#R OpenCPU Spark Executor (ROSE) Library
ROSE is a Scala library offering the full scientific computing power of the R programming language to Apache Spark batch and streaming applications on the JVM. This library is built on top of the opencpu-r-executor library, a lightweight solution for integrating R analytics executed on the OpenCPU server into any application running on the JVM.
ROSE Motivation
The popular Apache SparkR package provides a lightweight front-end for data scientists to use Apache Spark from R. This approach is ideally suited to investigative analytics, such as ad-hoc and exploratory analysis at scale.
The ROSE library provides the same R analytics capabilities available to
Apache SparkR applications within traditional Spark applications on the JVM.
It does this by exposing new analyze operations that execute R analytics on
compatible RDDs. This new facility is designed specifically for
operational analytics and can be used alongside Spark core, SQL, Streaming,
MLib and GraphX.
If you need to query R machine-learning models, score R prediction models or leverage any other aspect of the R library in real-time environments at scale, then the ROSE library may be for you.
ROSE SBT Dependency
libraryDependencies ++= Seq(
"io.onetapbeyond" % "opencpu-spark-executor_2.10" % "1.0"
)
ROSE Basic Usage
This library exposes new analyze transformations on Spark RDDs of type
RDD[OCPUTask]. The following sections demonstrate how to use these new
RDD operations to execute R analytics directly within Spark batch and
streaming applications on the JVM.
See the documentation
on the underlying opencpu-r-executor library for details on building
OCPUTask and handling OCPUResult.
ROSE Spark Batch Usage
For this example we assume an input dataRDD, then transform it to generate
an RDD of type RDD[OCPUTask]. In this example each OCPUTask represents a
fraud score prediction to be generated by the R function fraud::score when
the RDD is eventually evaluated.
import io.onetapbeyond.opencpu.spark.executor.R._
import io.onetapbeyond.opencpu.r.executor._
val rTaskRDD = dataRDD.map(data => {
OCPU.R()
.pkg("fraud")
.function("score")
.input(data.asInput())
.library()
})
The set of OCPUTask within rTaskRDD can be scheduled for
processing by calling the new analyze operation provided by ROSE
on the RDD:
val rResultRDD = rTaskRDD.analyze
When rTaskRDD.analyze is evaluated by Spark the resultant rResultRDD
is of type RDD[OCPUResult]. The fraud prediction score for the original
OCPUTask are available within these OCPUResult. These values can be
optionally cached, further processed or persisted per the needs of your
Spark application.
Note, the use here of the R function fraud::score is simply representative
of any R function or script available within the full set of R packages
available on CRAN R,
Bioconductor or on github.
ROSE Spark Streaming Usage
For this example we assume an input stream dataStream, then transform
it to generate a new stream with underlying RDDs of type RDD[OCPUTask].
In this example each OCPUTask represents a fraud score prediction to
be generated by the R function fraud::score when the stream is
eventually evaluated.
import io.onetapbeyond.opencpu.spark.executor.R._
import io.onetapbeyond.opencpu.r.executor._
val rTaskStream = dataStream.transform(rdd => {
rdd.map(data => {
OCPU.R()
.pkg("fraud")
.function("score")
.input(data.asInput())
.library()
})
})
The set of OCPUTask within rTaskStream can be scheduled for processing
by calling the new analyze operation provided by ROSE on each RDD within
the stream:
val rResultStream = rTaskStream.transform(rdd => rdd.analyze)
When rTaskStream.transform is evaluated by Spark the resultant
rResultStream has underlying RDDs of type RDD[OCPUResult]. The fraud
prediction score for the original OCPUTask are available within these
OCPUResult. These values can be optionally cached, further processed
or persisted per the needs of your Spark application.
Note, the use here of the R function fraud::score is simply
representative of any R function or script available within the full
set of R packages available on CRAN R,
Bioconductor or on github.
Traditional v ROSE Spark Application Deployment
To understand how ROSE delivers the full scientific computing power of the R programming language to Spark applications on the JVM the following sections compare and constrast the deployment of traditional Scala, Java, Python and SparkR applications with Spark applications powered by the ROSE library.
The principal deployment requirement when working with ROSE is that your
Spark cluster have access to one or more
OpenCPU servers. Deployment
options for those servers in the context of Spark are discussed in
Application Deployment sections 3. and 4. that follow below.
####1. Traditional Scala | Java | Python Spark Application Deployment
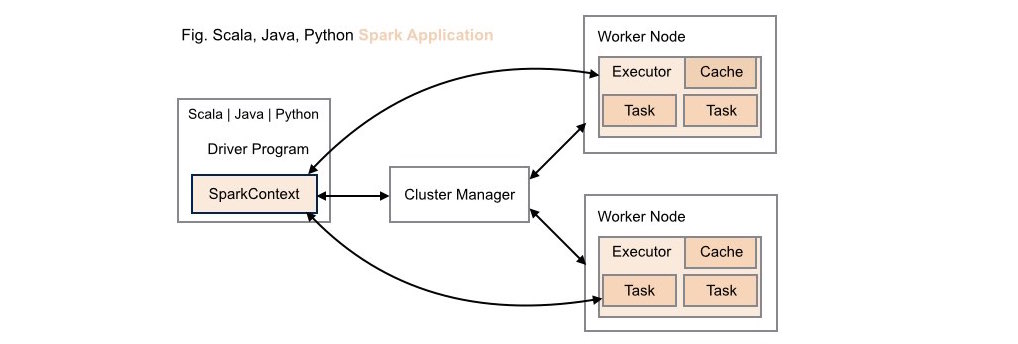
Without ROSE library support, neither data scientists nor application developers have access to R's analytic capabilities within these types of application deployments.
