blog's People
Contributors

Watchers

blog's Issues
康托展开
康托展开
给一个数字,求在全排列中的第几个
例:
231
在全排列中排第4:
123 132 213 231 312 321
方法
求出每个位比它小的数的个数,用阶乘求排名ok
#include<iostream>
using namespace std;
int cantor(int *a,int n)
{
static const int FAC[]={1,1,2,6,24,120,720,5040,40320,362880};//factor
int x=0;
for(int i=0;i<n;i++)
{
int smaller=0;
for(int j=i+1;j<n;j++)
{
if(a[j]<a[i])smaller++;
}
x+=FAC[n-i-1]*smaller;
}
return x;
}
int main()
{
int* a;
int n;
cin>>n;
a=new int [n];
for(int i=0;i<n;i++)
cin>>a[i];
cout<<cantor(a,n);
return 0;
}QQ:2644725489
mail;[email protected]
KD树
K-Dimension-Tree (KDT)
顾名思义,kd树其实就是多维二叉树(空间二叉树的一种特殊情况), 里面储存着k维的点的信息,是对k维空间进行划分的一种数据结构。
在竞赛中一般用来解决二维空间和三维空间的信息检索
KD树可以解决以下几个任务:
-
KNN问题。即查询离某个点第k邻近的点
-
查询最近最远(就是 KNN问题)
-
查询矩阵和
-
图像处理(与竞赛无关)
对于KD树,我们可以把它分为两部分
-
KD树的构建
-
对于KNN问题的最邻近查找算法
KD树的构建
KD树是一种平衡二叉树,它的各种操作都与我们学过的数据结构方法相似,对于我们一点也不陌生,很好理解。(目的是使我们能完成KNN问题)
KD树的构建有两种方法:一种利用方差,一种根据维度来划分。我们在竞赛中采用后者,因为后者更方便,也更好理解(而且十分简单)。
具体操作:
对于一个k维的超平面(维度>3想象不出来,就叫超平面),在KD树每一层的构建中都选择一个维度来进行划分,将k维的数据空间分为两部分,并使其尽量平衡。然后如此递归下去。
也就是说假如我们要储存n个三维的点(x,y,z)信息。
我们先按x坐标sort一遍,选出中间值 作为根节点,然后所有x比
小的点在左子树,比
大的在右子树。
然后左,右子树分别按照y坐标sort一遍选出中间值作为子树的根节点,接着再在子树中按照z坐标sort一遍。接着再按x坐标...以此类推。
sort顺序即为:x->y->z->x->y->z->x...
当然每一层的划分方法可以自己来决定,但一般都是按照维度来进行划分。你也可以按照自己的顺序来进行(例如:先按
sort两遍,再按
sort两遍...
一维的KD树即为一颗平衡二叉树
在构建过程中我们需要一个函数来选出中间值,但我们强大的STL里已经有了这个函数,所以我们不必再去手打一个
nth_element(a+start,a+nth,a+end)
这个函数作用是把a数组从a[start]到a[end]中的第n大的元素放在第n个位置,且nth左边元素都比a[nth]小,右边都比a[nth]大(类似快排的一部分)
时间复杂度为O(n)
那么我们整个build的时间复杂度即为O(nlogn)
这里举个例子: 将(4,7),(9,6),(8,1),(2,3),(5,4),(7,2),构造成一颗KD树。
(这里直接复制我自己的 PPT)







代码
const int dim=2;//定义维度数量
const int Maxn=5e5+10;
struct node{
int l,r,d[dim];//d为维度
inline void maintain()//初始化
{
l=r=0;
}
}tree[2*Maxn];
int d;//表示按d维排序
bool operator<(const node & a,const node & b){ return a.d[d]<b.d[d]; }
int build(int l,int r,int now)
{
int mid=(l+r)>>1;
d=now;
nth_element(tree+l,tree+mid,tree+r+1);
tree[mid].maintain();
if(l<mid)tree[mid].l=build(l,mid-1,(now+1)%dim);
if(mid<r)tree[mid].r=build(mid+1,r,(now+1)%dim);
push_up(mid);//这个函数为后面的更新操作,这里请先无视
return mid;
}最邻近算法



这个时候我们每个节点就需要维护一个最大空间(二维就是最大矩阵)
这里说明就用二维说明
struct node{
int l,r,d[dim],maxn[dim],minn[dim];//maxn为矩阵的右上角,minn为左下角
inline void maintain()//初始化
{
l=r=0;
for(int i=0;i<dim;i++)
maxn[i]=minn[i]=d[i];
}
}tree[2*Maxn];为什么要维护这个矩阵?
在上图中,我们在建树时将其分为了好几个矩阵,矩阵所存的就是以它为根节点root的子树的把所有点包括进来的最小矩阵
这个矩阵代表的就相当与当前根节点的父亲f[root]划分出来的矩形,因为只有这么多个点,所以维护的矩阵就是整个平面。
例如之前(7,2)把平面划分为了左右两部分,节点(5,4)中存的矩阵就将是包括(5,4),(2,3),(4,7)的最小矩阵,也就是左边这个平面。
在找到近似点x后的画圆操作就相当于求出查询点y到x的矩阵的距离,然后比较是否比左右儿子的矩阵的距离大,如果大则可能存在点z在左右子树中比当前点距离更进。那么就去搜索。
所以我们每次直接从根节点开始搜索,再来比较就行了。
查询复杂度
如果还没懂的话请结合代码理解。(作者语文不好)
如需查找k邻近就直接用优先队列储存就行了
/******************************
Author:galaxy yr
LANG:C++
Created Time:2019年02月17日 星期日 14时28分34秒
*******************************/
#include<bits/stdc++.h>
using namespace std;
const int Maxn=5e5+10;
const int dim=2;
const int inf=0x3f3f3f3f;
struct node{
int l,r,d[dim],maxn[dim],minn[dim];//maxn,minn表示当前节点能维护到的矩阵
inline void maintain()
{
l=r=0;
for(int i=0;i<dim;i++)
maxn[i]=minn[i]=d[i];
}
}tree[2*Maxn];
int d,root,ans;
bool operator<(const node & a,const node & b) { return a.d[d]<b.d[d]; }
void push_up(int p)//更新
{
int son[2]={tree[p].l,tree[p].r};
for(int i=0;i<2;i++)
{
if(!son[i])continue;
for(int j=0;j<dim;j++)
{
tree[p].maxn[j]=max(tree[son[i]].maxn[j],tree[p].maxn[j]);
tree[p].minn[j]=min(tree[son[i]].minn[j],tree[p].minn[j]);
}
}
}
int build(int l,int r,int now)
{
int mid=(l+r)>>1;
d=now;
nth_element(tree+l,tree+mid,tree+r+1);
tree[mid].maintain();
if(l<mid)tree[mid].l=build(l,mid-1,(now+1)%dim);
if(mid<r)tree[mid].r=build(mid+1,r,(now+1)%dim);
push_up(mid);
return mid;
}
void insert(int & o,int k,int now)
{
if(o==0) { o=k; return; }
if(tree[k].d[now]<tree[o].d[now])insert(tree[o].l,k,(now+1)%dim);
else insert(tree[o].r,k,(now+1)%dim);
push_up(o);
}
inline int dis_min(int o,int k)//曼哈顿距离
{
int rst=0;
for(int i=0;i<dim;i++)
{
if(tree[k].d[i]>tree[o].maxn[i])rst+=tree[k].d[i]-tree[o].maxn[i];
if(tree[k].d[i]<tree[o].minn[i])rst+=tree[o].minn[i]-tree[k].d[i];
}
return rst;
}
inline int dis_max(int o,int k)
{
int rst=0;
for(int i=0;i<dim;i++)
rst+=max(abs(tree[k].d[i]-tree[o].minn[i]),abs(tree[k].d[i]-tree[o].maxn[i]));
return rst;
}
int ansmin,ansmax;
void query_min(int o,int k)
{
int dm=abs(tree[o].d[0]-tree[k].d[0])+abs(tree[o].d[1]-tree[k].d[1]);
if(o==k)dm=inf;
if(dm<ansmin)ansmin=dm;
int dl=tree[o].l?dis_min(tree[o].l,k):inf;
int dr=tree[o].r?dis_min(tree[o].r,k):inf;
if(dl<dr)
{
if(dl<ansmin)query_min(tree[o].l,k);
if(dr<ansmin)query_min(tree[o].r,k);
}
else
{
if(dr<ansmin)query_min(tree[o].r,k);
if(dl<ansmin)query_min(tree[o].l,k);
}
}
void query_max(int o,int k)
{
int dm=abs(tree[o].d[0]-tree[k].d[0])+abs(tree[o].d[1]-tree[k].d[1]);
if(dm>ansmax)ansmax=dm;
int dl=tree[o].l?dis_max(tree[o].l,k):0;
int dr=tree[o].r?dis_max(tree[o].r,k):0;
if(dl>dr)
{
if(dl>ansmax)query_max(tree[o].l,k);
if(dr>ansmax)query_max(tree[o].r,k);
}
else
{
if(dr>ansmax)query_max(tree[o].r,k);
if(dl>ansmax)query_max(tree[o].l,k);
}
}
int main()
{
ios::sync_with_stdio(false);
int n;
return 0;
}例题
用优先队列
#include<bits/stdc++.h>
using namespace std;
const int Maxn=1e5+10;
const int dim=2;
const int inf=0x3f3f3f3f;
struct Node{
long long l,r,d[dim],maxn[dim],minn[dim];//maxn,minn表示当前节点能维护到的矩阵
inline void maintain()
{
l=r=0;
for(int i=0;i<dim;i++)
maxn[i]=minn[i]=d[i];
}
}tree[Maxn];
long long d,root,ans;
bool operator<(const Node & a,const Node & b) { return a.d[d]<b.d[d]; }
void push_up(int p)
{
long long son[2]={tree[p].l,tree[p].r};
for(int i=0;i<2;i++)
{
if(!son[i])continue;
for(int j=0;j<dim;j++)
{
tree[p].maxn[j]=max(tree[son[i]].maxn[j],tree[p].maxn[j]);
tree[p].minn[j]=min(tree[son[i]].minn[j],tree[p].minn[j]);
}
}
}
int build(int l,int r,int now)
{
int mid=(l+r)>>1;
d=now;
nth_element(tree+l,tree+mid,tree+r+1);
tree[mid].maintain();
if(l<mid)tree[mid].l=build(l,mid-1,(now+1)%dim);
if(mid<r)tree[mid].r=build(mid+1,r,(now+1)%dim);
push_up(mid);
return mid;
}
inline long long pf(long long x){return x*x;}
inline long long dis(const Node & x,const Node & y)
{
long long rst=0;
for(int i=0;i<dim;i++)
rst+=pf((long long)x.d[i]-y.d[i]);
return rst;
}
inline long long dis_max(int o,int k)//欧式距离
{
long long rst=0;
for(int i=0;i<dim;i++)
rst+=max(pf(tree[o].minn[i]-tree[k].d[i]),pf(tree[o].maxn[i]-tree[k].d[i]));
