fi3ework / blog Goto Github PK
View Code? Open in Web Editor NEW📝
📝





























































































































































wip
前段时间在看这篇文章 [译] React性能优化-虚拟Dom原理浅析 时发现了一些非常有意思的知识点,之前并没有考虑过,大家可以先看一下这篇文章,写的非常好,翻译的也很好。本文将对其中涉及到 unmount & re-mount 的地方展开分析。
在展开讲之前,我们先重新了解 JSX,JSX 并不审美,它只是一个弱弱的语法糖,所谓语法糖:
语法糖(Syntactic sugar),也译为糖衣语法,是由英国计算机科学家彼得·蘭丁发明的一个术语,指计算机语言中添加的某种语法,这种语法对语言的功能没有影响,但是更方便程序员使用。 语法糖让程序更加简洁,有更高的可读性。
看下 Babel 对 JSX 的转义就知道了。
JSX 代码如下:
const Button = (props) => <div>btn</div>
let x = <Button />被转义后的 JS 代码如下(其实老版本的 React 就是这么写的):
"use strict";
var Button = function Button(props) {
return React.createElement(
"div",
null,
"btn"
);
};
var x = React.createElement(Button, null);React.createElement 的函数签名如下
React.createElement(
type,
[props],
[...children]
)createElement 接受不限定个参数
type。对于HTML标签,它将是一个带有 标签名称 的字符串。对于自定义组件,它将是对应组件的引用(这点很重要,后面会讲到,语法糖在带来代码编写效率提升的同时,也会将细节隐藏掉,所以开发者有时会不理解其中的细节)。children)。最终所有的子元素都会被通过 … 组合成一个 children 的数组。针对可以传入 children 的子元素,可以有以下值:
false, null, undefined, true这么一看,似乎 children 是很特殊的一个参数,但是我们经常会写出 this.props.children 这样的参数,也就是说在 React 内部,children 也是 props 的一部分,
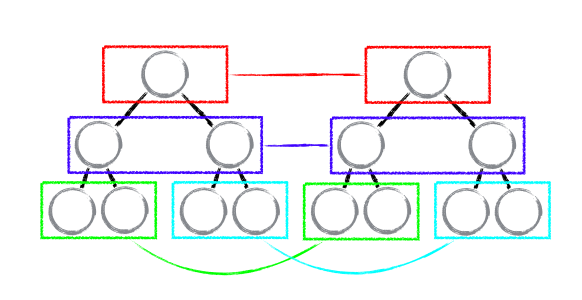
为了简化理解,我们可以看 React 15.0 版本(之后的版本加入了 Fiber)的 VDOM 的结构,其中,绿色框内的就是一个 VDOM 的结构。
(这里要注意,最外面的那个 _MyNode 并不是 VDOM,它是组件中的 this,我们一般称之为实例化对象,它的 render 中返回的值将会被用来生成真正的 VDOM。如果你还不信,那么想一下,真正的 VDOM 会有 shouldComponentWillUpdate 这种生命周期函数吗?)

所以,一个简略版的 React 的 VDOM 模型大致可以描述为:
{
type: 'div',
props: {
className: 'cn',
children: [
'Content 1!',
'Content 2!'
]
}
}再重复一下 React 的 reconciler 的原则,深入React技术栈 中这本书已经说得很好了,这里再整理一下。
tree diff
基于实际的浏览器中 DOM 变化的特点,我们可以认为 DOM 很少会跨层级移动,每次的变更都是某节点的变化,或者某节点的子节点的变化,所以基于次特点,diff 时只对相同层级的节点进行比较。
component diff
element diff
这里可以说是 diff 算的核心,通过 INSERT_MARKUP(插入),MOVE_EXISTING(移动) 和 REMOVE_NODE(删除)来完成最小化的更新,具体的不在这里展开。
我们都知道,在显示的返回一个数组时,数组中的每个子元素要有一个稳定的,独一无二的 key 来标明每个子元素的“身份”,标明身份是为了让 React 的 reconciler 的效率获得提升。
我们来看两个个例子:

B C 是同级节点,并且都有独特的 key,如果我问从左到右真实 DOM 是如何变化的?那么你肯定能说出来 B 不变,C 被移除了。没错,VDOM 的变化最后会 patch 到真实 DOM 上,在这里由于有 key,所以 React 可以知道 B 是没有变化的,只需要移除一个 C 即可。
还是上面的那个图,这一次,B 和 C 没有 key 了,真实 DOM 会如何变化?我改了一个小 DEMO,打印了它们的生命周期,我们先来看下打印的结果:

答案是:先创建一个新的 B,再将原来的 B 和 C 移除,最后将新的 B 放在 A 的下面,因为 B 和 C 对 React 来说根本就分别不出来,React 的 diff 算法就是会把他们先卸载掉再重新生成加载。
你可能会说,我平时都会写 key 的。React 也会在控制台对数组形式的子元素提示需要添加 key。但是非数组形式的则完全不会提示,如下两个组件。可以是一模一样,从 Babel 转义来看也几乎相同,唯一的区别就是,Arr2 返回的子元素是以数组形式包裹的而 Arr1 则是一个个参数。但是没关系,他们最后都会被 … 打包成一个 children 的组件,数组形式的子元素一方面是方便我们的书写,一方面是可以让 React 提示我们要加 key。所以会不会有那么一种情况,就是虽然我们的本意不是写一个不带 key 的数组,但是无意中写出了这种反模式的代码呢?

不必要的 unmount & re-mount 不仅会让其丢失自身的 state,还会带来性能上的负担。因为它不仅会在 VDOM 上进行 diff(其实 VDOM 上 diff 的负担会变少,因为直接卸载再重装其实很简单,真正的负担是真实 DOM),还会 patch 到真实 DOM 上,违背了 diff 最小化更新的原则。试想,一个有 10000 个条目的列表的真实 DOM 在每次更新时被 unmount 和 re-mount 带来的开销有多可怕。
开头提到的那篇文章中有一个很有意思的案例,我在这里简单再重复一下:
就是有这么个组件
<div>
<Message />
<Table />
<Footer />
</div>Table 是个有很多项目的列表(其实是什么无所谓,只是为了强调 Table 如果被 unmount & re-mount 是开销很大的操作)。现在呢,比如我们的用户读完一个通知了,那么就可以移除 Message 这个组件。
React会怎么处理呢?它会看作是一个 array 类型的 children,现在少了第一项,从前第一项是 Message 现在是 Table 了,也没有 key 作为索引,比较 type 的时候又发现它们俩不是同一个 function 或者 class 的同一个实例,于是会把整个 Table unmount,然后再 re-mount 回去,重新渲染它大量的子数据。
我们上面的 key 的 demo 中,也印证了在没有 key 时 React 会“傻傻得”去 unmount & re-mount。
作者还很贴心的给出了解决方案:
isShown && <Message />,我们可以使用 true, false, null, undefined ,这些都是 JSX 允许的,它们本身不会被渲染什么,但是确实合格的 “占位符”。但是我们平时在写类似这种需要移除的组建时,往往会写成一个表达式的形式,拿这个案例举例的话就是
<div>
{this.state.doesShow ? <Message onClickHandler={this.remove}/> : null}
<Table />
<Footer />
</div>这种表达式的写法自然而然的符合原文作者通过添加一个基础类型占位符来辅助 diff 的思路,笔者之前只是认为 null 表达的是不渲染任何东西(当然用 false 什么的也可以的,但是这里 null 更符合语意),其实 null 还有另一个重要作用就是辅助 diff。
既然如此,那么什么时候我们会陷入作者写的这个坑中的呢?
笔者能想到的一个点是"更换样式",比如很多网站都有,点击更换样式(不只是颜色,也会涉及到 DOM 的更改)。但是要注意,React 对相同位置不同类型的组件会直接卸载掉旧的组件然后加载一个新的组件,直接就没有子元素啥事了。
还是拿之前的那个例子举例,假设这是样式1
<Style1 data={...}>
<Message />
<Table />
<Footer />
</Style1>这是样式2
<Style2 data={...}>
<Table />
<Message />
</Style2>如果直接替换掉,那么由于 Style1 和 Style2 类型不同,Style1 会被直接卸载掉,Style2 再重新加载。
如果不想被直接替换掉,我们可以剥离掉最外层的样式组件,在渲染时直接执行来展开子元素们:
style1 = () => (
<div data={...}>
<Message key="message"/>
<Table key="table"/>
<Footer key="footer"/>
</div>
)
style2 = () => (
<div data={...}>
<Table key="table"/>
<Message key="message"/>
</div>
)在父组件中:
{this.state.style === 'style1' ? this.style1() : this.style2() }这样的确可以减少 unmount & re-mount 的次数,但是也会带来一些弊端:1. 如果嵌套的很复杂的组件将比较难分离出来。 2. 数据的传递变得更加复杂了。 3. 组件间的耦合变重了。
文中还提到了一个 HOC 的坑,这里再简要复述一下这个坑:
我们会经常这样写 HOC(事实上,这是很常见的一种 HOC,比如 react-router 的 withRouter 就是这样)
function withName(SomeComponent) {
// Computing name, possibly expensive...
return function(props) {
return <SomeComponent {...props} name={name} />;
}
}然后在父组件中如此调用:
class App extends React.Component() {
render() {
// Creates a new instance on each render
const ComponentWithName = withName(SomeComponent);
return <ComponentWithName />;
}
}或者,如此调用:
// Creates a new instance just once
const ComponentWithName = withName(Component);
class App extends React.Component() {
render() {
return <ComponentWithName />;
}
}看起来差不多,但其实如果父组件 re-render,第一种方法创建的 HOC 是会 unmount & re-mount 的。有的朋友读到这里可能会说不对啊,根据前面的 component 的 diff 的原则,前后两次 render 在 React.createElement 中的 type 都是 ComponentWithName。但是仔细看啊,当 type 为一个自定义的组件的时候,type 将不是一个字符串,而是一个指向对应的函数的引用。所以虽然都是 ComponentWithName,但是 re-render 时的引用已经改变。这对 React 来说会认为是换了一个类型的节点,所以直接将旧节点 unmount,新节点 re-mount,突突突突,一堆老的真实 DOM 被卸载,一堆新的真实 DOM 被装载。
还是那两句话。
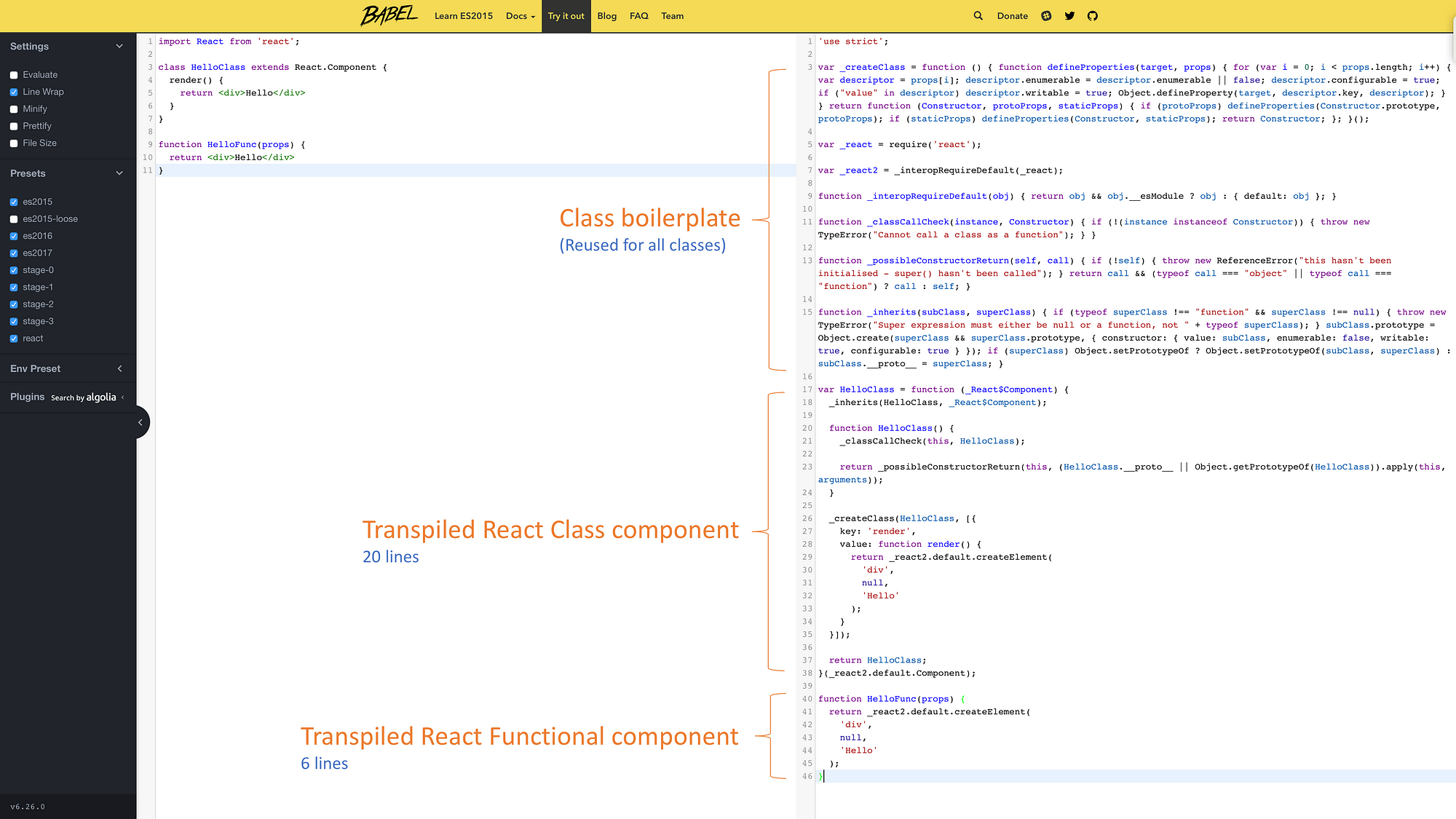
ES2015+ 有各种新特性(语法糖),尽管有很多特性尚未纳入标准或浏览器还没有原生支持,但是 Babel 的出现让前端可以不用担心兼容性问题而使用处于各种 stage 的 ES2015+ 语法。其实 class 关键字目前只是实现类的语法糖,但是可以帮助我们屏蔽掉每次实现类时的样本代码,逻辑更加清晰,并且阻止我们踩可能存在的坑,本篇文章从 ES5 的类实现到 ES6 中class 的 Babel 转码来分析类的实现与继承。
在 JavaScript 中,我们希望一个类能有以下特性:
Object.getPrototypeOf 能拿到 constructor 的 prototypeinstanceof 构造函数返回 trueES5 中的类是通过 构造函数模式 + 原型模式 实现的。
function Animal(name) {
this.name = name // 不共享实例属性
}
Animal.prototype.barking = function() {
console.log(this.name + ' : ah!') // 共享方法
}
Animal.hello = function() {
console.log('hello animal')
}以上几点都是实现了的,但是缺点就是封装性不好,样本代码多,这只是简陋版的实现,不过思路就是这样。
class Animal {
// 构造函数
constructor(name){
this.name = name
}
// 类的实例属性
age = 1
// 类的实例方法
sayAge = function(){
console.log(this.age)
}
// 类的方法
barking () {
console.log(this.name + ' : ah!')
}
// getter
get description () {
return 'description: ' + this.name;
}
// 类的静态属性
static id = 27
// 类的静态方法
static hello() {
console.log('hello animal ' + this.id)
}
}相当简洁了,整个类的声明都在一起,接下来我们看一下 Babel 编译出来的代码:
'use strict';
var _createClass = function () {
function defineProperties(target, props) {
for (var i = 0; i < props.length; i++) {
var descriptor = props[i];
descriptor.enumerable = descriptor.enumerable || false;
descriptor.configurable = true;
if ("value" in descriptor) descriptor.writable = true;
Object.defineProperty(target, descriptor.key, descriptor);
}
}
return function (Constructor, protoProps, staticProps) {
if (protoProps) defineProperties(Constructor.prototype, protoProps);
if (staticProps) defineProperties(Constructor, staticProps);
return Constructor;
};
}();
function _classCallCheck(instance, Constructor) {
if (!(instance instanceof Constructor)) {
throw new TypeError("Cannot call a class as a function");
}
}
var Animal = function () {
// 构造函数
function Animal(name) {
_classCallCheck(this, Animal);
this.age = 1;
this.sayAge = function () {
console.log(this.age);
};
this.name = name;
}
// 类的实例属性
// 类的实例方法
_createClass(Animal, [{
key: 'barking',
// 类的方法
value: function barking() {
console.log(this.name + ' : ah!')
}
// getter
}, {
key: 'description',
get: function get() {
return 'description: ' + this.name;
}
// 类的静态属性
}], [{
key: 'hello',
// 类的静态方法
value: function hello() {
console.log('hello animal ' + this.id);
}
}]);
return Animal;
}();
Animal.id = 27;下面开始分析:
'use strict';使用严格模式的原因阮老师在 ECMAScript 6 入门 中有解释,这里直接贴一下:
类和模块的内部,默认就是严格模式,所以不需要使用
use strict指定运行模式。只要你的代码写在类或模块之中,就只有严格模式可用。
考虑到未来所有的代码,其实都是运行在模块之中,所以 ES6 实际上把整个语言升级到了严格模式。
先从主函数入手
function Animal(name) {
_classCallCheck(this, Animal);
this.age = 1;
this.sayAge = function () {
console.log(this.age);
};
this.name = name;
}
_createClass(Animal, [{
key: 'barking',
value: function barking() {
console.log(this.name + ' : ah!')
}
}, {
key: 'description',
get: function get() {
return 'description: ' + this.name;
}
}], [{
key: 'hello',
value: function hello() {
console.log('hello animal ' + this.id);
}
}]);
return Animal;先执行构造函数,首先调用 _classCallCheck 用来确保类是通过 new 作为构造函数调用而不是直接调用,如果是直接调用则直接报错。
然后是在构造函数里绑定实例的属性和方法 —— age(直接写入类的定义的实例属性),sayAge(直接写入类的定义的实例方法),name (构造函数中的实例属性)。这里要注意,直接写入类的定义的实例属性/方法要先于构造函数中的实例属性/方法执行,所以如果在直接写入类的定义的实例方法中获取构造函数中定义的属性/方法,会返回 undefined。
然后就是用 _createClass,接受两个参数:类、[绑定在类的prototype上的方法, 绑定在类上的静态方法],作用是把方法绑定在对应的对象上。
var _createClass = function () {
function defineProperties(target, props) {
for (var i = 0; i < props.length; i++) {
var descriptor = props[i];
descriptor.enumerable = descriptor.enumerable || false; // 默认false,原型/静态方法不允许枚举
descriptor.configurable = true; // 默认为false,设为true,否则一切属性都无法修改
if ("value" in descriptor) descriptor.writable = true; // 默认false,设为true,方法都是可以可以被修改的
Object.defineProperty(target, descriptor.key, descriptor);
}
}
return function (Constructor, protoProps, staticProps) {
if (protoProps) defineProperties(Constructor.prototype, protoProps);
if (staticProps) defineProperties(Constructor, staticProps);
return Constructor;
};
}();通过 Object.defineProperty 将各个方法绑定到 类的 prototype/类 上,Object.defineProperty 可以指定对象的属性,让类的原型方法/静态方法无法被枚举。
还有一点比较有意思的是,这里 _createClass 是 IIFE 的返回值,这样能做到不污染全局作用域,但是最后还是会有一个 _createClass,那是不是直接可以在声明一个 class 后调用 _createClass 呢?答案当然是不可以,如果你在源代码里访问或操作 _createClass,这个默认叫 _createClass 函数就会被改成 _createClass2,总之就是不让你访问到。
最后,再补上一个类的静态属性就完事大吉了:
Animal.id = 27;但是类的静态属性也可以写成函数表达式的形式,这样的话类的静态方法就是可以枚举的了。
function Animal(name) {
this.name = name
}
Animal.prototype.barking = function() {
console.log(this.name + ' : ah!')
}
Animal.hello = function() {
console.log('hello animal')
}
function Cat(name, breed) {
Animal.call(this, name) // 已经生成了指向子类实例的this,再调用父类的构造函数
this.breed = breed
}
// 直接拿到父类的prototype,避免多次调用父类的构造函数
Cat.prototype = Object.create(Animal.prototype, {
constructor:{
value: Square,
enumerable: false,
writeable: false,
configurable: false
}
})
Cat.prototype.barking = function(){
var catPrototype = Object.getPrototypeOf(this)
var animalPrototype = Object.getPrototypeOf(catPrototype)
animalPrototype.barking.call(this);
console.log(this.name + ' : mew!')
}
var cat = new Cat('Tom', 'American shorthair')
console.log(cat.name) // "Tom"
console.log(cat.breed) // "American shorthair"
console.log(cat instanceof Animal) // "true"
console.log(cat instanceof Cat) // "true"
cat.barking() // "Tom : ah!" "Tom : mew!"class Animal{
constructor(name){
this.name = name
}
barking () {
console.log(this.name + ' : ah!')
}
static hello () {
console.log('hello animal')
}
}
class Cat extends Animal{
constructor(name, breed){
super(name)
// 子类必须在constructor方法中调用super方法,否则新建实例时会报错。这是因为子类没有自己的this对象,而是继承父类的this对象,然后对其进行加工。如果不调用super方法,子类就得不到this对象。
// ES5 的继承,实质是先创造子类的实例对象this,然后再将父类的方法添加到this上面(Parent.apply(this))。
// ES6 的继承机制完全不同,实质是先创造父类的实例对象this(所以必须先调用super方法),然后再用子类的构造函数修改this。 —— 阮老师的ES6教程
// ↑↑↑ 这是按照ES6标准,但是目前的class只是语法糖,所以依旧是先创建一个子类的对象,在用父类的方法去加工 ↑↑↑
this.breed = breed
}
barking(){
super.barking()
console.log(this.name + ' : mew!')
}
static hello () {
super.hello()
console.log('hello kitty')
}
}
var cat = new Cat('Tom', 'American shorthair')
console.log(cat.name) // "Tom"
console.log(cat.breed) // "American shorthair"
console.log(cat instanceof Animal) // true
console.log(cat instanceof Cat) // true
cat.barking() // "Tom : ah!" "Tom : mew!"
Cat.hello() // "hello animal" "hello kitty"Babel 编译后的代码太长了 ,我们只需要关注继承的类比不继承的类多了那些功能即可:
var Cat = function (_Animal) {
_inherits(Cat, _Animal); // 子类去继承父类,子类的原型去继承父类的原型
function Cat(name, breed) {
_classCallCheck(this, Cat);
var _this = _possibleConstructorReturn(this, (Cat.__proto__ || Object.getPrototypeOf(Cat)).call(this, name)); // 先生成一个父类的构造函数返回 this
_this.breed = breed; // 再用子类的构造函数去对这个 this 添加实例
return _this;
}
_createClass(Cat, [{
key: 'barking',
value: function barking() {
_get(Cat.prototype.__proto__ || Object.getPrototypeOf(Cat.prototype), 'barking', this).call(this); // 调用父类原型的barking方法
console.log(this.name + ' : mew!'); // 再执行子类的barking方法
}
}], [{
key: 'hello',
value: function hello() {
_get(Cat.__proto__ || Object.getPrototypeOf(Cat), 'hello', this).call(this); // 调用父类的hello静态方法
console.log('hello kitty'); // 再执行子类的barking静态方法
}
}]);
return Cat;
}(Animal);所以一共就多了三个函数 _inherits、_possibleConstructorReturn 和 _get
先看_inherits
// 调用
_inherits(Cat, _Animal);
// 定义
function _inherits(subClass, superClass) {
// 只能继承函数或者null
if (typeof superClass !== "function" && superClass !== null) {
throw new TypeError("Super expression must either be null or a function, not " + typeof superClass);
}
// subClass.prototype.__proto__ = superClass.prototype
// 子类的原型继承父类的原型
// subClass.prototype.constructor = subClass
// 子类的构造函数指向子类
subClass.prototype = Object.create(superClass && superClass.prototype, {
constructor: {
value: subClass,
enumerable: false,
writable: true,
configurable: true
}
});
// 子类继承父类
// subClass.__proto__ = superClass
if (superClass) Object.setPrototypeOf ? Object.setPrototypeOf(subClass, superClass) : subClass.__proto__ = superClass;
}这个函数完成了三个重要的任务:
至此,子类原型已近能够访问父类原型的方法了,子类也能够访问父类的静态方法。
再来看 _possibleConstructorReturn
//
var _this = _possibleConstructorReturn(this, (Cat.__proto__ || Object.getPrototypeOf(Cat)).call(this, name)); // 先生成一个父类的构造函数返回的this
// 两个参数,一个参数是指向子类实例的this,另一个参数是调用父类的构造函数返回的父类实例
function _possibleConstructorReturn(self, call) {
if (!self) {
throw new ReferenceError("this hasn't been initialised - super() hasn't been called");
}
// 如果父类返回的是对象或函数,则返回父类的构造函数生成的this,否则返回self
return call && (typeof call === "object" || typeof call === "function") ? call : self;
}作用是生成并返回一个调用父类的构造函数的this,再在主函数中用子类的构造函数进行加工。
再来看 _get
// 调用
_createClass(Cat, [{
key: 'barking',
value: function barking() {
_get(Cat.prototype.__proto__ || Object.getPrototypeOf(Cat.prototype), 'barking', this).call(this);
console.log(this.name + ' : mew!');
}
}]
...
// 定义
var _get = function get(object, property, receiver) {
if (object === null) object = Function.prototype;
var desc = Object.getOwnPropertyDescriptor(object, property);
if (desc === undefined) {
var parent = Object.getPrototypeOf(object);
if (parent === null) {
return undefined;
} else {
return get(parent, property, receiver);
}
} else if ("value" in desc) { // 如果是普通方法
return desc.value;
} else { // 如果是getter
var getter = desc.get;
if (getter === undefined) {
return undefined;
}
return getter.call(receiver);
}
};_get 接受三个参数,父类原型/父类,子类要 override 父类的方法,还有当前的子类实例。
但是要注意,再次强调,ES6 的 class 只是用 ES5 来实现的话就只是语法糖,因为还是无法完成原生构造函数的继承。
来自 Babel 的说明:
Built-in classes such as
Date,Array,DOMetc cannot be properly subclassed due to limitations in ES5 (for the es2015-classesplugin). You can try to use babel-plugin-transform-builtin-extend based onObject.setPrototypeOfandReflect.construct, but it also has some limitations.
测试:
class MyArray extends Array {
constructor(...args) {
super(...args);
}
}
var arr = new MyArray();
arr[0] = 12;
console.log(arr.length) // 理想输出:1 实际输出:0
arr.length = 0;
console.log(arr[0]) // 理想输出:undefined 实际输出:12到这里,Babel 编译的代码就分析完了,下面来看一下阮老师的ES6教程中的知识点,看看是不是能做到完全理解:
在子类 constructor() 中,super 指向 Parent,super 中的 this 指向 Child 类的实例,所以相当于Parent.call(this)
在子类方法中,super 指向 Parent.prototype,super 中的 this 指向子类的实例,所以如果有 super 调用就是 Parent.prototype.func.call(this)
super 在静态方法之中指向父类,而不是父类的原型对象。在子类的静态方法中通过 super 调用父类的方法时,方法内部的 this 指向当前的子类,而不是子类的实例。
子类的原型指向父类
Child.proto === Parent // true子类的 prototype 的原型指向父类的原型
Child.prototype.__proto__ = Parent.prototype // true
//相当于
B.prototype = Object.create(A.prototype)// o1 是父类的实例,o2 是子类的实例
o2.__proto__.__proto__ === o1.proto__ // true写到一半Typora崩溃了把我保存的内容都吞了是真的坑,在心态崩了的情况下再重写一次真是磨练心智 😭
cache-control 作为一个 general header,在 request 和 response 中都可以存在?那么如果假设我们在某 HTML 的 meta 中写了
<meta name="Cache-Control" content="no-cache">但是和这个 HTML 的 response 中由服务器设定的 cache-control 不一致时,如下图,demo

下一次请求的 cache-control 该听谁的呢?
在这个例子中,重复访问页面,第二次访问的 HTML 是 from disk,也就是说缓存生效了。
MDN 中语焉不详,只是说 a given directive in a request is not implying that the same directive is to be given in the response。我也没在 HTTP 规范中找到对应的规则。
查了一下资料,发现这应该是一个由服务器来控制的规则:服务器可以选择是否忽略 request 中的 cache-control,如果不忽略就按 request 中的 cache-control 规则来,忽略了就按 response 中的 cache-control 规则来。
比如Apache

比如 Nginx

expires: 0
pragma: no-cache
cache-control: no-store, no-cache, must-revalidate, proxy-revalidate
再加上兼容 HTTP/1.0 的 expires 和 pragma,即禁止一切缓存,请求每次都要发往源服务器。
Cache-Control: max-age=31536000
将 Cache-Control 设定的很长,即在 Cache-Control 没有过期的情况下将直接从浏览器中取出缓存(from memory cache 或 from disk cache),但是这样也彻底限制了资源更新的可能。
通过给资源的 URL 添加一个“指纹”,可以是版本号,hash,MD5 或日期等。
<script src="/script-f93bca2c.js"></script>
<link rel="stylesheet" href="/styles-a837cb1e.css">
<img src="/cats-0e9a2ef4.jpg" alt="…">通过 HTML 的更新来控制对应资源是否更新,这样做的好处是在 HTML 没更新的时候直接从浏览器中取缓存,有效避免 304,进一步减小服务器的压力;HTML 更新后也会更新资源文件的文件名,URI 变了浏览器自然会去向源服务器请求新的资源。
我们通过分析知乎和掘金的的 HTTP 缓存实践来看下这两个网站是如何进行缓存的:
*.html

知乎的主页是由服务端动态生成的,所以采用完全不缓存的策略。
*.js, *.css

.js 和 .css 采用的都是长 max-age + 指纹 的策略,由上面的 HTML 来控制是否更新。
静态资源

图片等同样适用 max-age + 指纹 的策略。
Ajax

对于涉及到用户个人的信息,要特别在 cache-control 中指出 private 来防止缓存服务器缓存,然后再禁止掉所有本地缓存。
*.html

掘金的 HTML 只在 Cache-Control 中写了 private,禁止缓存服务器缓存,但是也没有指定 max-age,所以每次还是会去请求源服务器。
不过根据 MSDN 中描述的,Cache-Control 默认值就是 private,所以不写应该也没问题。
*.js, *.css

对于加指纹的文件,与知乎的策略近似,这里多了一个 public,意欲何为?
静态资源

资源文件有指纹,所以采用长 max-age + 指纹的策略,又多了个 public?
Ajax

采用长 max-age + 指纹的策略并且不允许缓存服务器缓存。
*.html

采用 no-cache,这样可以利用缓存服务器,缓存服务器在发回备份前会先向源服务器确认缓存是否可用,如果可用则返回给浏览器备份,否则要再向源服务器发起请求。
*.js, *.css

同掘金
静态资源

不同于前两者的资源 URI,github 的资源 URI 采用的是 {id}?s={size}&v={version} 的格式,没有 指纹的加持,就要保证资源在改变时及时更新,

github 是默认给缓存五分钟,五分钟之内直接从本地浏览器缓存中拿,如果超过了五分钟则去比较 Etag,Last-Modified 和 Expires,如果改变了就向源服务器 200 一个新的,如果没改变就会返回一个 304。
Ajax

同 html。
HTTP 缓存不存在银弹,只有根据当前业务特点还有后端资源的配置寻求最适合的配置。
最近翻出了之前分析的 applyMiddleware 发现自己又看不懂了😳,重新看了一遍源代码,梳理了洋葱模型的实现方法,在这里分享一下。
applyMiddleware 函数虽短但却是 Redux 最精髓的地方,成功的让 Redux 在保持“自身函数式纯洁”的前提下,在 action 传递的过程中插入了提供了副作用的空间。
这个 middleware 的洋葱模型**是从 koa 的中间件拿过来的,用图来表示最直观。
上图之前先上一段用来示例的代码(via 中间件的洋葱模型),我们会围绕这段代码理解 applyMiddleware 的洋葱模型机制:
function M1(store) {
return function(next) {
return function(action) {
console.log('A middleware1 开始');
next(action)
console.log('B middleware1 结束');
};
};
}
function M2(store) {
return function(next) {
return function(action) {
console.log('C middleware2 开始');
next(action)
console.log('D middleware2 结束');
};
};
}
function M3(store) {
return function(next) {
return function(action) {
console.log('E middleware3 开始');
next(action)
console.log('F middleware3 结束');
};
};
}
function reducer(state, action) {
if (action.type === 'MIDDLEWARE_TEST') {
console.log('======= G =======');
}
return {};
}
var store = Redux.createStore(
reducer,
Redux.applyMiddleware(
M1,
M2,
M3
)
);
store.dispatch({ type: 'MIDDLEWARE_TEST' });再放上 Redux 的洋葱模型的示意图(via 中间件的洋葱模型),以上代码中间件的洋葱模型如下图:
--------------------------------------
| middleware1 |
| ---------------------------- |
| | middleware2 | |
| | ------------------- | |
| | | middleware3 | | |
| | | | | |
next next next ——————————— | | |
dispatch —————————————> | reducer | — 收尾工作->|
nextState <————————————— | G | | | |
| A | C | E ——————————— F | D | B |
| | | | | |
| | ------------------- | |
| ---------------------------- |
--------------------------------------
顺序 A -> C -> E -> G -> F -> D -> B
\---------------/ \----------/
↓ ↓
更新 state 完毕 收尾工作
我们将每个 middleware 真正带来副作用的部分(在这里副作用是好的,我们需要的就是中间件的副作用),称为 M?副作用,它的函数签名是 (action) => {}(记住这个名字)。

对这个示例代码来说,Redux 中间件的洋葱模型运行过程就是:
用户派发 action → action 传入 M1 副作用 → 打印 A → 执行 M1 的 next(这个 next 指向 M2 副作用)→ 打印 C → 执行 M2 的 next(这个 next 指向 M3 副作用)→ 打印 E → 执行 M3 的 next(这个 next 指向store.dispatch)→ 执行完毕返回到 M3 副作用打印 F → 返回到 M2 打印 E → 返回到 M1 副作用打印 B -> dispatch 执行完毕。
那么问题来了,M1 M2 M3的 next 是如何绑定的呢?
答:柯里化绑定,一个中间件完整的函数签名是 store => next => action {},但是最后执行的洋葱模型只剩下了 action,外层的 store 和 next 经过了柯里化绑定了对应的函数,接下来看一下 next 是如何绑定的。
const store = createStore(...args)
let chain = []
const middlewareAPI = {
getState: store.getState,
dispatch: (...args) => dispatch(...args)
}
chain = middlewares.map(middleware => middleware(middlewareAPI)) // 绑定 {dispatch和getState}
dispatch = compose(...chain)(store.dispatch) // 绑定 next关键点就是两句绑定,先来看第一句
chain = middlewares.map(middleware => middleware(middlewareAPI)) // 绑定 {dispatch和getState}为什么要绑定 getState?因为中间件需要随时拿到当前的 state,为什么要拿到 dispatch?因为中间件中可能会存在派发 action 的行为(比如 redux-thunk),所以用这个 map 函数柯里化绑定了 getState 和 dispatch。
此时 chain = [(next)=>(action)=>{…}, (next)=>(action)=>{…}, (next)=>(action)=>{…}],… 里闭包引用着 dispatch 和 getState。
接下来 dispatch = compose(...chain)(store.dispatch) ,先了解一下 compose 函数
compose(A, B, C)(arg) === A(B(C(arg)))这就是 compose 的作用,从右至左依次将右边的返回值作为左边的参数传入,层层包裹起来,在 React 中嵌套 Decorator 就是这么写,比如:
compose(D1, D2, D3)(Button)
// 层层包裹后的组件就是
<D1>
<D2>
<D3>
<Button />
</D3>
</D2>
</D1>再说回 Redux
dispatch = compose(...chain)(store.dispatch) 在实例代码中相当于
dispatch = MC1(MC2(MC3(store.dispatch)))
MC 就是 chain 中的元素,没错,这又是一次柯里化。

至此,真相大白,dispatch 做了一点微小的贡献,一共干了两件事:1. 绑定了各个中间件的 next。2. 暴露出一个接口用来接收 action。其实说了这么多,middleware 就是在自定义一个dispatch,这个 dispatch 会按照洋葱模型来进行 pipe。
OK,到现在我们已经拿到了想要的 dispatch,返回就可以收工了,来看最终执行的灵魂一图流:

