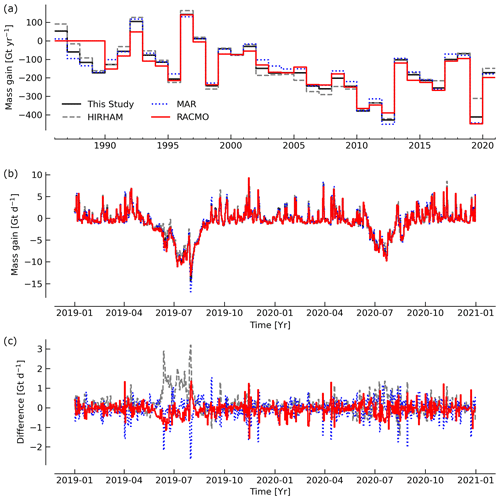
- Greenland ice sheet mass balance from 1840 through next week
- Citation
- Related Work
- Open science vs. reproducible science
This is the source for “Greenland ice sheet mass balance from 1840 through next week” and previous and subsequent versions.
- Paper: doi:10.5194/essd-13-5001-2021
- Data: available at https://doi.org/10.22008/FK2/OHI23Z with all daily historical versions archived.
- Twitter bot with daily updates: https://twitter.com/cryo_data/
- Code: https://github.com/GEUS-Glaciology-and-Climate/mass_balance/
- Issues: https://github.com/GEUS-Glaciology-and-Climate/mass_balance/issues
- This diff shows changes between the published version of the paper and the current (active) development version.
- Major changes post-publication are tagged “major_change”.
@article{mankoff_2021,
author = {Mankoff, Kenneth D. and Fettweis, Xavier and Langen,
Peter L. and Stendel, Martin and Kjeldsen, Kristian K. and
Karlsson, Nanna B. and Noël, Brice and {van den Broeke},
Michiel R. and Solgaard, Anne and Colgan, William and
Box, Jason E. and Simonsen, Sebastian B. and King, Michalea D.
and Ahlstrøm, Andreas P. and Andersen, Signe Bech and
Fausto, Robert S.},
title = {{G}reenland ice sheet mass balance from 1840 through next week},
journal = {Earth System Science Data},
year = 2021,
volume = 13,
number = 10,
pages = {5001--5025},
DOI = {10.5194/essd-13-5001-2021},
publisher = {Copernicus GmbH}}
- NOTE: The version number will change with each daily update.
@data{mankoff_2021_data,
author = {Mankoff, Ken and Fettweis, Xavier and Solgaard, Anne and Langen, Peter and Stendel,
Martin and Noël, Brice and van den Broeke, Michiel R. and Karlsson, Nanna and Box,
Jason E. and Kjeldsen, Kristian},
publisher = {GEUS Dataverse},
title = {{G}reenland ice sheet mass balance from from 1840 through next week},
year = {2021},
edition = {VERSION NUMBER},
doi = {10.22008/FK2/OHI23Z}}
- Companion paper: “Greenland Ice Sheet solid ice discharge from 1986 through March 2020”
- Companion paper: “Greenland liquid water runoff from 1958 through 2019”
| Dates | Organization | Program | Effort |
|---|---|---|---|
| 2023 – | NASA GISS | Modeling Analysis and Prediction program. | Maintenance |
| 2022 – | GEUS | PROMICE | Distribution (data hosting) |
| 2018 – 2022 | GEUS | PROMICE | Development; publication; distribution |

|
|
- This work is open - every line of code needed to recreate it is include in this git repository, although the ~300 GB of RCM inputs are not included.
- We recognize that “open” is not necessarily “reproducible”