[译] [PJA] [508] 基于 CommonJS、npm、Grunt 和 Browserify 构建客户端代码
Building Client-Side Code With CommonJS, npm, Grunt, and Browserify
基于 CommonJS、npm、Grunt 和 Browserify 构建客户端代码
There are a variety of competing standards for module management with JavaScript, but due to the popularity of Node, by far the most established is npm & CommonJS. There have been efforts to create a similar combination of features for the client-side, including AMD, Yeoman, and Bower, but none of them can compete with the simplicity and package availability of npm and CommonJS modules.
市面上有很多种相互竞争的 JavaScript 模块管理方案,不过由于 node 的流行,目前看来 npm 和 CommonJS 已经成为事实上的标准。于是,也有人在试图在客户端打造一个类似的功能组合,这其中包括 AMD、Yeoman 和 Bower,但它们在易用性和包的丰富程度方面还无法与 npm 和 CommonJS 的模块系统相媲美。
To demonstrate, take a look at how you might build a minimal client-side guestlist app (just in case you need a bouncer at your birthday party).
下面我们就来演示一下,怎样构建一款精简的、纯客户端的“来宾清单”应用(假设你的生日聚会有保镖守门)。
Defining the App
定义你的应用
Most new software projects use agile development methods to produce quick software creation and enhancement iterations. In agile software, the time between releases is measured in days or weeks rather than months or years. To learn more about agile, see The Art of Agile Development: Pragmatic guide to agile software development, by James Shore, Chromatic.
新的软件项目大多采用“敏捷开发”方式来提高开发速度和迭代频率。在敏捷开发中,版本更迭的周期往往只是数天或数周,而不是相隔几个月或几年。如果你想进一步了解敏捷开发,参见由 James Shore 和 Chromatic 编写的《The Art of Agile Development: Pragmatic guide to agile software development》一书。
Typically when you set out to build an app, you'll start with a list of user stories. You can use those scenarios to come up with acceptance criteria, which can be further distilled into functional unit tests.
通常当你着手构建一款应用时,你应该从一系列 用户故事(User Story)开始。你可以从这些场景中总结出 验收准则,它们可以进一步提练为功能性的单元测试。
A user story is a short, simple description of some action that your user might want to perform. For example, "As an event organizer, I want to check arriving guests against the guestlist." User stories should always contain a role along with the story. Answer the questions, "who is performing the action?" and "what is the user trying to accomplish?"
用户故事实际上是一种简短描述,它勾勒出用户想要完成的某些动作。比如这样:“作为一个活动的组织者,我想通过这个来宾清单来核对客人的出席情况”。用户故事必须要有一个角色贯穿始终。要把这些问题表述清楚:“谁来完成这个动作”以及“用户想要完成什么任务”。
To express this example story in code, you'll need a list element with clickable links in list items. The unit tests might look something like this:
为了用代码来描述这些需求,你需要有一个列表元素,每个列表项还需要包含可点击的链接。好的,单元测试看起来可能是这样的:
Example 5-2. guestlist/test/test.js
示例 5-2. guestlist/test/test.js
var $list = $('#guestlist-view'),
checkedinClass = 'icon-check',
guestSelector = '.guest';
test('Guestlist', function () {
ok($list.length,
'List element should have guests.');
});
test('Guests', function () {
// Grab the first guest from the list
// 从列表中抓取第一位客人
var $guest = $($list.find(guestSelector)[0]),
guestExists = !!$guest[0];
// Simulate click
// 模拟点击操作
$guest.click();
ok($guest.hasClass(checkedinClass),
'Should be checked on click');
$guest.click();
// To avoid a false positive, make sure
// you have a guest element to test against.
