连续爬取一个或多个新浪微博用户(如Dear-迪丽热巴、郭碧婷)的数据,并将结果信息写入文件。写入信息几乎包括了用户微博的所有数据,主要有用户信息和微博信息两大类,前者包含用户昵称、关注数、粉丝数、微博数等等;后者包含微博正文、发布时间、发布工具、评论数等等,因为内容太多,这里不再赘述,详细内容见输出部分。具体的写入文件类型如下:
- 写入csv文件(默认)
- 写入json文件(可选)
- 写入MySQL数据库(可选)
- 写入MongoDB数据库(可选)
- 写入SQLite数据库(可选)
- 下载用户原创微博中的原始图片(可选)
- 下载用户转发微博中的原始图片(可选)
- 下载用户原创微博中的视频(可选)
- 下载用户转发微博中的视频(可选)
- 下载用户原创微博Live Photo中的视频(可选)
- 下载用户转发微博Live Photo中的视频(可选)
- 下载用户原创和转发微博下的一级评论(可选)
- 下载用户原创和转发微博下的转发(可选)
如果你只对用户信息感兴趣,而不需要爬用户的微博,也可以通过设置实现只爬取微博用户信息的功能。程序也可以实现爬取结果自动更新,即:现在爬取了目标用户的微博,几天之后,目标用户可能又发新微博了。通过设置,可以实现每隔几天增量爬取用户这几天发的新微博。具体方法见定期自动爬取微博。
用户信息
- 用户id:微博用户id,如"1669879400"
- 用户昵称:微博用户昵称,如"Dear-迪丽热巴"
- 性别:微博用户性别
- 生日:用户出生日期
- 所在地:用户所在地
- 教育经历:用户上学时学校的名字
- 公司:用户所属公司名字
- 阳光信用:用户的阳光信用
- 微博注册时间:用户微博注册日期
- 微博数:用户的全部微博数(转发微博+原创微博)
- 粉丝数:用户的粉丝数
- 关注数:用户关注的微博数量
- 简介:用户简介
- 主页地址:微博移动版主页url,如https://m.weibo.cn/u/1669879400?uid=1669879400&luicode=10000011&lfid=1005051669879400
- 头像url:用户头像url
- 高清头像url:用户高清头像url
- 微博等级:用户微博等级
- 会员等级:微博会员用户等级,普通用户该等级为0
- 是否认证:用户是否认证,为布尔类型
- 认证类型:用户认证类型,如个人认证、企业认证、政府认证等
- 认证信息:为认证用户特有,用户信息栏显示的认证信息
微博信息
- 微博id:微博的id,为一串数字形式
- 微博bid:微博的bid,与cookie版中的微博id是同一个值
- 微博内容:微博正文
- 头条文章url:微博中头条文章的url,如果微博中存在头条文章,就获取该头条文章的url,否则该值为''
- 原始图片url:原创微博图片和转发微博转发理由中图片的url,若某条微博存在多张图片,则每个url以英文逗号分隔,若没有图片则值为''
- 视频url: 微博中的视频url和Live Photo中的视频url,若某条微博存在多个视频,则每个url以英文分号分隔,若没有视频则值为''
- 微博发布位置:位置微博中的发布位置
- 微博发布时间:微博发布时的时间,精确到天
- 点赞数:微博被赞的数量
- 转发数:微博被转发的数量
- 评论数:微博被评论的数量
- 微博发布工具:微博的发布工具,如iPhone客户端、HUAWEI Mate 20 Pro等,若没有则值为''
- 话题:微博话题,即两个#中的内容,若存在多个话题,每个url以英文逗号分隔,若没有则值为''
- @用户:微博@的用户,若存在多个@用户,每个url以英文逗号分隔,若没有则值为''
- 原始微博:为转发微博所特有,是转发微博中那条被转发的微博,存储为字典形式,包含了上述微博信息中的所有内容,如微博id、微博内容等等
- 结果文件:保存在当前目录weibo文件夹下以用户昵称为名的文件夹里,名字为"user_id.csv"形式
- 微博图片:微博中的图片,保存在以用户昵称为名的文件夹下的img文件夹里
- 微博视频:微博中的视频,保存在以用户昵称为名的文件夹下的video文件夹里
以爬取迪丽热巴的微博为例,我们需要修改config.json文件,文件内容如下:
{
"user_id_list": ["1669879400"],
"only_crawl_original": 1,
"since_date": "1900-01-01",
"query_list": [],
"write_mode": ["csv"],
"original_pic_download": 1,
"retweet_pic_download": 0,
"original_video_download": 1,
"retweet_video_download": 0,
"cookie": "your cookie"
}
对于上述参数的含义以及取值范围,这里仅作简单介绍,详细信息见程序设置。
user_id_list代表我们要爬取的微博用户的user_id,可以是一个或多个,也可以是文件路径,微博用户Dear-迪丽热巴的user_id为1669879400,具体如何获取user_id见如何获取user_id; only_crawl_original的值为1代表爬取全部原创微博,值为0代表爬取全部微博(原创+转发); since_date代表我们要爬取since_date日期之后发布的微博,因为我要爬迪丽热巴的全部原创微博,所以since_date设置了一个非常早的值; query_list代表要爬取的微博关键词,为空([])则爬取全部; write_mode代表结果文件的保存类型,我想要把结果写入csv文件和json文件,所以它的值为["csv", "json"],如果你想写入数据库,具体设置见设置数据库; original_pic_download值为1代表下载原创微博中的图片,值为0代表不下载; retweet_pic_download值为1代表下载转发微博中的图片,值为0代表不下载; original_video_download值为1代表下载原创微博中的视频,值为0代表不下载; retweet_video_download值为1代表下载转发微博中的视频,值为0代表不下载; cookie是可选参数,可填可不填,具体区别见添加cookie与不添加cookie的区别。
配置完成后运行程序:
python weibo.py程序会自动生成一个weibo文件夹,我们以后爬取的所有微博都被存储在weibo文件夹里。然后程序在该文件夹下生成一个名为"Dear-迪丽热巴"的文件夹,迪丽热巴的所有微博爬取结果都在这里。"Dear-迪丽热巴"文件夹里包含一个csv文件、一个img文件夹和一个video文件夹,img文件夹用来存储下载到的图片,video文件夹用来存储下载到的视频。如果你设置了保存数据库功能,这些信息也会保存在数据库里,数据库设置见设置数据库部分。
csv文件结果如下所示:
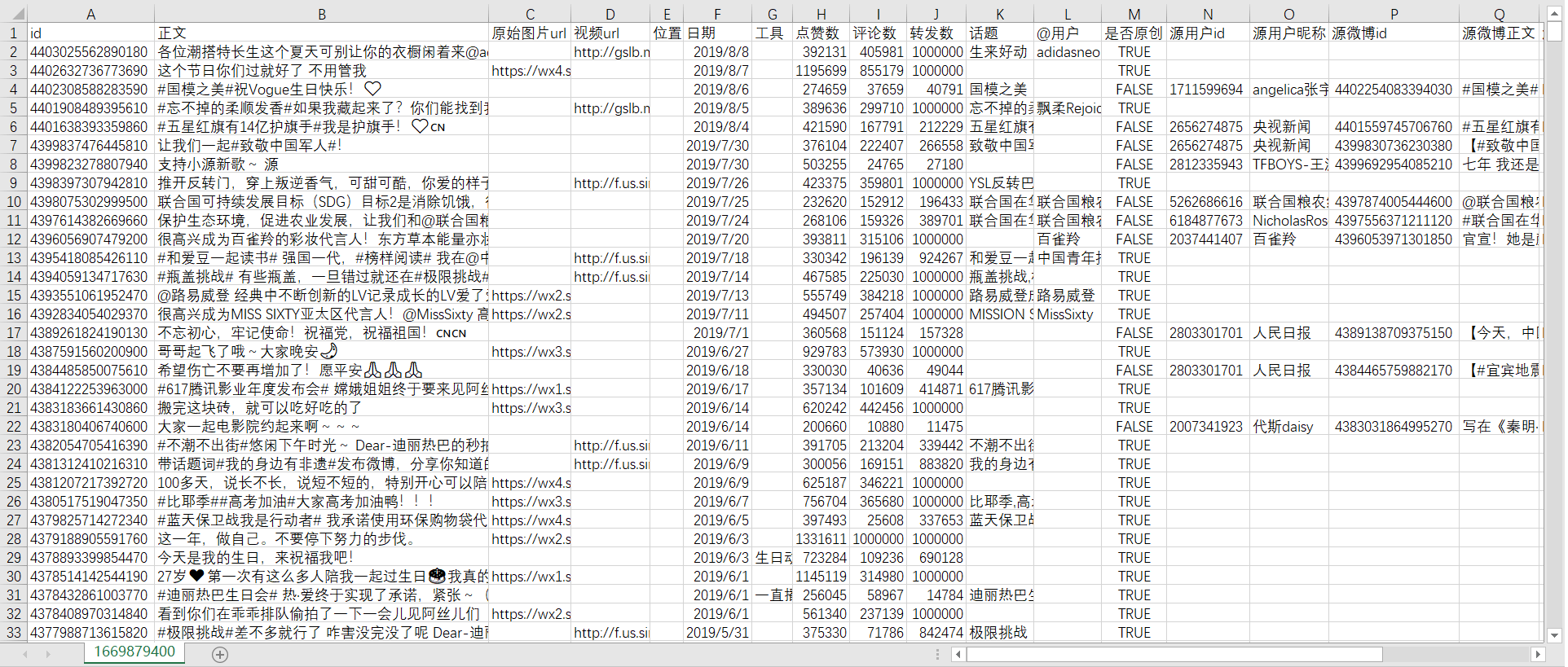
本csv文件是爬取“全部微博”(原创微博+转发微博)的结果文件。因为迪丽热巴很多微博本身都没有图片、发布工具、位置、话题和@用户等信息,所以当这些内容没有时对应位置为空。"是否原创"列用来标记是否为原创微博, 当为转发微博时,文件中还包含转发微博的信息。为了简便起见,姑且将转发微博中被转发的原始微博称为源微博,它的用户id、昵称、微博id等都在名称前加上源字,以便与目标用户自己发的微博区分。对于转发微博,程序除了获取用户原创部分的信息,还会获取源用户id、源用户昵称、源微博id、源微博正文、源微博原始图片url、源微博位置、源微博日期、源微博工具、源微博点赞数、源微博评论数、源微博转发数、源微博话题、源微博@用户等信息。原创微博因为没有这些转发信息,所以对应位置为空。若爬取的是"全部原创微博",则csv文件中不会包含"是否原创"及其之后的转发属性列;
