fengma1992 / fe-note Goto Github PK
View Code? Open in Web Editor NEW前端笔记
前端笔记




他人原文:https://juejin.im/post/5e7782dbf265da57584dc95e
Webpack 的使用目前已经是前端开发工程师必备技能之一。若是想在本地环境启动一个开发服务,大家只需在 webpack 的配置中,增加 devServer 的配置来启动。而 devServer 配置的本质是 webpack-dev-server 这个包提供的功能,而 webpack-dev-middleware 则是这个包的底层依赖。
截止2020.03.23,本文解读的
webpack-dev-server版本:[email protected],webpack-dev-middleware版本:[email protected]webpack-dev-middleware 是什么?先看看webpack-dev-server主要做了啥:
const wdm = require('webpack-dev-middleware');
const express = require('express');
const webpack = require('webpack');
const webpackConf = require('./webapck.conf.js'); // 引入webpack配置
const compiler = webpack(webpackConf); // 首先创建一个webpack compiler
const app = express(); // 建一个express服务
app.use(wdm(compiler)); // 用wdm(compiler)生成中间件并注册为express的中间函数
app.listen(8080); // 开启监听端口一句话概括,webpack-dev-middleware把webpack编译后的文件存在内存,并在用户访问express时将对应资源输出。
webpack-dev-middlewarewebpack可以通过watch mode启动,实现实时监听项目文件变化并编译输出,但输出结果需要存储到本地硬盘,而I/O操作非常消耗资源时间,无法满足本地开发调试需求(此处匿名吐槽gitbook的本地调试)。
而 webpack-dev-middleware 拥有以下几点特性:
以 watch mode 启动 webpack,监听的资源一旦发生变更,便会自动编译,生产最新的 bundle
在编译期间,停止提供旧版的 bundle 并且将请求延迟到最新的编译结果完成之后
webpack 编译后的资源会存储在内存中,当用户请求资源时,直接于内存中查找对应资源,减少去硬盘中查找的 I/O 操作耗时(这也是webpack-dev-middleware的核心部分)
到这一步了,其实不看源码,也能写出 webpack-dev-middleware 的大概流程:
watch mode启动webpackwebpack上挂编译中、编译完成、编译出错这些钩子webpack的bundle输出地址从原本的文件系统换成内存系统(关键)express用webpack-dev-middleware源码目录:
...
├── lib
│ ├── DevMiddlewareError.js
│ ├── index.js // 主文件
│ ├── middleware.js
│ └── utils
│ ├── getFilenameFromUrl.js // 解析url得到文件名
│ ├── handleRangeHeaders.js
│ ├── index.js
│ ├── ready.js
│ ├── reporter.js
│ ├── setupHooks.js // 挂钩子
│ ├── setupLogger.js // 日志设置
│ ├── setupOutputFileSystem.js // 输出文件系统设置
│ ├── setupRebuild.js // 重构建逻辑设置
│ └── setupWriteToDisk.js // 写入磁盘设置
├── package.json
...
其实看文件名就知道干了些啥了。
其中 lib 目录下为源代码,一眼望去有近 10 多个文件要解读。但刨除 utils 工具集合目录,其核心源码文件其实只有两个 index.js、middleware.js
下面我们就来分析核心文件 index.js、middleware.js 的源码实现
index.js从上文我们已经得知 wdm(compiler) 返回的是一个 express 中间件,所以入口文件 index.js 则为一个中间件的容器包装函数。它接收两个参数,一个为 webpack 的 compiler、另一个为配置对象,经过一系列的处理,最后返回一个中间件函数。下面对 index.js 中的核心代码进行讲解:
...
setupHooks(context);
...
// start watching
context.watching = compiler.watch(options.watchOptions, (err) => {
if (err) {
context.log.error(err.stack || err);
if (err.details) {
context.log.error(err.details);
}
}
});
...
setupOutputFileSystem(compiler, context);index.js 最为核心的是以上 3 个部分的执行,分别完成了我们上文提到的两点特性:
watch mode 启动 webpackwebpack 的编译内容,输出至内存中此函数的作用是在 compiler 的 invalid、run、done、watchRun 这 4 个编译生命周期上,注册对应的处理方法
context.compiler.hooks.invalid.tap('WebpackDevMiddleware', invalid);
context.compiler.hooks.run.tap('WebpackDevMiddleware', invalid);
context.compiler.hooks.done.tap('WebpackDevMiddleware', done);
context.compiler.hooks.watchRun.tap(
'WebpackDevMiddleware',
(comp, callback) => {
invalid(callback);
}
);done 生命周期上注册 done 方法,该方法主要是 report 编译的信息以及执行 context.callbacks 回调函数invalid、run、watchRun 等生命周期上注册 invalid 方法,该方法主要是 report 编译的状态信息此部分的作用是,调用 compiler 的 watch 方法,之后 webpack 便会监听文件变更,一旦检测到文件变更,就会重新执行编译。
其作用是使用 memory-fs 对象替换掉 compiler 的文件系统对象,让 webpack 编译后的文件输出到内存中。
fileSystem = new MemoryFileSystem();
compiler.outputFileSystem = fileSystem;通过以上 3 个部分的执行,我们以 watch mode 的方式启动了 webpack,一旦监测的文件变更,便会重新进行编译打包,同时我们又将文件的存储方法改为了内存存储,提高了文件的存储读取效率。最后,我们只需要返回 express 的中间件就可以了,而中间件则是调用 middleware(context) 函数得到的。下面,我们来看看 middleware 是如何实现的。
此文件返回的是一个 express 中间件函数的包装函数,其核心处理逻辑主要针对 request 请求,根据各种条件判断,最终返回对应的文件内容:
function goNext() {
if (!context.options.serverSideRender) {
return next();
}
return new Promise((resolve) => {
ready(
context,
() => {
res.locals.webpackStats = context.webpackStats;
res.locals.fs = context.fs;
resolve(next());
},
req
);
});
}首先,middleware 中定义了一个 goNext() 方法,该方法判断是否是服务端渲染。如果是,则调用 ready() 方法(此方法即为 ready.js 文件,作用为根据 context.state 状态判断直接执行回调还是将回调存储 callbacks 队列中)。如果不是,则直接调用 next() 方法,流转至下一个 express 中间件。
const acceptedMethods = context.options.methods || ['GET', 'HEAD'];
if (acceptedMethods.indexOf(req.method) === -1) {
return goNext();
}接着,判断 HTTP 协议的请求的类型,若请求不包含于配置中(默认 GET、HEAD 请求),则直接调用 goNext() 方法处理请求:
let filename = getFilenameFromUrl(
context.options.publicPath,
context.compiler,
req.url
);
if (filename === false) {
return goNext();
}然后,根据请求的 req.url 地址,在 compiler 的内存文件系统中查找对应的文件,若查找不到,则直接调用 goNext() 方法处理请求:
return new Promise((resolve) => {
function processRequest() {
...
}
...
ready(context, processRequest, req);
});最后,中间件返回一个 Promise 实例,而在实例中,先是定义一个 processRequest 方法,此方法的作用是根据上文中找到的 filename 路径获取到对应的文件内容,并构造 response 对象返回,随后调用 ready(context, processRequest, req) 函数,去执行 processRequest 方法。这里我们着重看下 ready 方法的内容:
if (context.state) {
return fn(context.webpackStats);
}
context.log.info(`wait until bundle finished: ${req.url || fn.name}`);
context.callbacks.push(fn);非常简单的方法,判断 context.state 的状态,将直接执行回调函数 fn,或在 context.callbacks 中添加回调函数 fn。这也解释了上文提到的另一个特性 “在编译期间,停止提供旧版的 bundle 并且将请求延迟到最新的编译结果完成之后”。若 webpack 还处于编译状态,context.state 会被设置为 false,所以当用户发起请求时,并不会直接返回对应的文件内容,而是会将回调函数 processRequest 添加至 context.callbacks 中,而上文中我们说到在 compile.hooks.done 上注册了回调函数 done,等编译完成之后,将会执行这个函数,并循环调用 context.callbacks。