return rst;
}
priority_queue<long long, vector<long long>,greater<long long> >Q;
void query_max(int o,int k)
{
long long dm=dis(tree[o],tree[k]);
if(dm>Q.top())
{
Q.pop();
Q.push(dm);
}
long long dl=tree[o].l?dis_max(tree[o].l,k):-inf;
long long dr=tree[o].r?dis_max(tree[o].r,k):-inf;
if(dl>dr)
{
if(dl>Q.top())query_max(tree[o].l,k);
if(dr>Q.top())query_max(tree[o].r,k);
}
else
{
if(dr>Q.top())query_max(tree[o].r,k);
if(dl>Q.top())query_max(tree[o].l,k);
}
}
int main()
{
//freopen("p4357.in","r",stdin);
//freopen("p4357.out","w",stdout);
ios::sync_with_stdio(false);
int n,k;
cin>>n>>k;
for(int i=1;i<=2*k;i++)
Q.push(0);
for(int i=1;i<=n;i++)
for(int j=0;j<dim;j++)
cin>>tree[i].d[j];
root=build(1,n,0);
for(int i=1;i<=n;i++)
query_max(root,i);
printf("%lld\n",Q.top());
return 0;
}
KDT矩阵求和操作
/*******************************
Author:galaxy yr
LANG:C++
Created Time:2019年03月14日 星期四 16时55分06秒
*******************************/
#include<iostream>
#include<cstdio>
#include<algorithm>
struct IO{
template<typename T>
IO & operator>>(T&res)
{
char ch=getchar();
T q=1;
while(ch<'0' or ch>'9'){if(ch=='-')q=-q;ch=getchar();}
res=(ch^48);
while((ch=getchar())>='0' and ch<='9')
res=(res<<1)+(res<<3)+(ch^48);
res*=q;
return *this;
}
}cin;
using std::cout; using std::endl;
const int Maxn=5e5+10;
const int dim=2;
struct Node{
int l,r,sum,val,d[dim],maxn[dim],minn[dim];
void maintain()
{
l=r=0; sum=val;
for(int i=0;i<dim;i++)
maxn[i]=minn[i]=d[i];
}
}tree[Maxn];
int d;
bool operator<(const Node & x,const Node & y) { return x.d[d]<y.d[d]; }
void push_up(int o)
{
int son[2]={tree[o].l,tree[o].r};
for(int i=0;i<2;i++)
{
if(!son[i])continue;
for(int j=0;j<dim;j++)
{
tree[o].maxn[j]=std::max(tree[o].maxn[j],tree[son[i]].maxn[j]);
tree[o].minn[j]=std::min(tree[o].minn[j],tree[son[i]].minn[j]);
}
}
tree[o].sum=tree[son[0]].sum+tree[son[1]].sum+tree[o].val;
}
int build(int l,int r,int now)
{
int mid=(l+r)>>1;
d=now;
std::nth_element(tree+l,tree+mid,tree+r+1);
tree[mid].maintain();
if(l<mid)tree[mid].l=build(l,mid-1,(now+1)%dim);
if(mid<r)tree[mid].r=build(mid+1,r,(now+1)%dim);
push_up(mid);
return mid;
}
void insert(int& o,int k,int now)
{
//if(tree[o].d[0]==tree[k].d[0] and tree[o].d[1]==tree[k].d[1]){tree[o].val+=tree[k].val;return;}
if(o==0) { o=k; return; }
if(tree[o].d[now]<tree[k].d[now])insert(tree[o].r,k,(now+1)%dim);
else insert(tree[o].l,k,(now+1)%dim);
push_up(o);
}
int xl,yl,xr,yr,n,opt,root,pos=1;
long long ans;
void query(int o)
{
if(xr<tree[o].minn[0] or xl>tree[o].maxn[0] or
yr<tree[o].minn[1] or yl>tree[o].maxn[1])
return;
if(xl<=tree[o].minn[0] and xr>=tree[o].maxn[0] and
yl<=tree[o].minn[1] and yr>=tree[o].maxn[1]) {
ans+=tree[o].sum;
return;
}
if(xl<=tree[o].d[0] and xr>=tree[o].d[0] and yl<=tree[o].d[1] and yr>=tree[o].d[1]) ans+=tree[o].val;
if(tree[o].l)query(tree[o].l);
if(tree[o].r)query(tree[o].r);
}
int main()
{
//freopen("p4148.in","r",stdin);
//freopen("p4148.out","w",stdout);
cin>>n;
while(true)
{
cin>>opt;
if(opt==3)break;
if(opt==1)
{
cin>>tree[pos].d[0]>>tree[pos].d[1]>>tree[pos].val;
tree[pos].d[0]^=ans;tree[pos].d[1]^=ans;tree[pos].val^=ans;
tree[pos].maintain();
insert(root,pos,0);
pos++;
if(pos%10000==0)root=build(1,pos-1,0);
}
else
{
cin>>xl>>yl>>xr>>yr;
xl^=ans;yl^=ans;xr^=ans;yr^=ans;
ans=0;
query(root);
printf("%lld\n",ans);
}
}
return 0;
}
有一个限制
/*******************************
Author:galaxy yr
LANG:C++
Created Time:2019年03月06日 星期三 21时46分54秒
*******************************/
#include<cstdio>
#include<algorithm>
struct IO{
template<typename T>
IO & operator>>(T&res)
{
char ch=getchar();
T q=1;
while(ch<'0' or ch>'9'){if(ch=='-')q=-q;ch=getchar();}
res=(ch^48);
while((ch=getchar())>='0' and ch<='9')
res=(res<<1)+(res<<3)+(ch^48);
res*=q;
return *this;
}
}cin;
const int Maxn=5e4+10;
const int dim=2;
int max(int a,int b){return a>b?a:b;}
int min(int a,int b){return a<b?a:b;}
struct node{
int l,r,w,d[dim],minn[dim],maxn[dim],val;
long long sum;
void maintain()
{
l=r=0; sum=val;
for(int i=0;i<dim;i++)
minn[i]=maxn[i]=d[i];
}
}tree[Maxn];
int d;
int root,n,m;
long long a,b,c;
bool operator<(const node & x,const node & y) { return x.d[d]<y.d[d]; }
inline void push_up(int o)
{
int son[2]={tree[o].l,tree[o].r};
for(int i=0;i<2;i++)
{
if(!son[i])continue;
for(int j=0;j<dim;j++)
{
tree[o].maxn[j]=max(tree[o].maxn[j],tree[son[i]].maxn[j]);
tree[o].minn[j]=min(tree[o].minn[j],tree[son[i]].minn[j]);
}
}
tree[o].sum=tree[son[0]].sum+tree[son[1]].sum+tree[o].val;
}
int build(int l,int r,int now)
{
d=now;
int mid=(l+r)>>1;
std::nth_element(tree+l,tree+mid,tree+r+1);
tree[mid].maintain();
if(l<mid)tree[mid].l=build(l,mid-1,(now+1)%dim);
if(mid<r)tree[mid].r=build(mid+1,r,(now+1)%dim);
push_up(mid);
return mid;
}
bool check(long long x,long long y) { return (x*a+y*b<c); }
long long ans;
void query(int o)
{
int q=0;
if(check(tree[o].maxn[0],tree[o].minn[1]))q++;
if(check(tree[o].minn[0],tree[o].maxn[1]))q++;
if(check(tree[o].maxn[0],tree[o].maxn[1]))q++;
if(check(tree[o].minn[0],tree[o].minn[1]))q++;
if(q==0)return;
if(q==4){ans+=tree[o].sum; return;}
if(check(tree[o].d[0],tree[o].d[1]))ans+=tree[o].val;
if(tree[o].l)query(tree[o].l);
if(tree[o].r)query(tree[o].r);
}
int main()
{
//freopen("p4475.in","r",stdin);
//freopen("p4475.out","w",stdout);
cin>>n>>m;
for(int i=1;i<=n;i++)
cin>>tree[i].d[0]>>tree[i].d[1]>>tree[i].val;
root=build(1,n,0);
while(m--)
{
cin>>a>>b>>c;
ans=0;
query(root);
printf("%lld\n",ans);
}
return 0;
}
最大MOD值
最大MOD值
题意:有一个长度为n的数列a,求数列中$a_i%a_j(a_i>a_j)$的最大值。n<=2e5
例:
n=3
a: 3 4 5
$max(a_i%a_j)=2$
思路:
对于取模运算$b%a=c$ ,我们可以把$b看成b=ak+c$ 现在问题则是要使c最大。
若一个数$x=ak+d,x%a>b%a$ 则x比b更加接近$a(k+1)$,换句话说:则是对于模数a,
可将所有数字分在区间$[0,a-1],[a,2a-1],[2a,3a-1]...[ka,(k+1)a-1]$的区间里。再对于每一个
区间,我们都采用二分找到属于该区间的最大的数x,那么这一段区间的数中模a最大的就是x。
如此对每一个数这样计算一遍,可以发现复杂度是可过的。(调和级数的复杂度)
/*******************************
Author:galaxy yr
LANG:C++
Created Time:2019年06月10日 星期一 22时09分07秒
*******************************/
#include<iostream>
#include<cstdio>
#include<algorithm>
using namespace std;
const int maxn=2e5+10;
int n,a[maxn],ans;
int main()
{
cin>>n;
for(int i=1;i<=n;i++)
cin>>a[i];
sort(a+1,a+n+1);
for(int i=1;i<=n;i++)
for(int l=a[i],r=2*l-1;l<=a[n];l=r+1,r+=a[i])
ans=max(ans,*(lower_bound(a+i,a+n+1,r+1)-1)%a[i]);
cout<<ans<<endl;
return 0;
}Hello World
Hello world!
