据
vm.user = 'who?'
// 因为调用了setter,所以我们可以知道数据更新了!看起来一切都搞定了。但上面的代码只是伪代码,实际开发中,我们必须要解决怎么定义依赖,怎么收集依赖,怎么通知更新的整个流程。
Dep),并设计了巧妙的 getter/setter 来收集依赖和通知更新:// 依赖,作为纽带来用,本身设计的很薄
class Dep {
// 添加订阅者——即谁依赖这个依赖
addSub(sub) { this.subs.push(sub) }
// 当有变化时,通知订阅者
notify() { this.subs.forEach(sub => sub.update()) }
// 很有意思的方法,下一步重点说,或者直接看源代码的注释
depend() { Dep.target.addDep(this) }
}接下来看看Dep是怎么用在 getter/setter里的:
// 假设有数据 vm,我们对 vm 的每个属性调用 defineReactive 来设置 getter/setter
// defineReactive(vm, 'user', 'creeper')
function defineReactive(obj, key, val) {
// 每个属性创建一个dep,这是一个一一对应的关系
const dep = new Dep()
Object.defineProperty(obj, key, {
enumerable: true,
configurable: true,
get: function reactiveGetter() {
if (Dep.target) {
// 收集依赖
dep.depend()
}
return val
},
set: function reactiveSetter(newVal) {
val = newVal
// 通知数据更新了
dep.notify()
}
})
}如上,getter/setter 配合对应的dep,可以完成依赖收集和更新通知。下面描述整个流程是怎么工作的
(比如dep.depend()怎么收集依赖的):
Watcher来串联整个流程。class Watcher {
// vm 是数据,expOrFn 是表达式,cb 是更新时的回调
constructor(vm, expOrFn, cb) {
this.vm = vm
// 用于收集依赖
this.deps = []
// 收集依赖
this.value = this.get()
}
get() {
// 设置Dep.target,方便依赖收集时 dep.depend 可以正确调用
Dep.target = this
// 调用 expOrFn 来收集依赖
const val = this.expOrFn.call(this.vm, this.vm)
}
// 联系上面的 dep.depend,是不是恍然大悟?
addDep(dep) {
this.deps.push(dep)
dep.addSub(this)
},
// 联系上面的 dep.notify,是不是懂了?
update() {
this.cb.call(this, this.get(), this.value)
}
}
const vm = { user: 'creeper' }
// 设置 getter/setter
observe(vm)
const exp = vm => vm.user
// 让exp可以监测数据变化
new Watcher(vm, exp, function updateCb() {})以上即整个observer流程,当然,里面简化了很多细节,详细的可看代码注释和下面的核心代码解读。
observe函数和Observer类observe(value, asRootData)方法用于为value创建getter/setter,从而实现对数据变化的监听;该方法会为value创建对应的Observer实例,而observer则是实际转化value的属性为getter/setter,收集依赖和转发更新的地方。
observer相关的核心代码是defineReactive来创建getter/setter,下面是相关注释:
/**
* 把 property 转化为 getter 和 setter
* - 创建dep(dep是一个纽带,连接watcher和数据,getter时收集依赖,setter时通知更新);
* - 在 getter 里面进行依赖收集,在非shallow时递归收集
* - 在 setter 里面进行更新通知,在非shallow时重新创建childOb
*/
export function defineReactive(
obj,
key,
val,
customSetter,
shallow
) {
const dep = new Dep()
const property = Object.getOwnPropertyDescriptor(obj, key)
if (property && property.configurable === false) {
return
}
// cater for pre-defined getter/setters
const getter = property && property.get
const setter = property && property.set
if ((!getter || setter) && arguments.length === 2) {
val = obj[key]
}
// ⚠️
// 大部分情况shallow默认是false的,即默认递归observe。
// - 当val是数组时,childOb被用来向当前watcher收集依赖
// - 当val是普通对象时,set/del函数也会用childOb来通知val的属性添加/删除
let childOb = !shallow && observe(val)
Object.defineProperty(obj, key, {
enumerable: true,
configurable: true,
// watcher 初始化时调用自己的 watcher.get(),最终调用这个 getter,
// 而 dep.depend 执行,把 watcher 放到了自己的 subs 里;所以当
// set 执行时,watcher 被通知更新。
get: function reactiveGetter() {
const value = getter ? getter.call(obj) : val
if (Dep.target) {
dep.depend()
// 现在问题是为什么要依赖 childOb 呢?
// 考虑到如果 value 是数组,那么 value 的 push/shift 之类的操作,
// 是触发不了下面的 setter 的,即 dep.depend 在这种情况不会被调用。
// 此时,childOb 即value这个数组对应的 ob,数组的操作会通知到childOb,
// 所以可以替代 dep 来通知 watcher。
if (childOb) {
childOb.dep.depend()
// 同时,对数组元素的操作,需要通过 dependArray(value) 来建立依赖。
if (Array.isArray(value)) {
dependArray(value)
}
}
}
return value
},
set: function reactiveSetter(newVal) {
const value = getter ? getter.call(obj) : val
/* eslint-disable no-self-compare */
if (newVal === value || (newVal !== newVal && value !== value)) {
return
}
/* eslint-enable no-self-compare */
if (process.env.NODE_ENV !== 'production' && customSetter) {
customSetter()
}
if (setter) {
setter.call(obj, newVal)
} else {
val = newVal
}
// 对新val重新创建childOb
childOb = !shallow && observe(newVal)
// 通知更新
dep.notify()
}
})
}Watcherobserver核心入口是Watcher,创建一个watcher可以监测数据的变化,并在变化时执行回调。
下面是 traverse 的代码:
// 递归遍历 val,深度收集依赖
function _traverse(val, seen) {
let i, keys
const isA = Array.isArray(val)
// 如果不是数组或对象,或者是 VNode,或者frozen,则不再处理。
if ((!isA && !isObject(val)) || Object.isFrozen(val) || val instanceof VNode) {
return
}
if (val.__ob__) {
const depId = val.__ob__.dep.id
// 如果已经收集过,则不再重复处理了。
if (seen.has(depId)) {
return
}
seen.add(depId)
}
// 对数组的每个元素调用 _traverse
if (isA) {
i = val.length
while (i--) _traverse(val[i], seen)
}
// 对子属性(val[keys[i]])访问,即调用 defineReactvie 定义的 getter,收集依赖
else {
keys = Object.keys(val)
i = keys.length
while (i--) _traverse(val[keys[i]], seen)
}
}下面是一些测试代码,帮助理解observer的运行。
const { observe } = require('./dist/core/observer')
const Watcher = require('./dist/core/observer/watcher').default
function createWather(data, expOrFn, cb, options) {
const vm = {
data: data || {},
_watchers: []
}
observe(vm.data, true)
return new Watcher(vm, expOrFn, cb, options)
}
const raw = {
s: 'hi',
n: 100,
o: {x: 1, arr: [1, 2]},
arr: [8, 9]
}
const w = createWather(raw, function expOrFn() {
// 1
return this.data.o
}, (a, b) => {
console.log('--->', a, b)
}, {
deep: false,
sync: true
})
// 2
raw.o.x = 2我在设置getter的地方加了一些输出语句:
get: function reactiveGetter() {
const value = getter ? getter.call(obj) : val;
console.log('call getter --->', key, val, !!_dep.default.target)
if (_dep.default.target) {
dep.depend();
if (childOb) {
childOb.dep.depend();
console.log('call childOb.dep.depend')
if (Array.isArray(value)) {
dependArray(value);
}
}
}
return value;
},并且测试代码中,序号1和2下面的一行代码会替换来测试不同的情况,测试结果如下:
1. retrun this.data.o 2. raw.o.x = 101
call getter ---> o { x: [Getter/Setter], arr: [Getter/Setter] } true
call childOb.dep.depend
call getter ---> o { x: [Getter/Setter], arr: [Getter/Setter] } false
1. retrun this.data.o 2. raw.o = 101
call getter ---> o { x: [Getter/Setter], arr: [Getter/Setter] } true
call childOb.dep.depend
call getter ---> o 101 true
---> 101 { x: [Getter/Setter], arr: [Getter/Setter] }
1. retrun this.data.arr 2. raw.arr.push(10)
call getter ---> arr [ 8, 9 ] true
call childOb.dep.depend // 因为child depend,数组的操作可以被监测。
call getter ---> arr [ 8, 9 ] false // push 产生的 getter
call getter ---> arr [ 8, 9, 10 ] true // 调用回调时调用了 this.get()
call childOb.dep.depend
---> [ 8, 9, 10 ] [ 8, 9, 10 ]
可下载本repo,在codes/vue下跑npm i && npm run build,然后如果是vscode,可以直接调试测试 vue-observer,了解 observer 的工作原理。
本篇的分析尽量不把Vue其它部分牵扯进来,所以遗留了 computed 型watcher和 scheduler 没有涉及。下一篇将解析
instance部分,会把遗留的补上。
前端开发中,构建(build)越来越普遍,我们的源码(ES6/typescript/JSX/sass/less...)一般都会经过编译压缩之后才会最终运行在浏览器中。而在这个过程中,出于调试需要,source map应运而生。
source map是一种文件,记录了生成代码和源码之间的映射关系;生成代码的某行某列,通过source map可以定位到源码的相应位置。
现代浏览器的devtools可以自动解析source map文件,并且让运行生成代码好像和运行源码一样,所以你可以轻松调试。
正则表达式是用来匹配字符串中字符组合的模式。
占坑,后面填
工作,日常学习,阅读文章等过程中的问题记录,包括解决方案(如果有)或者相关探索。
相关:
注意:
由于水平有限,不保证100%正确,欢迎讨论,共同进步。
虽然早放弃IE6/7,然而兼容仍然是前端必须面对的事。
今天(2015/08/21)产品突然报了个bug:Microsoft Edge浏览器内,报表下载无法正常使用。
然而我并不是win10用户:joy: 花了一番力气,成功定位到错误:
真是一头雾水,<a href='data:text/csv;charset=utf-8,xxxxxxx' download='y.csv'></a>在chrome,firefox甚至ie9-11都能工作,怎么你号称更标准的Edge就这样子?
查阅文档,终于弄明白了这迷惑的警告信息:
<a>,我大Edge准备跳转到data:text/csv;charset=utf-8,xxxxxxx';data:text/是协议,然后这:shit:内容csv;charset=utf-8,xxxxxxx完全不认识啊!doctype提示下?而Edge为什么没法智能识别data uri?
<a>的download属性并没有被Edge支持;怎么解决?
万幸的是Edge支持msSaveBlob,所以可以用它来代替data uri。
这里纪录了前端工具使用和工作流的问题,包括但不限于编译打包,版本管理,代码测试,工程化等等。
关键词:Babel Webpack git等等。
强调下,除非特殊说明,否则这里的babel, babel-cli都是6.x版本的。
mustache.js源码解析近些年各种前端模板引擎层出不穷,mustache就是其中比较出名的一种。mustache是一种弱逻辑的模板语法,mustache.js是它的JS实现。
mustache.js并去解析源码?underscore template和Micro-Templating等等模板是基于原生JS语法,解析基本是运用正则拼接字符串;相比它们,mustache.js基于自定义语法,解析更为复杂。解读mustache.js可以学习自定义语法的解析(简单的手写解析器)。mustache.js本身代码精简(v2.2.1只有600+行),结构清晰,易于理解。mustache.js的进阶版有handlebars等等,可以在mustache.js基础上自己定制/增强前端模板。600多行的mustache.js大致可以分为以下几部分:
├── context.js # Context类
├── parser.js # 主要是 parseTemplate 函数
├── scanner.js # Scanner类
├── utils.js # 工具函数:isArray, escapeHtml等等
└── writer.js # Writer类以上是我对代码按功能分块重构(ES6)后的文件组织形式,其中index.js主要暴露API,utils.js是一些工具函数,这里都省略掉,重点要讲的就是context.js/parser.js/scanner.js/writer.js四部分。完整的代码可以在项目sugar-template中查看。
scanner.jsScanner类很简单,主要功能是扫描字符串,按指定正则分割字符串。
class Scanner {
constructor(text) {
this.text = text
this.tail = text
this.pos = 0
}
eos() {
return this.tail === ''
}
scanUntil(re) {
const index = this.tail.search(re)
let match
switch (index) {
case -1:
match = this.tail
this.tail = ''
break
case 0:
match = ''
break
default:
match = this.tail.substring(0, index)
this.tail = this.tail.substring(index)
}
this.pos += match.length
return match
}
scan(re) {
const match = this.tail.match(re)
if (!match || match.index !== 0) return ''
const text = match[0]
this.tail = this.tail.substring(text.length)
this.pos += text.length
return text
}
}类只有3个方法,都很简短,稍微讲解scanUntil和scan。两者都接受一个正则作为参数,其中
scanUntil是把符合正则部分之前的字符串切分出来。假设this.tail.search(re) --> index,函数返回this.tail.slice(0, index)。scan是把符合正则部分(必须从开头符合正则)的字符串切分出来。两个方法都用来按正则截取字符串,并内部处理pos标记位置。
parser.js结下来讲parser.js,它是Scanner类的使用者,用于把模板解析为token树。
由于这段代码较长,所以解析放在代码注释里。
function parseTemplate(template, tags = sugar.tags) {
if (!template) return []
let sections = [] // Stack to hold section tokens
let tokens = [] // Buffer to hold the tokens
let spaces = [] // Indices of whitespace tokens on the current line
let hasTag = false // Is there a {{tag}} on the current line?
let nonSpace = false // Is there a non-space char on the current line?
let openingTagRe
let closingTagRe
let closingCurlyRe
// 解析tags, 生成 openingTagRe, closingTagRe, closingCurlyRe 这3个正则,
// 分别用来检测 开始标签(一般"{{"),结束标签(一般"}}"),raw输出结束标签(一般"}}}")
compileTags(tags)
// 用template创建Scanner实例
const scanner = new Scanner(template)
let start, type, value, chr, token, openSection
// 条件:只要template没有处理完
while (!scanner.eos()) {
start = scanner.pos // 当前处理位置,初始 0
// (1)把开始标签前的字符串截取出来(开始标签前的必然是纯粹的text)
value = scanner.scanUntil(openingTagRe)
if (value) {
for (let i = 0, valueLength = value.length; i < valueLength; ++i) {
chr = value.charAt(i)
// 如果字符是空白,把index(tokens数组位置)放到spaces数组中
if (isWhitespace(chr)) {
spaces.push(tokens.length)
} else {
nonSpace = true // nonSpace标志设为true
}
// 作为text类型的token放到tokens数组
tokens.push(['text', chr, start, ++start])
// 如果是换行,那么检查整行,看是否需要把空白删掉
if (chr === '\n') stripSpace()
}
}
// (2)截取开始标签,如果没有,跳出while
if (!scanner.scan(openingTagRe)) {
break
}
// 设置 hasTag 标志为 true,因为开始标签之后的就是标签类型及内容了
hasTag = true
// (3)截取标签类型,可能是`#,^,/,>,{,&,=,!`中的一种,如果都不是,那么就是 name
type = scanner.scan(tagRe) || 'name'
// (4) 截取(删掉)可能的空白
scanner.scan(whiteRe)
// (5) 根据标签类型来获取标签的内容
// 类型是 = ,用于切换开始结束标签,形式类似 {{=<% %>=}}
if (type === '=') {
// 所以我们把结束的 = 前的截取出来才是标签内容
value = scanner.scanUntil(equalsRe)
scanner.scan(equalsRe)
scanner.scanUntil(closingTagRe)
}
// 类型是 { ,表示内容不用转译,原样输出,形式类似 {{{name}}}
else if (type === '{') {
// 所以我们必须把 '}}}' 前的字符串截取出来作为标签内容
value = scanner.scanUntil(closingCurlyRe)
scanner.scan(curlyRe)
scanner.scanUntil(closingTagRe)
type = '&'
}
// 其他类型下结束标签 '}}' 前的就是内容
else {
value = scanner.scanUntil(closingTagRe)
}
// (6) 截取/删掉结束标签
if (!scanner.scan(closingTagRe))
throw new Error('Unclosed tag at ' + scanner.pos)
// 构造token并push
token = [type, value, start, scanner.pos]
tokens.push(token)
// 根据类型做一些额外处理
if (type === '#' || type === '^') {
sections.push(token) // 如果是section类的开始(#,^),push 到sections
}
// 如果是section类的结束(/),pop sections 并校验section完整性
else if (type === '/') {
// Check section nesting.