然而可达鸭眉头一皱,发现事情还没这么简单,有几个问题要想一下
const middlewareAPI = {
getState: store.getState,
dispatch: (...args) => dispatch(...args)
}在这里 dispatch 使用匿名函数是为了能在 middleware 中调用 compose 的最新的 dispatch(闭包),必须是匿名函数而不是直接写成 store.dispatch。
如果直接写成 store.dispatch,那么在某个 middleware(除最后一个,最后一个middleware拿到的是原始的 store.dispatch)dispatch 一个 action,比如 redux-thunk
function createThunkMiddleware(extraArgument) {
return ({ dispatch, getState }) => next => action => {
if (typeof action === 'function') {
return action(dispatch, getState, extraArgument);
}
return next(action);
};
}就是拦截函数类型的 action,再能够对函数形式的 action(其实是个 actionCreator)暴露 API 再执行一次,如果这个 actionCreator 是多层函数的嵌套,则必须每次执行 actionCreator 后的 actionCreator 都可以引用最新的 dispatch 才行。如果不写成匿名函数,那这个 actionCreator 又走了没有经过任何中间件修饰的 store.dispatch,这显然是不行的。所以要写成匿名函数的闭包引用。
还有,这里使用了 ...args 而不是 action,是因为有个 PR,这个 PR 的作者认为在 dispatch 时需要提供多个参数,像这样 dispatch(action, option) ,这种情况确实存在,但是只有当这个需提供多参数的中间件是第一个被调用的中间件时(即在 middlewares 数组中排最后)才肯定有效 ,因为无法保证上一个调用这个多参数中间件的中间件是使用的 next(action) 或是 next(...args) 来调用,所以被改成了 next(…args) ,在这个 PR 的讨论中可以看到 Dan 对这个改动持保留意见(但他还是改了),这个改动其实真的挺蛋疼的,我作为一个纯良的第三方中间件,怎么能知道你上个中间件传了什么乱七八糟的属性呢,再说传了我也不知道是什么意思啊大哥。感觉这就是为了某些 middleware 能够配合使用,不想往 action 里加东西,就加在参数中了,到底是什么参数只有这些有约定好参数的 middleware 才能知道了。
Note: logger must be the last middleware in chain, otherwise it will log thunk and promise, not actual actions (#20).
要求必须把自己放在 middleware 的最后一个,理由是
Otherwise it'll log thunks and promises but not actual actions.
试想,logger 想 log 什么?就是 store.dispatch 时的信息,所以 logger 肯定要在 store.dispatch 的前后 console,还记不记得上面哪个中间件拿到了 store.dispatch,就是最后一个,如果把 logger 放在第一个的话你就能打出所有的 action 了,比如 redux-thunk 的 actionCreator,打印的数量肯定比放在最后一个多,因为并不是所有的 action 都能走到最后,也有新的 action 在 middleware 在中间被派发。
在开发模式下,经常会用到 Go To Definition 这个功能,但是对于 package 下的 library,它们虽然是用 TS 写的,但是实际中项目引用的是 tsc -w 产生的 JS 文件,所以即使开了 declaration: true,也只能跳转到对应 TS 文件产生的 d.ts 上。
**解决方法:**使用 tsconfig 的 paths,
{
"compilerOptions": {
"paths": {
"@monodemo/service": ["../../service/src/index"],
"@monodemo/permission-detail": ["../../permission-detail/src/index"],
"@monodemo/check": ["../../check-detail/src/index"]
}
}
}将 package 名直接映射给对应包的 index.tsx 文件,这其中有两个点需要注意
{
test: /\.(ts|tsx)$/,
include: paths.appSrc,
loader: require.resolve('ts-loader'),
options: {
configFile: paths.appTsConfig,
},
},
https://medium.com/@NiGhTTraX/how-to-set-up-a-typescript-monorepo-with-lerna-c6acda7d4559
transition 对 display 无效,
使用 visibility: visible 和 visibility: hidden 代替 display: block 和 display: none
<div class="wrapper">
<h3>title</h3>
<p>Item</p>
</div>.wrapper{
position: relative;
}
.wrapper p {
position: absolute;
transition: all 0.3s ease-in 0s;
visibility: hidden;
opacity: 0;
}
.wrapper:hover p {
visibility: visible;
opacity: 1;
}不使用 transition,而是使用 animation
<div class="wrapper">
<h3>title</h3>
<p>Item</p>
</div>@keyframes fadeIn {
from { opacity: 0; }
to { opacity: 1; }
}
.wrapper p {
position: relative;
display: none;
}
.wrapper:hover p {
position: absolute;
display: block;
animation: fadeIn 1s;
}由于某些原因,我们团队负责在 GitLab 上做二次开发,简单理解就是在 GitLab 上挂个 DOM 渲染用 React 写的一些组件,组件库选择了 antd,尴尬的是引入之后发现,GitLab 自身是带一套全局样式的,而 antd 又带了一套全局样式,导致 GitLab 的部分样式被覆盖,如图:
a 标签颜色被 antd 覆盖:

checkbox 细微的样式错乱及大小改变:

antd 的全局样式也不是一天两天的问题了,在社区中已经有很多讨论(#4331 #9363
#13459),但直到今天也没有进展。因为 Ant-Design 是一套设计语言,所以 antd 会引入一套 fork 自 normalize.css 的浏览器默认样式重置库。
引入全局样式的这个文件是 style/core/base.less,就是这个 base.less 会对各种元素的默认样式一顿格式化,截取一段:
...
// remove inner border and padding from Firefox, but don't restore the outline like Normalize.
button::-moz-focus-inner,
[type='button']::-moz-focus-inner,
[type='reset']::-moz-focus-inner,
[type='submit']::-moz-focus-inner {
padding: 0;
border-style: none;
}
input[type='radio'],
input[type='checkbox'] {
box-sizing: border-box; // 1. Add the correct box sizing in IE 10-
padding: 0; // 2. remove the padding in IE 10-
}
...下图为 antd 的 CSS 打包时的依赖关系,这张图有助于我们理清怎样才能避免把 base.less 引入。

核心问题就是 base.less 这个文件对全局样式的侵入。那这个文件可以不要吗?不行,antd 的组件样式都是建立在这个格式化后的样式上的,不引这个文件样式就错位了(如下图),所以要在不影响全局样式的条件下引入。

并且,一般我们需要收敛 antd 全局样式时,都是因为当前页面存在另一套全局样式库(比如笔者遇到的 GitLab 的全局样式),我们需要达到的目的可以进一步变为 「收敛 base.less,并保证外部的全局样式无法轻易覆盖 antd 的样式」。
之前社区中出现过将 base.less 外面套一层 .ant-container 的方案,但一个显著的缺陷就是提高了 base.less 中样式的权重导致样式错位。
但是限定 base.less 这个思路是没有错的,base.less 需要被套一层「作用域」,那再给所有已有的 antd 组件提高权重保证原有的选择器优先级不变就好了。
幸运的是,antd 相关的组件都至少会有一个以 ant- 开头的 class,我们只要利用好这个特点及 CSS 属性选择器即可达到目的。
流程如下:
*[class*='ant-'] 限定其样式的「作用域」。这一步将全局样式限定在了所有有 ant- 的 class 的元素里。*[class*='ant-'] {
@import '~antd/lib/style/core/base.less';
}提高完了 base.less 的权重,再来提升组件的样式的权重,此举还能间接提升所有 antd 的样式的权重,避免外部的全局样式对 antd 造成侵入。
既然是改样式,那就用 CSS 界的 babel —— PostCSS,写个 PostCSS 插件,https://github.com/fi3ework/postcss-rename-selector ,将所有 .ant 开头的类选择器都同样升高即可,利用的是 postcss-selector-parser 这个 PostCSS 官方提供的解析选择器的库,过滤出「第一个以 ant- 开头的类选择器」,在其前面添加一个属性选择器 [class*='ant-'],如果这个选择器排在当前 rule 的第一个或者前面是一个 combinator,则再加一个通配符 *,这个同上面给 base.less 添加的选择器,两者同时提高相同权重既维持原有优先级不变。
另外,如果某些元素虽然不在 antd 的组件里,但是也想走 antd 的全局样式,只需在这些元素的最外层套一个 class className="ant-whatever",只要是 ant- 开头的就可以。
import parser, { Node } from 'postcss-selector-parser'
import { SelectorReplace } from '../index'
export function antdScopeReplacerFn(node: Node) {
if (node.type !== 'selector') return
const firstAntClassNodeIndex = node.nodes.findIndex((n) => {
return n.type === 'class' && n.value.startsWith('ant-')
})
if (firstAntClassNodeIndex < 0) return
const firstAntClassNode = node.nodes[firstAntClassNodeIndex]
const prevNode = node.nodes[firstAntClassNodeIndex - 1]
// preserve line break
const spaces = {
before: firstAntClassNode.rawSpaceBefore,
after: firstAntClassNode.rawSpaceAfter,
}
firstAntClassNode.setPropertyWithoutEscape('rawSpaceBefore', '')
const toInsert = []
if (firstAntClassNodeIndex === 0 || prevNode.type === 'combinator') {
const universal = parser.universal({
value: '*',
})
toInsert.push(universal)
}
const attr = parser.attribute({
attribute: 'class',
operator: '*=',
value: `"ant-"`,
raws: {},
})
toInsert.push(attr)
toInsert[0].spaces = spaces
firstAntClassNode.parent!.nodes.splice(firstAntClassNodeIndex, 0, ...toInsert)
}
export const antdReplacer: SelectorReplace = {
type: 'each',
replacer: antdScopeReplacerFn,
}这个 antd 的配置已经作为 preset 提供了,如果想使用直接引入即可
const { replacer, presets } = require('postcss-rename-selector')
plugins: [
replacer(presets.antdReplacer)
]效果如图:

建了 demo 仓库,下面几种的方式在 demo 仓库中都可以找到:https://github.com/fi3ework/restricted-antd-style-demo
思路是:在 post-install 阶段将 antd/lib/style/core/index.less 引入的 @import base; 这一行直接删掉,然后手动引入我们自己魔改的 base.less。
步骤:
antd/lib/style/core/index.less,这边已经有实现 ant-design/ant-design#9363 (comment)const { replacer, presets } = require('postcss-rename-selector')
plugins: [
replacer(presets.antdReplacer)
]import 'antd/dist/antd.less'@import '~antd/lib/style/mixins/index.less';
*[class*='ant-'] {
@import '~antd/lib/style/core/base.less';
}看下效果,antd 的样式正常,并且最上方的一个 a 标签并没有被 antd 所影响:

[
'import',
{
libraryName: 'antd',
style: true,
},
],post-install 的方法多少显得有些 hack,另一种方法是手动拼出 antd/dist/antd.less 的文件依赖然后引入。
@import '~antd/lib/style/themes/index.less';
@import '~antd/lib/style/mixins/index.less';
*[class*='ant-'] {
@import '~antd/lib/style/core/base.less';
}
@import '~antd/lib/style/core/iconfont.less';
@import '~antd/lib/style/core/motion.less';
@import '~antd/lib/style/components.less';结构与原本的引入相同,唯一不同的地方就是将 base.less 包裹了一层「作用域」,然后还需要在 webpack 的配置中添加 alias
alias: {
'antd/dist/antd.less$': path.resolve(__dirname, '../src/custom-dist.less')
}然后在整个文件的入口引入
import './custom-dist.less`就好啦。
很遗憾,在这种方式下,笔者折腾了半天也无法做到配合 babel-plugin-import 做按需引入。babel-plugin-import 提供了几种预置的样式加载方式及可定制化的方法,拿 Button 这个组件举例
antd/lib/button/index.css,就是将 babel-plugin-import 配成这样: [
'import',
{
libraryName: 'antd',
customStyleName: (name) => {
return `antd/lib/${name}/style/index.css`
}
}
],Button 这个组件没有问题,但是有些组件,比如 Col 是放在 Layout 这个目录的,按照组件名拼名字会找不到文件直接报错。还有,比如 Input 这个组件是依赖 Button 的样式的,只按需引 Input 的样式是不行的,还要手动引入 Button 的样式。
antd/lib/button/css.js,就是将 babel-plugin-import 配成这样: [
'import',
{
libraryName: 'antd',
style: 'css'
}
],这个文件长这个样子
'use strict'
require('../../style/index.css')
require('./index.css')只需要把 require("../../style/index.less"); 的这个引入干掉即可。但是遗憾的是,笔者试了 IgnorePlugin 和 alias 均无效。尤其是 IgnorePlugin,按照官方文档给的对 Moment.js 的处理方式,理论上应该可以忽略。
new webpack.IgnorePlugin(/\.\.\/\.\.\/style\/index\.css/, /antd$/),但实际没有任何效果,如果哪位知道是为什么请告知。
目前笔者所用的 antd 的版本还是 3.x,还没有升级到 v4 验证过,不过看了下 v4 的代码,base.less 还安安静静的躺在那里,目测使用方法是类似的。
这套方案在我们自己的业务上已经跑了几个月了,暂时没有发现什么问题。Ant Design 作为一套设计规范提供全局样式也是合理的,但还是希望官方可以提供一种可选的限定范围的全局样式,毕竟隔壁的 Material-UI 可是没这个问题(逃),默默许愿 antd v5 中可以解决!
之前为 antd 写了个 VS Code 生产力插件,自认为是最好用的 antd VS Code 插件了,欢迎 Star,Issue。
本文整理自:Google Developers 及 高性能 JavaScript,再加上了一些个人对其中提到的知识点的理解与补充。前端性能优化涉及很多方面,本文仅针对高性能渲染进行分析。
目前,大多数设备的刷新率都是 60 FPS,如果浏览器在交互的过程中能够时刻保持在 60FPS 左右,用户就不会感到卡顿,否则,就会影响用户的体验。
下图为浏览器运行的单个帧的渲染流水线,称为像素管道,如果其中的一个或多个环节执行时间过长就会导致卡顿。像素管道是作为开发者能够掌握的对帧性能有影响的部分,其他部分由浏览器掌握,我们无法控制。我们的目标就是就是尽快完成这些环节,以达到 60 FPS 的目标。

.headline 或 .nav > .nav__item)计算出哪些元素应用哪些 CSS 规则的过程,这个过程不仅包括计算层叠样式表中的权重来确定样式,也包括内联的样式,来计算每个元素的最终样式。上节渲染管道的每个环节都有可能引起卡顿,所以要尽可能减少通过的管道步骤。
修改不同的样式属性会有以下几种不同的帧流程,在这里就直接贴 Google Developers 的图了:
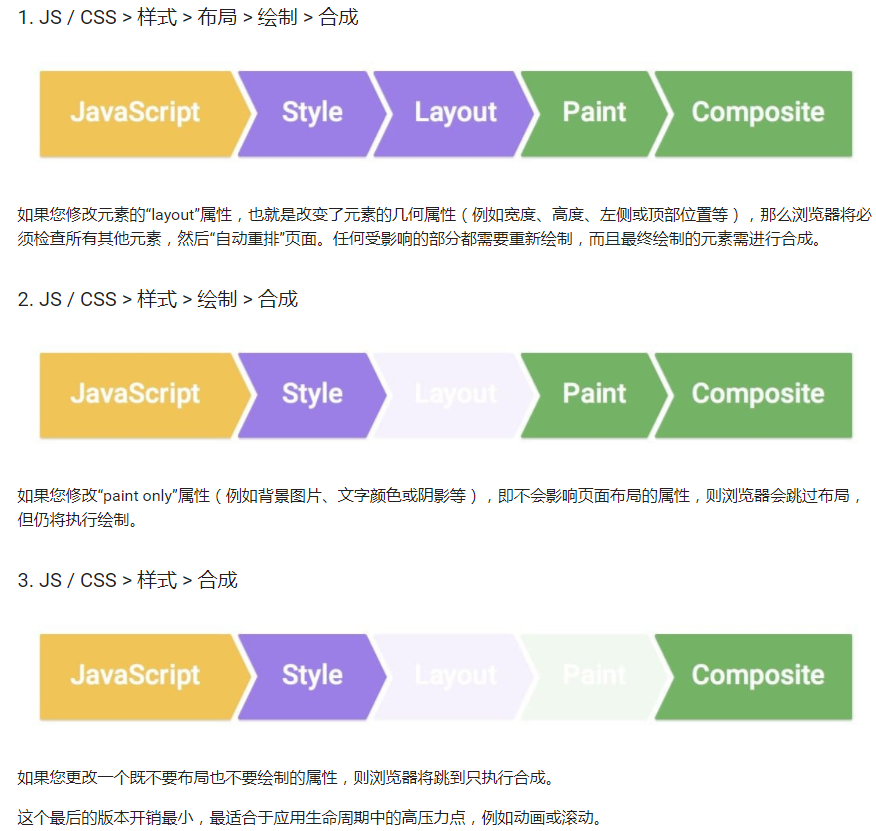
我们可以看到 JS,Style 和 Composite 是不可避免的,因为需要 JS 来引发样式的改变,Style 来计算更改后最终的样式,Composite 来合成各个层最终进行显示。Layout 和 Paint 这两个步骤不一定会被触发,所以在优化的过程中,如果是需要频繁触发的改变,我们应该尽可能避免 Layout 和 Paint。
性能最佳的像素管道版本会避免 Layout 和 Paint:

为了实现此目标,需要坚持更改可以由合成器单独处理的属性。常用的两个属性符合条件:transform 和 opacity。
想知道每种 CSS 属性的更改是否会触发 Layout,Paint,Composite,可以通过 csstriggers.com 查看。
除了 transform 和 opacity,只会触发 composite 的 CSS 属性还有:pointer-events(是否响应鼠标事件)、perspective (透视效果)、perspective-origin(perspective 的灭点)、cursor(指针样式)、orphans(设置当元素内部发生分页时必须在页面底部保留的最少行数(用于打印或打印预览))、widows(设置当元素内部发生分页时必须在页面顶部保留的最少行数(用于打印或打印预览))。
通过上面的几种不同流程的管道图可以发现,只要是修改样式那么必不可少会经过 Style,计算样式的第一步是创建一组匹配选择器,这实质上是浏览器计算出给指定元素应用哪些类、伪选择器和 ID 。第二步是从对应的匹配选择器中获取所有样式规则,并计算出此元素的最终样式,简单的来说就是第一步先确定选择器都匹配哪些元素,第二步根据每个元素所匹配的选择器,通过权重计算出最终的样式。
对于要匹配相同的元素,.final-box-title 比 .box:nth-last-child(-n+1) .title 明显复杂度要来的小得多,浏览器不需要去判断要查找的元素是不是最后一个元素即可根据类名快速找到 .final-box-title 对应的元素,相比复杂的选择器,简单地将选择器与元素匹配开销要小得多,而且嵌套过深的 CSS 选择器依赖了过多的类名,很容易在改动依赖的类名时不小心被影响到。
这里推荐使用 BEM(块、元素、修饰符) 编码规则简化选择器规则,该方法实际上纳入了上述选择器匹配的性能优势,因为它建议所有元素都有单个类,并且在需要层次结构时也纳入了类的名称。
有一种能有效减小 Layout 和 Paint 的方法是将元素提升,像 Photoshop 中层的概念一样,样式也有层的概念,不同的层根据不同顺序叠加起来,通过 Composite 最终显示出来。在每个层中对这个层进行 Layout 或者 Paint 是不会影响其他层的,一般会根据整个页面的语义将页面分为几个层。
但是不要滥用层,将每个元素都单独提升到一层, Composite 这个环节有两步,Update Layer Tree 和 Composite Layer Tree,前者负责计算页面中有多少个层,哪些层应该出现并应该按什么顺序叠加起来,后者负责将 layers 合成到屏幕上。层越多,这两个步骤花的时间越长,同时也会占用更多的内存,所以要在适当的地方提升元素而不是对所有元素都进行提升。
提升元素还有一个好处就是会将动画从 CPU 转移到 GPU 来完成,来实现硬件加速。
提升元素的两个方法:
.moving-element {
will-change: transform;
}.moving-element {
transform: translateZ(0);
}有些浏览器对 will-change 的支持还不够好,所以一般两个都写上。
参考:How (not) to trigger a layout in WebKit
经过测试,flex 布局在现代浏览器上相比早期的浮动或者定位布局性能更好,而且到现在 flex 布局已经很好的得到了浏览器的支持(IE10- 手动再见)。

浏览器的工作原理:新式网络浏览器幕后揭秘 将布局分为异步布局和同步布局:
增量布局是异步执行的。Firefox 将增量布局的“reflow 命令”加入队列,而调度程序会触发这些命令的批量执行。WebKit 也有用于执行增量布局的计时器:对呈现树进行遍历,并对 dirty 呈现器进行布局。
请求样式信息(例如“offsetHeight”)的脚本可同步触发增量布局。
全局布局往往是同步触发的。有时,当初始布局完成之后,如果一些属性(如滚动位置)发生变化,布局就会作为回调而触发。
除了影响所有呈现器的全局样式更改,例如字体大小更改和屏幕大小调整的更改都是增量修改,增量修改是异步的也就给了我们用 thunk 修改的机会。
再来看下单个帧的流程图

如果我们在 js 中这样写
let boxes = document.getElmentsByClassName('.box')
for(let i = 0; i < boxes.length; i++) {
let width = document.getElementById('table')
boxes[i].style.color = 'red'
} 这种情况下,这一帧相比上一帧没有布局没有发生改变,那么直接用旧的 Layout 去赋值 width 就可以,也不需要对页面进行重排。
但是如果这样写:
let boxes = document.getElmentsByClassName('.box')
for(let i = 0; i < boxes.length; i++) {
let width = document.getElementById('table').width
boxes[i].style.width = width
} 当下一次循环到来时浏览器还没进重排(因为一直处于 JS 阶段) ,为了获取正确的 width ,浏览器就不得不立刻重新 Layout 获取一个最新值,从而失去了浏览器自身的批量更新的优化,这就是强制同步布局。
为什么叫强制呢,大多数浏览器通过队列化修改并批量执行来优化重排过程(就是上面说的异步布局),但是如果触发了强制同步布局 ,每经过一次循环,都会要求浏览器强制刷新队列并要求计划任务立刻执行,这就失去了浏览器对重排的优化。
什么操作会触发强制同步布局 呢,这个 gist 里列出了对应的操作。
避免强制同步布局
使用 requestAnimationFrame(后面有介绍),将获取 width 的操作推迟到下一帧,在经过浏览器正常的 Layout 之后,下一帧可以直接拿到 Layout 值。
requestAnimationFrame(logBoxHeight);
function logBoxHeight() {
box.classList.add('super-big');
// Gets the height of the box in pixels
// and logs it out.
console.log(box.offsetHeight);
}缓存不动变量,对上面的那个强制同步布局的例子,避免在循环中进行可能会导致强制同步布局的操作
let boxes = document.getElmentsByClassName('.box')
let width = document.getElementById('table').width
for(let i = 0; i < boxes.length; i++) {
boxes[i].style.width = width
} 在做某些动画时,有可能会有连续触发 Layout 步骤的属性,如下图的动画

如果凭直觉来做,很可能就是 click 之后加上一个类似于
.element.expanded {
height: 100%;
left: 0;
position: absolute;
transition: top 200ms ease-in , height 200ms ease-in 50ms;
top: 0;
width: 100%;
z-index: 3;
} 这样的类。但是,可以看到下图中用 Chrome devTools 打开显示 Paint 区域的功能,发现重绘的区域很大,并且肯定伴随着重排,帧数也很低,出现了卡顿的现象。
这时候,就用 transform 来代替对 width 和 height 的改变。
其实到这里,就已经可以满足 60 FPS 的效果了,但是为了做到内容与样式分离,将起始于终结的样式全部由 CSS 管理,而中间通过 transform 动画的行为有 CSS 控制,则需要使用 FLIP 方法:
接下来,介绍一下 Paul Lewis 发明的 FLIP 方法,FLIP 就是 F (first) L (last) I (invert) P (play) 的缩写。
transform: translateX(-10px) scale(0.5),再给他一个 left: 10px; width: 200px; height: 200px;(假设原来是 left: 0; width: 100px; height: 100px;),这两个属性视觉效果上抵消,好像元素从来没有改变过。transition 效果,再移除元素的 transform 属性,因为此时元素已经是终止状态了,所以就会 transition 到 0,整个过程只有 transform ,可以轻松达到 60FPS。核心**就是 pre-calculation,用代码来表示就是这样,直接贴一下原作者的代码,已经很详细了:
// Get the first position.
var first = el.getBoundingClientRect();
// Now set the element to the last position.
el.classList.add('totes-at-the-end');
// Read again. This forces a sync
// layout, so be careful.
// 这里会触发强制同步,不过只有一帧,这是完全可以接受的
var last = el.getBoundingClientRect();
// You can do this for other computed
// styles as well, if needed. Just be
// sure to stick to compositor-only
// props like transform and opacity
// where possible.
var invert = first.top - last.top;
// Invert.
el.style.transform =
`translateY(${invert}px)`;
// Wait for the next frame so we
// know all the style changes have
// taken hold.
// 要用rAF,不用的话el.style.transform = `translateY(${invert}px)`; 和
// 必须放到下一帧触发transfrom
// el.style.transform = '';就在一帧中同步执行了,就不会有动画效果了,
requestAnimationFrame(function() {
// Switch on animations.
el.classList.add('animate-on-transforms');
// GO GO GOOOOOO!
el.style.transform = '';
});
// Capture the end with transitionend
// 结束后要el.classList.remove('animate-on-transforms')
el.addEventListener('transitionend',
tidyUpAnimations);
实际上,FLIP 是将复杂的计算放在了一开始(包括一次强制同步),根据 RAIL 规则,触发后 100ms 的反应时间是可以接受的,所以在 100ms 内完成为止的计算,之后的动画用 transform 来达到 60FPS。
附上一个自己写的小 demo,大家可以感受一下。
参考:
其实,JS 的执行速度是很快的,尤其是发展到了现在这个年代,像 V8 这样的解释器性能已经十分强悍了(吊打 Python),真正慢的是操作 DOM。浏览器请通常会将 DOM 和 JS 独立实现,DOM 是个与语言无关的 API,但是在浏览器中的接口却是用 JS 来实现的,这意味着通过 JS 去访问另一个模块实现提供的 API 时,会造成很大的开销,这就是造成操作 DOM 慢的原因。
使用 document.getElementsByName(), document.getElementsByClassName(), document.getElementsByTagName()时,返回值是一个实时的的 HTMLCollection,也就是所谓的 live,这些函数返回的集合是以一种 “假定实时态”,这意味着底层文档对象更新时,它也会自动更新,所以每次你获取这个集合中的信息时,这个集合都会重复执行查询的过程。所以,在不需要满足实时更新的情况下,推荐使用document.querySelectorAll(),它将返回一个非 live 的静态列表。
在 JS 同步代码中操作(比如添加、删除或者修改尺寸等)DOM 会让浏览器进行重排,包括
- 添加或删除可见的 DOM 元素
- 元素位置改变
- 元素尺寸改变(包括:外边距、内边距、边框厚度、宽度、高度等属性改变)
- 内容改变,例如:文字改变或图片被另一个不同尺寸的图片替代。
- 页面渲染器初始化。
- 浏览器窗口尺寸改变。
其中 Layout 分为全局布局及增量布局,全局布局是指触发了整个呈现树范围的布局,触发原因可能包括:
布局可以采用增量方式,也就是只对 dirty 呈现器进行布局(这样可能存在需要进行额外布局的弊端)。当呈现器为 dirty 时,会异步触发增量布局。例如,当来自网络的额外内容添加到 DOM 树之后,新的呈现器附加到了呈现树中。
解决方法是让 DOM 脱离文档流再对其进行操作,所有操作完成后添加进文档流,这样可以将重排及重绘的次数降低到一次或两次(脱离文档流及回归文档流的时候),以下方法可以让元素脱离文档流:
display: none;(事实上 display:none 不会让元素出现在 layout tree 中)。利用事件冒泡的机制来处理子元素事件的绑定,将子元素的 DOM 事件,交由它们的父元素来进行处理,可以有效降低页面的开销 —— 由于事件的冒泡特性,只需要给父组件添加一个监听事件,就能够捕获到冒泡自子元素的事件,再通过 e.target 来获取真正被操作的子元素。
现在浏览器都有 JIT(just in time)即时编译的引擎,所以会在运行中编译代码
附上一段 知乎 上对 JIT 带来的优化的解释:
动态编译之于静态编译,缺点是它需要即时编译代码,但是有一个优点---编译器可以获得静态编译期所没有的信息。比如:通过运行时的profiling可以知道哪些函数是被大量使用的。在哪些execution path上哪些函数的参数一直都没有变,等等。不要小看这些信息,当即时编译器了解这些信息之后可以在短时间内编译出比静态编译器更优质的二进制码。举例来说,一般程序也遵循90-10原则,即运行时的90%里计算机是在处理其中10%的代码,寻找到这些执行热点代码进行深度优化能得到比静态编译更好的性能(因为已知更多信息量)。
所以我们没有必要再去手工的做一些优化,比如在 for 循环中缓存 length,或者像 《高性能JavaScript》 (这已经是2010年的书了,好多结论都是拿 IE 来说的)中介绍的 for (var i=items.length; i--; ) 来减少每次迭代经过的步骤,我们无法知道这样的代码在经过 JIT 后,是否会带来任何好处,甚至是否会给 JIT 带来一个负面效果,并且这样做肯定会在一定程度上降低代码的可读性。
举个例子,Redux中,在执行 subscribe 的函数时,用的是 for (let i = 0; i < listeners.length; i++),listeners.length 本身是可以缓存的(不存在运行过程中 length 改变的情况),但是作者给出的理由是 V8 足够智能来做更好的优化,具体可以看我写的 通过GitHub Blame深入分析Redux源码 。
Web Worker 还暂时没研究过,按照MDN的解释
Web Workers is a simple means for web content to run scripts in background threads. The worker thread can perform tasks without interfering with the user interface. In addition, they can perform I/O using XMLHttpRequest (although the responseXML and channel attributes are always null). Once created, a worker can send messages to the JavaScript code that created it by posting messages to an event handler specified by that code (and vice versa.) This article provides a detailed introduction to using web workers.
Web Worker 是提供一种在主线程之外的多线程能力,我们可以将耗时的、阻塞的js操作放在 Web Worker 中,PWA 也是基于 Web Worker 来实现,并已经成为了前端的未来趋势之一。
在某个单个帧中,有可能发生这种情况,在某一帧中会被多次触发某个事件(比如 scroll),这个事件又会频繁的触发样式的修改,导致可能需要多次 Layout 或者 Paint,这是一种浪费,过于频繁的 Layout 和 Paint 会造成卡顿,而且实际上一帧中并不需要重复 Layout 或者 Paint 那么多次。
这个时候就可以用到 rAF 了,先放上一段 MDN 上对 rAF 的解释:
window.requestAnimationFrame() 方法告诉浏览器您希望执行动画并请求浏览器在下一次重绘之前调用指定的函数来更新动画。该方法使用一个回调函数作为参数,这个回调函数会在浏览器重绘之前调用。
简单来说,rAF 的作用就是将传给 rAF 的回调函数,安排在下一帧的一开始执行。这样就能保证这个回调函数最先执行,并且因为绝大多数浏览器都是 60FPS,所以 rAF 自带节流效果。
这里要提一下浏览器的事件循环,在浏览器的一轮事件循环中,会有 task -> microtask -> UI render,这么的一个循序,rAF 将回调函数放在下一帧的开头,就是已经让其所在的那一轮的 UI 先 render,然后再在下一帧的最开始去执行(关于 event loop 的更多介绍,可以看我写的 这篇文章)。
rAF 的一般调用方法为:
let scheduledAnimationFrame = false;
function readAndUpdatePage(){
doSomething()
scheduledAnimationFrame = false;
}
function onScroll (evt) {
// Store the scroll value for later.
lastScrollY = window.scrollY;
// Prevent multiple rAF callbacks.
if (scheduledAnimationFrame)
return;
scheduledAnimationFrame = true;
requestAnimationFrame(readAndUpdatePage);
}
window.addEventListener('scroll', onScroll);在调用 rAF 时,有一点切记:不要在 rAF 的回调函数中先修改样式,再查询样式,这样就失去了 rAF 的作用。可以将对样式的查询提前到回调函数中或者 rAF 中尽量靠前的位置。
举个例子:
function logBoxHeight() {
box.classList.add('super-big'); // 1
// Gets the height of the box in pixels
// and logs it out.
console.log(box.offsetHeight); // 2
}JS 连续执行,rAF 还没能等到下一帧在同一个流水线里被触发强制同步布局了,解决方法也很简单:将 1 和 2 换一下即可,直接用上一帧的样式,再去修改样式。
JavaScript 是自动管理内存的,浏览器引擎会自动 GC,作为开发者我们无需去操心内存(只需要别泄漏内存)。但是 GC 同样是需要消耗时间的(可以从 Chrome devTools 里的 Performance 里看到,GC 需要一段很短的时间),如果数据结构使用不当,造成了内存泄漏或者导致频繁的 GC,也是会对页面流畅度造成影响的。
下面是一些写出 GC 友好的代码的教程:
前端性能优化是个大话题,渲染部分的内容也远不止文章中写出的这些,就拿 Composite 来说,就有 无线性能优化:Composite | Taobao FED | 淘宝前端团队) 这样深入的文章,先在这里挖个坑,以后遇到可以补充的再继续更新,欢迎留言👏
英文一般般,看起来还蛮吃力的
在开发时,经常会需要从命令行中启用各种环境 (express, webpack, gulp 等等),而且大多数项目需要同时开启数个环境,如果每次开发时都一遍遍的开终端然后 cd 到指定目录再执行,难免有些繁琐,直接使用 shell 脚本来完成这些自动化的工作即可。
比如我在开发 hexo-theme-archer 时,需要以下几个步骤
hexo s 来开启 hexo 的本地服务器hexo/themes/archergulp dev 来开启 gulp 的 watch理想的解决方案就是将这些步骤写在一个 shell 脚本里,然后直接执行这个脚本即可。
解决方案1:
安装 ttab 这个包来提供打开新的 tab 页的命令,然后我们的 zsh / bash 就可以如下写法,代码很简单就不解释了(一般 mac 上都是使用 iterm2 + zsh + oh-my-zsh,所以我是用 zsh 写的,在自带的 terminal 下也能正常运行,不过要在 安全性与隐私 - 隐私 - 辅助 中设置允许 terminal 控制)
#!/bin/zsh
cd ~/Project/archer-demo
ttab -d themes/archer gulp dev
hexo s解决方案2:
目前来说解决方案1足够了,如果发现更好的解决办法(比如不是开启 new tab 而是 split)的话,再来补充。
Parcel 不能直接 console 出 process.env 的所有内容,parcel-bundler/parcel#2299 (comment)
下载历史版本的 Chrome:
在 heroku 上部署 React App 的展示页,并且这个 React App 需要 node 来做转发。
基本的 heroku 配置可以直接参照 文档。
如果是不需要 node 来做转发的单纯的 react 项目,可以直接参照官方文档的 Deploying React with Zero Configuration,顺便附上 GitHub项目地址。
但是需要 node 做转发的项目,这个老哥同样给出了解决方案:heroku-cra-node。
下面来分析一下究竟是如何配置的。
先放上目录结构
.
├── LICENSE
├── README.md
├── package-lock.json
├── package.json
├── react-ui
│ ├── LICENSE
│ ├── README.md
│ ├── build
│ ├── config
│ ├── doc
│ ├── node-proxy
│ ├── package.json
│ ├── public
│ ├── scripts
│ ├── src
│ └── tsconfig.json
└── server
└── index.js
简单来说,就是外面的 package.json 对 node 的包,react-ui 文件夹对应的是整个 react 项目。
在我的项目中外面的 package.json 如下
{
"name": "heroku-cra-node",
"version": "1.0.0",
"description": "How to use create-react-app with a custom Node API on Heroku",
"engines": {
"node": "6.11.x"
},
"scripts": {
"start": "node server",
"heroku-postbuild": "cd react-ui/ && npm install && npm run build"
},
"cacheDirectories": [
"node_modules",
"react-ui/node_modules"
],
"dependencies": {
"express": "^4.14.1",
"superagent": "^3.8.2"
},
"repository": {
"type": "git",
"url": "https://github.com/mars/heroku-cra-node.git"
},
"keywords": [
"node",
"heroku",
"create-react-app",
"react"
],
"license": "MIT",
"devDependencies": {}
}对 heroku 起作用的是以下两句
"scripts": {
"start": "node server",
"heroku-postbuild": "cd react-ui/ && npm install && npm run build"
},heroku 在检测到这是一个 nodejs 项目后,会自动执行 npm start,开启转发服务

这里的 heroku-postbuild 用到了 npm 的 post- 钩子,在安装完依赖后,在 npm start 之前,heroku 环境下应该会执行 npm run heroku,此时会调用 heroku-postbuild 这个命令。官方解释 在此

还有
"cacheDirectories": [
"node_modules",
"react-ui/node_modules"
],根据 文档,作用是在 heroku 上缓存下载好的 npm 包,就不必每次更新的时候再重新 npm i 了

app.set('port', (process.env.PORT || 8081))
app.use(express.static(path.resolve(__dirname, '../react-ui/build')));重点是这两句话,第一句是指定端口,如果是在 heroku 中部署的话,端口是动态分配的,所以要使用 process.env.PORT,本地的话自动变为 8081。
第二句是指定静态文件的位置。
把上述文件配置好之后,推送到 heroku,再 heroku open 就可以啦。
TypeScript: Restart TS server 重启即可(要在 TS/TSX 的文件中唤起控制台才会有对应的 command)。If the "files" and "include" are both left unspecified, the compiler defaults to including all TypeScript (.ts, .d.ts and .tsx) files in the containing directory and subdirectories except those excluded using the "exclude" property. JS files (.js and .jsx) are also included if allowJs is set to true. If the "files" or "include" properties are specified, the compiler will instead include the union of the files included by those two properties. Files in the directory specified using the "outDir" compiler option are excluded as long as "exclude" property is not specified.
进而导致 VSCode 提示包含文件过多的 warning(issue),所以 include 或 exclude如果有 node_modules 的话一定要指定。
There is rootDir compiler option, which is not used to specify input to a compiler. It’s used to control the output directory structure alongside with outDir.
根据官方对 rootDir 的默认值的解释:
(common root directory is computed from the list of input files)
如果不指定 rootDir 的话,自动计算的 rootDir 可能会是包含了所有 TS 文件的的顶层文件夹

