flashinfer-ai / flashinfer Goto Github PK
View Code? Open in Web Editor NEWFlashInfer: Kernel Library for LLM Serving
Home Page: https://flashinfer.ai
License: Apache License 2.0
FlashInfer: Kernel Library for LLM Serving
Home Page: https://flashinfer.ai
License: Apache License 2.0




![github-actions[bot] avatar](https://avatars.githubusercontent.com/in/15368?v=4 "github-actions[bot]")


























































































































As the combination of shapes and configurations increases, our pip wheel size grows and the compilation time becomes long.
PyTorch supports Just-In-Time compilation of extensions:
https://pytorch.org/tutorials/advanced/cpp_extension.html#jit-compiling-extensions, which makes it possible to only compile kernels corresponding to certain configurations/shapes, thus reducing both the wheel size and the development overhead on the codebase.
We can release a flashinfer_jit wheel where all kernels are compiled with JIT.
Hi,
Thanks for the great framework! I am trying to compile and run the benchmark. However, I meet some problems when I compile decode kernel tests/benchmarks. After I run make -j12, I met this error if set(FLASHINFER_DECODE ON):
[ 98%] Building CUDA object CMakeFiles/bench_batch_decode.dir/src/bench_batch_decode.cu.o
/home/admin/llm-acceleration/flashinfer/src/bench_batch_decode.cu(156): error: no instance of function template "flashinfer::BatchPrefillWithPagedKVCacheWrapper" matches the argument list
argument types are: (flashinfer::BatchPrefillHandler *, half *, int32_t *, std::nullptr_t, flashinfer::paged_kv_t<flashinfer::PageStorage::kIndices, flashinfer::QKVLayout::kNHD, half, int32_t>, half *, std::nullptr_t, size_t, __nv_bool, const flashinfer::RotaryMode)
cudaError_t status = BatchPrefillWithPagedKVCacheWrapper<PageStorage::kIndices, kv_layout, T, T, int32_t>(
^
detected during instantiation of "void bench_flashinfer_batch_decode_with_prefill(nvbench::state &) [with T=half]"
1 error detected in the compilation of "/home/admin/llm-acceleration/flashinfer/src/bench_batch_decode.cu".
make[2]: *** [CMakeFiles/bench_batch_decode.dir/build.make:76: CMakeFiles/bench_batch_decode.dir/src/bench_batch_decode.cu.o] Error 1
make[1]: *** [CMakeFiles/Makefile2:279: CMakeFiles/bench_batch_decode.dir/all] Error 2
make: *** [Makefile:136: all] Error 2
What can I do to figure it out? Thank you!
We have tested sglang with flashinfer 0.0.2 and flashinfer 0.0.3-dev (238563f) and both will crash in flashinfer with following stacktrace under A100.
Model: Yi-34B
OS: Ubuntu 22.04
Gpu: A100 80GB
Yi-6B and Yi-9B has no such issue. Yi is llama2 based arch if I am not mistaken.
@yzh119 Since the stacktrace is vague to me, BatchPrefillWithPagedKVCache failed to dispatch with dtype Half, I am first reproting the bug here. If you think this is sglang related, I will move bug to sglang. Thanks!
Traceback (most recent call last):
File "/root/miniconda3/lib/python3.11/site-packages/sglang/srt/managers/router/model_rpc.py", line 184, in exposed_step
self.forward_step()
File "/root/miniconda3/lib/python3.11/site-packages/torch/utils/_contextlib.py", line 115, in decorate_context
return func(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^
File "/root/miniconda3/lib/python3.11/site-packages/sglang/srt/managers/router/model_rpc.py", line 199, in forward_step
self.forward_fill_batch(new_batch)
File "/root/miniconda3/lib/python3.11/site-packages/sglang/srt/managers/router/model_rpc.py", line 412, in forward_fill_batch
) = self.model_runner.forward(
^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/root/miniconda3/lib/python3.11/site-packages/sglang/srt/managers/router/model_runner.py", line 506, in forward
return self.forward_extend(**kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/root/miniconda3/lib/python3.11/site-packages/torch/utils/_contextlib.py", line 115, in decorate_context
return func(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^
File "/root/miniconda3/lib/python3.11/site-packages/sglang/srt/managers/router/model_runner.py", line 411, in forward_extend
return self.model.forward(input_ids, input_metadata.positions, input_metadata)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/root/miniconda3/lib/python3.11/site-packages/sglang/srt/models/llama2.py", line 269, in forward
hidden_states = self.model(input_ids, positions, input_metadata, input_embeds)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/root/miniconda3/lib/python3.11/site-packages/torch/nn/modules/module.py", line 1511, in _wrapped_call_impl
return self._call_impl(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/root/miniconda3/lib/python3.11/site-packages/torch/nn/modules/module.py", line 1520, in _call_impl
return forward_call(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/root/miniconda3/lib/python3.11/site-packages/sglang/srt/models/llama2.py", line 239, in forward
hidden_states, residual = layer(
^^^^^^
File "/root/miniconda3/lib/python3.11/site-packages/torch/nn/modules/module.py", line 1511, in _wrapped_call_impl
return self._call_impl(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/root/miniconda3/lib/python3.11/site-packages/torch/nn/modules/module.py", line 1520, in _call_impl
return forward_call(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/root/miniconda3/lib/python3.11/site-packages/sglang/srt/models/llama2.py", line 191, in forward
hidden_states = self.self_attn(
^^^^^^^^^^^^^^^
File "/root/miniconda3/lib/python3.11/site-packages/torch/nn/modules/module.py", line 1511, in _wrapped_call_impl
return self._call_impl(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/root/miniconda3/lib/python3.11/site-packages/torch/nn/modules/module.py", line 1520, in _call_impl
return forward_call(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/root/miniconda3/lib/python3.11/site-packages/sglang/srt/models/llama2.py", line 140, in forward
attn_output = self.attn(q, k, v, input_metadata)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/root/miniconda3/lib/python3.11/site-packages/torch/nn/modules/module.py", line 1511, in _wrapped_call_impl
return self._call_impl(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/root/miniconda3/lib/python3.11/site-packages/torch/nn/modules/module.py", line 1520, in _call_impl
return forward_call(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/root/miniconda3/lib/python3.11/site-packages/sglang/srt/layers/radix_attention.py", line 115, in forward
return self.extend_forward(q, k, v, input_metadata)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/root/miniconda3/lib/python3.11/site-packages/sglang/srt/layers/radix_attention.py", line 91, in prefill_forward_flashinfer
o = input_metadata.prefill_wrapper.forward(
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/root/miniconda3/lib/python3.11/site-packages/flashinfer/prefill.py", line 507, in forward
return self._wrapper.forward(
^^^^^^^^^^^^^^^^^^^^^^
RuntimeError: BatchPrefillWithPagedKVCache failed to dispatch with dtype Half
Thanks again for the nice project! Are you interested in uploading the wheels (for CUDA 12.1) to PyPI? This will help users manage the dependency on the FlashInfer library.