openSection = sections.pop()
if (!openSection)
throw new Error('Unopened section "' + value + '" at ' + start)
if (openSection[1] !== value)
throw new Error('Unclosed section "' + openSection[1] + '" at ' + start)
}
// 对于 name,{,& ,说明需要输出字符,这一行就是 nonSpace 的
else if (type === 'name' || type === '{' || type === '&') {
nonSpace = true
}
// 对于 = ,重新解析开始结束标签,以供下面继续解析时更换开始结束标签正则
else if (type === '=') {
compileTags(value)
}
}
// 保证template处理完后不会剩余section,否则就是模板中有未闭合的section
openSection = sections.pop()
if (openSection)
throw new Error('Unclosed section "' + openSection[1] + '" at ' + scanner.pos)
return nestTokens(squashTokens(tokens))
// 不必多说,就是设置3个正则 openingTagRe,closingTagRe,closingCurlyRe
function compileTags(tagsToCompile) {
if (typeof tagsToCompile === 'string')
tagsToCompile = tagsToCompile.split(spaceRe, 2)
if (!isArray(tagsToCompile) || tagsToCompile.length !== 2)
throw new Error('Invalid tags: ' + tagsToCompile)
openingTagRe = new RegExp(escapeRegExp(tagsToCompile[0]) + '\\s*')
closingTagRe = new RegExp('\\s*' + escapeRegExp(tagsToCompile[1]))
closingCurlyRe = new RegExp('\\s*' + escapeRegExp('}' + tagsToCompile[1]))
}
// 如果某行只有section开始/结束标签,那么删除这行的所有空白
// 比如 1. {{#tag}} 2. {{/tag}} 这种,因为它们所在行如果只有空白加标签,那么空白是
// 无意义的,并且不应该影响最终生成的字符串
function stripSpace() {
if (hasTag && !nonSpace) {
while (spaces.length) {
tokens[spaces.pop()] = null
}
} else {
spaces = []
}
hasTag = false
nonSpace = false
}
}parseTemplate应该算比较长了,但总体来说并不复杂,就是完成一个template string ---> tokens的转换。
token的格式是:[type, value, startIndex, endIndex]。
另外:
squashTokens函数的作用是合并text token;nestTokens函数的作用是把tokens转化成tokens tree。([type, value, startIndex, endIndex, innerTokens])。总体来说两个函数都不难,这里只讲解下nestTokens:
function nestTokens(tokens) {
const nestedTokens = []
let collector = nestedTokens
const sections = []
let token, section
for (let i = 0, numTokens = tokens.length; i < numTokens; ++i) {
token = tokens[i]
// 唯一要注意的就是 遇到类型是 '#'/'^' 时,说明遇到section了,
// 那么collector = token[4] =[],push接下来的其他类型token,sections也push这个section
// 一旦遇到 '/',说明当前section结束,pop这个section
// section[5]填入pos信息,collector指向上一层的section或者根tokens
switch (token[0]) {
case '#':
case '^':
collector.push(token)
sections.push(token)
collector = token[4] = []
break
case '/':
section = sections.pop()
section[5] = token[2]
collector = sections.length > 0 ? sections[sections.length - 1][4] : nestedTokens
break
default:
collector.push(token)
}
}
return nestedTokens
}context.js到这里我们已经获得了tokens,那么怎么从tokens + data ---> html?
别急,先完成一个依赖任务,怎么处理这个data?
有人会问,data要处理吗?不同模板引擎有不同的态度,mustache处理data后可以做到:
// 作为渲染上下文,包装data,并且有一个父上下文的引用
class Context {
constructor(data, parentContext) {
this.data = data
this.cache = {
'.': this.data
}
this.parent = parentContext
}
// 返回新生成的子context,参数data作为新context的数据,父context指向this
push(data) {
return new Context(data, this)
}
// 根据name在当前上下文查找数据,找不到则递归向上找
lookup(name) {
let cache = this.cache
let value
// 首先检查cache
if (cache.hasOwnProperty(name)) {
value = cache[name]
} else {
let context = this
let names, index, lookupHit = false
while (context) {
if (name.indexOf('.') > 0) {
value = context.data
names = name.split('.')
index = 0
// 注意,name可以是 "prop1.prop2.prop3"
while (value != null && index < names.length) {
if (index === names.length - 1)
lookupHit = hasProperty(value, names[index])
value = value[names[index++]]
}
} else {
value = context.data[name]
lookupHit = hasProperty(context.data, name)
}
// 找到则跳出循环
if (lookupHit) break
// 找不到则递归向上
context = context.parent
}
cache[name] = value
}
if (isFunction(value)) {
value = value.call(this.data)
}
return value
}
}怎么说呢,Context的作用清晰简单,并没有什么需要特别讲解。下面以一个例子明确下它的作用:
const ctx = new Context({
title: 'welcome',
user: {
age: 18
}
})
ctx.lookup('user.age') // ---> 18,这在模板中很有用,因为我们经常写 {{user.age}} 这种writer.jswriter.js主要是Writer类,负责tokens + data ---> html。
Writer类主要需要关注的是render**形式的方法,
class Writer {
constructor() {
this.cache = {}
}
clearCache() {
this.cache = {}
}
// 并没有什么特别,对parseTemplate的包装,加入缓存
parse(template, tags) {
const cache = this.cache
let tokens = cache[template]
if (tokens == null) {
tokens = cache[template] = parseTemplate(template, tags)
}
return tokens
}
// template ---> tokens, data ---> context, 然后调用renderTokens
render(template, view, partials) {
const tokens = this.parse(template)
const context = (view instanceof Context) ? view : new Context(view)
return this.renderTokens(tokens, context, partials, template)
}
// 根据token的类型调用不同方法,拼接各个token生成的html
renderTokens(tokens, context, partials, originalTemplate) {
let buffer = ''
let token, symbol, value
for (let i = 0, numTokens = tokens.length; i < numTokens; ++i) {
value = undefined
token = tokens[i]
symbol = token[0]
if (symbol === '#') {
value = this.renderSection(token, context, partials, originalTemplate)
} else if (symbol === '^') {
value = this.renderInverted(token, context, partials, originalTemplate)
} else if (symbol === '>') {
value = this.renderPartial(token, context, partials, originalTemplate)
} else if (symbol === '&') {
value = this.unescapedValue(token, context)
} else if (symbol === 'name') {
value = this.escapedValue(token, context)
} else if (symbol === 'text') {
value = this.rawValue(token)
}
if (value !== undefined) {
buffer += value
}
}
return buffer
}
// 对于text类型,直接返回template中对应的字符串
rawValue(token) {
return token[1]
}
// 对于{{name}},返回 escape(context.lookup(name))
escapedValue(token, context) {
const value = context.lookup(token[1])
if (value != null)
return escapeHtml(value)
}
// 对于{{{name}}} 和 {{&name}},返回 context.lookup(name)
unescapedValue(token, context) {
const value = context.lookup(token[1])
if (value != null)
return value
}
// 对于{{>name}},获取 partials(name) 或者 partials[name]作为partial内容,
// 然后对这个内容再this.renderTokens(this.parse(value), context, partials, value)
// 即partial作为新的template,加上已有的context去渲染出html
renderPartial(token, context, partials) {
if (!partials) return
const value = isFunction(partials) ? partials(token[1]) : partials[token[1]]
if (value != null)
return this.renderTokens(this.parse(value), context, partials, value)
}
// 对于{{^name}},在context.lookup(name)是falsy时才渲染,
// 调用 this.renderTokens 渲染内层的tokens即可
renderInverted(token, context, partials, originalTemplate) {
const value = context.lookup(token[1]);
if (!value || (isArray(value) && value.length === 0))
return this.renderTokens(token[4], context, partials, originalTemplate);
}
// 对于{{#name}},作为重头戏,渲染section。
// 在value = context.lookup(name)是trusy时才渲染section的内层tokens
renderSection(token, context, partials, originalTemplate) {
let buffer = ''
const value = context.lookup(token[1])
const subRender = (template) => {
return this.render(template, context, partials)
}
if (!value) return
// value 是数组,构造子context,数组的每个元素作为data,渲染内层tokens
if (isArray(value)) {
for (let j = 0, valueLength = value.length; j < valueLength; ++j) {
buffer += this.renderTokens(token[4], context.push(value[j]), partials, originalTemplate)
}
}
// value 是对象,字符串,数字,value作为data构造子context,渲染内层tokens
else if (typeof value === 'object' || typeof value === 'string' || typeof value === 'number') {
buffer += this.renderTokens(token[4], context.push(value), partials, originalTemplate)
}
// value 是函数,函数执行返回值作为渲染后的html直接返回
else if (isFunction(value)) {
if (typeof originalTemplate !== 'string')
throw new Error('Cannot use higher-order sections without the original template')
value = value.call(context.view, originalTemplate.slice(token[3], token[5]), subRender)
if (value != null)
buffer += value
}
// value 是 `true`,不用构造子context,直接渲染内层tokens
else {
buffer += this.renderTokens(token[4], context, partials, originalTemplate)
}
return buffer
}
}来一个例子加深理解:
new Writer().render(
`
<h1>{{title}}</h1>
{{#user}}
<p>{{user.name}},{{user.age}}</p>
{{#user.hobbies}}
* <a>{{.}}</a>
{{/user.hobbies}}
{{/user}}
`, {
title: 'Info',
user: {
name: 'Jack',
age: 18,
hobbies: ['football', 'badminton', 'tennis']
}
})
// tokens:
[
["text", "\n<h1>", 0, 5],
["name", "title", 5, 14],
["text", "</h1>\n", 14, 20],
["#", "user", 20, 29, [
["text", " <p>", 30, 37],
["name", "user.name", 37, 50],
["text", ",", 50, 51],
["name", "user.age", 51, 63],
["text", "</p>\n", 63, 68],
["#", "user.hobbies", 72, 89, [
["text", " * <a>", 90, 103],
["name", ".", 103, 108],
["text", "</a>\n", 108, 113]
], 117]
], 135]
]
// html:
//
// <h1>Info</h1>
// <p>Jack,18</p>
// * <a>football</a>
// * <a>badminton</a>
// * <a>tennis</a>
//render**基本也没复杂逻辑,只要注意2点:
true时不用构造)去递归render;rawValue|escapedValue|unescapedValue3个基础方法。对mustache.js的源码解析到这里结束,希望看文章的各位没被我误导;如有不对或有疑问,也请直接回复 😄
非特别说明,
react-native版本是0.42。
Android中borderRadius和border冲突?Android中当borderRadius部分设置非0值(部分为0),border将无效。
手机:华为mate8
EMUI:4.1
android:6.0

iOS上正确的样式:

然后发现删除style
borderTopLeftRadius: 4,
borderBottomLeftRadius: 4,
borderTopRightRadius: 0,
borderBottomRightRadius: 0可正常显示border。
解决方案
把border放在两个按钮的父容器上。
// 第一种 三元运算
customer_type.length ? customer_type.forEach(item => {
$('select[name="question-lever"]').append('' + item.value + '')
}) : $('select[name="performance-income"]').append('暂无数据')
// 第二种 if else
if (customer_type.length) {
$('select[name="question-lever"]').append('' + item.value + '')
}else{
$('select[name="performance-income"]').append('暂无数据')
}
有几个问题想请教下
像这种$('select[name="question-lever"]').append('' + item.value + '')比较多的操作适合三目运算吗?
三目运算和if else谁的性能更好点?
题目很大,主要是相关知识点很多,可能涉及的面也很广。
写这个issue的用意:梳理ajax用法,前后台交互,API设计,HTTP协议等等的知识点,温故知新。在这里不尝试阐述的面面具到,但重点的地方还是会尽可能解释清楚。