比如 es 文件夹指定的 rootDir 为 src,es2 指定的 rootDir 为 ./
参考:https://stackoverflow.com/questions/41007001/output-and-directory-structure-in-typescript
遇到 @types 包之间类型重复导致冲突的时候,可以简单粗暴的通过 yarn autoclean 来将不需要的 @types 包干掉解决冲突。https://yarnpkg.com/lang/zh-hans/docs/cli/autoclean/
magic TypeScript
type K = 'foo' | 'bar'
// ❌
interface SomeInterface1 {
[prop: K]: any
}
// An index signature parameter type cannot be a union type. Consider using a mapped object type instead.
// ❌
type SomeType1 = {
[prop: K]: any
}
// An index signature parameter type cannot be a union type. Consider using a mapped object type instead.
// ❌
interface SomeInterface2 {
[prop in K]: any
}
// A computed property name in an interface must refer to an expression whose type is a literal type or a 'unique symbol' type.
// A computed property name in an interface must refer to an expression whose type is a literal type or a 'unique symbol' type.
// Cannot find name 'prop'.
// ✅
type SomeType2 = {
[prop in K]: any
}
// ✅
type Workaround = Record<K, any>https://stackoverflow.com/a/51114250
https://devblogs.microsoft.com/typescript/announcing-typescript-2-9-rc/
浏览器在渲染页面时需要将 HTML 标记转化成 DOM 对象
CSS 则会被转化成 CSSOM 对象
DOM 和 CSSOM 是独立的树形结构,
当 DOM 树和 CSSOM 树都构建完成的时候,他们就会合并在一起构建 render tree,因为要在页面上渲染不仅需要这个页面的结构,也需要知道整个页面的样式,所以 render tree 是 DOM 树和 CSSOM 树的结合体,有了 render tree,浏览器才能知道把什么内容按照什么样式渲染在屏幕上。
浏览器从获取 HTML 到最终在屏幕上显示内容需要完成以下步骤:
经过以上整个流程我们才能看见屏幕上出现渲染的内容,优化关键渲染路径就是指最大限度缩短执行上述第 1 步至第 5 步耗费的总时间,让用户最快的看到首次渲染的内容。
另外,这是一个渐进的过程。为达到更好的用户体验,呈现引擎会力求尽快将内容显示在屏幕上。它不必等到整个 HTML 文档解析完毕之后,就会开始构建呈现树和设置布局。在不断接收和处理来自网络的其余内容的同时,呈现引擎会将部分内容解析并显示出来,因为 HTML 采用基于流的布局模型,这意味着大多数情况下只要一次遍历就能计算出几何信息。处于流中靠后位置元素通常不会影响靠前位置元素的几何特征,因此布局可以按从左至右、从上至下的顺序遍历文档。但是也有例外情况,比如 HTML 表格的计算就需要不止一次的遍历。
从上面的整个流程我们已经知道,浏览器的渲染需要 render tree, render tree 需要 CSSOM 树才行,所以样式表的加载是会阻塞页面的渲染的,如果有一个外部的样式表处于下载中,那么即使 HTML 已经下载完毕,也会等待外部样式表下载并解析完毕才会开始构建 render tree。
脚本就更麻烦了,先明确一点, JS 引擎和 UI 的渲染引擎是互斥的,所以当脚本在执行的时候浏览器要将控制权就给 JS 引擎,等到 JS 执行完毕再还给 UI 引擎,不论这个脚本是以何种形式加载的,在执行时均会阻塞 UI 的渲染。
接下来分别看不同形式加载的脚本对页面渲染的阻塞情况:
<script>...</script>内联的脚本随着 HTML 一起下载,在开始执行时已经完成了 字节 → 字符 → 令牌 → 节点 → 对象模型 的整个过程,所以不存在下载的时间(其实也不能这么说,下载的时间算在了 HTML 的下载时间中),执行时是会阻塞关键渲染路径的。
<script src="sample.js"></script>外部脚本的整个加载过程及执行过程都是阻塞关键渲染路径的。
<script src="sample.js" defer></script>
<script src="sample.js" async></script>带 defer/async 的脚本会与 HTML 并行下载,下载的过程不会阻塞 DOM 的构建,但是执行是会的,不同的是 defer 是在 DomContentLoaded 之前执行,async 是加载完之后立刻执行。
defer/async 的脚本在下载期间不会阻塞页面解析不是一个技术原因而是一个选择,因为内联脚本/外部脚本是要等待他们执行,所以不得不等待他们下载。而页面并不需要等待 defer/async 的脚本,所以他们的下载与页面的解析是并行的。
var dynamicScript = document.creatElement('script')
dynamicScript.src = 'sample.js'
document.head.appendChild(dynamicScript)
dynamicScript.onload = function(){...}动态生成的脚本的下载过程不会阻塞页面的解析,执行会阻塞解析,有点 async 的感觉。
脚本不仅能够访问 DOM 元素,还能访问 DOM 的样式,如果将要执行脚本时浏览器尚未完成 CSSOM 的下载及构建,浏览器将延迟脚本执行和 DOM 构建,直至其完成 CSSOM 的下载和构建。
所以,CSSOM 的构建会阻塞 HTML 的渲染,也会阻塞 JS 的执行,JS 的下载与执行(内联及外部样式表)也会阻塞 HTML 的渲染。
为尽快完成首次渲染,我们需要最大限度减小以下三种可变因素:
优化关键渲染路径的常规步骤如下:
上面已经分析过了,样式表会阻塞渲染,在加载完毕之前是不会显示的,为了让用户以最快的速度看到页面上的内容,可以将页面的某一部分的样式抽离出来,单独放在一个样式表中或者内联在页面中,这样的样式称为关键样式,这部分样式会优先它可以是页面的骨架屏或者是用户刚加载进页面时看到的首屏的内容。
<!doctype html>
<head>
<style> /* inlined critical CSS */ </style>
<script> loadCSS('non-critical.css'); </script>
</head>
<body>
...body goes here
</body>
</html>使用 preload meta 来提升资源加载的优先级。preload 的定义
preload is a declarative fetch, allowing you to force the browser to make a request for a resource without blocking the document’s onload event.
注意和 prefetch 的区别
<link rel=“prefetch”>is a directive that tells a browser to fetch a resource that will probably be needed for the next navigation. That mostly means that the resource will be fetched with extremely low priority
preload 会提升资源的优先级因为它标明这个资源是本页肯定会用到 —— 本页优先
prefetch 会降低这个资源的优先级因为它标明这个资源是下一页可能用到的 —— 为下一页提前加载
preload 最大的作用就是将下载与执行分离,并且将下载的优先级提到了一个很高的地步,再由我们去控制资源执行的位置。
样式表是阻塞页面呈现的(注意是呈现,不是解析),正常通过 link 加载的外部样式表要等下载,构建 CSSOM 树才会让页面呈现完成,但是 preload 能够让样式表的下载和呈现分离。
试想,当你在页面的 head 中写了如下的两个样式表:
<link href="critial.css" rel="stylesheet" />
<link href="non-critial.css" rel="stylesheet" />第一个是关键 CSS,第二个不是关键 CSS,当页面解析了这两个 link 标签后开始下载,但是即使 critical.css 下载解析完毕也不会呈现页面,因为页面还要下载和解析 non-critical.css。
这时候,就要将 non-critial.css 作为预加载,当样式表作为被 preload 后,他就不会再阻塞页面的呈现,也就是所谓的异步下载,修改后的代码如下:
<link href="critial.css" rel="stylesheet" />
<link rel="preload" href="non-critial.css" as="style" />
<link href="non-critial.css" rel="stylesheet" />如此一来,页面在解析完 critical.css 之后就会呈现(暂不考虑脚本),而 non-critial 也在下载,但是并不阻塞页面,指导它下载和解析完毕后才会应用到页面上。
现在并不是所有的浏览器都支持 preload,我们可以用 loadCSS 这个库来做 polyfill,其实现的思路也是遍历所有带 preload 和 as 的标签,然后修改标签的 media 为不匹配任何条件并开始下载,在下载完毕后再还原该 link 原来的 media 标签将它应用。
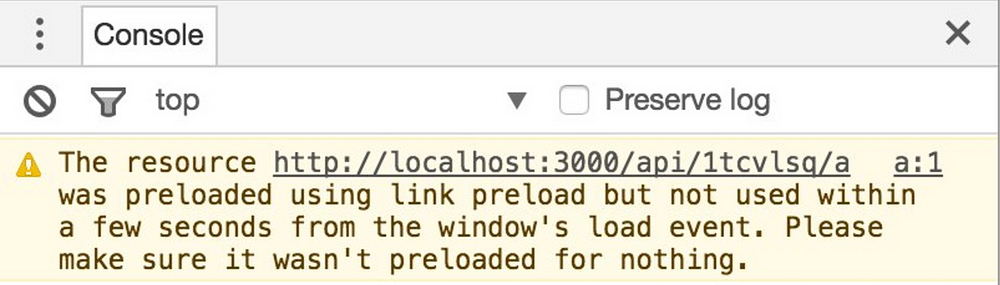
preload 将脚本的加载及执行分离,加了 preload 的 <link> 标签的作用是将脚本提到高优先级尽快完成下载,但并未执行。
<link rel="preload" href="//cdn.staticfile.org/jquery/3.2.1/jquery.min.js" as="script" />还需要在你想要他执行的地方引入一个正常的 <script> 标签执行这个脚本
<script src="//cdn.staticfile.org/jquery/3.2.1/jquery.min.js"></script>否则 chrome 大约会在 3s 后报一个 warning 来提醒你这个资源被浪费了完全没有被使用到。
preload 的功能听起来很像被 defer 的脚本,但是:
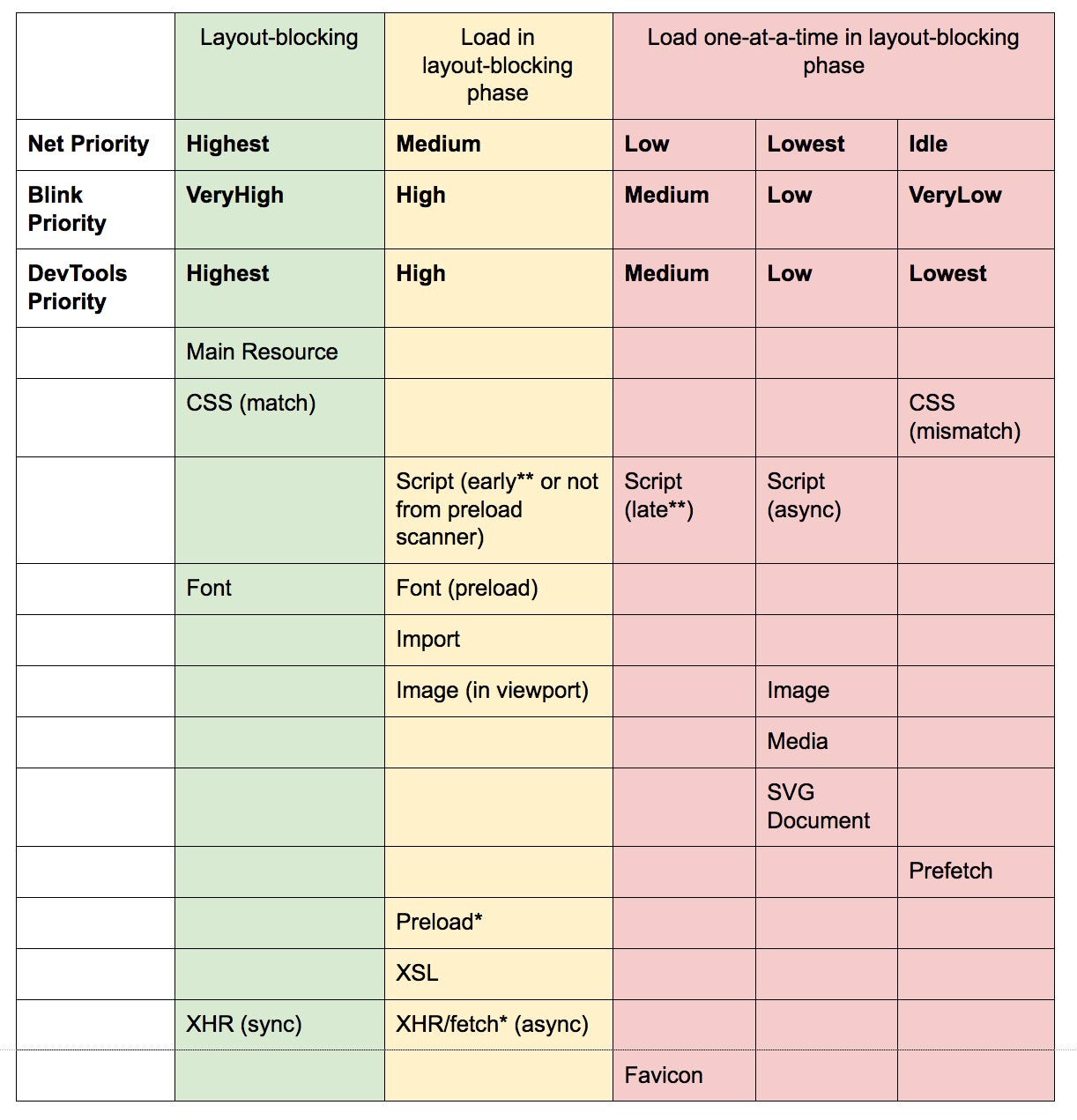
DOMContentLoaded 执行前触发DOMContentLoaded 事件根据脚本在文档中的位置不同和他们是否是 async,defer 和阻塞,它们会有不同的优先级:
我们以掘金的首页为例:

可以看到 high 的全是写在 HTML 中进行加载的静态资源,Low 的都是 thunk 在 JS 中的脚本,是为其他页面预加载的。
自定义的字体在加载之前会处于 FOIT(Flash of Invisible Text)现象,具体的可以看 这篇文章,虽然我们可以使用类似 webFont 一类的库来控制字体的闪现和添加钩子函数,但最佳解决方法还是让字体的加载达到最快的速度。
使用 preload 也可以来加速字体的下载,在 head 中声明 preload,比先下载样式表再从中读到 @font-face 的 src 再去加载要快得多。
<link rel="preload" as="font" href="https://at.alicdn.com/t/font_zck90zmlh7hf47vi.woff">但是要注意
preload 字体不带 crossorigin 也将会二次获取! 确保你对 preload 的字体添加 crossorigin 属性,否则他会被下载两次,这个请求使用匿名的跨域模式。这个建议也适用于字体文件在相同域名下,也适用于其他域名的获取(比如说默认的异步获取)。
preload 如果不带 crossorigin meta ,默认情况下 (即未指定 crossorigin 属性时), CORS 根本不会使用,这样 http 的 request header 中就不会有 origin,默认不去跨域,但是 @font-face 中去加载字体是默认跨域请求的,所以会造成两次的 request header 不同,无法命中缓存,造成重复请求。


解决方法就是带上 crossorigin,
<link rel="preload" as="font" href="//at.alicdn.com/t/font_327081_19o9k2m6va4np14i.woff" crossorigin>
<link rel="preload" as="font" href="//at.alicdn.com/t/font_327081_19o9k2m6va4np14i.woff" crossorigin="anonymous">
<link rel="preload" as="font" href="//at.alicdn.com/t/font_327081_19o9k2m6va4np14i.woff" crossorigin="fi3ework">空关键字和无效关键字都会被当做 anonymous。
preload 不仅可以将这些在 head 中的资源加速,还可以提前加载一些隐藏在 CSS 和 JS 中的资源,比如刚才隐藏在 CSS 中的字体资源,或者 JS 中请求的资源。
preload 的标签可以动态生成,这意味着在任何时候你都可以在页面中提前加载但不执行一个脚本,然后通过动态脚本来立刻执行它。
var preload = document.createElement("link");
link.href = "myscript.js";
link.rel = "preload";
link.as = "script";
document.head.appendChild(link);var script = document.createElement("script");
script.src = "myscript.js";
document.body.appendChild(script);
现在的页面基本上都具有响应式设计,即针对移动端或桌面端会采用 media 进行媒体查询,有两种包含媒体查询的 CSS 代码的方法:1. 将需要媒体查询的代码和基础样式代码放在同一文件中,使用 @media 来使媒体查询生效。 2. 将需要媒体查询的代码放在单独的一个外部样式表中,使用 media meta 对需要媒体查询的 link 进行控制。
这两种方法各有好处,如果需要媒体查询的代码量很小,那么和基础样式放在一起也没有关系,可以节省一次 HTTP 请求。如果比较大的话,那么就会让样式表的体积增加,造成 FOUC 的时间变长,这时候更适合使用第二种。
另外请注意“阻塞渲染”仅是指浏览器是否需要暂停网页的首次渲染,直至该资源准备就绪。无论哪一种情况,浏览器仍会下载 CSS 资源,但是不阻塞渲染的资源优先级较低。
优先级较低意味着浏览器在解析 HTML 时发现要下载这个样式表,但并不一定会立刻开始下载,而是可能会将它滞后一段时间再下载(等级低没人权),从 DevTools 上也可以看到 Highest 和 Lowest 的区别。


如果媒体查询的样式表符合当前的页面,那么媒体查询的样式表也会阻塞关键路径渲染(就好像他是个正常的一样),同时,它的下载优先级也会恢复到最高(恢复人权)。

media 配合 preload 能做到响应式加载资源,如下代码,分别是两副图片适配移动端与 PC 端,如果不加 preload 的话,那么其中一幅就会以 Lowest 的等级延迟加载,但是如果我们是一个移动端优先的网站,不希望用户浪费流量及网速下载PC 端的大图的话,就在每个 link 上加上 preload 即可,只有在打开网页时符合 media 的资源会被加载,不符合 media 的资源始终不会被加载,即使后面将浏览器的宽度拉宽也不会加载。
<link rel="preload" href="bg-image-narrow.png" as="image" media="(max-width: 600px)">
<link rel="preload" href="bg-image-wide.png" as="image" media="(min-width: 601px)">如果用户真的拉宽了屏幕,或者切换端设备,可以使用 Window.matchMedia,来进行 media 的匹配。
var mediaQueryList = window.matchMedia("(max-width: 600px)");
var header = document.querySelector('header');
if(mediaQueryList.matches) {
header.style.backgroundImage = 'url(bg-image-narrow.png)';
} else {
header.style.backgroundImage = 'url(bg-image-wide.png)';
}dns-prefetch 的使用方法更加简单:
<link rel="dns-prefetch" href="//host_name_to_prefetch.com">link 标签的 rel 设定为 dns-prefetch,href 设定为需要预加载的主机域名即可。
在讲 dns-prefetch 之前,先复习一遍 DNS 的作用及可以优化的点才能了解 dns-prefetch 带来的好处。
网络通讯大部分是基于TCP/IP的,而TCP/IP是基于IP地址的,所以计算机在网络上进行通讯时只能识别如“202.96.134.133”之类的IP地址,而不能认识域名。我们无法记住10个以上IP地址的网站,所以我们访问网站时,更多的是在浏览器地址栏中输入域名,就能看到所需要的页面,这是因为有一个叫“DNS服务器”的计算机自动把我们的域名“翻译”成了相应的IP地址,然后调出IP地址所对应的网页。
一图流表达如下,其中 3, 4, 5, 6, 7 都属于 DNS 解析的过程,也是 dns-prefetch 发挥作用的地方。
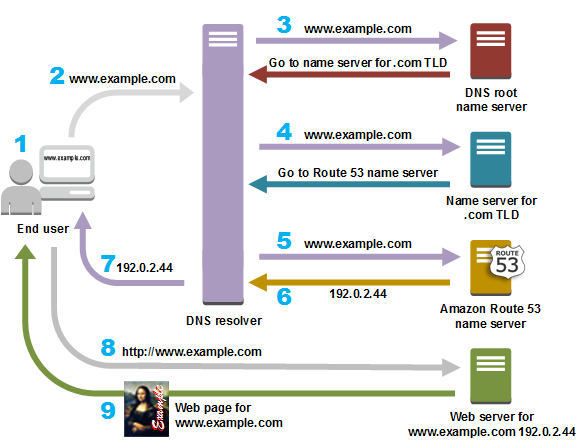
dns-prefetch 主要用来在用户点击一个链接之前解析对应的域名,这会自动去调用用户浏览器的解析机制。浏览器会在用户浏览网页时多线程完成预加载,当用户真正点击的时候就节省了用户等待域名解析的时间。
Chromium 的官方文档中很详细的介绍了 pre-fetch:
Chromium 会根据页面中超链接的 href 去寻找主机名自动去 prefetch
如果访问的链接被重定向,那么浏览器可能无法自动识别出真正的主机进行 prefetch,此时需要我么手工预加载,也就是使用 prefetch 标签来指定主机。(这也是决定是否使用 dns-prefetch 的判断方法)
预加载不会对页面渲染造成损害,因为 Chromium 有8个专门用来预加载的线程。
dns-prefetch 带来的网络消耗是很小的
Each request typically involves sending a single UDP packet that is under 100 bytes out, and getting back a response that is around 100 bytes
但是用最小的网络开销代价可以换来较好的用户体验。
默认情况下,Chromium 和 Firefox 出于安全考虑会关闭在 https 下的自动预加载,可以通过指定 meta http-equiv 来开启自动预加载。
<meta http-equiv="x-dns-prefetch-control" content="on">PS: 如果通过 meta 显示的关闭了预加载,之后将无法再次开启预加载。
拿知乎举个例子,打开知乎,进入控制台,搜索 dns-prefetch

发现知乎用了如下的 link,都是知乎的静态资源服务器,因为在没有缓存(假设没有打开过知乎)时打开某个知乎页面,如果该页面有图片,并且是从以上的域名获取的话 dns-prefetch 就不会起作用。如果没有图片,那么上面的 dns-prefetch 就会解析域名,等到打开一个有图的知乎页面时 DNS 解析已经完成了。
以上两者详见:
在 上一篇文章 中介绍了前端路由的实现及 react-router-v4(以下简称 rr4) 的源码分析,目前阶段 rr4 已经基本垄断了 react 生态圈的路由,虽然 v4 版本成功完成了一切皆组件的蜕变,但其实它本身还有诸多问题,比如 keep-alive。
keep-alive 的叫法取自 vue-keep-alive,在 vue 中,可以将某组件暂存于内存,然后跳转到其他页面再从内存中将这个组件拿出来。换算到路由中,我们可以想象这样一个情景 —— 有一个商品列表页,每个商品点进去都跳转到对应的商品详情页面,用户每次浏览完一个商品详情之后回退,列表页会重新渲染,那么如果用户已经往下划了几屏之后回退,那么每次返回后都要先滑到上次浏览的位置,这种体验可以说是灾难性的。
现在的浏览器非常贴心的实现了 Scroll Restoration(后退时恢复滚动位置),这在非 SPA 页面有非常好的体验效果,但是在 SPA 中,会有以下问题:
popstate 事件并触发 scroll restoration,通过点击链接无法触发滚动恢复。其实 iOS 和 Android 端的路由转换是十分理想的 —— 支持转场动画,手势返回,keep-alive。
本文中我们试图解决为 rr4 实现一个可以缓存的 Route 来解决上面例子中的问题,并借此探索一下 rr4 目前阶段的不足之处及可以加强的地方。说句题外话,rr4 的核心开发者又新搞了一个 reach-router 路由库,针对 rr4 的缺点进行了针对性的改进,已经钦点了是下一代的路由旗舰管理库。
先放上我造的轮子的仓库地址 react-live-route 感受一下本文的最终目的,react-live-route 可以使路由在路径不匹配时隐藏而不被卸载,在匹配路径时完全恢复离开页面时的样子。欢迎 star 和提 issue。
PC 端可以预览 demo
移动端扫码试玩 (点一下玩一年)

我们先重新将要解决的问题整理一下:
我们有列表页面和详情页,在列表页点击项目进入对应的详情页时,尽量保留列表页的视图与数据状态(包括滚动位置)。在从详情页回退到列表页的时候,希望列表页能恢复到上次离开时的状态。
其中我们要恢复的状态:
并且要做到无痛兼容 rr4,侵入性越小越好。我们的目标是为 react-router 设计一个增强型的 Route 组件,可以像 iOS 和 Android 端的路由切换一样“隐藏”上一个导航的页面,在这里有两种解决问题的思路:
unmount 时储存状态,re-mount 时取回状态
在列表页将要 unmount 的时候,将需要保留的数据状态存在 context(或者 window.sessionStorage 等等)
**优点:**可以在 unmount 和 re-mount 时利用生命周期。
缺点:
不 unmount,只是根据路由隐藏/显示对应页面
在切换到详情页的路径时,不将列表页 unmount,而是 display: none 掉它,在从详情页返回列表页的时候,再 display: block 将列表页显示回来。
优点: 简单粗暴,因为没有卸载组件,所以可以不用管页面的数据状态的保存情况。只需要管理好恢复显示、隐藏与正常 re-render,再恢复滚动位置即可。
缺点: 配合转场动画可能会有问题。
由于思路 1 的实现有很大的局限性,所以按照思路 2 来进行实现。
增强的 Route 组件称为 LiveRoute,我们首先要确定,这个增强组件在什么情况下起作用,以及它有哪几种状态,react-router 有一篇关于 Scroll Restoration 的文章 ,是关于 react-router 去除了滚动恢复的功能的原因,其中有提到原因:
What got tricky for me was defining an "opt-out" API for when I didn't want the window scroll to be managed.
就是因为实际的应用情况太多变,他们无法合适的判断什么时候需要进行滚动恢复的管理。
在一开始我是打算使用成对的路由来实现,其中一个 LiveRoute 的存活状态去控制另一个需要保留存活的 LiveRoute:
<LiveRoute path='/list' liveKey='listToItem' component={List}/>
<LiveRoute path='/item/:id' onLiveKey='listToItem' component={Item}/>但是路由间需要在 router 上创建 context 来辅助通信,如下是 react-router 正常更新一次的流程,路由间的通信会再一次触发被通知的路由的 setState,这是无法避免的,但是 Route 作为整个应用中非常靠上的组件,副作用要尽可能的小。

换个思路,其实缓存页面的匹配规则就是控制页面的隐藏/恢复显示与正常卸载,而 rr4 正常的路由匹配规则就是控制渲染/卸载,通过 path 这个 props 来完成。那么我们直接给 LiveRoute 一个额外的来控制隐藏/恢复显示的 livePath 的路径即可,其规则就可以直接套用 path,当路由 livePath 匹配时,则处于隐藏状态,其他路径则按照 rr4 的规则正常渲染/卸载。调用方法:
<LiveRoute path='/list' livePath='/item/:id' component={List}/>如此一来,LiveRoute 显示状态的依赖变为 context.router,这样做的好处是依赖变的简单,所有的路由都会“同时”获得依赖的更新,并且相互之间没有耦合。
LiveRoute 内部有一个状态机,有三种渲染组件的状态:
HIDE_RENDER:livePath 匹配则需要将 LiveRoute 渲染的组件隐藏掉。进入此状态时需要备份页面的滚动位置,然后通过 ReactDOM.findDOMNode 来获取路由渲染的组件的 DOM,将 dom.style.display = 'none',并备份修改之前的 display 的属性。
NORMAL_RENDER_MATCH:路由正常渲染并且匹配上了。调用原版 Route 的渲染方法即可
if (component) return match ? React.createElement(component, props) : null;
if (render) return match ? render(props) : null;但是在每次正常匹配渲染的时候都要保存当前的 context.router,作为之后隐藏渲染时需要保持渲染所需的 router,在 componnetDidUpdate 后查看有没有备份的滚动位置,如果有就恢复滚动位置并清除备份的滚动位置。
NORMAL_RENDER_UNMATCH:正常渲染但是不匹配,即要卸载当前路由的组件。要做的就比较简单了,清空 LiveRoute 中保存的 DOM 的引用,清除掉保存的滚动位置,然后调用原版的的 Route 的渲染方法(卸载)即可。当 router 与 livePath 匹配 的时候需要将 LiveRoute 置为隐藏状态。
但是新的 router 传入必然会计算出一个新的 match 去 setState,而新的 setState 与当前的 path 并不匹配,所以 LiveRoute 每次隐藏渲染时需要在 componentWillReceiveProps 中计算上次的 prevMatch。
在 render 的部分,需要当前的 router 在计算传递给组件的 props,所以需要在最后一次正常渲染的时候保存当前的 router。
最后,将 prevMatch 作为 setState 的 match,再拿出之前保存的 _prevRoute 完成渲染,一句话说就是将最后一次正常渲染的参数给保留了下来并在需要隐藏的时候拿出来伪装成最后一次正常渲染,再将 DOM 隐藏就完成了核心功能。
由于 LiveRoute 拦截了路由的卸载,所以滚动位置不需要再存储在全局的 sessionStorage 中,LiveRoute 会一直存活,滚动位置直接可以保存为 LiveRoute 的属性。并且,相比 sessionStorage 必须先 JSON.stringify() 保存对象的操作,有了更高的可拓展性。
有一个问题就是与 Switch 的不兼容性,这个是采用 display:none 这种方法无法避免的,我也在 文档 中写到了。因为 Switch 的目的就是仅渲染第一个匹配的子元素,而 LiveRoute 的目的是强行渲染不匹配的子元素,所以不能在 Switch 中直接嵌套一个 LiveRoute 来使用。解决方法也简单,就是将 LiveRoute 从 Switch 中拿到外面来,不要让 LiveRoute 和 Switch 相互干扰,但是要注意此时 LiveRoute 的渲染与否也失去了 Switch 的跳过功能了。
在一些情况下 LiveRoute 的 DOM 将会被直接修改,所以在切换路由时滚动位置将不会改变而界面已经发生改变。这并不是 react-live-route 带来的问题,你可以手动将页面滚动到顶部,这篇 react-router 提供的 教学文章 中可以提供一些帮助。另外,如果 LiveRoute 将要恢复滚动位置,由于 React 的渲染顺序,它将发生在 LiveRoute 渲染的组件的滚动操作之后发生(滚动操作发生在 componentDidMount 或 componentDidUpdate 中)。
react-live-route 实现了路由的缓存及复原,但是还有一些其他的问题需要解决,比如与转场动画的兼容性及给 LivePath 传入一个数组来实现多规则匹配的问题。(因为使用的是 react-router 的 computePath 方法解析 path,所以默认支持传入数组,具体详见 path-to-regexp 的 文档)
最后再放上 react-live-route 的仓库地址 react-live-route,欢迎 star 和提出 issue。
react-router 目前作为 react 最流行的路由管理库,已经成为了某种意义上的官方路由库(不过下一代的路由库 reach-router 已经蓄势待发了),并且更新到了 v4 版本,完成了一切皆组件的升级。本文将对 react-router v4(以下简称 rr4) 的源码进行分析,来理解 rr4 是如何帮助我们管理路由状态的。
在分析源码之前,先来对路由有一个认识。在 SPA 盛行之前,还不存在前端层面的路由概念,每个 URL 对应一个页面,所有的跳转或者链接都通过 <a> 标签来完成,随着 SPA 的逐渐兴盛及 HTML5 的普及,hash 路由及基于 history 的路由库越来越多。
路由库最大的作用就是同步 URL 与其对应的回调函数。对于基于 history 的路由,它通过 history.pushState 来修改 URL,通过 window.addEventListener('popstate', callback) 来监听前进/后退事件;对于 hash 路由,通过操作 window.location 的字符串来更改 hash,通过 window.addEventListener('hashchange', callback) 来监听 URL 的变化。
class Router {
constructor() {
// 储存 hash 与 callback 键值对
this.routes = {};
// 当前 hash
this.currentUrl = '';
// 记录出现过的 hash
this.history = [];
// 作为指针,默认指向 this.history 的末尾,根据后退前进指向 history 中不同的 hash
this.currentIndex = this.history.length - 1;
this.backIndex = this.history.length - 1
this.refresh = this.refresh.bind(this);
this.backOff = this.backOff.bind(this);
// 默认不是后退操作
this.isBack = false;
window.addEventListener('load', this.refresh, false);
window.addEventListener('hashchange', this.refresh, false);
}
route(path, callback) {
this.routes[path] = callback || function() {};
}
refresh() {
console.log('refresh')
this.currentUrl = location.hash.slice(1) || '/';
this.history.push(this.currentUrl);
this.currentIndex++;
if (!this.isBack) {
this.backIndex = this.currentIndex
}
this.routes[this.currentUrl]();
console.log('指针:', this.currentIndex, 'history:', this.history);
this.isBack = false;
}
// 后退功能
backOff() {
// 后退操作设置为true
console.log(this.currentIndex)
console.log(this.backIndex)
this.isBack = true;
this.backIndex <= 0 ?
(this.backIndex = 0) :
(this.backIndex = this.backIndex - 1);
location.hash = `#${this.history[this.backIndex]}`;
}
}完整实现 hash-router,参考 hash router 。
其实知道了路由的原理,想要实现一个 hash 路由并不困难,比较需要注意的是 backOff 的实现,包括 hash router 中对 backOff 的实现也是有 bug 的,浏览器的回退会触发 hashChange 所以会在 history 中 push 一个新的路径,也就是每一步都将被记录。所以需要一个 backIndex 来作为返回的 index 的标识,在点击新的 URL 的时候再将 backIndex 回归为 this.currentIndex。
class Routers {
constructor() {
this.routes = {};
// 在初始化时监听popstate事件
this._bindPopState();
}
// 初始化路由
init(path) {
history.replaceState({path: path}, null, path);
this.routes[path] && this.routes[path]();
}
// 将路径和对应回调函数加入hashMap储存
route(path, callback) {
this.routes[path] = callback || function() {};
}
// 触发路由对应回调
go(path) {
history.pushState({path: path}, null, path);
this.routes[path] && this.routes[path]();
}
// 后退
backOff(){
history.back()
}
// 监听popstate事件
_bindPopState() {
window.addEventListener('popstate', e => {
const path = e.state && e.state.path;
this.routes[path] && this.routes[path]();
});
}
}参考 H5 Router
相比 hash 路由,h5 路由不再需要有些丑陋去的去修改 window.location 了,取而代之使用 history.pushState 来完成对 window.location 的操作,使用 window.addEventListener('popstate', callback) 来对前进/后退进行监听,至于后退则可以直接使用 window.history.back() 或者 window.history.go(-1) 来直接实现,由于浏览器的 history 控制了前进/后退的逻辑,所以实现简单了很多。
react 作为一个前端视图框架,本身是不具有除了 view (数据与界面之间的抽象)之外的任何功能的,为 react 引入一个路由库的目的与上面的普通 SPA 目的一致,只不过上面路由更改触发的回调函数是我们自己写的操作 DOM 的函数;在 react 中我们不直接操作 DOM,而是管理抽象出来的 VDOM 或者说 JSX,对 react 的来说路由需要管理组件的生命周期,对不同的路由渲染不同的组件。
在前面我们了解了创建路由的目的,普通 SPA 路由的实现及 react 路由的目的,先来认识一下 rr4 的周边知识,然后就开始对 react-router 的源码分析。
history 库,是 rr4 依赖的一个对 window.history 加强版的 history 库。
源自 history 库,表示当前的 URL 与 path 的匹配的结果
match: {
path: "/", // 用来匹配的 path
url: "/", // 当前的 URL
params: {}, // 路径中的参数
isExact: pathname === "/" // 是否为严格匹配
}还是源自 history 库,是 history 库基于 window.location 的一个衍生。
hash: "" // hash
key: "nyi4ea" // 一个 uuid
pathname: "/explore" // URL 中路径部分
search: "" // URL 参数
state: undefined // 路由跳转时传递的 state我们带着问题去分析源码,先逐个分析每个组件的作用,在最后会有回答,在这里先举一个 rr4 的小 DEMO
rr4 将路由拆成了几个包 —— react-router 负责通用的路由逻辑,react-router-dom 负责浏览器的路由管理,react-router-native 负责 react-native 的路由管理,通用的部分直接从 react-router 中导入,用户只需引入 react-router-dom 或 react-router-native 即可,react-router 作为依赖存在不再需要单独引入。
import React from 'react'
import { render } from 'react-dom'
import { BrowserRouter } from 'react-router-dom'
import App from './components/App';
render(){
return(
<BrowserRouter>
<App />
</BrowserRouter>
)
)}这是我们调用 Router 的方式,这里拿 BrowserRouter 来举例。
BrowserRouter 的源码在 react-router-dom 中,它是一个高阶组件,在内部创建一个全局的 history 对象(可以监听整个路由的变化),并将 history 作为 props 传递给 react-router 的 Router 组件(Router 组件再会将这个 history 的属性作为 context 传递给子组件)
render() {
return <Router history={this.history} children={this.props.children} />;
}其实整个 Router 的核心是在 react-router 的 Router 组件中,如下,借助 context 向 Route 传递组件,这也解释了为什么 Router 要在所有 Route 的外面。
getChildContext() {
return {
router: {
...this.context.router,
history: this.props.history,
route: {
location: this.props.history.location,
match: this.state.match
}
}
};
}这是 Router 传递给子组件的 context,事实上 Route 也会将 router 作为 context 向下传递,如果我们在 Route 渲染的组件中加入
static contextTypes = {
router: PropTypes.shape({
history: PropTypes.object.isRequired,
route: PropTypes.object.isRequired,
staticContext: PropTypes.object
})
};来通过 context 访问 router,不过 rr4 一般通过 props 传递,将 history, location, match 作为三个独立的 props 传递给要渲染的组件,这样访问起来方便一点(实际上已经完全将 router 对象的属性完全传递了)。
在 Router 的 componentWillMount 中, 添加了
componentWillMount() {
const { children, history } = this.props;
invariant(
children == null || React.Children.count(children) === 1,
"A <Router> may have only one child element"
);
// Do this here so we can setState when a <Redirect> changes the
// location in componentWillMount. This happens e.g. when doing
// server rendering using a <sStaticRouter>.
this.unlisten = history.listen(() => {
this.setState({
match: this.computeMatch(history.location.pathname)
});
});
}history.listen 能够监听路由的变化并执行回调事件。
在这里每次路由的变化执行的回调事件为
this.setState({
match: this.computeMatch(history.location.pathname)
});相比于在 setState 里做的操作,setState 本身的意义更大 —— 每次路由变化 -> 触发顶层 Router 的回调事件 -> Router 进行 setState -> 向下传递 nextContext(context 中含有最新的 location)-> 下面的 Route 获取新的 nextContext 判断是否进行渲染。
之所以把这个 subscribe 的函数写在 componentWillMount 里,就像源码中给出的注释:是为了 SSR 的时候,能够使用 Redirect。
Route 的作用是匹配路由,并传递给要渲染的组件 props。
在 Route 的 componentWillReceiveProps 中
componentWillReceiveProps(nextProps, nextContext) {
...
this.setState({
match: this.computeMatch(nextProps, nextContext.router)
});
}Route 接受上层的 Router 传入的 context,Router 中的 history 监听着整个页面的路由变化,当页面发生跳转时,history 触发监听事件,Router 向下传递 nextContext,就会更新 Route 的 props 和 context 来判断当前 Route 的 path 是否匹配 location,如果匹配则渲染,否则不渲染。
是否匹配的依据就是 computeMatch 这个函数,在下文会有分析,这里只需要知道匹配失败则 match 为 null,如果匹配成功则将 match 的结果作为 props 的一部分,在 render 中传递给传进来的要渲染的组件。
接下来看一下 Route 的 render 部分。
render() {
const { match } = this.state; // 布尔值,表示 location 是否匹配当前 Route 的 path
const { children, component, render } = this.props; // Route 提供的三种可选的渲染方式
const { history, route, staticContext } = this.context.router; // Router 传入的 context
const location = this.props.location || route.location;
const props = { match, location, history, staticContext };
if (component) return match ? React.createElement(component, props) : null; // Component 创建
if (render) return match ? render(props) : null; // render 创建
if (typeof children === "function") return children(props); // 回调 children 创建
if (children && !isEmptyChildren(children)) // 普通 children 创建
return React.Children.only(children);
return null;
}rr4 提供了三种渲染组件的方法:component props,render props 和 children props,渲染的优先级也是依次按照顺序,如果前面的已经渲染后了,将会直接 return。
这里解释一下官网的 tips,component 是使用 React.createElement 来创建新的元素,所以如果传入一个内联函数,比如
<Route path='/' component={()=>(<div>hello world</div>)}的话,由于每次的 props.component 都是新创建的,所以 React 在 diff 的时候会认为进来了一个全新的组件,所以会将旧的组件 unmount,再 re-mount。这时候就要使用 render,少了一层包裹的 component 元素,render 展开后的元素类型每次都是一样的,就不会发生 re-mount 了(children 也不会发生 re-mount)。
我们紧接着 Route 来看 Switch,Switch 是用来嵌套在 Route 的外面,当 Switch 中的第一个 Route 匹配之后就不会再渲染其他的 Route 了。
render() {
const { route } = this.context.router;
const { children } = this.props;
const location = this.props.location || route.location;
let match, child;
React.Children.forEach(children, element => {
if (match == null && React.isValidElement(element)) {
const {
path: pathProp,
exact,
strict,
sensitive,
from
} = element.props;
const path = pathProp || from;
child = element;
match = matchPath(
location.pathname,
{ path, exact, strict, sensitive },
route.match
);
}
});
return match
? React.cloneElement(child, { location, computedMatch: match })
: null;
}Switch 也是通过 matchPath 这个函数来判断是否匹配成功,一直按照 Switch 中 children 的顺序依次遍历子元素,如果匹配失败则 match 为 null,如果匹配成功则标记这个子元素和它对应的 location、computedMatch。在最后的时候使用 React.cloneElement 渲染,如果没有匹配到的子元素则返回 null。
接下来我们看下 matchPath 是如何判断 location 是否符合 path 的。
matchPath 返回的是一个如下结构的对象
{
path, // 用来进行匹配的路径,其实是直接导出的传入 matchPath 的 options 中的 path
url: path === "/" && url === "" ? "/" : url, // 整个的 URL
isExact, // url 与 path 是否是 exact 的匹配
// 返回的是一个键值对的映射
// 比如你的 path 是 /users/:id,然后匹配的 pathname 是 /user/123
// 那么 params 的返回值就是 {id: '123'}
params: keys.reduce((memo, key, index) => {
memo[key.name] = values[index];
return memo;
}, {})
}这些信息将作为匹配的参数传递给 Route 和 Switch(Switch 只是一个代理,它的作用还是渲染 Route,Switch 计算得到的 computedMatch 会传递给要渲染的 Route,此时 Route 将直接使用这个 computedMatch 而不需要再自己来计算)。
在 matchPath 内部 compilePath 时,有个
const patternCache = {};
const cacheLimit = 10000;
let cacheCount = 0;作为 pathToRegexp 的缓存,因为 ES6 的 import 模块导出的是值的引用,所以将 patternCache 可以理解为一个全局变量缓存,缓存以 {option:{pattern: }} 的形式存储,之后如果需要匹配相同 pattern 和 option 的 path,则可以直接从缓存中获得正则表达式和 keys。
加缓存的原因是路由页面大部分情况下都是相似的,比如要访问 /user/123 或 /users/234,都会使用 /user/:id 这个 path 去匹配,没有必要每次都生成一个新的正则表达式。SPA 在页面整个访问的过程中都维护着这份缓存。
实际上我们可能写的最多的就是 Link 这个标签了,我们从它的 render 函数开始看
render() {
const { replace, to, innerRef, ...props } = this.props; // eslint-disable-line no-unused-vars
invariant(
this.context.router,
"You should not use <Link> outside a <Router>"
);
invariant(to !== undefined, 'You must specify the "to" property');
const { history } = this.context.router;
const location =
typeof to === "string"
? createLocation(to, null, null, history.location)
: to;
const href = history.createHref(location);
// 最终创建的是一个 a 标签
return (
<a {...props} onClick={this.handleClick} href={href} ref={innerRef} />
);
}可以看到 Link 最终还是创建一个 a 标签来包裹住要跳转的元素,但是如果只是一个普通的带 href 的 a 标签,那么就会直接跳转到一个新的页面而不是 SPA 了,所以在这个 a 标签的 handleClick 中会 preventDefault 禁止默认的跳转,所以这里的 href 并没有实际的作用,但仍然可以标示出要跳转到的页面的 URL 并且有更好的 html 语义。
在 handleClick 中,对没有被 “preventDefault的 && 鼠标左键点击的 && 非 _blank 跳转 的&& 没有按住其他功能键的“ 单击进行 preventDefault,然后 push 进 history 中,这也是前面讲过的 —— 路由的变化 与 页面的跳转 是不互相关联的,rr4 在 Link 中通过 history 库的 push 调用了 HTML5 history 的 pushState,但是这仅仅会让路由变化,其他什么都没有改变。还记不记得 Router 中的 listen,它会监听路由的变化,然后通过 context 更新 props 和 nextContext 让下层的 Route 去重新匹配,完成需要渲染部分的更新。
handleClick = event => {
if (this.props.onClick) this.props.onClick(event);
if (
!event.defaultPrevented && // onClick prevented default
event.button === 0 && // ignore everything but left clicks
!this.props.target && // let browser handle "target=_blank" etc.
!isModifiedEvent(event) // ignore clicks with modifier keys
) {
event.preventDefault();
const { history } = this.context.router;
const { replace, to } = this.props;
if (replace) {
history.replace(to);
} else {
history.push(to);
}
}
};const withRouter = Component => {
const C = props => {
const { wrappedComponentRef, ...remainingProps } = props;
return (
<Route
children={routeComponentProps => (
<Component
{...remainingProps}
{...routeComponentProps}
ref={wrappedComponentRef}
/>
)}
/>
);
};
C.displayName = `withRouter(${Component.displayName || Component.name})`;
C.WrappedComponent = Component;
C.propTypes = {
wrappedComponentRef: PropTypes.func
};
return hoistStatics(C, Component);
};
export default withRouter;withRouter 的作用是让我们在普通的非直接嵌套在 Route 中的组件也能获得路由的信息,这时候我们就要 WithRouter(wrappedComponent) 来创建一个 HOC 传递 props,WithRouter 的其实就是用 Route 包裹了 SomeComponent 的一个 HOC。
创建 Route 有三种方法,这里直接采用了传递 children props 的方法,因为这个 HOC 要原封不动的渲染 wrappedComponent(children props 比较少用得到,某种程度上是一个内部方法)。
在最后返回 HOC 时,使用了 hoistStatics 这个方法,这个方法的作用是保留 SomeComponent 类的静态方法,因为 HOC 是在 wrappedComponent 的外层又包了一层 Route,所以要将 wrappedComponent 类的静态方法转移给新的 Route,具体参见 Static Methods Must Be Copied Over。
现在回到一开始的问题,重新理解一下点击一个 Link 跳转的过程。
有两件事需要完成:
过程如下:
hitsory.push(to),这个函数实际上就是包装了一下 window.history.pushState(),是 HTML5 history 的 API,但是 pushState 之后除了地址栏有变化其他没有任何影响,到这一步已经完成了目标1:路由的改变。看到这里相信你已经能够理解前端路由的实现及 react-router 的实现,但是 react-router 有很多的不足,这也是为什么 reach-router 的出现的原因。
在下篇文章,我会介绍如何做一个可以缓存的 Route —— 比如在列表页跳转到详情页再后退的时候,恢复列表页的模样,包括状态及滚动位置等。
先放上仓库的地址: react-live-route,喜欢可以 star,欢迎提出 issue。
一个绝对路径,代表打包在本地磁盘上的物理位置。
比如:
output: {
filename: '[name].js',
path: path.resolve(__dirname, '../dist'),
publicPath: '/dev/'
},这个配置项在生产模式下是必须的(因为你要打包至少要指定打包到哪吧..),但是在开发模式下不是必须的,因为 webpackDevServer 打包出来的文件都在内存中而没有打包到磁盘中。
打包出来的资源的 URL 前缀(虽然名为打包,但是这个配置项在生产模式和开发模式中都很重要,因为开发模式就是打包在内存中),即在浏览器中访问的路径的前缀。可以填写相对路径或者绝对路径:
这个配置项会加到每个 runtime 或 loader (和 webpack 相关的路径)产生的 URL 中,所以这个配置项在大多数情况下都是以 / 结尾
The webpack-dev-server also takes a hint from publicPath, using it to determine where to serve the output files from.
决定了 webpackDevServer 启动时服务器资源的根目录,默认是项目的根目录。
在有静态文件需要 serve 的时候必填,contentBase 不会影响 path 和 publicPath,它唯一的作用就是指定服务器的根目录来引用静态文件。
可以这么理解 contentBase 与 publicPath 的关系:contentBase 是服务于引用静态文件的路径,而 publicPath 是服务于打包出来的文件访问的路径,两者是不互相影响的。
在开启 webpackDevServer 时浏览器中可通过这个路径访问 bundled 文件,静态文件会加上这个路径前缀,若是devServer里面的publicPath没有设置,则会认为是output里面设置的publicPath的值。
和 output.publicPath 非常相似,都是为浏览器制定访问路径的前缀。但是不同的是 devServer.publicPath 只影响于 webpackDevServer(一般来说就是 html),但各种 loader 打出来的路径还是根据 output.publicPath。
htmlWebpackPlugin 可以用来在 html 中插入打包好的 js,那么这个插入的 js 的路径是什么样的呢?
文档中有写这么一句:
If you've set a publicPath in your webpack config this will be reflected correctly in this assets hash.
答案是路径会根据 output.publicPath 来确定,这也就是为什么
It is recommended that
devServer.publicPathis the same asoutput.publicPath.
因为如果不一样的话,因为打包出来的 js 资源在 html 中会去 output.publicPath 找,但是这个 js 实际上会被 serve 到 devServer.publicPath 的位置,所以这两个在开发环境下强烈推荐一致。
WIP 🚧
TEMPORARILY CLOSED
All consumers that are descendants of a Provider will re-render whenever the Provider’s value prop changes. The propagation from Provider to its descendant consumers is not subject to the shouldComponentUpdate method, so the consumer is updated even when an ancestor component bails out of the update.
所以如果需要通过 shouldComponentUpdate 进行性能优化的话,需要再在需要性能优化的组件外套一层 HOC,HOC 可以跟随 context.Provider 的更新并传递 props 给组件。
React.createElement 来创建 react element,所以如果传递的是内联函数,如下const SomeCom = () => <br />
<Route path="/some-path" component={()=> <SomeCom />} />在调用 React.createElement 时机会变成(如下为 babel 转义的 JSX)
_react.default.createElement(function () {
return SomeCom;
});可以看到 createElement 的第一个参数 type 是一个「临时生成」的函数,所以会导致在每次 render 的时候这个 type 都会对应不同的函数,所以 Route 在每次 render 时就会 unmount 再 mount 一次组件,导致性能问题。
解决办法是使用 Route 的 render 这个 props,render 会直接调用传递的函数作为 element。
/:foo/:bar? 来匹配可选字符/:foo* 来匹配零个存在字符/:foo+ 来匹配一个或多个字符/:foo(\\d+) 来匹配纯数字字符React + TS 的类型推导似乎在某些边缘 case 下有问题,比如加入了自定义守卫类型之后,无法检测出 return undefined 会导致返回的类型不匹配

