描述:基于大数据、数据平台、微服务、机器学习、商城、自动化运维、DevOps、容器部署平台、数据平台采集、数据平台存储、数据平台计算、数据平台开发、数据平台应用搭建的大数据生态平台解决方案。
数据来源:
商城:使用SpringBoot,Java,Vue,React,Android开发多端商城,包括网站、App、微信小程序;
日志:使用Java开发服务端日志、客户端日志收集系统,使用DataX实现数据的导入导出系统;
爬虫:爬虫平台支持可配置的爬取公网数据的任务开发;
数据存储:
分布式文件系统使用HDFS,分布式数据库使用HBase,Mongodb、Elasticsearch,内存数据库使用redis;
数据计算:
使用Hive、MR、HiveSQL、ETL开发离线计算系统;
使用storm、flink、spark streaming开发实时计算系统;
使用kylin, spark开发多维度分析系统;
数据开发:
任务管理系统:负责调度、分配、提交任务到数据平台;
任务运维系统:查看Task运行情况;
数据应用:
使用python,ml,spark mllib实现个性化推荐系统;
使用python,scrapy,django,elasticsearch实现搜索引擎;
使用scala,flink开发反作弊系统;
使用FineReport,scala,playframework开发报表分析系统;
DevOps:
使用ELK技术栈搭建日志搜索平台;
使用skywalking,Phoenix实现监控平台;
使用scala、playframework,docker,k8s,shell实现云容器平台,包含服务管理(查看docker容器配置,添加容器实例,授权记录,操作记录,历史版本回溯,k8s启停服务,操作记录,对比yaml配置,更新服务)、任务管理、配置管理、镜像构建(包括环境变量和参数配置)、应用日志
使用自动化运维平台CoDo开发system-devops;
使用Kong开发统一网关入口系统system-api-gateway;
使用vue、scala、playframework、docker、k8s、Prometheus、grafana开发监控告警平台system-alarm-platform;
使用Apollo开发system-config配置中心;
# 2、数据平台展示
2.1 商城图片展示:
商城App:https://my-macro-oss.oss-cn-shenzhen.aliyuncs.com/mall/images/samples/mall-shopping-03.png
