

dstack is an open-source container orchestration engine designed for running AI workloads across any cloud or data
center. It simplifies dev environments, running tasks on clusters, and deployment.
The supported cloud providers include AWS, GCP, Azure, OCI, Lambda, TensorDock, Vast.ai, RunPod, and CUDO.
You can also use dstack to run workloads on on-prem clusters.
dstack natively supports NVIDIA GPU, and Google Cloud TPU accelerator chips.
- [2024/05] dstack 0.18.4: Google Cloud TPU, and more (Release)
- [2024/05] dstack 0.18.3: OCI, and more (Release)
- [2024/05] dstack 0.18.2: On-prem clusters, private subnets, and more (Release)
- [2024/04] dstack 0.18.0: RunPod, multi-node tasks, and more (Release)
- [2024/03] dstack 0.17.0: Auto-scaling, and other improvements (Release)
Before using dstack through CLI or API, set up a dstack server.
The easiest way to install the server, is via pip:
pip install "dstack[all]" -UIf you have default AWS, GCP, Azure, or OCI credentials on your machine, the dstack server will pick them up automatically.
Otherwise, you need to manually specify the cloud credentials in ~/.dstack/server/config.yml.
See the server/config.yml reference for details on how to configure backends for all supported cloud providers.
To start the server, use the dstack server command:
$ dstack server
Applying ~/.dstack/server/config.yml...
The admin token is "bbae0f28-d3dd-4820-bf61-8f4bb40815da"
The server is running at http://127.0.0.1:3000/Note It's also possible to run the server via Docker.
Once the server is up, you can use either dstack's CLI or API to run workloads.
Below is a live demo of how it works with the CLI.
You specify the required environment and resources, then run it. dstack provisions the dev