折腾了一周多的博客终于搭好啦!
以后陆续会发一些题解和游记吧。
网络流与二分图
图论
- 图: G=(V,E)
- 有向边: e(u,v)
网络流
网络流Dinic算法
/*******************************
Author:galaxy yr
LANG:C++
Created Time:2018年12月31日 星期一 18时34分13秒
*******************************/
#include<iostream>
#include<cstdio>
#include<cstring>
#include<algorithm>
#include<queue>
using namespace std;
const int INF=0x7fffffff;
const int maxn=1e5+10;
int w[2*maxn],n,m,ans,depth[2*maxn],s,t,u,v,val;
struct edge{
int to,next;
}e[maxn*2];
int head[maxn*2],cnt;
void add(int u,int v,int k)
{
e[cnt].next=head[u];
e[cnt].to=v;
w[cnt]=k;
head[u]=cnt;
cnt++;
}
int dfs(int u,int dist)
{
if(u==t)return dist;
for(int i=head[u];i!=-1;i=e[i].next)
{
if(depth[u]+1==depth[e[i].to] and w[i]>0)
{
int d=dfs(e[i].to,min(dist,w[i]));
if(d>0)
{
w[i]-=d;
w[i^1]+=d;
return d;
}
}
}
return 0;
}
bool bfs()
{
queue<int>q;
memset(depth,-1,sizeof depth);
q.push(s);
depth[s]=0;
while(!q.empty())
{
int v=q.front();q.pop();
for(int i=head[v];i!=-1;i=e[i].next)
{
if(w[i] >0 and depth[e[i].to] ==-1 )
{
depth[e[i].to]=depth[v]+1;
q.push(e[i].to);
}
}
}
return depth[t]!=-1;
}
int Dinic()
{
int ans=0;
while(bfs())
while(int d=dfs(s,INF))ans+=d;
return ans;
}
int main()
{
cin>>n>>m>>s>>t;
memset(head,-1,sizeof head);
for(int i=1;i<=m;i++)
{
cin>>u>>v>>val;
add(u,v,val);
add(v,u,0);
}
cout<<Dinic()<<endl;
return 0;
}
- 当前弧优化
其实是一个很强的优化
每次增广一条路后可以看做“榨干”了这条路,既然榨干了就没有再增广的可能了。但如果每次都扫描这些“枯萎的”边是很浪费时间的。那我们就记录一下“榨取”到那条边了,然后下一次直接从这条边开始增广,就可以节省大量的时间。这就是当前弧优化
具体实现
//dfs中枚举时改成
void dfs()
for(int &i=cur[u];i!=-1;i=e[i].next)
{
...
}
}
//bfs中每次清空cur
void bfs()
{
for(int i=1;i<=n;i++)
cur[i]=head[i];
....
}摘自hihocoder116周
-
容量 c(u,v)
-
割(S,T)
割的定义为一种点的划分方式:将所有的点划分S和T=V-S两个部分,其中源点s∈S,汇点t∈T。
净流f(S,T)表示穿过割(S,T)的流量之和,即:f(S,T) = Σf(u,v) | u∈S,v∈T
举个例子(该例子选自算法导论):
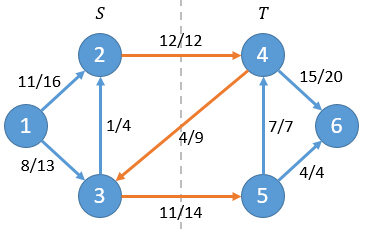
净流f = f(2,4)+f(3,4)+f(3,5) = 12+(-4)+11 = 19
-
割的容量C(S,T)为所有从S到T的边容量之和,即:
C(S,T) = Σc(u,v) | u∈S,v∈T同样在上面的例子中,其割的容量为:
C(S,T) = Σc(u,v) | u∈S,v∈T
小Ho:也就是说在计算割(S,T)的净流f(S,T)时可能存在反向的流使得f(u,v)<0,而容量C(S,T)一定是非负数。
小Hi:你这么说也没错。实际上对于任意一个割的净流f(S,T)总是和网络流的流量f相等。比如上面例子中我们改变一下割的方式:
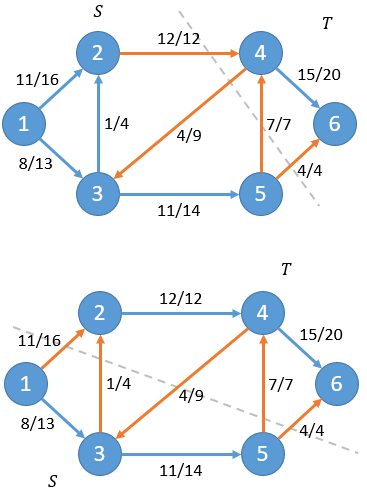
可以计算出对于这两种情况净流f(S,T)仍然等于19。
一个直观的解释是:根据网络流的定义,只有源点s会产生流量,汇点t会接收流量。因此任意非s和t的点u,其净流量一定为0,也即是Σ(f(u,v))=0。而源点s的流量最终都会通过割(S,T)的边到达汇点t,所以网络流的流f等于割的静流f(S,T)。
严格的证明如下:
f(S,T) = f(S,V) - f(S,S)
从S到T的流等于从S到所有节点的流减去从S到S内部节点的流
f(S,T) = f(S,V)
由于S内部的节点之间存在的流一定有对应的反向流,因此f(S,S)=0
f(S,T) = f(s,V) + f(S-s,V)
再将S集合分成源点s和其他属于S的节点
f(S,T) = f(s,V)
由于除了源点s以外其他节点不会产生流,因此f(S-s,V)=0
f(S,T) = f(s,V) = f
所以f(S,T)等于从源点s出来的流,也就是网络的流f。
小Ho:简单理解的话,也就是说任意一个割的净流f(S,T)都等于当前网络的流量f。
小Hi:是这样的。而对于任意一个割的净流f(S,T)一定是小于等于割的容量C(S,T)。那也即是,对于网络的任意一个流f一定是小于等于任意一个割的容量C(S,T)。
而在所有可能的割中,存在一个容量最小的割,我们称其为最小割。
这个最小割限制了一个网络的流f上界,所以有:
对于任一个网络流图来说,其最大流一定是小于等于最小割的。
小Ho:但是这和增广路又有什么关系呢?
小Hi:接下来就是重点了。利用上面讲的知识,我们可以推出一个最大流最小割定理:
对于一个网络流图G=(V,E),其中有源点s和汇点t,那么下面三个条件是等价的:
1. 流f是图G的最大流
2. 残留网络Gf不存在增广路
3. 对于G的某一个割(S,T),此时f = C(S,T)
首先证明1 => 2:
我们利用反证法,假设流f是图G的最大流,但是残留网络中还存在有增广路p,其流量为fp。则我们有流f'=f+fp>f。这与f是最大流产生矛盾。
接着证明2 => 3:
假设残留网络Gf不存在增广路,所以在残留网络Gf中不存在路径从s到达t。我们定义S集合为:当前残留网络中s能够到达的点。同时定义T=V-S。
此时(S,T)构成一个割(S,T)。且对于任意的u∈S,v∈T,有f(u,v)=c(u,v)。若f(u,v)<c(u,v),则有Gf(u,v)>0,s可以到达v,与v属于T矛盾。
因此有f(S,T)=Σf(u,v)=Σc(u,v)=C(S,T)。
最后证明3 => 1:
由于f的上界为最小割,当f到达割的容量时,显然就已经到达最大值,因此f为最大流。
这样就说明了为什么找不到增广路时,所求得的一定是最大流。
小Ho:原来是这样,我明白了。
最大闭合子图
- 闭合子图
所谓闭合子图就是给定一个有向图,从中选择一些点组成一个点集V。对于V中任意一个点,其后续节点都仍然在V中。比如:
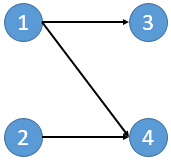
在这个图中有8个闭合子图:∅,{3},{4},{2,4},{3,4},{1,3,4},{2,3,4},{1,2,3,4}
- 求法:
使用网络流
对于一般的图来说:首先建立源点s和汇点t,将源点s与所有权值为正的点相连,容量为权值;将所有权值为负的点与汇点t相连,
容量为权值的绝对值;权值为0的点不做处理;同时将原来的边容量设置为无穷大。举个例子:
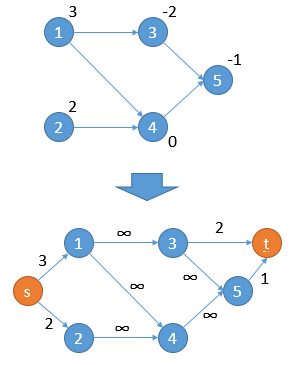
-
结论: 最大权闭合子图的权值等于所有正权点之和减去最小割
证明1.最小割一定是简单割
简单割指得是:割(S,T)中每一条割边都与s或者t关联,这样的割叫做简单割。
因为在图中将所有与s相连的点放入割集就可以得到一个割,且这个割不为正无穷。而最小割一定小于等于这个割,所以最小割一定不包含无穷大的边。因此最小割一定一个简单割。
2.简单割一定和一个闭合子图对应
闭合子图V和源点s构成S集,其余点和汇点t构成T集。
首先证明闭合子图是简单割:若闭合子图对应的割(S,T)不是简单割,则割(S,T)中存在一条边(u,v),u∈S,v∈T,且c(u,v)=∞。说明u的后续节点v不在S中,产生矛盾。(闭合子图与源点s相连,所以怎么地都只要割与源点s相连的边就行了,肯定是简单割)
接着证明简单割是闭合子图:对于V中任意一个点u,u∈S。u的任意一条出边c(u,v)=∞,不会在简单割的割边集中,因此v不属于T,v∈S。所以V的所有点均在S中,因此S-s是闭合子图。
由上面两个引理可以知道,最小割也对应了一个闭合子图,接下来证明最小割就是最大权的闭合子图。
首先有割的容量C(S,T)=T中所有正权点的权值之和+S中所有负权点的权值绝对值之和。
闭合子图的权值W=S中所有正权点的权值之和-S中所有负权点的权值绝对值之和。
则有C(S,T)+W=T中所有正权点的权值之和+S中所有正权点的权值之和=所有正权点的权值之和。
所以W=所有正权点的权值之和-C(S,T)
由于所有正权点的权值之和是一个定值,那么割的容量越小,W也就越大。因此当C(S,T)取最小割时,W也就达到了最大权。
最小费用最大流
-
引入
最大流的网络,可看作为辅送一般货物的运输网络,此时,最大流问题仅表明运输网络运输货物的能力,但没有考虑运送货物的费用。在实际问题中,运送同样数量货物的运输方案可能有多个,因此从中找一个输出费用最小的的方案是一个很重要的问题,这就是最小代价流所要讨论的内容。
-
算法**
采用贪心的**,每次找到一条从源点到达汇点的路径,增加流量,且该条路径满足使得增加的流量的花费最小,直到无法找到一条从源点到达汇点的路径,算法结束。由于最大流量有限,每执行一次循环流量都会增加,因此该算法肯定会结束,且同时流量也必定会达到网络的最大流量;同时由于每次都是增加的最小的花费,即当前的最小花费是所有到达当前流量flow时的花费最小值,因此最后的总花费最小。
-
解题步骤
- 找到一条从源点到达汇点的“距离最短”的路径,“距离”使用该路径上的边的单位费用之和来衡量。
- 然后找出这条路径上的边的容量的最小值f,则当前最大流max_flow扩充f,同时当前最小费用min_cost扩充 f*min_dist(s,t)。
- 将这条路径上的每条正向边的容量都减少f,每条反向边的容量都增加f。
- 重复(1)--(3)直到无法找到从源点到达汇点的路径。
-
需要注意的几点
- 注意超级源点和超级终点的建立。
- 初始化时,正向边的单位流量费用为
