收集大语言模型的学习路径和各种最佳实践
随着大模型的热度越来越高,我们有必要对大于语言模型进行深入的研究
大语言模型是什么?
大模型推荐
大模型评估基准
没有卡的条件下我们能做什么?
怎么开始学习?
在2017年,Transformer架构的出现导致深度学习模型的参数超越了1亿,从此RNN和CNN被Transformer取代,开启了大模型的时代。谷歌在2018年推出BERT,此模型轻松刷新了11个NLP任务的最佳记录,为NLP设置了一个新的标杆。它不仅开辟了新的研究和训练方向,也使得预训练模型在自然语言处理领域逐渐受到欢迎。此外,这一时期模型参数的数量也首次超过了3亿。到了2020年,OpenAI发布了GPT-3,其参数数量直接跃升至1750亿。2021年开始,Google先后发布了Switch Transformer和GLaM,其参数数量分别首次突破万亿和1.2万亿,后者在小样本学习上甚至超越了GPT-3。

Transformer是由Google Brain在2017年提出的一种新颖的网络结构。相对于RNN,它针对其效率问题和长程依赖传递的挑战进行了创新设计,并在多个任务上均展现出优越的性能。
如下图所示的是Transformer的架构细节。其核心技术是自注意力机制(Self-Attention)。简单地说,自注意力机制允许一个句子中的每个词对句子中的所有其他词进行加权,以生成一个新的词向量表示。这个过程可以看作是每个词都经过了一次类似卷积或聚合的操作。这种机制提高了模型对于上下文信息的捕获能力。
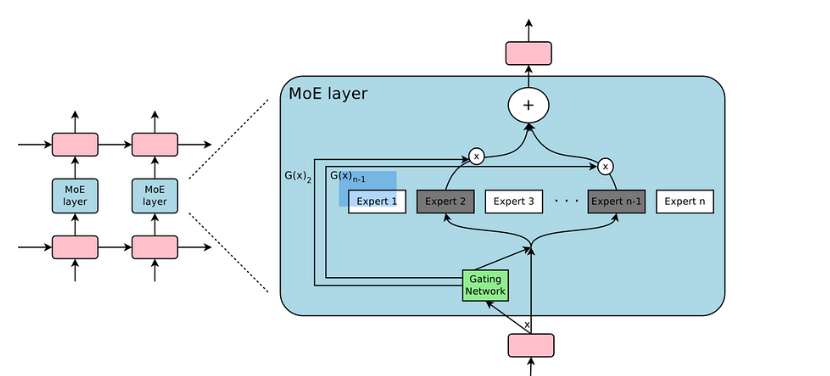
模型的增大和训练样本的增加导致了计算成本的显著增长。而这种计算上的挑战促使了技术的进步与创新。
考虑到这一问题,一个解决方案是将一个大型模型细分为多个小型模型。这意味着对于给定的输入样本,我们不需要让它通过所有的小型模型,而只是选择其中的一部分进行计算。这种方法显著地节省了计算资源。
那么,如何选择哪些小模型来处理一个特定的输入呢?这是通过所谓的“稀疏门”来实现的。这个门决定哪些小模型应该被激活,同时确保其稀疏性以优化计算。
稀疏门控专家混合模型(Sparsely-Gated MoE)是这一技术的名字。它的核心**是条件计算,意味着神经网络的某些部分是基于每个特定样本进行激活的。这种方式有效地提高了模型的容量和性能,而不会导致计算成本的相对增长。
实际上,稀疏门控 MoE 使得模型容量得到了1000倍以上的增强,但在现代GPU集群上的计算效率损失却非常有限。
总之,如果说Transformer架构是模型参数量的第一次重大突破,达到了亿级,那么MoE稀疏混合专家结构则进一步推动了这一突破,使参数量达到了千亿乃至万亿的规模。
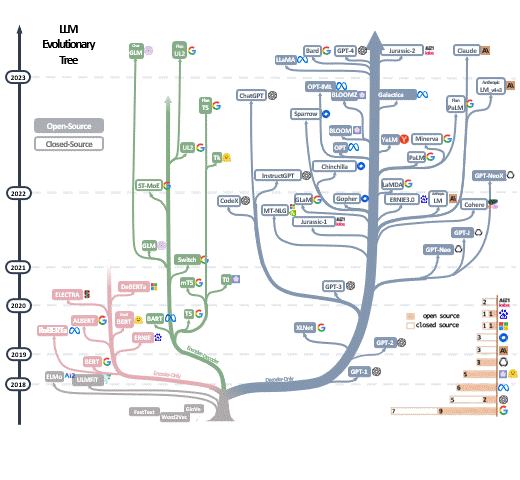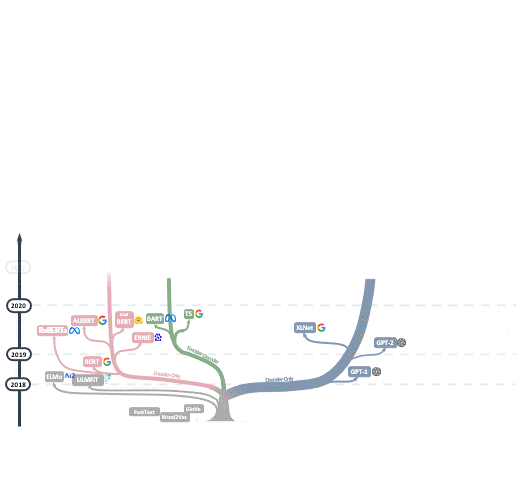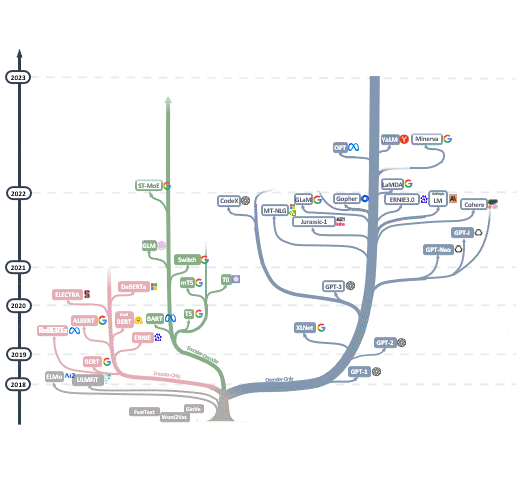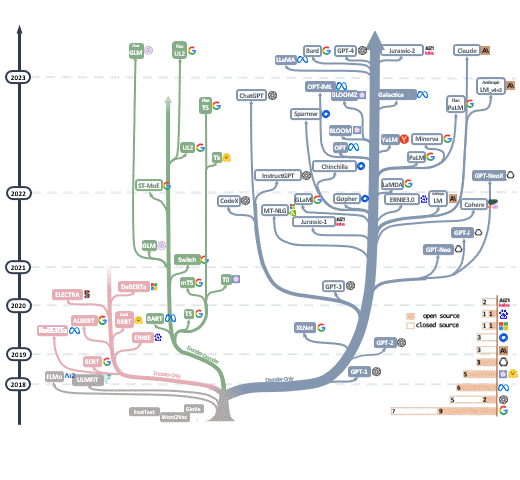
不同任务实验过程中,相对而言整体效果还不错的模型列表。
| 模型 | 最新时间 | 大小 | 项目地址 | 机构单位 |
|---|---|---|---|---|
| Baichuan2 | 2023-09 | 7/13B | Baichuan2 |
百川智能 |
| WizardLM | 2023-08 | 7/13/30/70B | WizardLM |
微软 |
| Vicuna | 2023-08 | 7/13/33B | FastChat |
Large Model Systems Organization |
| YuLan | 2023-08 | 13/65B | YuLan-Chat |
**人民大学高瓴人工智能学院 |
| InternLM | 2023-09 | 7/20B | InternLM |
上海人工智能实验室 |
| TigerBot | 2023-08 | 7/13/70B | TigerBot |
虎博科技 |
| Baichuan | 2023-08 | 7/13B | Baichuan-13B |
百川智能 |
| ChatGLM | 2023-07 | 6B | ChatGLM2-6B |
清华大学 |
| Chinese-LLaMA-Alpaca-2 | 2023-09 | 7/13B | Chinese-LLaMA-Alpaca-2 |
哈工大讯飞联合实验室 |

提供了13948个多项选择题的C-Eval是一个全方位的中文基本模型评估工具。该套件覆盖了52个学科并且分为四个难度等级。论文内有更多详细信息。

FlagEval的设计初衷是为AI基础模型提供评估,它集中于科学、公正和开放的评价准则和工具。该工具包旨在从多维度评估基础模型,推进技术创新和行业应用。

SuperCLUE琅琊榜是中文大模型评估的标准。它采用众包方式,提供匿名和随机对战。Elo评级系统,广泛应用于国际象棋,也被用于此评估中。

XiezhiBenchmark涵盖13个学科的220,000个多项选择题和15,000个问题。评估结果显示,大型语言模型在某些领域上超越了人类表现,而在其他领域上仍有待提高。