// 在个测试中,需要先确保操作对象是存在的,以免出现误报
ok(guestExists && !$guest.hasClass(checkedinClass),
'Should toggle off when clicked again');
});You'll need to include that in your QUnit HTML file:
然后你需要在 QUnit HTML 文件中加入以下代码:
Example 5-3. guestlist/test/index.html
示例 5-3. guestlist/test/index.html
<!DOCTYPE html>
<html>
<head>
</head>
<body>
<section>
<h1 id="qunit-header">QUnit Test Suite</h1>
<h2 id="qunit-banner"></h2>
<div id="qunit-testrunner-toolbar"></div>
<h2 id="qunit-userAgent"></h2>
<ol id="qunit-tests"></ol>
</section>
<section id="container"></section>
<script src="jquery.js"></script>
<script src="qunit.js"></script>
<script src="../public/app.js"></script>
<script src="test.js"></script>
<link href="qunit.css" rel="stylesheet"></style>
</body>
</html>
These tests will obviously fail at first. That's a good thing. If you can see your tests fail before you make them pass, you eliminate the possibility that your test results are showing you false positives. For this reason, TDD (Test Driven Development) proponents advocate writing your unit tests before you implement the code that they're written against. Because you're writing from an API user perspective when you write tests first, using test driven development forces you to write more modular, testable code. You may also notice that your APIs are easier to use because you're not worried about implementation details when you write your tests -- you won't accidentally leak implementation details into your APIs.
这些测试在第一次运行时显然会失败,不过这并不是坏事。因为,如果开始的测试结果是失败的,然后你一步步地让它们一条条通过,这就说明这些单元测试是可信的,并没有误报。基于这个原因, TDD(测试驱动开发)的支持者们主张在编写功能代码之前,先为这些代码编写单元测试。因为如果你先写测试代码,你就会从一个 API 用户的角度来做开发——换句话说,使用测试驱动开发强迫你写出更加模块化、更易于测试的代码。你可能也会发现,你写出来的 API 会更好用,因为你在写测试时并不关注实现的细节,这意味着你不会无意中把实现细节泄露到 API 中。
In fact, while I was writing this example, I started with the tests above, and then decided to implement the features. I was tempted to use some Twitter Bootstrap controls out of the box to implement my styles, but that would have forced me to expose unnecessary markup details in the API because Bootstrap makes assumptions about the tags you'll use to implement controls. As a result, I adapted the stylesheet to pass the tests, and the API is better for it. Had I not written failing tests first, I might have accepted the extra markup, and over-complicated the example, and then written tests that passed against the inferior implementation.
我在写这个示例的时候,事实上也是先从上面的测试代码入手,然后再开始完成具体功能的。在进入功能开发阶段时,我偷了个懒,引用了一些现成的 Twitter Bootstrap 控件来帮助我搞定样式问题。但我发现,这样一来,我就不得不把一些不必要的结构层细节暴露到 API 中,因为 Bootstrap 在实现控件时设立了一套结构层的约定。最终,我通过修改样式表的方法来通过测试(而不是去修改测试代码或 API),而 API 因此变得更好了(译注:这里的 API 不仅仅是指 JavaScript 方法,也包括事先定好的 CSS 类名或 HTML 标记)。如果我不是先写出了这些测试,我可能就会接受那些额外的结构层标签,并且把这个示例过度复杂化,然后又要为这个臃肿的实现来编写额外的测试代码。
(译注:作者这样做是为了避免单元测试和结构层发生不必要的耦合并增加不必要的复杂度。而且作者一直在强调一个原则:“先写单元测试,再做功能开发”,为了后者的便利而回头去修改前者,有违这个原则。不过在实际开发中,大家可以适当取舍,毕竟调样式也是需要成本的啊。)
[$]
Twitter Bootstrap is a popular CSS framework that is sometimes useful for prototyping web applications quickly. It's a good idea to play with it and see if it would be useful to you. Remember though that it's designed to be tweaked and customized. Don't feel like you have to conform to the default markup and classes if they don't fit your particular use-case.
Twitter Bootstrap 是一个流行的 CSS 框架,当你需要快速实现一个 web app 的原型时,它会很好用。值得花点时间来研究一下,看它是不是合你的胃口。不过别忘了它天生是可以微调和自定义的。如果它的标签和类名约定跟你的特定应用场景有冲突,不要以为你只能迁就它。
There's a running joke about how many sites look the same because they use all the same Bootstrap styles and controls. You may want to mix it up a little. There's an interesting blog post on the topic called, "Customize Twitter Bootstrap To Not Look Bootstrap-y" by Antonin Januska.