整体来看其实还挺简单的,前提是对 webpack 的完整打包流程及Hook 有了解。
强烈建议项目内使用 webpack 的同学完整读一遍 webpack 源码,那么像这些 webpack 的插件看用途就知道怎么实现的。
先让我们一起来了解一下media type,在css2中就支持media type。平时我们在写代码时,可能不太在意,但你应该见到过如下写法:
<link rel="stylesheet" type="text/css" href="reset.css" media="screen" />
实际上screen就是一种media type,目前media type有以下类型(摘自网上):
| 设备名称 | 指代 |
|---|---|
| all | 匹配所有设备 |
| braille | 匹配触觉反馈设备 |
| embossed | 凸点字符印刷设备 |
| handheld | 手持设备(尤其是小屏幕,有限带宽,不过注意:现在的Android,iPhone都不是Handheld设备,他们都是screen设备。所以,不要试图用handheld来识别iphone或者ipad,android等设备)PSP,NDS这种规格一般可以叫作Handheld,不过没有测试过,如有疏漏还请指正) |
| 打印机设备 | |
| projection | 投影仪设备 |
| screen | 彩色计算机显示器设备 |
| speech | 语音合成器设备 |
| tty | 栅格设备(终端,或者电传打字机) |
| tv | 电视设备 |
media type常用用法,除了放在link标签中,还可以有如下几种用法:
<link rel="stylesheet" type="text/css" href="reset.css" media="screen" />
<style media="screen">
.cont{
background: red;
}
</style>
<style>
@media screen{
.cont{
background: red;
}
}
</style>
@import url("style.css") screen;
media query是CSS 3对media type的增强,可将media query理解决为query条件的增强,可以对设备特性进行检验,那media query可以看作是 设备+特性+逻辑式 的结合。
media type的设备类型media query均支持,同时它又增加了一些设备特性,如下表(摘自网上):
| 媒体特性 | 说明/值 | 可用媒体类型 | 接受min/max |
|---|---|---|---|
| width | 长度正数值(单位一般为px下同) | 视觉屏幕/触摸设备 | 是 |
| heigth | 长度正数值 | 视觉屏幕/触摸设备 | 是 |
| device-width | 长度正数值 | 视觉屏幕/触摸设备 | 是 |
| device-heigth | 长度正数值 | 视觉屏幕/触摸设备 | 是 |
| orientation | 设备手持方向(portait横向/landscape竖向) | 位图介质类型 | 否 |
| aspect-ratio | 浏览器、纸张长宽比 | 位图介质类型 | 是 |
| device-aspect-ratio | 设备屏幕长宽比 | 位图介质类型 | 是 |
| color | 颜色模式(例如旧的显示器为256色) | 整数 | 视觉媒体 |
| color-index | 颜色模式列表整数 | 视觉媒体 | 是 |
| monochrome | 整数 | 视觉媒体 | 是 |
| resolution | 解析度 | 位图介质类型 | 是 |
| scan | progressive逐行扫描/interlace隔行扫描 | 电视类 | 否 |
| grid | 整数,返回0或1 | 栅格设备 | 否 |
media query支持的逻辑关键字主要有:“only”“and”“not”和“,”。
结合设备,设备特性及逻辑关键字,media query主要有以下几种形式
@media 设备类型 { //设备
}
@media (only|not) 设备类型 { //设备与逻辑关键字结合
}
@media (only|not) 设备类型 and (设备特征表达式) { //设备、设备特征与逻辑关键字结合
}
@media (设备特征表达式) | (设备特征表达式) |.... { //设备特征与逻辑关键字结合
}
@media (only|not) 设备类型 and (设备特征表达式), (only|not) 设备类型 and (设备特征表达式) {
//设备特征与逻辑关键字结合
}
用css3 media query可以很好的实现响应式设计,以下列出几种常见的表达式
@media only screen and (min-device-width: 320px) and (max-device-width: 480px) {
/* CSS Styles */
}
@media only screen and (min-width : 321px) {
/* CSS Styles */
}
@media only screen and (max-width : 320px) {
/* CSS Styles */
}
@media only screen and (min-device-width : 768px) and (max-device-width : 1024px) {
/* CSS Styles */
}
@media only screen and (min-device-width : 768px) and (max-device-width : 1024px) and (orientation : landscape) {
/* CSS Styles */
}
@media only screen and (min-device-width : 768px) and (max-device-width : 1024px) and (orientation : portrait) {
/* CSS Styles */
}
@media only screen and (-webkit-min-device-pixel-ratio : 1.5),only screen and (min-device-pixel-ratio : 1.5) {
/* CSS Styles */
}
@media only screen and (min-width : 1224px) {
/* CSS Styles */
}
css3为我们提供了很强大的media query,而我们时常需要在js中动态的知道什么时候某个状态满足了。CSS Object Model(CSSOM)Views规范增加了对JavaScript操作CSS media query的原生支持,它在window对象下增加了matchMedia()方法。
你可以传入一个CSS media query然后返回一个MediaQueryList对象。这个对象包括两个属性:matches,布尔值数据,表示CSS media query是否与当前的显示状态匹配;media对应传入的参数字符串。如下:
var mediaQueryList = window.matchMedia("screen and (max-width:480px)");
console.log(mediaQueryList.media); //"screen and (max-width:480px)"
console.log(mediaQueryList.matches); //true or false
当然为了有效监听这个变化,MediaQueryList对象还为我们提供了addListener和removeListener
var match = window.matchMedia("(orientation:portrait)");
match.addListener(function(mql){
if (mql.matches) {
}else {
}
});
当视图状态发生改变时,监听器对应的函数就会执行,而对应的MediaQueryList对象也会传入。用这个方式吗,你可以让你的JavaScript可以很快地响应布局变化,并且不需要用轮询的方式。另外关于media query的实现原理一直不太清楚,什么时候media query就生效的,比如说转屏,是否是只要当前屏幕width或height发生改变时就去查询media query估计就待看看webkit源码才能清楚了。
行高(行间距)指的是文本行的基线间的距离或者说是两行文字之间的垂直距离。
基线并不是汉字的下端沿,而是英文字母"x"的下端沿。具体英文字母x的角色可见张鑫旭大神的博客字母’x’在CSS世界中的角色和故事
CSS中起高度作用的应该就是height以及line-height了吧!如果一个标签没有定义height属性(包括百分比高度),那么其最终表现的高度一定是由line-height起作用
默认状态,浏览器使用1.0 - 1.2 line-height,这是一个初始值。
line-height有五种定义方式:
line-height: normal;
line-height: inherit; // 继承
line-height: 120%; // 百分比
line-height: 20px; // 长度值(单位px, em等)
line-height: 1.2; // 纯数字
五种属性值也可以在CSS的font属性中缩写:
font-size/line-height
body {
font: 100%/normal sans-serif;
}
body {
font: 100%/inherit sans-serif;
}
body {
font: 100%/120% sans-serif;
}
body {
font: 100%/20px sans-serif;
}
body {
font: 100%/1.2 sans-serif;
}
有些CSS属性是可继承(inherited)(从层叠的元素里传递), 如color属性是可继承的,如果body定义了color属性,那么其内部的所有元素的color属性均默认会继承
下面举例line-height属性值继承之间的差别
/* HTML */
<body>
<h1>百分比行高: font-size=32px, line-height=16px*200%(继承父级)</h1>
<p>百分比行高: font-size=24px, line-height=16px*200%(继承父级)</p>
<div class="footer">百分比行高: font-size=12px, line-height=16px*200%(继承父级)</div>
</body>
/* CSS */
body {
display: flex; // 仅为方便在同一行进行行高对比
font-size: 16px;
line-height: 200%;
}
h1 {
font-size: 32px;
background-color: #aaaaaa;
}
p {
font-size: 24px;
background-color: #bbbbbb;
}
.footer {
font-size: 12px;
background-color: #cccccc;
}