componetWillUnmount 是异步的,比如给组件换个 key 强行 re-mount 这种操作,可能老组件的 componentWillUnmount 是发生在新组件的 constructor 之前的,容易产生竞态的问题。
facebook/react#11106
本文适合有一定 Promise 使用基础的读者,如果你还没有使用过 Promise,建议先通过以下教程了解 Promise 的使用方法
本篇文章中我们要分析的 Promise 实现库的源码是 es6-promise,一个通过了 Promises/A+ Tests 的 polyfill,源码通过 ES6 书写比较简洁。为方便理解,放上我已经写了注释的仓库地址:es6-promise-annotated,可以配合阅读。
在正式进入源码分析之前,我们先明确 Promise 的一些基本准则:
new Promise() 自然都会返回一个 Promise 实例对象,调用 .then() Promise.resolve() Promise.reject() 返回的也都是一个被包装好的 Promise 对象。Promise.prototype.then 和 Promise.prototype.catch 的参数中的回调函数虽然是异步执行的,但是向 promise 对象注册执行成功时和失败时相应的回调函数的行为是同步执行的。Promise 的工作主要分为两个阶段,一是同步注册,二是异步触发链式调用。
一般来说在调用 Promise 时都是多个 Promise 对象串联起来的,then 中函数的调用是异步的, 但是 Promise 对象的创建是同步的,如下例子中:
const p1 = new Promise(function(resolve, reject){
setTimeout(()=>{
resolve('a', 'b')
}, 1000)
})
p1.then((value1, value2)=>{
console.log(value1, value2)
})p1 和 p1 被 then 包装出来的 Promise 对象是会在整个 script 脚本的执行过程中同步完成,这个过程就是注册,每个子 promise 都会添加到父 promise 的属性上来完成注册,以便在接下来的链式调用中按照顺序执行。
Promise 可以链式调用关键的一点就是确定好每个节点的调用接口(有点像递归的递归入口),这样每个 Promise 对象就可以通过相同的接口串联起来调用,Promise 对象的模型如下图:

每个父 promise 传递给子 promise 们它的 settled 状态来指示该触发子 promise 成功或失败的回调函数,并传递给子 promise 它的 settled 值。
每个 Promise 对象都有三个状态:pending fulfilled rejected,所以需要有一个内部属性来标识状态。向 Promise 对象注册的回调函数也会被同步存在一个内部属性中,在执行子 promise 的时候取出进行异步调用。
Promise 的构造函数只接受一个参数,函数签名为 function(resolve, reject){},所以要对传入的参数进行判断,传入的参数非函数时直接报错(如果想传入非函数的参数要使用 Promise.resolve,会自动包装出一个 Promise 对象,后面也会讲到)。
constructor(resolver) {
this[PROMISE_ID] = nextId();
// 初始化 promise
this._result = this._state = undefined;
// 向 promise 注册的回调函数
this._subscribers = [];
if (noop !== resolver) {
typeof resolver !== 'function' && needsResolver();
// 确保使用 new 调用 Promise
this instanceof Promise ? initializePromise(this, resolver) : needsNew();
}
}Promise 构造函数中的函数是同步执行的,通过 initializePromise 来启动这个 Promise 对象
// 在 new Promise() 时同步执行 resolver
// 执行到 resolver 中的 resolve 时,实际执行的是 resolve(promise, value)
function initializePromise(promise, resolver) {
try {
resolver(function resolvePromise(value) {
resolve(promise, value);
}, function rejectPromise(reason) {
reject(promise, reason);
});
} catch (e) {
reject(promise, e);
}
}但我们知道 new Promise(function(resolve, reject)) 中 resolve 和 reject 的执行是异步的,value 这个参数就是在 Promise 的构造函数中传递给 resolve 和 reject 的参数值(可以看到,resolve 和 reject 都只能接受一个参数,后面的参数会被直接忽略)。
到这一步,回调的 resolve(value) 和 reject(error) 实际上在内部被封装成了 (value) => resolve(promise, value) 和 (reason) => reject(promise, reason),promise 就是当前的 Promise 对象,value 在这里就是 'a',reject 同理。表面看上去只是多了一个 promise 的参数,但是子 promise 事先已经向父 promise 通过 then 完成了同步的注册,启动之后,就能异步的链式调用了。
在这里要注意 resolve 和 reject 是异步的,后面会讲到。
接下来我们来看下 then 和 catch 是如何在 Promise 上注册回调的。
if (child[PROMISE_ID] === undefined) {
makePromise(child);
}
const { _state } = parent;
// 如果当前 promise 已经 settled 了
// 则可以直接执行 then 的 promise
if (_state) {
const callback = arguments[_state - 1];
asap(() => invokeCallback(_state, child, callback, parent._result));
} else {
// then 前的 promise 作为 parent
// then 后的 promise 作为 child
// 将 then 后的 onFulfillment, onRejection 注册到 parent 的 _subscribers 上
subscribe(parent, child, onFulfillment, onRejection);
}then 中传入的一个或两个函数都会被包装成 Promise 对象来满足 Promises/A+ 规定,并且只有返回 Promise 对象才可以符合调用的接口。每次 then 的 Promise 对象(子 promise)会连同它的 resolve 和 reject 回调函数一同存入被 then 的 Promise 对象(父 promise)的 _subscribers 中。
// 将 then 的 promise 的 onFulfillment, onRejection 注册到被 then 的 promise 的 _subscribers 上
// 并且调用尽快开始异步执行
// 每次注册时添加三个对象:下一个 promise,下一个 promise 的 onFulfillment,下一个 promise 的 onRejection
function subscribe(parent, child, onFulfillment, onRejection) {
let { _subscribers } = parent;
let { length } = _subscribers;
parent._onerror = null;
_subscribers[length] = child;
_subscribers[length + FULFILLED] = onFulfillment;
_subscribers[length + REJECTED] = onRejection;
// promise 的启动
// 在当前 promise 在 then 的时候,就在下一个 microtask 中注册要执行所有注册的回调函数
if (length === 0 && parent._state) {
asap(publish, parent);
}
}在上一节中,then 的 Promise 对象向被 then 的 Promise 对象注册了回调事件,至此完成了第一阶段 —— 同步注册。接下来是第二个阶段 —— 启动链式调用。
Promise 有几种创建的方法:1. 通过构造函数 new 出来的。2. 通过 then 或 reject 出来的 3. 通过 Promise.resolve 或 Promise.reject 创建的。这三种创建 Promise 对象的启动的方法相同,不同的是
分别分情况来看:
对于通过构造函数创建的 Promise 对象,没有父 promise 来给它 settled 状态及返回值,这两者都是在传给 Promise 的函数的逻辑中传递的。
// 在 new Promise() 时同步执行 resolver
// 但是 new Promise(function(resolve, reject)) 中 resolve 和 reject 的执行是异步的
// 执行到 resolver 中的 resolve 时,实际执行的是 resolve(promise, value)
// 借助闭包多传入了当前的 promise 对象
function initializePromise(promise, resolver) {
try {
resolver(function resolvePromise(value) {
resolve(promise, value);
}, function rejectPromise(reason) {
reject(promise, reason);
});
} catch (e) {
reject(promise, e);
}
}对于 then 或 reject 出来的 Promise 对象,要先包装出一个 Promise 对象
if (child[PROMISE_ID] === undefined) {
makePromise(child);
}然后根据父 proimse 的状态来确定自己将要执行 onFulfilled 或 onRejected,如果父 promise 已经 settled 了,则可以直接执行 then 的回调函数。
如果父 promise 还没有 settled,就默默进行注册,上面已经提到过,subscribe 函数会在第一个次注册回调函数时执行所有父 promise 的回调函数。
const { _state } = parent;
// 如果当前 promise 已经 settled 了
// 则可以直接执行 then 的回调函数
if (_state) {
const callback = arguments[_state - 1];
asap(() => invokeCallback(_state, child, callback, parent._result));
} else {
// then 前的 promise 作为 parent
// then 后的 promise 作为 child
// 将 then 后的 onFulfillment, onRejection 注册到 parent 的 _subscribers 上
subscribe(parent, child, onFulfillment, onRejection);
}拿 Promise.resolve 来举例即可,Promise.reject 同理。
// 返回一个 promise,并且这个 promise 即将被 resolve 了
export default function resolve(object) {
/*jshint validthis:true */
let Constructor = this;
// 如果传入的就是一个 promise 那么就可以直接返回
if (object && typeof object === 'object' && object.constructor === Constructor) {
return object;
}
// 生成一个新的 promise
let promise = new Constructor(noop);
// 用传入的 value 去 resolve 它
_resolve(promise, object);
return promise;
}这里的 _resolve 就是之前出现多次的 resolve,表示当前 Promise 已走 onFulfilled 的回调了。
当一个 Promise 对象接受父 promise 传入的状态或根据自身的回调函数确定要执行 onFulfilled 的回调函数时可能遇到三种情况:1. 如果传入 onFulfilled 的参数是自身,会导致递归爆栈,这时要 reject 掉。 2. 传入的回调函数是一个 thenable 对象,那么 3. 如果传入的是其他对象,则可以直接 fulfill 掉当前的 Promise 对象。
// promise: 当前 promise 对象
// value: 传入 resolve 的 value
function resolve(promise, value) {
if (promise === value) {
// 自己 resolve 自己会递归爆栈
reject(promise, selfFulfillment());
} else if (objectOrFunction(value)) {
// 处理可能的 thenable 对象
// 如果上一个 promise 返回的是对象或函数
// 则可能有两种可能,一种是正常的返回结果
// 另一个中是返回的是 thenable 对象
handleMaybeThenable(promise, value, getThen(value));
} else {
// 传入基本类型可以直接 fulfill
fulfill(promise, value);
}
}fulfill 函数的功能就是确定当前 promise 的 state 和 result。之后,就可以通过 asap 异步通知所有子 promise 开始执行。
// 确定状态为 fulfilled
// 在 fulfilled 自己之后,会 publish 下一个 promise
function fulfill(promise, value) {
// 每个 promise 只能被 fulfill 或者 reject 一次
if (promise._state !== PENDING) { return; }
// 状态变为 fulfilled 并且保存结果
promise._result = value;
promise._state = FULFILLED;
// 如果 promise 后面有 then 的函数,则尽快异步执行下一个 promise
if (promise._subscribers.length !== 0) {
asap(publish, promise);
}
}对于 publish,就是依次同步处理所有子 promise 们。如果子 promise 有注册了回调,那么触发子 promise。
// 执行 promise 之后所有 then 的函数
function publish(promise) {
let subscribers = promise._subscribers;
let settled = promise._state;
// 如果后面没有 then 就直接返回
if (subscribers.length === 0) { return; }
let child, callback, detail = promise._result;
// 每次注册 then 的时候,都是往 _subscribers 添加 promise 和两个回调函数,所以 +3:
for (let i = 0; i < subscribers.length; i += 3) {
child = subscribers[i];
callback = subscribers[i + settled];
if (child) {
// 如果被 then 了,则执行子 promise 注册的回调函数
invokeCallback(settled, child, callback, detail);
} else {
// 如果后面没有 then 了,则可以直接执行回调
callback(detail);
}
}
promise._subscribers.length = 0;
}当到了 invokeCallback,实际上就是执行每个子 promise 的回调,这时会有几种情况:1. 如果注册的回调函数的确实是函数,则执行回调函数得到结果,如果没有返回错误则说明要 fulfill 这个 promise。2. 如果注册的回调函数却不是函数,则说明发生了值穿透,此时直接用父 promise 的 result 来作为子 promise 的 result 向下传递。
// 执行后续 then 中的回调函数
// 上一个 promise 的状态
// 下一个 promise
// 对应状态注册的回调函数
// 上一个 promise 的返回值
function invokeCallback(settled, promise, callback, detail) {
// 如果 then 中传入的 callback 不是函数,则会发生值穿透
let hasCallback = isFunction(callback),
value, error, succeeded, failed;
// then 中传入了函数,可以回调
// 判断自身是 fulfill 还是 reject
if (hasCallback) {
value = tryCatch(callback, detail);
if (value === TRY_CATCH_ERROR) {
failed = true;
error = value.error;
value.error = null;
} else {
succeeded = true;
}
// 防止 promise resolve 自己导致递归爆栈
if (promise === value) {
reject(promise, cannotReturnOwn());
return;
}
} else {
// 发生值穿透,则直接使用之前 promise 传递的值
value = detail;
succeeded = true;
}
if (promise._state !== PENDING) {
// 又重新来一轮,启发链式调用
} else if (hasCallback && succeeded) {
resolve(promise, value);
} else if (failed) {
reject(promise, error);
} else if (settled === FULFILLED) {
fulfill(promise, value);
} else if (settled === REJECTED) {
reject(promise, value);
}
}我们知道 Promise 处于的异步队列是 microTask,这里不再重复 task 和 mircoTask 的执行顺序,说一下 microTask 的意义,引用 顾轶灵 大神在这个问题下回答:
为啥要用 microtask?根据HTML Standard,在每个 task 运行完以后,UI 都会重渲染,那么在 microtask 中就完成数据更新,当前 task 结束就可以得到最新的 UI 了。反之如果新建一个 task 来做数据更新,那么渲染就会进行两次。
microTask 某种程度上来说就是 task 执行前的钩子函数,JS 引擎在执行完一个 task 后会更新 UI,有了 microTask 就能在改变 UI 改变前操作 DOM。
对于简易实现的 Promise,一般都是直接使用 setTimeout 来做延迟,但是 setTimeout 属于 marcotask,在 es6-promise 中按顺序使用以下方式来进行异步的延迟,优先使用可以使用的方法。
这是 Node 中特有的 microTask 函数,在 Node 环境中直接使用它即可。
MutationObserver 是 HMLT5 引入的能在某个范围内的DOM树发生变化时作出适当反应的能力.该API设计用来替换掉在DOM3事件规范中引入的Mutation事件.
在调用时创建一个 BrowserMutationObserver 来监视一个 node,回调函数为需要异步执行的回调函数。
const observer = new BrowserMutationObserver(flush);
const node = document.createTextNode('');
observer.observe(node, { characterData: true });
return () => {
node.data = (iterations = ++iterations % 2);
};Channel Messaging API的Channel Messaging接口允许我们创建一个新的消息通道,并通过它的两个
MessagePort属性发送数据。
同理,对其中一个通道随便发送一个消息,另一个通道执行回调即可。
另外
Note: 此特性在 Web Worker 中可用。
所以 MessageChannel 可以作为 MutationObserver 的替补及 Web Worker 中的异步方法。
// web worker
function useMessageChannel() {
const channel = new MessageChannel();
channel.port1.onmessage = flush;
return () => channel.port2.postMessage(0);
}笔者之前从来没听说个这个东西,找到了官网,就不在这里过多研究了。
如果以上方法皆不行则最后采用 setTimeout 的方法来执行。但是使用 setTimeout 来进行异步操作的话就不再是 microTask 的 Promise 了。
race 的实现比较简单,因为 promise 只能被 settle 一次,所以直接对 race 中传递的 promise 们都 then 上 race 的回调函数即可,回调函数会被最先完成的 promise å给 settle,。
export default function race(entries) {
/*jshint validthis:true */
let Constructor = this;
if (!isArray(entries)) {
return new Constructor((_, reject) => reject(new TypeError('You must pass an array to race.')));
} else {
// 新建一个要返回的 promise,然后同步 resolve 要 race 的几个 promise
// 要返回的 promise 都 then 这几个要 race 的 promise
// 当最快的那个 promise settle 后,会 resolve 或 reject 要返回的 promise
// 之后的再 settle 的 promise 就不再起作用了
return new Constructor((resolve, reject) => {
let length = entries.length;
for (let i = 0; i < length; i++) {
Constructor.resolve(entries[i]).then(resolve, reject);
}
});
}
}在内部维护一个保存结果的数组及记录未 settled 的 promise 的数量值,在每一次 settled 的时候都将这个值减1,当最后一个 promise settled 之后,记录结果的数组也都保存好了每个 promise 的返回值,可以触发包装的 promise 的回调了。
export default class Enumerator {
constructor(Constructor, input) {
this._instanceConstructor = Constructor;
this.promise = new Constructor(noop);
// 所有传入 promise 必须是本 promise 的实例
if (!this.promise[PROMISE_ID]) {
makePromise(this.promise);
}
if (isArray(input)) {
// 一共 all 了几个 promise
this.length = input.length;
// 还剩几个没执行完的,初始是所有 promise 的数量
this._remaining = input.length;
// 保存结果的数组
this._result = new Array(this.length);
if (this.length === 0) {
fulfill(this.promise, this._result);
} else {
this.length = this.length || 0;
this._enumerate(input);
// 如果传入的 input 都是同步执行,那么直接在这一轮 event-loop 中就结束了。
if (this._remaining === 0) {
fulfill(this.promise, this._result);
}
}
} else {
// 不是数组直接 reject
reject(this.promise, validationError());
}
}
_enumerate(input) {
for (let i = 0; this._state === PENDING && i < input.length; i++) {
this._eachEntry(input[i], i);
}
}
_eachEntry(entry, i) {
let c = this._instanceConstructor;
let { resolve } = c;
// 如果是本 promise 的 resolve
if (resolve === originalResolve) {
let then = getThen(entry);
// 如果是一个已经 settled 的 promise,则 _remaining--,并记录其结果
if (then === originalThen && entry._state !== PENDING) {
this._settledAt(entry._state, i, entry._result);
}
// 如果不是一个函数,则 _remaining--,并直接将其作为结果
else if (typeof then !== "function") {
this._remaining--;
this._result[i] = entry;
}
// 如果是本 promise 的实例,则设置回调
else if (c === Promise) {
let promise = new c(noop);
handleMaybeThenable(promise, entry, then);
this._willSettleAt(promise, i);
}
// 如果不是本 promise 的实例,则包装一下设置回调
else {
this._willSettleAt(new c(resolve => resolve(entry)), i);
}
}
// 如果不是本 promise 的 resolve
else {
this._willSettleAt(resolve(entry), i);
}
}
// 同步
_settledAt(state, i, value) {
let { promise } = this;
if (promise._state === PENDING) {
this._remaining--;
// 如果有一个 reject,则直接 reject
if (state === REJECTED) {
reject(promise, value);
}
// 设置结果
else {
this._result[i] = value;
}
}
// 如果所有 input 都 settled 了,可以执行 all 的回调了
if (this._remaining === 0) {
fulfill(promise, this._result);
}
}
// 通过 then 给 promise 注册 _settledAt
_willSettleAt(promise, i) {
let enumerator = this;
subscribe(
promise,
undefined,
value => enumerator._settledAt(FULFILLED, i, value),
reason => enumerator._settledAt(REJECTED, i, reason)
);
}
}可以看到,一个可以用于生产环境中的 Promise 库,对各种边界条件都有很好的处理,并且能兼容第三方的 thenable 对象,选用合适的 API 来实现将任务推到 microtask 中。不过,做的更好的 Promise 库还应该有很强的拓展性,比如 bluebird,但是,通过了解 es6-promise 对梳理 Promise 中的各种非常规操作还是大有好处。
原文: Resource Hints – What is Preload, Prefetch, and Preconnect?
作者:BRIAN JACKSON
今天我们将研究一下能显著提升页面性能的方法 —— 资源提示与指令。你也许听说过 preload,prefetch 和 preconnect,可是我们想研究的更深一点,搞清他们之间的区别并且充分的利用它们。它们带来的好处包括允许前端开发人员来优化资源的加载,减少往返路径并且在浏览页面时可以更快的加载到资源。
Preload 是一个新的控制特定资源如何被加载的新的 Web 标准,这是已经在 2016 年 1 月废弃的 subresource prefetch 的升级版。这个指令可以在 <link> 中使用,比如 <link rel="preload">。一般来说,最好使用 preload 来加载你最重要的资源,比如图像,CSS,JavaScript 和字体文件。这不要与浏览器预加载混淆,浏览器预加载只预先加载在HTML中声明的资源。preload 指令事实上克服了这个限制并且允许预加载在 CSS 和JavaScript 中定义的资源,并允许决定何时应用每个资源。
Preload 与 prefetch 不同的地方就是它专注于当前的页面,并以高优先级加载资源,Prefetch 专注于下一个页面将要加载的资源并以低优先级加载。同时也要注意 preload 并不会阻塞 window 的 onload 事件。
使用 preload 指令的好处包括:
as 属性来决定这个请求是否符合 content security policy。accept 头。这里有一个非常基本的预加载图像的例子:
<link rel="preload" href="image.png">这里有一个预加载字体的例子,记住:如果你的预加载需要 CORS 的跨域请求,那么也要加上 crossorigin 的属性。
<link rel="preload" href="https://example.com/fonts/font.woff" as="font" crossorigin>这里有一个通过 HTML 和 JavaScript 预加载样式表的例子:
<!-- Via markup -->
<link rel="preload" href="/css/mystyles.css" as="style"><!-- Via JavaScript -->
<script>
var res = document.createElement("link");
res.rel = "preload";
res.as = "style";
res.href = "css/mystyles.css";
document.head.appendChild(res);
</script>来自 filament group 的 Scott Jehl 也有了一些相关研究并写了 async loaded styles using markup 说明了 preload 是不阻塞页面渲染的!
Chrome 50 在 2016 年 4 月添加了对 Preload 的支持,Opera 37 等浏览器也支持它。不过目前 Mozilla Firefox 还没有确定要支持,Microsoft Edge 开发者版似乎要支持。
(译者注,下图是 2018 年 7 月末浏览器对 preload 的支持情况)

可以读一下我们对 preload 的一篇深入分析的文章。
Prefetch 是一个低优先级的资源提示,允许浏览器在后台(空闲时)获取将来可能用得到的资源,并且将他们存储在浏览器的缓存中。一旦一个页面加载完毕就会开始下载其他的资源,然后当用户点击了一个带有 prefetched 的连接,它将可以立刻从缓存中加载内容。有三种不同的 prefetch 的类型,link,DNS 和 prerendering,下面来详细分析。
像上面提到的,link prefetching 假设用户将请求它们,所以允许浏览器获取资源并将他们存储在缓存中。浏览器会寻找 HTML <link> 元素中的 prefetch 或者 HTTP 头中如下的 Link:
<link rel="prefetch" href="/uploads/images/pic.png">Link: </uploads/images/pic.png>; rel=prefetch"这项技术有为很多有交互网站提速的潜力,但并不会应用在所有地方。对于某些站点来说,太难猜测用户下一步的动向,对于另一些站点,提前获取资源可能导致数据过期失效。还有很重要的一点,不要过早进行 prefetch,否则会降低你当前浏览的页面的加载速度 —— Google Developers"
除了 Safari, iOS Safari 和 Opera Mini,现代浏览器已经支持了 link Prefetch,Chrome 和 Firefox 还会在网络面板上显示这些 prefetched 资源。
(译者注,下图是 2018 年 7 月末浏览器对 link prefetch 的支持情况)

DNS prefetching 允许浏览器在用户浏览页面时在后台运行 DNS 的解析。如此一来,DNS 的解析在用户点击一个链接时已经完成,所以可以减少延迟。可以在一个 link 标签的属性中添加 rel="dns-prefetch' 来对指定的 URL 进行 DNS prefetching,我们建议对 Google fonts,Google Analytics 和 CDN 进行处理。
"DNS 请求在带宽方面流量非常小,可是延迟会很高,尤其是在移动设备上。通过 prefetching 指定的 DNS 可以在特定的场景显著的减小延迟,比如用户点击链接的时候。有些时候,甚至可以减小一秒钟的延迟 —— Mozilla Developer Network"
这也对需要重定向的资源很有用,如下:
<!-- Prefetch DNS for external assets -->
<link rel="dns-prefetch" href="//fonts.googleapis.com">
<link rel="dns-prefetch" href="//www.google-analytics.com">
<link rel="dns-prefetch" href="//opensource.keycdn.com">
<link rel="dns-prefetch" href="//cdn.domain.com">不过要注意的是 Chrome 已经在敲击地址栏的时候做了类似的事情,比如 DNS preresolve 和 TCP preconnect,这些措施太酷了!你可以通过 chrome://dns/ 来查看你的优化列表。
你可以利用 Pagespeed 的过滤器 insert_dns_prefetch 来自动化的为所有域名插入 <link rel="dns-prefetch">。
DNS prefetch 已经被除了 Opera Mini 之外的所有现代浏览器支持了。
(译者注,下图是 2018 年 7 月末浏览器对 DNS-prefetch 的支持情况)

Prerendering 和 prefetching 非常相似,它们都优化了可能导航到的下一页上的资源的加载,区别是 prerendering 在后台渲染了整个页面,整个页面所有的资源。如下:
<link rel="prerender" href="https://www.keycdn.com">"prerender 提示可以用来指示将要导航到的下一个 HTML:用户代理将作为一个 HTML 的响应来获取和处理资源,要使用适当的 content-types 获取其他内容类型,或者不需要 HTML 预处理,可以使用 prefetch。—— W3C"
Source: Chrome Prerendering
要小心的使用 prerender,因为它将会加载很多资源并且可能造成带宽的浪费,尤其是在移动设备上。还要注意的是,你无法在 Chrome DevTools 中进行测试,而是在 chrome://net-internals/#prerender 中看是否有页面被 prerendered 了,你也可以在 prerender-test.appspot.com 进行测试。
除了 Mozilla Firefox,Safari,iOS Safari,Opera Mini 和 Android 浏览器外的一些现代浏览器已经支持了 prerendering。

