enjalot / blockbuilder-search-index Goto Github PK
View Code? Open in Web Editor NEWdownload and process d3.js blocks for further indexing and visualization
License: BSD 3-Clause "New" or "Revised" License
download and process d3.js blocks for further indexing and visualization
License: BSD 3-Clause "New" or "Revised" License



























tell others in the community how they can host a blockbuilder search instance
better support for manual exploration
perhaps by storing files in directories by user then by gistID
user/gistID/
ninja edit: the solution is to increase the max memory available to nodejs with this command:
coffee --nodejs --max-old-space-size=8000 elasticsearch.coffee
when running the command coffee elasticsearch.coffee
load gists data into modern Elasticsearch. today, modern Elasticsearch === version6.3.2 https://www.elastic.co/downloads/elasticsearch-oss
do this locally first an as exercise.
when all goes well locally
Micah asked me to mention difficulties on my first install of this script. I noted this:
gist-cloner wanted to log its progress into ES, but failed because I was not at the point of using ES yet. There was no clear indication about that error message.
it wasn't obvious how to start without loading thousands of blocks — maybe an example showing how to download two or three specific users would help. I've managed to find coffee gist-meta.coffee data/user1.json '' "user1" but I have no idea how to extend that to a few users.
h/t @redblobgames for this set of related ideas
we can index the bl.ocks directly, but we probably want to also add the github users to our users csv file and use the existing scripts (gist-cloner.coffee?) to get all of the gists for each new github user
If Kibana is installed locally open http://localhost:5601 and choose “DevTools” from the left menu.
use HTML5 details https://gist.github.com/ericclemmons/b146fe5da72ca1f706b2ef72a20ac39d
would like a block that contains a file with a filename gapminder2015.csv to appear in a search for gapminder
add update pipeline script
add a shell script for the pipeline to update the blocks gist data to update a local blockbuilder search instance.
add the script with the commands that @micahstubbs normally uses, rather than the set of all possible options that we list in README.md
add a script that can be run as a script, rather than pasted from manually, command by command (like we do with the commands listed in the README.md today)
it looks like the deployed blockbuilder search knows about more users than our data directory does.
if we browse over to http://blockbuilder.org/search, we see 25298 blocks (hooray d3 community!)

yet running coffee gist-meta.coffee returns a total of 24095 blocks

the difference between these two is 1203 new blocks that the deployed blockbuilder search knows about but that our local script does not. I'm guessing that these are blocks created by new users of the blockbuilder editor.
@enjalot when you have a moment, could you retrieve that latest users csv from the blockbuilder search server and commit it to this repo? (github tells me this user data was updated 3 months ago, so should be straightforward to update again 😄 )
https://github.com/enjalot/blockbuilder-search-index/tree/master/data
the goal is to contribute back the most complete user list that we have so that other d3 example research (like graph search) can benefit from it 🌱
http://commoncrawl.org/ h/t @redblobgames for this idea
could also possibly use links in this data as an search ranking score component
https://twitter.com/patrickm145/status/896738789397340161
tags can be expressed as a yaml sequence in the .block config file
https://stackoverflow.com/a/33136212/1732222
a way to improve http://blockbuilder.org/search
we can query all of the repos in Google BigQuery for d3, and then collect the github users from the results
dataset description
https://cloud.google.com/bigquery/public-data/github
direct link
https://bigquery.cloud.google.com/dataset/bigquery-public-data:github_repos
example:
https://bl.ocks.org/syntagmatic/77c7f7e8802e8824eed473dd065c450b
I think we are missing this because of the version, or lack of .js
we should be able to fix with a new regex or change to existing
from a conversation with @enjalot
then rm concat.coffee
I have an experimental file where I clone entire gists from our list of blocks. This ends up taking up about 2x the space of just the text files (current way we are indexing). Thats still only about 4gb which is rather trivial.
I'd like to do this at the same time we refactor to store the downloaded gist content by user ( #3 )
setup gcp (google cloud platform) hosted search
strategy:
and store them
calculate pairwise block similarity
using doc2vec on code or some similar approach
related to enjalot/blockbuilder-search#83
map github login to twitter handles
public google spreadsheet
gSheets
every 15 minutes
this will enable new users to see their blocks in blockbuilder search 15 minutes or less after they take action that adds them to the user list built by combine.coffee
in elasticsearch.coffee
# we may want to check if a document is in ES before trying to write it
# this can help us avoid overloading the server with writes when reindexing
skip = true
offset = 0
On my local install, the cloning process sometimes will try to clone the block into {user}/gist.github.com/ instead of {user}/{gist.id}.
I have traced the error to:
cmd = "cd #{userfolder};git clone [email protected]:#{gist.id}"
which is solved with
cmd = "cd #{userfolder};git clone [email protected]:#{gist.id} #{gist.id}/"
(I don't know why it does this only for some blocks, not all.)
do a full re-index on the elasticsearch server. the command to do that should be:
coffee --nodejs --max-old-space-size=12000 elasticsearch.coffee
related to enjalot/blockbuilder-search#27
it would be cool to be able to search for blocks by what external libraries they import with script tags.
specifically, I would like to be able to search for blocks that only load d3, so that I can find an example of a technique implemented in pure d3 and javascript, without the overhead of some other charting library.
motivation: make it easier to run an interactive query app like sense
reading the release notes as a starting point:
breaking changes in Elasticsearch v5.0.0 https://www.elastic.co/guide/en/elasticsearch/reference/5.0/release-notes-5.0.0.html