商城小程序:https://my-macro-oss.oss-cn-shenzhen.aliyuncs.com/mall/images/samples/shopping-app-04.png
商城移动端:https://my-macro-oss.oss-cn-shenzhen.aliyuncs.com/mall/images/samples/shopping-app-05.png
商城PC端: https://my-macro-oss.oss-cn-shenzhen.aliyuncs.com/mall/images/samples/shopping-app-06.png
商城后台管理:https://my-macro-oss.oss-cn-shenzhen.aliyuncs.com/mall/images/samples/shopping-app-07.png
2.2 compute-mr
1、mr-website-analyse:
1.1 主要做的事情:
hadoop HA集群搭建部署;
mapreduce基础掌握;
使用 oozie进行任务调度;
使用 hive保存数据到hdfs,以及从hdfs导出到 mysql;
使用hbase结合mapreduce处理业务,如用户行为分析;
使用flume,nginx模拟收集日志,从java sdk端和js 网站端收集数据等;
1.2 主要模块
用户基本信息分析
浏览器分析
地域分析
浏览深度分析
搜索引擎分析
事件分析
订单分析
2、mr-website-sdk
2.1 java服务端sdk采集
2.2 JS前端页面的数据模拟采集
3、mr-website-view
3.1 数据可视化显示
3.2 主要使用highcharts,html,css, js显示mr-website-analyse数据处理的统计数据,存在mysql
https://my-macro-oss.oss-cn-shenzhen.aliyuncs.com/mall/images/mr/2791587557292_.pic.jpg
https://my-macro-oss.oss-cn-shenzhen.aliyuncs.com/mall/images/mr/2801587557292_.pic.jpg
https://my-macro-oss.oss-cn-shenzhen.aliyuncs.com/mall/images/mr/2811587557292_.pic.jpg
https://my-macro-oss.oss-cn-shenzhen.aliyuncs.com/mall/images/mr/2821587557292_.pic.jpg
