Reproduce the CVPR 2019 oral paper "Semantic Image Synthesis with Spatially-Adaptive Normalization" (pdf) in PyTorch
View demo videos on the authors' project page.
View an interactive demo on my page. The training on COCO-Stuff has not finished. It is currently at epoch 4 (96 epochs to complete).
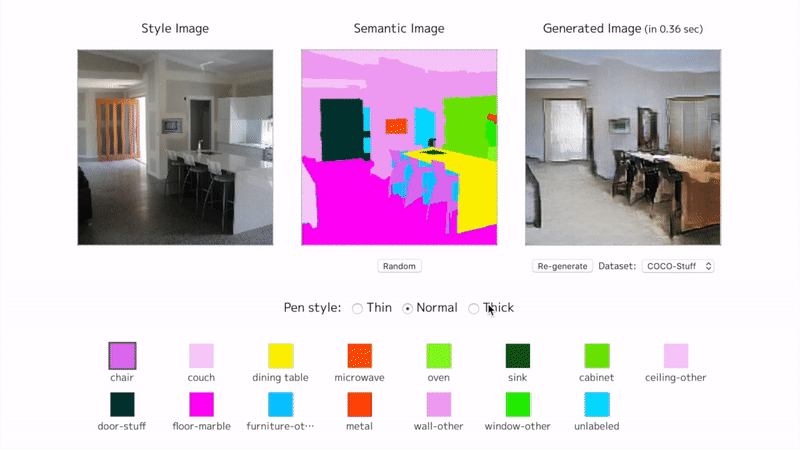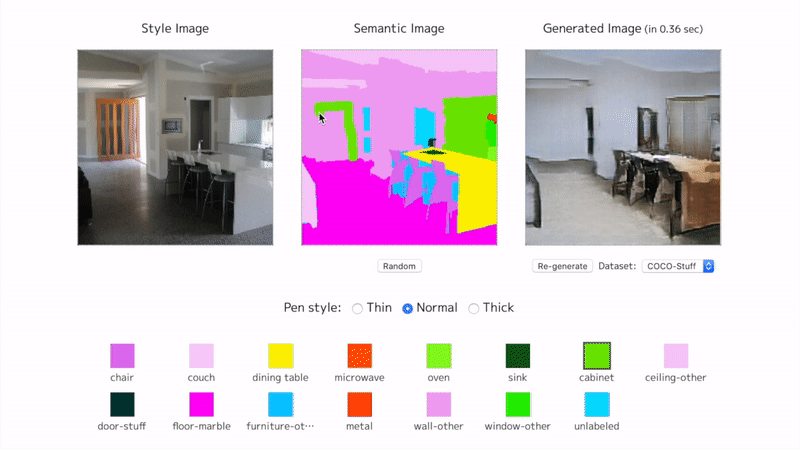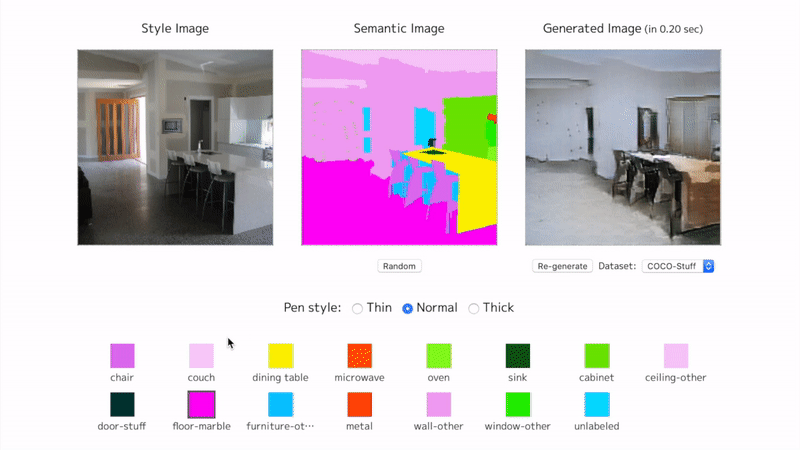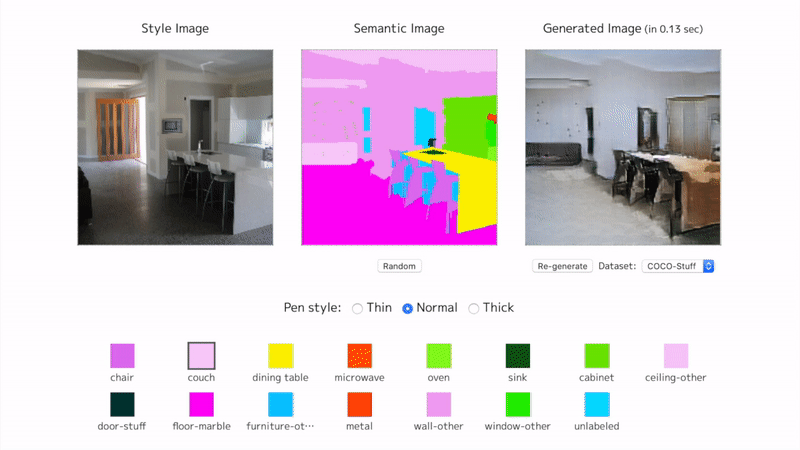
SPADE from scratch
I just finished the coding and started training on the datasets mentioned in the paper. The results will be updated in the following days.