HuggingFace推出的LLM评估榜单,以英语为主,集中于大语言模型和聊天机器人的评估。任何社区成员都可以提交模型以供自动评估。
[官方网站]

该平台利用完备的评测框架,涉及多个安全类别如仇恨言论、隐私等,进行大模型的安全评估。

OpenCompass是一个开源平台,专为大语言模型和多模态模型设计。即便是千亿参数模型,也能迅速完成评测。
微调和数据增强
训练后量化:
- SmoothQuant
- ZeroQuant
- GPTQ
- LLM.int8()
量化感知训练:
量化感知微调:
- QLoRA
- PEQA
结构化剪枝:
- LLM-Pruner
非结构化剪枝:
- SparseGPT
- LoRAPrune
- Wanda
- 大模型知识蒸馏概述
Standard KD:
使学生模型学习教师模型(LLM)所拥有的常见知识,如输出分布和特征信息,这种方法类似于传统的KD。
- MINILLM
- GKD
EA-based KD:
不仅仅是将LLM的常见知识转移到学生模型中,还涵盖了蒸馏它们独特的涌现能力。具体来说,EA-based KD又分为了上下文学习(ICL)、思维链(CoT)和指令跟随(IF)。
In-Context Learning:
- In-Context Learning distillation
Chain-of-Thought:
- MT-COT
- Fine-tune-CoT
- DISCO
- SCOTT
- SOCRATIC CoT
Instruction Following:
- Lion
https://zhuanlan.zhihu.com/p/646831196
低秩分解旨在通过将给定的权重矩阵分解成两个或多个较小维度的矩阵,从而对其进行近似。低秩分解背后的核心**是找到一个大的权重矩阵W的分解,得到两个矩阵U和V,使得W≈U V,其中U是一个m×k矩阵,V是一个k×n矩阵,其中k远小于m和n。U和V的乘积近似于原始的权重矩阵,从而大幅减少了参数数量和计算开销。
在LLM研究的模型压缩领域,研究人员通常将多种技术与低秩分解相结合,包括修剪、量化等。
- ZeroQuant-FP(低秩分解+量化)
- LoRAPrune(低秩分解+剪枝)
第一步先学会科学上网,最好学会自己搭梯子,这样才能保证你的学习不会被打断。
第二步,体验大模型,可以通过以下方式体验大模型:chatgpt,cluade,bard等等
吴恩达大模型系列课程
https://github.com/datawhalechina/prompt-engineering-for-developers
包括 提示词工程,langchain
学习后可以入门大模型的基本概念和应用
在了解大模型的基本概念后,可以通过查阅论文来了解大模型的最新进展
https://github.com/Hannibal046/Awesome-LLM
可以自己开始动手实践,可以从以下几个方面入手:
调用大模型的API
自己部署大模型调用
微调大模型
- BERT BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding, 2018, Paper
- RoBERTa RoBERTa: A Robustly Optimized BERT Pretraining Approach, 2019, Paper
- DistilBERT DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter, 2019, Paper
- ALBERT ALBERT: A Lite BERT for Self-supervised Learning of Language Representations, 2019, Paper
- UniLM Unified Language Model Pre-training for Natural Language Understanding and Generation, 2019 Paper
- ELECTRA ELECTRA: PRE-TRAINING TEXT ENCODERS AS DISCRIMINATORS RATHER THAN GENERATORS, 2020, Paper
- T5 "Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer". Colin Raffel et al. JMLR 2019. Paper
- GLM "GLM-130B: An Open Bilingual Pre-trained Model". 2022. Paper
- AlexaTM "AlexaTM 20B: Few-Shot Learning Using a Large-Scale Multilingual Seq2Seq Model". Saleh Soltan et al. arXiv 2022. Paper
- ST-MoE ST-MoE: Designing Stable and Transferable Sparse Expert Models. 2022 Paper
