- Dance Diffusion - Train an unconditional diffusion model on your sounds to get similar ones. It generates 1-2 seconds (usually 65536 or 131072 audio samples) of whatever sample rate it was trained on (usually 44.1 or 48khz). It's especially good for things like neurobass, which typically has a lot of noise that masks the noisy imperfections the diffusion process leaves. i have successfully trained it on kicks, snares, hardstyle kicks, top loops, neuro basses, and pads.
- Musicgen - Either use pretrained for things like percussion loops, OR finetune it on 30-second chunks of songs. This model makes longer loops and song snippets, not so good for sample gen. You'll probably want to use Dance Diffusion for that. This model is limited to 32khz and mono (the stereo version is... not particularly good. Way too wide/imbalanced)
- Stable Audio - As of Mar. 2024, there is only the web interface, no model you can run yourself. However, there is plans to release the model weights in the near future, and we'll be able to fairly easily finetune it on your sounds like the other models. Unlike musicgen, this model does 44.1khz stereo - much better for sampling.
- Other Generative Models - Tools like Riffusion, Suno, Soundry, etc are also potentially worth playing with, although they all have limitations. Riffusion is usually pretty terrible quality since it generates image spectrograms with a finetuned stable diffusion and reverses those to audio instead of directly denoising audio samples or VAE latents. Suno does "full song generation" but focuses more on lyrics and getting coherent vocals, and the beats are not really sampling quality. Soundry is a decent service if you want to generate dubstep sounds, but there's no way to finetune or generate locally with it.
- Demucs is a stem splitter. Given a mixed input track, it tries to separate it into 4 stems (Drums, Bass, Vocals, Other) that mix together into the original track. It does leave pretty bad compression artifacts, but works well enough to use for bootleg remixes. FL Studio 21 has it built in as Stem Separator, and there's a variety of options if you use a different DAW. There are websites you can pay for that do this, like lalal.ai and similar, but there's no need if you have a decent GPU- instead you can download Ultimate Vocal Remover aka UVR5 which is 100% free and has a wide variety of splitting options. Not only does it have Demucs (change Process Method to
Demucsand Demucs Model tov4 | htdemucs), it also has DeReverb models that will try and remove reverb/echo/ambiance from a track. You get these by clickingDownload More Modelsand selecting an arch/model from the radio/dropdowns. A couple of the DeReverb models areMDX-Net Model: Reverb HQ by FoxJoyandUVR-DeEcho-DeReverb. These models are crazy fun, and I'd recommend trying a variety of them to get familiar. - RVC is a voice transfer model. This is how everyone is making those Minecraft Villager remixes, or Squidward singing, or those Presidents saying dumb stuff Youtube shorts. You can download (and use!!) models for specific voices from this site (voice-models.com). If you click the
Runbutton next to a voice and sign in to the site that appears, you can run them without code or fancy setup, but you can also run it in Colab or similar. There are a wide variety of notebooks available for that, googling "RVC inference colab" gives you a bunch of options. I ran into environment errors installingRVC-webuilocally, weird dependency conflicts that I was unable to easily resolve. If you're just looking to run it a couple times, just use the site above- it's much easier than dealing with uploading checkpoints to colab or solving weird code bugs.
Literally just sample from them. Make some snares with Dance Diffusion. Paulstretch some Stable Audio outputs into a weird pad. Tune Musicgen on top loops. Send VR Bass loops through RVC Squidward and distort them. Generate some DnB with Google's MusicFX and replace every single sound with your own. Make a Mariah Carey riddim remix with Demucs stems. You're a producer, you know what to do, just have fun!