Gemma uses head_dim=256 which is enabled in pip wheels by default. We should compile kernels for head_dim=256 and change some kernel parameters for best performance in this case.
Ranked by priority (from high to low):
While I saw this item in the roadmap, I'm wondering if this feature will be supported in the near future or not.
Hi team, thanks for the wonderful library! I'm just wondering if you can include Python 3.8 in your release. We are trying to ship FlashInfer to vLLM, and just found that Python 3.8 was not included in the last release. Is there any technical reason for this? Otherwise, could you include it in your release?
The examples are all tensors of half() type. I wonder if flashinfer supports fp32 dtype?
Prepare PyPI wheels for users to trying-out directly:

I found that during shared-prefix calculation, this kenerl won't use qo_indptr to split batch queries which may cause rope error.
Hi! I'm playing with batch_decode_with_padded_kv_cache and wanted to test out the FP8 KVCache. I couldn't find some good instructions on the docs,
I've tried the following:
num_qo_heads = 32
num_kv_heads = 32
batch_size = 16
head_dim = 128
padded_kv_len = 1024
q = torch.empty(
batch_size,
num_qo_heads,
head_dim,
device=torch.device("cuda"),
dtype=torch.float8_e4m3fn,
)
k_padded = torch.randn(batch_size, padded_kv_len, num_kv_heads, head_dim).to("cuda:0").to(torch.float8_e4m3fn)
v_padded = torch.randn(batch_size, padded_kv_len, num_kv_heads, head_dim).to("cuda:0").to(torch.float8_e4m3fn)
o = flashinfer.batch_decode_with_padded_kv_cache(
q, k_padded, v_padded, "NHD", "NONE"
)
But it gives me a BatchDecodeWithPaddedKVCache kernel launch failed: supported data type.
How can I enable FP8 KV cache? Thanks in advance!
Hello, I see there was a PR for VLLM support but it was not active since Feb. I wonder if Flashinfer has a roadmap for vllm support. Many thanks. @yzh119
In the 2024-02-02 blog post, for example
I tried to repro it simply with ncu data for numseq 1 and seqlen 16384 on 4090:
void vllm::paged_attention_v2_kernel<unsigned short, (int)128, (int)16, (int)128, (int)512>(float *, float *, T1 *, const T1 *, const T1 *, const T1 *, int, float, const int *, const int *, int, const float *, int, int, int) (32, 1, 32)x(128, 1, 1), Context 1, Stream 7, Device 0, CC 8.9
Section: GPU Speed Of Light Throughput
----------------------- ------------- ------------
Metric Name Metric Unit Metric Value
----------------------- ------------- ------------
DRAM Frequency cycle/nsecond 10.24
SM Frequency cycle/nsecond 2.23
Elapsed Cycles cycle 608178
Memory Throughput % 94.59
DRAM Throughput % 94.59
Duration usecond 272.16
...
void vllm::paged_attention_v2_reduce_kernel<unsigned short, (int)128, (int)128, (int)512>(T1 *, const float *, const float *, const T1 *, const int *, int) (32, 1, 1)x(128, 1, 1), Context 1, Stream 7, Device 0, CC 8.9
Section: GPU Speed Of Light Throughput
----------------------- ------------- ------------
Metric Name Metric Unit Metric Value
----------------------- ------------- ------------
DRAM Frequency cycle/nsecond 10.11
SM Frequency cycle/nsecond 2.20
Elapsed Cycles cycle 10792
Memory Throughput % 5.89
DRAM Throughput % 5.89
Duration usecond 4.90
...
