dnplab / dnplab Goto Github PK
View Code? Open in Web Editor NEWDNPLab - Bringing the power of Python to DNP-NMR Spectroscopy
Home Page: http://dnplab.net/
License: MIT License
DNPLab - Bringing the power of Python to DNP-NMR Spectroscopy
Home Page: http://dnplab.net/
License: MIT License













What happened:
Cannot create dnpdata from numeric lists.
What you expected to happen:
The following should work
Minimal Complete Verifiable Example:
from dnplab import dnpdata
dd = dnpdata(values=[[1,2,3],
[4,5,6],
[7,8,9]],
dims=['x', 'y'],
coords=[[1,2,3],[2,3,4]])Anything else we need to know?:
Traceback (most recent call last):
File "/Users//Library/Application Support/JetBrains/PyCharmCE2020.1/scratches/scratch_39.py", line 14, in <module>
coords=[[1,2,3],[2,3,4]])
File "/Users//github/dnplab-yl/dnplab/dnpData.py", line 40, in __init__
super().__init__(values, dims, coords, attrs)
File "/Users//github/dnplab-yl/dnplab/core/nddata.py", line 30, in __init__
'values must be type "numpy.ndarray" not %s' % str(type(values))
TypeError: values must be type "numpy.ndarray" not <class 'list'>dnpNMR.integrate changes the nature of the data, it is not an additional processing step. It should add the new single point, or array for 2D data, as a separate entry and 'proc' should still be the processed spectrum. For example, the dnpFit module doesn't replace 'proc', just uses 'proc' to make and add ['fit'], .attrs['t1'], and .attrs['t1_stdd']. This should be the way the integrate function works as well
./dnplab/core/nddata.py:508:66: F821 undefined names 'lost_dims', 'ix', 'lost_coords'
"Attribute lost {}:{}".format(lost_dims[ix], lost_coords[ix])
Take a look at the first example in the documentation. The different functions generate output that is not necessary.
To create a 2D data set currently we have to do the following operation:
filenames = [
"../data/prospa/toluene_10mM_Tempone/1/data.1d",
"../data/prospa/toluene_10mM_Tempone/29/data.1d",
"../data/prospa/toluene_10mM_Tempone/30/data.1d",
"../data/prospa/toluene_10mM_Tempone/31/data.1d",
]
data_list = []
powers = np.array([1,2,3,4])
for filename in filenames:
tmp = dnp.dnpImport.load(filename, data_type = "prospa")
data_list.append(tmp)
data = dnp.concat(data_list, "power", powers)
This should be simpler. Can we modify the import function so that, if there is more than one attribute in the filename list, it automatically creates the 2D data object? This would greatly simplify the code and will make it simpler for newcomers to used DNPLab without having too much knowledge of Python and the different variable types.
@thcasey3 : this is not much of a start, but here is my starting point on translating the specman matlab code:
import os
from numpy import *
def load_specman(file_name):
with open(file_name,'rb') as fp:
header = fromfile(fp, dtype=[('ndim1','>u1'),# number of heders
('dformat','>u1')], count=1)
if header['dformat'] == 0:
sformat = '>f8'
elif header['dformat'] == 1:
sformat = '>f4'
else:
raise ValueError("dformat of %d not supported!!"%header['dformat'])
print("header is",repr(header))
dstrms = {};
ntotal = 1;
for k in range(header['ndim1'].item()):
diminfo = fromfile(fp, dtype='>i4', count=6)
print("for %d, diminfo is"%k,diminfo)
ndim2 = diminfo[0]
newshape = diminfo[1:5]
if ndim2 > len(newshape):
raise ValueError("ndim2 is greater than 4 -- this doesn't make sense!")
newshape[ndim2:] = 1
if __name__ == '__main__':
result = load_specman(os.path.expanduser('~/exp_data/reference_data/epr8k.d01'))Users should be allowed to raise two successive plots, rather than plot everything on the same plot. For example, these should work and raise two plots:
plot1 = dnp.dnpResults.plot(ws["raw"])
plot1.show()
dnp.dnpTools.integrate(ws)
plot2 = dnp.dnpResults.plot(ws["proc"])
plot2.show()
The dnpResults.plot method should return the plot object to be interacted with.