- GPT Improving Language Understanding by Generative Pre-Training. 2018. Paper
- GPT-2 Language Models are Unsupervised Multitask Learners. 2018. Paper
- GPT-3 "Language Models are Few-Shot Learners". NeurIPS 2020. Paper
- OPT "OPT: Open Pre-trained Transformer Language Models". 2022. Paper
- PaLM "PaLM: Scaling Language Modeling with Pathways". Aakanksha Chowdhery et al. arXiv 2022. Paper
- BLOOM "BLOOM: A 176B-Parameter Open-Access Multilingual Language Model". 2022. Paper
- MT-NLG "Using DeepSpeed and Megatron to Train Megatron-Turing NLG 530B, A Large-Scale Generative Language Model". 2021. Paper
- GLaM "GLaM: Efficient Scaling of Language Models with Mixture-of-Experts". ICML 2022. Paper
- Gopher "Scaling Language Models: Methods, Analysis & Insights from Training Gopher". 2021. Paper
- chinchilla "Training Compute-Optimal Large Language Models". 2022. Paper
- LaMDA "LaMDA: Language Models for Dialog Applications". 2021. Paper
- LLaMA "LLaMA: Open and Efficient Foundation Language Models". 2023. Paper
- GPT-4 "GPT-4 Technical Report". 2023. Paper
- BloombergGPT BloombergGPT: A Large Language Model for Finance, 2023, Paper
- GPT-NeoX-20B: "GPT-NeoX-20B: An Open-Source Autoregressive Language Model". 2022. Paper
- PaLM 2: "PaLM 2 Technical Report". 2023. Tech.Report
- LLaMA 2: "Llama 2: Open foundation and fine-tuned chat models". 2023. Paper
- Claude 2: "Model Card and Evaluations for Claude Models". 2023. Model Card
- RedPajama, 2023. Repo
- The Pile: An 800GB Dataset of Diverse Text for Language Modeling, Arxiv 2020. Paper
- How does the pre-training objective affect what large language models learn about linguistic properties?, ACL 2022. Paper
- Scaling laws for neural language models, 2020. Paper
- Data-centric artificial intelligence: A survey, 2023. Paper
- How does GPT Obtain its Ability? Tracing Emergent Abilities of Language Models to their Sources, 2022. Blog
- Benchmarking zero-shot text classification: Datasets, evaluation and entailment approach, EMNLP 2019. Paper
- Language Models are Few-Shot Learners, NIPS 2020. Paper
- Does Synthetic Data Generation of LLMs Help Clinical Text Mining? Arxiv 2023 Paper
- Shortcut learning of large language models in natural language understanding: A survey, Arxiv 2023. Paper