####2. Traditional SparkR Application Deployment
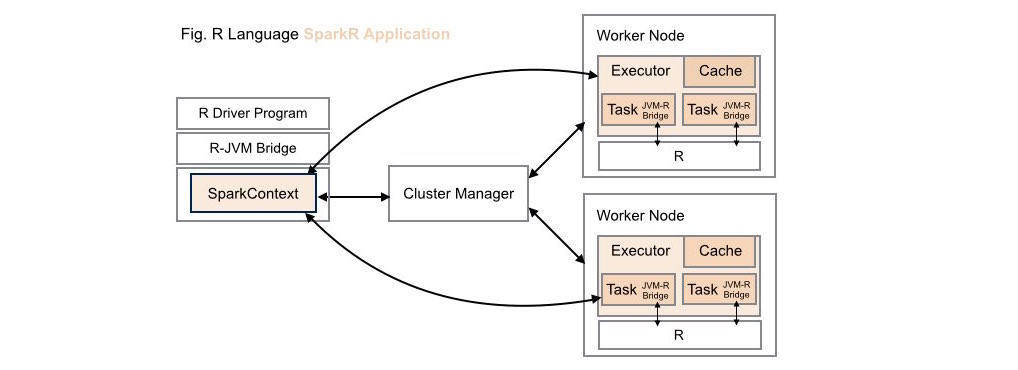
While data scientists can leverage the computing power of Spark within R applications in these types of application deployments, these same R capabilities are not available to Scala, Java or Python developers.
####3. Scala | Java + R (ROSE) Spark Application Deployment
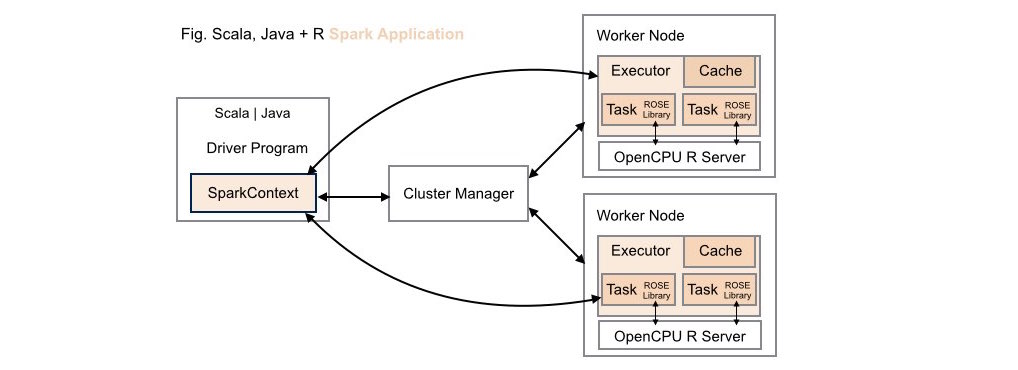
Both data scientists and application developers working in either Scala or Java can leverage the full power of R using the ROSE library within these types of application deployments.
Using this deployment configuration, each worker node on the Spark cluster
has its own dedicated OpenCPU server installed locally on the node. This
configuration delivers optimal runtime throughput on the cluster. Note, this
deployment configuration mirrors the configuration required by Apache
SparkR, where the R runtime environment must be installed locally on each
worker node on the cluster.
####4. Scala | Java + R (ROSE) Spark Application Deployment (Alternative)
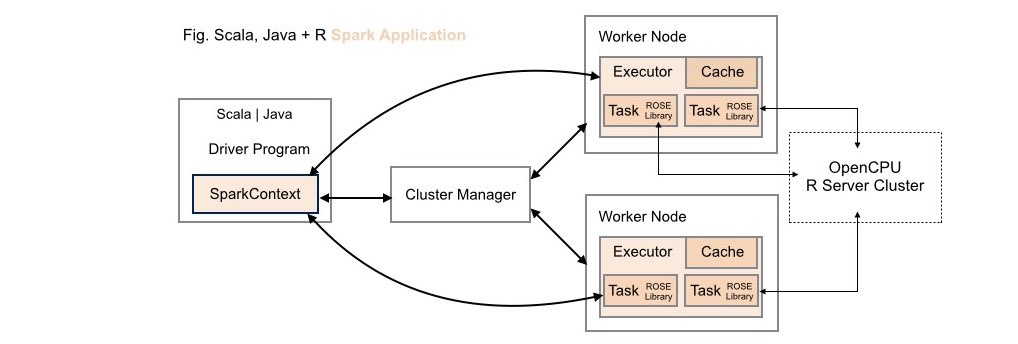
Both data scientists and application developers working in either Scala or Java can leverage the full power of R using the ROSE library within these types of application deployments.
Using this deployment configuration, a cluster of one or more
OpenCPU servers is maintained external to the Spark cluster. While
maintaining these servers external to the Spark cluster potentially introduces
runtime costs associated with networking latencies this approach does allow
fast prototyping for ROSE-enabled Spark applications as no configuration
changes need to be made to an existing Spark cluster to get up and running.
To take advantage of an external OpenCPU server cluster when working with
ROSE simply pass an Array[String] of one or more server endpoints to the
analyze transformation. For example, identify an external cluster of 3
OpenCPU servers for use by your Spark application:
val ocpuCluster = sc.broadcast(Array("http://1.1.x.x/ocpu",
"http://1.1.y.y/ocpu",
"http://1.1.z.z/ocpu"))
val rResultRDD = rTaskRDD.analyze(ocpuCluster.value)
As shown, the array of server endpoints should be maintained as a
broadcast variable within your Spark application. Each OCPUTask within
your ROSE application will automatically be distributed for execution at random
across the OpenCPU server cluster.