OR this should raise two plots,
dnp.dnpResults.plot(ws["raw"])
dnp.dnpTools.integrate(ws)
dnp.dnpResults.plot(ws["proc"])
while this plots them together,
dnp.dnpResults.plot(ws["raw"], ws["proc"])
Some functions (e.g. in the dnpNMR module) modify the processing buffer, others (e.g. calculate_enhancements) create a new key in the workspace.
We should come up with a consistent way how to handle that. Some functions for example in the NMR processing module create temporary data, which is probably not important to store. Others like integrate or enhancement create data that is worth keeping. However, the integrate does not do that currently.
We should make this very clear in the documentation if a function modifies the proc buffer or not.
Default plot behavior for:
dnpResult.plot(object)
should be object.real to avoid:
ComplexWarning: Casting complex values to real discards the imaginary part
Users can see imaginary with:
dnpResult.plot(object.imag)
OR both with:
dnpResult.plot(object.real, object.imag)
syntax phase = dnplab.dnpData.phase(workspace) returns error:
AttributeError: module 'dnplab.dnpData' has no attribute 'phase'
it seems the functions are within an extra layer "dnpdata"
syntax phase = dnplab.dnpData.dnpdata.phase(workspace) returns error:
...line 86, in phase
return np.arctan(np.sum(np.imag(self.values))/np.sum(np.real(self.values)))
TypeError: unsupported operand type(s) for /: 'int' and 'method'
import dnplab
dnplab.core.nddata.nddata_core()
Results
~/dnplab/core/nddata.py:55: UserWarning: Dimensions not consistent
warnings.warn("Dimensions not consistent")
Add procedure to DNPTools to have access to most common constants.
A very good reference for constants is here: [http://physics.nist.gov/constants]
Handling the h5 that is saved using dnplab by using dnplab functions is simple and intuitive. However, using the h5 with h5py is not. For example, using dnplab this works and is simple:
h5in = dnplab.dnpImport.h5.loadh5("..pathtofile..")
ksigma = h5in["hydration_results"]["ksigma"]
However, using h5py.File() requires:
h5in = h5py.File("..pathtofile..", "r")
ksigma = ["hydration_results"]["attrs"].attrs["ksigma"]
The two layered ["attrs"].attrs is not intuitive and will present a challenge to users integrating dnplab code into their own.
Currently, the coordinates for the direct (and indirect dimension I guess) is still called t2 after fourier transformation. This needs to be corrected to f2 (f1, etc. correspondingly).
Option to load the processed version of data and processing parameters where possible
Implement function to left shift data for example to discard the first few points. Do not add to the end, this can be dealt later with by the fourier transformation.
This is helpful when using an echo sequence for detection so the user does not have to adjust the acquisition delay accurately but can do this later when post-processing the data.
Change integration function so it supports definition of multiple regions for integration. E.g. being able to integrate the aromatic region separately from the aliphatic region.
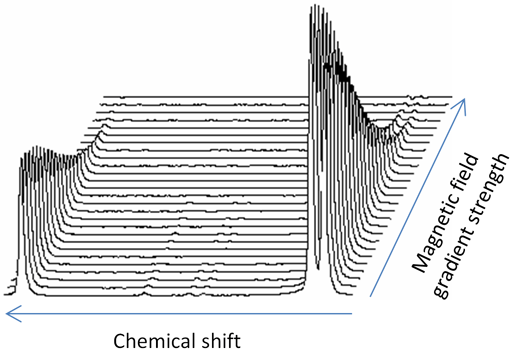
We should be able to display pseudo-2D spectra (e.g. NMR spectrum vs. power) in a waterfall plot or stacked plot.