请注意,webpack >= 3.0
记录下日常使用 webpack 的一些注意点/优化点,记忆和自用更多一点,同学们谨慎阅读。
webpack.optimize.CommonsChunkPlugin 比你想的更强大/配置更复杂实际项目:
['babel-polyfill', './src/client.js']import() (split point) 分离出 chunk 文件。webpack 配置:
new webpack.optimize.CommonsChunkPlugin({
name: 'vendor',
minChunks: module => {
// 所有 node_modules 下的文件
return module.resource && /node_modules/.test(module.resource)
}
}),build 情况:

可以看到,我们生成了 vendor.hash.js ,里面包括了入口文件使用到的所有 node_modules 下的文件,但是,我们同时看到,同样位于 node_modules 下的 bluebird 并没有被打包进 vendor.hash.js,并且在多个 chunk 文件中重复。
可见,CommonsChunkPlugin 比我们想象的要复杂,我们的配置并没有达到预期。
阅读完文档和资料,算是重新认识下 CommonsChunkPlugin 的配置项。
首先我们理解下 webpack 的 chunk:
CommonsChunkPlugin 创建的文件也是 chunk,即 commons chunk。其次我们要明确:CommonsChunkPlugin 是把共用模块的代码从 bundles 分离出来合并到单独的文件(commons chunk)。
有了这些概念后我们可以重新理解下 CommonsChunkPlugin 的各个选项:
name 可以是已经存在的 chunk 的 name (一般是入口文件),那么共用模块代码会合并到这个已存在的 chunk;否则,创建名字为 name 的 commons chunk 来合并。
filenames,即这个 commons chunk 的文件名(最终保存到本地的文件)。
chunks 指定 source chunks,即从哪些 chunk 去查找共用模块。省略 chunks 选项时,默认为所有 entry chunks。
minChunks 可以
(module, count) 两个参数,用法如上。Infinity ,即创建 commons chunk 但不合并任何共用模块。这时一般搭配 entry 的配置一起用: entry: {
vendor: ["jquery", "other-lib"],
app: "./entry"
}
new webpack.optimize.CommonsChunkPlugin({
name: "vendor",
// filename: "vendor.js"
// (Give the chunk a different name)
minChunks: Infinity,
// (with more entries, this ensures that no other module
// goes into the vendor chunk)
})children 设为 true 时,指定 source chunks 为 children of commons chunk。这里的 children of commons chunk 比较难理解,可以认为是 entry chunks 通过 code split 创建的 children chunks。children 与 chunks不可同时设置(它们都是指定 source chunks 的)。
children 可以用来把 entry chunk 创建的 children chunks 的共用模块合并到自身,但这会导致初始加载时间较长:
new webpack.optimize.CommonsChunkPlugin({
// names: ["app", "subPageA"]
// (choose the chunks, or omit for all chunks)
children: true,
// (select all children of chosen chunks)
// minChunks: 3,
// (3 children must share the module before it's moved)
})async 即解决children: true时合并到 entry chunks 自身时初始加载时间过长的问题。async 设为 true 时,commons chunk 将不会合并到自身,而是使用一个新的异步的 commons chunk。当这个 commons chunk 被下载时,自动并行下载相应的共用模块。
好了,解读了这么多选项的各种用法,是时候见证实际效果了:
new webpack.optimize.CommonsChunkPlugin({
name: 'vendor',
minChunks: module => {
return module.resource && /node_modules/.test(module.resource)
}
}),
new webpack.optimize.CommonsChunkPlugin({
name: 'client',
async: 'chunk-vendor',
children: true,
minChunks: (module, count) => {
// 被 3 个及以上 chunk 使用的共用模块提取出来
return count >= 3
}
}),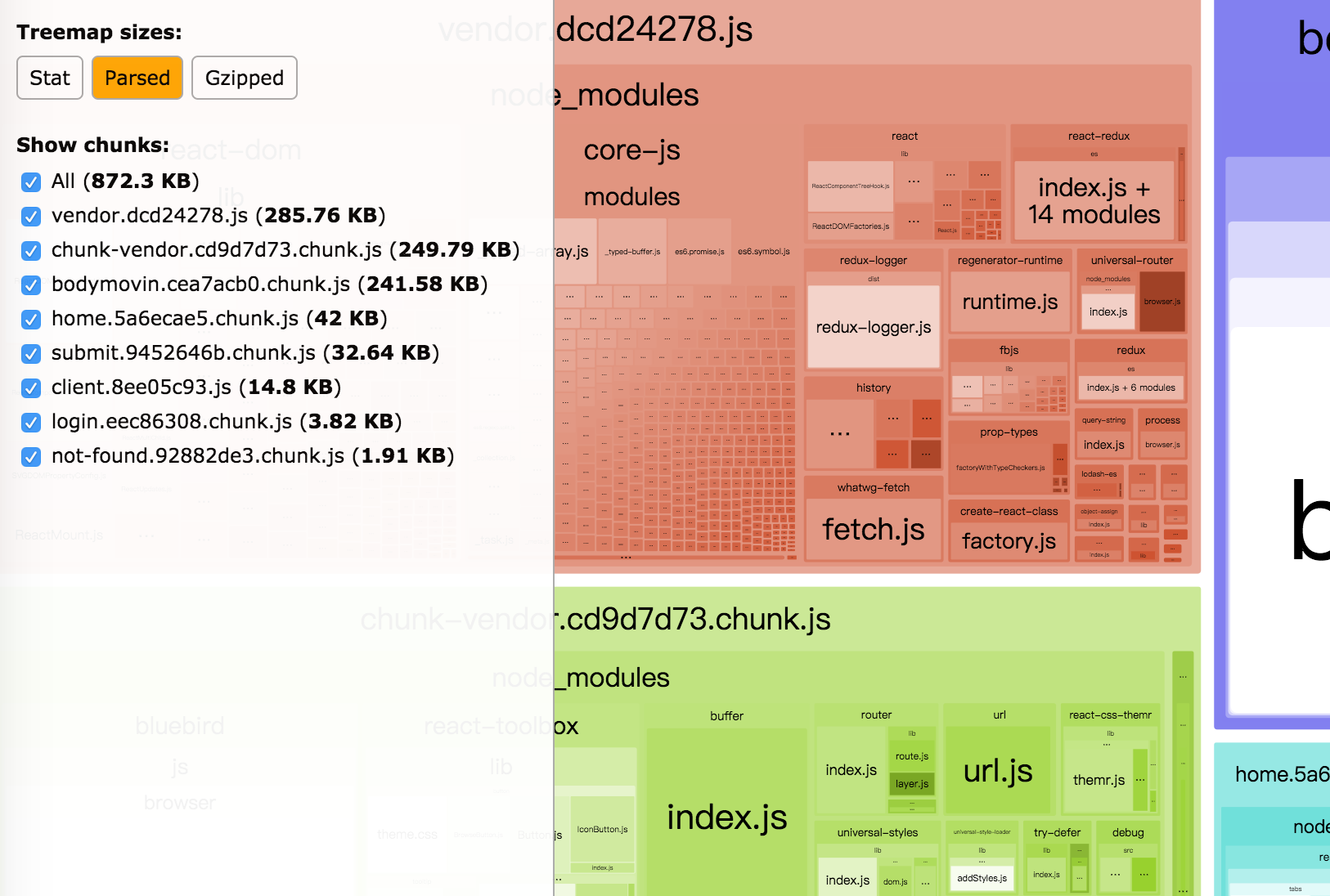
可以看到,我们把 client 创建的多个 chunk 的共用模块分离到了 chunk-vendor.hash.chunk.js,大大减少了这些 chunk 里的重复代码,总 size 从 1.36MB 减少到 872.3KB。
参考
我在微信小程序开发工具里面测试,不能用Intl.Collator.supportedLocalesOf
本文是大名鼎鼎的雅虎前端优化规则(Yslow)的翻译。翻译并不逐字逐句,部分难以逐字翻译的被意译了,另外一些不重要的举例等也被精简。
原文: Best Practices for Speeding Up Your Web Site。
如何让web页面更快,雅虎团队实践总结了7类35条规则,下面一一列出。
Minimize HTTP Requests减少/最小化 http 请求数。
到终端用户的响应时间80%花在前端:大部分用于下载组件(js/css/image/flash等等)。减少组件数就是减少渲染页面所需的http请求数。这是更快页面的关键。
减少组件数的一个方法就是简化页面设计。保持富内容的页面且能减少http请求,有以下几个技术:
background-image 和 background-position 来显示不同部分。data:url scheme来內连图片。减少请求数是为第一次访问页面的用户提高性能的最重要的指导。
减少DNS查询。
就像电话簿,你在浏览器地址栏输入网址,通过DNS查询得到网站真实IP。
DNS查询被缓存来提高性能。这种缓存可能发生在特定的缓存服务器(ISP/local area network维护),或者用户的计算机。DNS信息留存在操作系统DNS缓存中(在windows中就是 DNS Client Serve )。大多浏览器有自己的缓存,独立于操作系统缓存。只要浏览器在自己的缓存里有某条DNS记录,它就不会向操作系统发DNS解析请求。
IE默认缓存DNS记录30分钟,FireFox默认缓存1分钟。
当客户端的DNS缓存是空的,DNS查找次数等于页面中的唯一域名数。
减少DNS请求数可能会减少并行下载数。避免DNS查找减少响应时间,但减少并行下载数可能会增加响应时间。指导原则是组件可以分散在至少2个但不多于4个的不同域名。这是两者的妥协。
避免跳转。
跳转用301或302状态码来达成。一个301响应http头的例子:
HTTP/1.1 301 Moved Permanently
Location: http://example.com/newuri
Content-Type: text/html
浏览器自动跳转到Location指定的路径。跳转所需的所有信息都在http头,所以http主体一般是空的。301 302响应一般不会被缓存,除非有额外的头部信息,比如Expires或Cache-Control指定要缓存。meta刷新标签或 JavaScript 也可以跳转,但如果真要跳转,3xx跳转更好,主要是保证返回键可用。
跳转显然拖慢响应速度。在跳转的页面被获取前浏览器没什么能渲染,没什么组件能下载。
最浪费的跳转之一发生在url尾部slash(/)缺失。比如http://astrology.yahoo.com/astrology会301跳转到http://astrology.yahoo.com/astrology/。这可以被Apache等服务器修复,用Alias,mod_rewrite等等。
让Ajax可缓存。
使用ajax的好处是可以向用户提供很快的反馈,因为它是向后台异步请求数据。但是,这些异步请求不保证用户等待的时间——异步不意味着瞬时。
提高ajax性能的最重要的方法是让响应被缓存,即在Add an Expires or a Cache-Control Header中讨论的 Expires 。其它方法是:
延迟加载组件。
再看看你的页面然后问问自己,“什么是页面初始化必须的?”。剩下的内容和组件可以延迟。
JavaScript是理想的(延迟)候选者,可以切分到onload事件之前和之后。比如拖放的js库可以延迟,因为拖动必须在页面初始化之后。其它可延迟的包括隐藏的内容,折叠起来的图片等等。
预加载组件。
预加载看起来与延迟加载相反,但它的确有个不同的目标。通过预加载你可以利用浏览器的空闲时间来请求你将来会用到的组件。这样当用户访问下一个页面时,你会有更多的组件已经在缓存中,这样会极大加快页面加载。
有几种预加载类型:
onload触发,你立即获取另外的组件。比如谷歌会在主页这样加载搜索结果页面用到的雪碧图。减少dom数。
一个复杂的页面意味着更多的内容要下载,以及更慢的dom访问。比如在有500dom数量的页面添加事件处理就和有5000dom数量的不同。
如果你的页面dom元素很多,那么意味着你可能需要删除无用的内容和标签来优化。
把组件分散到不同的域名。
把组件分散到不同的域名允许你最大化并行下载数。由于DNS查询的副作用,最佳的不同域名数是2-4。
最小化iframe的数量。
iframe允许html文档被插入到父文档。
<iframe>优点:
<iframe>缺点:
onload不要404。
http请求是昂贵的,所以发出http请求但获得没用的响应(如404)是完全不必要的,并且会降低用户体验。
一些网站会有特别的404页面提高用户体验,但这仍然会浪费服务器资源。特别坏的是当链接指向外部js但却得到404结果。这样首先会降低(占用)并行下载数,其次浏览器可能会把404响应体当作js来解析,试图从里面找出可用的东西。
使用CDN。
用户接近你的服务器会减少响应时间。把你的内容发布到多个,地理上分散的服务器可以让页面加载更快。但怎么开始?
首先不要试图把你的架构重新设计成分布式架构。因为可能引进更多复杂性和不可控。
记住80-90%的终端用户响应时间花费在下载页面中的所有组件:图片、样式、脚本、falsh等等。这是_Performance Golden Rule_。不要从困难的重新设计后台架构开始,最好首先分发你的静态内容。这不仅可以减少响应时间,用CDN还很容易来做。
CDN是一群不同地点的服务器,可以更高效地分发内容到用户。一些大公司有自己的CDN。
加Expires或者Cache-Control头部。
这条规则有两个方面:
Expires头部来实现“永不过期”策略。Cache-Control头部来帮助浏览器进行有条件请求。页面越来越丰富,意味着更多脚本,样式,图片等等。第一次访问的用户可能需要发出多个请求,但使用Expires可以让这些组件被缓存。这避免了访问子页面时没必要的http请求。Expires一般用在图片上,但应该用在所有的组件上。
浏览器(以及代理)使用缓存来减少http请求数,加快页面加载。服务器使用http响应的Expires头部来告诉客户端一个组件可以缓存多久。比如下面:
Expires: Thu, 15 Apr 2010 20:00:00 GMT //2010-04-15之前都是稳定的
注意,如果你设置了Expires头部,当组件更新后,你必须更改文件名。
传输时用gzip等压缩组件。
http请求或响应的传输时间可以被前端工程师显著减少。终端用户的带宽,ISP,接近对等交换点等等没法被开发团队控制,但是,压缩可以通过减少http响应的大小减少响应时间。
从HTTP/1.1开始,客户端通过http请求中的Accept-Encoding头部来提示支持的压缩:
Accept-Encoding: gzip, deflate
如果服务器看到这个头部,它可能会选用列表中的某个方法压缩响应。服务器通过Content-Encoding头部提示客户端:
Content-Encoding: gzip
gzip一般可减小响应的70%。尽可能去gzip更多(文本)类型的文件。html,脚本,样式,xml和json等等都应该被gzip,而图片,pdf等等不应该被gzip,因为它们本身已被压缩过,gzip它们只是浪费cpu,甚至增加文件大小。
实体标记(Entity tags,ETag)是服务器和浏览器之间判断浏览器缓存中某个组件是否匹配服务器端原组件的一种机制。实体就是组件:图片,脚本,样式等等。ETag被当作验证实体的比最后更改(last-modified)日期更高效的机制。服务器这样设置组件的ETag:
HTTP/1.1 200 OK
Last-Modified: Tue, 12 Dec 2006 03:03:59 GMT
ETag: "10c24bc-4ab-457e1c1f"
Content-Length: 12195
之后,如果浏览器要验证组件,它用If-None-Match头部来传ETag给服务器。如果ETag匹配,服务器返回304:
GET /i/yahoo.gif HTTP/1.1
Host: us.yimg.com
If-Modified-Since: Tue, 12 Dec 2006 03:03:59 GMT
If-None-Match: "10c24bc-4ab-457e1c1f"
HTTP/1.1 304 Not Modified
ETag的问题是它们被构造来使它们对特定的运行这个网站的服务器唯一。浏览器从一个服务器获取组件,之后向另一个服务器验证,ETag将不匹配。然而服务器集群是处理请求的通用解决方案。
如果不能解决多服务器间的ETag匹配问题,那么删除ETag可能更好。
早一点刷新buffer(尽早给浏览器数据)。
当用户请求一个页面,服务器一般要花200-500ms来拼凑整个页面。这段时间,浏览器是空闲的(等数据返回)。在php,有个方法flush()允许你传输部分准备好的html响应给浏览器。这样的话浏览器就可以开始下载组件,而同时后台可以继续生成页面剩下的部分。这种好处更多是在忙碌的后台或轻前端网站可以看到。
一个比较好的flush的位置是在head之后,因为浏览器可以加载其中的样式和脚本文件,而后台继续生成页面剩余部分。
<!-- css, js -->
</head>
<?php flush(); ?>
<body>
<!-- content -->ajax请求用get。
Yahoo! Mail团队发现当使用XMLHttpRequest,POST 被浏览器实现为两步:首先发送头部,然后发送数据。所以使用GET最好,仅用一个TCP包发送(除非cookie太多)。IE的url长度限制是2K。
POST但不提交任何数据根GET行为类似,但从语义上讲,获取数据应该用GET,提交数据到服务器用POST。
避免空src的图片。
空src属性的图片的行为可能跟你预期的不一样。它有两种形式:
<img src="">var img = new Image(); img.src = "";两种都会造成同一种后果:浏览器会向你的服务器发请求。
为什么这种行为很糟糕?
这种行为的根源是uri解析发生在浏览器。RFC 3986 定义了这种行为,空字符串被当作相对路径,Firefox, Safari, 和 Chrome都正确解析,而IE错误。总之,浏览器解析空字符串为相对路径的行为被认为是符合预期的。
html5在_4.8.2_添加了对标签src属性的描述,指导浏览器不要发出额外的请求。
The src attribute must be present, and must contain a valid URL referencing a non-interactive, optionally animated, image resource that is neither paged nor scripted. If the base URI of the element is the same as the document's address, then the src attribute's value must not be the empty string.
幸运的是将来浏览器不会有这个问题了(在图片上)。不幸的是,<script src="">和<link href="">没有这样的规范。
http cookie的使用有多种原因,比如授权和个性化。cookie的信息通过http头部在浏览器和服务器端交换。尽可能减小cookie的大小来降低响应时间。
用没有cookie的域名提供组件。
当浏览器请求静态图片并把cookie一起发送到服务器时,cookie此时对服务器没什么用处。所以这些cookie只是增加了网络流量。所以你应该保证静态组件的请求是没有cookie的。可以创建一个子域名来托管所有静态组件。
比如,你域名是www.example.org,可以把静态组件托管在static.example.org。不过,你如果把cookie设置在顶级域名example.org下,这些cookie仍然会被传给static.example.org。这种情况下,启用一个全新的域名来托管静态组件。
另外一个用没有cookie的域名提供组件的好处是,某些代理可能会阻止缓存待cookie的静态组件请求。
把样式放在顶部。
研究雅虎网页性能时发现把样式表移到<head>里会让页面更快。这是因为把样式表移到<head>里允许页面逐步渲染。
关注性能的前端工程师希望页面被逐步渲染,这时因为,我们希望浏览器尽早渲染获取到的任何内容。这对大页面和网速慢的用户很重要。给用户视觉反馈,比如进度条的重要性已经被大量研究和记录。在我们的情况中,HTML页面就是进度条。当浏览器逐步加载页面头部,导航条,logo等等,这些都是给等待页面的用户的视觉反馈。这优化了整体用户体验。
把样式表放在文档底部的问题是它阻止了许多浏览器的逐步渲染,包括IE。这些浏览器阻止渲染来避免在样式更改时需要重绘页面元素。所以用户会卡在白屏。
HTML规范清楚表明样式应该在<head>里。
避免CSS表达式。
CSS表达式是强大的(可能也是危险的)设置动态CSS属性的方法。IE5开始支持,IE8开始不赞成使用。例如,背景颜色可以设置成每小时轮换:
background-color: expression( (new Date()).getHours()%2 ? "#B8D4FF" : "#F08A00" );CSS表达式的问题是它们可能比大多数人预期的计算的更频繁。它们不仅在页面载入和调整大小时重新计算,也在滚动页面甚至是用户在页面上移动鼠标时计算。比如在页面上移动鼠标可能轻易计算超过10000次。
要避免CSS表达式计算太多次,可以在它第一次计算后替换成确切值,或者用事件处理函数而不是CSS表达式。
<link> over @import选择<link>而不是@import。
之前的一个最佳原则是说CSS应该在顶部来允许逐步渲染。
在IE用@import和把CSS放到页面底部行为一致,所以最好别用。
避免使用(IE)过滤器。
IE专有的AlphaImageLoader过滤器用于修复IE7以下版本的半透明真彩色PNG的问题。这个过滤器的问题是它阻止了渲染,并在图片下载时冻结了浏览器。另外它还引起内存消耗,并且它被应用到每个元素而不是每个图片,所以问题(的严重性)翻倍了。
最佳做法是放弃AlphaImageLoader,改用PNG8来优雅降级。
把脚本放到底部。
脚本引起的问题是它们阻塞了并行下载。HTTP1.1规范建议浏览器每个域名下不要一次下载超过2个组件。如果你的图片分散在不同服务器,那么你能并行下载多个图片。但当脚本在下载,浏览器不会再下载其它组件,即使在不同域名下。
有些情况下把脚本移动到底部并不简单。比如,脚本中用了document.write来插入内容,它就不能被移动到底部。另外有可能有作用域问题。但大多数情况,有方法可以解决这些问题。
一个替代建议是使用异步脚本。defer属性表明脚本不包含document.write,是提示浏览器继续渲染的线索。不幸的是,Firefox不支持。如果脚本能异步,那么也就可以移动到底部。
使用外部JS和CSS。
这里的很多性能规则涉及外部组件怎么管理。但你首先要明白一个基本问题:JS和CSS是应该包含在外部文件还是內连在页面本身?