line-height的百分比(200%)和body的文字大小(16px)被用来计算值(16px * 200% = 32px),这个计算出来的值会被层叠下去的元素所继承,所有继承下来的元素会忽略本身的font-size而使用相同的、body计算出来的line-height
| element | font-size | line-height | 最终值 |
|---|---|---|---|
| body | 16px | 200% | 16px*200%=32px |
| h1 | 32px | 继承值-32px | 32px |
| p | 24px | 继承值-32px | 32px |
| .footer | 12px | 继承值-32px | 32px |
| line-height不会随着元素自身font-size做相应比例缩放 |
/* HTML */
<body>
<h1>长度值行高: font-size=32px, line-height=20px(继承父级)</h1>
<p>长度值行高: font-size=24px, line-height=20px(继承父级)</p>
<div class="footer">长度值行高: font-size=12px, line-height=20px(继承父级)</div>
</body>
/* CSS */
body {
display: flex; // 仅为方便在同一行进行行高对比
font-size: 16px;
line-height: 20px;
}
h1 {
font-size: 32px;
background-color: #aaaaaa;
}
p {
font-size: 24px;
background-color: #bbbbbb;
}
.footer {
font-size: 12px;
background-color: #cccccc;
}

body的line-height长度值(20px)会被层叠下去的元素所继承,所有继承下来的元素会忽略本身的font-size而使用相同的、body设定的line-height值
| element | font-size | line-height | 最终值 |
|---|---|---|---|
| body | 16px | 20px | 20px |
| h1 | 32px | 继承值-20px | 20px |
| p | 24px | 继承值-20px | 20px |
| .footer | 12px | 继承值-20px | 20px |
| line-height不会随着元素自身font-size做相应比例缩放 |
/* HTML */
<body>
<h1>normal行高: font-size=32px, line-height=32px*1.2</h1>
<p>normal行高: font-size=24px, line-height=24px*1.2</p>
<div class="footer">normal行高: font-size=12px, line-height=12px*1.2</div>
</body>
/* CSS */
body {
display: flex; // 仅为方便在同一行进行行高对比
font-size: 16px;
line-height: normal;
}
h1 {
font-size: 32px;
background-color: #aaaaaa;
}
p {
font-size: 24px;
background-color: #bbbbbb;
}
.footer {
font-size: 12px;
background-color: #cccccc;
}

