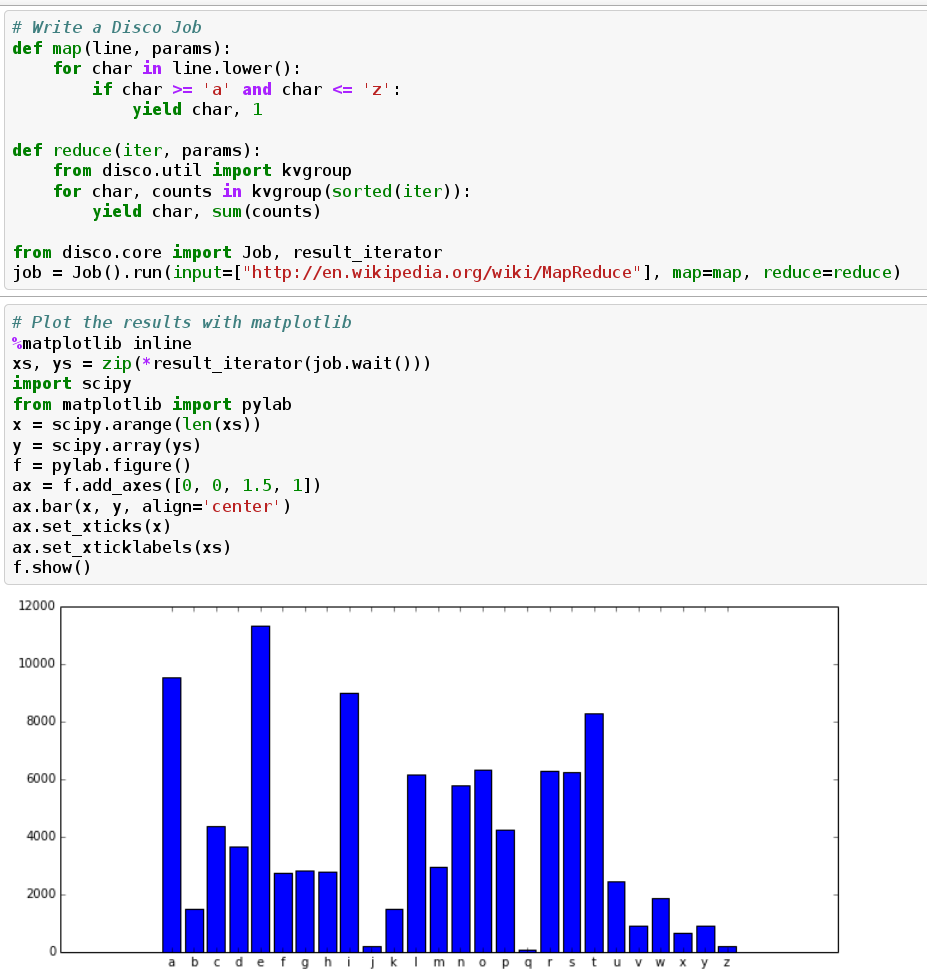
In the git source, the homedisco example (at the bottom of util/homedisco.py) fails to run with the following error:
sqs2 ~/src/disco: python util/homedisco.py
*[09/01/02 00:47:19 none ()] Received a new map job!
*[09/01/02 00:47:19 none ()] Done: 3 entries mapped in total
*[09/01/02 00:47:19 none ()] 0 chunk://localhost/homedisco@1230878839/map-chunk-0
*[09/01/02 00:47:19 none ()] Received a new reduce job!