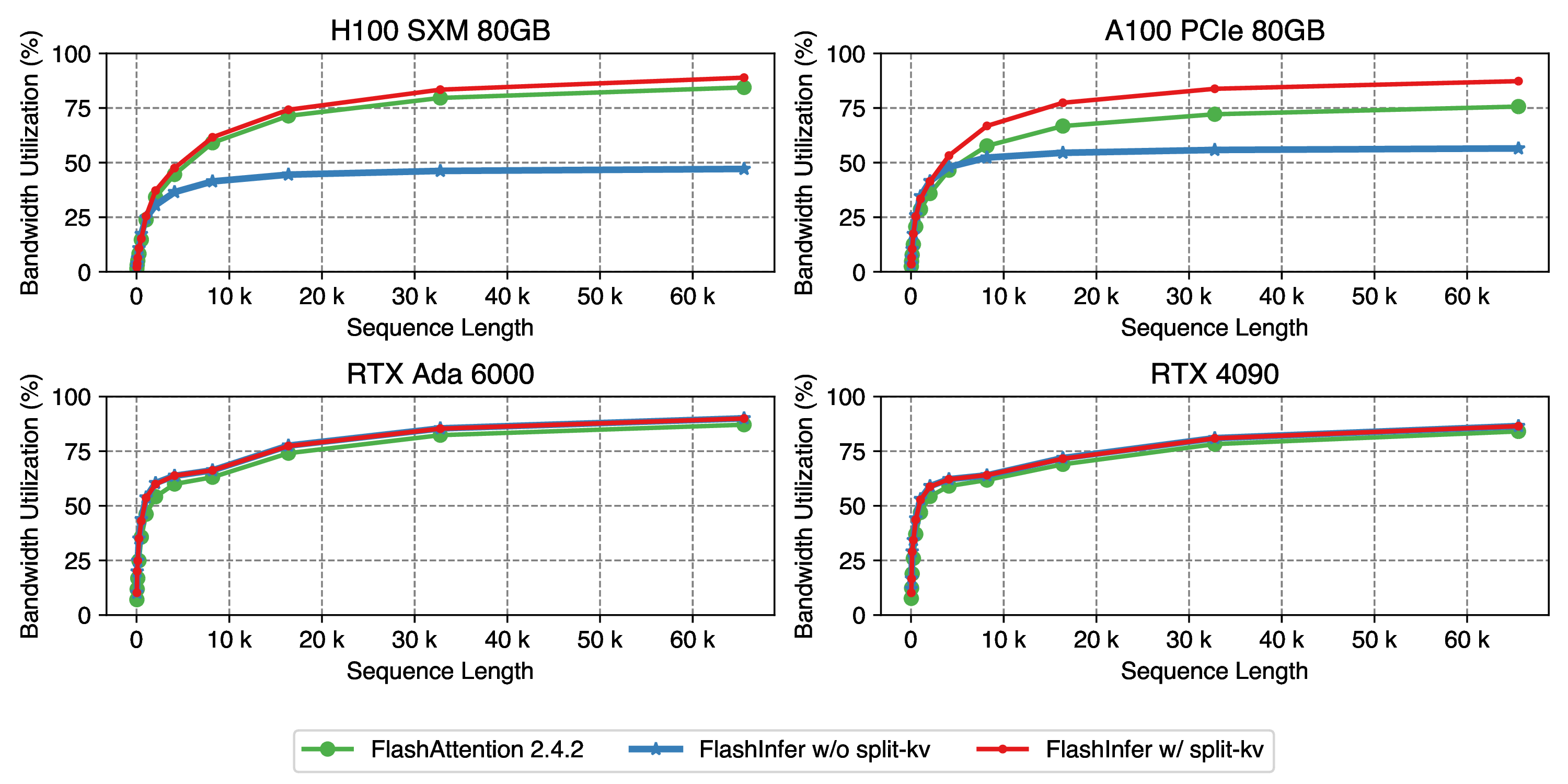
It is definitely as low as 70%-ish, could you please share more details about the measurement, or better the benchmark code. Are you measuring the timing with events?
Currently only a fraction of supported operators as exposed as PyTorch bindings, this issue tracks the progress of exposing these operators as PyTorch APIs.
Thanks for the great work!
I'm trying to compare the results of flashinfer BatchPrefillWithPagedKVCache's output with xformers, but got different outputs, this is the minimum reproducible code. I might also misunderstand flashinfer's API, please correct me if I'm wrong, thanks!
from xformers import ops as xops
import torch
import random
import flashinfer
from xformers.ops.fmha.attn_bias import BlockDiagonalCausalFromBottomRightMask
import pytest
NUM_HEADS = [8]
NUM_QUERIES_PER_KV = [1]
HEAD_SIZES = [128]
DTYPES = [torch.float16]
@pytest.mark.parametrize("num_heads", NUM_HEADS)
@pytest.mark.parametrize("num_queries_per_kv", NUM_QUERIES_PER_KV)
@pytest.mark.parametrize("head_size", HEAD_SIZES)
@pytest.mark.parametrize("dtype", DTYPES)
@torch.inference_mode()
def test_flashinfer_append(
num_heads: int, num_queries_per_kv: int, head_size: int, dtype: torch.dtype
):
random.seed(0)
torch.manual_seed(0)
if torch.cuda.is_available():
torch.cuda.manual_seed(0)
torch.set_default_device("cuda")
batch_size = 10
cache_size = 640
block_size = 32
prefix_lens = [random.randint(16, 128) for _ in range(batch_size)]
append_lens = [random.randint(16, 128) for _ in range(batch_size)]
seq_lens = [a + b for a, b in zip(prefix_lens, append_lens)]
num_tokens = sum(append_lens)
query = torch.empty(num_tokens, num_heads, head_size, dtype=dtype)
query.uniform_(-1e-3, 1e-3)
num_kv_heads = num_heads // num_queries_per_kv
key_value = torch.empty(sum(seq_lens), 2, num_kv_heads, head_size, dtype=dtype)
key_value.uniform_(-1e-3, 1e-3)
key, value = key_value.unbind(dim=1)
append_key = torch.zeros(sum(append_lens), num_kv_heads, head_size, dtype=dtype)
append_value = torch.zeros(sum(append_lens), num_kv_heads, head_size, dtype=dtype)
values = torch.arange(0, cache_size, dtype=torch.long)
values = values[torch.randperm(cache_size)]
max_block_per_request = int(cache_size / batch_size)
block_table = values[: batch_size * max_block_per_request].view(
batch_size, max_block_per_request
)
k_cache = torch.zeros(cache_size, block_size, num_kv_heads, head_size, dtype=dtype)
v_cache = torch.zeros(cache_size, block_size, num_kv_heads, head_size, dtype=dtype)
qo_indptr = torch.cumsum(torch.tensor([0] + append_lens), dim=0, dtype=torch.int32)
seq_start_loc = torch.cumsum(
torch.tensor([0] + seq_lens[:-1]), dim=0, dtype=torch.int32
)
paged_kv_last_page_len = []
paged_kv_indptr = [0]
page_kv_indices = []
total_block_num = 0
for i in range(batch_size):
# copy key, value to append_key, append_value
for j in range(append_lens[i]):
append_key[qo_indptr[i] + j].copy_(
key[seq_start_loc[i] + prefix_lens[i] + j]
)
append_value[qo_indptr[i] + j].copy_(
value[seq_start_loc[i] + prefix_lens[i] + j]
)
# copy key, value to kv cache
cur_prefix_id = 0
block_id = 0
while cur_prefix_id < prefix_lens[i]:
start_loc = seq_start_loc[i] + cur_prefix_id
if cur_prefix_id + block_size > prefix_lens[i]:
end_loc = seq_start_loc[i] + prefix_lens[i]
else:
end_loc = start_loc + block_size
start_slot = block_table[i, block_id] * block_size
end_slot = start_slot + end_loc - start_loc
k_cache.view(-1, num_kv_heads, head_size)[start_slot:end_slot].copy_(
key[start_loc:end_loc]
)
v_cache.view(-1, num_kv_heads, head_size)[start_slot:end_slot].copy_(
value[start_loc:end_loc]
)
cur_prefix_id += block_size
block_id += 1
paged_kv_last_page_len.append((seq_lens[i] - 1) % block_size + 1)
cur_block_num = (seq_lens[i] - 1) // block_size + 1
page_kv_indices.extend(block_table[i, :cur_block_num])
total_block_num += cur_block_num
paged_kv_indptr.append(total_block_num)
workspace_buffer = torch.empty(16 * 1024 * 1024, dtype=torch.uint8, device="cuda")
append_wrapper = flashinfer.BatchPrefillWithPagedKVCacheWrapper(
workspace_buffer, "NHD"
)
append_wrapper.begin_forward(
qo_indptr,
torch.tensor(paged_kv_indptr, dtype=torch.int32),
torch.tensor(page_kv_indices, dtype=torch.int32),
torch.tensor(paged_kv_last_page_len, dtype=torch.int32),
num_heads,
num_kv_heads,
)
kv_cache = torch.cat((k_cache.unsqueeze(1), v_cache.unsqueeze(1)), dim=1)
output = append_wrapper.forward(query, kv_cache, causal=True)
append_wrapper.end_forward()
query = query.unsqueeze(0)
key = key.unsqueeze(0)
value = value.unsqueeze(0)
attn_bias = BlockDiagonalCausalFromBottomRightMask.from_seqlens(