现在所有继承body的line-height属性的元素不会忽略本身的font-size,使用基于自身font-size计算出来的line-height
| element | font-size | line-height | 最终值 |
|---|---|---|---|
| body | 16px | normal | 16px*1.2=19.2px |
| h1 | 32px | 继承值-normal | 32px*1.2=38.4px |
| p | 24px | 继承值-normal | 24px*1.2=28.8px |
| .footer | 12px | 继承值-normal | 12px*1.2=14.4px |
| line-height会随着元素自身font-size做相应比例缩放 |
/* HTML */
<body>
<h1>纯数字行高: font-size=32px, line-height=32px*2</h1>
<p>纯数字行高: font-size=24px, line-height=24px*2</p>
<div class="footer">纯数字行高: font-size=12px, line-height=12px*2</div>
</body>
/* CSS */
body {
display: flex; // 仅为方便在同一行进行行高对比
font-size: 16px;
line-height: 2;
}
h1 {
font-size: 32px;
background-color: #aaaaaa;
}
p {
font-size: 24px;
background-color: #bbbbbb;
}
.footer {
font-size: 12px;
background-color: #cccccc;
}

现在所有继承body的line-height属性的元素不会忽略本身的font-size,使用基于自身font-size计算出来的line-height
| element | font-size | line-height | 最终值 |
|---|---|---|---|
| body | 16px | 2 | 16px*2=32px |
| h1 | 32px | 继承值-2 | 32px*2=64px |
| p | 24px | 继承值-2 | 24px*2=48px |
| .footer | 12px | 继承值-2 | 12px*2=24px |
| line-height会随着元素自身font-size做相应比例缩放 |
一般来说,设置行高值为纯数字是最理想的方式,因为其会随着元素对应的font-size而缩放。
WCAG 2.0规定
段落中的行距至少要1.5倍
// TODO: 待续
偶然想到了display: none时图片是否加载的问题,特此总结一下页面中的图片资源的加载和渲染时机。
先了解一下浏览器解析HTML的原理,以Webkit引擎为例:

从上图可见,浏览器加载一个HTML页面后进行如下操作:
从上图我们不能很直观的看出图片资源从什么时候开始加载,下面结合浏览器解析顺序标出图片加载和渲染的时机:
<img>标签加载图片】并构建 DOM 树页面中不是所有的<img>标签图片和样式表背景图片都会加载。
display: none<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8" >
<title>display: none test1</title>
</head>
<body>
<img src="a.jpeg" style="display: none">
<div style="display: none; background-image: url(b.jpeg)"></div>
</body>
</html>图片资源请求如下:

可见,设置了display: none属性的元素,图片不会渲染出来,但会加载。
构建渲染树,浏览器大体上完成了下列工作:
从 DOM 树的根节点开始遍历每个可见节点。
img节点,不会出现在渲染树中,因为有一个显式规则在该节点上设置了display: none属性。对于每个可见节点,为其找到适配的 CSSOM 规则并应用它们。
发射可见节点,连同其内容和计算的样式。
上面代码中,因为<img>标签src里的图片是在解析HTML的时候加载的,而无论本身是display: none还是父元素display: none的元素,都是会被解析到的,因此<img>标签里的图片都会被加载。
当把DOM树和CSSOM树匹配构建渲染树时,遍历DOM树上的元素,发现元素对应的样式规则上有background-image属性时会加载背景图片,但是因为这个元素是不可见元素(对应的样式规则上有diaplay:none),不会把该元素和它对应的样式规则产出到渲染树。
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8" >
<title>display: none test2</title>
</head>
<body>
<div style="display: none">
<img src="a.jpeg">
<div style="background-image: url(b.jpeg)"></div>
</div>
</body>
</html>图片资源请求如下:

可见,设置了display: none属性元素的子元素,样式表中的背景图片不会渲染出来,也不会加载;而<img>标签的图片不会渲染出来,但会加载。
如例1所说,当匹配DOM树和CSSOM树时,若发现元素的对应的样式规则上有display: none,浏览器会认为该元素的子元素是不可见的,因此不会把该元素的子元素产出到渲染树上。
当构建渲染树遇到了设置了display: none属性的不可见元素时,不会继续遍历不可见元素的子元素,因此不会加载该元素中子元素的背景图片。
当绘制时也因为渲染树上没有设置了display: none属性的元素,也没有该元素的子元素,因此该元素中子元素的背景图片不会渲染出来。
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8" >
<title>duplicate image test</title>
</head>
<body>
<img src="a.jpeg">
<img src="a.jpeg">
</body>
</html>图片资源请求如下:

页面中多个<img>标签或样式表中的背景图片图片路径是同一个,图片只加载一次。
浏览器请求资源时,都会先判断是否有缓存,若有缓存且未过期则会从缓存中读取,不会再次请求。先加载的图片会存储到浏览器缓存中,后面再次请求同路径图片时会直接读取缓存中的图片。
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8" >
<title>nonexisting image test</title>
<style>
.img-a {
background-image: url(a.jpeg);
}
.img-b {
background-image: url(b.jpeg);
}
</style>
</head>
<body>
<div class="img-a"></div>
</body>
</html>图片资源请求如下:
不存在元素的背景图片不会加载。
不存在的元素不会产出到DOM树上,构建渲染树过程中遍历DOM树时无法遍历不存在的元素,因此不会加载图片,也不会产出到渲染树上。当解析渲染树时无法解析不存在的元素,不存在的元素自然也不会渲染。
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8" >
<title>pseudo image test</title>
<style>
.img-a {
background-image: url(a.jpeg);
}
.img-a:hover {
background-image: url(b.jpeg);
}
</style>
</head>
<body>
<div class="img-a"></div>
</body>
</html>触发hover前的图片资源请求如下:

触发hover后图片资源请求如下:

当触发伪类的时候,伪类样式上的背景图片才会加载。
触发hover前,构建渲染树过程中,遍历DOM树时,该元素匹配的样式规则是无hover状态选择器.img-a的样式,因此加载无hover状态选择器.img-a的样式上a.jpeg图片。该元素是可见元素,因此会被产出到渲染树上,绘制时渲染的也是a.jpeg。
触发hover后,因为.img-a:hover的优先级比较高,构建新的渲染树过程中,该元素匹配的是有hover状态选择器,因此加载有hover状态选择器.img-a:hover的样式上的b.jpeg图片。该元素是可见元素,因此会被产出到渲染树上,绘制时渲染的也是b.jpeg。
当使用样式表中的背景图片作为占位符时,要把背景图片转为base64格式。这是因为背景图片加载的顺序在<img>标签后面,背景图片可能会在<img>标签图片加载完成后才开始加载,达不到想要的效果。
很多场景里图片是在改变或触发状态后才显示出来的,例如点击一个Tab后,一个设置display: none隐藏的父元素变为显示,这个父元素里的子元素图片会在父元素显示后才开始加载;又如当鼠标hover到图标后,改变图标图片,图片会在hover上去后才开始加载,导致出现闪一下这种不友好的体验。
在这种场景下,我们就需要把图片预加载,预加载有很多种方式:
若是小图标,可以合并成雪碧图,在改变状态前就把所有图标都一起加载了。
使用上文讲到的,设置了display: none属性的元素,图片不会渲染出来,但会加载。把要预加载的图片加到设置了display: none的元素背景图或<img>标签里。
使用javascript创建img对象,把图片url设置到img对象的src属性里。
HTML <meta>元素表示那些不能由其它HTML元相关元素 (<base>, <link>, <script>, <style> 或 <title>) 之一表示的任何元数据信息。
<meta>常用于定义页面的说明,关键字,最后修改日期,和其它的元数据。这些元数据将服务于浏览器(如何布局或重载页面),搜索引擎和其它网络服务。
<meta>包含全局属性。
注意:<meta>是一个空元素,因此必选写开始标签,不需写结束标签
<meta> // 正确
<meta/> // 没必要
<meta></meta> // 没必要声明页面的字符编码:
<meta charset="UTF-8">需要注意的是,
此处附上charset可用值:standard IANA MIME name for character encodings
content属性的内容是htp-equiv或name属性的值,具体取决于你用哪一个。
该属性可以包含HTTP头的名称,属性的英文全称为http-equivalent。它定义了可以改变server和user-agent行为的指令。该指令的值在content属性内定义,可以是以下之一:
用于设定网页的到期时间,过期后网页必须到服务器上重新传输
<meta http-equiv="expires" content="Thursday August 02 2018 15:00:00 GMT+0800">指定请求和响应遵循的缓存机制。共有以下几种用法:
no-cache: 先发送请求,与服务器确认该资源是否被更改,如果未被更改,则使用缓存。
no-store: 不允许缓存,每次都要去服务器上,下载完整的响应。(安全措施)
public: 缓存所有响应,但并非必须。因为max-age也可以做到相同效果。
private: 只为单个用户缓存,因此不允许任何中继进行缓存。(比如说CDN就不允许缓存private的响应)
max-age: 表示当前请求开始,该响应在多久内能被缓存和重用,而不去服务器重新请求。例如:max-age=60表示响应可以再缓存和重用 60 秒。
允许页面作者定义当前页面的内容策略。内容策略主要指定允许的服务器地址和脚本端点,这有助于防止cross-site scripting攻击。
CSP 的实质就是白名单制度,开发者明确告诉客户端,哪些外部资源可以加载和执行,等同于提供白名单。它的实现和执行全部由浏览器完成,开发者只需提供配置。
CSP 大大增强了网页的安全性。攻击者即使发现了漏洞,也没法注入脚本,除非还控制了一台列入了白名单的可信主机。
两种方法可以启用 CSP。一种是通过 HTTP 头信息的Content-Security-Policy的字段。
Content-Security-Policy: script-src 'self'; object-src 'none';
style-src cdn.example.org third-party.org; child-src https:
另一种是使用 <meta> 标签
<meta http-equiv="Content-Security-Policy" content="script-src 'self'; object-src 'none'; style-src cdn.example.org third-party.org; child-src https:">上面代码中,CSP 做了如下配置:
脚本:只信任当前域名
<object>标签:不信任任何URL,即不加载任何资源
样式表:只信任cdn.example.org和third-party.org
框架(frame):必须使用HTTPS协议加载
其他资源:没有限制
启用后,不符合 CSP 的外部资源就会被阻止加载。
更多介绍可见:阮一峰Content Security Policy 入门教程
<meta http-equiv="refresh" content="2;url=http://www.github.com/"> //2秒后跳转到GitHub用于告知浏览器以何种版本来渲染页面。
<meta http-equiv="X-UA-Compatible" content="IE=edge,chrome=1"> //指定IE和Chrome使用最新版本渲染当前页面定义页面的默认语言,可被任意元素的lang属性覆盖,更推荐在元素中写lang属性。
定义文档的MIME type,推荐使用元素的charset属性。
<meta http-equiv="content-Type" content="text/html charset=UTF-8">定义页面的cookie,推荐使用HTTP头Set-Cookie。
此处附上IETF HTTP Cookie Specification
该属性定义文档级元数据的名称。定义之后全局生效。不能和以下属性同时设置: itemprop, http-equiv 或 charset。
<!DOCTYPE HTML>
<html>
<head>
<title>demo</title>
<meta name="keywords" content="meta,笔记">
<meta name="author" content="fengma1992">
<meta name="description" content="HTML<meta>小记">
</head>
<body>