https://my-macro-oss.oss-cn-shenzhen.aliyuncs.com/mall/images/mr/2831587557293_.pic.jpg
https://my-macro-oss.oss-cn-shenzhen.aliyuncs.com/mall/images/mr/2841587557293_.pic.jpg
https://my-macro-oss.oss-cn-shenzhen.aliyuncs.com/mall/images/mr/2851587557293_.pic.jpg
2.3 compute-realtime:
1、compute-realtime-spark:
1.1 主要做的事情:
基于Javee平台展示的Spark实时数据分析平台
hadoop HA集群搭建部署;
基于zookeeper的kafka HA集群搭建部署;
HA: 本地搭建时共5个节点,2个namenode,3个datanode;
spark core, spark sql, spark streaming基础掌握;
kafka实时模拟生成数据并使用spark streaming实时处理来自kafka的数据;
实时处理分析结果保存到mysql, 由highcharts动态刷新;
highcharts实时展示统计分析结果,以及spark sql算子执行结果;
1.2 主要模块
广告点击流量分析
广告点击趋势分析
各省份top3热门广告分析
各区域top3热门商品统计
页面单跳转化率
用户访问session分析
Top10热门品类分析
Top10用户session分析
2、compute-realtime-view
2.1 数据可视化显示,定时模拟kafka消息队列的数据
2.2 主要使用highcharts,html,css, js显示compute-realtime-spark数据处理的统计数据,存在mysql
https://my-macro-oss.oss-cn-shenzhen.aliyuncs.com/mall/images/spark/2871587557435_.pic.jpg
https://my-macro-oss.oss-cn-shenzhen.aliyuncs.com/mall/images/spark/2881587557459_.pic.jpg
https://my-macro-oss.oss-cn-shenzhen.aliyuncs.com/mall/images/spark/2891587557479_.pic.jpg