cost[u][v],那么反向边的单位流量费用就为-cost[u][v]。因为回流费用减少。 - 费用cost数组和容量cap数组每次都要初始化为0。
- 求解从源点到汇点的“最短”路径时,由于网络中存在负权边,因此使用SPFA来实现。
-
实现
/*******************************
Author:galaxy yr
LANG:C++
Created Time:2019年01月17日 星期四 19时36分32秒
*******************************/
#include<iostream>
#include<cstdio>
#include<cstring>
#include<queue>
using namespace std;
const int maxn=1005;
const int INF=0x7fffffff;
struct edge{
int to,next,cost,w;
}e[maxn*maxn*50];
int head[maxn*10],cnt,path[maxn*10],pre[maxn*10],dis[maxn*10];
void add(int u,int v,int w,int c)
{
e[cnt].to=v;
e[cnt].next=head[u];
e[cnt].cost=c;
e[cnt].w=w;
head[u]=cnt++;
}
bool SPFA(int s,int t)
{
memset(pre,-1,sizeof pre);
memset(dis,0x7f,sizeof dis);
dis[s]=0;
queue<int>q;
q.push(s);
while(!q.empty())
{
int u=q.front(); q.pop();
for(int i=head[u];i!=-1;i=e[i].next)
{
if(e[i].w>0 and dis[u]+e[i].cost<dis[e[i].to])
{
dis[e[i].to]=dis[u]+e[i].cost;
pre[e[i].to]=u;
path[e[i].to]=i;
q.push(e[i].to);
}
}
}
return (pre[t]!=-1);
}
int MinCost_Flow(int s,int t)
{
int cost=0,flow=0;
while(SPFA(s,t))
{
int f=INF;
for(int u=t;u!=s;u=pre[u])
{
if(e[path[u]].w<f)
f=e[path[u]].w;
}
flow+=f;
cost+=dis[t]*f;
for(int u=t;u!=s;u=pre[u])
{
e[path[u]].w-=f;
e[path[u]^1].w+=f;
}
}
return cost;
}
- 使用dijkstra求费用流
众所周知,dijkstra比SPFA会稳定一些(不会被卡)
但在费用流中费用可以为负数,怎么办呢?
我们可以考虑给每个点都附一个值(称为'势')h[i]然后每次使dis[u]=dis[v]+h[u]-h[v]
这样我们求得的最短路就成了,然后再减去
(h[s]-h[t])就是答案了。
如果势取的好的话,就可以使dis都>0。
怎么取呢?
对于边e(u,v),考虑三角不等式:
dis(v)'=dis(v)+h(u)-h(v)>=0
又有
dis(v)<=dis(u)+w(e)
dis(u)+w(e)-dis(v)>=0
若我们每次使h[i]选成上次的dis[i],则可以完美解决问题。
又
dis[i]=$\sum_{e.cost}+h[s]-h[i]$
所以新的h[i]为h[i]+dis[i]
代码如下
/*******************************
Author:galaxy yr
LANG:C++
Created Time:2019年04月04日 星期四 12时29分11秒
*******************************/
#include<iostream>
#include<cstdio>
#include<cstring>
#include<queue>
#include<algorithm>
using namespace std;
const int maxn=5055;
const int inf=0x3f3f3f3f;
struct edge{
int next,to,cost,f;
}e[maxn*25];
int dis[maxn],head[maxn],cnt,prevv[maxn],preve[maxn],n,m,s,t,flow,cost,h[maxn];
void add(int u,int v,int c,int f)
{
e[cnt].next=head[u];
e[cnt].cost=c;
e[cnt].f=f;
e[cnt].to=v;
head[u]=cnt++;
}
typedef pair<int,int> P;
inline void min_cost_flow(int s,int t,int f)
{
while(f>0)
{
memset(dis,inf,sizeof dis);
priority_queue<P,vector<P>,greater<P> >q;
dis[s]=0;
q.push(P(0,s));
while(!q.empty())
{
P now=q.top(); q.pop();
if(dis[now.second]<now.first)continue;
if(now.second==t)break;
int u=now.second;
for(int i=head[u];~i;i=e[i].next)
{
if(e[i].f>0 and dis[e[i].to]>dis[u]+e[i].cost+h[u]-h[e[i].to])
{
dis[e[i].to]=dis[u]+e[i].cost+h[u]-h[e[i].to];
preve[e[i].to]=i;
prevv[e[i].to]=u;
q.push(P(dis[e[i].to],e[i].to));
}
}
}
if(dis[t]==inf)break;
for(int i=0;i<=n;i++)h[i]+=dis[i];
int d=inf;
for(int v=t;v!=s;v=prevv[v])
d=min(d,e[preve[v]].f);
flow+=d;
cost+=h[t]*d;
f-=d;
for(int v=t;v!=s;v=prevv[v])
{
e[preve[v]].f-=d;
e[preve[v]^1].f+=d;
}
}
return;
}
int main()
{
freopen("MMF.in","r",stdin);
freopen("MMF.out","w",stdout);
memset(head,-1,sizeof head);
cin>>n>>m>>s>>t;
for(int i=1,u,v,c,w;i<=m;i++)
{
cin>>u>>v>>w>>c;
add(u,v,c,w);
add(v,u,-c,0);
}
min_cost_flow(s,t,inf);
cout<<flow<<' '<<cost<<endl;
return 0;
}
二分图
二分图:简单来说,如果图中点可以被分为两组,并且使得所有边都跨越组的边界,则这就是一个二分图。
准确地说:把一个图的顶点划分为两个不相交集 U
-
匹配:
在图论中,一个「匹配」(matching)是一个边的集合,其中任意两条边都没有公共顶点。 -
最大匹配:
一个图所有匹配中,所含匹配边数最多的匹配,称为这个图的最大匹配。图 4 是一个最大匹配,它包含 4 条匹配边。 -
完美匹配:
如果一个图的某个匹配中,所有的顶点都是匹配点,那么它就是一个完美匹配。图 4 是一个完美匹配。显然,完美匹配一定是最大匹配(完美匹配的任何一个点都已经匹配,添加一条新的匹配边一定会与已有的匹配边冲突)。但并非每个图都存在完美匹配。 -
交替路,增广路
- 交替路:从一个未匹配点出发,依次经过非匹配边、匹配边、非匹配边...形成的路径叫交替路
2.增广路:从一个未匹配点出发,走交替路,如果途径另一个未匹配点(出发点不算),则这条交替路称为增广路(agumenting path)。
- 交替路:从一个未匹配点出发,依次经过非匹配边、匹配边、非匹配边...形成的路径叫交替路
-
匈牙利树: 匈牙利树一般由 BFS 构造(类似于 BFS 树)。从一个未匹配点出发运行 BFS(唯一的限制是,必须走交替路),直到不能再扩展为止。例如下图可以得到一颗BFS树


-
最大匹配算法 匈牙利算法:我们可以通过不停地找增广路来增加匹配中的匹配边和匹配点。找不到增广路时,达到最大匹配(这是增广路定理)
-
最大匹配数: 最大匹配的匹配边的数目
-
最小点覆盖数 选取最少的点,使任意一条边至少有一个端点被选择
Koning定理:最大匹配数=最小点覆盖数
-
最大独立数: 选取最多的点,使任意所选两点均不相连
-
最小路径覆盖数: 对于一个 DAG(有向无环图),选取最少条路径,使得每个顶点属于且仅属于一条路径。路径长可以为 0(即单个点)。
最小路径覆盖数=顶点数-最大匹配数
最小点覆盖
结论:最小点覆盖数=最大匹配数
最大独立集
依旧转化为图G=(V,E),则问题转化为:
在图G中选取尽可能多的点,使得任意两个点之间没有连边。
这个问题在二分图问题中被称为最大独立集问题。
结论:最大独立集的点数 = 总点数 - 二分图最大匹配
证明:
假设最大独立集的点数为|U|,二分图最大匹配的匹配数为|M|,最大匹配中所有顶点集合为EM
先证明 |U|≤|V|-|M|
M中任意一条边的两个端点是连接的,所有对于M中的边必有一个端点不在|U|集合中,所以|M|≤|V|-|U|
再证明|U|≥|V|-|M|
首先我们知道一定有|U|≥|V|-|EM|,即将最大匹配的点删除之后,剩下的点一定都不相连。
接下来我们考虑能否将M集合中的一个端点放入U中:
假设(x,y)属于M,存在(a,x),(b,y),且a,b都在U中,则会出现两种情况:
如果(a,b)连接,则有一个更大的匹配存在,矛盾
如果(a,b)不连接,a->x->y->b有一个新的增广路,因此有一个更大的匹配,矛盾
故有a,b两点中至多只有1个点属于U,则我们总是可以选取x,y中一个点放入集合U
所以|U|≥|V|-|EM|+|M|=|V|-|M|
综上有|U|=|V|-|M|
最佳匹配
KM算法
km算法与匈牙利算法有些相似。
巧妙的运用了标杆。
-
算法步骤
1.用邻接矩阵(或其他方法也行啦)来储存图,注意:如果只是想求最大权值匹配而不要求是完全匹配的话,请把各个不相连的边的权值设置为0。
2.运用贪心算法初始化标杆。
3.运用匈牙利算法找到完备匹配。
4.如果找不到,则通过修改标杆,增加一些边。
5.重复3,4的步骤,直到完全匹配时可结束
-
标杆
标杆是KM算法**的精髓
标杆的引入
二分图最佳匹配还是二分图匹配,所以跟和匈牙利算法思路差不多 二分图是特殊的网络流,最佳匹配相当于求最大(小)费用最大流,所以FF方法也能实现 所以我们可以把这匈牙利算法和FF方法结合起来 FF方法里面,我们每次是找最长(短)路进行通流
所以二分图匹配里面我们也找最大边进行连边!