- On the Robustness of ChatGPT: An Adversarial and Out-of-distribution Perspective Arxiv, 2023. Paper
- SuperGLUE: A Stickier Benchmark for General-Purpose Language Understanding Systems Arxiv 2019. Paper
- A benchmark for toxic comment classification on civil comments dataset Arxiv 2023 Paper
- Is chatgpt a general-purpose natural language processing task solver? Arxiv 2023Paper
- Benchmarking large language models for news summarization Arxiv 2022 Paper
- News summarization and evaluation in the era of gpt-3 Arxiv 2022 Paper
- Is chatgpt a good translator? yes with gpt-4 as the engine Arxiv 2023 Paper
- Multilingual machine translation systems from Microsoft for WMT21 shared task, WMT2021 Paper
- Can ChatGPT understand too? a comparative study on chatgpt and fine-tuned bert, Arxiv 2023, Paper
- Measuring massive multitask language understanding, ICLR 2021 Paper
- Beyond the imitation game: Quantifying and extrapolating the capabilities of language models, Arxiv 2022 Paper
- Inverse scaling prize, 2022 Link
- Atlas: Few-shot Learning with Retrieval Augmented Language Models, Arxiv 2022 Paper
- Large Language Models Encode Clinical Knowledge, Arxiv 2022 Paper
- Training Compute-Optimal Large Language Models, NeurIPS 2022 Paper
- Scaling Laws for Neural Language Models, Arxiv 2020 Paper
- Solving math word problems with process- and outcome-based feedback, Arxiv 2022 Paper
- Chain of thought prompting elicits reasoning in large language models, NeurIPS 2022 Paper
- Emergent abilities of large language models, TMLR 2022 Paper
- Inverse scaling can become U-shaped, Arxiv 2022 Paper
- Towards Reasoning in Large Language Models: A Survey, Arxiv 2022 Paper
- Image as a Foreign Language: BEiT Pretraining for All Vision and Vision-Language Tasks, Arixv 2022 Paper
- PaLI: A Jointly-Scaled Multilingual Language-Image Model, Arxiv 2022 Paper
- AugGPT: Leveraging ChatGPT for Text Data Augmentation, Arxiv 2023 Paper
- Is gpt-3 a good data annotator?, Arxiv 2022 Paper
- Want To Reduce Labeling Cost? GPT-3 Can Help, EMNLP findings 2021 Paper
- GPT3Mix: Leveraging Large-scale Language Models for Text Augmentation, EMNLP findings 2021 Paper