append_lens, seq_lens
)
scale = float(1.0 / (head_size**0.5))
attn_op = xops.fmha.cutlass.FwOp()
output_ref = xops.memory_efficient_attention_forward(
query,
key,
value,
attn_bias=attn_bias,
p=0.0,
scale=scale,
op=attn_op,
).squeeze(0)
assert torch.allclose(output_ref, output, atol=1e-6, rtol=0)

We only support gqa_group_size of 1/4/8 at the moment but some models use other choices (e.g. Yi uses 7), we should support other gqa_group_size as well.
Support more head dimensions to 64/128/256
The AliBi attention bias is widely used for open-source LLMs such as MPT and Baichuan. Can FlashInfer support it?
We need to set up CI to guarantee the robustness of FlashInfer, following is the list of unit tests:
Test environments: cuda 12.3, on RTX 4090 (sm89), A100 (sm80).
Performance Regression Testing
From the blog I noticed that FlashInfer implements low-precision attention kernels so that we can achieve nearly linear speedup to the compression ratio (~4x for 4bit, ~2x for 8bit). This feature is great! and I try to use it. But there is no demo or toy code about how to use it. Could you please share more details about it?
I saw that support for sm75 / sm70 is listed in progress (https://docs.flashinfer.ai/installation.html) but didn't see an issue to track. Is this something planned in the near-term or further out on the roadmap? Thanks!
Using flashinfer in sglang with google/gemma-7b-it
File "/home/ubuntu/sglang-venv/lib/python3.11/site-packages/flashinfer/prefill.py", line 462, in forward
return self._wrapper.forward(
^^^^^^^^^^^^^^^^^^^^^^
RuntimeError: BatchPrefillWithPagedKVCache failed to dispatch with dtype HalfI don't know if this is caused by Gemma's bfloat16 dtype or my inappropriate usage.
Hi @yzh119, I see the documentation has been updated to 0.0.3, but the wheels are still 0.0.2.
Looking forward to the new release of wheels.
Hello Team,
Thanks for the great work! It seems FlashInfer has very useful and well-written CUDA kernels for LLM inference. I'm excited to find this repository!
Could you provide some end-to-end examples (or any documentation) of how to use these kernels? I really want to try them out on my machine.
Additionally, I've noticed that some of the kernels appear to reimplement existing algorithms like FlashAttention and PagedAttention. Is there any performance benchmark available that compares these to their original implementations? I'm curious about how the kernels perform.
Thanks!
In the c++ unit test, I only found case about paged tensor。
How to use ragged tensor in c++?
When I try use BatchPrefillWithRaggedKVCacheWrapper, it will link error。
Reproduce steps for current head dd88deaed6aea4fec49eec721f62dd6b53ffbd5b:
mkdir build
cd build
cmake ..
build -j16Error log:
[ 4%] Generating additional source file /home/luban/flashinfer/src/generated/batch_padded_decode_group_6_head_128_layout_1_posenc_2_dtypein_e4m3_dtypeout_e4m3.cu
Traceback (most recent call last):
File "/home/luban/flashinfer/python/generate_batch_paged_prefill_inst.py", line 92, in <module>
f.write(get_cu_file_str(*match.groups()))
TypeError: get_cu_file_str() missing 1 required positional argument: 'idtype'
Traceback (most recent call last):
File "/home/luban/flashinfer/python/generate_batch_paged_prefill_inst.py", line 92, in <module>
f.write(get_cu_file_str(*match.groups()))
TypeError: get_cu_file_str() missing 1 required positional argument: 'idtype'
Fp8 kernels have different filenames, and do not contain idtype.
Expected release date: Feb 28th, 2024
Hi @yzh119 Thank you for your excellent work. Are there any current plans to support quantization, such as AWQ, SmoothQuant, KV Cache Int8, KV Cache FP8?Thanks.
Thank you for the awesome project! I am interested in doing some experimentation using this kernel as a base, however the compilation times are quite long. What temporary changes can be made to the codebase to speed it up, selecting only a particular set of kernel template arguments?
I attempted to modify https://github.com/flashinfer-ai/flashinfer/blob/main/python/setup.py#L51-L58 and comment out branches in https://github.com/flashinfer-ai/flashinfer/blob/main/include/flashinfer/utils.cuh, unfortunately still got "symbol not found" errors upon trying to load the C++ extension. Any help would be welcome. Thanks again.
Hello,
When I compile flashinfer directly from the repo, running begin_forward of BatchPrefillWithPagedKVCacheWrapper crashes with the error:
*** stack smashing detected ***: terminated
Running the same code with the version installed from pip works without a problem. Any suggestions what could be the problem?