真实世界中使用外部文件一般会加快页面,因为JS和CSS文件被浏览器缓存了。內连的JS和CSS怎在每次HTML文档下载时都被下载。內连减少了http请求,但增加了HTML文档大小。另一方面,如果JS和CSS被缓存了,那么HTML文档可以减小大小而不增加HTTP请求。
核心因素,就是JS和CSS被缓存相对于HTML文档被请求的频率。尽管这个因素很难被量化,但可以用不同的指标来计算。如果网站用户每个session有多个pv,许多页面重用相同的JS和CSS,那么有很大可能用外部JS和CSS更好。
许多网站用这些指标计算后在中间位置。对这些网站来说,最佳方案还是用外部JS和CSS文件。唯一例外是內连更被主页偏爱,如http://www.yahoo.com/。主页每个session可能只有少量的甚至一个pv,这时候內连可能更快。
对多个页面的首页来说,可以通过技术减少(其它页面的)http请求。在首页用內连,初始化后动态加载外部文件,接下来的页面如果用到这些文件,就可以使用缓存了。
压缩JS和CSS。
压缩就是删除代码中不必要的字符来减小文件大小,从而提高加载速度。当代码压缩时,注释删除,不需要的空格(空白,换行,tab)也被删除。
混淆是对代码可选的优化。它比压缩更复杂,并且可能产生bug。在对美国top10网站的调查,压缩可减小21%,而混淆可减小25%。
除了外部脚本和样式,內连的脚本和样式同样应该被压缩。
删除重复的脚本。
在页面中引入相同的脚本两次会伤害性能。可能超出你的预料,美国top10网站的2家有重复脚本引入。两个主要因素造成同一页面引入相同脚本:团队大小和脚本数量。当确实引入重复脚本,会发出不必要的http请求和浪费js执行时间。
发出不必要的http请求发生在IE而不是Firefox。在IE,如果外部脚本引入两次且没有缓存,它会发出2个请求。即使脚本被缓存,刷新时也会发出额外请求。
除了增加http请求,时间被浪费在执行脚本多次上。不管IE还是Firefox都会执行多次。
一种避免多次引入脚本的方法是在模板系统实现一个脚本管理模块。
最小化DOM访问。
用JS访问DOM元素是缓慢的,所以为了响应更好的页面,你应该:
开发聪明的事件处理
有时候页面看起来不那么响应(响应速度慢),是因为绑定到不同元素的大量事件处理函数执行太多次。这是为什么使用_事件委托_是一种好方法。
另外,你不必等到onload事件来开始处理DOM树,DOMContentLoaded更快。大多时候你需要的只是想访问的元素已在DOM树中,所以你不必等到所有图片被下载。
优化图片
在设计师建好图片后,在上传图片到服务器前你仍可以做些事:
pngcrush或其它工具压缩png。jpegtran或其它工具压缩jpeg。优化CSS雪碧图
不要在html中缩放图片
不要因为你可以设置图片的宽高就去用比你需要的大得多的图片。如果你需要
<img width="100" height="100" src="mycat.jpg" alt="My Cat" /> 那么,就用100x100px的图片,而不是500x500px的。
favicon.ico小且缓存
favicon.ico是在你服务器根路径的图片。邪恶的是即使你不关心它,浏览器仍然会请求它。所以最好不要响应404。另外由于在同一服务器,每次请求favicon.ico时也会带上cookie。这个图片还会影响下载顺序,比如在IE,如果你在onload时下载额外的组件,fcvicon会在这些组件之前被下载。
怎么减轻favicon.ico的缺点?
保持组件小于25K
这个限制与iPhone不缓存大于25K的组件相关。注意,这是非压缩(uncompressed)的文件大小。在这里minification(压缩,不要与compress混淆)很重要,因为gzip无法满足(iPhone)。
打包组件到一个多部父文档
打包组件到一个多部父文档类似于带附件的邮件。它帮助你在一个http请求中获取多个组件,但注意,iPhone不支持。
这一章节内容主要是 HashTable,中文即哈希表,散列表等等。HashTable 是编程中日常使用,不可或缺的一个数据结构,本章节最终会代码实现一个简单哈希表,来解释哈希表相关的重要概念。
对前端同学而言,哈希表是个每天用但说起来可能陌生的概念。说每天用,是因为在 JavaScript 中,对象({})的底层实现即哈希表,我们也经常用对象来做缓存等各种用法,利用其查找时间复杂度为 O(1) 的特性。
对若干个元素(key-value对),如果我们想通过 key 来找到对应的 value,通常情况下,我们需要遍历所有元素,一一比较 key,来找到对应的 value。这个时间复杂度是 O(n) 。
然后我们假设这些元素是有序的,那么通过二分查找,时间复杂度可以降到 O(log n) 。
那么有没有更好的方法呢?这就是 hash table 出现的原因,它可以达到 O(1) 的时间复杂度。
哈希表是一种用于存储键值对(key-value pairs)的数据结构,它可以实现key到value的映射,一般情况下查找的时间复杂度是O(1) 。

/**
* 哈希函数,接收字符串返回数字
* https: //github.com/darkskyapp/string-hash
*
* @param str 字符串
* @returns number,32位整数,0~4294967295
*/
function hash(str) {
var hash = 5381,
i = str.length;
while (i) {
hash = (hash * 33) ^ str.charCodeAt(--i);
}
/* JavaScript does bitwise operations (like XOR, above) on 32-bit signed
* integers. Since we want the results to be always positive, convert the
* signed int to an unsigned by doing an unsigned bitshift. */
return hash >>> 0;
}
class HashTable {
static hash(key) {
return hash(key)
}
constructor() {
this.buckets = [];
}
set(key, value) {
const index = HashTable.hash(key);
let bucket = this.buckets[index];
// 直接使用数组来处理哈希函数冲突的问题
if (!bucket) {
this.buckets[index] = bucket = [];
}
if (!bucket.some(el => el.key === key)) {
bucket.push({ key, value });
}
}
get(key) {
const index = HashTable.hash(key);
const bucket = this.buckets[index];
if (!bucket) return;
let result;
bucket.some(el => {
if (el.key === key) {
result = el.value;
return true;
}
return false;
});
return result;
}
}以上是一个简单的哈希表实现,还有很多细节没有考虑,比如:
填装因子(填装因子 = 哈希表的元素数量 / 哈希表的位置总数)。根据经验,一旦填装因子大于 0.7,我们就需要调整哈希表的长度。
buckets 数组这里没有规定长度,如果考虑 buckets 的长度,那么我们就要对哈希函数返回的值进行取余操作。
参考:
本文是对Node.js官方文档The Node.js Event Loop, Timers, and process.nextTick()的翻译和理解。文章并不是一字一句严格对应原文,其中会夹杂其它相关资料,以及相应的理解和扩展。
相关资料:
Event loop)?Event loop是什么?
WIKI定义:
In computer science, the event loop, message dispatcher, message loop, message pump, or run loop is a programming construct that waits for and dispatches events or messages in a program.
Event loop是一种程序结构,是实现异步的一种机制。Event loop可以简单理解为:
所有任务都在主线程上执行,形成一个执行栈(execution context stack)。
主线程之外,还存在一个"任务队列"(task queue)。系统把异步任务放到"任务队列"之中,然后主线程继续执行后续的任务。
一旦"执行栈"中的所有任务执行完毕,系统就会读取"任务队列"。如果这个时候,异步任务已经结束了等待状态,就会从"任务队列"进入执行栈,恢复执行。
主线程不断重复上面的第三步。
对JavaScript而言,Javascript引擎/虚拟机(如V8)之外,JavaScript的运行环境(runtime,如浏览器,node)维护了任务队列,每当JS执行异步操作时,运行环境把异步任务放入任务队列。当执行引擎的线程执行完毕(空闲)时,运行环境就会把任务队列里的(执行完的)任务(的数据和回调函数)交给引擎继续执行,这个过程是一个不断循环的过程,称为事件循环。
注意:JavaScript(引擎)是单线程的,Event loop并不属于JavaScript本身,但JavaScript的运行环境是多线程/多进程的,运行环境实现了Event loop。
另外,视频What the heck is the event loop anyway 站在前端的角度,用动画的形式描述了上述过程,可以便于理解。
当Node.js启动时,它会初始化event loop,处理提供的代码(代码里可能会有异步API调用,timer,以及process.nextTick()),然后开始处理event loop。
下面是node启动的部分相关代码:
// node.cc
{
SealHandleScope seal(isolate);
bool more;
do {
v8_platform.PumpMessageLoop(isolate);
more = uv_run(env.event_loop(), UV_RUN_ONCE);
if (more == false) {
v8_platform.PumpMessageLoop(isolate);
EmitBeforeExit(&env);
// Emit `beforeExit` if the loop became alive either after emitting
// event, or after running some callbacks.
more = uv_loop_alive(env.event_loop());
if (uv_run(env.event_loop(), UV_RUN_NOWAIT) != 0)
more = true;
}
} while (more == true);
}下面的示意图展示了一个简化的event loop的操作顺序:
┌───────────────────────┐
┌─>│ timers │
│ └──────────┬────────────┘
│ ┌──────────┴────────────┐
│ │ I/O callbacks │
│ └──────────┬────────────┘
│ ┌──────────┴────────────┐
│ │ idle, prepare │
│ └──────────┬────────────┘ ┌───────────────┐
│ ┌──────────┴────────────┐ │ incoming: │
│ │ poll │<─────┤ connections, │
│ └──────────┬────────────┘ │ data, etc. │
│ ┌──────────┴────────────┐ └───────────────┘
│ │ check │
│ └──────────┬────────────┘
│ ┌──────────┴────────────┐
└──┤ close callbacks │
└───────────────────────┘(图来自Node.js API)
图中每个“盒子”都是event loop执行的一个阶段(phase)。
每个阶段都有一个FIFO的回调队列(queue)要执行。而每个阶段有自己的特殊之处,简单说,就是当event loop进入某个阶段后,会执行该阶段特定的(任意)操作,然后才会执行这个阶段的队列里的回调。当队列被执行完,或者执行的回调数量达到上限后,event loop会进入下个阶段。
setTimeout()和setInterval()设定的回调。close回调,timer的回调,和setImmediate()的回调。setImmediate()设定的回调。socket.on('close', ...)的回调。一个timer指定一个下限时间而不是准确时间,在达到这个下限时间后执行回调。在指定时间过后,timers会尽可能早地执行回调,但系统调度或者其它回调的执行可能会延迟它们。
注意:技术上来说,poll 阶段控制 timers 什么时候执行。
注意:这个下限时间有个范围:[1, 2147483647],如果设定的时间不在这个范围,将被设置为1。
这个阶段执行一些系统操作的回调。比如TCP错误,如一个TCP socket在想要连接时收到ECONNREFUSED,
类unix系统会等待以报告错误,这就会放到 I/O callbacks 阶段的队列执行。
poll 阶段有两个主要功能:
当event loop进入 poll 阶段,并且 没有设定的timers(there are no timers scheduled),会发生下面两件事之一:
如果 poll 队列不空,event loop会遍历队列并同步执行回调,直到队列清空或执行的回调数到达系统上限;
如果 poll 队列为空,则发生以下两件事之一:
setImmediate()设定了回调, event loop将结束 poll 阶段进入 check 阶段来执行 check 队列(里的回调)。setImmediate()设定回调,event loop将阻塞在该阶段等待回调被加入 poll 队列,并立即执行。但是,当event loop进入 poll 阶段,并且 有设定的timers,一旦 poll 队列为空(poll 阶段空闲状态):
1. event loop将检查timers,如果有1个或多个timers的下限时间已经到达,event loop将绕回 **timers** 阶段,并执行 **timer** 队列。
这个阶段允许在 poll 阶段结束后立即执行回调。如果 poll 阶段空闲,并且有被setImmediate()设定的回调,event loop会转到 check 阶段而不是继续等待。
setImmediate()实际上是一个特殊的timer,跑在event loop中一个独立的阶段。它使用libuv的API
来设定在 poll 阶段结束后立即执行回调。
通常上来讲,随着代码执行,event loop终将进入 poll 阶段,在这个阶段等待 incoming connection, request 等等。但是,只要有被setImmediate()设定了回调,一旦 poll 阶段空闲,那么程序将结束 poll 阶段并进入 check 阶段,而不是继续等待 poll 事件们 (poll events)。
如果一个 socket 或 handle 被突然关掉(比如 socket.destroy()),close事件将在这个阶段被触发,否则将通过process.nextTick()触发。
var fs = require('fs');
function someAsyncOperation (callback) {
// 假设这个任务要消耗 95ms
fs.readFile('/path/to/file', callback);
}
var timeoutScheduled = Date.now();
setTimeout(function () {
var delay = Date.now() - timeoutScheduled;
console.log(delay + "ms have passed since I was scheduled");
}, 100);
// someAsyncOperation要消耗 95 ms 才能完成
someAsyncOperation(function () {
var startCallback = Date.now();
// 消耗 10ms...
while (Date.now() - startCallback < 10) {
; // do nothing
}
});当event loop进入 poll 阶段,它有个空队列(fs.readFile()尚未结束)。所以它会等待剩下的毫秒,
直到最近的timer的下限时间到了。当它等了95ms,fs.readFile()首先结束了,然后它的回调被加到 poll
的队列并执行——这个回调耗时10ms。之后由于没有其它回调在队列里,所以event loop会查看最近达到的timer的
下限时间,然后回到 timers 阶段,执行timer的回调。
所以在示例里,回调被设定 和 回调执行间的间隔是105ms。
setImmediate() vs setTimeout()setImmediate() 和 setTimeout()是相似的,区别在于什么时候执行回调:
setImmediate()被设计在 poll 阶段结束后立即执行回调;setTimeout()被设计在指定下限时间到达后执行回调。下面看一个例子:
// timeout_vs_immediate.js
setTimeout(function timeout () {
console.log('timeout');
},0);
setImmediate(function immediate () {
console.log('immediate');
});代码的输出结果是:
$ node timeout_vs_immediate.js
timeout
immediate
$ node timeout_vs_immediate.js
immediate
timeout是的,你没有看错,输出结果是 不确定 的!
从直觉上来说,setImmediate()的回调应该先执行,但为什么结果随机呢?
再看一个例子:
// timeout_vs_immediate.js
var fs = require('fs')
fs.readFile(__filename, () => {
setTimeout(() => {
console.log('timeout')
}, 0)
setImmediate(() => {
console.log('immediate')
})
})结果是:
$ node timeout_vs_immediate.js
immediate
timeout
$ node timeout_vs_immediate.js
immediate
timeout很好,setImmediate在这里永远先执行!
所以,结论是:
setImmediate的回调永远先执行。那么又是为什么呢?