Finetuning notebook, Inference notebook
Ingredients:
- At least 100 audio samples (preferably closer to 1000)
- The Finetuning notebook linked above
- A Google account (you'll need Drive and Colab)
Steps:
- Upload all your samples to a folder in Google Drive
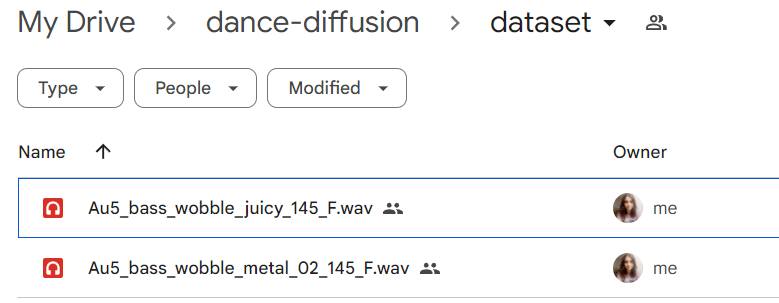
- In the finetuning notebook, change
TRAINING_DIRto the path to that folder, making sure it matches the format/content/drive/MyDrive/your_folder_here

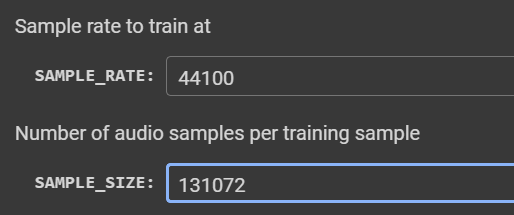
- Adjust
SAMPLE_RATEandSAMPLE_SIZE- you should match the sample rate of your training audio. The defaultSAMPLE_SIZEgives ~1.5 seconds of audio, doubling it to 131072 gives you ~2.5-3 seconds at the cost of more training & inference time. You can also change the run name if you like.
- You should probably make a wandb account, it will let you track the model progress as it trains and displays generated samples during training. The numbers will often be all over the place, so ear test (listening to the demos) is your best indicator of actual progress. The notebook should guide you through what to do with the account, and you can always skip this also (but the demos are really nice!).