environment in the cloud and enables access via your desktop IDE.
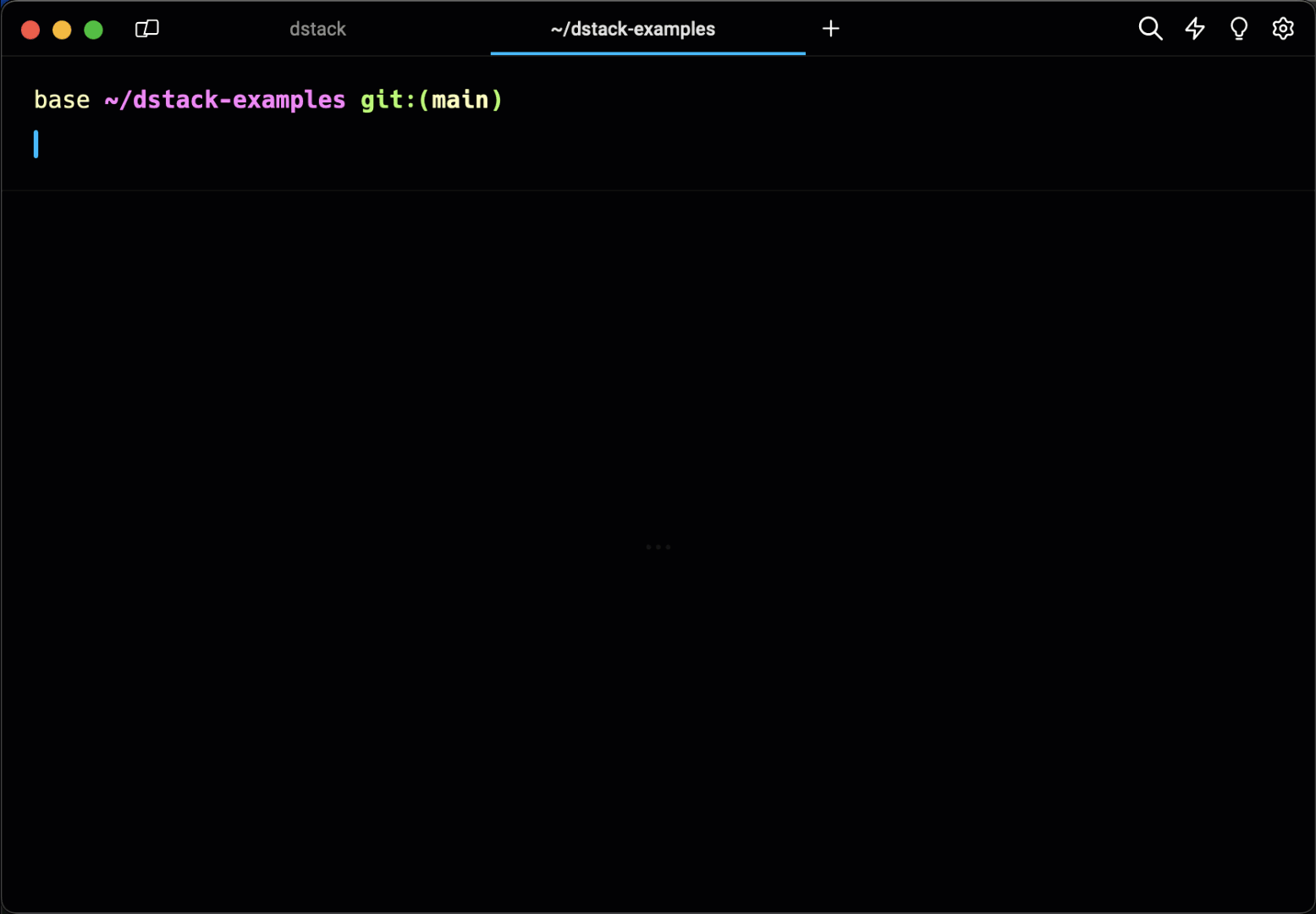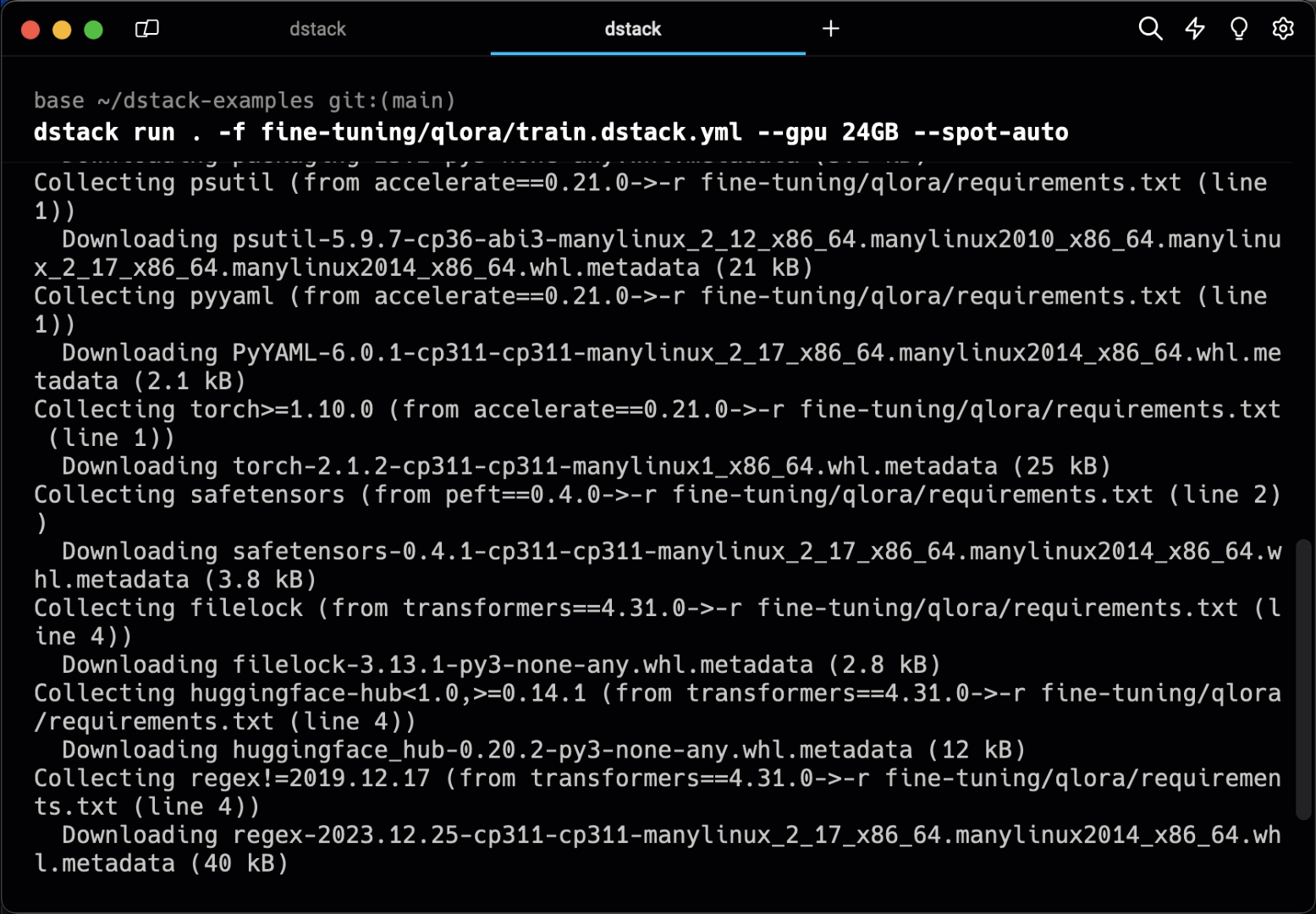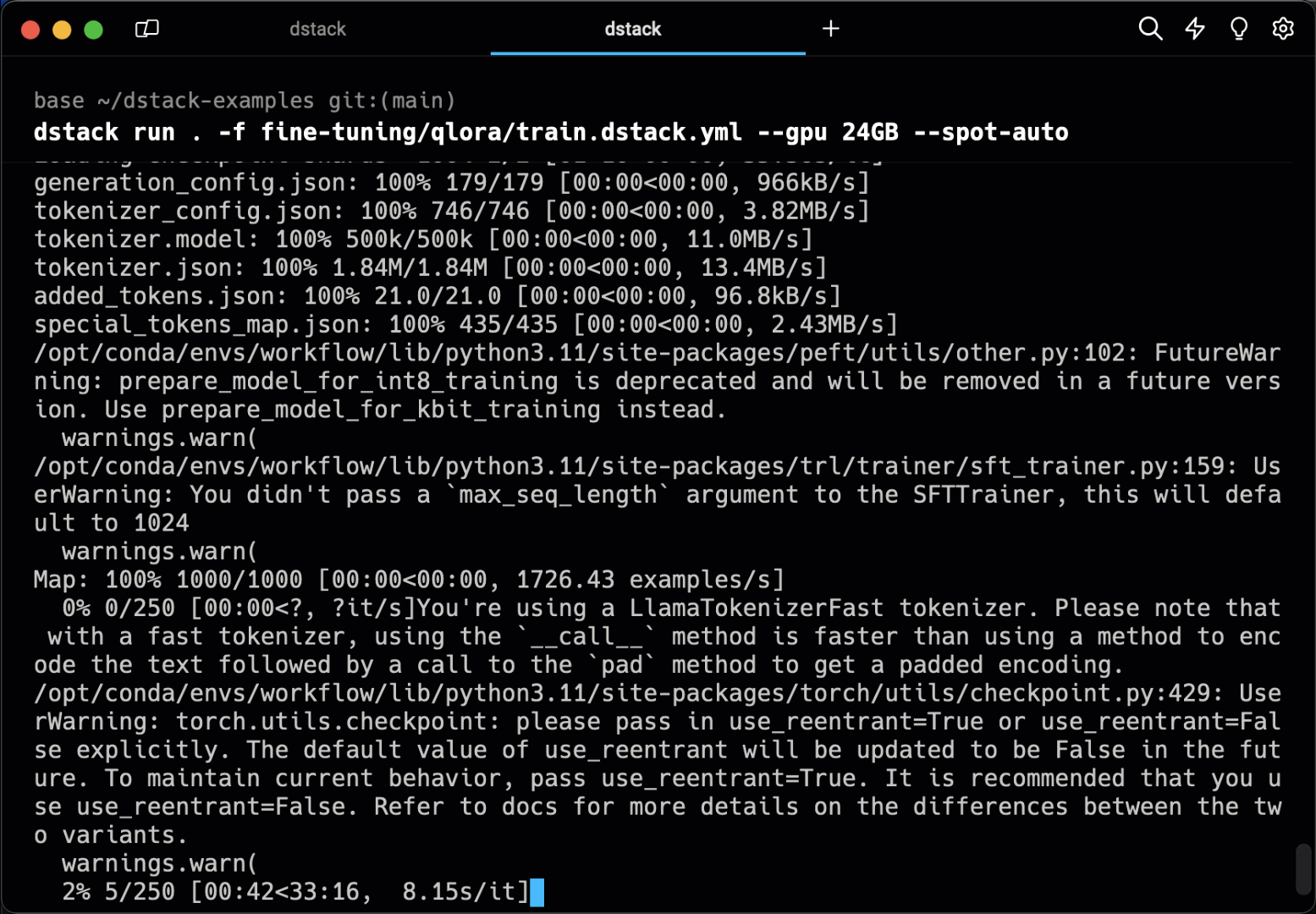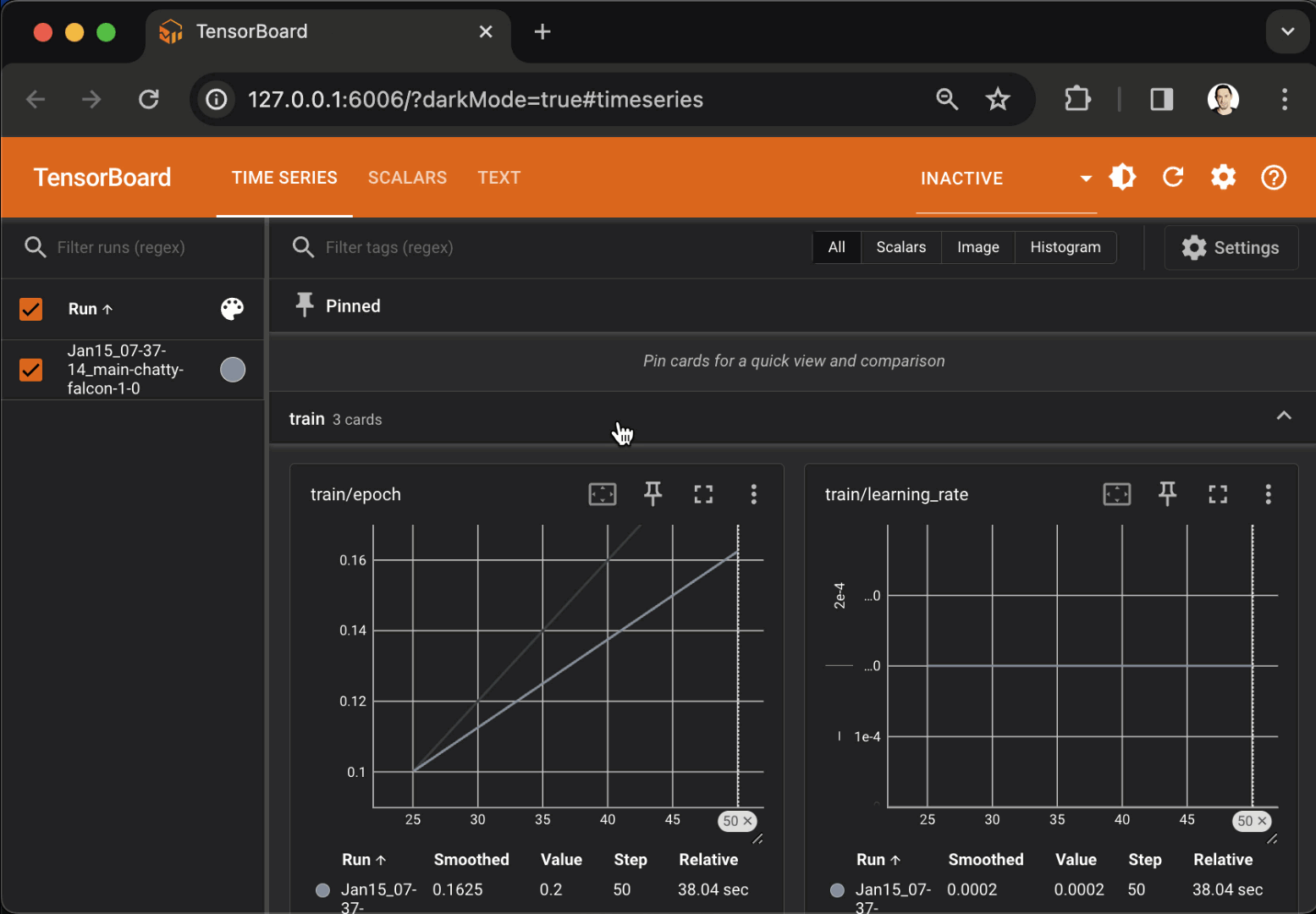
Tasks allow for convenient scheduling of any kind of batch jobs, such as training, fine-tuning, or data processing, as well as running web applications.
Specify the environment and resources, then run it. dstack executes the task in the
cloud, enabling port forwarding to your local machine for convenient access.
Services make it very easy to deploy any kind of model or web application as public endpoints.
Use any serving frameworks and specify required resources. dstack deploys it in the configured
backend, handles authorization, and provides an OpenAI-compatible interface if needed.