除了多余的资源加载外,使用 prefetch 还有一切 额外的副作用,比如对隐私的损害:
可以读一下我们对 prefetching 的一篇深入分析的文章。
本文介绍的最后一个资源提示是 preconnect,preconnect 允许浏览器在一个 HTTP 请求正式发给服务器前预先执行一些操作,这包括 DNS 解析,TLS 协商,TCP 握手,这消除了往返延迟并为用户节省了时间。
"Preconnect 是优化的重要手段,它可以减少很多请求中的往返路径 —— 在某些情况下可以减少数百或者数千毫秒的延迟。—— lya Grigorik"
preconnect 可以直接添加到 HTML 中 link 标签的属性中,也可以写在 HTTP 头中或者通过 JavaScript 生成,如下是一个为 CDN 使用 preconnect 的例子:
<link href="https://cdn.domain.com" rel="preconnect" crossorigin>如下是为 Google Fonts 使用 preconnect 的例子,通过给 fonts.gstatic.com 加入 preconnect 提示,浏览器将立刻发起请求,和 CSS 请求并行执行。在这个场景下,preconnect 从关键路径中消除了三个 RTTs(Round-Trip Time) 并减少了超过半秒的延迟,lya Grigorik 的 eliminating RTTS with preconnect 一文中有更详细的分析。
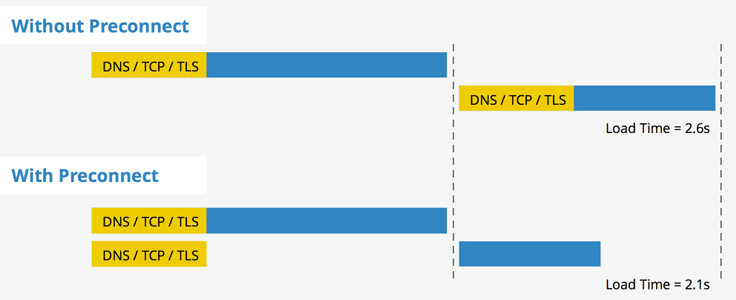
使用 preconnect 是个有效而且克制的资源优化方法,它不仅可以优化页面并且可以防止资源利用的浪费。除了 Internet Explorer,Safari,IOS Safari 和 Opera Mini 的现代浏览器已经支持了 preconnect。

可以读一下我们对 preconnect 的一篇深入分析的文章。
希望你现在对 preload,prefetch 和 preconnect 有了一些理解并知道如何利用它们来加速资源的加载,希望在未来的几个月能看到更多的浏览器支持这些预加载提示并且有更多的开发者使用它们。
你对这些资源提示有何理解?你试着使用过它们吗?欢迎留言讨论。
本文所分析的Redux版本为3.7.2
分析直接写在了注释里,放在了GitHub上 —> 仓库地址
分析代码时通过查看Github blame,参考了Redux的issue及PR来分析各个函数的意图而不仅是从代码层面分析函数的作用,并且分析了很多细节层面上写法的原因,比如:
dispatch: (...args) => dispatch(…args) 为什么不只传递一个 action ?
listener 的调用为什么从 forEach 改成了 for ?
为什么在 reducer 的调用过程中不允许 dispatch(action) ?
...
水平有限,有写的不好或不对的地方请指出,欢迎留issue交流😆
Redux的文件结构并不复杂,每个文件就是一个对外导出的函数,依赖很少,分析起来也比较容易,只要会用Redux基本上都能看懂本文。
这是Redux的目录结构:
.
├── applyMiddleware.js 将middleware串联起来生成一个更强大的dispatch函数,就是中间件的本质作用
├── bindActionCreators.js 把action creators转成拥有同名keys的对象
├── combineReducers.js 将多个reducer组合起来,每一个reducer独立管理自己对应的state
├── compose.js 将middleware从右向左依次调用,函数式编程中的常用方法,被applyMiddleware调用
├── createStore.js 最核心功能,创建一个store,包括实现了subscribe, unsubscribe, dispatch及state的储存
├── index.js 对外export
└── utils 一些小的辅助函数供其他的函数调用
├── actionTypes.js redux内置的action,用来初始化initialState
├── isPlainObject.js 用来判断是否为单纯对象
└── warning.js 报错提示
源码分析的顺序推荐如下,就是跟着pipeline的顺序来
index.js -> createStore.js -> applyMiddleware.js (compose.js) -> combineReducers.js -> bindActionCreators.js
主题思路我会写出来,很细节的部分就直接写在代码注释里了。
function isCrushed () {}
// 如果使用minified的redux代码会降低性能。
// 这里的isCrushed函数主要是为了验证在非生产环境下的redux代码是否被minified
// 如果被压缩了那么isCrushed.name !== 'isCrushed'
if (
process.env.NODE_ENV !== 'production' &&
typeof isCrushed.name === 'string' && // 有的浏览器(IE)并不支持Function.name,必须判断先判断是否支持Function.name,才能判断是否minified
isCrushed.name !== 'isCrushed'
) {
warning(
"...'
)
}
export {
createStore,
combineReducers,
bindActionCreators,
applyMiddleware,
compose,
__DO_NOT_USE__ActionTypes
}只有两个功能:
createStore 由于有两种生成 store 的方法,所以起手先确定各个参数
// 传递两个参数时,实际传递的是 reducer 和 enhancer,preloadedState 为 undefined
if (typeof preloadedState === 'function' && typeof enhancer === 'undefined') {
enhancer = preloadedState
preloadedState = undefined
}
// 传递三个参数时,传递的是 reducer preloadedState enhancer(enhancer必须为函数)
if (typeof enhancer !== 'undefined') {
if (typeof enhancer !== 'function') {
throw new Error('Expected the enhancer to be a function.')
}
// 如果传入了 enhancer(一个组合 store creator 的高阶函数)则控制反转,交由enhancer来加强要生成的store
// 再对这个加强后的 store 传递 reducer 和 preloadedState
return enhancer(createStore)(reducer, preloadedState)
}
// 传入的reducer必须是一个纯函数,且是必填参数
if (typeof reducer !== 'function') {
throw new Error('Expected the reducer to be a function.')
}然后声明中间变量,后面会讲到这些中间变量的作用
let currentReducer = reducer
let currentState = preloadedState
let currentListeners = []
let nextListeners = currentListeners
let isDispatching = false然后看怎么订阅一个事件,其实这就是一个发布-订阅模式,但是和普通的发布订阅模式不同的是, 多了一个ensureCanMutateNextListeners 函数。 我去翻了一下redux的commit message,找到了对listener做深拷贝的原因:https://github.com/reactjs/redux/issues/461,简单来说就是在listener中可能有unsubscribe操作,比如有3个listener(下标0,1,2),在第2个listener执行时unsubscribe了自己,那么第3个listener的下标就变成了1,但是for循环下一轮的下标是2,第3个listener就被跳过了,所以执行一次深拷贝,即使在listener过程中unsubscribe了也是更改的nextListeners(nextListeners会去深拷贝currentListeners)。当前执行的currentListeners不会被修改,也就是所谓的快照。
redux在执行subscribe和unsubscribe的时候都要执行ensureCanMutateNextListeners来确定是否要进行一次深拷贝,只要执行dispatch,那么就会被const listeners = (currentListeners = nextListeners),所以currentListeners === nextListeners,之后的subscribe和unsubscribe就必须深拷贝一次, 否则可以一直对nextListeners操作而不需要为currentListeners拷贝赋值,即只在必要时拷贝。
function subscribe (listener) {
// 传入的listener必须是一个可以调用的函数,否则报错
if (typeof listener !== 'function') {
throw new Error('Expected listener to be a function.')
}
// 同上,保证纯函数不带来副作用
if (isDispatching) {
throw new Error(
'...'
)
}
let isSubscribed = true
// 在每次subscribe的时候,nextListenerx先拷贝currentListeners,再push新的listener
ensureCanMutateNextListeners()
nextListeners.push(listener)
return function unsubscribe () {
if (!isSubscribed) {
return
}
// 同上,保证纯函数不带来副作用
if (isDispatching) {
throw new Error(
'...'
)
}
isSubscribed = false
// 在每次unsubscribe的时候,深拷贝一次currentListeners,再对nextListeners取消订阅当前listener
ensureCanMutateNextListeners()
// 从nextListeners中去掉unsubscribe的listener
const index = nextListeners.indexOf(listener)
nextListeners.splice(index, 1)
}
}接下来看 dispatch 这个函数,可以看到每次dispatch时会const listeners = (currentListeners = nextListeners),为可能到来的mutateNextListener做好准备。
function dispatch (action) {
// action必须是一个plain object,如果想要能处理传进来的函数的话必须使用中间件(redux-thunk等)
if (!isPlainObject(action)) {
throw new Error(
'Actions must be plain objects. ' +
'Use custom middleware for async actions.'
)
}
// action必须定义type属性
if (typeof action.type === 'undefined') {
throw new Error(
'Actions may not have an undefined "type" property. ' +
'Have you misspelled a constant?'
)
}
// 同上,保证纯函数不带来副作用
if (isDispatching) {
throw new Error('Reducers may not dispatch actions.')
}
// currentReducer不可预料是否会报错,所以try,但不catch
try {
isDispatching = true
currentState = currentReducer(currentState, action)
} finally {
// 必须在结束的时候将isDispatching归位
isDispatching = false
}
// 在这里体现了currentListeners和nextListeners的作用
const listeners = (currentListeners = nextListeners)
// 这里使用for而不是forEach,是因为listeners是我们自己创造的,不存在稀疏组的情况,所有直接用for性能来得更好
// 见 https://github.com/reactjs/redux/commit/5b586080b43ca233f78d56cbadf706c933fefd19
// 附上Dan的原话:This is an optimization because forEach() has more complicated logic per spec to deal with sparse arrays. Also it's better to not allocate a function when we can easily avoid that.
// 这里没有缓存listeners.length,Dan相信V8足够智能会自动缓存,相比手工缓存性能更好
for (let i = 0; i < listeners.length; i++) {
// 这里将listener单独新建一个变量而不是listener[i]()
// 是因为直接listeners[i]()会把listeners作为this泄漏,而赋值为listener()后this指向全局变量
// https://github.com/reactjs/redux/commit/8e82c15f1288a0a5c5c886ffd87e7e73dc0103e1
const listener = listeners[i]
listener()
}
return action
}接下来看getState,就是一个return
function getState () {
// 参考:https://github.com/reactjs/redux/issues/1568
// 为了保持reducer的pure,禁止在reducer中调用getState
// 纯函数reducer要求根据一定的输入即能得到确定的输出,所以禁止了getState,subscribe,unsubscribe和dispatch等会带来副作用的行为
if (isDispatching) {
throw new Error(
'You may not call store.getState() while the reducer is executing. ' +
'The reducer has already received the state as an argument. ' +
'Pass it down from the top reducer instead of reading it from the store.'
)
}
return currentState
}observable函数,这个是为了配合RxJS使用,如果不使用RxJS可以忽略,在这里略过。
replaceReducer函数是替换整个store的reducer,一般不经常用到,代码也含简单,换个reducer重新init一下
function replaceReducer (nextReducer) {
if (typeof nextReducer !== 'function') {
throw new Error('Expected the nextReducer to be a function.')
}
currentReducer = nextReducer
// ActionTypes.REPLACE其实就是ActionTypes.INIT
// 重新INIT依次是为了获取新的reducer中的默认参数
dispatch({ type: ActionTypes.REPLACE })
}最后,暴露的接口的功能都已经具备了,还需要取一下默认值,你可能会说不是已经有preloadedState了吗但是默认值不是只有一个的,每个reducer都可以指定对应部分的state的默认值,那些默认值需要先经过一个action的洗礼才可以被赋值,还记得reducer要求每个不可识别的action.type返回原始state吗?就是为了取得默认值。
// reducer要求对无法识别的action返回state,就是因为需要通过ActionTypes.INIT获取默认参数值并返回
// 当initailState和reducer的参数默认值都存在的时候,参数默认值将不起作用
// 因为在调用初始化的action前currState就已经被赋值了initialState
// 同时这个initialState也是服务端渲染的初始状态入口
dispatch({ type: ActionTypes.INIT })为了保证这个type是无法识别的,被定义成了一个随机值
const ActionTypes = {
// INIT和REPLACE一模一样,只是含义不同,REPLACE其实就是INIT
INIT:
'@@redux/INIT' +
Math.random()
.toString(36)
.substring(7)
.split('')
.join('.'),
REPLACE:
'@@redux/REPLACE' +
Math.random()
.toString(36)
.substring(7)
.split('')
.join('.')
}至此,我们的已经能够createStore,getState,subscribe,unsubscribe,dispatch了
combineReducer的代码挺长的,但是主要都是用来检查错误了,核心代码就是将要合并的代码组织组织成一个树结构,然后将传入的reduce挨个跑action,跑出的新的state替换掉原来的state,因为无法识别的action会返回原来的state,所以大部分无关的reducer会返回相同引用的state,只有真正捕获action的reducer会返回新的state,这样做到了局部更新,否则每次state的一部分更新导致所有的state都原地深拷贝一次就麻烦了。
export default function combineReducers (reducers) {
// 第一次筛选:将reducers中为function的属性赋值给finalReducers
const reducerKeys = Object.keys(reducers)
const finalReducers = {}
for (let i = 0; i < reducerKeys.length; i++) {
const key = reducerKeys[i]
if (process.env.NODE_ENV !== 'production') {
if (typeof reducers[key] === 'undefined') {
warning(`No reducer provided for key "${key}"`)
}
}
if (typeof reducers[key] === 'function') {
finalReducers[key] = reducers[key]
}
}
const finalReducerKeys = Object.keys(finalReducers)
let unexpectedKeyCache
if (process.env.NODE_ENV !== 'production') {
unexpectedKeyCache = {}
}
// 用来检查reducer是否会返回undefined
// 因为combineReducers有可能会嵌套多层,当嵌套的某一层如果返回undefined
// 那么当访问这一层的子reducer的时候就会发生TypeError的错误
let shapeAssertionError
try {
assertReducerShape(finalReducers)
} catch (e) {
shapeAssertionError = e
}
// combination:组合起来的reducer
return function combination (state = {}, action) {
// 如果之前的reducer检查不合法,则throw错误
if (shapeAssertionError) {
throw shapeAssertionError
}
// 检查excepted state并打印错误
if (process.env.NODE_ENV !== 'production') {
const warningMessage = getUnexpectedStateShapeWarningMessage(
state,
finalReducers,
action,
unexpectedKeyCache
)
if (warningMessage) {
warning(warningMessage)
}
}
//
let hasChanged = false
const nextState = {}
for (let i = 0; i < finalReducerKeys.length; i++) {
const key = finalReducerKeys[i]
const reducer = finalReducers[key]
const previousStateForKey = state[key]
const nextStateForKey = reducer(previousStateForKey, action)
// 不允许任何action返回undefined
if (typeof nextStateForKey === 'undefined') {
const errorMessage = getUndefinedStateErrorMessage(key, action)
throw new Error(errorMessage)
}
nextState[key] = nextStateForKey
hasChanged = hasChanged || nextStateForKey !== previousStateForKey
}
return hasChanged ? nextState : state
}这个用的不多,一般是为了方便,直接import *来引入多个actionCreators,原理很简单:实际上就是返回一个高阶函数,通过闭包引用,将 dispatch 给隐藏了起来,正常操作是发起一个 dispatch(action),但bindActionCreators 将 dispatch 隐藏,当执行bindActionCreators返回的函数时,就会dispatch(actionCreators(...arguments))。所以参数叫做 actionCreators,作用是返回一个 action
如果是一个对象里有多个 actionCreators 的话,就会类似 map 函数返回一个对应的对象,每个 key 对应的 value 就是上面所说的被绑定了的函数。
// 真正需要获取参数的函数被柯里化了起来
function bindActionCreator (actionCreator, dispatch) {
// 高阶函数,闭包引用 dispatch
return function () {
return dispatch(actionCreator.apply(this, arguments))
}
}
export default function bindActionCreators (actionCreators, dispatch) {
// 如果是actionCreators是函数,那么直接调用,比如是个需要被thunk的函数�
if (typeof actionCreators === 'function') {
return bindActionCreator(actionCreators, dispatch)
}
if (typeof actionCreators !== 'object' || actionCreators === null) {
throw new Error(
`...`
)
}
const keys = Object.keys(actionCreators)
const boundActionCreators = {}
for (let i = 0; i < keys.length; i++) {
const key = keys[i]
const actionCreator = actionCreators[key]
if (typeof actionCreator === 'function') {
// 每个 key 再次调用一次 bindActionCreator
boundActionCreators[key] = bindActionCreator(actionCreator, dispatch)
}
}
// map 后的对象
return boundActionCreators
}精髓来了,这个函数最短但是最精髓,这个 middleware 的洋葱模型的**是从koa的中间件拿过来的,我没看过koa的中间件(因为我连koa都没用过...),但是重要的是**。
放上redux的洋葱模型的示意图(via 中间件的洋葱模型)
--------------------------------------
| middleware1 |
| ---------------------------- |
| | middleware2 | |
| | ------------------- | |
| | | middleware3 | | |
| | | | | |
next next next ——————————— | | |
dispatch —————————————> | reducer | — 收尾工作->|
nextState <————————————— | G | | | |
| A | C | E ——————————— F | D | B |
| | | | | |
| | ------------------- | |
| ---------------------------- |
--------------------------------------
顺序 A -> C -> E -> G -> F -> D -> B
\---------------/ \----------/
↓ ↓
更新 state 完毕 收尾工作
单独理解太晦涩,放一个最简单的redux-thunk帮助理解。
redux-thunk:
function createThunkMiddleware(extraArgument) {
return ({ dispatch, getState }) => next => action => {
if (typeof action === 'function') {
return action(dispatch, getState, extraArgument);
}
return next(action);
};
}
const thunk = createThunkMiddleware();
thunk.withExtraArgument = createThunkMiddleware;
export default thunk;最难理解的就是那三个柯里化箭头,这三个箭头相当于欠了真正的middleware实体三个参数{dispatch, getState}, next, action,作为一个中间件,就是将这几个像管道一样在各个中间件中传递,与此同时加上一些副作用,比如后续管道的走向或者发起异步请求等等。
那么开始看欠的这三个参数是怎么还给中间件的,代码不长,所以直接写在注释里了,一行一行看就可以。
applyMiddleware:
export default function applyMiddleware (...middlewares) {
// 传入createStore
return createStore => (...args) => {
// 先用传入的createStore来创建一个最普通的store
const store = createStore(...args)
// 初始化dispatch,记住这个dispatch是最终我们要将各个中间件串联起来的dispatch
let dispatch = () => {
throw new Error(
`Dispatching while constructing your middleware is not allowed. ` +
`Other middleware would not be applied to this dispatch.`
)
}
// 储存将要被串联起来的中间件,函数签名为next => action => {...}
// 下一个中间件作为next传进去,被当前中间件调用
let chain = []
const middlewareAPI = {
getState: store.getState,
// 在这里dispatch使用匿名函数是为了能在middleware中调用最新的dispatch(闭包):
// 必须是匿名函数而不是直接写成dispatch: store.dispatch
// 这样能保证在middleware中传入的dispatch都通过闭包引用着最终compose出来的dispatch
// 如果直接写成store.dispatch,在`dispatch = compose(...chain)(store.dispatch)`中
// middlewareAPI.dispatch并没有得到更新,依旧是最老的,只有在最后才得到了更新
// 但是我们要保证在整个中间件的调用过程中,任何中间件调用的都是最终的dispatch
// 我写了个模拟的调用,可以在 http://jsbin.com/fezitiwike/edit?js,console 上感受一下
// 还有,这里使用了...args而不是action,是因为有个PR https://github.com/reactjs/redux/pull/2560
// 这个PR的作者认为在dispatch时需要提供多个参数,像这样`dispatch(action, option)`
// 这种情况确实存在,但是只有当这个需提供多参数的中间件是第一个被调用的中间件时(即在middlewares数组中排最后)才有效
// 因为无法保证上一个调用这个多参数中间件的中间件是使用的next(action)或是next(...args)来调用
// 在这个PR的讨论中可以看到Dan对这个改动持保留意见
dispatch: (...args) => dispatch(...args)
}
// 还了 {dispatch, getState}
chain = middlewares.map(middleware => middleware(middlewareAPI))
// 还了 next
// 最开始的 next 就是 store.dispatch
// 相当于就是每个中间件在自己的过程中做一些操作,做完之后调用下一个中间件(next(action))
dispatch = compose(...chain)(store.dispatch)
// 最终返回一个dispatch被修改了的store,这个dispatch串联起了中间件
// 欠的那个action会在dispatch的时候传入
return {
...store,
dispatch
}
}
}HTML页面的生命周期有以下三个重要事件:
DOMContentLoaded —— 浏览器已经完全加载了 HTML,DOM 树已经构建完毕,但是像是 <img> 和样式表等外部资源可能并没有下载完毕。load —— 浏览器已经加载了所有的资源(图像,样式表等)。beforeunload/unload —— 当用户离开页面的时候触发。每个事件都有特定的用途
DOMContentLoaded —— DOM 加载完毕,所以 JS 可以访问所有 DOM 节点,初始化界面。load —— 附加资源已经加载完毕,可以在此事件触发时获得图像的大小(如果没有被在 HTML/CSS 中指定)beforeunload/unload —— 用户正在离开页面:可以询问用户是否保存了更改以及是否确定要离开页面。来看一下每个事件的细节。
DOMContentLoaded 由 document 对象触发。
我们使用 addEventListener 来监听它:
document.addEventListener("DOMContentLoaded", ready);举个例子
<script>
function ready() {
alert('DOM is ready');
// image is not yet loaded (unless was cached), so the size is 0x0
alert(`Image size: ${img.offsetWidth}x${img.offsetHeight}`);
}
document.addEventListener("DOMContentLoaded", ready);
</script>
<img id="img" src="https://en.js.cx/clipart/train.gif?speed=1&cache=0">在这个例子中 DOMContentLoaded 在 document 加载完成后就被触发,无需等待其他资源的载入,所以 alert 输出的图像的大小为 0。
这么看来 DOMContentLoaded 似乎很简单,DOM 树构建完毕之后就运行该事件,不过其实存在一些陷阱。
当浏览器在解析 HTML 页面时遇到了 <script>...</script> 标签,将无法继续构建DOM树(译注:UI 渲染线程与 JS 引擎是互斥的,当 JS 引擎执行时 UI 线程会被挂起),必须立即执行脚本。所以 DOMContentLoaded 有可能在所有脚本执行完毕后触发。
外部脚本(带 src 的)的加载和解析也会暂停DOM树构建,所以 DOMContentLoaded 也会等待外部脚本。
不过有两个例外是带 async 和 defer 的外部脚本,他们告诉浏览器继续解析而不需要等待脚本的执行,所以用户可以在脚本加载完成前可以看到页面,有较好的用户体验。
async 和 defer 属性仅仅对外部脚本起作用,并且他们在 src 不存在时会被自动忽略。
它们都告诉浏览器继续处理页面上的内容,而在后台加载脚本,然后在脚本加载完毕后再执行。所以脚本不会阻塞DOM树的构建和页面的渲染。
(译注:带有 async 和 defer 的脚本的下载是和 HTML 的下载与解析是并行的,但是 JS 的执行一定是和 UI 线程是互斥的,像下面这张图所示,async 在下载完毕后的执行会阻塞HTML的解析)
他们有两处不同:
async |
defer |
|
|---|---|---|
| 顺序 | 带有 async 的脚本是优先执行先加载完的脚本,他们在页面中的顺序并不影响他们执行的顺序。 |
带有 defer 的脚本按照他们在页面中出现的顺序依次执行。 |
DOMContentLoaded |
带有 async 的脚本也许会在页面没有完全下载完之前就加载,这种情况会在脚本很小或本缓存,并且页面很大的情况下发生。 |
带有 defer 的脚本会在页面加载和解析完毕后执行,刚好在 DOMContentLoaded 之前执行。 |
所以 async 用在那些完全不依赖其他脚本的脚本上。
外部样式表并不会阻塞 DOM 的解析,所以 DOMContentLoaded 并不会被它们影响。
不过仍然有一个陷阱:如果在样式后面有一个内联脚本,那么脚本必须等待样式先加载完。
(译注:简单来说,JS 因为有可能会去获取 DOM 的样式,所以 JS 会等待样式表加载完毕,而 JS 是阻塞 DOM 的解析的,所以在有外部样式表的时候,JS 会一直阻塞到外部样式表下载完毕)
<link type="text/css" rel="stylesheet" href="style.css">
<script>
// 脚本直到样式表加载完毕后才会执行。
alert(getComputedStyle(document.body).marginTop);
</script>发生这种事的原因是脚本也许会像上面的例子中所示,去得到一些元素的坐标或者基于样式的属性。所以他们自然要等到样式加载完毕才可以执行。
DOMContentLoaded 需要等待脚本的执行,脚本又需要等待样式的加载。
Firefox, Chrome 和 Opera 会在 DOMContentLoaded 执行时自动补全表单。
例如,如果页面有登录的界面,浏览器记住了该页面的用户名和密码,那么在 DOMContentLoaded 运行的时候浏览器会试图自动补全表单(如果用户设置允许)。
所以如果 DOMContentLoaded 被一个需要长时间执行的脚本阻塞,那么自动补全也会等待。你也许见过某些网站(如果你的浏览器开启了自动补全)—— 浏览器并不会立刻补全登录项,而是等到整个页面加载完毕后才填充。这就是因为在等待 DOMContentLoaded 事件。
使用带 async 和 defer 的脚本的一个好处就是,他们不会阻塞 DOMContentLoaded 和浏览器自动补全。(译注:其实执行还是会阻塞的)
2018.02.05:defer 是会阻塞 DOMContentLoaded 的,被 defer 的脚本要在 DOMContentLoaded 触发前执行,所以如果HTML很快就加载完了(先不考虑 CSS 阻塞 DOMContentLoaded 的情况),而 defer 的脚本还没有加载完,浏览器就会等,等到脚本加载完,执行完,再触发 DOMContentLoaded,放上一张图(取自在 devTool 下分析自己写的一个页面)