- LLM for Patient-Trial Matching: Privacy-Aware Data Augmentation Towards Better Performance and Generalizability, Arxiv 2023 Paper
- ChatGPT Outperforms Crowd-Workers for Text-Annotation Tasks, Arxiv 2023 Paper
- G-Eval: NLG Evaluation using GPT-4 with Better Human Alignment, Arxiv 2023 Paper
- GPTScore: Evaluate as You Desire, Arxiv 2023 Paper
- Large Language Models Are State-of-the-Art Evaluators of Translation Quality, Arxiv 2023 Paper
- Is ChatGPT a Good NLG Evaluator? A Preliminary Study, Arxiv 2023 Paper
- 花费
- Openai’s gpt-3 language model: A technical overview, 2020. Blog Post
- Measuring the carbon intensity of ai in cloud instances, FaccT 2022. Paper
- In AI, is bigger always better?, Nature Article 2023. Article
- Language Models are Few-Shot Learners, NeurIPS 2020. Paper
- Pricing, OpenAI. Blog Post
- 延迟
- HELM: Holistic evaluation of language models, Arxiv 2022. Paper
- 微调方法
- LoRA: Low-Rank Adaptation of Large Language Models, Arxiv 2021. Paper
- Prefix-Tuning: Optimizing Continuous Prompts for Generation, ACL 2021. Paper
- P-Tuning: Prompt Tuning Can Be Comparable to Fine-tuning Across Scales and Tasks, ACL 2022. Paper
- P-Tuning v2: Prompt Tuning Can Be Comparable to Fine-tuning Universally Across Scales and Tasks, Arxiv 2022. Paper
- 预训练系统
- ZeRO: Memory Optimizations Toward Training Trillion Parameter Models, Arxiv 2019. Paper
- Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism, Arxiv 2019. Paper
- Efficient Large-Scale Language Model Training on GPU Clusters Using Megatron-LM, Arxiv 2021. Paper
- Reducing Activation Recomputation in Large Transformer Models, Arxiv 2021. Paper
- 稳健性和校准
- Calibrate before use: Improving few-shot performance of language models, ICML 2021. Paper
- SPeC: A Soft Prompt-Based Calibration on Mitigating Performance Variability in Clinical Notes Summarization, Arxiv 2023. Paper
- 虚假偏差
- Large Language Models Can be Lazy Learners: Analyze Shortcuts in In-Context Learning, Findings of ACL 2023 Paper
- Shortcut learning of large language models in natural language understanding: A survey, 2023 Paper
- Mitigating gender bias in captioning system, WWW 2020 Paper
- Calibrate Before Use: Improving Few-Shot Performance of Language Models, ICML 2021 Paper
- Shortcut Learning in Deep Neural Networks, Nature Machine Intelligence 2020 Paper