PMeinshausen
migurski
alper
cartoda

so I'm updating my local elasticsearch, and I use this command from our docs
coffee --nodejs --max-old-space-size=8000 elasticsearch.coffee
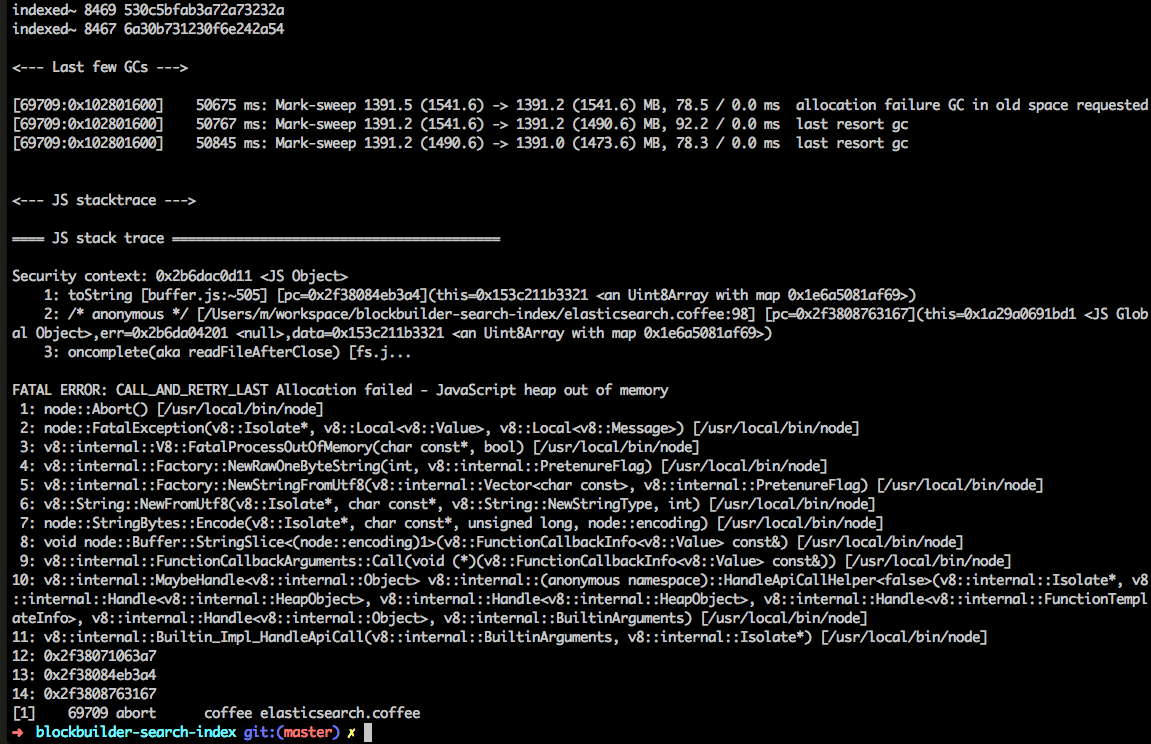
oh no, at gist 30179 I see this error message
indexed 30182 7067e1cc1b623959eacda6e34a2f63da
indexed 30181 7acb36eccb6280d95634f3d6f4d8f0f7
indexed 30179 c2acadc0809fcad97e403212333234d8
<--- Last few GCs --->
[12055:0x102801e00] 210399 ms: Mark-sweep 7845.3 (8060.4) -> 7844.9 (8060.9) MB, 247.6 / 0.0 ms allocation failure GC in old space requested
[12055:0x102801e00] 210742 ms: Mark-sweep 7844.9 (8060.9) -> 7844.9 (8048.9) MB, 343.3 / 0.0 ms last resort GC in old space requested
[12055:0x102801e00] 210957 ms: Mark-sweep 7844.9 (8048.9) -> 7844.9 (8043.9) MB, 215.4 / 0.0 ms last resort GC in old space requested
<--- JS stacktrace --->
==== JS stack trace =========================================
Security context: 0x184b31ca55e9 <JSObject>
1: toString [buffer.js:~634] [pc=0x30f302b1d0b8](this=0x184b9b53c4c1 <Uint8Array map = 0x184b022da259>,encoding=0x184bef8022d1 <undefined>,start=0x184bef8022d1 <undefined>,end=0x184bef8022d1 <undefined>)
2: arguments adaptor frame: 0->3
3: /* anonymous */ [/Users/m/workspace/blockbuilder-search-index/elasticsearch.coffee:98] [bytecode=0x184b2ebd2fa1 offset=19](this=0x184bead866f1 <JS...
FATAL ERROR: CALL_AND_RETRY_LAST Allocation failed - JavaScript heap out of memory