https://my-macro-oss.oss-cn-shenzhen.aliyuncs.com/mall/images/spark/2901587557498_.pic.jpg
https://my-macro-oss.oss-cn-shenzhen.aliyuncs.com/mall/images/spark/2911587557535_.pic.jpg
# 3、数据来源
商城前台:
mall-shopping-app: 商城App
mall-shopping-app-service: 商城App服务
mall-shopping-wc: 商城小程序
mall-shopping-mobile: 商城前台
mall-shopping-pc: 商城pc端
mall-shopping-pc-service: 商城pc端服务
mall-shopping-service: 商城前台服务(小程序和前台接入此接口)
商城后台:
mall-admin-web: 商城后台
mall-admin-service: 商城后台服务
https://my-macro-oss.oss-cn-shenzhen.aliyuncs.com/mall/images/design/microservice.png
https://my-macro-oss.oss-cn-shenzhen.aliyuncs.com/mall/images/design/system-api-gateway01.png
https://my-macro-oss.oss-cn-shenzhen.aliyuncs.com/mall/images/design/system-api-gateway02.png
https://my-macro-oss.oss-cn-shenzhen.aliyuncs.com/mall/images/design/system-apm.png
```
# 4、数据收集
log-collect-server:
服务端日志收集系统
log-collect-client:
支持各app集成的客户端SDK,负责收集app客户端数据;
data-import-export:
基于DataX实现数据集成(导入导出)
data-spider:
爬虫平台支持可配置的爬取公网数据的任务开发;
https://my-macro-oss.oss-cn-shenzhen.aliyuncs.com/mall/images/design/Prometheus.png
https://my-macro-oss.oss-cn-shenzhen.aliyuncs.com/mall/images/design/apollo.png