<div>welcome</div>
</body>
</html>该元数据名称与content属性包含的值相关联。 name属性的可能值为:
| 元数据名称(name的值) | 说明 |
|---|---|
| application-name | 当前页所属Web应用系统的名称 |
| keywords | 描述网站内容的关键词,以逗号隔开,用于SEO搜索 |
| description | 当前页的说明 |
| author | 当前页的作者名 |
| copyright | 版权信息 |
| referrer | referrer 控制document发起的Request请求中附加的Referer HTTP header,相应的值在content中 |
| viewport | 提供了关于viewport初始大小的大小的提示。仅供移动设备使用。目前处于Working Draft阶段 |
| robots | robots用来告诉爬虫哪些页面需要索引,哪些页面不需要索引。 |
| revisit-after | 爬虫重访时间 |
| renderer | renderer是为双核浏览器准备的,用于指定双核浏览器默认以何种方式渲染页面 |
| content | 含义 |
|---|---|
| no-referrer | 不发送HTTP Referer头 |
| origin | 发送document的origin |
| no-referrer-when-downgrade | 将origin作为referer发送到和当前页面同等安全的URLs(https->https),但不会将origin发送到不安全的URLS(https->http)。这是默认行为。 |
| origin-when-crossorigin | same-origin的请求,发送的完整URL(剥离参数),但在其他情况下只发送origin |
| unsafe-URL | same-origin 或 cross-origin的请求,将发送完整的URL(剥离参数) |
注意:
| 值 | content取值 | 描述 |
|---|---|---|
| width | 整数或device-width | 定义viewport的像素宽度,或允许viewport适应设备的屏幕宽度。 |
| height | 整数或device-height | 定义viewport的高度。没有任何浏览器使用(???MDN这么写) |
| initial-scale | 0.0 - 10.0 | 定义设备宽度(纵向模式下的设备宽度或横向模式下的设备高度)与viewport大小之间的比例。 |
| maximum-scale | 0.0 - 10.0 | 定义最大的缩放级别。它必须大于或等于minimum-scale,否则视为未定义。浏览器设置可以忽略此规则,iOS10 +默认情况下忽略它。 |
| minimum-scale | 0.0 - 10.0 | 定义最小的缩放级别。它必须小于或等于maximum-scale,否则视为未定义。浏览器设置可以忽略此规则,iOS10 +默认情况下忽略它。 |
| user-scalable | yes 或 no | 如果设置为no,用户将无法放大网页。默认值为yes。浏览器设置可以忽略此规则,iOS10 +默认情况下忽略它。 |
| 值 | 描述 | Used By |
|---|---|---|
| index | 允许robot索引本页面(默认) | All |
| noindex | 不允许robot索引本页面 | All |
| follow | 允许搜索引擎继续通过此网页的链接索引搜索其它的网页(默认) | All |
| nofollow | 搜索引擎不继续通过此网页的链接索引搜索其它的网页 | All |
| none | 相当于noindex,nofollow | |
| noodp | 禁止使用Open Directory Project描述(如果有的话)作为搜索引擎结果中的页面描述。 | Google, Yahoo, Bing |
| noarchive | 要求搜索引擎不缓存页面内容 | Google, Yahoo, Bing |
| nosnippet | 禁止在搜索引擎结果中显示该页面的任何描述。 | Google, Bing |
| noimageindex | 要求此页面不作为引用页面的索引图像的显示。 | |
| nocache | 和noarchive同义 | Bing |
如果页面不是经常更新,为了减轻搜索引擎爬虫对服务器带来的压力,可以设置一个爬虫的重访时间。如果重访时间过短,爬虫将按它们定义的默认时间来访问。
<meta name="revisit-after" content="7 days" ><meta name="renderer" content="webkit"> //默认webkit内核
<meta name="renderer" content="ie-comp"> //默认IE兼容模式
<meta name="renderer" content="ie-stand"> //默认IE标准模式
<meta name="renderer" content="webkit|ie-comp|ie-stand"><meta name="viewport" content="initial-scale=1.0, minimum-scale=1.0, maximum-scale=1.0, user-scalable=no">对于某些需重复请求数据的页面如文字直播等可用(虽然体验很差)
<meta http-equiv="refresh" content="5"><meta http-equiv="refresh" content="5;url=http://www.github.com"><meta http-equiv="Cache-Control" content="no-siteapp">屏蔽检测数字为电话号码
<meta name="format-detection" content="telephone=no">| 运算符 | 描述 |
|---|---|
| . [] () | 字段访问、数组下标、函数调用以及表达式分组 |
++ — - + ~ ! delete new typeof void |
一元运算符、返回数据类型、对象创建、未定义值 |
| * / % | 乘法、除法、取模 |
| + - + | 加法、减法、字符串连接 |
| << >> >>> | 移位 |
< <= > >= instanceof |
小于、小于等于、大于、大于等于、instanceof |
| == != === !== | 等于、不等于、严格相等、非严格相等 |
| & | 按位与 |
| ^ | 按位异或 |
| && | 逻辑与 |
| ?: | 条件 |
| = oP= | 赋值、运算赋值 |
| , | 多重求值 |
一元运算符只有一个参数,即要操作的对象或值。它们是 ECMAScript 中最简单的运算符。
delete, void, --, ++ 在W3school里有详细讲解。