可以看到,HTML很快就加载和解析完毕(CSS 在这里是动态加载的,不阻塞 DOMContentLoaded),jQuery 和main.js 的脚本是 defer 的, DOMContentLoaded(蓝线)一直在等,等到这两个脚本下载完并执行完,才触发了 DOMContentLoaded。
从这个角度看来,defer 和把脚本放在 </body> 前真是没啥区别,只不过 defer 脚本位 于head 中,更早被读到,加载更早,而且不担心会被其他的脚本推迟下载开始的时间。
window 对象上的 onload 事件在所有文件包括样式表,图片和其他资源下载完毕后触发。
下面的例子正确检测了图片的大小,因为 window.onload 会等待所有图片的加载。
<script>
window.onload = function() {
alert('Page loaded');
// image is loaded at this time
alert(`Image size: ${img.offsetWidth}x${img.offsetHeight}`);
};
</script>
<img id="img" src="https://en.js.cx/clipart/train.gif?speed=1&cache=0">用户离开页面的时候,window 对象上的 unload 事件会被触发,我们可以做一些不存在延迟的事情,比如关闭弹出的窗口,可是我们无法阻止用户转移到另一个页面上。
所以我们需要使用另一个事件 — onbeforeunload。
如果用户即将离开页面或者关闭窗口时,beforeunload 事件将会被触发以进行额外的确认。
浏览器将显示返回的字符串,举个例子:
window.onbeforeunload = function() {
return "There are unsaved changes. Leave now?";
};有些浏览器像 Chrome 和火狐会忽略返回的字符串取而代之显示浏览器自身的文本,这是为了安全考虑,来保证用户不受到错误信息的误导。
如果我们在整个页面加载完毕后设置 DOMContentLoaded 会发生什么呢?
啥也没有,DOMContentLoaded 不会被触发。
有一些情况我们无法确定页面上是否已经加载完毕,比如一个带有 async 的外部脚本的加载和执行是异步的**(译注:执行不是异步的 -_-)**。在不同的网络状况下,脚本有可能是在页面加载完毕后执行也有可能是在页面加载完毕前执行,我们无法确定。所以我们需要知道页面加载的状况。
document.readyState 属性给了我们加载的信息,有三个可能的值:
loading 加载 —— document仍在加载。interactive 互动 —— 文档已经完成加载,文档已被解析,但是诸如图像,样式表和框架之类的子资源仍在加载。complete —— 文档和所有子资源已完成加载。状态表示 load 事件即将被触发。所以我们可以检查 document.readyState 的状态,如果没有就绪可以选择挂载事件,如果已经就绪了就可以直接立即执行。
像这样:
function work() { /*...*/ }
if (document.readyState == 'loading') {
document.addEventListener('DOMContentLoaded', work);
} else {
work();
}每当文档的加载状态改变的时候就有一个 readystatechange 事件被触发,所以我们可以打印所有的状态。
// current state
console.log(document.readyState);
// print state changes
document.addEventListener('readystatechange', () => console.log(document.readyState));readystatechange 是追踪页面加载的一个可选的方法,很早之前就已经出现了。不过现在很少被使用了,为了保持完整性还是介绍一下它。
readystatechange 的在各个事件中的执行顺序又是如何呢?
<script>
function log(text) { /* output the time and message */ }
log('initial readyState:' + document.readyState);
document.addEventListener('readystatechange', () => log('readyState:' + document.readyState));
document.addEventListener('DOMContentLoaded', () => log('DOMContentLoaded'));
window.onload = () => log('window onload');
</script>
<iframe src="iframe.html" onload="log('iframe onload')"></iframe>
<img src="http://en.js.cx/clipart/train.gif" id="img">
<script>
img.onload = () => log('img onload');
</script>输出如下:
[1] initial readyState:loading[2] readyState:interactive[2] DOMContentLoaded[3] iframe onload[4] readyState:complete[4] img onload[4] window onload方括号中的数字表示他们发生的时间,真实的发生时间会更晚一点,不过相同数字的时间可以认为是在同一时刻被按顺序触发(误差在几毫秒之内)
document.readyState 在 DOMContentLoaded 前一刻变为 interactive,这两个事件可以认为是同时发生。document.readyState 在所有资源加载完毕后(包括 iframe 和 img)变成 complete,我们可以看到complete、 img.onload 和 window.onload 几乎同时发生,区别就是 window.onload 在所有其他的 load 事件之后执行。页面事件的生命周期:
DOMContentLoaded 事件在DOM树构建完毕后被触发,我们可以在这个阶段使用 JS 去访问元素。
async 和 defer 的脚本可能还没有执行。load 事件在页面所有资源被加载完毕后触发,通常我们不会用到这个事件,因为我们不需要等那么久。beforeunload 在用户即将离开页面时触发,它返回一个字符串,浏览器会向用户展示并询问这个字符串以确定是否离开。unload 在用户已经离开时触发,我们在这个阶段仅可以做一些没有延迟的操作,由于种种限制,很少被使用。document.readyState 表征页面的加载状态,可以在 readystatechange 中追踪页面的变化状态:
loading —— 页面正在加载中。interactive —— 页面解析完毕,时间上和 DOMContentLoaded 同时发生,不过顺序在它之前。complete —— 页面上的资源都已加载完毕,时间上和 window.onload 同时发生,不过顺序在他之前。原文地址:A Simple React Router v4 Tutorial
React Router v4 是一个完全使用 React 重写的流行的 React 包,之前版本的 React Router 版本配置是使用伪组件也很晦涩难懂。现在 v4 版本的 React Router,所有的东西都 “仅仅是组件”。
在这个教程中,我们将建立一个本地的 "运动队" 页面,我们将完成所有的基本需求来建立我们的网站和路由,这包括:
router。routes。React Router 现在已经被划分成了三个包:react-router,react-router-dom,react-router-native。
你不应该直接安装 react-router,这个包为 React Router 应用提供了核心的路由组件和函数,另外两个包提供了特定环境的组件(浏览器和 react-native 对应的平台),不过他们也是将 react-router 导出的模块再次导出。
你应该选择这两个中适应你开发环境的包,我们需要构建一个网站(在浏览器中运行),所以我们要安装 react-router-dom
npm install --save react-router-dom当开始一个新项目时,你应该决定要使用哪种 router。对于在浏览器中运行的项目,我们可以选择 <BrowserRouter 和 <HashRouter> 组件,<BrowserRouter> 应该用在服务器处理动态请求的项目中(知道如何处理任意的URI),<HashRouter> 用来处理静态页面(只能响应请求已知文件的请求)。
通常来说更推荐使用 <BrowserRouter>,可是如果服务器只处理静态页面的请求,那么使用 <HashRouter> 也是一个足够的解决方案。
对于我们的项目,我们假设所有的页面都是由服务器动态生成的,所以我们的 router 组件选择 <BrowserRouter>。
每个 router 都会创建一个 history 对象,用来保持对当前位置[1]的追踪还有在页面发生变化的时候重新渲染页面。React Router 提供的其他组件依赖在 context 上储存的 history 对象,所以他们必须在 router 对象的内部渲染。一个没有 router 祖先元素的 React Router 对象将无法正常工作,如果你想学习更多的关于 history 对象的知识,可以参照 这篇文章。
<Router>Router 的组件只能接受一个子元素,为了遵照这种限制,创建一个 <App> 组件来渲染其他的应用将非常方便(将应用从 router 中分离对服务器端渲染也有重要意义,因为我们在服务器端转换到 <MemoryRouter> 时可以很快复用 <App>)
import { BrowserRouter } from 'react-router-dom'
ReactDOM.render((
<BrowserRouter>
<App />
</BrowserRouter>
), document.getElementById('root'))现在我们已经选择了 router,我们可以开始渲染我们真正的应用了。
<App>我们的应用定义在 <App> 组件中,为了简化 <App>,我们将我们的应用分为两个部分,<Header> 组件包含链接到其他页面的导航,<Main> 组件包含其余的需要渲染的部分。
// this component will be rendered by our <___Router>
const App = () => (
<div>
<Header />
<Main />
</div>
)Note: 你可以任意布局你的应用,分离 routes 和导航让你更加容易了解 React Router 是如何工作的。
我们先从渲染我们路由内容的 <Main> 组件开始。
<Route> 组件是 React Router 的主要组成部分,如果你想要在路径符合的时候在任何地方渲染什么东西,你就应该创造一个 <Route> 元素。
一个 <Route> 组件需要一个 string 类型的 path prop 来指定路由需要匹配的路径。举例来说,<Route path='/roster/' 将匹配以 /roster [2] 开始的路径,当当前的路径和 path 匹配时,route 将会渲染对应的 React 元素。当路径不匹配的时候 ,路由不会渲染任何元素 [3]。
<Route path='/roster'/>
// when the pathname is '/', the path does not match
// when the pathname is '/roster' or '/roster/2', the path matches
// If you only want to match '/roster', then you need to use
// the "exact" prop. The following will match '/roster', but not
// '/roster/2'.
<Route exact path='/roster'/>
// You might find yourself adding the exact prop to most routes.
// In the future (i.e. v5), the exac t prop will likely be true by
// default. For more information on that, you can check out this
// GitHub issue:
// https://github.com/ReactTraining/react-router/issues/4958**Note: **在匹配路由的时候,React Router 只会关心相对路径的部分,所以如下的 URL
http://www.example.com/my-projects/one?extra=false
React Router 只会尝试匹配 /my-projects/one。
React Router使用 path-to-regexp 包来判断路径的 path prop 是否匹配当前路径,它将 path 字符串转换成正则表达式与当前的路径进行匹配,关于 path 字符串更多的可选格式,可以查阅 path-to-regexp 文档。
当路由与路径匹配的时候,一个具有以下属性的 match 对象将会被作为 prop 传入
url - 当前路径与路由相匹配的部分path - 路由的pathisExact - path === pathnameparams - 一个包含着 pathname 被 path-to-regexp 捕获的对象**Note: **目前,路由的路径必须是绝对路径 [4]。
<Route>s 可以在router中的任意位置被创建,不过一般来说将他们放到同一个地方渲染更加合理,你可以使用 <Switch> 组件来组合 <Route>s,<Switch> 将遍历它的 children 元素(路由),然后只匹配第一个符合的 pathname。
对于我们的网站来说,我们想要匹配的路径为:
/ - 主页/roster - 队伍名单/roster/:number - 队员的资料,使用球员的球衣号码来区分/schedule - 队伍的赛程表为了匹配路径,我们需要创建带 path prop的 <Route> 元素
<Switch>
<Route exact path='/' component={Home}/>
{/* both /roster and /roster/:number begin with /roster */}
<Route path='/roster' component={Roster}/>
<Route path='/schedule' component={Schedule}/>
</Switch><Route> 将会渲染什么Routes 可以接受三种 prop 来决定路径匹配时渲染的元素,只能给 <Route> 元素提供一种来定义要渲染的内容。
<component> - 一个 React 组件,当一个带有 component prop 的路由匹配的时候,路由将会返回 prop 提供的 component 类型的组件(通过 React.createElement 渲染)。render - 一个返回 React 元素 [5] 的方法,与 component 类似,也是当路径匹配的时候会被调用。写成内联形式渲染和传递参数的时候非常方便。children - 一个返回 React 元素的方法。与前两种不同的是,这种方法总是会被渲染,无论路由与当前的路径是否匹配。<Route path='/page' component={Page} />
const extraProps = { color: 'red' }
<Route path='/page' render={(props) => (
<Page {...props} data={extraProps}/>
)}/>
<Route path='/page' children={(props) => (
props.match
? <Page {...props}/>
: <EmptyPage {...props}/>
)}/>一般来说,我们一般使用 component 或者 render,children 的使用场景不多,而且一般来说当路由不匹配的时候最好不要渲染任何东西。在我们的例子中,不需要向路由传递任何参数,所有我们使用 <component>。
由 <Route> 渲染的元素将会带有一系列的 props,有 match 对象,当前的 location 对象 [6],还有 history 对象(由 router 创建)[7]。
<Main>现在我们已经确定了 route 的结构,我们只需要将他们实现即可。在我们的应用中,我们将会在 <Main> 组件中渲染 <Switch> 和 <Route>,它们将会在 <main> 中渲染 HTML 元素。
import { Switch, Route } from 'react-router-dom'
const Main = () => (
<main>
<Switch>
<Route exact path='/' component={Home}/>
<Route path='/roster' component={Roster}/>
<Route path='/schedule' component={Schedule}/>
</Switch>
</main>
)**Note: **主页的路由带有 exact prop,这表明只有路由的 path 完全匹配 pathname 的时候才会匹配主页。
队员资料页的路由 /roster/:number 是在 <Roster> 组件而没有包含在 <Switch> 中。但是,只要 pathname 由 /roster 开头,它就会被 <Roster> 组件渲染。
在 <Roster> 组件中我们将渲染两种路径:
/roster - 只有当路径完全匹配 /roster 时会被渲染,我们要对该路径指定 exact 参数。/roster/:number - 这个路由使用一个路径参数来捕获 /roster 后面带的 pathname 的部分。const Roster = () => (
<Switch>
<Route exact path='/roster' component={FullRoster}/>
<Route path='/roster/:number' component={Player}/>
</Switch>
)将带有相同前缀的路由放在同一个组件中很方便,这样可以简化父组件并且让我们可以让我们在一个地方渲染所有带有相同前缀的组件。
举个例子,<Roster> 可以为所有以 /roster 开头的路由渲染一个标题
const Roster = () => (
<div>
<h2>This is a roster page!</h2>
<Switch>
<Route exact path='/roster' component={FullRoster}/>
<Route path='/roster/:number' component={Player}/>
</Switch>
</div>
)有的时候我们想捕捉 pathname 中的多个参数,举例来说,在我们的球员资料路由中,我们可以通过向路由的 path 添加路径参数来捕获球员的号码。
:number 部分代表在pathname中 /roster/ 后面的内容将会被储存在 match.params.number。举例来说,一个为 /roster/6 的 pathname 将会生成一个如下的params 对象。
{ number: '6' } // note that the captured value is a string<Player> 组件使用 props.match.params 对象来决定应该渲染哪个球员的资料。
// an API that returns a player object
import PlayerAPI from './PlayerAPI'
const Player = (props) => {
const player = PlayerAPI.get(
parseInt(props.match.params.number, 10)
)
if (!player) {
return <div>Sorry, but the player was not found</div>
}
return (
<div>
<h1>{player.name} (#{player.number})</h1>
<h2>{player.position}</h2>
</div>
)关于 path 参数可以查阅 path-to-regexp 文档。
紧挨着 <Player>,还有一个 <FullRoster>,<Schedule> 和 <Home> 组件。
const FullRoster = () => (
<div>
<ul>
{
PlayerAPI.all().map(p => (
<li key={p.number}>
<Link to={`/roster/${p.number}`}>{p.name}</Link>
</li>
))
}
</ul>
</div>
)
const Schedule = () => (
<div>
<ul>
<li>6/5 @ Evergreens</li>
<li>6/8 vs Kickers</li>
<li>6/14 @ United</li>
</ul>
</div>
)
const Home = () => (
<div>
<h1>Welcome to the Tornadoes Website!</h1>
</div>
)最后,我们的网站需要在页面之间导航,如果我们使用 <a> 标签导航的话,将会载入一整个新的页面。React Router 提供了一个 <Link> 组件来避免这种情况,当点击 <Link> 时,URL 将会更新,页面也会在不载入整个新页面的情况下渲染内容。
import { Link } from 'react-router-dom'
const Header = () => (
<header>
<nav>
<ul>
<li><Link to='/'>Home</Link></li>
<li><Link to='/roster'>Roster</Link></li>
<li><Link to='/schedule'>Schedule</Link></li>
</ul>
</nav>
</header>
)<Link>s 使用 to prop 来决定导航的目标,可以是一个字符串,或者是一个 location 对象(包含 pathname, search, hash 和 state 属性)。当只是一个字符串的时候,将会被转化为一个 location 对象
<Link to={{ pathname: '/roster/7' }}>Player #7</Link>**Note: **目前,链接的 pathname 必须是绝对路径。
两个在线的例子:
[1] locations 是包含描述 URL 不同部分的参数的对象
// a basic location object
{ pathname: '/', search: '', hash: '', key: 'abc123' state: {} }[2] 可以一个无路径的 <Route>,这个路由将会匹配所有路径,这样可以很方便的访问存储在 context 上的对象和方法。
[3] 当使用 children prop 时,即使在路径不匹配的时候也会渲染。
[4] 让 <Route>s 和 <Link>s 接受相对路径的工作还未完成,相对的 <Link>s 比看上去要复杂的多,因为它们需要父组件的 match 对象来工作,而不是当前的 URL。
[5] 这是个基本的无状态组件,component 和 render 的区别是,component 会使用 React.createElement 来创建一个元素,render 使用将组件视作一个函数。如果你想创建一个内联函数并传递给 component,那么 render 会比 component 来的快得多。
<Route path='/one' component={One}/>
// React.createElement(props.component)
<Route path='/two' render={() => <Two />}/>
// props.render()[6] <Route> 和 <Switch> 组件都可以接受一个 location prop,这可以让他们被一个不同的 location 匹配到,而不仅仅是他们实际的 location(当前的 URL)。
[7] props 也可以传递 staticContext 这个 prop,但是只在使用服务端渲染的时候有效。
作为一个基本上只会 push 和 pull 的还依赖于 SourceTree 的 git 弱渣,随手记录一下自己主要使用的 git 命令,让自己以后找起来更方便🙄
场景:你在最后一条 commit 消息里有个笔误,已经执行了 git commit -m "Fxies bug #42",但在git push 之前你意识到消息应该是 “Fixes bug #42″。
方法:git commit --amend 或 git commit --amend -m "Fixes bug #42"
详细:git commit --amend 会用一个新的 commit 更新并替换最近的 commit ,这个新的 commit 会把任何修改内容和上一个 commit 的内容结合起来。如果当前没有提出任何修改,这个操作就只会把上次的 commit 消息重写一遍。
场景:突然发现之前的一次或几次commit不是十分满意,想要撤销或修改这条commit记录
方法:git rebase -i HEAD~X
详细: git rebase 可以用来修改历史的 commit 记录,包括压缩快进等。也可以用来修改 commit message,在需要修改 commit message 前修改为 e 或 r 即可。
参考:How to modify existing, unpushed commits?
场景:在完成了一次本地commit之后,对这次commit不是十分满意,想要撤销这条commit记录
方法:git reset <last good SHA> 或 git reset --hard <last good SHA>
详细:git reset 会把你的代码库历史返回到指定的 SHA 状态。 这样就像是这些提交从来没有发生过。缺省情况下,撤销的 commit 的修改的代码将会恢复到工作区,对应的 commit 的记录被撤销掉。如果加了--hard,那么撤销的 commit 的代码也会消失掉。如果想一并撤销远端的提交,使用 git push origin master --force 或者 git push -f origin master 即可,sourceTree 里也有开启 force push 的选项。
参考:Force “git push” to overwrite remote files
场景:在本地开了一个仓库并且有了一些 commit,同时在 Github 上也开了一个仓库,这种情况下是无法直接 pull 将两个仓库同步的,会报错 fatal: refusing to merge unrelated histories
方法:git pull origin master --allow-unrelated-histories
详细:要合并的两个仓库没有共同的节点,相当于是要将两段不同的 history 合并,默认情况下是不允许的,需要添加 --allow-unrelated-histories
参考:
场景: 将多次提交的commit合并为一次提交。
方法:
场景:在 master 分支下我们是开发环境,里面有 node_modules,这个文件夹在 gitignore 中当然是被忽略的的。然后我们在 gh-pages 中要做一个展示分支,放一些静态资源。那么每次当我们切换到 gh-pages 再切回 master 下时,master 下的 node_modules 就不!见!了!(因为没有被 track),导致还要重新 npm install 一次。
方法:
git worktree add ../temp gh-pagesgit worktree add ../temp -b gh-pages然后我们就可以在 temp 文件中中随意操作,任何操作都会和原来的仓库保持同步。
commit 后,即可删除掉这个 temp 文件夹,然后执行 git worktree prune 清理一下 linked working tree 记录即可。
详细:git worktree 可以将分支切换到其他文件夹下,原来的文件夹叫做 main working tree,其他文件夹又叫做 linked working tree, linked working tree 已经完成了 git init 和 git clone 的操作,在 linked working tree 会被自动合并到 main linked working tree。
参考:
本文基于 react 16.3- 版本,所讨论的都是老版本的生命周期函数。
React 作为一个视图框架,速度已经很快了,并且在 React16 新推出的 Fiber 架构中,通过时间切片及高优先级任务中断来尽快相应用户的操作。尽管如此,React 也并不能揣测出开发者真正的意图,如果开发者的代码没有遵循最佳实践,就容易造成性能上的负担。
React 在内部维护了一套虚拟 DOM(VDOM),在内部维护着一颗 VDOM 树,这颗 VDOM 树映射到浏览器真实的 DOM 树,React 通过更新 VDOM 树来对真实 DOM 更新,VDOM 是 plain object 所以很明显操作 VDOM 的开销要比操作真实 DOM 快得多,再加上 React 内部的 reconciler,React 会在 reconsilation 之后最小化的进行 VDOM 的更新,再 patch 到真实 DOM 上最终完成用户看得到的更新。
但是 React 不是万能的,当我们更新一个组件时,整个 reconciliation 会经过如下阶段(并不是完整的,但是会经过)
组件的 props/state 更改(开发者控制) -> shouldComponentUpdate(开发者控制)-> 计算 VDOM 的更新(React 的 diff 算法会计算出最小化的更新)-> 更新真实 DOM (React 控制)
这几个箭头,每个箭头都是 YES or NO,返回 NO 就会中断后面的流程。每一步都会带来开销,所以对不需要更新的元素,我们一定要尽早中断这个流程,作为开发者能控制的就是第一个和第二个箭头。即是否传递新的 props/state,和 shouldComponentUpdate 的返回值控制。
你应该为每个使用 class 声明的组件添加 shouldComponentUpdate,否则一旦接受新的 props/state 就可能进行不必要的 re-render。
如果你很清楚每次的 props 或 state 的都是一个指向新引用的对象,那么可以直接使用 PureComponent,PureComponent 已经实现了一套浅比较的(shallowCompare)的 shouldComponentUpdate 的规则。
在React里,shouldComponentUpdate 源码为:
if (this._compositeType === CompositeTypes.PureClass) {
shouldUpdate = !shallowEqual(prevProps, nextProps) || ! shallowEqual(inst.state, nextState);
}来看下 shallowEqual 的源码
'use strict';
const hasOwnProperty = Object.prototype.hasOwnProperty;
/**
* inlined Object.is polyfill to avoid requiring consumers ship their own
* https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Object/is
*/
function is(x: mixed, y: mixed): boolean {
// SameValue algorithm
if (x === y) { // Steps 1-5, 7-10
// Steps 6.b-6.e: +0 != -0
// Added the nonzero y check to make Flow happy, but it is redundant
return x !== 0 || y !== 0 || 1 / x === 1 / y;
} else {
// Step 6.a: NaN == NaN
return x !== x && y !== y;
}
}
/**
* Performs equality by iterating through keys on an object and returning false
* when any key has values which are not strictly equal between the arguments.
* Returns true when the values of all keys are strictly equal.
*/
function shallowEqual(objA: mixed, objB: mixed): boolean {
if (is(objA, objB)) { // 如果 ===,返回 true
return true;
}
if (typeof objA !== 'object' || objA === null ||
typeof objB !== 'object' || objB === null) {
return false;
}
const keysA = Object.keys(objA);
const keysB = Object.keys(objB);
if (keysA.length !== keysB.length) {
return false;
}
// Test for A's keys different from B.
for (let i = 0; i < keysA.length; i++) {
if (
!hasOwnProperty.call(objB, keysA[i]) || // A B 中包含相同元素且相等,函数也是直接用 === 来比较
!is(objA[keysA[i]], objB[keysA[i]])
) {
return false;
}
}
return true;
}shallowEqual 会对两个对象的每个属性进行比较,如果是非引用类型,那么可以直接比较判断是否相等。如果是引用类型,则通过比较引用的地址进行严格比较(===)。
当 props 和 state 是不可突变数据的时候,可以直接使用 PureComponent,PureComponent 非常适合配合 immutablejs 来做优化。
官方推荐使用 stateless component(以下简称 sc),对它的定义是这么写的
This simplified component API is intended for components that are pure functions of their props.
sc 的表达式是一个纯函数,完全符合 UI = f(state) 的公式,纯函数意味着可预测(给定输入可以获得可预测的输出),这样我们在写代码及调试的时候能对组有更好的把握,如果需要引入副作用则请使用 class。
sc 一般被用来当作展示组件,这样做的好处有:
但是要注意,这并不意味着滥用 sc:
state should be managed by higher-level “container” components, or via Flux/Redux/etc.
不要让 sc 直接暴露在数据逻辑中,sc 的父组件要完成对 sc 以下行为的控制:
第二点一般来说没有问题,因为 sc 的渲染的数据是外层的逻辑组件传入的,sc 只负责 view。
第一点一定要控制好,因为 sc 没有生命周期,只要传入新的 props/state 就会 re-render,而且这意味着,一旦 sc 的父组件更新,sc 就会 re-render。re-render 就会带来 VDOM的 diff,这会带来一笔开销(这比开销也可能会是更好的选择,也可能不是,见下文)。
sc 和 PureComponent 各有优缺点。
sc 的缺点:
PureComponent 的缺点
shallowCompare 比 diffing 算法需要耗费更多的时间
所以一个组件如果经常变更的话,那么 PureComponent 多带来的两次检查会让他通常更慢。
使用这个经验法则:pure component适用于复杂的表单和表格,但它们通常会减慢简单元素(按钮、图标)的效率。
一般来说,sc 适用于小的组件(就索性让它做 diff,diff 的开销小,反正不变就不会改变真实 DOM)。PureComponent 适用于稍大一点的组件,diff 的代价是随着组件的增大而提升,shallowCompare 与组件无关的复杂度无关而是与 props 的数量挂钩,不同的组件和 props 的要根据实际情况来判断。
无论是编写哪个阶段的
render函数,请牢记一点:保证它的“纯粹”(pure)。怎样才算纯粹?最基本的一点是不要尝试在render里改变组件的状态。
很多人喜欢在 render 函数中子组件通过构造一个箭头函数来传递给子组件,但是这样有一个问题就是,每次都会声明一个新的箭头函数,因而每次声明的函数都肯定是不同的,所以就会导致如果你用了 PureComponent 也无法阻止 re-render,如下:
class Parent extends React.Component {
constructor(props) {
super(props);
this.state = {
count: 0
};
}
onClick() {
this.setState({
count: this.state.count + 1
});
}
render() {
return (
<div>
{this.state.count}
<Child onClick={() => {
this.onClick();
}}
/>
</div>
);
}
}
class Child extends React.PureComponent {
render() {
console.log("Child re-render");
return <button onClick={this.props.onClick}>add</button>;
}
}解决方案:在 constructor 中 bind,甚至或者是闭包引用一个 self = this ,或者在类声明中直接定义实例属性**(推荐)**,都可以做到绑定 this。
作为 key 的键应该符合以下条件
唯一的: 元素的 key 在它的兄弟元素中应该是唯一的。没有必要拥有全局唯一的 key。
稳定的: 元素的 key 不应随着时间,页面刷新或是元素重新排序而变。
可预测的: 你可以在需要时拿到同样的 key,意思是 key 不应是随机生成的。
在渲染一个列表时最好不要用每个项的 index 去当做他的 key,因为如果其中有一个项被删除或移动,则整个 key 就失去了与原项的对应关系,加大了 diff 的开销。
通常,你应该依赖于数据库生成的 ID 如关系数据库的主键,Mongo 中的对象 ID。如果数据库 ID 不可用,你可以生成内容的哈希值来作为 key。关于哈希值的更多内容可以在这里阅读。
多数情况下我们的应用是要配合 Redux 或者 MobX 使用的。拿 Redux 举例,Redux store 的组织是一门大学问,Redux 官方推荐将 store 组织得扁平化和范式化,所谓扁平化,就是整个 store 的嵌套关系不要太深,实体之下不再挂载实体,扁平化带来的好处是
当某些数据需要在不同的地方出现时,就会存在必然重复。例如,可能存在很多 state 部分都要存储同一份“用户评论列表”,这样需要花费很多心思去保障多处“用户评论列表”数据状态一致,否则就会造成页面数据不同步的 Bug;
嵌套深层的数据结构,会直接造成你 reducers 编写复杂。比如,你想更新一个很深层次的数据片段,很容易代码就变得丑陋。具体可以参考我的这篇文章:如何优雅安全地在深层数据结构中取值;
**造成负面的性能影响。**即便你使用了类似 immutable.js 这样的不可变数据类库,最大限度的想保障深层数据带来的性能压力,那你是否知道 immutable.js 采用的 “Persistent data structure” 思路,更新节点会造成同一条链儿上的祖先节点的更新。更恐怖的是,也许这些都会关联到众多 React 组件的 re-render;
范式化是指尽量去除数据的冗余,因为这样会给维护数据的一致性带来困难,就像官方推荐 state 记录尽可能少的数据,不应该存放计算得到的数据和 props 的副本,而是将他们直接在 render 中使用,这也是避免了维护数据一致性的困难,并且避免了相同数据满天飞不知道源头数据是哪个的尴尬。
首先要明确,不要将所有的状态全部放在 store 中,其实再延伸一下可以延伸出 render(){} 中的变量,也就是 store vs state vs render,store 中应该存放异步获取的数据或者多个组件需要访问的数据等等,redux 官方文档中也有写什么数据应该放入 store 中。
- 应用中的其他部分需要用到这部分数据吗?
- 是否需要根据这部分原始数据创建衍生数据?
- 这部分相同的数据是否用于驱动多个组件?
- 你是否需要能够将数据恢复到某个特定的时间点(比如:在时间旅行调试的时候)?
- 是否需要缓存数据?(比如:直接使用已经存在的数据,而不是重新请求)
而 store 中不应该保存 UI 的状态(除非符合上面的某一点,比如回退时页面的滚动位置)。UI 的状态应该被限定在 UI 的 state 中,随着组件的卸载而销毁。而 state 也应该用最少的数据表示尽可能多的信息。在 render 函数中,根据 state 去衍生其他的信息而不是将这样冗余的信息都存在 state 中。store 和 state 都应该尽可能的做到熵最小,具体的可以看 redux store取代react state合理吗?。而 render 中的变量应该尽可以去承担一个衍生数据的责任,这个过程是无副作用的,可以减少在 state 中产生冗余数据的情况。
下面来看一个例子,一个 list 有 10000 个未标记的 Item,点击某一 Item 该 Item 就会变为已标记,再点击就会变为未标记。很简单对不对,我们采用 redux + react-redux 来实现。
store 中存储的 state 为
{
[{id:0, marked: false}, {id:1, marked: false}, ...]
}然后 App 组件里直接用 map 去渲染
class App extends Component {
render() {
const { items, markItem } = this.props;
return (
<div className="main" style={{overflow: 'scroll', height: '600px'}}>
{items.map(item =>
<Item key={item.id} id={item.id} marked={item.marked} onClick={markItem} />
)}
</div>
);
}
};
function mapStateToProps(state) {
return state;
}
export default connect(mapStateToProps, {markItem})(App);每个条目的 onClick 对应的回调函数
function itemsReducer(state = initial_state, action) {
switch (action.type) {
case 'MARK':
return state.map((item) =>
action.id === item.id ? {...item, marked: !item.marked } : item
);
default:
return state;
}
}每次点击时派发一个 action
const markItem = (id) => ({type: 'MARK', id});很简单对不对,在数量少时看不出任何问题,但是到了 10000 时就会暴露出性能问题,点击一个 Item,UI 的反应可以说慢到爆炸。

慢的原因就是 App 组件被更新,触发了 re-render,也可以发现,App[update] 下面是密密麻麻的 Item 的 re-render 耗时,fiber 已经将整个更新的过程切片,这样不会导致在 re-render 的过程中失去对界面的操控,但是真正的渲染依旧耗时很长。
问题就是每次点击派发 action 之后,reducer 都会返回一个新的 state,这个新的 state 会触发 connect 的 App 的 re-render,App 又重新渲染每个 Item,Item 直接 render,导致不必要的 reconciliation。
基于上上面的改进,那就对每个 Item 增加一个 shouldComponentUpdate,在每次更新来临的时候拒绝掉这次更新。
shouldComponentUpdate(nextProps) {
if (this.props["marked"] === nextProps["marked"]) {
return false;
}
return true;
}速度快了一些:

但是,shouldComponentUpdate 也是有开销的的,密密麻麻的 shouldComponentUpdate 即使返回 false 也拖慢了整体的时间,而且本例中的 shouldComponentUpdate 相对来说并不复杂,如果遇到更复杂的 model 耗时将会更久。
继续改进,想一下最优解,当我们在更新一个 Item 时,如果其他未被修改的 Item 的 props 和 state 没有任何的改变,那么就完全不会经过他们的生命周期。
所以,这里要将数据和组件重新组合。为了避免父组件的 re-render,我们将每个 Item 和 redux store 直接连接,将 store 拆分为 ids 和 items,用 ids 给父组件完成 Item 初始化提供一些必要的信息,用 items 对 Item 进行初始化和更新。每次点击的时候 ids 不变,所以父组件不会 re-render,只更新对应的子组件。子组件的 reducer:
function items(state = initial_state, action) {
switch (action.type) {
case 'MARK':
const item = state[action.id];
return {
...state,
[action.id]: {...item, marked: !item.marked}
};
default:
return state;
}
}当某个 Item 被 mark 时,虽然返回了一个新的对象,但是 … 解构函数是浅拷贝,所以 items 数组中对象的引用不变,只有发生更新的那个对象是新的。这样就做到了只改变需要改变的 Item 的 props。

除了真正要更新的 Item,其他所有 Item 对这次点击都是无感知的,性能好了很多。
但是 ids 和 items 中的 id 冗余了,如果后面还要再加上添加和删除的功能就要同时修改两个属性,如果 ids 只是用来初始化 App 的话就会一直在 store 中残留,还容易引起误会。所以,还是将 store 变回如下的组织:
store:{
items:[
{id: 0, marked: false},
{id: 1, marked: false},
...
]
}其他的处理的方式类似 better list 2,每次进行局部更新
但是要补全 App 的 shouldComponentUpdate,因为虽然是局部更新,但是 reducer 是一个纯函数,纯函数每次不修改原 state,返回一个新 state,所以只要手动控制一个 App 的 shouldComponentUpdate 即可,根据业务需要写即可,这里只是做个演示,就直接返回了 false,相当于 App 只是完成初始化的功能。
shouldComponentUpdate() {
return false
}来看一下跑分(误)

跑分依旧不错。
这里在说一下 react-redux 的 HOC 触发更新的条件:
这里有两个问题:1. 在 react-redux 中,connect 出来的 HOC 是怎么感知 store 的变化的?2. 什么的变化会触发 HOC 的更新?
先来解决第一个问题:
react-redux 通过 Provider 提供的 context 上的 store,在内部向 store subscribe 了 onStateChange 事件
trySubscribe() {
if (!this.unsubscribe) {
this.unsubscribe = this.parentSub
? this.parentSub.addNestedSub(this.onStateChange)
: this.store.subscribe(this.onStateChange)
this.listeners = createListenerCollection()
}
}只要派发了 action,就会触发一次 onStateChange 事件,HOC 就能感知 store 的更新再根据 onStateChange 的结果决定是否要 update。再来看 onStateChange 的源码:
onStateChange() {
this.selector.run(this.props)
if (!this.selector.shouldComponentUpdate) {
this.notifyNestedSubs()
} else {
this.componentDidUpdate = this.notifyNestedSubsOnComponentDidUpdate
this.setState(dummyState)
}
}是由 run 这个是个方法来每次决定每一次的 shouldComponentUpdate
function makeSelectorStateful(sourceSelector, store) {
// wrap the selector in an object that tracks its results between runs.
const selector = {
run: function runComponentSelector(props) {
try {
const nextProps = sourceSelector(store.getState(), props)
if (nextProps !== selector.props || selector.error) {
selector.shouldComponentUpdate = true
selector.props = nextProps
selector.error = null
}
} catch (error) {
selector.shouldComponentUpdate = true
selector.error = error
}
}
}
return selector
}在这里,sourceSelector 我们就知道它是一个 selector 就好,后面会再去研究。也就是说,当 store 更新的通知到来,就会调用 sourceSelector 重新计算一次结果,与上次缓存的结果进行 === 比较。如果发现比较不相等,即需要更新,shouldComponent 置为 true,同时本次新计算出来的结果作为缓存,用来与下次更新进行比较判断是否要 update。
OK,下面来看 sourceSelector 到底 select 了出个什么东西用来判断是否更新:
export default function finalPropsSelectorFactory(dispatch, {
initMapStateToProps,
initMapDispatchToProps,
initMergeProps,
...options
}) {
const mapStateToProps = initMapStateToProps(dispatch, options)
const mapDispatchToProps = initMapDispatchToProps(dispatch, options)
const mergeProps = initMergeProps(dispatch, options)
if (process.env.NODE_ENV !== 'production') {
verifySubselectors(mapStateToProps, mapDispatchToProps, mergeProps, options.displayName)
}
const selectorFactory = options.pure
? pureFinalPropsSelectorFactory
: impureFinalPropsSelectorFactory
return selectorFactory(
mapStateToProps,
mapDispatchToProps,
mergeProps,
dispatch,
options
)
}函数中的 mapStateToProps 和 mapDispatchToProps 是通过两个 initxxxx 函数来生成的,options 中包含了用户传入的 mapXXXXToProps,我们拿 mapStateToProps 来说,在 connect 中
const initMapStateToProps = match(mapStateToProps, mapStateToPropsFactories, 'mapStateToProps')match 的作用就是将第一个参数依次放入第二个参数的每一项中(第二个参数是一个数组),返回第一个不为 undefined 的结果。
正常情况下是返回这个函数的结果:
export function wrapMapToPropsFunc(mapToProps, methodName) {
return function initProxySelector(dispatch, { displayName }) {
const proxy = function mapToPropsProxy(stateOrDispatch, ownProps) {
return proxy.dependsOnOwnProps
? proxy.mapToProps(stateOrDispatch, ownProps)
: proxy.mapToProps(stateOrDispatch)
}
// allow detectFactoryAndVerify to get ownProps
proxy.dependsOnOwnProps = true
proxy.mapToProps = function detectFactoryAndVerify(stateOrDispatch, ownProps) {
proxy.mapToProps = mapToProps
proxy.dependsOnOwnProps = getDependsOnOwnProps(mapToProps)
let props = proxy(stateOrDispatch, ownProps)
if (typeof props === 'function') {
proxy.mapToProps = props
proxy.dependsOnOwnProps = getDependsOnOwnProps(props)
props = proxy(stateOrDispatch, ownProps)
}
if (process.env.NODE_ENV !== 'production')
verifyPlainObject(props, displayName, methodName)
return props
}
return proxy
}
}这个函数其实作用不大,返回一个 initProxy,proxy 其实还是调用了用户定义的 mapStateToProps,但是对初始化有作用。我们可以把它理解成一个健全版本的 mapStateToProps。回到 finalPropsSelectorFactory,我们拿到了一个初始化过的 mapStateToProps,mapDispatchToProps 和 mergeProps,等下,mergeProps是什么?这个函数可以看做是我们合并的策略,新的 props 或者 mapXXX 传入时,通过这个策略去合并出要传给包裹的组件的 props。
这三个参数会一并传入 pureFinalPropsSelectorFactory
export function pureFinalPropsSelectorFactory(
mapStateToProps,
mapDispatchToProps,
mergeProps,
dispatch,
{ areStatesEqual, areOwnPropsEqual, areStatePropsEqual }
) {
let hasRunAtLeastOnce = false
// 以下为缓存
let state
let ownProps
let stateProps
let dispatchProps
let mergedProps
// 界面初始化时的入口
// 缓存 state, ownProps, stateProps, dispatchProps,mergedProps(同时也是我们要的结果)
function handleFirstCall(firstState, firstOwnProps) {
state = firstState
ownProps = firstOwnProps
stateProps = mapStateToProps(state, ownProps)
dispatchProps = mapDispatchToProps(dispatch, ownProps)
mergedProps = mergeProps(stateProps, dispatchProps, ownProps)
hasRunAtLeastOnce = true
return mergedProps
}
// 如果 store 和 props 都更新了
function handleNewPropsAndNewState() {
stateProps = mapStateToProps(state, ownProps)
if (mapDispatchToProps.dependsOnOwnProps)
dispatchProps = mapDispatchToProps(dispatch, ownProps)
mergedProps = mergeProps(stateProps, dispatchProps, ownProps)
return mergedProps
}
// 如果 props 更新了
function handleNewProps() {
if (mapStateToProps.dependsOnOwnProps)
stateProps = mapStateToProps(state, ownProps)
if (mapDispatchToProps.dependsOnOwnProps)
dispatchProps = mapDispatchToProps(dispatch, ownProps)
mergedProps = mergeProps(stateProps, dispatchProps, ownProps)
return mergedProps
}
// 如果 store 更新了
function handleNewState() {
const nextStateProps = mapStateToProps(state, ownProps)
const statePropsChanged = !areStatePropsEqual(nextStateProps, stateProps)
stateProps = nextStateProps
if (statePropsChanged)
mergedProps = mergeProps(stateProps, dispatchProps, ownProps)
return mergedProps
}
// 界面非初始化时的入口
function handleSubsequentCalls(nextState, nextOwnProps) {
const propsChanged = !areOwnPropsEqual(nextOwnProps, ownProps) // 被赋值为 shallowEqual
const stateChanged = !areStatesEqual(nextState, state) // 被赋值为 shallowEqual
state = nextState
ownProps = nextOwnProps
if (propsChanged && stateChanged) return handleNewPropsAndNewState() // props & store 都更新
if (propsChanged) return handleNewProps() // props 更新
if (stateChanged) return handleNewState() // store 更新
return mergedProps // 如果 store 和 props 都没改变直接返回缓存
}
return function pureFinalPropsSelector(nextState, nextOwnProps) {
return hasRunAtLeastOnce
? handleSubsequentCalls(nextState, nextOwnProps)
: handleFirstCall(nextState, nextOwnProps)
}
}这个函数根据不同的更新来计算新的需要 merge 的状态(在 connect 中我们一般是不传入 mergeProps 这个参数的,会调用默认的 mergeProps 充当)。
然后传入 mergeProps 来进行合并,来看 mergeProps 的合并策略:
export function defaultMergeProps(stateProps, dispatchProps, ownProps) {
return { ...ownProps, ...stateProps, ...dispatchProps }
}就是用解构操作符返回一个新对象。再返回上面的 pureFinalPropsSelectorFactory,这个函数中缓存了 state, ownProps, stateProps, dispatchProps,mergedProps,如果 store 和 props 都不更新的话,那么直接返回上次计算的 mergedProps,如果 props 改变了,那么重新计算 props 的部分,其他的部分用之前的缓存,(store 更新同理,哪部分不变就用之前的缓存,变的再重新计算)再通过解构操作符返回一个浅拷贝的新对象用来表明已更新。
所以到这里就已经清楚了:当 store 更新到来时,会调用 mergeProps 将新的参数直接 shallowMerge,重新将 ownProps, mapDispatchToProps,mapStateToProps 经过缓存优化(1. 不计算没改变的值 2. 如果都没改变那么直接返回缓存的结果,什么都不计算)。之后作为 selector 的结果传出去,再通过一次缓存进行比较(上层的函数也要再判断一次 selector 的结果变没变),如果不相同那么再更新被包裹的组件。
本次优化中并没有使用 reselect。reselect 的作用就是缓存上一次 selector 的结果,和下一次 selector 的结果进行对比,如果相同就直接拿出之前缓存的 state。一般是为了防止其他无关状态的修改影响影响当前界面对应的 state,导致重渲染。在本例中,state 逻辑较简单,不存在其他的业务逻辑修改的情况。但是使用 reselect 优化的思路是一样,reselect 在 data -> view 之间添加了一层缓存来避免不必要的 re-render,我们可以使用它来进行 selector 的定义,很适合配合 react-redux 的 connect 之后生成的监听 store 的 HOC 使用。
immutablejs 拥有持久化数据结构 + 结构共享的特点。immutable 能带来颇多好处:
相比普通深拷贝和浅拷贝,immutable 的“拷贝”不会造成 CPU 和内存的浪费
由于对象创建之后具有不可变性,我们不用担心它在其他地方被修改,足够安全。
便于 undo/redo,copy/paste。试想,不用 immutable 做时间旅行,那么需要将涉及回溯部分的 state 深拷贝下来然后用一个栈保存起来。
能够对深层嵌套的数据准确的修改而不修改任何其他任何对象。比如 JS Bin1 中,
由于 setState 是 shallowMerge(相当于解构操作符或者 Object.assgn),所以每次 setState 触发时 middle 会消失掉,如果要用原生 JS 来解决这个问题,可以这样:
this.setState({
user: {
school: [...this.state.user.school, high: test]
}
})如果使用 immutable 的话,就:
handleChangeSchool(e) {
var v = e.target.value;
this.setImmState(d => d.updateIn(['user','school', 'high'], ()=>v));
}安全的修改,不用担心修改了不该修改的对象的部分。
在性能方面来说,刚才的例子中我们使用解构操作符来完成新的 state 的生成:
function items(state = initial_state, action) {
switch (action.type) {
case 'MARK':
const item = state[action.id];
return {
...state,
[action.id]: {...item, marked: !item.marked}
};
default:
return state;
}
}解构操作符是浅拷贝,和 Ojbect.assign 类似,通过 window.performance.now() 来测试每次生成新的 state 的时间大约是 ~5ms,如果state 使用 immutable 来填充,经过测试一次不到 1ms。看似收益很小,但是 state 中的数据数量更多或者嵌套的结构更加复杂时性能的问题就会凸显出来,而且在结构更加复杂的时候,原生的操作也会变得更加复杂(一层一层的解构还要判断是否为 undefined 才能进入下一层),使用 immutable 会大大简化操作。还有,在使用 immutable 时对象的比较一般是 shallowCompare ,相比 deepCompare 要快得多。
但是 immutable 也不是没有代价的,immutable 由于共享解构,所以对某一项的修改会非常快,但是与原生 JS 的转化会花费较多时间(fromJS 和 toJS,因为要访问原生对象的每个节点并且生成字典树)。这就导致如果使用 immutable,那么最好都在 immutable 的数据结构中处理数据,如果非要转化为原生 JS,一定要找一个开销更少的出口。
但是 connect 出来的 HOC 的 shouldComponent 已近实现了,所以配合 immutable 时还需要 reselect 的缓存利用 Immutable.is 进行比较。
即使是 better list 3,页面更新也需要 200ms,在每个 Event(click) 的右上角都有一个小红三角,代表造成了帧率过低,性能低下的原因就是在浏览器及 React 中维护了过多的真实 DOM 和 VDOM,但实际上用户可见的视窗是有限的,只需要渲染视窗可见的 Item 即可,这就是长列表的问题范畴了,大家可以去了解一下,有各种不同的解决方案,比如 react-virtualized。
React 官方文档里推荐的性能检测方法,是对 Chrome Devtool 的加强,可以将 Devtool 中 JS 部分的火焰图细分为组件各个声明周期的时间,在目前的开发模式下,不用输入 ?rect_perf 也已经开启了这个功能,生产模式下的页面仍然需要加上这个命令。
官方已经介绍了使用方法,方法也很简单:
Chrome浏览器内:
- 在项目地址栏内添加查询字符串
?react_perf(例如,http://localhost:3000/?react_perf)。- 打开Chrome开发工具Performance 标签页点击Record.
- 执行你想要分析的动作。不要记录超过20s,不然Chrome可能会挂起。
- 停止记录。
- React事件将会被归类在 User Timing标签下。
还有额外的几点
放上一个用来测试的页面:TODOMVC,这个页面故意加入了会导致性能问题的代码,我们来通过 Devtool 找出是哪段代码的问题。
按照上面的步骤,记录一个 Todo Item 被执行的过程的性能,如下:

可以看到,有一点很长的 JS 持续运行时间,而 JS 线程和 UI 线程是互斥的,也就是说这在 JS 疯狂执行的这 467ms 中,用户完全无法操作页面,接下来再分析是怎样的代码造成了如此长时间的执行。


原来是被加了一个 200ms 的循环,以此类推,就可以找到 React 渲染的瓶颈组件。
这个库可以在控制台上打印出可能的可以避免多次 re-render 的操作。查看源码,原理也很简单,通过比较每次 render 时组件的 prevProps 和 this.props,这里的比较是深比较,对 plain object 递归比较,对同为函数的相同属性只通过比较函数名来判断是否相同。
配置也非常简单。
import React from 'react';
if (process.env.NODE_ENV !== 'production') {
const {whyDidYouUpdate} = require('why-did-you-update');
whyDidYouUpdate(React);
}通过官方的 DevTools 我们可以手动修改 state 和 prop 的属性