看int uv_run(uv_loop_t* loop, uv_run_mode mode)源码(deps/uv/src/unix/core.c#332):
int uv_run(uv_loop_t* loop, uv_run_mode mode) {
int timeout;
int r;
int ran_pending;
r = uv__loop_alive(loop);
if (!r)
uv__update_time(loop);
while (r != 0 && loop->stop_flag == 0) {
uv__update_time(loop);
//// 1. timer 阶段
uv__run_timers(loop);
//// 2. I/O callbacks 阶段
ran_pending = uv__run_pending(loop);
//// 3. idle/prepare 阶段
uv__run_idle(loop);
uv__run_prepare(loop);
// 重新更新timeout,使得 uv__io_poll 有机会跳出
timeout = 0;
if ((mode == UV_RUN_ONCE && !ran_pending) || mode == UV_RUN_DEFAULT)
timeout = uv_backend_timeout(loop);
//// 4. poll 阶段
uv__io_poll(loop, timeout);
//// 5. check 阶段
uv__run_check(loop);
//// 6. close 阶段
uv__run_closing_handles(loop);
if (mode == UV_RUN_ONCE) {
uv__update_time(loop);
// 7. UV_RUN_ONCE 模式下会再次检查timer
uv__run_timers(loop);
}
r = uv__loop_alive(loop);
if (mode == UV_RUN_ONCE || mode == UV_RUN_NOWAIT)
break;
}
if (loop->stop_flag != 0)
loop->stop_flag = 0;
return r;
}上面的代码看起来很清晰,一一对应了我们的几个阶段。
setTimeout(fn, 0) 等价于setTimeout(fn, 1)),那么setTimeout的回调会首先执行。setImmediate的回调会先执行。fs.readFile回调里设置的,setImmediate始终先执行?因为fs.readFile的回调执行是在 poll 阶段,所以,接下来的 check 阶段会先执行 setImmediate 的回调。UV_RUN_ONCE模式下,event loop会在开始和结束都去执行timer。process.nextTick()直到现在,我们才开始解释process.nextTick()。因为从技术上来说,它并不是event loop的一部分。相反的,process.nextTick()会把回调塞入nextTickQueue,nextTickQueue将在当前操作完成后处理,不管目前处于event loop的哪个阶段。
看看我们最初给的示意图,process.nextTick()不管在任何时候调用,都会在所处的这个阶段最后,在event loop进入下个阶段前,处理完所有nextTickQueue里的回调。
process.nextTick() vs setImmediate()两者看起来也类似,区别如下:
process.nextTick()立即在本阶段执行回调;setImmediate()只能在 check 阶段执行回调。工作需要,开始写原生安卓项目;本文记录一个前端学习安卓相关知识的历程 😄
https://www.w3cschool.cn/java/ 可用于快速补充一些Java的基础知识,作为一个基本的工具手册。
Java 是一门强类型的面向对象的解释型语言,通过JVM可以在多平台运行。
8种内置类型,六种数字类型(四个整数型,两个浮点型),一种字符类型,还有一种布尔型:
byte:8位,有符号整数,-128(-2^7)-- 127(2^7-1);short:16位,有符号整数,-32768(-2^15)-- 32767(2^15 - 1);int:32位,有符号整数,-2,147,483,648(-2^31)-- 2,147,483,647(2^31 - 1);long:64位,有符号整数,-9,223,372,036,854,775,808(-2^63)-- 9,223,372,036,854,775,807(2^63 -1);float:32位、单精度、符合IEEE 754标准的浮点数,不能表示精确的值,如货币;double:64位、双精度、符合IEEE 754标准的浮点数,不能表示精确的值,如货币;boolean:1位,只有两个取值:true和false;char:16位,表示Unicode字符,最小值是’\u0000’(即为0),最大值是’\uffff’(即为65,535)。引用类型
对象、数组都是引用数据类型,所有引用类型的默认值都是null。
对前端而言,需要额外注意两点:
变量一旦声明,则类型确定,且不能更改(不能赋值其它类型)。
char 和 String 的区别:char是基本类型,对应一个字符;String 是引用类型,对应0或多个字符。
char a = 'a'; String x = "hi!";
MyFirstJavaClass。public static void main(String args[])**方法开始执行。总的来说,Java基本语法和一般程序语言的语法一致。相比JS,我们可能要注意 修饰符,接口等概念。
和JS基本一致;不过可以注意下增强的for循环:
String [] names ={"James", "Larry", "Tom", "Lacy"};
for( String name : names ) {
System.out.print( name );
System.out.print(",");
}for(声明语句 : 表达式) 中表达式为数组。
与JS一致。
对象是类的一个实例,有状态和行为。类可以看成是创建Java对象的模板。一个类可以包含以下类型变量:
每个类都有构造方法。如果没有显式为类定义构造方法,Java编译器将会为该类提供一个默认构造方法。
包主要用来对类和接口进行分类。我们用package pkgName 来声明包,用import java.io.* 来引入包。
Java中,可以使用访问控制符来保护对类、变量、方法和构造方法的访问。Java支持4种不同的访问权限。
默认的,也称为default,在同一包内可见,不使用任何修饰符。
接口里的变量都隐式声明为public static final,而接口里的方法默认情况下访问权限为public。
私有的,以private修饰符指定,在同一类内可见。
私有访问修饰符是最严格的访问级别,所以被声明为private的方法、变量和构造方法只能被所属类访问,并且类和接口不能声明为private。
公有的,以public修饰符指定,对所有类可见。
被声明为public的类、方法、构造方法和接口能够被任何其他类访问。
受保护的,以protected修饰符指定,对同一包内的类和所有子类可见。
被声明为protected的变量、方法和构造器能被同一个包中的任何其他类访问,也能够被不同包中的子类访问。
protected访问修饰符不能修饰类和接口,方法和成员变量能够声明为protected,但是接口的成员变量和成员方法不能声明为protected。
子类能访问protected修饰符声明的方法和变量。
父类中声明为public的方法在子类中也必须为public。
父类中声明为protected的方法在子类中要么声明为protected,要么声明为public。不能声明为private。
父类中默认修饰符声明的方法,能够在子类中声明为private。
父类中声明为private的方法,不能够被继承。
为了实现一些其他的功能,Java也提供了许多非访问修饰符。
static修饰符,用来创建类方法和类变量。
final修饰符,用来修饰类、方法和变量,final修饰的类不能够被继承,修饰的方法不能被继承类重新定义,修饰的变量为常量,是不可修改的。
abstract修饰符,用来创建抽象类和抽象方法。
synchronized和volatile修饰符,主要用于线程的编程。
Java是完全面向对象的语言,继承是最重要的topic。Java只有单继承(相比多继承,减少复杂度和潜在的一些问题(比如函数重写)),但通过接口来保留多继承的一些优点。
典型的继承语法:
class Pet {
public String name;
private int age = 0;
public Pet() {}
public String getName() {
System.out.println("yes, in Pet!");
return name;
}
public int getAge() {
return age;
}
}
interface Animal {
public void eat(String food);
}
class Dog extends Pet implements Animal {
int age = 10;
@Override
public int getAge() {
System.out.println("hey!" + age);
return age;
}
public void eat(String food) {
System.out.println("dog eat " + food);
}
}
public class Test {
public static void main(String[] args) {
Pet a = new Pet();
Pet b = new Pet();
Dog d = new Dog();
System.out.println(a.getName());
System.out.println(d.getName());
System.out.println("--------------");
d.eat("gouliang");
}
}子类可以从父类继承所有的 protected/public 属性和方法。
我们知道,JS 中,基于原型链的继承机制,所有实例的方法调用的方法最终都指向原型(链)的某个方法,即方法在内存中只有一份,那在Java中一样吗?
答案是:是。
Java中,类在加载时,类的信息(类信息,常量,静态变量,类方法)被存储到方法区。
类信息除了有类的版本、字段、方法、接口等描述信息外,还有一项信息是常量池(Constant Pool Table),用于存放编译期生成的各种字面量、符号引用,文字字符串、final变量值、类名和方法名常量,这部分内容将在类加载后存放到方法区的运行时常量池中。它们以数组形式访问,是调用方法、与类联系及类的对象化的桥梁。
其中 方法信息,包括方法名、返回值类型、参数类型、修饰符、异常、方法的字节码。
在Java中 new 一个对象时,为类的成员(包括(继承的)父类的成员)分配了内存空间,然后执行构造函数,初始化这些属性的值。
但对象并不会为方法分配内存,当调用对象的方法时,实质上是去方法区查找到对应的方法执行。
静态方法和私有方法在解析阶段确定唯一的调用版本,而其它实例方法,会去动态查找(沿继承链)。
参考:
泛型,即“参数化类型”。一提到参数,最熟悉的就是定义方法时有形参,然后调用此方法时传递实参。那么参数化类型怎么理解呢?顾名思义,就是将类型由原来的具体的类型参数化,类似于方法中的变量参数,此时类型也定义成参数形式(可以称之为类型形参),然后在使用/调用时传入具体的类型(类型实参)。
泛型的本质是为了参数化类型(在不创建新的类型的情况下,通过泛型指定的不同类型来控制形参具体限制的类型)。也就是说在泛型使用过程中,操作的数据类型被指定为一个参数,这种参数类型可以用在类、接口和方法中,分别被称为泛型类、泛型接口、泛型方法。
泛型类型用于类的定义中,被称为泛型类。通过泛型可以完成对一组类的操作对外开放相同的接口。最典型的就是各种容器类,如:List、Set、Map。
泛型类的定义:
class 类名称 <泛型标识:可以随便写任意标识号,标识指定的泛型的类型>{
private 泛型标识 /*(成员变量类型)*/ var;
.....
}
}例子:
class Demo <T> {
private T key;
public Demo(T key) {
this.key = key;
}
public T getKey() {
return key;
}
}
// 泛型的类型参数只能是类类型(包括自定义类),不能是简单类型
// 传入的实参类型需与泛型的类型参数类型相同,即为Integer.
Demo<Integer> demoInt = new Demo<Integer>(10);泛型的类型参数只能代表引用型类型,不能是原始类型(像int,double,char等)
//定义一个泛型接口
public interface Generator<T> {
public T next();
}
public class FruitGenerator implements Generator<String> {
private String[] fruits = new String[]{"Apple", "Banana", "Pear"};
@Override
public String next() {
Random rand = new Random();
return fruits[rand.nextInt(3)];
}
}泛型类,是在实例化类的时候指明泛型的具体类型;泛型方法,是在调用方法的时候指明泛型的具体类型 。
public class GenericMethodTest
{
// 泛型方法 printArray
public static < E > void printArray( E[] inputArray )
{
// 输出数组元素
for ( E element : inputArray ){
System.out.printf( "%s ", element );
}
System.out.println();
}
public static void main( String args[] )
{
// 创建不同类型数组: Integer, Double 和 Character
Integer[] intArray = { 1, 2, 3, 4, 5 };
Double[] doubleArray = { 1.1, 2.2, 3.3, 4.4 };
Character[] charArray = { 'H', 'E', 'L', 'L', 'O' };
System.out.println( "Array integerArray contains:" );
printArray( intArray ); // 传递一个整型数组
System.out.println( "\nArray doubleArray contains:" );
printArray( doubleArray ); // 传递一个双精度型数组
System.out.println( "\nArray characterArray contains:" );
printArray( charArray ); // 传递一个字符型型数组
}
}有界的类型参数:
可能有时候,你会想限制那些被允许传递到一个类型参数的类型种类范围。例如,一个操作数字的方法可能只希望接受Number或者Number子类的实例。这就是有界类型参数的目的。
要声明一个有界的类型参数,首先列出类型参数的名称,后跟extends关键字,最后紧跟它的上界。
// 比较三个值并返回最大值
// T 必须继承自 Comparable 接口
public static <T extends Comparable<T>> T maximum(T x, T y, T z)
{
T max = x; // 假设x是初始最大值
if ( y.compareTo( max ) > 0 ){
max = y; //y 更大
}
if ( z.compareTo( max ) > 0 ){
max = z; // 现在 z 更大
}
return max; // 返回最大对象
}源于同事的一次分享,查阅资料了解了Java虚拟机和内存管理相关知识。利于深入了解Java,对比JS可能有更大收获。

堆区:存放所有类实例(对象)和数组,虚拟机启动时创建。由GC自动管理。
方法区(Method area and runtime constant pool):存放类的结构信息,虚拟机启动时创建。类似于传统语言中存放编译后代码的地方,它存放类的 (1)run-time constant pool(类似传统语言的符号表+其它),(2)成员和方法信息,(3)静态变量,(4)方法的代码等等。
It stores per-class structures such as the run-time constant pool, field and method data, and the code for methods and constructors.
虽然逻辑上来说,方法区也是堆的一部分,不过方法区一般不被GC管理(取决于JVM的具体实现)。
JVM Stack:每个Java线程创建时都会创建一个私有的JVM Stack,存储局部变量和部分结果,参与函数调用和返回。Stack本身只负责存储(push/pop)frames,frame 对应方法,负责存数据和部分结果,执行动态链接,返回方法的值或者dispatch异常。
Native Method Stacks:线程私有,但不是所有JVM都实现了。类似JVM Stack,用于执行 Native 方法服务。
frame通常包含:
PC register:线程私有。每个JVM线程都有自己的pc register,在任意时刻,每个线程都是在执行一个方法(记作 current method)。如果这个方法不是native的,那么pc register存着当前执行的JVM指令的地址;否则pc register的值是undefined。
程序基本概念
同步与异步,阻塞与非阻塞是两组概念,但很容易混淆。比如同步不代表阻塞,同步也可以是非阻塞的。
同步与异步同步和异步关注的是消息通信机制 (synchronous communication/ asynchronous communication)。
所谓同步,就是在发出调用时,
换句话说,就是由调用者主动等待这个调用的结果。
异步则是相反,调用在发出之后,调用就直接返回,但没有返回结果。
换句话说,当一个异步过程调用发出后,调用者不会立刻得到结果。而是在调用发出后,被调用者通过状态、通知来通知调用者,或通过回调函数处理这个调用。
阻塞与非阻塞以打电话让书店老板查找某本书为例来讲:
总结:阻塞与非阻塞 与 是否同步异步无关(跟老板通过什么方式回答你无关)。
hmmm...
本文是JavaScript问题集锦的姊妹篇,或者就是它的一部分。
至于为什么分开,一是防止篇幅过大,分开有利于更好的组织;二是本文仍然从某些问题开始,但会更深入更系统地阐述某些知识点,而不是局限于解决问题。
React 在 v16 引入了众多新特性,其中最核心的更新属于引入了新的核心架构 Fiber (Fiber reconciler,代替之前的 Stack reconciler),本文主要是对 fiber 的学习过程的记录。
长话短说就是:性能。
In its current implementation React walks the tree recursively and calls render functions of the whole updated tree during a single tick.
React 15 及之前版本,协调算法(Stack Reconciler)会一次同步处理整个组件树。它会递归遍历每个组件(虚拟DOM树),去比较新旧两颗树,得到需要更新的部分。这个过程基于递归调用,一旦开始,很难去打断。也就是说,一旦工作量大,就会堵塞整个主线程(The main thread is the same as the UI thread.)。
而事实上,我们的更新工作可能并不需要一次性全部完成,比如 offscreen 的 UI 更新并不紧急,比如 动画 需要优先完成——我们可以根据优先级调整工作,把diff过程按时间分片!
If something is offscreen, we can delay any logic related to it. If data is arriving faster than the frame rate, we can coalesce and batch updates. We can prioritize work coming from user interactions (such as an animation caused by a button click) over less important background work (such as rendering new content just loaded from the network) to avoid dropping frames.
所以 React 引入了 Fiber。
Fiber 的基本目标是可以利用 scheduling(scheduling 即决定工作什么时候执行),即可以:
要达成以上目标,首先我们必须能把工作分成小单元(break work down into units)。从这一点来说,A fiber represents a unit of work。
进一步讲,React 的一个核心概念是 UI 是数据的投影 ,组件的本质可以看作输入数据,输出UI的描述信息(虚拟DOM树),即:
ui = f(data)也就是说,渲染一个 React app,其实是在调用一个函数,函数本身会调用其它函数,形成调用栈。前面我们已经讲到,递归调用导致的调用栈我们本身无法控制,
只能一次执行完成。而 Fiber 就是为了解决这个痛点,可以去按需要打断调用栈,手动控制 stack frame——就这点来说,Fiber 可以理解为 reimplementation of the stack,即 virtual stack frame。
React Fiber is a virtual stack frame, with React Fiber being a reimplementation of a stack frame specialized for React components. Each fiber can be thought of as a virtual stack frame where information from the frame is preserved in memory on the heap, and because info is saved on the heap, you can control and play with the data structures and process the relevant information as needed.