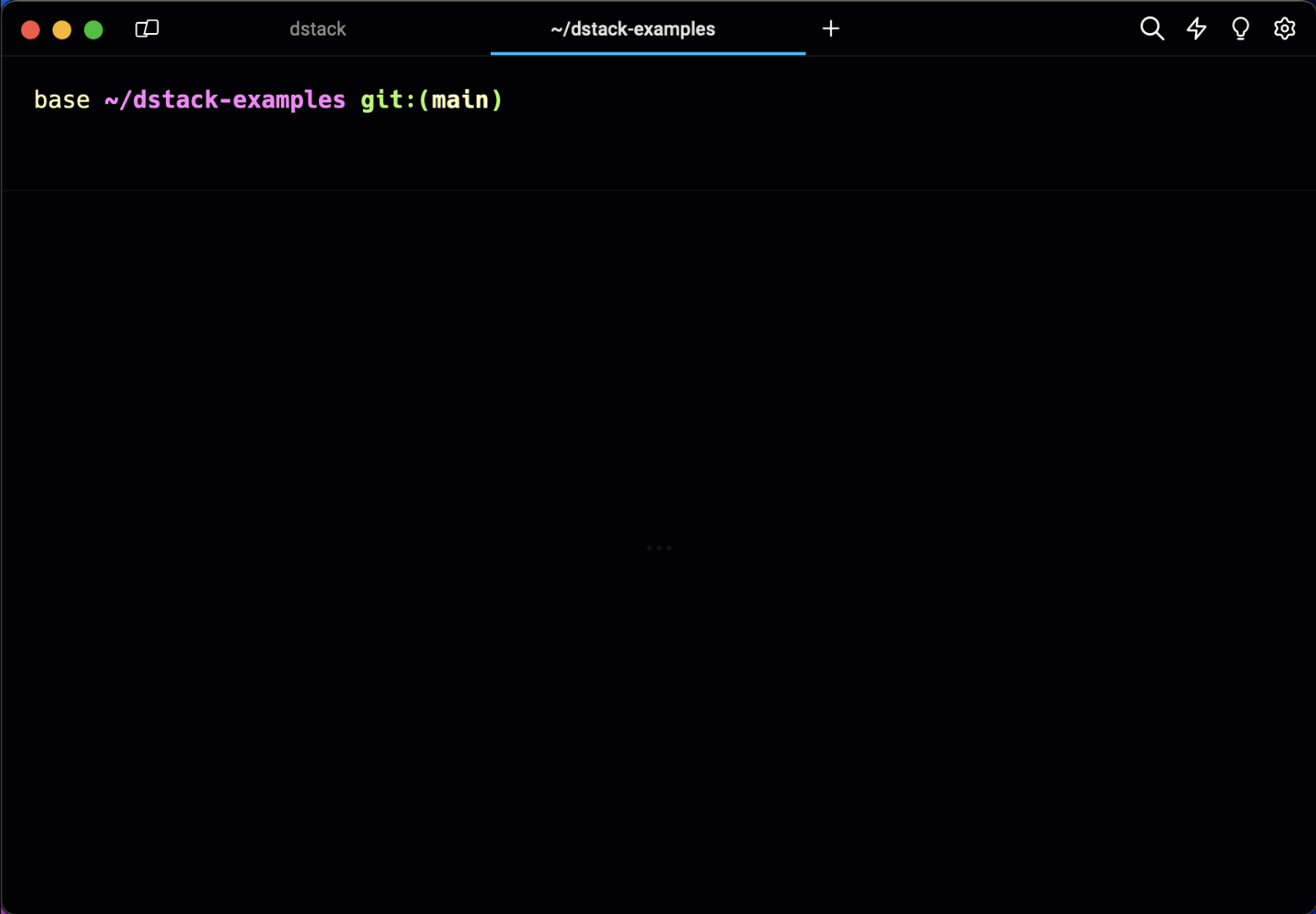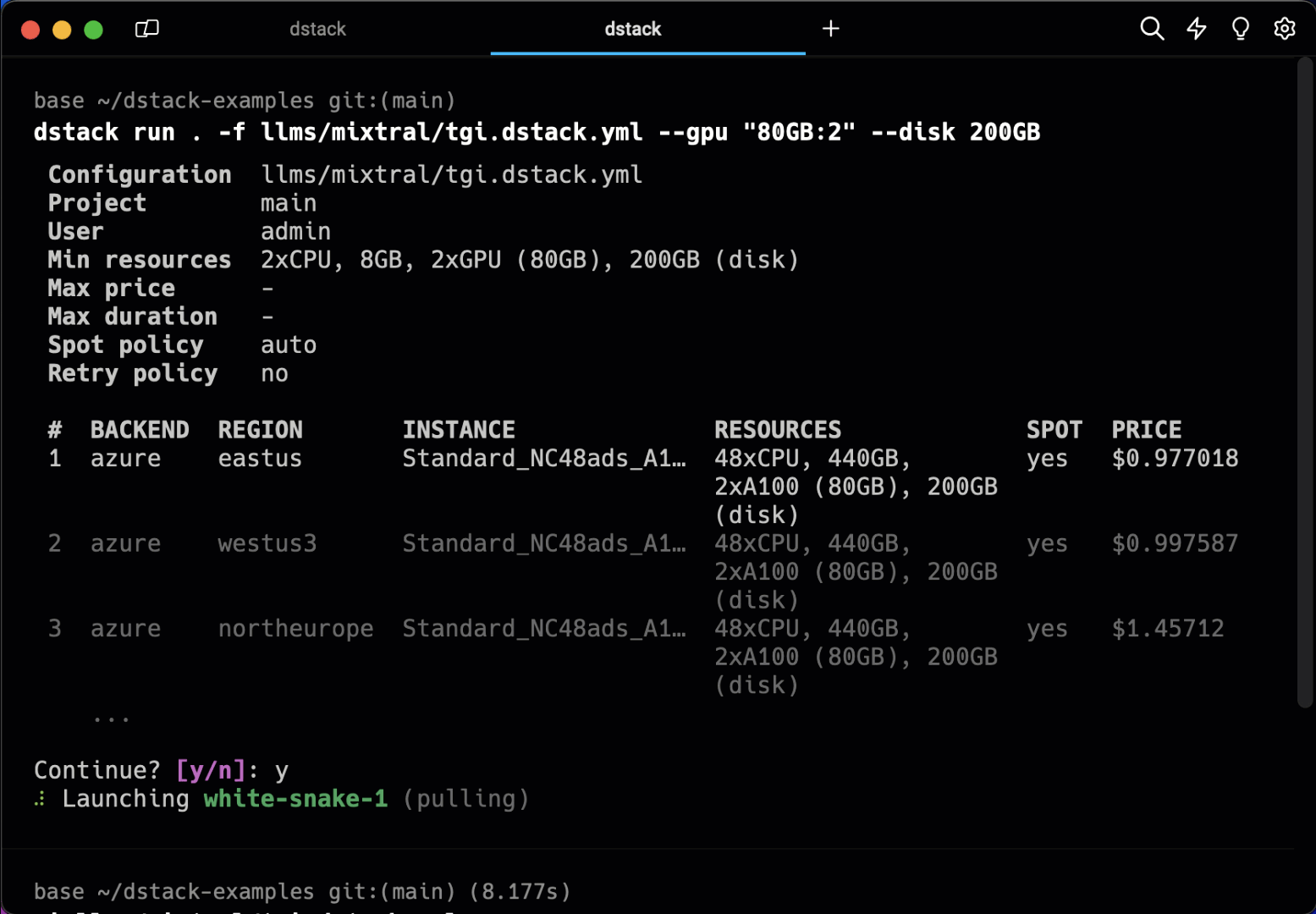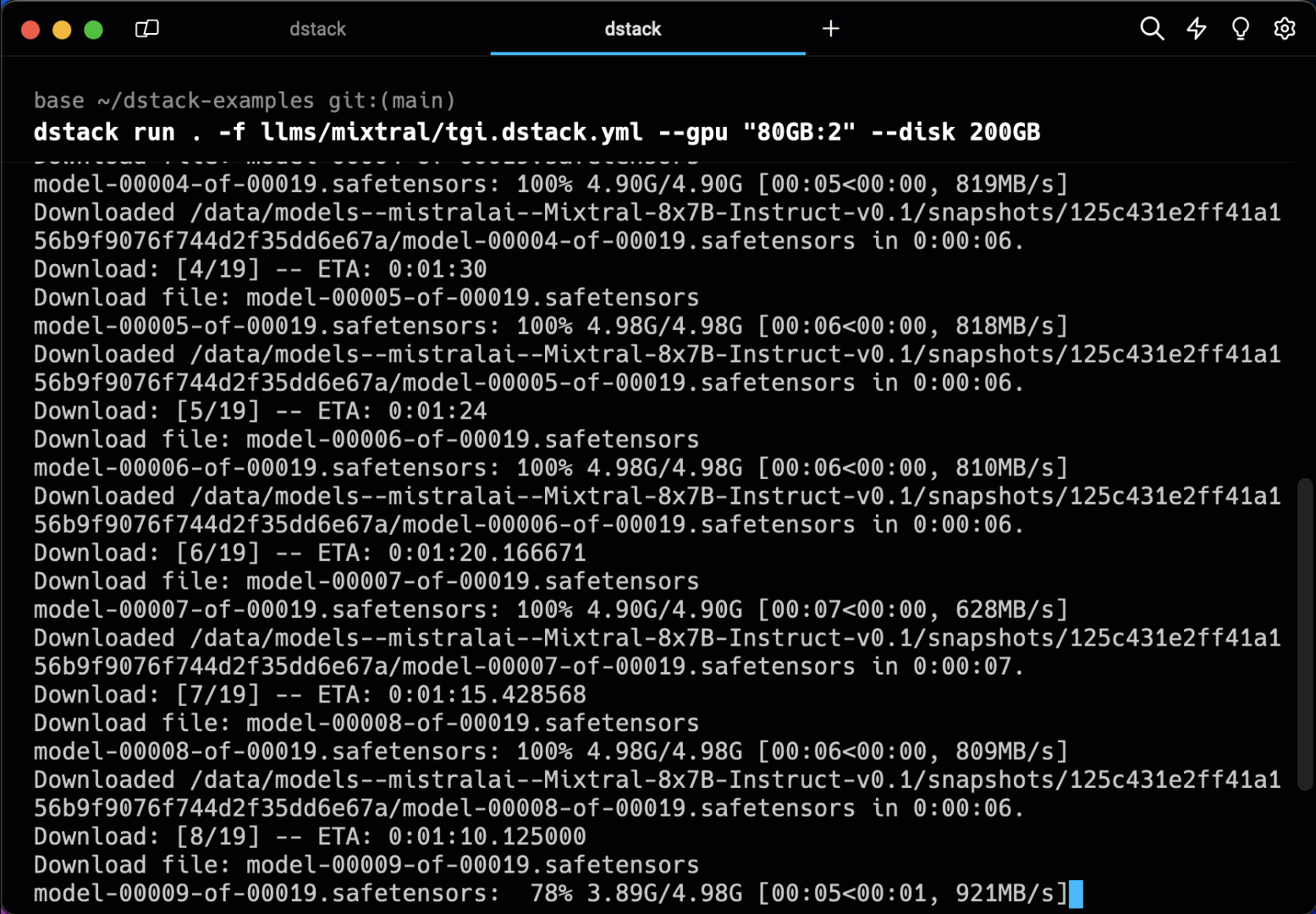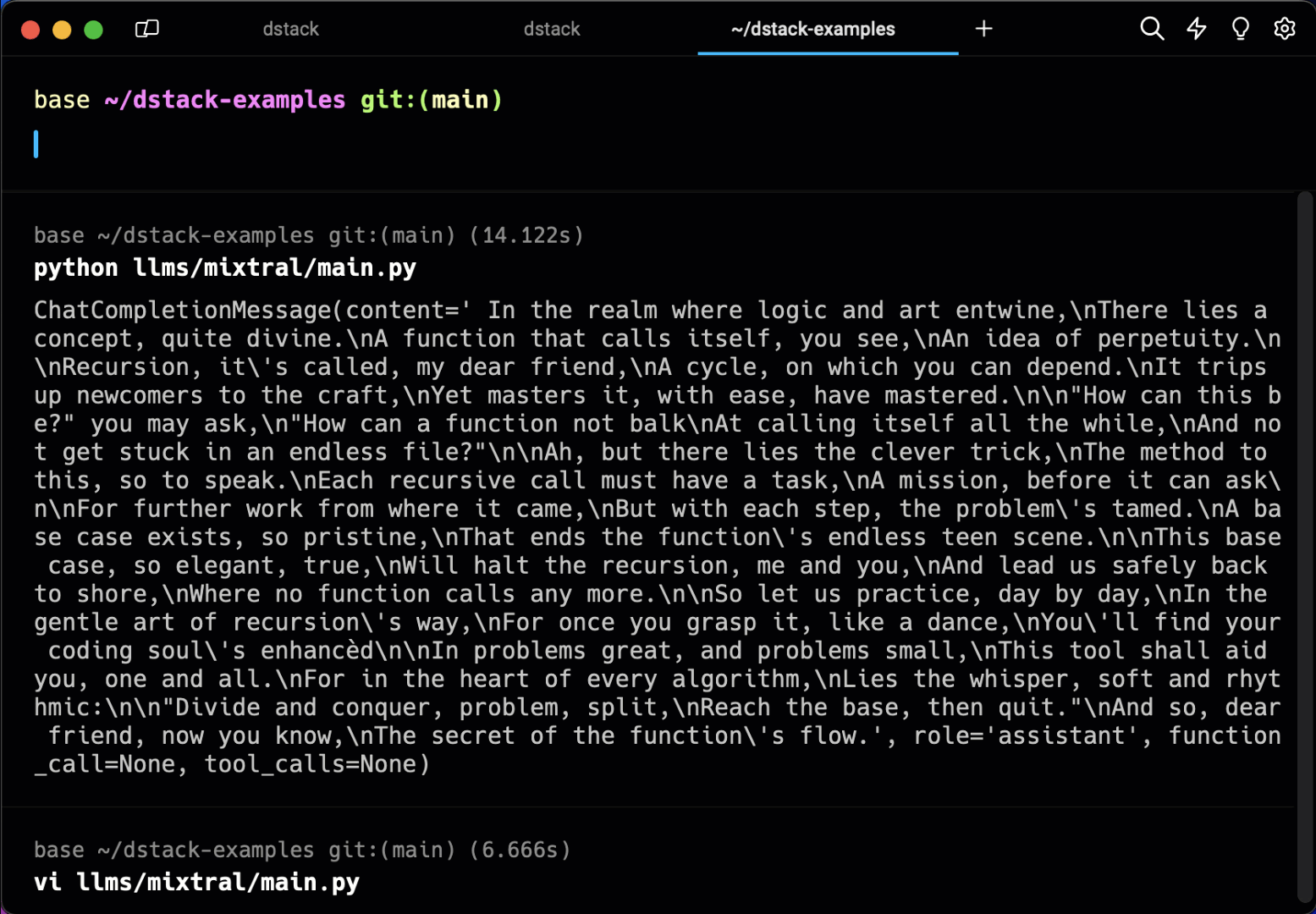
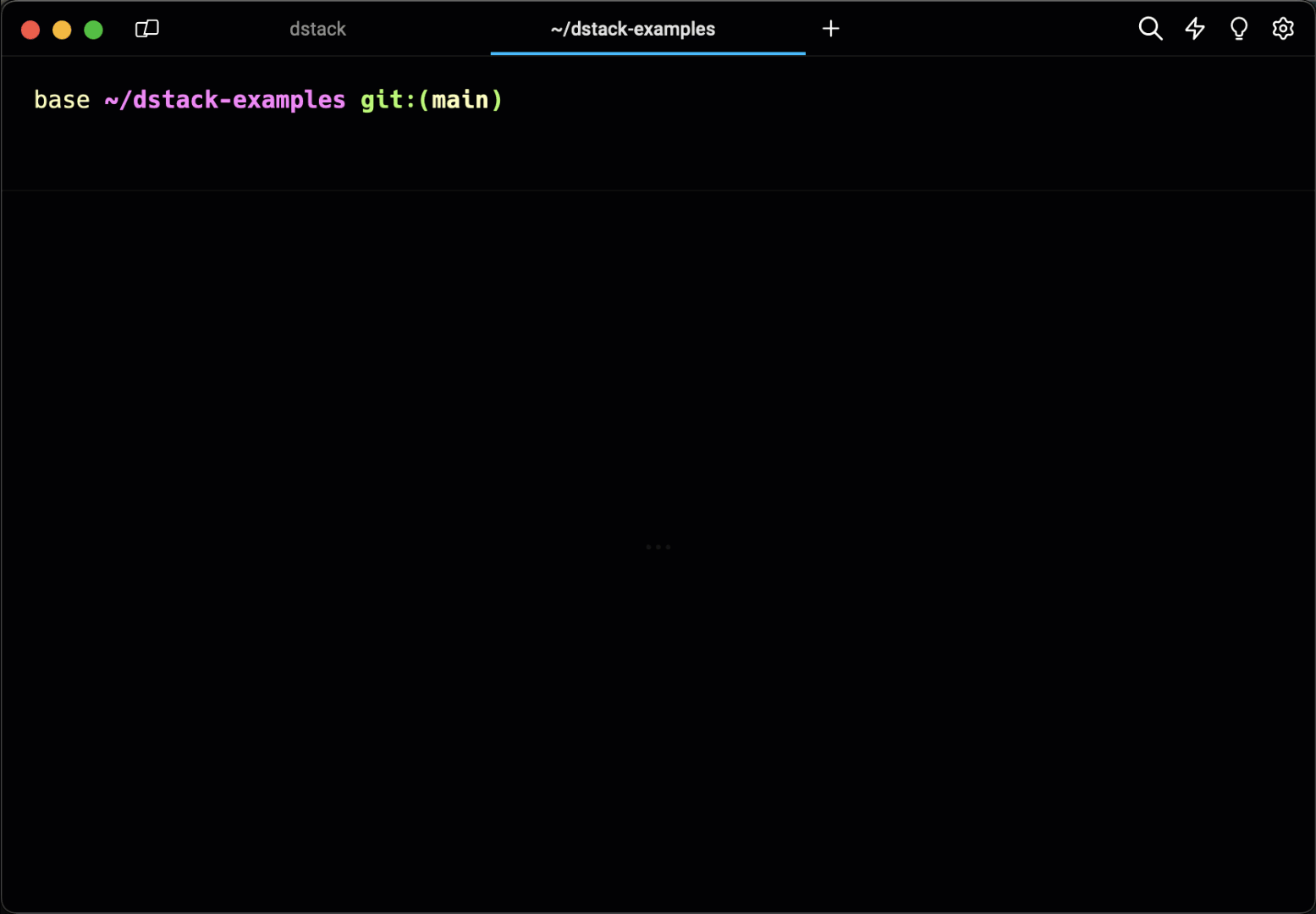