还可以高亮出正在 re-render 的代码,蓝色框代表很少 re-render 的组件,随着 re-render 次数的增长依次是绿色,黄色,红色,这里要注意 highlight 对 React15 和 16 的处理不同。
With React 15 and earlier, "Highlight Updates" had false positives and highlighted more components than were actually re-rendering.
Since React 16, it correctly highlights only components that were re-rendered.
还可以
$r 获得元素的引用,比如可以选中 Provider,然后 $r.store.getState() 获得 Redux store。更多的信息可以查看官方文档。
Make React Fast Again Part 1: Performance Timeline
Make React Fast Again Part 2: why-did-you-update
Make React Fast Again Part 3: Highlighting Component Updates
High Performance React: 3 New Tools to Speed Up Your Apps
Chrome Profiler: Self-Time vs. Total-Time
React Stateless Functional Components: Nine Wins You Might Have Overlooked
React: Component Class vs Stateless Component
How to greatly improve your React app performance
Understanding the trade-offs between stateless functional components and PureComponent
React, Inline Functions, and Performance
实现一个 LazyMan,可以按照以下方式调用:
LazyMan("Hank")
输出:
Hi! This is Hank!
LazyMan("Hank").sleep(10).eat("dinner")
输出:
Hi! This is Hank!
等待10秒..
Wake up after 10
Eat dinner
LazyMan("Hank").eat("dinner").eat("supper")
输出:
Hi This is Hank!
Eat dinner
Eat supper
LazyMan("Hank").sleepFirst(5).eat("supper")
等待5秒
Wake up after 5
Hi This is Hank!
Eat supper
纯 callback 实现, 每个注册的事件的最后会调用对象队列中的下一个事件。
class LazyMan {
constructor(name) {
this.name = name
this.sayName = this.sayName.bind(this)
this.next = this.next.bind(this)
this.queue = [this.sayName]
setTimeout(this.next, 0)
}
callByOrder(queue) {
let sequence = Promise.resolve()
this.queue.forEach(item => {
sequence = sequence.then(item)
})
}
next(){
const currTask = this.queue.shift()
currTask && currTask()
}
sayName() {
console.log(`Hi! this is ${this.name}!`)
this.next()
}
holdOn(time) {
setTimeout(() => {
console.log(`Wake up after ${time} second`)
this.next()
}, time * 1000)
}
sleep(time) {
this.queue.push(this.holdOn(time))
return this
}
eat(meal) {
this.queue.push(() => {
console.log(`eat ${meal}`)
this.next()
})
return this
}
sleepFirst(time) {
this.queue.unshift(this.holdOn(time))
return this
}
}手工在每次方法执行后通过 then 调整 Promise 链的序列,缺点是因为 sleepFirst 要强行插入 Promise 链的第一位,要单独抽象出一部分逻辑来前置它的 Promise。
class LazyMan {
constructor(name) {
this.name = name
this._preSleepTime = 0
this.sayName = this.sayName.bind(this)
this.p = Promise.resolve().then(() => {
if (this._preSleepTime > 0) {
return this.holdOn(this._preSleepTime)
}
}).then(this.sayName)
}
sayName() {
console.log(`Hi! this is ${this.name}!`)
}
holdOn(time) {
return new Promise(resolve => {
setTimeout(() => {
console.log(`Wake up after ${time} second`)
resolve()
}, time * 1000)
})
}
sleep(time) {
this.p = this.p.then(
() => this.holdOn(time)
)
return this
}
eat(meal) {
this.p = this.p.then(() => {
console.log(`eat ${meal}`)
})
return this
}
sleepFirst(time) {
this._preSleepTime = time
return this
}
}在对象内部维护一个队列,让所有的事件都变成异步的,然后在内部通过 Promise.resolve.then() 来将队列的执行启动推迟到下一个 eventloop,这样做逻辑更清楚,所有事件都由队列来管理。
class LazyMan {
constructor(name) {
this.name = name
this.sayName = this.sayName.bind(this)
this.queue = [this.sayName]
Promise.resolve().then(() => this.callByOrder(this.queue))
}
callByOrder(queue) {
let sequence = Promise.resolve()
this.queue.forEach(item => {
sequence = sequence.then(item)
})
}
sayName() {
return new Promise((resolve) => {
console.log(`Hi! this is ${this.name}!`)
resolve()
})
}
holdOn(time) {
return () => new Promise(resolve => {
setTimeout(() => {
console.log(`Wake up after ${time} second`)
resolve()
}, time * 1000)
})
}
sleep(time) {
this.queue.push(this.holdOn(time))
return this
}
eat(meal) {
this.queue.push(() => {
console.log(`eat ${meal}`)
})
return this
}
sleepFirst(time) {
this.queue.unshift(this.holdOn(time))
return this
}
}基本思路与第 2 种方法相同,不同的地方只在于使用了 async 来顺序执行队列。
class LazyMan {
constructor(name) {
this.name = name
this.sayName = this.sayName.bind(this)
this.queue = [this.sayName]
setTimeout(async () => {
for (let todo of this.queue) {
await todo()
}
}, 0)
}
callByOrder(queue) {
let sequence = Promise.resolve()
this.queue.forEach(item => {
sequence = sequence.then(item)
})
}
sayName() {
return new Promise((resolve) => {
console.log(`Hi! this is ${this.name}!`)
resolve()
})
}
holdOn(time) {
return () => new Promise(resolve => {
setTimeout(() => {
console.log(`Wake up after ${time} second`)
resolve()
}, time * 1000)
})
}
sleep(time) {
this.queue.push(this.holdOn(time))
return this
}
eat(meal) {
this.queue.push(() => {
console.log(`eat ${meal}`)
})
return this
}
sleepFirst(time) {
this.queue.unshift(this.holdOn(time))
return this
}
}整个过程其实还挺有意思的,多写几种方法挺练 Promise 和整个异步调用的思维的..
koa2 的目录结构相当整洁,只有四个文件,搭起了整个 server 的框架,koa 只是负「开头」(接受请求)和「结尾」(响应请求),对请求的处理都是由中间件来实现。
├── lib
│ ├── application.js // 负责串联起 context request response 和中间件
│ ├── context.js // 一次请求的上下文
│ ├── request.js // koa 中的请求
│ └── response.js // koa 中的响应
└── package.json
application.js:负责串联起 context request response 和中间件
context.js:一次请求的上下文
request.js:koa 中的请求
response.js:koa 中的响应
我们从官网给的一个最小化的 demo 一步一步解析 koa 的源码了解其整个流程:
const Koa = require('koa');
// 初始化
const app = new Koa();
// 添加中间件
app.use(async ctx => {
ctx.body = 'Hello World';
});
// 启动
app.listen(3000);Koa 这个类是从 application.js 中导入的 Application,Application 继承自 Emmiter,Emmiter 唯一的作用就是去回调 onerror 事件,因为一次成功的 HTTP 请求会由 HTTP 模块来负责回调,但 error 是可能在中间件中 throw 出来的,此时就需要去通知 app 发生错误了。这在运行中的部分会有分析。
既然是初始化,就来看 koa 的构造函数:
constructor() {
super();
this.proxy = false;
this.middleware = []; // 存储中间件,构造洋葱模型
this.subdomainOffset = 2;
this.env = process.env.NODE_ENV || "development";
this.context = Object.create(context); // 继承自 context
this.request = Object.create(request); // 继承自 request
this.response = Object.create(response); // 继承自 response
if (util.inspect.custom) {
this[util.inspect.custom] = this.inspect;
}
}request 和 response 就是继承自 ./request.js 和 ./response, ./request.js 和 ./response 中的 request 和 response 做的事情并不复杂,就是将 Node 原生的 http 的 req 和 res 再次做了封装,便于读取和设置,每个属性和方法的封装都不复杂,具体的属性和方法 koa 的文档上已经写的很清楚了,这里就不再介绍了。
至于 context,context 是一个「传递的纽带」,每个中间件传递的就是 context,它承载了这次访问的所有内容,直到其被最终 response 掉。
其实看源码 context 就是一个普通的对象,普通对象就可以完成「记录并传递」这个作用,context 还额外提供了 error 和 cookie 的处理,因为 app 是继承自 Emmiter 只有它能订阅 onerror 事件,所以传递的 context 要包裹一个 app 的 onerror 事件来在中间件中传递。
运行中有一个很重要和基本的概念就是:HTTP 请求是幂等的。
Methods can also have the property of "idempotence" in that (aside from error or expiration issues) the side-effects of N > 0 identical requests is the same as for a single request.
一次和多次请求某一个资源应该具有同样的副作用,也就是说每个 HTTP 请求都会有一套全新的 context,request,response。
整个运行中的流程如下:

核心代码如下:
构建新的 context,request,response,其中 context/request/response/app 中各种引用对方来保证各自方便的传递。
这里比较有意思的是,在构造函数中,this.context 是继承自 context.js 文件,这里在每次请求时又继承自 this.context。
这样的好处是你可以为你的 app 设定一个类似模板的 context,这样一来每个请求的 context 在继承时就会有一些预设的方法或属性,同理 this.request 和 this.response。
createContext(req, res) {
const context = Object.create(this.context); // 从 this.context 中继承
const request = (context.request = Object.create(this.request)); // 从 this.request 中继承
const response = (context.response = Object.create(this.response)); // this.response 中继承
context.app = request.app = response.app = this;
context.req = request.req = response.req = req;
context.res = request.res = response.res = res;
request.ctx = response.ctx = context;
request.response = response;
response.request = request;
context.originalUrl = request.originalUrl = req.url;
// 中间件中用来传递的命名空间
context.state = {};
return context;
}调用 http 的端口监听
listen(...args) {
debug("listen");
// node 的 http 模块会去监听这个端口并触发回调
const server = http.createServer(this.callback());
return server.listen(...args);
}构建 http 的回调函数
callback() {
// compose 一个中间件洋葱模型【运行时确定中间件】
const fn = compose(this.middleware);
// koa 会挂载一个默认的错误处理【运行时确定异常处理】
if (!this.listenerCount("error")) this.on("error", this.onerror);
// node 的 http 模块会回调这个函数
const handleRequest = (req, res) => {
// 构造 koa context【运行时构造新的 ctx req res】
const ctx = this.createContext(req, res);
// 由 ctx 和中间件去响应
return this.handleRequest(ctx, fn);
};
return handleRequest;
}中间件及异常处理
handleRequest(ctx, fnMiddleware) {
const res = ctx.res;
res.statusCode = 404;
const onerror = err => ctx.onerror(err);
// koa 在中间件处理完之后返回 response
const handleResponse = () => respond(ctx);
// Execute a callback when a HTTP request closes, finishes, or errors.
// 兜底的错误处理
onFinished(res, onerror);
return fnMiddleware(ctx) // 中间件先处理
.then(handleResponse) // ctx.res 就是最后想要的结果
.catch(onerror); // catch 中间件中抛出的异常
}koa 自带的成功 res 处理
function respond(ctx) {
// allow bypassing koa
if (false === ctx.respond) return;
if (!ctx.writable) return;
const res = ctx.res;
let body = ctx.body;
const code = ctx.status;
// ignore body
// 后面都是处理 body 的了,如果是不需要 body 的请求,则 body 直接为 null 就可以返回了。
// statuses 库中有三种请求会直接是无 body 的(其实也就是根据 HTTP 规范),分别是:
// 204: No Content 响应,就表示执行成功,但是没有数据,浏览器不用刷新页面,也不用导向新的页面。
// 205: Reset Content 响应,205的意思是在接受了浏览器 POST 请求以后处理成功以后,告诉浏览器,执行成功了,请清空用户填写的 Form 表单,方便用户再次填写。
// 304: 协商缓存
// refer: http://www.laruence.com/2011/01/20/1844.html
if (statuses.empty[code]) {
// strip headers
ctx.body = null;
return res.end();
}
// HEAD 请求:
if ("HEAD" == ctx.method) {
if (!res.headersSent && isJSON(body)) {
ctx.length = Buffer.byteLength(JSON.stringify(body));
}
return res.end();
}
// status body
// 表示状态码的 body:
if (null == body) {
if (ctx.req.httpVersionMajor >= 2) {
body = String(code);
} else {
body = ctx.message || String(code);
}
if (!res.headersSent) {
ctx.type = "text";
ctx.length = Buffer.byteLength(body);
}
return res.end(body);
}
// responses
if (Buffer.isBuffer(body)) return res.end(body); // 允许返回 Buffer 类型
if ("string" == typeof body) return res.end(body); // 允许返回 string 类型
if (body instanceof Stream) return body.pipe(res); // 允许返回 stream 类型
// body: json
// 允许返回 json 类型,还是会被 JSON.stringify 化为字符串
body = JSON.stringify(body);
if (!res.headersSent) {
ctx.length = Buffer.byteLength(body);
}
res.end(body);
}在初始化中提到了,koa 继承自 Emiiter,是为了处理可能在任意时间抛出的异常所以订阅了 error 事件。error 处理有两个层面,一个是 app 层面全局的(主要负责 log),另一个是一次响应过程中的 error 处理(主要决定响应的结果),koa 有一个默认 app-level 的 onerror 事件,用来输出错误日志。
onerror(err) {
if (!(err instanceof Error))
throw new TypeError(util.format("non-error thrown: %j", err));
if (404 == err.status || err.expose) return;
if (this.silent) return;
const msg = err.stack || err.toString();
console.error();
console.error(msg.replace(/^/gm, " "));
console.error();
}function async(u, c) {
var d = document, t = 'script',
o = d.createElement(t),
s = d.getElementsByTagName(t)[0];
o.src = '//' + u;
if (c) { o.addEventListener('load', function (e) { c(null, e); }, false); }
s.parentNode.insertBefore(o, s);
}usage
async('snapabug.appspot.com/snapabug.js', function() {
SnapABug.init('XXXXX-XXXXX-XXXXX-XXXXX-XXXXX');
});原文:Prefetch & preconnect-dns priority
作者: JUSTIN AVERY
如果你想要浏览器在你访问某个域名前先执行 DNS 解析,那么你使用 preconnect 和 prefetch-dns 都是可以的,这将会节省关键渲染路径的时间。本文主要分析这两者的区别,结论无法一句话概括。
举个例子,当我们访问 https://responsivedesign.is/articles/prefetch-preconnect-dns-priority/ 这个页面时,最开始发生的事情是浏览器需要知道 responsivedesign.is 在哪 —— 就是我们所知道的 DNS 握手,如果你观察 网络的瀑布图, 你将会发现请求最开始的部分是水绿色的,这代表着 DNS 解析。
preconnect 和 prefetch-dns 的作用就是让 DNS 的解析尽快发生,在真正有请求发送到那个 DNS 对应的域名前就完成。这样可以在你想请求资源的时候节约时间(preconnect 比 prefetch-dns 做的多一点,不过是在 DNS 解析之后)
节约了多少时间?在上面的瀑布图示例中 DNS 解析的时间是
每个都是一百多毫秒,可是当你将他们加起来就发现有 502ms 之多,将它们从关键渲染路径的加载时间中去除掉,将获得半秒的加载提速。
这两者的区别是 —— dns-prefetch 将只会做 DNS 解析,preconnect 将会做 DNS 解析,TLS 协商和 TCP 握手,这意味着要下载资源时可以额外避免两个 RTT(Rount-trip Time)。
不过当我在 Web Page Test 测试的时候似乎只避免了 DNS 解析,我无法对此做出合理的解释。可能是浏览器对 dns-prefetch 的支持要远好于 preconnect 的支持,我推测我用来测试的 Chrome 版本不完全支持,不过还是避免了 DNS 的解析。
写这篇文章的原因是当我浏览 Victoria and Albert Museum 的网站时,在检查时我发现这个网站使用如下的代码段来提前完成 DNS 的解析来节省以后的请求时间:
<link rel="dns-prefetch" href="//vanda-production-assets.s3.amazonaws.com" />这是写在 <head> 标签中的,不过这个网站同时也使用了 <style> 标签来声明一系列的需要发送请求的背景图片,这些 background-image 声明在 dns-prefetch 标签前出现,这让我不禁疑问它们谁将先被触发:
为了测试我写了一系列的 Code Pen 来进行测试 DNS 解析在以下五种情况下会在什么时候发生,每种场景都通过 Web Page Test 来在 Chrome 和 Fast 3G 网络条件下测试,我选择这个网络条件是它们之间的差别在这种移动网络条件下会被放大(我还没用 2G 呢)。
每个 code pen 都在 head 中有一个 style 标签,设置了 background-image,它们之间的区别就是 DNS 预解析的顺序与类型不同,如下:
(译者注:我不知道为啥以上链接的 code pen 中都看不到代码页面还有内容... 不过通过检查元素还是可以看到 HTML 的结构...)
没有任何 resource hint 我们可以看到一个页面通常是如何被请求的,注意 DNS 解析是关键路径的一部分:
<style>
body {background-image:url('https://s3-us-west-2.amazonaws.com/s.cdpn.io/7635/Ayers-Rock-Australia.jpg')}
</style>Critical load path when no prefetch/preconnect of the DNS is included in the
<style>
body {background-image:url('https://s3-us-west-2.amazonaws.com/s.cdpn.io/7635/Ayers-Rock-Australia.jpg')}
</style>
<link href="https://s3-us-west-2.amazonaws.com" rel="dns-prefetch">你可以从瀑布图中看到尽管 background-image 在 dns-prefetch 所在的 link 标签之前声明,DNS 解析还是在整个 HTML 文档解析完毕后立即开始,并且和其他页面一开始请求的资源的 DNS 解析并行执行,比如说来自 //cdnjs.cloudflare.com 的 normalise.css。
Critical load path when preconnect is included in the after the <style> tag
如你所想,如果我们想让握手发生在它想发生的时候,在图像之前或者之后声明 DNS 预解析都是一样的。
<link href="https://s3-us-west-2.amazonaws.com" rel="dns-prefetch">
<style>
body {background-image:url('https://s3-us-west-2.amazonaws.com/s.cdpn.io/7635/Ayers-Rock-Australia.jpg')}
</style>Critical load path when dns-prefetch is included in the before the <style> tag
这个测试中,我想看下 preconnect 将三个 RTT 都提前执行了能比 dns-prefetch 多节约多少时间,不幸的是根本没有区别,我需要以后再看下。
<style>
body {background-image:url('https://s3-us-west-2.amazonaws.com/s.cdpn.io/7635/Ayers-Rock-Australia.jpg')}
</style>
<link href="https://s3-us-west-2.amazonaws.com" rel="preconnect" crossorigin>Critical load path when dns-prefetch is included in the after the <style> tag
这个测试的结果也是 DNS 的预解析立刻发生,可是同样没有看到 TCP 和 TLS 的握手..
<link href="https://s3-us-west-2.amazonaws.com" rel="preconnect" crossorigin>
<style>
body {background-image:url('https://s3-us-west-2.amazonaws.com/s.cdpn.io/7635/Ayers-Rock-Australia.jpg')}
</style>Critical load path when preconnect is included in the before the <style> tag
如上你可以看到,无论你将 link 标签在 head 中如何防止,只要它存在它就会完成 DNS 的预解析因此节省你浏览网页的时间。
值得为你的网站中的外部的域名都添加上预解析,尤其是图片的 CDN,字体库(比如 Google Fonts)或者外部的你可能使用的 JS 文件。
译者在今天(2018 年 7 月 26 日),对 preconnect before styles 进行了测试,用的是 Chrome Canary + 3G,如下图,可以看到 TCP 和 TLS 都紧跟着 DNS 解析发生了,期待 preconnect 被更多浏览器支持!
测试结果:Web Page Performance Test fors.codepen.io/justincavery/debug/jBVdxE

其实这篇文章主要就说了两个点:
Please read: sw-yx / react-typescript-cheatsheet
中文版的于一年前翻译,从今天看来当时的翻译有很多的错误,所以已经被废弃掉了。swyx 和合作者们在这一年中更新了很多非常酷的新内容,并且使用的是最新版的 TypeScript。所以尽管一开始可能阅读英文会有一点困难,不过还是高度推荐阅读英文原版教程。
The Chinese version was translated a year ago and with a lot of errors from today so it has been deprecated. swyx and collaborators has updated quite a lot fantastic new content with the latest TypeScript version. So please read the English version although it will be a little difficult at first.
如果你想阅读中文版的 TypeScript 教程,可以参考以下教程:
However, if you wanna learn TypeScript in Chinese. You can read following tutorials below.
目前前端代码的编译器基本都是 Babel,更确切地说是源码到源码的编译器,通常也叫做“转换编译器(transpiler)”。 意思是说你为 Babel 提供一些 JavaScript 代码,Babel 更改这些代码,然后返回给你新生成的代码。实际上 Babel 就是完成了"ES6 代码的字符串 -> ES5 代码的字符串"的转化,虽然输入输出都字符串,但是整个过程需要经历三个阶段:
Babylon 解析和理解 JavaScript 代码
babel-traverse 分析和修改 AST
babel-generator 将 AST 转换回正常的代码
抽象语法树(Abstract Syntax Tree,AST),或简称语法树(Syntax tree),是源代码语法结构的一种抽象表示。它以树状的形式表现编程语言的语法结构,树上的每个节点都表示源代码中的一种结构。之所以说语法是“抽象”的,是因为这里的语法并不会表示出真实语法中出现的每个细节。
目前来说,已经有 babylon(现在已变成 babel/core)来帮助我们完成第一步的 AST 生成工作和第三步的再建
Babel 使用一个基于 ESTree 并修改过的 AST,它的内核说明文档可以在[这里](https://github. com/babel/babel/blob/master/doc/ast/spec. md)找到。.
其中第二步变化,包括各种 babel 插件就在 AST 的这个阶段进行操作。
上面已经提到了 babel 的 plugin 是第二步中,插件拿到代码的 AST 进行处理再返回。
先介绍 Babel 插件的基本格式:
export default function({ types: t }) {
return {
visitor: {
// visitor contents
Identifier(path, state) {/* do something */},
ASTNodeTypeHere(path, state) {/* do something */}
}
};
};Babel 通过 babel-traverse 来遍历各个节点,我们在 visitor 中的属性的 key 就是会被遍历到并处理的 AST 中的节点名,并且还能传入这个节点的两个参数:path 和 state。最外层的函数传入的是 babel,一般直接解构获得 babel-types 来辅助进行类型判断。
Path 是表示两个节点之间连接的对象。当你有一个
Identifier()成员方法的访问者时,你实际上是在访问路径而非节点。 通过这种方式,你操作的就是节点的响应式表示(译注:即路径)而非节点本身。
path 中包含了我们可以修改的属性,也包含添加、更新、移动和删除节点有关的其他很多方法。
state 是从 plugin 的配置文件中传递的参数。
我们来看一个 babel 官方的插件的实现:babel-plugin-transform-undefined-to-void ,有些代码中允许 undefined 被修改,这个插件的功能是使用 void 0 代替 undefined 来保证 undefined 的正确性。
module.exports = function({ types: t }) {
const VOID_0 = t.unaryExpression("void", t.numericLiteral(0), true); // 生成 `void 0` 对象
return {
name: "transform-undefined-to-void",
visitor: {
ReferencedIdentifier(path) { // 如果是被引用的标识符
if (path.node.name === "undefined") { // 如果被赋值的对象是 undefined
path.replaceWith(VOID_0); // 将 undefined 替换为 `void 0`
}
}
}
};
};整体流程参考 minipack,minipack 写了很详细的注释,也有 中文版 的,不再过多重复。
这里再整理一下整个流程的思路:

function(require, modules, export){ code } 中,在执行每个模块的时候按照相同的函数签名传入对应参数即可。在 深入react 技术栈 一书中,提到了基于 Decorator 的 HOC。而不是直接通过父组件来逐层传递 props,因为当业务逻辑越来越复杂的时候,props 的传递和维护也将变得困难且冗余。
书里对基于 Decorator 的 HOC 没有给出完整的实现,在这里实现并记录一下实现的思路。
整个实现的代码放到了 我的Github 上,是用来获取豆瓣的电影列表的,npm start 即可。

书里描述的整体思路,先将整个组件,按照 view 抽象为互不重叠的最小的原子组件,使组件间组合更自由。在这里最小的组件就是 SearchInput、SelectInput、List。原子组件一定是纯粹的、木偶式的组件,如果他们自身带有复杂的交互/业务逻辑,那么在组合起来以后可想需要修改多少个原子组件,也就失去了相对配置式的优势。
这是对原书代码稍加修改的 SearchInput 原子组件,因为没加 Icon,所以改了一下(逃),整体思路不变。原子组件没什么可说的,木偶组件就是接收 props 来实现功能,是对 view 的抽象。
需要一提的是 displayName,是用来确定组件的『身份』的,会被包裹它的组合组件用到,后面会提到组合组件。
export default class SearchInput extends PureComponent {
static displayName = 'SearchInput'
render() {
const { onSearch, placeholder } = this.props
return (
<div>
<p>SearchSelect</p>
<div>
<Input
type="text"
placeholder={placeholder}
onChange={onSearch}
/>
</div>
</div>
)
}
}先放代码
const searchDecorator = WrappedComponent => {
class SearchDecorator extends Component {
constructor(props) {
super(props)
this.handleSearch = this.handleSearch.bind(this)
this.state = {
keyword: ''
}
}
handleSearch(e) {
this.setState({
keyword: e.target.value
})
this.props.onSearch(e)
}
render() {
const { keyword } = this.state
return (
<WrappedComponent
{...this.props}
data={this.props.data}
keyword={keyword}
onSearch={this.handleSearch}
/>
)
}
}Decorator 的作用就是将业务/交互逻辑抽象出来进行了处理,view 还是交由原子组件来实现,可以看到最后的render 渲染的还是 wrappedComponent,只不过是在经过 Decorator 之后多了几个 props,这些 props 的中有钩子函数,有要传递给原子组件的参数。
这样,视图逻辑就由原子组件组成,交互/业务逻辑由 Decorator 来抽象。
先上代码。
export default class Selector extends Component {
render() {
return (
<div>
{
this.props.children.map((item) => {
// SelectInput
if (item.type.displayName === 'SelectInput') {
...
}
// SearchInput
if (item.type.displayName === 'SearchInput') {
return React.cloneElement(item,
{
key: 'searchInput',
onSearch: this.props.onSearch,
placeholder: this.props.searchPlaceholder
}
)
}
// List
if (item.type.displayName === 'List') {
...
})
}
</div>
)
}
}组合组件的 children 为根据不同业务需要包裹起来的原子组件,组合组件的逻辑处理功能来自于 Decorator,各种 Decorator 的钩子函数或者参数作为 props 传递给了 Selector,Selector 再用它们去完成原子组件之间的交互。组合组件通过之前提到的 displayName 为不同的原子组件分配 props 并根据业务需要进行组件间逻辑交互的调整。
一个 Decorator 只做最简单的逻辑,只是给组件增加一个原子的智能特性。业务组件通过组织和拼接 Decorator 来实现功能,而不是改变 Decorator 本身的逻辑。
当我们业务逻辑变得复杂的时候,不要去增加 Decorator 的复杂度,而是去拼接多个 Decorator 再通过组合组件去处理具体的业务逻辑,这样能保证 Decorator 的可复用性。
const FinalSelector = compose(asyncSelectDecorator, selectedItemDecorator, searchDecorator)(Selector)
class SearchSelect extends Component {
render() {
return (
<FinalSelector {...this.props}>
<SelectInput />
<SearchInput />
<List />
</FinalSelector>
)
}
}
class App extends Component {
render() {
return (
<SearchSelect
searchPlaceholder={'请搜索电影'}
onSearch={(e) => { console.log(`自定义onSearch: ${e.target.value}`) }}
onClick={(text) => { console.log(`自定义onClick: ${text}`) }}
url="/v2/movie/in_theaters"
/>
)
}
}通过 compose 赋予组合组件不同的逻辑处理功能,然后根据业务需要让 compose 后的组合组件包含原子组件,最后给从最外层传递参数就完成了。
在实际的场景中也不能滥用 HOC,基于 Decorator 的 HOC 一般是用来处理偏数据逻辑的部分,而 DOM 相关的东西就直接简单粗暴的用父组件就好了。
对比 HOC 范式 **compose(render)(state) **与父组件(Parent Component)的范式 render(render(state)),如果完全利用 HOC 来实现 React 的 implement,将操作与 view 分离,也未尝不可,但却不优雅。HOC 本质上是统一功能抽象,强调逻辑与 UI 分离。但在实际开发中,前端无法逃离 DOM ,而逻辑与 DOM 的相关性主要呈现 3 种关联形式:
- 与 DOM 相关,建议使用父组件,类似于原生 HTML 编写
- 与 DOM 不相关,如校验、权限、请求发送、数据转换这类,通过数据变化间接控制 DOM,可以使用 HOC 抽象
- 交叉的部分,DOM 相关,但可以做到完全内聚,即这些 DOM 不会和外部有关联,均可

生命周期函数的更改是因为 16.3 采用了 Fiber 架构,在新的 Fiber 架构中,组件的更新分为了两个阶段:
commit phase 的执行很快,但是真实 DOM 的更新很慢,所以 React 在更新的时候会暂停再恢复组件的更新以免长时间的阻塞浏览器,这就意味着 render phase 可能会被执行多次(因为有可能被打断再重新执行)。
constructorcomponentWillMountcomponentWillReceivePropscomponentWillUpdategetDerivedStateFromPropsshouldComponentUpdaterendersetState updater functions (the first argument)这些生命周期都属于 render phase,上面已经说了,render phase 可能被多次执行,所以要避免在 render phase 中的生命周期函数中引入副作用。但是 16.3 之前的生命周期很容易引入副作用,所以 16.3 之后引入新的生命周期来限制开发者引入副作用。
react 16.3 新加入的 API,对标的是之前的 componentWillReceiveProps,在一个组件已经实例化后,re-render 之前被调用。这个新的生命周期具有如下特点:
虽然 getDerivedStateFromProps 对标的是 componentWillReceiveProps,但是 componentWillReceiveProps 作为 16.3 之前的“大杂烩“周期,各种脏活累活都能干。在 16.3 之后 componentWillReceiveProps 要通过 getDerivedStateFromProps 与 componentDidUpdate 合力才能替代。之所以要分拆 componentWillReceiveProps,我个人认为有两方面的原因:
Fiber 架构导致组件的更新被随时打断再重来,所以 componentWillReceiveProps 可能会被执行多次,但是无法阻止开发者在 componentWillReceiveProps 中引入副作用(事实上 componentWillReceiveProps 是开发者最喜欢引入副作用的生命周期),所以只能将这个 API 拆成在 render phase 中的纯函数 getDerivedStateFromProps 和在 commit phase 中的 componentDidUpdate 来让组件更好预测和维护。
这篇文章 中一针见血得指出:
React 团队试图通过框架级别的 API 来约束或者说帮助开发者写出可维护性更佳的 JavaScript 代码
框架最大的特点就是“限制”,通过这么一个限制重重的静态生命周期不让你调用实例方法,就给你 props 和 prevState 让你来 derived state,甚至连这个生命周期的都是一反常态的用一个具体的行为而不是用一个更新过程的时间节点来命名,就是让开发者只做 derived state 这个行为,并且通过返回值来更新 state 可以保证只更新一次 state(以前的 componentWillReceiveProps 是通过 batchUpdate 来保证只更新一次)。
不过官方并不推荐使用 getDerivedStateFromProps,倒不是 getDerivedStateFromProps 这个 API 带来的问题,而是 derived state 带来的问题,之前的 componentWillReceiveProps 也有这个问题。
derived state 会造成不只一个 source of truth,我们都知道,React 的哲学是 view = f(data),但是当有两个 data 去表征同一个参数造成 view 的修改时就有麻烦了,所以在使用 getDerivedStateFromProps 之前一定要想好是否可以直接使用 props。
getDerivedStateFromProps 作为一个静态函数是不能访问实例属性的,如果需要通过实例方法和 state 或者 props 来计算一个值在 render 周期中使用的 state,那么最好的方法是直接在 render 中计算出这个值然后直接使用,因为这会是一个纯函数的操作。这从侧面反映出来,这次生命周期的升级通过添加限制在一定程度上规范了生命周期的使用。
那么,之前的副作用在要放在哪里呢?答案就是 componentDidUpdate。
不过这又带来了一个问题,在之前版本的生命周期中,开发者最喜欢使用 componentWillReceiveProps 的一个原因就是 componentWillReceiveProps 不会引起 re-render,而 componentDidUpdate 中 setState,会再次引发一轮的 re-render。
所以我们要尽量避免在 componentDidUpdate 中 setState,而是提前到 getDerivedStateFromProps,将网络操作的副作用放在 componentDidUpdate 中,一方面网络总是有一定延迟的,不管放在哪个生命周期中都会引发 re-render,另一方面是 componentDidUpdate 中 DOM 已经更新。
将通过 props 或 state 计算的衍生数据放在 render 中,一方面符合 render 的纯函数理念,另一方面减少了产生新的 truth of source 的概率。
getSnapshotBeforeUpdate 处于 render phase 和 commit phase 的中间,不过准确的说是处于 commit phase 的阶段,因为它只会被执行一次,在 react 修改 DOM 之前会被紧挨着调用,所以在这个生命周期能够获取这一次更新前的 DOM 的信息。这个生命周期返回的值将作为 componentDidUpdate 的第三个参数。
我们都知道 JavaScript 是一门单线程语言,这意味着同一事件只能执行一个任务,结束了才能去执行下一个。如果前面的任务没有执行完,后面的任务就会一直等待。试想,有一个耗时很长的网络请求,如果所有任务都需要等待这个请求完成才能继续,显然是不合理的并且我们在浏览器中也没有体验过这种情况(除非你要同步请求 Ajax),究其原因,是 JavaScript 借助异步机制来实现了任务的调度。
程序中现在运行的部分和将来运行的部分之间的关系就是异步编程的核心。
我们先看一个面试题:
try {
setTimeout(() => {
throw new Error("Error - from try statement");
}, 0);
} catch (e) {
console.error(e);
}上面这个例子会输出什么?答案是:

说明并没有 catch 到丢出来的 error,这个例子可能理解起来费劲一点。
如果我换一个例子
console.log("A");
setTimeout(() => {
console.log("B");
}, 100);
console.log("C");稍微了解一点浏览器中异步机制的同学都能答出会输出 “A C B”,本文会通过分析 event loop 来对浏览器中的异步进行梳理,并搞清上面的问题。
函数调用栈其实就是执行上下文栈(Execution Context Stack),每当调用一个函数时就会产生一个新的执行上下文,同时新产生的这个执行上下文就会被压入执行上下文栈中。
全局上下文最先入栈,并且在离开页面时开会出栈,JavaScript 引擎不断的执行上下文栈中栈顶的那个执行上下文,在它执行完毕后将它出栈,直到整个执行栈为空。关于执行栈有五点比较关键:
- 单线程(这是由 JavaScript 引擎决定的)。
- 同步执行(它会一直同步执行栈顶的函数)。
- 只有一个全局上下文。
- 可有无数个函数上下文(理论是函数上下文没有限制,但是太多了会爆栈)。
- 每个函数调用都会创建一个新的
执行上下文,哪怕是递归调用。
这里首先要明确一个问题,函数上下文执行栈是与 JavaScript 引擎(Engine)相关的概念,而异步/回调是与运行环境(Runtime)相关的概念。
如果执行栈与异步机制完全无关,我们写了无数遍的点击触发回调是如何做到的呢?是运行环境(浏览器/Node)来完成的, 在浏览器中,异步机制是借助 event loop 来实现的,event loop 是异步的一种实现机制。JavaScript 引擎只是“傻傻”的一直执行栈顶的函数,而运行环境负责管理在什么时候压入执行上下文栈什么函数来让引擎执行。
JavaScript 引擎本身并没有时间的概念,只是一个按需执行 JavaScript 任意代码片段的环境。“事件”( JavaScript 代码执行)调度总是由包含它的环境进行。
另外,从一个侧面可以反应出执行上下文栈与异步无关的 —— 执行上下文栈是写在 ECMA-262 的规范中,需要遵守它的是浏览器的 JavaScript 引擎,比如 V8、Quantum 等。event loop 的是写在 HTML 的规范中,需要遵守它的是各个浏览器,比如 Chrome、Firefox 等。
我们通过 HTML5规范 的定义来看 event loop 的定义来看模型,本章节所有引用的部分都是翻译自规范。
为了协调时间,用户交互,脚本,界面渲染,网络等等,用户代理必须使用下一节描述的 event loops。event loops 分为两种:浏览器环境及为 Web Worker 服务的。
本文只关注浏览器部分,所以忽略 Web Worker。JavaScript 引擎并不是独立运行的,它需要运行在宿主环境中, 所以其实用户代理(user agent)在这个情境下更好的翻译应该是运行环境或者宿主环境,也就是浏览器。
每个用户代理必须至少有一个 browsing context event loop,但每个 unit of related similar-origin browsing contexts 最多只能有一个。
关于 unit of related similar-origin browsing contexts,节选一部分规范的介绍:
Each unit of related browsing contexts is then further divided into the smallest number of groups such that every member of each group has an active document with an origin that, through appropriate manipulation of the
document.domainattribute, could be made to be same origin-domain with other members of the group, but could not be made the same as members of any other group. Each such group is a unit of related similar-origin browsing contexts.
简而言之就是一个浏览器环境(unit of related similar-origin browsing contexts.),只能有一个事件循环(event loop)。
event loop 又是干什么的呢?
每个 event loop 都有一个或多个 task queues. 一个 task queue 是 tasks 的有序的列表, 是用来响应如下如下工作的算法:
事件
在
EventTarget触发的时候发布一个事件Event对象,这通常由一个专属的 task 完成。注意:并不是所有的事件都从是 task queue 中发布,也有很多是来自其他的 tasks。
解析
HTML 解析器 令牌化然后产生 token 的过程,是一个典型的 task。
回调函数
一般使用一个特定的 task 来调用一个回调函数。
使用资源(译者注:其实就是网络)
当算法 获取 到了资源,如果获取资源的过程是非阻塞的,那么一旦获取了部分或者全部的内容将由 task 来执行这个过程。
响应 DOM 的操作
有一些元素会对 DOM 的操作产生 task,比如当元素被 插入到 document 时。
可以看到,一个页面只有一个 event loop,但是一个 event loop 可以有多个 task queues。
每个来自相同 task source 并由相同 event loop(比如,
Document的计时器产生的回调函数,Document的鼠标移动产生的事件,Document的解析器产生的 tasks) 管理的 task 都必须加入到同一个 task queue 中,可是来自不同 task sources 的 tasks 可能会被排入到不同的 task queues 中。
来自相同的 task source 的 task 将会被排入相同的 task queue,但是规范说来自不同 task sources 的 tasks 可能会被排入到不同的 task queues 中,也就是说一个 task queue 中可能排列着来自不同 task sources 的 tasks,但是具体什么 task source 对应什么 task queue,规范并没有具体说明。
但是规范对 task source 进行了分类:
如下 task sources 被大量应用于本规范或其他规范无关的特性中:
DOM 操作的 task source
这种 task source 用来对 DOM 的操作进行反应,比如像 inserted into the document 的非阻塞的行为。
用户操作的 task source
这种 task source 用来响应用户的反应,比如鼠标和键盘的事件。这些用来反应用户输入的事件必须由 user interaction task source 来触发并排入 tasks queued。
网络 task source
这种 task source 用来反应网络活动的响应。
时间旅行 task source
这种 task source 用来将
history.back()等 API 排入 task queue。
一般我们看个各个文章中对于 task queue 的描述都是只有一个,不论是网络,用户时间内还是计时器都会被 Web APIs 排入到用一个 task queue 中,但事实上规范中明确表示了是有多个 task queues,并举例说明了这样设计的意义:
举例来说,一个用户代理可以有一个处理键盘鼠标事件的 task queue(来自 user interaction task source),还有一个 task queue 来处理所有其他的。用户代理可以以 75% 的几率先处理鼠标和键盘的事件,这样既不会彻底不执行其他 task queues 的前提下保证用户界面的响应, 而且不会让来自同一个 task source 的事件顺序错乱。
接着看。
当用户代理将要排入任务时,必须将任务排入相关的 event loop 的 task queues。
这句话很关键,是用户代理(宿主环境/运行环境/浏览器)来控制任务的调度,这里就引出了下一章的 Web APIs。
接下来我么来看看 event loop 是如何执行 task 的。
我们可以形象的理解 event loop 为如下形式的存在:
while (queue.waitForMessage()) {
queue.processNextMessage();
}event loop 会在整个页面存在时不停的将 task queues 中的函数拿出来执行,具体的规则如下:
一个 event loop 在它存在的必须不断的重复一下的步骤:
- 从 task queues 中取出 event loop 的最先添加的 task,如果没有可以选择的 task,那么跳到第
Microtasks步。- 设定 event loop 当前执行的 task 为上一步中选择的 task。
执行:执行选中的 task。- 将 event loop 的当前执行 task 设为 null。
- 从 task queue 中将刚刚执行的 task 移除。
Microtasks: 执行 microtask 检查点的任务。- 更新渲染,如果是浏览器环境中的 event loop(相对来说就是 Worker 中的 event loop)那么执行以下步骤:
- 如果是 Worker 环境中的 event loop(例如,在 WorkerGlobalScope 中运行),可是在 event loop 的 task queues 中没有 tasks 并且 WorkerGlobalScope 对象为关闭的标志,那么销毁 event loop,终止这些步骤的执行,恢复到 run a worker 的步骤。
- 回到第 1 步。
规范引出了 microtask,
每个 event loop 都有一个 microtask queue。microtask 是一种要排入 microtask queue 的而不是 task queue 的任务。有两种 microtasks:solitary callback microtasks 和 compound microtasks。
规范只介绍了 solitary callback microtasks,compound microtasks 可以先忽略掉。
当一个 microtask 要被排入的时候,它必须被排如相关 event loop 的 microtask queue,microtask 的 task source 是 microtask task source.
当用户代理执行到了 microtasks 检查点的时候,如果 performing a microtask checkpoint flag 为 false,则用户代理必须运行下面的步骤:
将 performing a microtask checkpoint flag 置为 true。
处理 microtask queue:如果 event loop 的 microtask queue 是空的,直接跳到Done步。选择 event loop 的 microtask queue 中最老的 microtask。
设定 event loop 当前执行的 task 为上一步中选择的 task。
执行:执行选中的 task。注意:这有可能包含执行含有 clean up after running script 步骤的脚本,然后会导致再次 执行 microtask 检查点的任务,这就是我们要使用 performing a microtask checkpoint flag 的原因。
将 event loop 的当前执行 task 设为 null。
将上一步中执行的 microtask 从 microtask queue 中移除,然后返回
处理 microtask queue步骤。
完成: 对每一个 responsible event loop 就是当前的 event loop 的 environment settings object,给 environment settings object 发一个 rejected promises 的通知。将 performing a microtask checkpoint flag 设为 false。
整个流程如下图:
以下是 task 和 microTask 的分类,规范中有明确的写道,比如 MutationObserver,在这里引用 Promise A+ 规范翻译 中的分类:
task 主要包含:
microtask 主要包含:
在上一章讲讲到了用户代理(宿主环境/运行环境/浏览器)来控制任务的调度,task queues 只是一个队列,它并不知道什么时候有新的任务推入,也不知道什么时候任务出队。event loop 会根据规则不断将任务出队,那谁来将任务入队呢?答案是 Web APIs。
我们都知道 JavaScript 的执行是单线程的,但是浏览器并不是单线程的,Web APIs 就是一些额外的线程,它们通常由 C++ 来实现,用来处理非同步事件比如 DOM 事件,http 请求,setTimeout 等。他们是浏览器实现并发的入口,对于 Node.JavaScript 来说,就是一些 C++ 的 APIs。
WebAPIs 本身并不能直接将回调函数放在函数调用栈中来执行,否则它会随机在整个程序的运行过程中出现。每个 WebAPIs 会在其执行完毕的时候将回调函数推入到对应的任务队列中,然后由 event loop 按照规则在函数调用栈为空的时候将回调函数推入执行栈中执行。event loop 的基本作用就是检查函数调用栈和任务队列,并在函数调用栈为空时将任务队列中的的第一个任务推入执行栈中,每一个任务都在下一个任务执行前执行完毕。
WebAPIs 提供了多线程来执行异步函数,在回调发生的时候,它们会将回调函数和推入任务队列中并传递返回值。
至此,我们已经了解了执行上下文栈,event loop 及 WebAPIs,它们的关系可以用下图来表示(图片来自网络,原始出处已无法考证),一轮 event loop 的文字版流程如下:
首先执行一个 task,如果整个第一轮 event loop,那么整体的 script 就是一个 task,同步执行的代码会直接放进 call stack(调用栈)中,诸如 setTimeout、fetch、ajax 或者事件的回调函数会由 Web APIs 进行管理,然后 call stack 继续执行栈顶的函数。当网络请求获取到了响应或者 timer 的时间到了,Web APIs 就会将对应的回调函数推入对应的 task queues 中。event loop 不断执行,一旦 event loop 中的 current task 为 null,它就回去扫 task queues 有没有 task,然后按照一定规则拿出 task queues 中一个最早入队的回调函数(比如上面提到的以 75% 的几率优先执行鼠标键盘的回调函数所在的队列,但是具体规则我还没找到),取出的回调函数放入上下文执行栈就开始同步执行了,执行完之后检查 event loop 中的 microtask queue 中的 microtask,按照规则将它们全部同步执行掉,最后完成 UI 的重渲染,然后再执行下一轮的 event loop...