Here are some training samples until epoch 4.
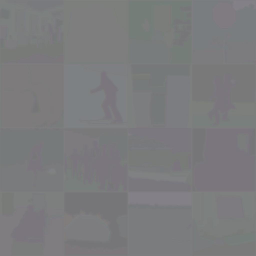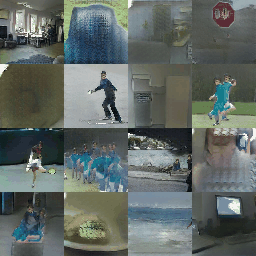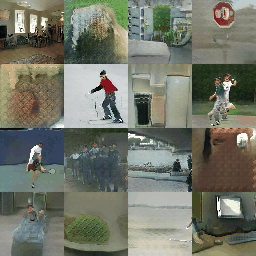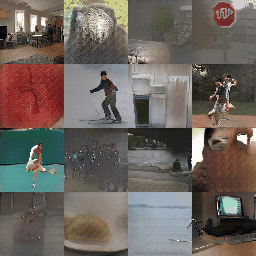
The proposed method is actually named (SPADE) SPatially-Adaptive DEnormalization. By denormalizing the batch normalized convolutional features according to the semantic inputs, the network keeps perceiving the semantic information in each step of the image generation.
The network architectures are explained in Appendix A of the paper. The generator consists of a fully-connected layer, a set of SPADE residual blocks and nearest-neighbor upsampling layers, and ends with a convolutional layer. The discriminator is made up of fully convolutional layers. The encoder is composed of a series of convolutional layers followed by two fully-connected layers for mean and variance respectively.
The losses are mostly follow pix2pixHD but with a little change:
- Adversarial loss is hinge loss (SPADE) instead of least square loss (pix2pixHD)
- Feature matching loss with k=1,2,3 (k-th layer of D) (lambda 10.0) (pix2pixHD)
- Perceptual loss with the VGG net (lambda 10.0) (required in SPADE; optional in pix2pixHD)
- PatchGAN discriminator (pix2pixHD)
- KL divergence loss for encoder (lambda 0.05) (SPADE)
- Python 3.5
- PyTorch 1.0.0
pip3 install -r requirements.txt- COCO-Stuff, 256x256 (100 epochs)
- ADE20K (link1, link2), 256x256 (100 epochs + 100 epochs linearly decaying)
- ADE20K-outdoor, 256x256
- Cityscapes, 512x256 (100 epochs + 100 epochs linearly decaying)
- Flickr Landscapes, 256x256 (50 epochs; not released)
Prepare the data as follows
data
└── COCO-Stuff
├── images
├── train2017 (118,000 images)
└── val2017 (5,000 images)
├── annotations
├── train2017 (118,000 annotations)
└── val2017 (5,000 annotations)
└── labels.txt (annotation list)
Train a model on the training set of a given dataset
python3 train.py --experiment_name spadegan_cocostuff --dataset COCO-Stuff --epochs 100 --epochs_decay 0 --gpu
# python3 train.py --experiment_name spadegan_ade20k --dataset ADE20K --epochs 100 --epochs_decay 100 --gpu
# python3 train.py --experiment_name spadegan_cityscapes --dataset Cityscapes --epochs 100 --epochs_decay 100 --gpuGenerate images from the validation set with a trained model
python3 generate.py --experiment_name spadegan_cocostuff --batch_size 32 --gpu
# python3 generate.py --experiment_name spadegan_ade20k --batch_size 32 --gpu
# python3 generate.py --experiment_name spadegan_cityscapes --batch_size 32 --gpuInstall all dependencies for demo site
pip3 install -r requirements_demo.txtRename demo/config.js.example and server/config.json.example
mv demo/config.js.example demo/config.js
mv server/config.json.example server/config.jsonSpecify your IP address and port in demo/config.js
const GuaGANHost = 'http://127.0.0.1:[PORT]';Set the experiement and epoch to load, and also the data path in server/config.json
{
"experiment_name": "YOUR EXPERIMENT NAME",
"load_epoch": null,
"data_root":
{
"cocostuff": "YOUR COCO-STUFF PATH"
}
}Preprocess demo datasets
python3 -m server.preprocess [DATASET] [DATAPATH] [optional: --num NUM_IMG]Start the GuaGAN server
./demo.sh --port [PORT]Then you'll be able to see the site on http://localhost:[PORT].
- It fails with small batch sizes. I tried training on a single GPU with a batch size of 8. However, it collapsed in the first dozens of iterations and the output images were full of white color. Training with a batch size of 24 on 4 GPUs seems okay so far.
- After adding the perceptual loos, my batch size shrinked to 16. Perceptual loss is the most essential one for an adaptive normalized generative adversarial network to learn from scratch. It takes me half a day for an epoch.


