为了说明json结果文件格式,这里以迪丽热巴2019年12月27日到2019年12月28日发的2条微博为例。
json结果文件格式如下:
{
"user": {
"id": "1669879400",
"screen_name": "Dear-迪丽热巴",
"gender": "f",
"birthday": "双子座",
"location": "上海",
"education": "上海戏剧学院",
"company": "嘉行传媒",
"registration_time": "2010-07-02",
"sunshine": "信用极好",
"statuses_count": 1121,
"followers_count": 66395881,
"follow_count": 250,
"description": "一只喜欢默默表演的小透明。工作联系[email protected] 🍒",
"profile_url": "https://m.weibo.cn/u/1669879400?uid=1669879400&luicode=10000011&lfid=1005051669879400",
"profile_image_url": "https://tvax2.sinaimg.cn/crop.0.0.1080.1080.180/63885668ly8gb5sqc19mqj20u00u0mz5.jpg?KID=imgbed,tva&Expires=1584108150&ssig=Zay1N7KhK1",
"avatar_hd": "https://wx2.sinaimg.cn/orj480/63885668ly8gb5sqc19mqj20u00u0mz5.jpg",
"urank": 44,
"mbrank": 7,
"verified": true,
"verified_type": 0,
"verified_reason": "嘉行传媒签约演员 "
},
"weibo": [
{
"user_id": 1669879400,
"screen_name": "Dear-迪丽热巴",
"id": 4454572602912349,
"bid": "ImTGkcdDn",
"text": "今天的#星光大赏# ",
"pics": "https://wx3.sinaimg.cn/large/63885668ly1gacppdn1nmj21yi2qp7wk.jpg,https://wx4.sinaimg.cn/large/63885668ly1gacpphkj5gj22ik3t0b2d.jpg,https://wx4.sinaimg.cn/large/63885668ly1gacppb4atej22yo4g04qr.jpg,https://wx2.sinaimg.cn/large/63885668ly1gacpn0eeyij22yo4g04qr.jpg",
"video_url": "",
"location": "",
"created_at": "2019-12-28",
"source": "",
"attitudes_count": 551894,
"comments_count": 182010,
"reposts_count": 1000000,
"topics": "星光大赏",
"at_users": ""
},
{
"user_id": 1669879400,
"screen_name": "Dear-迪丽热巴",
"id": 4454081098040623,
"bid": "ImGTzxJJt",
"text": "我最爱用的娇韵诗双萃精华穿上限量“金”装啦,希望阿丝儿们跟我一起在新的一年更美更年轻,喜笑颜开没有细纹困扰!限定新春礼盒还有祝福悄悄话,大家了解一下~",
"pics": "",
"video_url": "",
"location": "",
"created_at": "2019-12-27",
"source": "",
"attitudes_count": 190840,
"comments_count": 43523,
"reposts_count": 1000000,
"topics": "",
"at_users": "",
"retweet": {
"user_id": 1684832145,
"screen_name": "法国娇韵诗",
"id": 4454028484570123,
"bid": "ImFwIjaTF",
"text": "#点萃成金 年轻焕新# 将源自天然的植物力量,转化为滴滴珍贵如金的双萃精华。这份点萃成金的独到匠心,只为守护娇粉们的美丽而来。点击视频,与@Dear-迪丽热巴 一同邂逅新年限量版黄金双萃,以闪耀开运金,送上新春宠肌臻礼。 跟着迪迪选年货,还有双重新春惊喜,爱丽丝们看这里! 第一重参与微淘活动邀请好友关注娇韵诗天猫旗舰店,就有机会赢取限量款热巴新年礼盒,打开就能聆听仙女迪亲口送出的新春祝福哦!点击网页链接下单晒热巴同款黄金双萃,并且@法国娇韵诗,更有机会获得热巴亲笔签名的礼盒哦! 第二重转评说出新年希望娇韵诗为你解决的肌肤愿望,截止至1/10,小娇将从铁粉中抽取1位娇粉送出限量版热巴定制礼盒,抽取3位娇粉送出热巴明信片1张~ #迪丽热巴代言娇韵诗#养成同款御龄美肌,就从现在开始。法国娇韵诗的微博视频",
"pics": "",
"video_url": "http://f.video.weibocdn.com/003vQjnRlx07zFkxIMjS010412003bNx0E010.mp4?label=mp4_hd&template=852x480.25.0&trans_finger=62b30a3f061b162e421008955c73f536&Expires=1578322522&ssig=P3ozrNA3mv&KID=unistore,video",
"location": "",
"created_at": "2019-12-27",
"source": "微博 weibo.com",
"attitudes_count": 18389,
"comments_count": 3201,
"reposts_count": 1000000,
"topics": "点萃成金 年轻焕新,迪丽热巴代言娇韵诗",
"at_users": "Dear-迪丽热巴,法国娇韵诗"
}
}
]
}
1669879400.json
下载的图片如下所示:
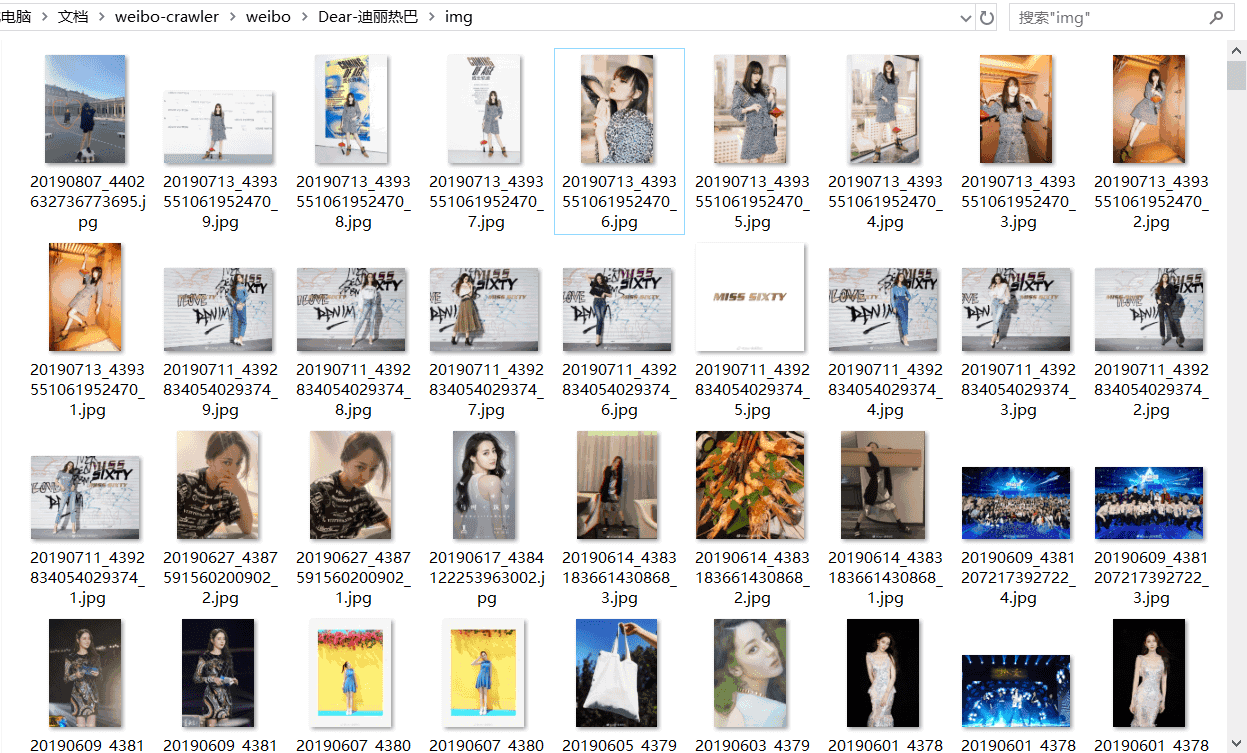
本次下载了788张图片,大小一共1.21GB,包括她原创微博中的所有图片。图片名为yyyymmdd+微博id的形式,若某条微博存在多张图片,则图片名中还会包括它在微博图片中的序号。若某图片下载失败,程序则会以“weibo_id:pic_url”的形式将出错微博id和图片url写入同文件夹下的not_downloaded.txt里;若图片全部下载成功则不会生成not_downloaded.txt;
下载的视频如下所示:
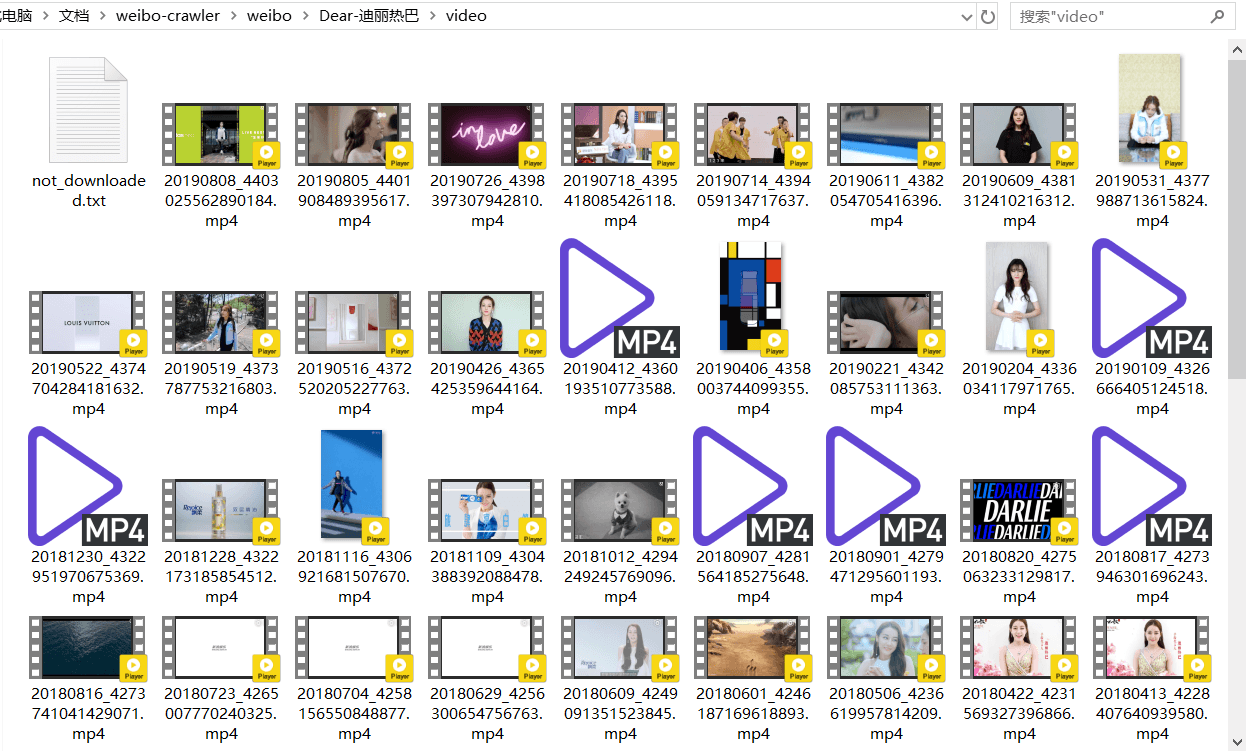
本次下载了66个视频,是她原创微博中的视频和原创微博Live Photo中的视频,视频名为yyyymmdd+微博id的形式。有三个视频因为网络原因下载失败,程序将它们的微博id和视频url分别以“weibo_id:video_url”的形式写到了同文件夹下的not_downloaded.txt里。
因为我本地没有安装MySQL数据库和MongoDB数据库,所以暂时设置成不写入数据库。如果你想要将爬取结果写入数据库,只需要先安装数据库(MySQL或MongoDB),再安装对应包(pymysql或pymongo),然后将mysql_write或mongodb_write值设置为1即可。写入MySQL需要用户名、密码等配置信息,这些配置如何设置见设置数据库部分。