For example see this:
http://chem.ch.huji.ac.il/nmr/techniques/other/diff/diff_files/stackplot.gif
I tried to import 2D T1-IR-FID data in Kea/Prospa format and DNPLab does not assign proper axis to the data set.
Is your feature request related to a problem? Please describe.
A clear and concise description of what the problem is. Ex. I'm always frustrated when [...]
I'm always frustrated when I try to sum a dnpdata. Instead of getting the sum, it generates a TypeError.
>>> import numpy, dnplab
>>> numpy.sum(numpy.array(1))
1
>>> numpy.sum(dnplab.dnpData.dnpdata(numpy.array(1)))
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "<__array_function__ internals>", line 6, in sum
File "/lib/python3.7/site-packages/numpy/core/fromnumeric.py", line 2242, in sum
initial=initial, where=where)
File "/lib/python3.7/site-packages/numpy/core/fromnumeric.py", line 85, in _wrapreduction
return reduction(axis=axis, out=out, **passkwargs)
TypeError: sum() got an unexpected keyword argument 'axis'Describe the solution you'd like
A clear and concise description of what you want to happen.
assert numpy.sum(dnplab.dnpData.dnpdata(numpy.array(1))) == numpy.sum(numpy.array(1)) == numpy.sum(1) == 1same for numpy.cos, numpy.sin etcs defined in numpy ufuncs
Describe alternatives you've considered
A clear and concise description of any alternative solutions or features you've considered.
by accessing the .values attribute
assert numpy.sum(dnplab.dnpData.dnpdata(numpy.array(1)).values) == 1Additional context
Add any other context about the feature request here.
add more tests for each dnpNMR function
Pros:
pytest is compatible with unittest. No need to change existing codes.(1 + 1, 1 + 2, ..., 1 + 10, ..., 10 + 1, 10 + 2, ..., 10 + 10) can be written with pytest.mark.parameterize('a', list(range(1,10))). pytest.mark.parameterize('b', list(range(1,10)))pytest or pytest ./unittests/.Cons:
unittests to testsCan we have multiple axis for data sets? For example, have an axis with power in dBm but also in W. It should be easy and convenient for the user to just create an additional axis.
.window() on Workspacedef window(*args, inplace=False, **kwargs):
"""
Args:
inplace: whether to mutate the instance inplace
*args & **kwargs: inherited from dnpNMR.window()
Returns:
mutated Workspace
"""
\# call dnpNMR.window()pd.DataFrame for inplace manipulationTake this example:
`powers = np.array([1,2,3,4,5,6,7])
filenames = [
"../data/prospa/toluene_10mM_Tempone/1/data.1d",
"../data/prospa/toluene_10mM_Tempone/2/data.1d",
"../data/prospa/toluene_10mM_Tempone/3/data.1d",
"../data/prospa/toluene_10mM_Tempone/4/data.1d",
"../data/prospa/toluene_10mM_Tempone/29/data.1d",
"../data/prospa/toluene_10mM_Tempone/30/data.1d",
"../data/prospa/toluene_10mM_Tempone/31/data.1d",
]
data = dnp.dnpImport.load(filenames, dim = "power", coord = powers)`
The the size of the array does not match the number of spectra that are imported an error is reported ("ValueError: x and y must have same first dimension, but have shapes (3,) and (6,)")
However, this error is not very descriptive and a user unfamiliar with Python will not immediately able to figure out what the problem is.
Can we add a dimension check to the import function, raising an error if the number of spectra and coords do not match?
This is following #14
./dnplab/core/nddata.py:143:20: F821 undefined name 'self'
for key in self._attrs:
^
./dnplab/core/nddata.py:145:17: F821 undefined name 'self'
self._attrs, (list, np.ndarray, int, float, complex, str)
^
./dnplab/core/nddata.py:289:63: F821 undefined name 'result'
(self.error / result) ** 2.0 + (b.error / result) ** 2.0
^
./dnplab/core/nddata.py:320:35: F821 undefined name 'result'
(self.error / result) ** 2.0 + (b.error / result) ** 2.0
^
One user reported an issue with two of the buttons. Run the example code and observe the terminal output to test for the issue. When asked to select a directory select your desktop, enter "test" as the save name. It appears that where the selected folder doesn't include the path on my OS, it includes the path for the user.