*[09/01/02 00:47:19 none ()] Starting reduce
connect_input(fname=chunkfile://data/homedisco@1230878839/map-chunk-0)
Traceback (most recent call last):
File "/Users/sqs/src/disco/node/disconode/disco_worker.py", line 39, in open_local
f = file(fname)
IOError: [Errno 2] No such file or directory: 'data/homedisco@1230878839/map-chunk-0'
None
*[09/01/02 00:47:19 none (chunkfile://data/homedisco@1230878839/map-chunk-0)] Can't access a local input file: chunkfile://data/homedisco@1230878839/map-chunk-0
Traceback (most recent call last):
File "util/homedisco.py", line 78, in
reduce = fun_reduce)
File "util/homedisco.py", line 44, in new_job
disco_worker.op_reduce(req)
File "/Users/sqs/src/disco/node/disconode/disco_worker.py", line 430, in op_reduce
fun_reduce(red_in.iter(), red_out, red_params)
File "util/homedisco.py", line 60, in fun_reduce
for k, v in iter:
File "/Users/sqs/src/disco/node/disconode/disco_worker.py", line 285, in multi_file_iterator
sze, fd = connect_input(fname)
File "/Users/sqs/src/disco/node/disconode/disco_worker.py", line 131, in connect_input
return open_local(input, local_file, is_chunk)
File "/Users/sqs/src/disco/node/disconode/disco_worker.py", line 50, in open_local
% input, input)
File "/Users/sqs/src/disco/node/disconode/disco_worker.py", line 39, in open_local
f = file(fname)
IOError: [Errno 2] No such file or directory: 'data/homedisco@1230878839/map-chunk-0'
It appears that the open_local path is incorrectly determining the filename from the chunkfile:// URI it is given. It does not prepend the value of the DISCO_ROOT environment variable as it should.
Result_iterator also tries to load the result from a relative path when it should be applying DISCO_ROOT to the beginning. It fails with this error if only the open_local issue is fixed:
*[09/01/02 00:55:54 none ()] Received a new map job!
*[09/01/02 00:55:54 none ()] Done: 3 entries mapped in total
*[09/01/02 00:55:54 none ()] 0 chunk://localhost/homedisco@1230879354/map-chunk-0
*[09/01/02 00:55:54 none ()] Received a new reduce job!
*[09/01/02 00:55:54 none ()] Starting reduce
connect_input(fname=chunkfile://data/homedisco@1230879354/map-chunk-0)
*[09/01/02 00:55:54 none ()] Reduce done: 3 entries reduced in total
*[09/01/02 00:55:54 none ()] Reduce done
*[09/01/02 00:55:54 none ()] 0 disco://localhost/homedisco@1230879354/reduce-disco-0
['file://data/homedisco@1230879354/reduce-disco-0']
Traceback (most recent call last):
File "util/homedisco.py", line 80, in
for k, v in result_iterator(res):
File "build/bdist.macosx-10.5-i386/egg/disco/core.py", line 261, in result_iterator
IOError: [Errno 2] No such file or directory: 'data/homedisco@1230879354/reduce-disco-0'
After applying this patch, the correct output is returned:
sqs2 ~/src/disco: python util/homedisco.py
*[09/01/02 00:57:57 none ()] Received a new map job!
*[09/01/02 00:57:57 none ()] Done: 3 entries mapped in total
*[09/01/02 00:57:57 none ()] 0 chunk://localhost/homedisco@1230879477/map-chunk-0
*[09/01/02 00:57:57 none ()] Received a new reduce job!
*[09/01/02 00:57:57 none ()] Starting reduce
*[09/01/02 00:57:57 none ()] Reduce done: 3 entries reduced in total
*[09/01/02 00:57:57 none ()] Reduce done
*[09/01/02 00:57:57 none ()] 0 disco://localhost/homedisco@1230879477/reduce-disco-0
KEY red:dog VALUE dog
KEY red:cat VALUE cat
KEY red:possum VALUE possum
The patch also fixes the problem for a custom HomeDisco job I wrote, but there's no test suite for me to determine whether it is correct in all cases. Specifically, it does not appear to introduces issues when running remote jobs (i.e., not through HomeDisco), but I can't guarantee anything. Also, there may be a better way of doing this. (I saw that the LOCAL_PATH env var exists, but it already has "/data" at the end, and the filenames we are appending to $DISCO_ROOT have "/data" at the beginning, so using LOCAL_PATH would result in an incorrect "/data/data".)