这一节本来是要直接去探索 React 怎么实现 Fiber 的。但 Rodrigo Pombo 有篇非常棒的自定义 Fiber 实现博文,这里先讲一讲这个实现,有助于我们理解 Fiber 到底是什么,是怎么实现手动控制 stack frame 的。
我阅读了 Rodrigo Pombo 的实现,并用 typescript 重写了一遍(有助于我自己理解),并加上了详细的注释(理解有谬误的大家可以帮忙提出):
blog/codes/didact/src/reconciler.ts
Lines 1 to 459 in a660a47
原作者的博客还是很易读易懂的,这里不再赘述。下面主要列出一些帮助理解的重点:
blog/codes/didact/src/interface.ts
Lines 44 to 69 in a660a47
React 中 reconciliation 和 render 是两个独立的过程,其中 reconciliation 过程是纯粹的 virtual dom diff,不涉及任何 DOM 操作——这是我们为什么能够把 reconciliation 分割为多个工作单元 (unit of work) 的原因。而 didact 中是怎么分割/设置工作单元呢?
didact 中,reconciliation 可以理解为是创建 work-in-progress fiber tree 的过程。从 root fiber 开始,每处理一个 fiber 都是一个工作单元。每个 fiber 的处理过程基本是:
通过 requestIdleCallback API 来 schedule 工作;同时以 nextUnitOfWork 为下一步需要执行的工作对象。
在开发者工具的timeline里,我们可以看到一个典型的渲染过程基本如下:
满足上述某个条件,浏览器就会单独创建一个layer。
什么叫流畅?60fps,即要在16.7ms内把一帧准备好。
想要流畅需考虑两个问题:
setTimeout不够精确会导致丢帧,因为屏幕刷新频率60HZ是不变的。比如设置setTimeout 16,每隔一段时间后,就会有丢帧。
读取以下属性会引起Layout:
clientHeight/Left/Top/Width, focus(),getBoundingClientRect(),getClientRects(),innerText,offsetHeight/Left/Top/Width/Parent,outerText(),scrollByLines(),scrollByPages(),scrollHeight/Left/Top/Width,scrollIntoView()...
用transform代替top/left
var h1 = el1.clientHeight;
el1.style.height = (h1 + 4)+ 'px'; // 等待layout
var h2 = el2.clientHeight; // 读属性,强制layout
el2.style.height = (h2 + 4)+ 'px'; // 等待layout
var h3 = el3.clientHeight; // 读属性,强制layout
el3.style.height = (h3 + 4)+ 'px'; // 等待layout分离读写操作,比如用requestAnimationFrame把写操作推到下一帧。
修改box-shadow,border-radius,color等展示相关属性时,会触发Paint
box-shadow等Paint代价昂贵。
UTF-8(8-bit Unicode Transformation Format) 是一种针对Unicode的可变长度字元编码,也是一种前缀码。它可以用来表示Unicode标准中的任何字元,且其编码中的第一个字节仍与ASCII兼容,这使得原来处理ASCII字元的软件无须或只须做少部分修改,即可继续使用。
UTF-8使用一至六个字节为每个字符编码(尽管如此,2003年11月UTF-8被RFC 3629重新规范,只能使用原来Unicode定义的区域,U+0000到U+10FFFF,也就是说最多四个字节)。
Unicode字元的比特被分区为数个部分,并分配到UTF-8的字节串中较低的比特的位置。在U+0080的以下字元都使用内含其字元的单字节编码。这些编码正好对应7比特的ASCII字符。在其他情况,有可能需要多达4个字元组来表示一个字元。这些多字节的最高有效比特会设置成1,以防止与7比特的ASCII字符混淆,并保持标准的字节主导字符串运作顺利。
| 代码范围(十六进制) | 标量值(scalar value,二进制) | UTF-8(二进制/十六进制) | 注释 |
|---|---|---|---|
| 000000 - 00007F | 00000000 00000000 0zzzzzzz | 0zzzzzzz(00-7F) | ASCII字元范围,字节由零开始 |
| 000080 - 0007FF | 00000000 00000yyy yyzzzzzz | 110yyyyy(C0-DF) 10zzzzzz(80-BF)(五个y;六个z) | 第一个字节由110开始,接着的字节由10开始 |
| 000800 - 00D7FF 00E000 - 00FFFF | 00000000 xxxxyyyy yyzzzzzz | 1110xxxx(E0-EF) 10yyyyyy 10zzzzzz(四个x;六个y;六个z) | 第一个字节由1110开始,接着的字节由10开始 |
| 010000 - 10FFFF | 000wwwxx xxxxyyyy yyzzzzzz | 11110www(F0-F7) 10xxxxxx 10yyyyyy 10zzzzzz (三个w;六个x;六个y;六个z) | 将由11110开始,接着的字节由10开始 |
以实例来解释utf8编码:
// 假设字符串 '10h我'
var buf = new Buffer('10h我'); // buf: <Buffer 31 30 68 e6 88 91>
// 所以utf8编码的'10h我'最终就是 0x31 0x30 0x68 0xe6 0x88 0x91
// 1 ascii 0001 1111 <-----> 0x31
// 0 ascii 0001 1110 <-----> 0x30
// h ascii 0100 0100 <-----> 0x31
// 我 显然不在ascii码范围内,那么看 0xe6 0x88 0x91 的二进制形式: 1110 0110 1000 1000 1001 0001
// 显然 1110 确认 字元用3个字节表示,且接下来的2个字节以10开头
// 去掉标识,"我" <------> 0110 0010 0001 0001 <------> 0x6211
'10h我'.charCodeAt(3) // 25105
0x6211 === 25105 // true2003年11月UTF-8被RFC 3629重新规范,只能使用原来Unicode定义的区域,U+0000到U+10FFFF。根据规范,以下字节值将无法出现在合法UTF-8序列中:
| 编码(二进制) | 编码(十六进制) | 注释 |
|---|---|---|
| 1100000x | C0, C1 | 过长编码:双字节序列的头字节,但码点 <= 127 |
| 1111111x | FE, FF | 无法达到:7或8字节序列的头字节 |
| 111110xx-1111110x | F8, F9, FA, FB, FC, FD | 被RFC 3629规范:5或6字节序列的头字节 |
| 11110101-1111011x | F5, F6, F7 | 被RFC 3629规范:码点超过10FFFF的头字节 |
function convertBytesToUTF8(bytes, maxBytes) {
var index = 0;
maxBytes = Math.min(maxBytes || bytes.length, bytes.length);
if (bytes[0] === 0xEF && bytes[1] === 0xBB && bytes[2] === 0xBF) {
index = 3;
}
var arr = [];
for (var j = 0; index < maxBytes; j++) {
var byte1 = bytes[index++],
byte2, byte3, byte4, codepoint;
if (byte1 === 0x00) {
break;
} else if (byte1 < 0x80) {
arr[j] = String.fromCharCode(byte1);
} else if (byte1 >= 0xC2 && byte1 < 0xE0) {
byte2 = bytes[index++];
arr[j] = String.fromCharCode(((byte1 & 0x1F) << 6) + (byte2 & 0x3F));
} else if (byte1 >= 0xE0 && byte1 < 0xF0) {
byte2 = bytes[index++];
byte3 = bytes[index++];
arr[j] = String.fromCharCode(((byte1 & 0x0F) << 12) + ((byte2 & 0x3F) << 6) + (byte3 & 0x3F));
} else if (byte1 >= 0xF0 && byte1 < 0xF5) {
byte2 = bytes[index++];
byte3 = bytes[index++];
byte4 = bytes[index++];
codepoint = ((byte1 & 0x07) << 18) + ((byte2 & 0x3F) << 12) + ((byte3 & 0x3F) << 6) + (byte4 & 0x3F) - 0x10000;
arr[j] = String.fromCharCode(
(codepoint >> 10) + 0xD800, (codepoint & 0x3FF) + 0xDC00
);
}
}
return arr.join('');
}
// example
convertBytesToUTF8([0x31, 0x30, 0x68, 0xe6, 0x88, 0x91])
// "10h我"代码中看出需要注意2点:
0xEF,0xBB,0xBF 是 BOM(Byte order mark),UTF8编码允许BOM存在,但不依赖也不推荐使用BOM。不能正确识别BOM时,就会输出。React是目前(2017.04)流行的创建组件化UI的框架,自身有一套完整和强大的生态系统;同时它也是我目前工作中的主力框架,所以学习和理解React是很自然的需求。
本文在翻译React Components, Elements, and Instances的基础上,主要专注理解React的一个核心理念:用Elements Tree描述UI。本文也应该是接下来几片React相关文章的开头,所以更合适的标题可能是:
请注意,阅读本文最好对React有基本的了解,但React新手也应该可以畅通阅读。
现在我们写React应用,相当部分都是在写JSX。
JSX本身是对JavaScript语法的一个扩展,看起来像是某种模板语言,但其实不是。但正因为形似HTML,描述UI就更直观了,也极大地方便了开发;你想如果我们没有HTML,必须手写一堆的document.createElement(),我想前端们肯定已经崩溃了。
不过如果你一直写JSX,并且从来没脱离过JSX,可能某种程度上会阻碍我们理解React。当我们有一个JSX片段,它实际上是调用React API构建了一个Elements Tree:
var profile = <div>
<img src="avatar.png" className="profile" />
<h3>{[user.firstName, user.lastName].join(' ')}</h3>
</div>;借助babel-plugin-transform-react-jsx,上面的JSX将被转译成:
var profile = React.createElement("div", null,
React.createElement("img", { src: "avatar.png", className: "profile" }),
React.createElement("h3", null, [user.firstName, user.lastName].join(" "))
);那么,React.createElement是在做什么?看下相关部分代码:
var ReactElement = function(type, key, ref, self, source, owner, props) {
var element = {
// This tag allow us to uniquely identify this as a React Element
$$typeof: REACT_ELEMENT_TYPE,
// Built-in properties that belong on the element
type: type,
key: key,
ref: ref,
props: props,
// Record the component responsible for creating this element.
_owner: owner,
};
// ...
return element;
};
ReactElement.createElement = function(type, config, children) {
// ...
return ReactElement(
type,
key,
ref,
self,
source,
ReactCurrentOwner.current,
props
);
};看起来,ReactElement.createElement最终返回了一个对象,这个对象大概是这样的形状:
{
type,
key,
props: {
children
}
}非常明显,这就是一个Elements Tree!很好,我们知道了react的render方法是返回一个Elements Tree,react的核心就是围绕Elements Tree做文章。
下面我们就主要讲讲Components,Elements(Tree)和Instances,以及三者之间的关系。
如果你是React的新手,那么之前你可能只接触过组件的类和实例(component classes and instances )。比如,你可能会
创建一个类来声明Button组件,当app运行时,屏幕上可能会有多个Button的实例,每个都有自己的属性和私有状态。这就是传统面向对象的UI编程,那么为什么要引入Elements的概念?
传统UI模型中,你必须自己负责创建和销毁子组件的实例(child component instances):
每个组件实例必须保存自己的DOM nodes和子组件实例的引用,并在对的时间创建,更新,销毁它们。代码的行数将会以可能的状态的数量的 平方 增长,而且组件可以直接访问子组件实例将会使解耦变得困难。
那么,React有什么不同呢?
An element is a plain object describing a component instance or DOM node and its desired properties.
一个元素(element)就是一个纯对象,描述了一个组件实例或DOM node,以及它需要的属性。它仅仅包含这些信息:组件类型,属性(properties),及子元素。
元素不是实例,实际上,它更像是告诉React你需要在屏幕上显示什么的一种方式。它就是一个有2个数据域(field)的不可变描述对象(immutable description object):
{
type: (string | ReactClass),
props: Object
}当元素的type是string时,那么这个元素就表示一个DOM node(type的值就是tagName,props就是attributes)。 这node就是React将渲染的。比如:
{
type: 'button',
props: {
className: 'button button-blue',
children: {
type: 'b',
props: {
children: 'OK!'
}
}
}
}将被渲染成:
<button class='button button-blue'>
<b>
OK!
</b>
</button>注意下元素是怎么嵌套的。当我们想创建元素树时,我们设置children属性。
注意:子元素和父元素都只是描述,并不是实际的实例。当你创建它们的时候,它们并不指向屏幕上的任何东西。 显然,它们比DOM轻量多了,它们只是对象。
此外,元素的type也可以是function或者class(即对应的React Component):
{
type: Button,
props: {
color: 'blue',
children: 'OK!'
}
}An element describing a component is also an element, just like an element describing the DOM node. They can be nested and mixed with each other.
这是React的核心idea:一个描述组件的元素同样是元素,和描述DOM node的元素没什么区别。它们可以互相嵌套和混合。
你可以混合搭配DOM和Component Elements:
const DeleteAccount = () => ({
type: 'div',
props: {
children: [{
type: 'p',
props: {
children: 'Are you sure?'
}
}, {
type: DangerButton,
props: {
children: 'Yep'
}
}, {
type: Button,
props: {
color: 'blue',
children: 'Cancel'
}
}]
}
});或者,如果你更喜欢JSX:
const DeleteAccount = () => (
<div>
<p>Are you sure?</p>
<DangerButton>Yep</DangerButton>
<Button color='blue'>Cancel</Button>
</div>
);这种混合搭配帮助组件可以彼此解耦,因为它们可以仅仅通过组合(composition)就能表达is-a和has-a的关系:
Button是有特定属性(specific properties)的DOM<button>。DangerButton是有特定属性的Button。DeleteAccount在<div>里包含了Button和DangerButton。当React碰到type是function|class时,它就知道这是个组件了,它会问这个组件:"给你适当的props,你返回什么元素(树)?"。
比如当它看到:
{
type: Button,
props: {
color: 'blue',
children: 'OK!'
}
}React会问Button要渲染什么,Button返回:
{
type: 'button',
props: {
className: 'button button-blue',
children: {
type: 'b',
props: {
children: 'OK!'
}
}
}
}React会重复这种过程,直到它知道页面上所有的组件想渲染出什么DOM nodes。
对React组件来说,props是输入,元素树(Elements tree)是输出。
我们选择让React来 创建,更新,销毁 实例,我们用元素来描述它们,而React负责管理这些实例。
声明组件的3种方式:
class,推荐。React.createClass,不推荐。function,类似只有render的class。ReactDOM.render({
type: Form,
props: {
isSubmitted: false,
buttonText: 'OK!'
}
}, document.getElementById('root'));
const Form = ({ isSubmitted, buttonText }) => {
if (isSubmitted) {
// Form submitted! Return a message element.
return {
type: Message,
props: {
text: 'Success!'
}
};
}
// Form is still visible! Return a button element.
return {
type: Button,
props: {
children: buttonText,
color: 'blue'
}
};
};当你调用ReactDOM.render时,React会问Form组件,给定这些props,它要返回什么元素。React会以更简单的基础值逐渐提炼("refine")它对Form组件的理解,这个过程如下所示:
// React: You told me this...
{
type: Form,
props: {
isSubmitted: false,
buttonText: 'OK!'
}
}
// React: ...And Form told me this...
{
type: Button,
props: {
children: 'OK!',
color: 'blue'
}
}
// React: ...and Button told me this! I guess I'm done.
{
type: 'button',
props: {
className: 'button button-blue',
children: {
type: 'b',
props: {
children: 'OK!'
}
}
}
}上面是被React叫做 reconciliation 的过程的一部分。每当你调用ReactDOM.render()或setState()时,都会开始reconciliation过程。在reconciliation结束时,React知道了结果的DOM树,一个如react-dom或 react-native的renderer会应用必须的最小变化来更新DOM nodes(或平台特定的视图,如React Native)。
这种渐进式的提炼(refining)过程也是React应用可以容易优化的原因。如果组件树的某部分大太了,你可以让React跳过这部分的refining,如果相关props没有变化。如果props是 immutable 的话,非常容易比较它们是否变化, 所以React可以和 immutability搭配一起并提高效率。
你可能注意到这篇文章讲了很多关于组件和元素,却没讲实例。这是因为相比传统面向对象的UI框架,在React中实例没那么重要。
仅仅以类声明的组件才有实例,并且你从来不会直接创建它——React为你创建它。尽管有父组件实例访问子组件实例的机制,但这只是在必要的情况下才使用,通常应该避免。
元素(Element)是React的一个核心概念。一般情况下,我们用React.createElement|JSX来创建元素,但不要以对象来手写元素,只要知道元素本质上是对象即可。
本文围绕 Components,Elements和Instances 来讲解了元素,而下一篇文章将借助snabbdom来讲 virtual-dom :怎么从元素生成对应的dom,怎么diff元素来最小更新dom。
知乎上有这样一个问题:为什么node出现之后,各种前端构建工具和手段才如雨后春笋般层出不穷?,里面的答案挺有意思的。其实自从有了Node.js,
Jser们可以脱离浏览器做各种各样有趣的事,在开发中,各种JS库帮助我们改善开发流程,提高开发效率,
比如webpack/babel等等。
今天这里我们就主要讲讲怎么基于Node.js来开发(小)工具,提高我们的工作效率,满足各种实际需要。
The environment is an area that the shell builds every time that it starts a session that contains variables that define system properties.
每当shell新开启一个会话时,shell都会生成environment,environment里都是些定义系统属性的变量。
$ env
TERM_PROGRAM=Apple_Terminal
SHELL=/bin/zsh
USER=creeper
PATH=/Users/creeper/git/depot_tools:/usr/local/sbin:/Users/creeper/.nvm/versions/node/v6.9.0/bin:/usr/local/bin:/usr/bin:/bin:/usr/sbin:/sbin
NVM_NODEJS_ORG_MIRROR=https://npm.taobao.org/dist
...