但是遇到某个点被匹配了两次怎么办?
那就用匈牙利算法进行更改匹配!
这就是KM算法的思路了:尽量找最大的边进行连边,如果不能则换一条较大的。
所以,根据KM算法的思路,我们一开始要对边权值最大的进行连线,那问题就来了,我们如何让计算机知道该点对应的权值最大的边 是哪一条?或许我们可以通过某种方式记录边的另一端点,但是呢,后面还要涉及改边,又要记录边权值总和,而这个记录端点方法 似乎有点麻烦,于是KM采用了一种十分巧妙的办法: 添加标杆(顶标)
是怎样子呢?我们对左边每个点Xi和右边每个点Yi添加标杆Cx和Cy。
其中我们要满足Cx+Cy>=`w[x][y](w[x][y]即为点Xi、Yi之间的边权值)`
对于一开始的初始化,我们对于每个点分别进行如下操作
`Cx=max(w[x][y]);`
Cy=0;
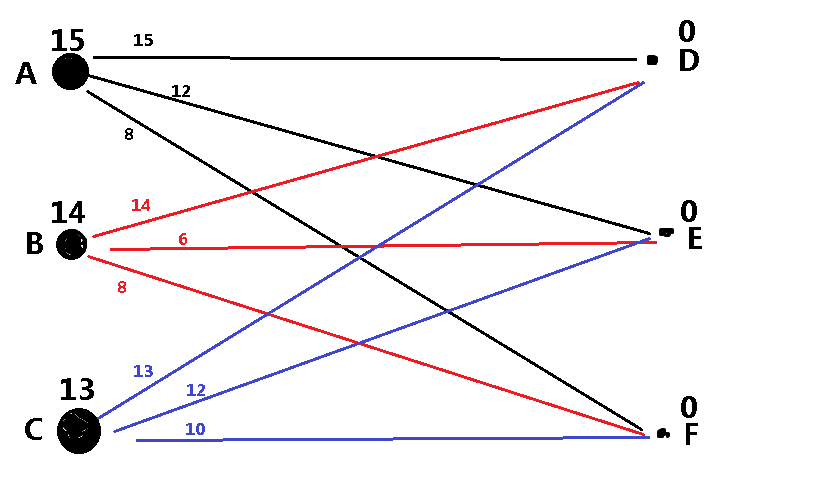
然后,我们可以进行连边,即采用匈牙利算法,只是在判断两点之间是否有连线的条件下,因为我们要将最大边进行连线,所以原来判断是否有边的条件
w[x][y]==0换成了
Cx+Cy==
w[x][y]
此时,有一个新的名词——相等子图。
因为我们通过了巧妙的处理让计算机自动连接边权最大的边,换句话说,其他边计算机就不会连了,也就“不存在”这个图中,但我们可以随时加上这些“不存在”图中的边。此时这个图可以认为是原图的子图,并且是等效。
这样,计算机在枚举右边的点的时候,满足以上条件,就能够知道这条边是我们要连的最大的边,就能进行连边了。
于是乎我们连了AD。
接下来就尴尬了,计算机接下来要连B点的BD,但是D点已经和A点连了,怎么办呢???
根据匈牙利算法,我们做的是将A点与其他点进行连线,但此时的子图里“不存在”与A点相连的其他边,怎么办呢??
为此,我们就需要加上这些边!
很明显,我们添边,自然要加上不在子图中边权最大的边,也就是和子图里这个边权值差最小的边。
于是,我们再一度引入了一变量d,d=min{Cx[i]+Cy[j]-
w[i][j]}
其中,在这个题目里Cx[i]指的是A的标杆,Cy[j]是除D点(即已连点)以外的点的标杆。
随后,对于原先存在于子图的边AD,我们将A的标杆Cx[i]减去d,D的标杆Cy[d]加上d。
这样,这就保证了原先存在AD边保留在了子图中,并且把不在子图的最大权值的与A点相连的边AE添加到了子图。
因为计算机判断一条边是否在该子图的条件是其两端的顶点的标杆满足
Cx+Cy==
w[x][y]
对于原先的边,我们对左端点的标杆减去了d,对右端点的标杆加上了d,所以最终的结果还是不变,仍然是
w[x][y]。
对于我们要添加的边,我们对于左端点减去了d,即Cx[i]=Cx[i]-d;为方便表示我们把更改后的的Cx[i]视为Cz[i],即Cz[i]=Cx[i]-d;
对于右端点,我们并没有对其进行操作。那这条我们要添加边的两端点的标号是否满足Cz[i]+Cy[j]=
w[i][j]?
因为Cz[i]=Cx[i]-d;
d=Cx[i]+Cy[j]-w[i][j];
我们把d代入左式可得
Cz[i]=Cx[i]-(Cx[i]+Cy[j]-w[i][j]);
化简得
Cz[i]+Cy[j]=w[i][j]。
满足了要求!即添加了新的边。
值得注意的是,这里我们只是对于一条边操作,当我们添加了几条边,要进行如上操作时,要保证原先存在的边不消失,那么我们就要先求出了d,然后
对于每个连边的左端点(记作集合S)的每个点的标号减去了d之后,然后连边的右端点(记作T)加上d,这样就保证了原先的边不消失啦~
实际上这就是一直在寻找着增广路,通过不断修改标杆进行添边实现。
接下来就继续着匈牙利算法,直到完全匹配完为止。
该算法的正确性就在于 它每次都选择最大的边进行连边
至此,我们再回顾KM算法的步骤:
1.用邻接矩阵(或其他方法也行啦)来储存图。
2.运用贪心算法初始化标杆。
3.运用匈牙利算法找到完备匹配。
4.如果找不到,则通过修改标杆,增加一些边。
5.重复3,4的步骤,直到完全匹配时可结束。
是不是清楚了许多??
因为二分图是网络流的一种特殊情况,在网络流里我们是通过不断的SPFA找到费用最大(小)的路径进行通流,跟这个有点类似。
- 实现
懒得打了~
也可以用最大费用流实现
线性筛
筛法
筛出1-n中所有的素数
埃拉托斯特尼筛法
基本**:素数的倍数一定不是素数
所以可以考虑用数组prime[]表示一个数是不是素数,再枚举它所有的倍数。
时间复杂度O(olglgn)
for(int i=1;i<=n;i++)prime[i]=1;
for(int i=2;i<=n;i++)
{
if(!prime[i])
continue;
for(int j=i*2;j<=n;j+=i)
prime[j]=0;
}欧拉筛
欧拉筛在埃拉托斯特尼筛法上做了改进。
基本**:任何一个合数可以被质因数分解,我们可以使其变成一个最小质因数(p)乘以另一个数(q),
1-n枚举所有数字时同时枚举p,以它本身为q的所有数字p*q,这样保证了所有数字只筛了一遍。
时间复杂度O(N)
int prime[maxn],tot;
bool vis[maxn];
void euler_sieve()
{
for(int i=2;i<=n;i++)
{
if(!vis[i]) prime[++tot]=i;
for(int j=1;j<=tot and prime[j]*i<=n;j++)
{
vis[prime[j]*i]=1;
if(i%prime[j]==0)
break;
}
}
}用欧拉筛求其他东西
对于欧拉筛,如果我们可以发现在筛选的过程中可能还有许多的性质可以加以利用,
从而获得更多的信息。
比如:求出某个积性函数在1-n的值
-
求出每个数的最小质因数mn(i)
这个枚举时保存一下就好了
-
求出每个数最小质因子的个数e(i)
枚举时保存一下就好了
-
求出正因子的个数d(i)
一个数的因子个数:
首先将这个数质因数分解,得到每个质因数的个数
显然d函数为积性函数,这个好求
若i%prime[j]==0
i*prime[j]的$p_1=prime[j]个数为k_1$ -
求出phi(i)
-
求出莫比乌斯函数
-
...
