
![]()
dbt enables data analysts and engineers to transform their data using the same practices that software engineers use to build applications.

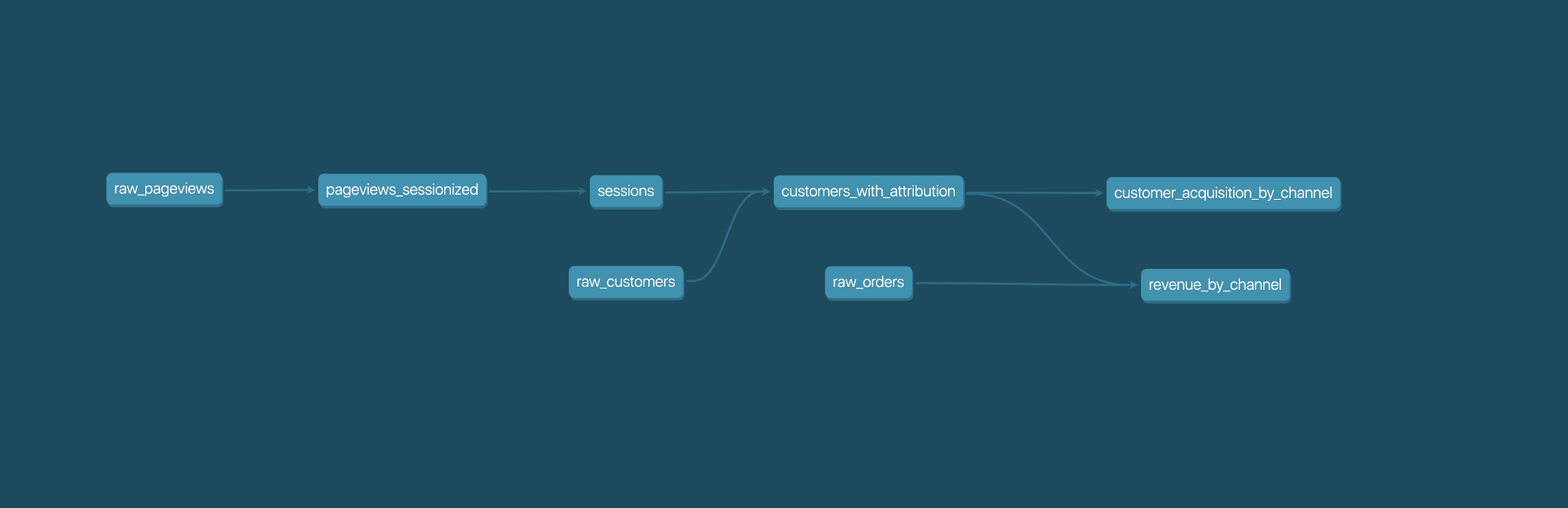
Analysts using dbt can transform their data by simply writing select statements, while dbt handles turning these statements into tables and views in a data warehouse.
These select statements, or "models", form a dbt project. Models frequently build on top of one another – dbt makes it easy to manage relationships between models, and visualize these relationships, as well as assure the quality of your transformations through testing.
- Install dbt Core or explore the dbt Cloud CLI, a command-line interface powered by dbt Cloud that enhances collaboration.
- Read the introduction and viewpoint
- Be part of the conversation in the dbt Community Slack
- Read more on the dbt Community Discourse
- Want to report a bug or request a feature? Let us know and open an issue
- Want to help us build dbt? Check out the Contributing Guide
Everyone interacting in the dbt project's codebases, issue trackers, chat rooms, and mailing lists is expected to follow the dbt Code of Conduct.







![dependabot[bot] avatar](https://avatars.githubusercontent.com/in/29110?v=4 "dependabot[bot]")



![github-actions[bot] avatar](https://avatars.githubusercontent.com/in/15368?v=4 "github-actions[bot]")























































































































































































