最近流行一个笑话,说的是现在的网站看起来千篇一律,原因是它们都在用 Bootstrap 的样式和控件。你可能希望自己能稍微有点儿与众不同。有一篇有趣的博文就是专门说这个的,是 Antonin Januska 写的《怎样把 Twitter Bootstrap 整得不那么俗》。
Time to see the test output from QUnit:
我们该看一下 QUnit 的测试输出了:

Figure 5-3. Failing QUnit Screenshot
图 5-3. 失败的 QUnit 截图
Failing tests will be listed in red. To make the tests turn green, you'll need to implement the features. Normally it's wise to break the code up into separate concerns. There's a lot more on that topic in Chapter 6. In this case, you'll separate presentation concerns from data management. The data will come from a stubbed model module named guestlistmodel.js. For now it will just return some hard-coded names. You can implement loading and saving later:
失败的测试会显示为红色。如果想让测试结果变绿,你需要把这些特性开发完成。一般来说,把代码拆解为分离的关注点是一个明智之举。我们会在 第六章 详细讨论这个话题。在这里,你将从数据管理中剥离出表现层的关注点。数据取自一个名为 guestlistmodel.js 的独立的模型模块(译注:“模型”一词通常表示以一定方式组织的数据源)。目前它只会返回一些事先写好的名字,你可以稍后自己实现增删改之类的功能:
Example 5-4. guestlist/src/guestlistmodel.js
示例 5-4. guestlist/src/guestlistmodel.js
var api = {
load: function load() {
return [
'Jimi Hendrix',
'Billie Holiday',
'Nina Simone',
'Jim Morrison',
'Duke Ellington',
'John Bonham'
];
}
};
module.exports = api;As you can see, this file is pretty straightforward. It just defines an api object and sets it on module.exports to expose it to other modules in accordance with the CommonJS specification.
如你所见,这个文件非常直接了当。它仅仅定义了一个 api 对象,然后通过 module.exports 暴露给其它模块,这与 CommonJS 的模块规范保持一致。
The code to manipulate the list DOM elements will go into a file named guestlistview.js:
接下来,负责 DOM 操作的代码将写进 guestlistview.js 文件中:
Example 5-5. guestlist/src/guestlistview.js
示例 5-5. guestlist/src/guestlistview.js
var $ = require('jquery-browserify'),
checkedinClass = 'icon-check',
listClass = 'dropdown-menu',
guestClass = 'guest',
toggleCheckedIn = function toggleCheckedIn(e) {
$(this).toggleClass(checkedinClass);
},
$listView = $('<ol>', {
id: 'guestlist-view',
'class': listClass
}).on('click', '.' + guestClass, toggleCheckedIn),
render = function render(guestlist) {
$listView.empty();
guestlist.forEach(function (guest) {
$guest = $('<li class="' + guestClass + '">' +
'<span class="name">' + guest +
'</span></li>');
$guest.appendTo($listView);
});
return $listView;
},
api = {
render: render
};
module.exports = api;This is the file doing all the work. First it uses .require() to get a reference to jQuery, and sets a few self-documenting variable names. The toggleCheckedIn() function is an event handler for the click event.
这就是这个文件完成了所有的核心功能。首先它使用 require() 来获取对 jQuery 的引用,然后定义了一些很直观的变量名。那个 toggleCheckedIn() 函数是一个事件处理函数,用于处理 click 事件。
The list element gets added. Note that it's using jQuery's .on() method to delegate the click events. .on() is the recently recommended way to hook up event handlers in jQuery. It replaces the deprecated .bind(), .live(), and .delegate() methods with a simplified syntax, and more consistent signature.
接下来,列表元素被添加到页面中。请注意它使用的是 jQuery 的 .on() 方法来委托点击事件。.on() 是目前 jQuery 推荐绑定事件处理函数的方式。它的语法更简单,而且传参方式更统一,取代了过时的 .bind()、.live() 和 .delegate() 方法。
[$]
By delegating to the parent ordered list element, you can replace, remove, and add children to the list without worrying about removing and replacing event listeners. There won't be any memory leaks, and you don't have to wait until the whole list is rendered before you attach the listener. If you're hooking up listeners to DOM elements, most of the time, delegating to an ancestor is the right approach.