Thank you.
Dear exploiter,
I am a computer architecture PhD student, and I hope to use flashinfer to profile the details computing process like dense layer or attention layer, instead of the whole kernel, like the experiments in https://le.qun.ch/en/blog/2023/05/13/transformer-batching/. However, when I see the code like 'python/csrc/single_decode.cu', it seems the matrix multiplication process is not included in it.
I am not familiar with the CUDA code but I am trying to do that. Can I use flashinfer to do that? Could you pls give me some advices? Thank you.
Hey there,
Thanks for sharing your library!
Is there a basic Llama/Mistral example implemented that we could read through?
I'd like to test the inference code on the Mistral 7B reference implementation. Thanks!
Thanks for creating these awesome kernels! I am trying to get flashinfer kernels to work with cuda graphs. But it appears that several parallelism decisions (block size, num_q_tiles, etc.) are made on the fly based on the input data in the forward function. This makes it difficult to capture flashinfer kernels in cuda graphs in a generic manner. I think one solution to the problem would be to introduce a launcher kernel which would factor in the input metadata and launch the actual the actual cuda kernel using dynamic parallelism. Towards that, following are the items I have identified --
1. BatchPrefillWithPagedKVCachePyTorchWrapper::Forward -- handle return lse?
2. BatchPrefillWithPagedKVCachePyTorchWrapper::Forward -- paged_kv_t batch_size should not be on cpu side
3. BatchPrefillWithPagedKVCacheWrapperDispatched -- make cuda device function or get rid of it
4. BatchPrefillWithPagedKVCacheWrapperDispatched -- num_frags_x, num_qo_tiles, batch size need to be
5. BatchPrefillWithPagedKVCacheWrapperDispatched -- do not access handler state directly in the function
6. BatchPrefillWithPagedKVCacheDispatched -- make cuda device function
7. BatchPrefillWithPagedKVCacheDispatched -- put num_qo_tiles on device accessible memory
8. BatchPrefillWithPagedKVCacheDispatched -- Make validations gpu friendly
9. Batch size should be explicit input parameter not be based on length of indptr, so that inputs can be padded.
@yzh119 please let me know what would be the best way to proceed?
Our pre-built wheel is built with PyTorch 2.1.0, which is not compatible with PyTorch 2.2.0. We should build PyTorch version-specific wheels.
Expected release date: Mar 15th, 2024
Required operators for paper Atom: Low-bit Quantization for Efficient and Accurate LLM Serving:
Required operators for paper Punica: Multi-Tenant LoRA Serving:
Required operators for Quest:
Hi! Thanks for the awesome library.
vLLM recently upgraded its torch version to 2.3.0. And we have issues when trying to integrate flash infer to it because it doesn't have a wheel built with torch 2.3 yet. Do you guys have any plan to have a release soon with wheels built with torch 2.3?
To support non-contiguous inputs.
Release 0.0.3 does not have proper wheels built/uploaded to https://flashinfer.ai/whl/cu121/torch2.2/flashinfer/
Please upload the prebuilt wheels. Thanks!
Normally this is not a problem but flashinfer is a quite a beast to compile.
Hi, thanks for your awesome work!
I'm trying to implement https://github.com/SafeAILab/EAGLE with high-performance kernels. I read this blog and it says
FlashInfer implements prefill/append kernels for Paged KV-Cache which none of the existing libraries have done before, and it can be used to serve models in speculative decoding setting.
However, I was unable to locate arguments like position_id (utilized for rotary embedding) and attention_mask (for enforcing causality constraints).
Could you please provide an example of implementing a tree attention model using flashinfer? Any guidance you can offer would be greatly appreciated.
After #183, I can't build main branch successfully.
Here is error log:
/home/roy/flashinfer/python/csrc/batch_decode.cu(86): warning #174-D: expression has no effect
[&]() -> bool { switch (q.scalar_type()) { case at::ScalarType::Half: { using c_type = nv_half; return [&] { c_type* tmp = nullptr; return [&]() -> bool { switch (num_qo_heads / num_kv_heads) { case 1: { constexpr auto GROUP_SIZE = 1; return GROUP_SIZE, [&] { return [&]() -> bool { switch (head_dim) { case 64: { constexpr auto HEAD_DIM = 64; return HEAD_DIM, [&] { return [&]() -> bool { switch (PosEncodingMode(pos_encoding_mode)) { case PosEncodingMode::kNone: { constexpr auto POS_ENCODING_MODE = PosEncodingMode::kNone; return POS_ENCODING_MODE, [&] { return [&]() -> bool { switch (kv_layout) { case QKVLayout::kNHD: { constexpr auto KV_LAYOUT = QKVLayout::kNHD; return KV_LAYOUT, [&] { cudaError_t status = BatchDecodeWithPaddedKVCacheDispatched< GROUP_SIZE, HEAD_DIM, KV_LAYOUT, POS_ENCODING_MODE, c_type, c_type>( static_cast<c_type*>(q.data_ptr()), static_cast<c_type*>(k_padded.data_ptr()), static_cast<c_type*>(v_padded.data_ptr()), static_cast<c_type*>(o.data_ptr()), tmp, return_lse ? static_cast<float*>(lse.data_ptr()) : nullptr, batch_size, padded_kv_len, num_qo_heads, sm_scale, rope_scale, rope_theta, torch_current_stream); if (!