- Press all the run buttons in the notebook from top down, starting with
Check GPU Status. Follow any additional prompts it gives you as it runs, but it should be mostly hands-free after the last cell has started. Now.... you wait. It takes a few hours to train, typically. My longest training run lasted 3 days, and my shortest was 1.5 hours. If everything worked correctly, colab should output this:
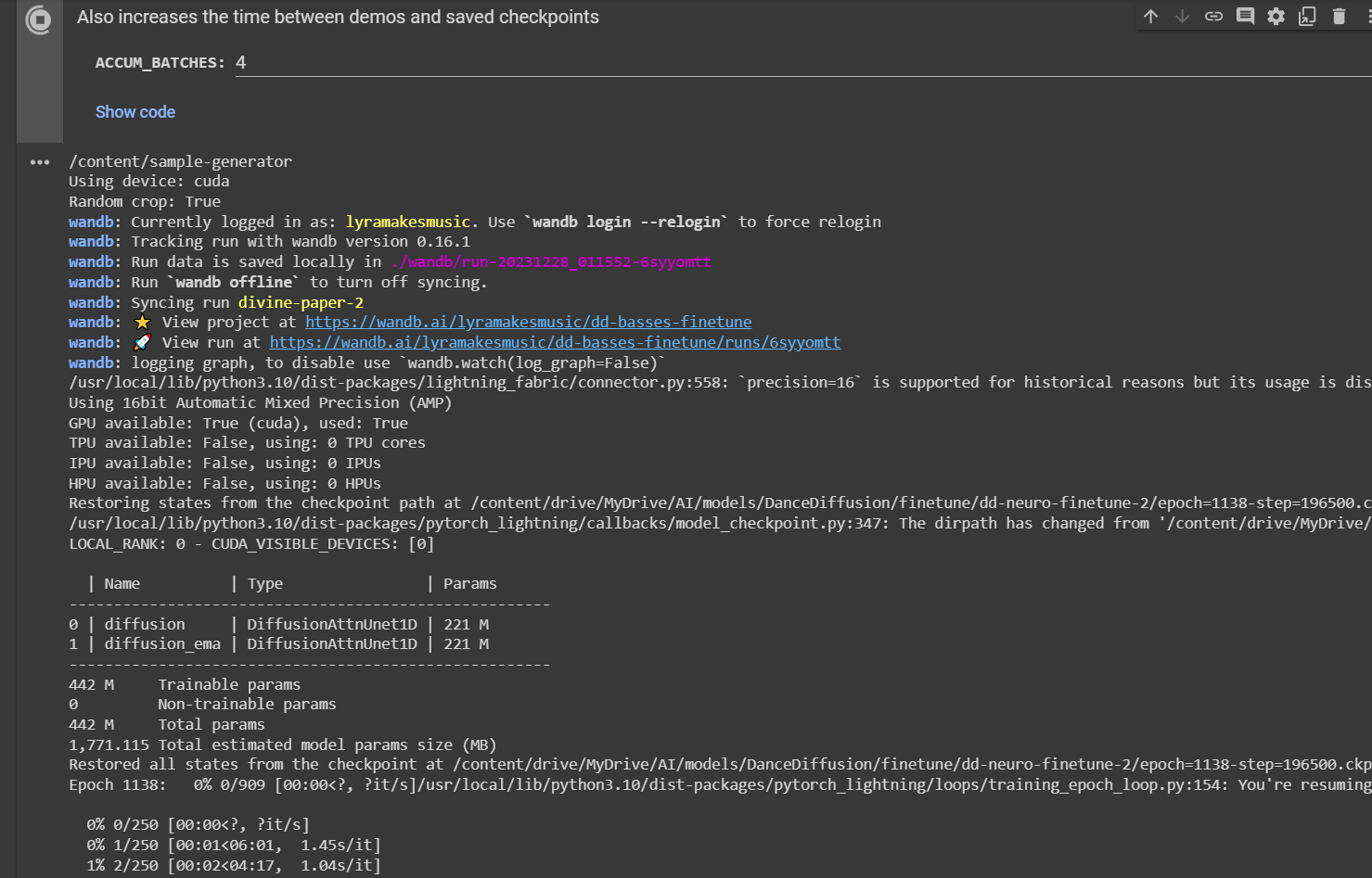
- If you click the wandb link it gave you, you'll hear the first batch of demos- they're generated before it starts training on your sound, so be patient and wait for the next demos 250 steps later.
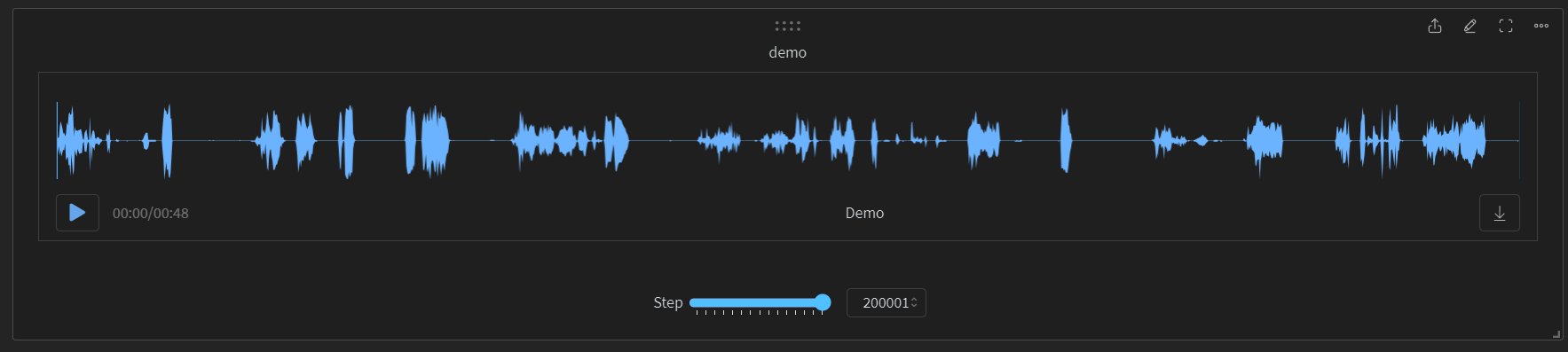
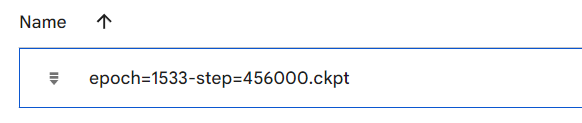
- After every 500 steps, a copy of the trained model will be saved to your Google Drive, in
/content/drive/MyDrive/AI/models/DanceDiffusion/finetuneor whatever you might possibly have changed that line to. You'll be able to download this and run it locally (after writing some inference code and installing pytorch with gpu etc), or point the inference notebook to that checkpoint.