通过在有序列表(父元素)身上进行事件委托,你可以在列表中替换、移除、增加列表项,而不用操心增减相应的事件监听器。这种方式一来避免了内存泄露,二来不需要在等待整个列表渲染完成之后再绑定监听器。如果你需要在多个 DOM 元素上绑定监听器,那么委托给一个祖先元素往往是正确的选择。
The .render() method takes an array of guest names, iterates over each one, and adds a corresponding list item to the $listView element. It then returns the rendered element to the calling function.
.render() 方法可以接收一个数组,并遍历数组中各位来宾的姓名,然后把对应的列表项添加到 $listView 元素中。最后它将返回渲染完成的列表元素。
The rest of the code simply defines the public API and exposes it via CommonJS.
剩下的代码就很简单了——定义公开 API,并且以 CommonJS 的方式暴露出来。
[$]
Some developers will intersperse module.exports assignments throughout a module. I find that having a single module.exports at the bottom of the file more clearly documents the module's public API.
有些开发者可能会在模块内部零星地为 module.exports 赋值。而我更倾向于在模块底部只保留一条赋值语句,这样可以更加清晰地展示出这个模块的所有公开 API。
So far, the modules don't know about each other, so there's no way for them to do any work. To bring all the pieces together and manage the initial render, you'll need a higher level abstraction to kick things off. Enter app.js:
到目前为止,模块之间还并不了解,所以它们还无法协同工作。为了把所有的零件组合起来,并处理好页面的初始化渲染,你需要一个更高级别的抽象来启动这些工作。进入 app.js 文件:
Example 5-6. guestlist/src/app.js
示例 5-6. guestlist/src/app.js
var $ = require('jquery-browserify'),
guestlistModel = require('./guestlistmodel'),
guestlistView = require('./guestlistview'),
$container = $('#container');
$(function init() {
var guestlistData = guestlistModel.load(),
$guestlist = guestlistView.render(guestlistData);
$container.empty().append($guestlist);
});This one should be fairly simple to follow. It uses .require() to reference guestlistModel and guestlistView, loads the guestlist, passes the data into guestlistView.render(), and adds it to the container element.
这段代码应该很容易看明白。这里先使用 .require() 来引入 guestlistModel 和 guestlistView 模块,然后读取来宾的名单数据,再将数据传入 guestlistView.render() 方法,最后将渲染结果添加到 #container 元素中。
[$]
The .append() line at the end of the init() function calls jQuery's .empty() method first for a couple of important reasons: First, if there's anything in that space already, it should be replaced, but it also releases references to event listeners so that the memory can be garbage collected. This is a better strategy than simply calling .html(). The latter is by far the more popular method, but it can be a major source of bugs and confusion when you start to develop large, client-heavy applications in JavaScript.
在 init() 函数的尾部,.append() 所在的那一行首先调用了 jQuery 的 .empty() 方法,这样做是基于以下一些重要原因:首先,如果那里已经有一些东西的话,它应该被替换掉;同时,这样做也将释放对事件监听器的引用,从而触发垃圾回收,释放内存。这个策略比单纯地调用 .html() 方法要更好一些。虽然后者明显更加流行,但当你在开发重量级的客户端 JavaScript 应用程序时,它可能会导致 bug 或一些莫名其妙的情况。
(译注:这里再展开讲一下这两者的区别。.html() 的本质是对容器元素的 .innerHTML 属性进行赋值,浏览器需要经过一个“HTML→DOM”的解析步骤才能在容器内部生成子元素。而这个过程如果发生在 DOM 树上,往往会消耗大量时间,因此浏览器可能会出于优化的目的,把这个过程作异步处理。此时,如果你立即操作子元素,可能会出现错误,因为子元素还没有生成。而作者所使用的方法实际上是在先“异次元空间”中构建好 $listView 及其子元素,然后再把它们附着到 DOM 树上,这样就有效避免了上述问题。)
None of this is going to work yet, because the modules all need to be compiled together in order of their dependencies. For that, you'll need Browserify.