(status == cudaSuccess)) { ::c10::detail::torchCheckFail( __func__, "/home/roy/flashinfer/python/csrc/batch_decode.cu", static_cast<uint32_t>(101), (::c10::detail::torchCheckMsgImpl( "Expected " "status == cudaSuccess" " to be true, but got false. " "(Could this error message be improved? If so, " "please report an enhancement request to PyTorch.)", "BatchDecodeWithPaddedKVCache failed with error code ", status))); }; return true; }(); } case QKVLayout::kHND: { constexpr auto KV_LAYOUT = QKVLayout::kHND; return KV_LAYOUT, [&] { cudaError_t status = BatchDecodeWithPaddedKVCacheDispatched< GROUP_SIZE, HEAD_DIM, KV_LAYOUT, POS_ENCODING_MODE, c_type, c_type>( static_cast<c_type*>(q.data_ptr()), static_cast<c_type*>(k_padded.data_ptr()), static_cast<c_type*>(v_padded.data_ptr()), static_cast<c_type*>(o.data_ptr()), tmp, return_lse ? static_cast<float*>(lse.data_ptr()) : nullptr, batch_size, padded_kv_len, num_qo_heads, sm_scale, rope_scale, rope_theta, torch_current_stream); if (!(status == cudaSuccess)) { ::c10::detail::torchCheckFail( __func__, "/home/roy/flashinfer/python/csrc/batch_decode.cu", static_cast<uint32_t>(101), (::c10::detail::torchCheckMsgImpl( "Expected " "status == cudaSuccess" " to be true, but got false. " "(Could this error message be improved? If so, " "please report an enhancement request to PyTorch.)", "BatchDecodeWithPaddedKVCache failed with error code ", status))); }; return true; }(); } default: std::ostringstream oss; oss << __PRETTY_FUNCTION__ << " failed to dispatch " "kv layout" " " << int(kv_layout); if (!(false)) { ::c10::detail::torchCheckFail( __func__, "/home/roy/flashinfer/python/csrc/batch_decode.cu", static_cast<uint32_t>(92), (::c10::detail::torchCheckMsgImpl( "Expected " "false" " to be true, but got false. " "(Could this error message be improved? If so, " "please report an enhancement request to PyTorch.)", oss.str()))); }; return false; } }(); }(); } case PosEncodingMode::kRoPELlama: { constexpr auto POS_ENCODING_MODE = PosEncodingMode::kRoPELlama; return POS_ENCODING_MODE, [&] { return [&]() -> bool { switch (kv_layout) { case QKVLayout::kNHD: { constexpr auto KV_LAYOUT = QKVLayout::kNHD; return KV_LAYOUT, [&] { cudaError_t status = BatchDecodeWithPaddedKVCacheDispatched< GROUP_SIZE, HEAD_DIM, KV_LAYOUT, POS_ENCODING_MODE, c_type, c_type>( static_cast<c_type*>(q.data_ptr()), static_cast<c_type*>(k_padded.data_ptr()), static_cast<c_type*>(v_padded.data_ptr()), static_cast<c_type*>(o.data_ptr()), tmp, return_lse ? static_cast<float*>(lse.data_ptr()) : nullptr, batch_size, padded_kv_len, num_qo_heads, sm_scale, rope_scale, rope_theta, torch_current_stream); if (!(status == cudaSuccess)) { ::c10::detail::torchCheckFail( __func__, "/home/roy/flashinfer/python/csrc/batch_decode.cu", static_cast<uint32_t>(101), (::c10::detail::torchCheckMsgImpl( "Expected " "status == cudaSuccess" " to be true, but got false. " "(Could this error message be improved? If so, " "please report an enhancement request to PyTorch.)", "BatchDecodeWithPaddedKVCache failed with error code ", status))); }; return true; }(); } case QKVLayout::kHND: { constexpr auto KV_LAYOUT = QKVLayout::kHND; return KV_LAYOUT, [&] { cudaError_t status = BatchDecodeWithPaddedKVCacheDispatched< GROUP_SIZE, HEAD_DIM, KV_LAYOUT, POS_ENCODING_MODE, c_type, c_type>( static_cast<c_type*>(q.data_ptr()), static_cast<c_type*>(k_padded.data_ptr()), static_cast<c_type*>(v_padded.data_ptr()), static_cast<c_type*>(o.data_ptr()), tmp, return_lse ? static_cast<float*>(lse.data_ptr()) : nullptr, batch_size, padded_kv_len, num_qo_heads, sm_scale, rope_scale, rope_theta, torch_current_stream); if (!(status == cudaSuccess)) { ::c10::detail::torchCheckFail( __func__, "/home/roy/flashinfer/python/csrc/batch_decode.cu", static_cast<uint32_t>(101), (::c10::detail::torchCheckMsgImpl( "Expected " "status == cudaSuccess" " to be true, but got false. " "(Could this error message be improved? If so, " "please report an enhancement request to PyTorch.)", "BatchDecodeWithPaddedKVCache failed with error code ", status))); }; return true; }(); } default: std::ostringstream oss; oss << __PRETTY_FUNCTION__ << " failed to dispatch " "kv layout" " " << int(kv_layout); if (!(false)) { ::c10::detail::torchCheckFail( __func__, "/home/roy/flashinfer/python/csrc/batch_decode.cu", static_cast<uint32_t>(92), (::c10::detail::torchCheckMsgImpl( "Expected " "false" " to be true, but got false. " "(Could this error message be improved? If so, " "please report an enhancement request to PyTorch.)", oss.str()))); }; return false; } }(); }(); } case PosEncodingMode::kALiBi: { constexpr auto POS_ENCODING_MODE = PosEncodingMode::kALiBi; return POS_ENCODING_MODE, [&] { return [&]() -> bool { switch (kv_layout) { case QKVLayout::kNHD: { constexpr auto KV_LAYOUT = QKVLayout::kNHD; return KV_LAYOUT, [&] { cudaError_t status = BatchDecodeWithPaddedKVCacheDispatched< GROUP_SIZE, HEAD_DIM, KV_LAYOUT, POS_ENCODING_MODE, c_type, c_type>( static_cast<c_type*>(q.data_ptr()), static_cast<c_type*>(k_padded.data_ptr()), static_cast<c_type*>(v_padded.data_ptr()), static_cast<c_type*>(o.data_ptr()), tmp, return_lse ? static_cast<float*>(lse.data_ptr()) : nullptr, batch_size, padded_kv_len, num_qo_heads, sm_scale, rope_scale, rope_theta, torch_current_stream); if (!