-
开发语言:python2/python3
-
系统: Windows/Linux/macOS
git clone https://github.com/dataabc/weibo-crawler.git运行上述命令,将本项目下载到当前目录,如果下载成功当前目录会出现一个名为"weibo-crawler"的文件夹;
pip install -r requirements.txt打开config.json文件,你会看到如下内容:
{
"user_id_list": ["1669879400"],
"only_crawl_original": 1,
"remove_html_tag": 1,
"since_date": "2018-01-01",
"write_mode": ["csv"],
"original_pic_download": 1,
"retweet_pic_download": 0,
"original_video_download": 1,
"retweet_video_download": 0,
"download_comment":1,
"comment_max_download_count":1000,
"download_repost": 1,
"repost_max_download_count": 1000,
"user_id_as_folder_name": 0,
"cookie": "your cookie",
"mysql_config": {
"host": "localhost",
"port": 3306,
"user": "root",
"password": "123456",
"charset": "utf8mb4"
},
"mongodb_URI": "mongodb://[username:password@]host[:port][/[defaultauthdb][?options]]",
"post_config": {
"api_url": "https://api.example.com",
"api_token": ""
}
}
下面讲解每个参数的含义与设置方法。
设置user_id_list
user_id_list是我们要爬取的微博的id,可以是一个,也可以是多个,例如:
"user_id_list": ["1223178222", "1669879400", "1729370543"],
上述代码代表我们要连续爬取user_id分别为“1223178222”、 “1669879400”、 “1729370543”的三个用户的微博,具体如何获取user_id见如何获取user_id。
user_id_list的值也可以是文件路径,我们可以把要爬的所有微博用户的user_id都写到txt文件里,然后把文件的位置路径赋值给user_id_list。
在txt文件中,每个user_id占一行,也可以在user_id后面加注释(可选),如用户昵称等信息,user_id和注释之间必需要有空格,文件名任意,类型为txt,位置位于本程序的同目录下,文件内容示例如下:
1223178222 胡歌
1669879400 迪丽热巴
1729370543 郭碧婷
假如文件叫user_id_list.txt,则user_id_list设置代码为:
"user_id_list": "user_id_list.txt",
设置only_crawl_original
only_crawl_original控制爬取范围,值为1代表爬取全部原创微博,值为0代表爬取全部微博(原创+转发)。例如,如果要爬全部原创微博,请使用如下代码:
"only_crawl_original": 1,
设置since_date
since_date值可以是日期,也可以是整数。如果是日期,代表爬取该日期之后的微博,格式应为“yyyy-mm-dd”,如:
"since_date": "2018-01-01",
代表爬取从2018年1月1日到现在的微博。
如果是整数,代表爬取最近n天的微博,如:
"since_date": 10,
代表爬取最近10天的微博,这个说法不是特别准确,准确说是爬取发布时间从10天前到本程序开始执行时之间的微博。
since_date是所有user的爬取起始时间,非常不灵活。如果你要爬多个用户,并且想单独为每个用户设置一个since_date,可以使用定期自动爬取微博方法二中的方法,该方法可以为多个用户设置不同的since_date,非常灵活。
设置query_list(可选)
query_list是一个关键词字符串列表或以,分隔关键词的字符串,用于指定关键词搜索爬取,若为空[]或""则爬取全部微博。例如要爬取用户包含“梦想”和“希望”的微博,则设定如下:
"query_list": ["梦想","希望"],
"query_list": "梦想,希望",
请注意,关键词搜索必须设定cookie信息。
query_list是所有user的爬取关键词,非常不灵活。如果你要爬多个用户,并且想单独为每个用户设置一个query_list,可以使用定期自动爬取微博方法二中的方法,该方法可以为多个用户设置不同的query_list,非常灵活。
设置remove_html_tag
remove_html_tag控制是否移除抓取到的weibo正文和评论中的html tag,值为1代表移除,值为0代表不移除,如
"remove_html_tag": 1,
代表移除html tag。例如专属新意,色彩启程~<a href='/n/路易威登'>@路易威登</a> CAPUCINES 手袋正合我意,打开灵感包袋的搭配新方式!会被处理成专属新意,色彩启程~@路易威登 CAPUCINES 手袋正合我意,打开灵感包袋的搭配新方式!。
设置write_mode
write_mode控制结果文件格式,取值范围是csv、json、post、mongo、mysql和sqlite,分别代表将结果写入csv、json文件,通过POST发出,MongoDB、MySQL和SQLite数据库。write_mode可以同时包含这些取值中的一个或几个,如:
"write_mode": ["csv", "json"],
代表将结果信息写入csv文件和json文件。特别注意,如果你想写入数据库,除了在write_mode添加对应数据库的名字外,还应该安装相关数据库和对应python模块,具体操作见设置数据库部分。
设置original_pic_download
original_pic_download控制是否下载原创微博中的图片,值为1代表下载,值为0代表不下载,如
"original_pic_download": 1,
代表下载原创微博中的图片。
设置retweet_pic_download
retweet_pic_download控制是否下载转发微博中的图片,值为1代表下载,值为0代表不下载,如
"retweet_pic_download": 0,
代表不下载转发微博中的图片。特别注意,本设置只有在爬全部微博(原创+转发),即only_crawl_original值为0时生效,否则程序会跳过转发微博的图片下载。
设置original_video_download
original_video_download控制是否下载原创微博中的视频和原创微博Live Photo中的视频,值为1代表下载,值为0代表不下载,如
"original_video_download": 1,
代表下载原创微博中的视频和原创微博Live Photo中的视频。
设置retweet_video_download
retweet_video_download控制是否下载转发微博中的视频和转发微博Live Photo中的视频,值为1代表下载,值为0代表不下载,如
"retweet_video_download": 0,