https://my-macro-oss.oss-cn-shenzhen.aliyuncs.com/mall/images/design/log-collect.png
# 5、数据存储
分布式文件系统:hdfs
分布式数据库:hbase、mongodb、elasticsearch
分布式内存存储系统:redis
# 6、数据计算
compute-mr(离线计算): Hive、MR
compute-realtime(流计算): storm、flink
multi-dimension-analysis(多维度分析): kylin, spark
# 7、数据开发
task-schedular: 任务调度
task-ops: 任务运维
https://my-macro-oss.oss-cn-shenzhen.aliyuncs.com/mall/images/design/system-deploy.png
https://my-macro-oss.oss-cn-shenzhen.aliyuncs.com/mall/images/design/system-deploy02.png
https://my-macro-oss.oss-cn-shenzhen.aliyuncs.com/mall/images/design/system-devops.png
# 8、数据产品
data-face: 数据可视化
data-insight: 用户画像分析
# 9、数据应用
system-recommender: 推荐
system-ad: 广告
system-search: 搜索
system-anti-cheating: 反作弊
system-report-analysis: 报表分析
system-elk: ELK日志系统,实现日志搜索平台
https://my-macro-oss.oss-cn-shenzhen.aliyuncs.com/mall/images/design/system-elk.png
https://my-macro-oss.oss-cn-shenzhen.aliyuncs.com/mall/images/design/system-elk(2).png
system-apm: skywalking监控平台
system-deploy: k8s,scala,playframework,docker打包平台。
system-tasksubmit: 任务提交平台
# 10、启动配置教程
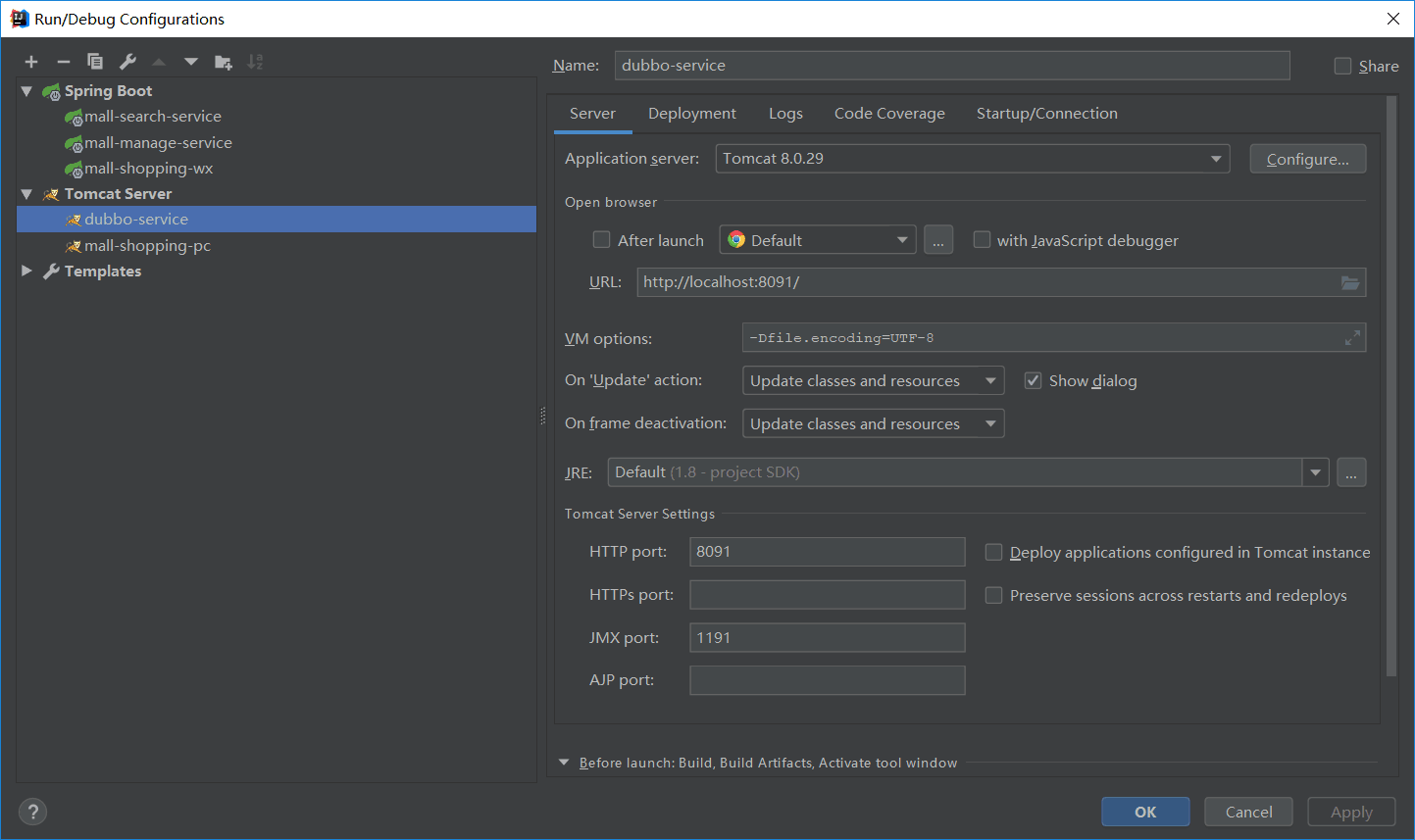