(status == cudaSuccess)) { ::c10::detail::torchCheckFail( __func__, "/home/roy/flashinfer/python/csrc/batch_decode.cu", static_cast<uint32_t>(101), (::c10::detail::torchCheckMsgImpl( "Expected " "status == cudaSuccess" " to be true, but got false. " "(Could this error message be improved? If so, " "please report an enhancement request to PyTorch.)", "BatchDecodeWithPaddedKVCache failed with error code ", status))); }; return true; }(); } case QKVLayout::kHND: { constexpr auto KV_LAYOUT = QKVLayout::kHND; return KV_LAYOUT, [&] { cudaError_t status = BatchDecodeWithPaddedKVCacheDispatched< GROUP_SIZE, HEAD_DIM, KV_LAYOUT, POS_ENCODING_MODE, c_type, c_type>( static_cast<c_type*>(q.data_ptr()), static_cast<c_type*>(k_padded.data_ptr()), static_cast<c_type*>(v_padded.data_ptr()), static_cast<c_type*>(o.data_ptr()), tmp, return_lse ? static_cast<float*>(lse.data_ptr()) : nullptr, batch_size, padded_kv_len, num_qo_heads, sm_scale, rope_scale, rope_theta, torch_current_stream); if (!(status == cudaSuccess)) { ::c10::detail::torchCheckFail( __func__, "/home/roy/flashinfer/python/csrc/batch_decode.cu", static_cast<uint32_t>(101), (::c10::detail::torchCheckMsgImpl( "Expected " "status == cudaSuccess" " to be true, but got false. " "(Could this error message be improved? If so, " "please report an enhancement request to PyTorch.)", "BatchDecodeWithPaddedKVCache failed with error code ", status))); }; return true; }(); } default: std::ostringstream oss; oss << __PRETTY_FUNCTION__ << " failed to dispatch " "kv layout" " " << int(kv_layout); if (!(false)) { ::c10::detail::torchCheckFail( __func__, "/home/roy/flashinfer/python/csrc/batch_decode.cu", static_cast<uint32_t>(92), (::c10::detail::torchCheckMsgImpl( "Expected " "false" " to be true, but got false. " "(Could this error message be improved? If so, " "please report an enhancement request to PyTorch.)", oss.str()))); }; return false; } }(); }(); } default: std::ostringstream oss; oss << __PRETTY_FUNCTION__ << " failed to dispatch " "positional encoding mode" " " << int(PosEncodingMode(pos_encoding_mode)); if (!(false)) { ::c10::detail::torchCheckFail( __func__, "/home/roy/flashinfer/python/csrc/batch_decode.cu", static_cast<uint32_t>(90), (::c10::detail::torchCheckMsgImpl( "Expected " "false" " to be true, but got false. " "(Could this error message be improved? If so, " "please report an enhancement request to PyTorch.)", oss.str()))); }; return false; } }(); }(); } case 128: { constexpr auto HEAD_DIM = 128; return HEAD_DIM, [&] { return [&]() -> bool { switch (PosEncodingMode(pos_encoding_mode)) { case PosEncodingMode::kNone: { constexpr auto POS_ENCODING_MODE = PosEncodingMode::kNone; return POS_ENCODING_MODE, [&] { return [&]() -> bool { switch (kv_layout) { case QKVLayout::kNHD: { constexpr auto KV_LAYOUT = QKVLayout::kNHD; return KV_LAYOUT, [&] { cudaError_t status = BatchDecodeWithPaddedKVCacheDispatched< GROUP_SIZE, HEAD_DIM, KV_LAYOUT, POS_ENCODING_MODE, c_type, c_type>( static_cast<c_type*>(q.data_ptr()), static_cast<c_type*>(k_padded.data_ptr()), static_cast<c_type*>(v_padded.data_ptr()), static_cast<c_type*>(o.data_ptr()), tmp, return_lse ? static_cast<float*>(lse.data_ptr()) : nullptr, batch_size, padded_kv_len, num_qo_heads, sm_scale, rope_scale, rope_theta, torch_current_stream); if (!(status == cudaSuccess)) { ::c10::detail::torchCheckFail( __func__, "/home/roy/flashinfer/python/csrc/batch_decode.cu", static_cast<uint32_t>(101), (::c10::detail::torchCheckMsgImpl( "Expected " "status == cudaSuccess" " to be true, but got false. " "(Could this error message be improved? If so, " "please report an enhancement request to PyTorch.)", "BatchDecodeWithPaddedKVCache failed with error code ", status))); }; return true; }(); } case QKVLayout::kHND: { constexpr auto KV_LAYOUT = QKVLayout::kHND; return KV_LAYOUT, [&] { cudaError_t status = BatchDecodeWithPaddedKVCacheDispatched< GROUP_SIZE, HEAD_DIM, KV_LAYOUT, POS_ENCODING_MODE, c_type, c_type>( static_cast<c_type*>(q.data_ptr()), static_cast<c_type*>(k_padded.data_ptr()), static_cast<c_type*>(v_padded.data_ptr()), static_cast<c_type*>(o.data_ptr()), tmp, return_lse ? static_cast<float*>(lse.data_ptr()) : nullptr, batch_size, padded_kv_len, num_qo_heads, sm_scale, rope_scale, rope_theta, torch_current_stream); if (!(status == cudaSuccess)) { ::c10::detail::torchCheckFail( __func__, "/home/roy/flashinfer/python/csrc/batch_decode.cu", static_cast<uint32_t>(101), (::c10::detail::torchCheckMsgImpl( "Expected " "status == cudaSuccess" " to be true, but got false. " "(Could this error message be improved? If so, " "please report an enhancement request to PyTorch.)", "BatchDecodeWithPaddedKVCache failed with error code ", status))); }; return true; }(); } default: std::ostringstream oss; oss << __PRETTY_FUNCTION__ << " failed to dispatch " "kv layout" " " << int(kv_layout); if (!(false)) { ::c10::detail::torchCheckFail( __func__, "/home/roy/flashinfer/python/csrc/batch_decode.cu", static_cast<uint32_t>(92), (::c10::detail::torchCheckMsgImpl( "Expected " "false" " to be true, but got false. " "(Could this error message be improved? If so, " "please report an enhancement request to PyTorch.)", oss.str()))); }; return false; } }(); }(); } case PosEncodingMode::kRoPELlama: { constexpr auto POS_ENCODING_MODE = PosEncodingMode::kRoPELlama; return POS_ENCODING_MODE, [&] { return [&]() -> bool { switch (kv_layout) { case QKVLayout::kNHD: { constexpr auto KV_LAYOUT = QKVLayout::kNHD; return KV_LAYOUT, [&] { cudaError_t status = BatchDecodeWithPaddedKVCacheDispatched< GROUP_SIZE, HEAD_DIM, KV_LAYOUT, POS_ENCODING_MODE, c_type, c_type>( static_cast<c_type*>(q.data_ptr()), static_cast<c_type*>(k_padded.data_ptr()), static_cast<c_type*>(v_padded.data_ptr()), static_cast<c_type*>(o.data_ptr()), tmp, return_lse ? static_cast<float*>(lse.data_ptr()) : nullptr, batch_size, padded_kv_len, num_qo_heads, sm_scale, rope_scale, rope_theta, torch_current_stream); if (!