其中涉及到几个ECMAScript定义的抽象操作,ToNumber(x),ToPrimitive(x)等等 下一章详细解答,下面出现的抽象定义也同理,先不管这个,有基础想深入了解可以提前熟读ECMAScript5规范(点击查看)。
一元加法对数字无作用,但会把字符串转换成数字。
与一元加法运算符相似,一元减法运算符也会把字符串转换成近似的数字,此外还会对该值求负
在多数程序设计语言中,加性运算符(即加号或减号)通常是最简单的数学运算符。
在 ECMAScript 中,加性运算符有大量的特殊行为。
ES5规范:

第七条,运算数中至少有一个为字符串,则将运算数转为字符串,结果为两个字符串相加。这就是为什么1 + '1' = '11'而不是2的原因。
var result = 5 + 5; //两个数字
alert(result); //输出 "10"
var result2 = 5 + "5"; //一个数字和一个字符串
alert(result); //输出 "55"在处理特殊值时,ECMAScript 中的加法也有一些特殊行为:
减、乘和除没有加法特殊,都是一个性质,这里我们就单独解读减法运算符(-)

与加法运算符一样,在处理特殊值时,减法运算符也有一些特殊行为:
某个运算数是 NaN,那么结果为 NaN。

直接从 C(和 Java)借用的两个运算符是前增量运算符和前减量运算符。
所谓前增量运算符,就是数值上加 1,形式是在变量前放两个加号(++):
var num = 10;
++num;第二行代码把 iNum 增加到了 11,它实质上等价于:
var num = 10;
num = num + 1;尽管 JavaScript 有 C 的代码风格,但是它不强制要求在代码中使用分号,实际上可以省略它们。
JavaScript 不是一个没有分号的语言,恰恰相反,它需要分号来就解析源代码。 因此 JavaScript 解析器在遇到由于缺少分号导致的解析错误时,会自动在源代码中插入分号。
var foo = function() {
} // 解析错误,分号丢失
test()自动插入分号,解析器重新解析。
var foo = function() {
}; // 没有错误,解析继续
test()下面的代码没有分号,因此解析器需要自己判断需要在哪些地方插入分号。
(function(window, undefined) {
function test(options) {
log('testing!')
(options.list || []).forEach(function(i) {
})
options.value.test(
'long string to pass here',
'and another long string to pass'
)
return
{
foo: function() {}
}
}
window.test = test
})(window)
(function(window) {
window.someLibrary = {}
})(window)下面是解析器插入分号后的结果。
(function(window, undefined) {
function test(options) {
// 没有插入分号,两行被合并为一行
log('testing!')(options.list || []).forEach(function(i) {
}); // <- 插入分号
options.value.test(
'long string to pass here',
'and another long string to pass'
); // <- 插入分号
return; // <- 插入分号, 改变了 return 表达式的行为
{ // 作为一个代码段处理
foo: function() {}
}; // <- 插入分号
}
window.test = test; // <- 插入分号
// 两行又被合并了
})(window)(function(window) {
window.someLibrary = {}; // <- 插入分号
})(window); //<- 插入分号解析器显著改变了上面代码的行为,在另外一些情况下也会做出错误的处理。
查看7.9章节,看看其中插入分号的机制和原理,清楚以后就可以尽量少踩坑。



看着头晕,看看具体的总结说明, 化抽象为具体 。
首先这些规则是基于两点:
6.3.1 ASI的规则
a. 新行并入当前行将构成非法语句,自动插入分号。
if(1 < 10) a = 1
console.log(a)
// 等价于
if(1 < 10) a = 1;
console.log(a);b. 在continue,return,break,throw后自动插入分号
return
{a: 1}
// 等价于
return;
{a: 1};c. ++、--后缀表达式作为新行的开始,在行首自动插入分号
a
++
c
// 等价于
a;
++c;d. 代码块的最后一个语句会自动插入分号
function(){ a = 1 }
// 等价于
function(){ a = 1; }6.3.2 No ASI的规则
a. 新行以 ( 开始
var a = 1
var b = a
(a+b).toString()
// 会被解析为以a+b为入参调用函数a,然后调用函数返回值的toString函数
var a = 1
var b =a(a+b).toString()b. 新行以 [ 开始
var a = ['a1', 'a2']
var b = a
[0,1].slice(1)
// 会被解析先获取a[1],然后调用a[1].slice(1)。
// 由于逗号位于[]内,且不被解析为数组字面量,而被解析为运算符,而逗号运算符会先执行左侧表达式,然后执行右侧表达式并且以右侧表达式的计算结果作为返回值
var a = ['a1', 'a2']
var b = a[0,1].slice(1) // 2c. 新行以 / 开始
var a = 1
var b = a
/test/.test(b)
// /会被解析为整除运算符,而不是正则表达式字面量的起始符号。浏览器中会报test前多了个.号
var a = 1
var b = a / test / .test(b)d. 新行以 + 、 - 、 % 和 * 开始
var a = 2
var b = a
+a
// 会解析如下格式
var a = 2
var b = a + ae. 新行以 , 或 . 开始
var a = 2
var b = a
.toString()
console.log(typeof b)
// 会解析为
var a = 2
var b = a.toString()
console.log(typeof b)到这里我们已经对ASI的规则有一定的了解了,另外还有一样有趣的事情,就是“空语句”。
// 三个空语句
;;;
// 只有if条件语句,语句块为空语句。
// 可实现unless条件语句的效果
if(1>2);else
console.log('2 is greater than 1 always!');
// 只有while条件语句,循环体为空语句。
var a = 1
while(++a < 100);提倡将花括号和相应的表达式放在一行, 对于只有一行代码的 if 或者 else 表达式,也不应该省略花括号。 这些良好的编程习惯不仅可以提到代码的一致性,而且可以防止解析器改变代码行为的错误处理。
关于JavaScript 语句后应该加分号么?(点我查看)我们可以看看知乎上大牛们对着个问题的看法。
Prefetching 是 W3C 新草案提出一种资源预加载的的标记。它允许你提前将一些将来的用到的资源或者图片提前进行请求,并将它存在缓存中方便你调用:
<link rel="prefetch" href="./image.png"/>
<link rel="prefetch" href="./lib.js"/>
它对浏览器有要求,但是不能识别这个标记类型的,浏览器会自行忽略掉;can I use: prefetch