10.1 启动前,打包dubbo-servie项目,进入dubbo-service目录,执行mvn clean package -DskipTests=TRUE打包,然后执行mvn install.
10.2 启动dubbo-service项目,配置tomcat端口为8091
10.3 启动商城项目的多个子系统
后台:访问http://localhost:8090
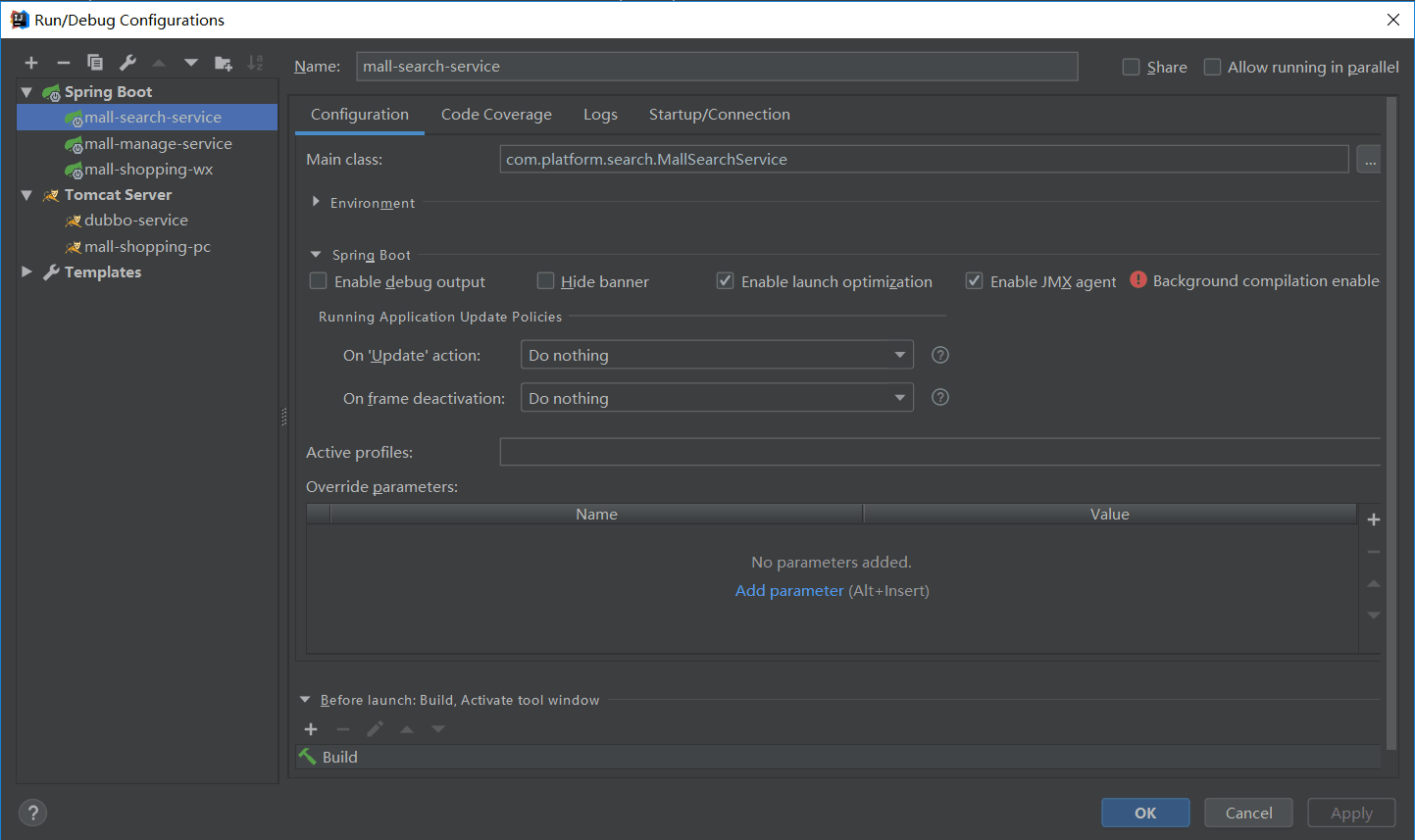
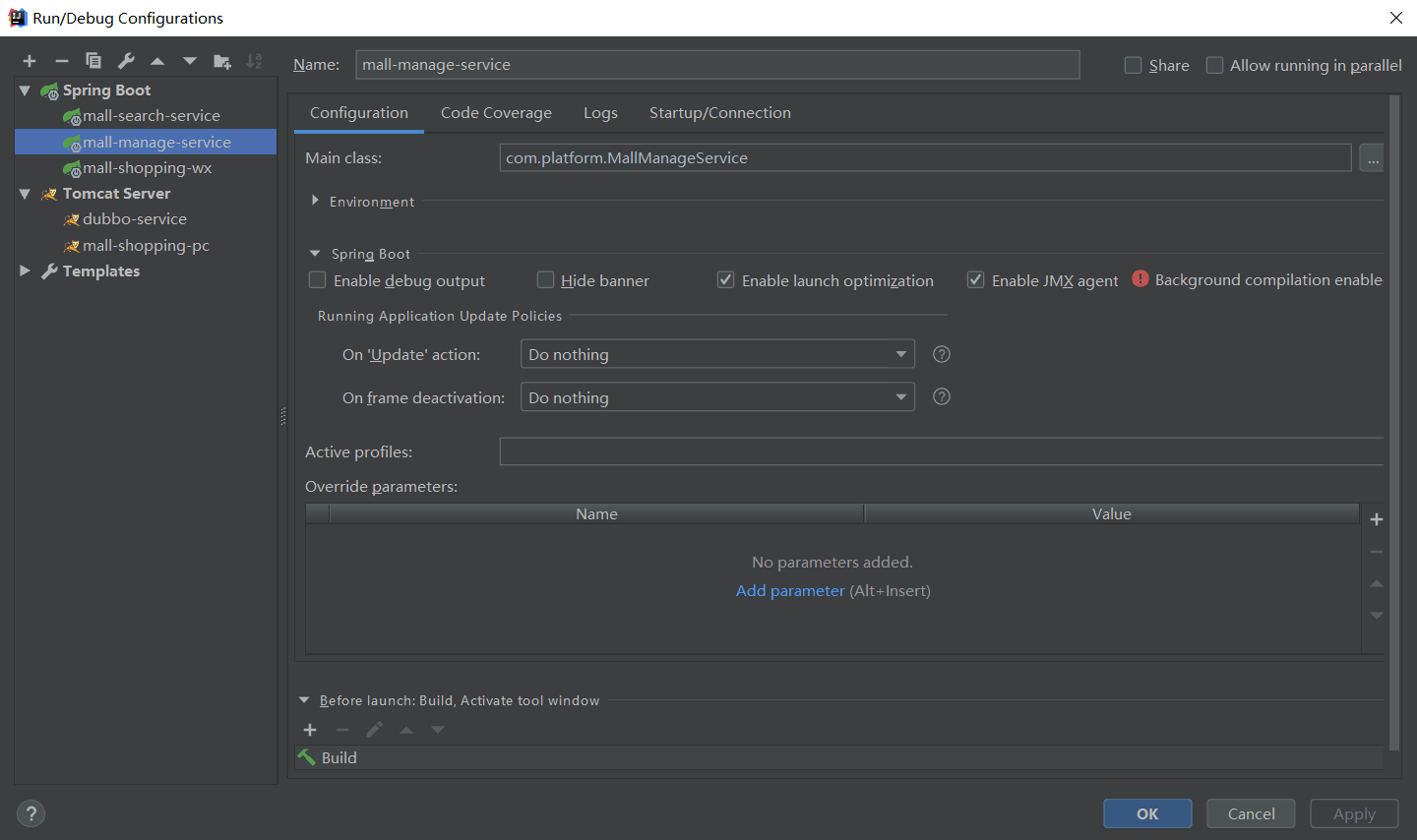
10.3.1、前端:启动mall-admin-web项目,进入项目目录,执行npm install,然后执行npm run dev;
10.3.2、后端:启动mall-admin-service/mall-admin-search项目,配置tomcat端口为8092,接着启动mall-manage-service项目,tomcat端口配置为8093;
前台:小程序手机预览,移动端访问:http://localhost:6255
10.3.3、小程序和移动端
10.3.3.1、前端:商城小程序,启动mall-shopping-wc项目,安装微信开发者工具,配置开发者key和secret,使用微信开发者工具导入即可,然后点击编译,可以手机预览使用。
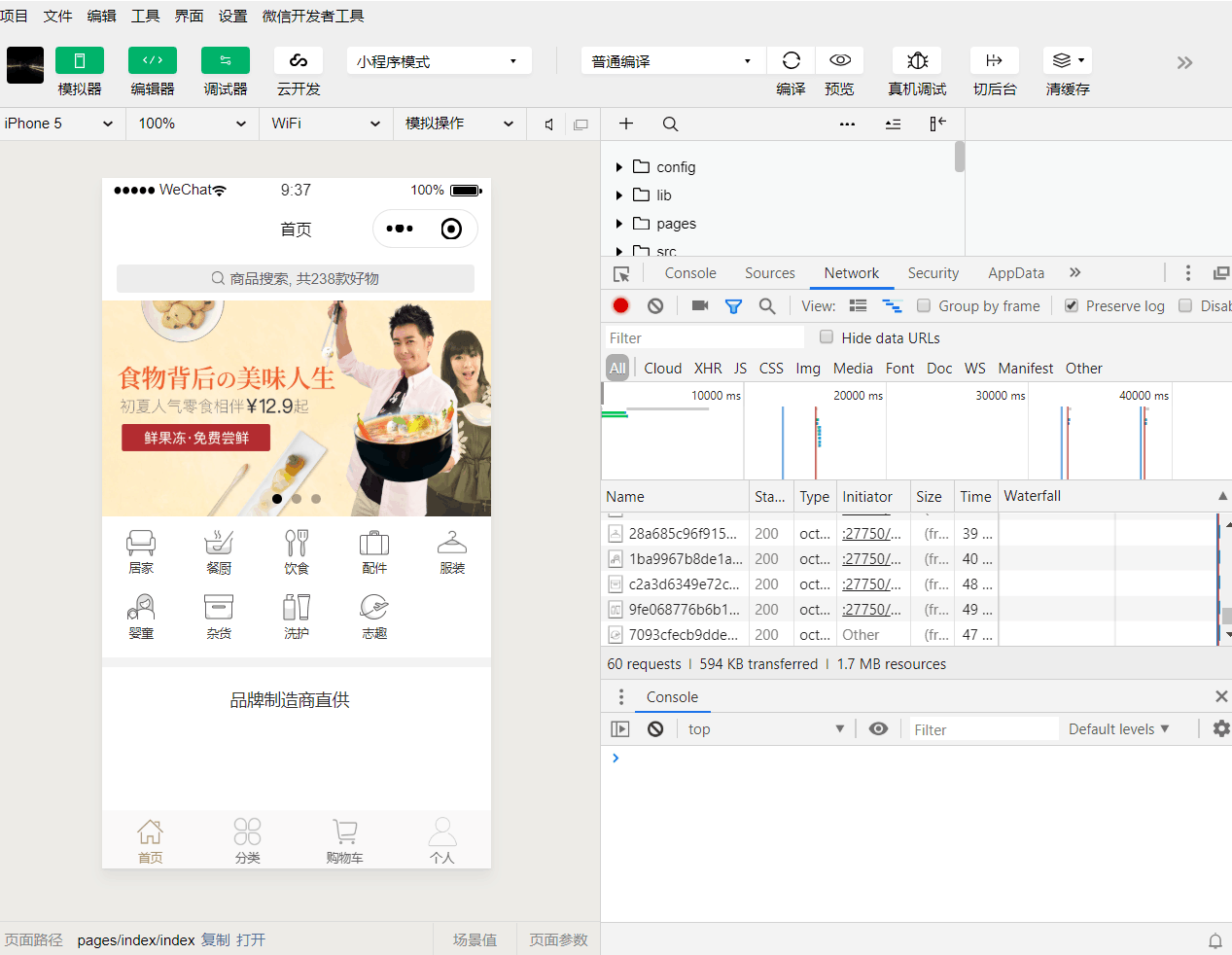
10.3.3.2、前端:商城移动端,启动mall-shopping-mobile,进入项目目录,执行npm install和npm run dev;
10.3.3.3、后端:小程序和移动端用的是同一个后台服务,启动mall-shopping-service项目,进入项目目录,配置tomcat端口8094
10.3.4、商城PC端 访问http://localhost:8099
10.3.4.1、前端:启动mall-shopping-pc项目,进入项目目录,执行npm install和npm run dev;
10.3.4.2、后端:启动mall-shopping-pc-service项目,配置tomcat端口为8095;
11 开发计划
https://my-macro-oss.oss-cn-shenzhen.aliyuncs.com/mall/images/design/%E5%BC%80%E5%8F%91%E8%AE%A1%E5%88%92v1.0.png
1.1 base-search
技术:java, db,es
搜索系统
统一搜索入口,搜索nosql db、es、db的数据
1.2 base-common
技术:java, db, spring cloud