代表不下载转发微博中的视频和转发微博Live Photo中的视频。特别注意,本设置只有在爬全部微博(原创+转发),即only_crawl_original值为0时生效,否则程序会跳过转发微博的视频下载。
设置user_id_as_folder_name
user_id_as_folder_name控制结果文件的目录名,可取值为0和1,默认为0:
"user_id_as_folder_name": 0,
值为0,表示将结果文件保存在以用户昵称为名的文件夹里,这样结果更清晰;值为1表示将结果文件保存在以用户id为名的文件夹里,这样能保证多次爬取的一致性,因为用户昵称可变,用户id不可变。
设置download_comment
download_comment控制是否下载每条微博下的一级评论(不包括对评论的评论),仅当write_mode中有sqlite时有效,可取值为0和1,默认为1:
"download_comment": 1,
值为1,表示下载微博评论;值为0,表示不下载微博评论。
设置comment_max_download_count
comment_max_download_count控制下载评论的最大数量,仅当write_mode中有sqlite时有效,默认为1000:
"comment_max_download_count": 1000,
设置download_repost
download_repost控制是否下载每条微博下的转发,仅当write_mode中有sqlite时有效,可取值为0和1,默认为1:
"download_repost": 1,
值为1,表示下载微博转发;值为0,表示不下载微博转发。
设置repost_max_download_count
repost_max_download_count控制下载转发的最大数量,仅当write_mode中有sqlite时有效,默认为1000:
"repost_max_download_count": 1000,
值为1000,表示最多下载每条微博下的1000条转发。
设置cookie(可选)
cookie为可选参数,即可填可不填,具体区别见添加cookie与不添加cookie的区别。cookie默认配置如下:
"cookie": "your cookie",
如果想要设置cookie,可以按照如何获取cookie中的方法,获取cookie,并将上面的"your cookie"替换成真实的cookie即可。
设置mysql_config(可选)
mysql_config控制mysql参数配置。如果你不需要将结果信息写入mysql,这个参数可以忽略,即删除或保留都无所谓;如果你需要写入mysql且config.json文件中mysql_config的配置与你的mysql配置不一样,请将该值改成你自己mysql中的参数配置。
设置mongodb_URI(可选)
mongodb_URI是mongodb的连接字符串。如果你不需要将结果信息写入mongodb,这个参数可以忽略,即删除或保留都无所谓;如果你需要写入mongodb,则需要配置为完整的mongodb URI。
设置start_page(可选)
start_page为爬取微博的初始页数,默认参数为1,即从所爬取用户的当前第一页微博内容开始爬取。 若在大批量爬取微博时出现中途被限制中断的情况,可通过查看csv文件内目前已爬取到的微博数除以10,向下取整后的值即为中断页数,手动设置start_page参数为中断页数,重新运行即可从被中断的节点继续爬取剩余微博内容。
本部分是可选部分,如果不需要将爬取信息写入数据库,可跳过这一步。本程序目前支持MySQL数据库和MongoDB数据库,如果你需要写入其它数据库,可以参考这两个数据库的写法自己编写。
MySQL数据库写入
要想将爬取信息写入MySQL,请根据自己的系统环境安装MySQL,然后命令行执行:
pip install pymysqlMongoDB数据库写入
要想将爬取信息写入MongoDB,请根据自己的系统环境安装MongoDB,然后命令行执行:
pip install pymongo
MySQL和MongDB数据库的写入内容一样。程序首先会创建一个名为"weibo"的数据库,然后再创建"user"表和"weibo"表,包含爬取的所有内容。爬取到的微博用户信息或插入或更新,都会存储到user表里;爬取到的微博信息或插入或更新,都会存储到weibo表里,两个表通过user_id关联。如果想了解两个表的具体字段,请点击"详情"。
详情
user表
id:微博用户id,如"1669879400";
screen_name:微博用户昵称,如"Dear-迪丽热巴";
gender:微博用户性别,取值为f或m,分别代表女和男;
birthday:生日;
location:所在地;
education:教育经历;
company:公司;
sunshine:阳光信用;
registration_time:注册时间;
statuses_count:微博数;
followers_count:粉丝数;
follow_count:关注数;
description:微博简介;
profile_url:微博主页,如https://m.weibo.cn/u/1669879400?uid=1669879400&luicode=10000011&lfid=1005051669879400;
profile_image_url:微博头像url;
avatar_hd:微博高清头像url;
urank:微博等级;
mbrank:微博会员等级,普通用户会员等级为0;
verified:微博是否认证,取值为true和false;
verified_type:微博认证类型,没有认证值为-1,个人认证值为0,企业认证值为2,政府认证值为3,这些类型仅是个人猜测,应该不全,大家可以根据实际情况判断;
verified_reason:微博认证信息,只有认证用户拥有此属性。
weibo表
user_id:存储微博用户id,如"1669879400";
screen_name:存储微博昵称,如"Dear-迪丽热巴";
id:存储微博id;
text:存储微博正文;
article_url:存储微博中头条文章的url,如果微博中存在头条文章,就获取该头条文章的url,否则该值为'';
pics:存储原创微博的原始图片url。若某条微博有多张图片,则存储多个url,以英文逗号分割;若该微博没有图片,则值为'';
video_url:存储原创微博的视频url和Live Photo中的视频url。若某条微博有多个视频,则存储多个url,以英文分号分割;若该微博没有视频,则值为'';
location:存储微博的发布位置。若某条微博没有位置信息,则值为'';
created_at:存储微博的发布时间;
source:存储微博的发布工具;
attitudes_count:存储微博获得的点赞数;
comments_count:存储微博获得的评论数;
reposts_count:存储微博获得的转发数;
topics:存储微博话题,即两个#中的内容。若某条微博没有话题信息,则值为'';
at_users:存储微博@的用户。若某条微博没有@的用户,则值为'';
retweet_id:存储转发微博中原始微博的微博id。若某条微博为原创微博,则值为''。
脚本会自动建立并配置数据库文件weibodata.db。
大家可以根据自己的运行环境选择运行方式,Linux可以通过
python weibo.py运行;
本部分为可选部分,如果你不需要自己修改代码或添加新功能,可以忽略此部分。
本程序所有代码都位于weibo.py文件,程序主体是一个Weibo类,上述所有功能都是通过在main函数调用Weibo类实现的,默认的调用代码如下:
if not os.path.isfile('./config.json'):