(status == cudaSuccess)) { ::c10::detail::torchCheckFail( __func__, "/home/roy/flashinfer/python/csrc/batch_decode.cu", static_cast<uint32_t>(101), (::c10::detail::torchCheckMsgImpl( "Expected " "status == cudaSuccess" " to be true, but got false. " "(Could this error message be improved? If so, " "please report an enhancement request to PyTorch.)", "BatchDecodeWithPaddedKVCache failed with error code ", status))); }; return true; }(); } case QKVLayout::kHND: { constexpr auto KV_LAYOUT = QKVLayout::kHND; return KV_LAYOUT, [&] { cudaError_t status = BatchDecodeWithPaddedKVCacheDispatched< GROUP_SIZE, HEAD_DIM, KV_LAYOUT, POS_ENCODING_MODE, c_type, c_type>( static_cast<c_type*>(q.data_ptr()), static_cast<c_type*>(k_padded.data_ptr()), static_cast<c_type*>(v_padded.data_ptr()), static_cast<c_type*>(o.data_ptr()), tmp, return_lse ? static_cast<float*>(lse.data_ptr()) : nullptr, batch_size, padded_kv_len, num_qo_heads, sm_scale, rope_scale, rope_theta, torch_current_stream); if (!(status == cudaSuccess)) { ::c10::detail::torchCheckFail( __func__, "/home/roy/flashinfer/python/csrc/batch_decode.cu", static_cast<uint32_t>(101), (::c10::detail::torchCheckMsgImpl( "Expected " "status == cudaSuccess" " to be true, but got false. " "(Could this error message be improved? If so, " "please report an enhancement request to PyTorch.)", "BatchDecodeWithPaddedKVCache failed with error code ", status))); }; return true; }(); } default: std::ostringstream oss; oss << __PRETTY_FUNCTION__ << " failed to dispatch " "kv layout" " " << int(kv_layout); if (!(false)) { ::c10::detail::torchCheckFail( __func__, "/home/roy/flashinfer/python/csrc/batch_decode.cu", static_cast<uint32_t>(92), (::c10::detail::torchCheckMsgImpl( "Expected " "false" " to be true, but got false. " "(Could this error message be improved? If so, " "please report an enhancement request to PyTorch.)", oss.str()))); }; return false; } }(); }(); } case PosEncodingMode::kALiBi: { constexpr auto POS_ENCODING_MODE = PosEncodingMode::kALiBi; return POS_ENCODING_MODE, [&] { return [&]() -> bool { switch (kv_layout) { case QKVLayout::kNHD: { constexpr auto KV_LAYOUT = QKVLayout::kNHD; return KV_LAYOUT, [&] { cudaError_t status = BatchDecodeWithPaddedKVCacheDispatched< GROUP_SIZE, HEAD_DIM, KV_LAYOUT, POS_ENCODING_MODE, c_type, c_type>( static_cast<c_type*>(q.data_ptr()), static_cast<c_type*>(k_padded.data_ptr()), static_cast<c_type*>(v_padded.data_ptr()), static_cast<c_type*>(o.data_ptr()), tmp, return_lse ? static_cast<float*>(lse.data_ptr()) : nullptr, batch_size, padded_kv_len, num_qo_heads, sm_scale, rope_scale, rope_theta, torch_current_stream); if (!(status == cudaSuccess)) { ::c10::detail::torchCheckFail( __func__, "/home/roy/flashinfer/python/csrc/batch_decode.cu", static_cast<uint32_t>(101), (::c10::detail::torchCheckMsgImpl( "Expected " "status == cudaSuccess" " to be true, but got false. " "(Could this error message be improved? If so, " "please report an enhancement request to PyTorch.)", "BatchDecodeWithPaddedKVCache failed with error code ", status))); }; return true; }(); } case QKVLayout::kHND: { constexpr auto KV_LAYOUT = QKVLayout::kHND; return KV_LAYOUT, [&] { cudaError_t status = BatchDecodeWithPaddedKVCacheDispatched< GROUP_SIZE, HEAD_DIM, KV_LAYOUT, POS_ENCODING_MODE, c_type, c_type>( static_cast<c_type*>(q.data_ptr()), static_cast<c_type*>(k_padded.data_ptr()), static_cast<c_type*>(v_padded.data_ptr()), static_cast<c_type*>(o.data_ptr()), tmp, return_lse ? static_cast<float*>(lse.data_ptr()) : nullptr, batch_size, padded_kv_len, num_qo_heads, sm_scale, rope_scale, rope_theta, torch_current_stream); if (!(status == cudaSuccess)) { ::c10::detail::torchCheckFail( __func__, "/home/roy/flashinfer/python/csrc/batch_decode.cu", static_cast<uint32_t>(101), (::c10::detail::torchCheckMsgImpl( "Expected " "status == cudaSuccess" " to be true, but got false. " "(Could this error message be improved? If so, " "please report an enhancement request to PyTorch.)", "BatchDecodeWithPaddedKVCache failed with error code ", status))); }; return true; }(); } default: std::ostringstream oss; oss << __PRETTY_FUNCTION__ << " failed to dispatch " "kv layout" " " << int(kv_layout); if (!(false)) { ::c10::detail::torchCheckFail( __func__, "/home/roy/flashinfer/python/csrc/batch_decode.cu", static_cast<uint32_t>(92), (::c10::detail::torchCheckMsgImpl( "Expected " "false" " to be true, but got false. " "(Could this error message be improved? If so, " "please report an enhancement request to PyTorch.)", oss.str()))); }; return false; } }(); }(); } default: std::ostringstream oss; oss << __PRETTY_FUNCTION__ << " failed to dispatch " "positional encoding mode" " " <<
...
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.