-
Inference: You'll need to run the Inference notebook also linked above. Scroll down to the "Create the Model" section, change the model type to "Custom" and link the trained checkpoint using the same
/content/Drive/MyDrive/format. You'll need to remember what sample rate and length you trained it on, because the inference notebook defaults to 65536@16k- your model should be in the ballpark of 65536@44100 or 131072@48k. Go ahead and put those values in.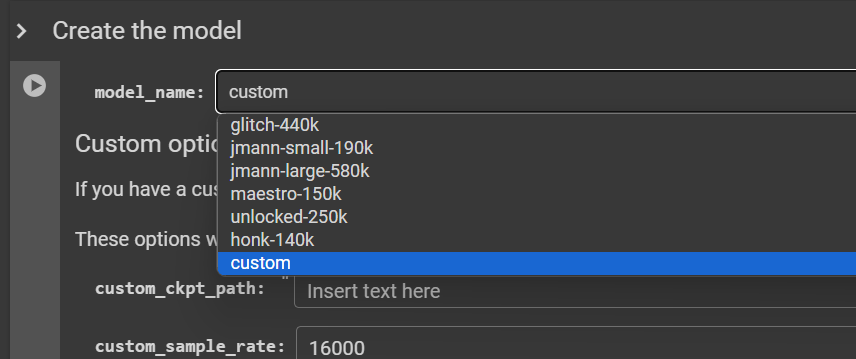
Run all the cells, again starting at the top, and going down to Generate new sounds. The ones below that are for different types of inference, ie audio2audio, we don't need those to run. I do recommend playing with them, they can make some cool stuff, but not needed just to get sounds. Enjoy your samples! If you want to use some pretrained models before trying to finetune your own, here are a few I trained:
| Model | Sample Length | Sample Rate | Finetuning Steps | Link |
|---|---|---|---|---|
| Neuro & dubstep basses | 131072 | 44100 | 6500 steps | Download (3.3GB) |
| Drum fills | 131072 | 44100 | 1500 steps | Download (3.3GB) |
| Hardstyle kicks | 65536 | 44100 | 5500 steps | Download (3.3GB) |
| Top loops | 131072 | 44100 | 3500 steps | Download (3.3GB) |
| Snares | 65536 | 44100 | 0 steps | Download (3.3GB) |
Quality will vary! You'll need to do multiple generations and manually slice up the samples for good results.
Detailed explanation, I just want to run it
Info on training this model is outside the scope of this readme, a detailed guide (screenshot below) is linked above. If you want to finetune without bothering with technical setup, you can use the second link to finetune with a youtube playlist link. If you want to just run it without finetuning, you can use the Musicgen Huggingface space.
There's no Stable Audio model weights currently available, this section will be updated on model release. I could explain the tuning process already, but it won't be very useful without weights since training from scratch is very expensive
Oh boy here we go. [TBA later, there's many details to figure out how to communicate]