sys.exit(u'当前路径:%s 不存在配置文件config.json' %
(os.path.split(os.path.realpath(__file__))[0] + os.sep))
with open('./config.json') as f:
config = json.loads(f.read())
wb = Weibo(config)
wb.start() # 爬取微博信息用户可以按照自己的需求调用或修改Weibo类。
通过执行本程序,我们可以得到很多信息:
wb.user:存储目标微博用户信息;
wb.user包含爬取到的微博用户信息,如用户id、用户昵称、性别、生日、所在地、教育经历、公司、阳光信用、微博注册时间、微博数、粉丝数、关注数、简介、主页地址、头像url、高清头像url、微博等级、会员等级、是否认证、认证类型、认证信息等,大家可以点击"详情"查看具体用法。
详情
id:微博用户id,取值方式为wb.user['id'],由一串数字组成;
screen_name:微博用户昵称,取值方式为wb.user['screen_name'];
gender:微博用户性别,取值方式为wb.user['gender'],取值为f或m,分别代表女和男;
birthday:微博用户生日,取值方式为wb.user['birthday'],若用户没有填写该信息,则值为'';
location:微博用户所在地,取值方式为wb.user['location'],若用户没有填写该信息,则值为'';
education:微博用户上学时的学校,取值方式为wb.user['education'],若用户没有填写该信息,则值为'';
company:微博用户所属的公司,取值方式为wb.user['company'],若用户没有填写该信息,则值为'';
sunshine:微博用户的阳光信用,取值方式为wb.user['sunshine'];
registration_time:微博用户的注册时间,取值方式为wb.user['registration_time'];
statuses_count:微博数,取值方式为wb.user['statuses_count'];
followers_count:微博粉丝数,取值方式为wb.user['followers_count'];
follow_count:微博关注数,取值方式为wb.user['follow_count'];
description:微博简介,取值方式为wb.user['description'];
profile_url:微博主页,取值方式为wb.user['profile_url'];
profile_image_url:微博头像url,取值方式为wb.user['profile_image_url'];
avatar_hd:微博高清头像url,取值方式为wb.user['avatar_hd'];
urank:微博等级,取值方式为wb.user['urank'];
mbrank:微博会员等级,取值方式为wb.user['mbrank'],普通用户会员等级为0;
verified:微博是否认证,取值方式为wb.user['verified'],取值为true和false;
verified_type:微博认证类型,取值方式为wb.user['verified_type'],没有认证值为-1,个人认证值为0,企业认证值为2,政府认证值为3,这些类型仅是个人猜测,应该不全,大家可以根据实际情况判断;
verified_reason:微博认证信息,取值方式为wb.user['verified_reason'],只有认证用户拥有此属性。
wb.weibo:存储爬取到的所有微博信息;
wb.weibo包含爬取到的所有微博信息,如微博id、正文、原始图片url、视频url、位置、日期、发布工具、点赞数、转发数、评论数、话题、@用户等。如果爬的是全部微博(原创+转发),除上述信息之外,还包含原始用户id、原始用户昵称、原始微博id、原始微博正文、原始微博原始图片url、原始微博位置、原始微博日期、原始微博工具、原始微博点赞数、原始微博评论数、原始微博转发数、原始微博话题、原始微博@用户等信息。wb.weibo是一个列表,包含了爬取的所有微博信息。wb.weibo[0]为爬取的第一条微博,wb.weibo[1]为爬取的第二条微博,以此类推。当only_crawl_original=1时,wb.weibo[0]为爬取的第一条原创微博,以此类推。wb.weibo[0]['id']为第一条微博的id,wb.weibo[0]['text']为第一条微博的正文,wb.weibo[0]['created_at']为第一条微博的发布时间,还有其它很多信息不在赘述,大家可以点击下面的"详情"查看具体用法。
详情
user_id:存储微博用户id。如wb.weibo[0]['user_id']为最新一条微博的用户id;
screen_name:存储微博昵称。如wb.weibo[0]['screen_name']为最新一条微博的昵称;
id:存储微博id。如wb.weibo[0]['id']为最新一条微博的id;
text:存储微博正文。如wb.weibo[0]['text']为最新一条微博的正文;
article_url:存储微博中头条文章的url。如wb.weibo[0]['article_url']为最新一条微博的头条文章url,若微博中不存在头条文章,则该值为'';
pics:存储原创微博的原始图片url。如wb.weibo[0]['pics']为最新一条微博的原始图片url,若该条微博有多张图片,则存储多个url,以英文逗号分割;若该微博没有图片,则值为'';
video_url:存储原创微博的视频url和原创微博Live Photo中的视频url。如wb.weibo[0]['video_url']为最新一条微博的视频url,若该条微博有多个视频,则存储多个url,以英文分号分割;若该微博没有视频,则值为'';
location:存储微博的发布位置。如wb.weibo[0]['location']为最新一条微博的发布位置,若该条微博没有位置信息,则值为'';
created_at:存储微博的发布时间。如wb.weibo[0]['created_at']为最新一条微博的发布时间;
source:存储微博的发布工具。如wb.weibo[0]['source']为最新一条微博的发布工具;
attitudes_count:存储微博获得的点赞数。如wb.weibo[0]['attitudes_count']为最新一条微博获得的点赞数;
comments_count:存储微博获得的评论数。如wb.weibo[0]['comments_count']为最新一条微博获得的评论数;
reposts_count:存储微博获得的转发数。如wb.weibo[0]['reposts_count']为最新一条微博获得的转发数;
topics:存储微博话题,即两个#中的内容。如wb.weibo[0]['topics']为最新一条微博的话题,若该条微博没有话题信息,则值为'';
at_users:存储微博@的用户。如wb.weibo[0]['at_users']为最新一条微博@的用户,若该条微博没有@的用户,则值为'';
retweet:存储转发微博中原始微博的全部信息。假如wb.weibo[0]为转发微博,则wb.weibo[0]['retweet']为该转发微博的原始微博,它存储的属性与wb.weibo[0]一样,只是没有retweet属性;若该条微博为原创微博,则wb[0]没有"retweet"属性,大家可以点击"详情"查看具体用法。
详情
假设爬取到的第i条微博为转发微博,则它存在以下信息:
user_id:存储原始微博用户id。wb.weibo[i-1]['retweet']['user_id']为该原始微博的用户id;