import sys
import os
from PyQt5 import QtWidgets, QtGui, QtCore
from PyQt5.QtWidgets import QApplication, QMainWindow, QSizePolicy, QWidget, QFileDialog, QPushButton
from PyQt5.QtCore import Qt
class bug_example(QMainWindow):
def __init__(self):
super().__init__()
self.setWindowTitle('bug')
self.setGeometry(10, 10, 400, 200)
self.setContentsMargins(0, 0, 0, 0)
self.singleButton = QPushButton('button', self)
self.singleButton.move(175, 5)
self.singleButton.resize(80, 30)
self.singleButton.clicked.connect(self.button_Button)
self.initUI()
def initUI(self):
self.show()
def button_Button(self):
dirname = QFileDialog.getExistingDirectory(self)
print('GET DIRECTORY NAME: ' + dirname)
pthnm = dirname + os.sep
print('GET PATH NAME: ' + pthnm)
x = pthnm.split(os.sep)
singlefolder = x[len(x) - 2]
print('GET SINGLE FOLDER: ' + singlefolder)
path = pthnm.replace(str(singlefolder) + os.sep, '')
print('GET TOTAL PATH: ' + path)
svpthnm1 = QFileDialog.getSaveFileName(self)
svpthnm = svpthnm1[0]
spltpthnm = svpthnm.split(os.sep)
flnm = spltpthnm[-1]
svpthnm2 = svpthnm + ' add on string'
print('SAVE FILE NAME: ' + flnm)
print('SAVE PATH NAME: ' + svpthnm2)
def main_func():
app = QApplication(sys.argv)
ex = bug_example()
sys.exit(app.exec_())
if __name__ == '__main__':
main_func()
On Windows 10 the user observes:
GET DIRECTORY NAME: C:/Users/thoma/Desktop
GET PATH NAME: C:/Users/thoma/Desktop\
GET SINGLE FOLDER: C:/Users/thoma/Desktop
GET TOTAL PATH:
SAVE FILE NAME: C:/Users/thoma/Desktop/test
SAVE PATH NAME: C:/Users/thoma/Desktop/test add on string
(also notice the os.sep that is added to GET PATH NAME is wrong for the user, but this doesn't seem to matter)
On MacOS I observe:
GET DIRECTORY NAME: /Users/thomascasey/Desktop
GET PATH NAME: /Users/thomascasey/Desktop/
GET SINGLE FOLDER: Desktop
GET TOTAL PATH: /Users/thomascasey/
SAVE FILE NAME: test
SAVE PATH NAME: /Users/thomascasey/Desktop/test add on string
update functions to function(object, keyword=value) style rather than function(object, dictionary) style.
We should have a function that returns the DNPLab version number and the installation path and whatever else is helpful to troubleshoot issues that may arise from using different versions.
Our functions should allow for either functionality:
Option 1, modification in place: dnplab.dnpNMR.integrate(object,args)
Option 2, make something new and retain original: something_new = dnplab.dnpNMR.integrate(object,args)
Option 1 is good for linear paths to one outcome while Option 2 allows for easier implementation of loops, GUI sliders, or any other cases of using our functions within iteratively called functions that require retention of the original object that is operated on.
Examples should emphasize and encourage modification in place as it offers many advantages but also show how to handle special cases where Option 2 is needed.
Currently the calculate_enhancement function is also performing an integration of the data. However, this will lead to duplicate functions in DNPLab. This issue is also related (somehow) to #100
I would suggest the following:
Need docs on how to contribute for long-term maintenance. Can start from a basic one.