MANPATH=/Users/creeper/.nvm/versions/node/v6.9.0/share/man:/usr/local/share/man:/usr/share/man:/Applications/Xcode.app/Contents/Developer/Platforms/MacOSX.platform/Developer/SDKs/MacOSX10.12.sdk/usr/share/man:/Applications/Xcode.app/Contents/Developer/usr/share/man:/Applications/Xcode.app/Contents/Developer/Toolchains/XcodeDefault.xctoolchain/usr/share/man
NVM_PATH=/Users/creeper/.nvm/versions/node/v6.9.0/lib/node
NVM_BIN=/Users/creeper/.nvm/versions/node/v6.9.0/bin
_=/usr/bin/env很多程序都会用到这里的变量,比如nvm会用这里的NVM_NODEJS_ORG_MIRROR=https://npm.taobao.org/dist
作为代理服务器地址,去淘宝的源下载node来安装,提高速度。
在environment这么多变量里,有一个变量需要特别注意,就是PATH=/Users/creeper/git/depot_tools:/usr/local/sbin:/Users/creeper/.nvm/versions/node/v6.9.0/bin:/usr/local/bin:/usr/bin:/bin:/usr/sbin:/sbin。
In UNIX / Linux file systems, the human-readable address of a resource is defined by PATH. It is an environmental variable that tells the shell which directories to search for executable files (i.e., ready-to-run programs) in response to commands issued by a user.
PATH指定了Shell从哪些目录去查找执行文件(PATH在windows里可以通过环境变量去设置)。
当我们在shell里输入比如ls时,其实shell会找到/bin/ls来执行。
上面一段提到了可执行文件,在这里我们只讲其中的一块——script文件。任何以shebang line(#!)
开头的文件即可执行的脚本,其中shebang line指定了用什么(解释器)来解释执行脚本。
比如常见的python脚本,你可以看到第一行是这样的:
#!/usr/bin/env python对node.js来说,shebang line通常这么写:
#!/usr/bin/env node对有这行的文件,当你shell里执行./my_script时,系统会调用node来解释执行my_script文件。
注意,shebang line是可以加上参数的,如#!/usr/bin/env node --harmony。
以常见的webpack为例,当你npm i webpack之后,你可以找到这样一个文件node_modules/.bin/webpack,
它即webpack的可执行文件。你可以shell里执行node_modules/.bin/webpack,那么会输出help信息。
那么我们稍微看下node_modules/.bin/webpack这个文件:
#!/usr/bin/env node
/*
MIT License http://www.opensource.org/licenses/mit-license.php
Author Tobias Koppers @sokra
*/
var path = require("path");果然是shebang line加上js代码。
接着上面两段,我们差不多明白用node.js写工具的原理了,和python没什么不同。
但是,我们全局安装的一些npm包,比如grunt/gulp/webpack,为什么可以直接在shell里执行呢,和ls之类一样?
其实就是因为:
/Users/creeper/.nvm/versions/node/v6.9.0/lib/node_modules,可执行文件放在/Users/creeper/.nvm/versions/node/v6.9.0/bin:$ ls -al /Users/creeper/.nvm/versions/node/v6.9.0/bin
drwxr-xr-x 19 creeper staff 646 3 16 16:37 .
drwxr-xr-x 10 creeper staff 340 10 27 20:01 ..
lrwxr-xr-x 1 creeper staff 33 10 27 20:06 cnpm -> ../lib/node_modules/cnpm/bin/cnpm
lrwxr-xr-x 1 creeper staff 43 3 16 16:37 crn-cli -> ../lib/node_modules/@ctrip/crn-cli/index.js当然,这里的路径都是我本机的,不同机器会有不一样的路径。另外,可执行文件用放在 这个词描述可能不准确,这里其实是 软链接(symlink)。
/Users/creeper/.nvm/versions/node/v6.9.0/bin这个路径是在环境变量PATH里的,所以当你crn-cli时,shell可以正确找到这个命令。PATH=/Users/creeper/git/depot_tools:/usr/local/sbin:/Users/creeper/.nvm/versions/node/v6.9.0/bin:/usr/local/bin:/usr/bin:/bin:/usr/sbin:/sbinnpm run command时,我们是在做什么?我们一般的开发中,经常会用到npm run command,比如npm test等等,这里简单补充下。
npm run-script <command> [-- <args>...]可以执行在package.json的scripts中的相应命令。
// 来自 React repo
{
"scripts": {
"build": "grunt build",
"linc": "git diff --name-only --diff-filter=ACMRTUB `git merge-base HEAD master` | grep '\\.js$' | xargs eslint --",
"lint": "grunt lint",
"postinstall": "node node_modules/fbjs-scripts/node/check-dev-engines.js package.json",
"test": "jest",
"flow": "flow"
}
}上面是从React的package.json截出的,当我们在shell里执行npm run build时,其实执行的就是
grunt build。
注意:除了shell已经存在的PATH,npm run会添加node_modules/.bin到PATH里。也就是说,
node_modules/.bin的执行文件是可以直接执行的,不用node_modules/.bin/grunt build这种。
前面讲完了一些前置知识,下面结合实例来讲工具编写,主要是我们组实际用到的 :)
虽然前面讲了一大堆可执行文件相关的,但对一些一次性工作,我们其实可以直接写JS,然后node执行就好了。
这是最简单快捷的。
当我们shell里执行node x.js --args,args可以通过process.argv来访问:
$ node run.js *.png
[ '/Users/creeper/.nvm/versions/node/v6.9.0/bin/node',
'/Users/creeper/Downloads/切图/run.js',
'*.png' ]
$ node run.js test/*.jpg
[ '/Users/creeper/.nvm/versions/node/v6.9.0/bin/node',
'/Users/creeper/Downloads/切图/run.js',
'test/00010_西安_SIA_12_**.jpg',
'test/00012_南京_NKG_15_**.jpg',
'test/00013_无锡_WUX_15_**.jpg',
'test/00015_扬州_YTY_15_**.jpg',
'test/00017_杭州_HGH_16_**.jpg',
'test/00019_舟山_HSN_16_**.jpg' ]可以看到process.argv[0]固定是node本身路径,process.argv[1]是文件路径,process.argv.slice(2)
才是我们输入的参数。
具体到我们这里图片处理(UED有很多图片处理工作):
需求: 有一大堆大图(几百张),请导出640x420, 582×178, 284x178, 178x178, 268x106五种尺寸(中心缩放/切割),
且每种尺寸有高斯模糊和正常两种。
方案: 手动PS处理肯定不行,所以 imagemagick(负责图片处理)+ JS(负责参数和一些额外工作,比如图片分类/改名)。
核心代码:
// ...
const GaussianBlur = `20x8`
const getCmd = (file, size, destFile, gaus) => {
return `convert ${file} -resize "${size}^"${
gaus ? (' -gaussian-blur ' + GaussianBlur) : ''
} -gravity center -crop ${size}+0+0 +repage ${destFile}`
}
// ...使用:
node processImg.js images/**/*.jpg
注: 使用通配符时,你获取的参数是通配符匹配的文件列表(如前面代码所示),如果你想获取原字符串,
请用引号,如node processImg.js "images/**/*.jpg"。
这个是某种程度的css组件开发(专注CSS),一些我们机票部门的公用组件,比如paybar这些,可以通过这个项目有个
公共的最优实现,并在各个应用中保持一致。
以上并没有难点,难点主要在部署:即我们希望每次提交后(gitlab),可以在我们组的服务器同步最新的代码,
有最新的预览,并且这些应该完全自动化的。
代码的同步我们用了gitlab的API(这块是我同事在做),但预览呢?
基于性能原因,第2种当然更好,所以我们选择hook仓库的post-merge(每册服务器本地仓库更新后调用)。
稍微看下post-merge的内容:
#!/bin/sh
cd /usr/share/nginx/html/repos/Dolphin-UI/
npm run build
不能更简单了,但的确做到了自动化和高效。
注: 一个坑,需要注意/usr/share/nginx/html/repos/Dolphin-UI/.git/hooks/post-merge文件的权限,
没有执行权限会导致脚本执行失败。

sugar-cli--npm packagesugar-cli是我们组原型开发(除RN外)的工具,主要提供模版和css编译的功能。
背景和需求: 原来还是基于PHP那一套开发原型,比较笨重;新的开发环境希望基于node.js,有简单
但足够的模板语法,支持一种(或多种)css预处理语言,易于部署(预览)等等。
结合这些需求,最终开发了一个npm包sugar-cli,只要全局安装后,一个命令即可快速开始开发:
postcss/sass/less全支持,完善的sourcemap。这里就不具体描述功能了,下面主要讲讲怎么开发一个cli工具。
核心很简单:代码(含shebang line) + package.json配置。
下面是sugar-cli中sugar static(运行一个静态文件服务器)的实现:
#!/usr/bin/env node
const program = require('commander')
program
.option('-a, --host <host>', 'server host, default to "0.0.0.0"')
.option('-p, --port <port>', 'server port, default to 2333')
.on('--help', () => {
console.log(colors.green(' Examples:'))
console.log()
console.log(colors.gray(' $ sugar static'))
})
.parse(process.argv)
const root = program.args[0]
serveStatic(root, program.host, program.port)
// 这里省略 serveStatic 具体实现然后,我们需要在package.json中配置:
"bin": {
"sugar": "bin/sugar.js"
},bin是个map,其中key是command,value
是对应可执行文件。当全局安装时,npm会 symlink 这个可执行文件到 prefix/bin;本地安装时,
则 symlink 这个可执行文件到 ./node_modules/.bin/。 (这一段可配合上面 全局安装的npm包为什么可以在shell里直接使用? 一起食用)。
结合这两个,我们即可轻松开发一个前端工具。剩下的我们可以发布到npm,然后请同学们试用即可。

Thanks
有问题直接问我即可。
时值公司全面切换到HTTPS和HTTP/2,讨论HTTP/2有了更现实的意义。以前也断断续续看了些文章,做了些了解,这里算作一个学习和总结吧。
本文定位入门级别,分作两大块:
本文参考了一些博文和资料,后面已列出,感谢他们的分享。
HTTP/2 is a replacement for how HTTP is expressed “on the wire.” It is not a ground-up rewrite of the protocol; HTTP methods, status codes and semantics are the same, and it should be possible to use the same APIs as HTTP/1.x (possibly with some small additions) to represent the protocol.
HTTP/2是现行HTTP协议(HTTP/1.x)的替代,但它不是重写,HTTP方法/状态码/语义都与HTTP/1.x一样。HTTP/2基于SPDY3,专注于性能,最大的一个目标是在用户和网站间只用一个连接(connection)。
HTTP/2由两个规范(Specification)组成:
我们知道,影响一个HTTP网络请求的因素主要有两个:带宽和延迟。在今天的网络情况下,带宽一般不再是瓶颈,所以我们主要讨论下延迟。延迟一般有下面几个因素:
说完背景,我们讨论下HTTP/1.x中到底存在哪些问题?
连接无法复用:连接无法复用会导致每次请求都经历三次握手和慢启动。三次握手在高延迟的场景下影响较明显,慢启动则对文件类大请求大量小文件请求影响较大(没有达到最大窗口请求就被终止)。
Head-Of-Line Blocking:导致带宽无法被充分利用,以及后续健康请求被阻塞。HOLB是指一系列包(package)因为第一个包被阻塞;HTTP/1.x中,由于服务器必须按接受请求的顺序发送响应的规则限制,那么假设浏览器在一个(tcp)连接上发送了两个请求,那么服务器必须等第一个请求响应完毕才能发送第二个响应——HOLB。更详细解释见下面
协议开销大:HTTP/1.x中header内容过大(每次请求header基本不怎么变化),增加了传输的成本。
安全因素:HTTP/1.x中传输的内容都是明文,客户端和服务端双方无法验证身份。
因为HTTP/1.x的问题,人们提出了各种解决方案。比如希望复用连接的长链接/http long-polling/websocket等等,解决HOLB的Domain Sharding(域名分片)/inline资源/css sprite等等。
不过以上优化都绕开了协议,直到谷歌推出SPDY,才算是正式改造HTTP协议本身。降低延迟,压缩header等等,SPDY的实践证明了这些优化的效果,也最终带来HTTP/2的诞生。
1. 新的二进制格式(Binary Format)
http1.x诞生的时候是明文协议,其格式由三部分组成:start line(request line或者status line),header,body。要识别这3部分就要做协议解析,http1.x的解析是基于文本。基于文本协议的格式解析存在天然缺陷,文本的表现形式有多样性,要做到健壮性考虑的场景必然很多,二进制则不同,只认0和1的组合。基于这种考虑http2.0的协议解析决定采用二进制格式,实现方便且健壮。

http2的格式定义十分高效且精简。length定义了整个frame的大小,type定义frame的类型(一共10种),flags用bit位定义一些重要的参数,stream id用作流控制,payload就是request的正文。

2. Header压缩
http1.x的header由于cookie和user agent很容易膨胀,而且每次都要重复发送。
http2.0使用encoder来减少需要传输的header大小,通讯双方各自cache一份header fields表,既避免了重复header的传输,又减小了需要传输的大小。高效的压缩算法可以很大的压缩header,减少发送包的数量从而降低延迟。
3. 流(stream)和多路复用(MultiPlexing)
什么是stream?
Multiplexing of requests is achieved by having each HTTP request/response exchange associated with its own stream. Streams are largely independent of each other, so a blocked or stalled request or response does not prevent progress on other streams.
A "stream" is an independent, bidirectional sequence of frames exchanged between the client and server within an HTTP/2 connection.
A client sends an HTTP request on a new stream, using a previously unused stream identifier. A server sends an HTTP response on the same stream as the request.
Multiplexing of requests is achieved by having each HTTP request/response exchange associated with its own stream.
翻译下,stream就是在HTTP/2连接上的双向帧序列。每个http request都会新建自己的stream,response在同一个stream上返回。
多路复用(MultiPlexing),即连接共享。之所以可以复用,是因为每个stream高度独立,堵塞的stream不会影响其它stream的处理。一个连接上可以有多个stream,每个stream的frame可以随机的混杂在一起,接收方可以根据stream id将frame再归属到各自不同的request里面。
3.1 流量控制(Flow Control)
类似TCP协议通过sliding window的算法来做流量控制,http2.0使用 WINDOW_UPDATE frame 来做流量控制。每个stream都有流量控制,这保证了数据接收方可以只让自己需要的数据被传输。

3.2 流优先级(Stream Priority)
每个流可以设置优先级。优先级的目标是允许终端高速对端(当对端处理并发流时)怎么分配资源。
更重要的是,当传输能力有限时,优先级可以用来挑选哪些流(高优先级)优先传输——这是优化浏览器渲染的关键,即服务端负责设置优先级,使重要的资源优先加载,加速页面渲染。
4. Server Push
Server Push即服务端能通过push的方式将客户端需要的内容预先推送过去,也叫“cache push”。

相比ES3到ES5,ES5到ES6是更重大的升级,既有大量语法糖,如Arrow Function、Template string等等,更有模块化、class、generator等等强大的新特性。相信ES6会极大的改变我们编写JS的方式,而且ES6(ES2015)已经在2015年6月17日发布,所以说可以开始学习ES6了。
本文是我学习ES6的笔记,大部分是概念摘要,代码演示等等,以弄清概念为要。
另,学习资料来源(会及时更新):
for of和迭代器ES5中,forEach可以用来遍历数组元素,但它的缺陷是不能使用break语句中断循环,也不能使用return语句返回到外层函数。
for (let value of [1, 2, 3]) {
console.log(value); //输出 1 2 3
}forEach()不同的是,它可以正确响应break、continue和return语句for-of循环不仅支持数组,还支持大多数类数组对象,例如DOM的NodeList对象。它也支持字符串:
for (let chr of "abc12") {
console.log(chr); // 输出 "a" "b" "c" "1" "2"
}另外还支持Map和Set对象的遍历。
正如其它语言中的for/foreach语句一样,for-of循环语句通过方法调用来遍历各种集合。数组、Map、Set以及我们讨论的其它对象有一个共同点,它们都有一个迭代器方法。
任何对象都可以有/添加迭代器方法。
就像为对象添加myObject.toString()方法,JS知道怎么把这个对象转化为字符串;你为对象添加迭代器方法myObject[Symbol.iterator](),JS也就知道了如何遍历这个对象。
[Symbol.iterator]语法看起来很怪。Symbol是ES6引入的新类型,标准定义了全新的symbol(如Symbol.iterator),来保证不与任何已有代码产生冲突。
任何有迭代器方法[Symbol.iterator]()的对象都是可迭代的。
迭代器方法[Symbol.iterator]()返回一个迭代器对象。迭代器对象可以是任何有next()方法的对象。for-of循环将重复调用这个方法。
最简单的迭代器对象:
var zeroesForeverIterator = {
[Symbol.iterator]: function() {
return this;
},
next: function() {
return {
done: false,
value: 0
};
}
};每一次调用next()方法,它都返回相同的结果,告诉for-of循环:(a) 我们尚未完成迭代;(b)下一个值为0。这意味着for (value of zeroesForeverIterator) {}是一个无限循环。当然,一般来说迭代器不会如此简单。
原文: Redux 官方文档 EN | Redux 官方文档 CN
1. 有删减重组,需要细读的请直接浏览官方文档。
2. 专注 Redux 核心概念和开发流程,希望可以通过 15-20 分钟的阅读,对 Redux 有比较全面的了解,可以快速上手。
Redux is a predictable state container for JavaScript apps.