不过它们目前还无法正常工作,因为所有模块都需要按照它们的依赖关系进行编译打包。要完成这一步,你需要用到 Browserify。
Browserify is a Node module that makes CommonJS modules work in the browser, using a server-side build step. The browserify command is available to kick off the bundle:
Browserify 本身是一个 Node 模块,它通过一个服务器端的构建步骤,来使 CommonJS 模块工作在浏览器中。使用 browserify 命令可以启动软件包。
$ browserify src/app.js -o public/app.js
That's a bit too manual, though. You'll want to use grunt to automate the build. That way you can lint, build, and run your unit tests all in one step. Start with package.json:
不过这种方式看起来有一点“人肉”。你可能想用 grunt 来把这个构建环节自动化。通过它的帮助,你可以一键完成代码校验、构建打包、单元测试等任务。我们从 package.json 开始入手:
Example 5-7. guestlist/package.json
示例 5-7. guestlist/package.json
{
"name": "guestlist",
"version": "0.1.0",
"author": "Eric Elliott",
"description": "A handy tool for bouncers.",
"keywords": ["party", "guestlist"],
"main": "dist/app.js",
"scripts": {
"test": "grunt test"
},
"dependencies": {
"jquery-browserify": "*"
},
"devDependencies": {
"traverse": "*",
"grunt": "*",
"grunt-browserify": "*",
"browserify": "*"
},
"engines": {
"node": ">=0.6"
}
}Since you'll be deploying this app, you should consider all of the code it uses to be part of the app, including its dependencies. You don't want those dependency versions shifting around under your feet during your deploy step. The less uncertainty and moving parts you have in a deploy step the better. For that reason, you're going to want to check in your node_modules directory (don't add it to .gitignore).
如果你将来打算把这个应用部署到各处或持续更新下去,那么,除了应用本身的代码之外,你还应该把应用的依赖库也看作应用的一部分。你肯定不愿意在每次部署时都担心这些依赖库的版本是不是又变了。在部署环节中,不确定因素和外围部件当然是越少越好。因此,你需要把你的 node_modules 目录提交至代码仓库(千万不要把它加到 .gitignore 文件中,以防被版本控制系统忽略)。
Because all of the dependencies are going to be checked into the repository, you don't need to specify the versions to install. The "*" indicates that you want to use the latest version.
由于所有的依赖库都将被提交到仓库,你就不需要在这里指定安装什么版本了。这里的 "*" 表明你想使用最新的版本。
You'll also need a gruntfile. Currently the latest stable version of grunt looks for grunt.js by default. That's changed in the current alpha version, so you might need to use gruntfile.js as the filename. Here's what it looks like:
你还需要有一个 Grunt 启动文件。目前 Grunt 的最新稳定版会默认去找 grunt.js 文件。但在最新的内测版中,这一行为发生了变化,因此你可能需要使用 gruntfile.js 作为文件名。这个文件看起来是这样的:
Example 5-8. guestlist/grunt.js
示例 5-8. guestlist/grunt.js
/*global module*/
module.exports = function(grunt) {
'use strict';
grunt.initConfig({
// Read package.json into an object for later
// reference (for example, in meta, below).
// 读取 package.json 并存入一个对象以便稍后引用,
// 比如在下面的 meta 字段中会用到。
pkg: '<json:package.json>',
meta: {
// A template to add to the top of the bundled
// output.
// 这个模板会插入到打包输出文件的顶部。
banner: '\n/*! <%= pkg.title || pkg.name %> ' +
'- v<%= pkg.version %> - ' +
'<%= grunt.template.today("yyyy-mm-dd") %>\n ' +
'<%= pkg.homepage ? "* " + pkg.homepage + "\n' +
' *\n " : "" %>' +
'* Copyright (c) ' +
'<%= grunt.template.today("yyyy") %> ' +
'<%= pkg.author.name %>;\n' +
' * Licensed under the <%= ' +
'_.pluck(pkg.licenses, "type").join(", ") %>' +
' license */'
},
// Specify which files to send through JSHint.