公共系统
属于公共系统抽离,提供基础公共服务
1.3 base-task
任务管理系统
场景1:数据分析的task管理
场景2:跑数据的task管理
场景3:定时task管理
1.4 base-canal
数据binlog采集
配置mysql binlog, 实时采集到kakfa队列,然后基于kafka队列做spark计算
1.5 base-spider
基础爬虫系统
提供基础爬虫服务:扩展为gold爬虫,store爬虫
1.6 base-dts
封装数据传输系统,基于数据进行互传,暴露接口服务给其他服务调用
基于dataX封装数据传输系统
1.7 base-alarm
基于grafana、promethus做一个运维告警系统
运维告警系统
1.8 base-apm
基于skywalking搭建分布式应用调用追踪系统,用于系统调优和排查调用错误
Skywalking 应用分布式监控系统
1.9 base-config
统一配置中心,从这里获取配置
apollo 配置中心
1.10 base-report
扩展为gold、store的报表系统
报表系统
1.11 架构图
1.12 集群 (集群维护)
2.1 个性化推荐系统 gold-recommender
2.2 日志收集系统 gold-logclient gold-logserver
2.3 人群画像系统 gold-profile
2.4 数据传输系统(删除)
2.5 实时计算系统
2.6 反作弊系统 gold-anti-fraud
2.7 多维度分析系统 gold-multianaly
2.8 商场系统 linjiashop
埋点:
前端埋点,后端起一个服务,实时消费kafka队列的消息,然后做流计算统计
前端调用埋点api到后端上报到kafka数据一致,前端调用失败 后端上报失败,失败重传 数据格式校验
android开发埋点:https://github.com/foolchen/AndroidTracker
3.1 智能营销推荐分析
3.2 消费者画像分析
3.3 店家信誉声量分析
3.4 topN商品分析
3.5 累计评论分析
3.6 宝贝详情分析
3.7 增量销售数据分析
3.8 活动效果分析
3.9 爬虫系统
3.10 店家Dashboard系统
4.1 发布平台
5、数据中台
5.1 数据目录服务
5.2 数据分析服务
5.3 数据消费者图谱
5.4 数据开放服务
5.5 数据供需对接
5.6 数据治理服务
5.7 数据存储
大数据存储
分布式数据库
内存数据库
文档数据库
并行数据仓库
关系型数据库
5.8 主题库服务