Redux 是一个给JavaScript app使用的可预测的状态容器。
为什么需要Redux?(动机)
JavaScript单页应用越来越复杂,代码必须管理远比以前多的状态(state)。这个状态包括服务端返回数据,缓存数据,本地创建的数据(未同步到服务器);也包括UI状态,如需要管理激活的路由,选中的标签,是否显示加载动效或者分页器等等。
管理不断变化的状态是很难的。如果一个 model 可以更新另一个 model ,那么一个 view 也可以更新一个 model 并导致另一个 model 更新,然后相应地,可能导致另一个 view 更新 —— 你理不清你的 app 发生了什么,失去了对 state 什么时候,为什么,怎么变化的控制 。当系统变得 不透明和不确定,就很难去重现 bug 和增加 feature 了。
通过 限制何时以及怎么更新,Redux 试图让 state 的变化可以预测 。
这里可以配合阅读 You Might Not Need Redux : Redux 的引入并不一定改善开发体验,必须权衡它的限制与好处。
Redux本身很简单,我们下面首先阐述它的核心概念和三大原则。
想象一下用普通 JavaScript 对象 来描述 app 的 state:
// 一个 todo app 的 state 可能是这样的:
{
todos: [{
text: 'Eat food',
completed: true
}, {
text: 'Exercise',
completed: false
}],
visibilityFilter: 'SHOW_COMPLETED'
}这个对象就像没有 setter 的 model,所以其它部分的代码不能随意修改它而造成难以复现的 bug 。
如果要改变 state ,我们必须 dispatch 一个 action。action 是描述发生了什么的普通 JavaScript 对象。
// 下面都是action:
{ type: 'ADD_TODO', text: 'Go to swimming pool' }
{ type: 'TOGGLE_TODO', index: 1 }
{ type: 'SET_VISIBILITY_FILTER', filter: 'SHOW_ALL' }强制 每个 change 都必须用 action 来描述,可以让我们清楚 app 里正在发生什么, state 是为什么改变的。最后,把 state 和 actions 联结起来,我们需要 reducer 。
reducer 就是函数,以之前的 state 和 action 为参数,返回新的 state :
// 关注 visibilityFilter 的 reducer
function visibilityFilter(state = 'SHOW_ALL', action) {
if (action.type === 'SET_VISIBILITY_FILTER') {
return action.filter;
} else {
return state;
}
}
function todoApp(state = {}, action) {
return {
visibilityFilter: visibilityFilter(state.visibilityFilter, action)
};
}以上就是 Redux 的核心概念,注意到我们并没有用任何 Redux 的 API,没加入任何 魔法。 Redux 里有一些工具来简化这种模式,但是主要的想法是描述如何根据这些 action 对象来更新 state。
整个应用的 state 被储存在一棵 object tree 中,并且这个 object tree 只存在于唯一一个 store 中。
console.log(store.getState())
/* Prints
{
visibilityFilter: 'SHOW_ALL',
todos: [
{
text: 'Consider using Redux',
completed: true,
},
{
text: 'Keep all state in a single tree',
completed: false
}
]
}
*/改变 state 的唯一方式是触发 (emit) action,action 是描述发生了什么的对象。
这确保了视图和网络请求等都不能直接修改 state,相反它们只能表达想要修改的意图。因为所有的修改都被集中化处理,且严格按照一个接一个的顺序执行,因此不用担心 race condition 的出现。
store.dispatch({
type: 'COMPLETE_TODO',
index: 1
})
store.dispatch({
type: 'SET_VISIBILITY_FILTER',
filter: 'SHOW_COMPLETED'
})为描述 action 怎么改变 state tree,你要编写 reducers。
Reducer 只是一些纯函数,它接收之前的 state 和 action,并返回新的 state。刚开始你可能只需要一个 reducer ,但随着应用变大,你会需要拆分 reducer 。
Action 就是把数据从应用(这些数据有可能是服务器响应,用户输入或其它非 view 的数据)发送到 store 的有效载荷。 它是 store 数据的唯一来源,你通过 store.dispatch(action) 来发送它到 store。
添加新 todo 任务的 action 是这样的:
const ADD_TODO = 'ADD_TODO'
{
type: ADD_TODO,
text: 'Build my first Redux app'
}Action 本质上是 JavaScript 普通对象。Action 必须有一个字符串类型的 type 字段来表示将要执行的动作。多数情况下,type 会被定义成字符串常量。当应用规模越来越大时,建议使用单独的模块/文件来存放 action。
除了 type 字段外,action 对象的结构完全由你自己决定。但通常,我们希望减少 action 中传递的数据。
Action 创建函数 就是生成 action 的方法。“action” 和 “action 创建函数” 这两个概念很容易混在一起,使用时最好注意区分。
// 生成一个 ADD_TODO 类型的 action
function addTodo(text) {
return {
type: ADD_TODO,
text
}
}Action 只是描述了有事情发生了这一事实,并没有指明应用如何更新 state。而这正是 reducer 要做的事情。
在 Redux 应用中,所有的 state 都被保存在一个单一对象中。最好可以在写代码之前想好 state tree 应该是什么形状的。
通常,这个 state tree 需要存放一些数据,以及一些 UI 相关的 state。这样做没问题,但尽量把数据与 UI 相关的 state 分开。
// todo app 的 state
{
visibilityFilter: 'SHOW_ALL',
todos: [
{
text: 'Consider using Redux',
completed: true,
},
{
text: 'Keep all state in a single tree',
completed: false
}
]
}有了 state 结构后,我们可以来写 reducer 了。 reducer 就是一个纯函数,接收旧的 state 和 action,返回新的 state。
(previousState, action) => newState保持 reducer 纯净非常重要。永远不要在 reducer 里做这些操作:
Date.now() 或 Math.random()。在高级篇里会介绍如何执行有副作用的操作。现在只需要记住 reducer 一定要保持纯净。只要传入参数相同,返回计算得到的下一个 state 就一定相同。没有特殊情况、没有副作用,没有 API 请求、没有变量修改,单纯执行计算。
import { VisibilityFilters } from './actions'
function todoApp(state = initialState, action) {
switch (action.type) {
case SET_VISIBILITY_FILTER:
return Object.assign({}, state, {
visibilityFilter: action.filter
})
case ADD_TODO:
return Object.assign({}, state, {
todos: [
...state.todos,
{
text: action.text,
completed: false
}
]
})
case TOGGLE_TODO:
return Object.assign({}, state, {
todos: state.todos.map((todo, index) => {
if(index === action.index) {
return Object.assign({}, todo, {
completed: !todo.completed
})
}
return todo
})
})
default:
return state
}
}注意:
Object.assign({}, ...) 新建了一个副本。default 情况下返回旧的 state。 遇到未知的 action 时,一定要返回旧的 state。我们看到,多个 action 下,reducer 开始变得复杂。是否可以更通俗易懂?这里的 todos 和 visibilityFilter 的更新看起来是相互独立的,我们可以尝试拆分到单独的函数里。
function todos(state = [], action) {
switch (action.type) {
case ADD_TODO:
return [
...state,
{
text: action.text,
completed: false
}
]
case TOGGLE_TODO:
return state.map((todo, index) => {
if (index === action.index) {
return Object.assign({}, todo, {
completed: !todo.completed
})
}
return todo
})
default:
return state
}
}
function todoApp(state = initialState, action) {
switch (action.type) {
case SET_VISIBILITY_FILTER:
return Object.assign({}, state, {
visibilityFilter: action.filter
})
case ADD_TODO:
case TOGGLE_TODO:
return Object.assign({}, state, {
todos: todos(state.todos, action)
})
default:
return state
}
}注意 todos 依旧接收 state,但它变成了一个数组!现在 todoApp 只把需要更新的一部分 state 传给 todos 函数,todos 函数自己确定如何更新这部分数据。这就是所谓的 reducer 合成,它是开发 Redux 应用最基础的模式。
现在更进一步,把 visibilityFilter 独立出去。那么我们可以有个主 reducer,它调用多个子 reducer 分别处理 state 中的一部分数据,然后再把这些数据合成一个大的单一对象。主 reducer 不再需要知道完整的 initial state。初始时,如果传入 undefined, 子 reducer 将负责返回它们(负责部分)的默认值。
// 彻底地拆分:
function todos(state = [], action) {
switch (action.type) {
case ADD_TODO:
return [
...state,
{
text: action.text,
completed: false
}
]
case TOGGLE_TODO:
return state.map((todo, index) => {
if (index === action.index) {
return Object.assign({}, todo, {
completed: !todo.completed
})
}
return todo
})
default:
return state
}
}
function visibilityFilter(state = SHOW_ALL, action) {
switch (action.type) {
case SET_VISIBILITY_FILTER:
return action.filter
default:
return state
}
}
function todoApp(state = {}, action) {
return {
visibilityFilter: visibilityFilter(state.visibilityFilter, action),
todos: todos(state.todos, action)
}
}注意每个 reducer 只负责管理全局 state 中它负责的一部分。每个 reducer 的 state 参数都不同,分别对应它管理的那部分 state 数据。
当应用越来越复杂,我们还可以将拆分后的 reducer 放到不同的文件中, 以保持其独立性并用于专门处理不同的数据域。
最后,Redux 提供了 combineReducers() 工具来做上面 todoApp 做的事情。可以用它这样重构 todoApp:
import { combineReducers } from 'redux';
const todoApp = combineReducers({
visibilityFilter,
todos
})
// 完全等价于
function todoApp(state = {}, action) {
return {
visibilityFilter: visibilityFilter(state.visibilityFilter, action),
todos: todos(state.todos, action)
}
}前面两小节中,我们学会了使用 action 来描述“发生了什么”,和使用 reducers 来根据 action 更新 state 的用法。
Store 就是把它们联系到一起的对象。Store 有以下职责:
getState() 方法获取 state;dispatch(action) 方法更新 state;subscribe(listener) 注册监听器;subscribe(listener) 返回的函数注销监听器。再次强调一下 Redux 应用只有一个 单一 的 store。当需要拆分数据处理逻辑时,你应该使用 reducer 组合 而不是创建多个 store。
根据已有的 reducer 来创建 store 是非常容易的。在前面我们使用 combineReducers() 将多个 reducer 合并成为一个。现在我们将其导入,并传给 createStore()。
import { createStore } from 'redux'
import todoApp from './reducers'
let store = createStore(todoApp)你可以把初始状态 intialState 作为第二个参数传给 createStore()。这对开发同构应用时非常有用,服务器端 redux 应用的 state 结构可以与客户端保持一致, 那么客户端可以将从网络接收到的服务端 state 直接用于本地数据初始化。
let store = createStore(todoApp, window.STATE_FROM_SERVER)现在我们已经创建好了 store ,可以验证一下:
import { addTodo, toggleTodo, setVisibilityFilter, VisibilityFilters } from './actions'
// 打印初始状态
console.log(store.getState())
// 每次 state 更新时,打印日志
// 注意 subscribe() 返回一个函数用来注销监听器
let unsubscribe = store.subscribe(() =>
console.log(store.getState())
)
// 发起一系列 action
store.dispatch(addTodo('Learn about actions'))
store.dispatch(addTodo('Learn about reducers'))
store.dispatch(addTodo('Learn about store'))
store.dispatch(toggleTodo(0))
store.dispatch(toggleTodo(1))
store.dispatch(setVisibilityFilter(VisibilityFilters.SHOW_COMPLETED))
// 停止监听 state 更新
unsubscribe();严格的单向数据流 是 Redux 架构的设计核心。
这意味着应用中所有的数据都遵循相同的生命周期,这样可以让应用变得更加可预测且容易理解。同时也鼓励做数据范式化,这样可以避免使用多个且独立的无法相互引用的重复数据。
Redux 应用中数据的生命周期遵循下面 4 个步骤:
调用 store.dispatch(action)
Redux store 调用传入的 reducer 函数。
根 reducer 应该把多个子 reducer 输出合并成一个单一的 state 树。
Redux store 保存了根 reducer 返回的完整 state 树。
这个新的树就是应用的下一个 state!所有订阅 store.subscribe(listener) 的监听器都将被调用;监听器里可以调用 store.getState() 获得当前 state。
首先强调一下:Redux 和 React 之间没有关系。Redux 支持 React、Angular、Ember、jQuery 甚至纯 JavaScript。
尽管如此,Redux 还是和 React 和 Deku 这类框架搭配起来用最好,因为这类框架允许你以 state 函数的形式来描述界面,Redux 通过 action 的形式来发起 state 变化。
Redux 自身并不包含对 React 的绑定库,我们需要单独安装 react-redux。
绑定库是基于 容器组件和展示组件相分离 的开发**。建议先读完这篇文章。
| 展示组件 | 容器组件 | |
|---|---|---|
| 作用 | 描述如何展现(骨架、样式) | 描述如何运行(数据获取、状态更新) |
| 直接使用 Redux | 否 | 是 |
| 数据来源 | props | 监听 Redux state |
| 数据修改 | 从 props 调用回调函数 | 向 Redux 派发 actions |
| 调用方式 | 手动 | 通常由 React Redux 生成 |
技术上讲,我们可以手动用 store.subscribe() 来编写容器组件,但这就无法使用 React Redux 做的大量性能优化了。一般使用 React Redux 的 connect() 方法来生成容器组件。(不必为了性能而手动实现 shouldComponentUpdate 方法)
还记得前面 设计 state 根对象的结构 吗?现在就要定义与它匹配的界面的层次结构。这不是 Redux 相关的工作,React 开发**在这方面解释的非常棒。
展示组件: 纯粹的UI组件,定义外观而不关心数据怎么来,怎么变。传入什么就渲染什么。
容器组件: 把展示组件连接到 Redux。监听 Redux store 变化并处理如何过滤出要显示的数据。
其它组件 有时很难分清到底该使用容器组件还是展示组件,并且组件并不复杂,这时可以混合使用。
省略其它部分,主要讲讲容器组件一般怎么写。
import { connect } from 'react-redux'
// 3. connect 生成 容器组件
const ContainerComponent = connect(
mapStateToProps,
mapDispatchToProps
)(PresentationalComponent)
// 2. mapStateToProps 指定如何把当前 Redux store state 映射到展示组件的 props 中
const getVisibleTodos = (todos, filter) => {
switch (filter) {
case 'SHOW_ALL':
return todos
case 'SHOW_COMPLETED':
return todos.filter(t => t.completed)
case 'SHOW_ACTIVE':
return todos.filter(t => !t.completed)
}
}
const mapStateToProps = (state) => {
return {
todos: getVisibleTodos(state.todos, state.visibilityFilter)
}
}
// 1. mapDispatchToProps() 方法接收 dispatch() 方法并返回期望注入到展示组件的 props 中的回调方法。
const mapDispatchToProps = (dispatch) => {
return {
onTodoClick: (id) => {
dispatch(toggleTodo(id))
}
}
}
// 可以使用 Redux 的 bindActionCreators 把所有的暴露出来的 actionCreators 转成方法注入 props
export default ContainerComponentconnect 本身还是很明确的,指定我们注入哪些 data 和 function 到展示组件的 props ,给展示组件使用。
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.