// 指定哪个文件将被发送给 JSHint 工具。
lint: {
all: ['./grunt.js', './src/**/*.js',
'./test-src/test.js']
},
// JSHint configuration options.
// JSHint 的选项设置。
jshint: {
browser: false,
node: true,
strict: false,
curly: true,
eqeqeq: true,
immed: true,
latedef: true,
newcap: true,
nonew: true,
noarg: true,
sub: true,
undef: true,
unused: true,
eqnull: true,
boss: false
},
// Specify test locations for QUnit.
// 为 QUnit 指定测试地址。
qunit: {
browser: ['test/index.html']
},
// Configuration for browserify.
// browserify 的配置信息。
browserify: {
"public/app.js": {
requires: ['traverse'],
entries: ['src/**/*.js'],
prepend: ['<banner:meta.banner>'],
append: [],
hook: function () {
// bundle is passed in as first param
// 打包文件会作为第一个参数传进来。
}
}
}
});
// Load browserify tasks. Needed for bundling.
// 读取 browserify 任务,用于打包。
grunt.loadNpmTasks('grunt-browserify');
// Setup command line argument tasks. For e.g.:
// $ grunt # executes lint, browserify, qunit
// $ grunt test # runs qunit task, only.
// 设置命令行参数:
// $ grunt # 执行 lint, browserify, qunit 任务
// $ grunt test # 只执行 qunit 任务
grunt.registerTask('default', 'lint browserify qunit');
grunt.registerTask('install', 'browserify');
grunt.registerTask('test', 'qunit');
};The Grunt configuration file is just a Node JavaScript module, so you can write functions in it, evaluate expressions, and so on.
Grunt 配置文件就是一个 Node 版的 JavaScript 模块,因此你可以在它里面编写函数、执行表达式等等。
Browserify requires a little extra configuration sometimes. Please refer to the grunt-browserify documentation for specific settings. Just don't forget to load the grunt tasks with grunt.loadNpmTasks('grunt-browserify').
有时 Browserify 还需要做一点额外的配置工作。详细设置请参考 grunt-browserify 的相关文档。别忘了要使用 grunt.loadNpmTasks('grunt-browserify') 来加载 grunt 任务。
The .registerTask() calls make grunt command line arguments available. For example, all the default tasks will run when you execute grunt without any arguments, and grunt test will only run the tests.
最后几个 .registerTask() 语句将使 grunt 的命令行参数变得可用。举个例子,当你以不指定任何参数的方式执行 grunt 命令时,所有的 default 任务都将运行;而 grunt test 命令将只运行测试任务。
Time for some action:
现在可以跑起来了:
$ grunt
Running "lint:all" (lint) task
Lint free.
Running "browserify:public/app.js" (browserify) task
Running "qunit:browser" (qunit) task
Testing index.html..OK
>> 3 assertions passed (32ms)
Done, without errors.
Notice the QUnit task output. The tests are green, and in this form, you can run them on an automated continuous integration system.