/*******************************
Author:galaxy yr
LANG:C++
Created Time:2019年01月22日 星期二 15时53分29秒
*******************************/
#include<iostream>
#include<cstdio>
using namespace std;
const int maxn=1e6+10;
int n=1e6,prime[maxn],vis[maxn],tot,mn[maxn],e[maxn],phi[maxn],d[maxn],mu[maxn];
void euler_sieve()
{
mu[1]=1;
for(int i=2;i<=n;i++)
{
if(!vis[i]) { prime[++tot]=i;mn[i]=i;e[i]=1;phi[i]=i-1;d[i]=2;mu[i]=-1; }
for(int j=1;j<=tot and prime[j]*i<=n;j++)
{
vis[prime[j]*i]=1;
mn[prime[j]*i]=prime[j];
e[prime[j]*i]=1;
if(i%prime[j]==0)
{
phi[i*prime[j]]=phi[i]*prime[j];
e[prime[j]*i]=e[i]+1;
d[i*prime[j]]=d[i]/(e[i]+1)*(e[i]+2);
break;
}
else phi[i*prime[j]]=phi[i]*(prime[j]-1);
mu[i*prime[j]]=-mu[i];
d[i*prime[j]]<<=1;
}
}
}
int main()
{
}
友链
Morning Glory
link: //www.cnblogs.com/Morning-Glory/
cover: //i.loli.net/2019/04/04/5ca5f075baaec.png
avatar: //i.loli.net/2019/04/04/5ca5f0ead3072.jpg
关于
2019,4,4 start
主题:Aurora
在主题作者大大的帮助下完成。
给OIer节约5s的快速创建子目录的程序
每次考试考完的时候教练都会要求建立子目录,然后又会在这个时候浪费我们生命中美好的5s,这个时候,这个轮子孕育而生,有了它,你就比其他人多拥有了5s的美好时光~
用法:在选手文件夹下输入Mkdir回车,即可为当前文件夹的所有cpp文件创建一个文件夹,同时把文件复制进去
方法: 复制以下内容到一个叫做"Mkdir"的文件里
然后
sudo chmod 777 Mkdir
sudo mv Mkdir /bin
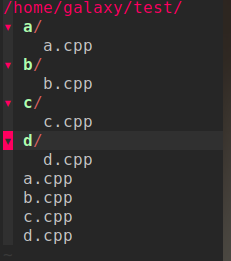
Mkdir -h效果图:

#!/bin/bash
if [[ "$1" == "-h" ]]
then
echo "---------------------------------------------------------------------------------"
echo
echo "-h --help 输出此帮助界面"
echo "-a --ask 按询问模式执行"
echo "-q --quiet 安静的执行程序"
echo "-c --copy 仅仅将文件复制进文件夹"
echo "文件名 shell默认跳出参数 并将后面的变量不创建文件夹(且删除此文件目录)"
echo
echo "例: Mkdir a.cpp b.cpp"
echo
echo "这将不会为a.cpp b.cpp创建目录,且如果也会删掉和文件 询问模式除外"
echo -e "\033[;31m默认复制并替换文件 \033[;0m"
echo
echo "---------------------------------------------------------------------------------"
exit 0
fi
ask=0
quiet=0
copy=0
while getopts ayqc opt
do
case "$opt" in
a)ask=1 ;;
q)quiet=1 ;;
c)copy=1 ;;
*) echo "未知的参数!" ;;
esac
done
if echo "$1" | grep "-" >/dev/null 2>&1
then
shift
fi
if [ $ask -eq 1 ]
then
echo "以询问模式执行..."
fi
if [ $copy -eq 1 ]
then
echo "以copy模式执行..."
fi
for file in `ls *.cpp`
do
pre=`echo "$file" | cut -d '.' -f1`
if [ $# -ne 0 ]
then
for list in "$@"
do
if [[ $list = $file ]]
#if echo "$file" | grep "$*" >/dev/null 2>&1
then
if [ $ask -eq 1 ]
then
if [ -d $pre ]
then
echo -e "\033[;33m 找到 $pre 文件夹,是否删除?\033[0m"
read -l opt
if [[ $opt = 'y' ]] || [[ $opt = 'Y' ]]
then
echo -e "\033[;31m 删除 $pre 文件夹.\033[0m"
echo -e "\033[;31m 删除 $file 文件.\033[0m"
echo
rm -rf $pre
rm $file
else
echo -e "\033[;32m 保留原文件夹\033[0m"
fi
fi
else
echo -e "\033[;31m 删除 $pre 文件夹.\033[0m"
echo -e "\033[;31m 删除 $file 文件.\033[0m"
echo
rm -rf $pre
rm $file
fi
continue 2
fi
done
fi
if [ $copy -eq 1 ]
then
echo -e "\033[;33m 复制 $file 进入 $pre 文件夹...\033[0m"
cp $file $pre
continue
fi
if [ $quiet -ne 1 ]
then
echo -e "\033[;32m 正在创建 '$pre' 文件夹 ... \033[0m"
fi
if [ -d "$pre" ]
then
if [ $quiet -ne 1 ]
then
echo -e "\033[;31m $pre 文件夹已经存在 \033[0m"
fi
else
if [ $ask -eq 1 ]
then
echo -e "\033[;33m 是否创建 $pre 文件夹?(y/n)\033[0m"
read -l opt
if [[ $opt == y ]]|| [[ $opt = 'Y' ]]
then
mkdir "$pre"
else
echo -e "\033[;33m 跳过此文件\033[0m"
continue
fi
else
mkdir "$pre"
fi
if [ $quiet -ne 1 ]
then
echo -e "\033[;37m $pre 文件夹创建成功 \033[0m"
fi
fi
if [ $quiet -ne 1 ]
then
echo -e "\033[;32m 正在复制 $file 到 $pre 文件夹 ... \033[0m"
fi
if [ -f "$pre/$file" ]
then
if [ $quiet -ne 1 ]
then
echo -e "\033[;31m 文件 $file 已经存在! \033[0m"
fi
if [ $ask -eq 1 ]
then
echo -e "\033[;33m 是否强制替换?(y/n) \033[0m"
read opt
if [[ $opt == y ]] || [[ $opt = 'Y' ]]
then
cp "$file" "$pre"
fi
elif [ $quiet -ne 1 ]
then
echo -e "\033[;32m 强制替换文件 \033[0m"
fi
cp "$file" "$pre"
else
cp "$file" "$pre"
fi
echo
done
echo -e "\033[;31m 程序执行结束\033[0m"
最初的一堂课
最初的一堂课
作者:[新加坡]叶孝忠
有很多记忆,在当时微不足道,甚至看不出深意,只觉得应该是某种启示。要到很多年后,才会发现:哦,原来是这样的,也应该是这样的。那真是一件不应该被记住的事情,但很多年以后,竟然还记得。
那是在路上经常会发生的事,一次最普通不过的萍水相逢。当我正要离开开罗的时候,在旅舍里遇见日本人K,我们曾经在耶路撒冷住过同一家小旅社。K刚抵达开罗,我就要走了,不如一起吃顿晚餐吧,饭后我就得搭乘夜车,去下一个陌生的目的地。晚餐之后,K说:“我送你到车站吧。”我们穿过混乱的街头,抵达车站,找到月台。我上了即将出发的大巴,时间到了,说了再见,车门关上,司機发动了引擎。两个世界。
夜色迷离,估计是路上的灯不多,不一会儿,就是一片天地漆黑、星辰灿亮,我心中隐隐约约觉得不舒服,但说不出为什么。后来遇见的人多了,说再见的次数也多了,说了再见却不会再见也成了常态,慢慢也就习惯了,道别变得越来越轻松,越来越无所谓。习惯就好,习惯能让一切变好。
然后又过了好多年,这份不太值得书写的记忆又突然变得鲜活起来。那个夜晚,杂沓的声音、在陌生地的恐惧、那真诚却不忍说出口的再见,历历在目。而我不是更应该记得金字塔高耸的智慧,和埃及博物馆里陈列着的伟大死亡吗?
我终于能理解那个开罗夜里莫名的忧伤。最初那场道别的意义也渐渐变得清晰。原来人生就是由举足轻重到微不足道的道别所组成的。十分钟或几十年,甚至一生一世,到了应该告别的时候,也都变成一瞬间。那一份最初的忧伤,其实就是用来提醒你,这一切总会走到说再见的那一天。但我用了那么长的时间,才读懂生命最初想要教会我们的一堂课。
平衡树
声明:此篇参考了许多博客和文章,所以也借用了某些地方
二叉搜索树(BST)
二叉搜索树又称二叉查找树,二叉排序树。是具有以下性质的二叉树:
对于每个节点,左子树每个节点的权值都比当前节点的权值小,右子树每个节点的权值都比当前节点的权值大。其左右子树均为二叉搜索树。
二叉搜索树支持以下几个基本操作:
- 插入
- 删除
- 查找
- 访问全部节点
- 清空
C primer plus
A Binary Tree ADT
As usual, we’ll start by defining a binary tree in general terms. This particular definition
assumes the tree contains no duplicate items. Many of the operations are the same as list opera-
tions. The difference is in the hierarchical arrangement of data. Here is an informal summary of
this ADT:
Type Name: Binary Search Tree
Type Properties: A binary tree is either an empty set of nodes (an empty tree) or a set
of nodes with one node designated the root.
Each node has exactly two trees, called the left subtree and the right
subtree , descending from it.
Each subtree is itself a binary tree, which includes the possibility of
being an empty tree.
A binary search tree is an ordered binary tree in which each node con-
tains an item, in which all items in the left subtree precede the root
item, and in which the root item precedes all items in the right subtree.
Type Operations:
Initializing tree to empty.
Determining whether tree is empty.
Determining whether tree is full.
Determining the number of items in the tree.
Adding an item to the tree.
Removing an item from the tree.
Searching the tree for an item.
Visiting each item in the tree.
Emptying the tree.