1: node::Abort() [/Users/m/.nvm/versions/node/v9.11.1/bin/node]
2: node::FatalTryCatch::~FatalTryCatch() [/Users/m/.nvm/versions/node/v9.11.1/bin/node]
3: v8::internal::V8::FatalProcessOutOfMemory(char const*, bool) [/Users/m/.nvm/versions/node/v9.11.1/bin/node]
4: v8::internal::Factory::NewRawTwoByteString(int, v8::internal::PretenureFlag) [/Users/m/.nvm/versions/node/v9.11.1/bin/node]
5: v8::internal::Factory::NewStringFromUtf8(v8::internal::Vector<char const>, v8::internal::PretenureFlag) [/Users/m/.nvm/versions/node/v9.11.1/bin/node]
6: v8::String::NewFromUtf8(v8::Isolate*, char const*, v8::NewStringType, int) [/Users/m/.nvm/versions/node/v9.11.1/bin/node]
7: node::StringBytes::Encode(v8::Isolate*, char const*, unsigned long, node::encoding, v8::Local<v8::Value>*) [/Users/m/.nvm/versions/node/v9.11.1/bin/node]
8: void node::Buffer::(anonymous namespace)::StringSlice<(node::encoding)1>(v8::FunctionCallbackInfo<v8::Value> const&) [/Users/m/.nvm/versions/node/v9.11.1/bin/node]
9: 0x30f302248327
10: 0x30f302b1d0b8
➜ blockbuilder-search-index git:(micah/55/exp/parse-modules) ✗
questions
parse out d3 version 5 v5
the backend companion issue to frontend issue enjalot/blockbuilder-search#75
everytime the cron job runs
how can I collect a dataset of block thumbnails to study? asking this question here on behalf of @dhexonian 😄
now I am curious what % of blocks have a reference to an external but local js file 🤔
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.