请注意 QUnit 任务的输出,测试都是绿色的了。你还可以在一个自动化的持续集成系统中以这种形式运行测试。
In case you're curious, the browser output looks like this:
如果你好奇的话,可以看一下浏览器中的测试结果:
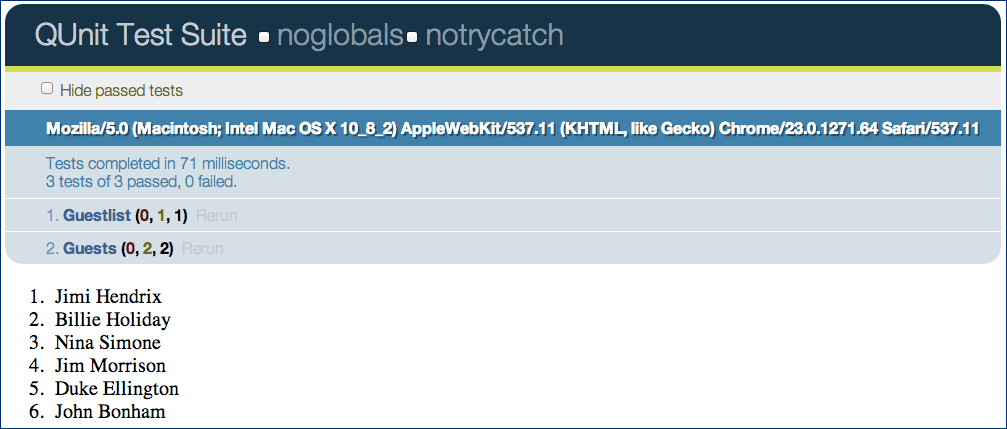
Figure 5-4. Passing QUnit Screenshot
图 5-4. Passing QUnit Screenshot
In general, CSS is a little outside the scope of this book, but there are a few tips you should be aware of. For some great ideas on how to use CSS for applications, see Scalable and Modular Architecture for CSS, by Jonathan Snook.
大体来说,CSS 有点超出了本书的范畴,但有些小技巧还是应该掌握的。关于如何在应用程序中使用 CSS,你可以在 Jonathan Snook 的《可扩展与模块化的 CSS 架构》一书中找到一些好想法。
The Guestlist code employs a custom icon font for the checkbox. Fonts provide a major advantage over traditional methods like png icons. For instance, they are infinitely scaleable, and you can apply any CSS you'd normally apply to text. You can also create a single, custom font that is easy for clients to download. The font was created using a free custom font app called IcoMoon. The icon font related CSS looks like this:
这个应用使用了一个自定义的“图标字体”来显示复选框。字体提供了比传统方式(比如 png 图片)更大的优势。比如说,它们可以被无限放大而不失真(译注:因为它们是矢量的),而且你可以对它们应用任何适用于文本的 CSS 样式。你也可以创建一个单字符的字体文件,从而易于在客户端下载。有一个免费的字体自定义应用叫做 IcoMoon,可以用来创建这种字体。跟图标字体相关的 CSS 代码如下:
Example 5-9. Icon Font CSS
示例 5-9. Icon Font CSS
@font-face {
font-family: 'guestlist';
src:url('fonts/guestlist.eot');
src:url('fonts/guestlist.eot?#iefix')
format('embedded-opentype'),
url('fonts/guestlist.svg#guestlist')
format('svg'),
url('fonts/guestlist.woff') format('woff'),
url('fonts/guestlist.ttf') format('truetype');
font-weight: normal;
font-style: normal;
}
[class^="icon-check"]:before,
[class*=" icon-check"]:before {
font-family: 'guestlist';
font-style: normal;
font-size: .75em;
speak: none;
font-weight: normal;
-webkit-font-smoothing: antialiased;
}
.icon-check:before {
content: "\e000";
}
.dropdown-menu .icon-check .name {
padding-left: 1em;
}(译注:本节简要演示了一个客户端项目的开发流程和构建工具链。不过,如果想在浏览器端用 CommonJS 方式来写模块,国内开发者应该还是会选择 Sea.js 作为解决方案吧。)
© Creative Commons BY-NC-ND 4.0 | 我要订阅 | 我要打赏



























































































































































































































































































































