>>> import dnplab as dnp
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/Users/tmaly/Documents/Repositories/ODNP/DNPLab/dnplab/__init__.py", line 8, in <module>
from . import hydrationGUI
File "/Users/tmaly/Documents/Repositories/ODNP/DNPLab/dnplab/hydrationGUI.py", line 10, in <module>
from PyQt5 import QtWidgets, QtGui, QtCore
ModuleNotFoundError: No module named 'PyQt5.sip'
PqQt5 is still version 5.14. I already uninstalled it and let DNPLab re-install it (so I get a version that is compatible). But no luck yet.we should use scipy.integrate rather than a sum if we are going to call the function "integrate"
Currently, to load topspin data the path has to end with a backslash:
path = '../data/topspin/'
data = dnplab.load(path, 'topspin',20)
It the backslash is missing the export won't work. Maybe we can check whether the path ends with a backslash and add it when it is missing.
User is getting "dspfvs not defined" printed from line 117 in dnpIO.topspin. We don't have an option for the user's DSPFVS = 21.0 and DECIM = 133.3333_.
the import modules each take a different number and type of inputs. All import modules should have the same style of inputs:
data = .import(path, par1=None, par2=True, par3='fid', etc.)
We should consider a unified import module that applies necessary import functions based on file type, rather than individual submodules. Either have it auto-detect based on file extensions, or have something like:
data = .import(path, type='topspin', par2=True, par3=None, etc.)
wrapper could be:
if type is "topspin":
topsin code
elif type is "prospa":
prospa code
etc.
This may be related to issue #6
When the workspace is saved in an h5 file and later loaded back into DNPLab it doesn't create the same workspace structure. This makes it difficult to use data saved in h5 and continue processing.
Add window functions for FID processing.
At the minimum we should have:
-add dnpIO module for .DTA/.DSC and .spc/.par data
-update dnpImport wrapper function accordingly
make a robust function for saving data to csv and excel formats
It is not clear why we need a data object and workspace, and when one is preferred over the other. It seems all of the functions could be simplified and users would need a few less lines of code to accomplish the same if we just choose one
@thcasey3 : this is not much of a start, but here is my starting point on translating the specman matlab code:
import os
from numpy import *
def load_specman(file_name):
with open(file_name,'rb') as fp:
header = fromfile(fp, dtype=[('ndim1','>u1'),# number of heders
('dformat','>u1')], count=1)
if header['dformat'] == 0:
sformat = '>f8'
elif header['dformat'] == 1:
sformat = '>f4'
else:
raise ValueError("dformat of %d not supported!!"%header['dformat'])
print("header is",repr(header))
dstrms = {};
ntotal = 1;
for k in range(header['ndim1'].item()):
diminfo = fromfile(fp, dtype='>i4', count=6)
print("for %d, diminfo is"%k,diminfo)
ndim2 = diminfo[0]
newshape = diminfo[1:5]
if ndim2 > len(newshape):
raise ValueError("ndim2 is greater than 4 -- this doesn't make sense!")
newshape[ndim2:] = 1
if __name__ == '__main__':
result = load_specman(os.path.expanduser('~/exp_data/reference_data/epr8k.d01'))By default, when a spectrum is loaded the x-axis is named "f2". This doesn't make much sense for EPR data and currently the user has to manually rename the x-axis to e.g. "B". Can we add a feature that automatically renames the axis to "B" when an EPR spectrum is imported?
What happened:
Creating nddata_coord_collection from a list of coordinates does not return a collection of nddata_coord.
What you expected to happen:
The following should print True
Minimal Complete Verifiable Example:
from dnplab.core.nddata_coord import nddata_coord, nddata_coord_collection
ncc = nddata_coord_collection(
dims=["a", "b"],
coords=[[1, 2, 3], [4, 5, 6]]
)
print(isinstance(ncc[0], nddata_coord))Anything else we need to know?:
coords arguments simply got stored as ncc._coords without explicit reconciling with dims. Even when the dims have different length with coords. e.g.
from dnplab.core.nddata_coord import nddata_coord, nddata_coord_collection
ncc = nddata_coord_collection(
dims=["a", "b", "c", "d"],
coords=[[1, 2, 3], [4, 5, 6]]
)No error was raised
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.
{kind=link}