JavaScript 引擎并不是独立运行的,它运行在宿主环境中
了解了上面 Web APIs,我们知道浏览器中有一个 Timers 的 Web API 用来管理 setTimeout 和 setInterval 等计时器,在同步执行了 setTimeout 后,浏览器并没有把你的回调函数挂在事件循环队列中。 它所做的是设定一个定时器。 当定时器到时后, 浏览器会把你的回调函数放在事件循环中, 这样, 在未来某个时刻的 tick 会摘下并执行这个回调。
但是如果定时器的任务队列中已经被添加了其他的任务,后面的回调就要等待。
let t1, t2
t1 = new Date().getTime();
// 1
setTimeout(()=>{
let i = 0;
while (i < 50000000) {i++}
console.log('block finished')
}
, 300)
// 2
setTimeout(()=>{
t2 = new Date().getTime();
console.log(t2 - t1)
}
, 300)这个例子中,打印出来的时间戳就不会等于 300,虽然两个 setTimeout 的函数都会在时间到了时被 Web API 排入任务队列,然后 event loop 取出第一个 setTimeout 的回调开始执行,但是这个回调函数会同步阻塞一段时间,导致只有它执行完毕 event loop 才能执行第二个 setTimeout 的回调函数。
try {
setTimeout(() => {
throw new Error("Error - from try statement");
}, 0);
} catch (e) {
console.error(e);
}回到最开始的那个问题,整个过程是这样的:执行到 setTimeout 时先同步地将回调函数注册给 Web APIs 的 timer,要清楚此时 setTimeout 的回调函数此时根本没有入调用栈甚至连 task queue 都没有进入,所以 try 的这个代码块就执行结束了,没有抛出任何 error,catch 也被直接跳过,同步执行完毕。
等到 timer 的计时到了(要注意并不一定是下一个 event loop,因为 setTimeout 在每个浏览器中的最短时间是不确定的,在 Chrome 中执行几次也会发现每次时间都不同,0 ms ~ 2 ms 都有),会将 setTimeout 中的回调放入 task queue 中,此时 event loop 中的 current task 为 null,就将这个回调函数设为 current task 并开始同步执行,此时调用栈中只有一个全局上下文,try catch 已经结束了,就会直接将这个 error 丢出。
for (var i = 0; i < 5; i++) {
setTimeout((function(i) {
console.log(i);
})(i), i * 1000);
}正确答案是立即输出 “0 1 2 3 4”,setTime 的第一个参数接受的是一个函数或者字符串,这里第一个参数是一个立即执行函数,返回值为 undefined,并且在立即执行的过程中就输出了 "0 1 2 3 4",timer 没有接收任何回调函数,就与 event loop 跟无关了。
new Promise(resolve => {
resolve(1);
Promise.resolve().then(() => console.log(2));
console.log(4)
}).then(t => console.log(t)); // a
console.log(3);是阮老师推特上的一道题,首先 Promise 构造函数中的对象同步执行(不了解 Promise 的同学可以先看下 这篇文章),碰到 resolve(1),将当前 Promise 标记为 resolve,但是注意它 then 的回调函数还没有被注册,因为还没有执行到 a 处。继续执行又碰到一个 Promise,然后也立刻被 resolved 了,并且执行它的 then 注册,将第二个 then 的回调函数推入空的 microtaskQueue 中。继续执行输出一个 4,然后 a 处的 then 现在才开始注册,将第一个 Promise 的 then 回调函数推入 microtaskQueue 中。继续执行输出一个 3。现在 task queue 中的任务已经执行完毕,到了 microtask checkpoint flag,发现有两个 microtask,按照添加的顺序执行,第一个输出一个 2,第二个输出一个 1,最后再更新一下 UI 然后这一轮 event loop 就结束了,最终的输出是"4 3 2 1"
笔者本人并没有使用过 Vue,但是稍微知道一点 Vue 的 DOM 更新中有批量更新,缓冲在同一事件循环中的数据变化,即 DOM 只会被修改一次。
为啥要用 microtask?根据HTML Standard,在每个 task 运行完以后,UI 都会重渲染,那么在 microtask 中就完成数据更新,当前 task 结束就可以得到最新的 UI 了。反之如果新建一个 task 来做数据更新,那么渲染就会进行两次。
在 event loop 那章的规范中明确的写到,在 event loop 的一轮中会按照 task -> microTask -> UI render 的顺序。用户的代码可能会多次修改数据,而这些修改中后面的修改可能会覆盖掉前面的修改,再加上 DOM 的操作是很昂贵的,一定要尽量减少,所以要将用户的修改 thunk 起来然后只修改一次 DOM,所以需要使用 microTask 在 UI 更新渲染前执行,就算有多次修改,也会只修改一次 DOM,然后进行渲染。
更新一下,现在 Vue 的 nextTick 实现移除了 MutationObserver 的方式(兼容性原因),取而代之的是使用 MessageChannel。
其实用什么具体的 API 不是最关键的,重要的是使用 microTask 在 在 UI render 前进行 thunk。


划重点!都是有用的!都给我记住了!我们的口号是!没有鼠标!(逃
cmd + d:选中光标当前所在的单词cmd + /:注释 / 反注释cmd + Enter:当前行上面新开一行cmd + shift + Enter:当前行下面新开一行alt + ↑/↓:上 / 下移行cmd + shift + alt + arrow :跨行列选择cmd + shift + K:删除当前行,太长了,我直接定义成了 ctrl + Dctrl + shift + ↑/↓:向上 / 下复制当前行ctrl + ↑/↓:向上/下滚屏一行cmd + PageUp/PageDown:向上/下滚屏一页alt + cmd + s:保存全部文件,要按出这个键位的姿势简直反人类,我改成了 ctrl + shift + scmd + k, cmd + 1:一级折叠,折叠最外层的函数,在读源码的时候很有用cmd + k, cmd + 2/3/4/5...: n 级折叠,折叠第 n 层的嵌套cmd + k, cmd + 0:全部折叠cmd + k, cmd + j:展开所有alt + cmd + [:普通折叠光标所在的代码alt + cmd + ]:普通展开光标所在的代码cmd + k, cmd + [:递归折叠光标所在的代码(即里面的嵌套也会折叠)cmd + k, cmd + ]:递归展开光标所在的代码(即里面的嵌套也会展开)ctrl + b:展开/隐藏侧边栏cmd + 0:聚焦到侧边栏cmd + shift + e:打开资源管理器cmd + shift + d:打开 debug 栏cmd + shift + f:打开搜索栏ctrl + j:打开/关闭底部面板ctrl + ` :打开/关闭终端shift + cmd + u:打开/关闭输出shift + cmd + m:打开/关闭问题shift + cmd + [/]:切换打开的编辑器(页面),太麻烦了,被我改成了 ctrl + [/]ctrl + tab:显示当前编辑器组中所有编辑器并切换,长按可以不断切换,短按则会切换到上一个使用的编辑器。ctrl + number:切换组内不同的编辑器cmd + 1/2/3 :切换并聚焦到不同的编辑器组cmd + \:拆分编辑器cmd + f:搜索cmd + e:搜索当前选中的内容,如果没有选中的内容就搜索当前光标所在单词,相当于 ctrl + d + ctrl + fcmd + alt + f:替换在根目录的 .vscode 中的 settings.json 中如下配置(也就是工作区配置)
{
"files.exclude": {
"**/.git": true,
"**/*.js.map": true,
"**/*.d.ts": true,
}
}参考: Hide .js.map files in Visual Studio Code
module.exports = {
// printWidth: 80,
tabWidth: 2,
// useTabs: false,
semi: false,
singleQuote: true
// trailingComma: 'none',
// bracketSpacing: true,
// jsxBracketSameLine: false,
// arrowParens: 'avoid',
// rangeStart: 0,
// rangeEnd: Infinity,
// proseWrap: "preserve"
}先来看一下 FOIT(Flash of Invisible Text) 的表现(GitHub 只会播放一次 GIF,拖到一个新窗口刷新可重放):

简单来说 FOIT 就是文字使用了自定义的 font-face,所以导致在自定义的字体加载完毕在之前,对应的文字会显示一片空白。
在老版本的浏览器中,会优先显示 font-family 中已经可以显示的候选字体,然后当 font-face 的字体加载完毕后,再变成 font-face 的字体,这被称作 FOUT(Flash of Unstyled Text)
下面是对 FOUT 和 FOIT 的一段英文解释,比较全面:
Remember FOUT? When using a custom font via @font-face, browsers used to display a fallback font in the font stack until the custom one loaded. This created a "Flash of Unstyled Text" — which was unsettling and could cause layout shifts. We worked on techniques for fighting it, for instance, making the text invisible until the font was ready.
\A number of years ago, browsers started to shift their handling of this. They started to detect if text was set in a custom font that hasn't loaded yet, and made it invisible until the font did load (or X seconds had passed). That's FOIT: "Flash of Invisible Text". Should a font asset fail or take a long time, those X seconds are too long for people rightfully concerned about render time performance. At worst, this behavior can lead to permanently invisible content.
之所以从 FOUT 变成 FOIT,就是在字体变更的时候会因此 re-flow,而 re-flow 的代价是很大的,所以干脆就直接不显示,在 font-face 载入后再显示。
在实际的工程中,我们可能有几种对于 font-face 加载的需求:
1. 使用 font-display 来实现 FOUT
font-display: swap:浏览器会直接使用 font-family 中最先匹配到的已经能够使用的字体,然后当 font-family 中更靠前的字体成功载入时,切换到更靠前的字体,相当于是 FOUT。font-display: fallback:浏览器会先等待最靠前的字体加载,如果没加载到就不显示任何东西,这个过程大约持续 100ms,然后按照顺序显示已经成功载入的字体。在此之后有大约 3s 的时间来提供切换到加载完毕的更靠前的字体。font-display: optional:浏览器会先等待最靠前的字体加载,如果没加载到就不显示任何东西,这个过程大约持续 100ms,然后字体就不会再更改了(一般第一次打开某页面的时候都会使用 fallabck 字体,字体被下载但是没被使用,之后打开时会使用缓存中的字体)。2. 使用 Web Font Loader
使用 JS 而不是 CSS 来引入字体,WFL 会在字体引入的整个过程提供多个钩子函数,具体可以参考 官方文档 和 Loading Web Fonts with the Web Font Loader
举个小例子,比如我想让某标题使用 font-face 字体。载入页面后,标题一开始是不可见的,直到自定义字体被成功加载后标题才向上浮动显示,当超过 5s 还没成功载入字体时将按 fallback 字体显示。这就需要判断自定义字体什么时候成功加载,什么时候载入失败。
function asyncCb(){
WebFont.load({
custom: {
families: ['Oswald-Regular']
},
loading: function () { //所有字体开始加载
console.log('loading');
},
active: function () { //所有字体已渲染
fontLoaded();
},
inactive: function () { //字体预加载失败,无效字体或浏览器不支持加载
console.log('inactive: timeout');
fontLoaded();
},
timeout: 5000 // Set the timeout to two seconds
});
}还有一些关于 font-face 的知识我们也必须了解
HTTPS:是以安全为目标的HTTP通道,简单讲是HTTP的安全版,即HTTP下加入SSL层,HTTPS的安全基础是SSL,因此加密的详细内容就需要SSL。
HTTPS协议的主要作用可以分为两种:一种是建立一个信息安全通道,来保证数据传输的安全;另一种就是确认网站的真实性。
公开密钥加密(英语:Public-key cryptography),也称为非对称加密(英语:asymmetric cryptography),是密码学的一种算法,它需要两个密钥,一个是公开密钥,另一个是私有密钥;一个用作加密的时候,另一个则用作解密。使用其中一个密钥把明文加密后所得的密文,只能用相对应的另一个密钥才能解密得到原本的明文;甚至连最初用来加密的密钥也不能用作解密。由于加密和解密需要两个不同的密钥,故被称为非对称加密;不同于加密和解密都使用同一个密钥的对称加密。虽然两个密钥在数学上相关,但如果知道了其中一个,并不能凭此计算出另外一个;因此其中一个可以公开,称为公钥,任意向外发布;不公开的密钥为私钥,必须由用户自行严格秘密保管,绝不通过任何途径向任何人提供,也不会透露给要通信的另一方,即使他被信任。
以上是来自维基百科的公钥私钥的定义,HTTPS 是基于非对称加密的,公钥和私钥是整个 HTTPS 的基础。简单来说,公钥是公开的(要不叫公钥),比如小 A 想给我发送加密信息就要他我的公钥,让他用我的公钥对信息进行加密,这个信息只有我的私钥能打开。所以私钥是绝对不能泄漏的,那么私钥只能用来解开公钥吗?并不是,公钥私钥都可以加密和用对方来解密,私钥用来签发数字签名,我用独一无二的私钥签发了一个数字签名,你们都有我的公钥,只有我签发的数字签名能用我的公钥解开,才能证明这个签名发自我。
知乎上有个回答特别精辟:
不要去硬记。 你只要想:既然是加密,那肯定是不希望别人知道我的消息,所以只有我才能解密,所以可得出公钥负责加密,私钥负责解密;同理,既然是签名,那肯定是不希望有人冒充我发消息,只有我才能发布这个签名,所以可得出私钥负责签名,公钥负责验证。
迪菲-赫尔曼密钥交换(英语:Diffie–Hellman key exchange,缩写为D-H) 是一种安全协议。它可以让双方在完全没有对方任何预先信息的条件下通过不安全信道创建起一个密钥。这个密钥可以在后续的通讯中作为对称密钥来加密通讯内容。
笔者本人并没很仔细理解这个算法的原理,但是作为前端在实际应用中只需要知道这个加密算法的作用就好了,中间就是黑箱。简单来说这个算法的作用就是:Alice 和 Bob 各自有对方的公钥(当然其他人也有),Alice 和 Bob 再产生一个随机数(不告诉别人),然后用两个人的公钥和自己手里的随机数产生两个数 A B,然后它们交换这两个数,每个人可以用自己手头的随机数和交换得来的数再次计算,两个人得到的数是一样的,就得到了一个共享密钥。
在知乎上找到一个这个共享秘钥计算过程的描述
(1)Alice与Bob确定两个大素数n和g,这两个数不用保密
(2)Alice选择另一个大随机数x,并计算A如下:A=gxmod n
(3)Alice将A发给Bob
(4)Bob 选择另一个大随机数y,并计算B如下:B=gymod n
(5)Bob将B发给Alice
(6)计算秘密密钥K1如下:K1=Bxmod n
(7)计算秘密密钥K2如下:K2=Aymod n K1=K2,因此Alice和Bob可以用其进行加解密
因此,client 和 server 可以“离线“计算出一份只有对方知道的秘钥。
公开密钥认证(英语:Public key certificate),又称公开密钥证书、公钥证书、数字证书(digital certificate)、数字认证、身份证书(identity certificate)、电子证书或安全证书,是用于公开密钥基础建设的电子文件,用来证明公开密钥拥有者的身份。此文件包含了公钥信息、拥有者身份信息(主体)、以及数字证书认证机构(发行者)对这份文件的数字签名,以保证这个文件的整体内容正确无误。
包含的内容有:
版本:现行通用版本是 V3
序号:用以辨识每一张证书,特别在撤消证书的时候有用
主体:拥有此证书的法人或自然人身份或机器,包括:
国家(C,Country)
州/省(S,State)
地域/城市(L,Location)
组织/单位(O,Organization)
通用名称(CN,Common Name):在TLS应用上,此字段一般是网域
发行者:以数字签名形式签署此证书的数字证书认证机构
有效期开始时间:此证书的有效开始时间,在此前该证书并未生效
有效期结束时间:此证书的有效结束时间,在此后该证书作废
公开密钥用途:指定证书上公钥的用途,例如数字签名、服务器验证、客户端验证等
公开密钥
公开密钥指纹
数字签名
数字签名算法
主体别名:例如一个网站可能会有多个网域(www.wikipedia.org, zh.wikipedia.org, zh.m.wikipedia.org 都是维基百科)、一个组织可能会有多个网站(*.wikipedia.org, *.wikibooks.org, *.wikidata.org 都是维基媒体基金会旗下的网域),不同的网域可以一并使用同一张证书,方便实现应用及管理
其中,在加密过程中最重要的是公开密钥和数字签名算法,前者用来生成 session key,后者是验算 hash 的方法。
数字证书认证机构(英语:Certificate Authority,缩写为CA),也称为电子商务认证中心、电子商务认证授权机构,是负责发放和管理数字证书的权威机构,并作为电子商务交易中受信任的第三方,承担公钥体系中公钥的合法性检验的责任。
在 CA 给服务端颁发证书的同时会产生一个私钥和公钥。私钥由服务端自己保存,不可泄漏。公钥则是附带在证书的信息中,可以公开的。证书本身也附带一个证书电子签名,这个签名用来验证证书的完整性和真实性,可以防止证书被串改。
SSL协议分为两部分:Handshake Protocol 和 Record Protocol。其中 Handshake Protocol 用来协商密钥,协议的大部分内容就是通信双方如何利用它来安全的协商出一份密钥。 Record Protocol 则定义了传输的格式。
相比对称加密,非对称加密的速度比较慢,所以它一般用于密钥交换,双方通过公钥算法协商出一份密钥,然后通过这个密钥对称加密来通信,充分结合这两者的优势。
首先,由客户端向服务端发起一个明文的无保护的请求,用来初始化 SSL(这里的客户端只是一个职责的代号,代表"首先发送信息的一方",对前端来说,就是浏览器)。
message
clinet +---------------> server
message 中包含以下内容:
这个随机数是会在后面中用到的,其他的是用来标明客户端支持的特性的。
ServerHello
Certificate*
ServerKeyExchange*
CertificateRequest*
ServerHelloDone
clinet <---------------------+ server
服务端收到客户端发来的信息,返回给客户端自己的信息,message 中包括
这里要说一下数字证书与数字签名,数字证书这个东西是向第三方机构去申请的。
数字签名用来保证数字证书没有被篡改过,因为数字签名是用 CA 的私钥来加密的,如果第三方篡改了签名是无法用 CA 的公钥解密的(就伪装不下去了),数字签名也是 CA 给的。
数字签名的过程如下,使用证书中的数字签名算法计算证书的一个 HASH 值,然后 CA 用私钥给加密,然后给服务端,服务端保管好即可。
数字签名算法 CA私钥加密
数字证书 +-------------> HASH +-------------> 数字签名
最后服务器发送 Server Hello Done 报文通知客户端, 最初阶段的 SSL握手协商部分结束,客户端应该发送信息了。
client:
+---------------------------------------------------------------------+
| CA公钥解密 |
| 数字签名 +--------------------> 服务端的HASH +-----+ |
| | |
| +-----> 是否相同 |
| 数字证书中的数字签名算法 | |
| 数字证书 +--------------------> 客户端计算的HASH +-- + |
| |
+----------------------------------------------------------------------+客户端根据证书中的数字签名算法计算出数字证书的 HASH,再用本地的 CA 公钥(浏览器厂商会内置根证书,可以通过证书链将服务端的证书用内置的根证书认证)。解密出数字签名的 HASH,比较一致则表明这确实是未被篡改过的数字证书。到这一步,客户端已经成功拿到了服务端的证书。
Certificate*
ClientKeyExchange
CertificateVerify*
[ChangeCipherSpec]
Finished
clinet +---------------------> server
客户端的证书,如果服务端需要的话会发送(比如某些网银需要 U 盾来生成证书验证客户端的身份)。
如果服务端需要对客户端进行验证,在客户端收到服务端的 Server Hello 消息之后,首先需要向服务端发送客户端的证书,让服务端来验证客户端的合法性。
如果证书没有问题,客户端就会从服务器证书中取出服务器的公钥来加密以下信息回应服务端:
ChangeCipherSpec 是一个独立的协议,体现在数据包中就是一个字节的数据,用于告知服务端,客户端已经切换到之前协商好的加密套件(Cipher Suite)的状态,准备使用之前协商好的加密套件加密数据并传输了。它标志着从客户端之后发出的信息将使用 shared secret 来进行加密。
在ChangecipherSpec传输完毕之后,客户端会使用之前协商好的加密套件和 shared secret 加密一段 Finish 的数据传送给服务端,此数据是为了在正式传输应用数据之前对刚刚握手建立起来的加解密通道进行验证。
[ChangeCipherSpec]
Finished
clinet <---------------------+ server
在这一步,服务端无论如何将得到 pre-master key,但是 SSL 有几种不同的交换密钥的算法,由 cipher suite 来决定,每种密钥交换算法需要不同的公钥来推倒,这里介绍两种:
不管用哪种方法,服务端和客户端现在都已经持有 pre-master key 后,使用私钥进行解密获得 pre-master key。再加上自己手上的 server_random 和 client_random,然后客户端和服务端会使用一个 PRF (Pseudo-Random Function) 算法来产生 master-secret。
master_secret = PRF(pre_master_secret, "master secret", ClientHello.random + ServerHello.random)
再由 master-secret 推导出 session-key(也称 shared-secret),这是双方后续通信用来最终加密的对称密钥。
一切准备好之后,服务端也回应客户端一个自己的用 session-key 加密的 ChangeCipherSpec,标明自己之后的信息也将使用 session-key 来加密。之后,服务端也会使用 session-key 加密一段 Finish 消息发送给客户端,以验证之前通过握手建立起来的加解密通道是否成功。
根据之前的握手信息,服务器和客户端的 Finished 报文交换完毕之后,如果客户端和服务端都能对 Finish 信息进行正常加解密且消息正确的被验证,则说明 SSL 连接就算建立完成。接下来,双方可以进行应用层的通信,使用上面产生的 session-key 对 HTTP 进行加密传输了。
在以上流程中, 应用层发送数据时会附加一种叫做 MAC( Message Authentication Code) 的报文摘要。 MAC 能够查知报文是否遭到篡改, 从而保护报文的完整性。
最后放上一张图来总结整个 SSL 的过程,其中加密方式采用的是 RSA,但是整个流程是思路是一致的。
其实 HTTPS 要复杂的多,本文介绍的过程是简化了的,主要是理清如何安全获得对称公钥。
via The SSL/TLS Handshake: an Overview

放上 HTTPS 的好处与坏处,via https是什么?使用https的好处与不足?
正是由于 HTTPS 非常的安全,攻击者无法从中找到下手的地方,从站长的角度来说,HTTPS 的优点有以下2点:
SEO 方面
谷歌曾在 2014 年 8 月份调整搜索引擎算法,并称"比起同等 HTTP 网站,采用 HTTPS 加密的网站在搜索结果中的排名将会更高”。
安全性
尽管 HTTPS 并非绝对安全,掌握根证书的机构、掌握加密算法的组织同样可以进行中间人形式的攻击,但HTTPS 仍是现行架构下最安全的解决方案,主要有以下几个好处:
虽然说 HTTPS 有很大的优势,但其相对来说,还是有些不足之处的,具体来说,有以下2点:
SEO 方面
据 ACM CoNEXT 数据显示,使用 HTTPS 协议会使页面的加载时间延长近50%,增加 10% 到 20% 的耗电,此外,HTTPS 协议还会影响缓存,增加数据开销和功耗,甚至已有安全措施也会受到影响也会因此而受到影响。
而且 HTTPS 协议的加密范围也比较有限,在黑客攻击、拒绝服务攻击、服务器劫持等方面几乎起不到什么作用。
最关键的,SSL 证书的信用链体系并不安全,特别是在某些国家可以控制CA根证书的情况下,中间人攻击一样可行。
经济方面
图解 HTTP
项目一开始使用的是 create-react-app 创建的,配置的 ESLint 是用的 AlloyTeam 的 eslint-config-alloy/react, 默认配置已经很合理了,并且每条配置都有相应的说明,只需要再根据个人喜好修改一些 rule 即可,我个人修改的 .eslintrc.json 配置如下
{
"extends": [
"eslint-config-alloy/react"
],
"globals": {
// 这里填入你的项目需要的全局变量
// 这里值为 false 表示这个全局变量不允许被重新赋值,比如:
//
// jQuery: false,
// $: false
},
"rules": {
"indent": [
"warn",
2,
{
"SwitchCase": 1,
"flatTernaryExpressions": true
}
],
"semi": [
"error",
"never"
],
"react/jsx-indent": [
"warn",
2
],
"react/jsx-indent-props": [
"warn",
2
],
"no-unused-vars": [
"warn",
{
"vars": "all",
"args": "none",
"caughtErrors": "none"
}
]
}
}但是在 eject 之后运行 npm start 后会直接报错

按理说,eject 前后配置不变,只不过是将配置弹出,npm start 应该可以直接运行,但是却报了 ESLint 的错误。
一开始我以为是 eslint-config-alloy/react 的问题,然后重新手写了一些配置依然会报错,证明不是 eslint-config-alloy/react 的问题。Google 之后在一个 issue 发现:
By default Eslint errors will raise webpack errors unless you change the config as shown above.
也就是说,ESLint 会在发现 error 级别错误的时候触发 webpack 报错,导致编译失败。
但是这无法解释为什么在 eject 之前能通过审查的代码在 eject 后就遇到 error 报错了呢?
简单粗暴我们直接看 create-react-app 文档 中关于 ESLint 的部分
If you want to enable even more accessibility rules, you can create an
.eslintrcfile in the root of your project with this content:{ "extends": ["react-app", "plugin:jsx-a11y/recommended"], "plugins": ["jsx-a11y"] }However, if you are using Create React App and have not ejected, any additional rules will only be displayed in the IDE integrations, but not in the browser or the terminal.
现在回想一下 create-react-app 中 ESLint 是如何工作的,终端有 warning/error 的信息,但是这个打印出来的信息的其实并不是依照 eslint-config-alloy/react 规则,而是 create-react-app 的默认规则。集成在编辑器(我用的 VSCode)中的波浪线错误提醒功能则是根据 eslint-config-alloy/react 规则显示的。
但是在 eject 后,编译与波浪提示都根据 eslint-config-alloy/react 规则进行代码审查,所以 eject 前根据默认规则审查通过的代码在eject后并不能通过 eslint-config-alloy/react 的审查报了错(eslint-config-alloy/react 规则真的很严格)。
在这里还有一个设计思路与使用思路上的冲突:ESLint 默认 error 级别直接报错退出,是因为将某种 rule 的错误等级定为 error 时,当出错代码触发了这个 rule,就意味着程序根据规则来说已经不对了,就不需要再往后进行编译等等了。所以代码必须先过了 ESLint 这关(也就是用户自己对代码定下的规则),才能放到 babel 里去进行编译。(具体的可以看 zakas 大神关于这个问题的讨论)
(我个人之前本来比较喜欢 error 时不退出,然后选择性的去修改部分有问题的代码,有些报错的代码就不理会等重构的时候再说。但是仔细一想其实违背了 ESLint 的**,既然有 warning 和 error 的区分,那些不重要的 error 其实就应该定义为 warning,况且背着一堆 error 工作的代码本身就是有风险的,lint 工具就是来规避这些风险的)
按照 ESLint-loader 的 文档
failOnError(default:false)Loader will cause the module build to fail if there are any ESLint errors.
failOnError 默认是 false,按照说明应该是不会阻止 build。
ESLint-loader 的作者也 提到(不过远在 2015 年 3 月)
failOn* are off by default to avoid webpack to break the build for "just some linting issues". So you should not have any error/warning that break the build by default.
然而,实际上 build 依然失败,具体原因我也不清楚,有几个 issue 也在反应 failOnError 不起作用,我猜可能是 ESLint-loader 没能成功的配置 ESLint,这个坑以后仔细研究一下再来填(逃)。
eslint-loader 的作者给出的 解决方案
Like I said, you can use
emitWarning: trueoption to force all ESLint error/warning being reported as warnings
将 emitWarning 设为 true 就可以了,所有的 error/warning 信息都会打印出来,error 也不会阻止编译,简单粗暴。
rules: [{
enforce: 'pre',
test: /\.jsx?$/,
loader: 'ESLint-loader',
options: {
emitWarning: true
}
}]遵照 Zakas 大神的设计思路,报 error 的就阻止编译,改到通过为止,报 warning 的就打印出来,个人认为这才是正确遵照 ESLint 的使用方法。
将 ./node_modules/ESLint-loader/index.js 中的
emitter(webpack.version === 2 ? new ESLintError(messages) : messages)直接注释掉!不给 ESLint 传递任何错误信息,也不会返回错误码了,这样终端永远都是 0 errors 0 warnings,错误就只能通过编辑器的红线提示来看了。
Also to note, the actual build still finishes and produces output. This only affects wrappers that would call webpack, such as
webpack-dev-server(won't automatically reload the browser if lint errors exist) orfrontend-maven-plugin(will fail the maven build if lint errors exist).
这位仁兄 提到了 关于 ESLint 其实并不会阻止 build,只是会在遇到 error 时阻止像 webpack-dev-server 这种服务器自动刷新页面,并弹出一个遮罩层显示错误。
在看 React 的内联函数和性能 看到了一段很有意思的代码段,乍一看挺简单的代码,但是弄懂还是认真的想了一下,在这里分享一下思考的过程。
// 1. App 会传递一个 prop 给 From 表单
// 2. Form 将向下传递一个函数给 button
// 这个函数与它从 App 得到的 prop 相接近
// 3. App 会在 mounting 之后 setState,并传递
// 一个**新**的 prop 给 Form
// 4. Form 传递一个新的函数给 Button,这个函数与
// 新的 prop 相接近
// 5. Button 会忽略新的函数, 并无法
// 更新点击处理程序,从而提交陈旧的数据
class App extends React.Component {
state = { val: "one" }
componentDidMount() {
this.setState({ val: "two" })
}
render() {
return <Form value={this.state.val} />
}
}
const Form = props => (
<Button
onClick={() => {
submit(props.value)
}}
/>
)
class Button extends React.Component {
shouldComponentUpdate() {
// 让我们假装比较了除函数以外的一切东西
return false
}
handleClick = () => this.props.onClick()
render() {
return (
<div>
<button onClick={this.props.onClick}>这个的数据是旧的</button>
<button onClick={() => this.props.onClick()}>这个工作正常</button>
<button onClick={this.handleClick}>这个也工作正常</button>
</div>
)
}
}在线把玩地址:这是一个运行该应用程序的沙箱
上面的三个 button。
第一个会打印 "one"。
第一个会打印 "two"。
第一个会打印 "two"。
奇怪,明明长得都差不多为什么会有区别呢?
首先,从上到下看,App 的 state 更新,导致 re-render。Form 是一个 stateless component,接受一个新的 prop 必然会 re-render。然后是关键的 Button,Button 将 shouldComponent 给直接 return false 了,这会导致 render 不会被再次调用,在 Button 第一次 render 后(事实上也只有一个 render,因为 shouldComponentUpdate 直接 return false 了),onClick 指向的是 prevProps 的 this.props.onClick。
在这里还需要将 JSX 还原一下方便理解,JSX 调用 React.createElemennt 生成的 VDOM 的简化版可以表达为
{
type: button,
onClick: this.props.onClick,
children: "这个的数据是旧的",
...
}此时,onClick 已经被赋值为了 prevProps.onClick 了,之后都不会再有任何改变。
prevProps.onClick 又是个什么样的函数呢?是这个样子的:
() => { submit(props.value) }在第一次 render 传递给 Button 时,props.value 值为 "one",之后 Form re-render,会生成新的 onClick 函数传递给 Button,但是很遗憾,Button 内的 onClick 已经定死了,无法改变,所以总是会输出 "one"。
第二次和第三次是一个道理,这里只说第二次。
第二次相比第一次,区别就是不是直接去执行 props.onClick,而是每次都包一个新的箭头函数,在每一次执行的时候都会去获取一个新的 this.props.onClick,这就是一切的关键,虽然 shouldComponentUpdate 为 false,但是新的 props 还是已经来了,可以通过 this.props 引用。
这段代码对我们有什么启发吗?
文章中作者说可以写一个 PureComponentMinusHandlers 高阶组件,作用类似高阶组件,但是对类似 onClick 的 props 的更新函数不会触发 update(因为它们基本也不会变化),而只对数据类的 props 的变化进行 PureComponent 的 shallowCompare,这是一种 react 的优化方法。
通过之前的分析还可以玩出下面的花样:
主动拉取更新的子组件来进行性能优化:像上例中的第二种和第三种方法,将子组件的 shouldComponentUpdate 返回 false,然后在传入的 props 的 handler 外面包一层匿名函数,这样每次调用 handler 都会去访问最新的 this.props.handler 等“非计划更新的 props”(函数的 props),这些函数的 props 可以返回父组件的一些内部状态传递给子组件。如此一来,子组件就从单向状态流变成了子组件向父组件主动拉取。但这与 React 的单向数据理念相左,是属奇技淫巧。
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.