6.1 应用开放服务
6.2 统一身份认证
6.3 统一消息推送
6.4 消息队列服务
6.5 表单引擎
6.6 统一支付服务
6.7 统一用户中心
6.8 微服务
6.9 云容器平台
包含服务管理(查看docker容器配置,添加容器实例,授权记录,操作记录,
历史版本回溯,k8s启停服务,操作记录,对比yaml配置,更新服务)
任务管理、配置管理、镜像构建(包括环境变量和参数配置)、应用日志
7.1 应用服务
7.2 运营服务
7.3 流程编排
7.4 模版服务
7.5 图像服务
7.6 语义服务
7.7 语音服务
7.8 模型服务
7.9 算法管理
7.10 适配服务
8.1 安全专家服务
8.2 数据脱敏
8.3 数据审计
8.4 安全接入
8.5 安全核查
8.6 应用安全
8.7 业务安全
8.8 日志审计
8.9 安全监测
全面融合线下线上数据的客户数据中台
9.1 数据采集
客户触点: 全终端、全渠道、全类型
数据类型:线下/线上、业务数据、客户属性、三方数据
9.2 数据融合
超级ID融合
多数仓调度
自动化ETL
智能匹配
9.3 标签管理
基础标签
智能标签
自助标签
行为创建
ID上传
组合运算
9.4 客户洞察
客户群体画像
一方DMP
个体洞察
场景标签分析
人群管理
核心优势
全渠道、全链路业务协同
从加工生产到销售订单,打造拉动式“柔性”供应链。在加工环节、采购流程、库存管理、物流运输、财务管控等各业务线形成数据通道。通过可视化、规范化的管理流程,全面提升企业效率。
AI人工智能辅助决策
借力AI、通过模型与算法,进行预测与模拟,辅助企业制定销售目标、明确营销方向、优化品类格局、改善仓储布局,提升企业价值。
多平台无缝连接
支持市场主流社交平台、第三方电商平台、物流平台、仓储平台、财务等系统的无缝对接,快速响应企业市场需求。
场景解释
客户痛点
√ 供应链弹性低、效率低、成本高。
√ 仓库周转慢、库存积压重。
√ 企业IT孤岛、协作慢、运营效率低。
√ 营销成本高、命中率底。
√ 业务探索和创新难,经营决策难。
解决方案
业务中台 + 数据中台
业务中台——支持多系统、多平台业务数据接入,打通各业务线壁垒、形成全方位、可视化业务中心,快速响应灵活多变的前端业务。
数据中台——沉淀业务数据、利用AI进行数据挖掘与分析,形成多层面、多角度的数据监控和分析,为业务的决策和自动化服务等企业需求提供科学依据。
实现价值
√ 打造柔性供应链,实现拉动式生产。
√ 打通信息壁垒,协同企业各部门高效运转。
√ 以顾客为中心,个性化精准营销。
√ 以数据为依托,辅助企业智能决策。
√ 协助企业快速响应并融入创新市场。