screen_name:存储原始微博昵称。wb.weibo[i-1]['retweet']['screen_name']为该原始微博的昵称;
id:存储原始微博id。wb.weibo[i-1]['retweet']['id']为该原始微博的id;
text:存储原始微博正文。wb.weibo[i-1]['retweet']['text']为该原始微博的正文;
article_url:存储原始微博中头条文章的url。如wb.weibo[i-1]['retweet']['article_url']为该原始微博的头条文章url,若原始微博中不存在头条文章,则该值为'';
pics:存储原始微博的原始图片url。wb.weibo[i-1]['retweet']['pics']为该原始微博的原始图片url,若该原始微博有多张图片,则存储多个url,以英文逗号分割;若该原始微博没有图片,则值为'';
video_url:存储原始微博的视频url和原始微博Live Photo中的视频url。如wb.weibo[i-1]['retweet']['video_url']为该原始微博的视频url,若该原始微博有多个视频,则存储多个url,以英文分号分割;若该微博没有视频,则值为'';
location:存储原始微博的发布位置。wb.weibo[i-1]['retweet']['location']为该原始微博的发布位置,若该原始微博没有位置信息,则值为'';
created_at:存储原始微博的发布时间。wb.weibo[i-1]['retweet']['created_at']为该原始微博的发布时间;
source:存储原始微博的发布工具。wb.weibo[i-1]['retweet']['source']为该原始微博的发布工具;
attitudes_count:存储原始微博获得的点赞数。wb.weibo[i-1]['retweet']['attitudes_count']为该原始微博获得的点赞数;
comments_count:存储原始微博获得的评论数。wb.weibo[i-1]['retweet']['comments_count']为该原始微博获得的评论数;
reposts_count:存储原始微博获得的转发数。wb.weibo[i-1]['retweet']['reposts_count']为该原始微博获得的转发数;
topics:存储原始微博话题,即两个#中的内容。wb.weibo[i-1]['retweet']['topics']为该原始微博的话题,若该原始微博没有话题信息,则值为'';
at_users:存储原始微博@的用户。wb.weibo[i-1]['retweet']['at_users']为该原始微博@的用户,若该原始微博没有@的用户,则值为''。
我们爬取了微博以后,很多微博账号又可能发了一些新微博,定期自动爬取微博就是每隔一段时间自动运行程序,自动爬取这段时间产生的新微博(忽略以前爬过的旧微博)。本部分为可选部分,如果不需要可以忽略。
思路是利用第三方软件,如crontab,让程序每隔一段时间运行一次。因为是要跳过以前爬过的旧微博,只爬新微博。所以需要设置一个动态的since_date。很多时候我们使用的since_date是固定的,比如since_date="2018-01-01",程序就会按照这个设置从最新的微博一直爬到发布时间为2018-01-01的微博(包括这个时间)。因为我们想追加新微博,跳过旧微博。第二次爬取时since_date值就应该是当前时间到上次爬取的时间。 如果我们使用最原始的方式实现追加爬取,应该是这样:
假如程序第一次执行时间是2019-06-06,since_date假如为2018-01-01,那这一次就是爬取从2018-01-01到2019-06-06这段时间用户所发的微博;
第二次爬取,我们想要接着上次的爬,需要手动将since_date值设置为上次程序执行的日期,即2019-06-06
上面的方法太麻烦,因为每次都要手动设置since_date。因此我们需要动态设置since_date,即程序根据实际情况,自动生成since_date。 有两种方法实现动态更新since_date:
方法一:将since_date设置成整数
将config.json文件中的since_date设置成整数,如:
"since_date": 10,
这个配置告诉程序爬取最近10天的微博,更准确说是爬取发布时间从10天前到本程序开始执行时之间的微博。这样since_date就是一个动态的变量,每次程序执行时,它的值就是当前日期减10。配合crontab每9天或10天执行一次,就实现了定期追加爬取。
方法二:将上次执行程序的时间写入文件(推荐)
这个方法很简单,就是用户把要爬的用户id写入txt文件,然后再把文件路径赋值给config.json中的user_id_list参数。
txt文件名格式可以参考程序设置中的设置user_id_list部分,这样设置就全部结束了。
说下这个方法的原理和好处,假如你的txt文件内容为:
1669879400
1223178222 胡歌
1729370543 郭碧婷 2019-01-01
第一次执行时,因为第一行和第二行都没有写时间,程序会按照config.json文件中since_date的值爬取,第三行有时间“2019-01-01”,程序就会把这个时间当作since_date。每个用户爬取结束程序都会自动更新txt文件,每一行第一部分是user_id,第二部分是用户昵称,第三部分是程序准备爬取该用户第一条微博(最新微博)时的日期。爬完三个用户后,txt文件的内容自动更新为:
1669879400 Dear-迪丽热巴 2020-01-18
1223178222 胡歌 2020-01-18
1729370543 郭碧婷 2020-01-18
下次再爬取微博的时候,程序会把每行的时间数据作为since_date。这样的好处一是不用修改since_date,程序自动更新;二是每一个用户都可以单独拥有只属于自己的since_date,每个用户的since_date相互独立,互不干扰,格式为yyyy-mm-dd或整数。比如,现在又添加了一个新用户,以杨紫的微博为例,你想获取她2018-01-23到现在的全部微博,可以这样修改txt文件:
1669879400 迪丽热巴 2020-01-18
1223178222 胡歌 2020-01-18
1729370543 郭碧婷 2020-01-18
1227368500 杨紫 3 梦想,希望
注意每一行的用户配置参数以空格分隔,如果第一个参数全部由数字组成,程序就认为此行为一个用户的配置,否则程序会认为该行只是注释,跳过该行;第二个参数可以为任意格式,建议写用户昵称;第三个如果是日期格式(yyyy-mm-dd),程序就将该日期设置为用户自己的since_date,否则使用config.json中的since_date爬取该用户的微博,第二个参数和第三个参数也可以不填。 也可以设置第四个参数,将被读取为query_list。
方法三:将const.py文件中的运行模式改为append
以追加模式运行程序,每次运行,每个id只获取最新的微博,而不是全部,避免频繁备份微博导致过多的请求次数。
注意:
- 该模式会跳过置顶微博。
- 若采集信息后用户又编辑微博,则不会记录编辑内容。
docker run
docker build -t weibo-crawler .
docker run -it -d \
-v path/to/config.json:/app/config.json \
-v path/to/weibo:/app/weibo \
-e schedule_interval=1 \ # 可选:循环间隔(分钟)
weibo-crawlerdocker compose
version: '3'
services:
weibo-crawler:
build:
context: .