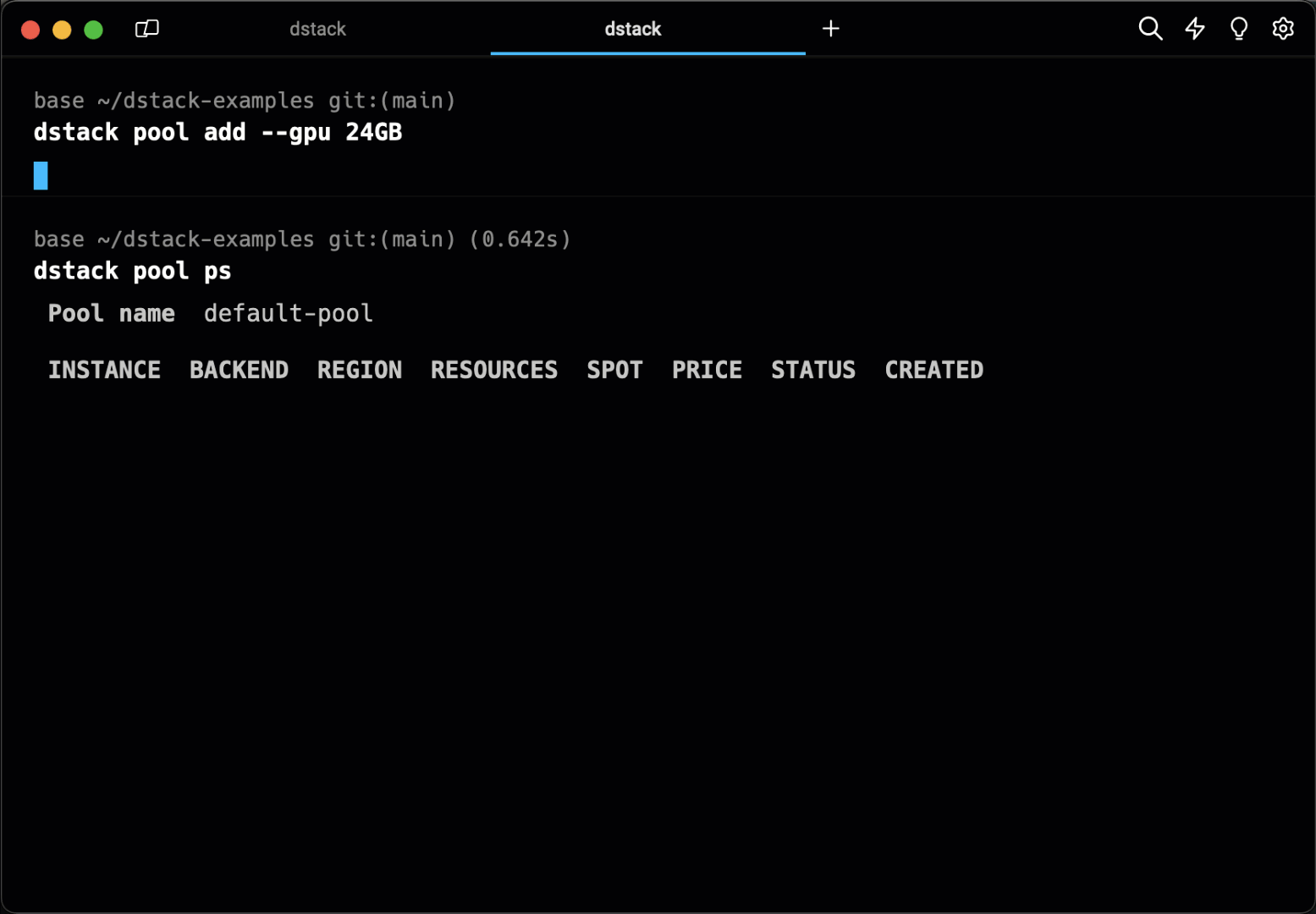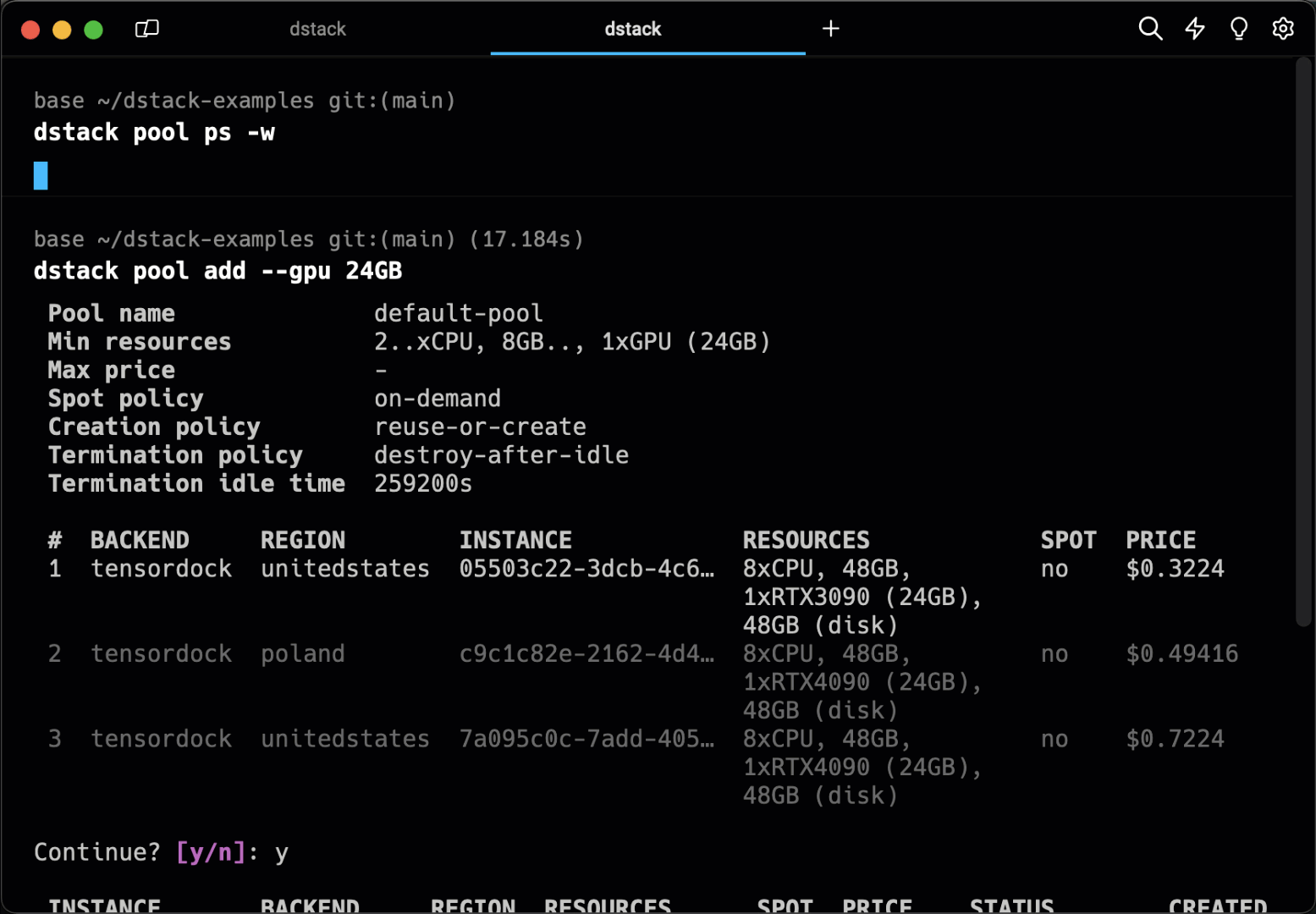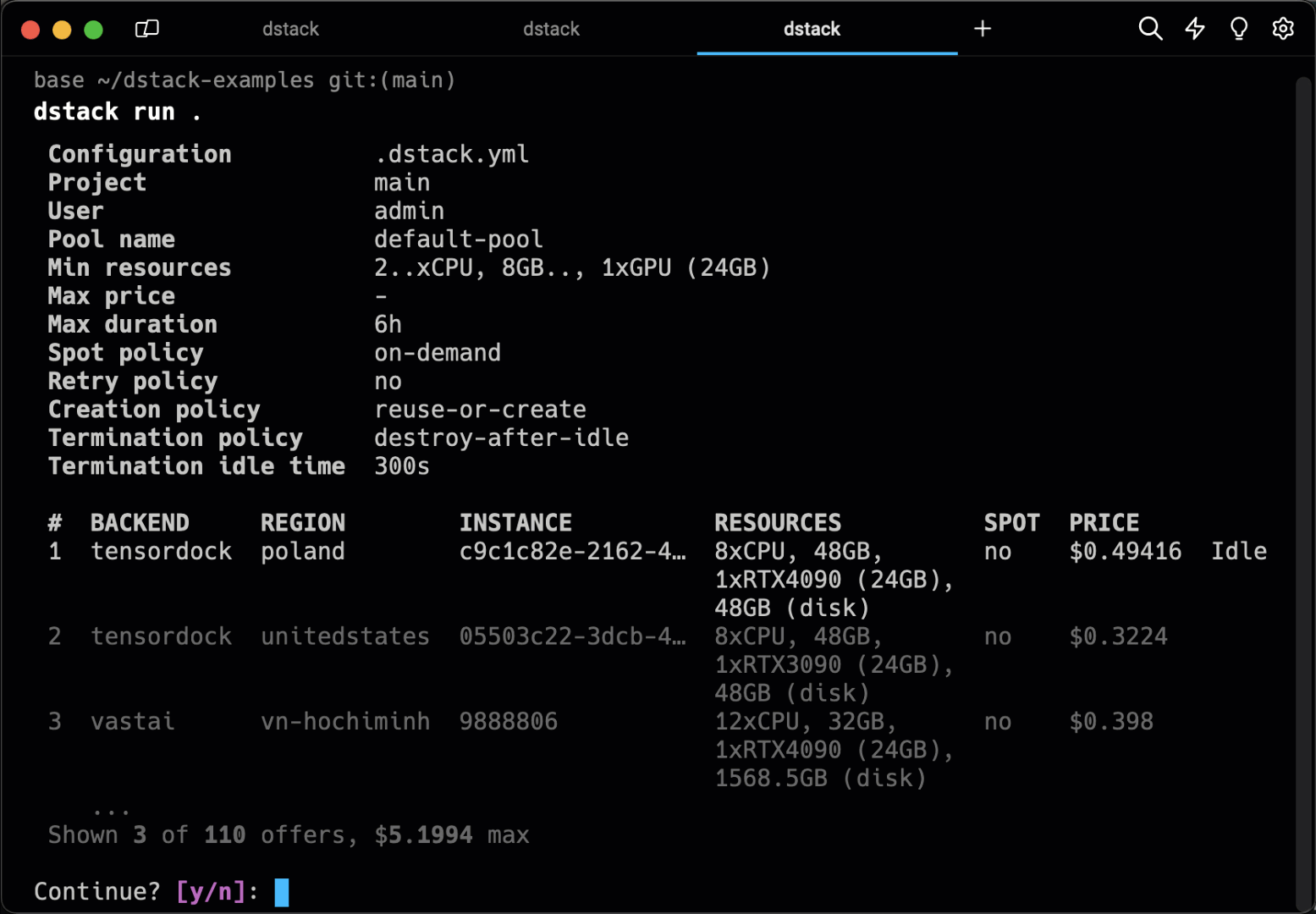
Pools simplify managing the lifecycle of cloud instances and enable their efficient reuse across runs.
You can have instances provisioned in the cloud automatically, or add them manually, configuring the required resources, idle duration, etc.
Here are some featured examples:
Browse examples for more examples.
For additional information and examples, see the following links:
We welcome contributions to dstack!
To learn more about getting involved in the project, please refer to CONTRIBUTING.md.








































































































