虽然不同浏览器的实现不一致,但是最新版本的浏览器都还是支持了这个属性,不过它还取决于网络条件,如果网络条件不是怎么好的话,可能浏览器会放弃这个请求;
当然除了 prefetch 我们还可以了解下 dns-prefetch
提前进行 DNS 解析。
<link rel="dns-prefetch" href="//example.com">
我们知道 video 支持 preload 但是浏览器的限制,它并不能进行全量加载,它会依据网络状况和你设置的属性进行加载。不过有了 prefetch 我们可以完成全量视频的加载。
<link rel="preload" as="video" href="./a.mp4">
<video id="video" controls></video>
<script>
// preloaded video URL.
video.src = './a.mp4';
video.play().then(_ => {
});
</script>
点击查看实例:prefetch example
同样我们也可以进行一些音乐的请求,比如做游戏的时候,我们可以提前加载游戏的资源:
<link rel="preload" as="audio" href="./a.mp3">
<link rel="preload" as="audio" href="./b.mp3">
<audio id="audio" style="display:none;"></audio>
<script>
// preloaded audio URL.
audio.src = './a.mp3';
</script>
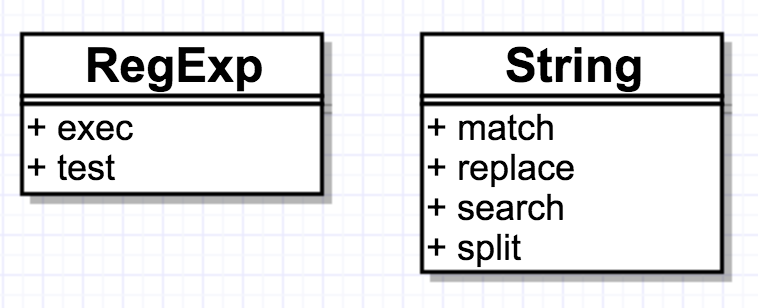
js中有两个类可以让正则发挥作用
方式一:正则表达字面量,这种直接是常量的表示用法可以让js解析器提高性能
const re = /ab+c/
方式二:构造函数,这种方式可以在runtime的时候动态确定正则是什么,更加灵活
const re = new RegExp('ab+c')
例子是最好的老师。。。。 例子来源于MDN
const myRe = /d(b+)d/g;
myRe.exec('cdbbdbsdbdbz') // ["dbbd", "bb", index: 1, input: "cdbbdbsdbdbz"]
myRe.exec('cdbbdbsdbdbz') // ["dbd", "b", index: 7, input: "cdbbdbsdbdbz"]
myRe.exec('cdbbdbsdbdbz') // null
注意:
对于每个正则对象的exec每次调用都只返回一个匹配,如果需要拿到全部匹配就需要while循环获取,循环结束标志是返回值为null
'cdbbdbsdbdbz'.match(/d(b+)d/g) // ["dbbd", "dbd"]
'cdbbdbsdbdbz'.match(/d(b+)d/) // ["dbbd", "bb", index: 1, input: "cdbbdbsdbdbz"]
string的match挺奇怪的,如果是global匹配则出所有匹配的数组,如果不是,则出第一个匹配的字符串,以及相应的捕获内容
const str = 'hello world!';
const result = /^hello/.test(str); // true
'cdbbdbsdbdbz'.search(/d(b+)d/) // 1
'xxx'.search(/d(b+)d/) // -1 没有匹配
const names = 'Harry Trump ;Fred Barney; Helen Rigby ; Bill Abel ;Chris Hand ';
const re = /\s*;\s*/;
const nameList = names.split(re);
// [ "Harry Trump", "Fred Barney", "Helen Rigby", "Bill Abel", "Chris Hand " ]
const re = /apples/gi;
const str = 'Apples are round, and apples are juicy.';
const newstr = str.replace(re, 'oranges');
// // oranges are round, and oranges are juicy.
众所周知,数组实例的reduce方法有callback回调函数和initialValue两个参数,其中initialValue为可选的。借用MDN中的说明:

initialValue用作callback函数中的第一个参数accumulator的初始值,无initialValue时callback中的accumulator取数组的第一个值,每次循环时accumulator取上一次callback函数的返回值,currentValue 取数组的下一个位置的值,在调用空数组的reduce方法时不设initialValue会抛出一个错误。
下面介绍几个reduce方法的用途:
a. 数组求和
const sum = [0, 1, 2, 3].reduce(function (accumulator, currentValue) {
return accumulator + currentValue
}, 0)
// sum is 6
b. 实现Array.prototype.flattern
const flattened = [[0, 1], [2, 3], [4, 5]].reduce(
function(accumulator, currentValue) {
return accumulator.concat(currentValue)
},
[]
)
// flattened is [0, 1, 2, 3, 4, 5]
c. 数组元素计数
const names = ['Alice', 'Bob', 'Tiff', 'Bruce', 'Alice'];
const countedNames = names.reduce(function (allNames, name) {
name in allNames ? ++allNames[name] : (allNames[name] = 1)
return allNames
}, {})
// countedNames is:
// { 'Alice': 2, 'Bob': 1, 'Tiff': 1, 'Bruce': 1 }
继续说,上面提到了两个主要的reduce函数执行时的条件:
initialValue是否提供这两种条件一组合,就出现四种执行情况:
a. 数组不为空 && 提供initialValue
正常执行reduce的callback函数并返回最终的accumulator。
b. 数组不为空 && 不提供initialValue
initialValue,callback函数的循环从index===1开始;callback,直接返回数组的这个元素。c. 数组为空 && 提供initialValue
不调用callback,直接返回initialValue
d. 数组为空 && 不提供initialValue
抛出TypeError
代码说话:
const maxCallback = ( acc, cur ) => Math.max( acc.x, cur.x )
// reduce() without initialValue
[ { x: 22 }, { x: 42 } ].reduce( maxCallback ) // 42
[ { x: 22 } ].reduce( maxCallback ) // { x: 22 }
[ ].reduce( maxCallback ) // TypeError其实这几个例外情况可以这样理解:
b情况的第二个条件:数组只有一个元素而不提供initialValue,reduce会将数组的这个元素赋给initialValue,此时运行状态就和 c.数组为空,提供initialValue 一样了。而数组为空,length为0,当然不会执行reduce的callback函数,会直接返回accumulator=initialValue。
进一步,d.数组为空 && 不提供initialValue 中数组为空,不会执行reduce的callback函数,会直接返回accumulator=initialValue,而此时未提供initialValue,自然是报错了。
在数组长度未知的情况下,调用reduce方法时不提供initialValue会产生不想要的结果甚至报错。因此,我们使用reduce方法时最好是提供initialValue。
注:以上代码示例均取自MDN
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.