dockerfile: Dockerfile
volumes:
- path/to/config.json:/app/config.json
- path/to/weibo:/app/weibo
environment:
- schedule_interval=1 # 可选:循环间隔(分钟)1.打开网址https://weibo.cn,搜索我们要找的人,如"迪丽热巴",进入她的主页;
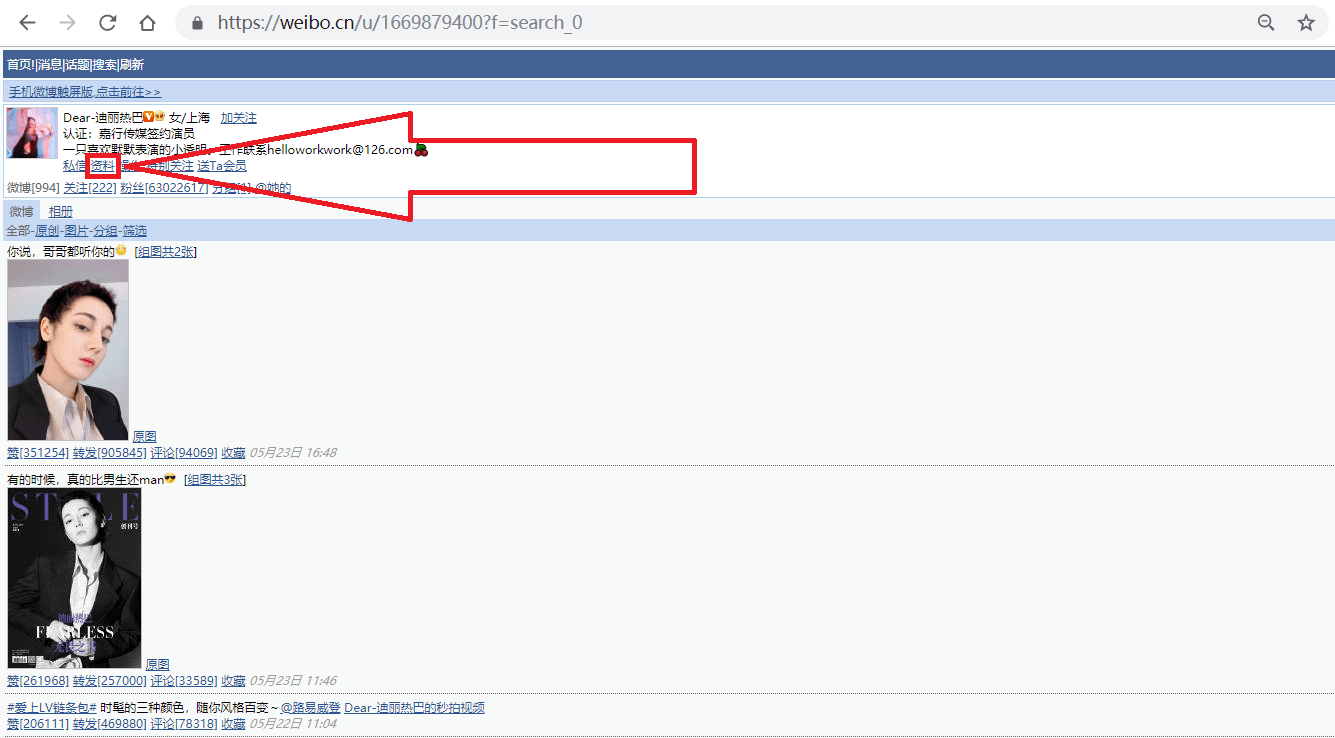
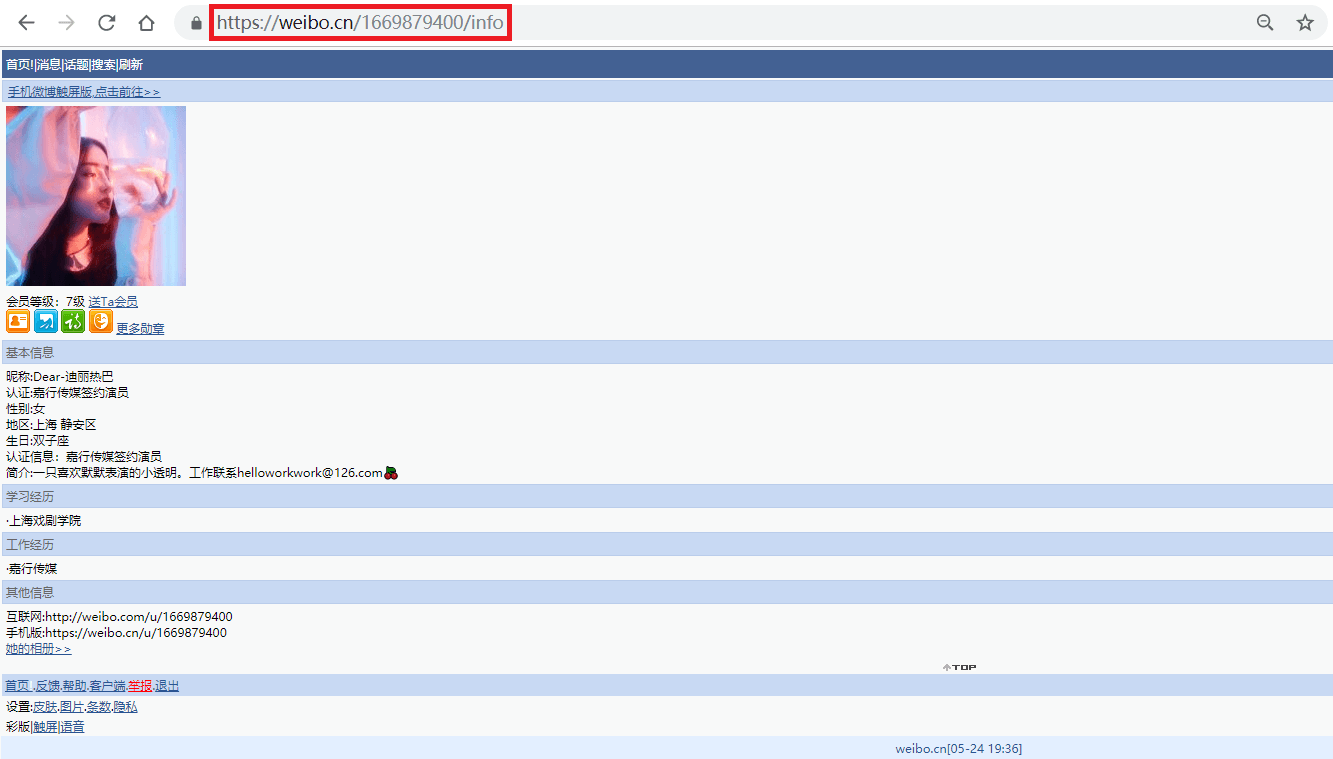
事实上,此微博的user_id也包含在用户主页(https://weibo.cn/u/1669879400?f=search_0)中,之所以我们还要点击主页中的"资料"来获取user_id,是因为很多用户的主页不是"https://weibo.cn/user_id?f=search_0"的形式,而是"https://weibo.cn/个性域名?f=search_0"或"https://weibo.cn/微号?f=search_0"的形式。其中"微号"和user_id都是一串数字,如果仅仅通过主页地址提取user_id,很容易将"微号"误认为user_id。
对于微博数2000条及以下的微博用户,不添加cookie可以获取其用户信息和大部分微博;对于微博数2000条以上的微博用户,不添加cookie可以获取其用户信息和最近2000条微博中的大部分,添加cookie可以获取其全部微博。以2020年1月2日迪丽热巴的微博为例,此时她共有1085条微博,在不添加cookie的情况下,可以获取到1026条微博,大约占全部微博的94.56%,而在添加cookie后,可以获取全部微博。其他用户类似,大部分都可以在不添加cookie的情况下获取到90%以上的微博,在添加cookie后可以获取全部微博。具体原因是,大部分微博内容都可以在移动版匿名获取,少量微博需要用户登录才可以获取,所以这部分微博在不添加cookie时是无法获取的。
有少部分微博用户,不添加cookie可以获取其微博,无法获取其用户信息。对于这种情况,要想获取其用户信息,是需要cookie的。
如需抓取微博转发,请添加cookie。
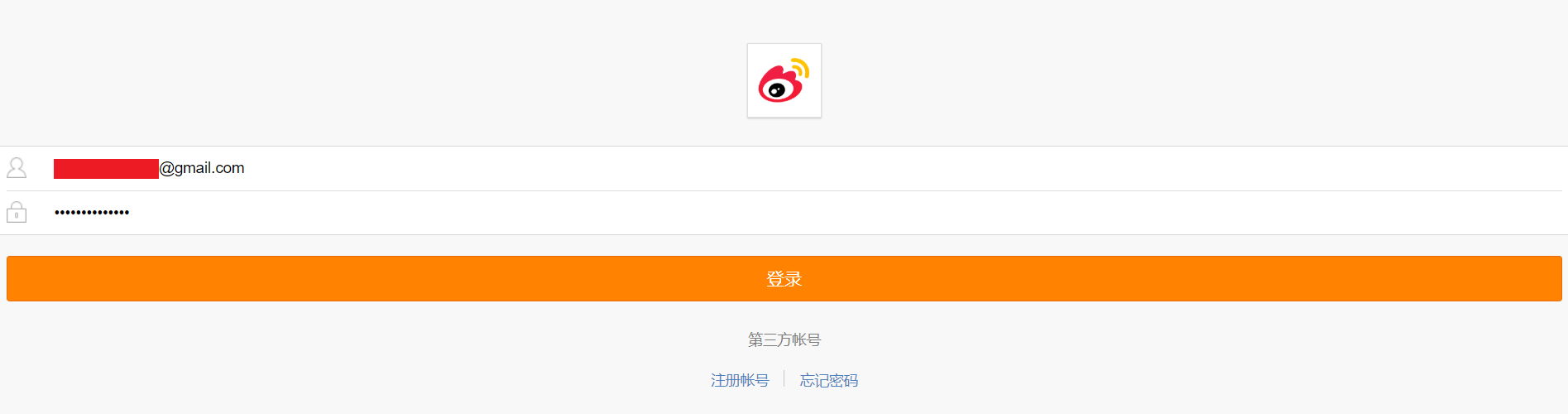
1.用Chrome打开https://passport.weibo.cn/signin/login;
2.输入微博的用户名、密码,登录,如图所示:
3.按F12键打开Chrome开发者工具,在地址栏输入并跳转到https://weibo.cn,跳转后会显示如下类似界面:
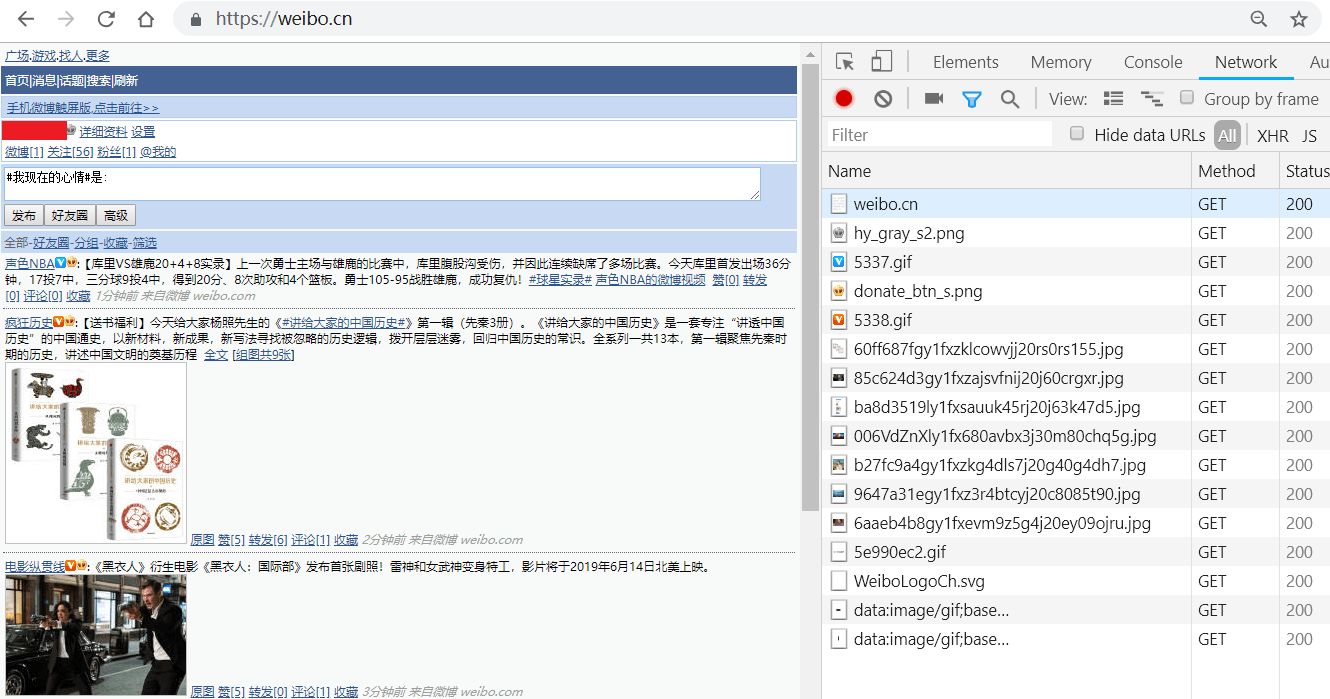
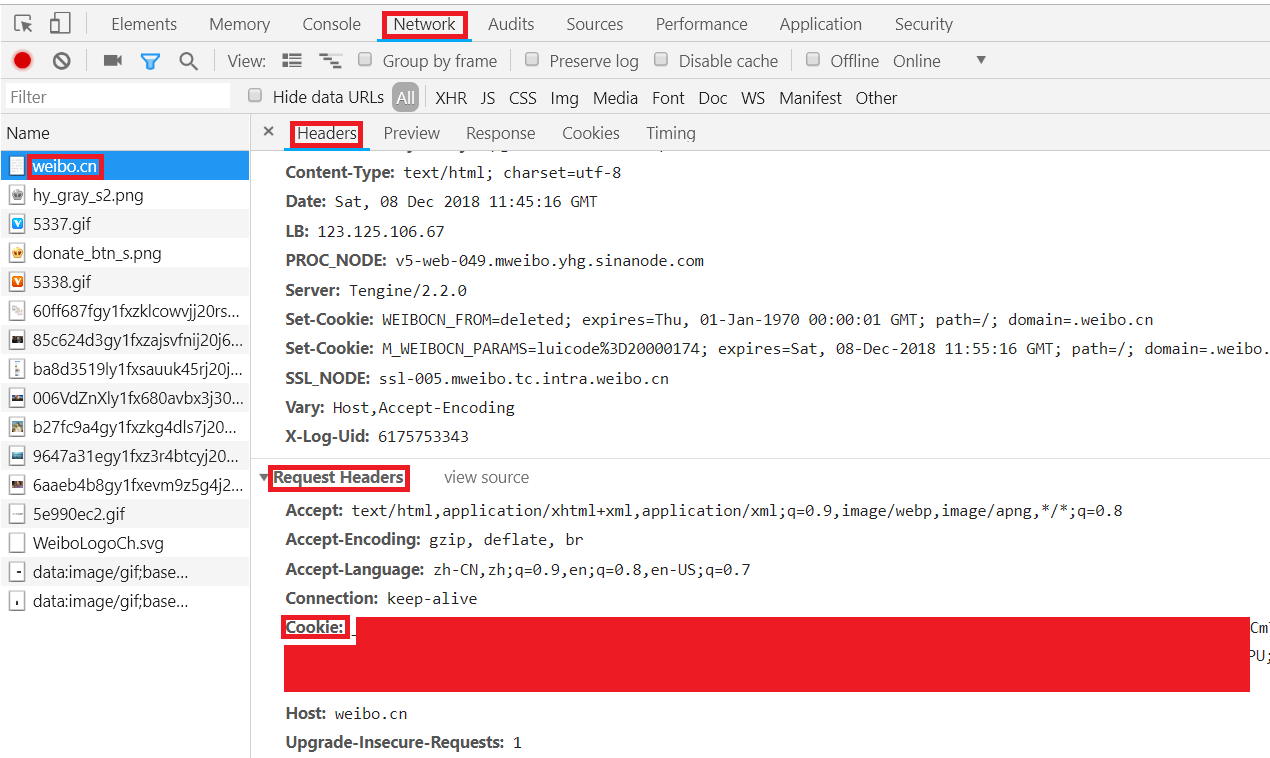
本程序cookie检查的逻辑是:使用cookie来源账号发布限定范围的微博,若cookie可用,则可以读取到该微博,否则读取不到。
操作方法
-
使用cookie的来源账号发布一条微博,该账号和微博需要满足以下条件:
-
该微博必须是非公开可见的,后续需要根据可见性判断cookie是否有效;
-
该微博需要是最近5条微博,不能在发布测试用微博内容后又发很多新微博;
-
在
config.json配置中的since_date之后,该账号必须有大于9条微博。
-
-
将
const.py文件中'CHECK': False中的False改为True,'HIDDEN_WEIBO': '微博内容'中的微博内容改为你发的限定范围的微博。 -
将提供cookie的微博id放置在
config.json文件中"user_id_list"设置项数组中的第一个。例如提供cookie的微博id为123456,则"user_id_list"设置为"user_id_list":["123456", "<其余id...>"]。
注:本方法也将会抓取提供cookie账号的微博内容。
在间歇运行程序时,cookie无效会导致程序不能按照预设目标执行,因此可以打开cookie通知功能。本项目使用开源项目pushdeer进行通知,在使用前用户需要申请push_key,具体可查看官网了解。打开方法为:
- 在
const.py文件中,将'NOTIFY': False中的False设为True; - 将
'PUSH_KEY': ''的''替换为'<你的push_key>'






![dependabot[bot] avatar](https://avatars.githubusercontent.com/in/29110?v=4 "dependabot[bot]")







































































































































































{kind=link}