- Do Prompt-Based Models Really Understand the Meaning of Their Prompts?, NAACL 2022 Paper
- 安全问题
- GPT-4 System Card, 2023 Paper
- The science of detecting llm-generated texts, Arxiv 2023 Paper
- How stereotypes are shared through language: a review and introduction of the aocial categories and stereotypes communication (scsc) framework, Review of Communication Research, 2019 Paper
- Gender shades: Intersectional accuracy disparities in commercial gender classification, FaccT 2018 Paper
- FLAN: Finetuned Language Models Are Zero-Shot Learners, Arxiv 2021 Paper
- T0: Multitask Prompted Training Enables Zero-Shot Task Generalization, Arxiv 2021 Paper
- Cross-task generalization via natural language crowdsourcing instructions, ACL 2022 Paper
- Tk-INSTRUCT: Super-NaturalInstructions: Generalization via Declarative Instructions on 1600+ NLP Tasks, EMNLP 2022 Paper
- FLAN-T5/PaLM: Scaling Instruction-Finetuned Language Models, Arxiv 2022 Paper
- The Flan Collection: Designing Data and Methods for Effective Instruction Tuning, Arxiv 2023 Paper
- OPT-IML: Scaling Language Model Instruction Meta Learning through the Lens of Generalization, Arxiv 2023 Paper
- Deep Reinforcement Learning from Human Preferences, NIPS 2017 Paper
- Learning to summarize from human feedback, Arxiv 2020 Paper
- A General Language Assistant as a Laboratory for Alignment, Arxiv 2021 Paper
- Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback, Arxiv 2022 Paper
- Teaching language models to support answers with verified quotes, Arxiv 2022 Paper
- InstructGPT: Training language models to follow instructions with human feedback, Arxiv 2022 Paper
- Improving alignment of dialogue agents via targeted human judgements, Arxiv 2022 Paper
- Scaling Laws for Reward Model Overoptimization, Arxiv 2022 Paper
- Scalable Oversight: Measuring Progress on Scalable Oversight for Large Language Models, Arxiv 2022 Paper
- Red Teaming Language Models with Language Models, Arxiv 2022 Paper
- Constitutional ai: Harmlessness from ai feedback, Arxiv 2022 Paper
- The Capacity for Moral Self-Correction in Large Language Models, Arxiv 2023 Paper
- OpenAI: Our approach to AI safety, 2023 Blog
- Reinforcement Learning for Language Models, 2023 Blog