二叉搜索树运用了二分**来提高查找速度。
也可能因为某些特殊数据而退化为一条链,从而使时间复杂度从O(logn)变成O(n)
平衡树(BBT)
平衡树是基于二叉搜索树上的一种数据结构。所有二叉搜索树的操作都能完成,同时还能进行以下基本操作:
- 查找第k大的数
- 查找某个数的排名
- 求前驱和后继
它有以下性质:
- 保持平衡,要么是空树要么它的左右子树高度差的绝对值不超过1,基本操作与树的高度h相关,与树的容量无关
- 左右子树都是平衡树
平衡树又叫平衡二叉树。一般有以下几种常用方法:
- 暴力平衡(替罪羊树)
- 高度平衡(avl)
- 重量平衡(treap)
- 自动平衡(红黑树,伸展树)
二叉左旋右旋
平衡树有很多种,其中常用的几种需要依靠旋转来实现
- 左旋
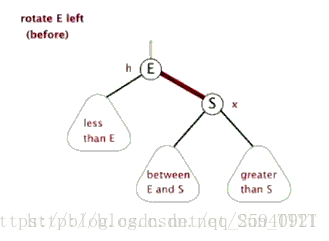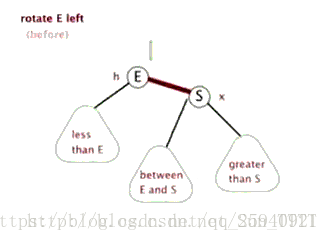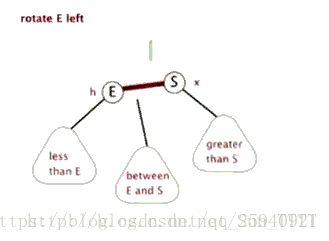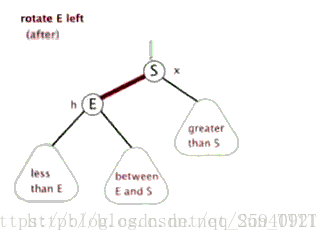
- 右旋
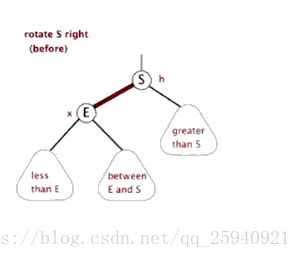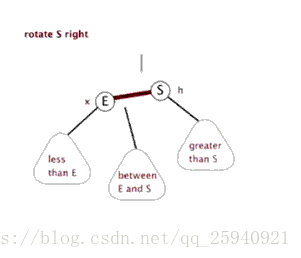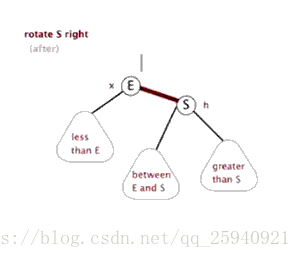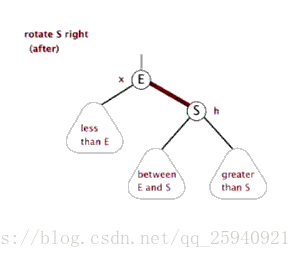
旋转的目的是为了把子节点旋转到上面去,其中会与父亲节点进行交换。

如图:节点2与节点1(注意顺序)交换叫左旋,节点3与节点1交换叫右旋
以左旋为例,根据二叉搜索树的特点,当子节点2和父亲节点1交换时,由于子节点在父亲节点左边,所以节点2的权值比节点1的权值小。
交换后2的右节点改为1,同时把原来的右节点5送给1当左儿子(因为5的权值比1小),3,4节点继续跟着1,2节点。
旋转结束后如图:

**注意:**若某些节点旋转前有空位置,则可能减少树的深度,使之变得更平衡些。如上面的两张动图,节点(between E and S)旋转后深度没变相当于与某些节点的相对高度减小了。
右旋也与此相似。大家可以自己手推一下。
实现代码:
void rotate(int x)//左旋右旋一起
{
//f[x]表示父亲,ch[x][0]左儿子,ch[x][1]右儿子
int y=f[x],z=f[y],c=(ch[f[x]][1]==x);//c判断x是左儿子还是右儿子
f[y]=x;ch[y][c]=ch[x][c^1];//父亲变儿子
f[ch[y][c]]=y;//这里把儿子交换
f[x]=z;ch[x][c^1]=y;//原儿子升级成父亲
if(z)
ch[z][(ch[z][1]==y)]=x;//如果有爷爷,也要改一下
//更新
update(y);update(x)//顺序不能变
}update 操作
在旋转以后需要更新节点(因为父子关系变了)
void update(int x)
{
if(x)
{
//size[x] 子节点个数 cnt[x] 和x值一样的个数
size[x]=cnt[x];
if(ch[x][0])size[x]+=size[ch[x][0]];
if(ch[x][1])size[x]+=size[ch[x][1]];
}
}splay
splay 是一种平衡树,可以自动平衡,平衡的手段是利用旋转。
方法是在每次查找和插入等完后,将其旋转(一般转到根节点),从而达到平衡状态。
所以最初的splay代码很短
void naive_splay(int x)
{
for(int y;y=fa[x];rotate(x));
root=x;
}
但旋转一次(单旋)往往不能使其平衡如图:

这样转后并没有改变什么。所以改用了双旋(旋转两次)。当然双旋并不是直接旋转两次,我们需根据不同的树的样子进行双旋。

若树长这样(目标是旋转3),则先旋转2再旋转3(若直接旋转3则结果跟上面一样),旋转结果为:

若树长如上结果图那样(目标是旋转1),则直接转1两次

其余情况类似。
代码:
void splay(int x)//可以再传一个参数控制转到哪
{
for(int y;y=f[x];rotate(x))
if(f[y])
rotate(((x==ch[y][1])==(y==ch[f[y]][1]))?y:x);
root=x;
}insert 操作。
插入与普通的二叉搜索树基本一样,但要记得旋转。(这样才能自动保持平衡)
解释在代码中
void insert(int v)
{
//sz 树的节点个数
if(root==0){sz++;ch[sz][0]=ch[sz][1]=f[sz]=0;key[sz]=v;cnt[sz]=1;size[sz]=1;root=sz;return;}
int now=root,fa=0;
while(true)
{
if(key[now]==v)//如果有这个值了,这个值个数加1
{
cnt[now]++;
update(now);
update(fa);
splay(now);//记得转一下
break;
}
fa=now; now=ch[now][v>key[now]];//不然继续往下走
if(now==0)//没有的话就新开一个节点
{
sz++;
ch[sz][0]=ch[sz][1]=0;key[sz]=v;size[sz]=1;
cnt[sz]=1;f[sz]=fa;ch[fa][v>key[fa]]=sz;
update(fa);
splay(sz);
break;
}
}
}查找 操作 查找x的排名
查找不难,注意向右子树找时要把ans加上左子树的大小和当前点的个数
记得最后splay上去
int find(int x)
{
int ans=0,now=root;
while(true)
{
if(x<key[now])
now=ch[now][0];
else
{
ans+=(ch[now][0]?size[ch[now][0]]:0);
if(x==key[now]){splay(now);return ans+1;}
ans+=cnt[now];
now=ch[now][1];
}
}
}查找第k大 操作
向左直接走,向右要减去
int find_kth(int x)
{
int now=root;
while(true)
{
if(ch[now][0] and x<=size[ch[now][0]])
now=ch[now][0];
else
{
int temp=cnt[now]+(ch[now][0]!=0?size[ch[now][0]]:0);
if(x<=temp){return key[now];}
x-=temp;now=ch[now][1];
}
}
}找前驱和后继
把x转到根,前驱即为左子树最右边的节点,后继即为右子树最左边的点
int pre()
{
//x 已为 root
int now=ch[root][0];
while(ch[now][1])now=ch[now][1];
return now;
}
int nxt()
{
int now=ch[now][1];
while(ch[now][1])
now=ch[now][1];
return now;
}删除 操作
把x转到根,再把左儿子转一下,右儿子给左儿子,再删除
void clear(int x) { ch[x][0]=ch[x][1]=f[x]=key[x]=size[x]=cnt[x]=0; }
void del(int x)
{
find(x);
if(cnt[x]>1){cnt[x]--;update(x);return;}//个数>1删一个就行了
if(!ch[x][0] and !ch[x][1]){ clear(x);root=0;return;}//没左右儿子,即为root,删除就行
if(!ch[x][0]) { root=ch[x][0]; f[root]=0; clear(x); return; }
else if(!ch[x][1]){ root=ch[x][1]; f[root]=0; clear(x); return; }
int l=pre();
splay(l);
f[ch[x][1]]=root;
ch[root][1]=ch[x][1];
clear(x);
update(root);
return;
}2019
HNOI2019总结
HNOI 2019 总结
Day 0
考前把所有学过的板子都打了一遍。
Day 1
开考后先把题目都看了一遍。
鱼:这是数学题吧。
JOJO:一看就是道字符串的题
多边形:这题目怎么这么长啊?好吧不会。
开始写题目。
| 做题顺序 | JOJO | 鱼 | 多边形 |
|---|---|---|---|
| 预计得分 | >=60 | 10 | 10 |
| 得分 | 0 | 10 | 0 |
| 算法 | 玄学算法。有点像自动机。对于每一个字符都插入一个点,然后计算答案,记下,然后就变成了一棵树,然后就在树上匹配。预计只会被一种数据卡,复杂度大部分是O(1)出答案。 | 暴力枚举 | 暴力枚举 |
| 后记 | 计算贡献的地方写错了, 对于tttt第4个t应该贡献为2,我以为是3,然后全错了啊啊啊啊 | . | . |
Day 2
开考后把题目都看了一遍。
序列:题目这么短,肯定很难
校园旅行:回文串
白兔之舞:.
开始写题目。
| 做题顺序 | 校园旅行 | 白兔之舞 | 序列 |
|---|---|---|---|
| 预计得分 | 30 | 30 | 0 |
| 得分 | 0 | 30 | 0 |
| 算法 | 如果这个串是回文的,那么这个串去头去尾后也是回文的。然后从最短的开始枚举 | 对于n=1的数据很好想,组合数就行了,n>1没想法 | 贪心 |
| 后记 | 我以为经过任意多次没有用,就没管,考完才发现有用 | 。 | 一开始以为打出来了,后来发现是错的 |
对失望很失望
对失望很失望
作者: 苏懂
我遇到过一个很特别的读者,他排在等待签名的队伍中,走到我的面前时,用尖锐的目光盯着我,那种眼神使我感到紧张。然后我听见他说:“你不應该随便出来签名,我是你的读者,但见到你,我觉得很失望。”
我一直记得这个直率得令人恐怖的中年男子。他使我震惊,使我恨不得找面镜子看看自己的模样。他的失望包含着什么样的内容?这是我一直想探询的事。
我不能面对读者对我的失望。我爱我的读者,因此在那个外地城市的一天里,我成了更加失望的人,我是对自己感到失望。我其实不知道那个读者对我的观感,是我疲倦的表情,还是僵硬的微笑使他失望?是我的模样、气质与作品不相符使他产生了受蒙蔽的感觉?他不说!我内心有一种过失犯罪的感觉,这次的经历使我后来对签名售书之类的活动避之唯恐不及。
亡羊补牢却难免百密一疏,可恨我这种人不是能够隐居的料子。不久前,我和几个作家同行去**,抵达当天,我随几个熟识的朋友去茶馆闲坐。没说几句话,一个当地的女士就诚恳地告诉我,她对同去的某个作家感到很失望。她说:“没想到他是这么沉默的人,像个老人!”
不知怎的,我又有了犯错误的感觉,我想她的失望也一定适用于我。这到底是怎么回事,为什么一个作家出现在别人面前那么容易让人感到失望?事实证明,我那天的联想并非出于敏感,要离开**的时候,一个几天来相处甚欢的记者朋友也用同样真诚的语气告诉我:“告诉你,我们对你很失望哦!”
这次我突然生气了。我不再有那种脆弱的、对不起大家的感觉了。我突然意识到,在这些失望的人面前,我是无辜的,我不该对他们的失望负责。我想他们的失望在于某种期望,可是为什么要对一个未曾谋面的人有所期望呢?假如我是一棵梨树,别人把我看成一棵桃树,我不能因此责备我自己。假如别人喜欢的是桃树,而我作为梨树,那就只能用外交辞令对那些失望的人说:“非常抱歉,你看错了,我不是桃树,而是一棵梨树。”
我不知道我的这种经历是否涉及一种人际关系,但我想,人与人的坦诚相待并不是一件危险和可怕的事。任何人不必对他人虚幻的期望负责,能让大家都喜欢你是幸运的,能让大家都讨厌你是不幸的,但是按照别人的期望呼吸、吃饭、说话、打哈欠是不必要的。一个人只能生活在自己的音容笑貌之中,即使它充满了缺陷。我的天性总是使我在那些失望的眼神中露出尴尬的微笑,但我想告诉一些勇敢的朋友,当有人对你说“我对你很失望”时,你可以这样回答他:“我对你的失望很失望。”
动态规划
动态规划题目
注:内容从易到难
开心的金明:背包入门题
solution
#include<iostream>
#include<algorithm>
using namespace std;
const int maxn=30005;
int f[maxn];
int w[maxn],v[maxn];
int n,m;
int main()
{
cin>>n>>m;
for(int i=1;i<=m;i++)cin>>w[i]>>v[i];
for(int i=1;i<=m;i++)
for(int j=n;j-w[i]>=0;j--)
f[j]=max(f[j],f[j-w[i]]+w[i]*v[i]);
cout<<f[n];
return 0;
}单源最短路与负环
单源最短路
Floyd算法
时间复杂度为n方
可以求所有点的最短路
枚举从i走到j的每一个中间点k,看dis(i,j)是否>dis(i,k)+dis(k,j),如果是就更新答案。
void Floyd()
{
//邻接链表存图
for(int k=1;k<=n;k++)
for(int i=1;i<=n;i++)
if(i!=k and dis[i][k]!=inf)
for(int j=1;j<=n;j++)
dis[i][j]=min(dis[i][j],dis[i][k]+dis[j][k]);
}SPFA算法
时间复杂度O(KM)可被卡成O(NM)
SPFA永远不会死
void SPFA()
{
queue<int>que;
dis[s]=0;
vis[s]=1;
que.push(s);
while(!que.empty())
{
int u=que.front();
que.pop();
for(int i=head[u];i;i=e[i].next)
{
if(dis[e[i].to]>dis[u]+e[i].w)
{
dis[e[i].to]=dis[u]+e[i].w;
if(!vis[e[i].to])
{
vis[e[i].to]=1;
que.push(e[i].to);
}
}
}
vis[u]=0;
}
}Dijkstra算法(队列优化)
时间复杂度O(nlogn)
采用贪心策略,蓝白点方法。
每次选择最小的边来松弛,vis数组标记是否已经找到最短路。
void dijkstra()
{
dis[s]=0;
priority_queue<pair<int,int> >q;
dis[s]=0;
q.push(make_pair(0,1));//前面存dis,后面存节点标号
while(!q.empty())
{
int k=q.top().second;q.pop();
if(vis[k])continue;
vis[k]=1;
for(int i=head[k];i;i=e[i].next)
{
if(dis[e[i].to]>dis[k]+e[i].w)
{
dis[e[i].to]=dis[k]+e[i].w;
q.push(make_pair(-dis[e[i].to],e[i].to));//选最小值,默认大根堆
}
}
}
}负环判定
**负环:**一个边权之和为负数的环
使用SPFA算法判定负环:
若一个点被加入队列超过n次,则这个点一定在负环上。
#include<iostream>
#include<queue>
#include<cstring>
using namespace std;
const int maxn=3005;
int n,m;
struct edge{
int to,next,w;
}e[maxn*2];
int head[maxn],num;
int cnt[maxn];
void add(int u,int v,int w)
{
e[++num].next=head[u];
e[num].w=w;
e[num].to=v;
head[u]=num;
}
long long dis[maxn];
bool vis[maxn];
bool SPFA(int start)
{
memset(dis,127,sizeof dis);
memset(vis,0,sizeof vis);
queue<int>q;
dis[start]=0,vis[start]=1;
q.push(start);
while(!q.empty())
{
int u=q.front();
q.pop();
vis[u]=0;
for(int i=head[u];i;i=e[i].next)
{
int v=e[i].to,w=e[i].w;
if(dis[v]>dis[u]+w)
{
dis[v]=dis[u]+w;
if(!vis[v])
vis[v]=1,q.push(v);
cnt[v]++;
if(cnt[v]>=n)
return true;
}
}
}
return false;
}
int T;
int main()
{
ios::sync_with_stdio(false);
cin>>T;
while(T--)
{
num=0;
memset(head,0,sizeof head);
memset(cnt,0,sizeof cnt);
cin>>n>>m;
int u,v,w;
for(int i=1;i<=m;i++)
{
cin>>u>>v>>w;
if(w<0)add(u,v,w);
else
{
add(u,v,w);
add(v,u,w);
}
}
cout<<(SPFA(1)?"YE5\n":"N0\n");
}
return 0;
}
花神的嘲讽计划I
花神的嘲讽计划Ⅰ
背景
花神是神,一大癖好就是嘲讽大J,举例如下:
“哎你傻不傻的!【hqz:大笨J】”
“这道题又被J屎过了!!”
“J这程序怎么跑这么快!J要逆袭了!”
……
描述
这一天DJ在给吾等众蒟蒻讲题,花神在一边做题无聊,就跑到了一边跟吾等众蒟蒻一起听。以下是部分摘录:
“J你在讲什么!”
“我在讲XXX!”
“哎你傻不傻的!这么麻烦,直接XXX再XXX就好了!”
“……”
“J你XXX讲过了没?”
“……”
“那个都不讲你就讲这个了?哎你傻不傻的!”
“……”
DJ对这种情景表示非常无语,每每出现这种情况,DJ都是非常尴尬的。
经过众蒟蒻研究,DJ在讲课之前会有一个长度为N方案,我们可以把它看作一个数列;
同样,花神在听课之前也会有一个嘲讽方案,有M个,每次会在x到y的这段时间开始嘲讽,为了减少题目难度,每次嘲讽方案的长度是一定的,为K。
花神嘲讽DJ让DJ尴尬需要的条件:
在xy的时间内DJ没有讲到花神的嘲讽方案,即J的讲课方案中的xy没有花神的嘲讽方案【这样花神会嘲讽J不会所以不讲】。
经过众蒟蒻努力,在一次讲课之前得到了花神嘲讽的各次方案,DJ得知了这个消息以后欣喜不已,DJ想知道花神的每次嘲讽是否会让DJ尴尬【说不出话来】。
Input
第1行3个数N,M,K;
第2行N个数,意义如上;
第3行到第3+M-1行,每行K+2个数,前两个数为x,y,然后K个数,意义如上;
Output
对于每一个嘲讽做出一个回答会尴尬输出‘Yes’,否则输出‘No’
Sample Input
8 5 3
1 2 3 4 5 6 7 8
2 5 2 3 4
1 8 3 2 1
5 7 4 5 6
2 5 1 2 3
1 7 3 4 5
Sample Output
No
Yes
Yes
Yes
No
Solution
这道题我是打算写一下主席树的题目才看到的。写了一下发现不需要主席树,直接每k个hash一下,再sort一遍,
然后直接二分匹配就行了。
跑的还是挺快的。

代码
/*******************************
Author:galaxy yr
LANG:C++
Created Time:2019年04月11日 星期四 17时01分12秒
*******************************/
#include<iostream>
#include<cstdio>
#include<algorithm>
using namespace std;
const int maxn=2e5+10;
const int base=131;
int n,m,k,a[maxn],cnt,val;
unsigned long long H[maxn];
struct hashmap{
unsigned long long key;
int rk;
friend bool operator<(hashmap s,hashmap t) { return s.key<t.key; }
}e[maxn],h;
int main()
{
freopen("bzoj3207.in","r",stdin);
freopen("bzoj3207.out","w",stdout);
scanf("%d%d%d",&n,&m,&k);
for(int i=1;i<=n;i++)
scanf("%d",&a[i]);
for(int i=1;i<=n;i++)
H[i]=H[i-1]*base+a[i];
unsigned long long M=1;
for(int i=1;i<=k;i++)
M*=base;
for(int i=k;i<=n;i++)
e[++cnt].key=H[i]-H[i-k]*M,e[cnt].rk=i-k+1;
sort(e+1,e+cnt);
int l,r,z,y;
while(m--)
{
scanf("%d%d",&l,&r);
h.key=0;
for(int i=1;i<=k;i++)
{
scanf("%d",&val);
h.key=h.key*base+val;
}
z=lower_bound(e+1,e+cnt,h)-e;
y=upper_bound(e+1,e+cnt,h)-e-1;
if(z<=y)
{
if(e[z].rk>=l and e[z].rk<=r-k+1)
printf("No\n");
else if(e[z].rk<l)
{
if(e[y].rk>l)
printf("No\n");
else
printf("Yes\n");
}
else
printf("Yes\n");
}
else
printf("Yes\n");
}
return 0;
}Recommend Projects
-
 React
React
A declarative, efficient, and flexible JavaScript library for building user interfaces.
-
Vue.js
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
-
 Typescript
Typescript
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
-
TensorFlow
An Open Source Machine Learning Framework for Everyone
-
Django
The Web framework for perfectionists with deadlines.
-
 Laravel
Laravel
A PHP framework for web artisans
-
D3
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
-
Recommend Topics
-
javascript
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
-
web
Some thing interesting about web. New door for the world.
-
server
A server is a program made to process requests and deliver data to clients.
-
Machine learning
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
-
Visualization
Some thing interesting about visualization, use data art
-
Game
Some thing interesting about game, make everyone happy.
Recommend Org
-
Facebook
We are working to build community through open source technology. NB: members must have two-factor auth.
-
Microsoft
Open source projects and samples from Microsoft.
-
Google
Google ❤️ Open Source for everyone.
-
Alibaba
Alibaba Open Source for everyone
-
D3
Data-Driven Documents codes.
-
Tencent
China tencent open source team.